Deep Pixel-Level Matching via Attention for Video Co-Segmentation

 ,
,
Abstract
1. Introduction
2. Related Work
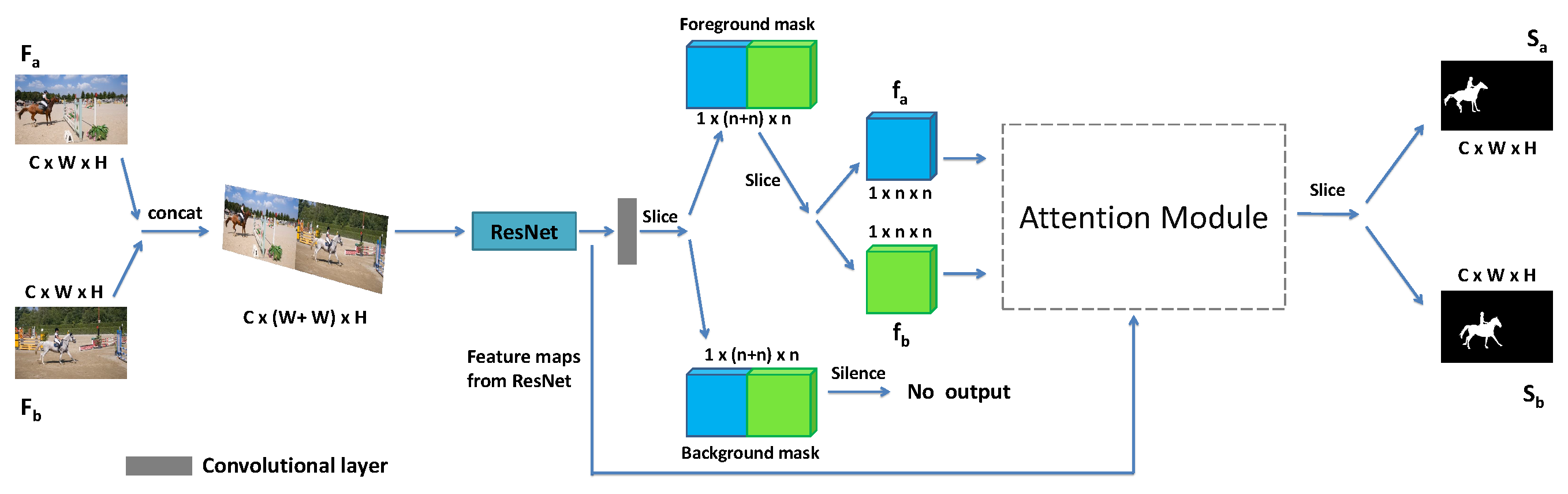
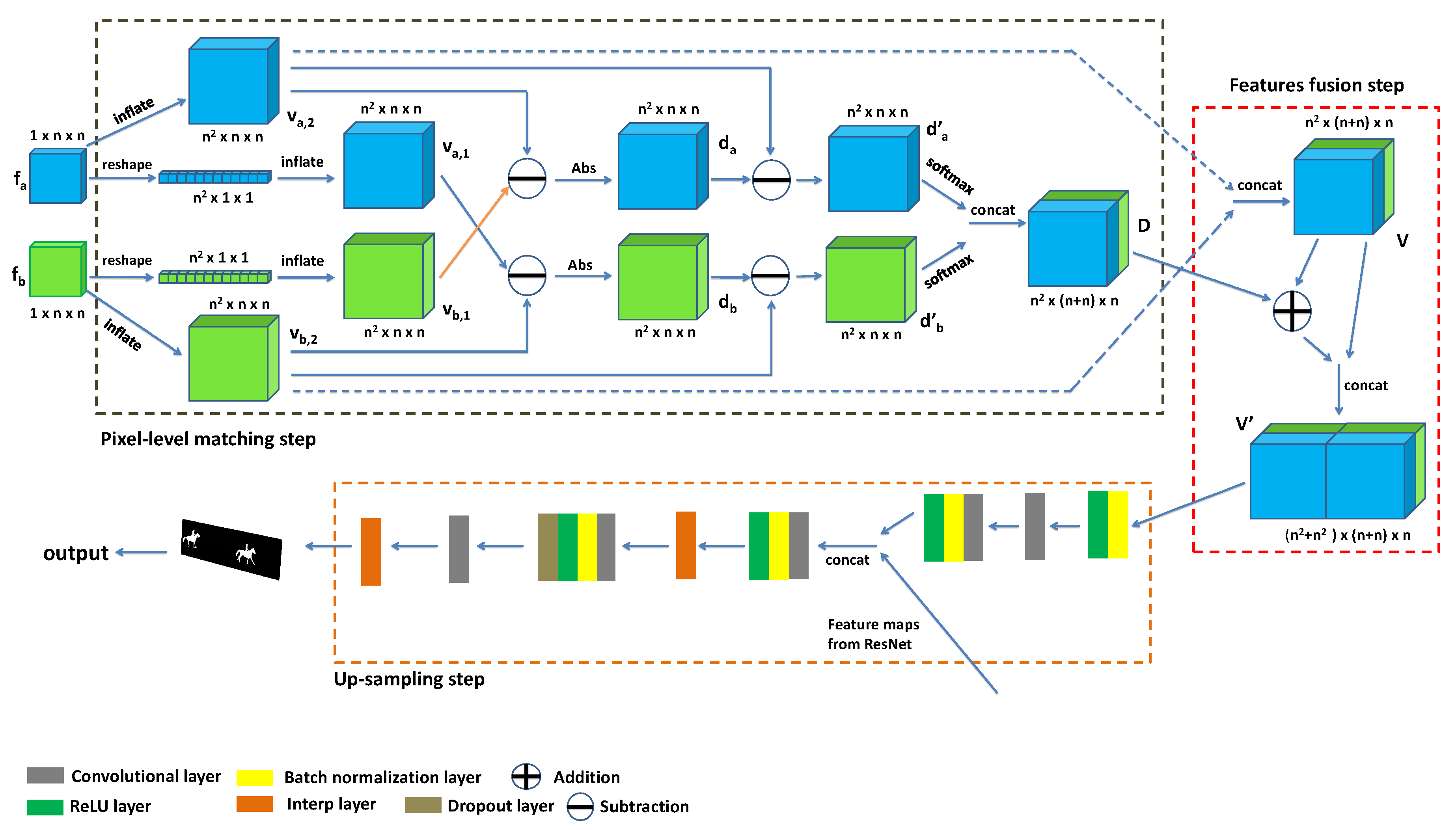
3. Our Framework
3.1. The Pipeline of Our Framework
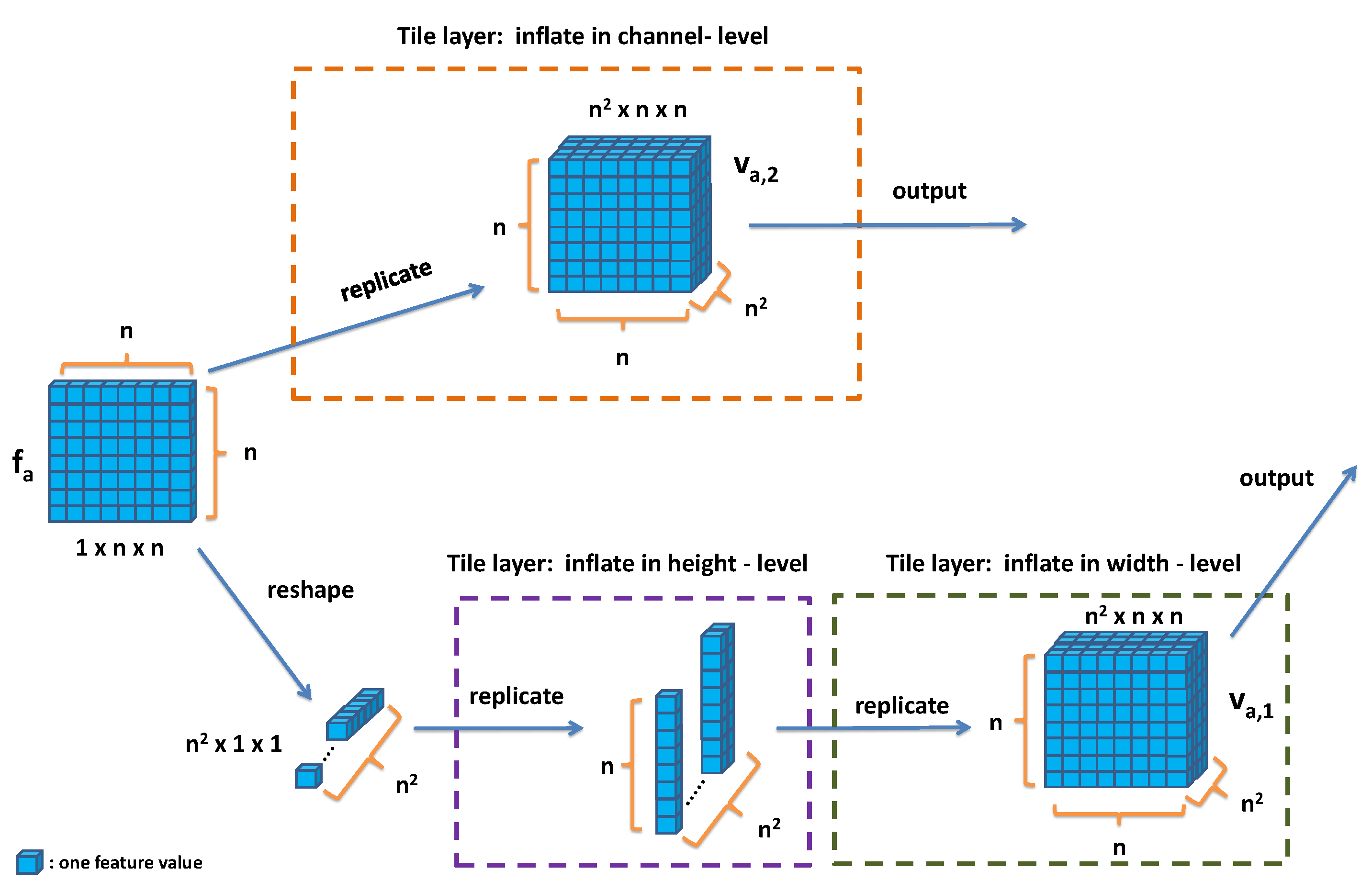
3.2. Our Attention Module
4. Experiments
4.1. Ablation Study
4.2. Comparisons with the State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2462–2470. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 3146–3154. [Google Scholar]
- Lu, X.; Wang, W.; Ma, C.; Shen, J.; Shao, L.; Porikli, F. See more, know more: Unsupervised video object segmentation with co-attention siamese networks. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3623–3632. [Google Scholar]
- Chen, D.; Chen, H.; Chang, L. Video object cosegmentation. In Proceedings of the 20th ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 805–808. [Google Scholar]
- Chiu, W.C.; Fritz, M. Multi-class video co-segmentation with a generative multi-video model. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition 2013, Portland, OR, USA, 23–28 June 2013; pp. 321–328. [Google Scholar]
- Lou, Z.; Gevers, T. Extracting primary objects by video co-segmentation. IEEE Trans. Multimed. 2014, 16, 2110–2117. [Google Scholar] [CrossRef]
- Rubio, J.C.; Serrat, J.; López, A. Video co-segmentation. In Proceedings of the 2nd Asian Conference on Computer Vision, Okinawa, Japan, 5–8 November 2013; pp. 13–24. [Google Scholar]
- Wang, C.; Guo, Y.; Zhu, J.; Wang, L.; Wang, W. Video object cosegmentation via subspace clustering and quadratic pseudo-boolean optimization in an MRF framework. IEEE Trans. Multimed. 2014, 16, 903–916. [Google Scholar] [CrossRef]
- Wang, W.; Shen, J.; Li, X.; Porikli, F. Robust video object cosegmentation. IEEE Trans. Image Proc. 2015, 24, 3137–3148. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Hua, G.; Sukthankar, R.; Xue, J.; Niu, Z.; Zheng, N. Video object discovery and co-segmentation with extremely weak supervision. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2074–2088. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Shen, J.; Sun, H.; Shao, L. Video co-saliency guided co-segmentation. IEEE Trans. Circ. Syst. Video Technol. 2017, 28, 1727–1736. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2019, 521, 436–555. [Google Scholar] [CrossRef] [PubMed]
- Tsai, Y.H.; Zhong, G.; Yang, M.H. Semantic co-segmentation in videos. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 760–775. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Fu, H.; Xu, D.; Zhang, B.; Lin, S.; Ward, R.K. Object-based multiple foreground video co-segmentation via multi-state selection graph. IEEE Trans. Image Proc. 2015, 24, 3415–3424. [Google Scholar] [CrossRef] [PubMed]
- Long, L.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 International Conference on Computer Vision, Araucano Park, Las Condes, Chile, 11–18 December 2015; pp. 3431–3440. [Google Scholar]
- Zhang, C.; Lin, F.; Yao, R.; Shen, C. CAN Net: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5127–5226. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Palermo, Italy, 3–5 June 2011; pp. 315–323. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Van Gool, L.; Gross, M.; Sorkine-Hornung, A. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 724–732. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lee, Y.J.; Kim, J.; Grauman, K. Key-segments for video object segmentation. In Proceedings of the 13th International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1995–2002. [Google Scholar]
- Papazoglou, A.; Ferrari, V. Fast object segmentation in unconstrained video. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition 2013, Portland, OR, USA, 23–28 June 2013; pp. 1777–1784. [Google Scholar]
- Marki, N.; Perazzi, F.; Wang, O.; Sorkine-Hornung, A. Bilateral space video segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 743–751. [Google Scholar]
- Liu, Z.; Wang, L.; Hua, G.; Zhang, Q.; Niu, Z.; Wu, Y.; Zheng, N. Joint video object discovery and segmentation by coupled dynamic Markov networks. IEEE Trans. Image Proc. 2018, 27, 5840–5853. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Pixel Acc. (%) | mIoU (%) |
|---|---|---|
| First frame w/o attention | 95.99 | 61.20 |
| Second frame w/o attention | 97.11 | |
| First frame with attention | 97.09 | 70.99 |
| Second frame with attention | 97.92 |
| Unsupervised Methods | Supervised Methods | |||||
|---|---|---|---|---|---|---|
| Video | VOS | FOS | BVS | DVCS | Baseline | Ours |
| Blackswan | 84.2 | 73.2 | 94.3 | 91.5 | 87.8 | 92.9 |
| Bmx-Bumps | 30.9 | 24.1 | 43.4 | 45.2 | 41.6 | 47.4 |
| Bmx-Trees | 19.3 | 18.0 | 38.2 | 41.1 | 45.1 | 50.9 |
| Breakdance | 54.9 | 46.7 | 50.0 | 52.9 | 81.0 | 84.4 |
| Breakdance-Flare | 55.9 | 61.6 | 72.7 | 60.2 | 84.0 | 87.9 |
| Camel | 57.9 | 56.2 | 66.9 | 82.7 | 85.8 | 91.9 |
| Car-Roundabout | 64.0 | 80.8 | 85.1 | 75.2 | 88.7 | 91.6 |
| Car-Shadow | 58.9 | 69.8 | 57.8 | 75.9 | 92.4 | 93.6 |
| Cows | 33.7 | 79.1 | 89.5 | 88.7 | 88.1 | 92.2 |
| Dance-Jump | 74.8 | 59.8 | 74.5 | 64.2 | 66.6 | 69.9 |
| Dance-Twirl | 38.0 | 45.3 | 49.2 | 60.6 | 77.3 | 81.6 |
| Dog | 69.2 | 70.8 | 72.3 | 86.4 | 91.3 | 93.6 |
| Drift-Chiance | 18.8 | 66.7 | 3.3 | 71.5 | 79.9 | 81.6 |
| Drift-Straight | 19.4 | 68.3 | 40.2 | 66.6 | 89.4 | 91.7 |
| Goat | 70.5 | 55.4 | 66.1 | 79.4 | 85.6 | 87.7 |
| Horsejump-High | 37.0 | 57.8 | 80.1 | 80.9 | 71.2 | 79.0 |
| Horsejump-Low | 63.0 | 52.6 | 60.1 | 75.8 | 77.1 | 82.2 |
| Kite-Surf | 58.5 | 27.2 | 42.5 | 68.7 | 54.5 | 63.5 |
| Kite-Walk | 19.7 | 64.9 | 87.0 | 71.6 | 71.3 | 75.5 |
| Libby | 61.1 | 50.7 | 77.6 | 79.9 | 64.9 | 72.2 |
| Mallard-Water | 78.5 | 8.7 | 90.7 | 74.6 | 89.6 | 92.3 |
| Motocross-Bumps | 68.9 | 61.7 | 40.1 | 83.3 | 83.5 | 88.1 |
| Motocross-Jump | 28.8 | 60.2 | 34.1 | 68.6 | 86.0 | 89.3 |
| Paragliding | 86.1 | 72.5 | 87.5 | 90.2 | 87.4 | 91.6 |
| Paragliding-Launch | 55.9 | 50.6 | 64.0 | 60.0 | 57.0 | 59.7 |
| Parkour | 41.0 | 45.8 | 75.6 | 77.9 | 81.0 | 84.7 |
| Rhino | 67.5 | 77.6 | 78.2 | 83.8 | 92.6 | 94.7 |
| Rollerblade | 51.0 | 31.8 | 58.8 | 77.0 | 81.0 | 85.0 |
| Scooter-Black | 50.2 | 52.2 | 33.7 | 44.5 | 85.6 | 87.2 |
| Scooter-Gray | 36.3 | 32.5 | 50.8 | 66.1 | 80.7 | 84.3 |
| Soapbox | 75.7 | 41.0 | 78.9 | 79.4 | 81.2 | 85.6 |
| Stroller | 75.9 | 58.0 | 76.7 | 87.8 | 78.5 | 84.9 |
| Avg. | 53.3 | 53.8 | 63.1 | 72.3 | 78.4 | 82.5 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Wong, H.-C.; He, S.; Lo, S.-L.; Zhang, G.; Wang, W. Deep Pixel-Level Matching via Attention for Video Co-Segmentation. Appl. Sci. 2020, 10, 1948. https://doi.org/10.3390/app10061948
Li J, Wong H-C, He S, Lo S-L, Zhang G, Wang W. Deep Pixel-Level Matching via Attention for Video Co-Segmentation. Applied Sciences. 2020; 10(6):1948. https://doi.org/10.3390/app10061948
Chicago/Turabian StyleLi, Junliang, Hon-Cheng Wong, Shengfeng He, Sio-Long Lo, Guifang Zhang, and Wenxiao Wang. 2020. "Deep Pixel-Level Matching via Attention for Video Co-Segmentation" Applied Sciences 10, no. 6: 1948. https://doi.org/10.3390/app10061948
APA StyleLi, J., Wong, H.-C., He, S., Lo, S.-L., Zhang, G., & Wang, W. (2020). Deep Pixel-Level Matching via Attention for Video Co-Segmentation. Applied Sciences, 10(6), 1948. https://doi.org/10.3390/app10061948