Learning, Improving, and Generalizing Motor Skills for the Peg-in-Hole Tasks Based on Imitation Learning and Self-Learning


Abstract
1. Introduction
- A general method is proposed that concatenates the parameters of two different models, one for classification (hidden Markov models (HMMs)) and one for motion generation (dynamic movement primitives (DMPs)), from human demonstrations. Robots are then able to select an appropriate motor skill from a library of motor skills. This method is used to classify various types of reaction force/moment signals and generate their corresponding reaction motion trajectories for the peg-in-hole task.
- The policy learning by weighting exploration with the returns (PoWER) algorithm is used in the reinforcement learning (RL) process. Using this algorithm, the RL process improves and/or generalizes motor skills. It not only optimizes the parameters to reduce the execution time step and improve path of a DMP, but also re-estimates the parameters of its corresponding HMM to improve the motor skill. Furthermore, the RL process estimates new targets and initial parameters of new motor skills for generalization.
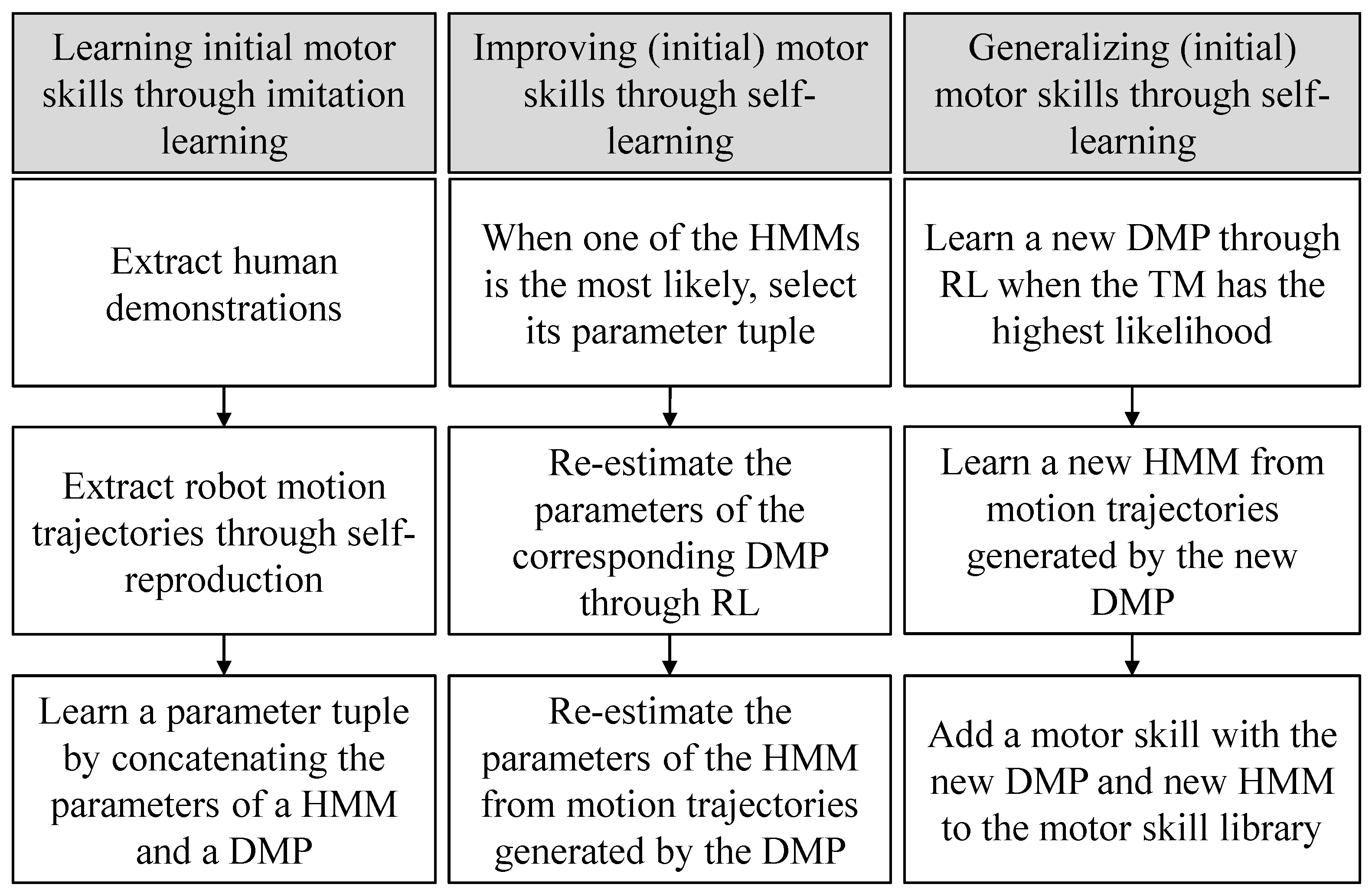
2. Learning, Improving, and Generalizing Motor Skills Based on Imitation Learning and Self-Learning
2.1. Learning (Initial) Motor Skills through Imitation Learning
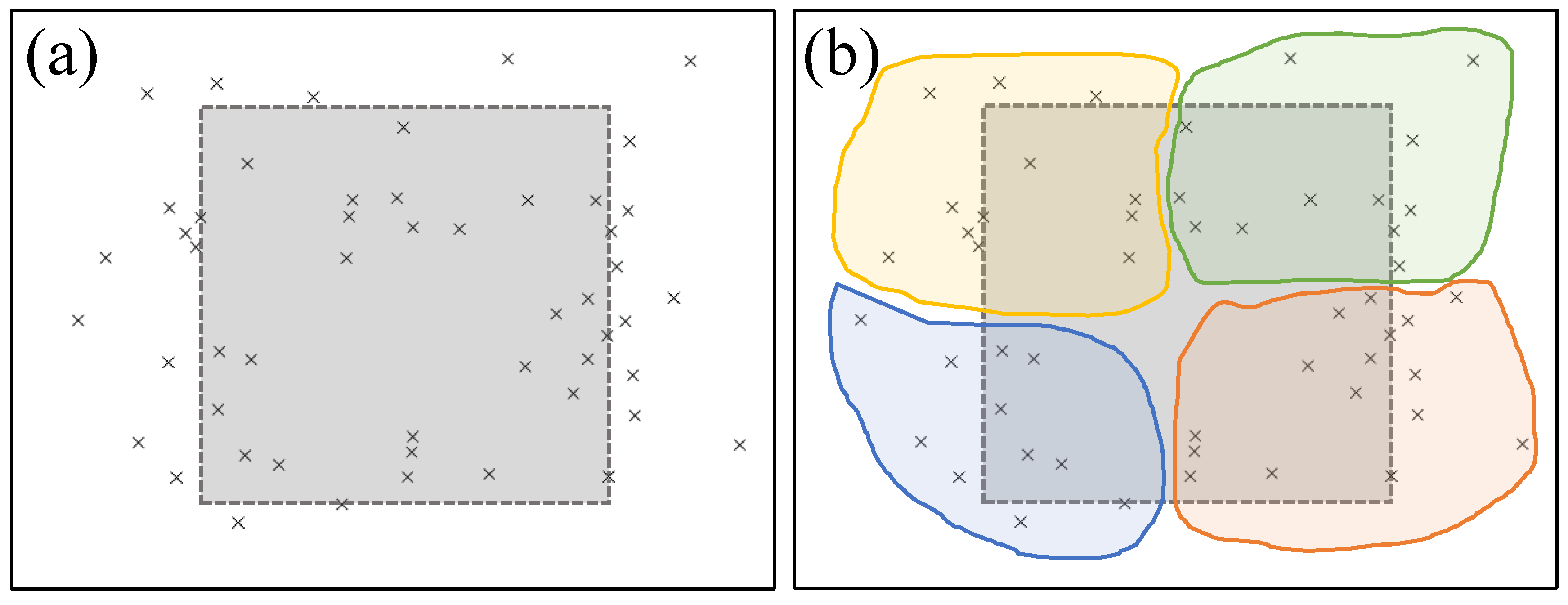
2.2. Improving and Generalizing Motor Skills through RL
| Algorithm 1 Overall algorithm for improving and/or generalizing motor skills |
| 1: Input: a set of initial parameters of all motor skills and the TM . |
| (Improvement) |
| 2: if then |
| 3: Using initial parameters of a motor skill belonging to the HMM with the |
| maximum likelihood, |
| 4: . |
| (Generalization) |
| 5: else if then |
| 6: Using initial parameters of a motor skill belonging to the HMM with the |
| maximum likelihood except for the TM |
| 7: . |
| 8: Add the parameters of a new motor skill with to the motor skill library. |
| 9: end if |
| 10: Output: the parameters of the (new) motor skill as well as the parameters |
| updated TM. |
| Algorithm 2 iPoWER algorithm for improving the parameters of motor skills considering execution time step and path optimization |
| 1: Input: initial parameters of a motor skill |
| 2: Set |
| 3: while true do |
| 4: Sampling: Using , and , generate rollout from based on Equation (1) |
| with exploration as a stochastic policy. |
| 5: if and then |
| 6: Set and collect all information for . |
| 7: else if and then |
| 8: Set and collect all information for . |
| 9: else |
| 10: Discard all information for . |
| 11: end if |
| 12: Estimating: Use unbiased estimate of the value function . |
| 13: Reweighting: Reweight rollouts and discard low-reward rollouts. |
| 14: Update the parameters of DMP using . |
| 15: Update the parameters of the HMM using reaction force/moment recorded |
| during the motion generation . |
| 16: Update . |
| 17: if then |
| 18: break |
| 19: end if |
| 20: end while |
| 21: Output: the optimized parameters . |
| Algorithm 3 gPoWER algorithm for generalizing motor skills to add new motor skills and new targets |
| 1: Input: initial parameters of a motor skill |
| 2: Set and . |
| 3: while true do |
| 4: Sampling: Using , and , generate rollout from based on Equation (1) |
| with exploration as a stochastic policy. |
| 5: Set with . |
| 6: if then |
| 7: Set and . |
| 8: Collect all information for . |
| 9: else |
| 10: Discard all information for . |
| 11: end if |
| 12: Estimating: Use unbiased estimate of the value function . |
| 13: Reweighting: Reweight rollouts and discard low-reward rollouts. |
| 14: Update the parameters of DMP using . |
| 15: Update the parameters of the HMM using reaction force/moment recorded |
| during the motion generation . |
| 16: Update and . |
| 17: if then |
| 18: break |
| 19: end if |
| 20: end while |
| 21: Output: the optimized parameters . |
3. Experiment
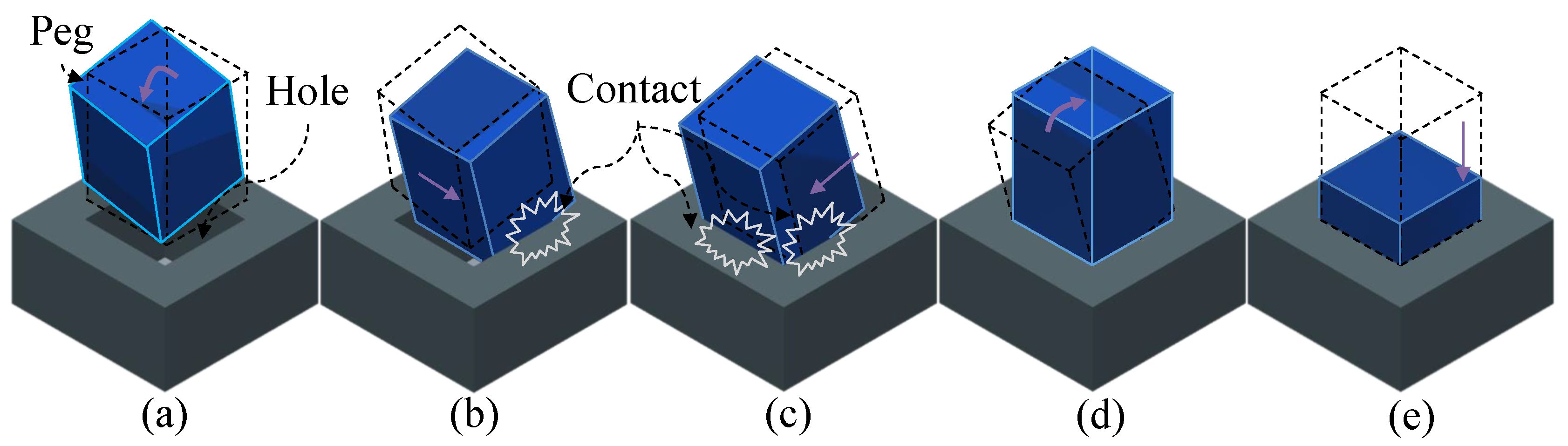
3.1. Description of the Peg-in-Hole Task
3.2. Reward Functions of Imitation Learning and Self-Learning in the Peg-in-Hole Task
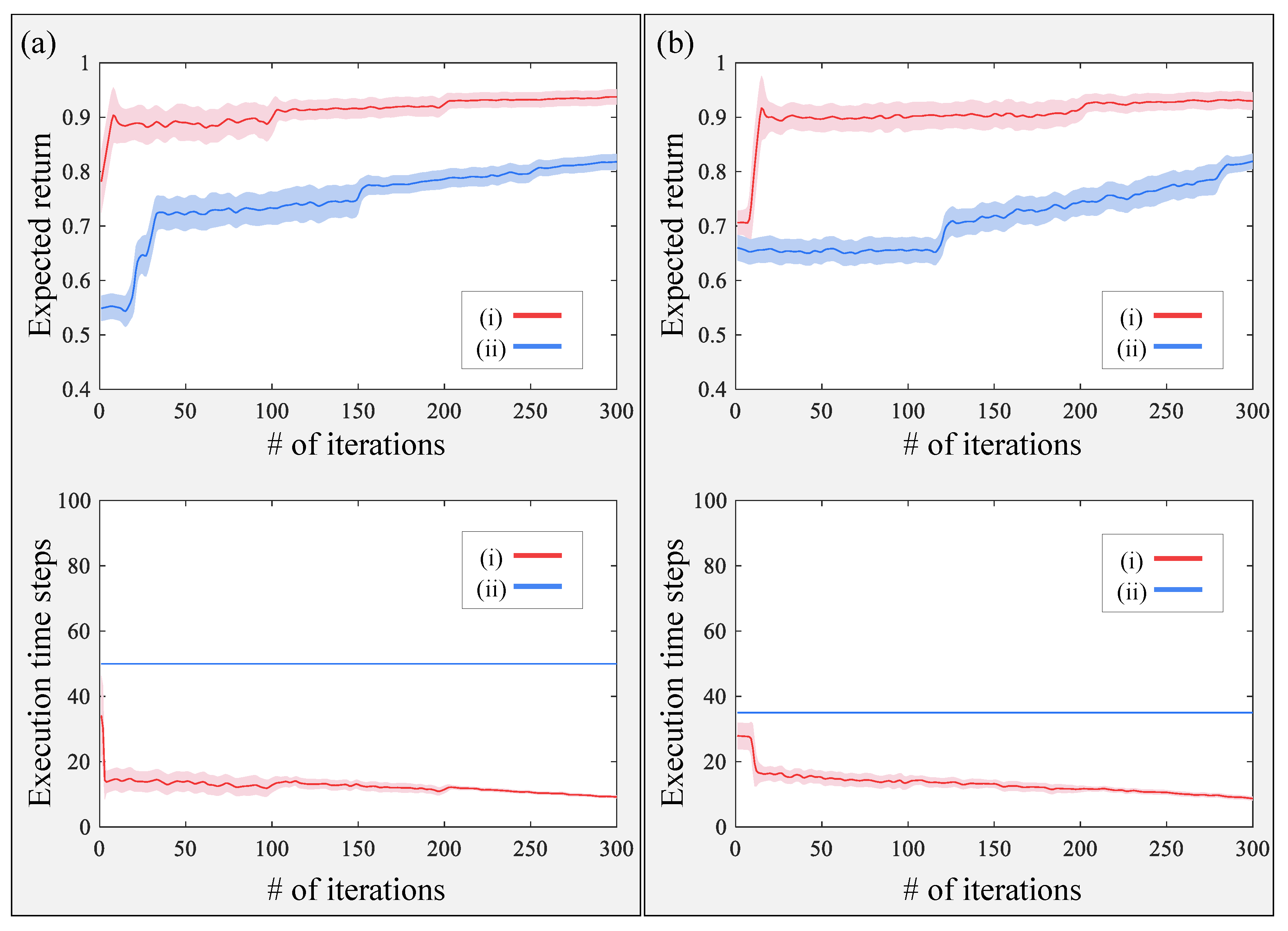
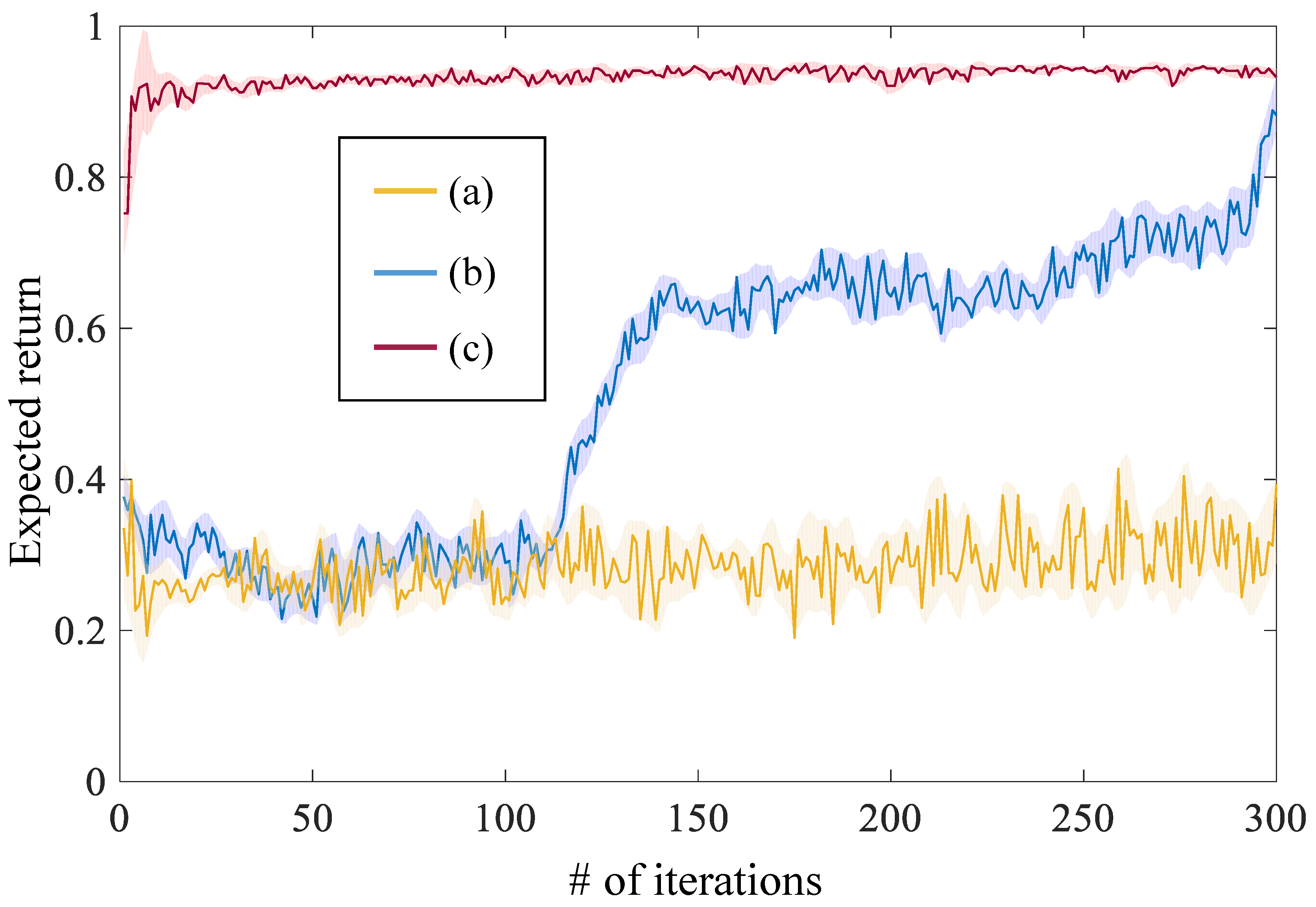
3.3. Results
4. Discussion
5. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kronander, K.; Burdet, E.; Billard, A. Task Transfer via Collaborative Manipulation for Insertion Assembly. In Proceedings of the Workshop on Human-Robot Interaction for Industrial Manufacturing, Robotics, Science and Systems, Bielefeld, Germany, 3–6 March 2014; pp. 1–6. [Google Scholar]
- Billard, A.; Calinon, S.; Dillmann, R. Learning from Demonstration. In Springer Handbook of Robotics; Springer: Berlin, Germany, 2016; pp. 1995–2014. [Google Scholar]
- Mollard, Y.; Munzer, T.; Thibaut, B.; Baisero, A.; Toussaint, M.; Manuel, M. Robot Programming from Demonstration, Feedback and Transfer. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 1825–1831. [Google Scholar]
- Gupta, A.; Eppner, C.; Levine, S.; Abbeel, P. Learning Dexterous Manipulation for a Soft Robotic Hand from Human Demonstrations. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 3786–3793. [Google Scholar]
- Kober, J.; Peters, J. Learning New Basic Movements for Robotics. In Autonome Mobile Systeme; Springer: Berlin, Germany, 2009; pp. 105–112. [Google Scholar]
- Koenig, N.; Mataric, M. Robot Life-long Task Learning from Human Demonstrations: A Bayesian Approach. Auton. Robot. 2017, 41, 1173–1188. [Google Scholar] [CrossRef]
- Zoliner, R.; Pardowitz, M.; Knoop, S.; Dillmann, R. Towards Cognitive Robots: Building Hierarchical Task Representations of Manipulations from Human Demonstrations. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation (ICRA), Barcelona, Spain, 18–22 April 2005; pp. 1535–1540. [Google Scholar]
- Abu-Dakka, F.J.; Nemec, B.; Kramberger, A.; Buch, A.; Kruger, N.; Ude, A. Solving Peg-in-Hole Tasks by Human Demonstrations and Exception Strategies. Ind. Robot Int. J. 2014, 41, 575–584. [Google Scholar] [CrossRef]
- Zhao, Y.; Al-Yacoub, A.; Goh, Y.; Justham, L.; Lohse, N.; Jackson, M. Human Skill Capture: A Hidden Markov Model of Force and Torque Data in Peg-in-Hole Assembly Process. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016; pp. 655–660. [Google Scholar]
- Cho, N.J.; Lee, S.H.; Suh, I.H.; Kim, H. Relationship Between the Order for Motor Skill Transfer and Motion Complexity in Reinforcement Learning. IEEE Robot. Autom. Lett. 2018, 4, 293–300. [Google Scholar] [CrossRef]
- Xu, Y.; Hu, Y.; Hu, L. Precision Peg-in-Hole Assembly Strategy Using Force-guided Robot. In Proceedings of the 3rd International Conference on Machinery, Materials and Information Technology Applications, Qingdao, China, 28–29 November 2015; pp. 6–11. [Google Scholar]
- Park, H.; Park, J.; Lee, D.; Park, J.; Baeg, M.; Bae, J. Compliance-based Robotic Peg-in-Hole Assembly Strategy without Force Feedback. IEEE Trans. Ind. Electron. 2017, 64, 6299–6309. [Google Scholar] [CrossRef]
- Zhang, X.; Zheng, Y.; Ota, J.; Huang, Y. Peg-in-Hole Assembly Based on Two-phase Scheme and F/T Sensor for Dual-arm Robot. Sensors 2017, 17, 2004. [Google Scholar] [CrossRef] [PubMed]
- Jokesch, M.; Suchy, J.; Alexander, W.; Fross, A.; Thomas, U. Generic Algorithm for Peg-in-Hole Assembly Tasks for Pin Alignments with Impedance Controlled Robots. In Proceedings of the Robot 2015: Second Iberian Robotics Conference, Lisbon, Portugal, 19–21 November 2016; pp. 105–117. [Google Scholar]
- Calinon, S.; Dhalluin, F.; Sauser, E.; Caldwell, D.; Billard, A. A Probabilistic Approach based on Dynamical Systems to Learn and Reproduce Gestures by Imitation. IEEE Robot. Autom. Mag. 2010, 17, 44–54. [Google Scholar] [CrossRef]
- Ude, A.; Gams, A.; Asfour, T.; Morimoto, J. Task-specific Generalization of Discrete and Periodic Dynamic Movement Primitives. IEEE Trans. Robot. 2010, 26, 800–815. [Google Scholar] [CrossRef]
- Kyrarini, M.; Haseeb, M.A.; Ristic-Durrant, D.A. Graser, Robot Learning of Industrial Assembly Task via Human Demonstrations. Autom. Robot. 2018, 43, 239–257. [Google Scholar]
- Yun, S. Compliant Manipulation for Peg-in-Hole: Is Passive Compliance a Key to Learn Contact Motion? In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Pasadena, CA, USA, 19–23 May 2008; pp. 1647–1652. [Google Scholar]
- Inoue, T.; Magistris, G.D.; Munawar, A.; Yokoya, T.; Tachibana, R. Deep Reinforcement Learning for High Precision Assembly Tasks. In Proceedings of the IEEE/RSJ International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 819–825. [Google Scholar]
- Kober, J.; Peters, J. Imitation Learning and Reinforcement Learning. IEEE Robot. Autom. Mag. 2010, 17, 55–62. [Google Scholar] [CrossRef]
- Kormushev, P.; Calinon, S.; Caldwell, D. Robot Motor Skill Coordination with EM-based Reinforcement Learning. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 3232–3237. [Google Scholar]
- Kroemer, O.; Daniel, C.; Neumann, G.; Hoof, H.V.; Peters, J. Towards Learning Hierarchical Skills for Multi-phase Manipulation Tasks. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1503–1510. [Google Scholar]
- Levine, S.; Abbeel, P. Learning Neural Network Policies with Guided Policy Search Under Unknown Dynamics. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1071–1079. [Google Scholar]
- Lee, H.; Kim, J. An HMM-based Threshold Model Approach for Gesture Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 2, 961–973. [Google Scholar]
- Lee, S.H.; Suh, I.H.; Calinon, S.; Johansson, R. Autonomous Framework for Segmenting Robot Trajectories of Manipulation Task. Auton. Robot. 2015, 38, 107–141. [Google Scholar] [CrossRef]
- Calinon, S.; Dhalluin, F.; Sauser, E.L.; Caldwell, D.G.; Billard, A. Learning and Reproduction of Gestures by Imitation. IEEE Robot. Autom. Mag. 2010, 17, 44–54. [Google Scholar] [CrossRef]
- Paster, P.; Hoffmann, H.; Asfour, T.; Schaal, S. Learning and Generalization of Motor Skills by Learning from Demonstration. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Kobe, Japan, 12–17 May 2009; pp. 763–768. [Google Scholar]
- Lee, S.H.; Kim, H.K.; Suh, I.H. Incremental Learning of Primitivie Skills from Demonstration of a Task. In Proceedings of the 6th International Conference on Human-Robot Interaction (HRI), Lausanne, Switzerland, 6–9 March 2011; pp. 185–186. [Google Scholar]
- Rautaray, S.S.; Agrawal, A. Vision based Hand Gesture Recognition for Human Computer Interaction: A Survey. Artif. Intell. Rev. 2015, 43, 1–54. [Google Scholar] [CrossRef]
- Savarimuthu, T.; Lijekrans, D.; Ellekilde, L.; Ude, A.; Nemec, B.; Kruger, N. Analysis of Human Peg-in-Hole Executions in a Robotic Embodiment using Uncertain Grasps. In Proceedings of the 9th International Workshop on Robot Motion and Control (RoMoCo), Kuslin, Poland, 3–5 July 2013; pp. 233–239. [Google Scholar]
- Dynamic Movement Primitives in Python. Available online: https://github.com/studywolf/pydmps (accessed on 7 April 2020).
- Hidden Markov Models in Python. Available online: https://github.com/hmmlearn/hmmlearn (accessed on 7 April 2020).
- Policy Learning by Weighting Exploration with the Returns (PoWER). Available online: http://www.jenskober.de/code.php (accessed on 7 April 2020).
- Scikit-Learning: Machine Learning in Python. Available online: https://scikit-learn.org/stable/ (accessed on 7 April 2020).
- Pehlivan, A.; Oztop, E. Dynamic Movement Primitives for Human Movement Recognition. In Proceedings of the Annual Conference of the IEEE Industrial Electronics Society, Yokohama, Japan, 9–12 November 2015; pp. 2178–2183. [Google Scholar]
- Suh, I.H.; Lee, S.H.; Cho, N.J.; Kwon, W.Y. Measuring Motion Significance and Motion Complexity. Inf. Sci. 2017, 388, 84–98. [Google Scholar] [CrossRef]
- Colomé, A.; Torras, C. Dimensionality Reduction for Dynamic Movement Primitives and Application to Bimanual Manipulation of Clothes. IEEE Trans. Robot. 2018, 34, 602–615. [Google Scholar] [CrossRef]
- Hazara, M.; Kyrki, V. Model Selection for Incremental Learning of Generalizable Movement Primitives. In Proceedings of the 2017 18th International Conference on Advanced Robotics (ICAR), Singapore, 29 May–3 June 2017; pp. 359–366. [Google Scholar]
- Winter, F.; Saveriano, M.; Lee, D. The Role of Coupling Terms in Variable Impedance Policies Learning. In Proceedings of the International Workshop on Human-Friendly Robotics, Genova, Italy, 29–30 September 2016; pp. 1–3. [Google Scholar]
- Englert, P.; Toussaint, M. Combined Optimization and Reinforcement Learning for Manipulation Skills. In Proceedings of the Robotics: Science and Systems, Ann Arbor, MI, USA, 18–22 June 2016; pp. 1–9. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hole Search | Peg Insertion | |
|---|---|---|
| (Tilt Search) | (Two-Point Contact) | |
| HMMs | Reaction force/moment | Reaction force/moment |
| DMPs | Rotation (No change of position) | Force, rotation |
| RL | Reaction force/moment and rotation | Reaction force/moment and z-position |
| Hole Search | Peg Insertion | ||||
|---|---|---|---|---|---|
| # of | Expected | # of execution | # of | Expected | # of |
| Iterations | Return | Time Steps | Iterations | Return | Time Steps |
| 1 | 0.7412 | 64 | 1 | 0.6233 | 75 |
| 50 | 0.9253 | 17 | 50 | 0.8803 | 20 |
| 150 | 0.9479 | 13 | 150 | 0.9053 | 14 |
| 300 | 0.9611 | 9 | 300 | 0.9249 | 10 |
| Improvement/Generalization | # of Iterations |
|---|---|
| Improvement of motor skills for the rectangle shape | 35 |
| from initial motor skills for the rectangle shape | |
| Improvement of motor skills for the triangle shape | 37 |
| from initial motor skills for the triangle shape | |
| Improvement of motor skills for the star shape | 41 |
| from initial motor skills for the star shape | |
| Generalization of motor skills for the triangle shape | 95 |
| from initial motor skills for the rectangle shape | |
| Generalization of motor skills for the triangle shape | 46 |
| from improved motor skills for the rectangle shape | |
| Generalization of motor skills for the star shape | 146 |
| from initial motor skills for the rectangle shape | |
| Generalization of motor skills for the triangle shape | 59 |
| from improved motor skills for the rectangle shape |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, N.J.; Lee, S.H.; Kim, J.B.; Suh, I.H. Learning, Improving, and Generalizing Motor Skills for the Peg-in-Hole Tasks Based on Imitation Learning and Self-Learning. Appl. Sci. 2020, 10, 2719. https://doi.org/10.3390/app10082719
Cho NJ, Lee SH, Kim JB, Suh IH. Learning, Improving, and Generalizing Motor Skills for the Peg-in-Hole Tasks Based on Imitation Learning and Self-Learning. Applied Sciences. 2020; 10(8):2719. https://doi.org/10.3390/app10082719
Chicago/Turabian StyleCho, Nam Jun, Sang Hyoung Lee, Jong Bok Kim, and Il Hong Suh. 2020. "Learning, Improving, and Generalizing Motor Skills for the Peg-in-Hole Tasks Based on Imitation Learning and Self-Learning" Applied Sciences 10, no. 8: 2719. https://doi.org/10.3390/app10082719
APA StyleCho, N. J., Lee, S. H., Kim, J. B., & Suh, I. H. (2020). Learning, Improving, and Generalizing Motor Skills for the Peg-in-Hole Tasks Based on Imitation Learning and Self-Learning. Applied Sciences, 10(8), 2719. https://doi.org/10.3390/app10082719