Business Analytics in Telemarketing: Cost-Sensitive Analysis of Bank Campaigns Using Artificial Neural Networks


Abstract
Featured Application
Abstract
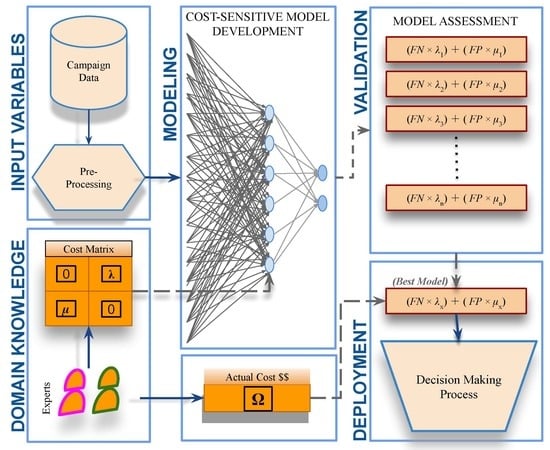
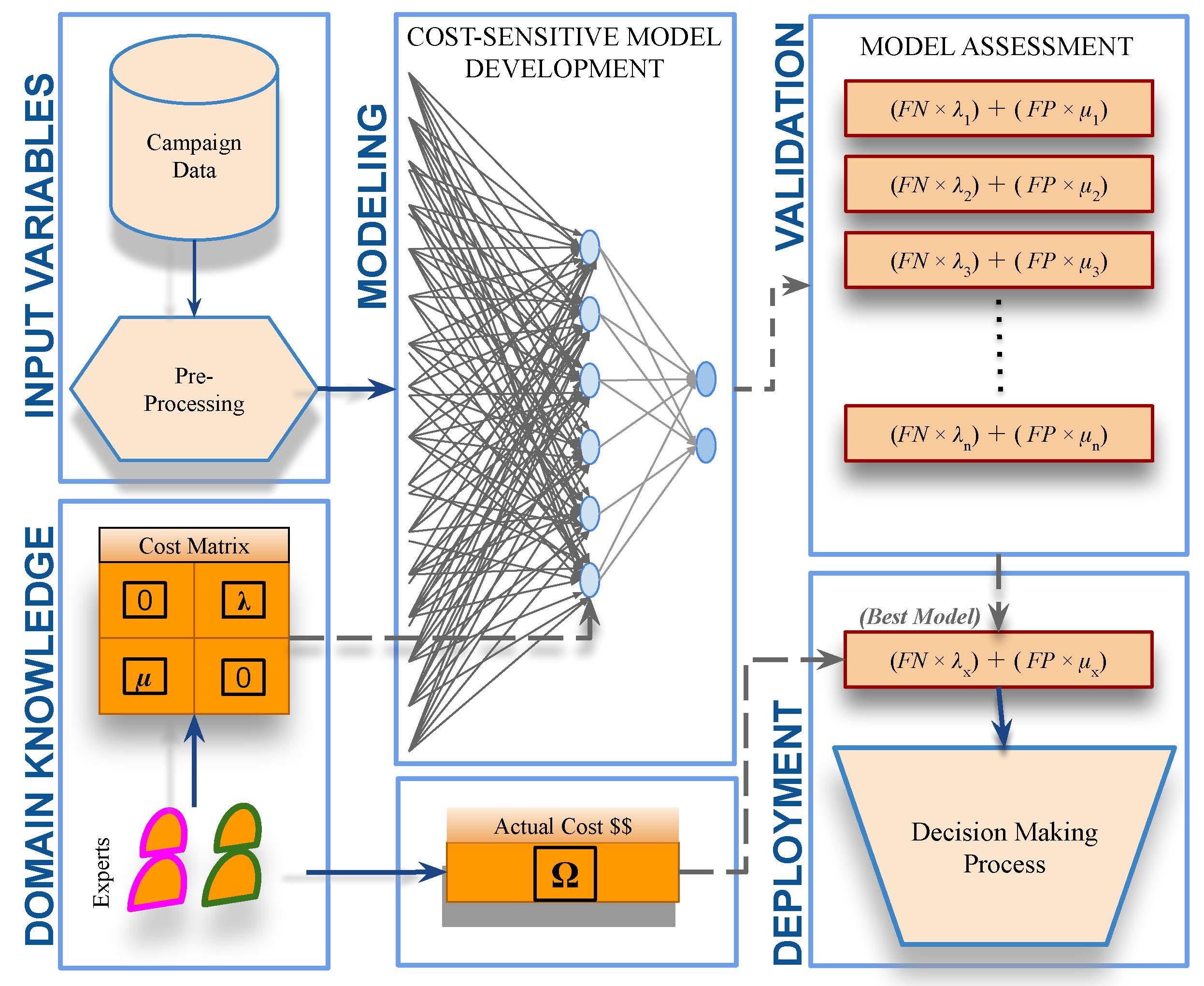
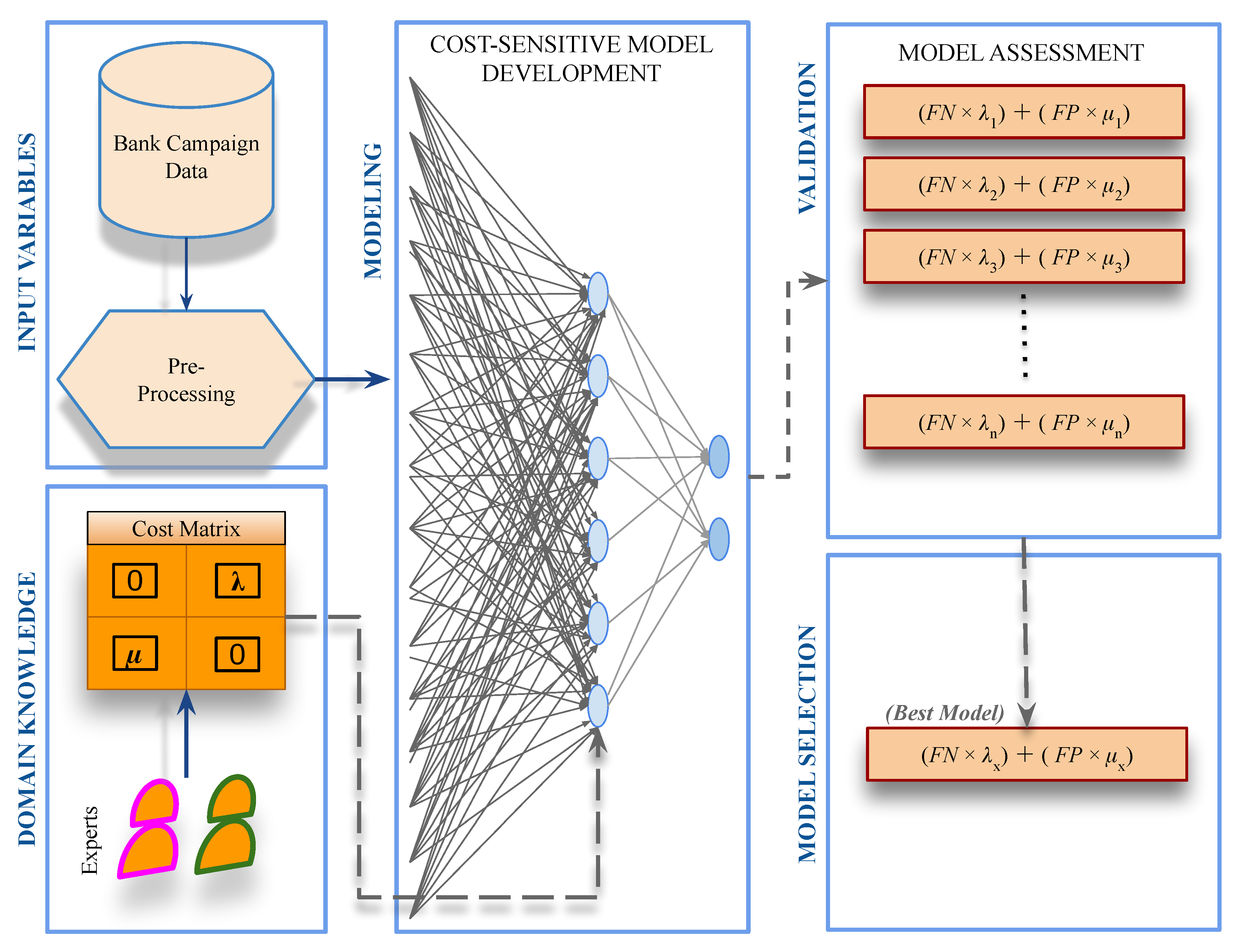
1. Introduction
- Proposing a relatively reliable cost-sensitive ANN model to predict the intentions of bank clients in applying for a long-term deposit.
- Mitigating the effects of imbalanced bank marketing data without distorting the distribution of real-world data.
- Translating the best outcomes into a decision support formula, which could be used to quantify the estimated costs of running a telemarketing campaign.
2. Theoretical Background
2.1. Base Classifier: Multilayer Perceptron
2.2. Cost-Sensitive Classification
2.3. Cost-Sensitive Learning
3. Data and Methodology
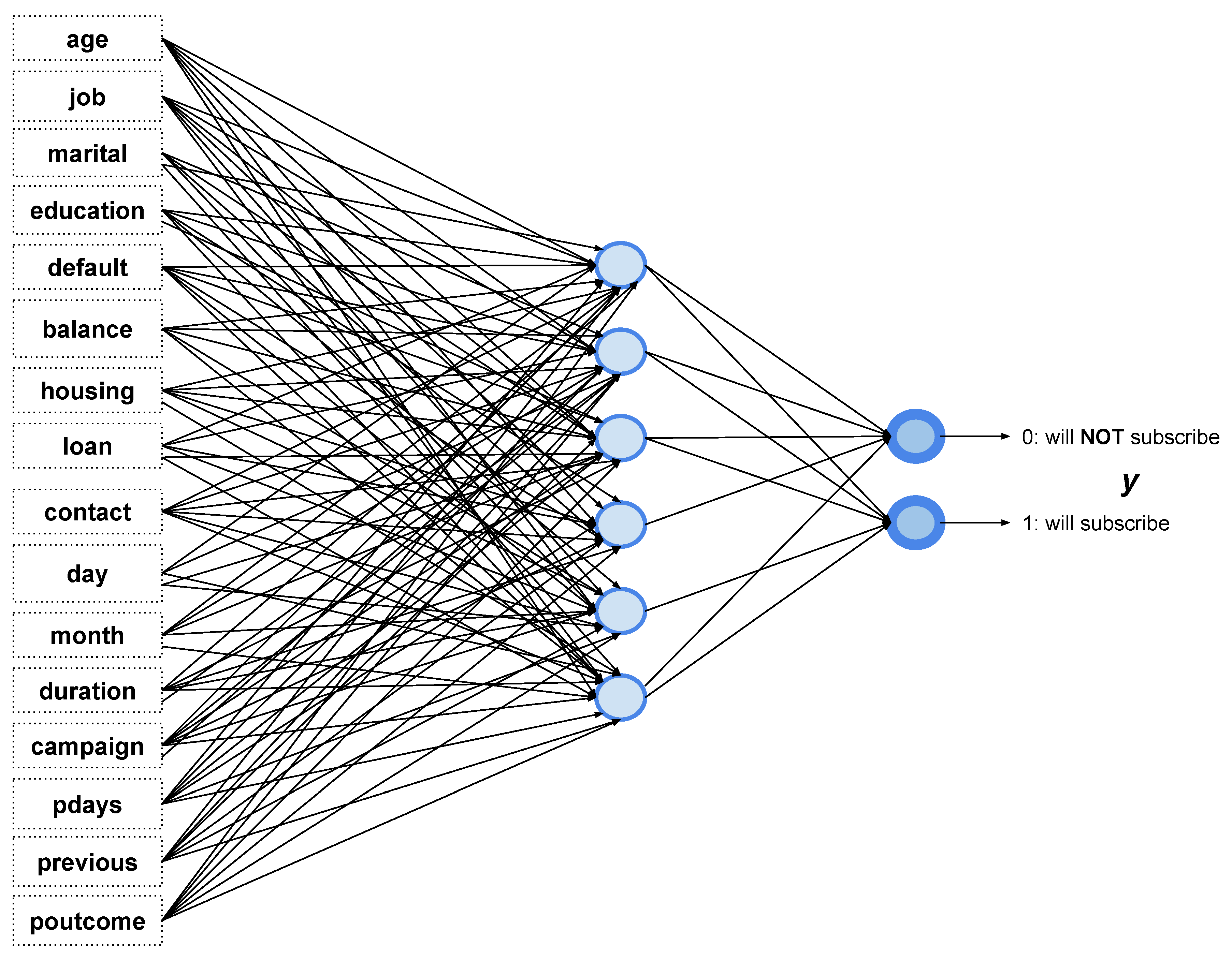
3.1. Data Description
3.2. The Proposed Methodology
3.2.1. CostSensitiveClassifier Method
3.2.2. Meta-Cost Method
| Algorithm 1: Meta-Cost Algorithm (Adapted from [44]) |
| Input: S - (Bank) training set L - (MLP) classification learning algorithm C - cost matrix m - number of resamples to generate n - number of examples in each resample p - True iff L produces class probabilities q - True iff all resamples are to be used for each example Procedure Meta-Cost(S, L, C, m, n, p, q) for i = 1 to m do  for each example x in S do  Let M = Model produced by applying L to S Return M |
3.3. Evaluation Measures
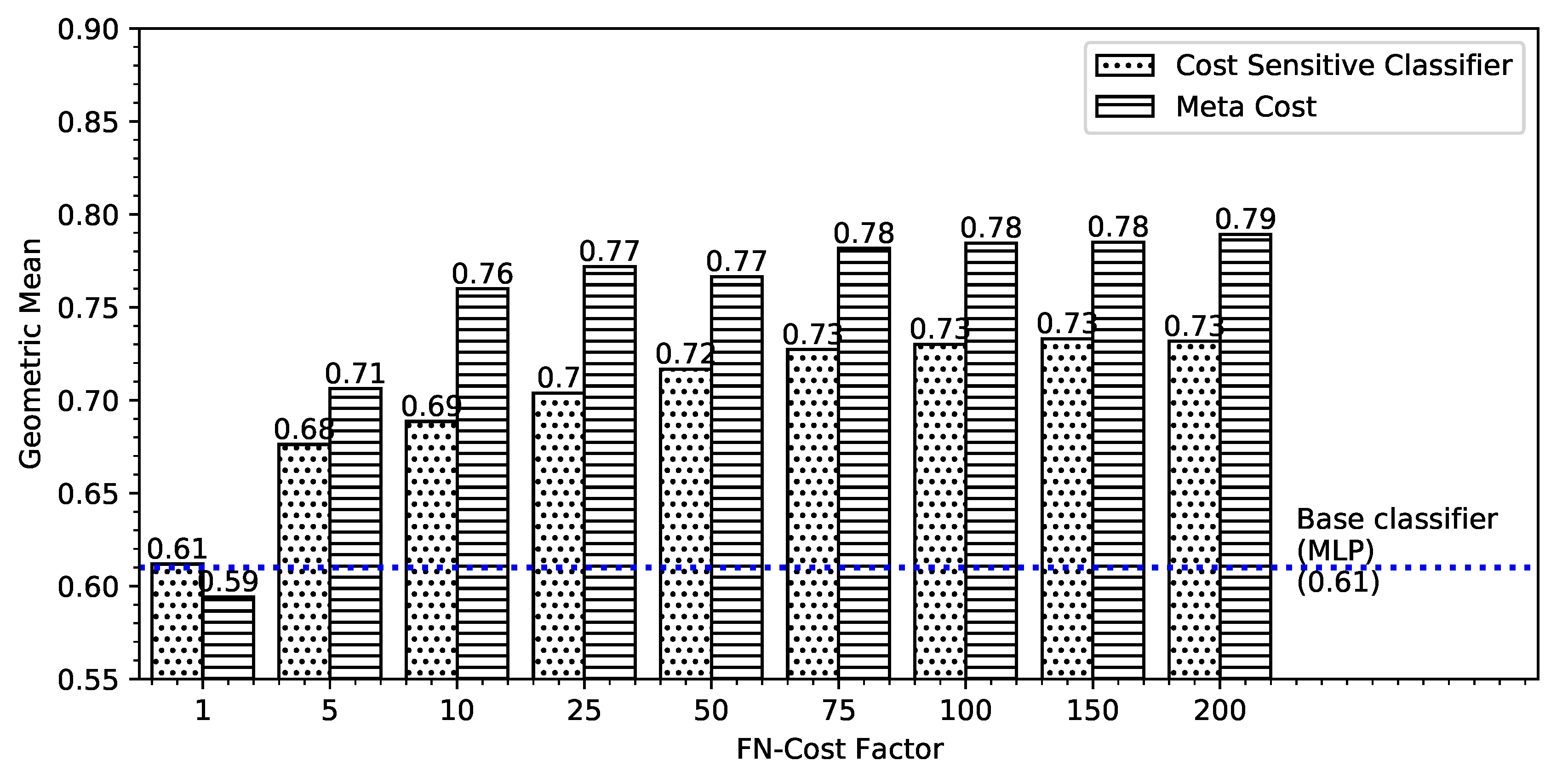
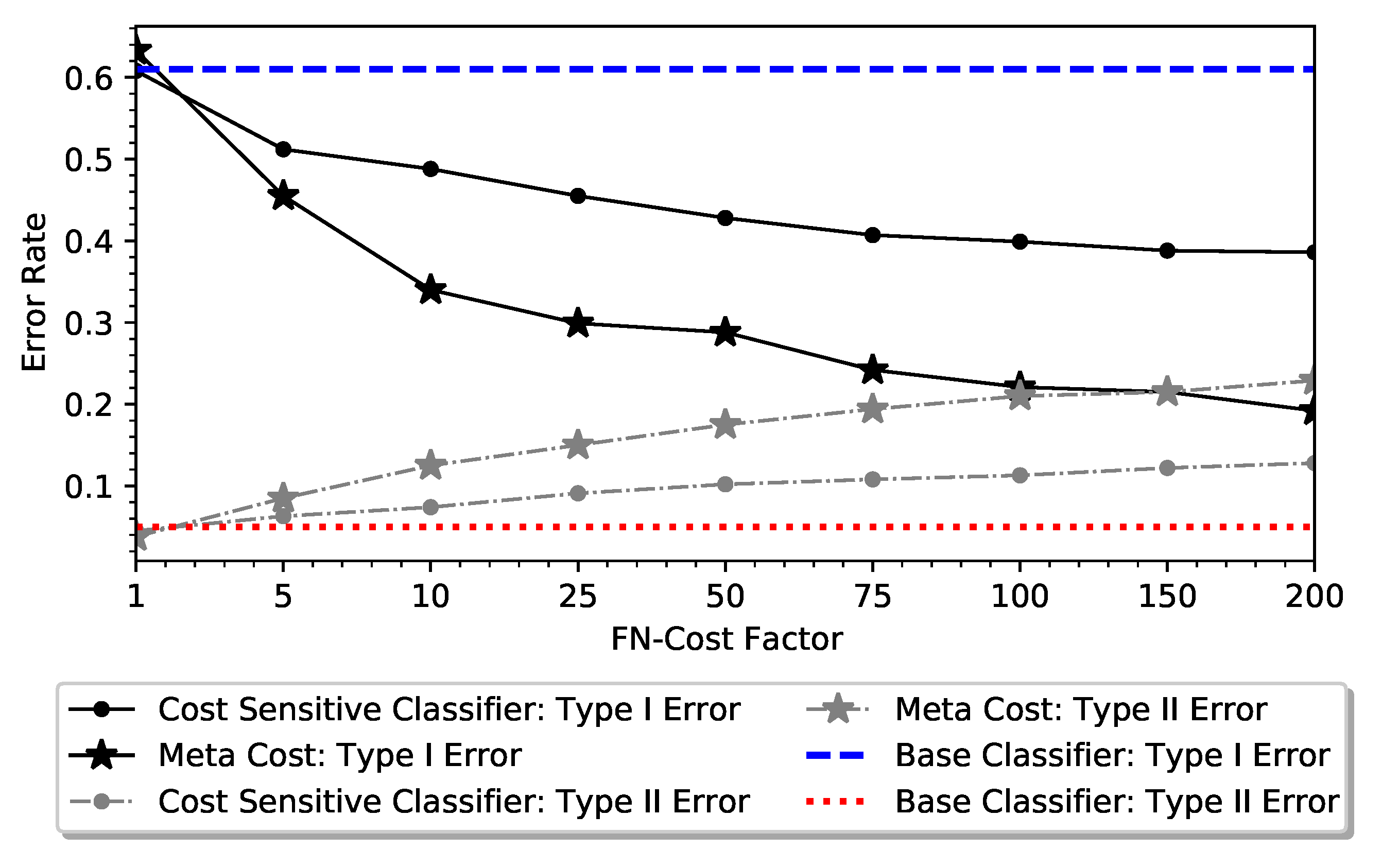
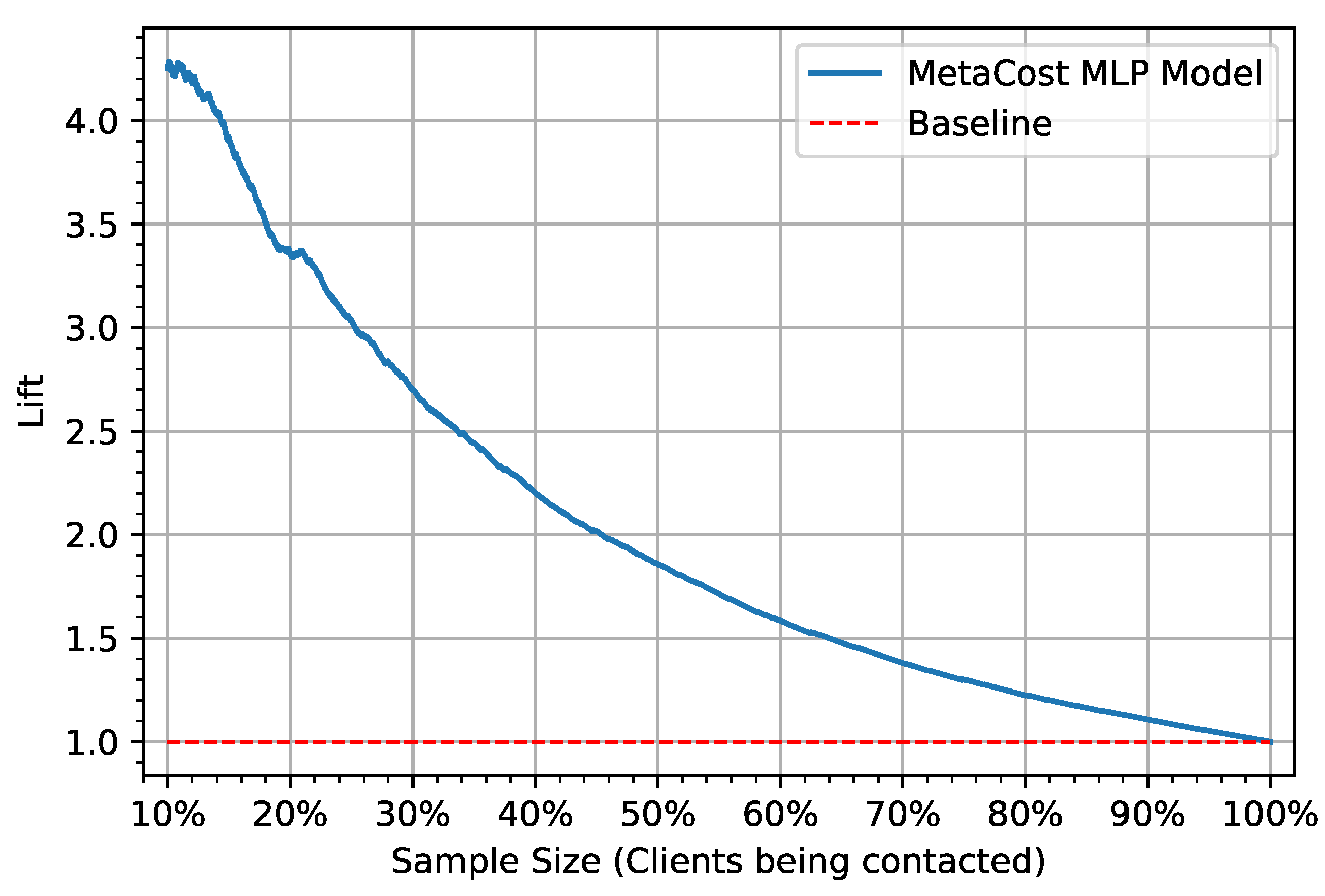
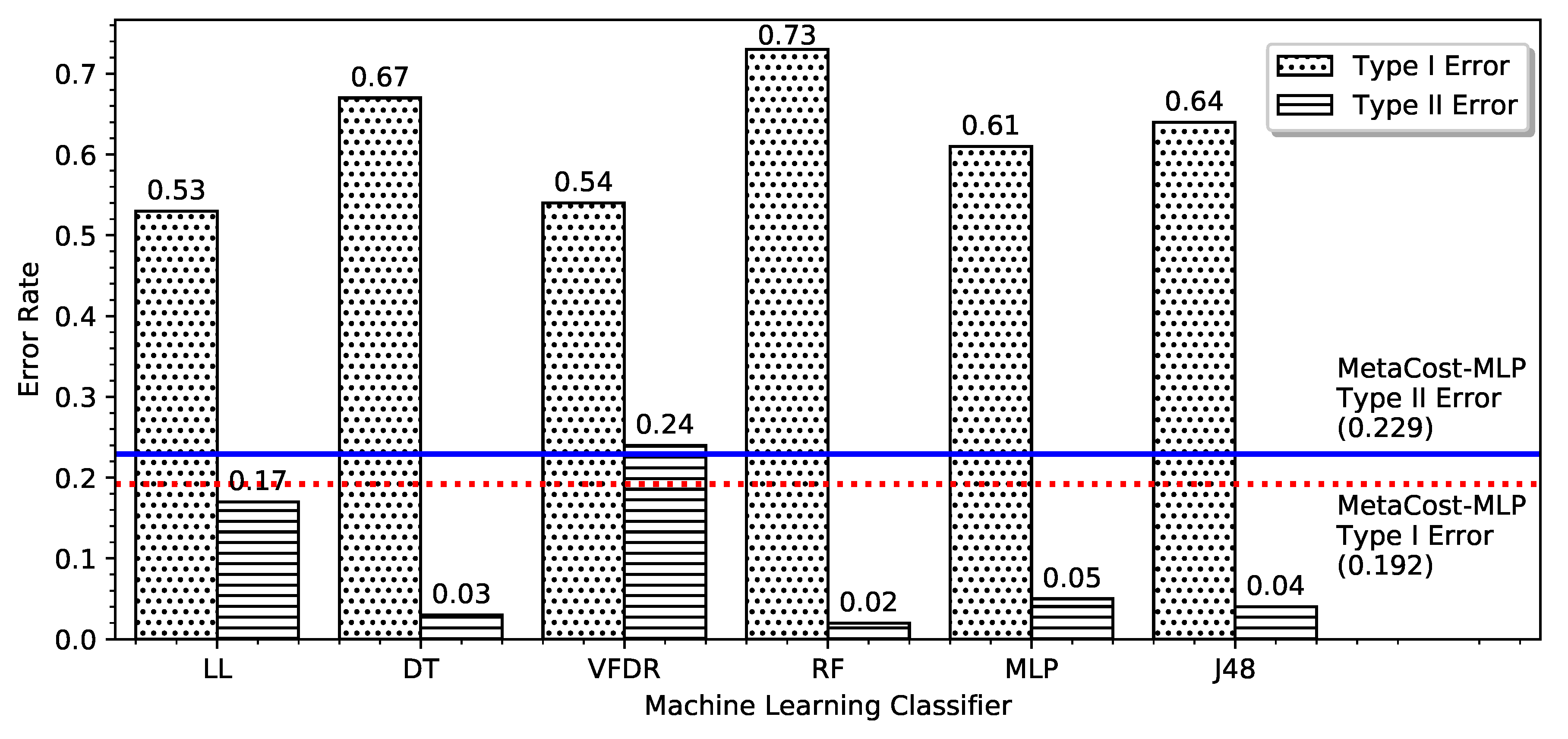
4. Results
5. Discussion and Implications
6. Limitations and Future Research
Author Contributions
Funding
Conflicts of Interest
References
- Wong, M.L.; Seng, K.; Wong, P.K. Cost-sensitive ensemble of stacked denoising autoencoders for class imbalance problems in business domain. Expert Syst. Appl. 2020, 141, 112918. [Google Scholar] [CrossRef]
- Bigus, J.P. Data Mining with Neural Networks: Solving Business Problems from Application Development to Decision Support; McGraw-Hill, Inc.: New York, NY, USA, 1996. [Google Scholar]
- Moro, S.; Cortez, P.; Rita, P. A data-driven approach to predict the success of bank telemarketing. Decis. Support Syst. 2014, 62, 22–31. [Google Scholar] [CrossRef]
- Waller, M.A.; Fawcett, S.E. Data science, predictive analytics, and big data: A revolution that will transform supply chain design and management. J. Bus. Logist. 2013, 34, 77–84. [Google Scholar] [CrossRef]
- Ghatasheh, N. Business Analytics using Random Forest Trees for Credit Risk Prediction: A Comparison Study. Int. J. Adv. Sci. Technol. 2014, 72, 19–30. [Google Scholar] [CrossRef]
- Faris, H.; Al-Shboul, B.; Ghatasheh, N. A genetic programming based framework for churn prediction in telecommunication industry. Lect. Notes Comput. Sci. 2014, 8733, 353–362. [Google Scholar]
- Ajah, I.A.; Nweke, H.F. Big Data and Business Analytics: Trends, Platforms, Success Factors and Applications. Big Data Cogn. Comput. 2019, 3, 32. [Google Scholar] [CrossRef]
- Chen, Y.; Guo, J.; Li, C.; Ren, W. FaDe: A Blockchain-Based Fair Data Exchange Scheme for Big Data Sharing. Future Internet 2019, 11, 225. [Google Scholar] [CrossRef]
- Liu, H.; Huang, Y.; Wang, Z.; Liu, K.; Hu, X.; Wang, W. Personality or Value: A Comparative Study of Psychographic Segmentation Based on an Online Review Enhanced Recommender System. Appl. Sci. 2019, 9, 1992. [Google Scholar] [CrossRef]
- Moro, S.; Cortez, P.; Rita, P. A divide-and-conquer strategy using feature relevance and expert knowledge for enhancing a data mining approach to bank telemarketing. Expert Syst. 2018, 35, e12253. [Google Scholar] [CrossRef]
- Gerrikagoitia, J.K.; Castander, I.; Rebón, F.; Alzua-Sorzabal, A. New trends of Intelligent E-Marketing based on Web Mining for e-shops. Procedia-Soc. Behav. Sci. 2015, 175, 75–83. [Google Scholar] [CrossRef]
- Burez, J.; Van den Poel, D. CRM at a pay-TV company: Using analytical models to reduce customer attrition by targeted marketing for subscription services. Expert Syst. Appl. 2007, 32, 277–288. [Google Scholar] [CrossRef]
- Corte, V.D.; Iavazzi, A.; D’Andrea, C. Customer involvement through social media: the cases of some telecommunication firms. J. Open Innov. Technol. Mark. Complex. 2015, 1. [Google Scholar] [CrossRef]
- Ayoubi, M. Customer Segmentation Based on CLV Model and Neural Network. Int. J. Comput. Sci. Issues 2016, 13, 31–37. [Google Scholar] [CrossRef][Green Version]
- Rendón, E.; Alejo, R.; Castorena, C.; Isidro-Ortega, F.J.; Granda-Gutiérrez, E.E. Data Sampling Methods to Deal With the Big Data Multi-Class Imbalance Problem. Appl. Sci. 2020, 10, 1276. [Google Scholar] [CrossRef]
- Kaur, H.; Pannu, H.S.; Malhi, A.K. A Systematic Review on Imbalanced Data Challenges in Machine Learning: Applications and Solutions. ACM Comput. Surv. 2019, 52. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Lin, H.I.; Nguyen, M.C. Boosting Minority Class Prediction on Imbalanced Point Cloud Data. Appl. Sci. 2020, 10, 973. [Google Scholar] [CrossRef]
- Gonzalez-Cuautle, D.; Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, L.K.; Portillo-Portillo, J.; Olivares-Mercado, J.; Perez-Meana, H.M.; Sandoval-Orozco, A.L. Synthetic Minority Oversampling Technique for Optimizing Classification Tasks in Botnet and Intrusion-Detection-System Datasets. Appl. Sci. 2020, 10, 794. [Google Scholar] [CrossRef]
- Suh, S.; Lee, H.; Jo, J.; Lukowicz, P.; Lee, Y. Generative Oversampling Method for Imbalanced Data on Bearing Fault Detection and Diagnosis. Appl. Sci. 2019, 9, 746. [Google Scholar] [CrossRef]
- Alejo, R.; Monroy-De-Jesús, J.; Pacheco-Sánchez, J.; López-González, E.; Antonio-Velázquez, J. A Selective Dynamic Sampling Back-Propagation Approach for Handling the Two-Class Imbalance Problem. Appl. Sci. 2016, 6, 200. [Google Scholar] [CrossRef]
- Ghochani, M.; Afzalian, M.; Gheitasi, S.; Gheitasi, S. Simulation of customer behavior using artificial neural network techniques. Int. J. Inf. Bus. Manag. 2013, 5, 59–68. [Google Scholar]
- Kim, Y.; Street, W.N.; Russell, G.J.; Menczer, F. Customer Targeting: A Neural Network Approach Guided by Genetic Algorithms. Manag. Sci. 2005, 51, 264–276. [Google Scholar] [CrossRef]
- Elsalamony, H.A.; Elsayad, A.M. Bank Direct Marketing Based on Neural Network and C5. 0 Models. Int. J. Eng. Adv. Technol. 2013, 2, 392–400. [Google Scholar]
- Guresen, E.; Kayakutlu, G.; Daim, T.U. Using artificial neural network models in stock market index prediction. Expert Syst. Appl. 2011, 38, 10389–10397. [Google Scholar] [CrossRef]
- Zakaryazad, A.; Duman, E. A profit-driven Artificial Neural Network (ANN) with applications to fraud detection and direct marketing. Neurocomputing 2016, 175, 121–131. [Google Scholar] [CrossRef]
- Koç, A.; Yeniay, Ö. A Comparative Study of Artificial Neural Networks and Logistic Regression for Classification of Marketing Campaign Results. Math. Comput. Appl. 2013, 18, 392–398. [Google Scholar] [CrossRef]
- Adwan, O.; Faris, H.; Jaradat, K.; Harfoushi, O.; Ghatasheh, N. Predicting customer churn in telecom industry using multilayer preceptron neural networks: Modeling and analysis. Life Sci. J. 2014, 11, 75–81. [Google Scholar]
- Mitik, M.; Korkmaz, O.; Karagoz, P.; Toroslu, I.H.; Yucel, F. Data Mining Approach for Direct Marketing of Banking Products with Profit/Cost Analysis. Rev. Socionetw. Strateg. 2017, 11, 17–31. [Google Scholar] [CrossRef]
- Khor, K.C.; Ng, K.H. Evaluation of Cost Sensitive Learning for Imbalanced Bank Direct Marketing Data. Indian J. Sci. Technol. 2016, 9. [Google Scholar] [CrossRef]
- Naseri, M.B.; Elliott, G. A Comparative Analysis of Artificial Neural Networks and Logistic Regression. J. Decis. Syst. 2010, 19, 291–312. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining, Fourth Edition: Practical Machine Learning Tools and Techniques, 4th ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2016. [Google Scholar]
- Kalid, S.N.; Khor, K.C.; Ng, K.H. Effective Classification for Unbalanced Bank Direct Marketing Data with Over-sampling. In Proceedings of the Knowledge Management International Conference (KMICe), Langkawi, Kedah, 12–15 August 2014; pp. 16–21. [Google Scholar]
- Jiang, X.; Pan, S.; Long, G.; Chang, J.; Jiang, J.; Zhang, C. Cost-sensitive hybrid neural networks for heterogeneous and imbalanced data. In Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Ghazikhani, A.; Monsefi, R.; Yazdi, H.S. Online cost-sensitive neural network classifiers for non-stationary and imbalanced data streams. Neural Comput. Appl. 2013, 23, 1283–1295. [Google Scholar] [CrossRef]
- Elkan, C. The Foundations of Cost-sensitive Learning. In Proceedings of the 17th International Joint Conference on Artificial Intelligence, Seattle, WA, USA, 4–10 August 2001; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001; Volume 2, pp. 973–978. [Google Scholar]
- Chandrasekara, V.; Tilakaratne, C.; Mammadov, M. An Improved Probabilistic Neural Network Model for Directional Prediction of a Stock Market Index. Appl. Sci. 2019, 9, 5334. [Google Scholar] [CrossRef]
- Feng, W.; Huang, W.; Ren, J. Class Imbalance Ensemble Learning Based on the Margin Theory. Appl. Sci. 2018, 8, 815. [Google Scholar] [CrossRef]
- Collell, G.; Prelec, D.; Patil, K.R. A simple plug-in bagging ensemble based on threshold-moving for classifying binary and multiclass imbalanced data. Neurocomputing 2018, 275, 330–340. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Wang, J. Encyclopedia of Data Warehousing and Mining, Second Edition, 2nd ed.; IGI Publishing: Hershey, PA, USA, 2008. [Google Scholar]
- Han, X.; Cui, R.; Lan, Y.; Kang, Y.; Deng, J.; Jia, N. A Gaussian mixture model based combined resampling algorithm for classification of imbalanced credit data sets. Int. J. Mach. Learn. Cybern. 2019. [Google Scholar] [CrossRef]
- Ling, C.X.; Sheng, V.S. Cost-Sensitive Learning and the Class Imbalance Problem. In Encyclopedia of Machine Learning; Springer: Berlin, Germany, 2008. [Google Scholar]
- Domingos, P. MetaCost: A General Method for Making Classifiers Cost-sensitive. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’99, San Diego, CA, USA, 15–18 August 1999; ACM: New York, NY, USA, 1999; pp. 155–164. [Google Scholar] [CrossRef]
- Powers, D.M.W. Evaluation: From Precision, Recall and F-Factor to ROC, Informedness, Markedness & Correlation; Technical Report SIE-07-001; School of Informatics and Engineering, Flinders University: Adelaide, Australia, 2007. [Google Scholar]
- Berry, M.J.; Linoff, G. Data Mining Techniques: For Marketing, Sales, and Customer Support; John Wiley & Sons, Inc.: New York, NY, USA, 1997. [Google Scholar]
- Palade, V. Class imbalance learning methods for support vector machines. In Imbalanced Learning: Foundations, Algorithms, and Applications; Wiley: Hoboken, NJ, USA, 2013; p. 83. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Description | Values | Count | Percent |
|---|---|---|---|---|
| job | Type of job | management | 969 | 21.4% |
| blue-collar | 946 | 20.9% | ||
| technician | 768 | 17.0% | ||
| admin | 478 | 10.6% | ||
| services | 417 | 9.2% | ||
| retired | 230 | 5.1% | ||
| self-employed | 183 | 4.0% | ||
| entrepreneur | 168 | 3.7% | ||
| unemployed | 128 | 2.8% | ||
| housemaid | 112 | 2.5% | ||
| student | 84 | 1.9% | ||
| unknown | 38 | 0.8% | ||
| marital | Marital status | single | 1196 | 26.5% |
| married | 2797 | 61.9% | ||
| divorced | 528 | 11.7% | ||
| education | Level of education | primary | 678 | 15.0% |
| secondary | 2306 | 51.0% | ||
| tertiary | 1350 | 29.9% | ||
| unknown | 187 | 4.1% | ||
| default | Has credit in default account | yes | 76 | 1.7% |
| no | 4445 | 98.3% | ||
| housing | If there is a housing loan | yes | 2559 | 56.6% |
| no | 1962 | 43.4% | ||
| loan | Has a personal loan | yes | 691 | 15.3% |
| no | 3830 | 84.7% | ||
| contact | Type of communication | cellular | 2896 | 64.1% |
| telephone | 301 | 6.7% | ||
| unknown | 1324 | 29.3% | ||
| month | Last contact month of the year | jan | 148 | 3.3% |
| feb | 222 | 4.9% | ||
| mar | 49 | 1.1% | ||
| apr | 293 | 6.5% | ||
| may | 1398 | 30.9% | ||
| jun | 531 | 11.7% | ||
| jul | 706 | 15.6% | ||
| aug | 633 | 14.0% | ||
| sep | 52 | 1.2% | ||
| oct | 80 | 1.8% | ||
| nov | 389 | 8.6% | ||
| dec | 20 | .4% | ||
| poutcome | Previous outcome results | failure | 490 | 10.8% |
| success | 129 | 2.9% | ||
| other | 197 | 4.4% | ||
| unknown | 3705 | 82.0% | ||
| y: Target Class | Has the client subscribed to a term deposit? | yes | 521 | 11.5% |
| no | 4000 | 88.5% |
| Variable | Description | Mean | SD | Percentile 25 | Percentile 50 | Percentile 75 |
|---|---|---|---|---|---|---|
| age | Integer indicating client’s age | 41.17 | 10.576 | 33.00 | 39.00 | 49.00 |
| balance | Average yearly balance | 1422.66 | 3009.638 | 69.00 | 444.00 | 1480.00 |
| day | Last contact day of the month | 15.92 | 8.248 | 9.00 | 16.00 | 21.00 |
| duration | Duration of last contact in seconds | 263.96 | 259.857 | 104.00 | 185.00 | 329.00 |
| campaign | Number of contacts performed during this campaign and for this client | 2.79 | 3.110 | 1.00 | 2.00 | 3.00 |
| days | Number of days passed since last campaign contact | 39.77 | 100.121 | −1.00 | −1.00 | −1.00 |
| previous | Number of contacts performed for this client from previous campaigns | 0.54 | 1.694 | 0.00 | 0.00 | 0.00 |
| Algorithm | Theoretical Base | Weka Implementation | Basis (Re-Sampling vs. Re-Weighting) |
|---|---|---|---|
| Cost-Sensitive Classifier | Meta-learning: Thresholding [43] | CostSensitiveClassifier [40] | Re-weighting |
| Meta-Cost | Meta-learning: Thresholding [43] | Meta-Cost [44] | Re-weighting |
| Configuration | Description |
|---|---|
| FN-Cost Factor () | 1, 5, 10, 25, 50, 75, 100, 150, 200 |
| FP-Cost Factor () | 1 always |
| Base Algorithm | MLP |
| Adding Cost Sensitivity | CostSensitiveClassifier, Meta-Cost |
| Validation | 10-Fold Cross Validation |
| Target Class | Yes ( the client will subscribe a term deposit ) |
| Predicted Willingness to Take a Term Deposit | |||
|---|---|---|---|
| Willing to | Not interested | ||
| Actual Willingness to Take a Term Deposit | Willing to | ||
| Not interested | |||
| Metric | Equation |
|---|---|
| Total Accuracy (All Correctly Classified Instances) | |
| True Positive Rate (TPR), alternatively Recall | |
| True Negative Rate (TNR), alternatively Precision | |
| Type I Error [45] | |
| Type II Error [45] | |
| Geometric Mean | |
| Lift [46] |
| Algorithm | TPR | TNR | Geometric Mean | Type I Error | Type II Error | Accuracy |
|---|---|---|---|---|---|---|
| (A) Our approach | ||||||
| Meta-Cost-MLP | 0.808 | 0.771 | 78.93% | 0.192 | 0.229 | 77.48 |
| CostSensitiveClassifier-MLP | 0.614 | 0.872 | 73.17% | 0.386 | 0.128 | 84.18 |
| (B) Conventional machine-learning classifiers | ||||||
| MLP (Baseline) | 0.39 | 0.95 | 60.87% | 0.61 | 0.05 | 88.98 |
| DL-MLP | 0.36 | 0.93 | 57.86% | 0.64 | 0.07 | 86.24 |
| J48 | 0.36 | 0.96 | 58.79% | 0.64 | 0.04 | 88.9 |
| LL | 0.47 | 0.83 | 62.46% | 0.53 | 0.17 | 78.61 |
| DT | 0.33 | 0.97 | 56.58% | 0.67 | 0.03 | 89.49 |
| VFDR | 0.46 | 0.76 | 59.13% | 0.54 | 0.24 | 72.61 |
| RF | 0.27 | 0.98 | 51.44% | 0.73 | 0.02 | 89.82 |
| (C) Other cost-sensitive results from related works | ||||||
| CSDE * [1] | 0.705 | 0.62.2 | 66.2% | n.a. | n.a. | n.a. |
| CSDNN ** [1] | 0.615 | 0.542 | 57.9% | n.a. | n.a. | n.a. |
| AdaCost [1] | 0.89 | 0.22 | 44.2% | n.a. | n.a. | n.a. |
| Meta-Cost [1] | 0.35 | 0.868 | 55.1% | n.a. | n.a. | n.a. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghatasheh, N.; Faris, H.; AlTaharwa, I.; Harb, Y.; Harb, A. Business Analytics in Telemarketing: Cost-Sensitive Analysis of Bank Campaigns Using Artificial Neural Networks. Appl. Sci. 2020, 10, 2581. https://doi.org/10.3390/app10072581
Ghatasheh N, Faris H, AlTaharwa I, Harb Y, Harb A. Business Analytics in Telemarketing: Cost-Sensitive Analysis of Bank Campaigns Using Artificial Neural Networks. Applied Sciences. 2020; 10(7):2581. https://doi.org/10.3390/app10072581
Chicago/Turabian StyleGhatasheh, Nazeeh, Hossam Faris, Ismail AlTaharwa, Yousra Harb, and Ayman Harb. 2020. "Business Analytics in Telemarketing: Cost-Sensitive Analysis of Bank Campaigns Using Artificial Neural Networks" Applied Sciences 10, no. 7: 2581. https://doi.org/10.3390/app10072581
APA StyleGhatasheh, N., Faris, H., AlTaharwa, I., Harb, Y., & Harb, A. (2020). Business Analytics in Telemarketing: Cost-Sensitive Analysis of Bank Campaigns Using Artificial Neural Networks. Applied Sciences, 10(7), 2581. https://doi.org/10.3390/app10072581