
MLUTNet: A Neural Network for Memory Based Reconfigurable Logic Device Architecture

Abstract
:1. Introduction
1.1. Neural Networks and Hardware Implementation
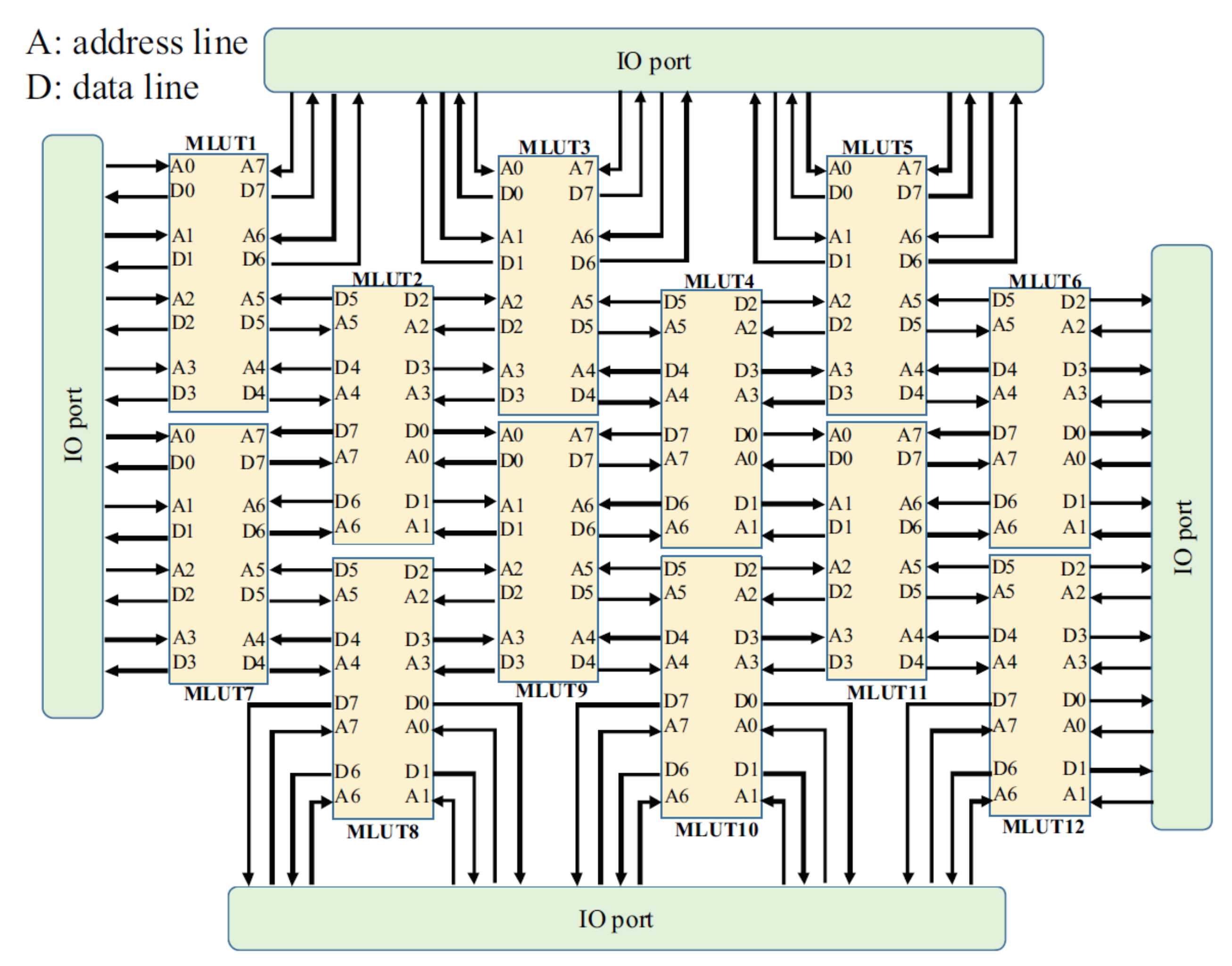
1.2. Memory Based Reconfigurable Logic Device
1.3. Motivations and Contributions
- We propose MLUTNet, a novel neural network with an atypical structure. MLUTNet combines the advantages of two aspects: the efficient learning performance of neural networks and the similar structure of MRLD, which makes MLUTNet easy to implement on MRLD or other similar logical storage devices without much extra effort;
- We conducted experiments and compared the results with their MLUTNet versions on three different popular datasets using standard and binary neural networks as the baselines, respectively. Compared to a fully connected neural network of the same size, MLUTNet saves over 50% of the weight matrix storage space and also reduces the size of individual weight matrices efficiently, with acceptable performance loss in accuracy on the dataset;
- The method is simple and easy to implement with good scalability; the MLUTNet version of a particular network can be substituted for the original network at no additional cost to meet the need to reduce the size of the network. This is very friendly for subsequent extension studies.
1.4. Organization of the Paper
2. Backgrounds
2.1. Low-Precision Neural Networks
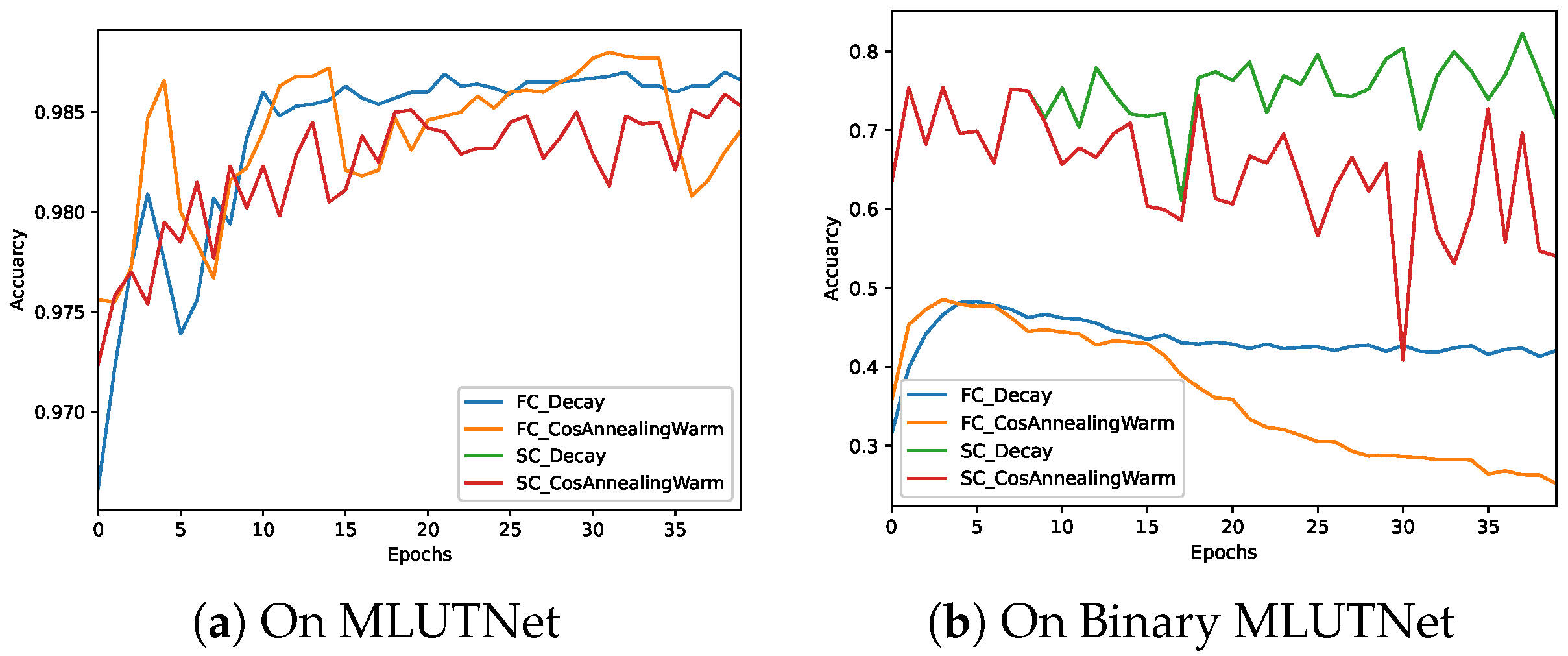
2.2. Optimizer and Learning Rate Scheduler
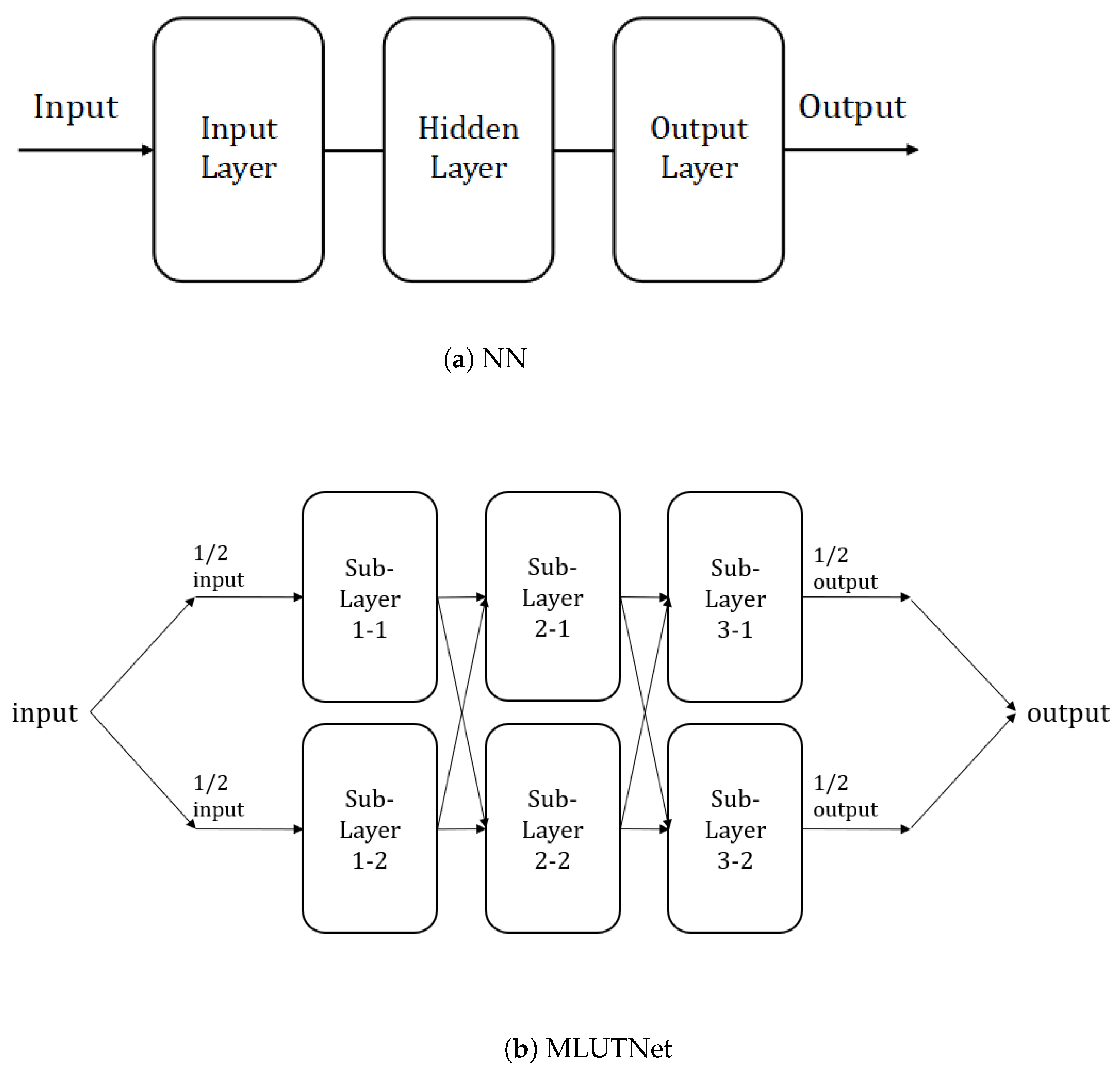
3. MLUTNet
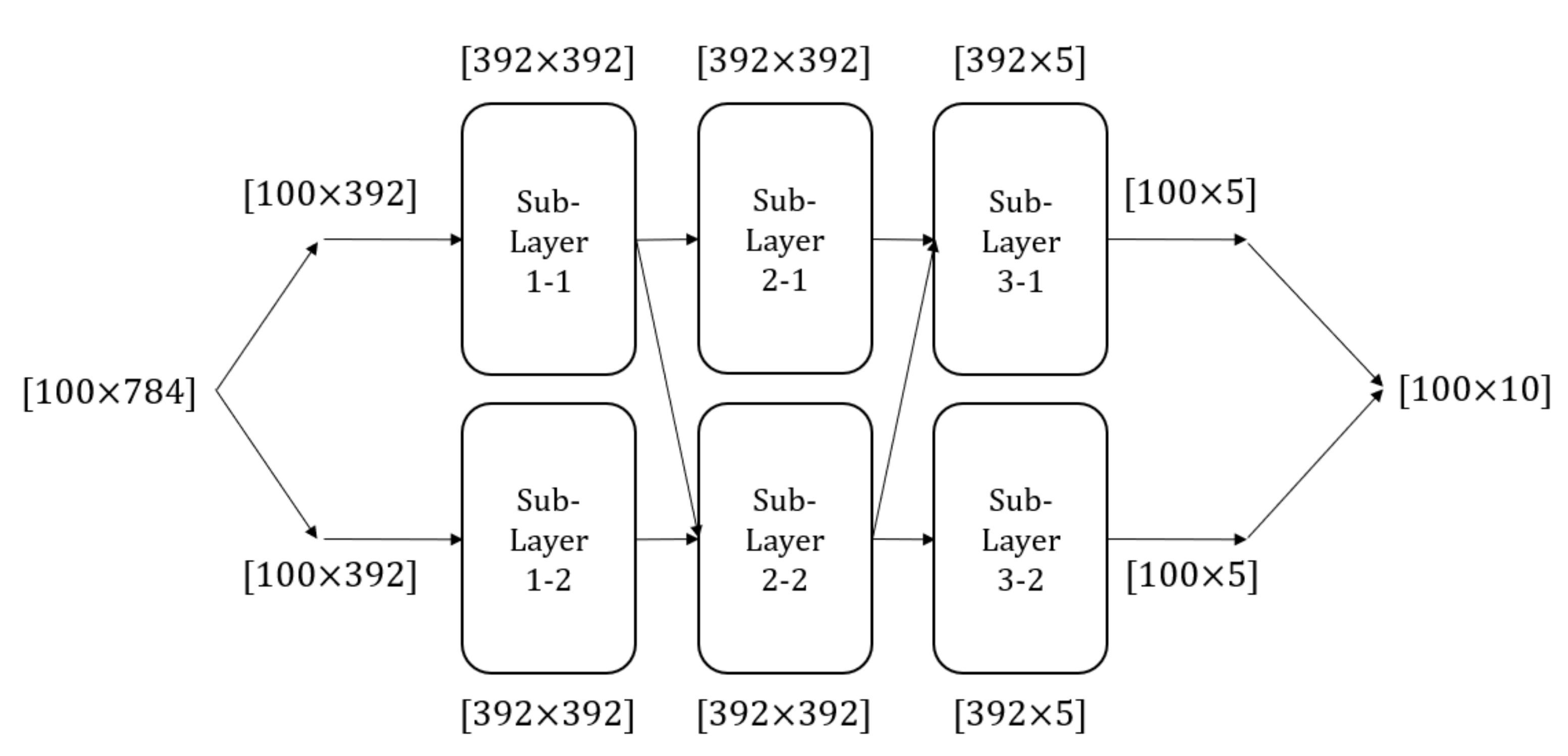
3.1. Network Definition
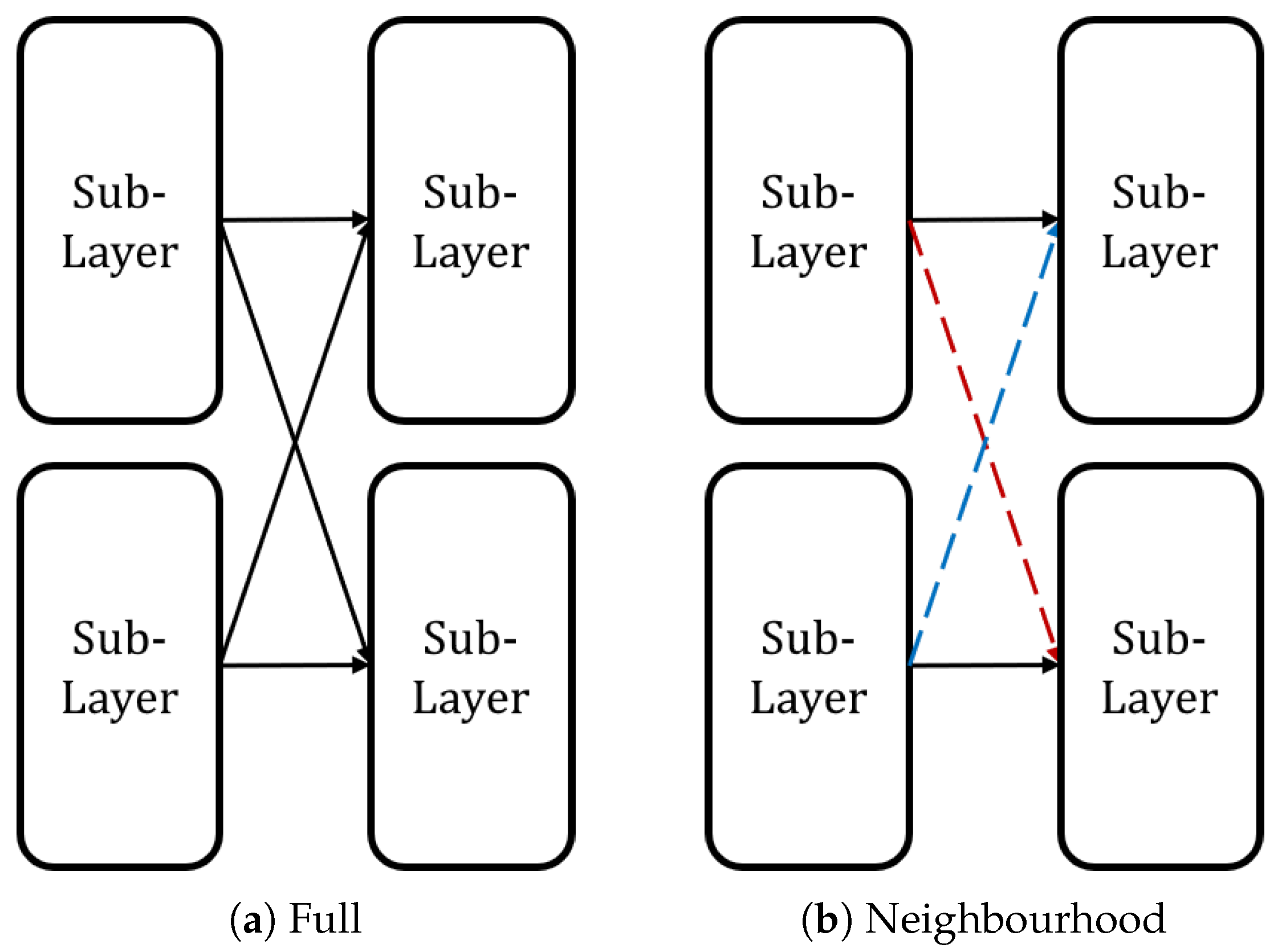
3.2. Training and Connection of MLUTNet
| Algorithm 1 Training of MLUTNet. |
|
4. Experimental Results
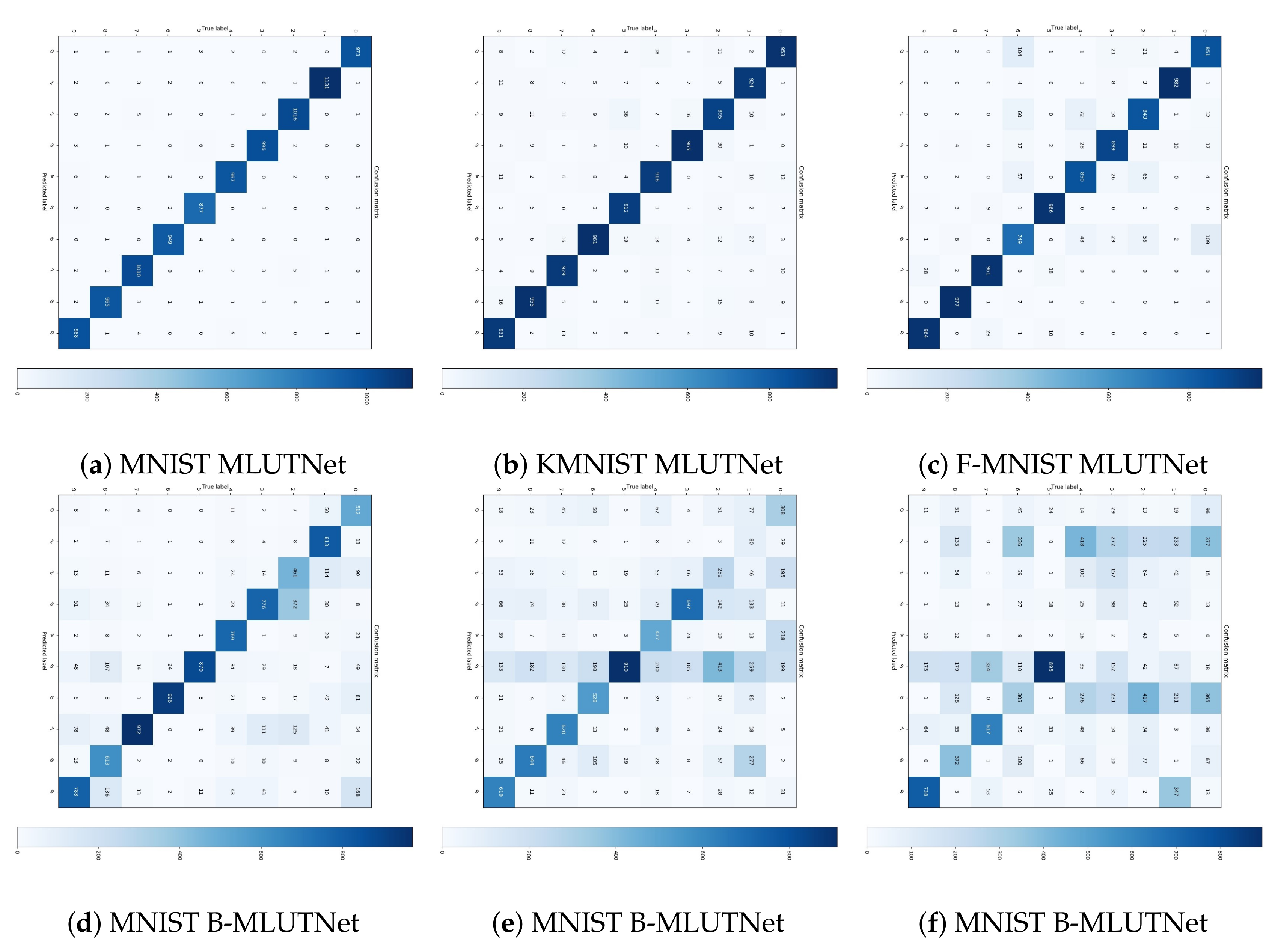
4.1. Performance on MNIST Series Datasets
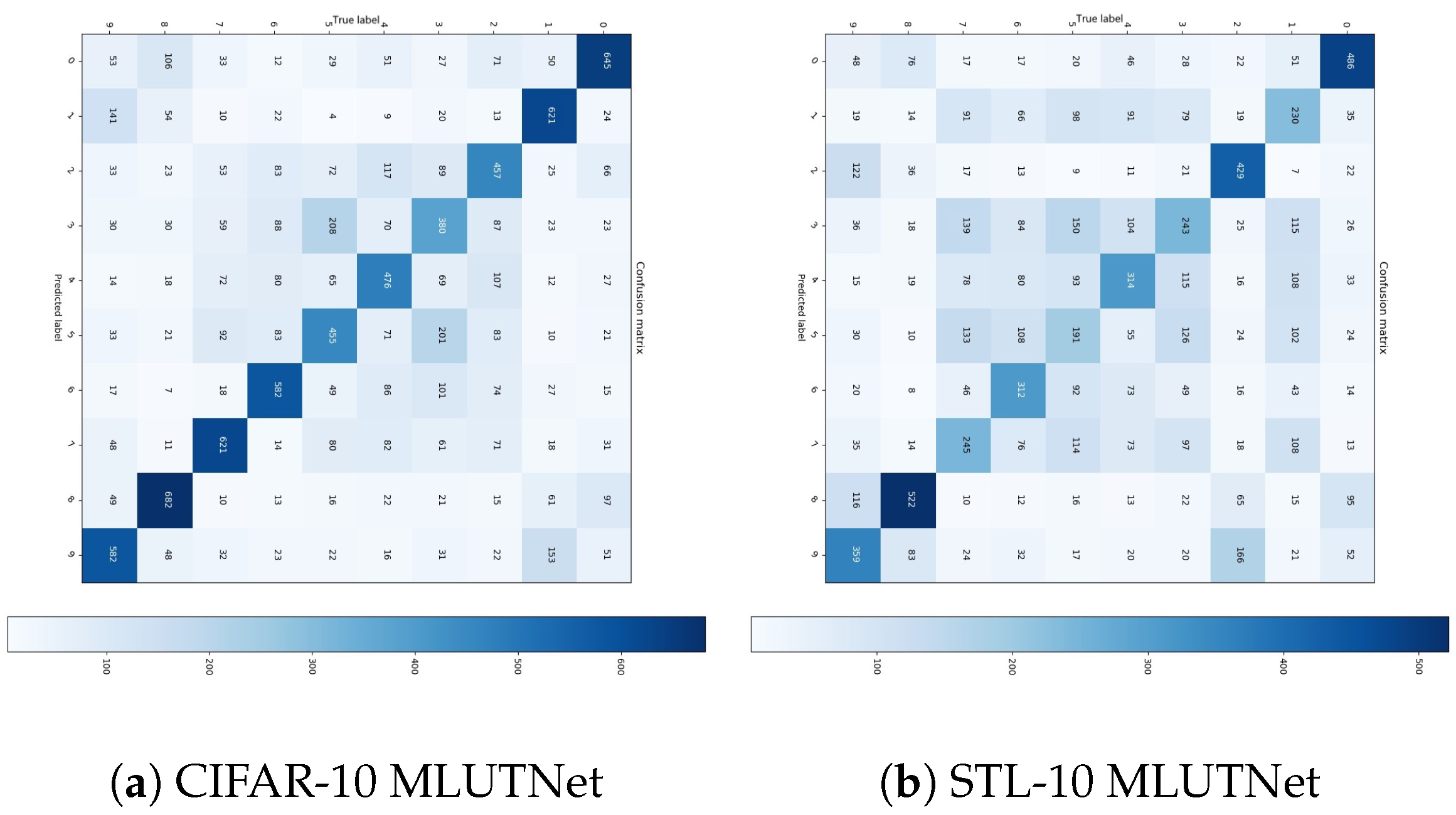
4.2. Performance on CIFAR-10 and STL-10 Datasets
4.3. Sparsely Connection Verification
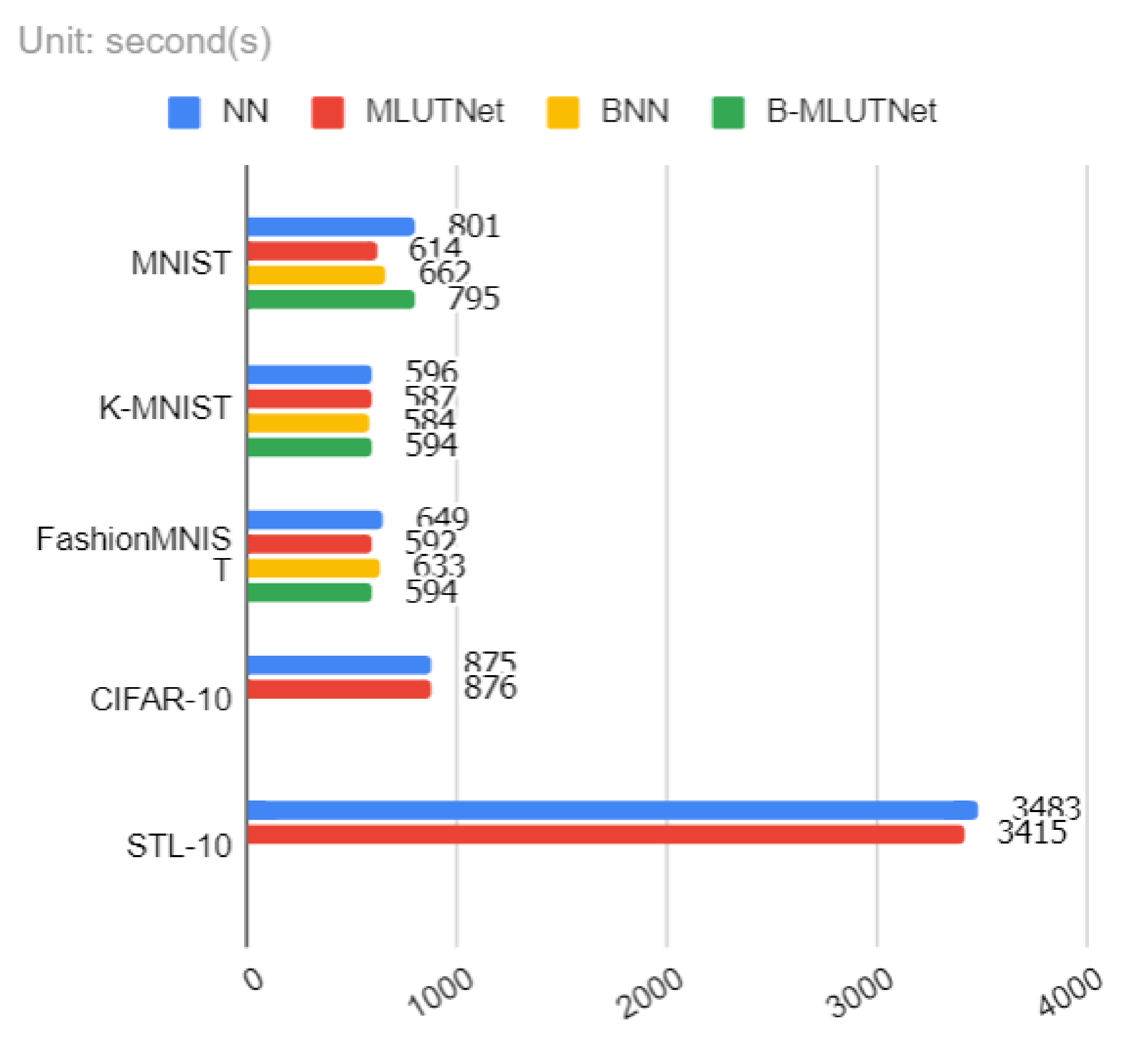
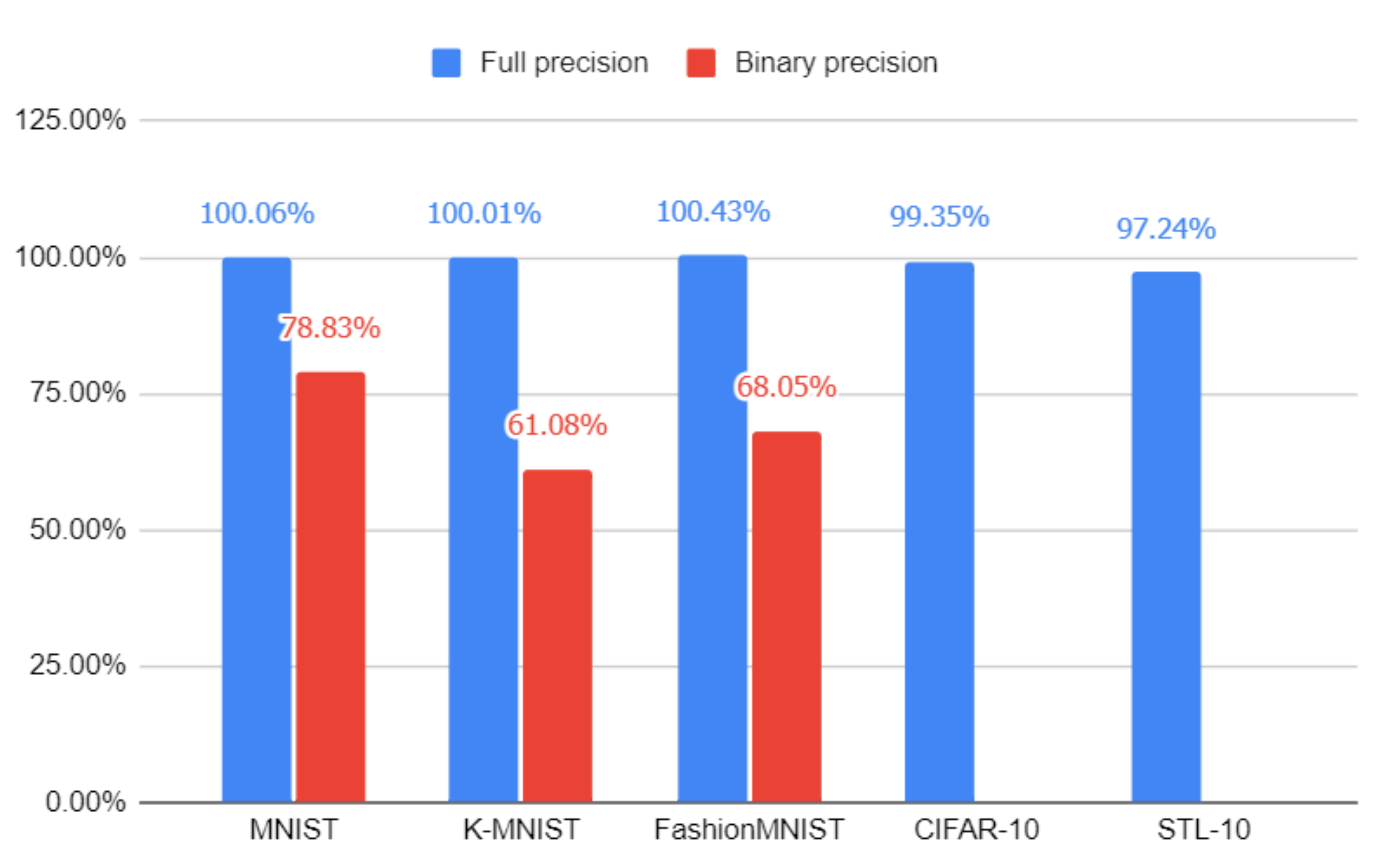
4.4. Results Summary
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shrestha, A.; Mahmood, A. Review of Deep Learning Algorithms and Architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Zhang, B.; Liu, B. Ternary Weight Networks. arXiv 2016, arXiv:cs.CV/1605.04711. [Google Scholar]
- Qin, H.; Gong, R.; Liu, X.; Bai, X.; Song, J.; Sebe, N. Binary neural networks: A survey. Pattern Recognit. 2020, 105, 107281. [Google Scholar] [CrossRef] [Green Version]
- Yonekawa, H.; Nakahara, H. On-Chip Memory Based Binarized Convolutional Deep Neural Network Applying Batch Normalization Free Technique on an FPGA. In Proceedings of the 2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Lake Buena Vista, FL, USA, 29 May–2 June 2017; pp. 98–105. [Google Scholar] [CrossRef]
- Yu, S.; Li, Z.; Chen, P.Y.; Wu, H.; Gao, B.; Wang, D.; Wu, W.; Qian, H. Binary neural network with 16 Mb RRAM macro chip for classification and online training. In Proceedings of the 2016 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 3–7 December 2016; pp. 16.2.1–16.2.4. [Google Scholar] [CrossRef]
- Wang, S.; Higami, Y.; Takahashi, H.; Sato, M.; Katsu, M.; Sekiguchi, S. Testing of Interconnect Defects in Memory Based Reconfigurable Logic Device (MRLD). In Proceedings of the 2017 IEEE 26th Asian Test Symposium (ATS), Taipei, Taiwan, 27–30 November 2017; pp. 17–22. [Google Scholar] [CrossRef]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1. arXiv 2016, arXiv:cs.LG/1602.02830. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. arXiv 2016, arXiv:cs.CV/1603.05279. [Google Scholar]
- Geoffrey Hinton, N.S.; Swersky, K. Neural Networks for Machine Learning, Lecture 6a, Overview of Mini-Batch Gradient Descent. Available online: http://www.cs.toronto.edu/~hinton/coursera/lecture6/lec6.pdf (accessed on 13 May 2021).
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2017, arXiv:cs.LG/1608.03983. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, ICML’10, Haifa, Israel, 21–24 June 2010; Omnipress: Madison, WI, USA, 2010; pp. 807–814. [Google Scholar]
- LeCun, Y.; Cortes, C. MNISThandwritten Digit Database. 2010. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 13 May 2021).
- Clanuwat, T.; Bober-Irizar, M.; Kitamoto, A.; Lamb, A.; Yamamoto, K.; Ha, D. Deep Learning for Classical Japanese Literature. arXiv 2018, arXiv:cs.CV/1812.01718. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:cs.LG/1708.07747. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NN | MLUTNet | BNN | B-MLUTNet | |
|---|---|---|---|---|
| MNIST | 0.9877 | 0.9883 | 0.9759 | 0.7693 |
| K-MNIST | 0.9347 | 0.9348 | 0.909 | 0.5552 |
| F-MNIST | 0.9053 | 0.9092 | 0.7909 | 0.5382 |
| CIFAR-10 | 0.5813 | 0.5775 | N/A | N/A |
| STL-10 | 0.4305 | 0.4186 | N/A | N/A |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zang, X.; Nakatake, S. MLUTNet: A Neural Network for Memory Based Reconfigurable Logic Device Architecture. Appl. Sci. 2021, 11, 6213. https://doi.org/10.3390/app11136213
Zang X, Nakatake S. MLUTNet: A Neural Network for Memory Based Reconfigurable Logic Device Architecture. Applied Sciences. 2021; 11(13):6213. https://doi.org/10.3390/app11136213
Chicago/Turabian StyleZang, Xuechen, and Shigetoshi Nakatake. 2021. "MLUTNet: A Neural Network for Memory Based Reconfigurable Logic Device Architecture" Applied Sciences 11, no. 13: 6213. https://doi.org/10.3390/app11136213
APA StyleZang, X., & Nakatake, S. (2021). MLUTNet: A Neural Network for Memory Based Reconfigurable Logic Device Architecture. Applied Sciences, 11(13), 6213. https://doi.org/10.3390/app11136213