
Deep Contrast Learning Approach for Address Semantic Matching

Abstract
:1. Introduction
2. Materials and Methods
| Algorithm 1 The ABLC algorithm |
| Input: address set Initialize sepResult with null divisionTree ← BuildTree(A) for ele in [ai, aj] do for node in divisionTree do if headof(ele, len(node)) == node: sepList ← node ele.delete(node) if node == LastNode(A): sepList ← ele sepResult ← set_List similarity ← ABLC(sepResult [0], sepResult [1]) sim(ai, aj) ← similarity |
2.1. Problem Definition
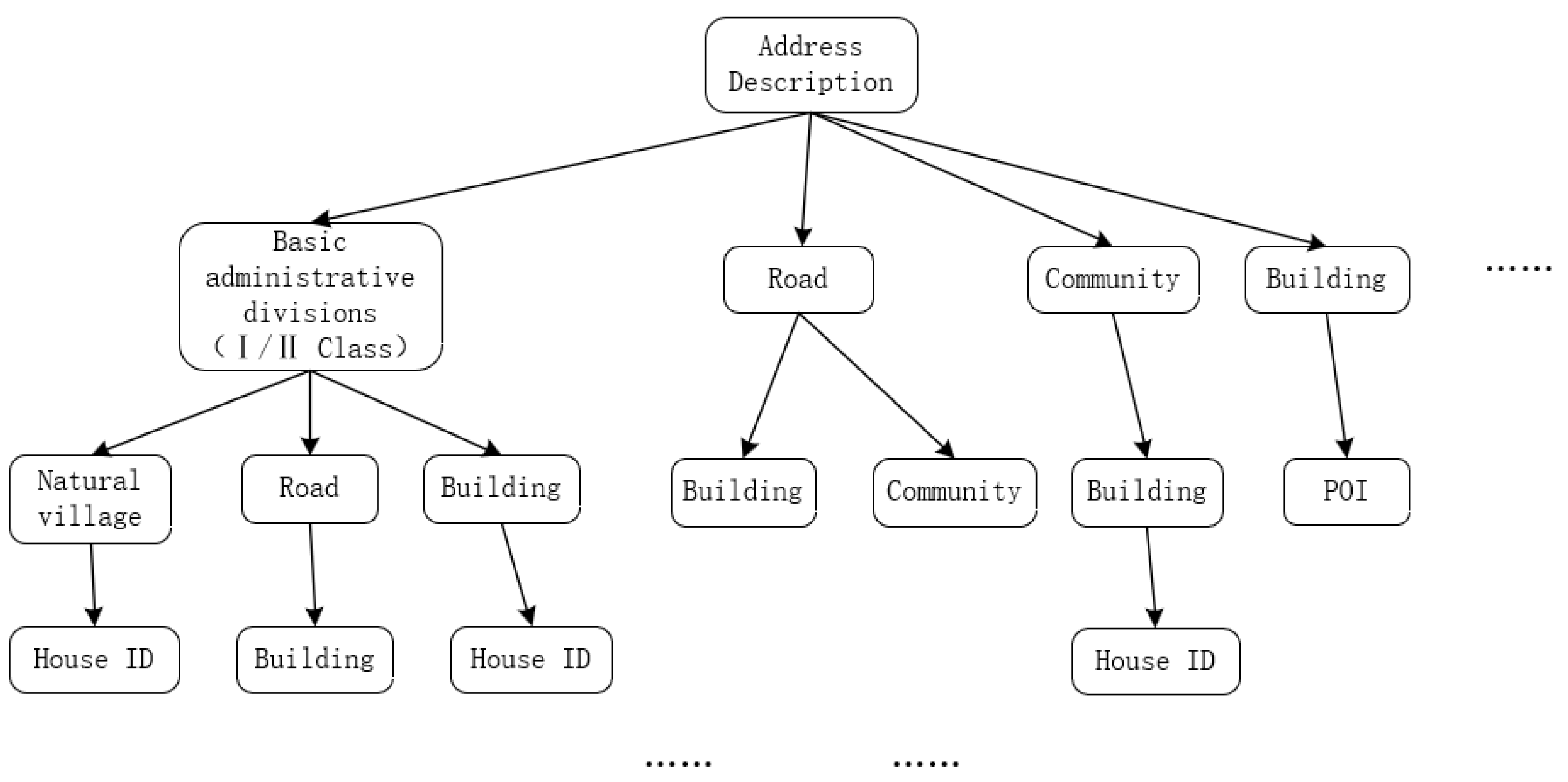
2.2. Address Model
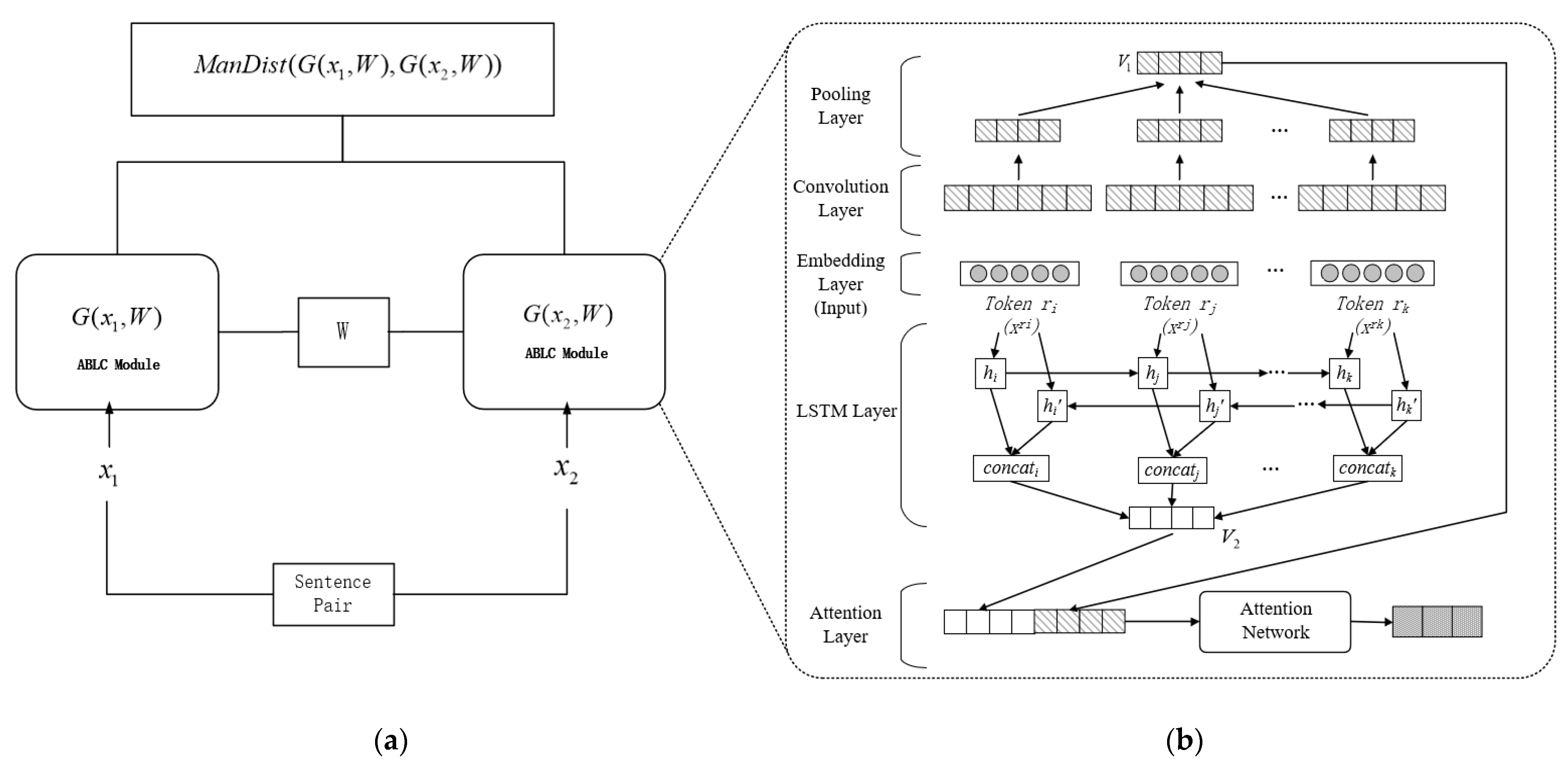
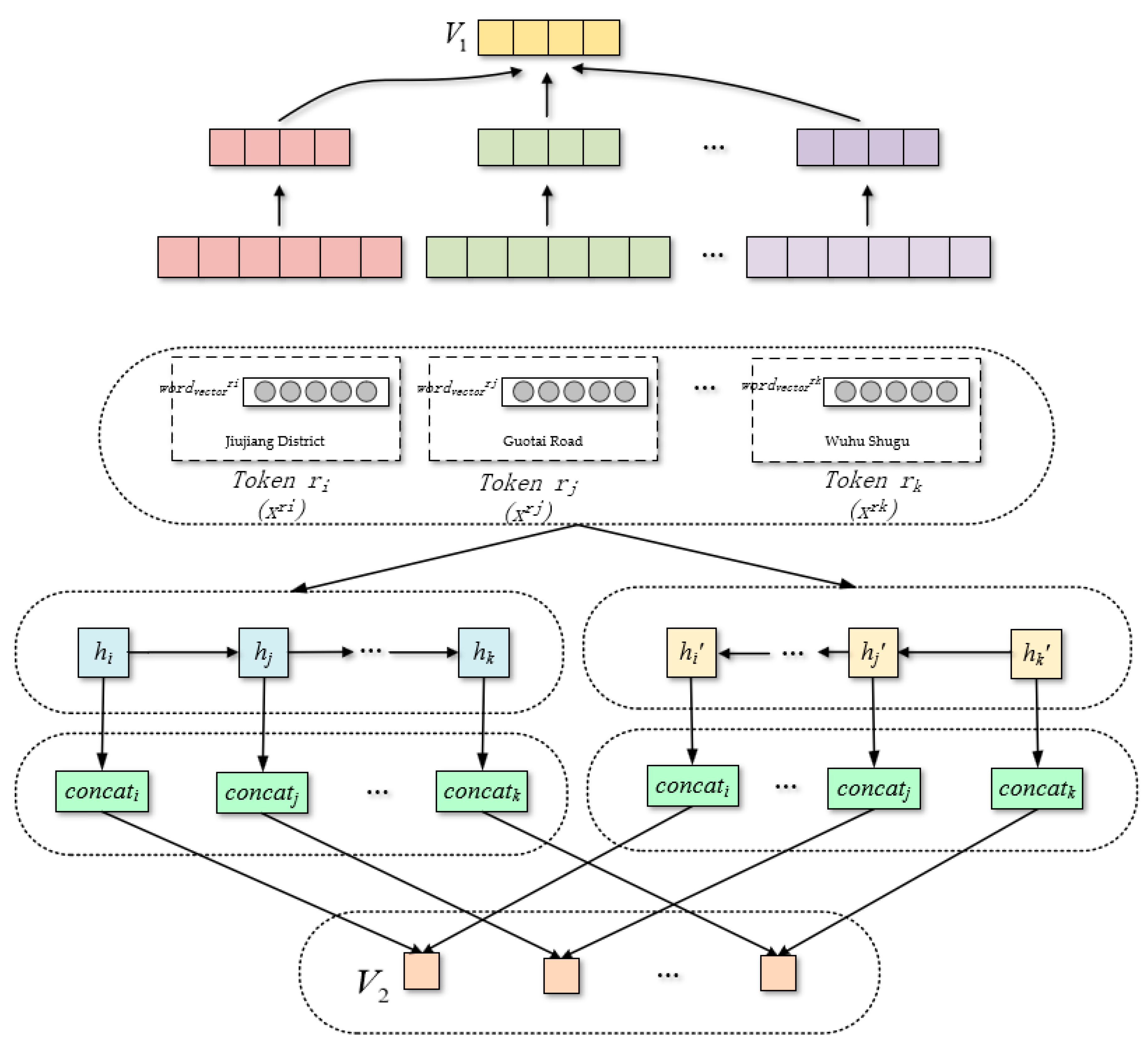
2.3. Address Semantic Contrast Learning Model
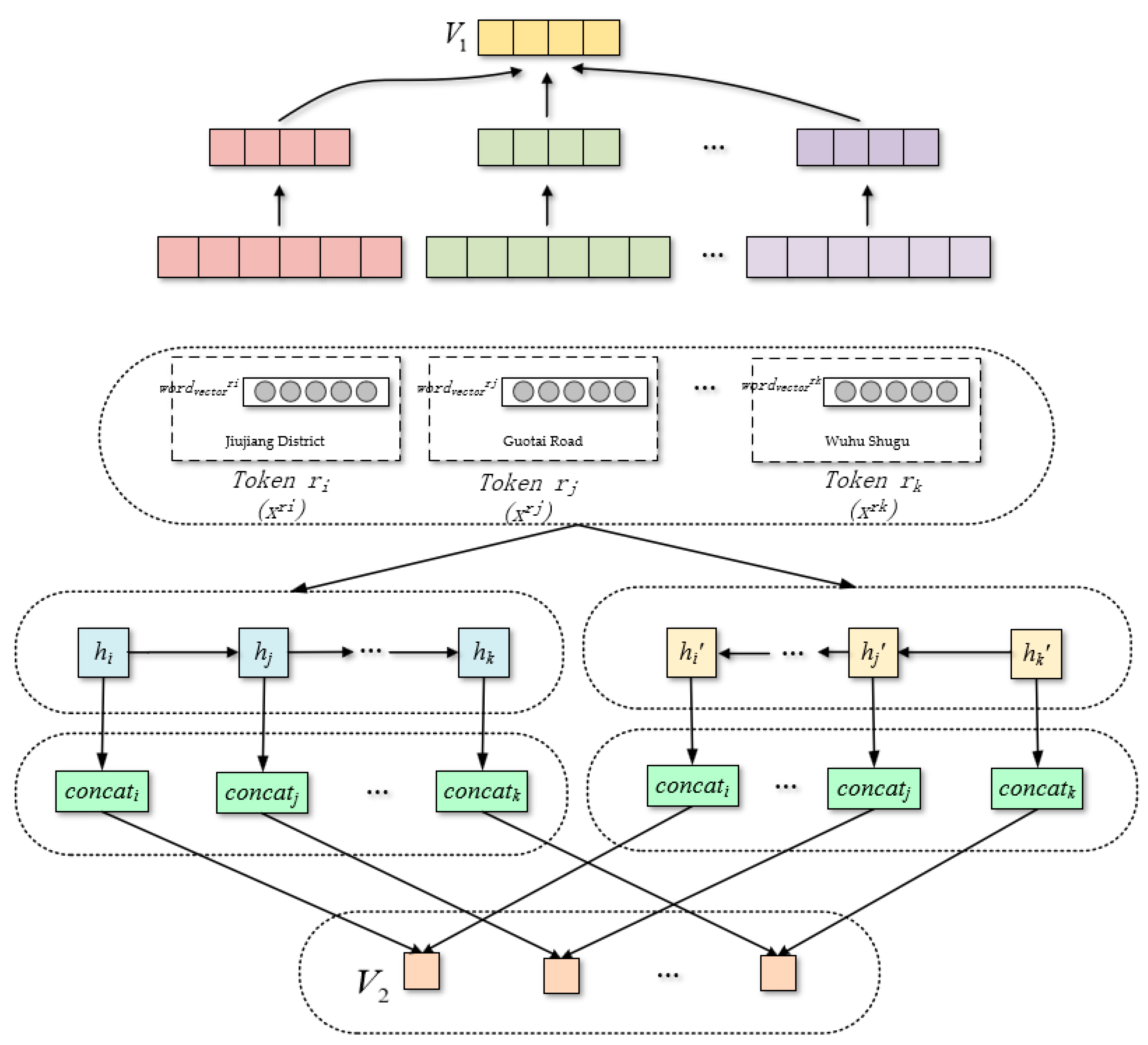
2.3.1. Embedding
2.3.2. Bi-LSTM
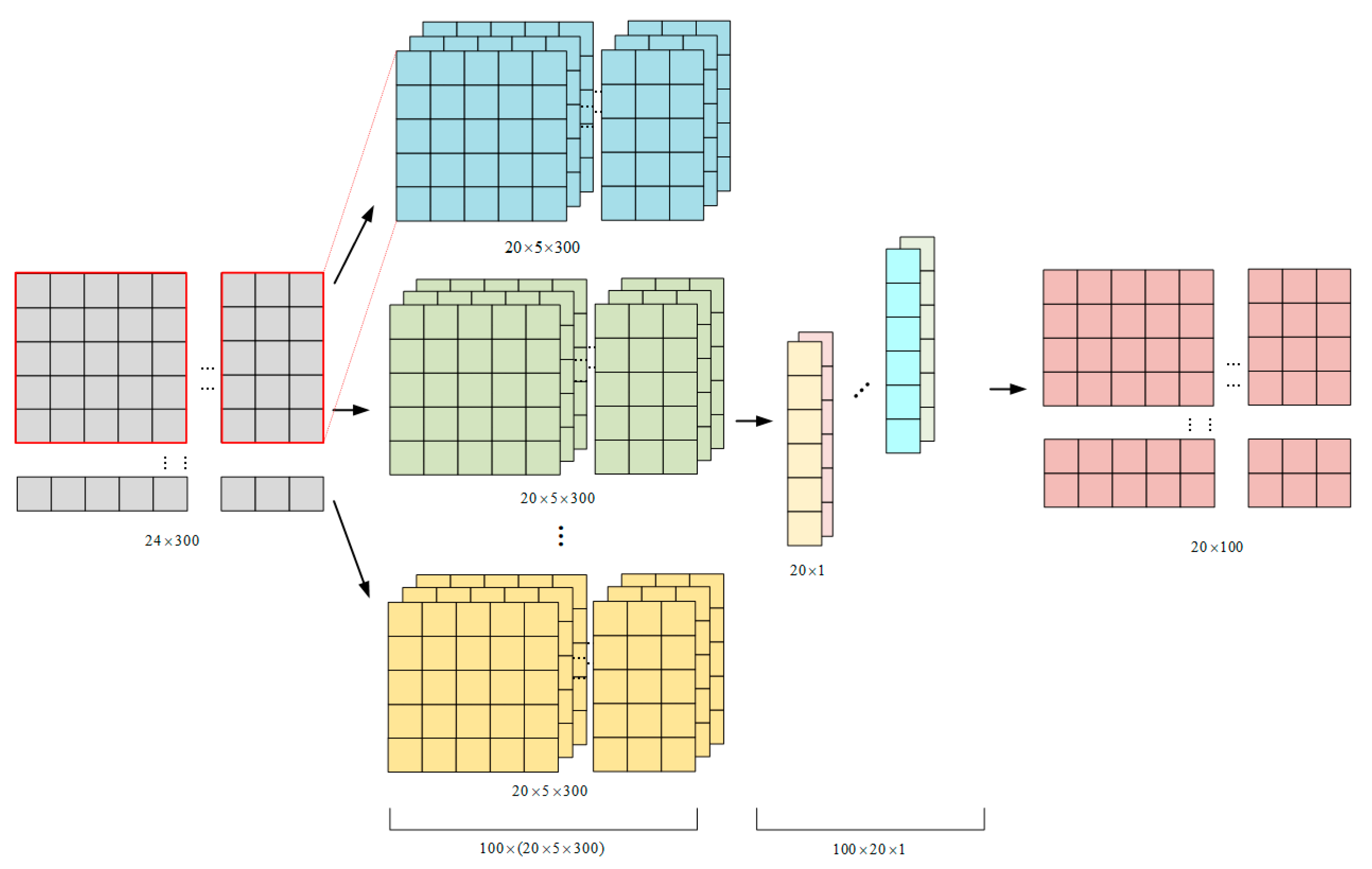
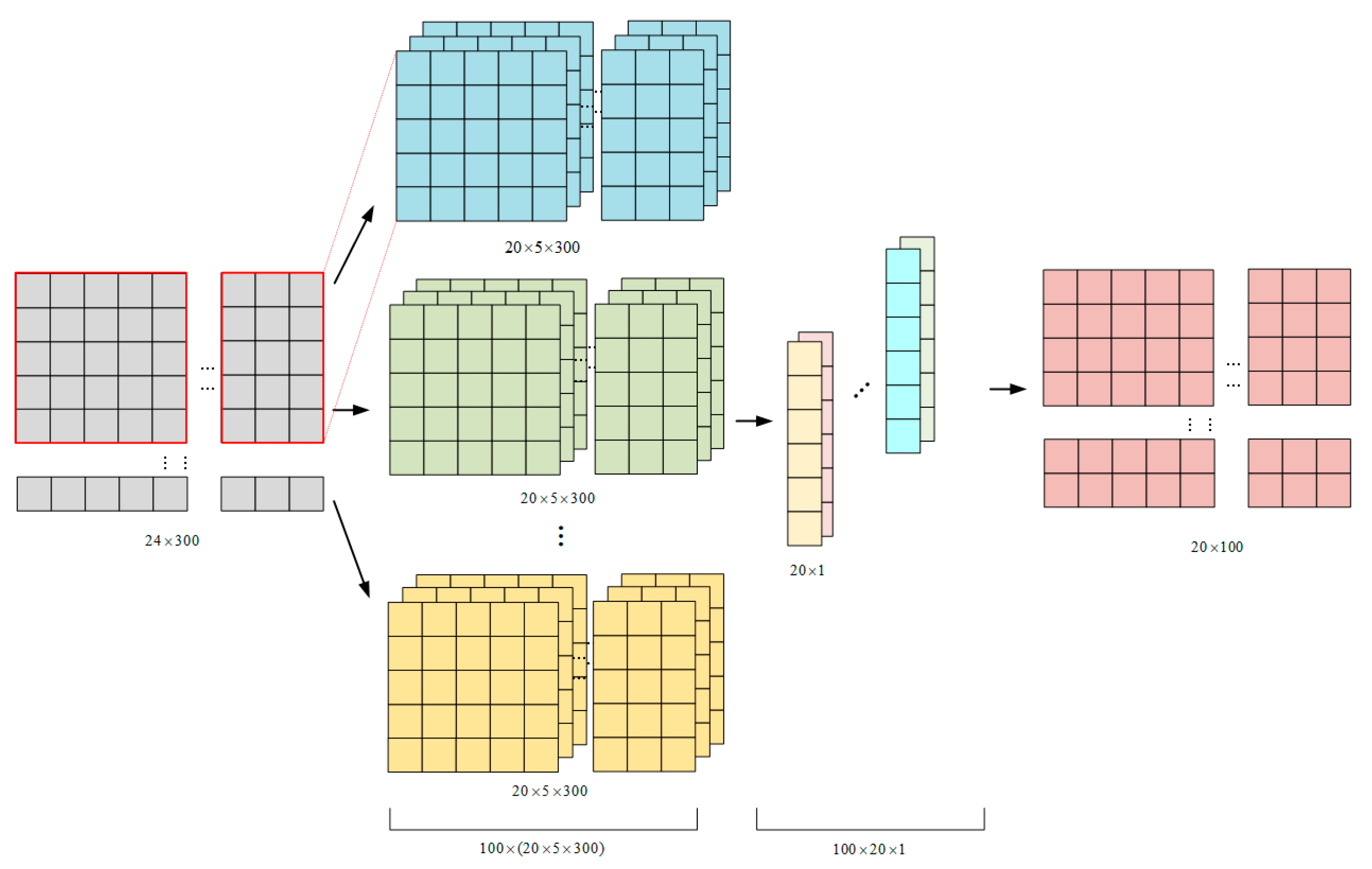
2.3.3. CNN
2.3.4. Attention
2.3.5. Manhattan Distance
3. Results
3.1. Dataset
3.2. Data Augmentation
3.3. Experiment
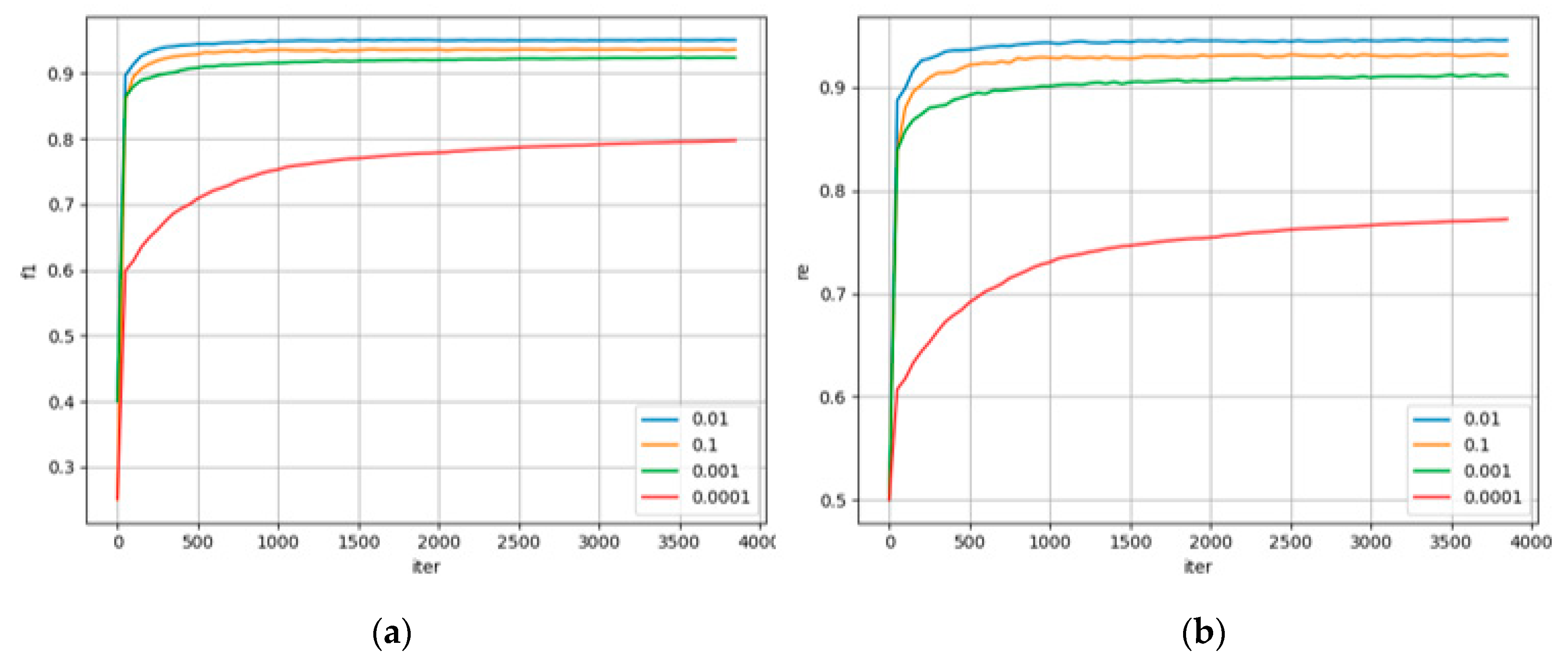
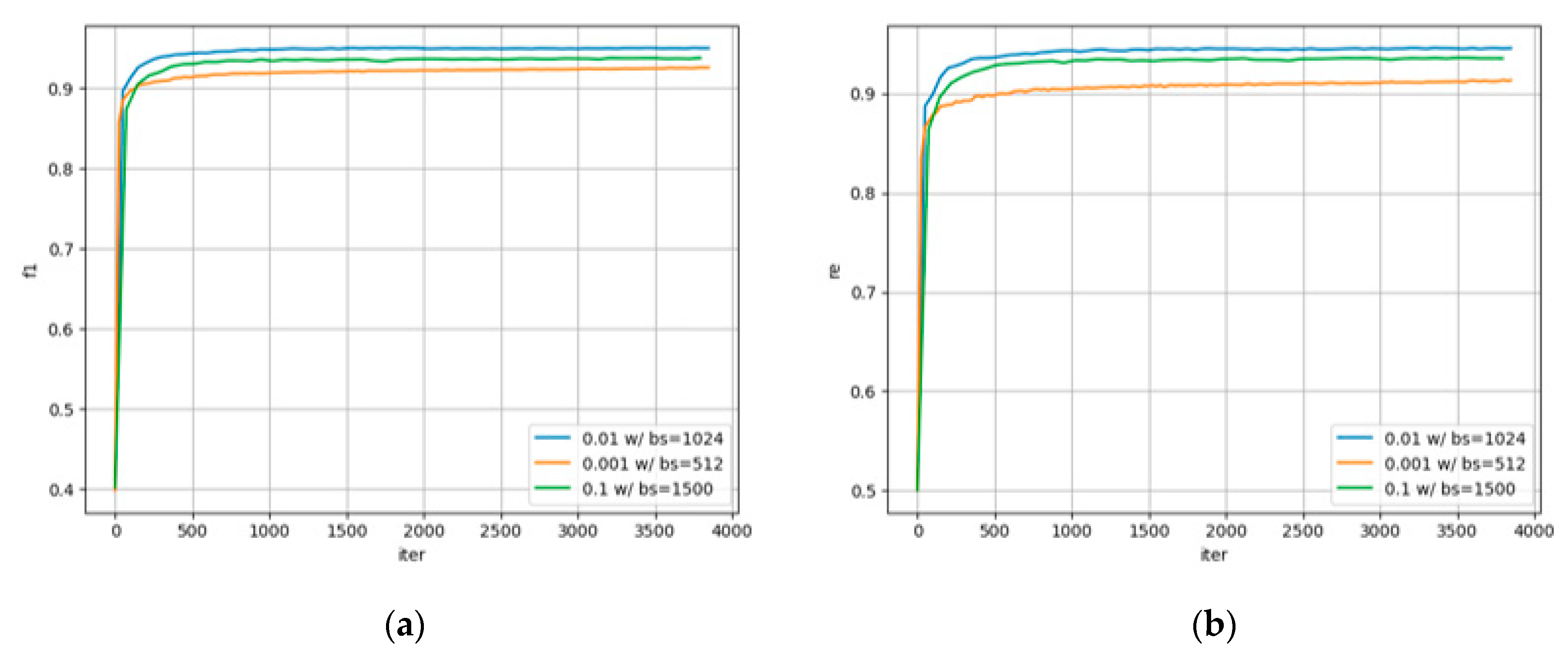
3.3.1. Parameter Experiment Analysis
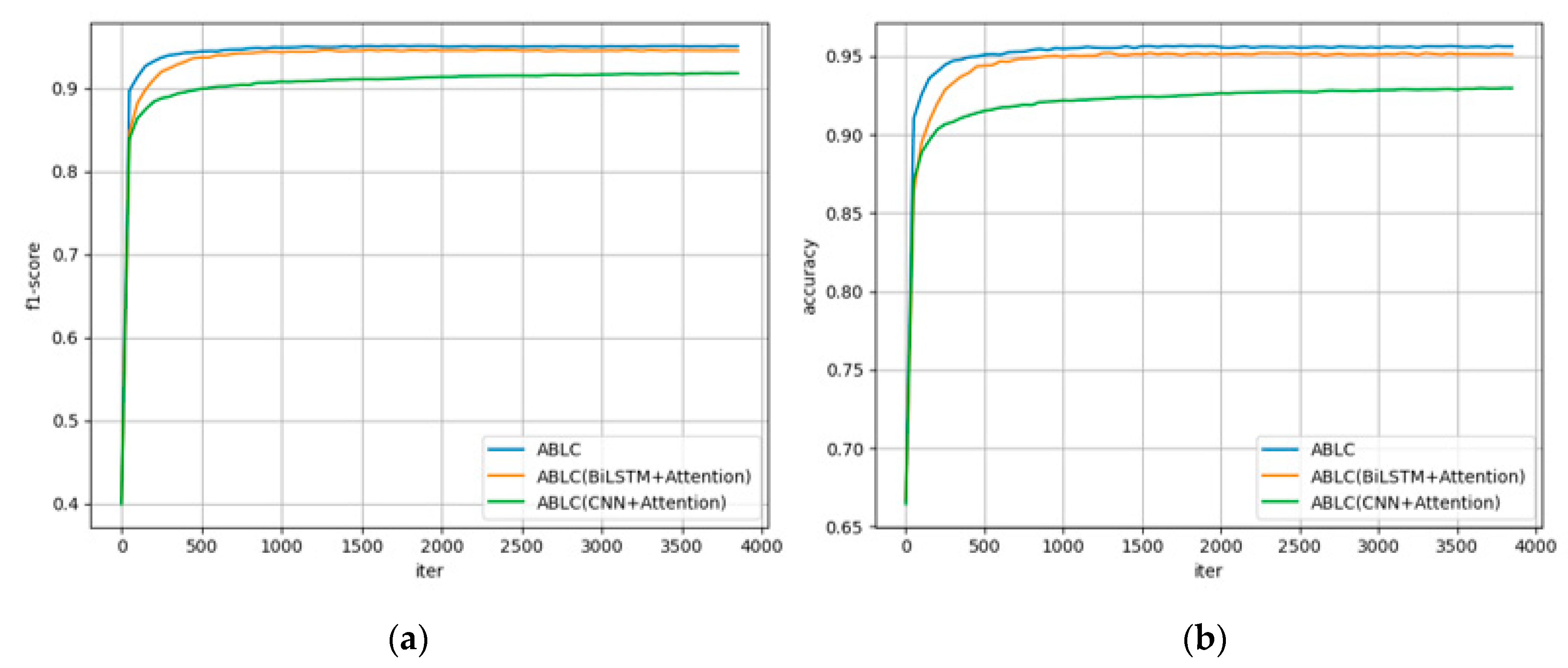
3.3.2. Analysis of Ablation Experiments
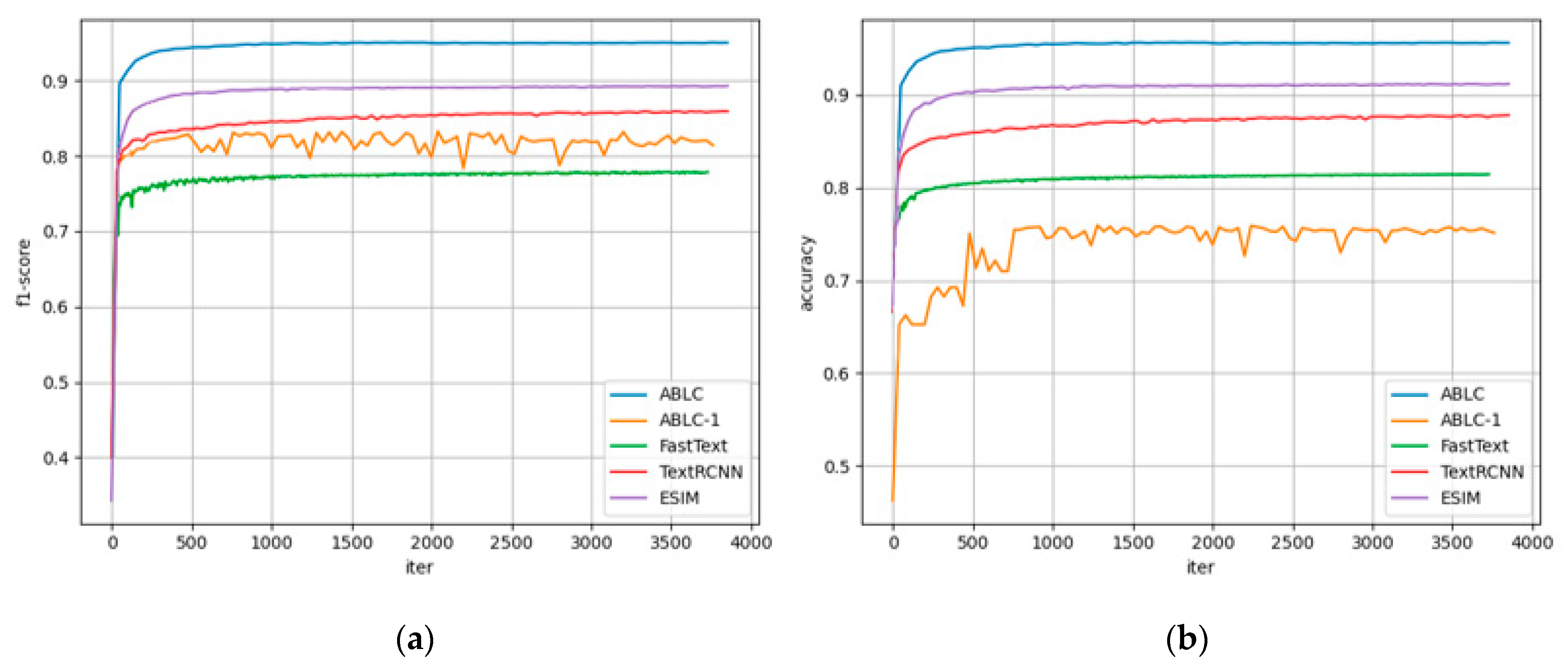
3.3.3. Comparative Experiment Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, B.H.Y.; Waddell, P.; Wang, L.; Pendyala, R.M. Reexamining the influence of work and nonwork accessibility on residential location choices with a microanalytic framework. Environ. Plan. A 2010, 42, 913–930. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Hadjieleftheriou, M.; Ooi, B.C.; Srivastava, D. Bed-tree: An all-purpose index structure for string similarity search based on edit distance. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, Indianapolis, IN, USA, 6–10 June 2010; pp. 915–926. [Google Scholar]
- Levenshtein, V.I. Binary Codes Capable of Correcting Deletions, Insertions and Reversals. Soviet Phys. Doklady 1966, 10, 707. [Google Scholar]
- Bilenko, M.; Mooney, R.J. Adaptive Duplicate Detection Using Learnable String Similarity Measures. In Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; Association for Computing Machinery: New York, NY, USA, 2003; pp. 39–48. [Google Scholar]
- Jaccard, P. Nouvelles Recherches Sur la Distribution Florale. Bull. Soc. Vaudoise Sci. Nat. 1908, 44, 223–270. [Google Scholar]
- Banerjee, S.; Pedersen, T. The Design, Implementation, and Use of the Ngram Statistics Package; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Li, B.; Han, L. Distance weighted cosine similarity measure for text classification. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Salamanca, Spain, 10–12 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 611–618. [Google Scholar]
- Kang, M.; Du, Q.; Wang, M. A New Method of Chinese Address Extraction Based on Address Tree Model. Acta Geod. Cartogr. Sin. 2015, 44, 99–107. [Google Scholar]
- Laferty, J.D.; McCallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the 18th International Conference on Machine Learning, San Francisco, CA, USA, 18–24 July 2001; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2001; pp. 282–289. [Google Scholar]
- Rabiner, L.; Juang, B. An introduction to hidden Markov models. IEEE ASSP Mag. 1986, 3, 4–16. [Google Scholar] [CrossRef]
- Sun, Z.; Qiu, A.G.; Zhao, J.; Zhang, F.; Zhao, Y.; Wang, L. Technology of fuzzy Chinese-geocoding method. In Proceedings of the 2013 International Conference on Information Science and Cloud Computing, Guangzhou, China, 7–8 December 2013; IEEE Computer Society: Washington, DC, USA, 2013; pp. 7–12. [Google Scholar]
- Xueying, Z.; Guonian, L.; Boqiu, L.; Wenjun, C. Rule-based approach to semantic resolution of Chinese addresses. J. Geo-Inf. Sci. 2010, 12, 9–16. [Google Scholar]
- Cangxiu, C.; Bin, Y. A rule-based segmenting and matching method for fuzzy Chinese addresses. Geogr. Geo-Inf. Sci. 2011, 27, 26–29. [Google Scholar]
- Tian, Q.; Ren, F.; Hu, T.; Liu, J.; Li, R.; Du, Q. Using an optimized Chinese address matching method to develop a geocoding service: A case study of Shenzhen, China. ISPRS Int. J. Geo-Inf. 2016, 5, 65. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Ren, F.; Li, H.; Yang, R.; Zhang, S.; Du, Q. Recognition Method of New Address Elements in Chinese Address Matching Based on Deep Learning. ISPRS Int. J. Geo-Inf. 2020, 9, 745. [Google Scholar] [CrossRef]
- Comber, S.; Arribas-Bel, D. Machine learning innovations in address matching: A practical comparison of word2vec and CRFs. Trans. GIS 2019, 23, 334–348. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 1746–1751. [Google Scholar]
- Santos, R.; Murrieta-Flores, P.; Calado, P.; Martins, B. Toponym matching through deep neural networks. Int. J. Geogr. Inf. Sci. 2018, 32, 324–348. [Google Scholar] [CrossRef] [Green Version]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; p. 29. [Google Scholar]
- He, J.; Li, X.; Yao, Y.; Hong, Y.; Jinbao, Z. Mining transition rules of cellular automata for simulating urban expansion by using the deep learning techniques. Int. J. Geogr. Inf. Sci. 2018, 32, 2076–2097. [Google Scholar] [CrossRef]
- Ding, R.; Chen, Z. RecNet: A deep neural network for personalized POI recommendation in location-based social networks. Int. J. Geogr. Inf. Sci. 2018, 32, 1631–1648. [Google Scholar] [CrossRef]
- Karimzadeh, M.; Pezanowski, S.; MacEachren, A.M.; Wallgrün, J.O. GeoTxt: A scalable geoparsing system for unstructured text geolocation. Trans. GIS 2019, 23, 118–136. [Google Scholar] [CrossRef]
- Du, P.; Bai, X.; Tan, K.; Xue, Z.; Samat, A.; Xia, J.; Li, E.; Su, H.; Liu, W. Advances of four machine learning methods for spatial data handling: A review. JGSA 2020, 4, 1–25. [Google Scholar]
- Grekousis, G. Artificial neural networks and deep learning in urban geography: A systematic review and meta-analysis. Computers Environ. Urban Syst. 2019, 74, 244–256. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Mining Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hintont, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Klein, T.; Nabi, M. Contrastive self-supervised learning for commonsense reasoning. arXiv 2020, arXiv:2005.00669. [Google Scholar]
- Yang, Z.; Cheng, Y.; Liu, Y.; Sun, M. Reducing word omission errors in neural machine translation: A contrastive learning approach. Proc. ACL 2019, 6191–6196. [Google Scholar]
- Meng, Y.; Xiong, C.; Bajaj, P.; Tiwary, S.; Bennett, P.; Han, J.; Song, X. Coco-lm: Correcting and contrasting text sequences for language model pretraining. arXiv 2021, arXiv:2102.08473. [Google Scholar]
- Wu, Z.; Wang, S.; Gu, J.; Khabsa, M.; Sun, F.; Ma, H. Clear: Contrastive learning for sentence representation. arXiv 2020, arXiv:2012.15466. [Google Scholar]
- Karim, F.; Majumdar, S.; Darabi, H.; Chen, S. LSTM fully convolutional networks for time series classification. IEEE Access 2017, 6, 1662–1669. [Google Scholar] [CrossRef]
- Khan, S.; Rahmani, H.; Shah, S.A.A.; Bennamoun, M. A guide to convolutional neural networks for computer vision. Synth. Lect. Computer Vision 2018, 8, 1–207. [Google Scholar] [CrossRef]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Shijie, J.; Ping, W.; Peiyi, J.; Siping, H. Research on data augmentation for image classification based on convolution neural networks. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 January 2017; IEEE: New York, NY, USA, 2017; pp. 4165–4170. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Sakamoto, T.; Yokozawa, M.; Toritani, H.; Shibayama, M.; Ishitsuka, N.; Ohno, H. A crop phenology detection method using time-series MODIS data. Remote Sens. Environ. 2005, 96, 366–374. [Google Scholar] [CrossRef]
- Wei, J.; Zou, K. Eda: Easy data augmentation techniques for boosting performance on text classification tasks. arXiv 2019, arXiv:1901.11196. [Google Scholar]
- Bouthillier, X.; Konda, K.; Vincent, P.; Memisevic, R. Dropout as data augmentation. arXiv 2015, arXiv:1506.08700. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Lin, Y.; Kang, M.; Wu, Y.; Du, Q.; Liu, T. A deep learning architecture for semantic address matching. Int. J. Geogr. Inf. Sci. 2020, 34, 559–576. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jégou, H.; Mikolov, T. Fasttext. zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. [Google Scholar]
- Zhou, X.; Chen, X.; Song, J.; Zhao, G.; Wu, J. Team Cat-Garfield at TREC 2018 Precision Medicine Track. In Proceedings of the TREC, Gaithersburg, MD, USA, 14–16 November 2018. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.X. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5754–5764. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Address 1 | Address 2 | Similarity |
|---|---|---|
| Dormitory of Xinhua Bookstore, Chaowu Road, Jinhe Community, Wuwei City | Interior of Xinhua Bookstore, Chaowulu, Jinhe Community, Wucheng Town, Wuwei County, Anhui Province | 1 |
| No. 1, Wuteng Village, Xinwu Economic Development Zone, Wuhu County, Wuhu | Xiaocun Nature Village, Zhongyao Village Villagers Committee, Liulang Town, Wuhu County, Anhui Province | 0 |
| Address 1 | Address 2 | Similarity |
|---|---|---|
| Xinhua Bookstore Dormitory of Xinhua Bookstore, Chaowu Road, Jinhe Community, Wuwei City, Interior of Xinhua Bookstore, Xinhua Bookstore, Chaowu Road, Jinhe Community, Wucheng Town, Wuwei County, Anhui Province | The interior of Xinhua Bookstore, Chaowulu Xinhua Bookstore, Jinhe Community, Wucheng Town, Wuwei County, Anhui Province, Dormitory of Xinhua Bookstore, Chaowu Road, Jinhe Community, Wuwei City | 1 |
| No. 1, Wuhu Wuteng Village, Xinwu Economic Development Zone, Wuhu County, Wuhu, Xiaocun Nature Village, Zhongyao Village Villagers Committee, Liulang Town, Wuhu County, Anhui Province | Xiaocun Nature Village, Zhongyao Village Villagers Committee, Liulang Town, Wuhu County, Anhui Province, No. 1, Wuhu Wuteng Village, Xinwu Economic Development Zone, Wuhu County, Wuhu | 1 |
| Dormitory of Xinhua Bookstore, Chaowu Road, Jinhe Community, Wuwei City, Interior of Xinhua Bookstore, Chaowu Road, Jinhe Community, Wucheng Town, Wuwei County, Anhui Province | No. 1, Wuhu Wuteng Village, Xinwu Economic Development Zone, Wuhu County, Wuhu, Xiaocun Nature Village, Zhongyao Village Villagers Committee, Liulang Town, Wuhu County, Anhui Province | 0 |
| Parameter Name | Parameter Value |
|---|---|
| epoch | 25 |
| batch_size | 1024 |
| optimizer | Adam |
| learning_rate | 0.01 |
| dropout | 0.5 |
| Model No. | Model Setting |
|---|---|
| 1 | learning_rate = 0.1 |
| 2 | learning_rate = 0.001 |
| 3 | learning_rate = 0.0001 |
| 4 | batch_size = 512, learning_rate = 0.001 |
| 5 | batch_size = 1500, learning_rate = 0.1 |
| Model | F1 Score | Accuracy | Recall | Precision |
|---|---|---|---|---|
| ABLC | 0.9504 | 0.9563 | 0.9460 | 0.9552 |
| 1 | 0.9362 | 0.9439 | 0.9315 | 0.9413 |
| 2 | 0.9234 | 0.9343 | 0.911 | 0.9402 |
| 3 | 0.8926 | 0.8435 | 0.9798 | 0.8197 |
| 4 | 0.9263 | 0.9362 | 0.9137 | 0.9436 |
| 5 | 0.9381 | 0.9458 | 0.9356 | 0.9407 |
| Model Name | F1 | Accuracy | Recall | Precision |
|---|---|---|---|---|
| ABLC | 0.9504 | 0.9563 | 0.9460 | 0.9552 |
| ABLC (BiLSTM + attention) | 0.9448 | 0.9512 | 0.9428 | 0.9468 |
| ABLC (CNN + attention) | 0.9178 | 0.9297 | 0.9020 | 0.9413 |
| Model Name | F1 Score | Accuracy | Recall | Precision |
|---|---|---|---|---|
| ABLC | 0.9504 | 0.9563 | 0.9460 | 0.9552 |
| ESIM | 0.8992 | 0.9146 | 0.9051 | 0.9020 |
| SVM | 0.7267 | 0.7782 | 0.7125 | 0.7662 |
| FastText | 0.6763 | 0.812 | 0.6132 | 0.7569 |
| TextRCNN | 0.8062 | 0.8774 | 0.7733 | 0.8424 |
| ABLC-1(Xlnet) | 0.8142 | 0.7515 | 0.8348 | 0.7947 |
| Address 1 | Address 2 | Similarity |
|---|---|---|
| No. 51, Changjiang Middle Road, Fanluoshan Street, Jinghu District, Wuhu City | Human Resources Security Bureau, Jinghu District, Wuhu City, Anhui Province | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Chen, J.; She, X.; Mao, J.; Chen, G. Deep Contrast Learning Approach for Address Semantic Matching. Appl. Sci. 2021, 11, 7608. https://doi.org/10.3390/app11167608
Chen J, Chen J, She X, Mao J, Chen G. Deep Contrast Learning Approach for Address Semantic Matching. Applied Sciences. 2021; 11(16):7608. https://doi.org/10.3390/app11167608
Chicago/Turabian StyleChen, Jian, Jianpeng Chen, Xiangrong She, Jian Mao, and Gang Chen. 2021. "Deep Contrast Learning Approach for Address Semantic Matching" Applied Sciences 11, no. 16: 7608. https://doi.org/10.3390/app11167608
APA StyleChen, J., Chen, J., She, X., Mao, J., & Chen, G. (2021). Deep Contrast Learning Approach for Address Semantic Matching. Applied Sciences, 11(16), 7608. https://doi.org/10.3390/app11167608