
An Insightful Overview of the Wiener Filter for System Identification





Abstract
:1. Introduction
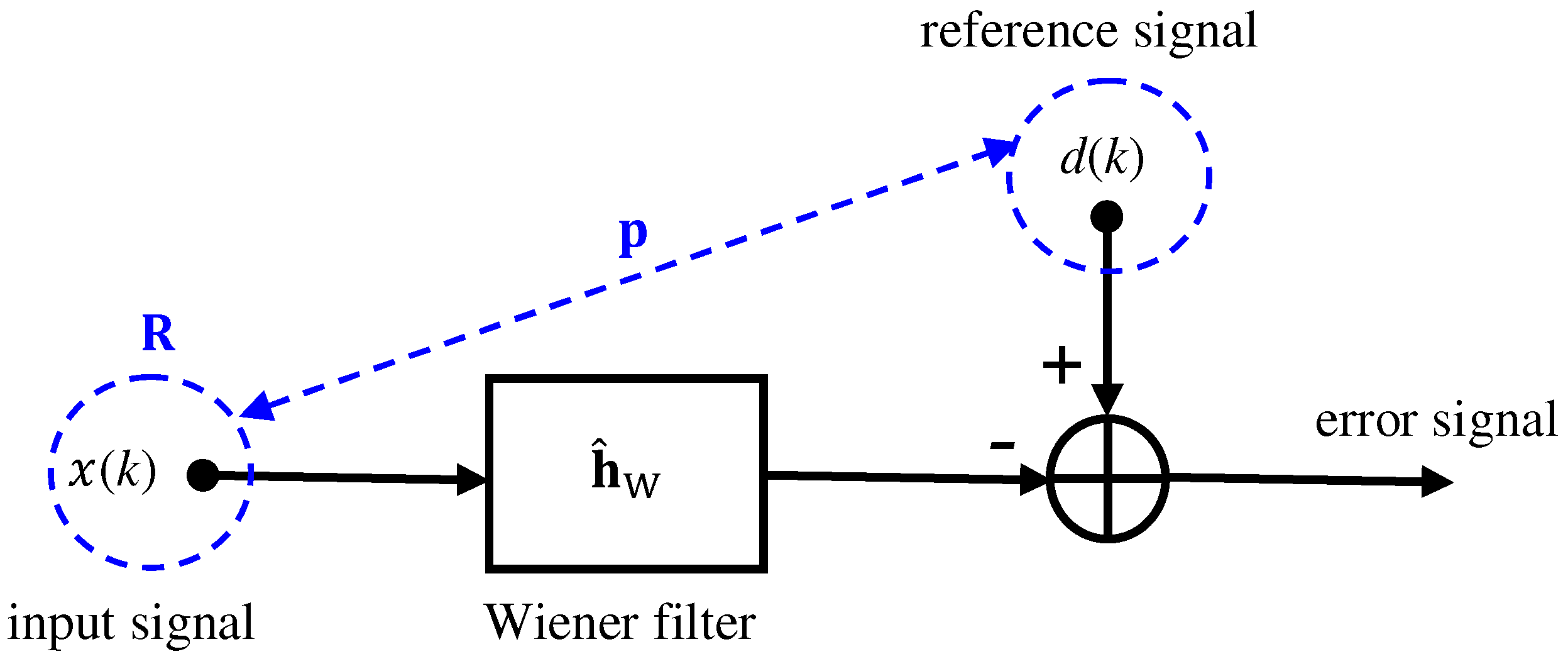
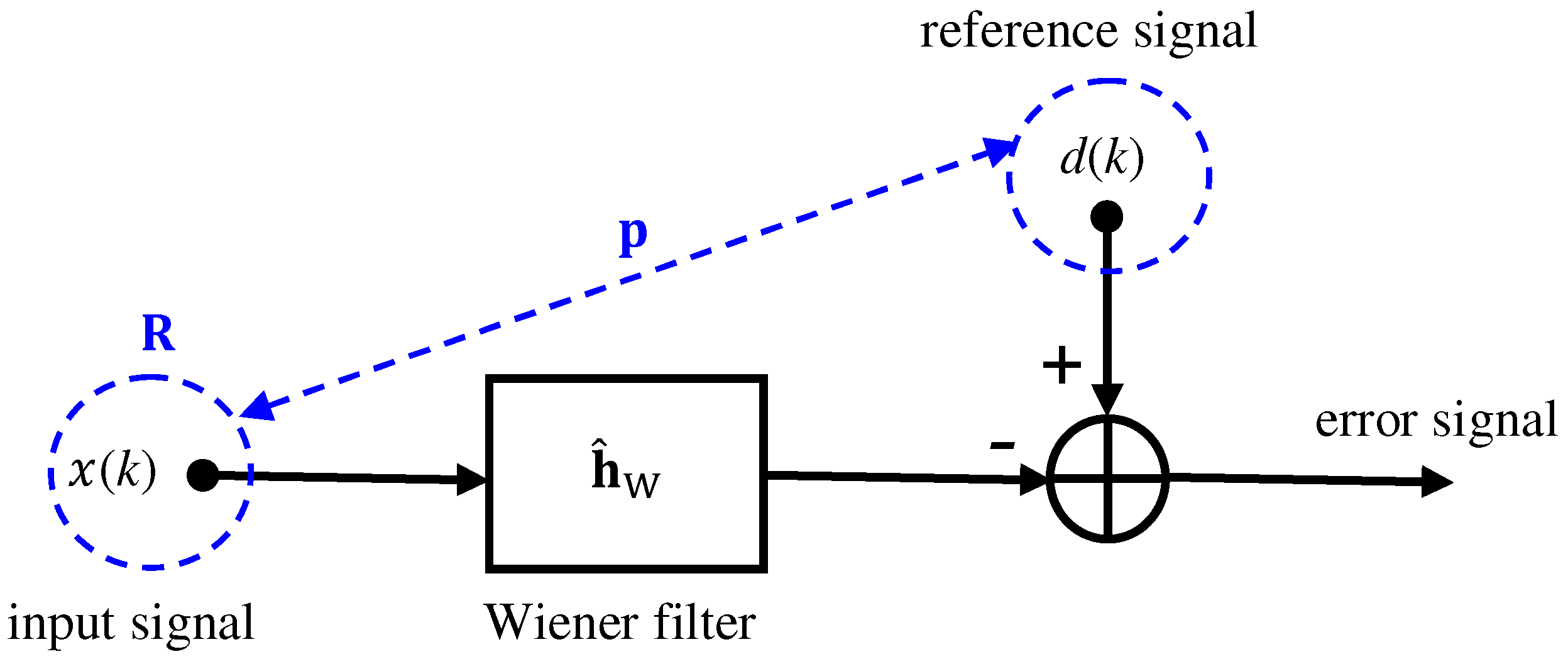
2. System Model and the Conventional Wiener Filter
3. Useful Definitions
4. Wiener Filter with Different Kinds of Regularization
5. Wiener Filter via Kronecker Product Decomposition
6. Wiener Filter with the Quadratic Eigenvalue Problem
7. Simulations
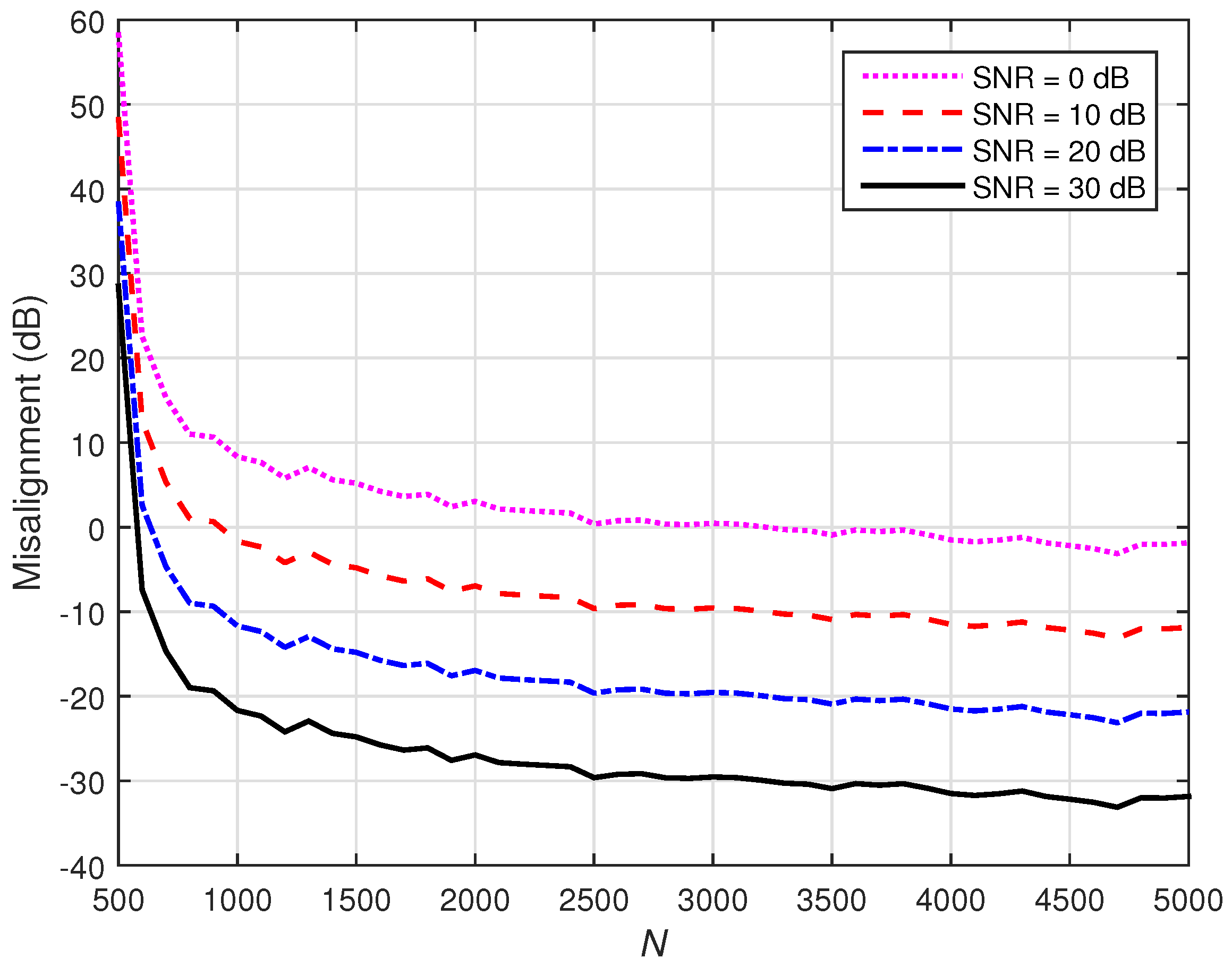
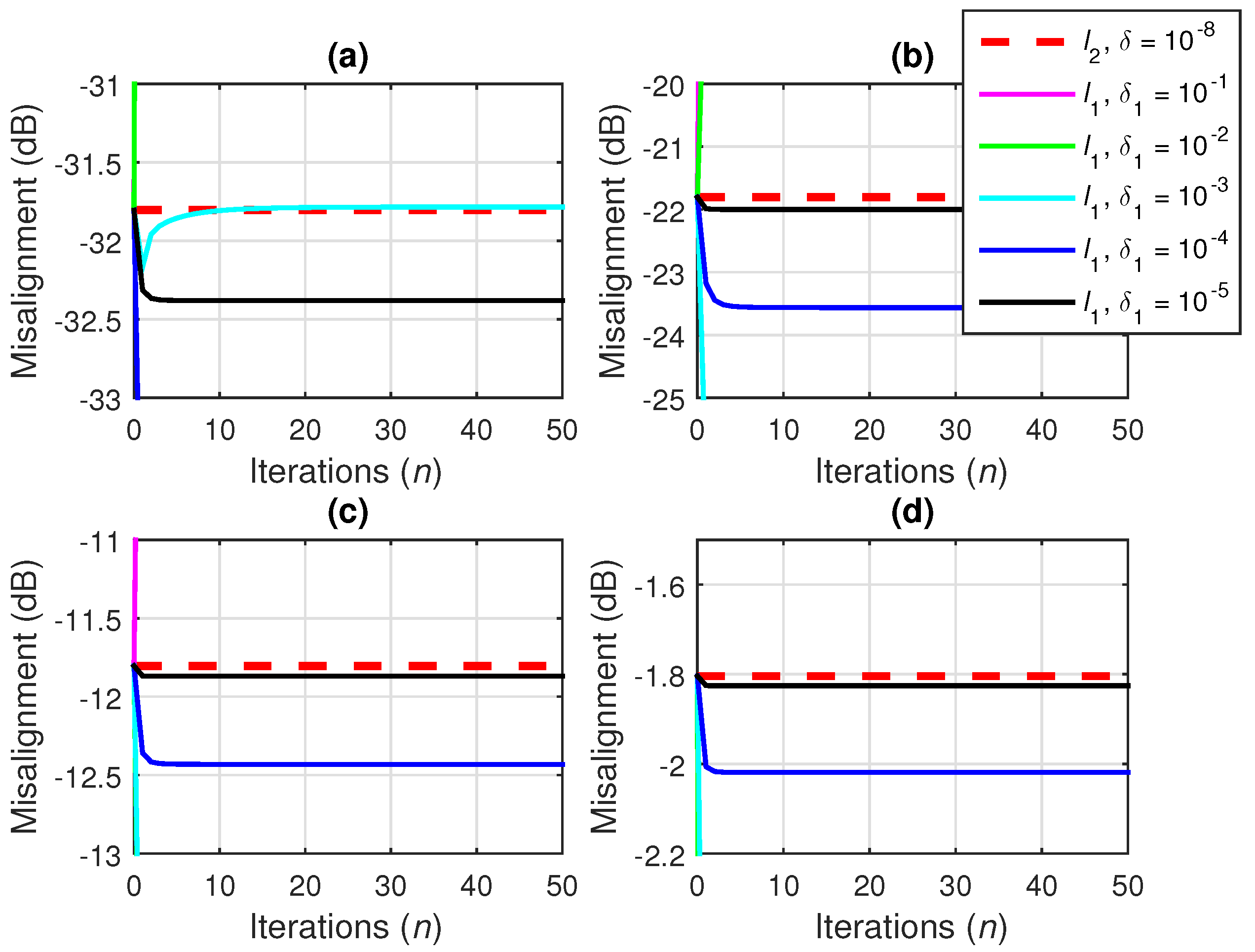
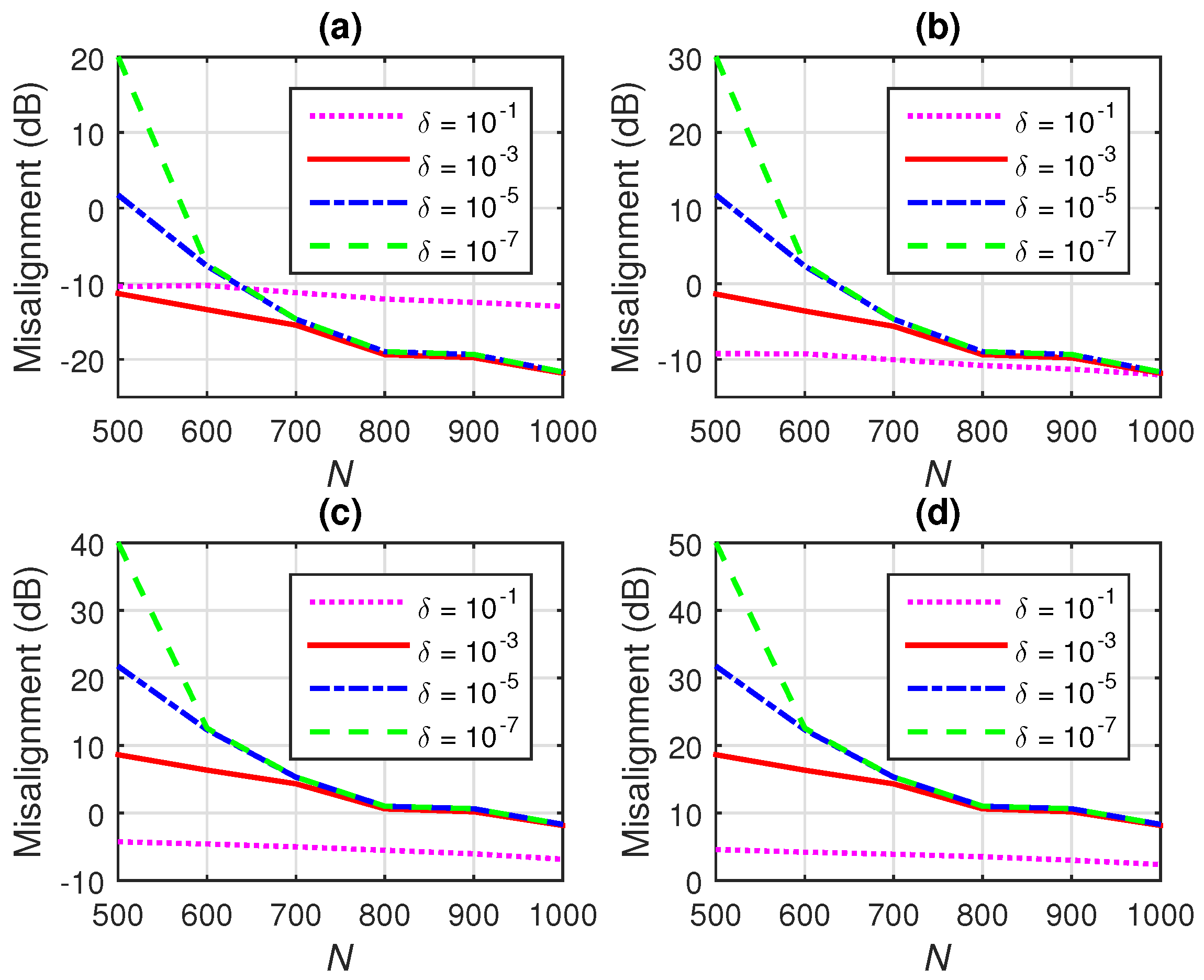
7.1. Conventional Wiener Filter with -Norm Regularization
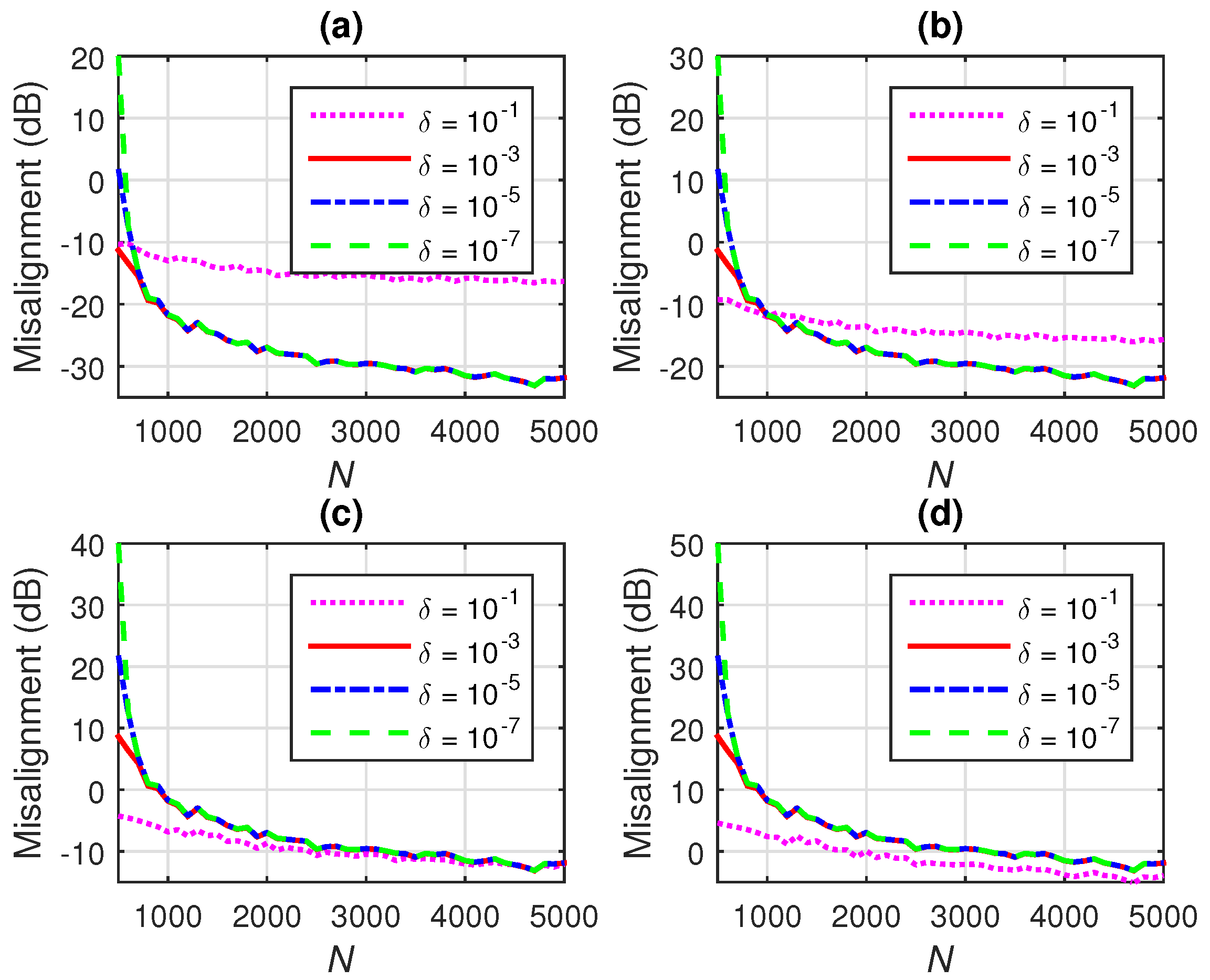
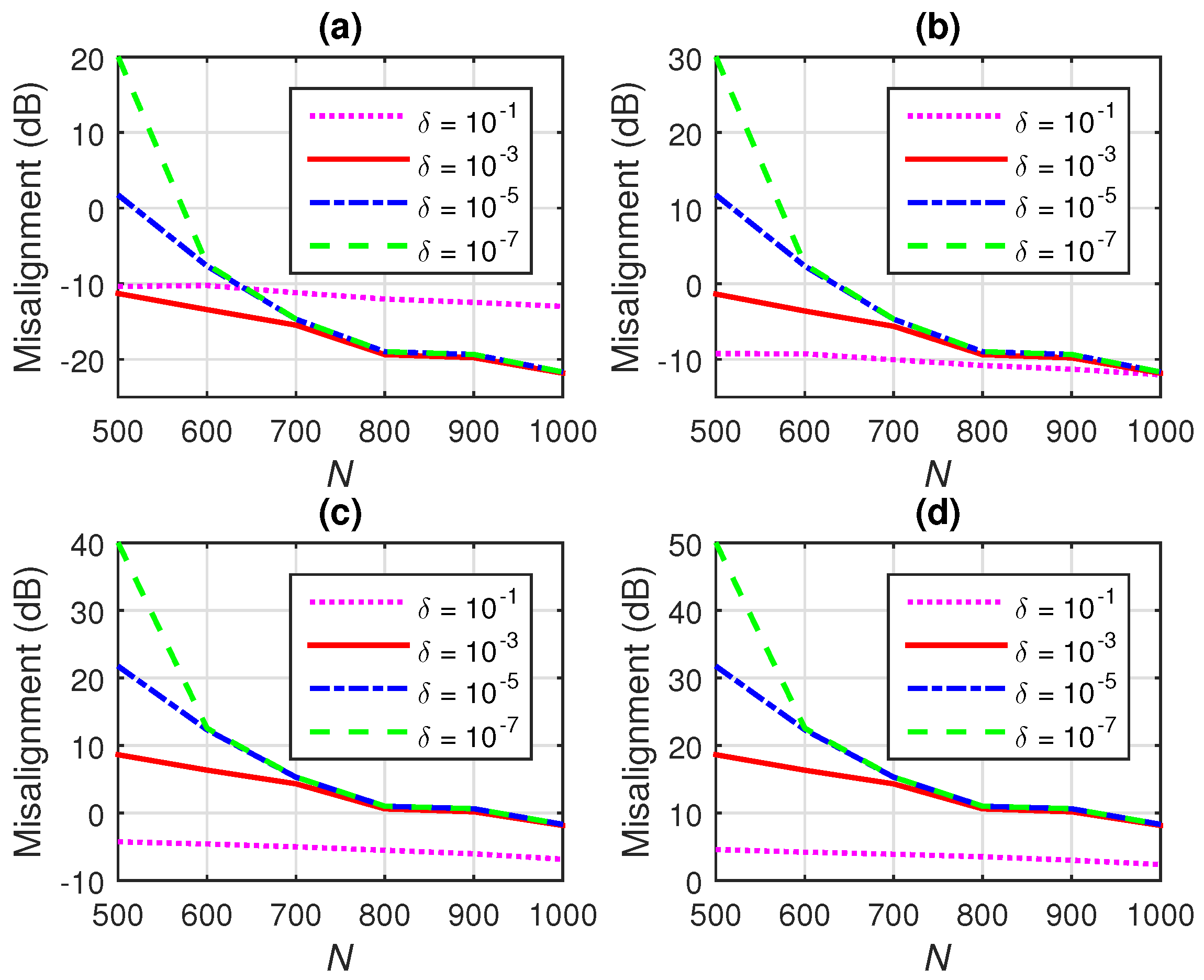
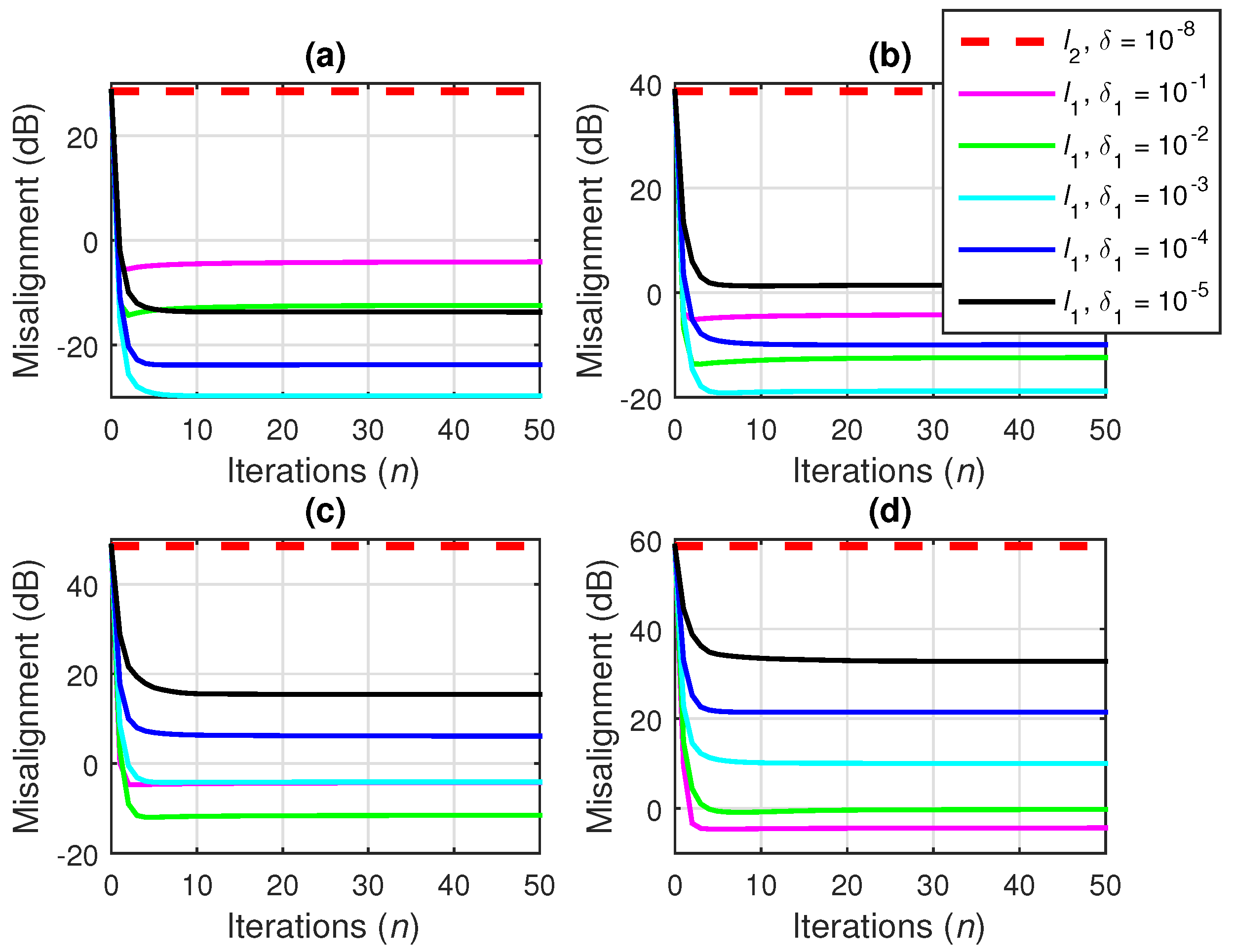
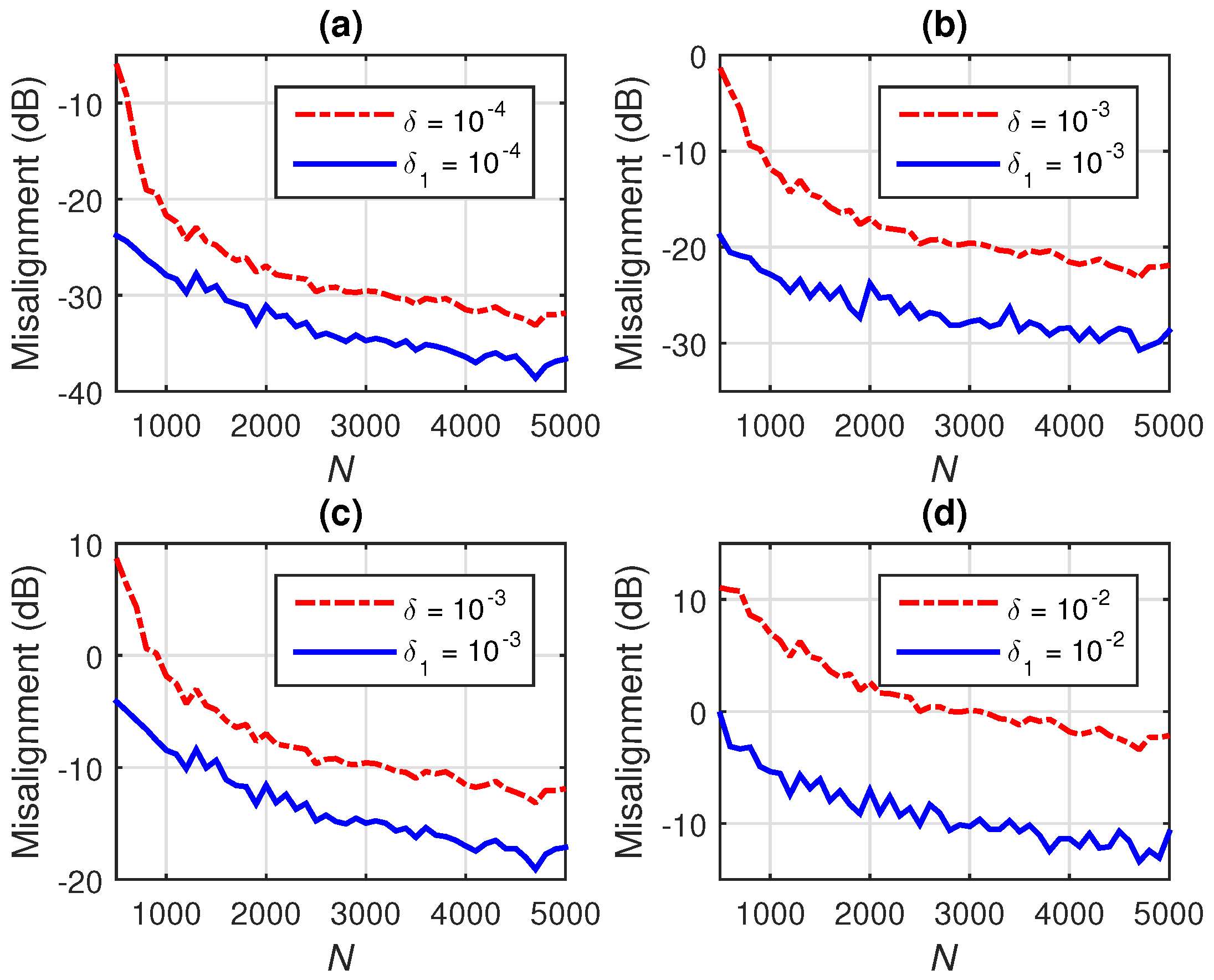
7.2. Iterative Wiener Filter with -Norm Regularization
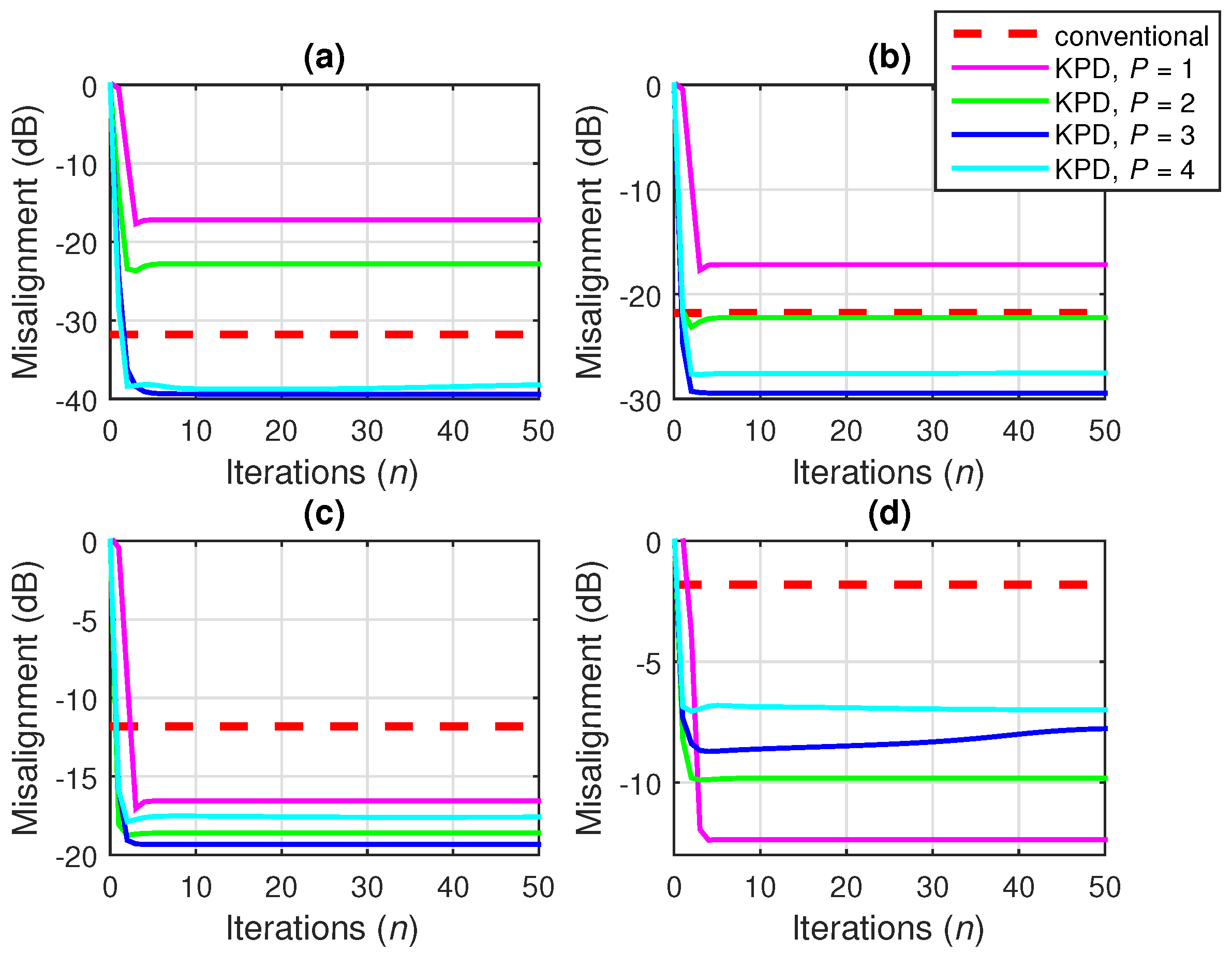
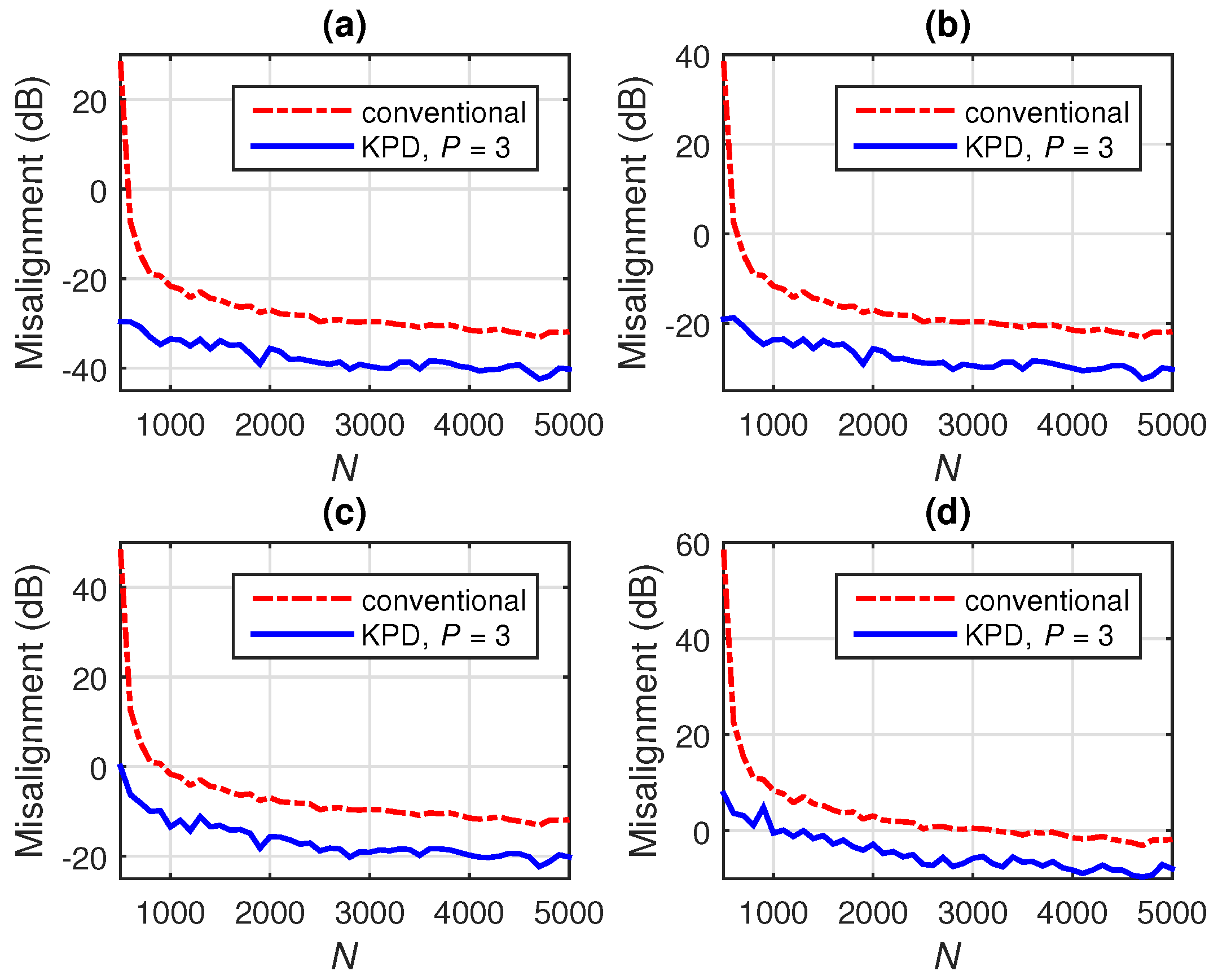
7.3. Wiener Filter Based on the Kronecker Product Decomposition
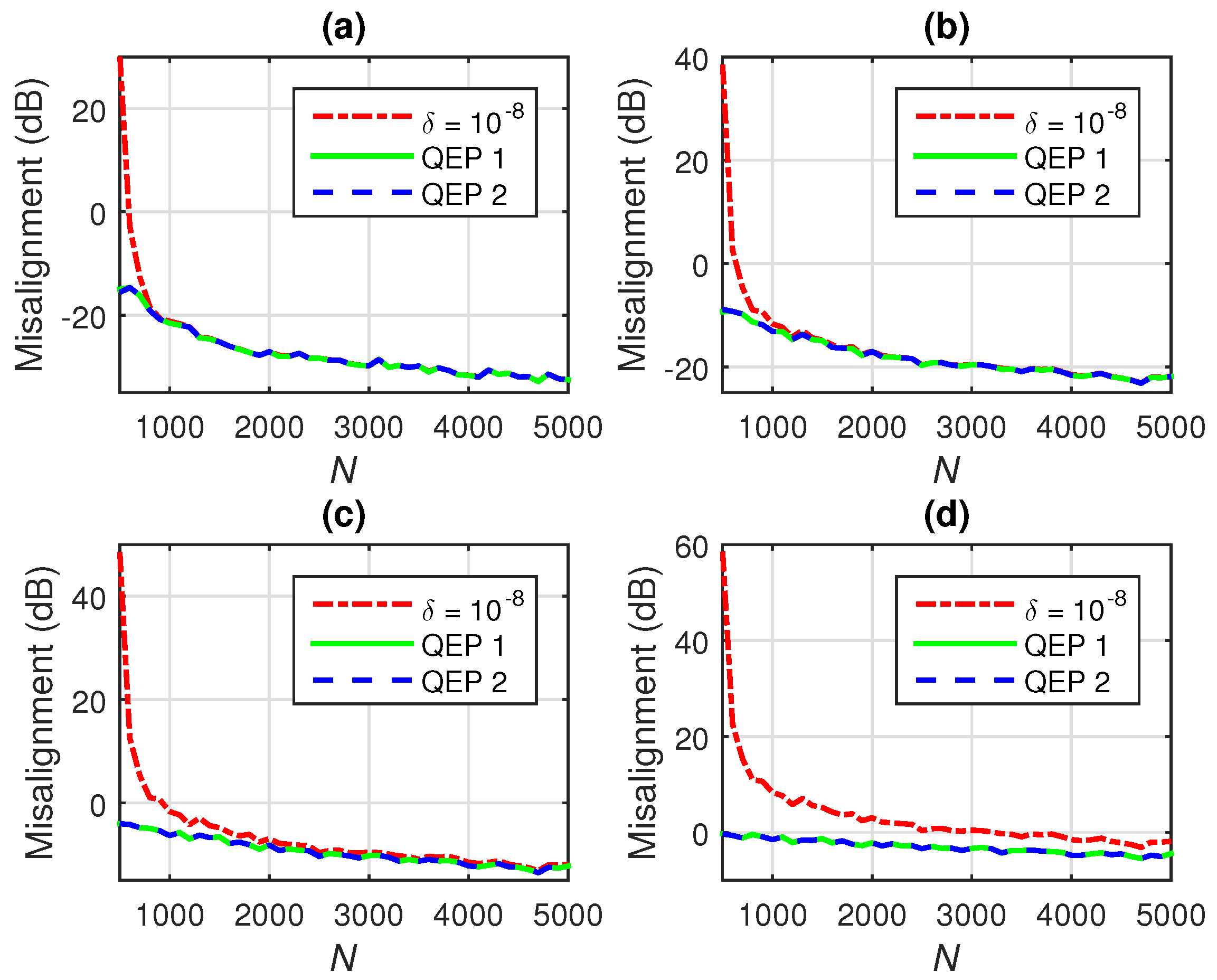
7.4. Wiener Filter with QEP Regularization
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wiener, N. Extrapolation, Interpolation, and Smoothing of Stationary Time Series; John Wiley & Sons: New York, NY, USA, 1949. [Google Scholar]
- Ljung, L. System Identification: Theory for the User, 2nd ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Haykin, S. Adaptive Filter Theory, 4th ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Benesty, J.; Huang, Y. (Eds.) Adaptive Signal Processing—Applications to Real-World Problems; Springer: Berlin, Germany, 2003. [Google Scholar]
- Diniz, P.S.R. Adaptive Filtering: Algorithms and Practical Implementation, 4th ed.; Springer: New York, NY, USA, 2013. [Google Scholar]
- Benesty, J.; Gänsler, T. Computation of the condition number of a nonsingular symmetric Toeplitz matrix with the Levinson–Durbin algorithm. IEEE Trans. Signal Process. 2006, 54, 2362–2364. [Google Scholar] [CrossRef]
- Benesty, J.; Paleologu, C.; Ciochină, S. On regularization in adaptive filtering. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 1734–1742. [Google Scholar] [CrossRef]
- Benesty, J.; Paleologu, C.; Ciochină, S. On the identification of bilinear forms with the Wiener filter. IEEE Signal Process. Lett. 2017, 24, 653–657. [Google Scholar] [CrossRef]
- Zakharov, Y.V.; Tozer, T.C. Multiplication-free iterative algorithm for LS problem. IEE Electron. Lett. 2004, 40, 567–569. [Google Scholar] [CrossRef]
- Paleologu, C.; Benesty, J.; Ciochină, S. Linear system identification based on a Kronecker product decomposition. IEEE ACM Trans. Audio Speech Lang. Process. 2018, 26, 1793–1808. [Google Scholar] [CrossRef]
- Constantin, I.; Richard, C.; Lengellé, R.; Soufflet, L. Nonlinear regularized Wiener filtering with kernels: Application in denoising MEG data corrupted by ECG. IEEE Trans. Signal Process. 2006, 54, 4796–4806. [Google Scholar] [CrossRef]
- Aguena, M.L.S.; Mascarenhas, N.D.A.; Anacleto, J.C.; Fels, S.S. MRI iterative super resolution with Wiener filter regularization. In Proceedings of the XXVI Conference on Graphics, Patterns and Images, Arequipa, Peru, 5–8 August 2013; pp. 155–162. [Google Scholar]
- Li, F.; Lv, X.-G.; Denga, Z. Regularized iterative Weiner filter method for blind image deconvolution. J. Comput. Appl. Math. 2018, 336, 425–438. [Google Scholar] [CrossRef]
- Benesty, J.; Paleologu, C.; Dogariu, L.M.; Ciochină, S. Identification of linear and bilinear systems: A unified study. Electronics 2021, 10, 1790. [Google Scholar] [CrossRef]
- Miller, S.K. Filtering and stochastic control: A historical perspective. IEEE Control Syst. Mag. 1996, 16, 67–76. [Google Scholar]
- Anderson, B.D.O. From Wiener to hidden Markov models. IEEE Control Syst. Mag. 1999, 19, 41–51. [Google Scholar]
- Glentis, G.-O.; Berberidis, K.; Theodoridis, S. Efficient least squares adaptive algorithms for FIR transversal filtering. IEEE Signal Process. Mag. 1999, 16, 13–41. [Google Scholar] [CrossRef]
- Benesty, J.; Sondhi, M.M.; Huang, Y. (Eds.) Springer Handbook of Speech Processing; Springer: Berlin, Germany, 2008. [Google Scholar]
- Pogula, R.; Kumar, T.K.; Albu, F. Robust sparse normalized LMAT algorithms for adaptive system identification under impulsive noise environments. Circuits Syst. Signal Process. 2019, 38, 5103–5134. [Google Scholar] [CrossRef]
- Golub, G.H.; Loan, C.F.V. Matrix Computations, 3rd ed.; The John Hopkins University Press: Baltimore, MD, USA, 1996. [Google Scholar]
- Hoyer, P.O. Non-negative matrix factorization with sparseness constraints. J. Mach. Learn. Res. 2001, 49, 1208–1215. [Google Scholar]
- Paleologu, C.; Benesty, J.; Ciochină, S. Sparse Adaptive Filters for Echo Cancellation; Morgan & Claypool Publishers: San Rafael, CA, USA, 2010. [Google Scholar]
- Hiriart-Urruty, J.B.; Lemaréchal, C. Convex Analysis and Minimization Algorithms II: Advanced Theory and Bundle Methods; Springer: New York, NY, USA, 1993. [Google Scholar]
- Natarajan, B.K. Sparse approximation solutions to linear systems. SIAM J. Comput. 1995, 24, 227–234. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Ma, S.; Goldfarb, D.; Chen, L. Fixed point and Bregman iterative methods for matrix rank minimization. Math. Program. Ser. A 2011, 128, 321–353. [Google Scholar] [CrossRef]
- Fazel, M.; Hindi, H.; Boyd, S. A rank minimization heuristic with application to minimum order system approximation. In Proceedings of the American Control Conference, Arlington, VA, USA, 25–27 June 2001; Volume 6, pp. 4734–4739. [Google Scholar]
- Chen, Y.; Chi, Y. Harnessing structures in big data via guaranteed low-rank matrix estimation: Recent theory and fast algorithms via convex and nonconvex optimization. IEEE Signal Process. Mag. 2018, 35, 14–31. [Google Scholar] [CrossRef]
- Tisseur, F.; Meerbergen, K. The quadratic eigenvalue problem. SIAM Rev. 2001, 43, 235–286. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Benesty, J.; Huang, G.; Chen, J. On the robustness of the superdirective beamformer. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 838–849. [Google Scholar] [CrossRef]
- Gander, W. Least squares with a quadratic constraint. Numer. Math. 1981, 36, 291–307. [Google Scholar] [CrossRef]
- Gander, W.; Golub, G.H.; von Matt, U. A constrained eigenvalue problem. Linear Algebra Appl. 1989, 114–115, 815–839. [Google Scholar] [CrossRef] [Green Version]
- Digital Network Echo Cancellers; ITU-T Recommendations G.168; ITU: Geneva, Switzerland, 2002.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dogariu, L.-M.; Benesty, J.; Paleologu, C.; Ciochină, S. An Insightful Overview of the Wiener Filter for System Identification. Appl. Sci. 2021, 11, 7774. https://doi.org/10.3390/app11177774
Dogariu L-M, Benesty J, Paleologu C, Ciochină S. An Insightful Overview of the Wiener Filter for System Identification. Applied Sciences. 2021; 11(17):7774. https://doi.org/10.3390/app11177774
Chicago/Turabian StyleDogariu, Laura-Maria, Jacob Benesty, Constantin Paleologu, and Silviu Ciochină. 2021. "An Insightful Overview of the Wiener Filter for System Identification" Applied Sciences 11, no. 17: 7774. https://doi.org/10.3390/app11177774
APA StyleDogariu, L.-M., Benesty, J., Paleologu, C., & Ciochină, S. (2021). An Insightful Overview of the Wiener Filter for System Identification. Applied Sciences, 11(17), 7774. https://doi.org/10.3390/app11177774