1. Introduction
Falls in the hospital setting are related to increased morbidity and mortality and a higher cost of care for the injured patient [
1,
2]. The prevention of such events is crucial to reduce the public health burden of in-hospital falls, which represent the most frequent adverse event occurring during the hospitalization [
3].
Several risk factors have been identified for these events, including both risk factors related to the patient and related to the environment [
4,
5]. Organizations worldwide involved in the improvement of the quality of care and patients’ safety have developed initiatives for falls’ risk management [
6,
7]. The core recommendations are represented by patients’ risk assessment using validated tools, and the development and implementation of multidisciplinary personalized fall prevention plans modifying all the potential risk factors identified.
Even though substantial efforts have been put forwards for falls’ risk management, this phenomenon continues to be worrying with more than 700,000 patients falling every year in the United States’ hospitals [
8]. It would be of interest understanding the reasons why falls continue to be so frequent. It might be hypothesized that risk management interventions are not adequately implemented in the in-hospital setting; however, it could be suggested that such interventions might be ineffective since the phenomenon of falls has not yet been fully understood.
Systematic epidemiological surveillance of the phenomenon is crucial to better characterize falls. In Italy, it has been established a data collection system of in-hospital sentinel events, including fatal falls and falls resulting in severe injury. Furthermore, it is recommended [
9] to the Local Health Authorities to report all falls (not necessarily resulting in severe injury or in the death of the patient). However, such reporting systems are highly variable among Italian Local Health Authorities. Anyway, generally, they are based on a data collection form that might include both pre-coded information and narratives. Therefore, it is crucial to adopt strategies of analyses allowing for the effective exploitation of information reported in narratives, since the manual revision of such information is unfeasible. The use of text mining would be a promising opportunity to exploit such information especially thank to the wide implementation of electronic health records [
10], and it has been suggested to have a good performance [
11]; however, applications in the field of injury surveillance are sparse.
Narratives could be a great source of additional information helping to better understand the phenomenon of injuries because it has been shown that integrating narratives with pre-coded information in injury surveillance can result in a better understanding of injury patterns [
12]. Such integrated information would serve as input for ad hoc data analysis approaches aimed at detecting and grouping observations with similar characteristics (e.g., cluster analysis) each one potentially identifying a specific pattern of injury i.e., in terms of subjects’ characteristics and falls’ characteristics. The recognition of such patterns would serve for guiding the development of further primary prevention strategies in the field.
The present study aimed to evaluate the value added by information reported in narratives (extracted through text mining techniques) in enhancing the characterization of falls patterns. To achieve this aim, the data from the incident reporting system of an Italian Local Health Authority were used.
2. Materials and Methods
Falls notified to the Risk Management Service of a Local Health Authority in Italy (name not disclosed as per research agreement) were considered in the analysis.
The Local Health Authority included two hospitals and three health districts aimed at outpatients’ care. Falls are notified via a data collection form made of two parts. In the first part, information was provided by the health care professional involved in patient’s care (e.g., nurse, physical therapist, midwife) and included socio-demographic information, risk factors for falls and strategies adopted for the management of the falls’ risk management, fall’s characteristics (place and dynamics), potential causes of the fall, and a brief description of the event. The second section of the data collection tool was under the physician’s responsibility and reported the potential complications resulting from the fall (injury type, procedures performed for the injury’s diagnosis, therapeutic interventions performed) and the drug therapy of the patient at the time of the fall.
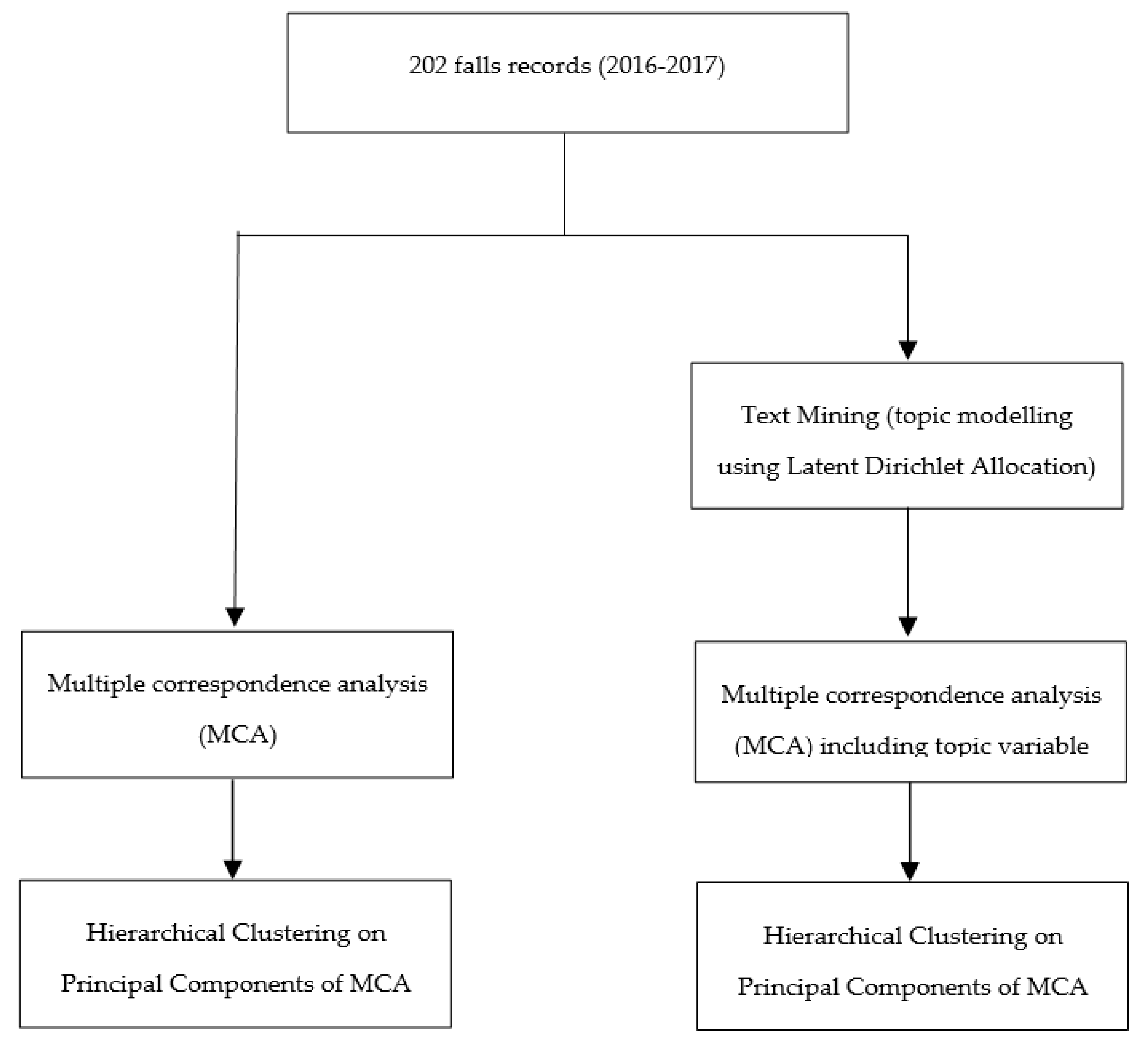
All the information was pre-coded except for the event’s description that was a narrative. The data analysis workflow is summarized in
Figure 1.
At first, multiple correspondence analysis (MCA) was performed on pre-coded information only. Then, it was re-rerun on the pre-coded data augmented with a variable representing the output analysis of the narrative records. This second analysis required a pre-processing of the narratives followed by text mining, which consisted in the implementation of topic modelling, using Latent Dirichlet Allocation (LDA) model, for clustering the narrative records into topics. Finally, a Hierarchical Clustering on the two MCAs was carried out to identify distinct fall patterns.
2.1. Pre-Processing of Narratives
The pre-processing of narratives consisted in the tokenization, stop words removal, and stemming. The first step of the pre-processing was the tokenization, by which the text was split into words. Then, a stop words list was identified including the most common words in the text of the documents (mainly articles, prepositions, and pronouns). Stop words were removed from the text along with terms with less than four characters. Finally, the Martin Porter’s stemming procedure [
13] implemented in the SnowballC R package was used to identify the root/stem of each word.
2.2. Text Mining: Latent Dirichlet Allocation Model
LDA [
14] model is the most popular probabilistic topic modelling. It assumes that each document contains a mixture of topics, and each topic is a probability distribution over words. LDA model was used to detect topics inside the pre-processed narratives.
To carry out the LDA model, a Dirichlet prior was specified on the per-topic word distributions and on the per-document topic distribution. According to Griffiths and Styvers [
15], the parameters were set equal to 0.1 and to 50 divided by the number of topics (50/k), respectively.
The input data for the LDA was the document-term matrix built over the pre-processed narratives records, each row corresponding to a record and each column to a term. In addition, to reduce the sparsity of the document-term matrix, only terms that occurred in a minimum number of 5 documents were retained. Finally, we used the mean term frequency inverse document frequency (TF-IDF) over the documents to reduce the sparsity of document-term matrix. TF-IDF allows for removing both less frequent and very common terms [
16].
Different models with a number of topics ranging from 2 to 50 were fitted and estimated using Gibbs sampling [
17] with a burn-in of 2000 iterations, retaining 1 every 100 iterations for the subsequent 1000 iterations. Model selection with respect to the number of topics was done by splitting the data into training and test sets and using 10-fold cross-validation.
The perplexity measure, a standard way of evaluating language models, i.e., the probability distribution constructed over the text, was used to assess the topic model on hold out data and then to identify the best number of topics [
18]. Perplexity is the geometric mean per word-likelihood and that can be interpreted how well a probability model predicts a sample.
2.3. Multiple Correspondence Analysis
As usual when analyzing questionnaire data, multiple correspondence analysis (MCA) was used as a pre-process step before clustering [
19]. MCA allows for coding the categorical variables into a set of principal components.
MCA was performed both on pre-coded information only and on the pre-coded information together with the information extracted from narratives. To include the information from the text mining of the events, a supplementary variable (topic variable) that identified each narrative with the most represented topic was added.
2.4. Hierarchical Clustering on Principal Components
The hierarchical clustering of the principal components (HCPC) obtained through MCA was used for the clustering process [
20]. Similarity measures were generated computing the Euclidean distance on the five first components by Ward’s method [
21]. The number of clusters was set equal at that one suggested by the algorithms, which was based on the ratio of the variance within-clusters and the total variance.
For each category of categorical variables, the V test was computed. The V-test was used to assess which categories are over-represented in the clusters. The V-test statistics can be considered as a standardized deviation between the mean of those individuals with the specific category and the general average [
21]. The categories that are over-represented in the clusters have a V-test statistics greater than 1.96 (
p-value < 0.05). The higher the statistics, the more strongly the category is over-represented in the cluster.
2.5. Model Validity
To compare the performance of the analyses with and without the topic variable (corresponding to the information retrieved from narratives), the within-cluster sum of square (WSS) was computed [
22]. WSS is a standard measure of the goodness of a clustering structure without considering external information and indicates how closely related are the individuals in a cluster. For our purpose, WSS was not used to determine the number of clusters, but just to formalize the within-groups sum of squares distances.
2.6. Statistical Analysis
Descriptive statistics were reported as a percentage and frequency for the categorical variables. Analyses were performed using R System ver 3.5.1 [
23]. The R packages FactoMiner [
24] and MissMDA [
25] were used to perform MCA and HCPC analyses. The R packages tm [
26] and topic models [
27] were used to perform the pre-processing of the text and the topic modelling.
3. Results
Two hundred and two falls were considered in the analysis. Patients’ median age was 77 years. Almost all falls occurred when the patients were hospitalized (95%) while they were alone (48%) in his hospital bedroom (70.1%) or in the toilet of his hospital bedroom (21.4%) during the afternoon (39.6%). About two-thirds of patients were at risk of fall (66.2%) according to the STRATIFY tool [
28], but only in a small proportion of patients, a personalized fall prevention plan (27.5%) was developed (
Table 1).
3.1. Pre-Processing Procedures and Text Mining
The pre-processing led to the identification of 212 vocabulary terms and 2310 tokens in the corpus. Using the cross-validation procedure, it was found out that ten topics were enough for a good sorting of documents, with a perplexity value of 443.5 (
Table 2).
Such procedures led to the identification of a topic variable that was incorporated in the further analyses.
3.2. MCA and HCPC Analyses
The MCA was run both with and without the topic variable. In the MCA model without the topic variable, the first three dimensions explained the 19.72% of the overall data space, while with the topic variable the first three dimensions were found to explain the 17.4% of the overall data space.
For what concerns the results of the HCPC, three clusters were identified using only pre-coded information (
Table 3).
The first one corresponded to elimination-related falls, accounting for 51 fall cases (27%). The second one grouped 139 (64%) falls occurred while the patient was in his hospital bedroom and was trying to get out from his hospital bed. The last cluster was the less represented (12, 8% of falls) corresponding to outpatients fell in the outpatient clinics without any fall risk with a resulting injury requiring a suture. The HCPC with the topic variable provided similar results (
Table 4).
The first cluster identified elimination-related falls, accounting for 53 falls; 113 falls were grouped in the cluster 2, which included falls in the hospital bedroom while the patient was trying to get out from the hospital bed. Even in this case, the cluster 3 was the less represented, with 11 falls involving outpatients.
The fact that results provided by the HCPC with only pre-coded information and with pre-codes information together with the topic variable was confirmed by the analysis of the WSS, which was 9.22 for the HCPC without the topic variable and 8.71 with the addition of the topic variable to the HCPC.
4. Discussion
The present study aimed to explore the value added by information reported in narratives in characterizing patterns of falls. Present findings showed that adding data from narratives did not improve the understanding of such phenomenon, even though the performance of the cluster analysis was good.
To our knowledge, no previous studies have assessed if the integration of information from narratives improves the understanding of falls in the hospital setting; however, similar studies have been conducted in other settings with promising results [
12,
29]. Results of the present study did not demonstrate the hypothesis that the integration of the information improves the understanding of in-hospital falls since the cluster analysis did not improve by adding information derived from narratives. Such findings suggest that a validated, well-conceived, data collection tool including only pre-coded information could be enough to characterize this phenomenon and guaranteeing its surveillance. Thus, avoiding the collection of narratives, which is time-consuming for healthcare professionals, and the application of sophisticated techniques to derive information from free text, which requires specific expertise in the field of text mining, not always readily available in the hospital services. In addition to that, the results of the MCA analysis showed that the proportion of variability explained by the pre-coded variables of the data collection tool was very low (less than 20%). This means that, probably, pre-coded information collected was not especially useful to differentiate falls. Such findings highlight the need for validating data collection tools before their use, avoiding the collection of redundant information that is not useful for the differentiation of falls patterns.
However, the present findings do not mean that free text information is not useful at all since we cannot rule out that such type of information would be useful in a different study setting using a different data collection form. We might hypothesize several reasons to understand the reason why in this specific study free-text information did not provide any additional value to the characterization of falls patterns. The main one is that the type of data collected are redundant and the data collection form needs to be improved through a validation process. For this reason, we might hypothesize to develop ad hoc strategies to overcome such issues, including the use of validated data collection forms and the improvement of narratives quality by involving health care professionals, e.g., by providing a training in the use of the data collection form.
4.1. Limitations
A limitation of this work is the small sample size. Text mining techniques implemented depend on whether the sample size is big enough to be representative of the heterogeneity of the corpus vocabulary. However, the small sample size is balanced by the nature of the narratives, which are usually written adopting a plain and standard vocabulary, without substantial variation in the choice of the words.
4.2. Implications for Clinical Practice
From the clinical point of view, the characteristics of falls are consistent with those reported in the international literature [
30,
31,
32]. They occurred most often in the elderly patients at fall risk in the hospital bedroom while they were trying to get out from bed (or getting on the bed) or they were using the toilet. The clustering analysis succeeded in the identification of three well-defined specific clusters of falls. The first two clusters identified two patterns of in-hospital falls that are already well-known in the literature [
30,
31,
32]. Patients with elimination-related falls and those fell off the hospital bed identified respectively the first and the second clusters. Conversely, the third cluster is represented by outpatients fell in the outpatient clinic with a fall-related injury requiring a suture. There is already a substantial body of literature on falls occurring among community-dwelling individuals, particularly the elderly [
33]. Even though a low number of events occurred in outpatients, such results further highlight the need for implementing risk management strategies also for outpatients attending the outpatient clinics. The risk management of the outpatients is much more difficult of that of the inpatients (often patients attend the outpatient clinic only once, not allowing for a comprehensive risk assessment). Considering such a framework, it could be useful to manage the risk of falls also in the outpatient setting [
34,
35].
5. Conclusions
Even though several efforts have been made to improve the risk management of in-hospital falls, they continue to represent a severe health care burden. The present findings showed that the cluster analysis is effective in characterizing fall patterns; however, they do not sustain the hypothesis that the analysis of free-text information improves our understanding of such phenomenon.
Author Contributions
Conceptualization, D.G.; Formal analysis, A.B.; Investigation, R.R.; Methodology, G.L.; Writing—original draft, G.L.; Writing—review and editing, P.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Review and approval were waived for this study, due to the retrospective nature of the study based on anonymized data.
Informed Consent Statement
Patient consent was waived since only anonymized data was collected.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Morello, R.T.; Barker, A.L.; Watts, J.J.; Haines, T.; Zavarsek, S.S.; Hill, K.D.; Brand, C.; Sherrington, C.; Wolfe, R.; Bohensky, M.A. The Extra Resource Burden of In-Hospital Falls: A Cost of Falls Study. Med. J. Aust. 2015, 203, 367. [Google Scholar] [CrossRef]
- Dunne, T.J.; Gaboury, I.; Ashe, M.C. Falls in Hospital Increase Length of Stay Regardless of Degree of Harm. J. Eval. Clin. Pract. 2014, 20, 396–400. [Google Scholar] [CrossRef]
- Rubenstein, L.Z.; Josephson, K.R. The Epidemiology of Falls and Syncope. Clin. Geriatr. Med. 2002, 18, 141–158. [Google Scholar] [CrossRef]
- Sillner, A.Y.; Holle, C.L.; Rudolph, J.L. The Overlap between Falls and Delirium in Hospitalized Older Adults: A Systematic Review. Clin. Geriatr. Med. 2019, 35, 221–236. [Google Scholar] [CrossRef]
- Lan, X.; Li, H.; Wang, Z.; Chen, Y. Frailty as a Predictor of Future Falls in Hospitalized Patients: A Systematic Review and Meta-Analysis. Geriatr. Nurs. 2020, 41, 69–74. [Google Scholar] [CrossRef]
- Ganz, D.A.; Huang, C.; Saliba, D.; Miake-Lye, I.M.; Hempel, S.; Ganz, D.A.; Ensrud, K.E. Preventing Falls in Hospitals: A Toolkit for Improving Quality of Care. Ann. Intern. Med. 2013, 158, 390–396. [Google Scholar]
- Commission, J. Preventing Falls and Fall-Related Injuries in Health Care Facilities. Jt. Comm. 2015, 55, 1–55. [Google Scholar]
- Hughes, R. Patient Safety and Quality: An Evidence-Based Handbook for Nurses; Agency for Healthcare Research and Quality: Rockville, MD, USA, 2008; Volume 3.
- Minsitero Della Salute. Dipartimento Della Programmazione e Dell’ordinamento Del Servizio Sanitario Nazionale (SSN) Direzione Generale Della Programmazione, Ex Ufficio III. Raccomandazione per La Prevenzione e La Gestione Della Caduta Del Paziente Nelle Strutture Sanitarie, Raccomandazione n. 13, Novembre 2011 (Aggiornata Al 1 Dicembre 2011). 2007. Available online: https://www.salute.gov.it/imgs/C_17_pubblicazioni_1639_allegato.pdf (accessed on 6 April 2021).
- Nguyen, L.; Bellucci, E.; Nguyen, L.T. Electronic Health Records Implementation: An Evaluation of Information System Impact and Contingency Factors. Int. J. Med. Inform. 2014, 83, 779–796. [Google Scholar] [CrossRef]
- Lucero, R.J.; Lindberg, D.S.; Fehlberg, E.A.; Bjarnadottir, R.I.; Li, Y.; Cimiotti, J.P.; Crane, M.; Prosperi, M. A Data-Driven and Practice-Based Approach to Identify Risk Factors Associated with Hospital-Acquired Falls: Applying Manual and Semi-and Fully-Automated Methods. Int. J. Med. Inform. 2019, 122, 63–69. [Google Scholar] [CrossRef]
- Vallmuur, K.; Marucci-Wellman, H.R.; Taylor, J.A.; Lehto, M.; Corns, H.L.; Smith, G.S. Harnessing Information from Injury Narratives in the ‘Big Data’Era: Understanding and Applying Machine Learning for Injury Surveillance. Inj. Prev. 2016, 22, i34–i42. [Google Scholar] [CrossRef]
- Jones, K.S. Readings in Information Retrieval; Morgan Kaufmann: San Francisco, CA, USA, 1997; ISBN 1-55860-454-5. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Griffiths, T.L.; Steyvers, M. Finding Scientific Topics. Proc. Natl. Acad. Sci. USA 2004, 101, 5228–5235. [Google Scholar] [CrossRef]
- Leskovec, J.; Rajaraman, A.; Ullman, J.D. Mining of Massive Datasets; Cambridge University Press: Cambridge, UK, 2014; ISBN 1-107-07723-0. [Google Scholar]
- Gilks, W.R.; Richardson, S.; Spiegelhalter, D. Markov Chain Monte Carlo in Practice; Chapman and Hall/CRC: Boca Raton, FL, USA, 1995; ISBN 1-4822-1497-0. [Google Scholar]
- Ueberla, J.P. More Efficient Clustering of N-Grams for Statistical Language Modeling. In Proceedings of the Fourth European Conference on Speech Communication and Technology, Madrid, Spain, 18–21 September 1995. [Google Scholar]
- Greenacre, M.; Blasius, J. Multiple Correspondence Analysis and Related Methods; Chapman and Hall/CRC: Boca Raton, FL, USA, 2006; ISBN 1-4200-1131-6. [Google Scholar]
- Husson, F.; Josse, J.; Pages, J. Principal Component Methods-Hierarchical Clustering-Partitional Clustering: Why Would We Need to Choose for Visualizing Data. Appl. Math. Dep. 2010. Available online: http://factominer.free.fr/more/HCPC_husson_josse.pdf (accessed on 6 April 2021).
- Husson, F.; Lê, S.; Pagès, J. Exploratory Multivariate Analysis by Example Using R; Chapman and Hall/CRC: Boca Raton, FL, USA, 2017; ISBN 1-315-30187-3. [Google Scholar]
- Celebi, M.E.; Kingravi, H.A.; Vela, P.A. A Comparative Study of Efficient Initialization Methods for the K-Means Clustering Algorithm. Expert Syst. Appl. 2013, 40, 200–210. [Google Scholar] [CrossRef]
- Team, R.C. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- Lê, S.; Josse, J.; Husson, F. FactoMineR: An R Package for Multivariate Analysis. J. Stat. Softw. 2008, 25, 1–18. [Google Scholar] [CrossRef]
- Josse, J.; Husson, F. MissMDA: A Package for Handling Missing Values in Multivariate Data Analysis. J. Stat. Softw. 2016, 70, 1–31. [Google Scholar] [CrossRef]
- Feinerer, I.; Hornik, K. Tm: Text Mining Package, R package version 0.5-7.1; R Foundation for Statistical Computing: Vienna, Austria, 2012; Volume 1. [Google Scholar]
- Hornik, K.; Grün, B. Topicmodels: An R Package for Fitting Topic Models. J. Stat. Softw. 2011, 40, 1–30. [Google Scholar]
- Oliver, D.; Britton, M.; Seed, P.; Martin, F.C.; Hopper, A.H. A 6-Point Risk Score Predicted Which Elderly Patients Would Fall in Hospital. BMJ 1998, 315, 1049–1053. [Google Scholar] [CrossRef]
- Altuncu, M.T.; Mayer, E.; Yaliraki, S.N.; Barahona, M. From Free Text to Clusters of Content in Health Records: An Unsupervised Graph Partitioning Approach. Appl. Netw. Sci. 2019, 4, 2. [Google Scholar] [CrossRef]
- Hitcho, E.B.; Krauss, M.J.; Birge, S.; Claiborne Dunagan, W.; Fischer, I.; Johnson, S.; Nast, P.A.; Costantinou, E.; Fraser, V.J. Characteristics and Circumstances of Falls in a Hospital Setting. J. Gen. Intern. Med. 2004, 19, 732–739. [Google Scholar] [CrossRef]
- López-Soto, P.J.; Smolensky, M.H.; Sackett-Lundeen, L.L.; De Giorgi, A.; Rodríguez-Borrego, M.A.; Manfredini, R.; Pelati, C.; Fabbian, F. Temporal Patterns of In-Hospital Falls of Elderly Patients. Nurs. Res. 2016, 65, 435–445. [Google Scholar] [CrossRef]
- Aranda-Gallardo, M.; Morales-Asencio, J.M.; Canca-Sanchez, J.C.; Toribio-Montero, J.C. Circumstances and Causes of Falls by Patients at a Spanish Acute Care Hospital. J. Eval. Clin. Pract. 2014, 20, 631–637. [Google Scholar] [CrossRef]
- Robertson, M.C.; Gillespie, L.D. Fall Prevention in Community-Dwelling Older Adults. JAMA 2013, 309, 1406–1407. [Google Scholar] [CrossRef]
- De Gomes, G.A.O.; Cintra, F.A.; Batista, F.S.; Neri, A.L.; Guariento, M.E.; de Sousa, M.d.L.R.; D’Elboux, M.J. Elderly Outpatient Profile and Predictors of Falls. Sao Paulo Med. J. 2013, 131, 13–18. [Google Scholar] [CrossRef] [PubMed]
- Kobayashi, K.; Ando, K.; Suzuki, Y.; Inagaki, Y.; Nagao, Y.; Ishiguro, N.; Imagama, S. Characteristics of Outpatient Falls That Occurred in Hospital. Nagoya J. Med. Sci. 2018, 80, 417. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 




{kind=link}