1. Introduction
The optimization of several practical large-scale engineering systems is computationally expensive. The computationally expensive simulation optimization problems (CESOP) are concerned about the limited budget being effectively allocated to meet a stochastic objective function which required running computationally expensive simulation [
1,
2]. The CESOP occur in various fields of automatic manufacturing process, such as the buffer resource allocation, machine allocation of multi-function product center, flow line manufacturing system, as well as numerous industrial managements, including the periodic review inventory system, pull-type production system, and facility-sizing of factory. Although computing devices continue to increase in power, the complexity of evaluating a solution continues to keep pace.
Several methods are adopted to resolve CESOP, such as the gradient descent approaches [
3], metaheuristic algorithms [
4], evolutionary algorithms (EA) [
5], and swarm intelligence (SI) [
6]. The gradient descent approaches [
3], including steepest descent method and conjugated gradient approach, maybe get stuck in a local optimum and fail to obtain the global optimum The metaheuristic algorithms [
4], including Tabu search (TS) and simulated annealing (SA), are developed to find the global optimum. However, the performance of the metaheuristics is extremely dependent on the suitable selection of user dependent parameters. EA [
5] are stochastic search optimization techniques inspired by the biological principle of evolution, survival of the fittest. There are five major types of EA: genetic algorithm (GA), genetic programming (GP), differential evolution (DE), evolutionary strategies (ES), and evolutionary programming (EP). However, EAs are very computationally intensive and require longer computation times to find an acceptable solution. SI [
6] is inspired by collective behaviors of social animals, which is observed in nature such as ants and bees, fish schools and bird flocks. Some of the novel SI methods are grey wolf optimizer (GWO), manta ray foraging optimization (MRFO), sailfish optimizer (SFO), fireworks algorithm (FWA), and ant lion optimization (ALO) [
7,
8,
9,
10]. In essence, SI approaches are stochastic search techniques, where heuristic information is shared to lead the search in the process. Although SI methods have been applied in different domains [
11], the identification of barriers and limitations have been found [
12].
It is hard to solve the CESOP, because (i) fitness evaluation is computationally expensive, (ii) objective function is usually intractable, and (iii) sensitivity information is frequently unavailable. Under such difficulties, traditional optimization and gradient-based methods may perform poorly. This motivates the application of swarm computing, computational intelligence and machine learning methods, which often perform well in such settings [
13]. For example, Sergeyev et al. proposed a geometric method using adaptive estimates of local Lipschitz constants to solve the global optimization problems with partially defined constraints, where the estimates were calculated by a local tuning technique [
14]. Kvasov proposed a diagonal adaptive partition strategy for constructing fast algorithms to solve the global optimization problem of a multidimensional “black-box” function, satisfying the Lipschitz condition [
15]. Gillard and Kvasov presented that the Lipschitz-based methods behaved better than existing deterministic methods for global optimization problems under a limited computing budget [
16]. Sergeyev et al. developed a visual technique for a systematic comparison of the nature-inspired metaheuristics and deterministic Lipschitz algorithms for expensive global optimization problems with limited budget [
17]. Kvasov and Mukhametzhanov presented popular black-box global optimization methods and compared nature-inspired metaheuristic algorithms with deterministic Lipschitz-based methods [
18]. Paulavicius et al. proposed a DIRECT-type global optimization algorithm to accelerate the search process for expensive black-box global optimization problems [
19].
Furthermore, structural optimization problems are also CESOP. Structural optimization problems are characterized by various objective functions and constraints, which are generally non-linear functions of the design variables. Optimization of complex structures using traditional optimization approaches is known to be computationally expensive, because a very large number of finite element analysis must be conducted for each possible structural design during the optimization [
20]. Saka et al. presented successful applications of metaheuristics in structural optimization [
21]. Zavala et al. reviewed the multi-objective metaheuristics for structural optimization of the topology, shape, and sizing of civil engineering structures [
22]. Wein et al. reviewed feature-mapping methods for implementing and solving structural optimization problems [
23]. However, the huge solution space makes the CESOP hard to solve by existing optimization approaches to find quasi-optimal solutions within a reasonable period of time.
To solve items (i) to (iii) simultaneously, an ordinal optimization (OO) theory [
24] has been developed as an efficient framework for simulation optimization. The core concept of OO is that the relative order in the performance of designs is robust to estimated noise. The goal of the OO theory is to accelerate the simulation optimization procedure by gradually narrowing down the solution space. The OO theory consists of three stages. First of all, a representative subset is constructed using a rough model to evaluate all designs. A rough model can quickly estimate the performance of a design. OO theory indicates that order of performances of all designs is preserved even using a rough model [
24]. Secondly, a selected subset containing N designs is chosen from the representative subset. Even if a rough model is utilized to rank N designs, some excellent designs will be kept within the selected subset with a high probability. Finally, critical designs in the selected subset are evaluated by an exact model. An exact model can accurately evaluate the performance of a design. The one with the optimum performance in the selected subset is the good enough design. We have successfully applied OO framework for simulation optimization problems, such as one-period multi-skill call center [
25], pull-type production system [
26], and facility-sizing optimization in factory [
27].
For reducing the computing time of CESOP, a heuristic algorithm integrating ordinal optimization with ant lion optimization, abbreviated as OALO, is proposed to find a quasi-optimal design within an acceptable computing time. The OALO algorithm comprises three parts: approximation model, global exploration and local exploitation. Firstly, the multivariate adaptive regression splines (MARS) [
28,
29] is adopted as an approximation model to evaluate the fitness of a design. Next, we proceed with a reformed ant lion optimization (RALO) to look for
N exceptional designs from the solution space. Finally, a ranking and selection (R&S) procedure is utilized to decide a quasi-optimal design from the
N exceptional designs. The above three parts substantially decrease the computation time which is required for solving CESOP.
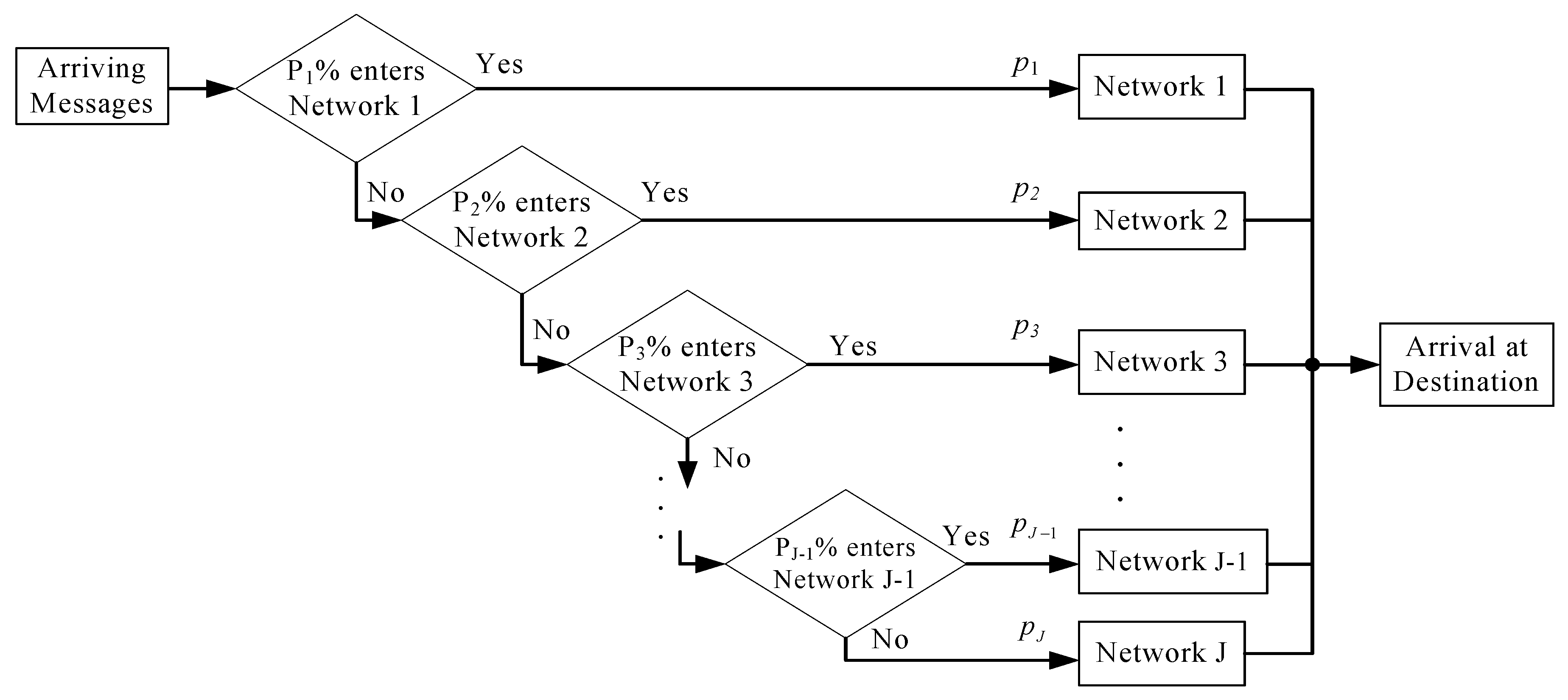
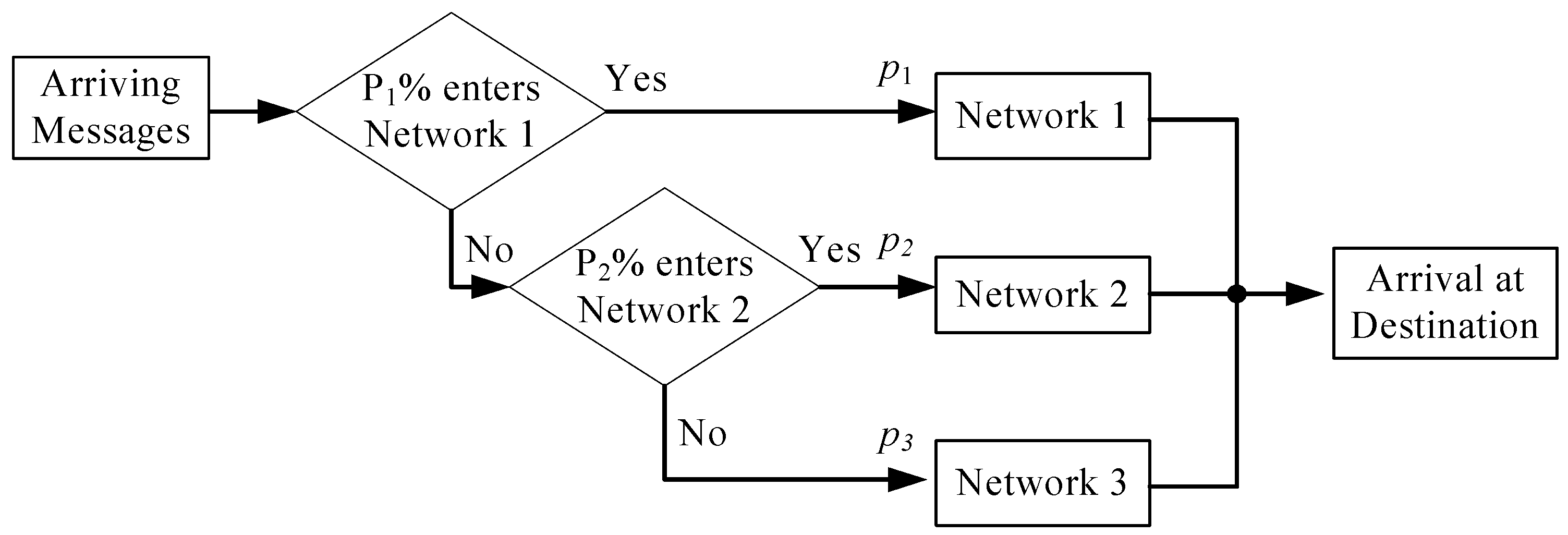
Subsequently, the OALO method is employed to minimize the operating cost of routing percentages in a communication system. The goal of queuing design optimization in a communication system is to look for the optimal routing percentages such that the expected total cost is minimal. The queuing design optimization in a communication system can be formulated as a CESOP. There are two contributions of this paper. The first one is to propose an OALO algorithm for CESOP to find a quasi-optimal design in an acceptable time. The second one is to apply the OALO algorithm to the queuing design optimization in a communication system.
The paper is organized as follows.
Section 2 states the OALO algorithm to find a quasi-optimal design of CESOP.
Section 3 formulates the queuing design optimization in a communication system as a CESOP. Then, the OALO is applied to resolve this CESOP.
Section 4 discusses the experimental results, comparison and relevant analysis.
Section 5 draws the conclusion and provides an outline on future works.
2. Integration of Ordinal Optimization with Ant Lion Optimizer
2.1. Computationally Expensive Simulation Optimization Problems
A typical CESOP can be formally stated as follows [
1].
where
denotes a
m-dimensional system parameters,
is the objective function,
is the performance of a simulation model,
denotes the trajectory of system when the simulation evolves over time,
G is a function of
which states the performance metric of system,
denotes all the randomness when it evolves during a specified sample trajectory,
represents the lower bound, and
denotes the upper bound. Generally, multiple replications are performed to obtain the objective value of
. However, it is impossible to carry out a very long simulation run. A standard approach is using the sample mean to approximate the objective function, which is formally stated as follows.
where
is the number of replications, and
represents the objective value of the
th replication. The sample mean
approximates to
, and
reaches a better result of
when the value of
is increased. There is a major issue when the simulation problem is stochastic. Ignoring the noise in the outcomes may not only lead to an imprecise estimation, but also to potential errors in identifying the optimal solutions among those sampled. Thus, we define the precise estimation of Equation (3) when
, where
denotes a sufficiently large of
. In addition, we define
as the sample mean for a given
obtained by precise estimation.
The benefit of the OO theory is the ability to separate the good designs from bad designs even with a rough model [
24]. Namely, the order of performance is relatively immune to large approximation errors. Thus, an approximation model can be treated as a rough model to evaluate a design quickly. Then, an efficient optimization technique assisted by this approximation model is utilized to find
N exceptional designs from solution space within an accepted computation time. The approximation model is based on the MARS [
28], and the optimization technique is the RALO.
2.2. Multivariate Adaptive Regression Splines
There have been many uses of approximation models in various applications, such as the radial basis function (RBF) [
30], support vector regression (SVR) [
31], kriging [
32], artificial neural network (ANN) [
33], and multivariate adaptive regression splines (MARS) [
28,
29]. Among them, MARS approximates the relationship between outputs and inputs as well as interprets the relationship between the various parameters. MARS has been applied to many real-world problems, such as function approximation, curve fitting, time series forecasting, prediction and classification [
29]. The main advantages of MARS include working well with a large amounts of predictor variables, automatically detecting interactions between variables, and robust to outliers. Thus, an approximation model based on the MARS is utilized to evaluate the fitness in this work.
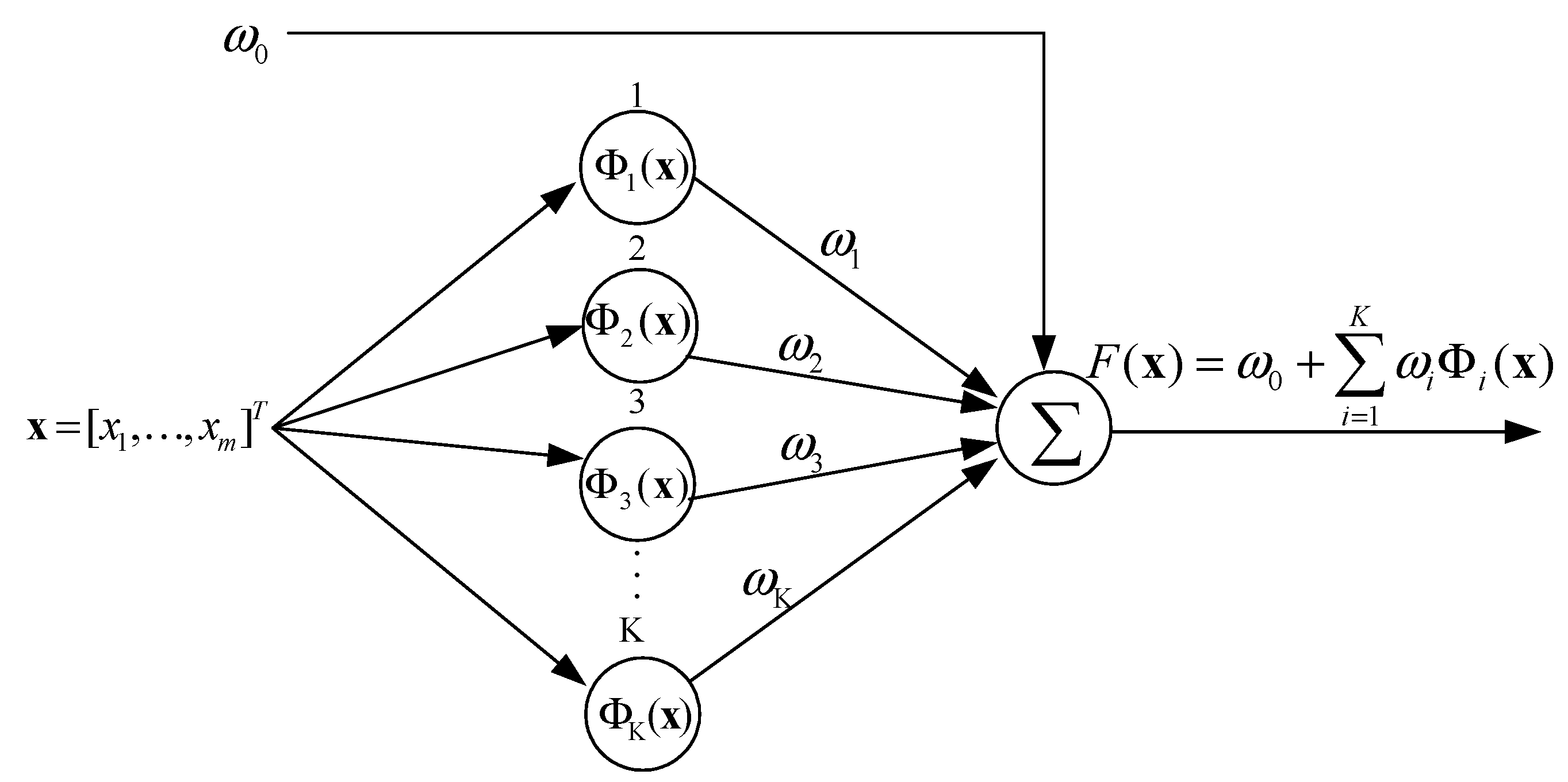
The MARS creates flexible nonlinear regression models by using separate regression slopes in distinct intervals of the independent variables. The end points of the intervals for each variable and the used variables are obtained by a very intensive searching process. The framework of MARS is demonstrated in
Figure 1. The typical model of MARS is formulated as follows.
where
represents an input variable,
is an intercept coefficient,
denotes the weight of basis functions, K indicates the amount of knots, and
denotes the basis functions.
The training data patterns are (), where and denote a design and their objective value obtained by precise estimation, respectively. The purpose of MARS is to make the target output closer to the actual output . The optimal MARS approximation model can be obtained by two-stage process: a forward stepwise selection and a backward prune. In the selection process, MARS selects basis functions which are added to the approximation model using a fast search scheme and builds a likely large model which is overfitting the training data. The selection process terminates when the model exceeds the maximum number of basis functions. In the prune process, the overfitting model is pruned for decreasing the complexity while maintaining the overall performance in order to fit to the training data. In this process, the basis functions without appreciably increasing the residual sum of squares are deleted from the overfitting model.
MARS is trained off-line, which can be further simplified to reduce significantly the computing time for on-line. After training the MARS, the target output can be calculated using simple arithmetic operations for any .
2.3. Reformed Ant Lion Optimization
With the aid of the MARS approximation model, existing search approaches can be adopted to determine
exceptional designs from the solution space. ALO is a biologically approach inspired by the hunting behavior of antlions and ants getting trapped in the trap set by the antlion [
7]. The ALO has a high exploration capability with the help of random walk and roulette wheel to build traps. The time-varying boundary shrinking mechanism and elitism are used to increase exploitation efficiency of the ALO. There are many advantages of ALO, such as avoidance of local optima, ease of implementation, reduced need for parameter adjustment, and high precision. ALO has been successfully employed to solve the multi-robot path planning problem with obstacles [
34], prediction of soil shear strength [
35], and structural damage assessment [
36]. Heidari et al. presented a comprehensive literature review on well-established researches of ALO from 2015 to 2018 [
37]. The comparative results revealed the dominance of ALO over other SI approaches including artificial bee colony (ABC), firefly algorithm (FA), ant colony optimization (ACO), cuckoo search (CS), bat algorithm (BA), and biogeography-based optimization (BBO). With the help of random walks and roulette wheel for building traps, ALO has a high exploration capability. The shrinking of trap boundaries and elitism provide the ALO with a high exploitation efficiency. These merits make ALO to avoid immature convergence shortcomings. Accordingly, it is particularly well suited to meet the requirements in global exploration.
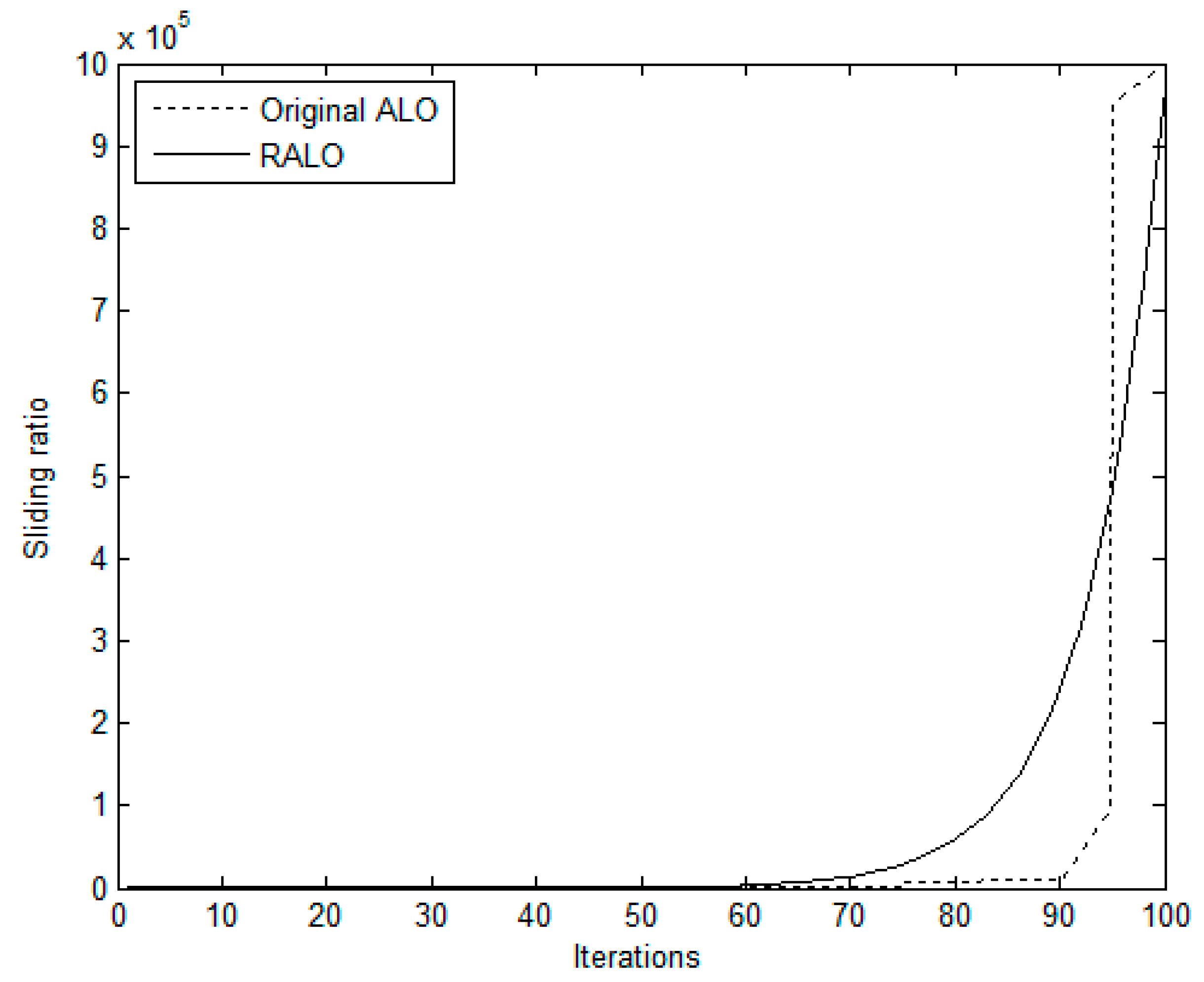
However, there are some issues of the original ALO, such as the local optima stagnation and occurrence of premature convergence for some problems. Therefore, the RALO is designed to enhance the convergent speed of the original ALO. The RALO has two self-adaptive control parameters, which are sliding factor and composition factor. The sliding factor determines the ants which are shifted toward the antlion using a given rate of slippage. The RALO uses a small value of sliding factor to increase diversification. When the sliding factor is small, the RALO intends to perform the global search. On the contrary, the RALO uses a large value of sliding factor to improve intensification. As the sliding factor is increased, the RALO intends to carry out the local search around the local optimum. The composition factor determines the degree of the elite antlion which affects the movements of all ants. The balance between exploitation and exploration of the RALO is mainly controlled by the composition factor. Large value of composition factor generates new positions of ants far from the elite antlion which will result in high exploration ability. Therefore, a large value of composition factor intends to perform exploration, while a small value leads to perform exploitation.
There are six steps of hunting prey in ALO: (i) using roulette wheel to construct antlion’s traps, (ii) random walk of ants, (iii) enter the ants to traps, (iv) adaptive shrinking boundaries of antlion’s trap, (v) catching ants and re-building traps, and (vi) performing elitism. The notations shown below are used in RALO. indicates the amount of ants and antlions, is the maximum number of iterations. The position of the ith ant at iteration k is denoted by . The position of the ith antlion at iteration k is denoted by . The position of the elite antlion is denoted by . is a sliding factor at iteration k, , where and indicate the minimum and maximum value, respectively. is a composition factor at iteration k, , where and represent the minimum and maximum value, respectively. The pseudo-code of RALO is represented in Algorithm 1.
| Algorithm 1: Pseudo-code of the R ALO algorithm. |
| Input: Amount of ants and antlions, range of two control parameters and maximum number of iterations (). |
| Output: The best antlion. |
| Initialize the positions of all ants and antlions inside V and U bounds. |
| Evaluate the fitness of all antlions by MARS. |
| Determine the elite antlion . |
| while do |
| for an ant do |
| Choose an antlion using the roulette wheel. |
| Random walk of nearby antlion to generate |
| Random walk of nearby elite antlion to generate |
| Update the minimum and maximum of each design variable. |
| Update the position of based on and |
| End for |
| Evaluate the fitness of all ants and antlions by MARS. |
| Replace an antlion with it corresponding ant. |
| Update sliding factor and composition factor. |
| Update the elite antlion. |
| End while |
The steps involved in the RALO Algorithm 2 are briefly explained below.
| Algorithm 2: The RALO |
- Step
1: Configuring basic parameters - (a)
Setting the values of , ,, , and . - (b)
Set , , . Let , where indicates the iteration index.
- Step
2: Initializing a population - (a)
A population containing Ψ ants and Ψ antlions are generated.
where indicates a random number in range from 0 to 1, and Vj and Uj express the lower and upper bound, respectively. - (b)
Calculate the fitness of antlion assisted by MARS, .
- Step
3: Ranking Rank the Ψ antlions based on the fitness from the smallest to the largest, and determine the elite antlion . - Step
4: Random walk of ants Generate new position of each ant.
where , cusum refers to the cumulative sum, denotes the random number at iteration k, either 1 or −1, and denote the minimum and maximum random walk of the j-th variable for the i-th ant, respectively, and express the minimum and maximum of the j-th variable at iteration k.- Step
5: Slide ants in a trap - (a)
Update the minimum and maximum of the j-th variable.
where denotes the sliding factor at iteration k, and express the minimum and maximum of the j-th variable at iteration k, is the j-th antlion position at iteration k, which can be either antlion selected by the roulette wheel or the elite antlion determined by the following equation.
- (b)
Update positions of all ants.
where αk denotes the composition factor at iteration k, denotes the random walk around an antlion which is selected by the roulette wheel at iteration k + 1, denotes the random walk around the elite antlion at iteration k + 1.
- Step
6: Calculate the fitness Calculate the fitness of ant and the fitness of antlion assisted by MARS, . - Step
7: Replace an antlion with it corresponding ant Apply the greedy selection between and . If , then set , . - Step
8: Update sliding factor and composition factor. - Step
9: Elitism Apply the greedy selection between and . If , then set , . - Step
10: Stop criteria If , then stop; else, let and return to Step 4.
|
The RALO terminates when it reaches a specified maximum number of iterations . When the RALO has stopped, the final antlions are ranked according to the fitness. Then, the former antlions are selected as the exceptional designs.
2.4. Ranking and Selection
We continue to determine the quasi-optimal design from the exceptional designs using the R&S procedure. The main idea of the R&S procedure is spending more computing efforts on few critical designs and less on most non-critical designs. The proposed R&S procedure composes of multiple stages, which select and allocate the most computational budget to critical designs that has a high probability to be the quasi-optimal design. The number of critical designs in each stage is decreased gradually. Remaining designs are continuing to perform simulation and some of them are eliminated in each stage, and the best one obtained in the last stage is the quasi-optimal design. The computational complexity can be gradually reduced, because the number of the critical designs had been greatly decreased when the evaluations are more refined.
The more refined evaluations used in those stages are simulation with various numbers of replications ranging from tiny to large. First, we choose an initial amount of replications as
. The amount of replications and the amount of critical designs in the
th stage are denoted as
and
, respectively. We set
(or
) for
., and
(or
) for
, where
. The Monte Carlo simulation with exponential rate provides a substantial computational speed-up without noticeable overshoot of the Probability of Correct Selection (PCS). The value of the
is rounded to the nearest integer. The number of stages, denoted as
, is obtained by
where
denotes the amount of replications in precise estimation, and
denotes the specified minimum size of selected subset. Equation (14) determines
by satisfying at least one of the following two conditions: (i) the value of
in the last stage exceeds the value of precise estimation, i.e.,
>
, and (ii) the size of selected subset in the last stage is smaller than the specified minimum size, i.e.,
. When the value of
is obtained, a simulation with
replications is adopted to calculate
in the
-th stage. Next, these
critical designs are ranked based on the value of
and the former
critical designs are selected into the selected subset for the (
)-th stage. A simulation with
replications is adopted to calculate
of all
critical designs in the last stage. The critical design with the smallest
in the last stage is the quasi-optimal design.
2.5. The OALO Algorithm
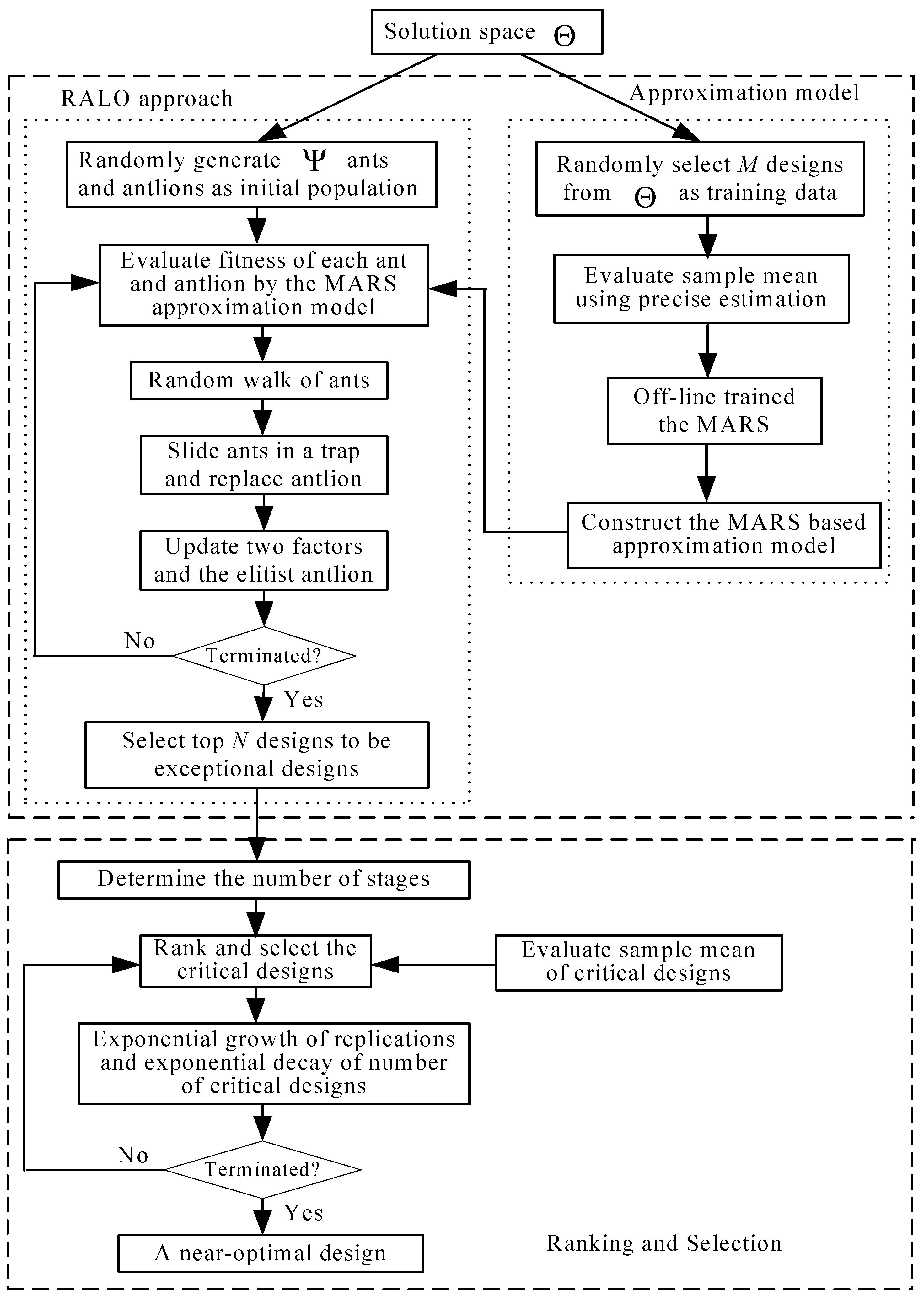
The OALO algorithm can be expressed by the flow diagram as shown in
Figure 2. Described below are the step-wise procedures of the OALO Algorithm 3.
| Algorithm 3: The OALO. |
- Step
0: Set the values of - Step
1: Randomly choose M x’s from solution space and calculate , then train the MARS off-line using these M designs. - Step
2: Randomly yield Ψ ants a’s and antlions x’s as the initial population and adopt Algorithm 2. After Algorithm 2 terminates, rank all the final Ψ x’s based on their approximate fitness from the lowest to the highest and choose the prior N x’s to be the N exceptional designs. - Step
3. Decide the number of stages, , of the R&S procedure. - Step
4. For i = 1 to , perform the simulation with replications to estimate of the designs in the i-th stage. Rank these designs based on their and select the former designs as the critical designs for the (i + 1)-th stage. - Step
5. Perform the simulation with replications to calculate of the designs. The design with the smallest is the quasi-optimal design.
|











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}