Seismic arrays have been widely used in the area of seismic monitoring and nuclear test monitoring. Seismic arrays are composed of multiple sensors located in a certain range, and the signal-to-noise ratio of far-field signals can be effectively improved by means of delay and sum beamforming. The detection capability of seismic signals can be improved [
1,
2]. Compared with three-component stations, seismic arrays can provide more accurate estimates of signal azimuth and slowness through techniques such as FK analysis [
3,
4]. Scholars have proposed various data processing and analysis methods for seismic arrays, which are powerful tools to improve detection capabilities and reduce manual workload. Impulsive noise signals usually come from the instrument, human-made, and nature. Noise signals are often mixed in seismic signals, which causes false detection of events and inaccurate parameter calculations. How to effectively detect seismic signals and accurately identify seismic phases from noise signals is one of the challenges we have to face.
Over the past decades, the traditional STA/LTA method [
5,
6,
7] has been used to pick up seismic signals. It reflects the instantaneous change in signal energy by calculating the ratio of the short-term and long-term average of data. It has been widely used in many real-time detection systems, such as Earthquake Early Warning (EEW), seismic data processing software Seiscomp3, CTBTO International Data Centre waveform data processing software IDCR3, Geotool, and so on. The limitation of STA/LTA is that it is sensitive to the time-varying background noise [
7], which increases the probability of small-signal misdetection. So it is not suitable for lower SNR signals [
8]. For the signals with SNR between 1.5 dB and 3 dB, researchers have used the denoising method based on discrete wavelet transform (DWT) to improve the performance of the STA/LTA algorithm [
9]. Besides, the setting of the threshold and the selection of the characteristic function also can affect the detection sensitivity [
10]. For local seismic signals, there are some high-frequency components, which are stronger than that in teleseismic signals. Besides the amplitude detection, we can use the frequency component information to detect the local seismic signals. However, for the teleseismic signals, the high-frequency components are weak due to the long propagation distance. It is more suitable for teleseismic signals to use multiple regional stations or arrays to enhance the detection reliability [
11]. Utilizing cross-correlation techniques [
12], we can efficiently detect the teleseimic signals. So the accuracy of receiving arrival time can be developed. Beamforming [
13,
14] also can increase the SNR and the detection performance by delaying and summing the records of substations of the same array using signal correlation and simultaneously eliminate the effects of non-coherent noise. Blandford [
15] firstly proposed to apply F detection to study strongly coherent teleseismic signals, but F detection has higher requirements for seismic signals and noise. For example, the seismic signals are stationary and Gaussian, while noise is uncorrelated. Generalized F (GF) detector can process small-aperture array signals and has no special demands for noise, which makes up for the shortcomings of F detection. However, GF is limited to other factors influencing the proportion of false alarms [
16], such as the prior SNR, the selection of signal model parameter
and requiring a usable noise correlation model for each array. Additionally, the signals across the array should not vary greatly. The matched signal detector [
17] performs correlation processing between the detection signal and the template waveform. The higher the similarity between the two waveforms, the larger the correlation function value is. Template matching solves the problem of weak seismic signals detection, which [
18,
19,
20,
21] advances the detection threshold with the coherent seismic signals. However, the generality of this method is limited by the dependence on source assumptions, and this method requires a huge number of historical earthquakes to form a template library. It will not be applied to some areas where earthquakes have never happened [
20,
22,
23,
24]. Machine learning (ML) and neural network have been widely used in seismology, especially for detecting and identifying P phase, S phase, and noise. With the rapid growth of seismic data, machine learning and deep learning plays a significant role in processing vast amounts of seismic data [
25,
26,
27,
28]. However, these algorithms often require a lot of work to deal with massive data in the previous stage to prepare data sets, and the precision of classification depends on the trained model [
29,
30,
31].
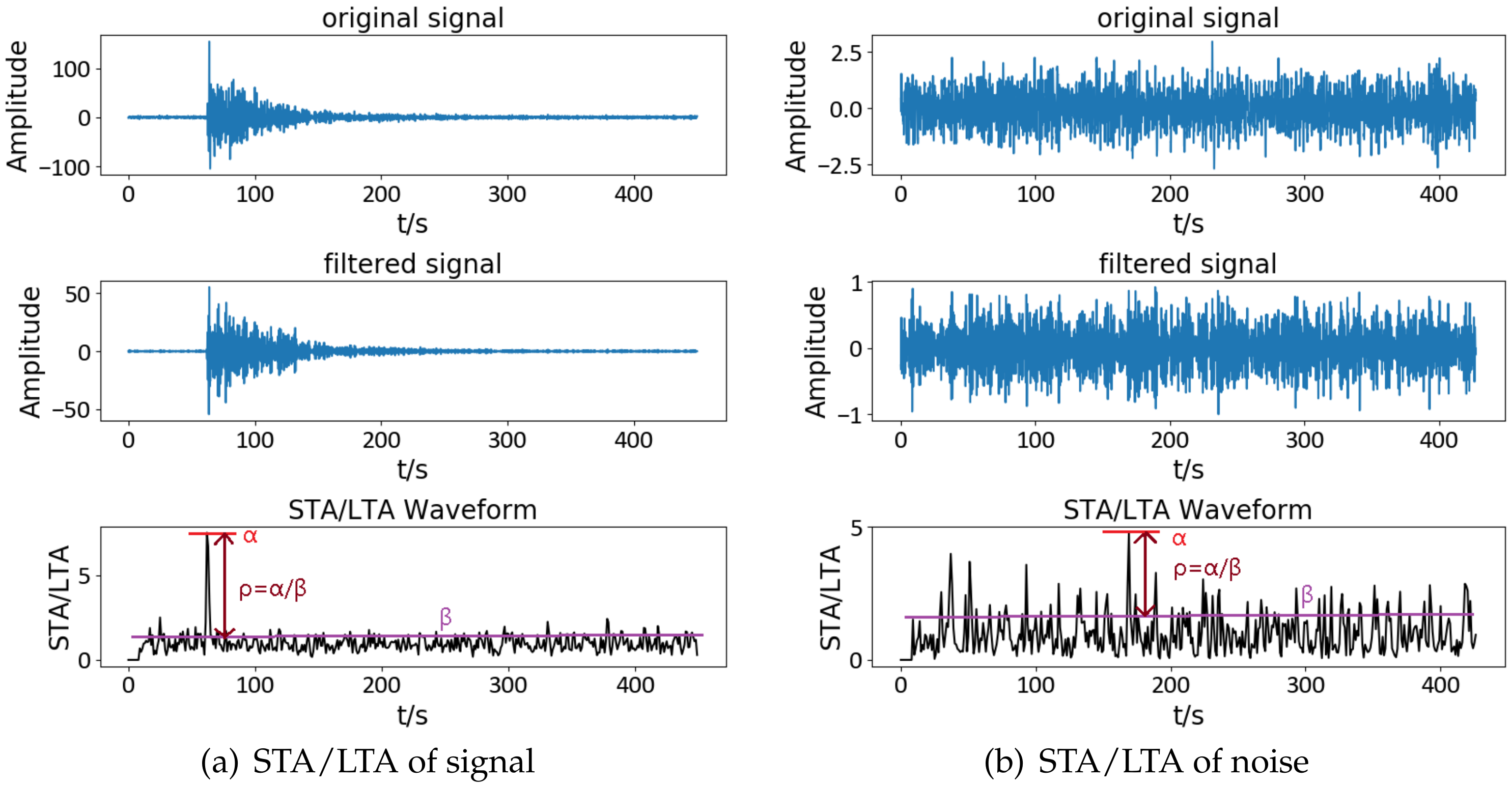
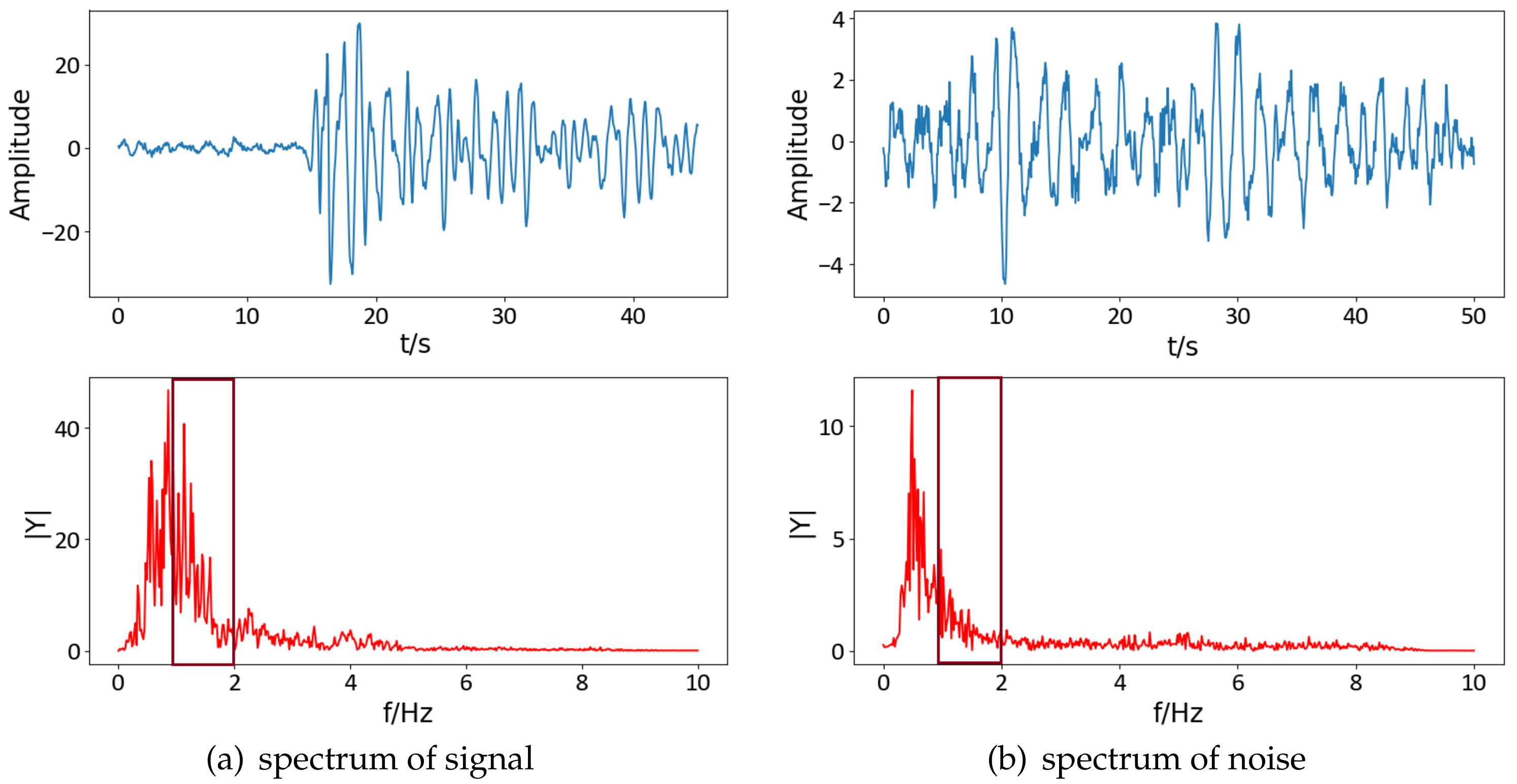
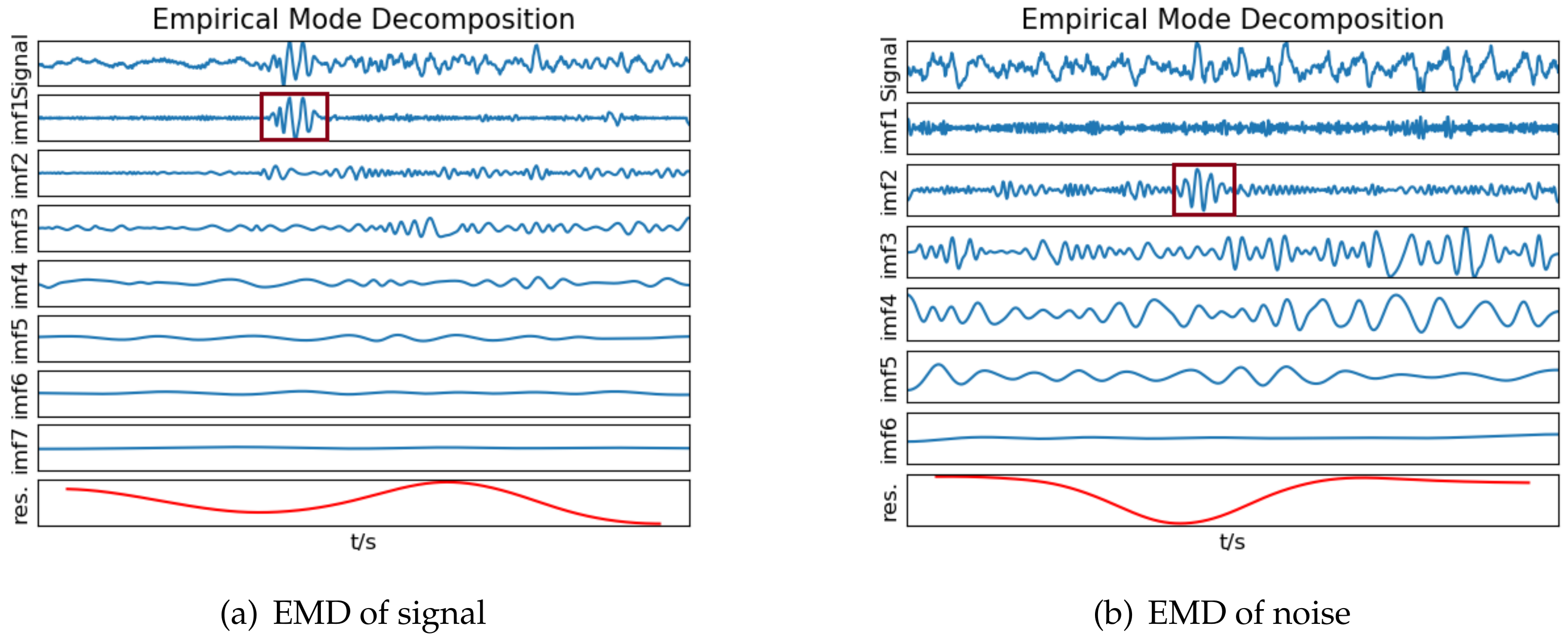
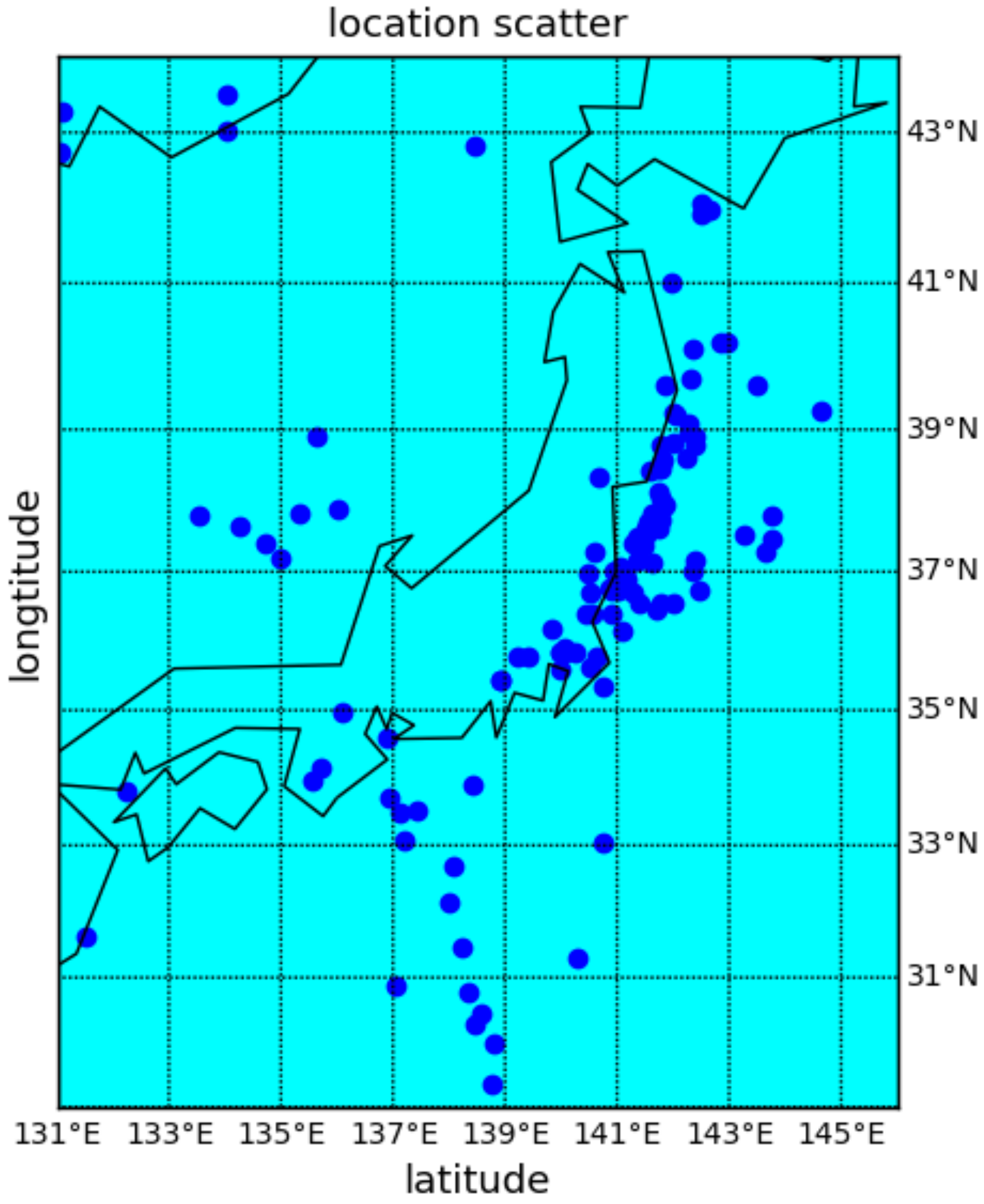
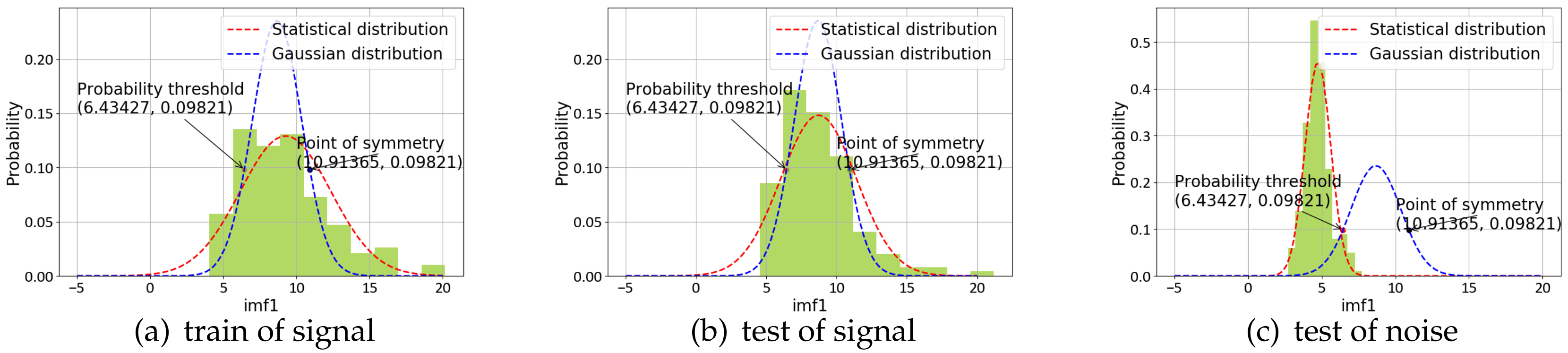
Seismic signal detection is constituted of four main steps in this paper. Firstly, data preparation is an essential step in the whole process, and it is used for selecting some observed seismic events for researching. Secondly, the feature extraction step obtains a lot of valuable information on original signals. By analyzing the signal, we choose some helpful features in the seismic signal detection, such as the peak and ratio of the STA/LTA trace, the average value of energy in a specific frequency band, and the energy value after empirical mode decomposition (EMD), which are independent of each other and introduced in detail later. Thirdly, the single-feature model is constructed by location and waveform information. Each feature obeys the Gaussian distribution generated from GP. Lastly, we calculate the posterior probability of the joint features to predict the possibility that new signal is a seismic signal. During the process, the optimal hyperparameters of GP are obtained by maximizing the marginal likelihood function
L(
) [
32].
In the following sections, first of all, a brief introduction of GP is introduced. Next, waveform features used in this paper are described in detail, and a joint multi-features probability model is constructed. Then the implementation of seismic signal detection method proposed in this paper is elaborated, including data preparation, feature extraction, model training, and etc. Finally, we analyze and discuss the results.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}