Detecting Vulnerabilities in Critical Infrastructures by Classifying Exposed Industrial Control Systems Using Deep Learning

 ,
,  , ,
, ,  , and
, and
Abstract
Featured Application
Abstract
1. Introduction
2. State of the Art
3. Methodology
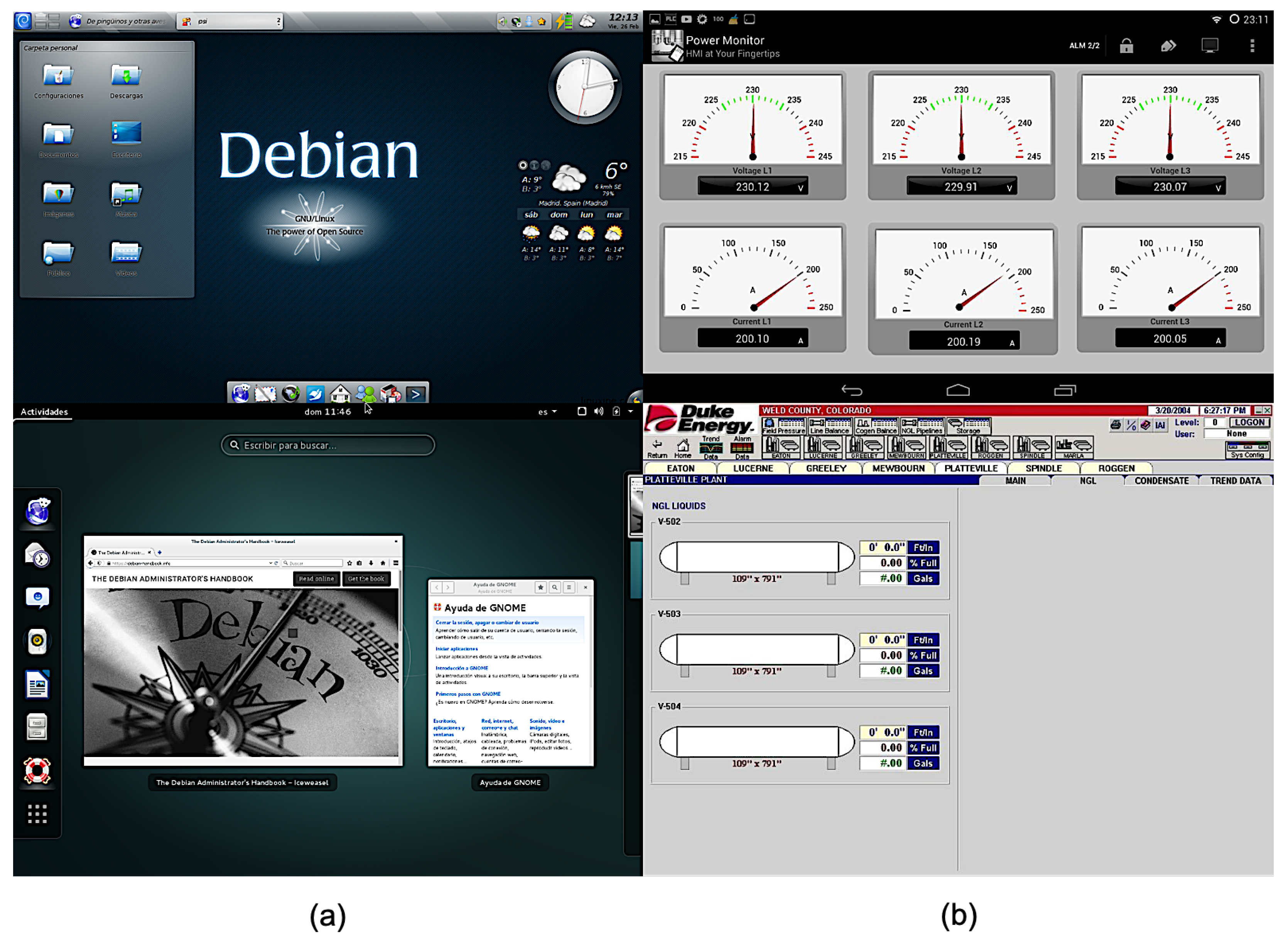
3.1. Critical Infrastructure Dataset
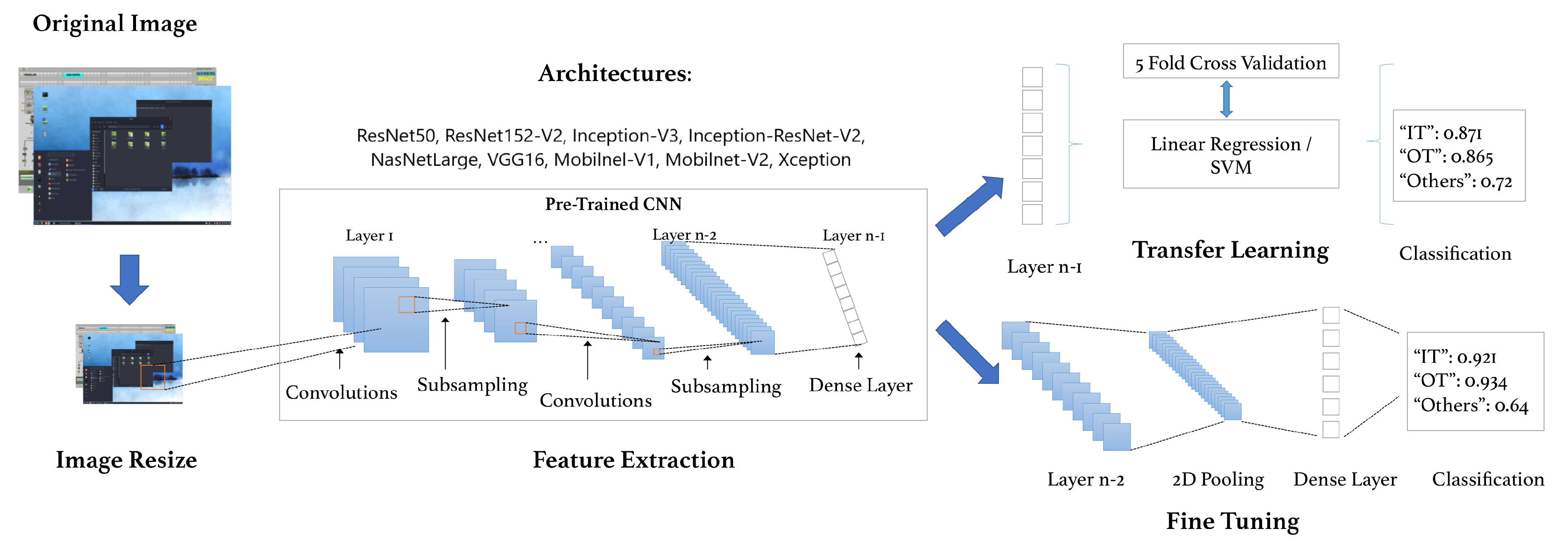
3.2. Proposed Pipeline
3.2.1. Transfer Learning and Fine-Tuning
3.2.2. Architectures
4. Experimental Results and Discussion
4.1. Experimental Settings
4.1.1. Transfer Learning Settings
4.1.2. Fine-Tuning Settings
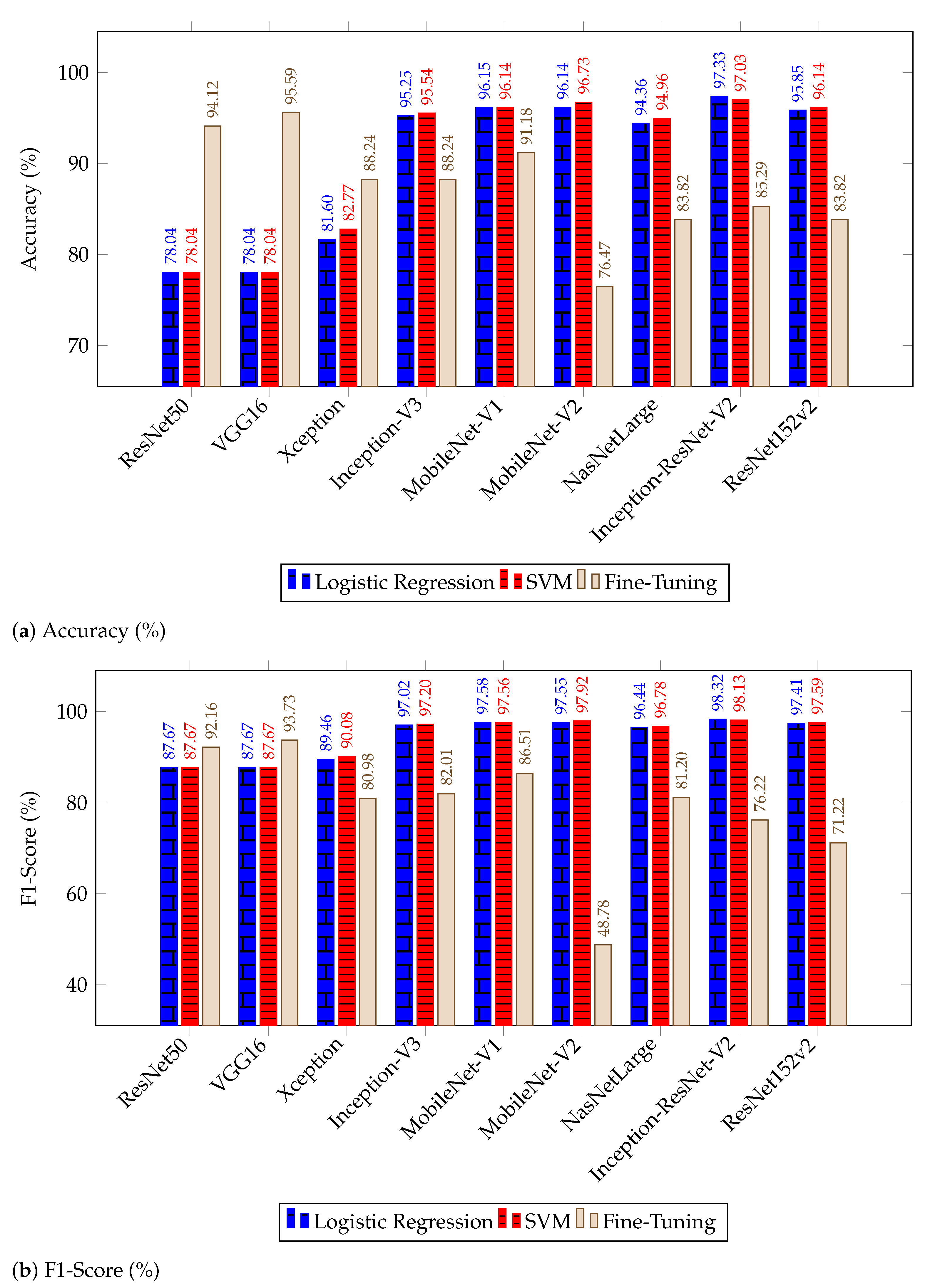
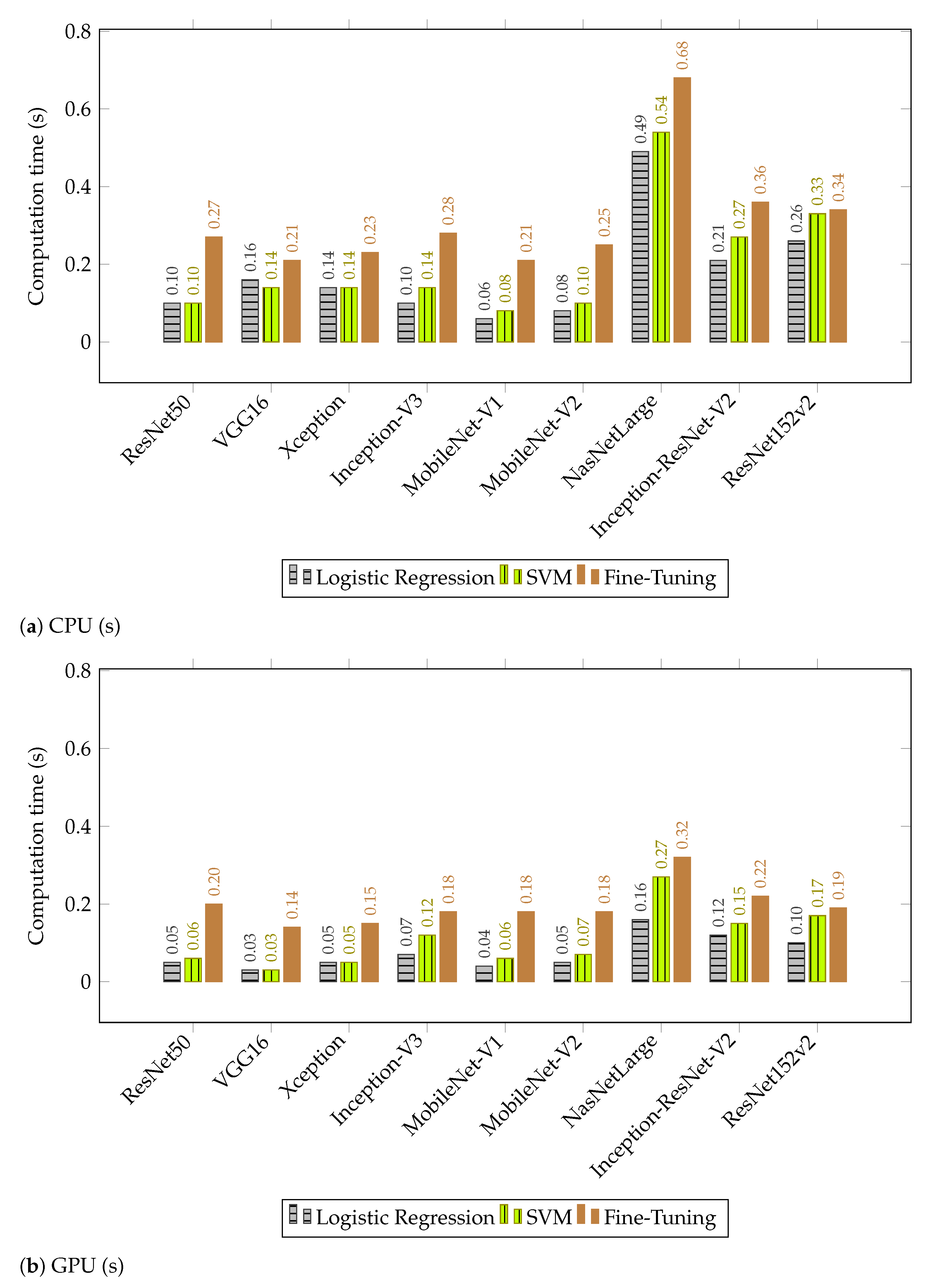
4.2. Discussion of Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wolf, M.; Serpanos, D. Safety and security in cyber-physical systems and internet-of-things systems. Proc. IEEE 2017, 106, 9–20. [Google Scholar] [CrossRef]
- Cherdantseva, Y.; Burnap, P.; Blyth, A.; Eden, P.; Jones, K.; Soulsby, H.; Stoddart, K. A review of cyber security risk assessment methods for SCADA systems. Comput. Secur. 2016, 56, 1–27. [Google Scholar] [CrossRef]
- Conklin, W.A. IT vs. OT security: A time to consider a change in CIA to include resilienc. In Proceedings of the 2016 49th Hawaii International Conference on System Sciences (HICSS), Koloa, HI, USA, 5–8 January 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2642–2647. [Google Scholar]
- Lee, S.; Shon, T. Open source intelligence base cyber threat inspection framework for critical infrastructures. In Proceedings of the 2016 Future Technologies Conference (FTC), San Francisco, CA, USA, 6–7 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1030–1033. [Google Scholar]
- Genge, B.; Enăchescu, C. ShoVAT: Shodan-based vulnerability assessment tool for Internet-facing services. Secur. Commun. Networks 2016, 9, 2696–2714. [Google Scholar] [CrossRef]
- Liu, Q.; Feng, C.; Song, Z.; Louis, J.; Zhou, J. Deep Learning Model Comparison for Vision-Based Classification of Full/Empty-Load Trucks in Earthmoving Operations. Appl. Sci. 2019, 9, 4871. [Google Scholar] [CrossRef]
- Han, D.; Liu, Q.; Fan, W. A new image classification method using CNN transfer learning and web data augmentation. Expert Syst. Appl. 2018, 95, 43–56. [Google Scholar] [CrossRef]
- Fidalgo, E.; Alegre, E.; Fernández-Robles, L.; González-Castro, V. Fusión temprana de descriptores extraídos de mapas de prominencia multi-nivel para clasificar imágenes. Rev. Iberoam. Automática E Informática 2019, 16, 358–368. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Fidalgo, E.; Alegre, E.; Fernández-Robles, L.; González-Castro, V. Classifying suspicious content in tor darknet through Semantic Attention Keypoint Filtering. Digit. Investig. 2019, 30, 12–22. [Google Scholar] [CrossRef]
- Fidalgo, E.; Alegre, E.; Gonzalez-Castro, V.; Fernández-Robles, L. Boosting image classification through semantic attention filtering strategies. Pattern Recognit. Lett. 2018, 112, 176–183. [Google Scholar] [CrossRef]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G.; Lv, J. Automatically Designing CNN Architectures Using the Genetic Algorithm for Image Classification. IEEE Trans. Cybern. 2020, 50, 3840–3854. [Google Scholar] [CrossRef] [PubMed]
- Ma, B.; Li, X.; Xia, Y.; Zhang, Y. Autonomous deep learning: A genetic DCNN designer for image classification. Neurocomputing 2020, 379, 152–161. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. arXiv 2019, arXiv:1901.06032. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 270–279. [Google Scholar]
- Hussain, M.; Bird, J.J.; Faria, D.R. A study on cnn transfer learning for image classification. In UK Workshop on Computational Intelligence; Springer: Cham, Switzerland, 2018; pp. 191–202. [Google Scholar]
- Xiao, Z.; Tan, Y.; Liu, X.; Yang, S. Classification Method of Plug Seedlings Based on Transfer Learning. Appl. Sci. 2019, 9, 2725. [Google Scholar] [CrossRef]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning multiple layers of features from tiny images. Citeseer 2009, 7, 1–58. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 1097–1105. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Sharma, N.; Jain, V.; Mishra, A. An analysis of convolutional neural networks for image classification. Procedia Comput. Sci. 2018, 132, 377–384. [Google Scholar] [CrossRef]
- Taormina, V.; Cascio, D.; Abbene, L.; Raso, G. Performance of Fine-Tuning Convolutional Neural Networks for HEp-2 Image Classification. Appl. Sci. 2020, 10, 6940. [Google Scholar] [CrossRef]
- Bello, I.; Zoph, B.; Vasudevan, V.; Le, Q.V. Neural optimizer search with reinforcement learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 459–468. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 29 November 2020).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Blanco-Medina, P.; Alegre, E.; Fidalgo, E.; Al-Nabki, M.; Chaves, D. Enhancing text recognition on Tor Darknet images. XL Jornadas Autom. 2019, 828–835. [Google Scholar] [CrossRef]
- Blanco-Medina, P.; Fidalgo, E.; Alegre, E.; Jáñez Martino, F. Improving Text Recognition in Tor darknet with Rectification and Super-Resolution techniques. In Proceedings of the 9th International Conference on Imaging for Crime Detection and Prevention (ICDP-2019), London, UK, 16–18 December 2019; pp. 32–37. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | Top-5 Accuracy (%) | Top-1 Accuracy (%) | Dataset |
|---|---|---|---|
| LeNet [20] | - | MNIST [20] | |
| DenseNet [21] | CIFAR-10 [22] | ||
| AlexNet [23] | ImageNet | ||
| ZFNet [24] | ImageNet | ||
| GoogleNet [25] | ImageNet | ||
| VGG16 [26] | ImageNet | ||
| ResNet [27] | ImageNet | ||
| ResNeXt-101 [28] | ImageNet | ||
| Inception-V3 [29] | ImageNet | ||
| SENet [30] | ImageNet | ||
| MobileNet-V1 [31] | ImageNet | ||
| MobileNet-V2 [32] | - | ImageNet | |
| MobileNet-V3 [33] | - | ImageNet | |
| EfficientNet [34] | ImageNet | ||
| Xception [35] | ImageNet | ||
| Inception-ResNet-V2 [36] | ImageNet | ||
| NasNetLarge [19] | ImageNet |
| Architecture | F1-Score (%) | Accuracy (%) | CPU (s) | GPU (s) |
|---|---|---|---|---|
| ResNet50 | (+/−) | (+/−) | (+/) | (+/) |
| VGG16 | (+/−) | (+/−) | (+/−) | (+/−) |
| Xception | (+/−) | (+/−) | (+/−) | (+/−) |
| Inception-V3 | (+/−) | (+/−) | (+/−) | (+/−) |
| Mobilenet-V1 | (+/−) | (+/−) | (+/−) | (+/−) |
| Mobilenet-V2 | (+/−) | (+/−) | (+/−) | (+/−) |
| NasNetLarge | (+/−) | (+/−) | (+/−) | (+/−) |
| Inception-ResNet-V2 | (+/−) | (+/−) | (+/−) | (+/−) |
| ResNet152v2 | (+/−) | (+/−) | (+/−) | (+/−) |
| Architecture | F1-Score (%) | Accuracy (%) | CPU (s) | GPU (s) |
|---|---|---|---|---|
| ResNet50 | (+/−) | (+/−) | (+/) | (+/−) |
| VGG16 | (+/−) | (+/−) | (+/−) | (+/−) |
| Xception | (+/−) | (+/−) | (+/−) | (+/−) |
| Inception-V3 | (+/−) | (+/−) | (+/−) | (+/−) |
| Mobilenet-V1 | (+/−) | (+/−) | (+/−) | (+/−) |
| Mobilenet-V2 | (+/−) | (+/−) | (+/−) | (+/−) |
| NasNetLarge | (+/−) | (+/−) | (+/−) | (+/−) |
| Inception-ResNet-V2 | (+/−) | (+/−) | (+/−) | (+/−) |
| ResNet152v2 | (+/−) | (+/−) | (+/−) | (+/−) |
| Architecture | F1-Score (%) | Accuracy (%) | CPU (s) | GPU (s) |
|---|---|---|---|---|
| ResNet50 | (+/−) | (+/−) | ||
| VGG16 | (+/− | (+/−) | ||
| Xception | (+/−) | (+/−) | ||
| Inception-V3 | (+/−) | (+/−) | ||
| MobileNet-V1 | (+/−) | (+/−) | ||
| MobileNet-V2 | (+/−) | (+/−) | ||
| NasNetLarge | (+/−) | (+/−) | ||
| Inception-ResNet-V2 | (+/−) | (+/−) | ||
| ResNet152v2 | (+/−) | (+/−) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Blanco-Medina, P.; Fidalgo, E.; Alegre, E.; Vasco-Carofilis, R.A.; Jañez-Martino, F.; Villar, V.F. Detecting Vulnerabilities in Critical Infrastructures by Classifying Exposed Industrial Control Systems Using Deep Learning. Appl. Sci. 2021, 11, 367. https://doi.org/10.3390/app11010367
Blanco-Medina P, Fidalgo E, Alegre E, Vasco-Carofilis RA, Jañez-Martino F, Villar VF. Detecting Vulnerabilities in Critical Infrastructures by Classifying Exposed Industrial Control Systems Using Deep Learning. Applied Sciences. 2021; 11(1):367. https://doi.org/10.3390/app11010367
Chicago/Turabian StyleBlanco-Medina, Pablo, Eduardo Fidalgo, Enrique Alegre, Roberto A. Vasco-Carofilis, Francisco Jañez-Martino, and Victor Fidalgo Villar. 2021. "Detecting Vulnerabilities in Critical Infrastructures by Classifying Exposed Industrial Control Systems Using Deep Learning" Applied Sciences 11, no. 1: 367. https://doi.org/10.3390/app11010367
APA StyleBlanco-Medina, P., Fidalgo, E., Alegre, E., Vasco-Carofilis, R. A., Jañez-Martino, F., & Villar, V. F. (2021). Detecting Vulnerabilities in Critical Infrastructures by Classifying Exposed Industrial Control Systems Using Deep Learning. Applied Sciences, 11(1), 367. https://doi.org/10.3390/app11010367