
From Classical Machine Learning to Deep Neural Networks: A Simplified Scientometric Review

 , , , and
, , , and 
Abstract

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
- Systematization of AI&ML sections according to literature data.
- Development of methods for collecting data from open sources and assessing changes in publication activity using differential indicators.
- Assessment of changes in publication activity in AI&ML using differential indicators to identify fast-growing and “fading” research domains.
2. Literature Review
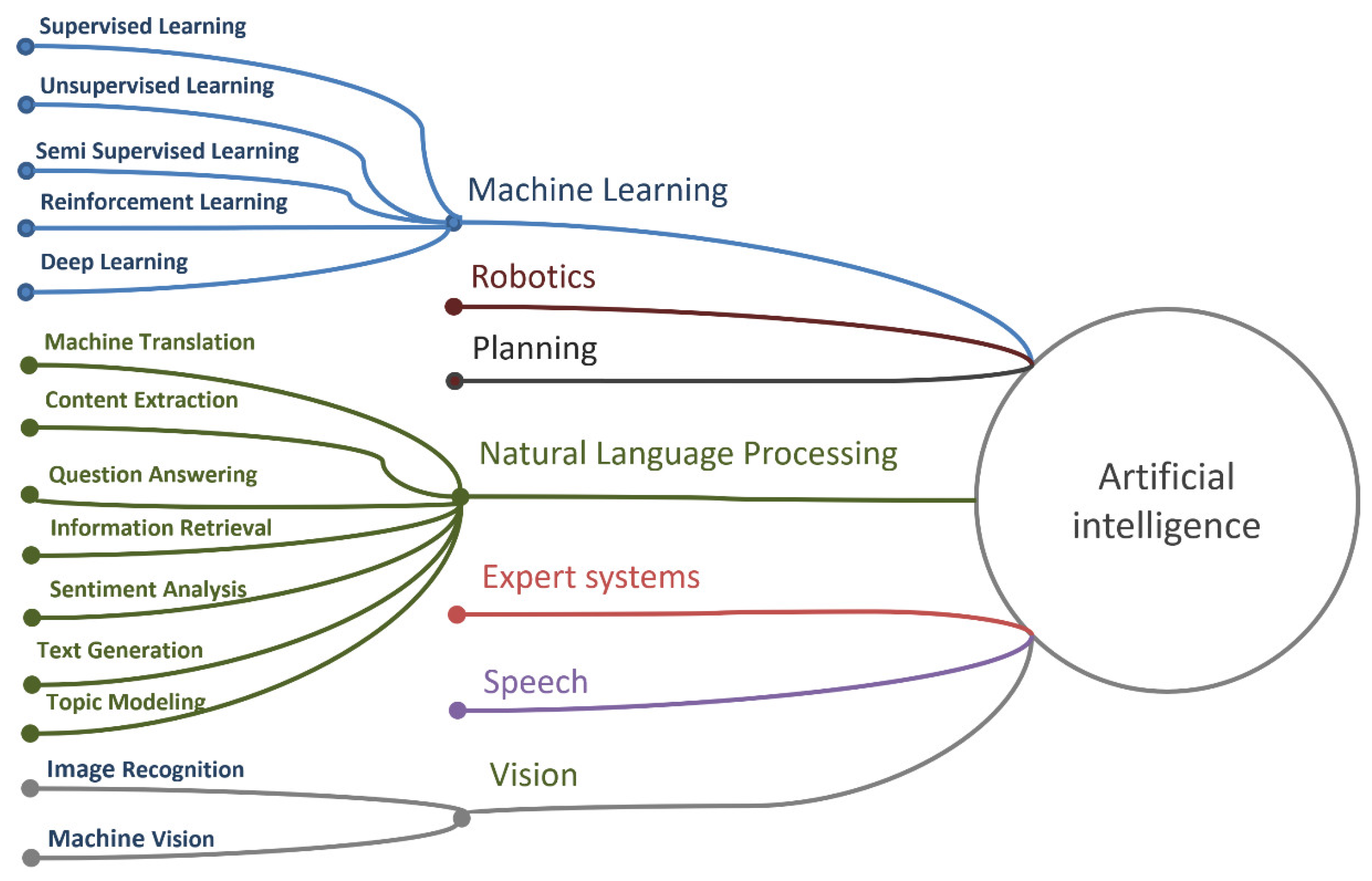
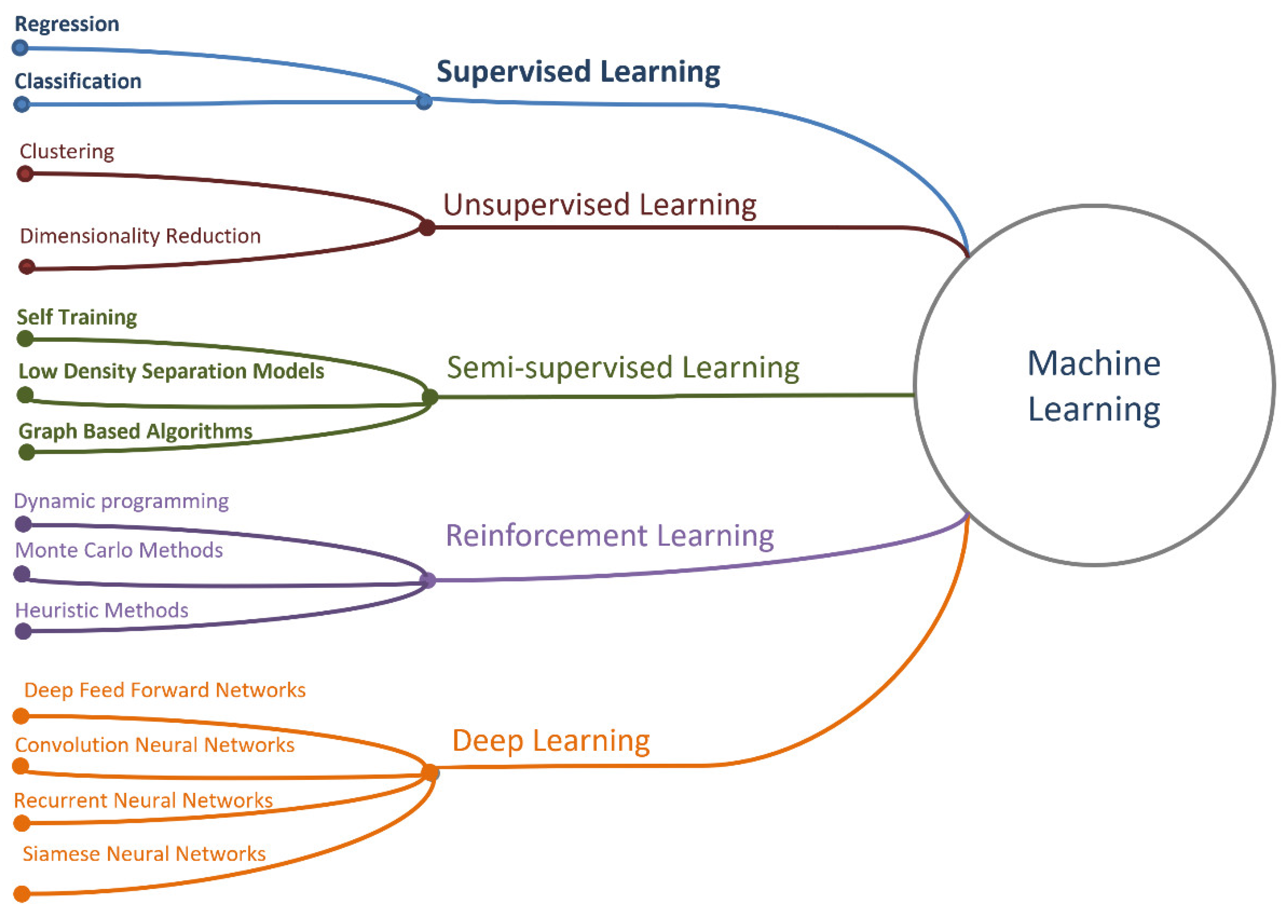
- Machine learning (ML) is a subset of artificial intelligence techniques that allow computer systems to learn from previous experience (i.e., from observations of data) and improve their behavior to perform a particular task. ML methods include support vector methods (SVMs), decision trees, Bayesian learning, k-means clustering, association rule learning, regression, neural networks, and more.
- Neural networks (NN) or artificial NNs are a subset of ML methods with some indirect relationship to biological neural networks. They are usually described as a set of connected elements called artificial neurons, in organized layers.
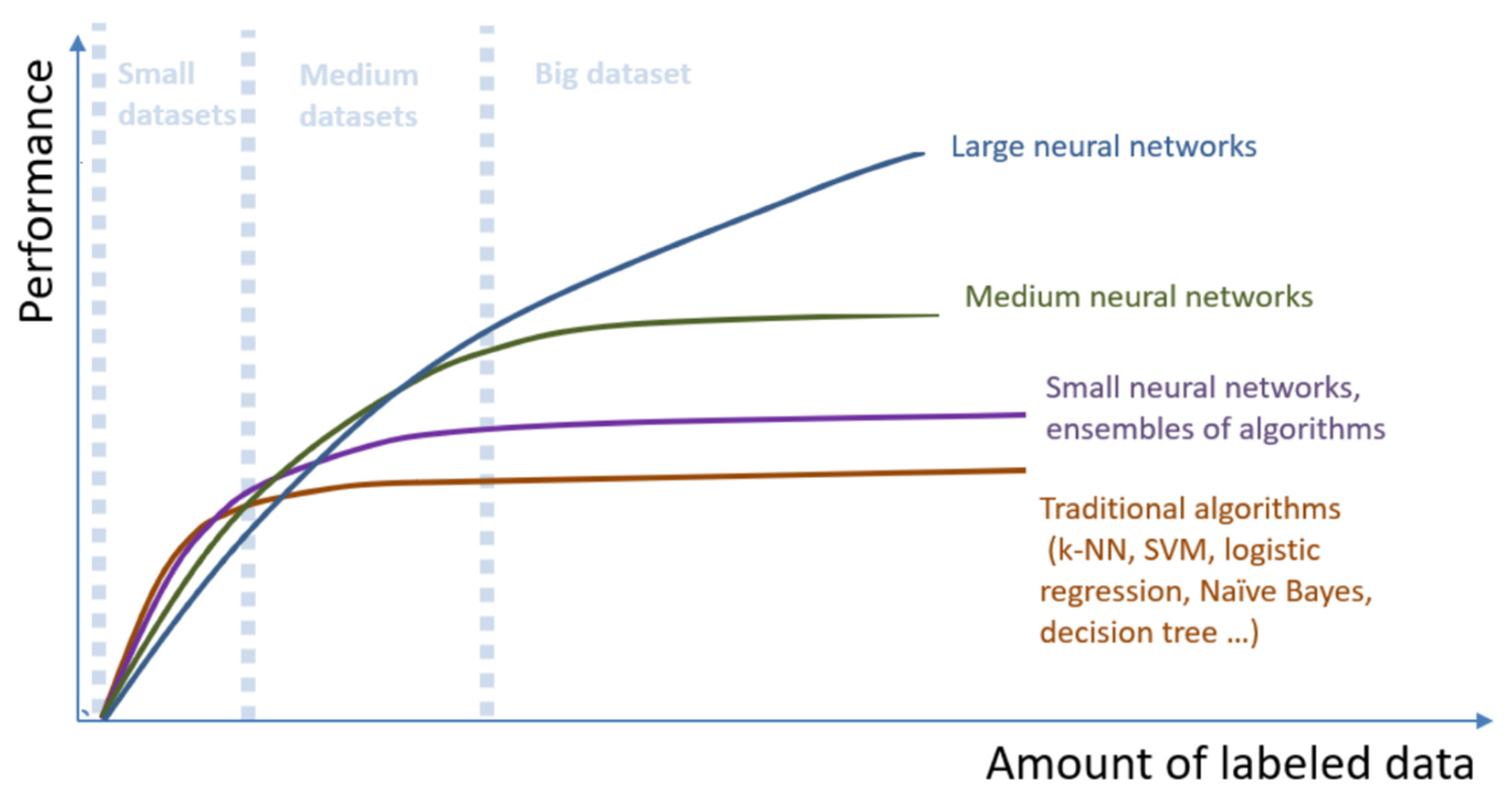
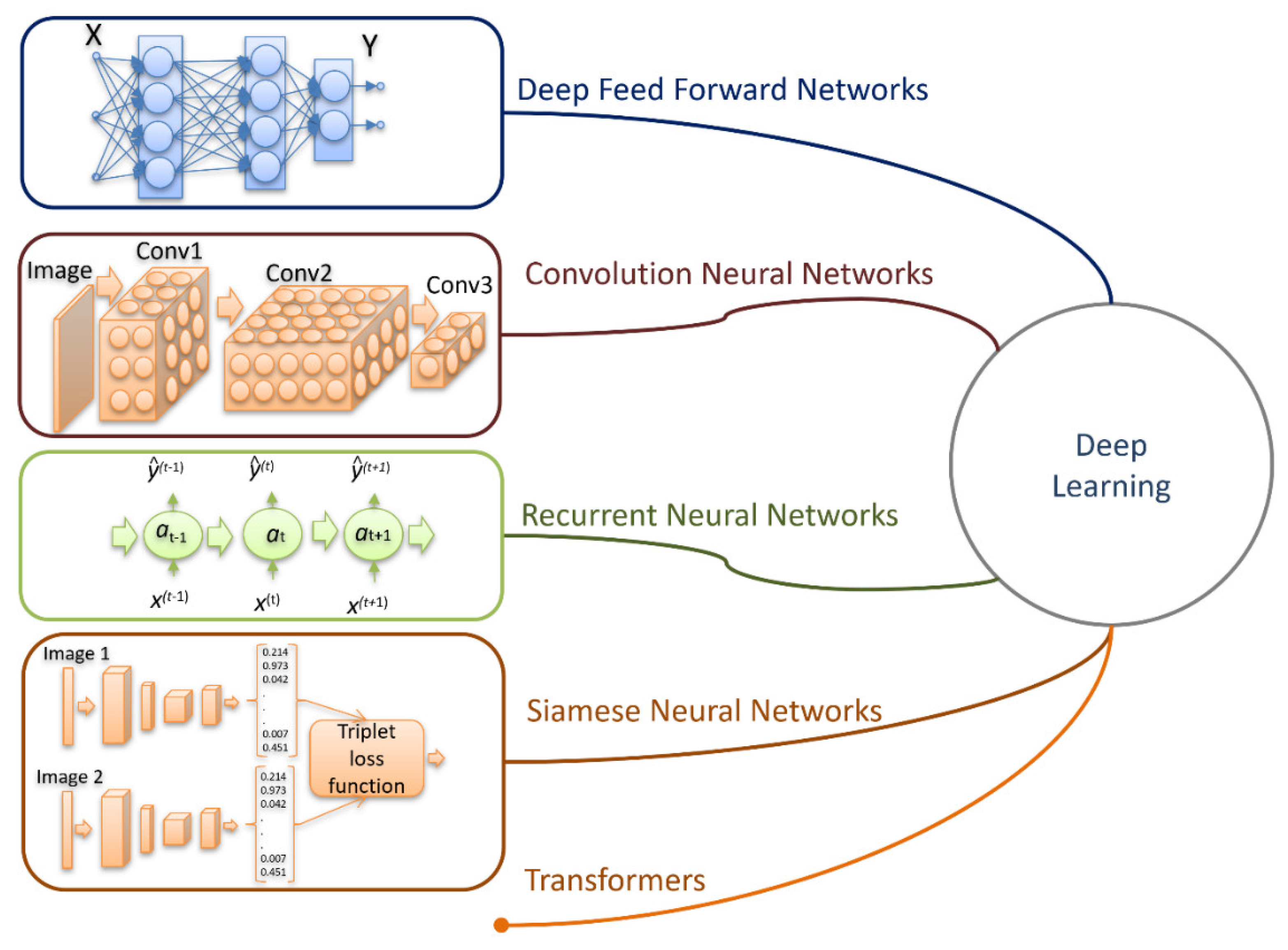
- Deep learning (DL) is a subset of NN that provides computation for multilayer NN. Typical DL architectures are deep neural networks (DNN), convolutional neural networks (CNN), recurrent neural networks (RNN), generating adversarial networks (GAN), and more.
- Standard feed forward neural network—NN.
- Recurrent neural network—RNN.
- Convolution neural network—CNN.
- Hybrid architectures that include elements of 1, 2, and 3 basic architectures, such as Siamese networks and transformers.
- DNA analysis [66], in which the nucleotide sequence determines the meaning of the gene.
- Classifications of the emotional coloring of the text or tone (sentiment analysis [67]). The tone of the text is determined not only by specific words, but also by their combinations.
- Name entity recognition [68], that is, proper names, days of the week and months, locations, dates, etc.
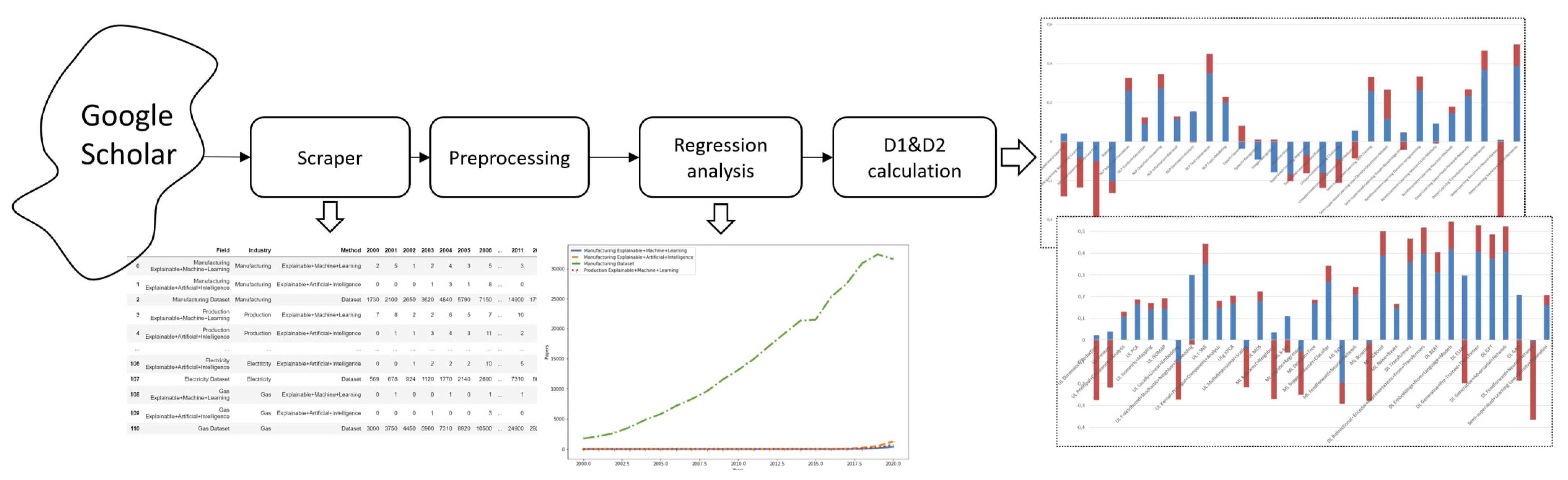
3. Method
- —actual value,
- —calculated value (hypothesis function value) for the i-th example,
- —part of the training sample (sets of marked objects).
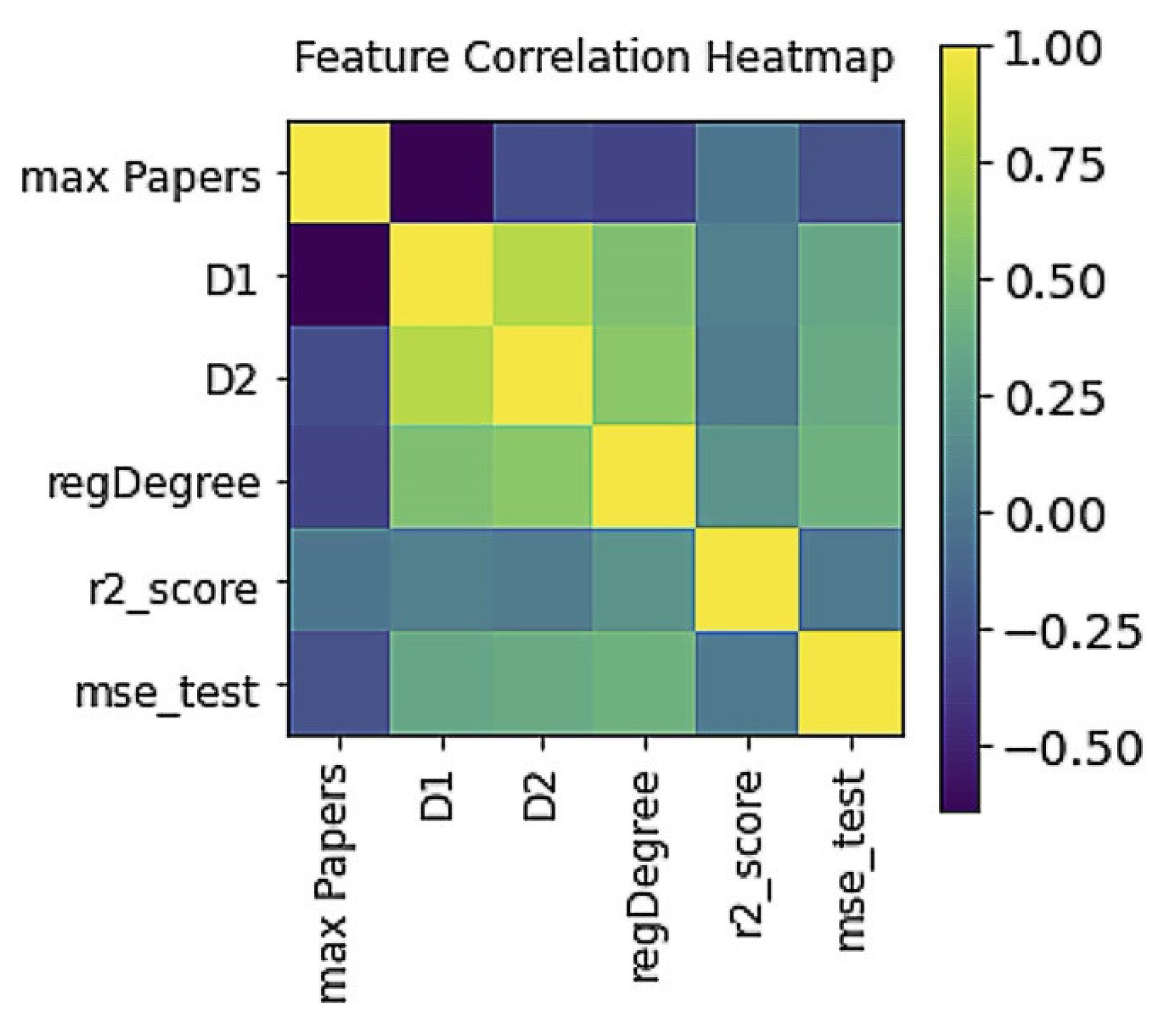
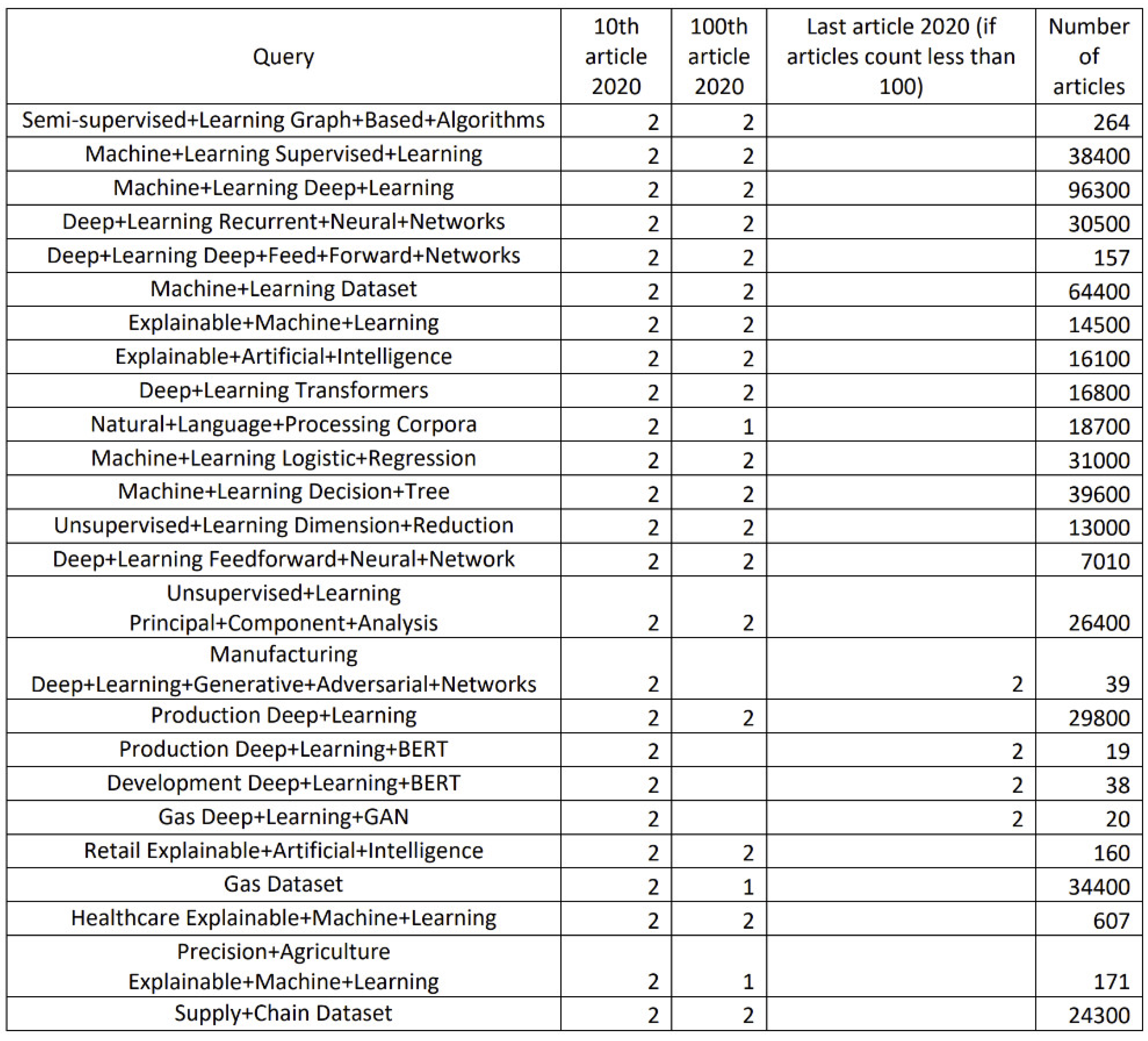
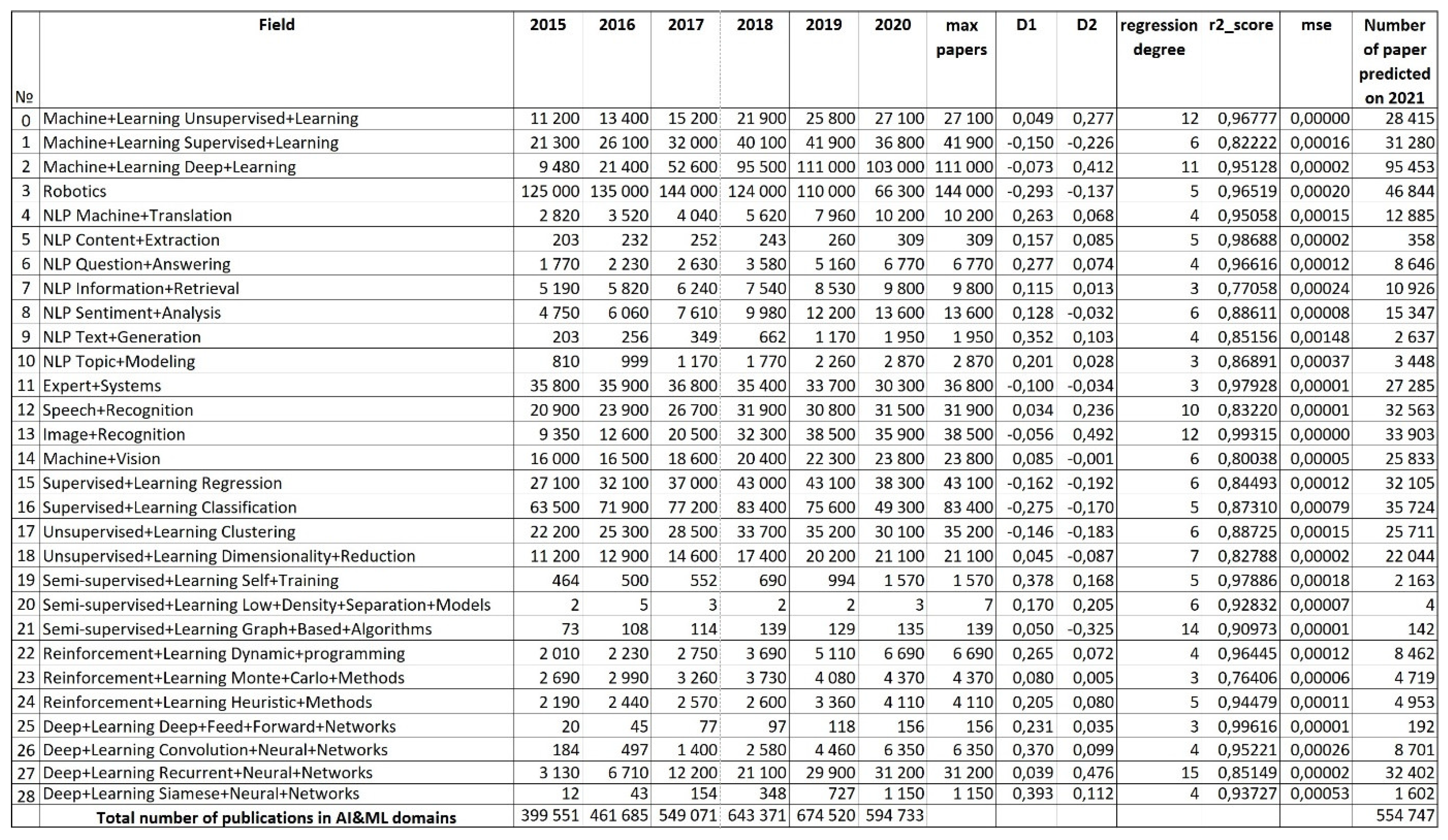
- For each search query, the regression order is chosen individually, starting from n = 3 to ensure r2_score ≥ 0.7. As soon as the specified boundary is reached, n is fixed and the selection process stops.
- Since we are most interested in the values of dynamic indicators for the last year, we used the last value (number of publications for 2020) and the value equal to half of the growth of articles achieved at the end of 2020, which we conventionally associate with the middle of the year, as a test set on which r2_score is determined.
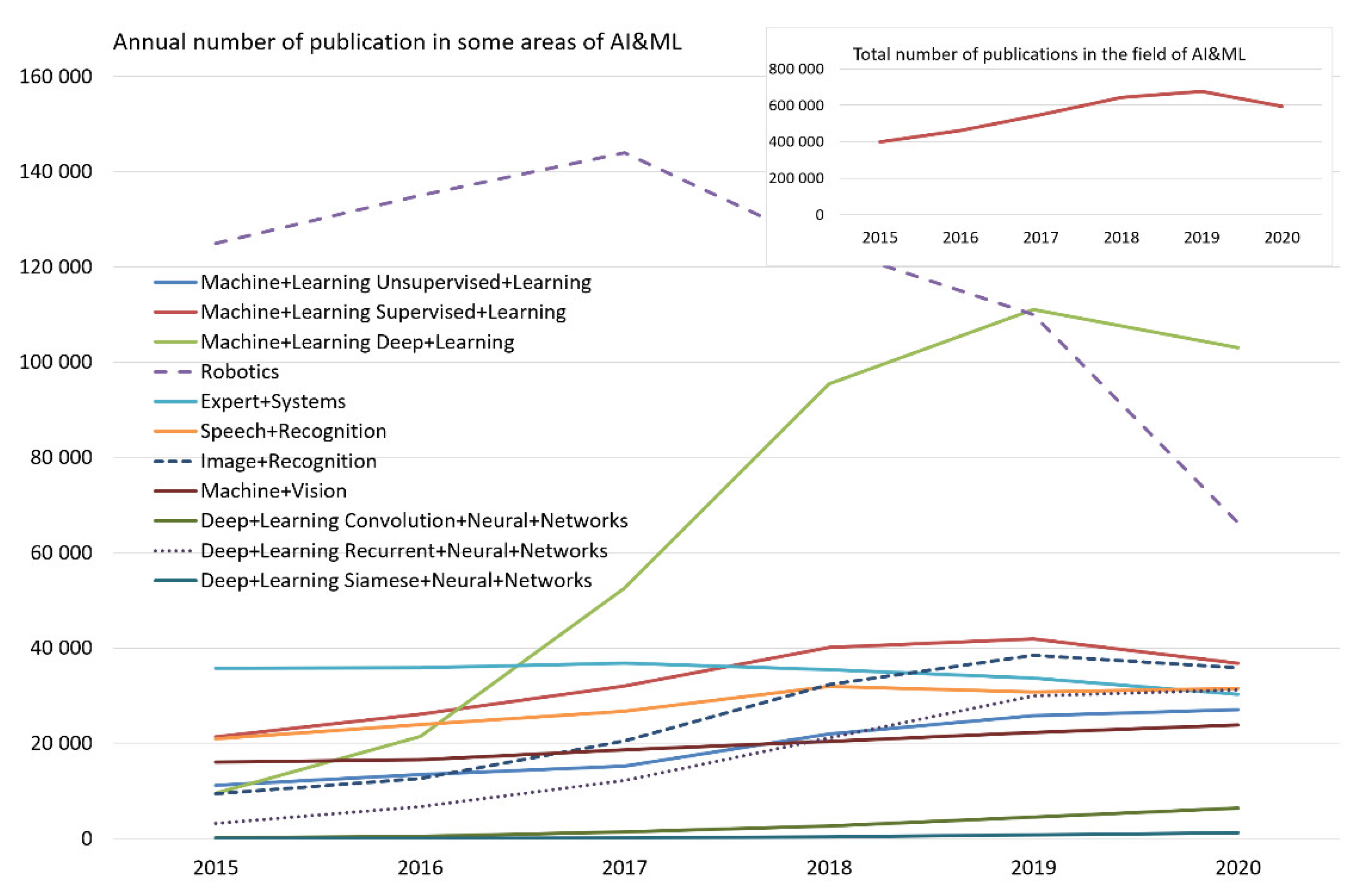
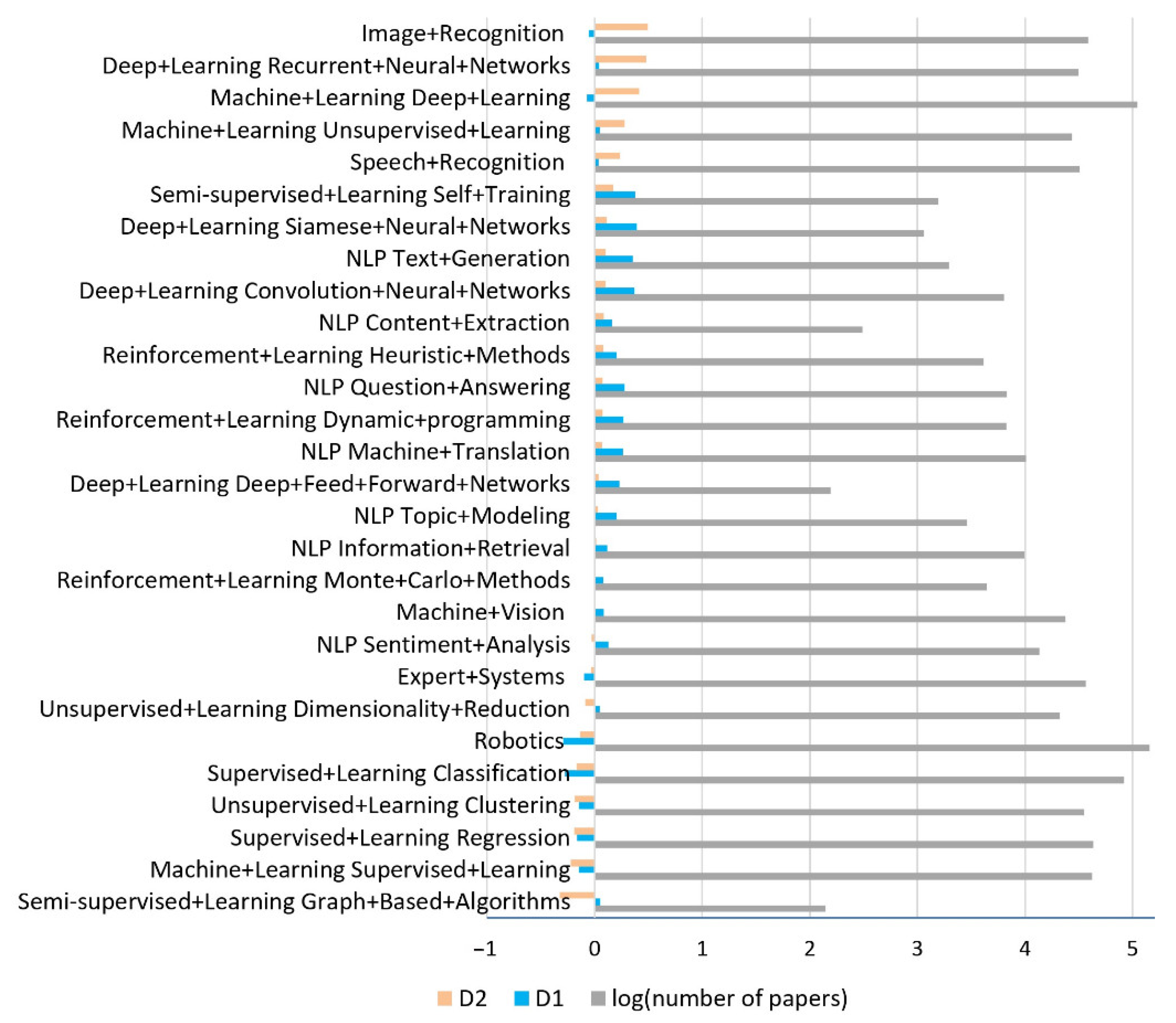
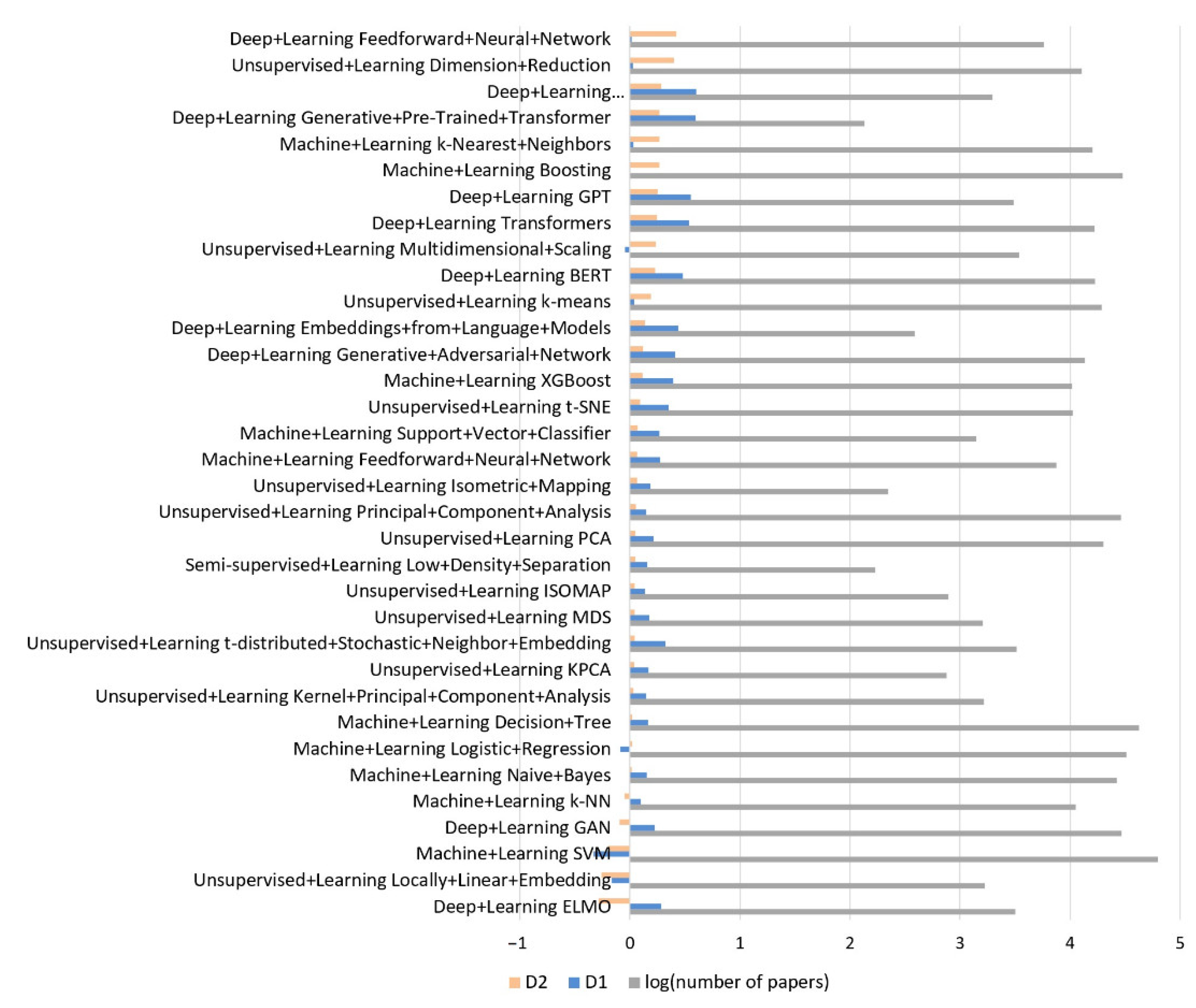
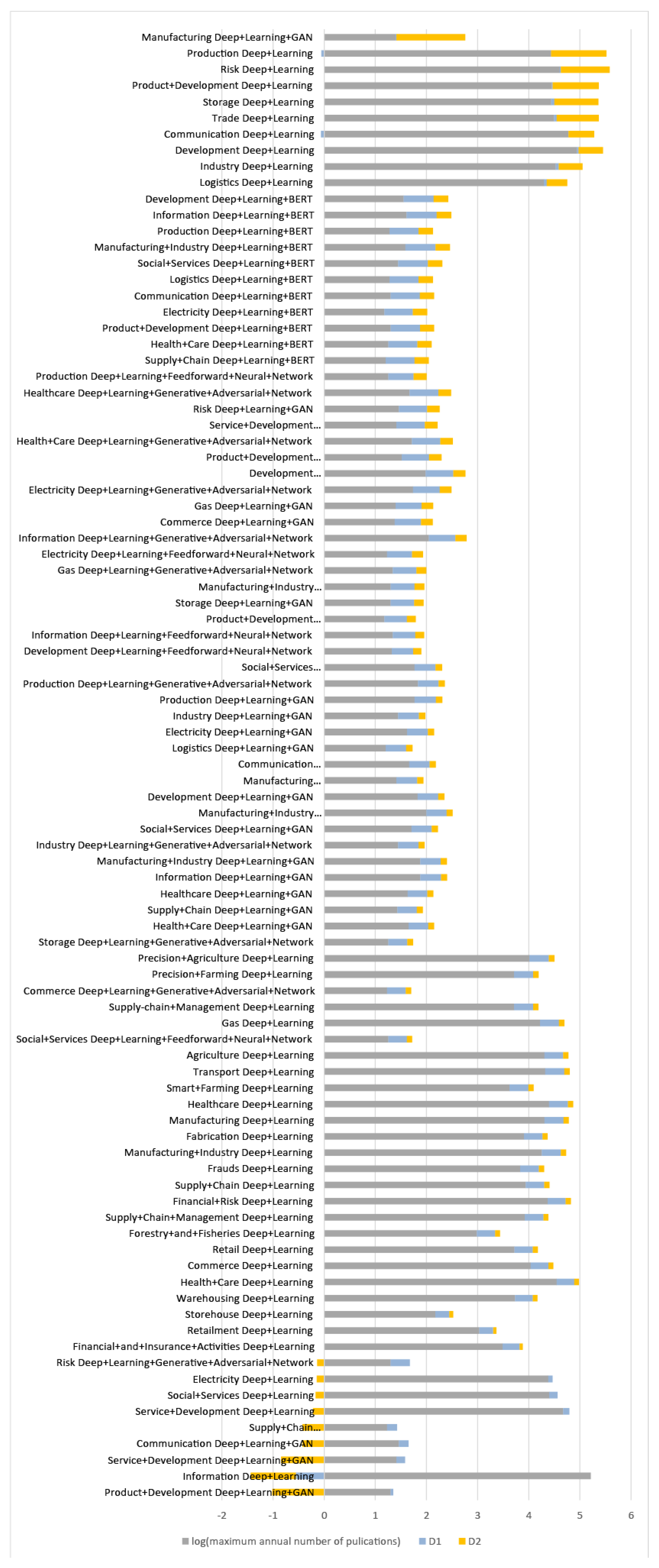
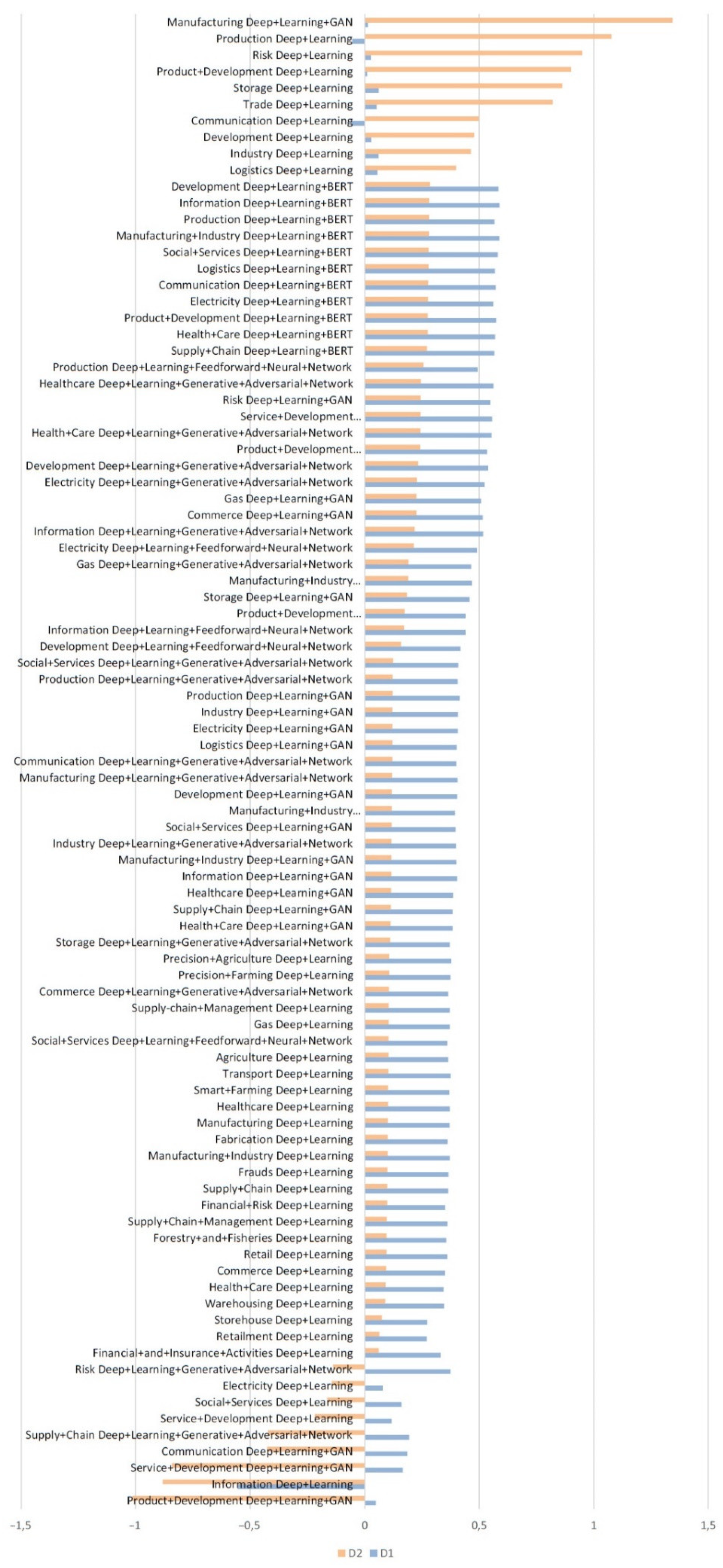
4. Results and Discussion
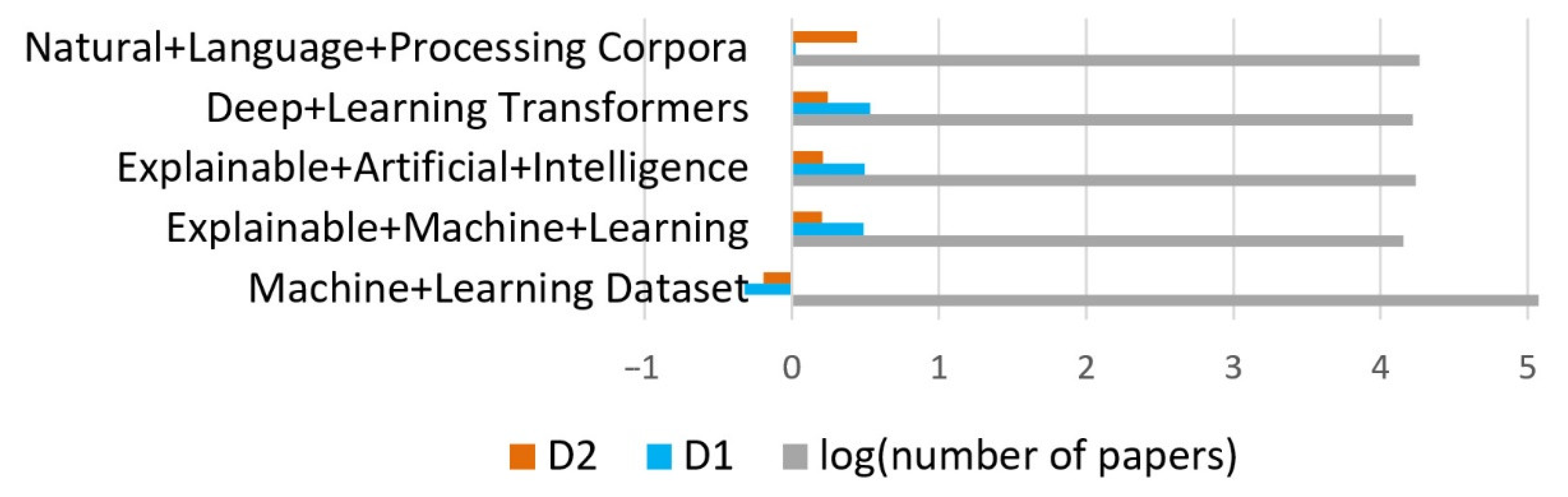
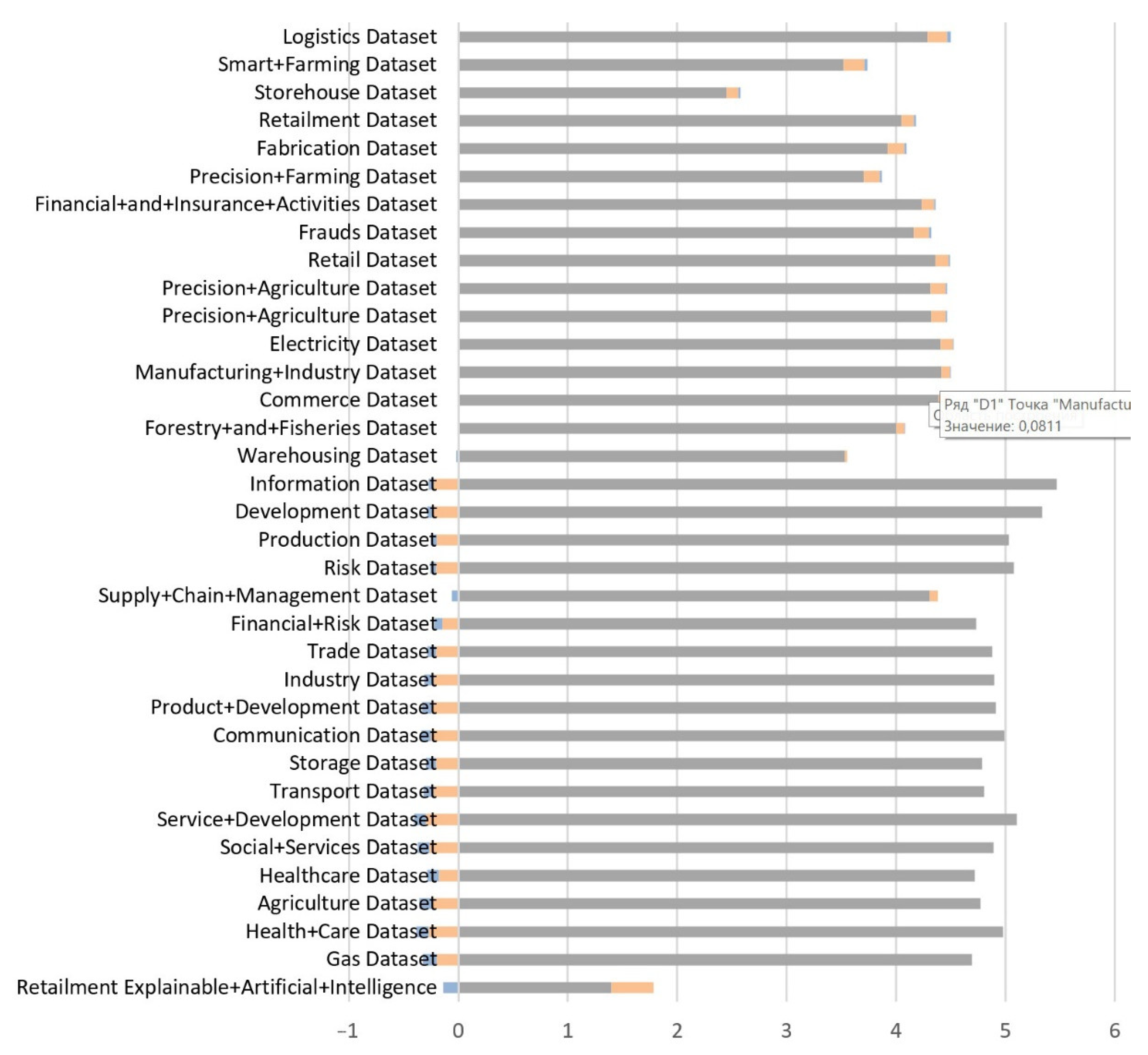
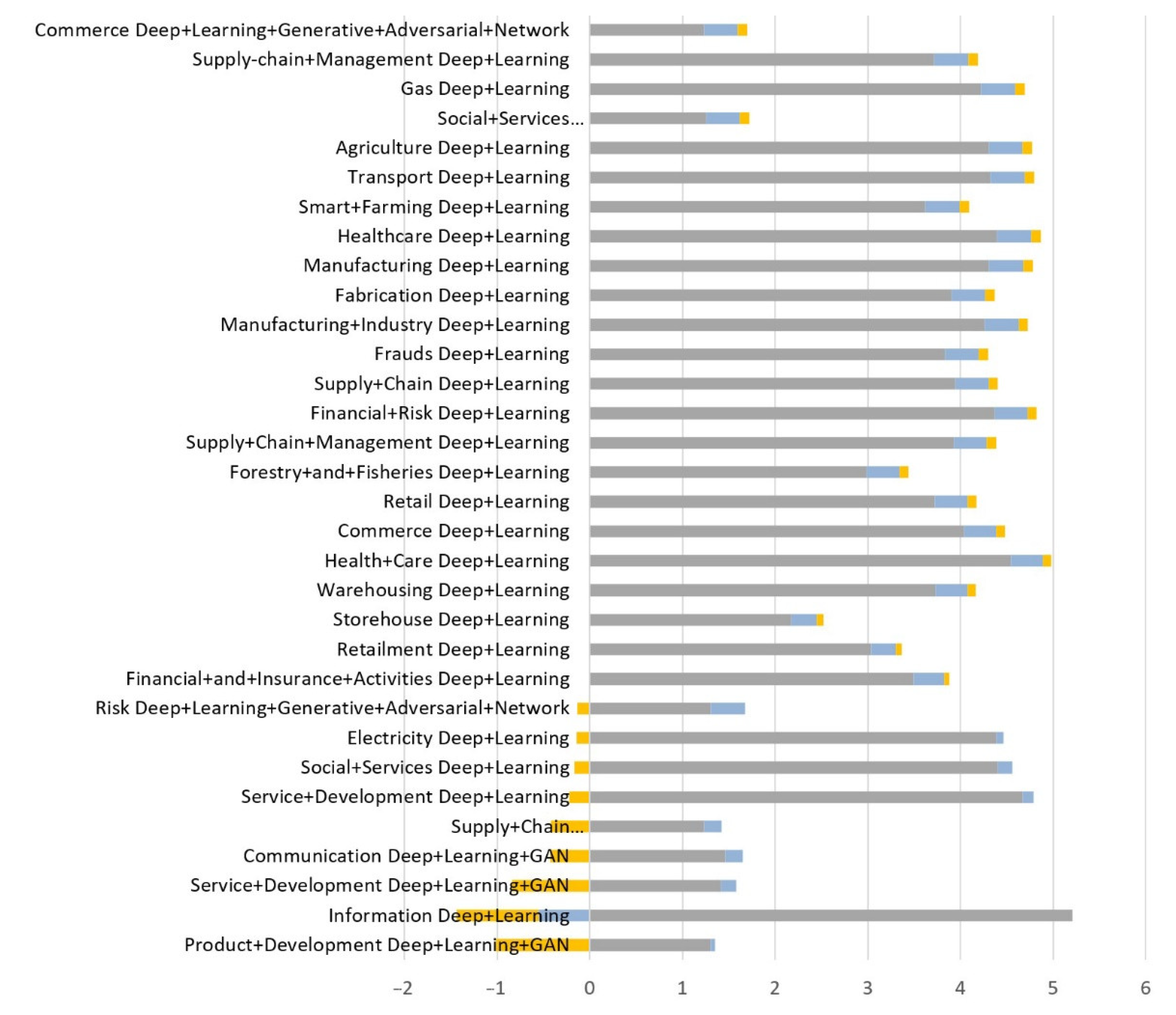
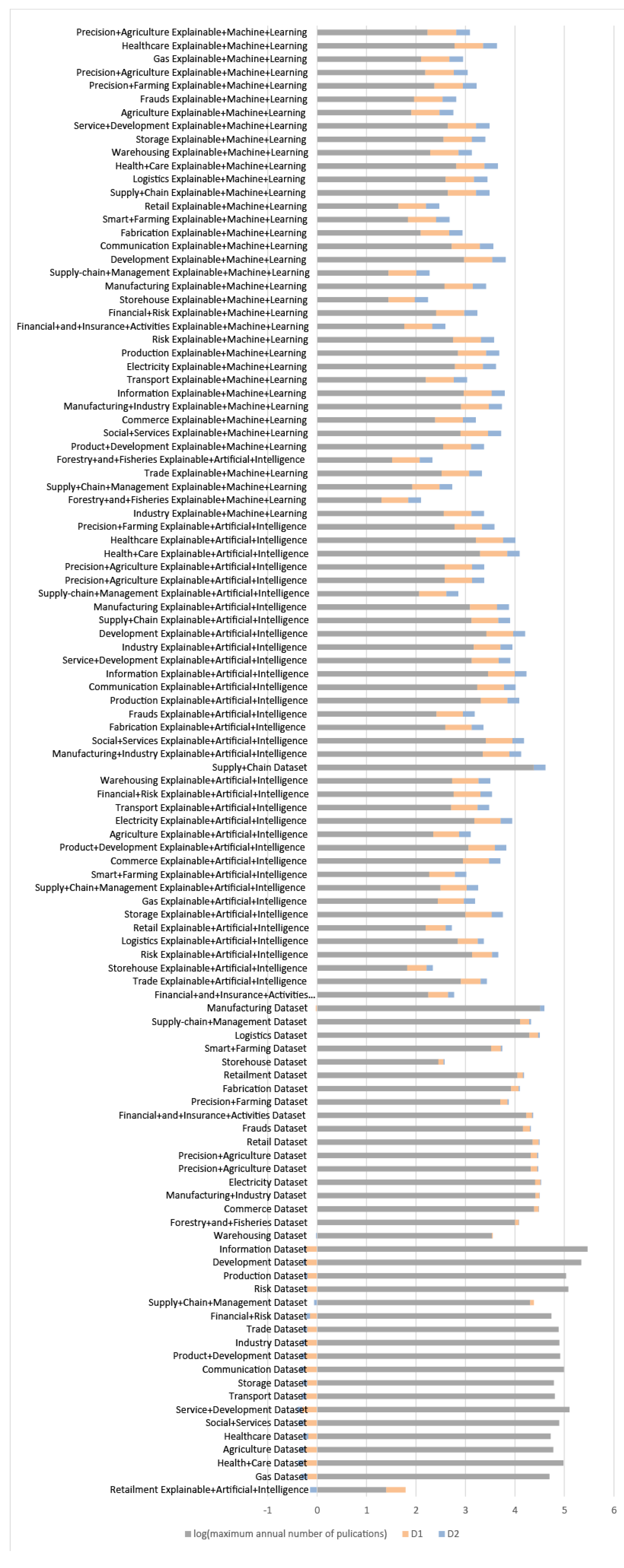
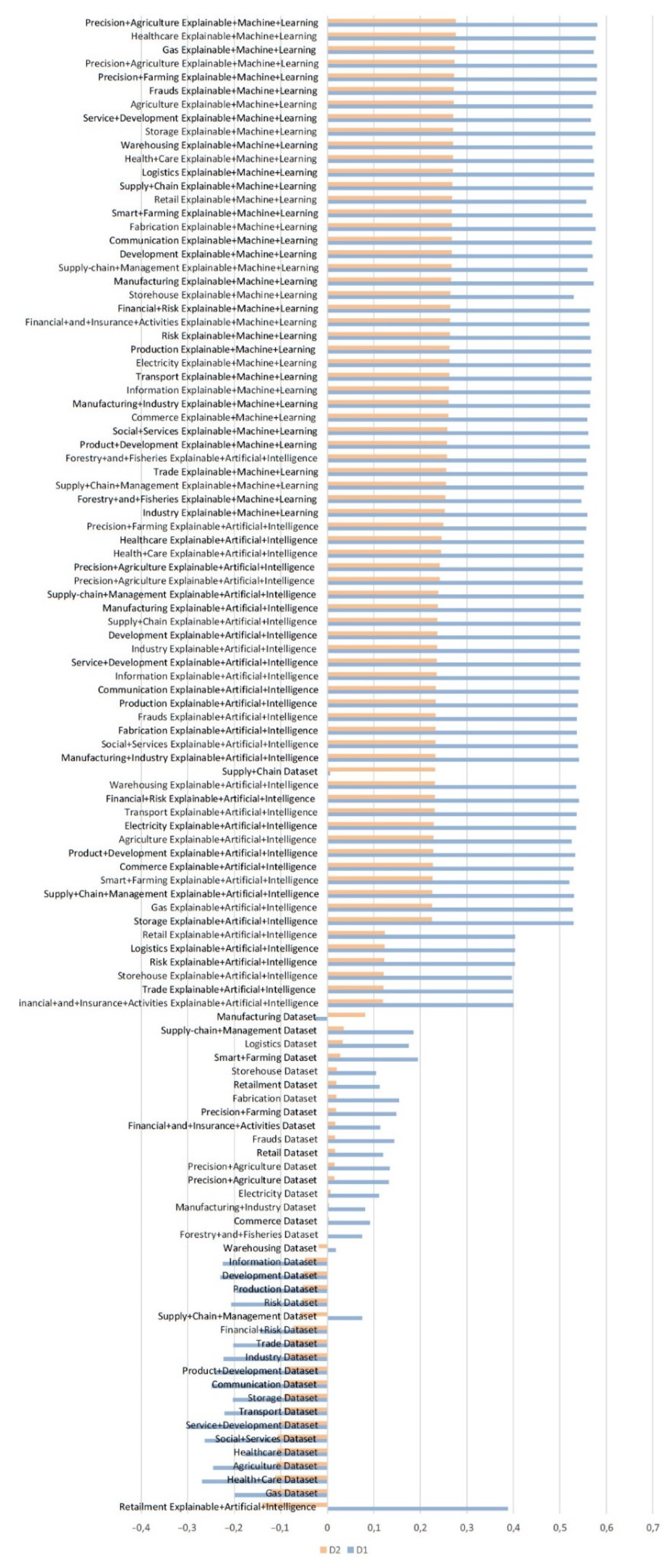
- When both values (D1, D2) are positive, it indicates an accelerated growth of the number of articles in this domain.
- When D1 is negative and D2 is positive, this indicates a slowdown in the number of items.
- When D1 is positive and D2 is negative, it indicates a slowdown in the growth of the number of items.
- When both values are negative, it indicates an accelerated decrease in the number of items.
- In general, the number of publications in the AI&ML domain will decrease.
- New domains such as applications of transformers and explainable machine learning will see rapid growth.
- Classic machine learning models such as SVM, k-NN, and logistic regression will attract less attention from researchers.
- The number of articles on clustering models will continue to increase.
5. Conclusions
- For all the depth of the informal analysis, the set of terms is still set by the researcher. Consequently, some of the articles that are part of the section under study may be left out, and, conversely, some publications may be incorrectly attributed to the topic in question. We also cannot guarantee the exhaustive completeness and consistency of the empirical review performed.
- This analysis does not take into account the fact that the importance of a particular scientific topic is determined not only by the number of articles, but also by the volume of citations, the “weight” of the individual characteristics of the authors, the quality of the journals, and so on.
- The method does not evaluate term change processes and semantic proximity of scientific domains.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

Appendix B

Appendix C


Appendix D


References
- The Socio-Economic Impact of AI in Healthcare. Available online: https://www.medtecheurope.org/wp-content/uploads/2020/10/mte-ai_impact-in-healthcare_oct2020_report.pdf (accessed on 10 May 2021).
- Haseeb, M.; Mihardjo, L.W.; Gill, A.R.; Jermsittiparsert, K. Economic impact of artificial intelligence: New look for the macroeconomic assessment in Asia-Pacific region. Int. J. Comput. Intell. Syst. 2019, 12, 1295–1310. [Google Scholar] [CrossRef]
- Van Roy, V. AI Watch-National Strategies on Artificial Intelligence: A European Perspective in 2019; Joint Research Centre (Seville Site): Seville, Spain, 2020. [Google Scholar]
- Garfield, E. Citation analysis as a tool in journal evaluation. Science 1972, 178, 471–479. [Google Scholar] [CrossRef]
- Van Raan, A. The use of bibliometric analysis in research performance assessment and monitoring of interdisciplinary scientific developments. TATuP Z. Tech. Theor. Prax. 2003, 12, 20–29. [Google Scholar] [CrossRef]
- Abramo, G.; D’Angelo, C.; Pugini, F. The measurement of Italian universities’ research productivity by a non parametric-bibliometric methodology. Scientometrics 2008, 76, 225–244. [Google Scholar] [CrossRef]
- Mokhnacheva, J.; Mitroshin, I. Nanoscience and nanotechnologies at the Moscow domain: A bibliometric analysis based on Web of Science (Thomson Reuters). Inf. Resour. Russ. 2014, 6, 17–23. [Google Scholar]
- Debackere, K.; Glänzel, W. Using a bibliometric approach to support research policy making: The case of the Flemish BOF-key. Scientometrics 2004, 59, 253–276. [Google Scholar] [CrossRef]
- Moed, H.F. The effect of “open access” on citation impact: An analysis of ArXiv’s condensed matter section. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 2047–2054. [Google Scholar] [CrossRef]
- Daim, T.U.; Rueda, G.R.; Martin, H.T. Technology forecasting using bibliometric analysis and system dynamics. In Proceedings of the A Unifying Discipline for Melting the Boundaries Technology Management, Portland, OR, USA, 31 July 2005; pp. 112–122. [Google Scholar]
- Daim, T.U.; Rueda, G.; Martin, H.; Gerdsri, P. Forecasting emerging technologies: Use of bibliometrics and patent analysis. Technol. Forecast. Soc. Chang. 2006, 73, 981–1012. [Google Scholar] [CrossRef]
- Inaba, T.; Squicciarini, M. ICT: A New Taxonomy Based on the International Patent Classification; Organisation for Economic Co-operation and Development: Paris, France, 2017. [Google Scholar]
- Egghe, L. Dynamic h-index: The Hirsch index in function of time. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 452–454. [Google Scholar] [CrossRef]
- Rousseau, R.; Fred, Y.Y. A proposal for a dynamic h-type index. J. Am. Soc. Inf. Sci. Technol. 2008, 59, 1853–1855. [Google Scholar] [CrossRef]
- Katz, J.S. Scale-independent indicators and research evaluation. Sci. Public Policy 2000, 27, 23–36. [Google Scholar] [CrossRef]
- Van Raan, A.F. Fatal attraction: Conceptual and methodological problems in the ranking of universities by bibliometric methods. Scientometrics 2005, 62, 133–143. [Google Scholar] [CrossRef]
- Muhamedyev, R.I.; Aliguliyev, R.M.; Shokishalov, Z.M.; Mustakayev, R.R. New bibliometric indicators for prospectivity estimation of research fields. Ann. Libr. Inf. Stud. 2018, 65, 62–69. [Google Scholar]
- Artificial Intelligence. Available online: https://www.britannica.com/technology/artificial-intelligence (accessed on 10 May 2021).
- Michael, M. Artificial Intelligence in Law: The State of Play 2016. Available online: https://www.neotalogic.com/wp-content/uploads/2016/04/Artificial-Intelligence-in-Law-The-State-of-Play-2016.pdf (accessed on 10 May 2021).
- Nguyen, G.; Dlugolinsky, S.; Bobák, M.; Tran, V.; García, Á.L.; Heredia, I.; Malík, P.; Hluchý, L. Machine learning and deep learning frameworks and libraries for large-scale data mining: A survey. Artif. Intell. Rev. 2019, 52, 77–124. [Google Scholar] [CrossRef]
- Cruz, J.A.; Wishart, D.S. Applications of machine learning in cancer prediction and prognosis. Cancer Inform. 2006, 2. [Google Scholar] [CrossRef]
- Miotto, R.; Wang, F.; Wang, S.; Jiang, X.; Dudley, J.T. Deep learning for healthcare: Review, opportunities and challenges. Brief. Bioinform. 2018, 19, 1236–1246. [Google Scholar] [CrossRef] [PubMed]
- Ballester, P.J.; Mitchell, J.B. A machine learning approach to predicting protein–ligand binding affinity with applications to molecular docking. Bioinformatics 2010, 26, 1169–1175. [Google Scholar] [CrossRef] [PubMed]
- Mahdavinejad, M.S.; Rezvan, M.; Barekatain, M.; Adibi, P.; Barnaghi, P.; Sheth, A.P. Machine learning for Internet of Things data analysis: A survey. Digit. Commun. Netw. 2018, 4, 161–175. [Google Scholar] [CrossRef]
- Farrar, C.R.; Worden, K. Structural Health Monitoring: A Machine Learning Perspective; John Wiley & Sons: New York, NY, USA, 2012. [Google Scholar]
- Lai, J.; Qiu, J.; Feng, Z.; Chen, J.; Fan, H. Prediction of soil deformation in tunnelling using artificial neural networks. Comput. Intell. Neurosci. 2016, 2016. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef]
- Recknagel, F. Applications of machine learning to ecological modelling. Ecol. Model. 2001, 146, 303–310. [Google Scholar] [CrossRef]
- Tatarinov, V.; Manevich, A.; Losev, I. A systematic approach to geodynamic zoning based on artificial neural networks. Min. Sci. Technol. 2018, 3, 14–25. [Google Scholar]
- Clancy, C.; Hecker, J.; Stuntebeck, E.; O’Shea, T. Applications of machine learning to cognitive radio networks. IEEE Wirel. Commun. 2007, 14, 47–52. [Google Scholar] [CrossRef]
- Ball, N.M.; Brunner, R.J. Data mining and machine learning in astronomy. Int. J. Mod. Phys. D 2010, 19, 1049–1106. [Google Scholar] [CrossRef]
- Amirgaliev, E.; Iskakov, S.; Kuchin, Y.; Muhamediyev, R.; Muhamedyeva, E. Integration of results of recognition algorithms at the uranium deposits. JACIII 2014, 18, 347–352. [Google Scholar]
- Amirgaliev, E.; Isabaev, Z.; Iskakov, S.; Kuchin, Y.; Muhamediyev, R.; Muhamedyeva, E.; Yakunin, K. Recognition of rocks at uranium deposits by using a few methods of machine learning. In Soft Computing in Machine Learning; Springer: Cham, Switzerland, 2014; pp. 33–40. [Google Scholar]
- Chen, Y.; Wu, W. Application of one-class support vector machine to quickly identify multivariate anomalies from geochemical exploration data. Geochem. Explor. Environ. Anal. 2017, 17, 231–238. [Google Scholar] [CrossRef]
- Hirschberg, J.; Manning, C.D. Advances in natural language processing. Science 2015, 349, 261–266. [Google Scholar] [CrossRef]
- Goldberg, Y. A primer on neural network models for natural language processing. J. Artif. Intell. Res. 2016, 57, 345–420. [Google Scholar] [CrossRef]
- Ayodele, T.O. Types of machine learning algorithms. New Adv. Mach. Learn. 2010, 3, 19–48. [Google Scholar]
- Ibrahim, H.A.H.; Nor, S.M.; Mohammed, A.; Mohammed, A.B. Taxonomy of machine learning algorithms to classify real time interactive applications. Int. J. Comput. Netw. Wirel. Commun. 2012, 2, 69–73. [Google Scholar]
- Muhamedyev, R. Machine learning methods: An overview. Comput. Model. New Technol. 2015, 19, 14–29. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press Cambridge: Massachusetts, MA, USA, 2016; Volume 1. [Google Scholar]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech recognition using deep neural networks: A systematic review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. Unsupervised learning. In The Elements of Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2009; pp. 485–585. [Google Scholar]
- Kotsiantis, S.B.; Zaharakis, I.; Pintelas, P. Supervised machine learning: A review of classification techniques. Emerg. Artif. Intell. Appl. Comput. Eng. 2007, 160, 3–24. [Google Scholar]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Ashour, B.W.; Ying, W.; Colin, F. Review of clustering algorithms. Non-standard parameter adaptation for exploratory data analysis. Stud. Comput. Intell. 2009, 249, 7–28. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA; 27 December 1965–7 January 1966, 21 June–18 July 1965. pp. 281–297.
- Tenenbaum, J.B.; De Silva, V.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Schölkopf, B.; Smola, A.; Müller, K.R. Kernel principal component analysis. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 1997; pp. 583–588. [Google Scholar]
- Borg, I.; Groenen, P.J. Modern multidimensional scaling: Theory and applications. J. Educ. Meas. 2003, 40, 277–280. [Google Scholar] [CrossRef]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Dudani, S.A. The distance-weighted k-nearest-neighbor rule. IEEE Trans. Syst. Manand Cybern. 1976, 6, 325–327. [Google Scholar] [CrossRef]
- K-nearest Neighbor Algorithm. Available online: http://en.wikipedia.org/wiki/K-nearest_neighbor_algorithm (accessed on 10 May 2021).
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Zhang, G.P. Neural networks for classification: A survey. IEEE Trans. Syst. Manand Cybern. Part C 2000, 30, 451–462. [Google Scholar] [CrossRef]
- The Neural Network Zoo. Available online: http://www.asimovinstitute.org/neural-network-zoo/ (accessed on 10 May 2021).
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 1189–1232. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Neural Network and Deep Learning. Available online: https://www.coursera.org/learn/neural-networks-deep-learning?specialization=deep-learning (accessed on 10 May 2021).
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Jurafsky, D. Speech & Language Processing; Pearson Education India: Andhra Pradesh, India, 2000. [Google Scholar]
- Liu, X. Deep recurrent neural network for protein function prediction from sequence. arXiv 2017, arXiv:1701.08318. [Google Scholar]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Nayebi, A.; Vitelli, M. Gruv: Algorithmic music generation using recurrent neural networks. In Course CS224D: Deep Learning for Natural Language Processing; Stanford, CA, USA, 2015; Available online: https://cs224d.stanford.edu/reports/NayebiAran.pdf (accessed on 8 June 2021).
- Lu, S.; Zhu, Y.; Zhang, W.; Wang, J.; Yu, Y. Neural text generation: Past, present and beyond. arXiv 2018, arXiv:1803.07133. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zelener, A. YAD2K: Yet Another Darknet 2 Keras. Available online: https://github.com/allanzelener/YAD2K (accessed on 10 May 2021).
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Sankaranarayanan, S.; Alavi, A.; Castillo, C.D.; Chellappa, R. Triplet probabilistic embedding for face verification and clustering. In Proceedings of the 2016 IEEE 8th International Conference on Biometrics Theory, Applications and Systems (BTAS), New York, NY, USA, 6–9 September 2016; pp. 1–8. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Major Barriers to AI Adoption. Available online: https://www.agiloft.com/blog/barriers-to-ai-adoption/ (accessed on 9 May 2021).
- AI Adoption Advances, but Foundational Barriers Remain. Available online: https://www.mckinsey.com/featured-insights/artificial-intelligence/ai-adoption-advances-but-foundational-barriers-remain (accessed on 10 May 2021).
- Machine Learning and the Five Vectors of Progress. Available online: https://www2.deloitte.com/us/en/insights/focus/signals-for-strategists/machine-learning-technology-five-vectors-of-progress.html (accessed on 10 May 2021).
- Davenport, T.; Kalakota, R. The potential for artificial intelligence in healthcare. Future Healthc. J. 2019, 6, 94. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.; Lee, S.-I. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Muhamedyev, R.I.; Yakunin, K.I.; Kuchin, Y.A.; Symagulov, A.; Buldybayev, T.; Murzakhmetov, S.; Abdurazakov, A. The use of machine learning “black boxes” explanation systems to improve the quality of school education. Cogent Eng. 2020, 7. [Google Scholar] [CrossRef]
- ImageNet. Available online: http://image-net.org/index (accessed on 10 May 2021).
- Open Images Dataset M5+ Extensions. Available online: https://storage.googleapis.com/openimages/web/index.html (accessed on 10 May 2021).
- COCO Dataset. Available online: http://cocodataset.org/#home (accessed on 10 May 2021).
- Wong, M.Z.; Kunii, K.; Baylis, M.; Ong, W.H.; Kroupa, P.; Koller, S. Synthetic dataset generation for object-to-model deep learning in industrial applications. PeerJ Comput. Sci. 2019, 5, e222. [Google Scholar] [CrossRef] [PubMed]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3234–3243. [Google Scholar]
- Sooyoung, C.; Sang, G.C.; Daeyeol, K.; Gyunghak, L.; Chae, B. How to generate image dataset based on 3D model and deep learning method. Int. J. Eng. Technol. 2018, 7, 221–225. [Google Scholar]
- Müller, M.; Casser, V.; Lahoud, J.; Smith, N.; Ghanem, B. Sim4cv: A photo-realistic simulator for computer vision applications. Int. J. Comput. Vis. 2018, 126, 902–919. [Google Scholar] [CrossRef]
- Doan, A.-D.; Jawaid, A.M.; Do, T.-T.; Chin, T.-J. G2D: From GTA to Data. arXiv 2018, arXiv:1806.07381. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Kuchin, Y.I.; Mukhamediev, R.I.; Yakunin, K.O. One method of generating synthetic data to assess the upper limit of machine learning algorithms performance. Cogent Eng. 2020, 7, 1718821. [Google Scholar] [CrossRef]
- Arvanitis, T.N.; White, S.; Harrison, S.; Chaplin, R.; Despotou, G. A method for machine learning generation of realistic synthetic datasets for Validating Healthcare Applications. medRxiv 2021. [Google Scholar] [CrossRef]
- Nikolenko, S.I. Synthetic data for deep learning. arXiv 2019, arXiv:1909.11512. [Google Scholar]
- Mukhamedyev, R.I.; Kuchin, Y.; Denis, K.; Murzakhmetov, S.; Symagulov, A.; Yakunin, K. Assessment of the dynamics of publication activity in the field of natural language processing and deep learning. In Proceedings of the International Conference on Digital Transformation and Global Society, Saint Petersburg, Russia, 19–21 June 2019; pp. 744–753. [Google Scholar]
- David, B.M.; Andrew, N.Y.; Michael, J.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Dieng, A.B.; Ruiz, F.J.; Blei, D.M. Topic modeling in embedding spaces. Trans. Assoc. Comput. Linguist. 2020, 8, 439–453. [Google Scholar] [CrossRef]












Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mukhamediev, R.I.; Symagulov, A.; Kuchin, Y.; Yakunin, K.; Yelis, M. From Classical Machine Learning to Deep Neural Networks: A Simplified Scientometric Review. Appl. Sci. 2021, 11, 5541. https://doi.org/10.3390/app11125541
Mukhamediev RI, Symagulov A, Kuchin Y, Yakunin K, Yelis M. From Classical Machine Learning to Deep Neural Networks: A Simplified Scientometric Review. Applied Sciences. 2021; 11(12):5541. https://doi.org/10.3390/app11125541
Chicago/Turabian StyleMukhamediev, Ravil I., Adilkhan Symagulov, Yan Kuchin, Kirill Yakunin, and Marina Yelis. 2021. "From Classical Machine Learning to Deep Neural Networks: A Simplified Scientometric Review" Applied Sciences 11, no. 12: 5541. https://doi.org/10.3390/app11125541
APA StyleMukhamediev, R. I., Symagulov, A., Kuchin, Y., Yakunin, K., & Yelis, M. (2021). From Classical Machine Learning to Deep Neural Networks: A Simplified Scientometric Review. Applied Sciences, 11(12), 5541. https://doi.org/10.3390/app11125541