A Causality Mining and Knowledge Graph Based Method of Root Cause Diagnosis for Performance Anomaly in Cloud Applications

Abstract
1. Introduction
- Large number of services and high expense. In a monolithic architecture, only one application must be guaranteed to run normally, whereas, in microservices, dozens or even hundreds of services need to be guaranteed to run and cooperate normally, which is a great challenge to O&M.
- Complex hosting environment. The hierarchy of the hosting environment for services is complex, and the corresponding network architecture is even more complex. Managing microservices depends on a container environment, which usually runs on a container management platform such as Kubernetes. The container environment is deployed on a virtual machine, which depends on a complex cloud infrastructure environment. The call dependencies among entities at the same level and among entities across levels are of high complexity.
- Large number of monitoring metrics. Based on the two facts above, application performance management (APM) and monitoring must monitor the metrics at least at the service, container, server, and system levels, especially when the properties of each indicator are different.
- Rapid iteration. Microservices can be deployed in many different ways. The development of microservices now follows the principles of DevOps, one of which requires versioning and continuous iterative updating. Obviously, continuous iterative updating poses great difficulty for the timeliness of O&M.
- The proposed system is the first RCA approach for cloud-native applications to combine a knowledge graph and a causality search algorithm.
- We have implemented a prototype for generating a causality graph and sorting possible root causes.
- We have proved experimentally that the proposed approach can rank the root causes in the top two with over 80% precision and recall for most scenarios.
2. Related Work
3. Problem Description and Proposed Solution
3.1. Problem of Finding a Root Cause
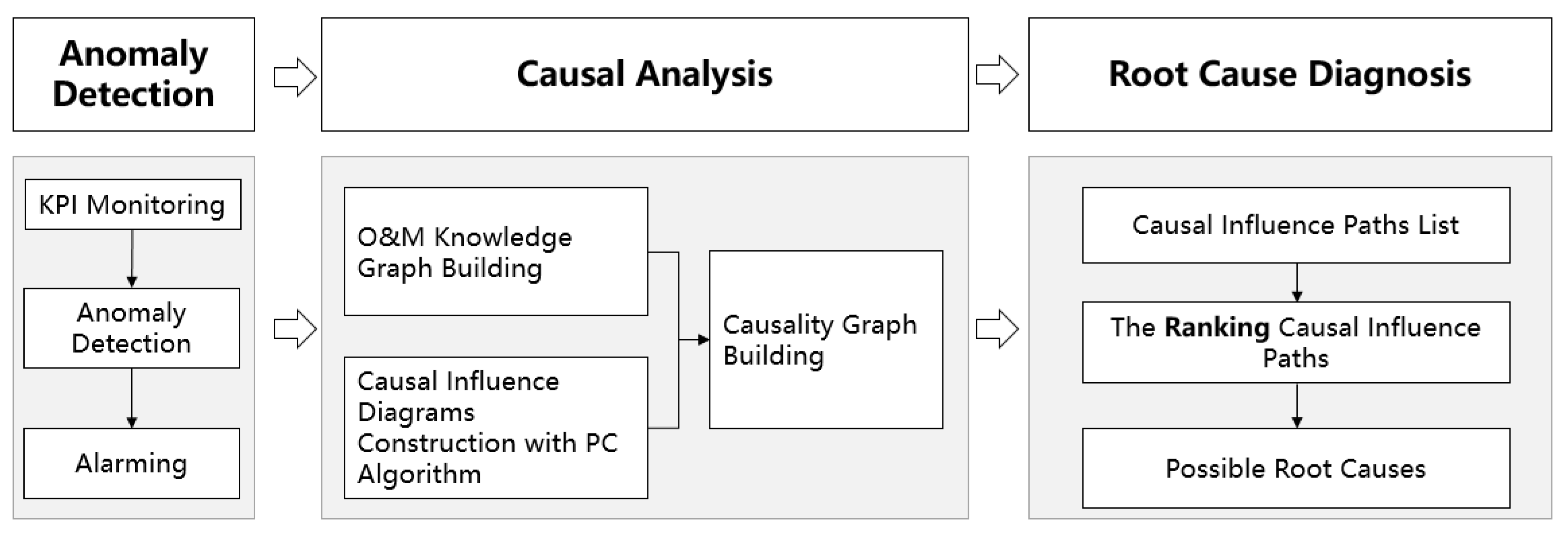
3.2. Method of the Proposed Approach
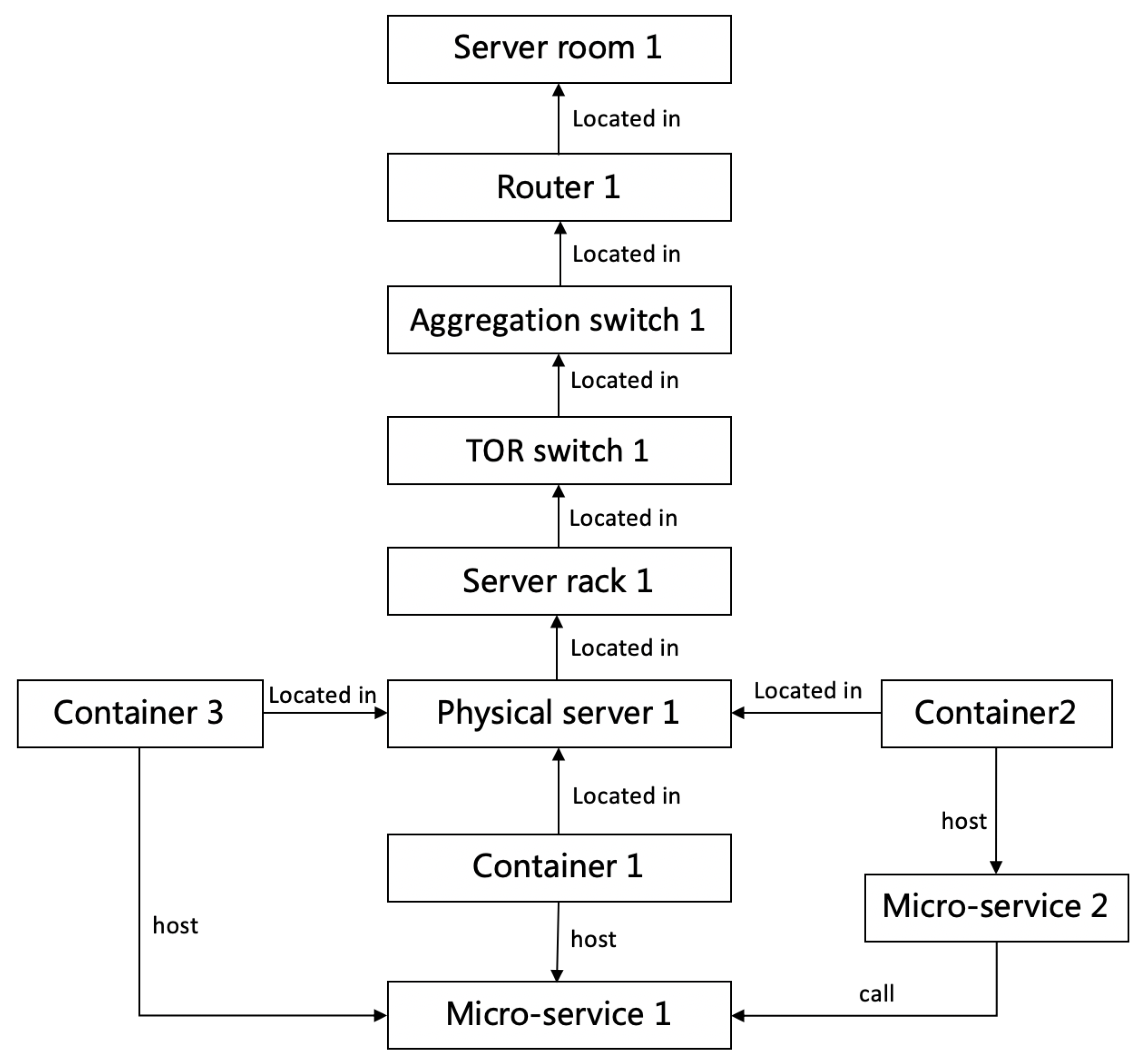
3.2.1. O&M Knowledge Graph Construction
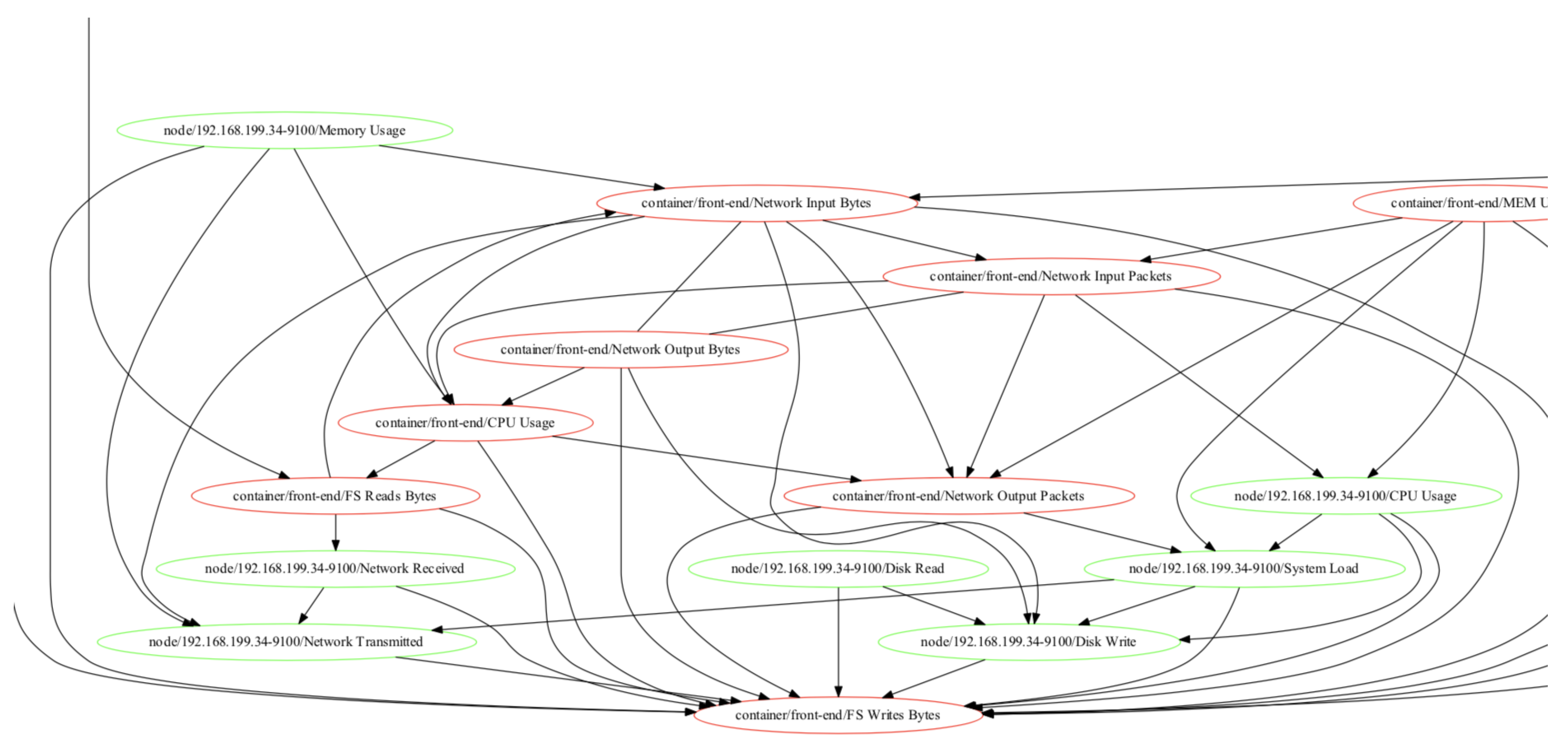
3.2.2. Causality Graph Construction
- In the DAG skeleton construction stage, the algorithm first constructs a complete graph with performance indicators as nodes in the dataset. Then, for any two performance indicators X and Y, the algorithm determines whether there is a causal relation between X and Y by judging whether X and Y are conditionally independent as defined in Definition 2. If X and Y conditions are independent, it shows that there is no causal relation between X and Y, and then the corresponding edges are deleted in the complete graph. Finally, a preliminary causal relation graph containing only undirected edges is obtained.
- In the direction orientation stage, the algorithm determines the direction of some edges in the existing causal relation graph according to the d-separation principle defined in Definition 3 and some logic inference rules. The final algorithm will output a causality graph containing directed and undirected edges.
- The first step is to respectively calculate the regression residuals of X on Z and the regression residuals of Y on Z. Regression methods (such as the least squares method) are used to calculate the residuals; they can be denoted as and , where is the correlation coefficient of the variables X and Y.
- The second step is to calculate the partial correlation coefficient. Calculate the correlation coefficients of the residuals and and the partial correlation coefficients .
- If there exists a chain where , then must be in
- If there exists a radiation where , then must be in
- If there exists a collider(v-structure) where , then and the descendants of MUST NOT be in
3.2.3. Optimized PC Algorithm Based on Knowledge Graph
| Algorithm 1: The optimized PC algorithm based on knowledge graph |
| Input: Dataset D with a set of variables V, Knowledge graph G’ |
| Output: The DAG G with a set of edges E assume all nodes are connected initially |
| Let depth d = 0 |
| repeat |
| for each ordered pair of adjacent vertices X and Y in G do |
| if then |
| for each subset and do |
| if (X,Y) in G’ then |
| Continue |
| end if |
| if I then |
| Remove edge between X and Y |
| Save Z as the separating set of |
| Update G and E |
| Break |
| end if |
| end for |
| end if |
| end for |
| Let d = d +1 |
| until for every pair of adjacent vertices in G |
| /* According to Definition 3 and [27], determine the edge orientation of the impact graph */ |
| for adjacent vertex in G do |
| if ,where C is a collection that blocks paths between X and Y then |
| Update the direction to |
| end if |
| if then |
| Update the direction to |
| end if |
| if and then |
| Update the direction to |
| end if |
| if and exist L, and then |
| Update the direction to |
| end if |
| end for |
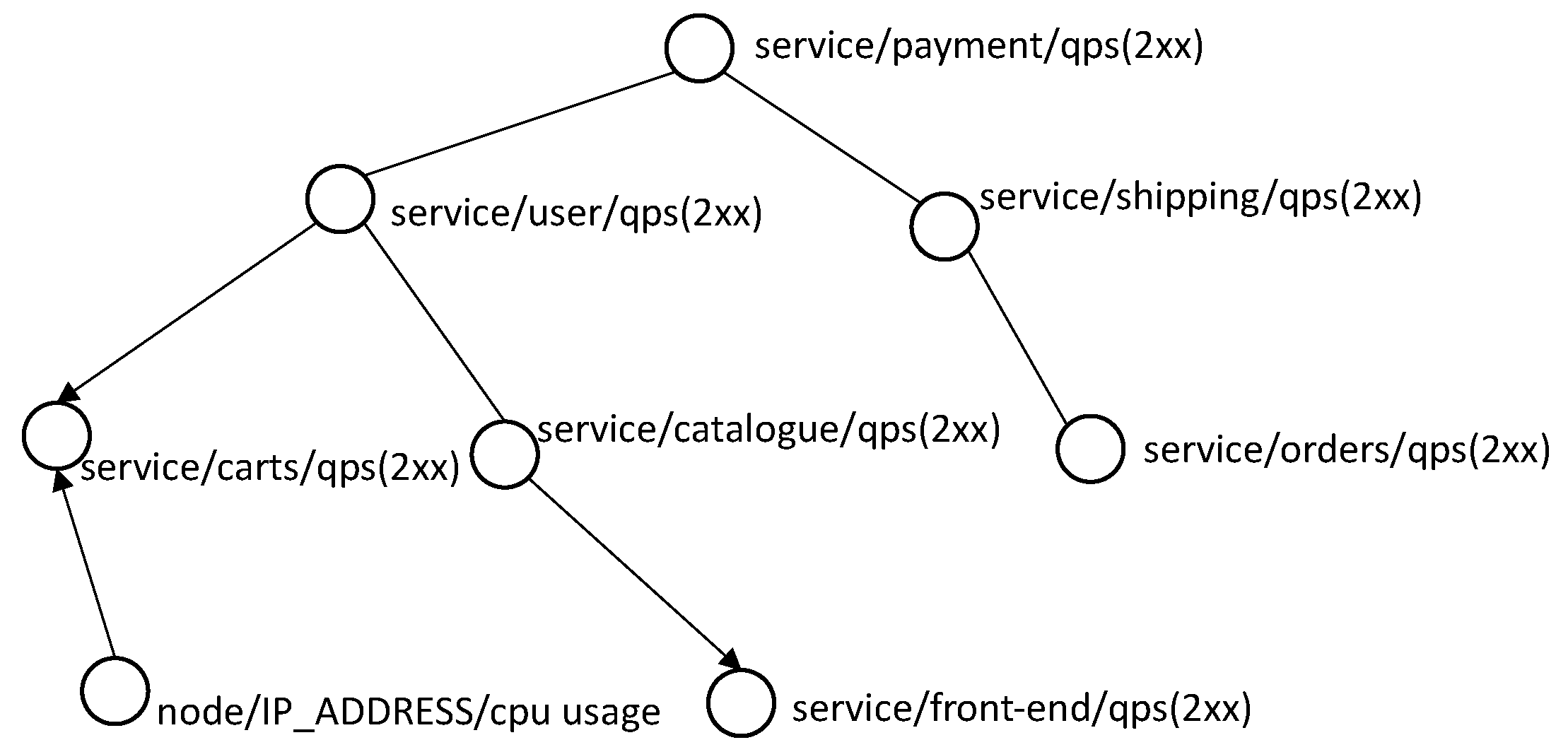
3.3. Ranking for the Causal Influence Graph
- Effectively represent the value changes for all the nodes during time period t; the value change events of a node could be denoted as a binary sequence E.
- Calculate the Pearson correlation coefficient as the weight between two sequences and , where is the value changes for node X, and is the value changes for node Y.
3.4. Root Cause Identification
| Algorithm 2: Casual search algorithm based on BFS method |
| Input: Causality graph G, Source vertex |
| Output: The linked paths |
| INIT a queue Q to store the current path |
| INIT a temporary stack to store the current path |
| PUSH vertex to |
| PUSH to Q |
| INIT a string list |
| while do |
| GET the last vertex from |
| if then |
| APPEND to |
| end if |
| if there is no predecessor of then |
| for vertex v in do |
| + “->” |
| + v |
| append to |
| end for |
| end for |
| for vertex v in G do |
| if v is not in then |
| PUSH v to |
| ENQUEUE to Q |
| end if |
| end for |
| end while |
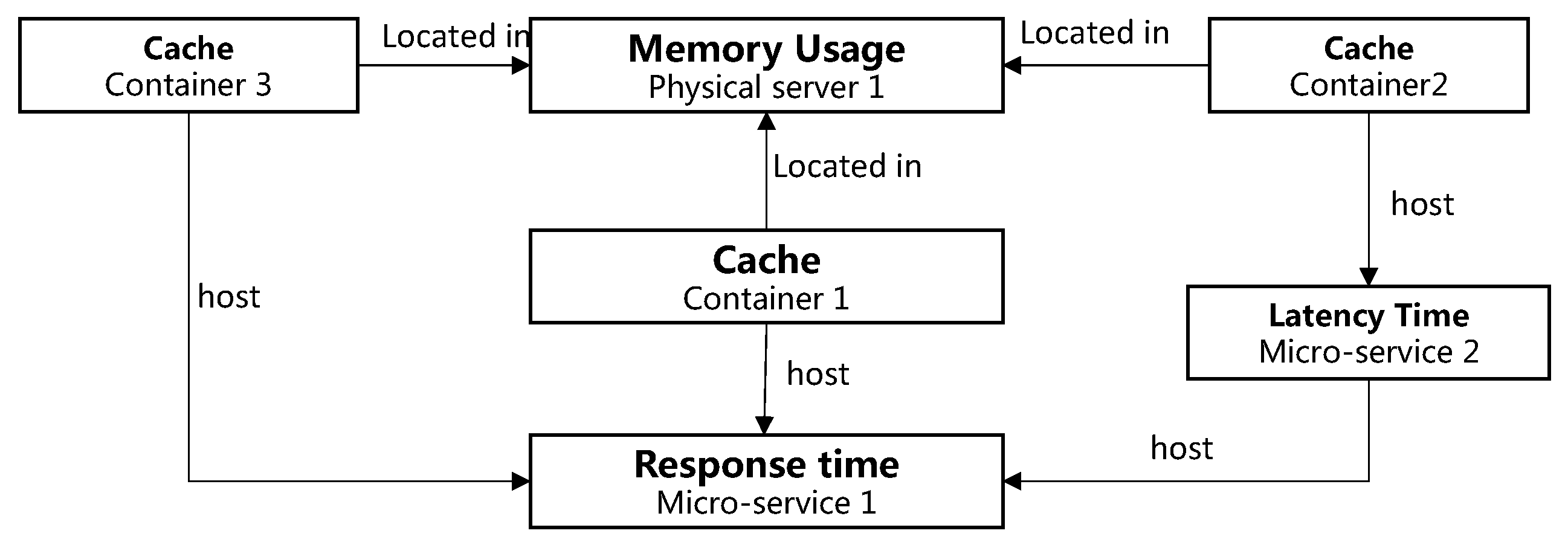
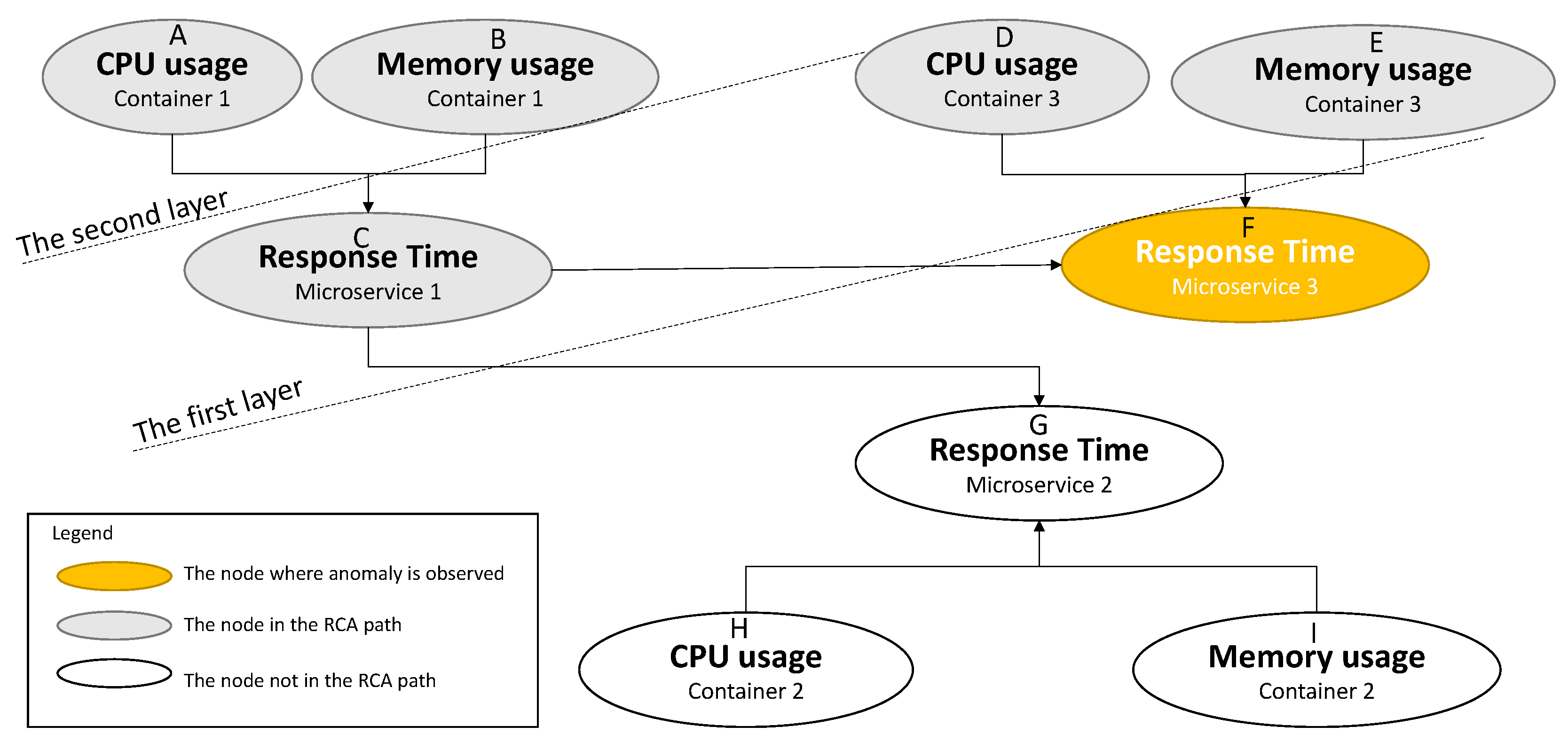
- Path 1: CPU usage of container 3 → Response time of microservice 3
- Path 2: Memory usage of container 3 → Response time of microservice 3
- Path 3: CPU usage of container 1→ Response time of micro-service 1 → Response time of microservice 3
- Path 4: Memory usage of container 1 → Response time of microservice1 → Response time of microservice 3
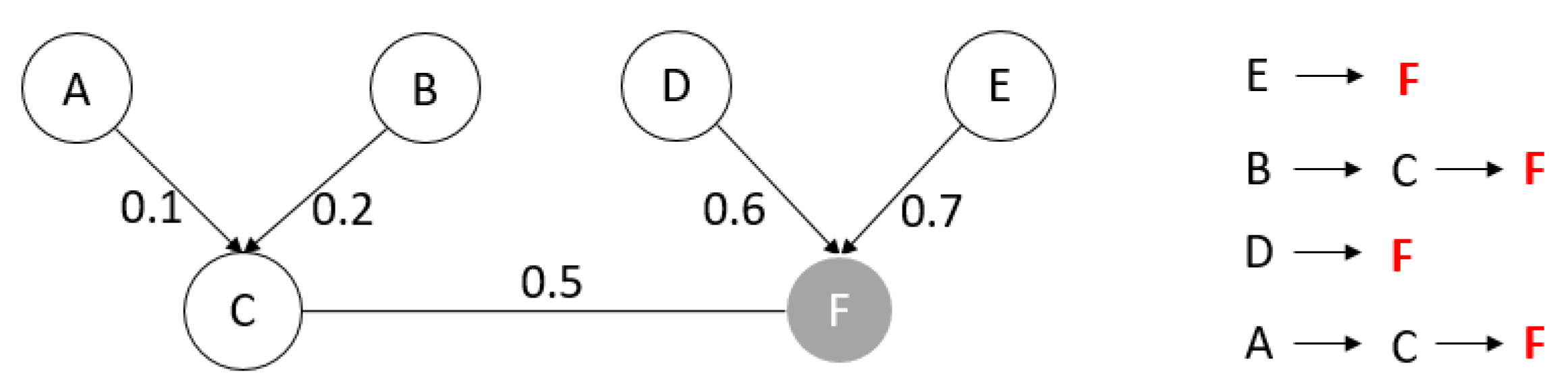
- Rule 1: The sum of the weights of all edges on the path: the larger the sum, the higher the priority.
- Rule 2: The length of the path: the shorter the length, the higher the priority.
4. Empirical Study
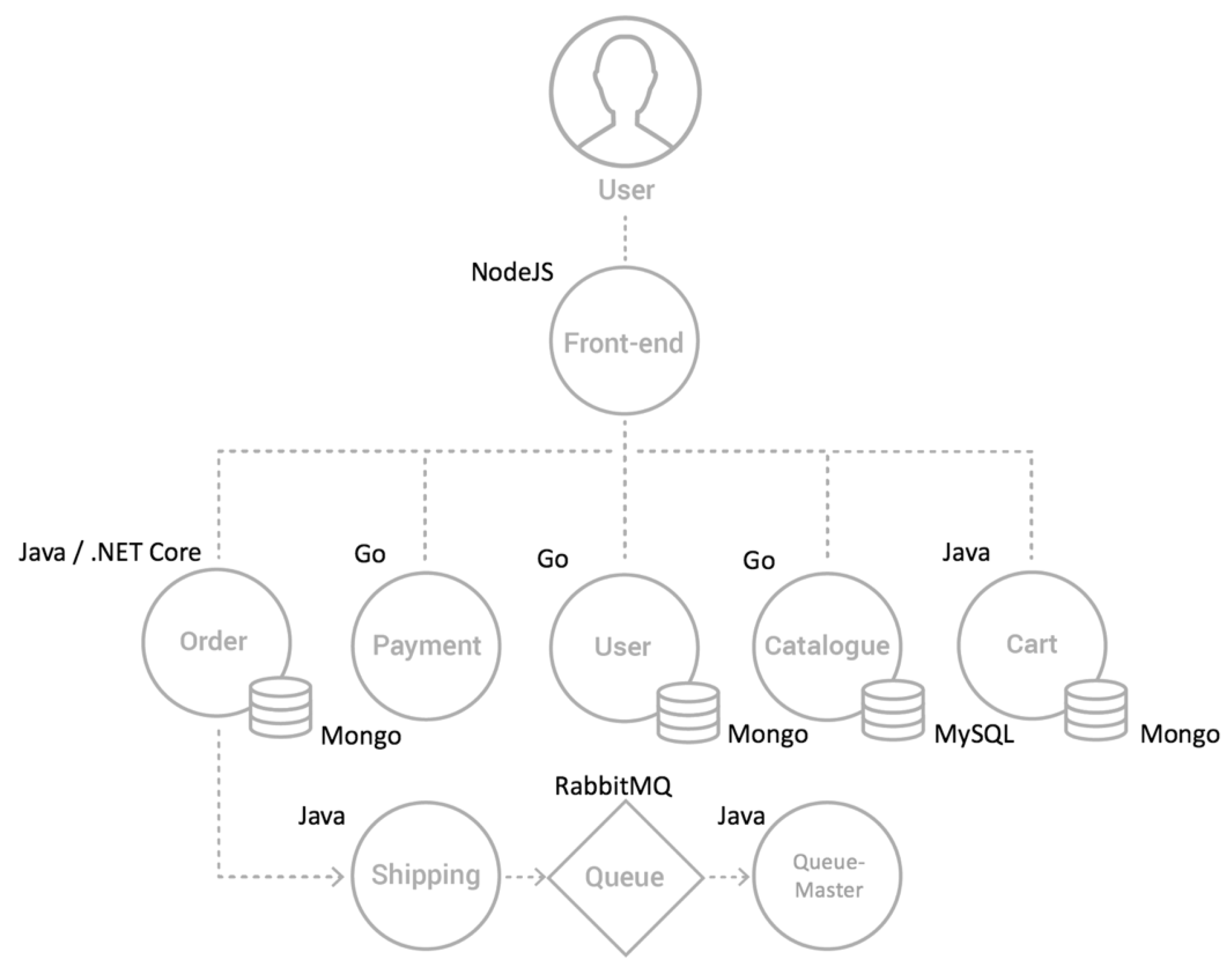
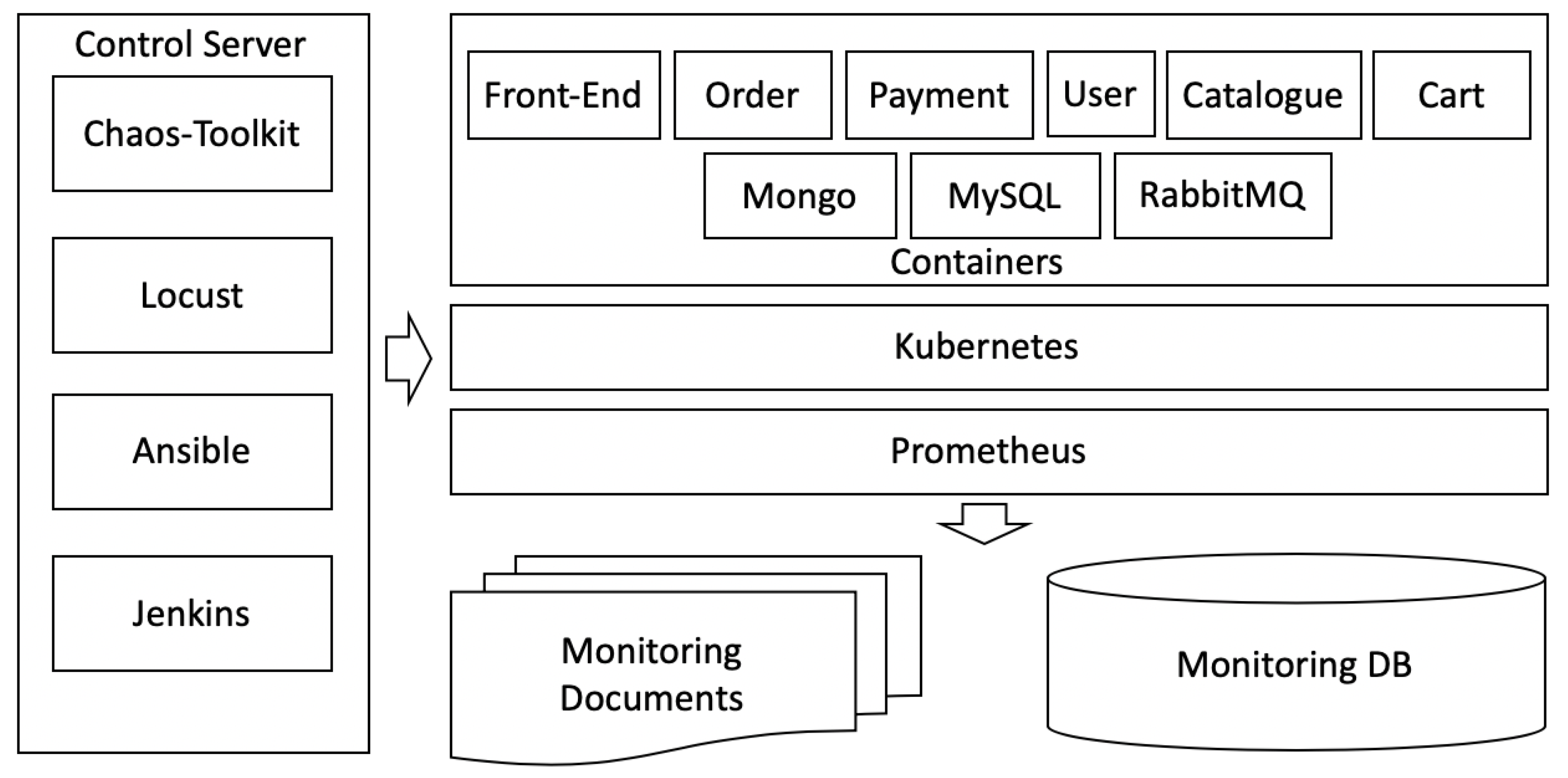
4.1. Test-Bed and Experiment Environment Setup
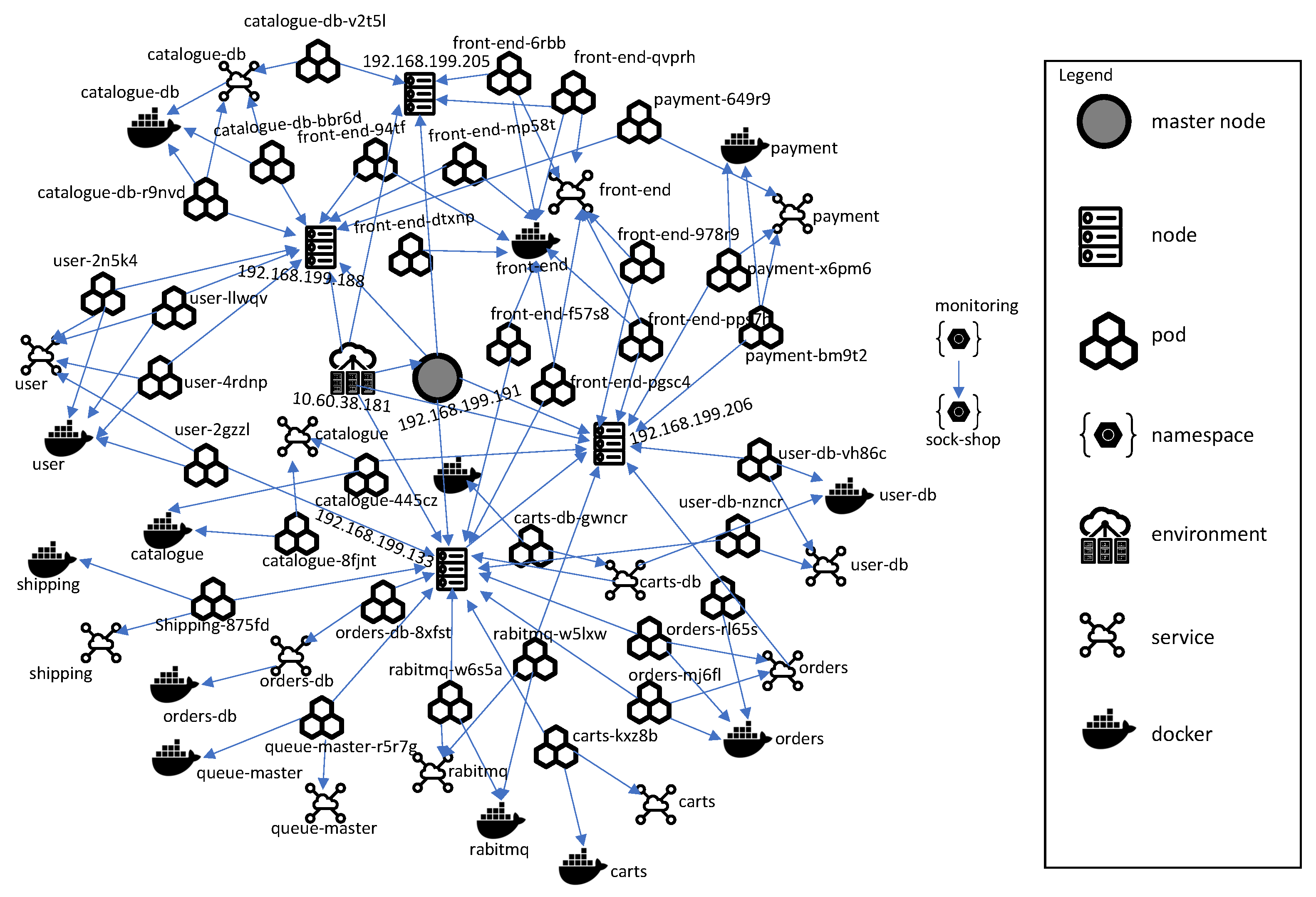
4.2. Building an O&M Knowledge Graph of the MSA System in the Kubernetes Environment
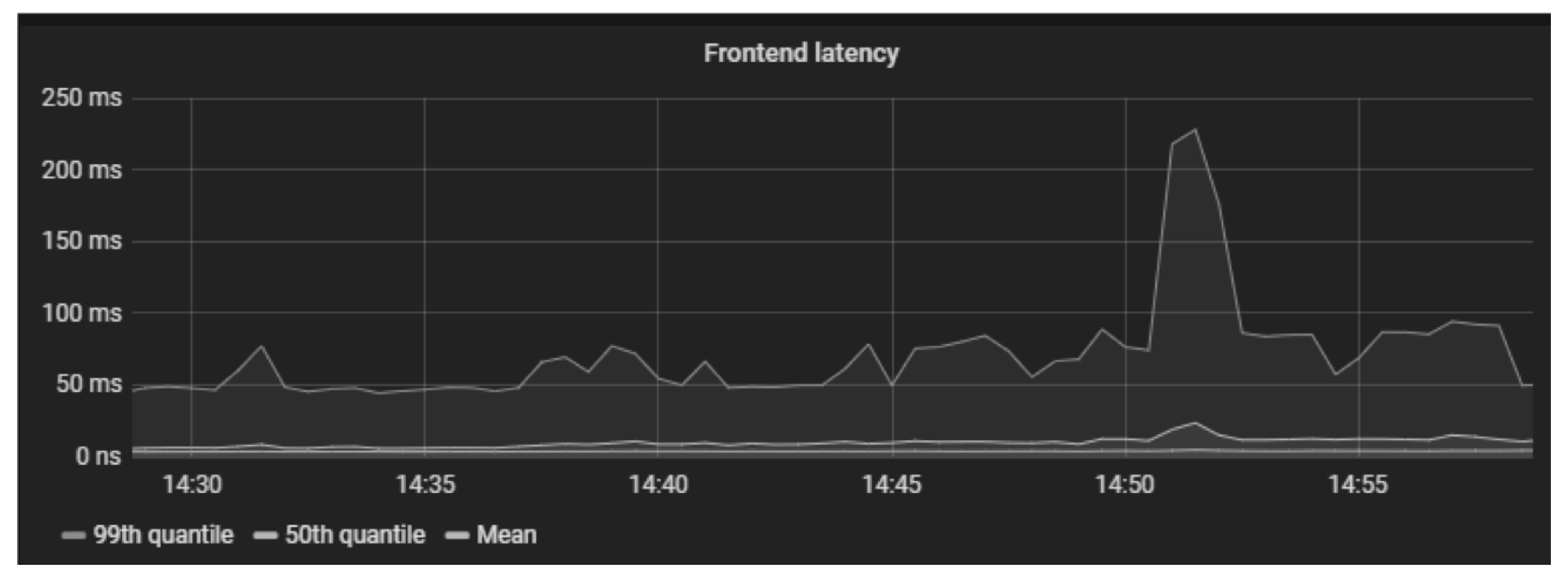
4.3. Simulation Experiment and Analysis
4.3.1. Testing for Causality Search
4.3.2. Effective Evaluation
- Precision at the top K indicates the probability that the root cause in the top K of the ranking list if the cause inference is triggered.
- Recall at the top K is the portion of the total amount of real causes that were actually retrieved at the top K of the ranking list.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kim, M.; Roshan, S.; Sam, S. Root Cause Detection in a Service-Ooriented Architecture; ACM SIGMETRICS Performance Evaluation Review 41.1; ACM: New York, NY, USA, 2013; pp. 93–104. [Google Scholar]
- Thalheim, J.; Rodrigues, A.; Akkus, I.E.; Bhatotia, P.; Chen, R.; Viswanath, B.; Jiao, L.; Fetzer, C. Sieve: Actionable insights from monitored metrics in distributed systems. In Proceedings of the 18th ACM/IFIP/USENIX Middleware Conference, Las Vegas, NV, USA, 11–15 December 2017. [Google Scholar]
- Weng, J.; Wang, J.H.; Yang, J.; Yang, Y. Root cause analysis of anomalies of multitier services in public clouds. IEEE/ACM Trans. Netw. 2018, 26, 1646–1659. [Google Scholar] [CrossRef]
- Marwede, N.; Rohr, M.; van Hoorn, A.; Hasselbring, W. Automatic failure diagnosis support in distributed large-scale software systems based on timing behavior anomaly correlation. In Proceedings of the IEEE 2009 13th European Conference on Software Maintenance and Reengineering, Kaiserslautern, Germany, 24–27 March 2009. [Google Scholar]
- Marvasti, M.A.; Poghosyan, A.; Harutyunyan, A.N.; Grigoryan, N. An anomaly event correlation engine: Identifying root causes, bottlenecks, and black swans in IT environments. VMware Tech. J. 2013, 2, 35–45. [Google Scholar]
- Zeng, C.; Tang, L.; Li, T.; Shwartz, L.; Grabarnik, G.Y. Mining temporal lag from fluctuating events for correlation and root cause analysis. In Proceedings of the IEEE 10th International Conference on Network and Service Management (CNSM) and Workshop, Rio de Janeiro, Brazil, 17–21 November 2014. [Google Scholar]
- Lin, Q.; Zhang, H.; Lou, J.-G.; Zhang, Y.; Chen, X. Log clustering based problem identification for online service systems. In Proceedings of the 2016 IEEE/ACM 38th International Conference on Software Engineering Companion (ICSE-C), Austin, TX, USA, 14–22 May 2016. [Google Scholar]
- Jia, T.; Chen, P.; Yang, L.; Meng, F.; Xu, J. An approach for anomaly diagnosis based on hybrid graph model with logs for distributed services. In Proceedings of the 2017 IEEE International Conference on Web Services (ICWS), Honolulu, HI, USA, 25–30 June 2017. [Google Scholar]
- Xu, J.; Chen, P.; Yang, L.; Meng, F.; Wang, P. LogDC: Problem diagnosis for declartively-deployed cloud applications with log. In Proceedings of the 2017 IEEE 14th International Conference on e-Business Engineering (ICEBE), Shanghai, China, 4–6 November 2017. [Google Scholar]
- Xu, X.; Zhu, L.; Weber, I.; Bass, L.; Sun, D. POD-diagnosis: Error diagnosis of sporadic operations on cloud applications. In Proceedings of the 2014 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks, Atlanta, GA, USA, 23–26 June 2014. [Google Scholar]
- Jia, T.; Yang, L.; Chen, P.; Li, Y.; Meng, F.; Xu, J. Logsed: Anomaly diagnosis through mining time-weighted control flow graph in logs. In Proceedings of the 2017 IEEE 10th International Conference on Cloud Computing (CLOUD), Honolulu, CA, USA, 25–30 June 2017. [Google Scholar]
- Mi, H.; Wang, H.; Cai, H.; Zhou, Y.; Lyu, M.R.; Chen, Z. P-tracer: Path-based performance profiling in cloud computing systems. In Proceedings of the 2012 IEEE 36th Annual Computer Software and Applications Conference, Izmir, Turkey, 16–20 July 2012. [Google Scholar]
- Chen, M.Y.; Kiciman, E.; Fratkin, E.; Fox, A.; Brewer, E. Pinpoint: Problem determination in large, dynamic internet services. In Proceedings of the Proceedings International Conference on Dependable Systems and Networks, Washington, DC, USA, 23–26 June 2002. [Google Scholar]
- Gao, H.; Yang, Z.; Bhimani, J.; Wang, T.; Wang, J.; Sheng, B.; Mi, N. AutoPath: Harnessing parallel execution paths for efficient resource allocation in multi-stage big data frameworks. In Proceedings of the 2017 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017. [Google Scholar]
- Di Pietro, R.; Lombardi, F.; Signorini, M. CloRExPa: Cloud resilience via execution path analysis. Future Gener. Comput. Syst. 2014, 32, 168–179. [Google Scholar] [CrossRef]
- Pengfei, C.; Yong, Q.; Pengfei, Z.; Di, H. CauseInfer: Automatic and distributed performance diagnosis with hierarchical causality graph in large distributed systems. In Proceedings of the IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014. [Google Scholar]
- Pengfei, C.; Yong, Q.; Di, H. CauseInfer: Automated end-to-end performance diagnosis with hierarchical causality graph in cloud environment. IEEE Trans. Serv. Comput. 2016, 12, 214–230. [Google Scholar]
- Lin, J.; Pengfei, C.; Zibin, Z. Microscope: Pinpoint performance issues with causal graphs in micro-service environments. In Proceedings of the International Conference on Service-Oriented Computing, Hangzhou, China, 12–15 November 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Ping, W.; Jingmin, X.; Meng, M.; Weilan, L.; Disheng, P.; Yuan, W.; Pengfei, C. Cloudranger: Root cause identification for cloud native systems. In Proceedings of the 2018 18th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID), Washington, DC, USA, 1–4 May 2018. [Google Scholar]
- Nie, X.; Zhao, Y.; Sui, K.; Pei, D.; Chen, Y.; Qu, X.; Zhao, Y.; Sui, K.; Pei, D.; Chen, Y.; et al. Mining causality graph for automatic web-based service diagnosis. In Proceedings of the 2016 IEEE 35th International Performance Computing and Communications Conference (IPCCC), Las Vegas, NV, USA, 9–11 December 2016. [Google Scholar]
- Lin, W.; Ma, M.; Pan, D.; Wang, P. FacGraph: Frequent anomaly correlation graph mining for root cause diagnose in MSA. In Proceedings of the 2018 IEEE 37th International Performance Computing and Communications Conference (IPCCC), Orlando, FL, USA, 17–19 November 2018. [Google Scholar]
- Hirochika, A.; Fukuda, K.; Abry, P.; Borgnat, P. Network application profiling with traffic causality graphs. Int. J. Netw. Manag. 2014, 24, 289–303. [Google Scholar]
- Abele, L.; Anic, M.; Gutmann, T.; Folmer, J.; Kleinsteuber, M.; Vogel-Heuser, B. Combining knowledge modeling and machine learning for alarm root cause analysis. IFAC Proc. Vol. 2013, 46, 1843–1848. [Google Scholar] [CrossRef]
- Qiu, J.; Qingfeng, D.; Chongshu, Q. KPI-TSAD: A Time-Series Anomaly Detector for KPI Monitoring in Cloud Applications. Symmetry 2019, 11, 1350. [Google Scholar] [CrossRef]
- Spirtes, P.; Glymour, C. An algorithm for fast recovery of sparse causal graphs. Soc. Sci. Comput. Rev. 1991, 9, 62–72. [Google Scholar] [CrossRef]
- Heim, P.; Hellmann, S.; Lehmann, J.; Lohmann, S.; Stegemann, T. RelFinder: Revealing relationships in RDF knowledge bases. In Proceedings of the International Conference on Semantic and Digital Media Technologies, Graz, Austria, 2–4 December 2009; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Neuberg, L.G. Causality: Models, reasoning, and inference, by judea pearl, cambridge university press, 2000. Econom. Theory 2003, 19, 675–685. [Google Scholar] [CrossRef]
- Luo, C.; Lou, J.-G.; Lin, Q.; Fu, Q.; Ding, R.; Zhang, D.; Wang, Z. Correlating events with time series for incident diagnosis. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014. [Google Scholar]
- Le, T.D.; Hoang, T.; Li, J.; Liu, L.; Liu, H.; Hu, S. A fast PC algorithm for high dimensional causal discovery with multi-core PCs. IEEE/ACM Trans. Comput. Biol. Bioinform. 2016, 16. [Google Scholar] [CrossRef] [PubMed]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
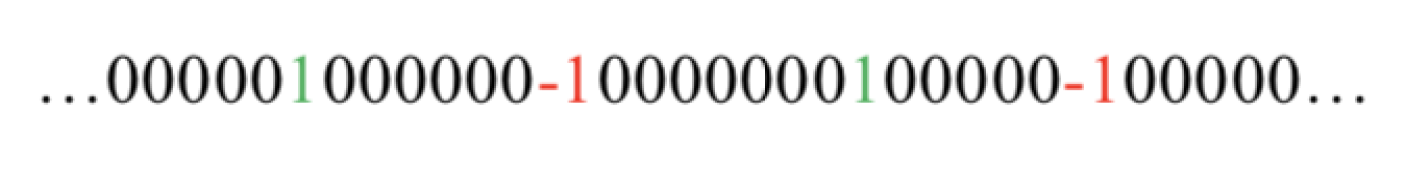{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Resources | KPIs | Description |
|---|---|---|
| Containers | CPU usage | CPU usage (%) |
| MEM Usage | MEM usage (%) | |
| FS Read Bytes | File system read bytes (bytes/s) | |
| FS Write Bytes | File system write bytes (bytes/s) | |
| Network Input Packets | Network input packets (packets/second) | |
| Network Output packets | Network input packets (packets/second) | |
| Server Nodes | CPU Usage | CPU usage (%) |
| MEM Usage | Memory usage (%) | |
| Disk Read Bytes | Disk read bytes (bytes/s) | |
| Disk Write Bytes | Disk write bytes (bytes/s) | |
| Network Input Packets | Network input packets (packets/s) | |
| Network Output Packets | Network output packets (packets/s) | |
| Services | Latency | Response per second |
| QPS | Query per second (query/s) | |
| Success orders | Success Orders (orders/s) |
| Front-End | Catalogue | User | Carts | Orders | Shipping | Payment | |
|---|---|---|---|---|---|---|---|
| CPU Burnout | |||||||
| precision | 100 | 85 | 90 | 80 | 95 | 60 | 55 |
| recall | 100 | 95 | 90 | 90 | 100 | 60 | 60 |
| Mem Overload | |||||||
| precision | 100 | 85 | 100 | 85 | 100 | 55 | 75 |
| recall | 100 | 95 | 100 | 100 | 100 | 55 | 75 |
| Disk I/O Block | |||||||
| precision | 100 | 95 | 100 | 90 | 100 | 55 | 65 |
| recall | 100 | 95 | 100 | 95 | 100 | 60 | 65 |
| Network Jam | |||||||
| precision | 100 | 100 | 100 | 85 | 100 | 70 | 55 |
| recall | 100 | 100 | 100 | 100 | 100 | 70 | 65 |
| Number of KPIs | 20 | 50 | 100 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Resource Usage/ Rows of Records | Time (s) | CPU (%) | MEM (MB) | Time (s) | CPU (%) | MEM (MB) | Time (s) | CPU (%) | MEM (MB) |
| 25 | 4.36 | 7.92 | 17.92 | 10.46 | 7.94 | 34.19 | 15.18 | 8.56 | 33.86 |
| 50 | 4.38 | 7.72 | 18.71 | 12.55 | 8.89 | 36.65 | 25.41 | 8.72 | 35.77 |
| 100 | 4.50 | 7.49 | 18.93 | 17.42 | 7.42 | 35.47 | 32.61 | 8.86 | 37.68 |
| 150 | 4.36 | 8.99 | 19.17 | 16.71 | 7.53 | 39.45 | 31.07 | 8.43 | 38.51 |
| 200 | 4.49 | 7.67 | 19.66 | 17.79 | 7.45 | 38.09 | 32.71 | 8.56 | 40.56 |
| 250 | 4.50 | 7.03 | 19.71 | 17.81 | 7.57 | 38.91 | 34.41 | 8.67 | 39.73 |
| 500 | 4.38 | 7.13 | 19.78 | 18.81 | 8.09 | 39.43 | 35.74 | 8.98 | 41.43 |
| 750 | 4.49 | 7.02 | 21.12 | 20.11 | 8.92 | 39.56 | 35.69 | 9.12 | 43.40 |
| 1000 | 4.40 | 7.67 | 21.29 | 20.43 | 8.01 | 39.84 | 37.88 | 9.43 | 44.99 |
| 1500 | 4.43 | 7.23 | 21.89 | 20.53 | 8.37 | 40.94 | 40.95 | 9.67 | 46.83 |
| 2000 | 4.45 | 7.37 | 22.07 | 27.19 | 8.85 | 43.37 | 43.39 | 9.77 | 49.33 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, J.; Du, Q.; Yin, K.; Zhang, S.-L.; Qian, C. A Causality Mining and Knowledge Graph Based Method of Root Cause Diagnosis for Performance Anomaly in Cloud Applications. Appl. Sci. 2020, 10, 2166. https://doi.org/10.3390/app10062166
Qiu J, Du Q, Yin K, Zhang S-L, Qian C. A Causality Mining and Knowledge Graph Based Method of Root Cause Diagnosis for Performance Anomaly in Cloud Applications. Applied Sciences. 2020; 10(6):2166. https://doi.org/10.3390/app10062166
Chicago/Turabian StyleQiu, Juan, Qingfeng Du, Kanglin Yin, Shuang-Li Zhang, and Chongshu Qian. 2020. "A Causality Mining and Knowledge Graph Based Method of Root Cause Diagnosis for Performance Anomaly in Cloud Applications" Applied Sciences 10, no. 6: 2166. https://doi.org/10.3390/app10062166
APA StyleQiu, J., Du, Q., Yin, K., Zhang, S.-L., & Qian, C. (2020). A Causality Mining and Knowledge Graph Based Method of Root Cause Diagnosis for Performance Anomaly in Cloud Applications. Applied Sciences, 10(6), 2166. https://doi.org/10.3390/app10062166