
Image Quality Assessment to Emulate Experts’ Perception in Lumbar MRI Using Machine Learning

 , ,
, ,
Abstract

1. Introduction
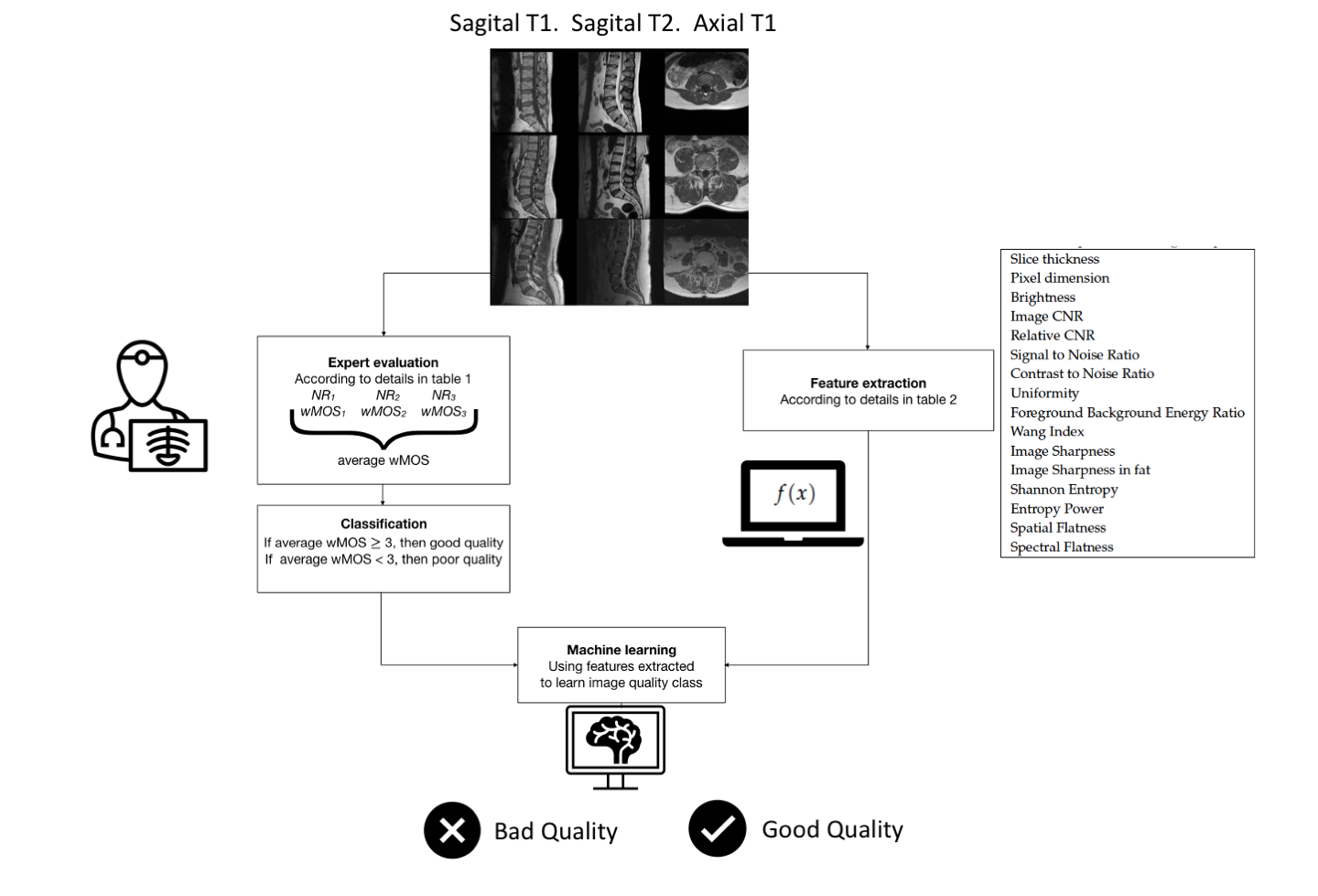
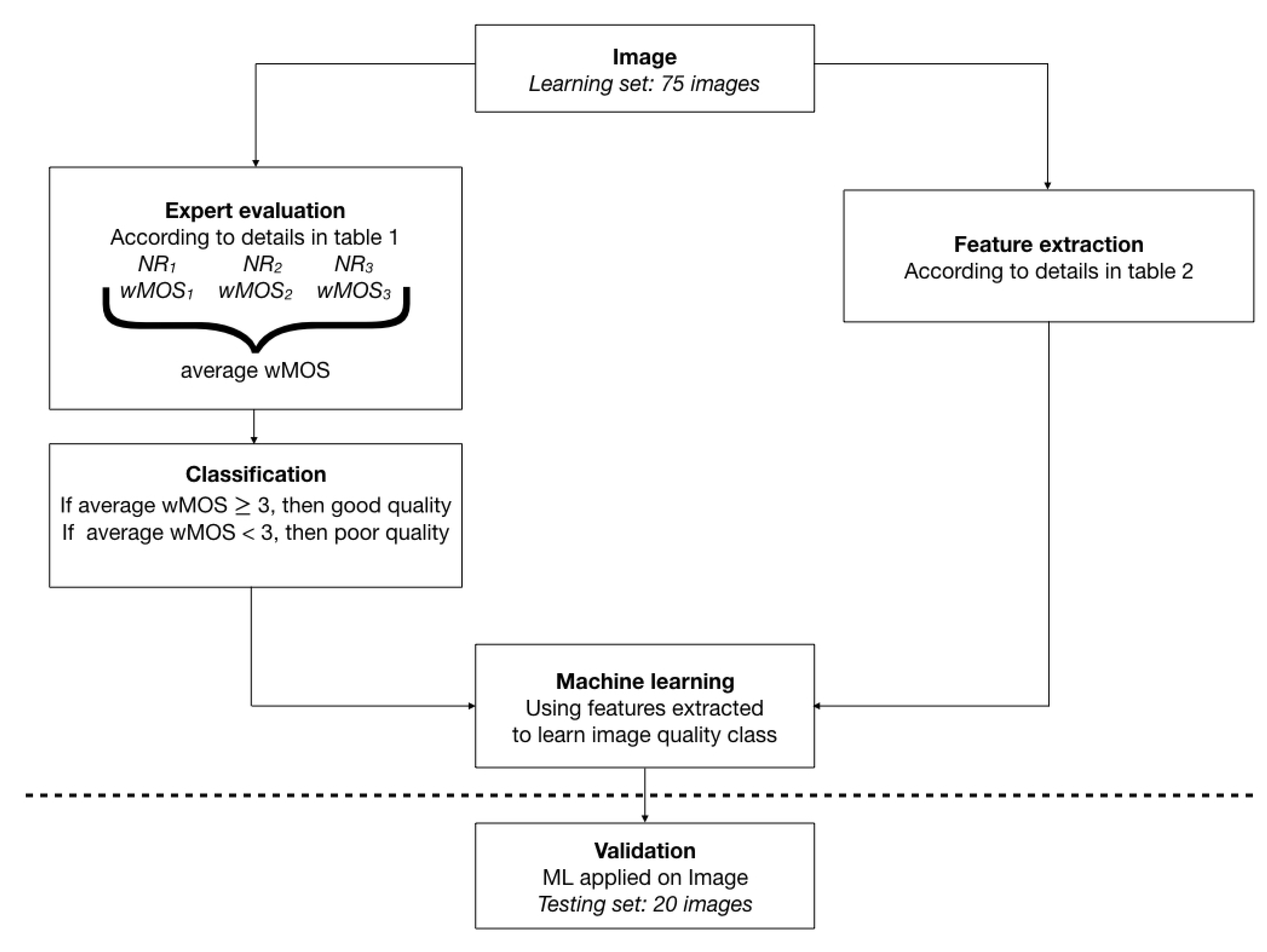
2. Methods and Materials
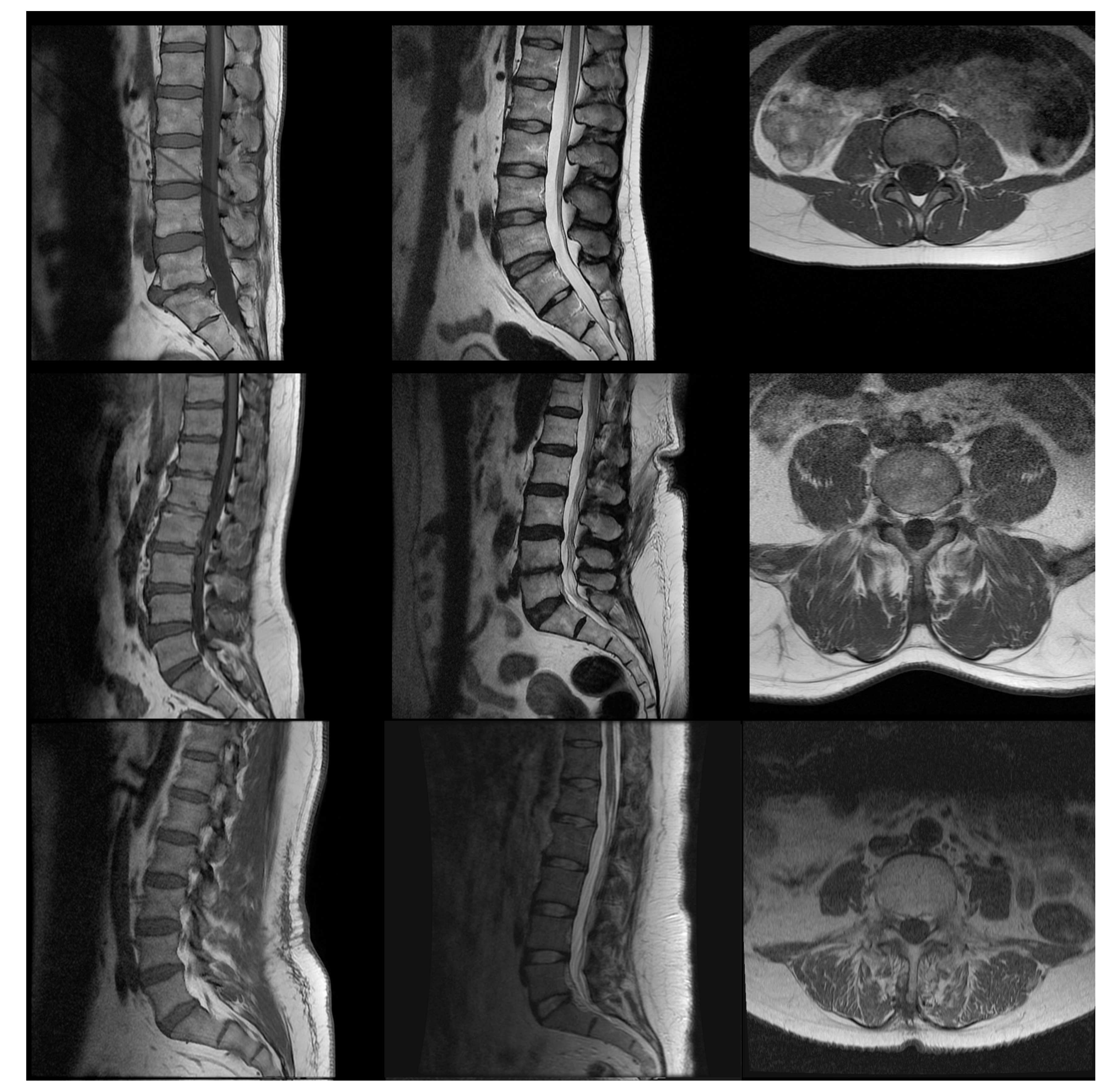
2.1. Data Set
- Noise addition, with a standard deviation ranging from 0.001 to 0.8
- Contrast manipulation using power transform with gamma values ranging from 0.7 to 1.15
- Convolution with Gaussian kernel, with the kernel used from to
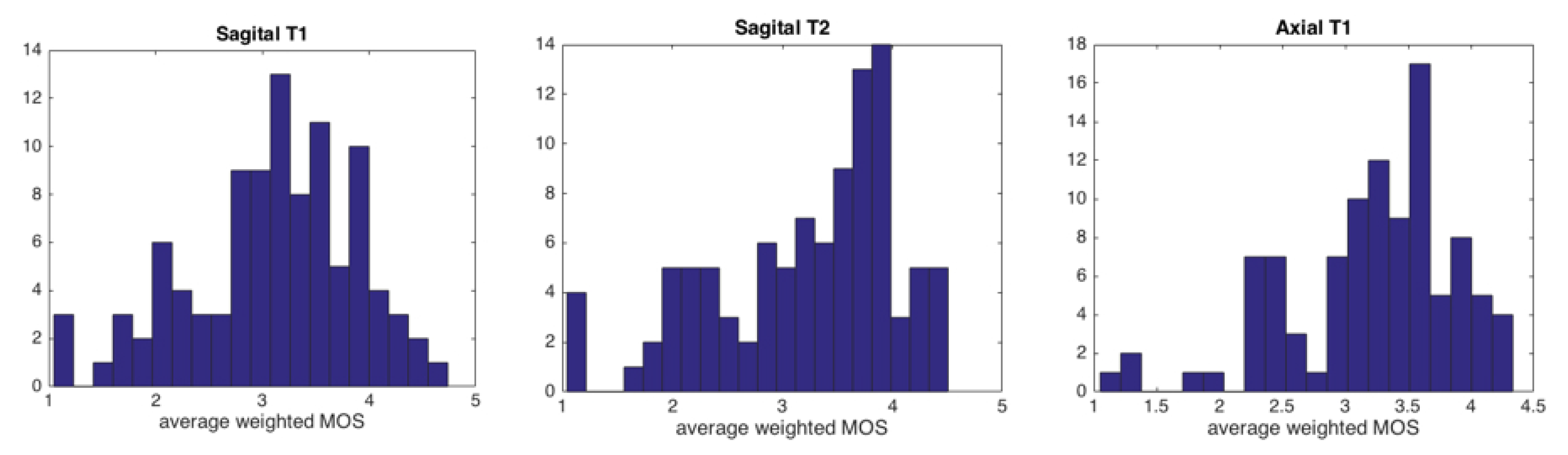
2.2. Subjective Evaluation
2.3. Objective Evaluation
2.4. Machine Learning
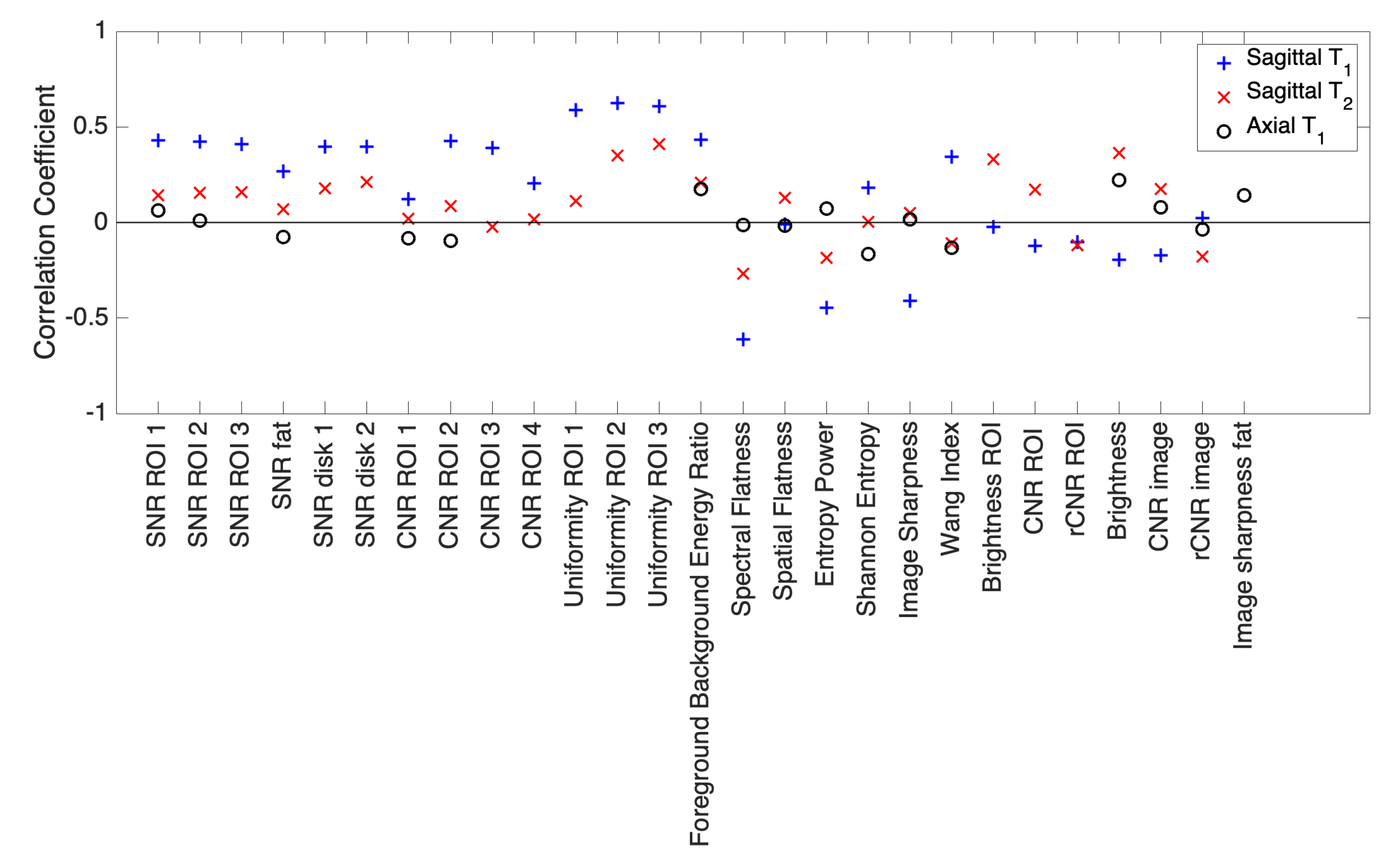
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krupinski, E.A.; Jiang, Y. Anniversary paper: Evaluation of medical imaging systems. Med Phys. 2008, 35, 645–659. [Google Scholar] [CrossRef]
- Commission, I.E. (Ed.) IEC62464—1 Magnetic Resonance Equipment for Medical Imaging—Determination of Essential Image Quality Parameters; British Standard Institute (BSI): London, UK, 2019. [Google Scholar]
- Attard, S.; Castillo, J.; Zarb, F. Establishment of image quality for MRI of the knee joint using a list of anatomical criteria. Radiography 2018, 24, 196–203. [Google Scholar] [CrossRef]
- Chow, L.S.; Paramesran, R. Review of medical image quality assessment. Biomed. Signal Process. Control 2016, 27, 145–154. [Google Scholar] [CrossRef]
- Kamble, V.; Bhurchandi, K.M. No-reference image quality assessment algorithms: A survey. Optik 2015, 126, 1090–1097. [Google Scholar] [CrossRef]
- Xu, S.; Jiang, S.; Min, W. No-reference/Blind Image Quality Assessment: A Survey. IETE Tech. Rev. 2017, 34, 223–245. [Google Scholar] [CrossRef]
- Narvekar, N.D.; Karam, L.J. A no-reference perceptual image sharpness metric based on a cumulative probability of blur detection. In Proceedings of the 2009 International Workshop on Quality of Multimedia Experience, IEEE, San Diego, CA, USA, 29–31 July 2009; pp. 87–91. [Google Scholar] [CrossRef]
- Varadarajan, S.; Karam, L.J. An improved perception-based no-reference objective image sharpness metric using iterative edge refinement. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, IEEE, San Diego, CA, USA, 12–15 October 2008; pp. 401–404. [Google Scholar] [CrossRef]
- Winter, R.M.; Leibfarth, S.; Schmidt, H.; Zwirner, K.; Mönnich, D.; Welz, S.; Schwenzer, N.F.; la Fougère, C.; Nikolaou, K.; Gatidis, S.; et al. Assessment of image quality of a radiotherapy-specific hardware solution for PET/MRI in head and neck cancer patients. Radiother. Oncol. 2018, 128, 485–491. [Google Scholar] [CrossRef] [PubMed]
- Alexander, D.C.; Zikic, D.; Ghosh, A.; Tanno, R.; Wottschel, V.; Zhang, J.; Kaden, E.; Dyrby, T.B.; Sotiropoulos, S.N.; Zhang, H.; et al. Image quality transfer and applications in diffusion MRI. NeuroImage 2017, 152, 283–298. [Google Scholar] [CrossRef] [PubMed]
- Veloz, A.; Moraga, C.; Weinstein, A.; Hernández-García, L.; Chabert, S.; Salas, R.; Riveros, R.; Bennett, C.; Allende, H. Fuzzy general linear modeling for functional magnetic resonance imaging analysis. IEEE Trans. Fuzzy Syst. 2019, 28, 100–111. [Google Scholar] [CrossRef]
- Chabert, S.; Verdu, J.; Huerta, G.; Montalba, C.; Cox, P.; Riveros, R.; Uribe, S.; Salas, R.; Veloz, A. Impact of b-Value Sampling Scheme on Brain IVIM Parameter Estimation in Healthy Subjects. Magn. Reson. Med. Sci. 2019, mp–2019. [Google Scholar] [CrossRef] [PubMed]
- Sotelo, J.; Salas, R.; Tejos, C.; Chabert, S.; Uribe, S. Análisis cuantitativo de variables hemodinámicas de la aorta obtenidas de 4D flow. Rev. Chil. Radiol. 2012, 18, 62–67. [Google Scholar] [CrossRef][Green Version]
- Veloz, A.; Orellana, A.; Vielma, J.; Salas, R.; Chabert, S. Brain Tumors: How Can Images and Segmentation Techniques Help; Diagnostic Techniques and Surgical Management of Brain Tumors, IntechOpen: London, UK, 2011; ISBN 978-953-307-589-1. [Google Scholar] [CrossRef]
- Saavedra, C.; Salas, R.; Bougrain, L. Wavelet-based semblance methods to enhance the single-trial detection of event-related potentials for a BCI spelling system. Comput. Intell. Neurosci. 2019, 2019. [Google Scholar] [CrossRef]
- Gupta, P.; Bampis, C.G.; Glover, J.L.; Paulter, N.G., Jr.; Bovik, A.C. Multivariate Statistical Approach to Image Quality Tasks. J. Imaging 2018, 4, 117. [Google Scholar] [CrossRef]
- Liu, L.; Dong, H.; Huang, H.; Bovik, A.C. No-reference image quality assessment in curvelet domain. Signal-Process.-Image Commun. 2014, 29, 494–505. [Google Scholar] [CrossRef]
- Alfaro-Almagro, F.; Jenkinson, M.; Bangerter, N.; Andersson, J.; Griffanti, L.; Douaud, G.; Sotiropoulos, S.; Jbabdi, S.; Hernandez-Fernandez, M.; Vallee, E.; et al. Image processing and Quality Control for the first 10,000 brain imaging datasets from UK Biobank. NeuroImage 2018, 166, 400–424. [Google Scholar] [CrossRef]
- Rosen, A.F.; Roalf, D.R.; Ruparel, K.; Blake, J.; Seelaus, K.; Villa, L.P.; Ciric, R.; Cook, P.A.; Davatzikos, C.; Elliott, M.A.; et al. Quantitative assessment of structural image quality. NeuroImage 2018, 169, 407–418. [Google Scholar] [CrossRef] [PubMed]
- Chacon, G.; Rodriguez, J.; Bermudez, V.; Florez, A.; Del Mar, A.; Pardo, A.; Lameda, C.; Madriz, D.; Bravo, A. A score function as quality measure for cardiac image enhancement techniques assessment. Rev. Latinoam. Hipertens. 2019, 14, 180–186. [Google Scholar]
- Barrett, H.H.; Kupinsky, M.A.; Müeller, S.; Halpern, H.; Moris, J., III; Dwyer, R. Objective assessment of image quality VI: Imaging in radiation therapy. Phys. Med. Biol. 2013, 58, 8197–8213. [Google Scholar] [CrossRef] [PubMed]
- Linstone, H.A.; Turoff, M. The Delphi Method: Techniques and Applications; Addison-Wesley: Reading, PA, USA, 1975. [Google Scholar]
- Boulkedid, R.; Abdoul, H.; Loustau, M.; Sibony, O.; Alberti, C. Using and Reporting the Delphi Method for Selecting Healthcare Quality Indicators: A Systematic Review. PLoS ONE 2011, 6, e20476. [Google Scholar] [CrossRef] [PubMed]
- Sá Dos Reis, C.; Gremion, I.; Richli Meystre, N. Consensus about image quality assessment criteria of breast implants mammography using Delphi method with radiographers and radiologists. Insights Imaging 2020, 11, 56. [Google Scholar] [CrossRef]
- Zhou, W.; Sheikh, H.R.; Bovik, A.C. No-reference perceptual quality assessment of JPEG compressed images. In Proceedings of the IEEE International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; Volume 1, p. I. [Google Scholar] [CrossRef]
- Hadjidemetriou, E.; Grossberg, M.; Nayar, S. Multiresolution histograms and their use for recognition. IEEE Trans. Pattern. Anal. Mach. Intell. 2004, 26, 831–847. [Google Scholar] [CrossRef] [PubMed]
- Jayant, N.; Noll, P. Digital Coding of Waveforms: Principles and Applications to Speech and Video; Prenctice Hall: Hoboken, NJ, USA, 1984. [Google Scholar]
- Woodward, J.; Carley-Spencer, M. No-reference image quality metrics for structural MRI. Neuroinformatics 2006, 4, 243–262. [Google Scholar] [CrossRef]
- Bowles, M. Machine Learning in Python: Essential Techniques for Predictive Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Khan, M.A.; Sharif, M.; Javed, M.Y.; Akram, T.; Yasmin, M.; Saba, T. License number plate recognition system using entropy-based features selection approach with SVM. IET Image Process. 2017, 12, 200–209. [Google Scholar] [CrossRef]
- Denoeux, T. Logistic regression, neural networks and Dempster–Shafer theory: A new perspective. Knowl.-Based Syst. 2019, 176, 54–67. [Google Scholar] [CrossRef]
- Golovko, V. Deep learning: An overview and main paradigms. Opt. Mem. Neural Netw. 2017, 26, 1–17. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Tanna, A.; Bandi, J.; Budenz, D.; Feuer, W.J.; Feldman, R.; Herndon, L.; Rhee, D.; Whiteside-de Vos, J. Interobserver agreement and intraobserver reproducibility of the subjective determination of glaucomatous visual field progression. Ophthalmology 2011, 118, 60–65. [Google Scholar] [CrossRef] [PubMed]
- Lima, A.; López, A.; van Genderen, M.E.; Hurtado, F.J.; Angulo, M.; Grignola, J.C.; Shono, A.; van Bommel, J. Interrater Reliability and Diagnostic Performance of Subjective Evaluation of Sublingual Microcirculation Images by Physicians and Nurses: A Multicenter Observational Study. Shock 2015, 44, 239–244. [Google Scholar] [CrossRef] [PubMed]
- Ganesan, A.; Alakhras, M.; Brennan, P.; Mello-Thoms, C. A review of factors influencing radiologists’ visual search behaviour. J. Med. Imaging Radiat. Oncol. 2018, 62, 747–757. [Google Scholar] [CrossRef] [PubMed]
- Kammerer, S.; Schulke, C.; Leclaire, M.; Schwindt, W.; Velasco Gonzalez, A.; Zoubi, T.; Heindel, W.; Buerke, B. Impact of Working Experience on Image Perception and Image Evaluation Approaches in Stroke Imaging: Results of an Eye-Tracking Study. Rofo 2019, 191, 836–844. [Google Scholar] [CrossRef] [PubMed]
- Nakanishi, R.; Sankaran, S.; Grady, L.; Malpeso, J.; Yousfi, R.; Osawa, K.; Ceponiene, I.; Nazarat, N.; Rahmani, S.; Kissel, K.; et al. Automated estimation of image quality for coronary computed tomographic angiography using machine learning. Eur. Radiol. 2018, 28, 4018–4026. [Google Scholar] [CrossRef]
- Küstner, T.; Gatidis, S.; Liebgott, A.; Schwartz, M.; Mauch, L.; Martirosian, P.; Schmidt, H.; Schwenzer, N.F.; Nikolaou, K.; Bamberg, F.; et al. A machine-learning framework for automatic reference-free quality assessment in MRI. Magn. Reson. Imaging 2018, 53, 134–147. [Google Scholar] [CrossRef]
- Pizarro, R.A.; Cheng, X.; Barnett, A.; Lemaitre, H.; Verchinski, B.A.; Goldman, A.L.; Xiao, E.; Luo, Q.; Berman, K.F.; Callicott, J.H.; et al. Automated quality assessment of structural magnetic resonance brain images based on a supervised machine learning algorithm. Front. Neuroinform. 2016, 10, 52. [Google Scholar] [CrossRef] [PubMed]
- Saad, M.A.; Bovik, A.C.; Charrier, C. A DCT Statistics-Based Blind Image Quality Index. IEEE Signal Process. Lett. 2010, 17, 583–586. [Google Scholar] [CrossRef]
- Yuan, Y.; Guo, Q.; Lu, X. Image quality assessment: A sparse learning way. Neurocomputing 2015, 159, 227–241. [Google Scholar] [CrossRef]
- Kleinberg, J.; Lakkaraju, H.; Ludwig, J.; Mullainathan, S. Human decisions and machine predictions. Q. J. Econ. 2018, 133, 237–293. [Google Scholar] [PubMed]
- Chabert, S.; Mardones, T.; Riveros, R.; Godoy, M.; Veloz, A.; Salas, R.; Cox, P. Applying machine learning and image feature extraction techniques to the problem of cerebral aneurysm rupture. Res. Ideas Outcomes 2017, 3, e11731. [Google Scholar] [CrossRef]
- Veloz, A.; Chabert, S.; Salas, R.; Orellana, A.; Vielma, J. Fuzzy spatial growing for glioblastoma multiforme segmentation on brain magnetic resonance imaging. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2007; pp. 861–870. [Google Scholar]
- Castro, J.S.; Chabert, S.; Saavedra, C.; Salas, R. Convolutional neural networks for detection intracranial hemorrhage in CT images. In Proceedings of the 5th Congress on Robotics and Neuroscience, CRoNe 2019, Valparaíso, Chile, 27–29 February 2020; pp. 37–43. [Google Scholar]
- Caviedes, J.; Gurbuz, S. No-reference sharpness metric based on local edge kurtosis. In Proceedings of the IEEE International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; Volume 3, pp. 53–56. [Google Scholar]
- Wee, C.; Paramesran, R. Image sharpness measure using eigenvalues. In Proceedings of the 2008 9th International Conference on Signal Processing, Beijing, China, 26–29 October 2008; Volume 9, pp. 840–843. [Google Scholar]
- Jayageetha, J.; Vasanthanayaki, C. Medical Image Quality Assessment Using CSO Based Deep Neural Network. J. Med. Syst. 2018, 42, 224. [Google Scholar] [CrossRef] [PubMed]
- Oakden-Rayner, L. Exploring Large-scale Public Medical Image Datasets. Acad. Radiol. 2019. in Press. [Google Scholar] [CrossRef] [PubMed]
- Torres, R.; Salas, R.; Astudillo, H. Time-based hesitant fuzzy information aggregation approach for decision making problems. Int. J. Intell. Syst. 2018, 29, 579–595. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Exam Type | Criterion Weight | Criterion |
|---|---|---|
| Sagittal | 2/50 | Visualization of vertebral bodies |
| 2/50 | Visualization of spinal cone | |
| 3/50 | Visualization of facet joints | |
| 2/50 | Signal from bone marrow | |
| 5/50 | Overall evaluation | |
| Sagittal | 3/50 | Signal homogeneity in vertebral bodies |
| 1/50 | Visualization of the entrance of basivertebral | |
| venous plexuses | ||
| 3/50 | Contrast between vertebral body and | |
| intervertebral disc | ||
| 3/50 | Spinal cone visualization | |
| 3/50 | Homogeneity of spinal cord signal | |
| 5/50 | Distinction between spinal roots | |
| 5/50 | Overall evaluation | |
| Axial | 1/50 | Similarity of signal between muscles: |
| paravertebral and psoas | ||
| 5/50 | Definition of the edge of the intervertebral | |
| discs | ||
| 1/50 | Visualization of fascias or grooves of | |
| subcutaneous fat | ||
| 1/50 | Root path through epidural fat | |
| 5/50 | Overall evaluation |
| Feature | Definition | Apply to |
|---|---|---|
| Slice thickness | From DICOM metadata | Whole image |
| Pixel dimension | From DICOM metadata | Whole image |
| Brightness | Average intensity | Whole image |
| Image CNR | Whole image | |
| Relative CNR | Whole image | |
| Signal to Noise Ratio | In sagittal exams: applied on | |
| three different ROIs in vertebral bodies, | ||
| in fatty tissues and two intervertebral | ||
| discs. In axial exams: applied on | ||
| ROI in psoas and paravertebral | ||
| muscles and one in fatty tissues. | ||
| Contrast to Noise Ratio | In sagittal exams: applied | |
| on vertebral bodies vs. disc, | ||
| and vertebral body and disc vs. fat. | ||
| In axial exams: applied on fatty tissues | ||
| vs. psoas and paravertebral muscles. | ||
| Uniformity | where | In sagittal exams: applied on ROIs in three |
| vertebral bodies | ||
| Foreground Background Energy Ratio FBER | where within foreground and background resp. | Whole image |
| Wang Index | See [25] for details | Whole image |
| Image Sharpness | Whole image | |
| Image Sharpness in fat | Same as Image Sharpness, but applied in ROI within fat | ROI within fat |
| Shannon Entropy | Whole image | |
| Entropy Power | Whole image | |
| Spatial Flatness | Whole image | |
| Spectral Flatness | Whole image |
| NR vs. NR | NR vs. NR | NR vs. NR | ||
|---|---|---|---|---|
| Sagittal | 0.66 | 0.39 | 0.34 | 0.46 ± 0.17 |
| Sagittal | 0.60 | 0.62 | 0.47 | 0.56 ± 0.08 |
| Axial | 0.63 | 0.29 | 0.23 | 0.38 ± 0.22 |
| 0.63 ± 0.03 | 0.43 ± 0.17 | 0.35 ± 0.12 |
| Metric | Image | LDA | QDA | LogReg | SVM | MLP |
|---|---|---|---|---|---|---|
| Sagittal | 0.740 | 0.713 | 0.721 | 0.763 | 0.731 | |
| Accuracy | Sagittal | 0.713 | 0.632 | 0.689 | 0.772 | 0.649 |
| Axial | 0.767 | 0.634 | 0.747 | 0.726 | 0.726 | |
| Sagittal | 0.731 | 0.467 | 0.518 | 0.673 | 0.635 | |
| Precision | Sagittal | 0.769 | 0.686 | 0.717 | 0.737 | 0.686 |
| Axial | 0.717 | 0.537 | 0.700 | 0.622 | 0.670 | |
| Sagittal | 0.625 | 0.275 | 0.583 | 0.817 | 0.692 | |
| Recall | Sagittal | 0.675 | 0.515 | 0.600 | 0.890 | 0.605 |
| Axial | 0.775 | 0.642 | 0.725 | 0.750 | 0.675 | |
| Sagittal | 0.631 | 0.340 | 0.535 | 0.719 | 0.646 | |
| F1 score | Sagittal | 0.705 | 0.553 | 0.640 | 0.797 | 0.735 |
| Axial | 0.725 | 0.578 | 0.693 | 0.674 | 0.648 | |
| Sagittal | 0.727 | 0.777 | 0.746 | 0.792 | 0.801 | |
| AUC ROC | Sagittal | 0.710 | 0.716 | 0.763 | 0.759 | 0.735 |
| Axial | 0.791 | 0.740 | 0.780 | 0.747 | 0.792 |
| SVM vs. NR | SVM vs. NR | SVM vs. NR | ||
|---|---|---|---|---|
| Sagittal | 0.53 | 0.37 | 0.56 | 0.49 ± 0.10 |
| Sagittal | 0.52 | 0.49 | 0.42 | 0.48 ± 0.05 |
| Axial | 0.38 | 0.41 | 0.33 | 0.37 ± 0.04 |
| 0.48 ± 0.08 | 0.42 ± 0.06 | 0.44 ± 0.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chabert, S.; Castro, J.S.; Muñoz, L.; Cox, P.; Riveros, R.; Vielma, J.; Huerta, G.; Querales, M.; Saavedra, C.; Veloz, A.; et al. Image Quality Assessment to Emulate Experts’ Perception in Lumbar MRI Using Machine Learning. Appl. Sci. 2021, 11, 6616. https://doi.org/10.3390/app11146616
Chabert S, Castro JS, Muñoz L, Cox P, Riveros R, Vielma J, Huerta G, Querales M, Saavedra C, Veloz A, et al. Image Quality Assessment to Emulate Experts’ Perception in Lumbar MRI Using Machine Learning. Applied Sciences. 2021; 11(14):6616. https://doi.org/10.3390/app11146616
Chicago/Turabian StyleChabert, Steren, Juan Sebastian Castro, Leonardo Muñoz, Pablo Cox, Rodrigo Riveros, Juan Vielma, Gamaliel Huerta, Marvin Querales, Carolina Saavedra, Alejandro Veloz, and et al. 2021. "Image Quality Assessment to Emulate Experts’ Perception in Lumbar MRI Using Machine Learning" Applied Sciences 11, no. 14: 6616. https://doi.org/10.3390/app11146616
APA StyleChabert, S., Castro, J. S., Muñoz, L., Cox, P., Riveros, R., Vielma, J., Huerta, G., Querales, M., Saavedra, C., Veloz, A., & Salas, R. (2021). Image Quality Assessment to Emulate Experts’ Perception in Lumbar MRI Using Machine Learning. Applied Sciences, 11(14), 6616. https://doi.org/10.3390/app11146616