Managing Energy Plus Performance in Data Centers and Battery-Based Devices Using an Online Non-Clairvoyant Speed-Bounded Multiprocessor Scheduling

 ,
,  ,
,  ,
,  and
and
Abstract
1. Introduction
2. Related Work
3. Definitions and Notations
4. Methodology
5. An -Competitive Algorithm
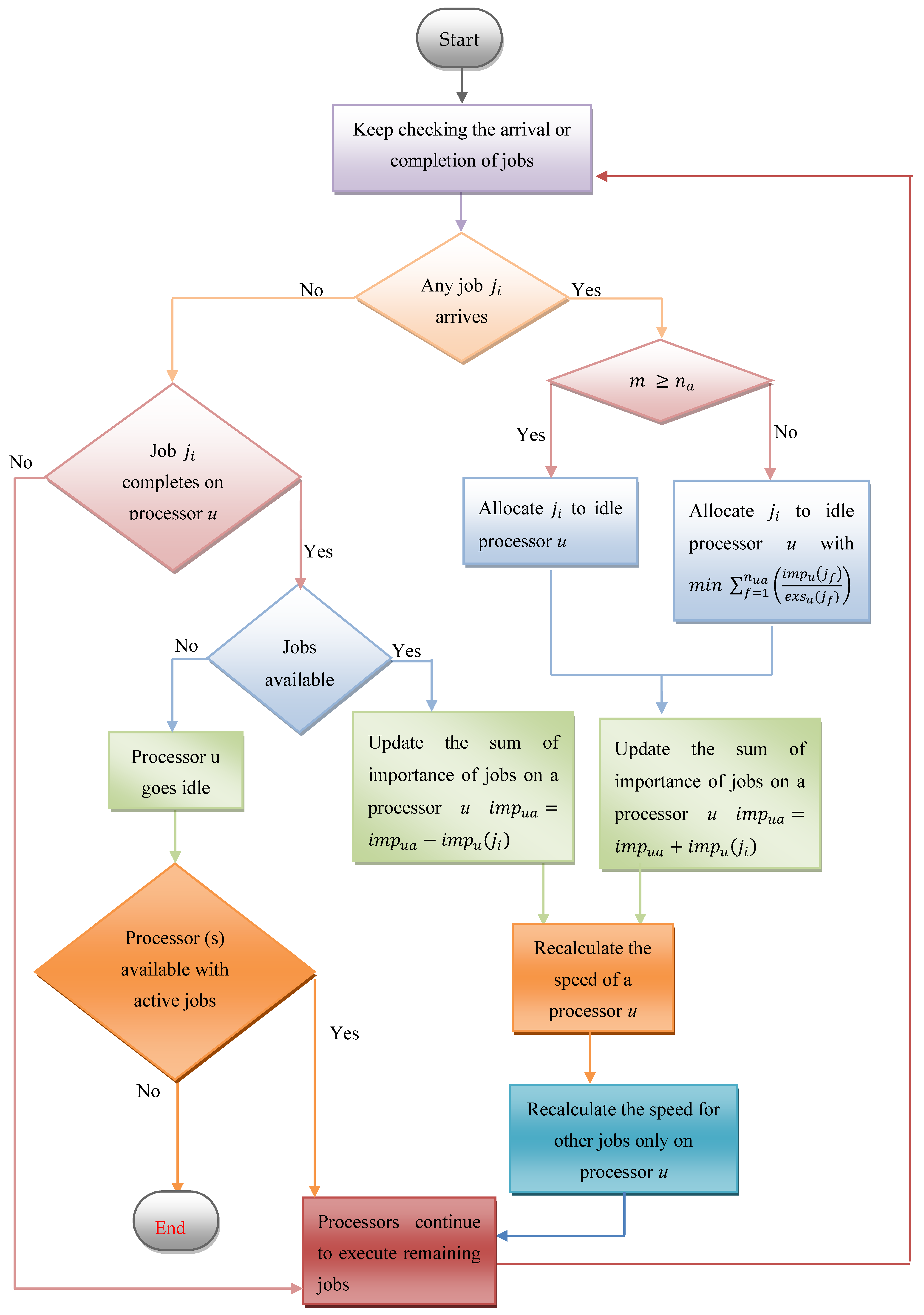
5.1. Multiprocessor with Bounded Speed Algorithm: MBS
| Algorithm 1: MBS (Multiprocessor with Bounded Speed) |
| Input: total m number of processors , NoAJ and the importance of all active jobs . Output: number of jobs allocated to every processor, the speed of all processors, at any time and execution speed share of each active job. Repeat until all processors become idle: 1. If any job arrives 2. if 3. allocate job to a idle processor u 4. otherwise, when 5. allocate job to a processor u with 6. 7. , where and is a constant value 8. Otherwise, if any job completes on any processor u and other active jobs are available for execution on that processor then 9. 10. , where and is a constant value 11. the speed received by any job , which is executing on a processor u, is 12. otherwise, processors continue to execute remaining jobs |
5.2. Necessary Conditions to be Fulfilled
5.3. Potential Function
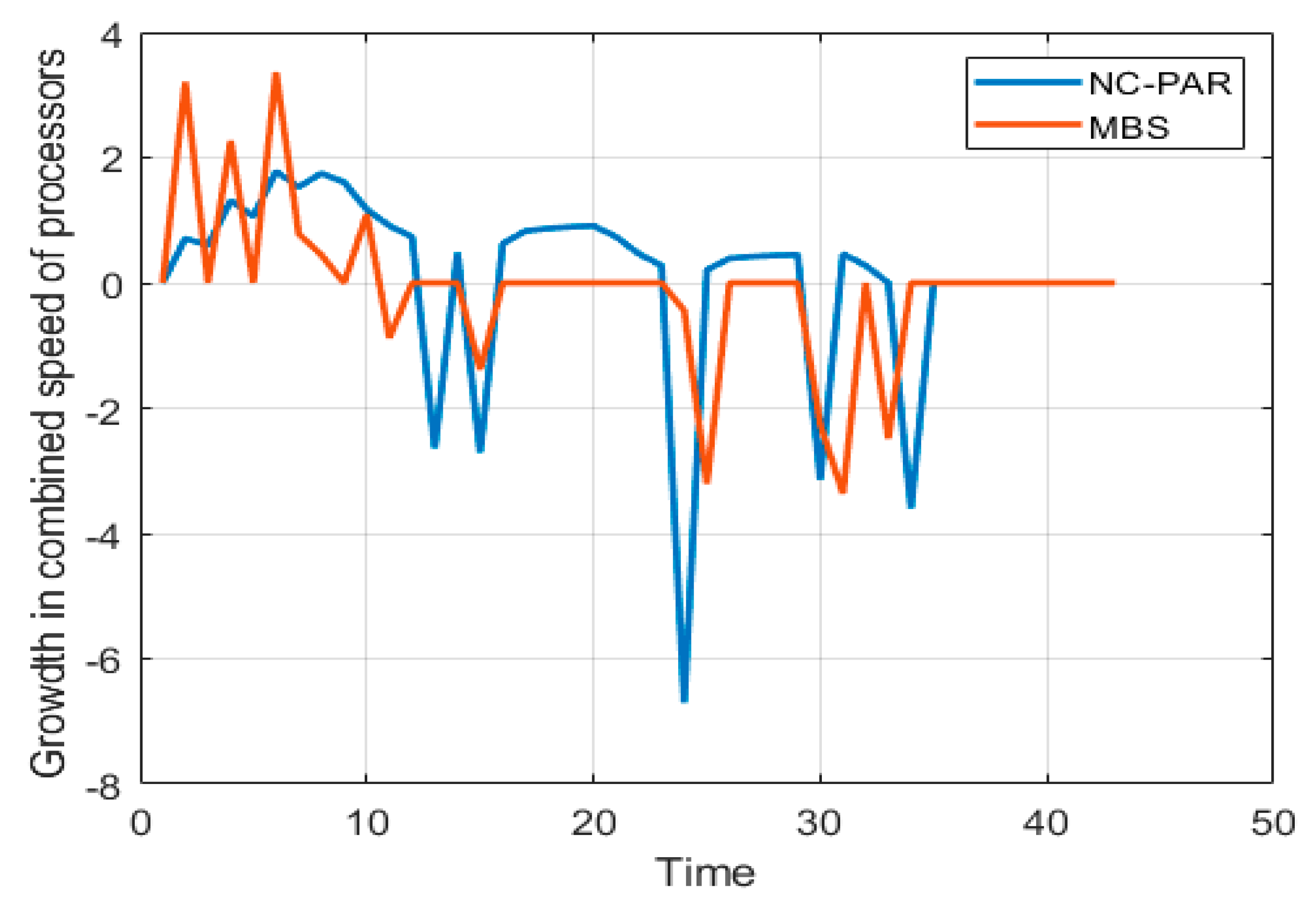
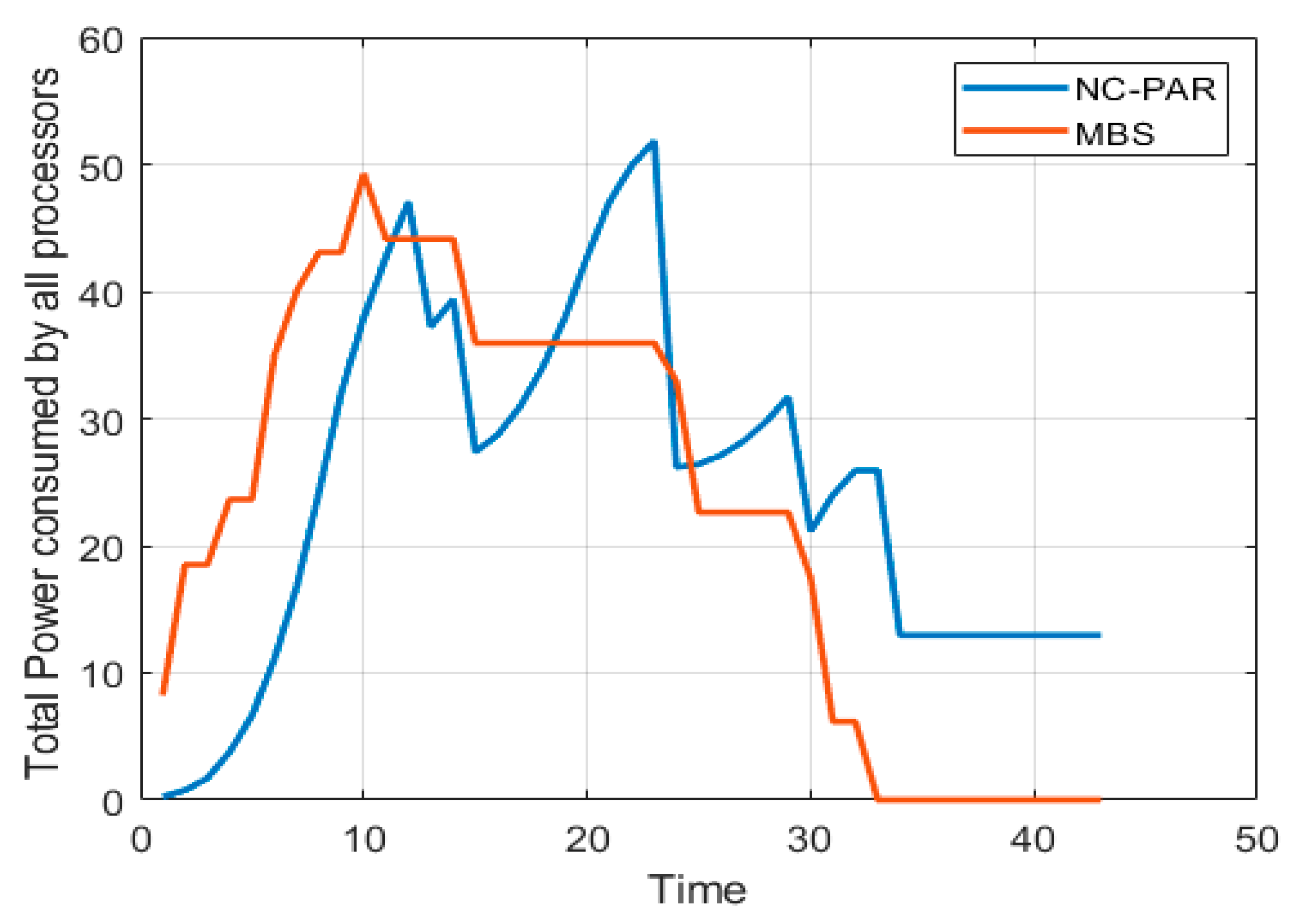
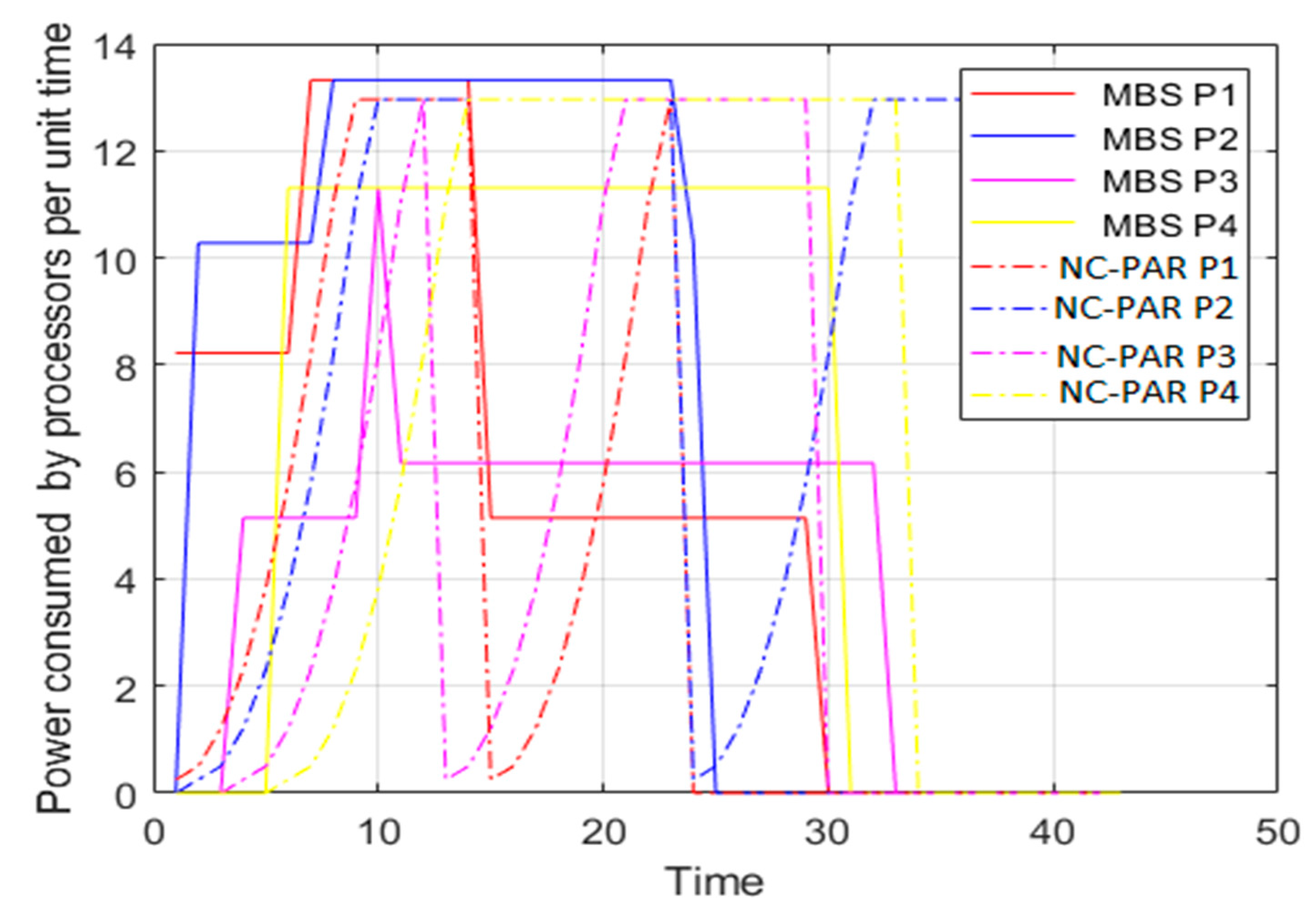
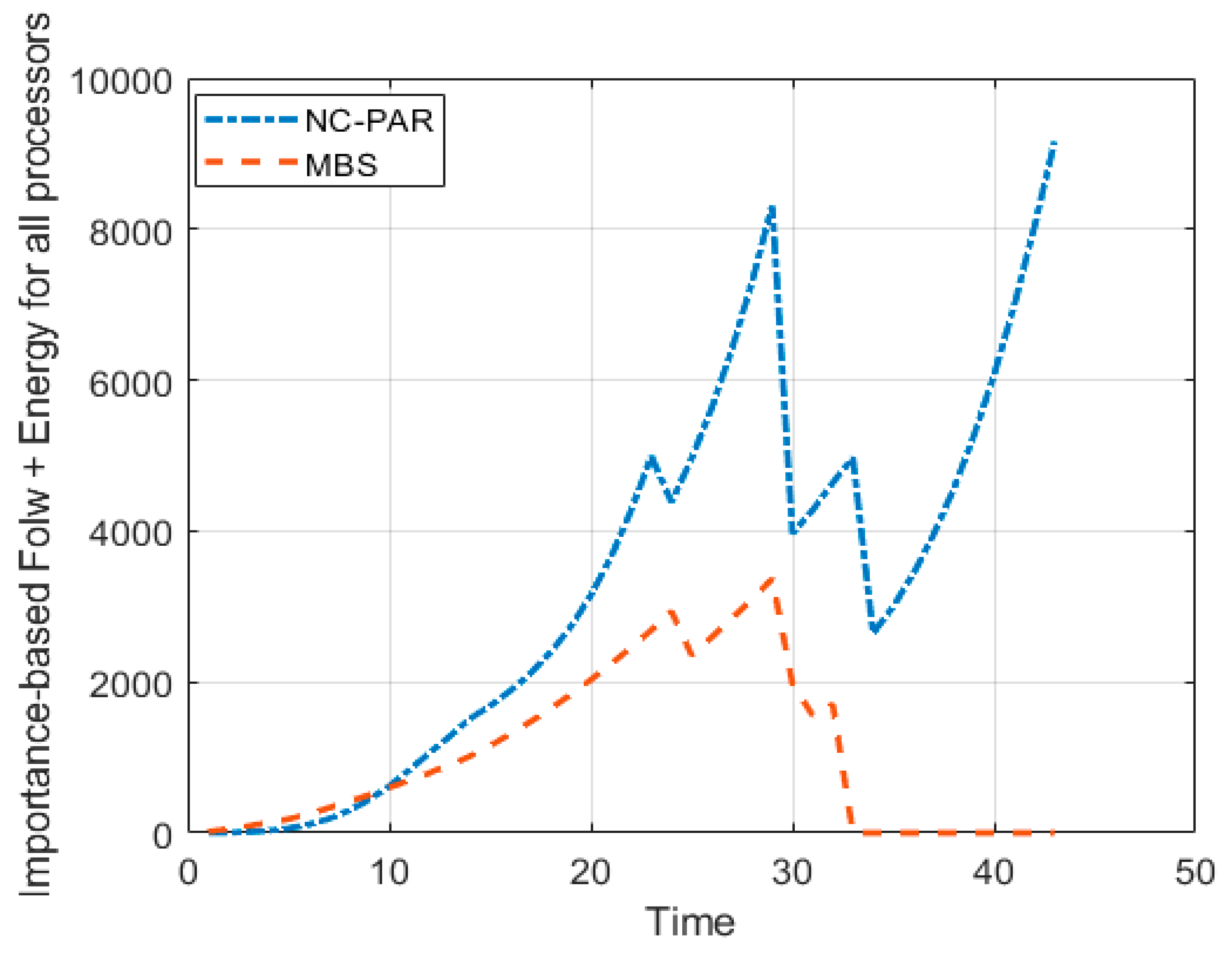
6. Illustrative Example
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Belady, C. In the Data Center, Power and Cooling Costs More Than the IT Equipment It Supports, Electronics Cooling Magazine. Available online: http://www.electronics-cooling.com/2007/02/in-the-data-center-power-and-cooling-costs-more-than-the-it-equipment-it-supports/ (accessed on 10 January 2020).
- Chan, H.L.; Edmonds, J.; Lam, T.W.; Lee, L.K.; Marchetti-Spaccamela, A.; Prush, K. Non-clairvoyant speed scaling for flow and energy. Algorithmica 2011, 61, 507–517. [Google Scholar] [CrossRef]
- Merritt, R. CPU Designers’ Debate Multi-Core Future, EE Times. 2 June 2008. Available online: http://www.eetimes.com/document.asp?doc_id=1167932 (accessed on 15 January 2020).
- U.S. Environmental Protection Agency, EPA Report on Server and Data Center Energy Efficiency. Available online: https://www.energystar.gov/ia/partners/prod_development/downloads/EPA_Report_Exec_Summary_Final.pdf (accessed on 14 January 2020).
- Singh, P.; Wolde-Gabriel, B. Executed-time Round Robin: EtRR an online non-clairvoyant scheduling on speed bounded processor with energy management. J. King Saud Univ. Comput. Inf. Sci. 2016, 29, 74–84. [Google Scholar] [CrossRef]
- Bansal, N.; Chan, H.L.; Pruhs, K. Speed scaling with an arbitrary power function. In Proceedings of the Annual ACM-SIAM Symposium on Discrete Algorithms, New York, NY, USA, 4–6 January 2009; pp. 693–701. [Google Scholar]
- Bansal, N.; Kimbrel, T.; Pruhs, K. Dynamic speed scaling to manage energy and temperature. J. ACM 2007, 54, 1–39. [Google Scholar] [CrossRef]
- Singh, P.; Khan, B.; Vidyarthi, A.; Haes Alhelou, H.; Siano, P. Energy-aware online non-clairvoyant scheduling using speed scaling with arbitrary power function. Appl. Sci. 2019, 9, 1467. [Google Scholar] [CrossRef]
- Lam, T.W.; Lee, L.K.; To, I.K.K.; Wong, P.W.H. Nonmigratory multiprocessor scheduling for response time and energy. IEEE Trans. Parallel Distrib. Syst. 2008, 19, 1–13. [Google Scholar]
- Motwani, R.; Phillips, S.; Torng, E. Nonclairvoyant scheduling. Theor. Comput. Sci. 1994, 30, 17–47. [Google Scholar] [CrossRef]
- Yao, F.; Demers, A.; Shenker, S. A scheduling model for reduced CPU energy. In Proceedings of the Annual Symposium on Foundations of Computer Science, Berkeley, CA, USA, 23–25 October 1995; pp. 374–382. [Google Scholar]
- Koren, G.; Shasha, D. Dover: An optimal on-line scheduling algorithm for overloaded uniprocessor real-time systems. SIAM J. Comput. 1995, 24, 318–339. [Google Scholar] [CrossRef]
- Leonardi, S.; Raz, D. Approximating total flow time on parallel machines. In Proceedings of the ACM Symposium on Theory of Computing, El Paso, TX, USA, 4–6 May 1997; pp. 110–119. [Google Scholar]
- Kalyanasundaram, B.; Pruhs, K. Speed is as powerful as clairvoyant. J. ACM 2000, 47, 617–643. [Google Scholar] [CrossRef]
- Edmonds, J. Scheduling in the dark. Theor. Comput. Sci. 2000, 235, 109–141. [Google Scholar] [CrossRef]
- Kalyanasundaram, B.; Pruhs, K. Minimizing flow time nonclairvoyantly. J. ACM 2003, 50, 551–567. [Google Scholar] [CrossRef]
- Becchetti, L.; Leonardi, S. Nonclairvoyant scheduling to minimize the total flow time on single and parallel machines. J. ACM 2004, 51, 517–539. [Google Scholar] [CrossRef]
- Chekuri, C.; Goel, A.; Khanna, S.; Kumar, A. Multiprocessor scheduling to minimize flow time with epsilon resource augmentation. In Proceedings of the 36th Annual ACM Symposium on Theory of Computing, Chicago, IL, USA, 13–15 June 2004; pp. 363–372. [Google Scholar]
- Chen, J.J.; Hsu, H.R.; Chuang, K.H.; Yang, C.L.; Pang, A.C.; Kuo, T.W. Multiprocessor energy efficient scheduling with task migration considerations. In Proceedings of the 16th Euromicro Conference on Real-Time Systems, Catania, Italy, 2 July 2004; pp. 101–108. [Google Scholar]
- Albers, S.; Fujiwara, H. Energy-efficient algorithms for flow time minimization. ACM Trans. Algorithms 2007, 3, 49. [Google Scholar] [CrossRef]
- Bansal, N.; Pruhs, K.; Stein, C. Speed scaling for weighted flow time. In Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 805–813. [Google Scholar]
- Lam, T.W.; Lee, L.K.; To, I.K.K.; Wong, P.W.H. Competitive non-migratory scheduling for flow time and energy. In Proceedings of the 20th ACM Symposium on Parallelism in Algorithms and Architectures, Munich, Germany, 14–16 June 2008; pp. 256–264. [Google Scholar]
- Chadha, J.; Garg, N.; Kumar, A.; Muralidhara, V. A competitive algorithm for minimizing weighted flow time on unrelated processors with speed augmentation. In Proceedings of the Annual ACM Symposium on Theory of Computing, Bethesda, MD, USA, 31 May–2 June 2009; pp. 679–684. [Google Scholar]
- Chan, S.H.; Lam, T.W.; Lee, L.K.; Liu, C.M.; Ting, H.F. Sleep management on multiple processors for energy and flow time. In Proceedings of the 38th International Colloquium on Automata, Languages and Programming, Zurich, Switzerland, 4–8 July 2011; pp. 219–231. [Google Scholar]
- Albers, S.; Antoniadis, A.; Greiner, G. On multi-processor speed scaling with migration. In Proceedings of the 23rd Annual ACM Symposium on Parallelism in Algorithms and Architectures, San Jose, CA, USA, 4–6 June 2011; pp. 279–288. [Google Scholar]
- Gupta, A.; Im, S.; Krishnaswamy, R.; Moseley, B.; Pruhs, K. Scheduling heterogeneous processors isn’t as easy as you think. In Proceedings of the 23rd Annual ACM-SIAM Symposium on Discrete Algorithms, Kyoto, Japan, 17–19 January 2012; pp. 1242–1253. [Google Scholar]
- Chan, S.H.; Lam, T.W.; Lee, L.K.; Zhu, J. Nonclairvoyant sleep management and flow-time scheduling on multiple processors. In Proceedings of the 25th Annual ACM Symposium on Parallelism in Algorithms and Architectures, Montreal, QC, Canada, 23–25 July 2013; pp. 261–270. [Google Scholar]
- Lawler, E.L.; Lenstra, J.K.; Kan, A.R.; Shmoys, D.B. Sequencing and Scheduling: Algorithms and Complexity. In Handbooks in Operations Research and Management Science; Elsevier: Amsterdam, The Netherlands, 1993; Volume 4, pp. 445–522. [Google Scholar]
- Hall, H. Approximation algorithm for scheduling. In Approximation Algorithm for NP-Hard Problems; Hochbaum, D.S., Ed.; PWS Publishing Company: Boston, MA, USA, 1997; pp. 1–45. [Google Scholar]
- Sgall, J. On-line scheduling. In Online Algorithms, The State of the Art; Fiat, A., Woeginger, G.J., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 196–231. [Google Scholar]
- Karger, D.; Stein, C.; Wein, J. Scheduling Algorithms, CRC Handbook of Theoretical Computer Science; CRC Press: Boca Raton, FL, USA, 1999. [Google Scholar]
- Irani, S.; Pruhs, K. Algorithmic problems in power management. ACM SIGACT News 2005, 36, 63–76. [Google Scholar] [CrossRef]
- Albers, S. Energy efficient algorithms. Commun. ACM 2010, 53, 86–96. [Google Scholar] [CrossRef]
- Albers, S. Algorithms for dynamic speed scaling. In Proceedings of the 28th International Symposium of Theoretical Aspects of Computer Science, Dortmund, Germany, 10–12 March 2011; pp. 1–11. [Google Scholar]
- Gupta, A.; Krishnaswamy, R.; Pruhs, K. Scalably scheduling power-heterogeneous processors. In Proceedings of the 37th International Colloquium on Automata, Languages and Programming, Bordeaux, France, 5–10 July 2010; pp. 312–323. [Google Scholar]
- Fox, K.; Im, S.; Moseley, B. Energy efficient scheduling of parallelizable jobs. In Proceedings of the 24th Annual Symposium on Discrete Algorithms, New Orleans, LA, USA, 6–8 January 2013; pp. 948–957. [Google Scholar]
- Thang, N.K. Lagrangian duality in online scheduling with resource augmentation and speed scaling. In Proceedings of the 21st European Symposium on Algorithms, Sophia Antipolis, France, 2–4 September 2013; pp. 755–766. [Google Scholar]
- Im, S.; Kulkarni, J.; Munagala, K.; Pruhs, K. SelfishMigrate: A scalable algorithm for non-clairvoyantly scheduling heterogeneous processors. In Proceedings of the 55th IEEE Annual Symposium on Foundations of Computer Science, Philadelphia, PA, USA, 18–21 October 2014; pp. 531–540. [Google Scholar]
- Bell, P.C.; Wong, P.W.H. Multiprocessor speed scaling for jobs with arbitrary sizes and deadlines. J. Comb. Optim. 2015, 29, 739–749. [Google Scholar] [CrossRef][Green Version]
- Azar, Y.; Devanue, N.R.; Huang, Z.; Panighari, D. Speed scaling in the non-clairvoyant model. In Proceedings of the 27th Annual ACM Symposium on Parallelism in Algorithms and Architectures, Portland, OR, USA, 13–15 June 2015; pp. 133–142. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Meaning |
|---|---|
| t | Current time |
| j | A job |
| u | A processor |
| or | Release/arrival time of a job j |
| Processing requirement (size) of a job j | |
| Number of processors | |
| On a processor u, the count of lagging jobs, at time t | |
| Maximum speed of a processor using Opt | |
| P | Power of a processor at speed s |
| or | At time t, speed of some processor |
| A constant, commonly believed that its value is 2 or 3 | |
| A constant, its value depends on the value of | |
| I, S | A set of jobs and their schedule, respectively |
| , and | Remaining/pending work of a job j at time t, using MBS and Opt, respectively |
| Flow time of a job j | |
| F | Total importance-based flow time |
| or | Importance/weight of a job j, at time t on a processor u |
| or and or | Importance of all active jobs using MBS and Opt at time t on a processor u, respectively |
| or and or | Total importance of lagging jobs, at time t on all m processors and on a processor u, respectively |
| or and or | Total number of active jobs (NoAJ) in MBS and Opt at time t on all m processors, respectively |
| or and or | NoAJ in MBS and Opt at time t on a processor u, respectively |
| or and or | Speed of a processor u for MBS and Opt at time t, respectively |
| Total importance of all active jobs , at time t | |
| Energy consumed by processors | |
| G | Total IbFt+E |
| Competitiveness | |
| A constant (), its value depends on the value of | |
| or and or | IbFt+E acquired till time t by the MBS and Opt, respectively |
| or and or | Rate of change (RoC) of due to MBS and due to Opt at time t, respectively |
| or and or | IbFt+E acquired on a processor u till time t by the MBS and Opt, respectively |
| or and or | RoC of due to MBS and Opt at time t on a processor u, respectively |
| A constant (> 0) | |
| Coefficient of a job at time t | |
| Difference of pending work of a job using MBS and Opt at time t | |
| A constant depends on , its value is | |
| A set of lagging jobs using MBS on a processor u | |
| A set of all lagging jobs using MBS on all m processors | |
| or | Total potential value of all m processors at time t |
| or | Potential value of a processor u at time t |
| and | RoC of due to Opt and MBS, respectively |
| RoC of due to Opt and MBS | |
| and | RoC of due to Opt and MBS on a processor u, respectively |
| RoC of due to Opt and MBS on a processor u |
| Number of Processors (m) | ||||
|---|---|---|---|---|
| Speed Ratio | Competitive Ratio (c) | Speed Ratio | Competitive Ratio (c) | |
| 2 | 1.02778 | 2.44189 | 1.01852 | 2.39936 |
| 4 | 1.01389 | 2.40822 | 1.00926 | 2.36604 |
| 8 | 1.00694 | 2.39155 | 1.00463 | 2.34961 |
| 16 | 1.00347 | 2.38326 | 1.00231 | 2.34145 |
| 64 | 1.00086 | 2.37706 | 1.00058 | 2.33536 |
| 128 | 1.00043 | 2.37603 | 1.00029 | 2.33435 |
| 512 | 1.00010 | 2.37526 | 1.00007 | 2.33359 |
| 1024 | 1.00005 | 2.37513 | 1.00003 | 2.37513 |
| 4096 | 1.00001 | 2.37503 | 1.00001 | 2.33336 |
| 11,264 | 1.000004 | 2.37501 | 1.000003 | 2.33334 |
| Multiprocessor | Competitiveness for Weighted Flow Time + Energy | Modelling Criteria | ||
|---|---|---|---|---|
| Algorithms | General | (Bounded (BS)/Unbounded Speed(US)) (Clairvoyant (C)/Non-Clairvoyant (NC) | ||
| GKP [35] | 4 | 9 | US, C | |
| WLAPS+E [36] | (where ) | 180 | 180 | US, NC |
| ALGThang [37] | 31.085 | 29.85 | US, C | |
| SM-E [38] | 4 | 9 | US, NC | |
| DCRR [39] | >2048 | >442368 | US, C | |
| NC-PAR [40] | 3 | 3.5 | US, NC | |
| MBS [This Paper] | (where ) | 2.442 | 2.399 | BS, NC |
| Job Details | MBS [This Paper] | NC-PAR [40] | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Job | Size | Importance | Arrival Time | Completion Time | Response Time | Turnaround Time | Completion Time | Response Time | Turnaround Time |
| J1 | 35 | 8 | 1 | 14 | 0 | 13 | 14 | 0 | 13 |
| J2 | 64 | 10 | 2 | 24 | 0 | 22 | 23 | 0 | 21 |
| J3 | 15 | 5 | 4 | 10 | 0 | 6 | 12 | 0 | 8 |
| J4 | 83 | 11 | 6 | 30 | 0 | 24 | 33 | 0 | 27 |
| J5 | 45 | 5 | 7 | 29 | 0 | 22 | 29 | 6 | 22 |
| J6 | 17 | 4 | 8 | 23 | 0 | 15 | 23 | 7 | 15 |
| J7 | 56 | 6 | 10 | 32 | 0 | 22 | 43 | 14 | 33 |
| Average Values | 23.143 | 0 | 17.714 | 25.286 | 3.857 | 19.857 | |||
| Simulation Parameters | Values |
|---|---|
| CPU | Intel(R) Core(TM) i5-4210U CPU @ 1.70 GHz |
| RAM | 4.00 GB RAM |
| Hard Drive | 1.0 TB |
| Operating System | Red Hat Linux 6.1 |
| Kernel | Linux kernel version 2.2.12 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singh, P.; Khan, B.; Mahela, O.P.; Haes Alhelou, H.; Hayek, G. Managing Energy Plus Performance in Data Centers and Battery-Based Devices Using an Online Non-Clairvoyant Speed-Bounded Multiprocessor Scheduling. Appl. Sci. 2020, 10, 2459. https://doi.org/10.3390/app10072459
Singh P, Khan B, Mahela OP, Haes Alhelou H, Hayek G. Managing Energy Plus Performance in Data Centers and Battery-Based Devices Using an Online Non-Clairvoyant Speed-Bounded Multiprocessor Scheduling. Applied Sciences. 2020; 10(7):2459. https://doi.org/10.3390/app10072459
Chicago/Turabian StyleSingh, Pawan, Baseem Khan, Om Prakash Mahela, Hassan Haes Alhelou, and Ghassan Hayek. 2020. "Managing Energy Plus Performance in Data Centers and Battery-Based Devices Using an Online Non-Clairvoyant Speed-Bounded Multiprocessor Scheduling" Applied Sciences 10, no. 7: 2459. https://doi.org/10.3390/app10072459
APA StyleSingh, P., Khan, B., Mahela, O. P., Haes Alhelou, H., & Hayek, G. (2020). Managing Energy Plus Performance in Data Centers and Battery-Based Devices Using an Online Non-Clairvoyant Speed-Bounded Multiprocessor Scheduling. Applied Sciences, 10(7), 2459. https://doi.org/10.3390/app10072459