
End to End Alignment Learning of Instructional Videos with Spatiotemporal Hybrid Encoding and Decoding Space Reduction



Abstract
:1. Introduction
1.1. The Motivation of Long-Term Temporal Encoding
- In action recognition, temporal localization is not taken into account, where input samples are previously truncated to contain exactly the temporal span of a certain target action, leading to relatively short inputs (e.g., 2∼20 s in UCF101 datasets). In frame-wise action alignment, inputs generally last minutes or hours. In action recognition, background class is not taken into account, where input samples may not contain any of the target actions.
- In action alignment, dependencies can also last temporally across seconds or even minutes. The types of temporal dependencies include individual action durations, pairwise compositions between consecutive actions, and long-term compositions lasting across multiple sub-actions. As an example of a cooking instance, when cutting a potato, it is difficult to recognize what is being cut because it tends to be occluded by hands holding it. The recognition of frames where the potato is being cut shares dependencies with previous frames where the potato is being taken out before being cut.
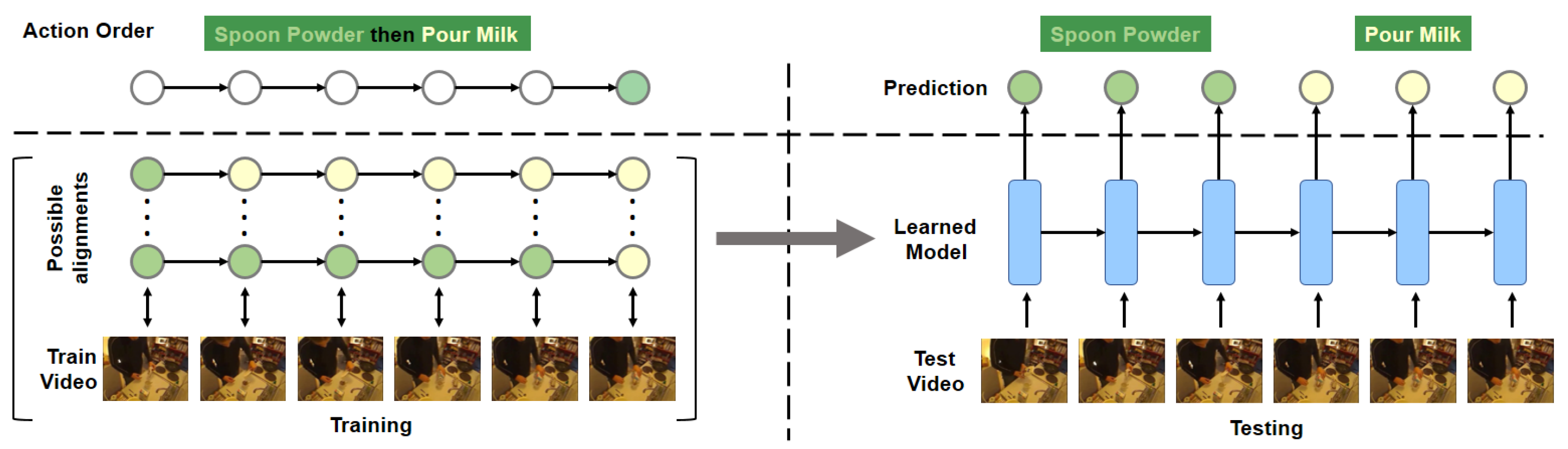
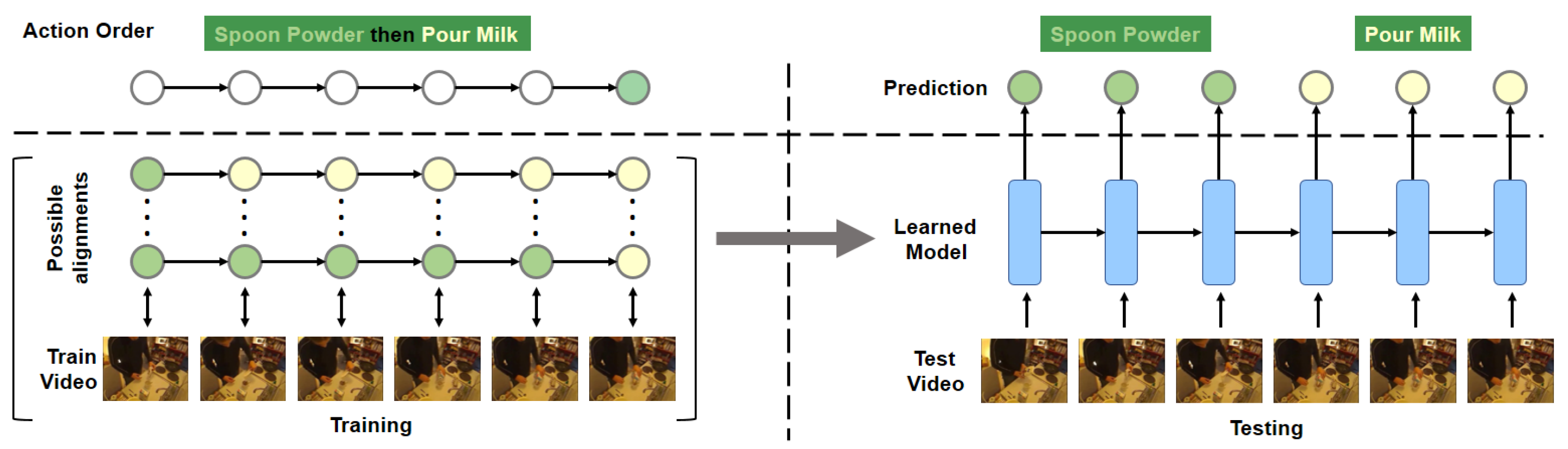
- In action recognition, only one label needs to be assigned to the whole video, whereas the action alignment task needs to densely assign a label to each frame. Consider a video instance consisting of 20 frames sharing the same class.
- In action recognition, even if a convolution network correctly predicts only for 10 frames, it is still very likely to correctly predict the whole video. A powerful temporal encoder, illustrated in Figure 2, on top of a convolution network would not bring any improvement in this case, because per video labels do not change whether or not per frame labels are neighboring. In action alignment, 10 accurate but not neighboring predictions would lead to over-segmentation error with 20 segments. Bidirectional temporal encoders would be motivated to predict neighboring segments, because they encode late samples together with the early ones for final judgement, leading to fewer false positives compared to a purely convolutionnetwork (see Figure 3).
1.2. The Motivation of Hybrid Spatiotemporal Encoding
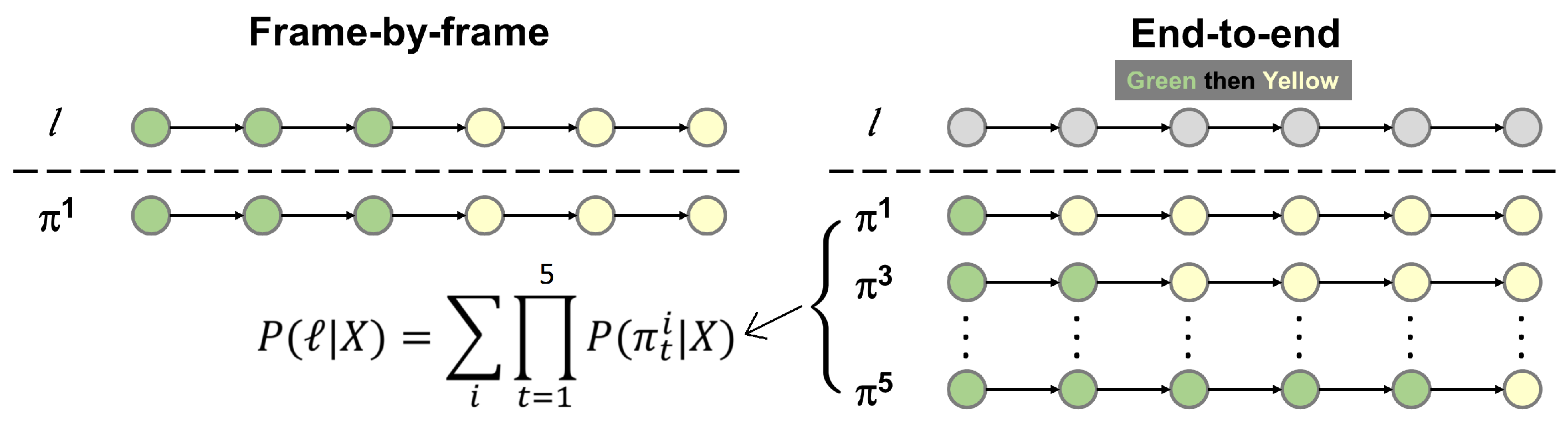
1.3. The Motivation of Decoding Space Reduction
- The first challenge is that densely aligning thousands of frames to a few sub-actions results in very large search spaces of possible alignments.
- The second challenge is that there exist degenerated alignments that are visually inconsistent.
2. Related Work
2.1. Action Segmentation
2.2. Action Alignment
2.3. Automatic Feature Extraction
2.4. Automatic Label Extraction
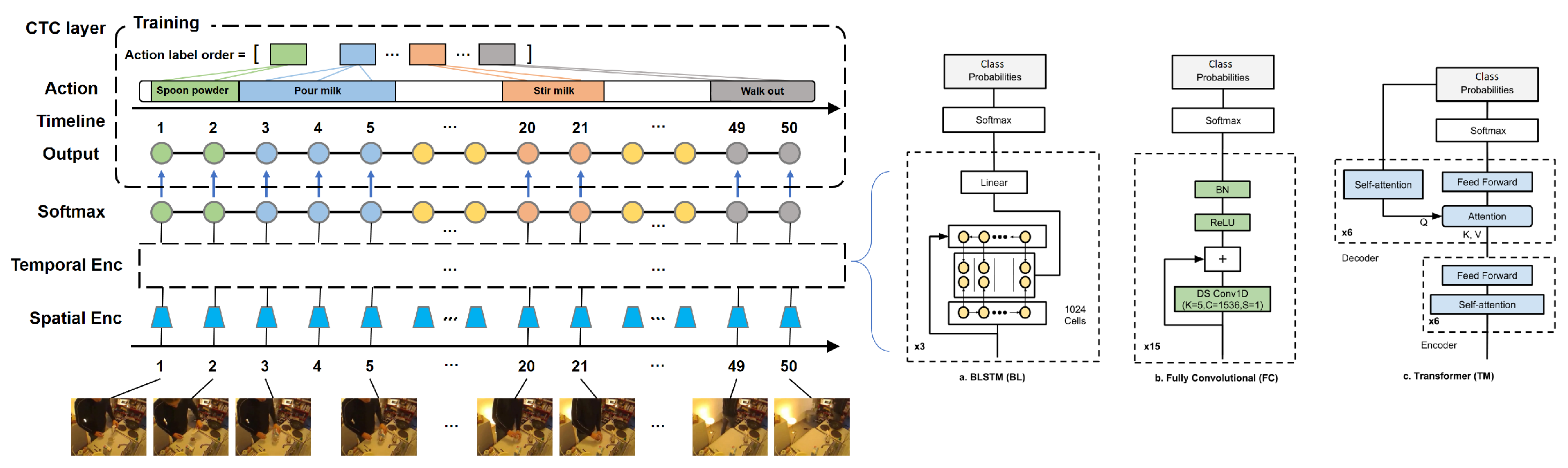
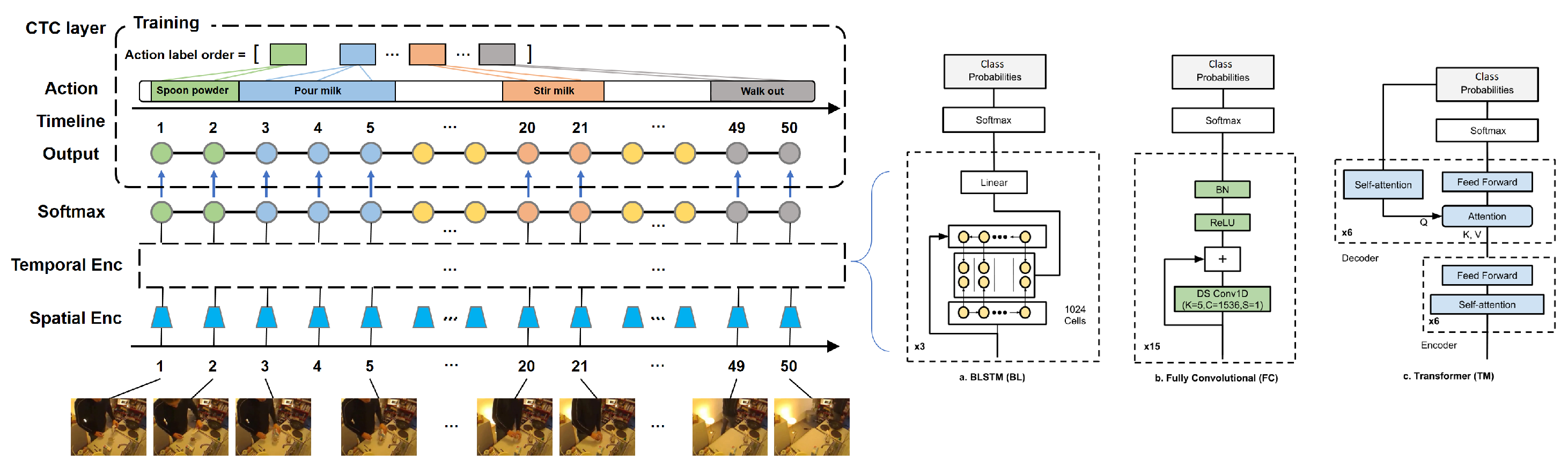
3. The Proposed Encoder–Decoder Network
3.1. Spatial Encoder
3.2. Temporal Encoder
3.2.1. LSTM
3.2.2. Full Convolution
3.2.3. Transformer
3.3. The Original CTC Decoding
3.4. Decoding Search Space Reduction
- When and (high similarity), reward path to stay at the same prediction.
- When and (low similarity), means no intervention after normalization.
3.4.1. Example
- , represented by green, yellow, and orange nodes, respectively.
- ℓ
- , which is supposed to be already known during training.
- .
- .
- has to be ;
- has to be ; and
- The difference among different s is to choose at which to transit the node label from to , with .
- .
- .
- For each middle node , there are only two possible options: (1) Stay the same as the previous node, which means if , as well. Whenever this case holds true, a ‘repetition’ happens in . (2) Transit from to the next label in ℓ, which means . Any other label assignment will cause holding false.
- Case 1: ,
- for path when is introduced to encourage , which has a ‘repetition’ at to yield a higher probability than after re-normalization at time step .
- for path since at , which means no encouragement after re-normalization at time step ; the calculation remains the same as the original Equation (3).
- Case 2: ,
- for path when , which means such a ‘repetition’ at is not encouraged and remains the same as the original Equation (3) after re-normalization.
- for path since at , which also means no intervention.
3.4.2. How to Train the Proposed Decoder
- are the un-normalised outputs before the softmax activation function is applied: , ranges over all outputs; and
- ,
- are forward and backward variables, respectively. is defined as the summed probability of all paths satisfying , and appends to from that completes , where is the first j actions of ℓ; both and can be calculated by recursive inductions:
4. Experimental Setup
4.1. Visual Similarity Measurement
- if and only if and fall within same cluster;
- if and only if or is at the boundary between clusters.
4.2. Datasets
- YouTube Instructions [24] contains 150 samples from YouTube on five tasks: making coffee, changing a car tire, CPR, jumping a car, and potting a plant, with approximately two minutes per sample.
- YouCook2 [25] contains about samples from YouTube on 90 cooking recipes, with approximately 3∼15 steps per recipe class, where each step is a temporally aligned narration collected from paid human workers.
- Breakfast [38] contains about samples on ten common kitchen tasks with approximately eight steps per task. The average length of each task varies from 30 s to 5 min.
- 50 Salads [18] contains 4.5 h of 25 people preparing 2 mixed salads each, with approximately frames per sample. Each sub-action corresponds to two levels of granularity, and each low-level granularity is further divided into pre-, core-, and post-phase.
4.3. Metrics
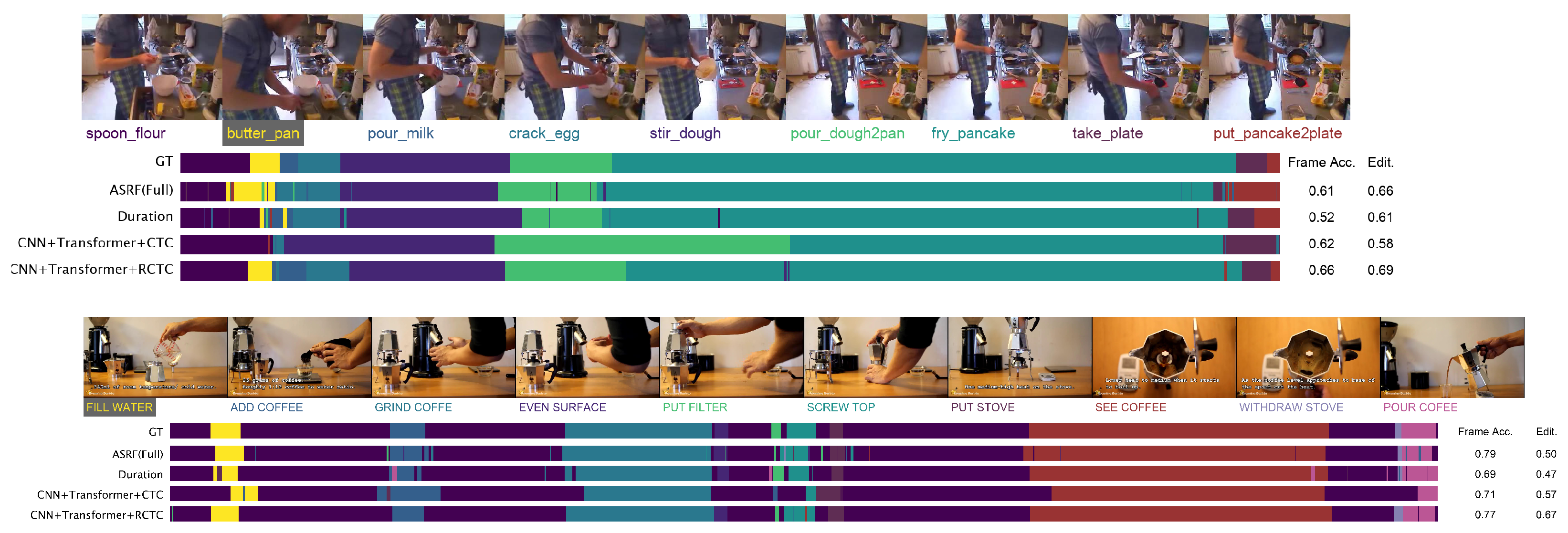
- Frame-level accuracy is calculated as the percentage of correct predictions. Intuitively, frame-wise metrics ignore temporal patterns and occurrence orders in the sequential inputs. It is possible to achieve high frame measures but at the same time generate considerable over-segmentation errors, as visualized later, raising the need to introduce segmental metrics to penalize predictions that are out of order or over-segmented.
- Segment-level edit distance is also known as the Levenshtein distance, and only measures the temporal order of occurrence, without considering durations. It is therefore useful for procedural tasks in this work, where the order is the most essential.It is calculated as segment insertions, deletions, and substitutions between predicted order and the ground-truth sequence, then normalized to range [0∼100] in Table 4 such that higher is better:
- Segment-level mean average precision (mAP@k) With an intersection over union (IoU) threshold k, calculated as dividing the intersection between each pair of predicted segments I and the ground-truth segment of the same action category by their union:I is considered as a ‘true positive’ () if , otherwise it is a ‘false positive’ (). Average precision is accumulated across all categories. is more invariant to small temporal shifts as compared to the above metric.
- Segment-level F1-score (F1@k) With an intersection over union (IoU) threshold k, where true positives are judged by with labels same as the ground truth:
4.4. Hyper-Parameters
- CNN pre-training: I3D Res-50 backbone [37] pre-trained on Kinetics [43] (https://github.com/deepmind/kinetics-i3d, accessed on 20 August 2020).
- Optimization: The BLSTM is trained with Vanilla SGD, a fixed momentum of 0.9, initial learning rate and reduced down to every time the error plateaus. Following [44], the fully convolutional network and Transformer are trained with the ADAM optimizer, initial learning rate , reduced down to on plateaus.
- Transformer embedding: The information about the sequence order of the encoder and decoder inputs is fed to the model via fixed positional embedding in the form of sinusoid functions. The Transformer is trained using teacher forcing—the ground truth of the previous decoding step is fed as the input to the decoder, while during inference the decoder prediction is fed back.
- Dropout: Following [45], the BLSTM is trained with dropout probability on the units of the inputs and recurrent layers. The fully convolutional network is trained with a dropout probability on the units of batch normalization layers. The Transformer is trained with dropout probability dropout .
- Termination: The loss function no longer drops on the validation set between 2 consecutive epochs.
- Software and Hardware: All the models are implemented in TensorFlow and trained on a single GeForce GTX 1080 Ti GPU with 11 GB memory.
5. Results and Discussion
5.1. Ablation Analysis
5.1.1. Ablation Analysis of Temporal Encoding Backbone
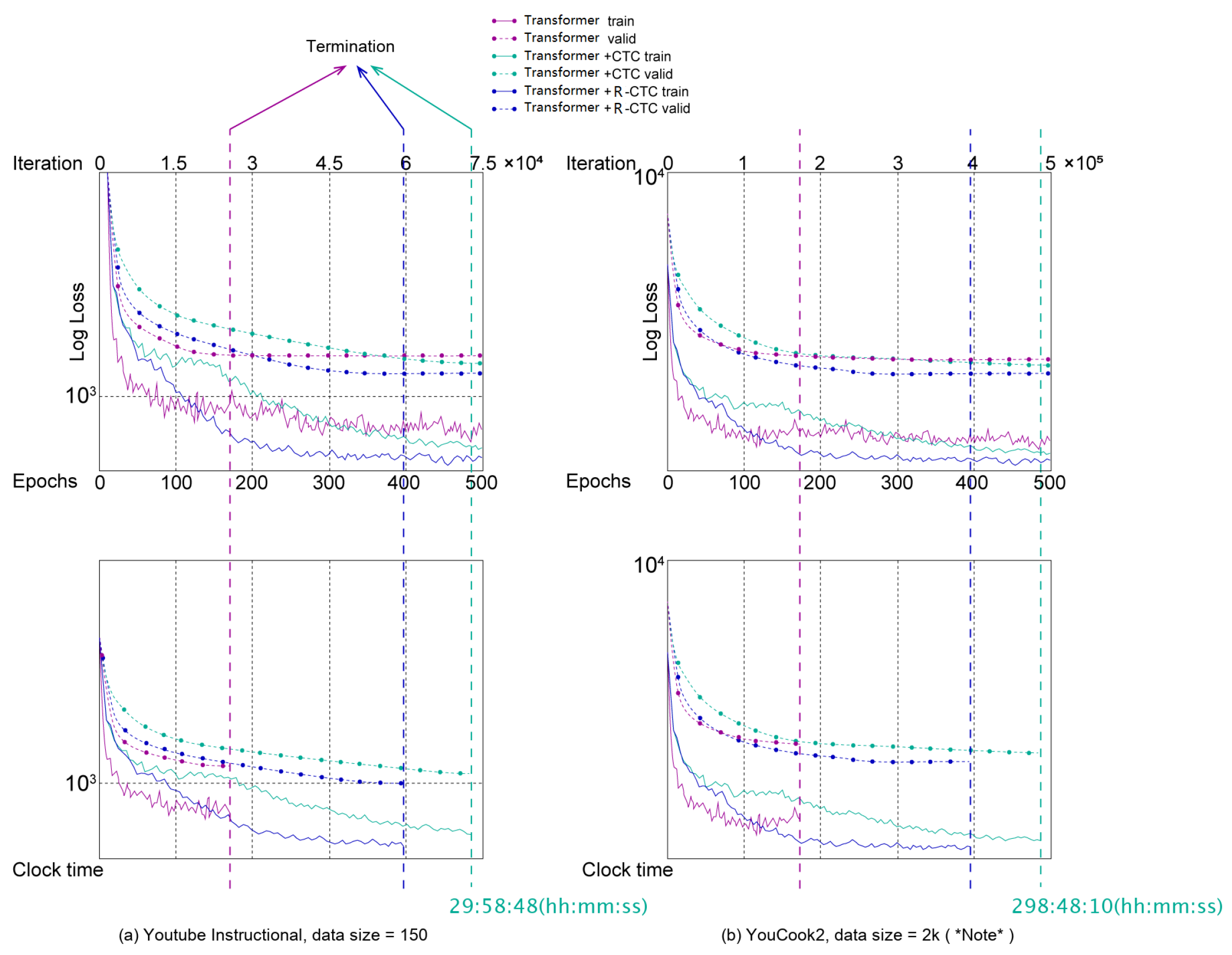
Training Time
5.1.2. Ablation Analysis of CTC Search Space Reduction
Training Time
5.2. Comparison with State-of-the-Art Frame-Wise Methods
5.3. Qualitative Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CTC | Connectionist Temporal Classification |
| LSTM | Long Short-Term Memory Network |
| CR-CTC | Reduced Connectionist Temporal Classification |
| FC Fully | Convolution |
| TM | Transformer |
| ED-TCN | Encoder–Decoder Temporal Convolutional Network |
References
- Richard, A.; Kuehne, H.; Gall, J. Weakly supervised action learning with rnn based fine-to-coarse modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 754–763. [Google Scholar]
- Ding, L.; Xu, C. Weakly-supervised action segmentation with iterative soft boundary assignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6508–6516. [Google Scholar]
- Li, J.; Lei, P.; Todorovic, S. Weakly supervised energy-based learning for action segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6243–6251. [Google Scholar]
- Alayrac, J.B.; Bojanowski, P.; Agrawal, N.; Sivic, J.; Laptev, I.; Lacoste-Julien, S. Learning from narrated instruction videos. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2194–2208. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tang, Y.; Ding, D.; Rao, Y.; Zheng, Y.; Zhang, D.; Zhao, L.; Lu, J.; Zhou, J. COIN: A large-scale dataset for comprehensive instructional video analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1207–1216. [Google Scholar]
- Fried, D.; Alayrac, J.B.; Blunsom, P.; Dyer, C.; Clark, S.; Nematzadeh, A. Learning to Segment Actions from Observation and Narration. arXiv 2020, arXiv:2005.03684. [Google Scholar]
- Graves, A. Connectionist Temporal Classification. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 61–93. [Google Scholar] [CrossRef]
- Pirsiavash, H.; Ramanan, D. Parsing videos of actions with segmental grammars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 612–619. [Google Scholar]
- Richard, A.; Gall, J. Temporal action detection using a statistical language model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3131–3140. [Google Scholar]
- Lea, C.; Reiter, A.; Vidal, R.; Hager, G.D. Segmental Spatiotemporal CNNs for Fine-Grained Action Segmentation. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science. Springer International Publishing: Cham, Switzerland, 2016; pp. 36–52. [Google Scholar]
- Singh, B.; Marks, T.K.; Jones, M.; Tuzel, O.; Shao, M. A multi-stream bi-directional recurrent neural network for fine-grained action detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1961–1970. [Google Scholar]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal Convolutional Networks for Action Segmentation and Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lei, P.; Todorovic, S. Temporal deformable residual networks for action segmentation in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6742–6751. [Google Scholar]
- Zhang, Y.; Tang, S.; Muandet, K.; Jarvers, C.; Neumann, H. Local temporal bilinear pooling for fine-grained action parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12005–12015. [Google Scholar]
- Ishikawa, Y.; Kasai, S.; Aoki, Y.; Kataoka, H. Alleviating Over-Segmentation Errors by Detecting Action Boundaries. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikola, HI, USA, 5–9 January 2021; pp. 2322–2331. [Google Scholar]
- Ghoddoosian, R.; Sayed, S.; Athitsos, V. Action Duration Prediction for Segment-Level Alignment of Weakly-Labeled Videos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikola, HI, USA, 5–9 January 2021; pp. 2053–2062. [Google Scholar]
- Rohrbach, M.; Rohrbach, A.; Regneri, M.; Amin, S.; Andriluka, M.; Pinkal, M.; Schiele, B. Recognizing Fine-Grained and Composite Activities Using Hand-Centric Features and Script Data. Int. J. Comput. Vis. 2015, 119, 346–373. [Google Scholar] [CrossRef] [Green Version]
- Stein, S.; McKenna, S.J. Combining Embedded Accelerometers with Computer Vision for Recognizing Food Preparation Activities. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp 13), Zurich, Switzerland, 8–12 September 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 729–738. [Google Scholar] [CrossRef]
- Fathi, A.; Ren, X.; Rehg, J.M. Learning to recognize objects in egocentric activities. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3281–3288. [Google Scholar]
- Gao, Y.; Vedula, S.S.; Reiley, C.E.; Ahmidi, N.; Varadarajan, B.; Lin, H.C.; Tao, L.; Zappella, L.; Béjar, B.; Yuh, D.D.; et al. Jhu-isi gesture and skill assessment working set (jigsaws): A surgical activity dataset for human motion modeling. In Proceedings of the Modeling and Monitoring of Computer Assisted Interventions (M2CAI), MICCAI Workshop, Boston, MA, USA, 14–18 September 2014; Volume 3, p. 3. [Google Scholar]
- Ahmidi, N.; Tao, L.; Sefati, S.; Gao, Y.; Lea, C.; Haro, B.B.; Zappella, L.; Khudanpur, S.; Vidal, R.; Hager, G.D. A dataset and benchmarks for segmentation and recognition of gestures in robotic surgery. IEEE Trans. Biomed. Eng. 2017, 64, 2025–2041. [Google Scholar] [CrossRef] [PubMed]
- Kuehne, H.; Arslan, A.B.; Serre, T. The Language of Actions: Recovering the Syntax and Semantics of Goal-Directed Human Activities. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Bojanowski, P.; Lajugie, R.; Grave, E.; Bach, F.; Laptev, I.; Ponce, J.; Schmid, C. Weakly-supervised alignment of video with text. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 4462–4470. [Google Scholar]
- Alayrac, J.B.; Bojanowski, P.; Agrawal, N.; Sivic, J.; Laptev, I.; Lacoste-Julien, S. Unsupervised learning from narrated instruction videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4575–4583. [Google Scholar]
- Zhou, L.; Xu, C.; Corso, J.J. Towards automatic learning of procedures from web instructional videos. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Kukleva, A.; Kuehne, H.; Sener, F.; Gall, J. Unsupervised learning of action classes with continuous temporal embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12066–12074. [Google Scholar]
- Oneata, D.; Verbeek, J.; Schmid, C. Action and event recognition with fisher vectors on a compact feature set. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 2–8 December 2013; pp. 1817–1824. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 2–8 December 2013; pp. 3551–3558. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–17 December 2015; pp. 4489–4497. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? In A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Piergiovanni, A.; Ryoo, M.S. Representation flow for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9945–9953. [Google Scholar]
- Malmaud, J.; Huang, J.; Rathod, V.; Johnston, N.; Rabinovich, A.; Murphy, K. What’s cookin’? interpreting cooking videos using text, speech and vision. arXiv 2015, arXiv:1503.01558. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, June 23–28 June 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Kuehne, H.; Gall, J.; Serre, T. An end-to-end generative framework for video segmentation and recognition. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–8. [Google Scholar]
- Graves, A.; Fernández, S.; Schmidhuber, J. Bidirectional LSTM networks for improved phoneme classification and recognition. In Proceedings of the International Conference on Artificial Neural Networks, Warsaw, Poland, 11–15 September 2005; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2005; pp. 799–804. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Li, A.; Thotakuri, M.; Ross, D.A.; Carreira, J.; Vostrikov, A.; Zisserman, A. The AVA-Kinetics Localized Human Actions Video Dataset. arXiv 2020, arXiv:2005.00214. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 23rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015; Bengio, Y., LeCun, Y., Eds.; Conference Track Proceedings. 2015. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Dauphin, Y. A Convolutional Encoder Model for Neural Machine Translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 123–135. [Google Scholar] [CrossRef]
- Kaiser, L.; Gomez, A.N.; Chollet, F. Depthwise Separable Convolutions for Neural Machine Translation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhang, Y.; Pezeshki, M.; Brakel, P.; Zhang, S.; Laurent, C.; Bengio, Y.; Courville, A. Towards End-to-End Speech Recognition with Deep Convolutional Neural Networks. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 410–414. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Deng, X.; Pu, S.; Huang, Z. Residual Convolutional CTC Networks for Automatic Speech Recognition. arXiv 2017, arXiv:1702.07793. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional Sequence to Sequence Learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; Volume 70, pp. 1243–1252. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trained with Frame-Wise Annotations: | MPII Cooking2 [17] | MERL Shopping [11] | 50 Salads [18] | GETA [19] | JIGSAWS [20,21] |
| MSB-RNN [11] (2016) | |||||
| ED-TCN [12] (2017) | |||||
| TCED [14] (2019) | |||||
| ASRF [15] (2021) | |||||
| Trained with Only Order of Actions: | Breakfast [22] | Hollywood Ext. [23] | 50 Salads | YouTube Instructions [24] | YouCook2 [25] |
| GRU + HMM [1] (2017) | |||||
| ProcNet [25] (2018) | |||||
| Unsupervised [26] (2019) | |||||
| Duration [16] (2021) |
| Layer | I3D Res-50 | Output Size |
|---|---|---|
| 7, 64 | ||
| global pooling → softmax |
| BLSTM | Full Convolution | Transformer | |
|---|---|---|---|
| Dimension | |||
| # Parameters | 22 M | 35 M | 40 M |
| Optimization | SGD, batch size | Adam, batch size | Adam, batch size |
| Momentum | 0.9 | − | − |
| Learning Rate | |||
| Dropout | 0.3 | 0.8 | 0.1 |
| Training Time/Batch | 0.76 s/32 | 0.34 s | 0.41 s |
| Convergence (Iterations) | |||
| Convergence (Clock Time) | 9 days | 3.4 days | 14 days |
| Datasets | 50 Salads [18] (2013) | YouTube Instructions [24] (2016) | Breakfast [38] (2016) | YouCook2 [25] (2018) | |||
|---|---|---|---|---|---|---|---|
| Size (hour) | 4.5 h | 5 h | 77 h | 176 h | |||
| #Samples | 50 | 150 | |||||
| #Classes/#Sub-actions | |||||||
| Sample Length | 4∼5 min | 2 min | 0.5∼5 min | 5 min | |||
| Label Length | 37∼72 steps | 7∼10 steps | 3∼10 steps | 3∼15 steps | |||
| Recording | YouTube | YouTube | |||||
| Recording | |||||||
| Frame-wise Annotation | 1. CNN + BLSTM [11] (2016) | Frame Acc. | 76.9 | 60.8 | 60.6 | 45.8 | |
| mAP @ 0.25 | 72.5 | 47.0 | 64.9 | 33.7 | |||
| Edit | 71.4 | 41.9 | 61.8 | 28.4 | |||
| 2. ED-TCN [12] (2017) | Frame Acc. | 82.1 | 64.9 | 64.7 | 48.9 | ||
| mAP @ 0.25 | 73.4 | 50.2 | 65.7 | 36.5 | |||
| Edit | 68.9 | 44.7 | 59.6 | 30.4 | |||
| 3. TCED [14] (2019) | Frame Acc. | 68.1 | 66.0 | 53.7 | 47.9 | ||
| mAP @ 0.25 | 68.5 | 54.0 | 61.3 | 35.9 | |||
| Edit | 66.0 | 48.3 | 57.1 | 30.7 | |||
| 4. ASRF [15] (2021) | Frame Acc. | 84.5 | 81.9 | 67.6 | 59.5 | ||
| mAP @ 0.25 | 83.5 | 65.8 | 72.4 | 43.8 | |||
| Edit | 79.3 | 58.0 | 68.9 | 36.9 | |||
| Video-level Annotation | 5. Duration [16] (2021) | Frame Acc. | 70.7 | 67.5 | 55.7 | 42.1 | 5. Baseline) |
| mAP @ 0.25 | 63.2 | 54.2 | 56.6 | 31.5 | |||
| Edit | 59.3 | 47.8 | 51.3 | 26.9 | |||
| 6. I3D + BLSTM + CTC (Ours) | Frame Acc. | 56.8 | 54.3 | 44.8 | 33.8 | ||
| mAP @ 0.25 | 50.8 | 43.6 | 45.5 | 25.3 | |||
| Edit | 47.7 | 38.4 | 41.3 | 21.7 | |||
| 7. I3D + FC + CTC (Ours) | Frame Acc. | 62.9 | 60.1 | 49.6 | 37.5 | ||
| mAP @ 0.25 | 56.5 | 48.5 | 50.6 | 28.2 | |||
| Edit | 59.6 | 48.1 ) | 51.6 | 27.1 | |||
| 8. I3D + Transformer + CTC (Ours) | Frame Acc. | 74.9 | 71.6 | 59.1 | 44.6 | ||
| mAP @ 0.25 | 67.1 | 57.6 | 60.1 | 33.5 | |||
| Edit | 70.6 | 56.9 | 61.1 | 32.1 | |||
| 9. I3D + Transformer + R-CTC (Ours) | Frame Acc. | 79.9 | 76.3 | 63.0 | 47.6 | ||
| mAP @ 0.25 | 71.5 | 61.3 | 64.0 | 35.6 | |||
| Edit | 75.1 | 60.5 | 65.0 | 34.1 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Wang, X.; Hawbani, A.; Xiong, Y. End to End Alignment Learning of Instructional Videos with Spatiotemporal Hybrid Encoding and Decoding Space Reduction. Appl. Sci. 2021, 11, 4954. https://doi.org/10.3390/app11114954
Wang L, Wang X, Hawbani A, Xiong Y. End to End Alignment Learning of Instructional Videos with Spatiotemporal Hybrid Encoding and Decoding Space Reduction. Applied Sciences. 2021; 11(11):4954. https://doi.org/10.3390/app11114954
Chicago/Turabian StyleWang, Lin, Xingfu Wang, Ammar Hawbani, and Yan Xiong. 2021. "End to End Alignment Learning of Instructional Videos with Spatiotemporal Hybrid Encoding and Decoding Space Reduction" Applied Sciences 11, no. 11: 4954. https://doi.org/10.3390/app11114954
APA StyleWang, L., Wang, X., Hawbani, A., & Xiong, Y. (2021). End to End Alignment Learning of Instructional Videos with Spatiotemporal Hybrid Encoding and Decoding Space Reduction. Applied Sciences, 11(11), 4954. https://doi.org/10.3390/app11114954