
Impact of View-Dependent Image-Based Effects on Perception of Visual Realism and Presence in Virtual Reality Environments Created Using Multi-Camera Systems


Abstract
:Featured Application
Abstract
1. Introduction
- We provide an overview of the challenges and opportunities linked to capturing and rendering real-world scenes using multi-view setups. We notably discuss how we applied this analysis to recreate a museum gallery in VR (see Figure 1 for an illustration of the results) using a custom outward-facing multi-camera rig. These points are notably discussed in Section 2 and Section 3.
- We present a user study investigating (1) whether rendering captured view-dependent effects significantly enhances perceived visual realism, by comparing 3D reconstructions rendered with and without these effects; and (2) the extent to which making the scene fade out beyond a fixed radius significantly reduces the sense of place illusion, considering different viewing radii ranging from tens of centimeters to over a meter. This is discussed in Section 3, Section 4 and Section 5.
2. Related Work
2.1. Recreating Real-World Scenes from Photographs
2.1.1. Issues with Single-Viewpoint Capture
2.1.2. Strengths of Multi-View Capture
2.1.3. Novel Issues and Need for User Evaluation
2.2. Visual Realism and Presence
2.2.1. Factors for Achieving the Application’s Goals
2.2.2. Evaluating Visual Realism
2.2.3. Evaluating Presence
3. Materials and Methods
3.1. Multi-View Rendering for a Mineralogy Museum
3.1.1. Relevance for Minerals and the Museum Context
3.1.2. Recreating Individual Minerals
3.1.3. Recreating Viewpoints in the Museum Gallery
3.2. Designing and Prototyping the Capture Rig
3.2.1. Hardware Setup
3.2.2. Software Implementation
3.2.3. On-Site Tests
3.3. Creating and Rendering a 3D Environment
3.3.1. Generating 3D Models from the Captured Photographs
3.3.2. Applying a View-Dependent Rendering Method
3.4. Study Protocol
3.4.1. Hypotheses
3.4.2. Scenes and Overall Procedure
3.4.3. Participants, Ethics, and Safety
3.5. Study Conditions and Measures
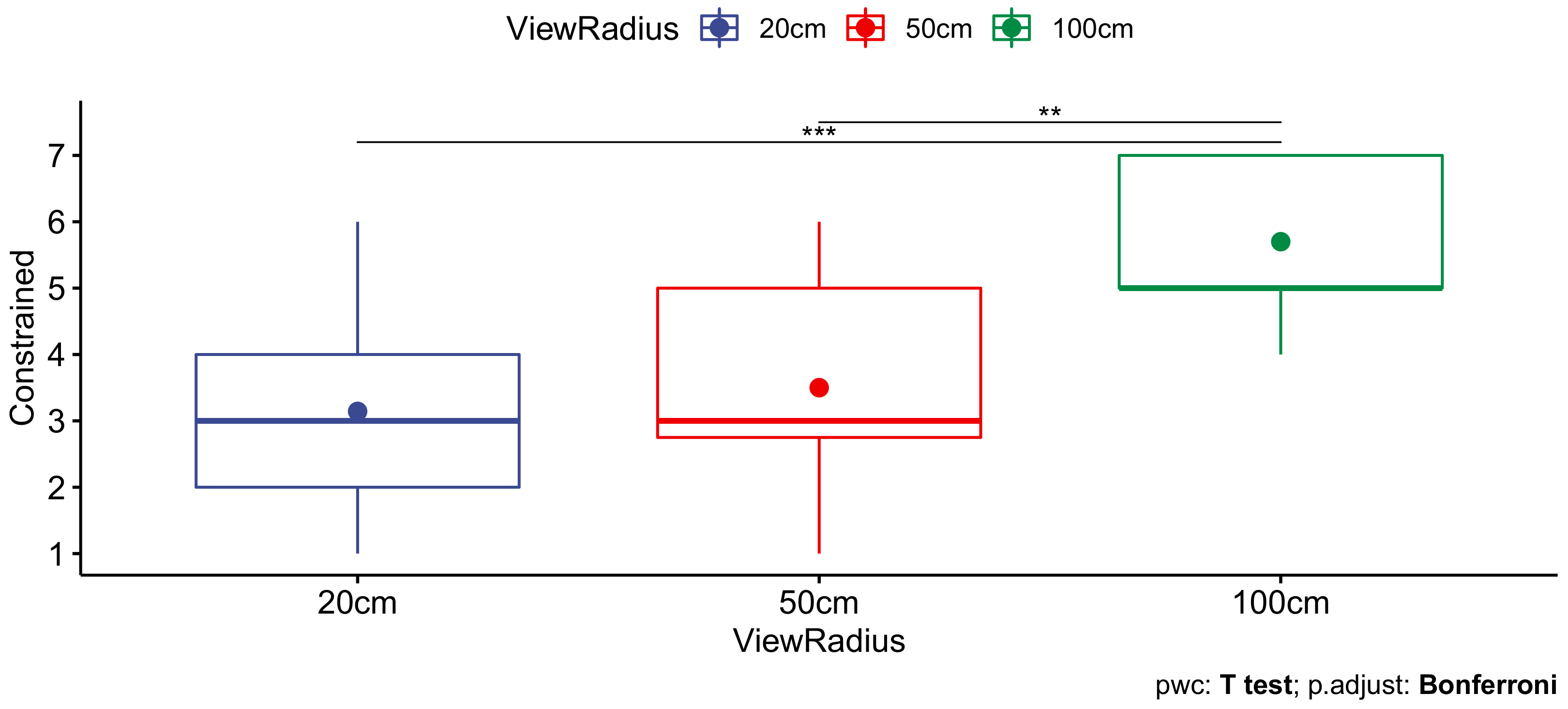
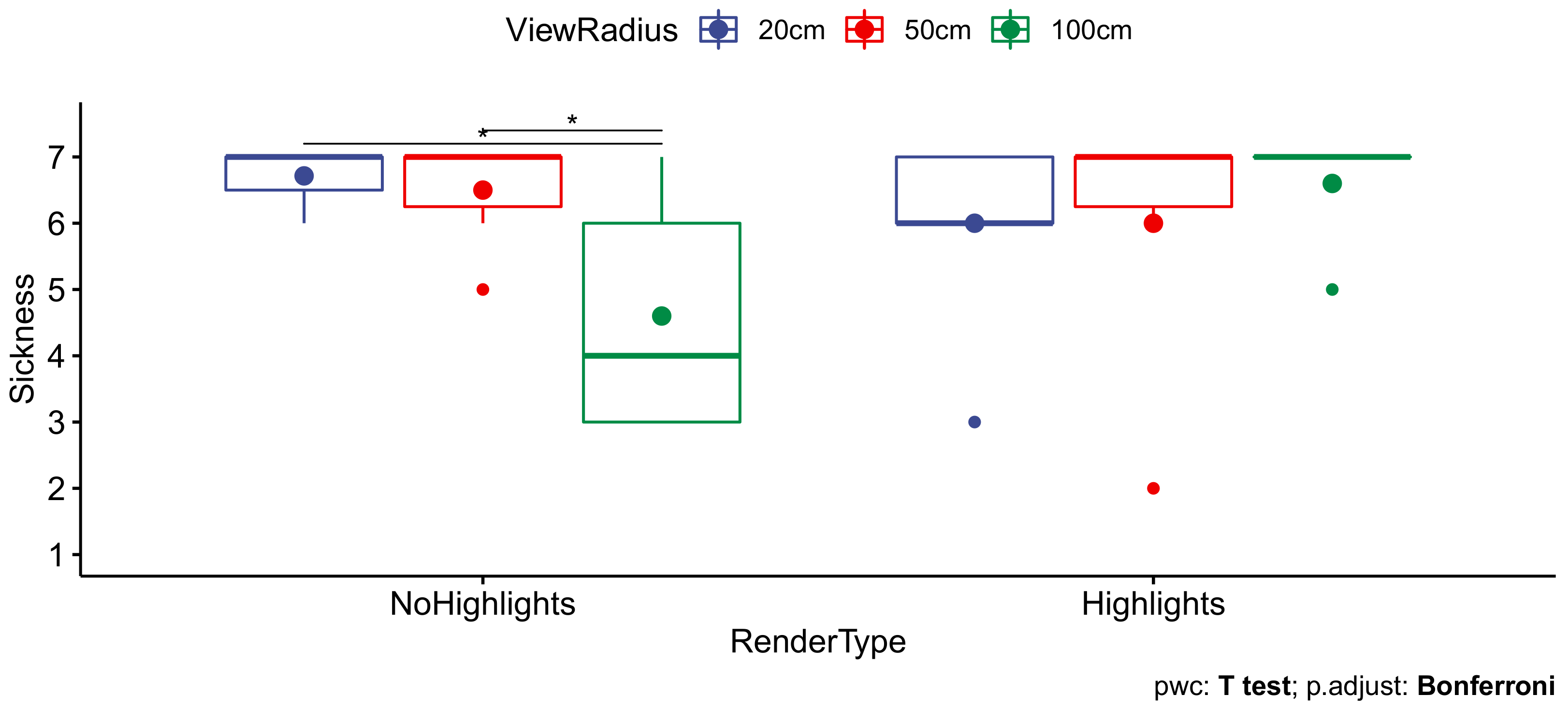
3.5.1. Independent Variable: ViewRadius
- 50 cm: This was an intermediate radius, which we expected would not be perceived as being extremely constraining. However, within the second half of the corresponding viewing volume in our sample scene, view-dependent effects were no longer accurately rendered.
- 100 cm: This was the volume which we considered to be a reasonable upper bound, given the size of our tracking space.
3.5.2. Independent Variable: RenderType
3.5.3. Dependent Variables: Questionnaire
4. Results
4.1. Experiment 1: “Pyrite” Scene
4.2. Experiment 2: “Museum” Scene
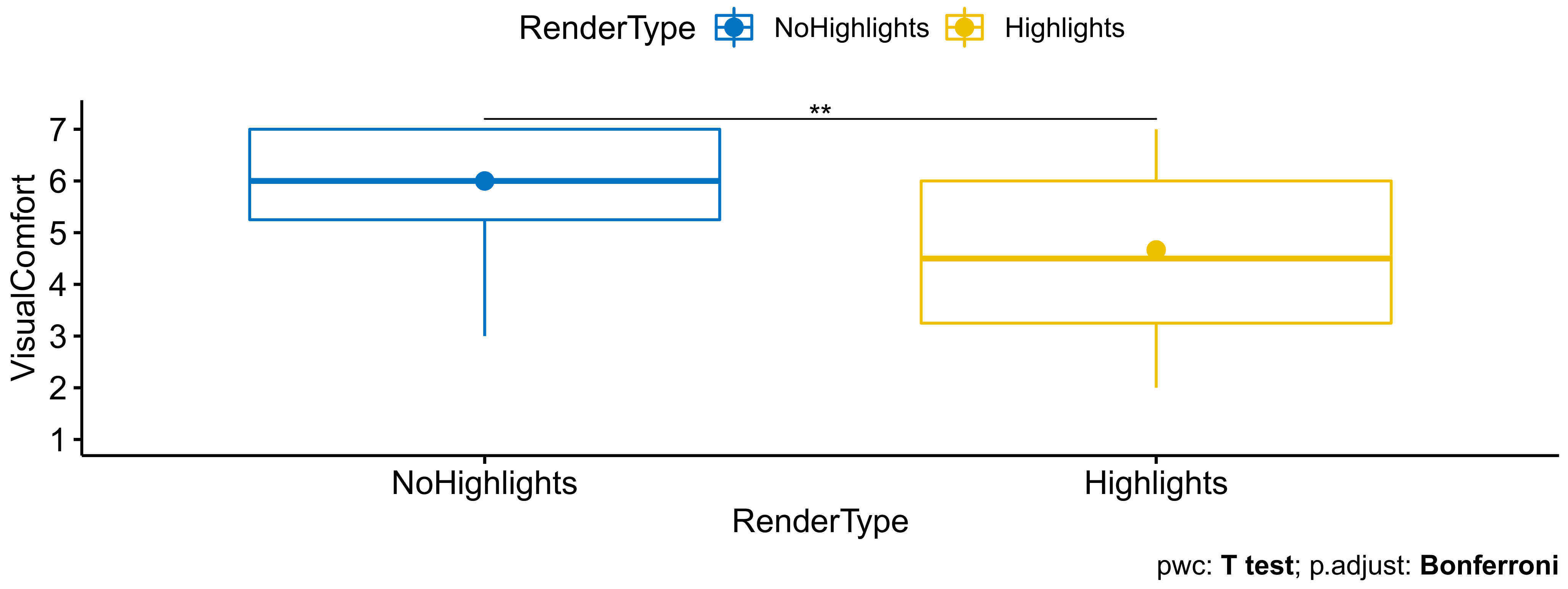
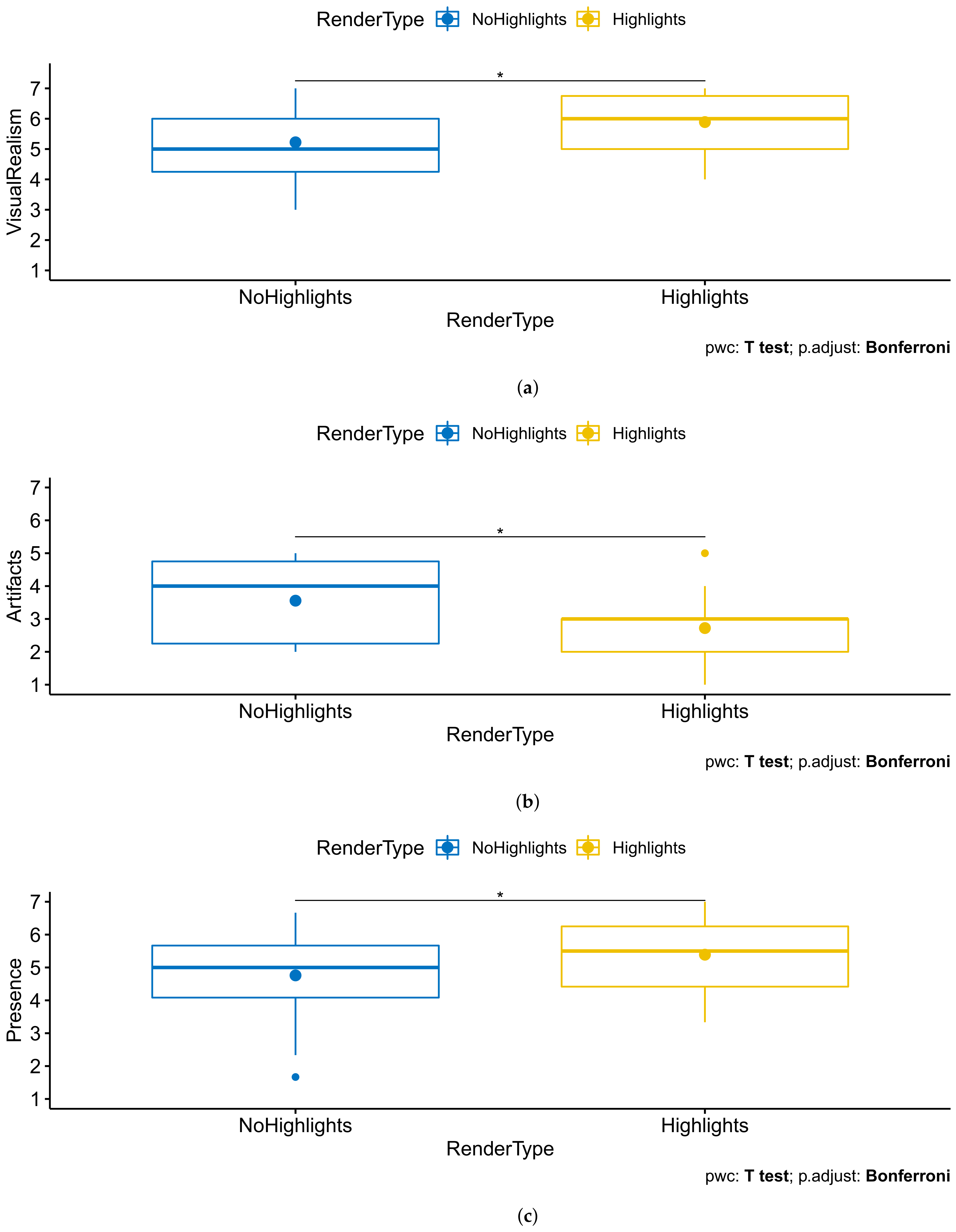
- VisualRealism (question 1): , . Users thus found the scene to be more visually realistic when there were rendered highlights (, ) than when these were not rendered (, ).
- Artifacts (question 2, higher is more comfortable): , . Users were thus more disturbed by artifacts when there were rendered view-dependent highlights (, ) than when these were not rendered (, ).
- Presence (questions 6–8): , . Users thus felt a stronger sense of presence when there were rendered view-dependent highlights (, ) than when these were not rendered (, ). Leading the test on each individual component showed a significant impact on the response to question 7 in particular.
5. Discussion
5.1. Results Analysis
5.2. Hypothesis Validation
5.3. Paths for Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Overbeck, R.S.; Erickson, D.; Evangelakos, D.; Pharr, M.; Debevec, P. A System for Acquiring, Processing, and Rendering Panoramic Light Field Stills for Virtual Reality. ACM Trans. Graph. 2018, 37, 197:1–197:15. [Google Scholar] [CrossRef] [Green Version]
- Bertel, T.; Yuan, M.; Lindroos, R.; Richardt, C. OmniPhotos: Casual 360° VR Photography. ACM Trans. Graph. 2020, 39, 266:1–266:12. [Google Scholar] [CrossRef]
- Buehler, C.; Bosse, M.; McMillan, L.; Gortler, S.; Cohen, M. Unstructured Lumigraph Rendering. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 12–17 August 2001; ACM: New York, NY, USA, 2001; pp. 425–432. [Google Scholar] [CrossRef]
- Hedman, P.; Ritschel, T.; Drettakis, G.; Brostow, G. Scalable Inside-out Image-based Rendering. ACM Trans. Graph. 2016, 35, 231:1–231:11. [Google Scholar] [CrossRef]
- Broxton, M.; Flynn, J.; Overbeck, R.; Erickson, D.; Hedman, P.; DuVall, M.; Dourgarian, J.; Busch, J.; Whalen, M.; Debevec, P. Immersive Light Field Video with a Layered Mesh Representation. ACM Trans. Graph. 2020, 39, 86:1–86:15. [Google Scholar] [CrossRef]
- de Dinechin, G.D.; Paljic, A. From Real to Virtual: An Image-Based Rendering Toolkit to Help Bring the World Around Us Into Virtual Reality. In Proceedings of the 2020 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), Atlanta, GA, USA, 22–26 March 2020. [Google Scholar] [CrossRef]
- Serrano, A.; Kim, I.; Chen, Z.; Di Verdi, S.; Gutierrez, D.; Hertzmann, A.; Masia, B. Motion parallax for 360° RGBD video. IEEE Trans. Vis. Comput. Graph. 2019, 25, 1817–1827. [Google Scholar] [CrossRef] [Green Version]
- Schwind, V.; Knierim, P.; Haas, N.; Henze, N. Using Presence Questionnaires in Virtual Reality. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; ACM: New York, NY, USA, 2019; pp. 1–12. [Google Scholar] [CrossRef]
- Slater, M. Place illusion and plausibility can lead to realistic behaviour in immersive virtual environments. Philos. Trans. R. Soc. B Biol. Sci. 2009, 364, 3549–3557. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weech, S.; Kenny, S.; Barnett-Cowan, M. Presence and Cybersickness in Virtual Reality Are Negatively Related: A Review. Front. Psychol. 2019, 10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, J.; LaFemina, P.; Carr, J.; Sajjadi, P.; Wallgrün, J.O.; Klippel, A. Learning in the Field: Comparison of Desktop, Immersive Virtual Reality, and Actual Field Trips for Place-Based STEM Education. In Proceedings of the 2020 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Atlanta, GA, USA, 22–26 March 2020; pp. 893–902. [Google Scholar] [CrossRef]
- Sayyad, E.; Sen, P.; Höllerer, T. PanoTrace: Interactive 3D Modeling of Surround-view Panoramic Images in Virtual Reality. In Proceedings of the 23rd ACM Symposium on Virtual Reality Software and Technology, Gothenburg, Sweden, 8–10 November 2017; ACM: New York, NY, USA, 2017; pp. 32:1–32:10. [Google Scholar] [CrossRef]
- He, L.; Li, H.; Xue, T.; Sun, D.; Zhu, S.; Ding, G. Am I in the Theater?: Usability Study of Live Performance Based Virtual Reality. In Proceedings of the 24th ACM Symposium on Virtual Reality Software and Technology, Tokyo, Japan, 28 November–1 December 2018; ACM: New York, NY, USA, 2018; pp. 28:1–28:11. [Google Scholar] [CrossRef]
- Hedman, P.; Alsisan, S.; Szeliski, R.; Kopf, J. Casual 3D Photography. ACM Trans. Graph. 2017, 36, 234:1–234:15. [Google Scholar] [CrossRef] [Green Version]
- Pozo, A.P.; Toksvig, M.; Schrager, T.F.; Hsu, J.; Mathur, U.; Sorkine-Hornung, A.; Szeliski, R.; Cabral, B. An integrated 6DoF video camera and system design. ACM Trans. Graph. 2019, 38, 216:1–216:16. [Google Scholar] [CrossRef] [Green Version]
- Guttentag, D.A. Virtual reality: Applications and implications for tourism. Tour. Manag. 2010, 31, 637–651. [Google Scholar] [CrossRef]
- Waechter, M.; Beljan, M.; Fuhrmann, S.; Moehrle, N.; Kopf, J.; Goesele, M. Virtual Rephotography: Novel View Prediction Error for 3D Reconstruction. ACM Trans. Graph. 2017, 36, 8:1–8:11. [Google Scholar] [CrossRef]
- Witmer, B.G.; Singer, M.J. Measuring Presence in Virtual Environments: A Presence Questionnaire. Presence Teleoperators Virtual Environ. 1998, 7, 225–240. [Google Scholar] [CrossRef]
- Slater, M.; Usoh, M.; Steed, A. Depth of Presence in Virtual Environments. Presence Teleoperators Virtual Environ. 1994, 3, 130–144. [Google Scholar] [CrossRef]
- Schönberger, J.L.; Frahm, J.M. Structure-from-Motion Revisited. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar] [CrossRef]
- Jakob, W.; Tarini, M.; Panozzo, D.; Sorkine-Hornung, O. Instant Field-aligned Meshes. ACM Trans. Graph. 2015, 34, 189:1–189:15. [Google Scholar] [CrossRef]
Short Biography of Authors







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1. How visually realistic was the scene? | MP |
| 2. If you perceived visual artifacts in the reconstruction, to what extent did you find them disturbing? | MP |
| 3. How visually comfortable was the scene? | MP |
| 4. How comfortable were you moving around in the scene? | M |
| 5. Did you feel constrained in your movements? | M |
| 6. To what extent did you feel like you were there, in the scene? | M |
| 7. To what extent did the scene become the reality for you? | M |
| 8. Did you feel more like you were seeing images of a place, or visiting a place? | M |
| 9. Did you feel nausea, vertigo, or headache? | M |
| 10. Overall, which method did you prefer? (after seeing the scene rendered with and without view-dependent effects) | MP |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Dinechin, G.D.; Paljic, A.; Tanant, J. Impact of View-Dependent Image-Based Effects on Perception of Visual Realism and Presence in Virtual Reality Environments Created Using Multi-Camera Systems. Appl. Sci. 2021, 11, 6173. https://doi.org/10.3390/app11136173
de Dinechin GD, Paljic A, Tanant J. Impact of View-Dependent Image-Based Effects on Perception of Visual Realism and Presence in Virtual Reality Environments Created Using Multi-Camera Systems. Applied Sciences. 2021; 11(13):6173. https://doi.org/10.3390/app11136173
Chicago/Turabian Stylede Dinechin, Grégoire Dupont, Alexis Paljic, and Jonathan Tanant. 2021. "Impact of View-Dependent Image-Based Effects on Perception of Visual Realism and Presence in Virtual Reality Environments Created Using Multi-Camera Systems" Applied Sciences 11, no. 13: 6173. https://doi.org/10.3390/app11136173
APA Stylede Dinechin, G. D., Paljic, A., & Tanant, J. (2021). Impact of View-Dependent Image-Based Effects on Perception of Visual Realism and Presence in Virtual Reality Environments Created Using Multi-Camera Systems. Applied Sciences, 11(13), 6173. https://doi.org/10.3390/app11136173