1. Introduction
With the dramatic improvement of people’s standards of living, the rapid expansion of cities, and the growing number of private cars, traffic congestion has become an important issue that restricts urban development and affects the quality of life. In the intelligent transportation system, accurate traffic predictions can provide the basis for making a decision on urban traffic management and for finding the optimization of transportation facilities. For that, the accurate prediction of traffic transportation is an important part of developing the smart transportation system of the modern intelligent city. The rapid detections of vehicles in traffic images or videos are the main tasks of urban traffic prediction, for that, investigating an algorithm with capabilities of real-time computation and correct detections of vehicles are very important [
1].
The traditional target detection methods are as follows: Xu et al. proposed a featured operator, which can extract features from the region of interest selected on the images and implement target detection by training a classifier [
2]. This method will greatly reduce the detection accuracy because the scene is a little complicated. Qiu et al. proposed an optical target detection, which is based on the methods of optical flow and the inter-frame differences [
3]. The accuracy of the optical flow method is ideal but it has the problem of lower detection speed. The inter-frame difference method is fast but the accuracy is not ideal. Felzenszwalb et al. had proposed a sliding window classification method, which first extracts the features of the region of interest through sliding windows and then performs classification by a support vector machine (SVM) classifier to achieve target detection [
4]. This method has a large amount of calculation, which leads to a slower detection speed [
5]. Suriya Prakash et al. proposed an edge-based object detection method, which is susceptible to interference from background and noise and leads to an increase in inaccurate detections [
6]. The above traditional target detection methods are not targeted at the sliding window area of selection strategies, they need a large number of calculations, result in a slow detection speed, and the area feature extraction has no generalization.
In recent years, with the rapid developments of computer vision and artificial intelligence technologies, object detection algorithms based on deep learning have been widely investigated. Among them, convolutional neural networks have a strong generalization of the feature extraction of images and are convenient [
7]. At present, there are two main methods of target detection in deep learning: one is a target detection algorithm combining convolutional neural networks and candidate region suggestions, represented by region-based convolutional neural networks (R-CNN) [
8] and spatial pyramid pooling (SPP)-net [
9]. The other is to use the series of the Single Shot MultiBox Detector (SSD) [
10] and the You Only Look Once (YOLO) model [
11,
12,
13] as the representative detection algorithms to convert the target detection problem into the regression problem by machine learning. The R-CNN algorithm uses a selective search to select the region suggestion box, which improves the accuracy of target detections. However, a large number of repeated calculations lead to a long time and the candidate box is scaled, which easily results in the loss of image feature information. The SPP-net algorithm proposes a pyramid pooling layer, which solves the problem of the size of the fixed input layer of the network in R-CNN, but its training steps are cumbersome and each step will generate a certain ratio of errors because the convolutional neural network and SVM classification need to be trained separately. As a result, the training takes a long time and a large number of feature files need to be saved after training, which occupies a large amount of hard disk space.
By combining the algorithm characteristics of the SPP-net into the R-CNN, the Faster R-CNN algorithm solves problems such as long training and test time and large space occupation, etc. However, the extraction of the proposed box is still based on the selective search method, that is, the time-consuming problem still exists. [
14]. By introducing the RPN (region proposal networks) algorithm instead of the selective search (SS) one, the candidate region frame extraction and back end of the Faster R-CNN are integrated into a convolutional neural network model. For that, the Faster R-CNN algorithm can greatly shorten the extraction time of the candidate region [
15]. The Faster R-CNN algorithm is considered to be the first truly end-to-end training and prediction, but its speed is far from the requirement of real-time target detection.
Based on the candidate box area idea of Faster R-CNN, the concept of Prior Box is proposed in the SSD algorithm. Due to the combination of YOLO’s regression thought, the detection speed of the SSD algorithm is the same as YOLO, and the detection accuracy is the same as Faster R-CNN. For that reason, the parameters of the priori frame cannot be obtained through network training automatically and the adjustment process of parameters depends on actual experience, the generalization of the SSD algorithm is not very good. The YOLO series is a regression-based network algorithm that directly uses the full map for training and returns the target frame and target category at different positions. The YOLO algorithm is the first one to choose a method based on the candidate frame area algorithm to train the network. It directly uses the full image for training and returns the target frame and target category at different positions, thereby making it easier to quickly distinguish target objects from the background area but is prone to serious positioning errors.
The YOLOv2 algorithm uses a series of methods to optimize the structure of the YOLO network model, which significantly improves its detection speed. For that, its detection accuracy is equal to that of the SSD algorithm. Because the YOLOv2 basic network is relatively simple, it does not improve target detection accuracy. The YOLOv3 algorithm uses the Feature Pyramid Networks (FPN) idea to achieve multi-scale prediction [
16] and uses deep residual network (ResNet) ideas to extract image features to achieve a certain balance between detection speed and detection accuracy [
17]. However, the size of the smallest feature map (13 × 13) is much larger than the SSD algorithm (1 × 1), the positioning accuracy of the object by YOLOv3 is low, and the false detection and miss detection is easy to occur. Our team previously published a YOLO-UA algorithm based on YOLO optimization for traffic flow detection, which mainly realized real-time detections and statistics of vehicle flows by adjusting the network structure and optimizing the loss function [
18]. According to the team’s achievements and foundation, in this article we investigate the YOLOv3-DL algorithm, a high-performance regression-based algorithm for detecting and collecting statistical information from the traffic flows in real-time. YOLOv3-DL is based on the YOLOv3 algorithm, both Intersection Over Union (IOU) and Distance-IOU (DIOU) are used to enhance its performance. The method of directly optimizing the loss function, which measures the parameters to improve the progress of target positioning, can solve the problems of insufficient positioning accuracy of the YOLOv3 model and low vehicles’ statistical accuracy. After optimization, it can be better applied to detect video vehicles in real-time and in real scenes. By optimizing models and algorithms, we can better improve the performance of the detection system of traffic flows.
2. The Composition and Principle of Traffic Flow Detection System
The traffic flow detection system consists of a video image acquisition module, an image pre-processing module, a vehicle detection and identification module, and a vehicle flows statistics module. The main modules of the detection system are shown in
Figure 1. The core of the system is the vehicle detection and recognition module, which locates and recognizes the vehicles in the video images. In order to combine target position and recognition into one, which needs to take requirements of the speed detection and recognition accuracy into consideration, the YOLOv3 algorithm is used for the vehicles’ detection and recognition.
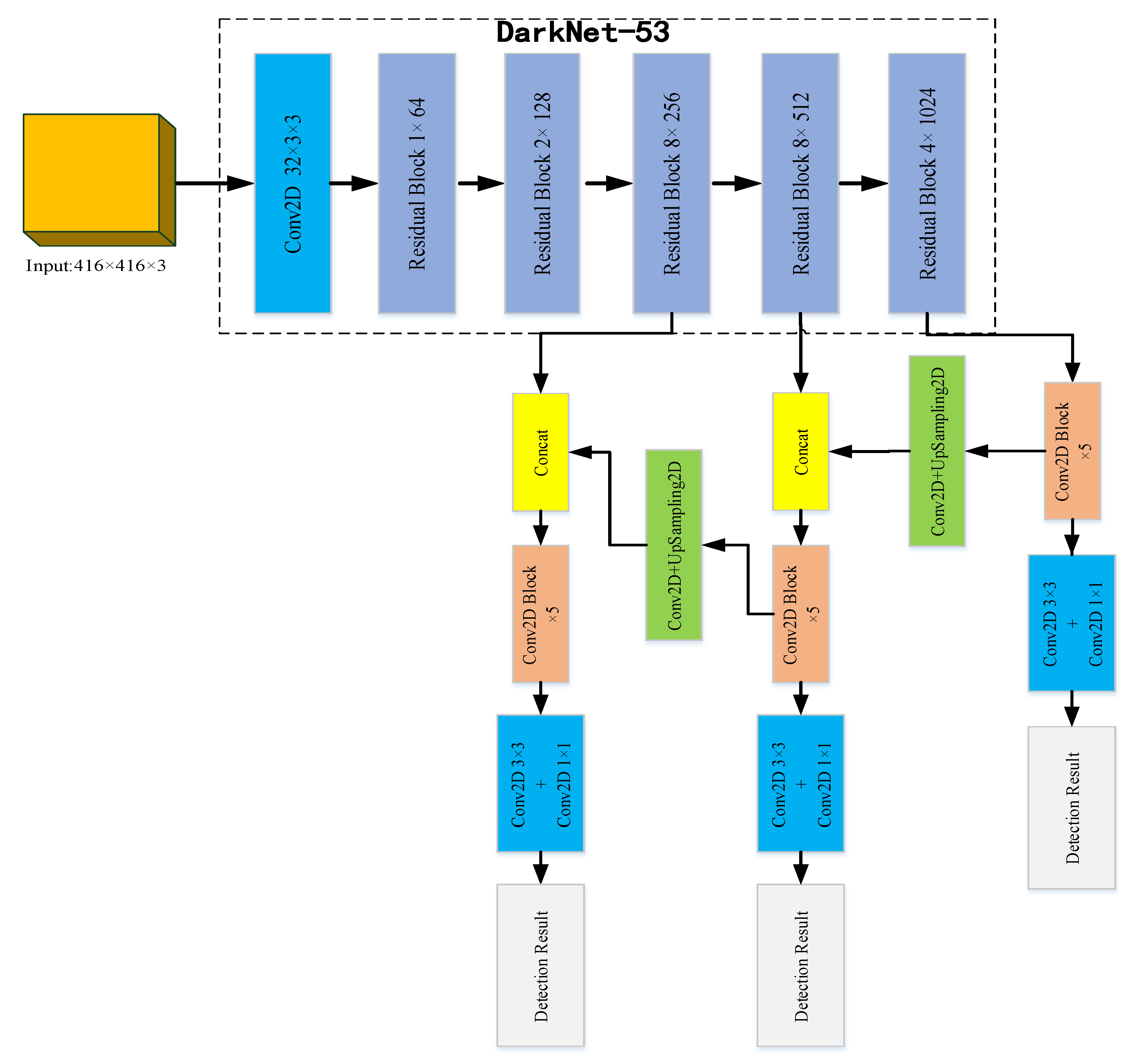
The YOLOv3 algorithm is an improvement on YOLOv1 and YOLOv2 because it has the advantages of high detection accuracy, accurate positioning, and fast speed. Especially when the multi-scale prediction methods are introduced, it can achieve the detection of small targets and has good robustness to environmental scenes, therefore, it has become a current research hotspot. The network structure of the YOLOv3 algorithm is shown in
Figure 2. The residual network is mainly used to upgrade the feature extraction network, and the basic backbone network is updated from Darknet-19 to Darknet-53 to extract features and obtain deeper feature information.
The Darknet-53 network in YOLOv3 uses a large number of 1 × 1 and 3 × 3 convolutional layers in order to connect local feature interactions and its function is equivalent to the global connection of the full feature layer and the addition of shortcut connections. This operation enables us to obtain more meaningful semantic information from up-sampled features and finer-grained information from earlier feature mappings. This feature extraction network has 53 convolutional layers, which is called Darknet-53, and its structure is shown at the top in
Figure 2. In Darknet-53, 1 × 1 and 3 × 3 alternating convolution kernels are used, and after each layer of convolution, the BN layer is used for normalization. The Leaky Relu function is used as the activation function, the pooling layer is discarded, and the step size of the convolution kernel is enlarged to reduce the size of the feature map. As the network structure is deeper, its ability to extract features is also enhanced. The function of the sampling layer (upsample) is to generate the small-size images by interpolation of small-size feature maps and other methods. When short connections are set up between some layers to connect low-level features with high-level ones, the fine-grained information of high-level abstract features is enhanced, and they can be used for class prediction and bounding box regression.
The YOLOv3 network prediction process is listed below:
- 1)
First, the images of size 416 × 416 are input into the Darknet-53 network. After performing many convolutions, a feature map of size 13 × 13 is obtained, and then 7 times by 1 × 1 and 3 × 3 convolution kernels are processed to realize the first class and regression bounding box prediction.
- 2)
The feature map with size 13 × 13 is processed 5 times by 1 × 1 and 3 × 3 convolution kernels, and then the convolution operation is performed by using 1 × 1 convolution kernel, followed by 2 times the upsampling layer, and stitching to the size on the 26 × 26 feature map. The new feature map of size 26 × 26 is then processed 7 times using 1 × 1 and 3 × 3 convolution kernels to achieve the second category and regression bounding box prediction.
- 3)
A new feature map has a size of 26 × 26. Firstly, we use 1 × 1 and 3 × 3 convolution kernels to process 5 times, perform a double upsampling operation, and stitch it onto the feature map of size 52 × 52. Then, the feature map is processed 7 times using 1 × 1 and 3 × 3 convolution kernels to achieve the third category and regression bounding box prediction.
It can be seen from the above results, that YOLOv3 can output three feature maps of different sizes at the same time, which are 13 × 13, 26 × 26, and 52 × 52. In this way, the feature maps of different sizes are optimized for the detections of small targets, but at the same time, the detections of large targets are weakened. Each feature map predicts three regression bounding boxes at each position, each bounding box contains a target confidence value, four coordinate values, and the probability of C different edges. There are (52 × 52 + 26 × 26 + 13 × 13) × 3 = 10647 regression bounding boxes.
4. Making the Data Set
In order to study the monitoring of traffic flows in actual scenarios, the data source of this study uses the large-scale data set of DETection and tRACking (DETRAC) for vehicle detection and tracking. The data set is mainly derived from video images of road crossing bridges in Beijing and Tianjin, and manually labeled 8250 vehicles and 1.21 million target object frames. The shooting scenes include sunny, cloudy, rainy, and night, and the height and angle of each shot are different.
The steps for making the experimental data set of this project are as follows:
- 1)
Collecting daytime, dusk, evening, and rainy pictures from the DETRAC data set, a total of 6203 pictures were collected;
- 2)
Combining the 6203 pictures and the VOC_2007 data set to make a DL_CAR data set containing 26,820 pictures;
- 3)
Randomly extracting 80% of the DL-CAR data set to make a training verification set;
- 4)
Randomly extracting 80% from the training verification set to make the training set;
- 5)
The remaining 20% of the DL-CAR data set is used as the verification set and test set in a 1:1 ratio;
- 6)
Organizing your own data set according to the structure of the VOC data set. The folder structure of the VOC data set is shown in
Figure 6;
- 7)
Use OpenCV to read all the images in the folder, name them in the order of reading and unify the format to facilitate later statistics.
In this paper, the LabelImg tool is used to uniformly label each target vehicle on the pictures of the training set, validation set, and test set, and an XML file corresponding to the pictures is generated to store the labeling information for subsequent network training. After that, the XML file corresponding to the picture is generated to store the label information for subsequent network training. The actual labeling steps are:
- 1)
Using the mouse to select and frame the target vehicle area;
- 2)
Double-clicking to mark the corresponding target category;
- 3)
Clicking “Save” after marking.
Each image in the training verification set initializes a 3D label in the form of [7, 7, 25] with 0, column 0 represents the confidence, column 1–4 represents the central coordinates (
xc,
yc,
w,
h), and column 5–24 represents the object class sequence number. Next, we parse the XML file and take out all target categories in the file and their coordinate values (
xmin,
ymin,
xmax,
ymax) in the upper left and lower corners, these data were then multiplied while using ratio values according to the 448 × 448 image scaling factor to obtain (
x1
min,
y1
min,
x2
max,
y2
max). Subsequently, Equation (6) is used to convert the coordinates into the form of center point coordinates, and Equation (7) is used to calculate which grid the target center falls into. In the image label, the grid confidence degree is set to 1, the coordinate of the center point is set to the calculation results of Equations (6)–(7), and the corresponding target category index is set to 1.
In order to enhance the robustness of the network, we use random horizontal flip, random cropping, random color distortion, etc. for data enhancement. We create a dictionary for each picture to store its path and label, and add all dictionaries to the list and save the list in a pkl file.
6. Conclusions
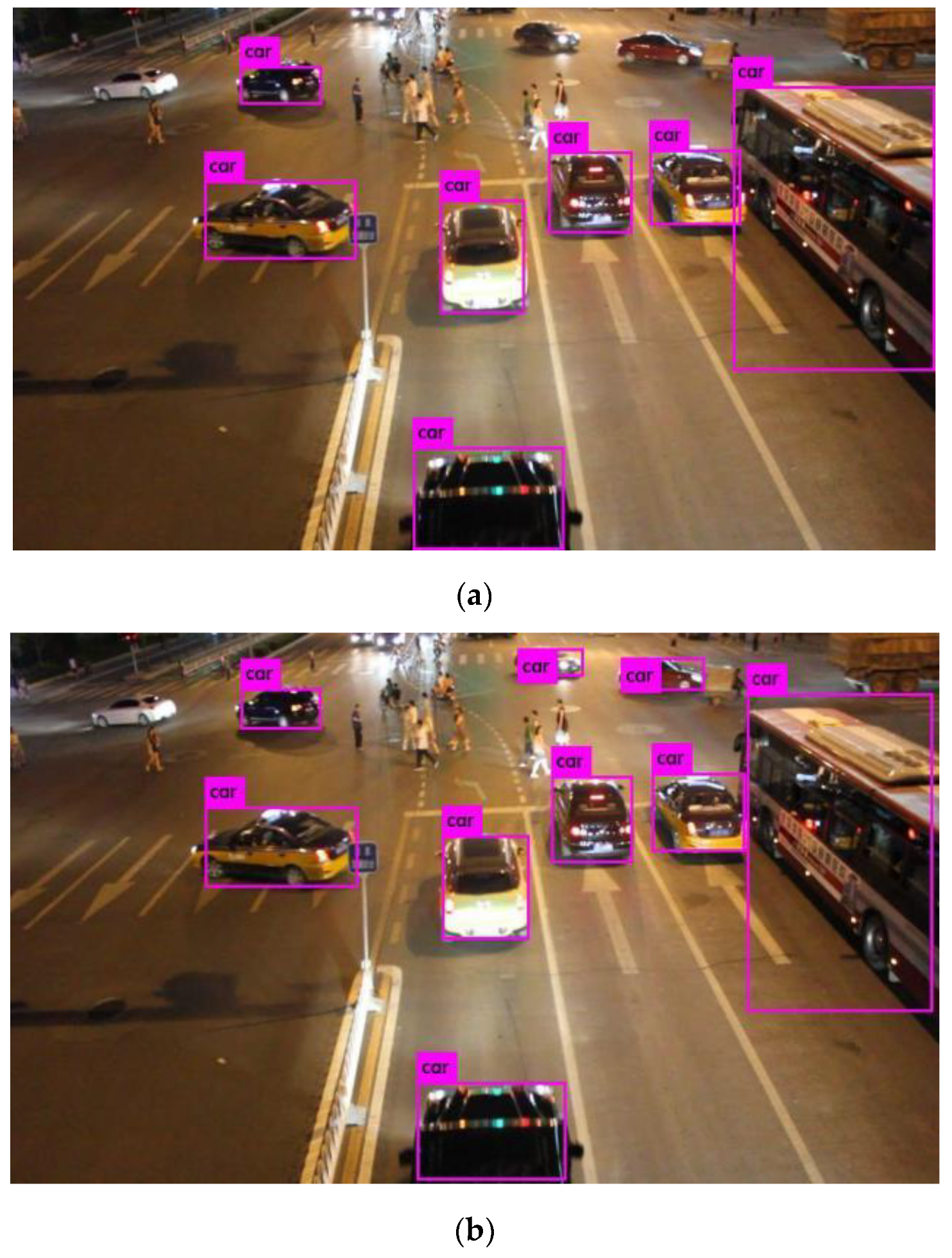
Due to the limitations of the YOLOv3 model, when more vehicles are close to each other in the images or the vehicles’ target size is not the same, it will have missed detections and positioning problems, further affecting the accuracy rates of traffic flow statistics and prediction information. By using the YOLOv3-Dl algorithm and optimized by DIOU, the traffic flow statistics with a high accuracy rate can be generated, and the results obtained after adjusting the threshold parameters are very close to the actual number of vehicles. After optimization, the algorithm can reliably conduct the monitoring of traffic flows and statistical analysis in a variety of scenarios and weather conditions. The experimental results show that the YOLOv3 model needs to be further improved in real-time and accuracy rate of traffic monitoring. Therefore, we will introduce the pyramid space module (i) the feature extraction of the network structure to optimize YOLOv3 themselves, (ii) DIOU loss to solve the problem of unbalanced category, (iii) during the training of batch standardization to further improve its adaptability to all kinds of weathers and scenarios. In this experiment, we can see on the test set, the detection accuracy rate of the YOLOv3-DL algorithm increased by 3.86% as compared with that of YOLOv3, and under different environmental conditions, the detection accuracy rate of the YOLOv3-DL algorithm increased by 4.53% as compared with that of YOLOv3. In the video monitoring of traffic flows, as compared with the previous Faster R-CNN, SSD, and YOLOv3 algorithms, the YOLOv3-DL algorithm achieves the accuracy rate of 98.8% and the detection speed of 25 ms at the same time, which meets the requirements of high precision and fast speed required by monitoring of traffic flows and further improves the real-time detection system of traffic flows.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}