1. Introduction
In recent years, the scale of renewable energy power generation has expanded rapidly. Many countries are considering incorporating renewable energy into the grid [
1]. Solar energy has become one of the main sources of renewable energy [
2]. The narrow definition of solar energy is solar radiation [
3]. Broadly speaking, solar energy also includes other forms of energy converted from the solar radiation, such as coal, oil, natural gas, hydropower, wind energy, biological energy, etc. Solar radiation is affected by the seasons and geography, and has obvious discontinuities and uncertainties [
4,
5]. These characteristics are the reason that the focus of prediction must be on solar radiation prior to predicting the output of a solar system.
Photovoltaic (PV) power generation is typically divided into two forms: off-grid and grid-connected. With the maturity and development of grid-connected PV technology, grid-connected PV power generation has become a mainstream trend [
6]. The capacity of large-sale centralized grid-connected PV power generation systems is rapidly increasing. However, the output power of grid-connected PV power generation systems is inherently intermittent and uncontrollable. These intrinsic characteristics cause an adverse impact on the grid and seriously restrict grid-connected PV power generation [
7].
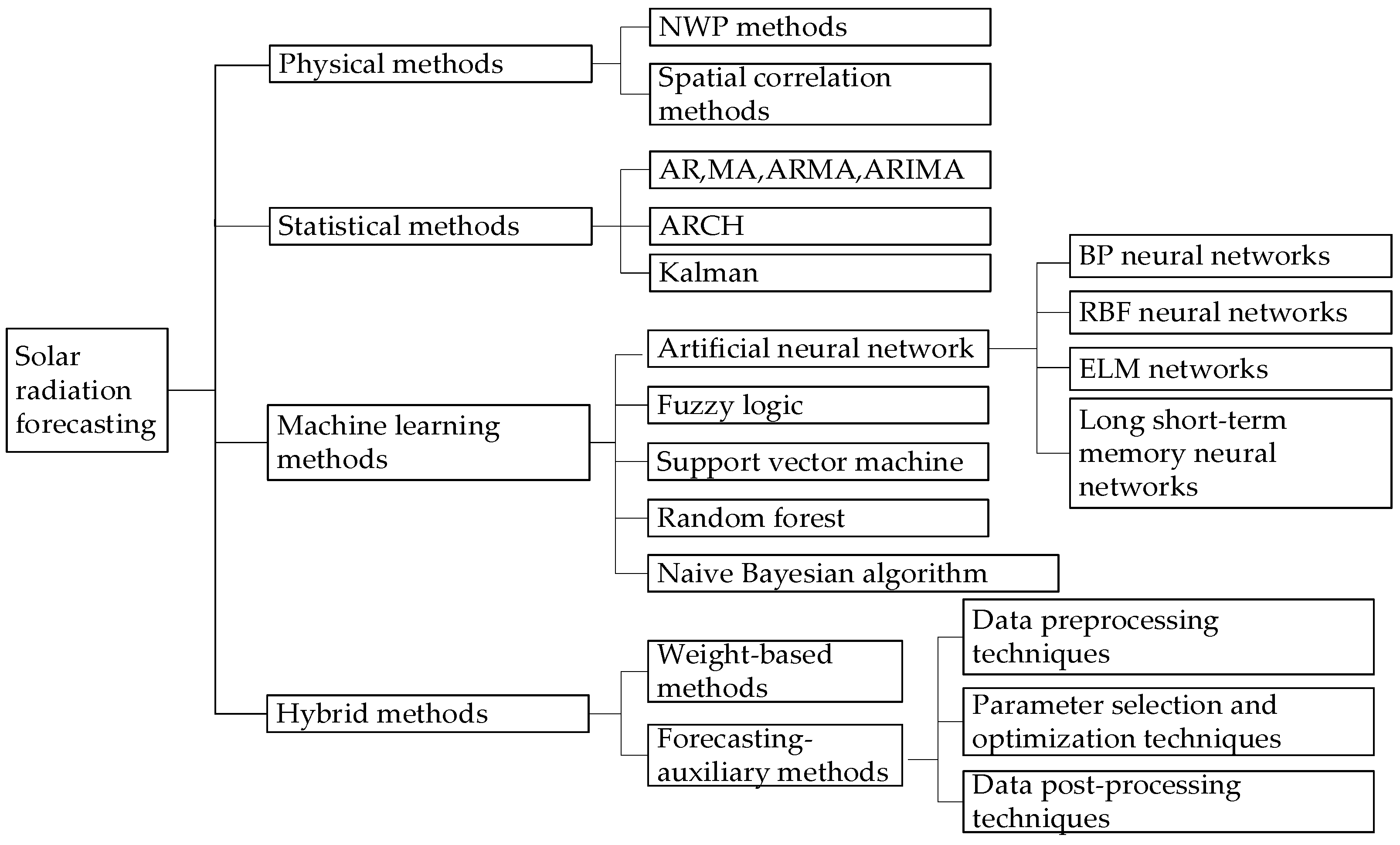
At present, research on solar radiation prediction has become more and more extensive and in depth. Among various prediction methods, the simplest is the persistence method which assumes that the future solar radiation is equal to the current solar radiation. Other solar radiation prediction methods can be classified into four categories: physical methods, statistical methods, machine learning methods and hybrid methods [
8,
9,
10,
11].
Figure 1 briefly summarizes four types of prediction methods on solar radiation.
Among the four categories in
Figure 1, the physical methods establish the solar power generation forecast model according to the geographical environment and weather data (such as temperature, humidity, pressure, etc.) [
8]. These methods can be further grouped into two subcategories: numerical weather prediction (NWP) methods [
12] and spatial correlation methods [
13]. NWP methods use numerical simulation to predict, that is, mathematical and physical models are applied on analyzing atmospheric conditions, and high-speed computers are utilized to forecast solar radiation [
14]. Under normal conditions, NWP methods probably take a long time to predict [
15]. Moreover, the meteorological and environmental factors in NWP methods are the most complicated and difficult to make accurate decisions [
8,
16]. In current research, it has always been difficult to improve forecast accuracy. The spatial correlation methods harness the spatial correlation of solar radiation to predict solar energy of several places. It should be noted that spatial correlation methods require rich historical data to simulate complex temporal and spatial changes. In summary, NWP methods and other physical models are not suitable for use in short-term cases and in small areas, owing to long runtimes. Meanwhile, they have high demands on computing resources.
The forecasting of solar radiation intensity and solar energy based on historical experimental data is more suitable for short-term prediction [
17]. Statistical methods can be mainly classified into moving average (MA), autoregressive (AR) and autoregressive moving average (ARMA), autoregressive integrated moving average (ARIMA), autoregressive conditional heteroscedasticity (ARCH) and Kalman filtering [
18,
19]. The above models have fast calculation speeds, a strong interpretation ability and simple structures. However, statistical methods establish rigorous mathematical relationships between the inputs and outputs, which means that they cannot learn and change prediction strategies. In addition, a large amount of historical recording is required. As a result, it is almost impossible to capture nonlinear behavior in a time series, so the prediction accuracy may be decreased as time goes by.
With the booming development of artificial intelligence, the application of machine learning technology on predicting PV generation is becoming more popular. These advanced techniques include artificial neural networks (ANN), fuzzy logic (FL), support vector machines (SVM), random forest (RF) and the naive Bayesian algorithm [
20,
21,
22,
23,
24,
25]. The main principle of machine learning methods is as follows. Among them, artificial neural networks are a frequently used method, mainly containing black-propagation (BP) neural networks [
26], radial basis function (RBF) neural networks [
27], extreme learning machine (ELM)networks [
28], and long short-term memory (LSTM) neural networks [
29]. Several types of elements affecting solar radiation are determined firstly as the input features, then a nonlinear and highly complex mapping relationship is constructed. Finally, the model parameters are learned according to historical data. Traditional statistical methods cannot attain the above complex representation in most situations. In contrast, machine learning methods can overcome this deficiency.
Hybrid methods of solar radiation prediction mainly consist of weight-based methods and prediction-assisted methods. The former type is a combined model composed of multiple single models with the same structure. Each model gives a unique prediction, and the weighted average of the prediction results of all models is regarded as the final prediction result [
30,
31]. Unlike weight-based methods, prediction assistance methods usually include two models, one for power prediction and the other for auxiliary processes, such as data filtering, data decomposition, optimal parameter selection, and residual evaluation. According to the auxiliary technology, the forecast methods can be further divided into three groups: data preprocessing techniques, parameter optimization techniques, and residual calibration techniques. Among them, data preprocessing techniques are the commonly used methods, and they mainly include principal component analysis (PCA) and cluster analysis [
31,
32], the wavelet transform (WT) [
33], empirical mode decomposition (EMD) [
34] and variational mode decomposition (VMD) [
35], etc. Reasonable selections of preprocessing methods can reduce the negative impact of the systematic error on prediction accuracy to a certain extent. In summary, each single model has its advantages and disadvantages, and the hybrid model combines advantages of different methods to obtain a better prediction performance.
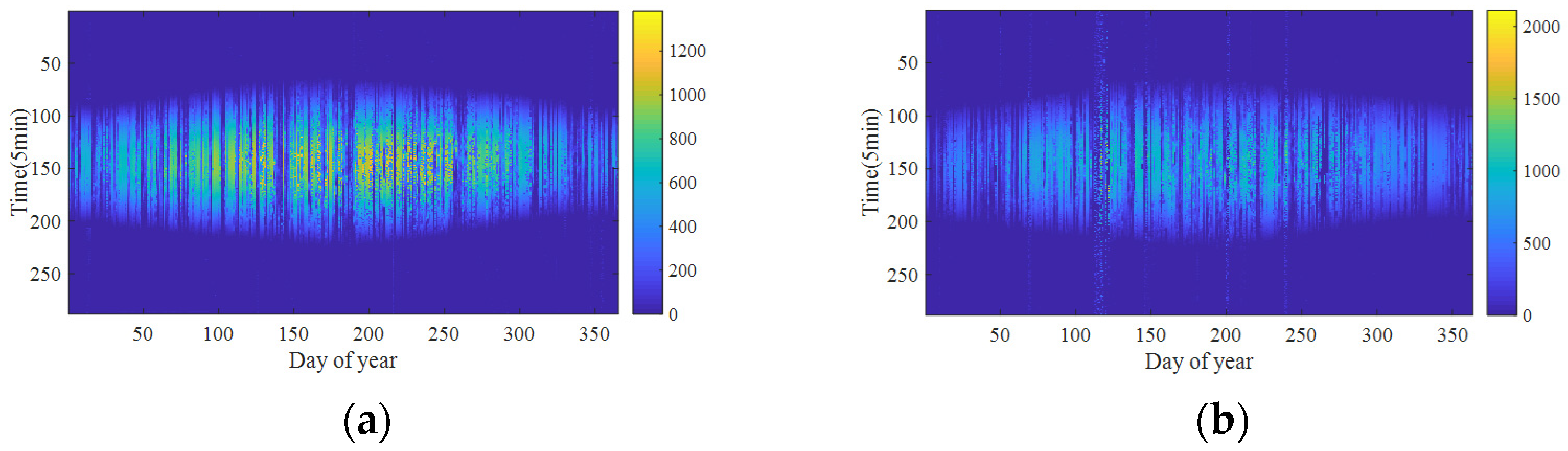
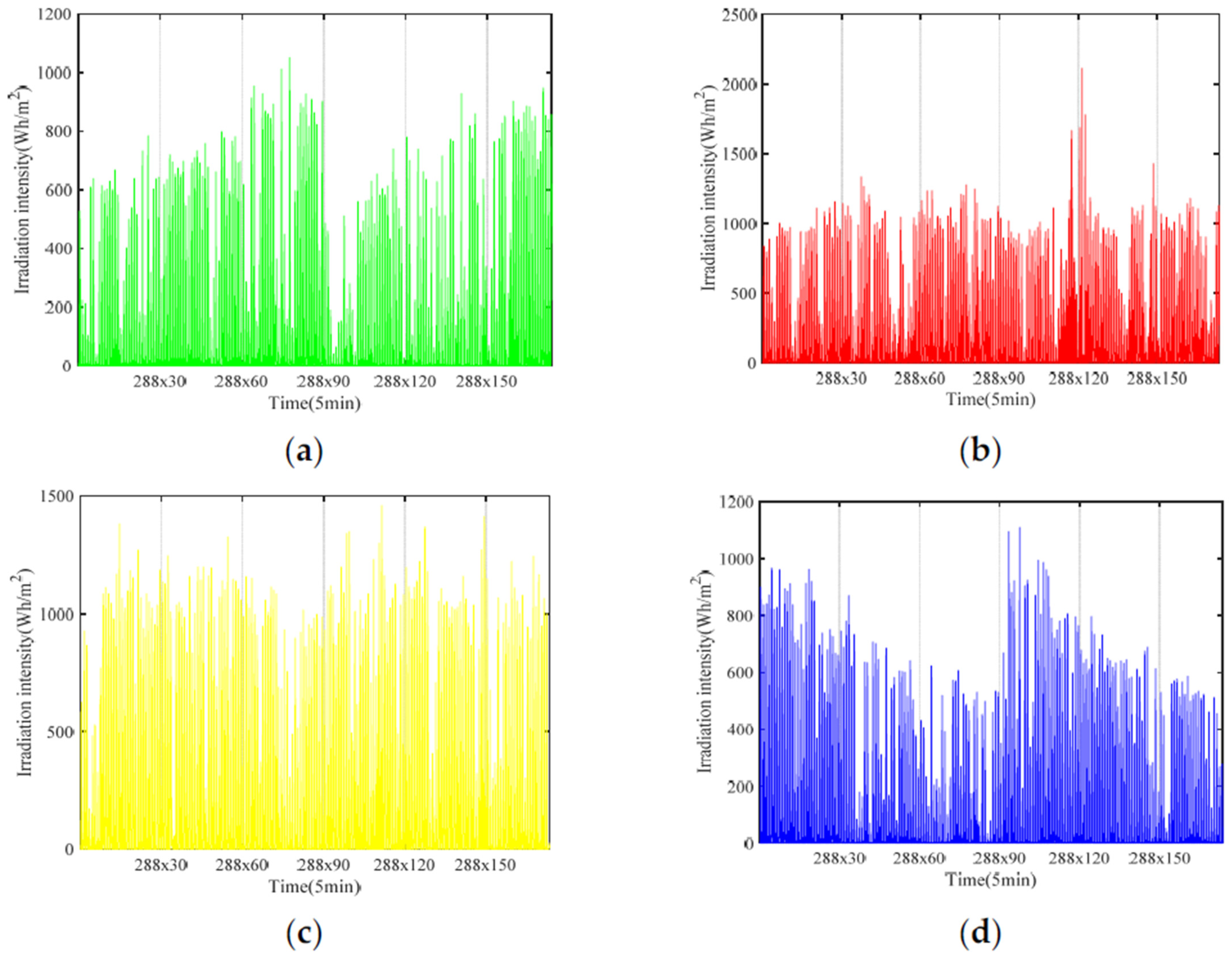
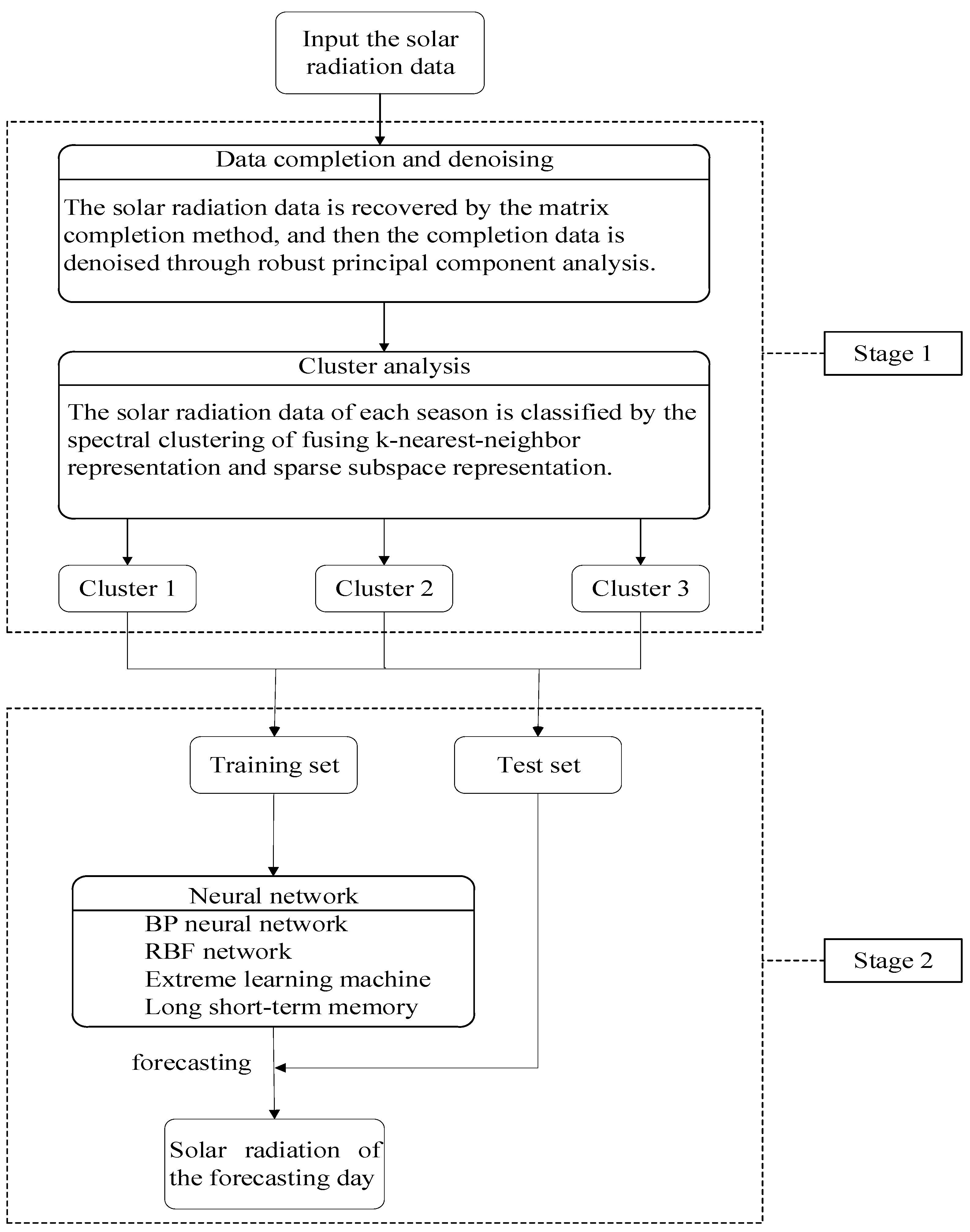
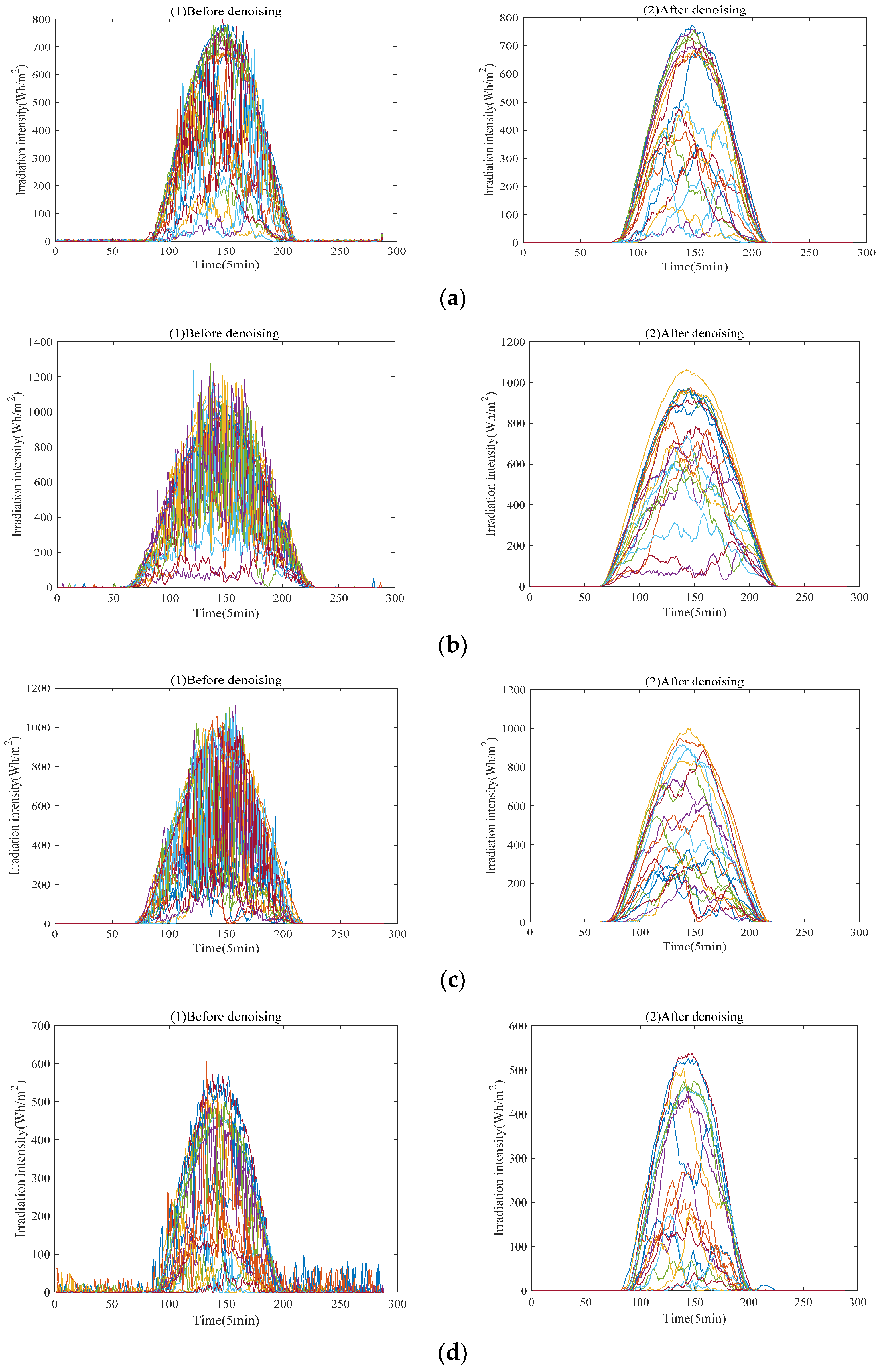
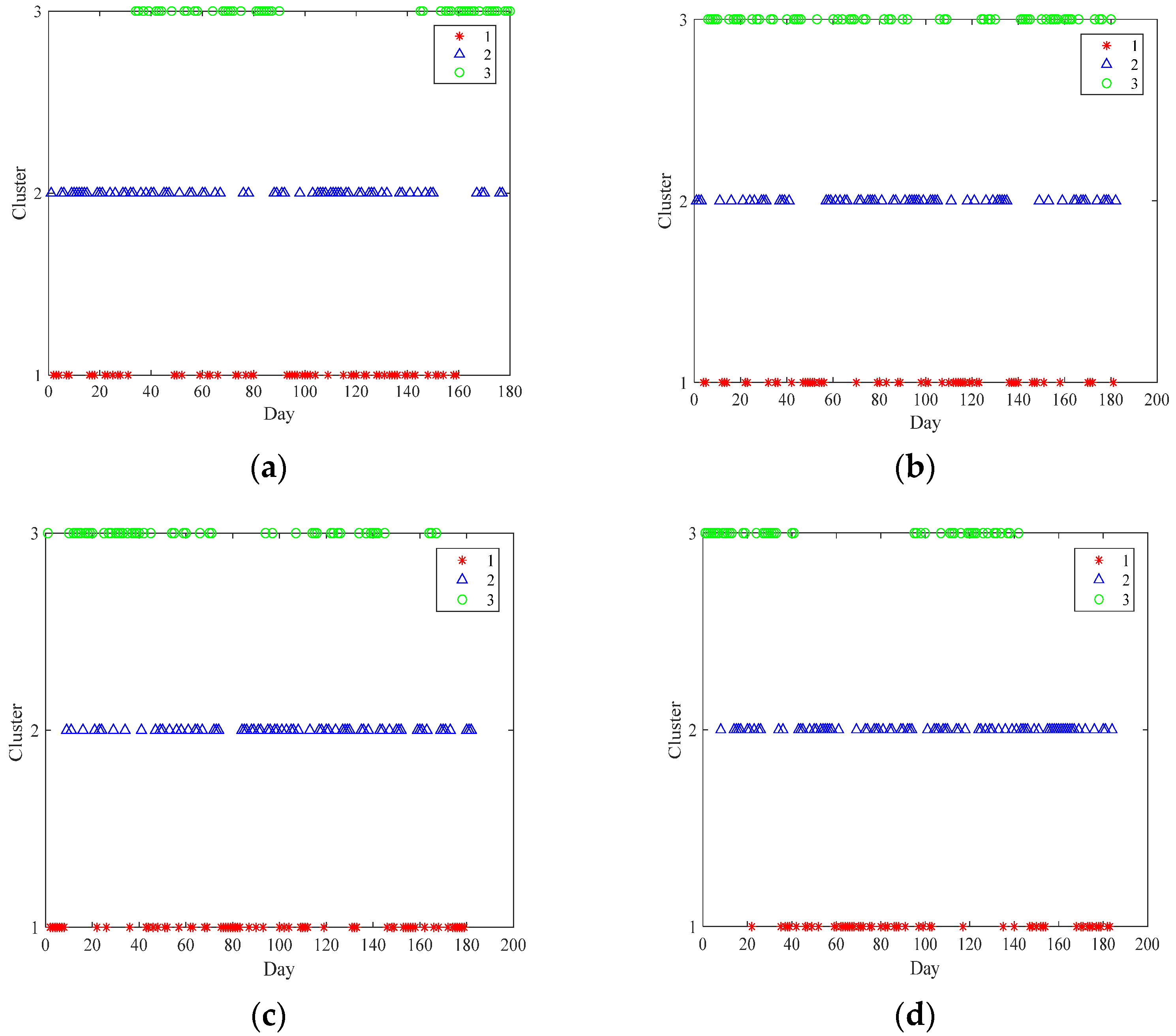
This paper aims to predict short-term solar radiation through a comprehensive application of machine learning techniques. Firstly, the missing values are recovered via the means of matrix completion with low-rank structure. Robust principal component analysis, a method of strong robustness to large spare noise, is employed to denoise the recovered data. Next, solar radiation data after denoising is clustered by fusing sparse subspace representation and k-nearest-neighbor. Subsequently, four artificial neural network models are used to forecast, and thus a kind of hybrid model for short-term solar radiation prediction is proposed.
The main structure of the paper is organized as follows.
Section 2 describes the experimental dataset and methods. Machine learning techniques for data preprocessing are introduced in
Section 3.
Section 4 presents several machine learning techniques for forecasting solar radiation. In
Section 5, the experiments are carried out, and a comparison of experimental results is provided.
Section 6 draws conclusions.
4. Machine Learning Techniques for Forecasting
Given input–output paired training samples , we consider the supervised learning task of seeking for an approximate function , where is the input vector and is the output vector. To learn the function relationship between the input and the output, this section will introduce four supervised machine learning methods, namely, BP neural networks, radial basis function networks, extreme learning machines and long-short term memory models.
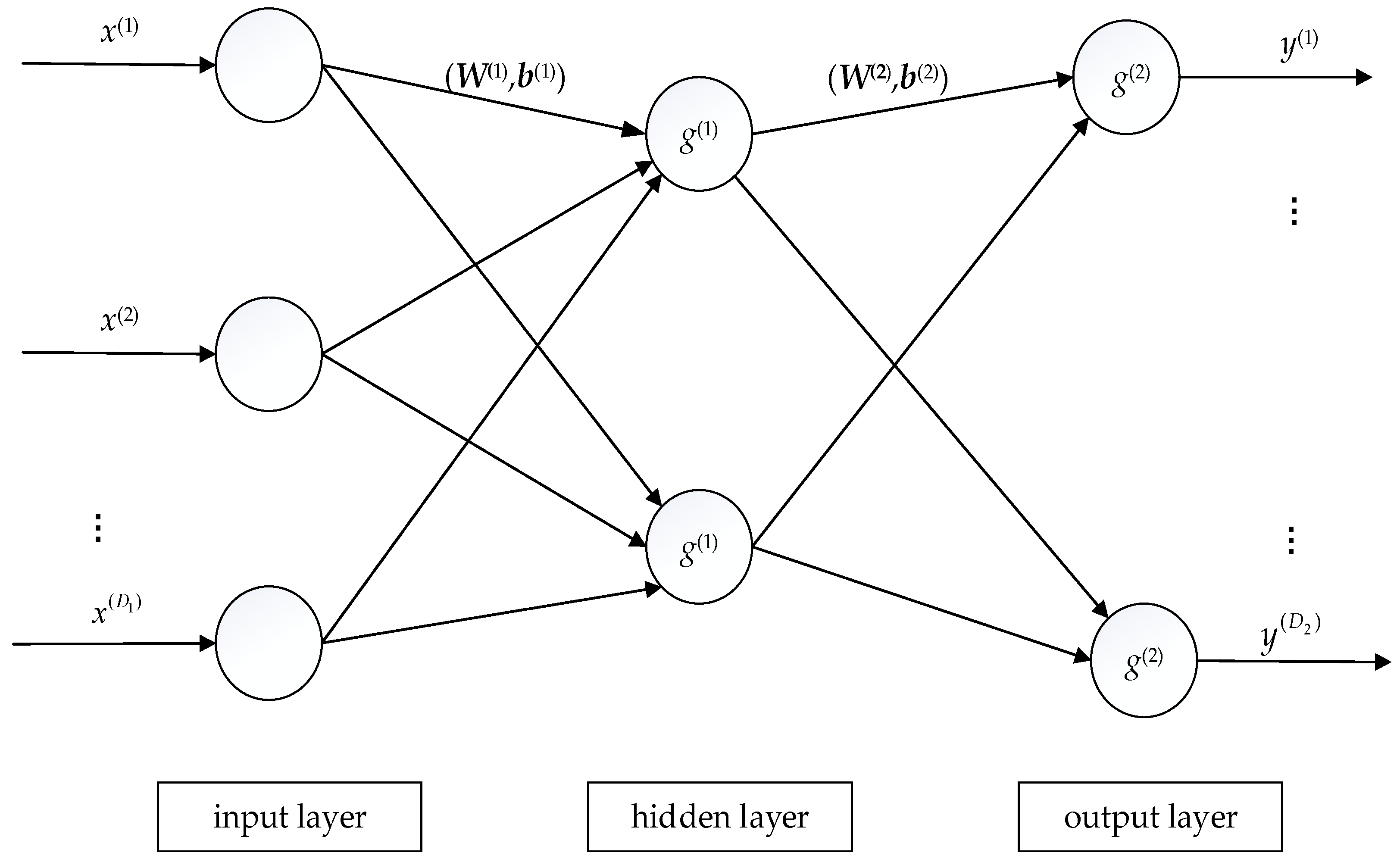
4.1. BP Neural Networks
Neural networks construct the functional form of
from the viewpoint of a network model [
26,
51]. For an input vector
, a feedforward network with
K-1 hidden layers can be expressed by:
where
is the weights matrix in the
k-th hidden layer,
is the corresponding bias vector,
is the nonlinear activation function adopted in the
k-th hidden layer,
and
.
Denote the model parameters set by
. By training the network according to all training samples, the optimal network parameters
can be obtained. For this purpose, we minimize the following error function:
The simplest and the most effective approach is the gradient descent, and the update formulation is
where
is the gradient of
with respect to
, and the step size
is called the learning rate.
Each parameter updating step consists of two stages. The first stage evaluates the derivatives of the error function with respect to the weight matrices and the bias vectors. The backpropagation technique propagates errors backwards through the network and it has become a computationally efficient method for evaluating the derivatives. The derivatives are employed to adjust all parameters in the second stage. Hence, the multilayer perceptron is also called a back-propagation (BP) neural network.
Figure 5 depicts the topological structure of a BP neural network with one hidden layer. In detailed implementation, mini-batch gradient descent is usually utilized to update parameters to reduce the computation burden.
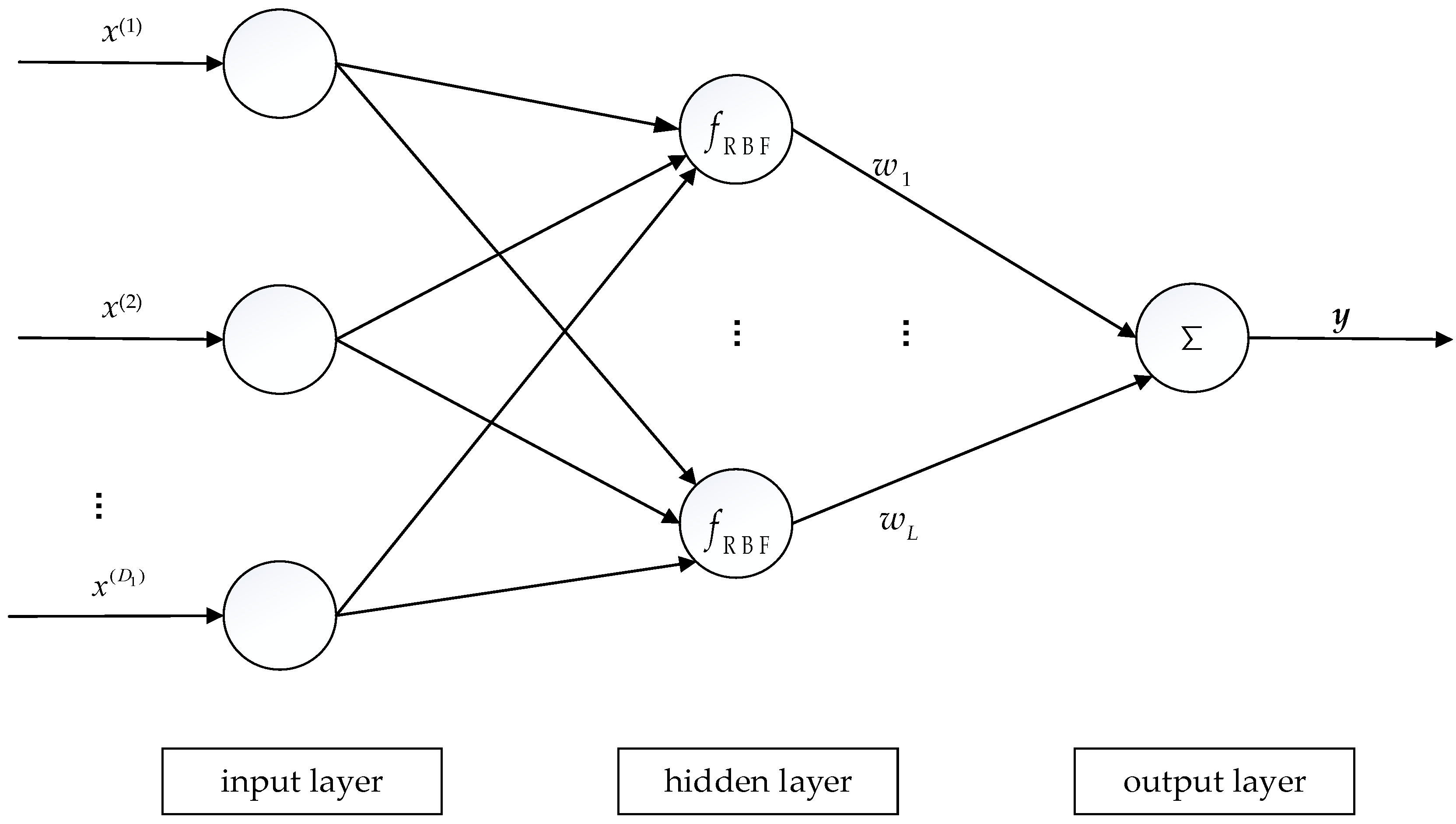
4.2. RBF Neural Networks
As a two-layer feedforward network, a radial basis function (RBF) neural network is composed of an input layer, a hidden layer and an output layer [
27]. An RBF network is a special case of BP network, and the major difference lies in that the former uses a radial basis function as activation function instead of other functions, such as a sigmoid activation function. The sigmoid activation function forces the neurons to have a large input visible area [
52]. In contrast, the activation function in an RBF network has a small input space region. Consequently, an RBF network needs more radial basis neurons. Moreover, an RBF network is mainly applied to the one-dimensional output case.
Figure 6 plots the RBF neural network with the case
.
The commonly used radial basis function in an RBF neural network is the Gaussian function. Under this circumstance, the activation function for a given input feature
can be expressed as
where
and
are the center and the standard deviation of the Gaussian function, respectively. The mathematical model of the RBF network with
L hidden units can be written as
where
is the weights vector connecting the hidden layer to the output layer,
is a set composed by
L center vectors and
L standard deviations.
Formally, the parameters of the RBF neural network can be obtained by minimizing the following errors:
If
is fixed, the optimal weights vector
is calculated as
where
, the notation
is the generalized inverse of a matrix,
is the design matrix with
. The parameters set can be determined by the gradient descent or cross-validation method. In practice,
and
can be updated alternately.
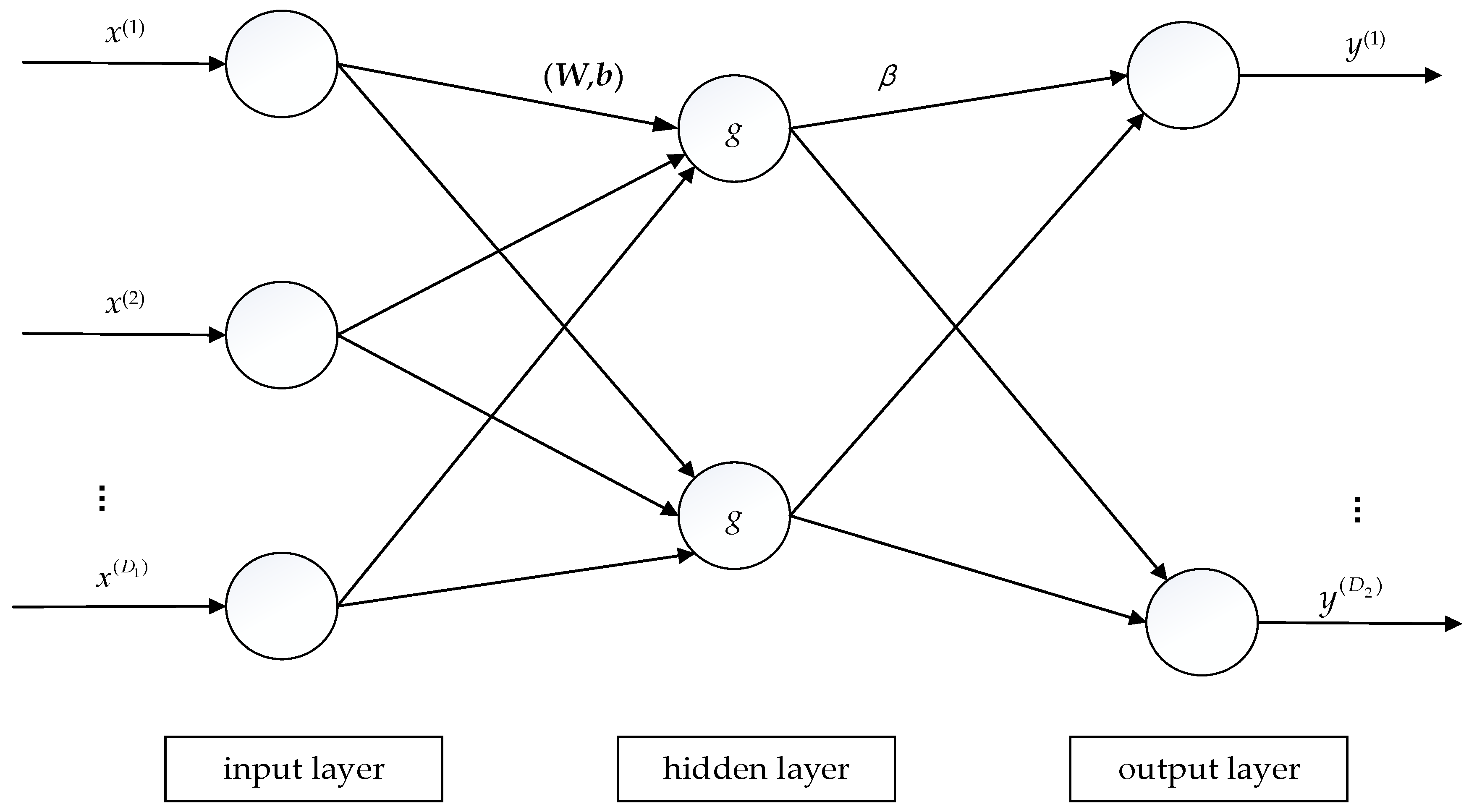
4.3. ELM Neural Networks
ELM generalizes single hidden layer feedforward networks [
53,
54,
55]. For an input sample
, ELM constructs a hidden layer with
L nodes and the output of the
i-th node is denoted by
, where
is a nonlinear feature mapping. We can choose the output of all hidden layer nodes as follows:
where
and
are the weight matrix and the bias vector in the hidden layer, respectively, and
is the mapping function. Subsequently, the linear combination of
is used as the resulting output of the prediction
where
is the output weight matrix.
Figure 7 illustrates the diagram of an ELM neural network with one single hidden layer.
When all parameters are unknown, the above prediction function can be regarded as the combination of RBF networks and BP neural networks with only one hidden layer. To simplify the network model, extreme learning machines generate randomly the hidden node parameters according to some probability distributions. In other words, W and b do not need to be trained explicitly, resulting in a remarkable efficiency.
Let
,
. The weights matrix
connecting the hidden layer and the output layer can be solved by minimizing the squared error loss:
where
is the Frobenius norm of one matrix.
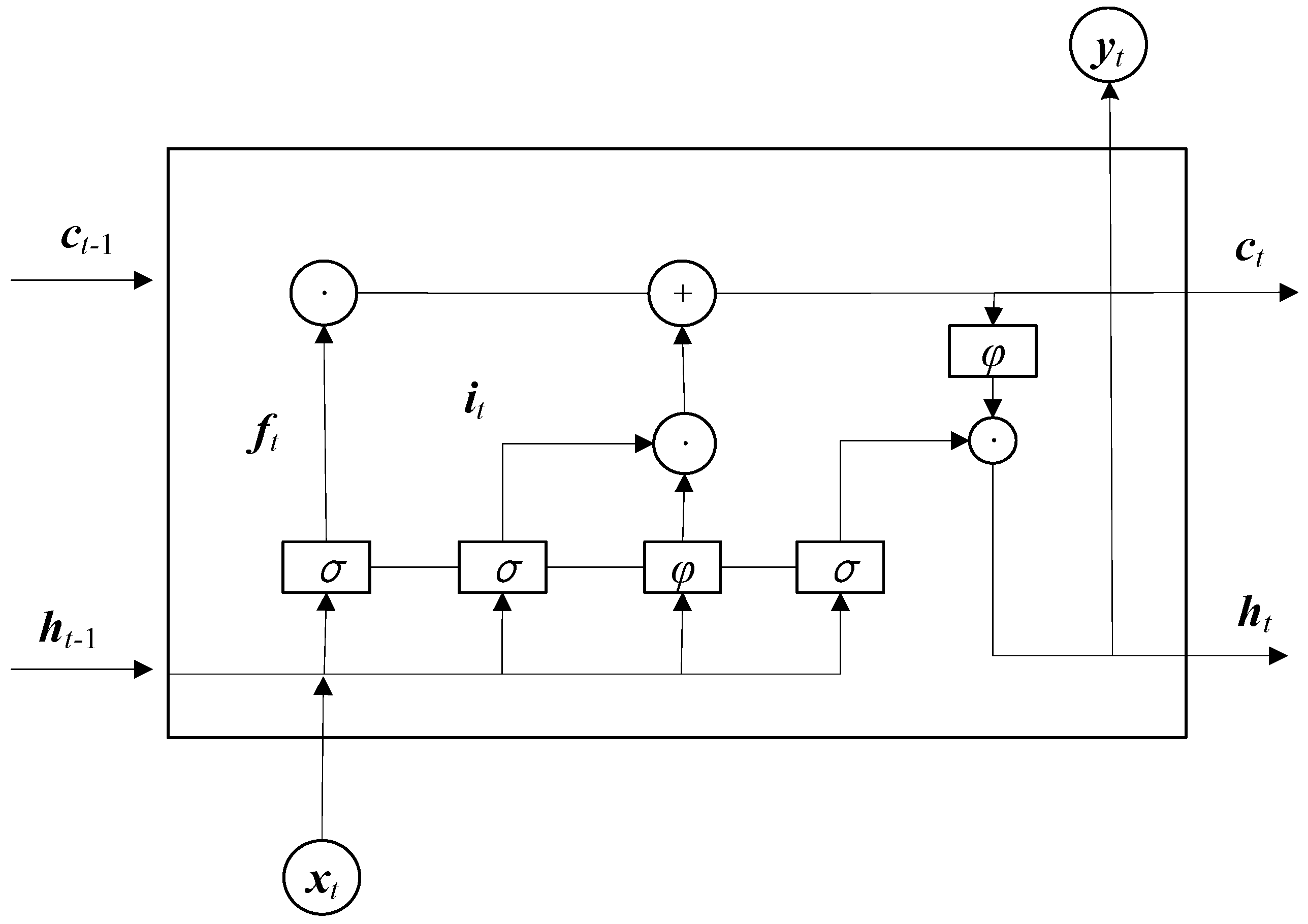
4.4. LSTM Neural Networks
As a special recurrent neural network (RNN), long short-term memory (LSTM) is suitable for processing and predicting important events with relatively long intervals and delays in the time series [
56,
57]. LSTM can alleviate the phenomenon of gradient disappearance in the structure of RNN [
58]. As the result of a powerful representation ability, LSTM utilizes a complex nonlinear unit to construct larger deep neural networks.
LSTM controls long and short-term memory through gates and cell states [
10]. As shown in
Figure 8, the neurons in LSTM include input gate
i, forget gate
f, cell state
c, output gate
y. Among them, three gates are calculated as follows:
where
,
,
are bias terms,
,
,
are respectively the weight matrices of three gates, and
is the sigmoid activation function. In Equation (18),
indicates
where
. At time
t, the update formula of cell state is:
where
is the Hadamard product and
is the candidate cell state. Let
and
be respectively the bias vector and the weight matrix of the candidate cell gate. Then
is computed as:
where the activation function
is usually chosen as the hyperbolic tangent. At last, the hidden vector is updated:
For the input information , Equation (22) calculates the candidate cell state at time t by and . Equation (21) combines the input gate and the forgetting gate to update the cell state at time t. Equation (23) calculates the hidden layer information at time t. Through the combination with gate control units, the LSTM network achieves the purpose of memorizing long- and short-term information of time series data by continuously updating the cell state at each moment.
6. Conclusions and Outlook
This paper proposes a comprehensive application of machine learning techniques for short-term solar radiation prediction. Firstly, aiming at the missing entries in solar radiation data, a matrix completion method is used to recover them. Then we denoise the completed data by robust principal component analysis. The denoised data is clustered into low, medium and high intensity types via fusing sparse subspace representation and k-nearest-neighbor. Subsequently, four commonly used neural networks (BP, RBF, ELM and LSTM) are adopted to predict the solar radiation. In order to quantitatively verify the performance of the prediction model, the RMSE and MAE indicators are applied for model evaluation. The experimental results show that the hybrid model can improve the solar radiation predication accuracy.
In future research work, we will try to improve the model in the following respects to enhance its prediction ability. A multi-step forward prediction is necessary in practice, and it is urgent to develop the corresponding forecasting models by an ensemble of machine learning techniques and signal decomposition methods. In the procedure of establishing the prediction model, the input meteorological element used in this paper is only global horizontal irradiance. In fact, there are many other elements that affect solar radiation, such as the variation of daily temperature and precipitation. The influence of multiple elements on solar radiation will be considered and analyzed so as to improve the prediction ability of solar radiation. Furthermore, this paper only merges a few machine learning techniques into the forecast of solar radiation. In particular, deep learning models have a powerful representative ability and their further application in forecasting solar radiation will be very prospective.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}