
Data-Driven Approach for Rainfall-Runoff Modelling Using Equilibrium Optimizer Coupled Extreme Learning Machine and Deep Neural Network


 , ,
, ,  ,
,
Abstract
:1. Introduction
2. Background of Soft Computing Methods
2.1. Particle Swarm Optimization
2.2. Equilibrium Optimizer (EO)
| Algorithm 1: The algorithm of EO |
| 1. Set number of particles 2. Assign of EO parameters value (a1, a2, GP) 3. Initialize the fitness of four equilibrium candidates [fitness(), fitness(), fitness(), fitness()] 4. for it = 1 to maximum iteration number do 5. for i = 1 to P do 6. Estimate the fitness of the ith particle 7. if fitness() < fitness() 8. Replace fitness() with fitness() and with 9. elseif fitness() < fitness() & fitness() < fitness() 10. Replace fitness() with fitness() and with 11. elseif fitness() < fitness() & fitness() < fitness() & fitness() < fitness() 12. Replace fitness() with fitness() and with 13. elseif fitness() < fitness() & fitness() < fitness() & fitness() < fitness() & fitness() < fitness() 14. Replace fitness() with fitness() and with 15. end if 16. end for 17. = 18. (Equilibrium pool) 19. Allocate (Equation (6)) 20. for i = 1 to P do 21. Random generation of vectors and (Equation (8)) 22. Random selection of equilibrium candidate from equilibrium pool 23. Evaluate (Equation (8)) 24. Evaluate (Equation (11)) 25. Evaluate (Equation (10)) 26. Evaluate (Equation (9)) 27. (Concentration updation) (Equation (12)) 28. end for 29. end for 34. Get (Best equilibrium candidate) |
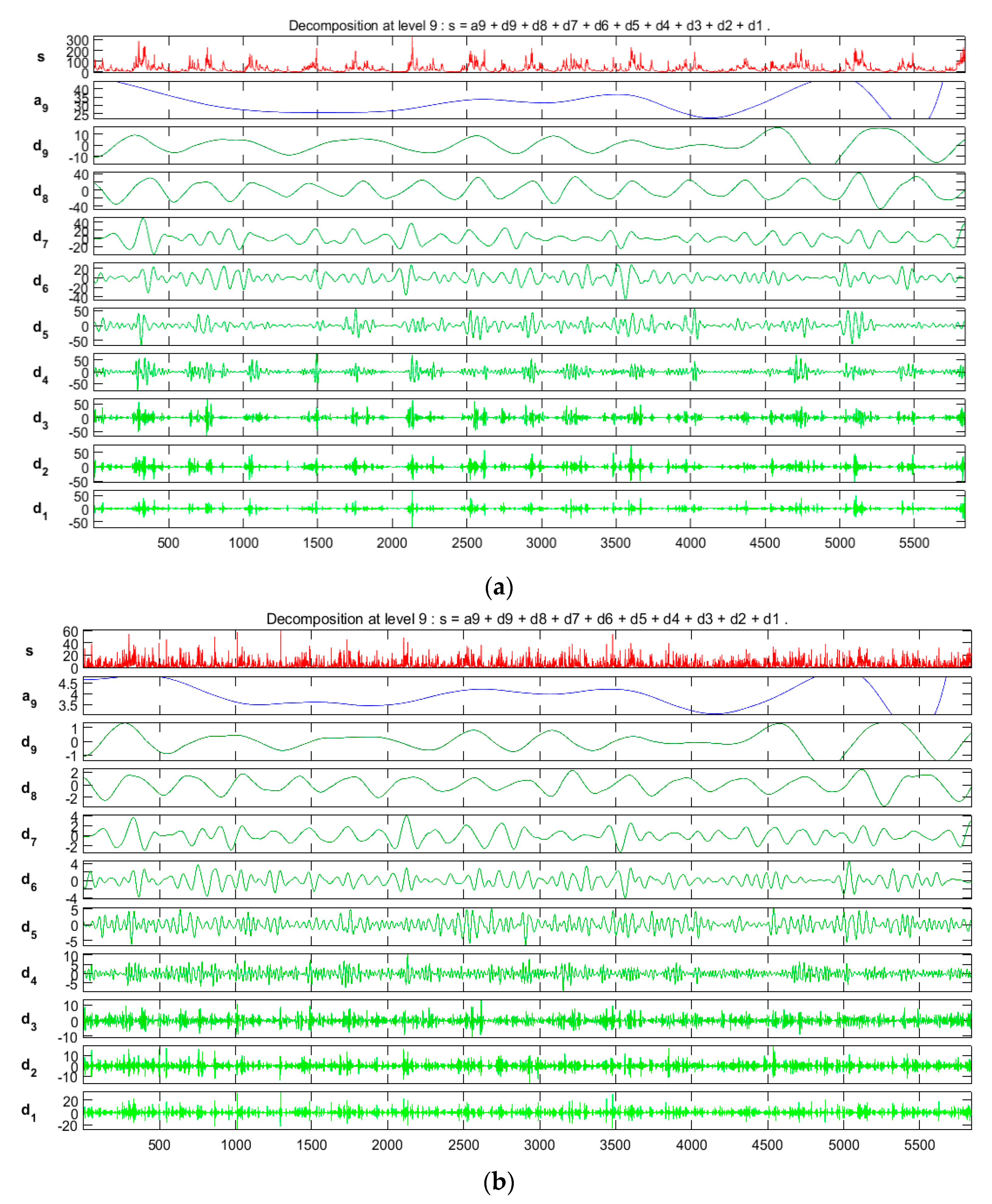
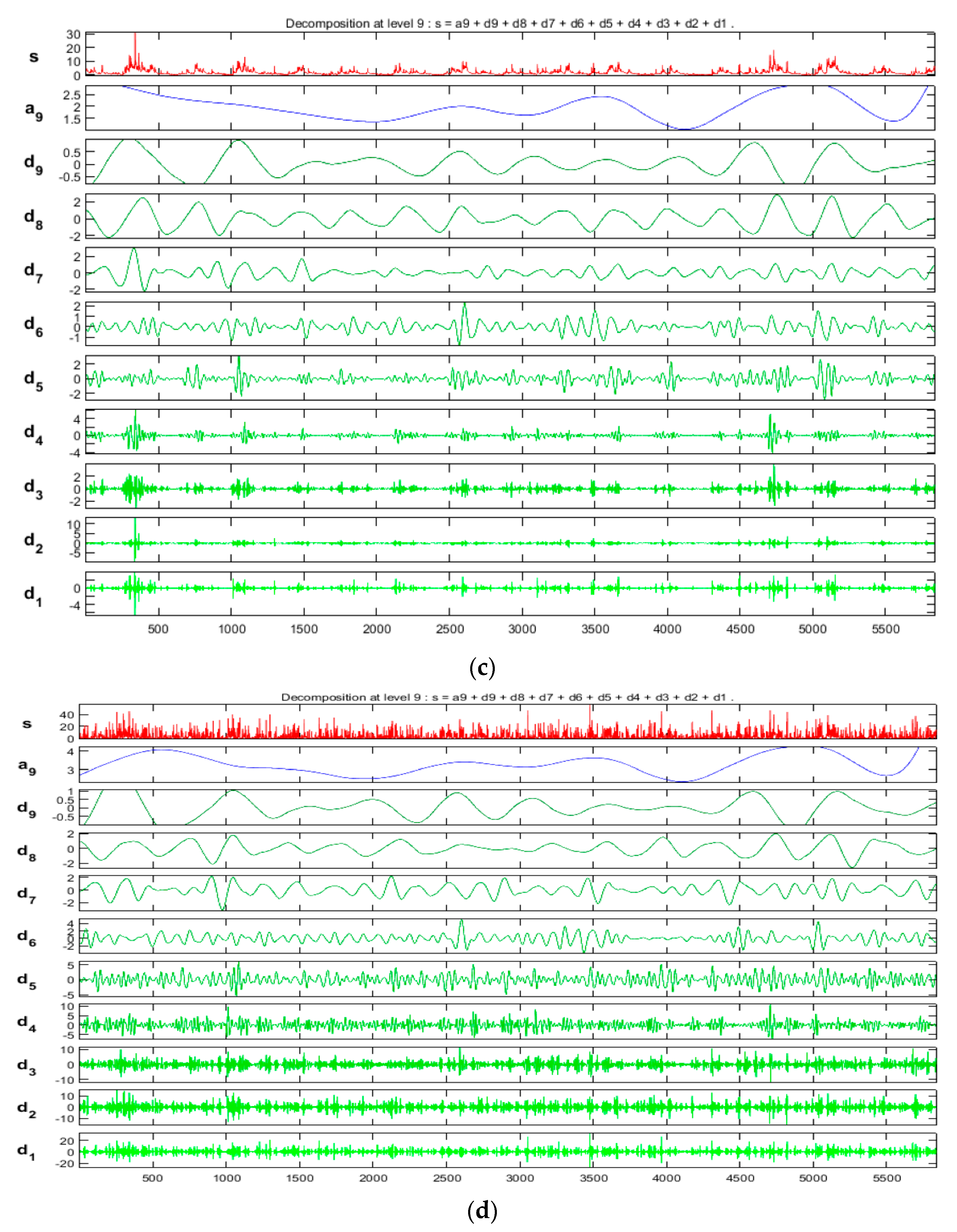
2.3. Discrete Wavelet Transforms
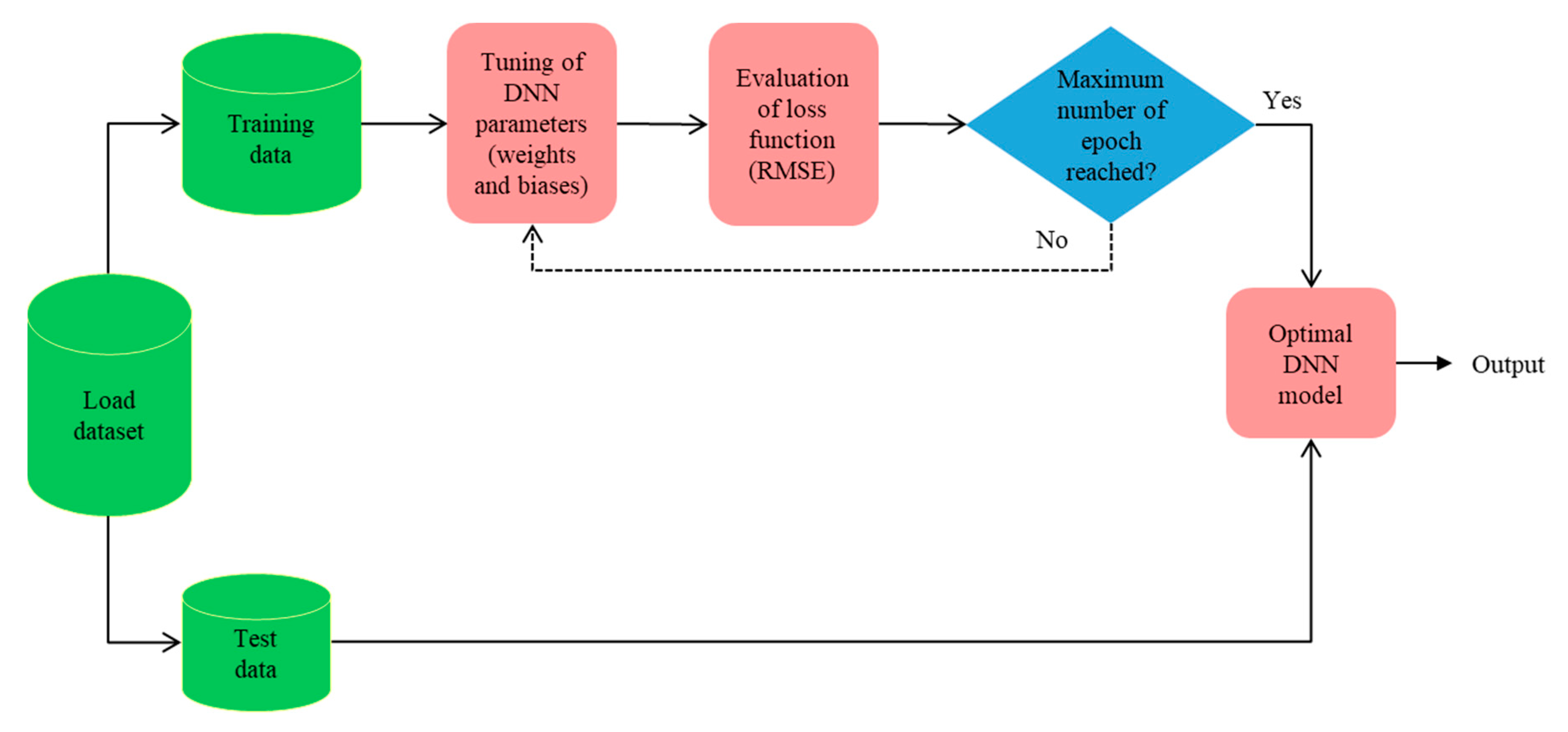
2.4. Deep Neural Network (DNN)
2.5. Extreme Learning Machine (ELM)
2.6. Support Vector Regression (SVR), Artificial Neural Network (ANN) and Gradient Boosting Machine (GBM)
3. Methodology
3.1. Study Area and Dataset Used
3.2. Proposed EO-ELM and DNN
| Algorithm 2: The algorithm of EO-ELM |
| Input: 1. Training and testing dataset 2. Set hidden units and biases of ELM using initialization of EO populations 3. Assign of EO parameters value (a1 = 2, a2 = 1, GP = 0.5) (optimized parameters based on several trials of proposed model) Output: 4. Optimized hidden units and biases of ELM from best fitness of a EO equilibrium candidate 5. Get output weights of ELM using Moore Penrose Inverse 6. EO optimized ELM testing using test dataset Begin EO-ELM training 7. Initialize the fitness of four equilibrium candidates [fitness(), fitness(), fitness(), fitness()] 8. for it = 1 to maximum iteration number do 9. for i = 1 to P do 10. Estimate the fitness of the ith particle 11. if fitness() < fitness() 12. Replace fitness() with fitness() and with 13. elseif fitness() < fitness() & fitness() < fitness() 14. Replace fitness() with fitness() and with 15. elseif fitness() < fitness() & fitness() < fitness() & fitness() < fitness() 16. Replace fitness() with fitness() and with 17. elseif fitness() < fitness() & fitness() < fitness() & fitness() < fitness() & fitness() < fitness() 18. Replace fitness() with fitness() and with 19. end if 20. end for 21. = 22. (Equilibrium pool) 23. Allocate (Equation (6)) 24. for i = 1 to P do 25. Random generation of vectors and (Equation (8)) 26. Random selection of equilibrium candidate from equilibrium pool 27. Evaluate (Equation (8)) 28. Evaluate (Equation (11)) 29. Evaluate (Equation (10)) 30. Evaluate (Equation (9)) 31. (Concentration updation) (Equation (12)) 32. end for 33. end for 34. Set ELM optimal input weights and hidden biases using (Best equilibrium candidate) 35. ELM testing |
4. Model Development and Performance Metrics
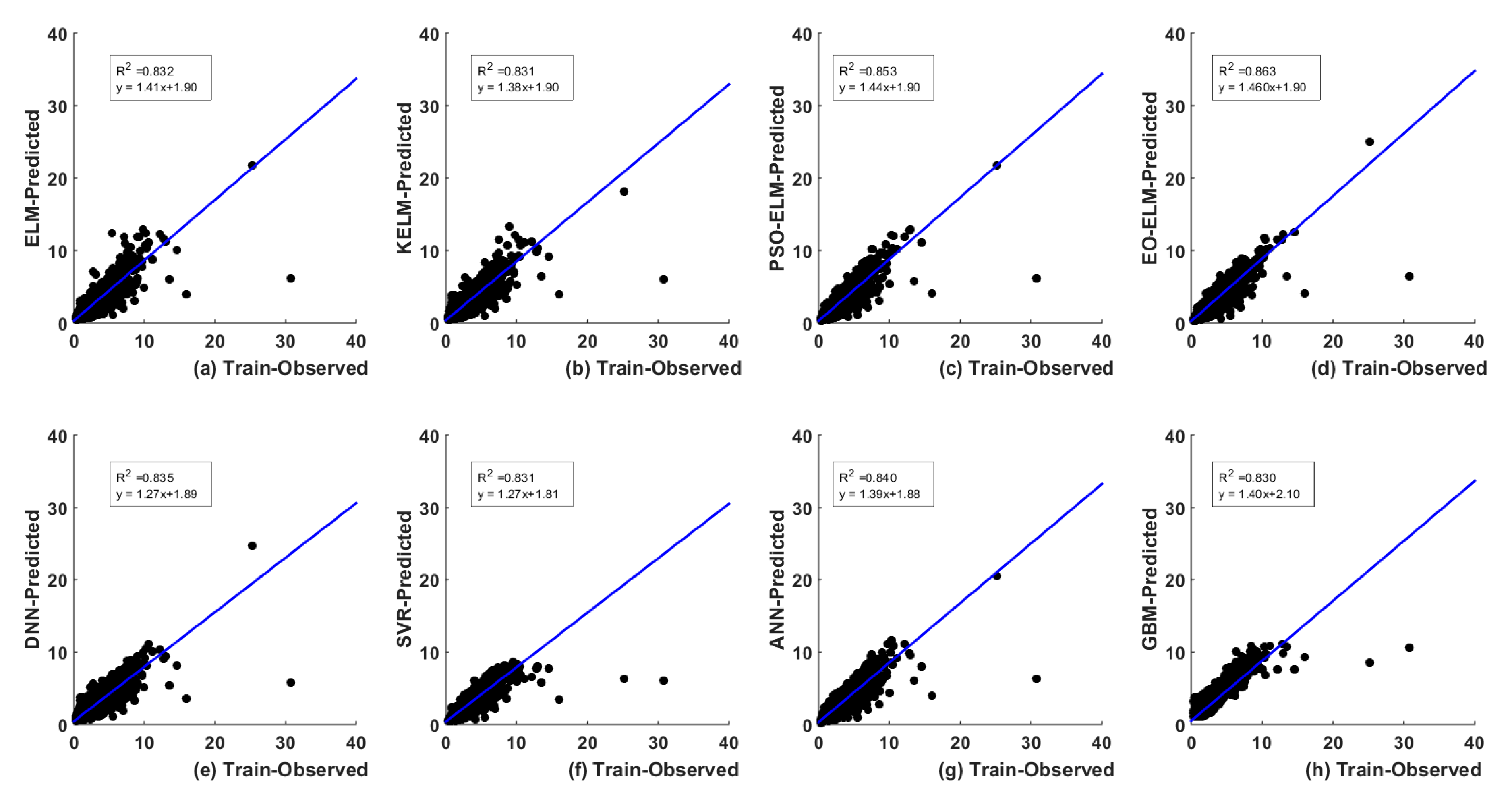
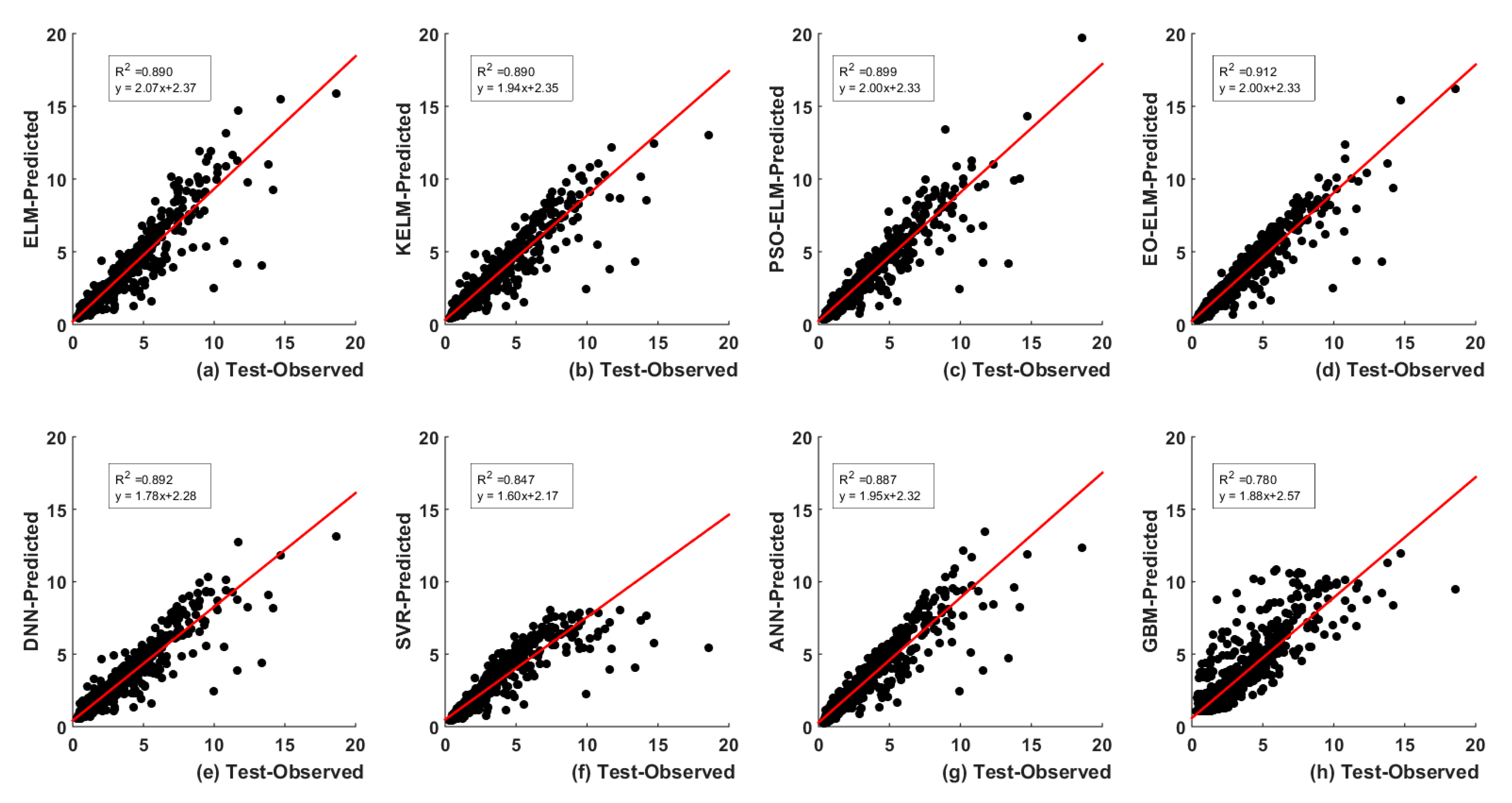
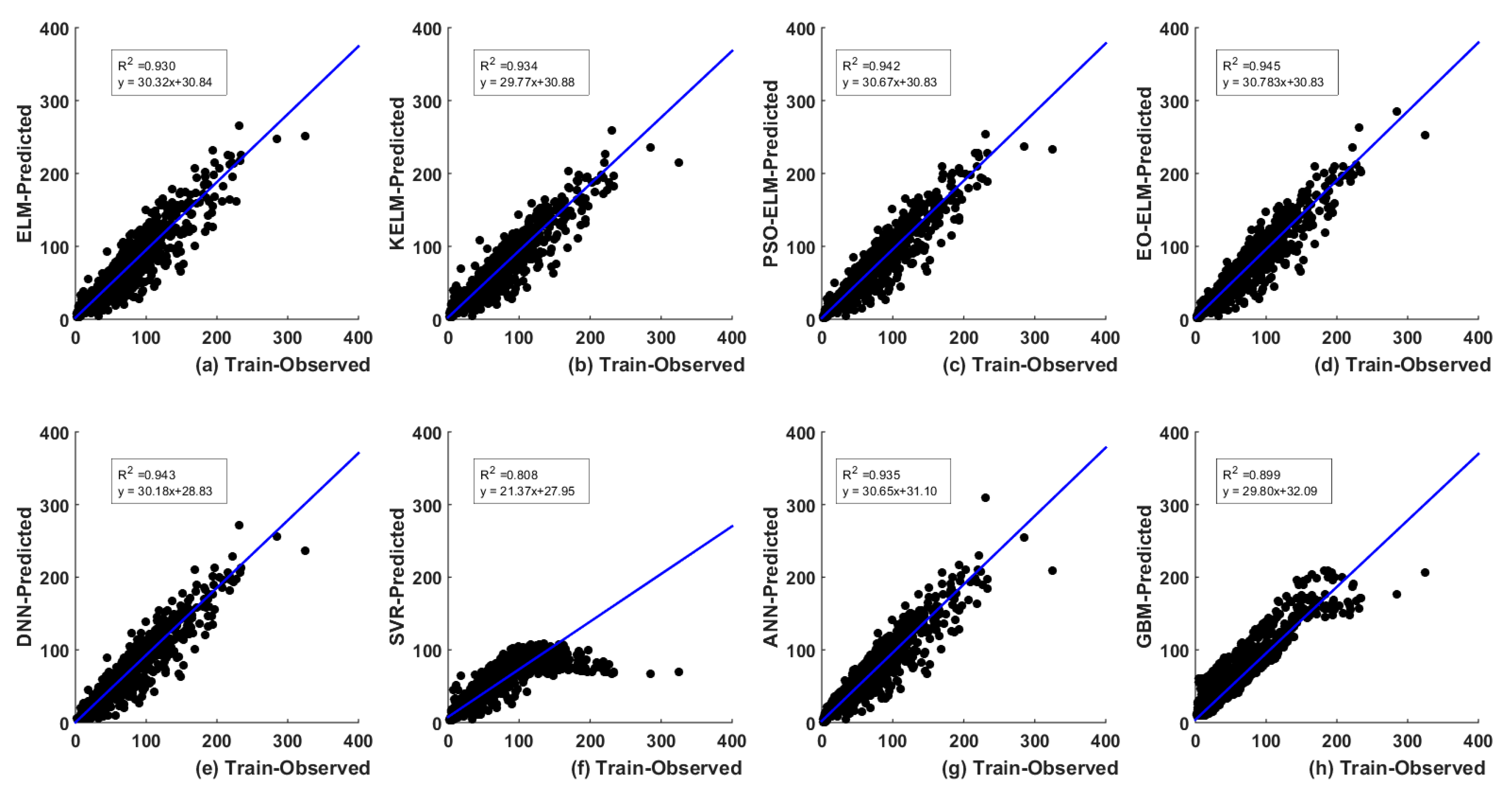
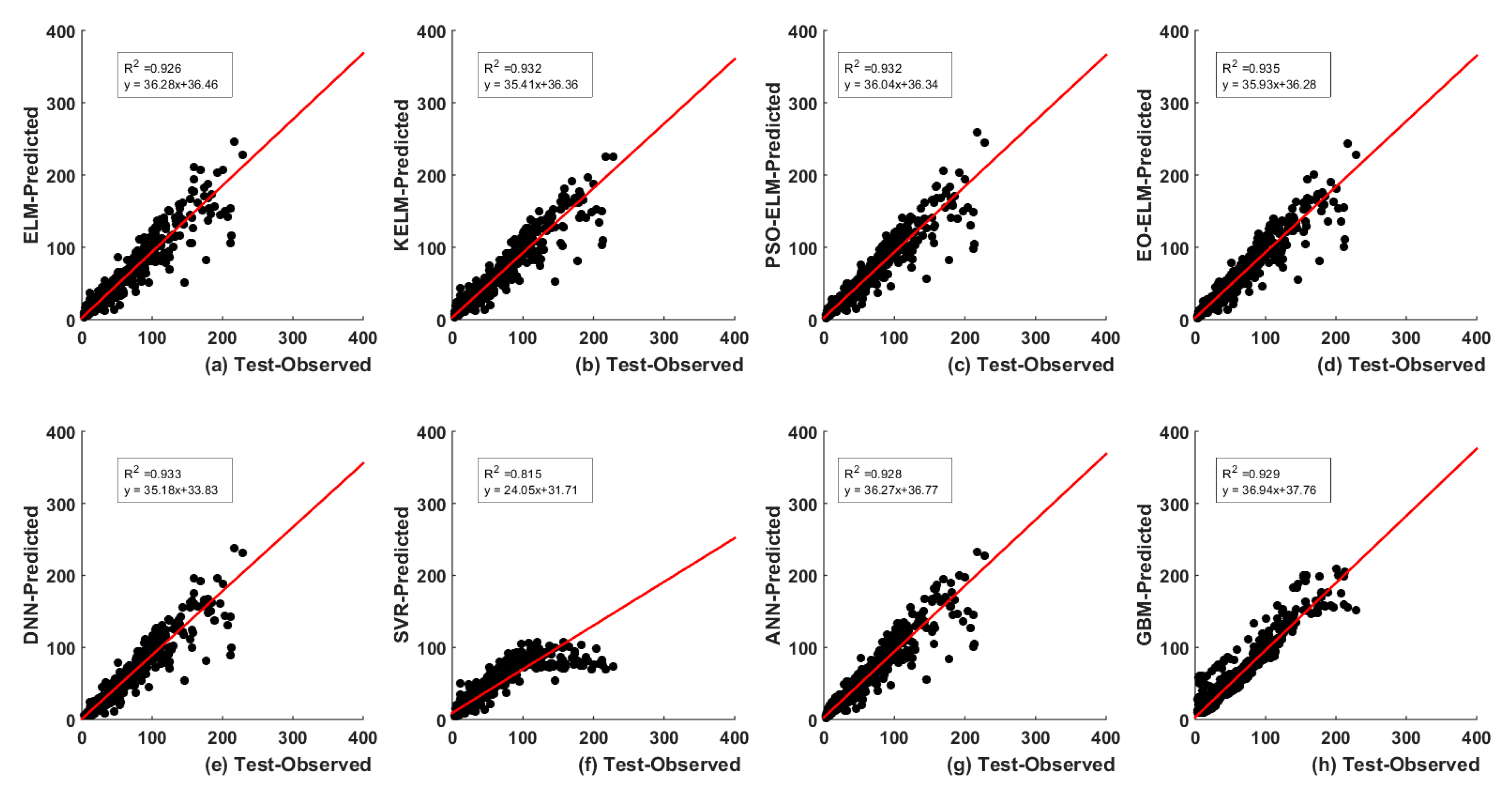
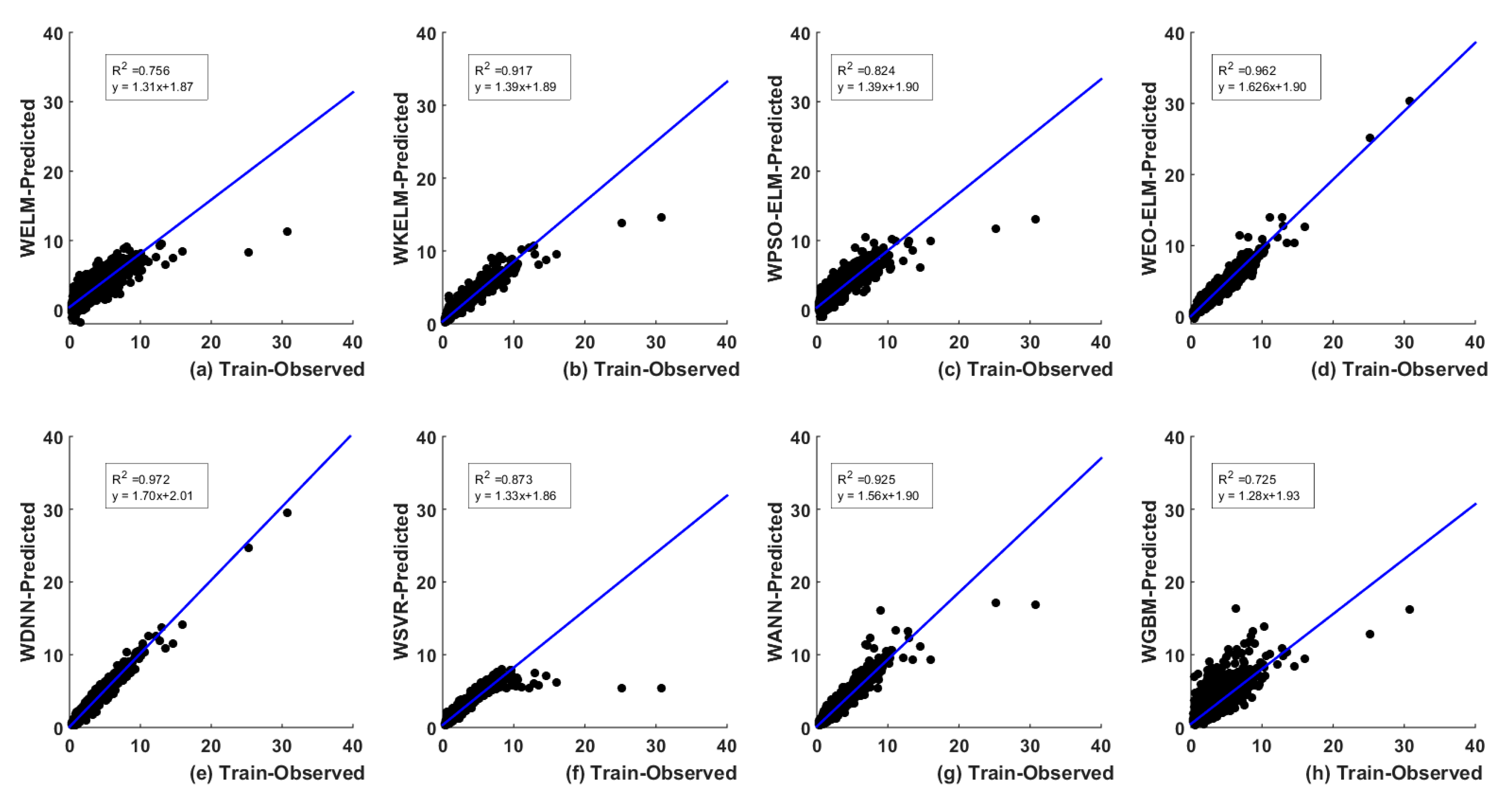
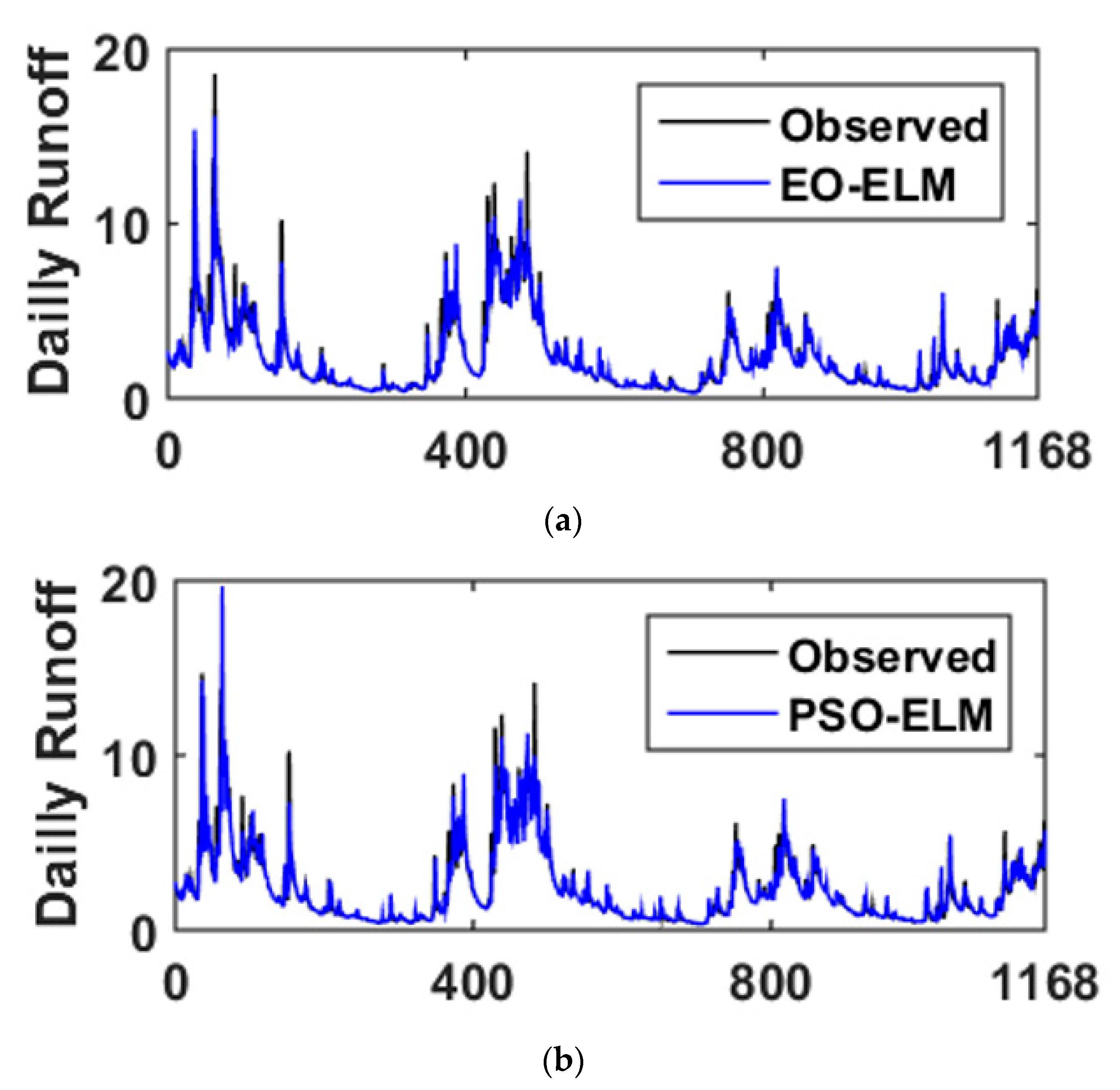
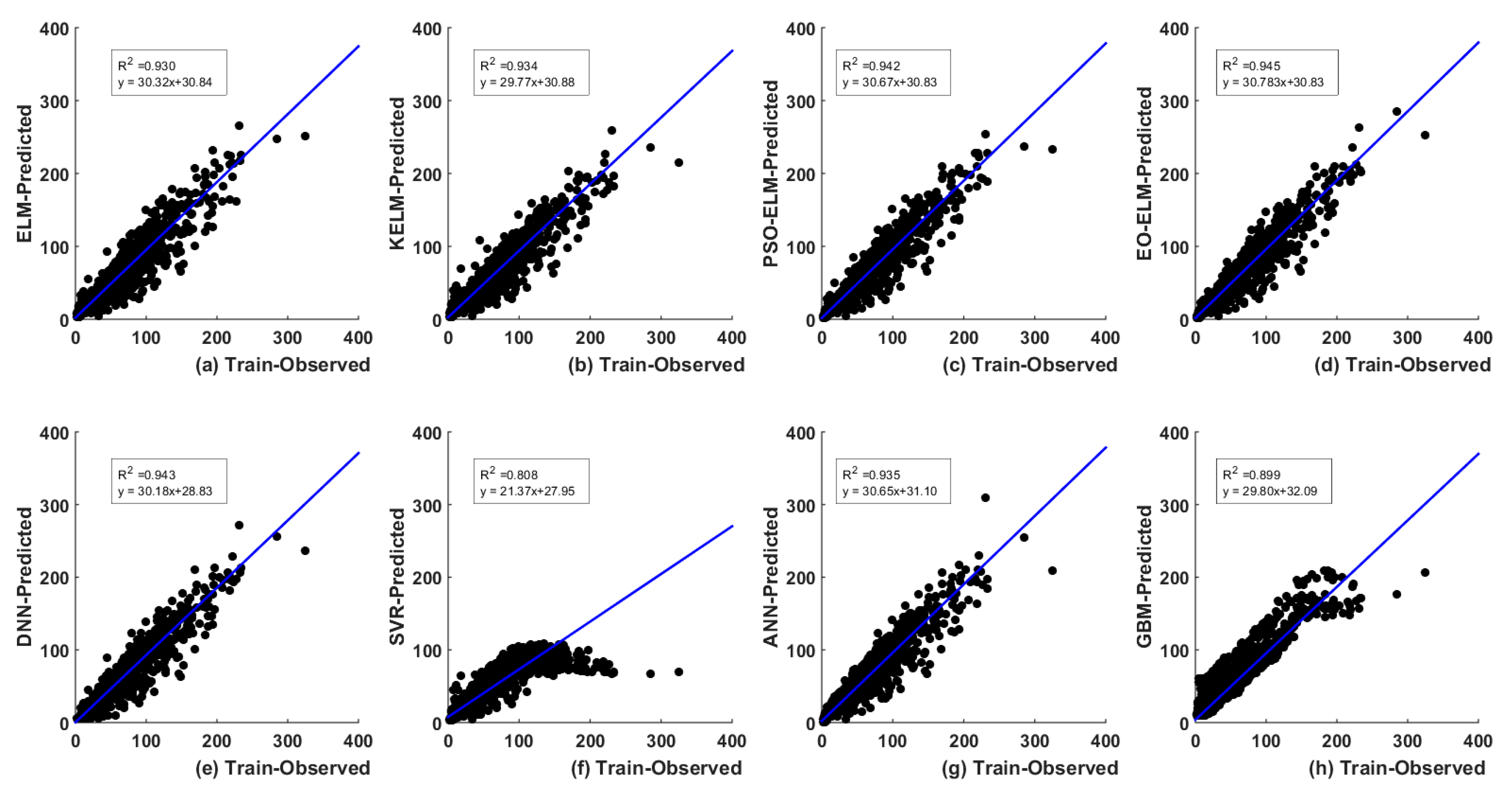
5. Results and Analysis
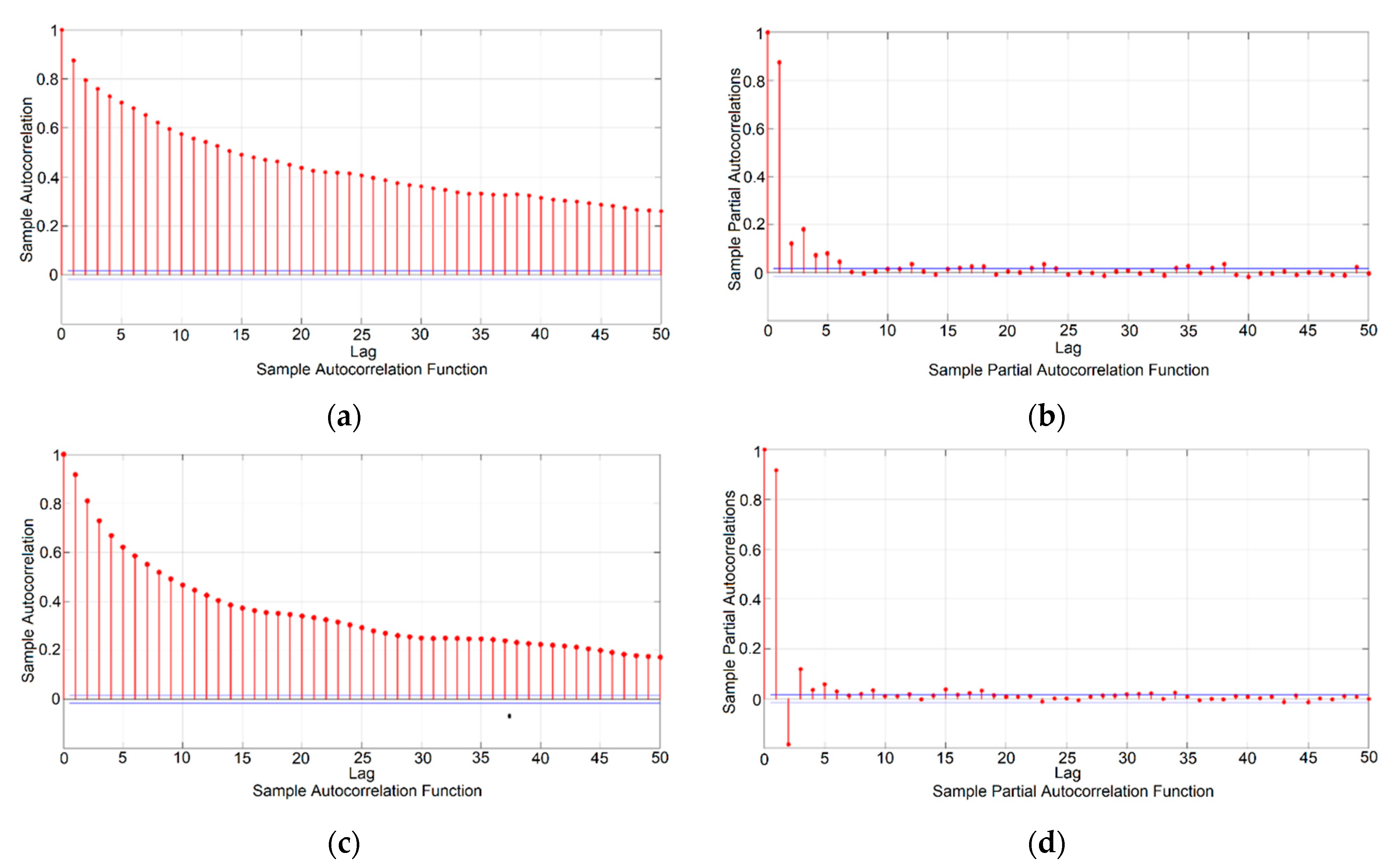
5.1. Optimal Lags-Based
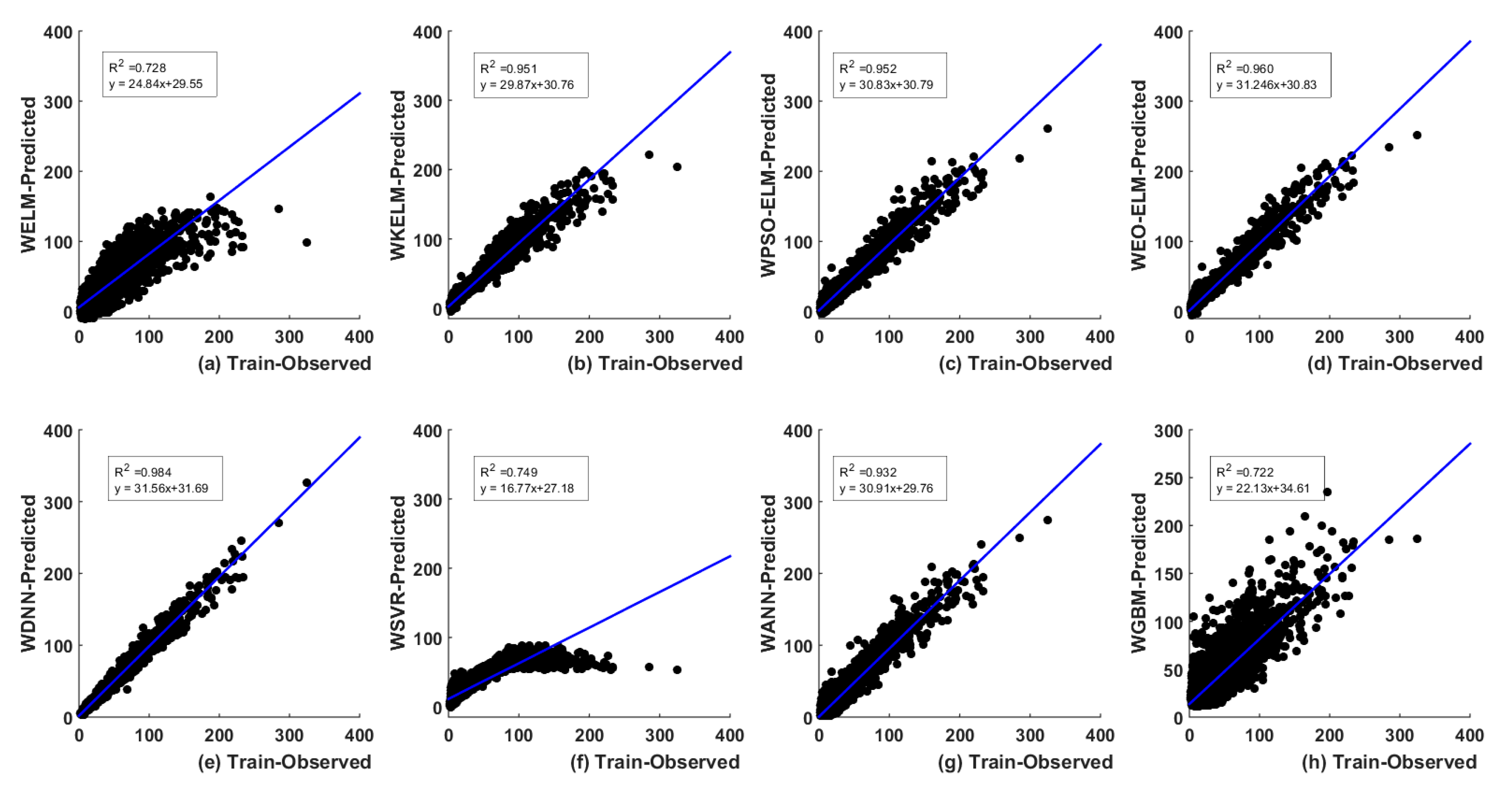
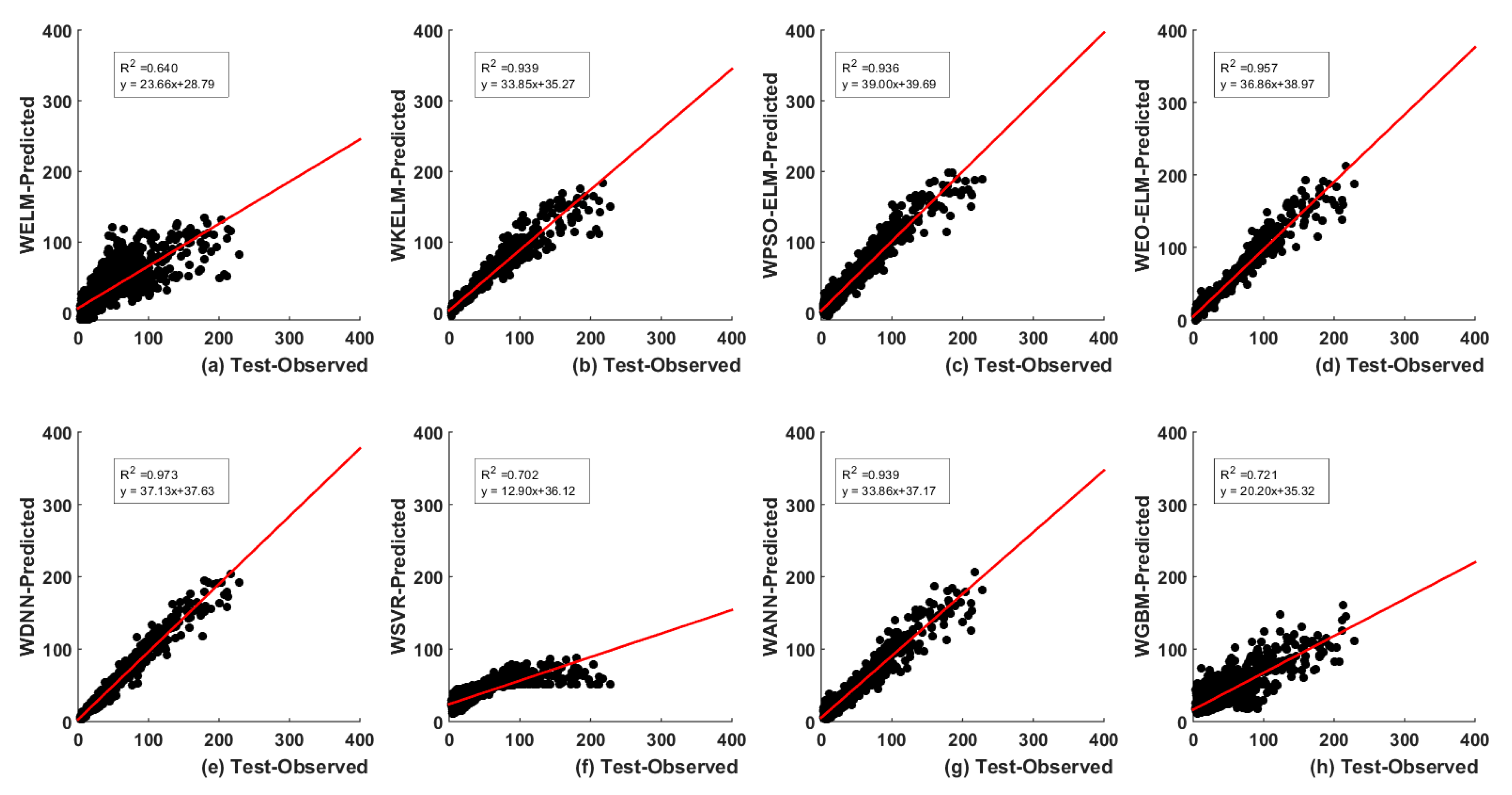
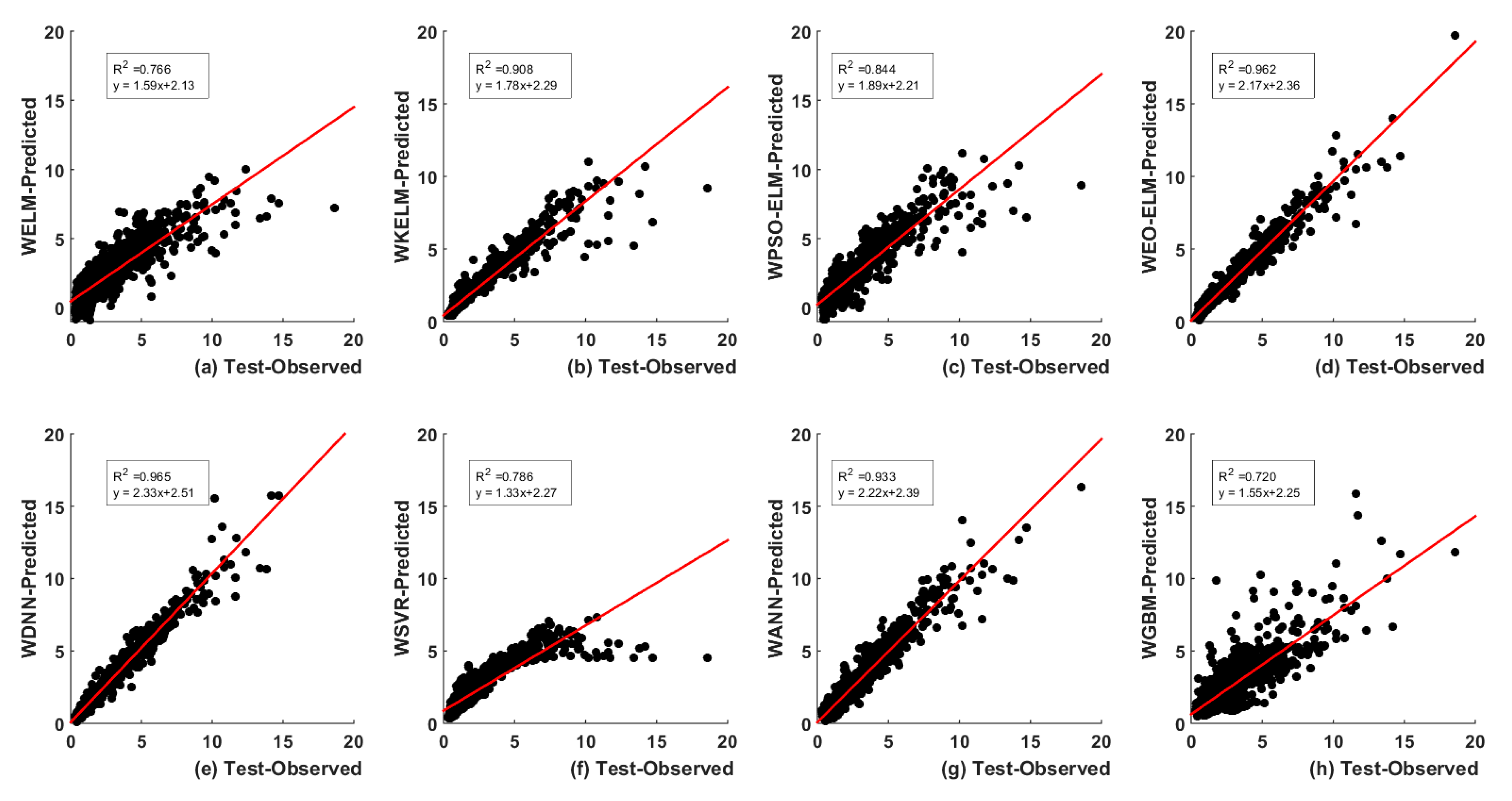
5.2. Discrete Wavelet Transform (DWT)-Based
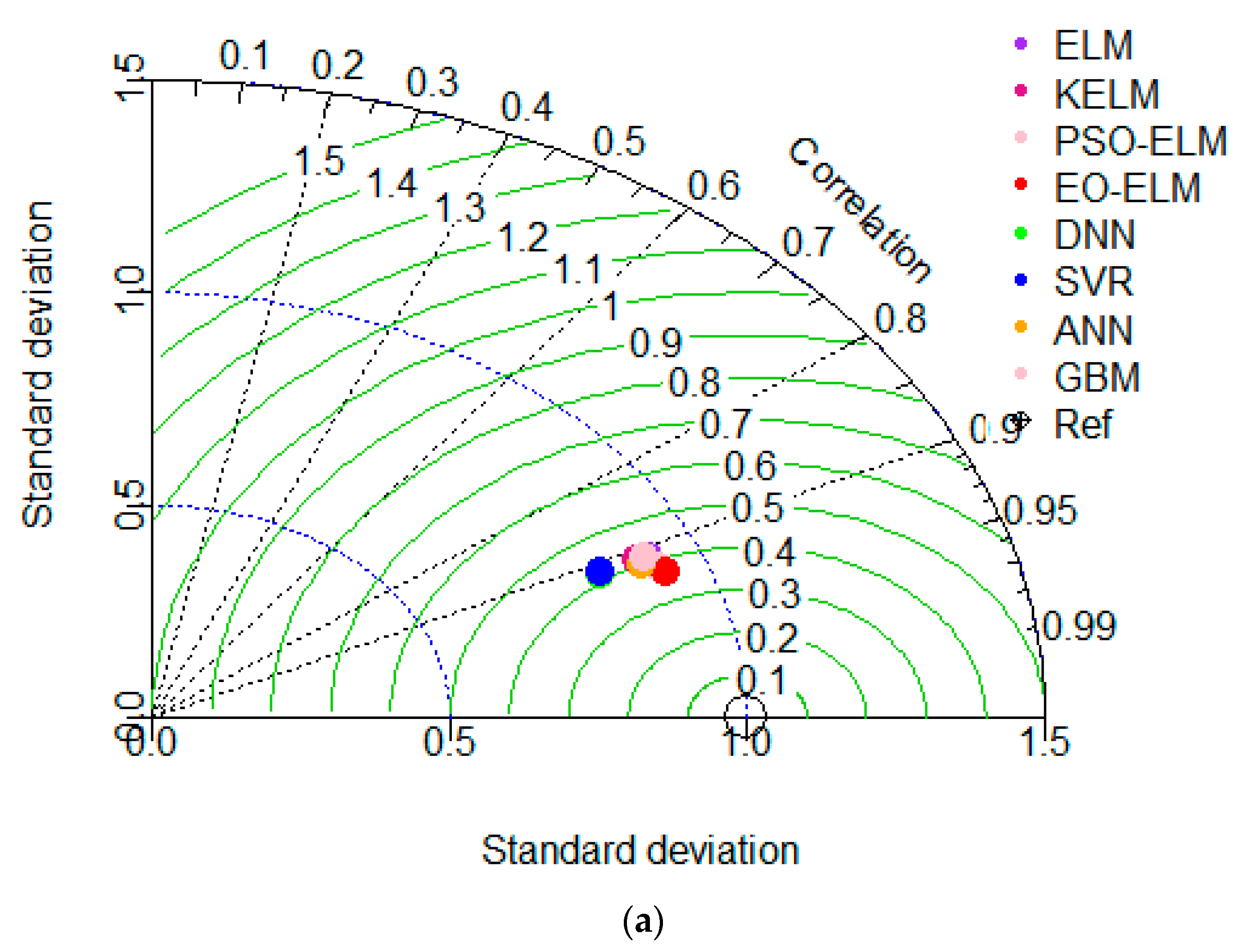
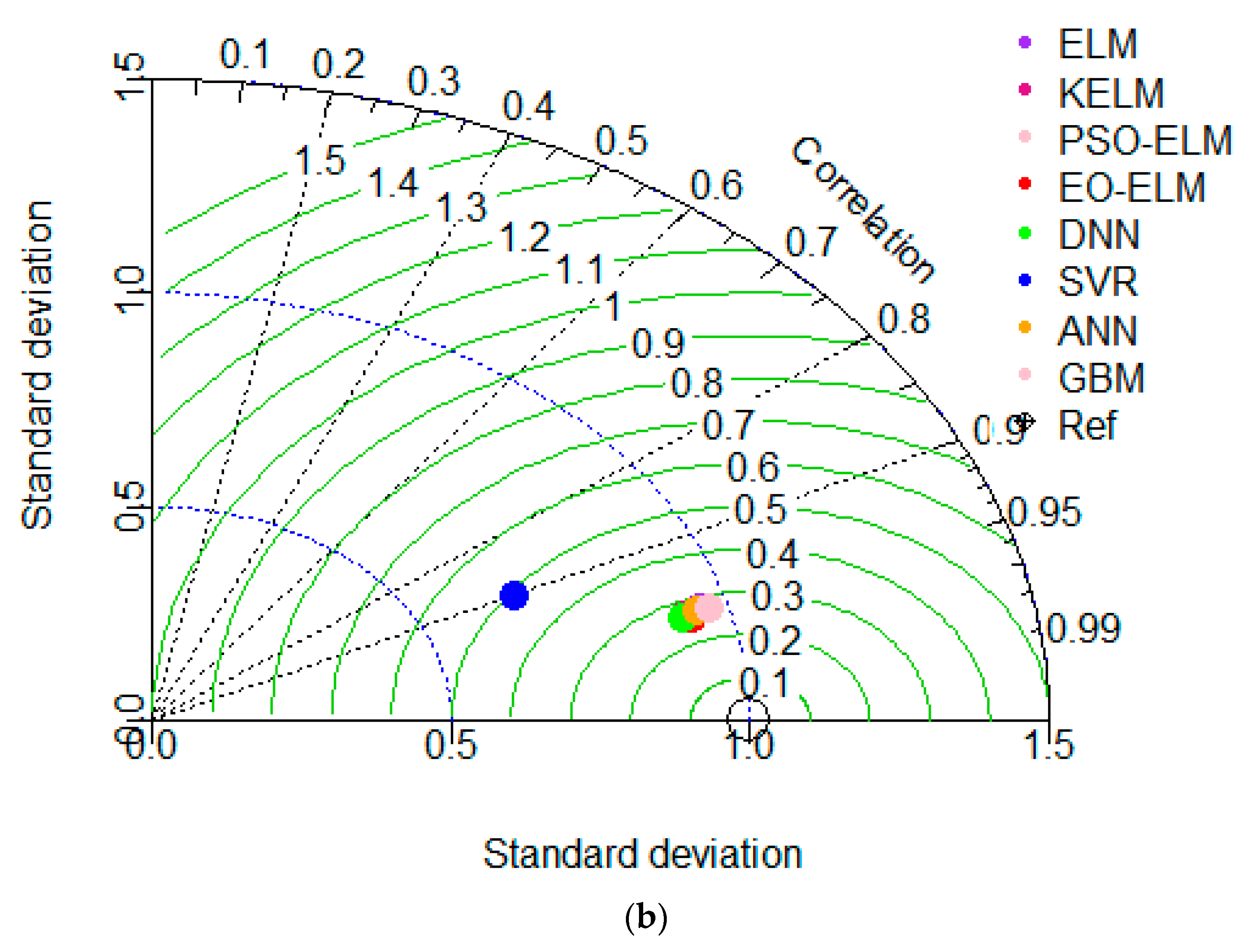
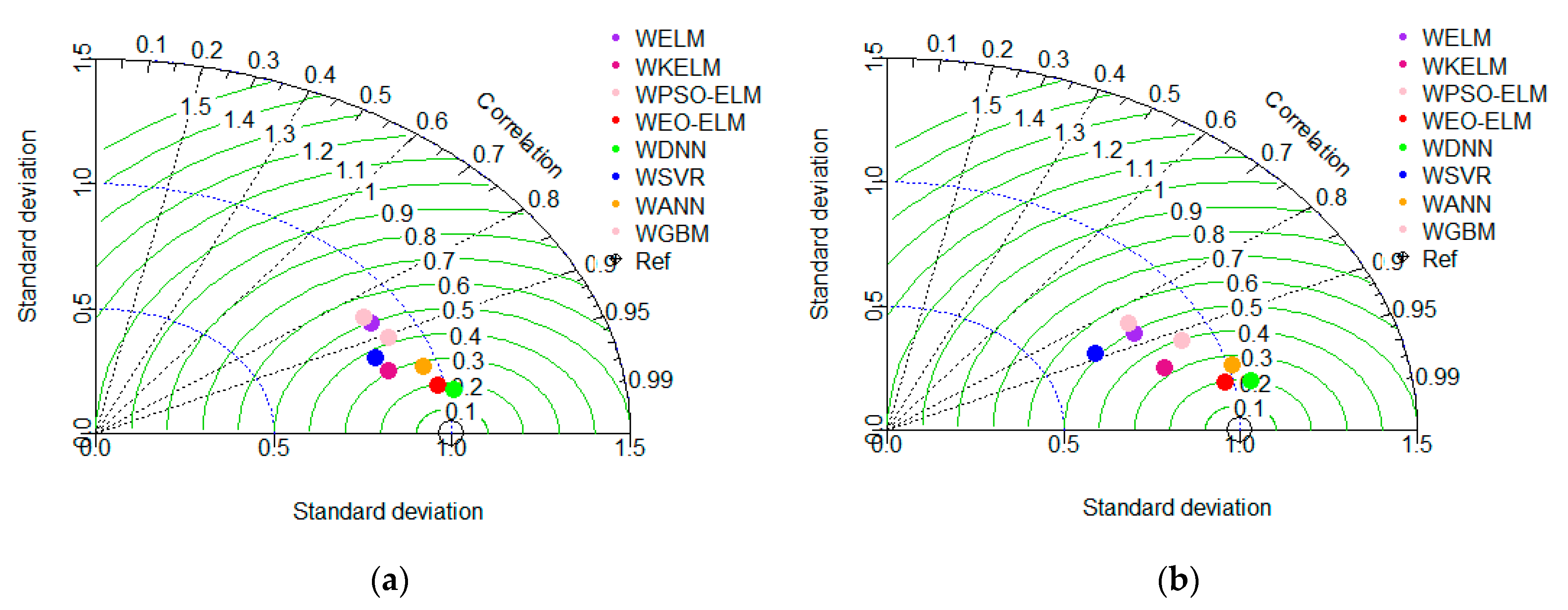
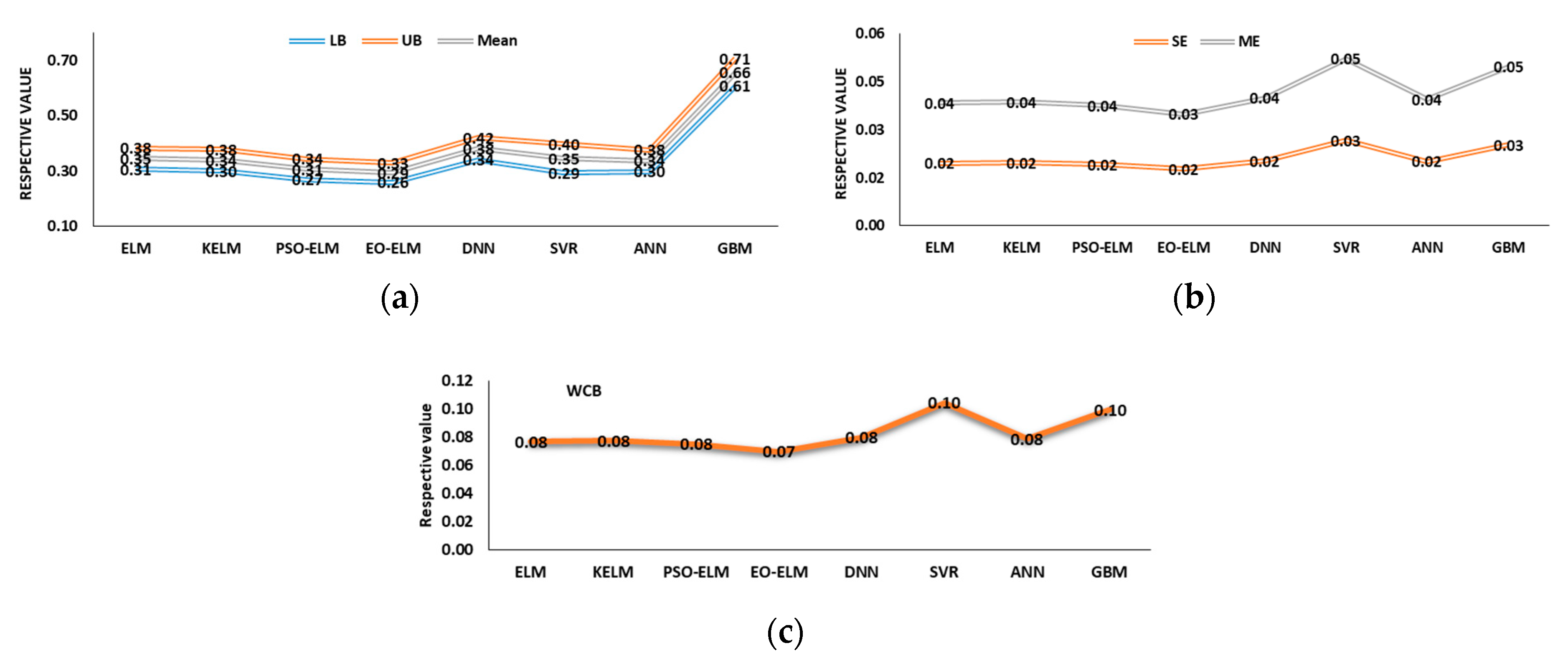
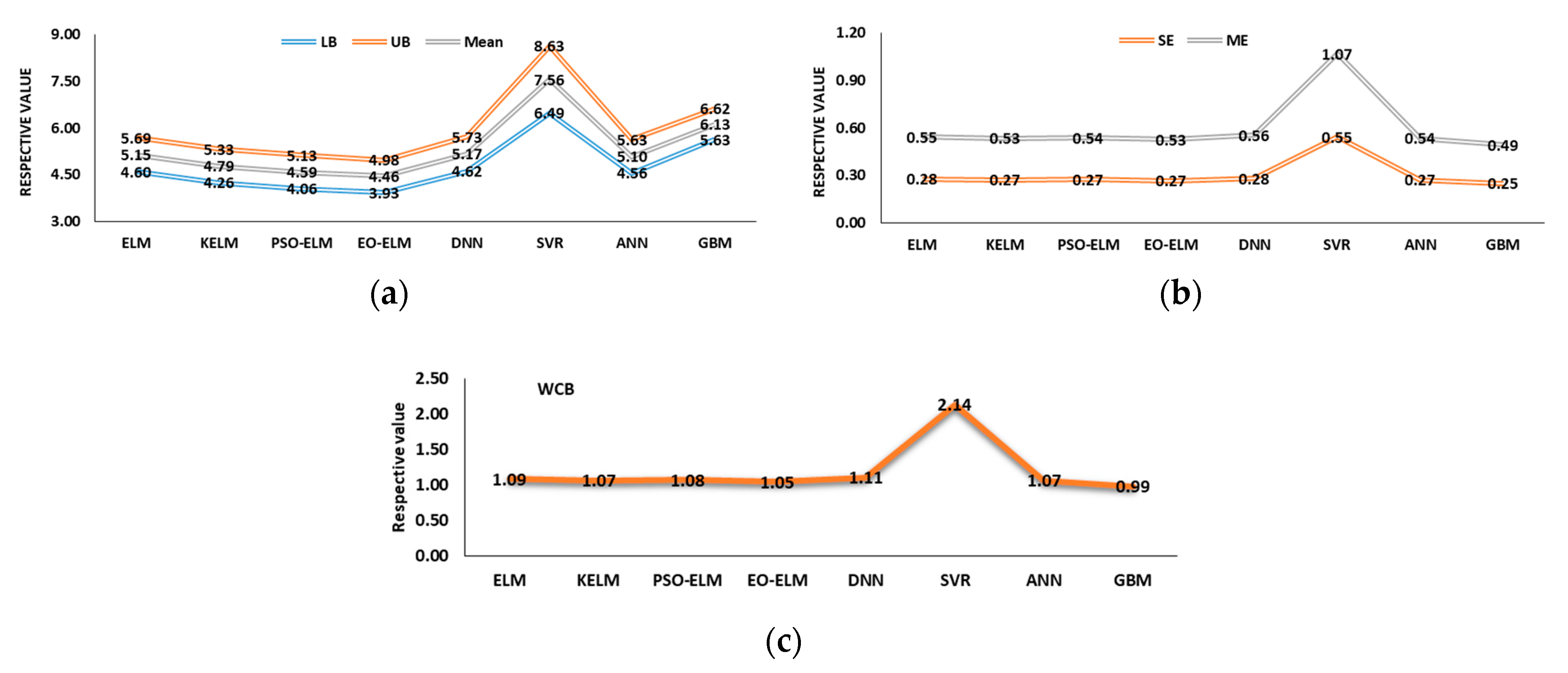
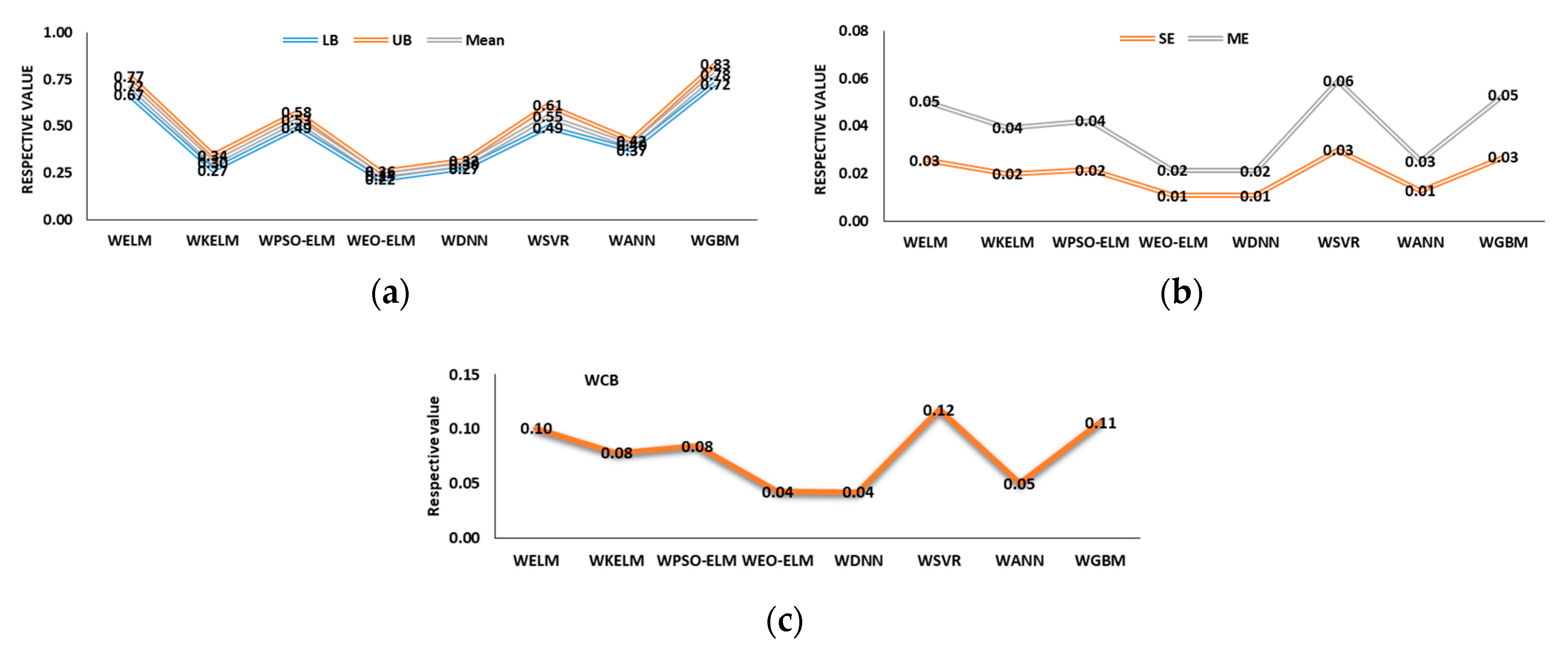
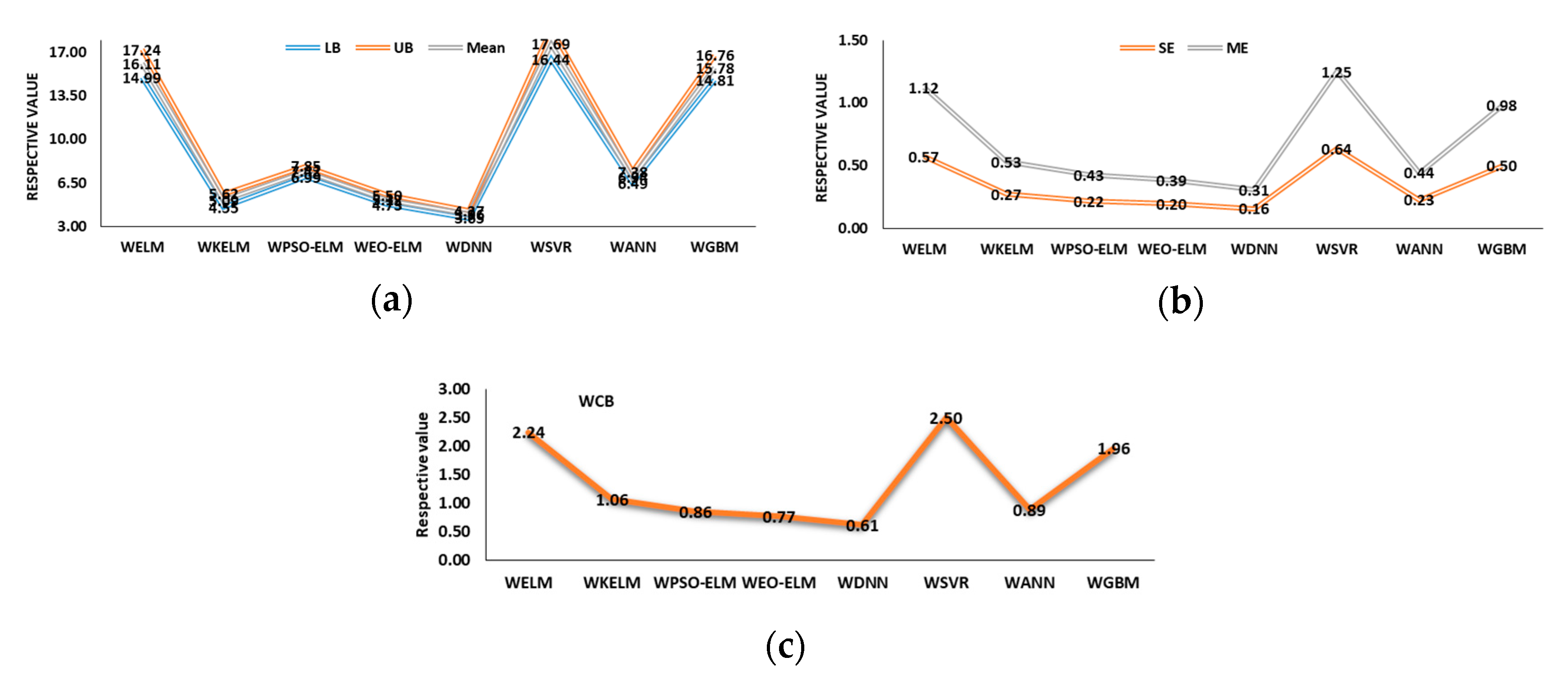
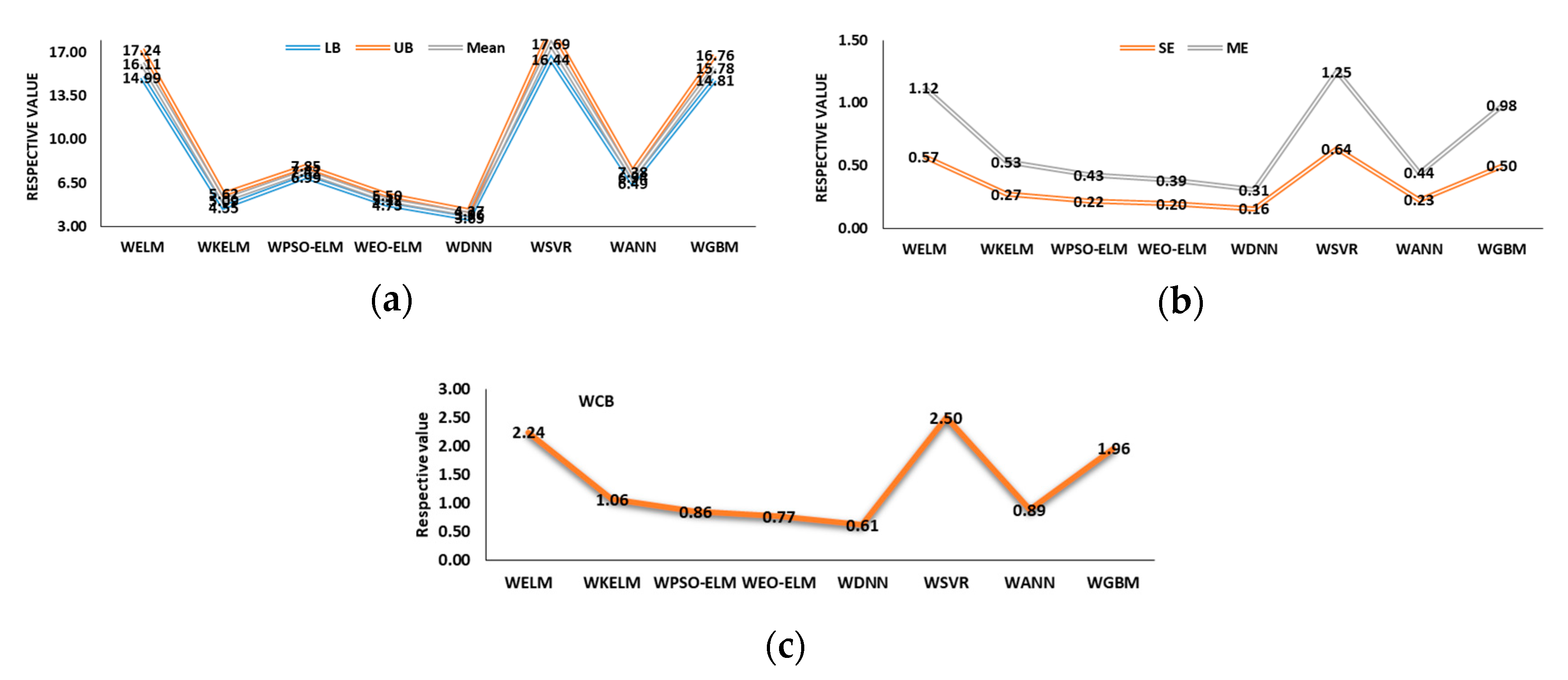
5.3. Uncertainty Analysis (UA) of Models
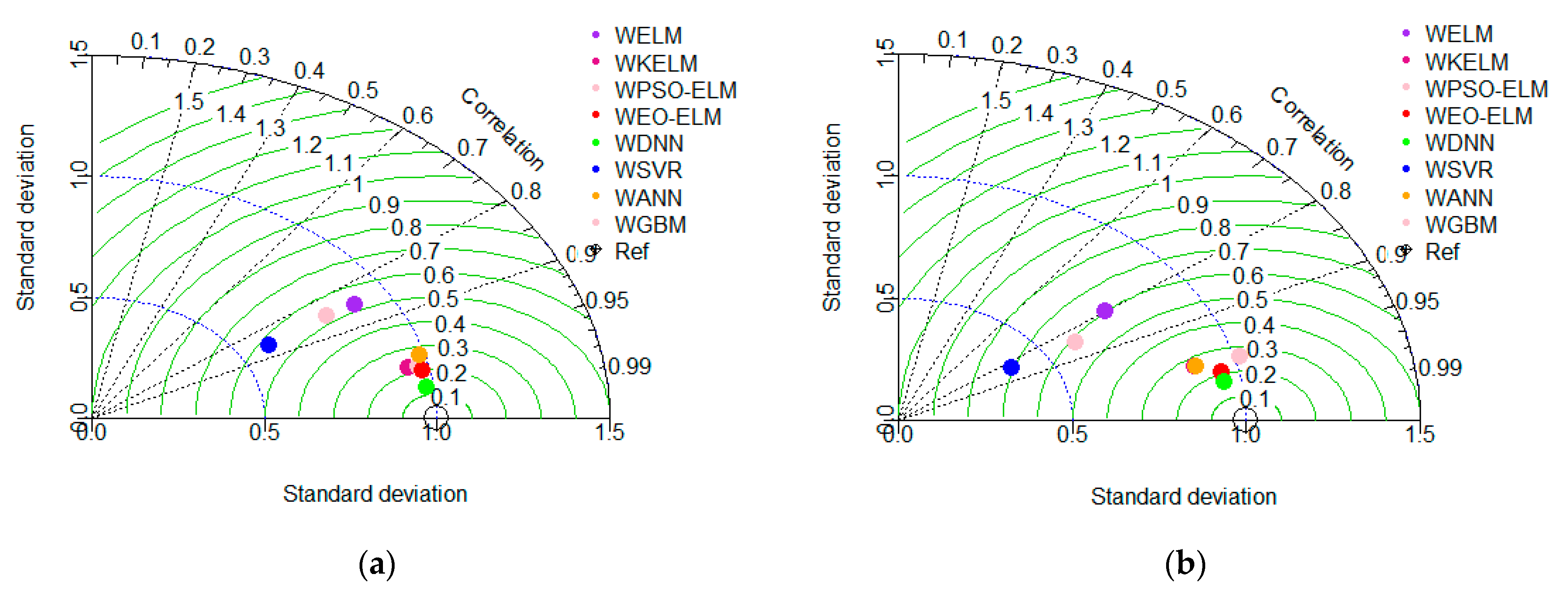
5.3.1. Lag-Based Models UA
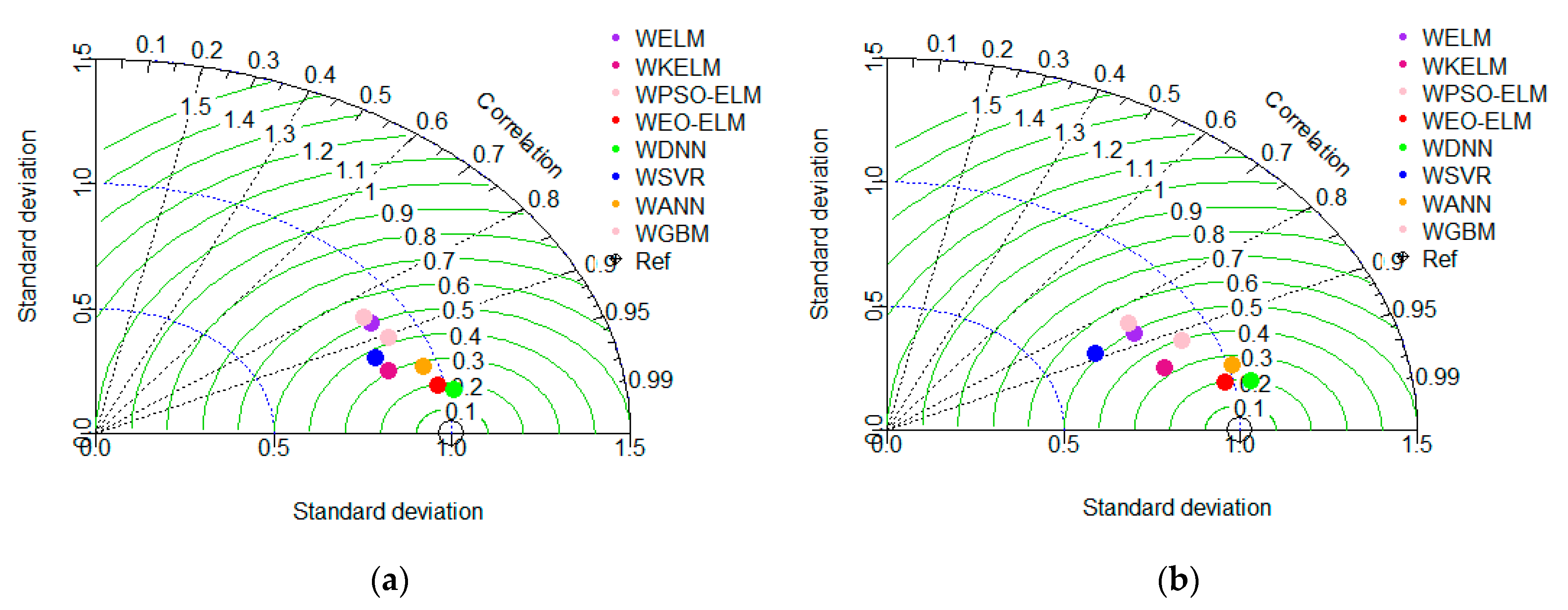
5.3.2. Wavelet-Based Models UA
5.4. Statistical Test: Two-Tailed t-Test
6. Conclusions
- (i)
- The use of a new metaheuristic algorithm (called EO) to optimize the input weights and hidden neuron biases of ELM are adequate for the better prediction performance by reducing the prediction error.
- (ii)
- The DWT is used to decompose the current day rainfall series (previous days rainfall series is already reflected in current day runoff series) and a runoff series (the highest correlated lag from PACF plot) to enhance the prediction performance of the proposed models (EO-ELM and DNN).
- (iii)
- Finally, the UA and two-tailed t-test confirm that EO-ELM performs best in optimal lag-based scenario and WDNN best for the wavelet-based scenario. WEO-ELM performs better compared to the other six models
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, W.-C.; Chau, K.-W.; Cheng, C.-T.; Qiu, L. A comparison of performance of several artificial intelligence methods for forecasting monthly discharge time series. J. Hydrol. 2009, 374, 294–306. [Google Scholar] [CrossRef] [Green Version]
- Salas, J.D. Applied Modeling of Hydrologic Time Series; Water Resources Publication: Littleton, CO, USA, 1980. [Google Scholar]
- Awchi, T.A. River Discharges Forecasting In Northern Iraq Using Different ANN Techniques. Water Resour. Manag. 2014, 28, 801–814. [Google Scholar] [CrossRef]
- Peng, Y.; Sun, X.; Zhang, X.; Zhou, H.; Zhang, Z. A Flood Forecasting Model that Considers the Impact of Hydraulic Projects by the Simulations of the Aggregate reservoir’s Retaining and Discharging. Water Resour. Manag. 2017, 31, 1031–1045. [Google Scholar] [CrossRef]
- Ming, B.; Liu, P.; Bai, T.; Tang, R.; Feng, M. Improving Optimization Efficiency for Reservoir Operation Using a Search Space Reduction Method. Water Resour. Manag. 2017, 31, 1173–1190. [Google Scholar] [CrossRef]
- Zhang, H.; Singh, V.P.; Wang, B.; Yu, Y. CEREF: A hybrid data-driven model for forecasting annual streamflow from a socio-hydrological system. J. Hydrol. 2016, 540, 246–256. [Google Scholar] [CrossRef]
- Hrachowitz, M.; Savenije, H.; Bloschl, G.; Mcdonnell, J.; Sivapalan, M.; Pomeroy, J.; Arheimer, B.; Blume, T.; Clark, M.; Ehret, U.; et al. A decade of Predictions in Ungauged Basins (PUB)—A review. Hydrol. Sci. J. 2013, 58, 1198–1255. [Google Scholar] [CrossRef]
- Mohammadi, K.; Eslami, H.; Kahawita, R. Parameter estimation of an ARMA model for river flow forecasting using goal programming. J. Hydrol. 2006, 331, 293–299. [Google Scholar] [CrossRef]
- Mehdizadeh, S.; Fathian, F.; Adamowski, J.F. Hybrid artificial intelligence-time series models for monthly streamflow modeling. Appl. Soft Comput. 2019, 80, 873–887. [Google Scholar] [CrossRef]
- Nayak, P.; Sudheer, K.; Rangan, D.; Ramasastri, K. A neuro-fuzzy computing technique for modeling hydrological time series. J. Hydrol. 2004, 291, 52–66. [Google Scholar] [CrossRef]
- Bui, Y.T.; Orange, D.; Visser, S.; Hoanh, C.T.; Laissus, M.; Poortinga, A.; Tran, D.T.; Stroosnijder, L. Lumped surface and sub--surface runoff for erosion modeling within a small hilly watershed in northern Vietnam. Hydrol. Process. 2014, 28, 2961–2974. [Google Scholar] [CrossRef]
- Beven, J.K. Rainfall-Runoff Modelling: The Primer; John Willey & Sons Ltd.: New York, NY, USA, 2000. [Google Scholar]
- Liu, Z.; Todini, E. Towards a comprehensive physically-based rainfall-runoff model. Hydrol. Earth Syst. Sci. 2002, 6, 859–881. [Google Scholar] [CrossRef]
- Modarres, R.; Ouarda, T. Modeling rainfall–runoff relationship using multivariate GARCH model. J. Hydrol. 2013, 499, 1–18. [Google Scholar] [CrossRef]
- Samsudin, R.A.; Saad, P.; Shabri, A. River flow time series using least squares support vector machines. Hydrol. Earth Syst. Sci. 2011, 15, 1835–1852. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.; Chau, K.W. Rainfall–runoff modeling using artificial neural network coupled with singular spectrum analysis. J. Hydrol. 2011, 399, 394–409. [Google Scholar] [CrossRef] [Green Version]
- Lolli, F.; Gamberini, R.; Regattieri, A.; Balugani, E.; Gatos, T.; Gucci, S. Single-hidden layer neural networks for forecasting intermittent demand. Int. J. Prod. Econ. 2017, 183, 116–128. [Google Scholar] [CrossRef]
- Nourani, V. An Emotional ANN (EANN) approach to modeling rainfall-runoff process. J. Hydrol. 2017, 544, 267–277. [Google Scholar] [CrossRef]
- Motahari, M.; Mazandaranizadeh, H. Development of a PSO-ANN Model for Rainfall-Runoff Response in Basins, Case Study: Karaj Basin. Civ. Eng. J. 2017, 3, 35–44. [Google Scholar] [CrossRef]
- Taormina, R.; Chau, K.-W. Neural network river forecasting with multi-objective fully informed particle swarm optimization. J. Hydroinform. 2015, 17, 99–113. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.-B. An Insight into Extreme Learning Machines: Random Neurons, Random Features and Kernels. Cogn. Comput. 2014, 6, 376–390. [Google Scholar] [CrossRef]
- Rezaie-Balf, M.; Kisi, O. New formulation for forecasting streamflow: Evolutionary polynomial regression vs. extreme learning machine. Hydrol. Res. 2018, 49, 939–953. [Google Scholar] [CrossRef] [Green Version]
- Yaseen, Z.M.; Jaafar, O.; Deo, R.C.; Kisi, O.; Adamowski, J.; Quilty, J.; El-Shafie, A. Stream-flow forecasting using extreme learning machines: A case study in a semi-arid region in Iraq. J. Hydrol. 2016, 542, 603–614. [Google Scholar] [CrossRef]
- Zhu, S.; Heddam, S.; Wu, S.; Dai, J.; Jia, B. Extreme learning machine-based prediction of daily water temperature for rivers. Environ. Earth Sci. 2019, 78, 202. [Google Scholar] [CrossRef]
- Deo, R.C.; Tiwari, M.K.; Adamowski, J.F.; Quilty, J. Forecasting effective drought index using a wavelet extreme learning machine (W-ELM) model. Stoch. Environ. Res. Risk Assess. 2017, 31, 1211–1240. [Google Scholar] [CrossRef]
- Fijani, E.; Barzegar, R.; Deo, R.; Tziritis, E.; Skordas, K. Design and implementation of a hybrid model based on two-layer decomposition method coupled with extreme learning machines to support real-time environmental monitoring of water quality parameters. Sci. Total Environ. 2019, 648, 839–853. [Google Scholar] [CrossRef] [PubMed]
- Cao, J.; Lin, Z.; Huang, G.-B. Self-Adaptive Evolutionary Extreme Learning Machine. Neural Process. Lett. 2012, 36, 285–305. [Google Scholar] [CrossRef]
- Zhu, Q.-Y.; Qin, K.; Suganthan, P.; Huang, G.-B. Evolutionary extreme learning machine. Pattern Recognit. 2005, 38, 1759–1763. [Google Scholar] [CrossRef]
- Huang, G.; Huang, G.B.; Song, S.; You, K. Trends in extreme learning machines: A review. Neural Netw. 2015, 61, 32–48. [Google Scholar] [CrossRef] [PubMed]
- Roy, B.; Singh, M.P.; Singh, A. A novel approach for rainfall-runoff modelling using a biogeography-based optimization technique. Int. J. River Basin Manag. 2019, 19, 1–14. [Google Scholar] [CrossRef]
- Chau, K. Particle swarm optimization training algorithm for ANNs in stage prediction of Shing Mun River. J. Hydrol. 2006, 329, 363–367. [Google Scholar] [CrossRef] [Green Version]
- Stagge, J.H.; Moglen, G.E. Evolutionary Algorithm Optimization of a Multireservoir System with Long Lag Times. J. Hydrol. Eng. 2014, 19, 05014011. [Google Scholar] [CrossRef]
- Li, P.; Chen, B.; Li, Z.L.; Jing, L. ASOC: A Novel Agent-Based Simulation-Optimization Coupling Approach-Algorithm and Application in Offshore Oil Spill Responses. J. Environ. Inform. 2016, 28, 90–100. [Google Scholar] [CrossRef]
- Yi, L.; Zhao, J.; Yu, W.; Liu, Y.; Yi, C.; Jiang, D. Catenary Fault Identification Based on PSO-ELM. J. Phys. Conf. Ser. 2019, 1302, 032017. [Google Scholar] [CrossRef] [Green Version]
- Cai, W.; Yang, J.; Yu, Y.; Song, Y.; Zhou, T.; Qin, J. PSO-ELM: A Hybrid Learning Model for Short-Term Traffic Flow Forecasting. IEEE Access 2020, 8, 6505–6514. [Google Scholar] [CrossRef]
- Kaloop, M.R.; Kumar, D.; Samui, P.; Gabr, A.R.; Hu, J.W.; Jin, X.; Roy, B. Particle Swarm Optimization Algorithm-Extreme Learning Machine (PSO-ELM) Model for Predicting Resilient Modulus of Stabilized Aggregate Bases. Appl. Sci. 2019, 9, 3221. [Google Scholar] [CrossRef] [Green Version]
- Murlidhar, B.R.; Kumar, D.; Armaghani, D.J.; Mohamad, E.T.; Roy, B.; Pham, B.T. A Novel Intelligent ELM-BBO Technique for Predicting Distance of Mine Blasting-Induced Flyrock. Nat. Resour. Res. 2020, 29, 4103–4120. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Kumar, D.; Samui, P.; Hasanipanah, M.; Roy, B. A novel approach for forecasting of ground vibrations resulting from blasting: Modified particle swarm optimization coupled extreme learning machine. Eng. Comput. 2020, 1–15. [Google Scholar] [CrossRef]
- Faramarzi, A.; Heidarinejad, M.; Stephens, B.; Mirjalili, S. Equilibrium optimizer: A novel optimization algorithm. Knowl. Based Syst. 2020, 191, 105190. [Google Scholar] [CrossRef]
- Bengio, Y. Learning Deep Architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Mikolov, T.; Deoras, A.; Povey, D.; Burget, L.; Cernocky, J. Strategies for training large scale neural network language models. In 2011 IEEE Workshop on Automatic Speech Recognition & Understanding; IEEE: Piscataway, NJ, USA, 2011. [Google Scholar]
- Arel, I.; Rose, D.C.; Karnowski, T.P. Deep Machine Learning-A New Frontier in Artificial Intelligence Research [Research Frontier]. IEEE Comput. Intell. Mag. 2010, 5, 13–18. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Längkvist, M.; Karlsson, L.; Loutfi, A. A review of unsupervised feature learning and deep learning for time-series modeling. Pattern Recognit. Lett. 2014, 42, 11–24. [Google Scholar] [CrossRef] [Green Version]
- Harrigan, S.; Hannaford, J.; Muchan, K.; Marsh, T.J. Designation and trend analysis of the updated UK Benchmark Network of river flow stations: The UKBN2 dataset. Hydrol. Res. 2018, 49, 552–567. [Google Scholar] [CrossRef] [Green Version]
- Mouatadid, S.; Adamowski, J.F.; Tiwari, M.K.; Quilty, J.M. Coupling the maximum overlap discrete wavelet transform and long short-term memory networks for irrigation flow forecasting. Agric. Water Manag. 2019, 219, 72–85. [Google Scholar] [CrossRef]
- Rhif, M.; Ben Abbes, A.; Farah, I.R.; Martínez, B.; Sang, Y. Wavelet Transform Application for/in Non-Stationary Time-Series Analysis: A Review. Appl. Sci. 2019, 9, 1345. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Niu, J.; Sivakumar, B. A comparative study of models for short-term streamflow forecasting with emphasis on wavelet-based approach. Stoch. Environ. Res. Risk Assess. 2019, 33, 1875–1891. [Google Scholar] [CrossRef]
- Altunkaynak, A.; Nigussie, T.A. Prediction of daily rainfall by a hybrid wavelet-season-neuro technique. J. Hydrol. 2015, 529, 287–301. [Google Scholar] [CrossRef]
- Niu, J.; Chen, J.; Wang, K.; Sivakumar, B. Multi-scale streamflow variability responses to precipitation over the headwater catchments in southern China. J. Hydrol. 2017, 551, 14–28. [Google Scholar] [CrossRef]
- Chong, K.L.; Lai, S.H.; El-Shafie, A. Wavelet Transform Based Method for River Stream Flow Time Series Frequency Analysis and Assessment in Tropical Environment. Water Resour. Manag. 2019, 33, 2015–2032. [Google Scholar] [CrossRef]
- Yong, N.K.; Awang, N. Wavelet-based time series model to improve the forecast accuracy of PM10 concentrations in Peninsular Malaysia. Environ. Monit. Assess. 2019, 191, 64. [Google Scholar] [CrossRef]
- Graf, R.; Zhu, S.; Sivakumar, B. Forecasting river water temperature time series using a wavelet–neural network hybrid modelling approach. J. Hydrol. 2019, 578, 124115. [Google Scholar] [CrossRef]
- Chen, L.; Hao, Y.; Hu, X. Detection of preterm birth in electrohysterogram signals based on wavelet transform and stacked sparse autoencoder. PLoS ONE 2019, 14, e0214712. [Google Scholar] [CrossRef] [PubMed]
- Farboudfam, N.; Nourani, V.; Aminnejad, B. Wavelet-based multi station disaggregation of rainfall time series in mountainous regions. Hydrol. Res. 2019, 50, 545–561. [Google Scholar] [CrossRef] [Green Version]
- Kennedy, J.; Eberhart, R. Particle swarm optimization (PSO). In Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995. [Google Scholar]
- Kisi, O.; Cimen, M. Precipitation forecasting by using wavelet-support vector machine conjunction model. Eng. Appl. Artif. Intell. 2012, 25, 783–792. [Google Scholar] [CrossRef]
- Labat, D.; Ronchail, J.; Guyot, J.L. Recent advances in wavelet analyses: Part 2—Amazon, Parana, Orinoco and Congo discharges time scale variability. J. Hydrol. 2005, 314, 289–311. [Google Scholar] [CrossRef]
- Wang, W.; Ding, J. Wavelet network model and its application to the prediction of hydrology. Nat. Sci. 2003, 1, 67–71. [Google Scholar]
- Jiang, S.; Xiao, R.; Wang, L.; Luo, X.; Huang, C.; Wang, J.-H.; Chin, K.-S.; Nie, X. Combining Deep Neural Networks and Classical Time Series Regression Models for Forecasting Patient Flows in Hong Kong. IEEE Access 2019, 7, 118965–118974. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2012, 42, 513–529. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.-B.; Wang, D.H.; Lan, Y. Extreme learning machines: A survey. Int. J. Mach. Learn. Cybern. 2011, 2, 107–122. [Google Scholar] [CrossRef]
- Huang, G.-B.; Siew, C.-K. Extreme learning machine: RBF network case. In Proceedings of the ICARCV 2004 8th Control, Automation, Robotics and Vision Conference, Kunming, China, 6–9 December 2004; IEEE: Piscataway, NJ, USA, 2004. [Google Scholar]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.J.; Vapnik, V. Support vector regression machines. Adv. Neural Inf. Process. Syst. 1997, 9, 155–161. [Google Scholar]
- Maheswaran, R.; Khosa, R. Comparative study of different wavelets for hydrologic forecasting. Comput. Geosci. 2012, 46, 284–295. [Google Scholar] [CrossRef]
- Gold, C.M. Surface interpolation, spatial adjacency and GIS. In Three Dimensional Applications in Geographic Information Systems; CRC Press: Boca Raton, FL, USA, 1989; pp. 21–35. [Google Scholar]
- Touzani, S.; Granderson, J.; Fernandes, S. Gradient boosting machine for modeling the energy consumption of commercial buildings. Energy Build. 2018, 158, 1533–1543. [Google Scholar] [CrossRef] [Green Version]
- Robinson, E.L.; Blyth, E.M.; Clark, D.B.; Finch, J.; Rudd, A.C. Trends in atmospheric evaporative demand in Great Britain using high-resolution meteorological data. Hydrol. Earth Syst. Sci. 2017, 21, 1189–1224. [Google Scholar] [CrossRef] [Green Version]
- Keller, V.; Tanguy, M.; Prosdocimi, I.; Terry, J.A.; Hitt, O.; Cole, S.J.; Fry, M.; Morris, D.G.; Dixon, H. CEH-GEAR: 1 km resolution daily and monthly areal rainfall estimates for the UK for hydrological and other applications. Earth Syst. Sci. Data 2015, 7, 143–155. [Google Scholar] [CrossRef] [Green Version]
- Tanguy, M.; Dixon, H.; Prosdocimi, I.; Morris, D.G.; Keller, V.D.J. Gridded Estimates of Daily and Monthly Areal Rainfall for the United Kingdom (1890–2015) [CEH-GEAR]; NERC Environmental Information Data Centre: Atlanta, GA, USA, 2016. [Google Scholar]
- Kumar, R.; Singh, M.P.; Roy, B.; Shahid, A.H. A Comparative Assessment of Metaheuristic Optimized Extreme Learning Machine and Deep Neural Network in Multi-Step-Ahead Long-term Rainfall Prediction for All-Indian Regions. Water Resour. Manag. 2021, 35, 1927–1960. [Google Scholar] [CrossRef]
- De Artigas, M.Z.; Elias, A.G.; de Campra, P.F. Discrete wavelet analysis to assess long-term trends in geomagnetic activity. Phys. Chem. Earth Parts A/B/C 2006, 31, 77–80. [Google Scholar] [CrossRef]
- Bigiarini, M.Z.; Bigiarini, M.M.Z. Package “hydroGOF”. R-Package. 2013. Available online: www.r-project.org/ (accessed on 7 May 2018).
- Gholami, A.; Bonakdari, H.; Samui, P.; Mohammadian, M.; Gharabaghi, B. Predicting stable alluvial channel profiles using emotional artificial neural networks. Appl. Soft Comput. 2019, 78, 420–437. [Google Scholar] [CrossRef]
- Zeng, J.; Roy, B.; Kumar, D.; Mohammed, A.S.; Armaghani, D.J.; Zhou, J.; Mohamad, E.T. Proposing several hybrid PSO-extreme learning machine techniques to predict TBM performance. Eng. Comput. 2021, 1–17. [Google Scholar] [CrossRef]
- Roy, B.; Singh, M.P. An empirical-based rainfall-runoff modelling using optimization technique. Int. J. River Basin Manag. 2019, 18, 49–67. [Google Scholar] [CrossRef]
- Roy, B.; Singh, M.P. A Metaheuristic-based Emotional ANN (EmNN) Approach for Rainfall-runoff Modeling. In Proceedings of the 2019 International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 17–19 July 2019; pp. 454–458. [Google Scholar] [CrossRef]
- Kardani, N.; Bardhan, A.; Kim, D.; Samui, P.; Zhou, A. Modelling the energy performance of residential buildings using advanced computational frameworks based on RVM, GMDH, ANFIS-BBO and ANFIS-IPSO. J. Build. Eng. 2021, 35, 102105. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Exploration | Exploitation | Exploration and Exploitation |
|---|---|---|
| a1, maximum value is 3. GP, value 0.5 provides good balance in optimization process. | a2, maximum value is 2. | sign(r-0.5) Peq,pool, in starting period it helps particle for global search patterns. In ending period, it helps particle for local search pattern. |
| Catchment | Mean | Sd. | Median | Min | Max | Skewness | |
|---|---|---|---|---|---|---|---|
| Fal at Tragony | Discharge (m3/s) | 2.03549 | 1.949909 | 1.37 | 0.208 | 48.24 | 3.69096 |
| Rainfall (mm/day) | 3.37865 | 5.742897 | 0.6 | 0 | 55.9 | 2.693286 | |
| Teifi at Glanteifi | Discharge (m3/s) | 29.6010 | 31.9316 | 18.290 | 0.7310 | 373.60 | 2.4780 |
| Rainfall (mm/day) | 3.8631 | 6.2733 | 1 | 0 | 73.100 | 2.7719 |
| MAE | MAPE | NSE | R2 | RMSE | VAF | TOTAL | ||
|---|---|---|---|---|---|---|---|---|
| ELM | Train | 0.29 | 15.79 | 0.84 | 0.83 | 0.69 | 83.16 | |
| Rank | 5 | 3 | 5 | 4 | 5 | 5 | 27 | |
| Test | 0.35 | 15.58 | 0.95 | 0.89 | 0.75 | 88.93 | ||
| Rank | 4 | 3 | 5 | 5 | 5 | 6 | 28 | |
| KELM | Train | 0.29 | 15.30 | 0.84 | 0.83 | 0.70 | 83.06 | |
| Rank | 4 | 4 | 3 | 3 | 3 | 4 | 21 | |
| Test | 0.34 | 14.99 | 0.95 | 0.89 | 0.75 | 88.90 | ||
| Rank | 6 | 4 | 6 | 6 | 6 | 5 | 33 | |
| PSO-ELM | Train | 0.26 | 12.21 | 0.86 | 0.85 | 0.65 | 85.26 | |
| Rank | 7 | 7 | 7 | 7 | 7 | 7 | 42 | |
| Test | 0.31 | 11.29 | 0.95 | 0.90 | 0.72 | 89.85 | ||
| Rank | 7 | 7 | 7 | 7 | 7 | 7 | 40 | |
| EO-ELM | Train | 0.25 | 11.75 | 0.87 | 0.86 | 0.62 | 86.34 | |
| Rank | 8 | 8 | 8 | 8 | 8 | 8 | 48 | |
| Test | 0.29 | 11.18 | 0.96 | 0.91 | 0.68 | 91.13 | ||
| Rank | 8 | 8 | 8 | 8 | 8 | 8 | 48 | |
| DNN | Train | 0.32 | 20.53 | 0.84 | 0.84 | 0.70 | 82.71 | |
| Rank | 2 | 2 | 4 | 5 | 4 | 2 | 19 | |
| Test | 0.38 | 20.40 | 0.94 | 0.89 | 0.79 | 87.90 | ||
| Rank | 2 | 2 | 3 | 3 | 3 | 3 | 16 | |
| SVR | Train | 0.30 | 14.66 | 0.83 | 0.83 | 0.72 | 82.36 | |
| Rank | 3 | 5 | 2 | 2 | 2 | 1 | 15 | |
| Test | 0.35 | 12.95 | 0.91 | 0.85 | 0.97 | 82.39 | ||
| Rank | 3 | 6 | 2 | 2 | 2 | 2 | 17 | |
| ANN | Train | 0.28 | 13.71 | 0.85 | 0.84 | 0.68 | 83.93 | |
| Rank | 6 | 6 | 6 | 6 | 6 | 6 | 36 | |
| Test | 0.34 | 13.48 | 0.94 | 0.89 | 0.77 | 88.61 | ||
| Rank | 5 | 5 | 4 | 4 | 4 | 4 | 26 | |
| GBM | Train | 0.42 | 39.1 | 0.83 | 0.83 | 0.72 | 83.04 | |
| Rank | 1 | 1 | 1 | 1 | 1 | 3 | 8 | |
| Test | 0.66 | 47.97 | 0.89 | 0.78 | 1.09 | 77.72 | ||
| Rank | 1 | 1 | 1 | 1 | 1 | 1 | 6 |
| MAE | MAPE | NSE | R2 | RMSE | VAF | TOTAL | ||
|---|---|---|---|---|---|---|---|---|
| ELM | Train | 4.29 | 16.20 | 0.93 | 0.93 | 8.64 | 92.97 | |
| Rank | 3 | 5 | 3 | 3 | 3 | 3 | 20 | |
| Test | 5.15 | 15.02 | 0.95 | 0.93 | 10.81 | 92.60 | ||
| Rank | 4 | 4 | 2 | 3 | 3 | 3 | 19 | |
| KELM | Train | 4.06 | 16.32 | 0.93 | 0.93 | 8.37 | 93.39 | |
| Rank | 6 | 4 | 4 | 4 | 4 | 5 | 27 | |
| Test | 4.79 | 14.93 | 0.95 | 0.93 | 10.47 | 93.06 | ||
| Rank | 6 | 5 | 6 | 6 | 6 | 6 | 35 | |
| PSO-ELM | Train | 3.64 | 11.26 | 0.94 | 0.94 | 7.87 | 94.16 | |
| Rank | 7 | 8 | 7 | 7 | 7 | 6 | 42 | |
| Test | 4.59 | 12.44 | 0.95 | 0.93 | 10.45 | 93.10 | ||
| Rank | 7 | 7 | 7 | 7 | 7 | 7 | 42 | |
| EO-ELM | Train | 3.58 | 11.77 | 0.95 | 0.95 | 7.64 | 94.50 | |
| Rank | 8 | 7 | 8 | 8 | 8 | 8 | 47 | |
| Test | 4.46 | 11.67 | 0.95 | 0.94 | 10.18 | 93.46 | ||
| Rank | 8 | 8 | 8 | 8 | 8 | 8 | 48 | |
| DNN | Train | 4.17 | 17.99 | 0.94 | 0.94 | 8.04 | 94.28 | |
| Rank | 5 | 2 | 6 | 6 | 6 | 7 | 32 | |
| Test | 5.17 | 16.47 | 0.95 | 0.93 | 10.97 | 93.06 | ||
| Rank | 3 | 2 | 2 | 2 | 2 | 5 | 16 | |
| SVR | Train | 5.14 | 12.45 | 0.77 | 0.81 | 15.56 | 77.96 | |
| Rank | 2 | 6 | 1 | 1 | 1 | 1 | 12 | |
| Test | 7.56 | 13.78 | 0.82 | 0.82 | 20.11 | 76.18 | ||
| Rank | 1 | 6 | 1 | 1 | 1 | 1 | 11 | |
| ANN | Train | 4.29 | 16.8 | 0.93 | 0.94 | 8.31 | 93.49 | |
| Rank | 4 | 3 | 5 | 5 | 5 | 4 | 26 | |
| Test | 5.1 | 16.28 | 0.95 | 0.93 | 10.63 | 92.82 | ||
| Rank | 5 | 3 | 4 | 4 | 4 | 2 | 22 | |
| GBM | Train | 5.98 | 41.37 | 0.89 | 0.90 | 10.43 | 89.89 | |
| Rank | 1 | 1 | 2 | 2 | 2 | 2 | 10 | |
| Test | 6.13 | 34.71 | 0.95 | 0.93 | 10.55 | 92.93 | ||
| Rank | 3 | 1 | 5 | 5 | 5 | 4 | 24 |
| MAE | MAPE | NSE | R2 | RMSE | VAF | TOTAL | ||
|---|---|---|---|---|---|---|---|---|
| WELM | Train | 0.51 | 36.00 | 0.77 | 0.76 | 0.84 | 75.53 | |
| Rank | 3 | 3 | 2 | 2 | 2 | 2 | 14 | |
| Test | 0.72 | 41.36 | 0.88 | 0.77 | 1.13 | 76.05 | ||
| Rank | 2 | 1 | 3 | 2 | 3 | 3 | 14 | |
| WKELM | Train | 0.72 | 41.36 | 0.91 | 0.92 | 0.51 | 90.75 | |
| Rank | 1 | 1 | 5 | 5 | 5 | 5 | 22 | |
| Test | 0.30 | 12.78 | 0.95 | 0.91 | 0.75 | 89.18 | ||
| Rank | 6 | 7 | 5 | 5 | 5 | 5 | 33 | |
| WPSO-ELM | Train | 0.42 | 29.06 | 0.84 | 0.82 | 0.71 | 82.36 | |
| Rank | 4 | 4 | 3 | 3 | 3 | 3 | 20 | |
| Test | 0.53 | 31.37 | 0.92 | 0.84 | 0.91 | 84.40 | ||
| Rank | 4 | 3 | 4 | 4 | 4 | 4 | 23 | |
| WEO-ELM | Train | 0.18 | 11.26 | 0.96 | 0.96 | 0.33 | 96.19 | |
| Rank | 8 | 8 | 7 | 7 | 7 | 7 | 44 | |
| Test | 0.24 | 11.81 | 0.98 | 0.96 | 0.47 | 96.18 | ||
| Rank | 8 | 8 | 7 | 7 | 7 | 8 | 45 | |
| WDNN | Train | 0.21 | 13.60 | 0.97 | 0.97 | 0.31 | 97.09 | |
| Rank | 7 | 7 | 8 | 8 | 8 | 8 | 46 | |
| Test | 0.30 | 15.70 | 0.98 | 0.97 | 0.44 | 96.04 | ||
| Rank | 7 | 6 | 8 | 8 | 8 | 7 | 43 | |
| WSVR | Train | 0.40 | 27.03 | 0.87 | 0.87 | 0.62 | 86.47 | |
| Rank | 5 | 5 | 4 | 4 | 4 | 4 | 26 | |
| Test | 0.55 | 26.44 | 0.87 | 0.79 | 1.17 | 73.65 | ||
| Rank | 3 | 4 | 2 | 3 | 1 | 2 | 15 | |
| WANN | Train | 0.24 | 16.24 | 0.93 | 0.93 | 0.46 | 92.46 | |
| Rank | 6 | 6 | 6 | 6 | 6 | 6 | 36 | |
| Test | 0.40 | 22.86 | 0.96 | 0.93 | 0.60 | 93.11 | ||
| Rank | 5 | 5 | 6 | 6 | 6 | 6 | 34 | |
| WGBM | Train | 0.53 | 36.09 | 0.74 | 0.73 | 0.89 | 72.42 | |
| Rank | 3 | 2 | 1 | 1 | 1 | 1 | 9 | |
| Test | 0.78 | 40.50 | 0.86 | 0.72 | 1.20 | 71.78 | ||
| Rank | 1 | 2 | 1 | 1 | 2 | 1 | 8 |
| MAE | MAPE | NSE | R2 | RMSE | VAF | TOTAL | ||
|---|---|---|---|---|---|---|---|---|
| WELM | Train | 11.18 | 60.20 | 0.73 | 0.73 | 17.07 | 72.68 | |
| Rank | 2 | 2 | 3 | 2 | 3 | 3 | 15 | |
| Test | 16.11 | 60.14 | 0.72 | 0.64 | 25.32 | 63.70 | ||
| Rank | 2 | 3 | 2 | 1 | 2 | 2 | 12 | |
| WKELM | Train | 3.76 | 16.53 | 0.95 | 0.95 | 7.32 | 94.95 | |
| Rank | 7 | 7 | 5 | 5 | 5 | 5 | 34 | |
| Test | 5.09 | 18.56 | 0.95 | 0.94 | 10.57 | 93.12 | ||
| Rank | 7 | 7 | 4 | 4 | 4 | 4 | 30 | |
| WPSO-ELM | Train | 4.53 | 26.26 | 0.95 | 0.95 | 7.15 | 95.19 | |
| Rank | 5 | 4 | 6 | 6 | 6 | 6 | 33 | |
| Test | 7.42 | 40.87 | 0.95 | 0.94 | 10.51 | 93.36 | ||
| Rank | 4 | 5 | 5 | 5 | 5 | 6 | 30 | |
| WEO-ELM | Train | 3.88 | 21.58 | 0.96 | 0.96 | 6.52 | 95.99 | |
| Rank | 6 | 6 | 7 | 7 | 7 | 7 | 40 | |
| Test | 5.12 | 25.49 | 0.97 | 0.96 | 8.44 | 95.67 | ||
| Rank | 6 | 6 | 7 | 7 | 7 | 7 | 40 | |
| WDNN | Train | 2.65 | 13.75 | 0.98 | 0.98 | 4.26 | 98.36 | |
| Rank | 8 | 8 | 8 | 8 | 8 | 8 | 48 | |
| Test | 3.96 | 17.21 | 0.98 | 0.97 | 6.65 | 97.20 | ||
| Rank | 8 | 8 | 8 | 8 | 8 | 8 | 48 | |
| WSVR | Train | 7.22 | 25.30 | 0.67 | 0.75 | 18.90 | 67.59 | |
| Rank | 3 | 5 | 1 | 3 | 1 | 1 | 14 | |
| Test | 17.69 | 99.68 | 0.65 | 0.70 | 28.05 | 49.98 | ||
| Rank | 1 | 1 | 1 | 3 | 1 | 1 | 8 | |
| WANN | Train | 6.21 | 38.07 | 0.93 | 0.93 | 8.60 | 93.13 | |
| Rank | 4 | 3 | 4 | 4 | 4 | 4 | 23 | |
| Test | 6.94 | 41.07 | 0.95 | 0.94 | 10.39 | 93.14 | ||
| Rank | 5 | 4 | 6 | 6 | 6 | 5 | 32 | |
| WGBM | Train | 12.84 | 99.42 | 0.71 | 0.72 | 17.66 | 71.94 | |
| Rank | 1 | 1 | 2 | 1 | 2 | 2 | 9 | |
| Test | 15.78 | 83.81 | 0.76 | 0.72 | 23.24 | 65.86 | ||
| Rank | 3 | 2 | 3 | 3 | 3 | 3 | 17 |
| Lag-Based | ELM | RBF-ELM | PSO-ELM | EOELM | DNN | SVM | ANN | GBM |
|---|---|---|---|---|---|---|---|---|
| Difference in mean abs. error | 0.35 | 0.34 | 0.31 | 0.29 | 0.38 | 0.35 | 0.34 | 0.66 |
| t Stat | 0.04 | 0.29 | 0.42 | 1.43 | 1.02 | 2.46 | 0.56 | −2.13 |
| P(T ≤ t) two-tail | 0.97 | 0.77 | 0.67 | 0.67 | 0.31 | 0.01 | 0.58 | 0.03 |
| t Critical two-tail | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 |
| Ho (accept if, |t Stat| < t Critical) | Accept | Accept | Accept | Accept | Accept | Reject | Accept | Accept |
| Wavelet-based | WELM | WRBF-ELM | WPSO-ELM | WEOELM | WDNN | SVM | ANN | WGBM |
| Difference in mean abs. error | 0.72 | 0.30 | 0.53 | 0.29 | 0.30 | 0.55 | 0.40 | 0.78 |
| t Stat | 2.88 | 0.91 | 1.82 | 1.84 | 1.89 | 1.29 | −0.22 | 1.44 |
| P(T ≤ t) two-tail | 0.00 | 0.36 | 0.07 | 0.92 | 0.14 | 0.20 | 0.82 | 0.15 |
| t Critical two-tail | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 |
| Ho (accept if, |t Stat| < t Critical) | Reject | Accept | Accept | Accept | Accept | Accept | Accept | Accept |
| Lag-Based | ELM | RBF-ELM | PSO-ELM | EOELM | DNN | SVM | ANN | GBM |
|---|---|---|---|---|---|---|---|---|
| Difference in mean abs. error | 5.15 | 4.79 | 4.59 | 4.46 | 5.17 | 7.56 | 5.10 | 6.13 |
| t Stat | 0.46 | 0.53 | 0.54 | 0.58 | 2.14 | 3.93 | 0.27 | −0.35 |
| P(T ≤ t) two-tail | 0.65 | 0.60 | 0.59 | 0.56 | 0.03 | 0.00 | 0.79 | 0.73 |
| t Critical two-tail | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 |
| Ho (accept if, |t Stat| < t Critical) | Accept | Accept | Accept | Accept | Reject | Reject | Accept | Accept |
| Wavelet-based | WELM | WRBF-ELM | WPSO-ELM | WEOELM | WDNN | WSVM | WANN | WGBM |
| Difference in mean abs. error | 16.11 | 5.09 | 7.42 | 4.12 | 3.96 | 17.69 | 6.94 | 15.78 |
| t Stat | 5.81 | 1.24 | −1.51 | 1.11 | 1.57 | 0.86 | 0.02 | 1.39 |
| P(T ≤ t) two-tail | 0.00 | 0.21 | 0.13 | 0.55 | 0.79 | 0.39 | 0.98 | 0.16 |
| t Critical two-tail | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 | 1.96 |
| Ho (accept if, |t Stat| < t Critical) | Reject | Accept | Accept | Accept | Accept | Accept | Accept | Accept |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roy, B.; Singh, M.P.; Kaloop, M.R.; Kumar, D.; Hu, J.-W.; Kumar, R.; Hwang, W.-S. Data-Driven Approach for Rainfall-Runoff Modelling Using Equilibrium Optimizer Coupled Extreme Learning Machine and Deep Neural Network. Appl. Sci. 2021, 11, 6238. https://doi.org/10.3390/app11136238
Roy B, Singh MP, Kaloop MR, Kumar D, Hu J-W, Kumar R, Hwang W-S. Data-Driven Approach for Rainfall-Runoff Modelling Using Equilibrium Optimizer Coupled Extreme Learning Machine and Deep Neural Network. Applied Sciences. 2021; 11(13):6238. https://doi.org/10.3390/app11136238
Chicago/Turabian StyleRoy, Bishwajit, Maheshwari Prasad Singh, Mosbeh R. Kaloop, Deepak Kumar, Jong-Wan Hu, Radhikesh Kumar, and Won-Sup Hwang. 2021. "Data-Driven Approach for Rainfall-Runoff Modelling Using Equilibrium Optimizer Coupled Extreme Learning Machine and Deep Neural Network" Applied Sciences 11, no. 13: 6238. https://doi.org/10.3390/app11136238
APA StyleRoy, B., Singh, M. P., Kaloop, M. R., Kumar, D., Hu, J.-W., Kumar, R., & Hwang, W.-S. (2021). Data-Driven Approach for Rainfall-Runoff Modelling Using Equilibrium Optimizer Coupled Extreme Learning Machine and Deep Neural Network. Applied Sciences, 11(13), 6238. https://doi.org/10.3390/app11136238