
Software Project Management Using Machine Learning Technique—A Review

 , , and
, , and
Abstract
:1. Introduction
2. Preliminary Study
2.1. Software Effort Estimation
2.2. Machine Learning (ML)
2.3. Software Project Management Estimation Based on ML
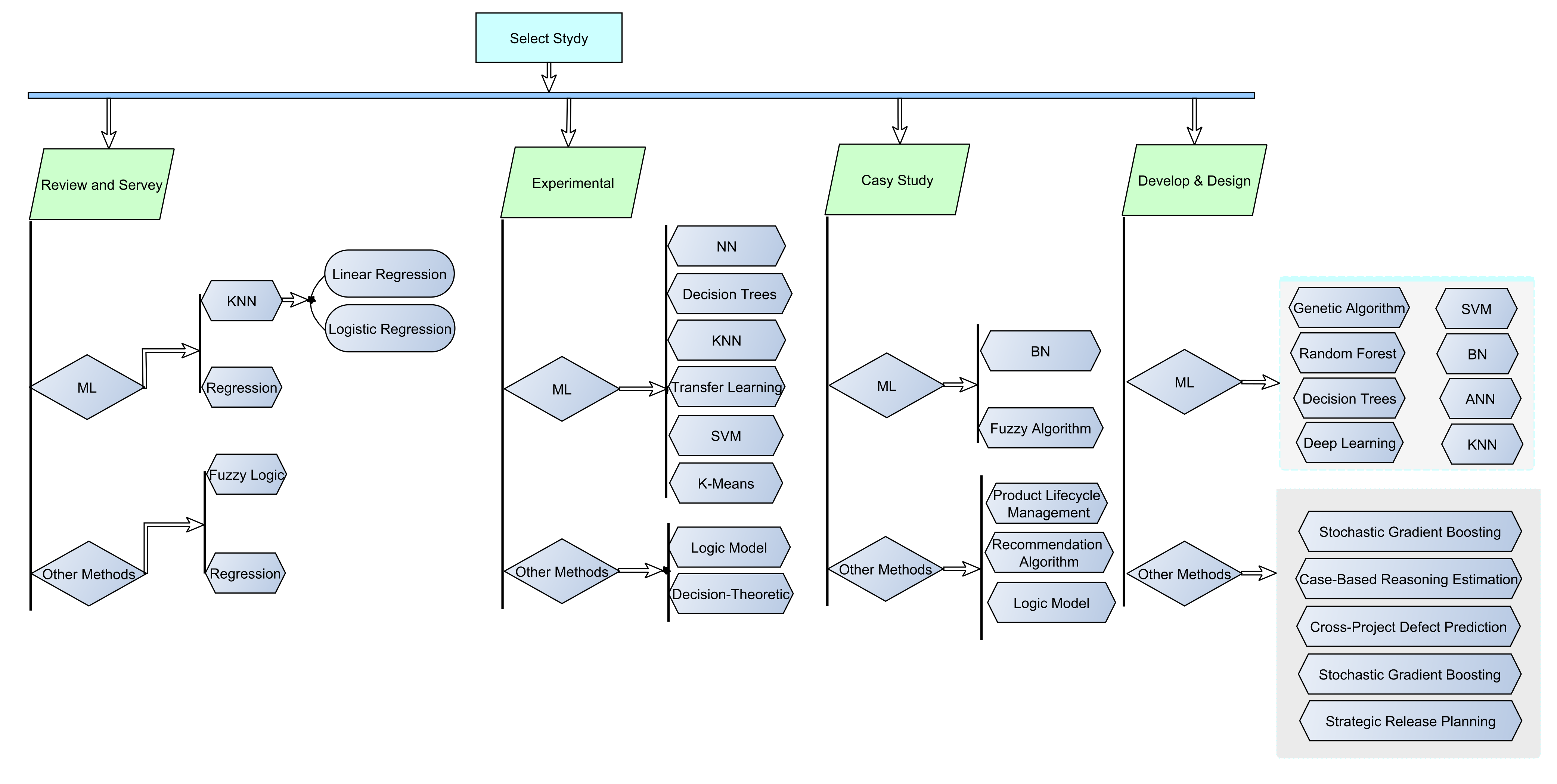
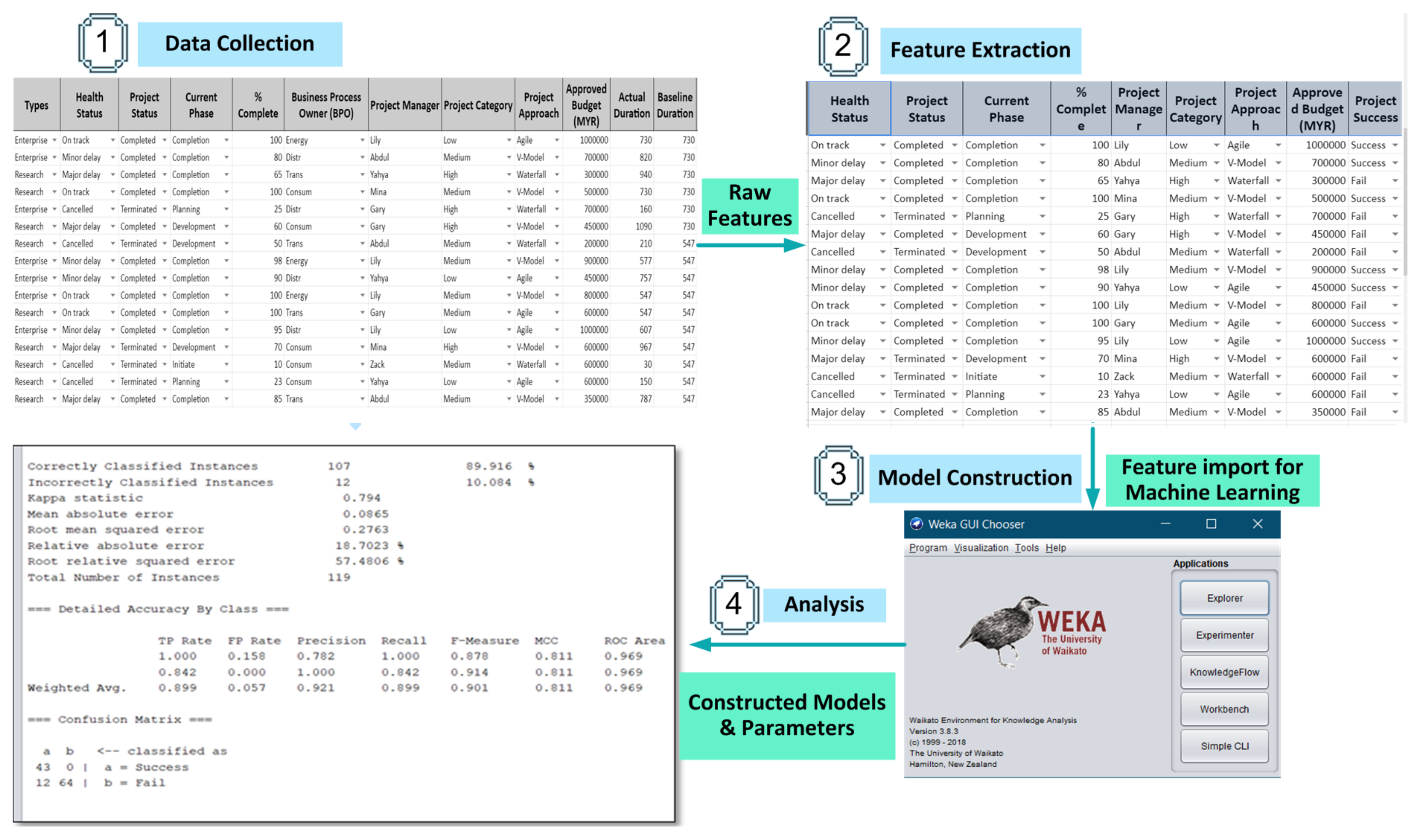
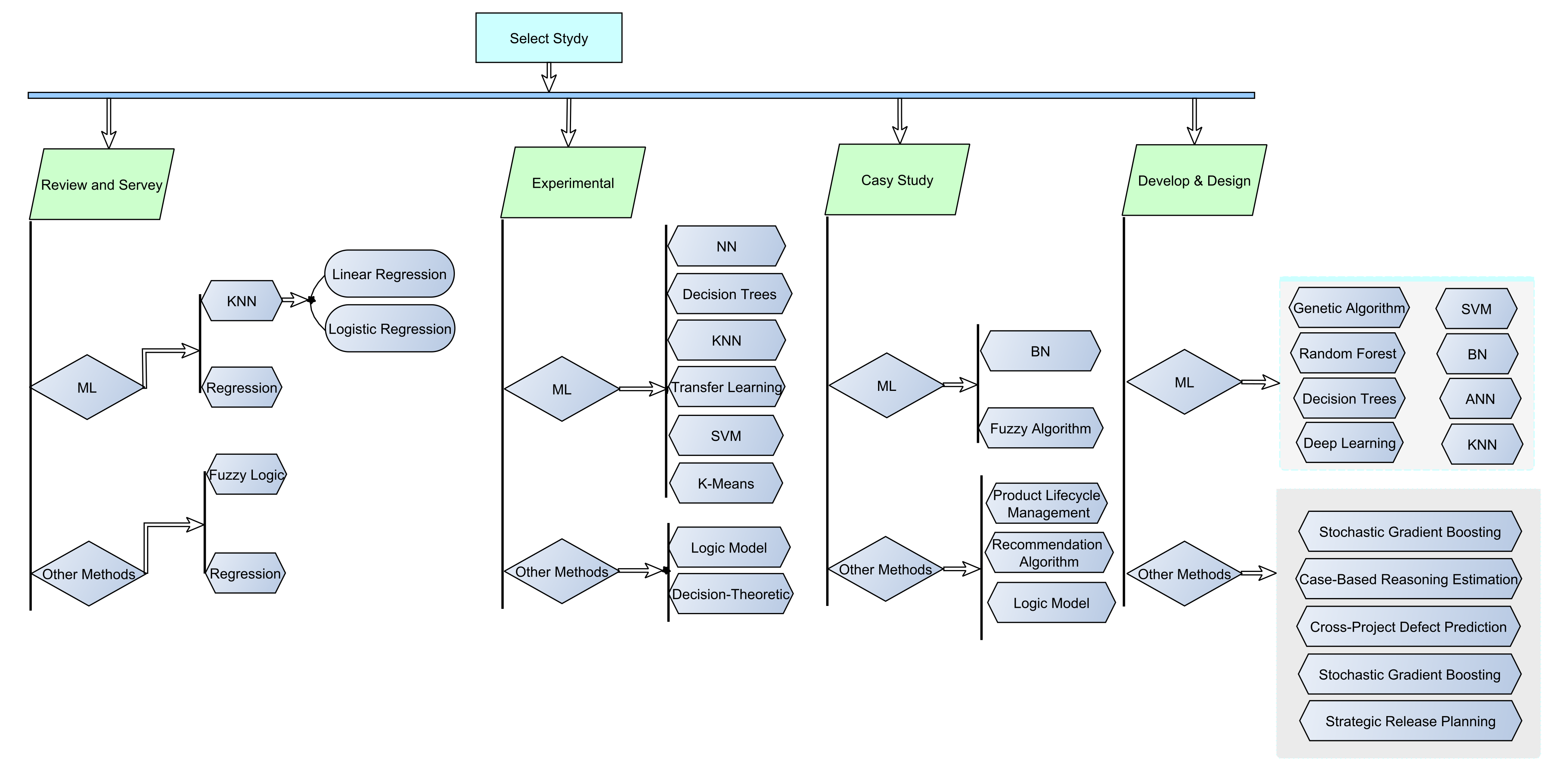
3. Methodology
3.1. Threats to Validity
3.2. Research Questions
- RQ1.
- What does the existing research literature reveal about Software Project Management using machine learning techniques?
- RQ2.
- Can we build better machine learning-based models in terms of accuracy prediction by applying feature transformation and feature selection to reduce the project failure probabilities efficiently?
- RQ3.
- What are the existing gaps for prospects of research in the field of Software Project Management?
- RQ4.
- What are the prediction metrics and their current level of accuracy evidenced by different estimation techniques?
- RQ5.
- Which machine learning algorithm tends to overestimate and which tends to underestimate?
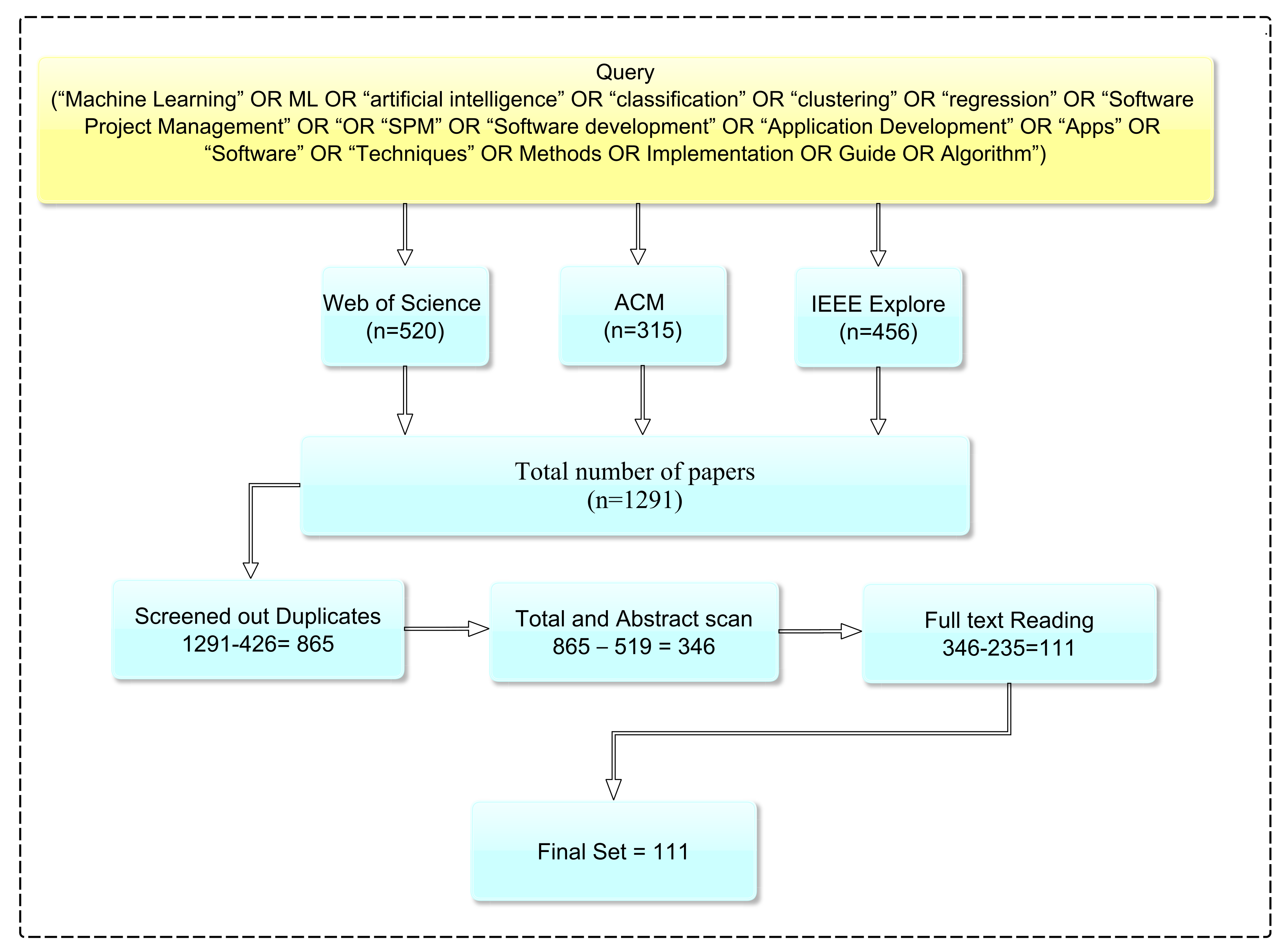
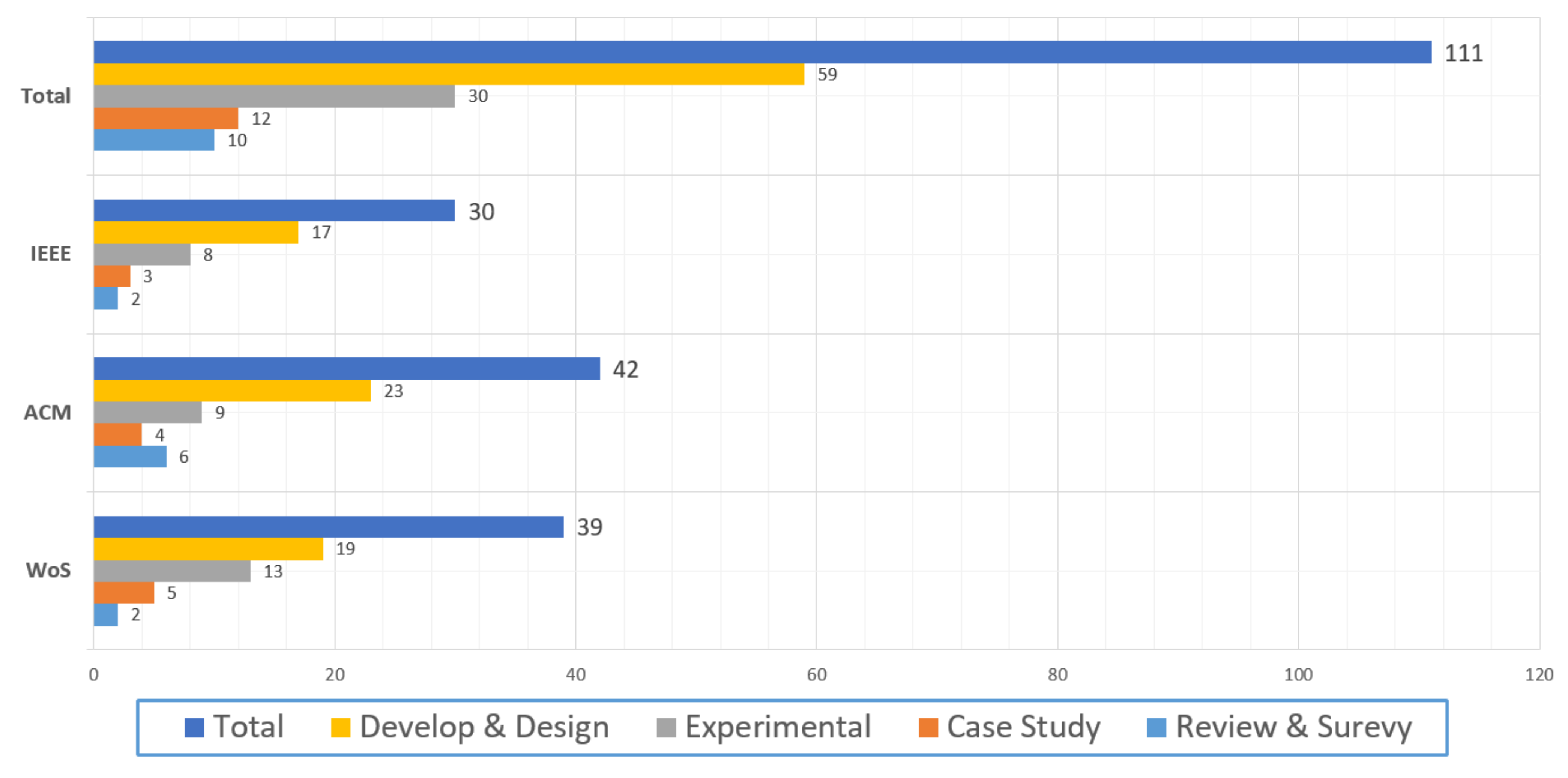
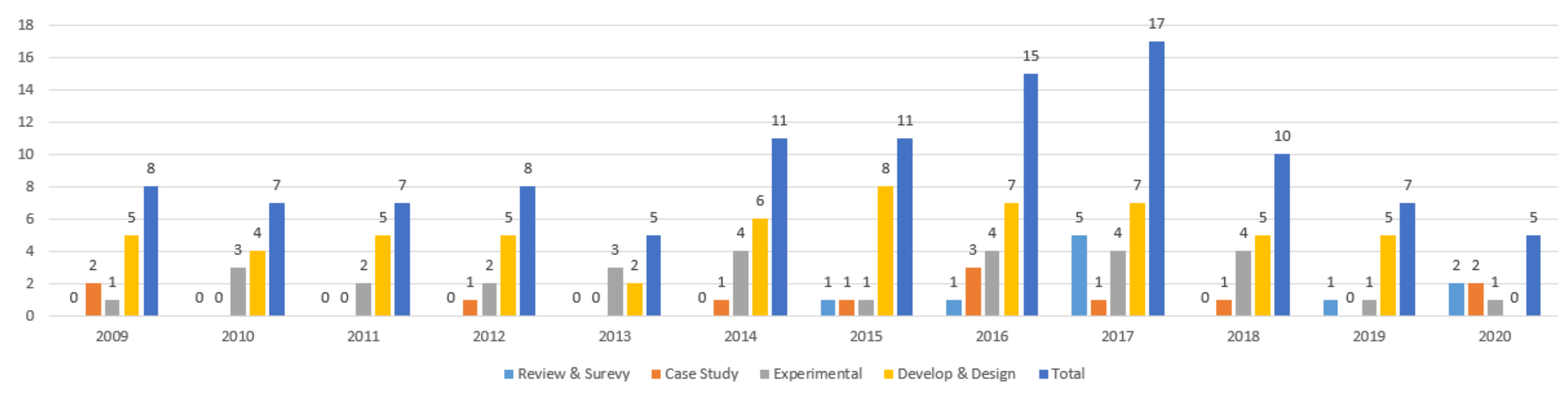
3.3. Statistical Information of Collects Articles
3.4. Review and Survey Articles
3.4.1. Studies Conducted on Machine Learning and Their Use in SPM
3.4.2. Other Methods
3.5. Experimental Studies
3.5.1. Studies Conducted on Machine Learning Methods
3.5.2. Studies Conducted on Other Methods
3.6. Case Study
Studies Conducted on Other Methods
3.7. Develop and Design
3.7.1. Studies Conducted on Machine Learning Methods
3.7.2. Studies Conducted on Other Methods
4. Discussion
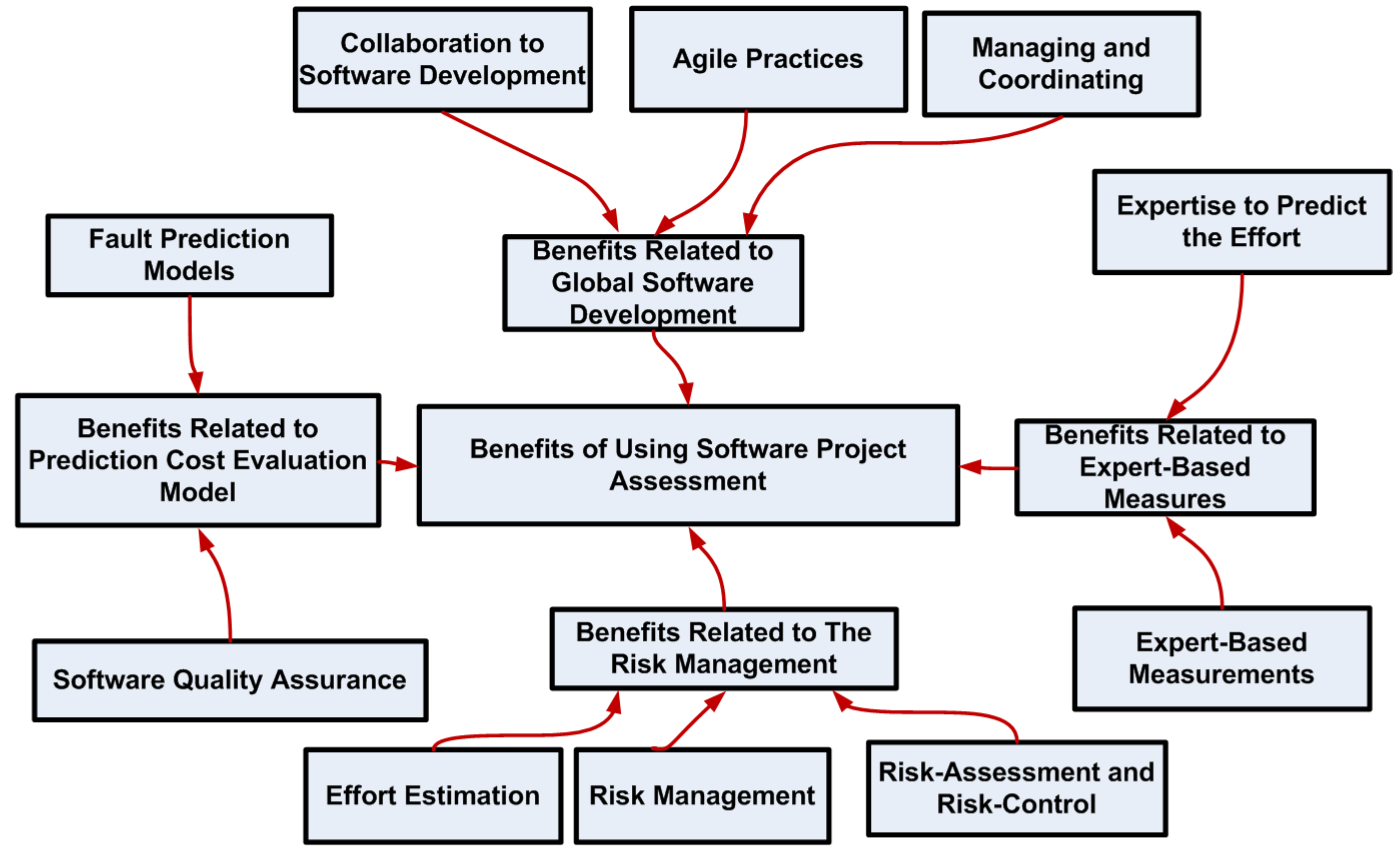
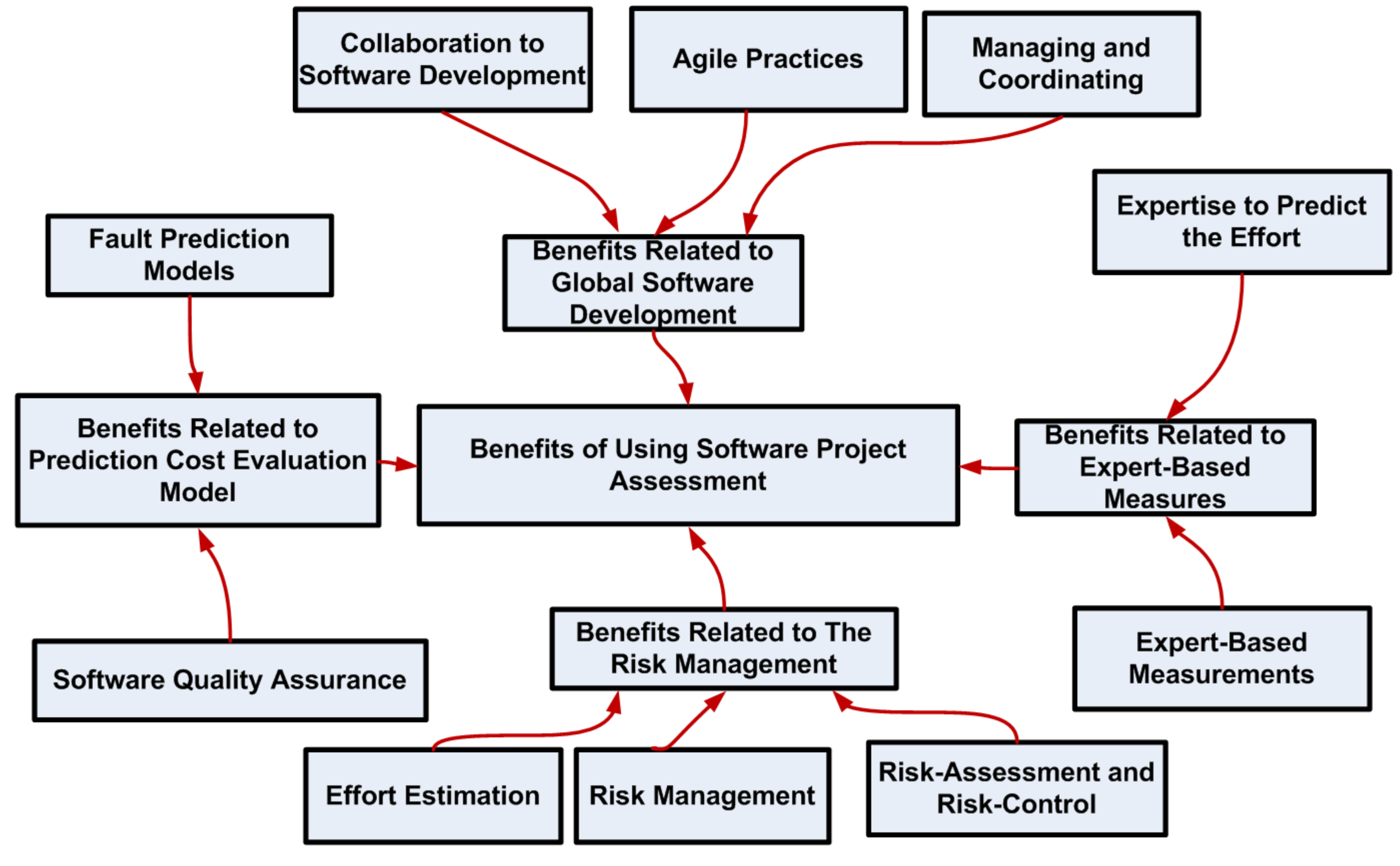
4.1. Motivations
4.1.1. Benefits Related to Prediction Cost Evaluation Model
4.1.2. Benefits Related to The Risk Management
4.1.3. Benefits Related to Global Software Development (GSD)
4.1.4. Benefits Related to Expert-Based Measures
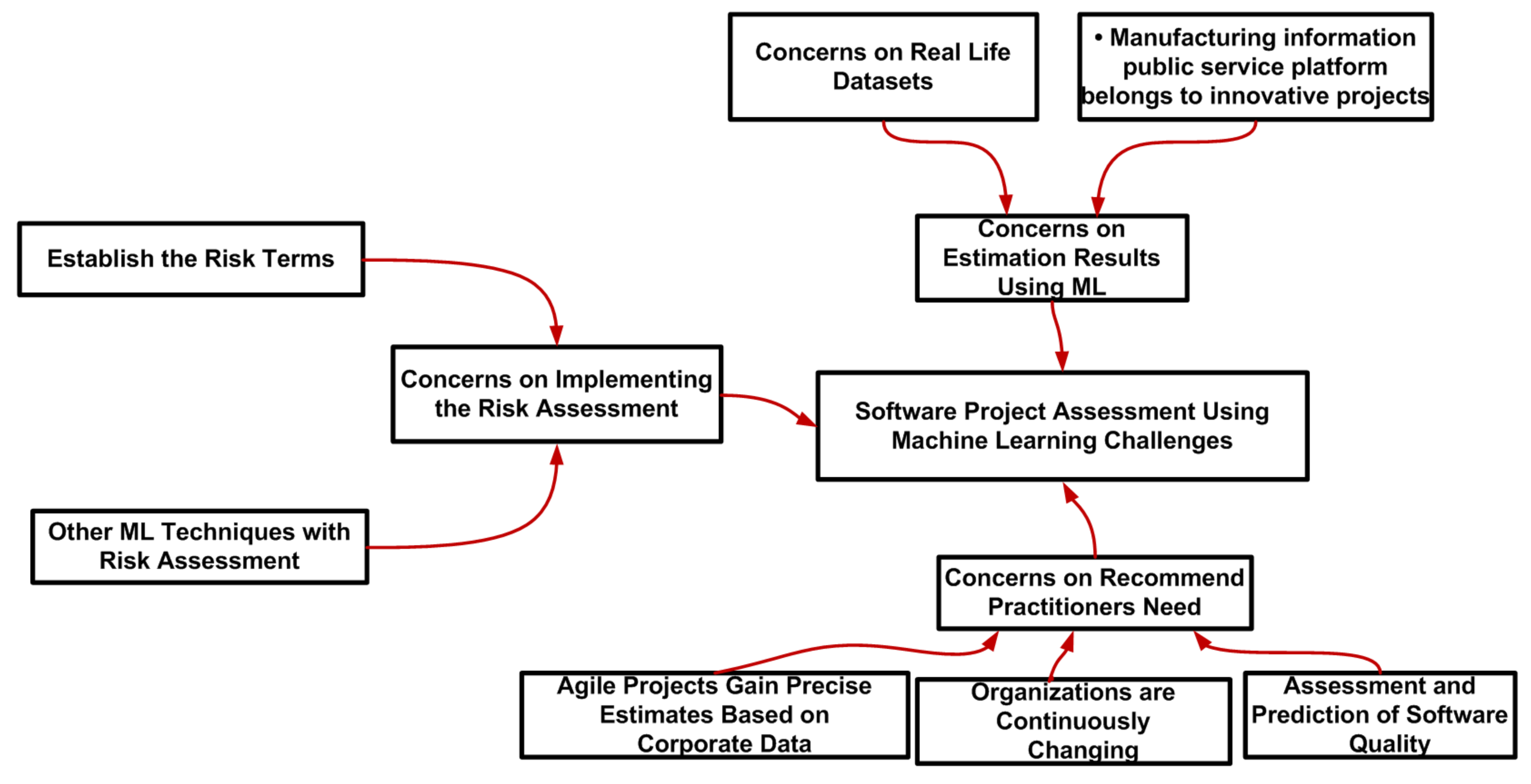
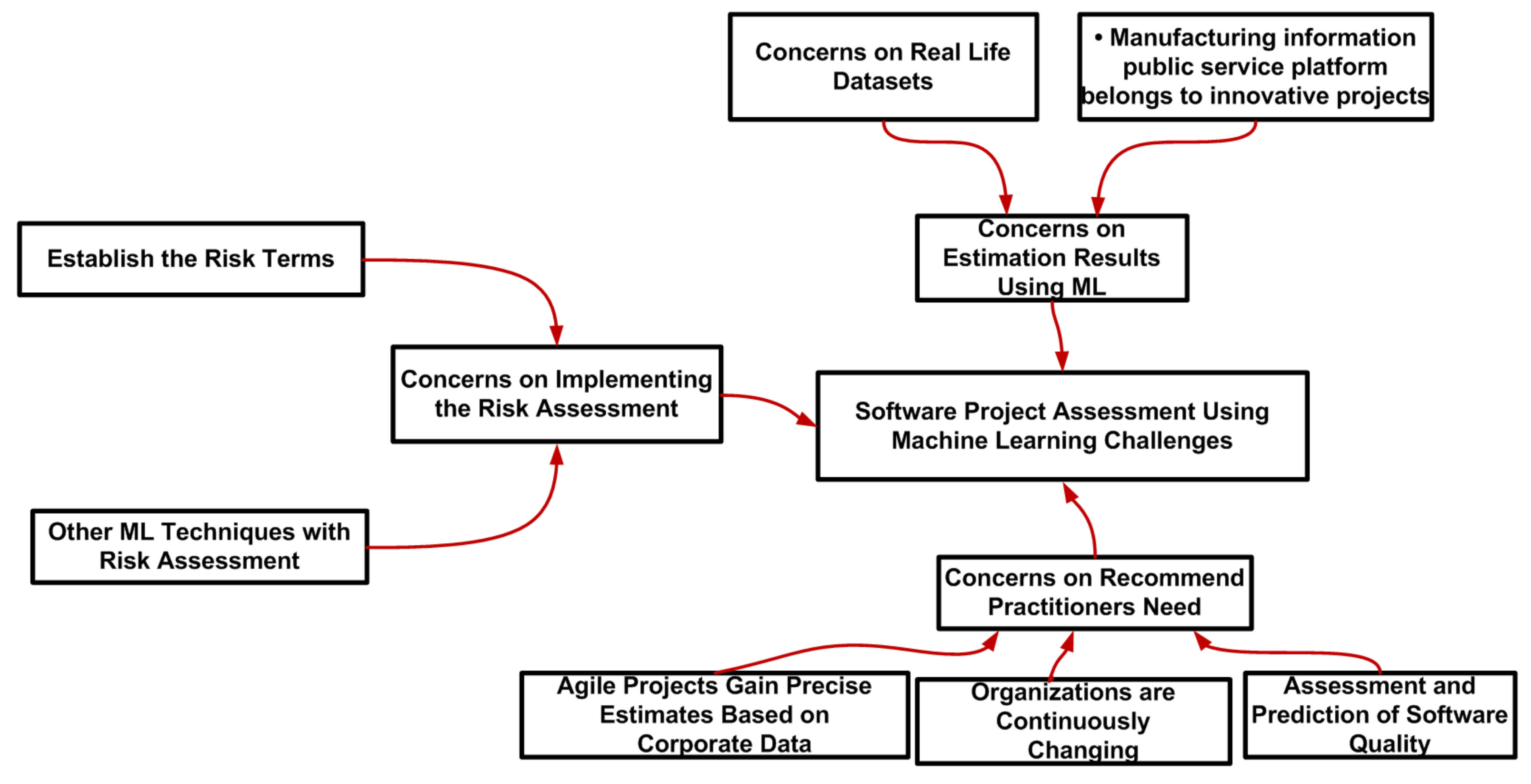
4.2. Challenges
4.2.1. Concerns on Estimation Results Using ML
4.2.2. Concerns on Implementing the Risk Assessment
4.2.3. Concerns on Recommend Practitioners Need
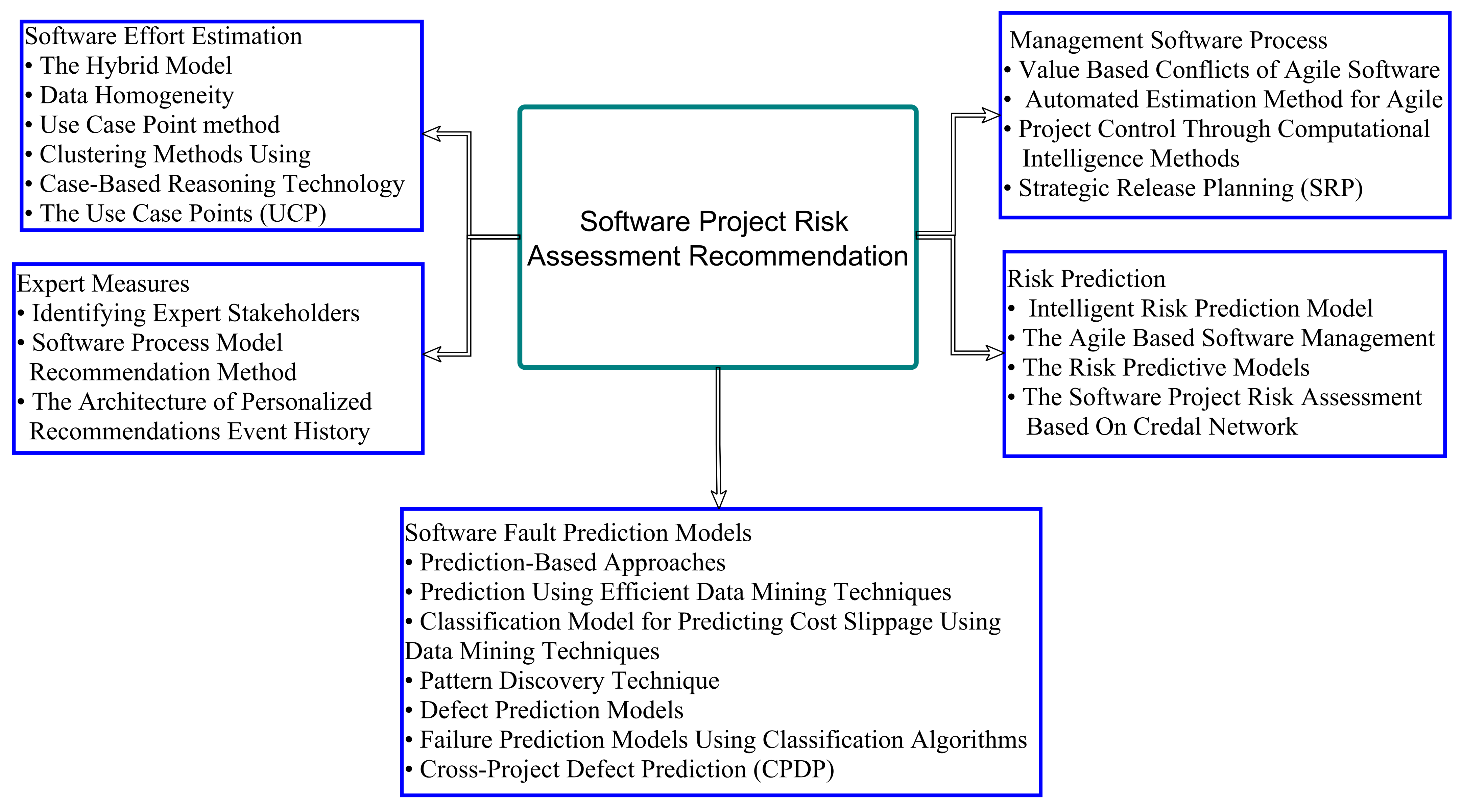
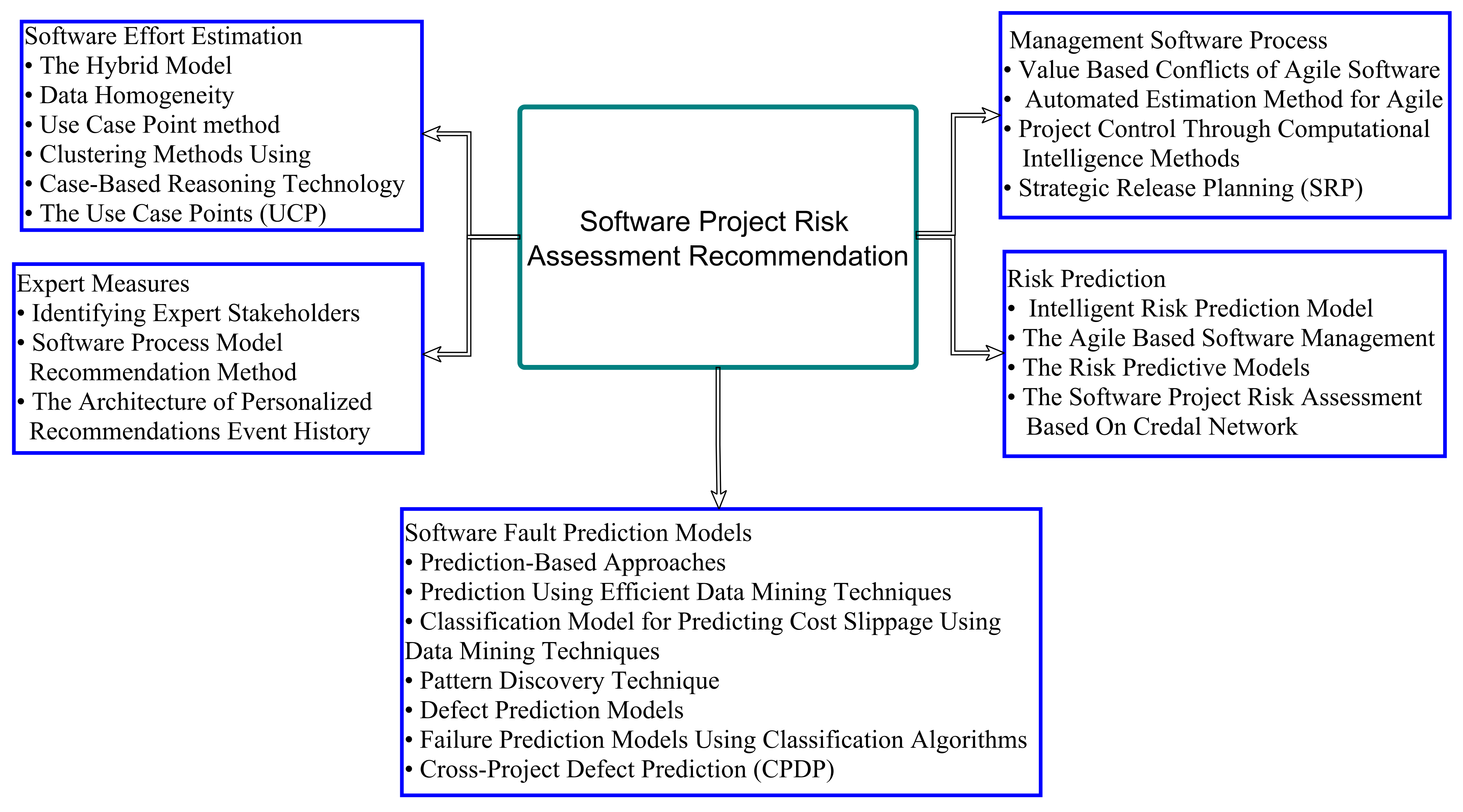
4.3. Recommendations
4.3.1. Recommendations for Software Effort Estimation
4.3.2. Recommendations for Expert Based Measures
4.3.3. Recommendations for Management Software Process
4.3.4. Recommendations for Risk Prediction
4.3.5. Recommendations for Software Fault Prediction Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Oun, T.A.; Blackburn, T.D.; Olson, B.A.; Blessner, P. An enterprise-wide knowledge management approach to project management. Eng. Manag. J. 2016, 28, 179–192. [Google Scholar] [CrossRef]
- Maimone, C. Good Enough Project Management Practices for Researcher Support Projects. In Proceedings of the Practice and Experience in Advanced Research Computing on Rise of the Machines (Learning), Chicago, IL, USA, 28 July–1 August 2019; pp. 1–8. [Google Scholar]
- Saleem, N. Empirical analysis of critical success factors for project management in global software development. In Proceedings of the 2019 ACM/IEEE 14th International Conference on Global Software Engineering (ICGSE), Montreal, QC, Canada, 25–26 May 2019; pp. 68–71. [Google Scholar]
- Gemünden, H.G. Success factors of global new product development programs, the definition of project success, knowledge sharing, and special issues of project management journal. Proj. Manag. J. 2015, 46, 2–11. [Google Scholar] [CrossRef]
- Hughes, S.W.; Tippett, D.D.; Thomas, W.K. Measuring project success in the construction industry. Eng. Manag. J. 2004, 16, 31–37. [Google Scholar] [CrossRef]
- Project Management Institute. Guide to the Project Management Body of Knowledge (Pmbok Guide); Project Management Institute: Newtown Square, PA, USA, 2013. [Google Scholar]
- Kirsch, L.J. Software project management: An integrated perspective for an emerging paradigm. In Framing the Domains of IT Management: Projecting the Future... Through the Past; Pinnaflex Educational Resources inc: Ann Arbor, MI, USA, 2000; pp. 285–304. [Google Scholar]
- Aladwani, A.M. IT project uncertainty, planning and success. Inf. Technol. People 2002, 210–226. [Google Scholar] [CrossRef]
- Cates, G.R.; Mollaghasemi, M. The project assessment by simulation technique. Eng. Manag. J. 2007, 19, 3–10. [Google Scholar] [CrossRef]
- Parsons, V.S. Project performance: How to assess the early stages. Eng. Manag. J. 2006, 18, 11–15. [Google Scholar] [CrossRef]
- Rosenfeld, Y. Root-cause analysis of construction-cost overruns. J. Constr. Eng. Manag. 2014, 140, 04013039. [Google Scholar] [CrossRef]
- Wang, J.; Li, J.; Wang, Q.; Zhang, H.; Wang, H. A simulation approach for impact analysis of requirement volatility considering dependency change. In Proceedings of the International Working Conference on Requirements Engineering: Foundation for Software Quality, Essen, Germany, 19–22 March 2012; pp. 59–76. [Google Scholar]
- Ferreira, S.; Collofello, J.; Shunk, D.; Mackulak, G. Understanding the effects of requirements volatility in software engineering by using analytical modeling and software process simulation. J. Syst. Softw. 2009, 82, 1568–1577. [Google Scholar] [CrossRef]
- Tiwana, A.; Keil, M. The one-minute risk assessment tool. Commun. ACM 2004, 47, 73–77. [Google Scholar] [CrossRef]
- Sommerville, I. Software Engineering, 9th ed.; Pearson: London, UK, 2011; ISBN 0137035152. [Google Scholar]
- Ali, N.; Hwang, S.; Hong, J.E. Your Opinions Let us Know: Mining Social Network Sites to Evolve Software Product Lines. Ksii Trans. Internet Inf. Syst. 2019, 13. [Google Scholar] [CrossRef]
- Malhotra, R.; Chug, A. Software maintainability: Systematic literature review and current trends. Int. J. Softw. Eng. Knowl. Eng. 2016, 26, 1221–1253. [Google Scholar] [CrossRef]
- Sharma, P.; Singh, J. Systematic literature review on software effort estimation using machine learning approaches. In Proceedings of the 2017 International Conference on Next Generation Computing and Information Systems (ICNGCIS), Jammu, India, 11–12 December 2017; pp. 43–47. [Google Scholar]
- Alsalemi, A.M.; Yeoh, E.-T. A Systematic Literature Review of Requirements Volatility Prediction. In Proceedings of the 2017 International Conference on Current Trends in Computer, Electrical, Electronics and Communication (CTCEEC), Mysore, India, 8–9 September 2017; pp. 55–64. [Google Scholar]
- Alsolai, H.; Roper, M. A systematic literature review of machine learning techniques for software maintainability prediction. Inf. Softw. Technol. 2020, 119, 106214. [Google Scholar] [CrossRef]
- Idri, A.; Abnane, I.; Abran, A. Systematic mapping study of missing values techniques in software engineering data. In Proceedings of the 2015 IEEE/ACIS 16th International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Takamatsu, Japan, 1–3 June 2015; pp. 1–8. [Google Scholar]
- Pillai, S.P.; Madhukumar, S.; Radharamanan, T. Consolidating evidence based studies in software cost/effort estimation—A tertiary study. In Proceedings of the TENCON 2017 IEEE Region 10 Conference, Penang, Malaysia, 5–8 November 2017; pp. 833–838. [Google Scholar]
- Sangwan, O.P. Software effort estimation using machine learning techniques. In Proceedings of the 2017 7th International Conference on Cloud Computing, Data Science & Engineering-Confluence, Noida, India, 12–13 January 2017; pp. 92–98. [Google Scholar]
- Stewart, C.A.; Hancock, D.Y.; Wernert, J.; Furlani, T.; Lifka, D.; Sill, A.; Berente, N.; McMullen, D.F.; Cheatham, T.; Apon, A.; et al. Assessment of financial returns on investments in cyberinfrastructure facilities: A survey of current methods. In Proceedings of the Practice and Experience in Advanced Research Computing on Rise of the Machines (learning), Chicago, IL, USA, 28 July–1 August 2019; pp. 1–8. [Google Scholar]
- García, J.A.L.; Peña, A.B.; Pérez, P.Y.P.; Pérez, R.B. Project control and computational intelligence: Trends and challenges. Int. J. Comput. Intell. Syst. 2017, 10, 320–335. [Google Scholar] [CrossRef] [Green Version]
- Raharjo, T.; Purwandari, B. Agile Project Management Challenges and Mapping Solutions: A Systematic Literature Review. In Proceedings of the 3rd International Conference on Software Engineering and Information Management, Sydney, NSW, Australia, 12–15 January 2020; pp. 123–129. [Google Scholar]
- Cleland-Huang, J.; Czauderna, A.; Gibiec, M.; Emenecker, J. A machine learning approach for tracing regulatory codes to product specific requirements. In Proceedings of the 32nd ACM/IEEE International Conference on Software Engineering, Cape Town, South Africa, 2–8 May 2010; Volume 1, pp. 155–164. [Google Scholar]
- Zhang, D.; Dang, Y.; Lou, J.-G.; Han, S.; Zhang, H.; Xie, T. Software analytics as a learning case in practice: Approaches and experiences. In Proceedings of the International Workshop on Machine Learning Technologies in Software Engineering, Lawrence, KS, USA, 12 November 2011; pp. 55–58. [Google Scholar]
- Pospieszny, P. Software estimation: Towards prescriptive analytics. In Proceedings of the 27th International Workshop on Software Measurement and 12th International Conference on Software Process and Product Measurement, Gothenburg, Sweden, 25–27 October 2017; pp. 221–226. [Google Scholar]
- ManikReddy, P.; Iyer, J. Effective collaboration across the globe through digital dash boards and machine learning. In Proceedings of the 2018 IEEE/ACM 13th International Conference on Global Software Engineering (ICGSE), Gothenburg, Sweden, 6 December 2018; pp. 30–34. [Google Scholar]
- Moharreri, K.; Sapre, A.V.; Ramanathan, J.; Ramnath, R. Cost-effective supervised learning models for software effort estimation in agile environments. In Proceedings of the 2016 IEEE 40th Annual Computer Software and Applications Conference (COMPSAC), Atlanta, GA, USA, 10–14 June 2016; pp. 135–140. [Google Scholar]
- Hosni, M.; Idri, A.; Nassif, A.B.; Abran, A. Heterogeneous ensembles for software development effort estimation. In Proceedings of the 2016 3rd International Conference on Soft Computing & Machine Intelligence (ISCMI), Dubai, United Arab Emirates, 23–25 November 2016; pp. 174–178. [Google Scholar]
- Samath, S.; Udalagama, D.; Kurukulasooriya, H.; Premarathne, D.; Thelijjagoda, S. Collabcrew—An intelligent tool for dynamic task allocation within a software development team. In Proceedings of the 2017 11th International Conference on Software, Knowledge, Information Management and Applications (SKIMA), Malabe, Sri Lanka, 6–8 December 2017; pp. 1–9. [Google Scholar]
- Li, Y.; Huang, Z.; Wang, Y.; Fang, B. Evaluating data filter on cross-project defect prediction: Comparison and improvements. IEEE Access 2017, 5, 25646–25656. [Google Scholar] [CrossRef]
- Ni, A.; Li, M. Poster: ACONA: Active Online Model Adaptation for Predicting Continuous Integration Build Failures. In Proceedings of the 2018 IEEE/ACM 40th International Conference on Software Engineering: Companion (ICSE-Companion), Gothenburg, Sweden, 3 June 2018; pp. 366–367. [Google Scholar]
- Sharma, P.; Singh, J. Machine Learning Based Effort Estimation Using Standardization. In Proceedings of the 2018 International Conference on Computing, Power and Communication Technologies (GUCON), Greater Noida, India, 29 September 2018; pp. 716–720. [Google Scholar]
- Papatheocharous, E.; Andreou, A.S. A hybrid software cost estimation approach utilizing decision trees and fuzzy logic. Int. J. Softw. Eng. Knowl. Eng. 2012, 22, 435–465. [Google Scholar] [CrossRef]
- Hongming, Z.; Bin, F.; Xizhu, M.; Lijun, S.; Xiangzhou, X.Z.; Yong, H. A Cost-sensitive Intelligent Prediction Model for Outsourced Software Project Risk. In Proceedings of the WHICEB 2013 Proceedings, Wuhan, China, 25–26 May 2013. [Google Scholar]
- Twala, B. Reasoning with Noisy Software Effort Data. Appl. Artif. Intell. 2014, 28, 533–554. [Google Scholar]
- Wu, J.H.; Keung, J. Decision support for global software development with pattern discovery. In Proceedings of the 2016 7th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 26–28 August 2016; pp. 182–185. [Google Scholar]
- Rahman, M.T.; Islam, M.M. A Comparison of Machine Learning Algorithms to Estimate Effort in Varying Sized Software. In Proceedings of the 2019 IEEE Region 10 Symposium (TENSYMP), Kolkata, India, 7–9 June 2019; pp. 137–142. [Google Scholar]
- Tumar, I.; Hassouneh, Y.; Turabieh, H.; Thaher, T. Enhanced binary moth flame optimization as a feature selection algorithm to predict software fault prediction. IEEE Access 2020, 8, 8041–8055. [Google Scholar] [CrossRef]
- Lopez-Martin, C.; Chavoya, A.; Meda-Campaña, M.E. A machine learning technique for predicting the productivity of practitioners from individually developed software projects. In Proceedings of the 15th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Las Vegas, NV, USA, 30 June–2 July 2014; pp. 1–6. [Google Scholar]
- Han, W.; Jiang, H.; Zhang, X.; Li, W. A Neural Network Based Algorithms for Project Duration Prediction. In Proceedings of the 2014 7th International Conference on Control and Automation, Hainan, China, 20–23 December 2014; pp. 60–63. [Google Scholar]
- Basgalupp, M.P.; Barros, R.C.; da Silva, T.S.; de Carvalho, A.C. Software effort prediction: A hyper-heuristic decision-tree based approach. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, Coimbra, Portugal, 18–22 March 2013; pp. 1109–1116. [Google Scholar]
- Twala, B.; Cartwright, M. Ensemble missing data techniques for software effort prediction. Intell. Data Anal. 2010, 14, 299–331. [Google Scholar] [CrossRef]
- Song, L.; Minku, L.L.; Yao, X. The impact of parameter tuning on software effort estimation using learning machines. In Proceedings of the 9th International Conference on Predictive Models in Software Engineering, Baltimore, MD, USA, 9 October 2013; pp. 1–10. [Google Scholar]
- Minku, L.L.; Yao, X. How to make best use of cross-company data in software effort estimation? In Proceedings of the 36th International Conference on Software Engineering, Hyderabad, India, 31 May–7 June 2014; pp. 446–456. [Google Scholar]
- Song, L.; Minku, L.L.; Yao, X. The potential benefit of relevance vector machine to software effort estimation. In Proceedings of the 10th International Conference on Predictive Models in Software Engineering, Torino, Italy, 17 September 2014; pp. 52–61. [Google Scholar]
- Scott, E.; Pfahl, D. Using developers’ features to estimate story points. In Proceedings of the 2018 International Conference on Software and System Process, Gothenburg, Sweden, 26–27 May 2018; pp. 106–110. [Google Scholar]
- Benala, T.R.; Bandarupalli, R. Least square support vector machine in analogy-based software development effort estimation. In Proceedings of the 2016 International Conference on Recent Advances and Innovations in Engineering (ICRAIE), Jaipur, India, 23–25 December 2016; pp. 1–6. [Google Scholar]
- Minku, L.L.; Hou, S. Clustering Dycom: An online cross-company software effort estimation study. In Proceedings of the 13th International Conference on Predictive Models and Data Analytics in Software Engineering, Toronto, ON, Canada, 8 November 2017; pp. 12–21. [Google Scholar]
- Brady, A.; Menzies, T. Case-based reasoning vs parametric models for software quality optimization. In Proceedings of the 6th International Conference on Predictive Models in Software Engineering, Timisoara, Romania, 12–13 September 2010; pp. 1–10. [Google Scholar]
- Borges, R.; Menzies, T. Learning to change projects. In Proceedings of the 8th International Conference on Predictive Models in Software Engineering, Lund, Sweden, 21–22 September 2012; pp. 11–18. [Google Scholar]
- Jiang, Y.; Cukic, B. Misclassification cost-sensitive fault prediction models. In Proceedings of the 5th International Conference on Predictor Models in Software Engineering, Vancouver, BC, Canada, 18–19 May 2009; pp. 1–10. [Google Scholar]
- Weld, D.S.; Dai, P. Execution control for crowdsourcing. In Proceedings of the 24th Annual ACM Symposium Adjunct on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; pp. 57–58. [Google Scholar]
- Shepperd, M. The scientific basis for prediction research. In Proceedings of the 8th International Conference on Predictive Models in Software Engineering, Lund, Sweden, 21–22 September 2012. [Google Scholar]
- Karim, M.R.; Alam, S.D.A.; Kabeer, S.J.; Ruhe, G.; Baluta, B.; Mahmud, S. Applying data analytics towards optimized issue management: An industrial case study. In Proceedings of the 2016 IEEE/ACM 4th International Workshop on Conducting Empirical Studies in Industry (CESI), Austin, TX, USA, 17 May 2016; pp. 7–13. [Google Scholar]
- Castro-Herrera, C.; Cleland-Huang, J. A machine learning approach for identifying expert stakeholders. In Proceedings of the 2009 Second International Workshop on Managing Requirements Knowledge, Atlanta, GA, USA, 1 September 2009; pp. 45–49. [Google Scholar]
- Abdellatif, T.M. A Comparison Study Between Soft Computing and Statistical Regression Techniques for Software Effort Estimation. In Proceedings of the 2018 IEEE Canadian Conference on Electrical & Computer Engineering (CCECE), Quebec, QC, Canada, 16 May 2018; pp. 1–5. [Google Scholar]
- Mendes, E.; Turhan, B.; Rodríguez, P.; Freitas, V. Estimating the value of decisions relating to managing and developing software-intensive Products and Projects. In Proceedings of the 11th International Conference on Predictive Models and Data Analytics in Software Engineering, Beijing, China, 21 October 2015; pp. 1–4. [Google Scholar]
- Asif, M.; Ahmed, J. A Novel Case Base Reasoning and Frequent Pattern Based Decision Support System for Mitigating Software Risk Factors. IEEE Access 2020, 8, 102278–102291. [Google Scholar] [CrossRef]
- Qu, Y.; Yang, T.-Z. Research on occurrence frequency of IT projects risk based on fuzzy influence diagram. In Proceedings of the 2016 International Conference on Machine Learning and Cybernetics (ICMLC), Jeju, Korea, 13 July 2016; pp. 166–171. [Google Scholar]
- Sree, S.R.; Ramesh, S. Analytical Structure of a Fuzzy Logic Controller for Software Development Effort Estimation. In Computational Intelligence in Data Mining—Volume 1; Springer: Berlin, Germany, 2016; pp. 209–216. [Google Scholar]
- Raza, M.B.; Kirkham, T.; Harrison, R.; Monfared, R.; Haq, I.; Wood, S. Evolving knowledge based product lifecycle management from a digital ecosystem to support automated manufacturing. In Proceedings of the International Conference on Management of Emergent Digital EcoSystems, Lyon, France, 27–30 October 2009; pp. 437–441. [Google Scholar]
- Yang, G.; Zhang, T.; Lee, B. Utilizing a multi-developer network-based developer recommendation algorithm to fix bugs effectively. In Proceedings of the 29th Annual ACM Symposium on Applied Computing, Gyeongju, Korea, 28 March 2014; pp. 1134–1139. [Google Scholar]
- Amasaki, S.; Lokan, C. A Virtual Study of Moving Windows for Software Effort Estimation Using Finnish Datasets. In Proceedings of the International Conference on Product-Focused Software Process Improvement, Innsbruck, Austria, 28 October 2017; pp. 71–79. [Google Scholar]
- Qahtani, A.M. An Empirical Study of Agile Testing in A Distributed Software Development Project. In Proceedings of the 2020 3rd International Conference on Geoinformatics and Data Analysis, Marseille, France, 17 April 2020; pp. 110–114. [Google Scholar]
- Bruegge, B.; David, J.; Helming, J.; Koegel, M. Classification of tasks using machine learning. In Proceedings of the 5th International Conference on Predictor Models in Software Engineering, Vancouver, BC, Canada, 18–19 May 2009; pp. 1–11. [Google Scholar]
- Minku, L.L.; Yao, X. Software effort estimation as a multiobjective learning problem. ACM Trans. Softw. Eng. Methodol. (TOSEM) 2013, 22, 1–32. [Google Scholar] [CrossRef] [Green Version]
- Shivhare, J.; Rath, S.K. Software effort estimation using machine learning techniques. In Proceedings of the 7th India Software Engineering Conference, Noida, Chennai, India, 21 February 2014; pp. 1–6. [Google Scholar]
- Ramaswamy, V.; Suma, V.; Pushphavathi, T. An approach to predict software project success by cascading clustering and classification. In Proceedings of the International Conference on Software Engineering and Mobile Application Modelling and Development (ICSEMA 2012), Chennai, India, 21 December 2012. [Google Scholar]
- Iwata, K.; Nakashima, T.; Anan, Y.; Ishii, N. Effort estimation for embedded software development projects by combining machine learning with classification. In Proceedings of the 2016 4th Intl Conf on Applied Computing and Information Technology/3rd Intl Conf on Computational Science/Intelligence and Applied Informatics/1st Intl Conf on Big Data, Cloud Computing, Data Science & Engineering (ACIT-CSII-BCD), Las Vegas, NV, USA, 14 December 2016; pp. 265–270. [Google Scholar]
- Ionescu, V.-S. An approach to software development effort estimation using machine learning. In Proceedings of the 2017 13th IEEE International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 9 September 2017; pp. 197–203. [Google Scholar]
- BaniMustafa, A. Predicting software effort estimation using machine learning techniques. In Proceedings of the 2018 8th International Conference on Computer Science and Information Technology (CSIT), Amman, Jordan, 12 July 2018; pp. 249–256. [Google Scholar]
- Menzies, T.; Bird, C.; Zimmermann, T.; Schulte, W.; Kocaganeli, E. The inductive software engineering manifesto: Principles for industrial data mining. In Proceedings of the International Workshop on Machine Learning Technologies in Software Engineering, Lawrence, KS, USA, 12 November 2011; pp. 19–26. [Google Scholar]
- Dehghan, A.; Blincoe, K.; Damian, D. A hybrid model for task completion effort estimation. In Proceedings of the 2nd International Workshop on Software Analytics, Seattle, WA, USA, 13 November 2016; pp. 22–28. [Google Scholar]
- Tollin, I.; Fontana, F.A.; Zanoni, M.; Roveda, R. Change prediction through coding rules violations. In Proceedings of the 21st International Conference on Evaluation and Assessment in Software Engineering, Karlskrona, Sweden, 15–16 June 2017; pp. 61–64. [Google Scholar]
- Hu, Y.; Zhang, X.; Sun, X.; Liu, M.; Du, J. An intelligent model for software project risk prediction. In Proceedings of the 2009 International Conference on Information Management, Innovation Management and Industrial Engineering, Xi’an, China, 27 December 2009; pp. 629–632. [Google Scholar]
- Manalif, E.; Capretz, L.F.; Nassif, A.B.; Ho, D. Fuzzy-ExCOM software project risk assessment. In Proceedings of the 2012 11th International Conference on Machine Learning and Applications, Boca Raton, FL, USA, 15 December 2012; pp. 320–325. [Google Scholar]
- Rana, R.; Staron, M. Machine learning approach for quality assessment and prediction in large software organizations. In Proceedings of the 2015 6th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 25 September 2015; pp. 1098–1101. [Google Scholar]
- Tariq, S.; Usman, M.; Wong, R.; Zhuang, Y.; Fong, S. On learning software effort estimation. In Proceedings of the 2015 3rd International Symposium on Computational and Business Intelligence (ISCBI), Bali, Indonesia, 9 December 2015; pp. 79–84. [Google Scholar]
- Kumar, L.; Rath, S.; Sureka, A. An empirical analysis on effective fault prediction model developed using ensemble methods. In Proceedings of the 2017 IEEE 41st Annual Computer Software and Applications Conference (COMPSAC), Turin, Italy, 8 July 2017; pp. 244–249. [Google Scholar]
- Hu, Y.; Feng, B.; Mo, X.; Zhang, X.; Ngai, E.W.T.; Fan, M.; Liu, M. Cost-sensitive and ensemble-based prediction model for outsourced software project risk prediction. Decis. Support Syst. 2015, 72, 11–23. [Google Scholar] [CrossRef]
- Pospieszny, P.; Czarnacka-Chrobot, B.; Kobylinski, A. An effective approach for software project effort and duration estimation with machine learning algorithms. J. Syst. Softw. 2018, 137, 184–196. [Google Scholar] [CrossRef]
- Lochmann, K.; Ramadani, J.; Wagner, S. Are comprehensive quality models necessary for evaluating software quality? In Proceedings of the 9th International Conference on Predictive Models in Software Engineering, Baltimore, MD, USA, 9 October 2013; pp. 1–9. [Google Scholar]
- Chen, N.; Hoi, S.C.; Xiao, X. Software process evaluation: A machine learning framework with application to defect management process. Empir. Softw. Eng. 2014, 19, 1531–1564. [Google Scholar] [CrossRef]
- Song, Q.; Zhu, X.; Wang, G.; Sun, H.; Jiang, H.; Xue, C.; Xu, B.; Song, W. A machine learning based software process model recommendation method. J. Syst. Softw. 2016, 118, 85–100. [Google Scholar] [CrossRef]
- Fitzgerald, C.; Letier, E.; Finkelstein, A. Early failure prediction in feature request management systems. In Proceedings of the 2011 IEEE 19th International Requirements Engineering Conference, Trento, Italy, 2 September 2011; pp. 229–238. [Google Scholar]
- Joseph, H.R. Poster: Software Development Risk Management: Using Machine Learning for Generating Risk Prompts. In Proceedings of the 2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, Florence, Italy, 24 May 2015; pp. 833–834. [Google Scholar]
- ERTUĞRUL, E.; Baytar, Z.; ÇATAL, Ç.; MURATLI, Ö.C. Performance tuning for machine learning-based software development effort prediction models. Turk. J. Electr. Eng. Comput. Sci. 2019, 27, 1308–1324. [Google Scholar] [CrossRef]
- Colomo-Palacios, R.; González-Carrasco, I.; López-Cuadrado, J.L.; Trigo, A.; Varajao, J.E. I-Competere: Using applied intelligence in search of competency gaps in software project managers. Inf. Syst. Front. 2014, 16, 607–625. [Google Scholar] [CrossRef]
- Nassif, A.B.; Azzeh, M.; Capretz, L.F.; Ho, D. Neural network models for software development effort estimation: A comparative study. Neural Comput. Appl. 2016, 27, 2369–2381. [Google Scholar] [CrossRef] [Green Version]
- Desai, V.S.; Mohanty, R. ANN-Cuckoo Optimization Technique to Predict Software Cost Estimation. In Proceedings of the 2018 Conference on Information and Communication Technology (CICT), Jabalpur, India, 28 October 2018; pp. 1–6. [Google Scholar]
- Schleier-Smith, J. An architecture for Agile machine learning in real-time applications. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 13 August 2015; pp. 2059–2068. [Google Scholar]
- Volf, Z.; Shmueli, E. Screening heuristics for project gating systems. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, Paderborn, Germany, 8 August 2017; pp. 872–877. [Google Scholar]
- Liyi, M.; Shiyu, Z.; Jian, G. A project risk forecast model based on support vector machine. In Proceedings of the 2010 IEEE International Conference on Software Engineering and Service Sciences, Beijing, China, 18 July 2010; pp. 463–466. [Google Scholar]
- Lopez-Martin, C.; Banitaan, S.; Garcia-Floriano, A.; Yanez-Marquez, C. Support vector regression for predicting the enhancement duration of software projects. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 21 December 2017; pp. 562–567. [Google Scholar]
- Chou, J.-S.; Cheng, M.-Y.; Wu, Y.-W.; Wu, C.-C. Forecasting enterprise resource planning software effort using evolutionary support vector machine inference model. Int. J. Proj. Manag. 2012, 30, 967–977. [Google Scholar] [CrossRef]
- Song, L.; Minku, L.L.; Yao, X. Software effort interval prediction via Bayesian inference and synthetic bootstrap resampling. Acm Trans. Softw. Eng. Methodol. (TOSEM) 2019, 28, 1–46. [Google Scholar] [CrossRef]
- Dahab, S.A.; Porras, J.J.H.; Maag, S. A Software Measurement Plan Management Guided by an Automated Metrics Suggestion Framework. In Proceedings of the 2017 European Conference on Electrical Engineering and Computer Science (EECS), Bern, Switzerland, 19 November 2017; pp. 9–16. [Google Scholar]
- Koroglu, Y.; Sen, A.; Kutluay, D.; Bayraktar, A.; Tosun, Y.; Cinar, M.; Kaya, H. Defect prediction on a legacy industrial software: A case study on software with few defects. In Proceedings of the 2016 IEEE/ACM 4th International Workshop on Conducting Empirical Studies in Industry (CESI), Austin, TX, USA, 17 May 2016; pp. 14–20. [Google Scholar]
- Azzeh, M.; Banitaan, S. An Application of Classification and Class Decomposition to Use Case Point Estimation Method. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 11 December 2015; pp. 1268–1271. [Google Scholar]
- Petkovic, D.; Sosnick-Pérez, M.; Huang, S.; Todtenhoefer, R.; Okada, K.; Arora, S.; Sreenivasen, R.; Flores, L.; Dubey, S. Setap: Software engineering teamwork assessment and prediction using machine learning. In Proceedings of the 2014 IEEE Frontiers in Education Conference (FIE) Proceedings, Madrid, Spain, 25 October 2014; pp. 1–8. [Google Scholar]
- del Águila, I.M.; Sagrado, J.D. Requirement risk level forecast using Bayesian networks classifiers. Int. J. Softw. Eng. Knowl. Eng. 2011, 21, 167–190. [Google Scholar] [CrossRef] [Green Version]
- Alsri, A.; Almuhammadi, S.; Mahmood, S. A model for work distribution in global software development based on machine learning techniques. In Proceedings of the 2014 Science and Information Conference, London, UK, 29 August 2014; pp. 399–403. [Google Scholar]
- Miandoab, E.E.; Gharehchopogh, F.S. A novel hybrid algorithm for software cost estimation based on cuckoo optimization and k-nearest neighbors algorithms. Eng. Technol. Appl. Sci. Res. 2016, 6, 1018–1022. [Google Scholar] [CrossRef]
- Basgalupp, M.P.; Barros, R.C.; Ruiz, D.D. Predicting software maintenance effort through evolutionary-based decision trees. In Proceedings of the 27th Annual ACM Symposium on Applied Computing, Riva del Garda, Italy, 29 March 2012; pp. 1209–1214. [Google Scholar]
- Bakır, A.; Turhan, B.; Bener, A.B. A new perspective on data homogeneity in software cost estimation: A study in the embedded systems domain. Softw. Qual. J. 2010, 18, 57–80. [Google Scholar] [CrossRef]
- Helming, J.; Koegel, M.; Hodaie, Z. Towards automation of iteration planning. In Proceedings of the 24th ACM SIGPLAN conference companion on Object oriented programming systems languages and applications, Orlando, FL, USA, 29 October 2009; pp. 965–972. [Google Scholar]
- Choetkiertikul, M.; Dam, H.K.; Tran, T.; Pham, T.; Ghose, A.; Menzies, T. A deep learning model for estimating story points. IEEE Trans. Softw. Eng. 2018, 45, 637–656. [Google Scholar] [CrossRef] [Green Version]
- Niinimäki, T.; Piri, A.; Hynninen, P.; Lassenius, C. Studying communication in agile software development: A research framework and pilot study. In Proceedings of the ICMI-MLMI’09 Workshop on Multimodal Sensor-Based Systems and Mobile Phones for Social Computing, Cambridge, MA, USA, 6 November 2009; pp. 1–4. [Google Scholar]
- Pechau, J. Rafting the agile waterfall: Value based conflicts of agile software development. In Proceedings of the 16th European Conference on Pattern Languages of Programs, Irsee, Germany, 17 July 2011; pp. 1–15. [Google Scholar]
- Gousios, G.; Zaidman, A. A dataset for pull-based development research. In Proceedings of the 11th Working Conference on Mining Software Repositories, Hyderabad, India, 18 May 2014; pp. 368–371. [Google Scholar]
- Makris, C.; Vikatos, P.; Visser, J. Classification model for predicting cost slippage in governmental ICT projects. In Proceedings of the 30th Annual ACM Symposium on Applied Computing, Salamanca, Spain, 17 April 2015; pp. 1238–1241. [Google Scholar]
- Qu, Y.; Tang, X.-L. Software project risk assessing model based on credal networks. In Proceedings of the 2010 International Conference on Machine Learning and Cybernetics, Qingdao, China, 14 July 2010; pp. 1976–1979. [Google Scholar]
- Gouthaman, P.; Sankaranarayanan, S. Agile Software Risk Management Architecture for IoT-Fog based systems. In Proceedings of the 2018 International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 14 December 2018; pp. 48–51. [Google Scholar]
- Andrés, J.D.; Landajo, M.; Lorca, P. Using nonlinear quantile regression for the estimation of software cost. In Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Oviedo, Spain, 22 June 2018; pp. 422–432. [Google Scholar]
- Pa, R.S.; Snsvsc, R. Improving efficiency of fuzzy models for effort estimation by cascading & clustering techniques. Procedia Comput. Sci. 2016, 85, 278–285. [Google Scholar]
- Nassif, A.B.; Azzeh, M.; Idri, A.; Abran, A. Software development effort estimation using regression fuzzy models. Comput. Intell. Neurosci. 2019, 2019. [Google Scholar] [CrossRef]
- Mohebzada, J.G.; Ruhe, G.; Eberlein, A. SRP-plugin: A strategic release planning plug-in for visual studio 2010. In Proceedings of the 1st Workshop on Developing Tools as Plug-ins, Honolulu, HI, USA, 28 May 2011; pp. 36–39. [Google Scholar]
- Baolong, Y.; Hong, W.; Haodong, Z. Research and application of data management based on Data Management Maturity Model (DMM). In Proceedings of the 2018 10th International Conference on Machine Learning and Computing, Macau, China, 10 February 2018; pp. 157–160. [Google Scholar]
- Sigweni, B. Feature weighting for case-based reasoning software project effort estimation. In Proceedings of the 18th International Conference on Evaluation and Assessment in Software Engineering, London, UK, 13–14 May 2014; pp. 1–4. [Google Scholar]
- Huang, Z.-W. Cost Estimation of Software Project Development by Using Case-Based Reasoning Technology with Clustering Index Mechanism. In Proceedings of the 2009 Fourth International Conference on Innovative Computing, Information and Control (ICICIC), Kaohsiung, Taiwan, 7–9 December 2009; pp. 1049–1052. [Google Scholar]
- Wang, Y.-H.; Jia, J.; Qu, Y. The “Earth-Moon” model on software project risk management. In Proceedings of the 2010 International Conference on Machine Learning and Cybernetics, Qingdao, China, 14 July 2010; pp. 1999–2003. [Google Scholar]
- Amasaki, S.; Kawata, K.; Yokogawa, T. Improving cross-project defect prediction methods with data simplification. In Proceedings of the 2015 41st Euromicro Conference on Software Engineering and Advanced Applications, Madeira, Portugal, 28 August 2015; pp. 96–103. [Google Scholar]
- Nassif, A.B.; Capretz, L.F.; Ho, D.; Azzeh, M. A treeboost model for software effort estimation based on use case points. In Proceedings of the 2012 11th International Conference on Machine Learning and Applications, Boca Raton, FL, USA, 15 December 2012; pp. 314–319. [Google Scholar]
- Wagner, S. A literature survey of the quality economics of defect-detection techniques. In Proceedings of the 2006 ACM/IEEE international symposium on Empirical software engineering, Rio de Janeiro Brazil, 21–22 September 2006; pp. 194–203. [Google Scholar]
- Pressman, R.S. Software Engineering: A Practitioner’s Approach; Palgrave Macmillan: London, UK, 2005. [Google Scholar]
- Nassif, A.B.; Ho, D.; Capretz, L.F. Towards an early software estimation using log-linear regression and a multilayer perceptron model. J. Syst. Softw. 2013, 86, 144–160. [Google Scholar] [CrossRef] [Green Version]
- Menzies, T.; Mizuno, O.; Takagi, Y.; Kikuno, T. Explanation vs performance in data mining: A case study with predicting runaway projects. J. Softw. Eng. Appl. 2009, 2, 221. [Google Scholar] [CrossRef] [Green Version]
- Kitchenham, B.; Mendes, E.; Travassos, G.H. A systematic review of cross-vs. In within-company cost estimation studies. In Proceedings of the 10th International Conference on Evaluation and Assessment in Software Engineering (EASE) 10, Swindon, UK, 11 April 2006; pp. 1–10. [Google Scholar]
- Mahdi, M.N.; Yusof, M.Z.M.H.A.; Cheng, L.K.; Azmi, M.S.M.; Ahmad, A.R. Design and Development of Machine Learning Technique for Software Project Risk Assessment-A Review. In Proceedings of the 2020 8th International Conference on Information Technology and Multimedia (ICIMU), Selangor, Malaysia, 26 August 2020; pp. 354–362. [Google Scholar]
- Lee, T.; Gu, T.; Baik, J. MND-SCEMP: An empirical study of a software cost estimation modeling process in the defense domain. Empir. Softw. Eng. 2014, 19, 213–240. [Google Scholar] [CrossRef]
- Mitchell, S.M.; Seaman, C.B. A comparison of software cost, duration, and quality for waterfall vs iterative and incremental development: A systematic review. In Proceedings of the 2009 3rd International Symposium on Empirical Software Engineering and Measurement, Lake Buena Vista, FL, USA, 16 October 2009; pp. 511–515. [Google Scholar]
- Jorgensen, M.; Shepperd, M. A systematic review of software development cost estimation studies. IEEE Trans. Softw. Eng. 2006, 33, 33–53. [Google Scholar] [CrossRef] [Green Version]
- González-Ladrón-de-Guevara, F.; Fernández-Diego, M.; Lokan, C. The usage of ISBSG data fields in software effort estimation: A systematic mapping study. J. Syst. Softw. 2016, 113, 188–215. [Google Scholar] [CrossRef] [Green Version]
- Iranmanesh, S.H.; Hojati, Z.T. Intelligent systems in project performance measurement and evaluation. In Proceedings of the Intelligent Techniques in Engineering Management, 5 May 2015; Springer: Berlin, Germany, 2015; pp. 581–619. [Google Scholar]
- Mellegård, N.; Staron, M. Characterizing model usage in embedded software engineering: A case study. In Proceedings of the Fourth European Conference on Software Architecture: Companion Volume, Copenhagen, Denmark, 23–26 August 2010; pp. 245–252. [Google Scholar]
- Antonellis, P.; Antoniou, D.; Kanellopoulos, Y.; Makris, C.; Theodoridis, E.; Tjortjis, C.; Tsirakis, N.; A data mining methodology for evaluating maintainability according to ISO/IEC-9126 software engineering–product quality standard. Special Session on System Quality and Maintainability-SQM2007. 2007. Available online: https://www.ihu.edu.gr/tjortjis/A%20Data%20Mining%20Methodology%20for%20Evaluating%20Maintainability%20according%20to%20SQM07.pdf (accessed on 5 May 2021).
- Azar, D.; Harmanani, H.; Korkmaz, R. A hybrid heuristic approach to optimize rule-based software quality estimation models. Inf. Softw. Technol. 2009, 51, 1365–1376. [Google Scholar] [CrossRef]
- Mahdi, M.N.; Azmi, M.S.M.; Cheng, L.K.; Yusof, A.; Ahmad, A.R. Software Project Management Using Machine Learning Technique-A Review. In Proceedings of the 2020 8th International Conference on Information Technology and Multimedia (ICIMU), Selangor, Malaysia, 26 August 2020; pp. 363–370. [Google Scholar]
- Zhang, H.; Dai, G. The strategy of traffic congestion management based on case-based reasoning. Int. J. Syst. Assur. Eng. Manag. 2019, 10, 142–147. [Google Scholar] [CrossRef]
- Agrawal, A.; Menzies, T. “Better Data” is Better than “Better Data Miners” (Benefits of Tuning SMOTE for Defect Prediction). arXiv 2017, arXiv:1705.03697. [Google Scholar]
- Amasaki, S.; Takahara, Y.; Yokogawa, T. Performance evaluation of windowing approach on effort estimation by analogy. In Proceedings of the 2011 Joint Conference of the 21st International Workshop on Software Measurement and the 6th International Conference on Software Process and Product Measurement, Nara, Japan, 4 November 2011; pp. 188–195. [Google Scholar]
- Arcuri, A.; Briand, L. A practical guide for using statistical tests to assess randomized algorithms in software engineering. In Proceedings of the 2011 33rd International Conference on Software Engineering (ICSE), Honolulu, HI, USA, 28 May 2011; pp. 1–10. [Google Scholar]
- Wan, S.; Li, D.; Gao, J.; Li, J. A knowledge based machine tool maintenance planning system Using case-based reasoning techniques. Robot. Comput. Integr. Manuf. 2019, 58, 80–96. [Google Scholar] [CrossRef]
- Kaur, A.; Kaur, K. Effort Estimation for Mobile Applications Using Use Case Point (UCP). In Proceedings of the Smart Innovations in Communication and Computational Sciences, Bangkok, Thailand, 30 June 2019; pp. 163–172. [Google Scholar]
- Srivastava, A.; Singh, S.; Abbas, S.Q. Performance Measure of the Proposed Cost Estimation Model: Advance Use Case Point Method. In Proceedings of the Soft Computing: Theories and Applications, Lviv, Ukraine, 20 September 2019; pp. 223–233. [Google Scholar]
- Larsson, S.; Jansson, M.; Boholm, Å. Expert stakeholders’ perception of nanotechnology: Risk, benefit, knowledge, and regulation. J. Nanoparticle Res. 2019, 21, 57. [Google Scholar] [CrossRef] [Green Version]
- Poth, A.; Sasabe, S.; Mas, A.; Mesquida, A.L. Lean and agile software process improvement in traditional and agile environments. J. Software Evol. Process. 2019, 31, e1986. [Google Scholar] [CrossRef] [Green Version]
- Sievi-Korte, O.; Beecham, S.; Richardson, I. Challenges and recommended practices for software architecting in global software development. Inf. Softw. Technol. 2019, 106, 234–253. [Google Scholar] [CrossRef]
- Lops, P.; Gemmis, M.D.; Semeraro, G. Content-based recommender systems: State of the art and trends. In Recommender Systems Handbook; Springer: Berlin, Germany, 2011; pp. 73–105. [Google Scholar]
- Fauzi, S.S.M.; Ramli, N.; Nasir, M.H.N.M. Software Configuration Management A Result from the Assessment and its Recommendation. In Proceedings of the 2009 International Conference on Information Management and Engineering, Kuala Lumpur, Malaysia, 3–5 April 2009; pp. 416–419. [Google Scholar]
- Khomyakov, I.; Mirgalimova, R.; Sillitti, A. An investigation of the project management approaches of agile and plan-based companies. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Brno, Czech Republic, 3 April 2020; pp. 1662–1665. [Google Scholar]
- Prakash, B.; Viswanathan, V.A. Survey on Software Estimation Techniques in Traditional and Agile Development Models. Indones. J. Electr. Eng. Comput. Sci. 2017, 7, 867–876. [Google Scholar] [CrossRef]
- Picha, P.; Brada, P. Software process anti-pattern detection in project data. In Proceedings of the 24th European Conference on Pattern Languages of Programs, Irsee, Germany, 19 July 2019; pp. 1–12. [Google Scholar]
- Kappen, T.H.; Vergouwe, Y.; Wolfswinkel, L.V.; Kalkman, C.; Moons, K.; Klei, W.V. Impact of adding therapeutic recommendations to risk assessments from a prediction model for postoperative nausea and vomiting. Br. J. Anaesth. 2015, 114, 252–260. [Google Scholar] [CrossRef] [Green Version]
- Kanimozhi, U.; Ganapathy, S.; Manjula, D.; Kannan, A. An intelligent risk prediction system for breast cancer using fuzzy temporal rules. Natl. Acad. Sci. Lett. 2019, 42, 227–232. [Google Scholar] [CrossRef]
- Matharu, G.S.; Mishra, A.; Singh, H.; Upadhyay, P. Empirical study of agile software development methodologies: A comparative analysis. ACM SIGSOFT Softw. Eng. Notes 2015, 40, 1–6. [Google Scholar] [CrossRef]
- Yang, M.Q.; Elnitski, L.L. Prediction-based approaches to characterize bidirectional promoters in the mammalian genome. BMC Genom. 2008, 9, S2. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nagwani, N.K.; Bhansali, A. A data mining model to predict software bug complexity using bug estimation and clustering. In Proceedings of the 2010 International Conference on Recent Trends in Information, Telecommunication and Computing, Kerala, India, 13 March 2010; pp. 13–17. [Google Scholar]
- Shan, X.; Jiang, G.; Huang, T. A framework of estimating software project success potential based on association rule mining. In Proceedings of the 2009 International Conference on Management and Service Science, Beijing, China, 22 September 2009; pp. 1–4. [Google Scholar]
- Khan, B.; Iqbal, D.; Badshah, S. Cross-Project Software Fault Prediction Using Data Leveraging Technique to Improve Software Quality. In Proceedings of the Evaluation and Assessment in Software Engineering, Trondheim, Norway, 17 April 2020; pp. 434–438. [Google Scholar]
- Chelly, Z.; Elouedi, Z. Improving the dendritic cell algorithm performance using fuzzy-rough set theory as a pattern discovery technique. In Proceedings of the Fifth International Conference on Innovations in Bio-Inspired Computing and Applications IBICA, Ostrava, Czech Republic, 25 June 2014; pp. 23–32. [Google Scholar]
- Ghotra, B.; McIntosh, S.; Hassan, A.E. Revisiting the impact of classification techniques on the performance of defect prediction models. In Proceedings of the 2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, Florence, Italy, 16–24 May 2015; pp. 789–800. [Google Scholar]
- Li, J.; Ji, X.; Jia, Y.; Zhu, B.; Wang, G.; Li, Z.; Liu, X. Hard drive failure prediction using classification and regression trees. In Proceedings of the 2014 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks, Atlanta, GA, USA, 26 June 2014; pp. 383–394. [Google Scholar]
- Ryu, D.; Choi, O.; Baik, J. Value-cognitive boosting with a support vector machine for cross-project defect prediction. Empir. Softw. Eng. 2016, 21, 43–71. [Google Scholar] [CrossRef]
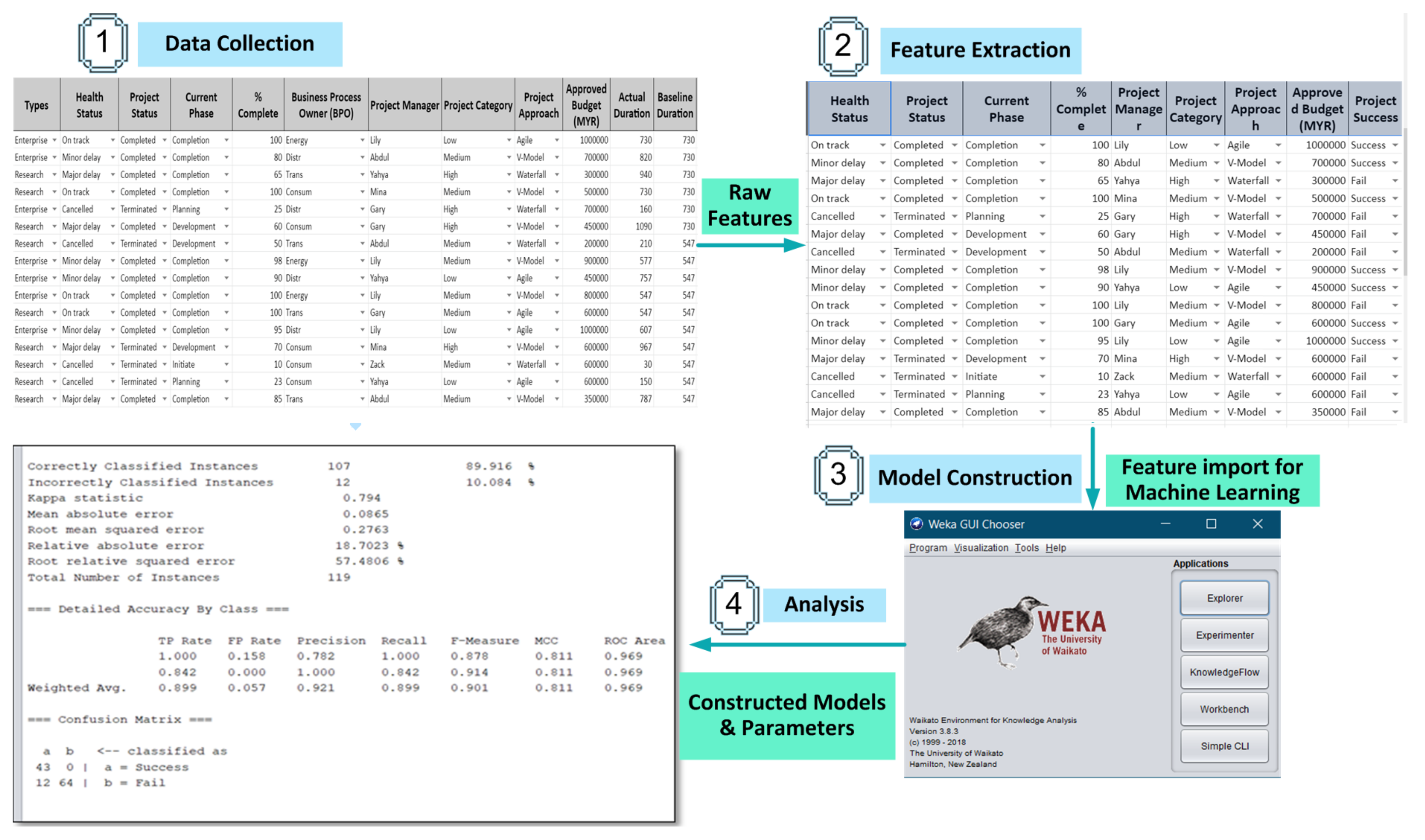
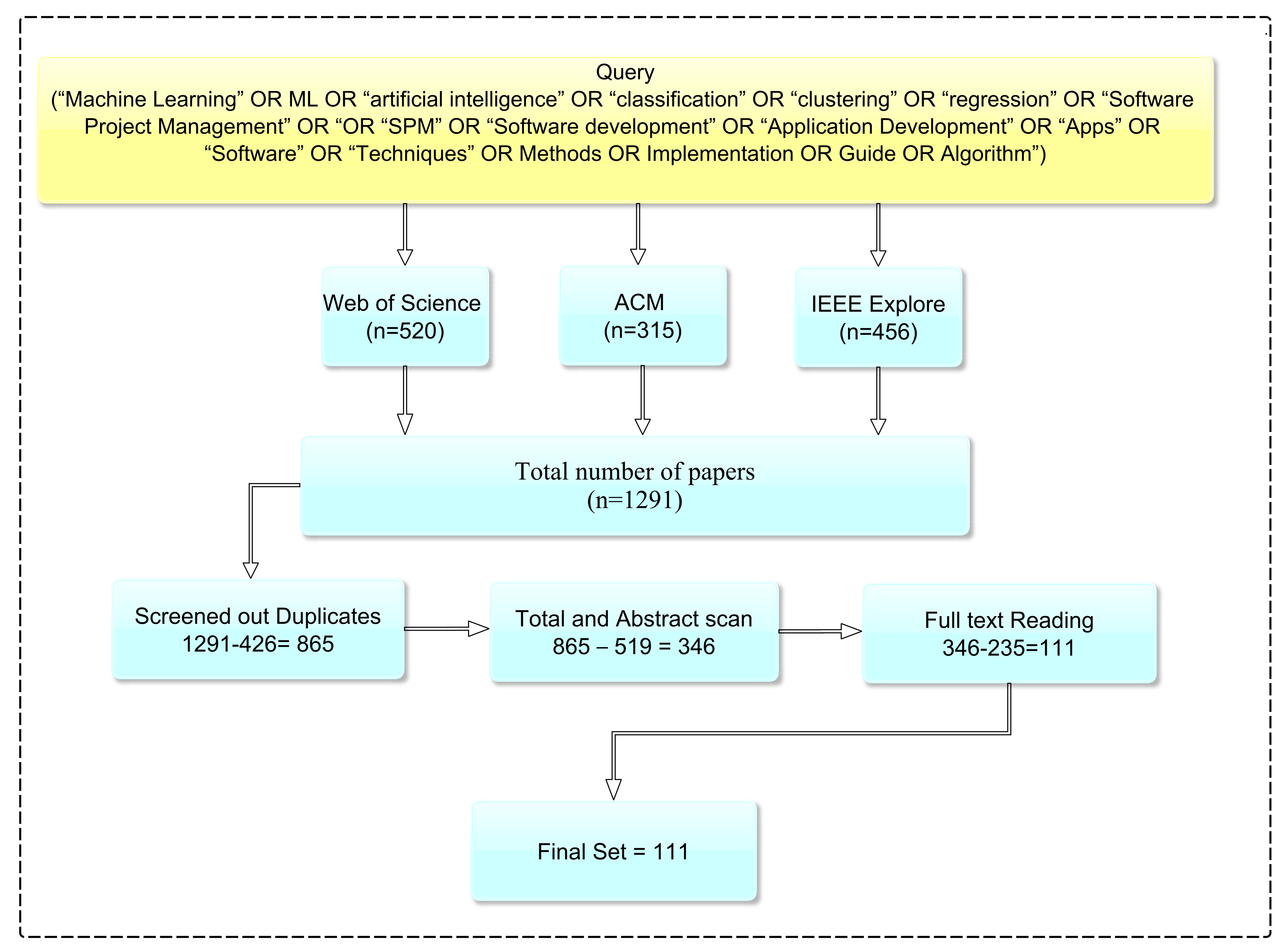
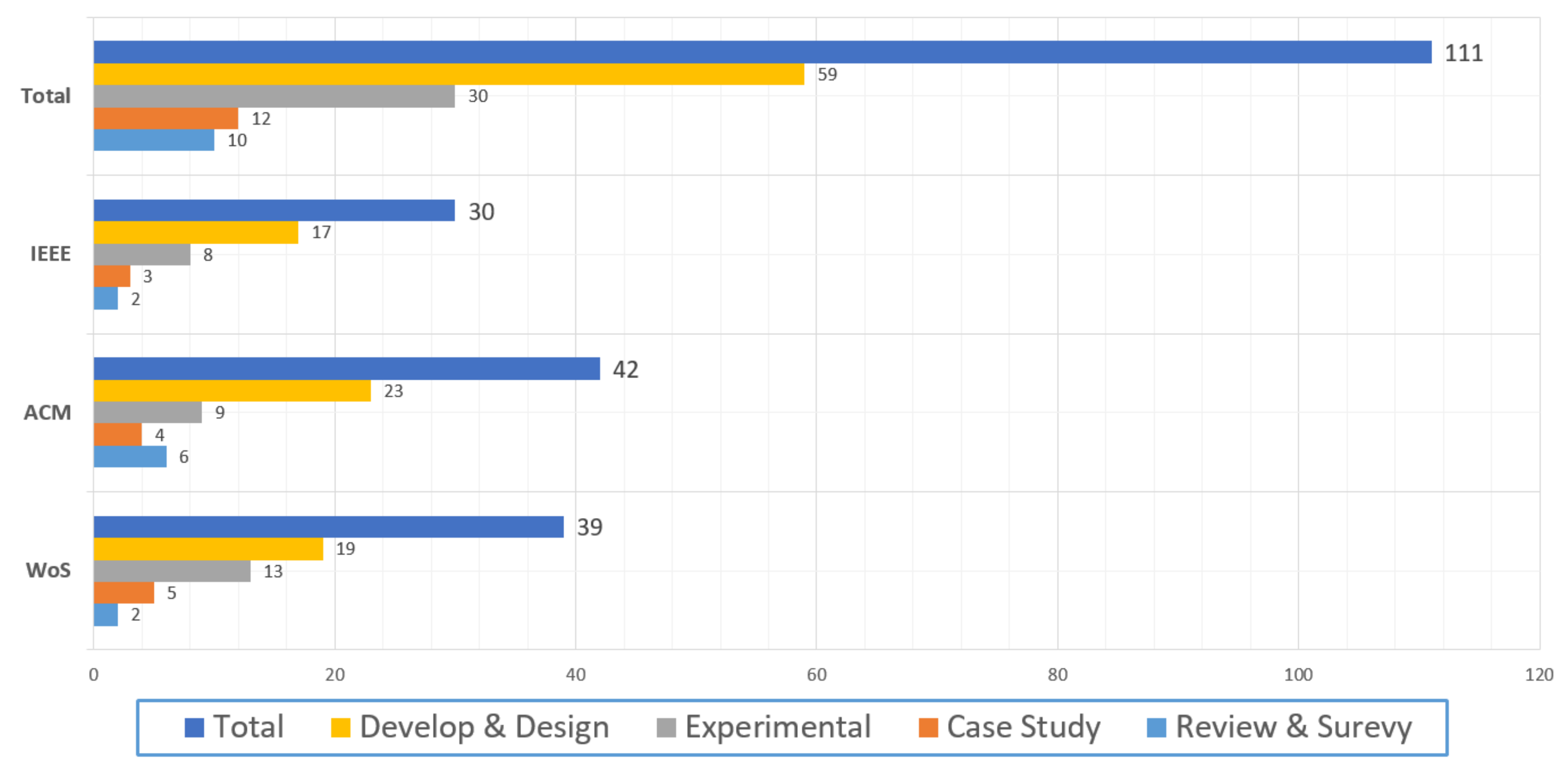
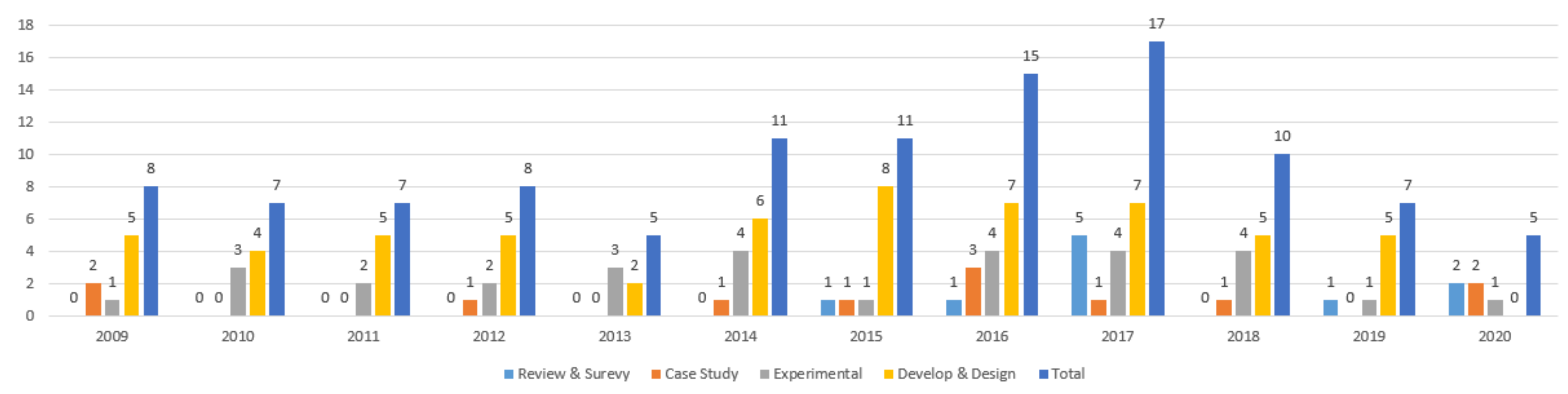

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Type of ML | Description | Domain | Feature Extraction | Limitation of Old System | Limitation of the New System |
|---|---|---|---|---|---|---|
| [27] | SVM | Evaluated two ML approaches to boost track consistency between regulatory codes and specifications at the commodity level | Security, and privacy in healthcare domain | Non | Limited success for tracing regulatory codes due to the disparity in terminology that can exist between the codes and product level requirements | Applied the data mining to a more fine-grained model of the HIPAA regulatory codes showing specific rights |
| [28] | Several type of ML | Argued that information analytics apply computational technologies | Broad spectrum of field experience and awareness | Non | Full machine analytics, software analysis, ML, data processing and knowledge visualization | Expertise to design and implement scalable data processing tools and learning tools |
| [29] | Several type of ML | Develop machine assessment, maximize the usage of capital | Effort and duration estimation | Non | Plan and commodity historical indicators depending on the learning method | Availability of granular data regarding project and product characteristics |
| [30] | Several type of ML | Demonstrates a novel solution to address this omnipresent dilemma through a modern synthesis of digitization and ML | Project evaluation, team pace and time estimation | Non | Creation of a waterfall concept about a decade ago | Extended to generate data on individual and team contribution, which can be helpful for management |
| [31] | Several type of ML | Complementing Agile manual planning poker | Software development effort estimation | Token Extraction | There is no framework for agile growth which is the most suitable | Larger data sets and functions in this experiment do not included |
| [32] | Several type of ML | Many solo strategies to forecast the software development effort were suggested System | Software effort estimation | Dataset figures include the number of ventures and the number of characteristics | It has been seen to be sufficient in any case | The goal was to evaluate the effect of the number of participants of the ensemble |
| [33] | Several type of ML | The goal was to reach a solution by implementing a smart device that assigns team members creatively to a specific mission | Software Project Management | CollabCrew ETL | Built primarily to tackle the software issue | Results of this research are a benefit to the real-time framework and provide insight into the efficiency, Precision and level of reliability |
| [34] | NB and SVM | Provided an extensive comparison of well-known data lters | Cross-project defect prediction | Feature based approaches | Data lter strategy significantly improves the efficiency of cross-project defect prediction and the hierarchical chosen method suggested significantly improves the performance | Find another classifier for the model building other than NB or SVM |
| [35] | Several type of ML | Give an active online adaptation model solution to ACONA, which adapts a pool of categories dynamically to different projects | Software development process management; Risk Management | Non | Using well-trained classifications to render good forecasts for the current project with streaming data on vast historical data from other projects | Attains improved outcomes with less concerns regarding the actual CI scheme, which reveals that ACONA can dramatically minimise CI costs more than current methods |
| [36] | RF, Multilayer Perceptron and SVM | Purpose of predicting the effort | Software project effort | Non-linear features | Accurate estimations of software project effort | Incorporating other ML models like treeboost like XBoost etc. and validating with other diverse datasets |
| [37] | DT, FL | In certain instances, it provides reasonably reliable figures | Software cost estimation | Feature subsets from ISBSG | Built exact and useful models are constrained in fact even though they give tech stakeholders considerable financial benefits | Models in an area of actual growth |
| [38] | SVM | The externalised development project is one of the key approaches to build software that has a large rate of failure. Smart risk prediction model can assist in the timing of high-risk projects | Software project | Selected 25 risk factors | Existing models are focused primarily on the premise that all costs of misclassification are equivalent, which does not correlate to the fact that risk prediction exists in the software project region | Applies stronger classifiers to improve the prediction accuracy of outsourced software project risk |
| [39] | SVM | Investigates the impact of noisy domains on eight ML accuracy and the recognition algorithms for statistical trends | Software effort prediction | Randomly selected feature | Solutions for the problem of noisy domains in software effort prediction from a probabilistic point of view | Extended by considering a more detailed simulation study using much more balanced types of datasets required to understand the merits of STOCHS, especially larger datasets |
| [40] | K-Means | Used a particular information engineering design strategy to identify faulty software | Global Software Development | Feature Subset Selection | To promote PM software decisions by data mining and produce practical results | Investigation and comparison with other methods for data mining |
| [41] | DT | Software Effort Estimation is the most crucial task in software engineering and PM | Software Effort Estimation | Non | Given a comparison of ML algorithms to estimate effort in varying sized software | Augmented by applying other ML algorithms and validating with other diversified datasets |
| [42] | kNN, DT, and LDA | Intelligent approach to predict software fault based on a Binary Moth Flame Optimization with Adaptive synthetic sampling was introduced | Software fault prediction (SFP) | Frequency of selecting each feature from all datasets using the EBMFOV3 | Improved the performance of all classifiers after solving imbalanced problems | Studied the importance of features to enhance the performance of classifiers and SFP model accuracy |
| [43] | Neural network | ML was named the general neural network regression for the efficiency forecast in practices of apps | Software practitioners | Non | Developers and managers refer to tech professionals’ output, which is typically calculated as the size/time ratio | The usage of a radial base feature neural network to forecast practitioners and developer teams’ efficiency |
| [44] | ANN, SVM | Several ML algorithms to predict the software duration | SPM | Non | Evaluated the algorithms according to their correlation coefficient | Prediction operates according to current/past project details will estimate the potential work and length of the project |
| [45] | Decision-tree | Proposed evolving decisions through an evolutionary algorithm and the corresponding tree for the prediction of device maintenance effort | Software effort prediction | Non | Usage of HEAD-DT to create a judgement treaties-based algorithm that adapts to the maintenance of data Application | Effectiveness of hyperheuristics in evaluating other primary software indicators, data creation in private and public software |
| [46] | Decision tree | A tool proposed to boost predictive performance of program effort | Software prediction | Four-dimensional feature | Beginnings of better understanding and utilizing decision-making bodies as the part classification of ensemble imputation methods | Incomplete data and machine estimation theoretical and observational analysis |
| [47] | k-NN | To explore how parameters are more adaptive to their parameters and how often the output of MLs in SEE may be influenced | Software effort estimation | Non | Systemic tests on three data sets were conducted with five ML in multiple parameter settings | Investigating additional ML and data sets; other forms of action-size, including non-parametric ones; and additional window sizes for online learning assessment |
| [48] | Regression Trees | Cross-company (CC) machine effort calculation (WC) details aim to explicitly utilize CC knowledge or models to predict in WC situations CC data or model data | Software Effort Estimation | Number of ventures with each characteristic | This system will not only use far less WC knowledge than a comparable WC model, but also produce an equivalent/better output | Dycom’s sensitivity to parameter values, simple pupils, inputs and separating CC ventures into separate parts |
| [49] | SVM | Systematic studies indicate that RVM is very successful in contrast to advanced SEE approaches | Software effort estimation | Account specific features of SEE | It has shown that RVM is an outstanding indicator of SEE and requires more analysis and usage | Using the automated validity evaluation of RVM, three unique case cases were established and the advice on whether the effort needed was suggested |
| [50] | SVM | The right calculation of effort helps determine which challenges to be corrected or solved in the next round | Effort Estimation | Computed characteristics on the criteria for the classification task dependent on the initial attributes | The development features have been used to construct statistical models that analyze story points for open source projects | Predictions can be enhanced by taking into consideration new features relevant to human development characteristics |
| [51] | ANN | Calibration methods depend on linear adjustment forms except ANN based non-linear adjustment | Software development effort estimation | Non-normality and categorical features of different datasets | Considered as a base method for the software development effort estimation | Extension to this study, there are other options for the kernel function in LS-SVM other than radial basis function |
| [52] | K-Means | Clustering approaches are generalized to be used to construct CC subsets. Three separate methods of clustering are researched | Software Effort Estimation | Different features can be used to describe training projects for clustering 1- Productivity, 2- Size effort, 3- All project input and output attributes | Clustering Dycom with K-Means will help separate the CC programs, producing good or better predictive efficiency than Dycom | Clustering processes, simple learners, input project attributes, clustering project functions, parameter values |
| Ref | Type of ML | Datasets | Model | Achieve Prediction | Advantages | Limitation |
|---|---|---|---|---|---|---|
| [73] | kNN | IBM commercial projects called RQM and RTC | Hybrid model uses three independent attribute sets (1) early metadata based attributes, (2) title and (3) description of software tasks | Accuracy 88% | Automatic effort estimation to a larger number of tasks | Datasets of this study did not have historical snapshots to make sure that the final value of included attributes for all tasks are equal to their value before they were assigned to a developer |
| [48] | Logistic linear regression | KitchenMax CocNasaCoc81 ISBSG2000 ISBSG2001 ISBSG | DYCOM | Accuracy 66% | Made best use of CC data, so that can reduce the amount of WC data while maintaining or improving performance in comparison to WC SEE models | Investigation of Dycom’s sensitivity to parameter values, base learners, input features and techniques for splitting CC projects into different sections |
| [72] | Naïve Bayes | Data sets University Student Projects developed in 2005) (USP05-FT) and USP05-RQ | Software Effort Estimation | Accuracy 87% | Based upon ML techniques for non-quantitative data and is carried out in two phases | Efficiency of other ML techniques such as SVM, Decision Tree learning etc. can be used for effort estimation |
| [47] | K-NN | PROMISE Repository | Software effort estimation | Accuracy 92% | Investigate to what extent parameter settings affect the performance of ML in SEE, and what learning machines are more sensitive to their parameters | Investigation of other learning machines and data sets; other types of effect size, in particular non-parametric ones; and other window sizes for the evaluation of the online learning procedure |
| [60] | SVR | NASA93 dataset | Software Effort Estimation | Accuracy 95% | Conduct a comparison between soft computing and statistical regression techniques in terms of a software development estimation regression problem | The need of more future research work to evaluate the efficiency of soft computing techniques compared to the popular statistical regression methods, especially in the context of software effort estimation |
| [81] | ANN | NASA 93 | Experiments Models | Accuracy 95% | Examined the effect of classification in estimating the amount of effort required in software development projects | Implemented a model to estimate the final amount of effort required in new projects, to estimate the partial effort at various stages in the project development process |
| [37] | Fuzzy logic | ISBSG, COCOMO and DESHARNAIS datasets | HYBRID Models | Accuracy 97% | Addresses the issue of Software cost estimation proposing an alternative approach that combines robust decision tree structures with fuzzy logic | Investigate a wider pool of type of attributes, such as categorical attributes, and concentrate mostly on those that are available at the early project development phases, to address the issue of proposing better and more practical cost models |
| [109] | SVR | International Software Benchmarking Standards Group (ISBSG) repository | Data homogeneity | Accuracy 98% | Investigate the homogeneity of cost data in terms of application domains, and to focus on the embedded domain | Data collection process in embedded systems domain may focus on searching for domain specific attributes, so that the information content of the attributes becomes richer and as a result prediction performance of the algorithm improves |
| [107] | KNN | KEMERER, MAXWELL, MIYAZAKI 1, NASA 60, NASA 63, NASA93 | Software Cost Estimation (SCE) models | Accuracy 91% | Model-based methods use a single formula and constant values, and these methods are not responsive to the increasing developments in the field of software engineering | Has not a good performance compared to the comparative algorithms, and its reason can be the lack of consistent data |
| [89] | SVR | ISBSG dataset | Software project estimation | Accuracy 72% | Narrow the gap between up-to-date research results and implementations within organisations by proposing effective and practical ML deployment and maintenance approaches by utilization of research findings and industry best practices | Focused on verifying the proposed approach through proof-of concept with different organisations to validate the model’s accuracy and adjust the deployment and maintenance framework |
| [46] | Decision tree | Kemerer Bank Test equipment DSI Moser, Desharnais Finnish, ISBSG CCCS, Company X | Software effort prediction | Accuracy 92% | Improving software effort prediction accuracy by generating the ensemble using two imputation methods as elements | In terms of the training parameters and the combination rules that can be employed. Second, empirical studies of the application of MIAMI to datasets from other areas of data mining should be undertaken to assess its performance across a more general field |
| [92] | Neural networks | Historical data | I-Competere | Accuracy 93% | Presented a tool developed to forecast competence gaps in key management personnel by predicting planning and scheduling competence levels | Centered on the inclusion of other types of projects in order to prove that the proposed framework can be adapted when predicting competency gaps in different projects |
| [94] | ANN | ISBSG datasets | Software development effort estimation | Accuracy 97% | Investigated in conjunction with feature transformation, feature selection, and parameter tuning techniques to estimate the development effort accurately and a model was proposed as part of an expert system | Suggested model will be used on new datasets they become available for experiments and our analysis |
| [166] | Logistic linear regression | Cross-Project Software Fault Prediction Using Data-Leveraging Technique to Improve Software Quality | Source + target | Accuracy 95% | Building a predictive model using instant-based transfer learning through the data leveraging method | Include more datasets from the same domain and by applying other machine algorithms by comparing their results |
| [101] | Random Forest | Real data | Defect Prediction | Accuracy 90% | Building a defect prediction model for a large industrial software project | Implement model as an online algorithm, which learns with each release |
| [55] | Random forest | 13 data sets | Misclassification cost-sensitive | Accuracy 95% | Analyze the benefits of techniques which incorporate misclassification costs in the development of software fault prediction models | Indicate that in projects where the exact misclassification cost is unknown, a likely scenario in practice, cost sensitive models with similar misclassification cost ratios are likely to exhibit performance which is not significantly different |
| [108] | Decision tree | Company effort data set | Evolutionary-based Decision Trees | Accuracy 64% | Employing an evolutionary algorithm to generate a decision tree tailored to a software effort data set provided by a large worldwide IT company | Determine its effectiveness in estimating other important software metrics, in private and public software development data sets |
| [83] | ANN | Experiments on 45 open source project dataset | Fault prediction model | Accuracy 98% | To validate the source code metrics and select the right set of metrics with the objective to improve the performance of the fault prediction model | Reduced feature attributes using proposed framework |
| [42] | KNN | Several dataset | EBMFO | Accuracy 89% | Enhanced Binary Moth Flame Optimization (EBMFO) with Adaptive synthetic sampling (ADASYN) to predict software faults | Study the importance of features to enhance the performance of classifiers and SFP model accuracy |
| [86] | SVM | Quanxi Mi data set | Defect management (DM) | Accuracy 97% | Focused on the procedure aspect of software processes, and formulate the problem as a sequence classification task, which is solved by applying ML | Investigated extra aspects of software processes and other ML techniques to develop more advanced solutions |
| [77] | Random Forest | NASA namely CM1, PC1 and JM1 | Software Effort Estimation | Accuracy 99% | Investigate the apt choice of data mining techniques in order to accurately estimate the success and failure rate of projects based on defect as one of the modulating factors | Process of project estimations and henceforth improves the quality, productivity and sustainability of the company in the industrial atmosphere |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahdi, M.N.; Mohamed Zabil, M.H.; Ahmad, A.R.; Ismail, R.; Yusoff, Y.; Cheng, L.K.; Azmi, M.S.B.M.; Natiq, H.; Happala Naidu, H. Software Project Management Using Machine Learning Technique—A Review. Appl. Sci. 2021, 11, 5183. https://doi.org/10.3390/app11115183
Mahdi MN, Mohamed Zabil MH, Ahmad AR, Ismail R, Yusoff Y, Cheng LK, Azmi MSBM, Natiq H, Happala Naidu H. Software Project Management Using Machine Learning Technique—A Review. Applied Sciences. 2021; 11(11):5183. https://doi.org/10.3390/app11115183
Chicago/Turabian StyleMahdi, Mohammed Najah, Mohd Hazli Mohamed Zabil, Abdul Rahim Ahmad, Roslan Ismail, Yunus Yusoff, Lim Kok Cheng, Muhammad Sufyian Bin Mohd Azmi, Hayder Natiq, and Hushalini Happala Naidu. 2021. "Software Project Management Using Machine Learning Technique—A Review" Applied Sciences 11, no. 11: 5183. https://doi.org/10.3390/app11115183
APA StyleMahdi, M. N., Mohamed Zabil, M. H., Ahmad, A. R., Ismail, R., Yusoff, Y., Cheng, L. K., Azmi, M. S. B. M., Natiq, H., & Happala Naidu, H. (2021). Software Project Management Using Machine Learning Technique—A Review. Applied Sciences, 11(11), 5183. https://doi.org/10.3390/app11115183