Dynamic-DSO: Direct Sparse Odometry Using Objects Semantic Information for Dynamic Environments



Abstract
1. Introduction
- The proposed system is entirely based on the direct method. We exploited the semantic information of dynamic objects and eliminated the dynamic candidate points from keyframes, which ensured that only static candidate points were reserved in the tracking and optimization process.
- In the pyramid motion tracking model and sliding window optimization, the photometric error calculated by the projection points in the image dynamic region are removed from the overall residuals, resulting in more accurate pose estimation and optimization.
- We evaluated the proposed system on the public TUM dynamic dataset and the modified Euroc dataset, and achieved robust and accurate results.
2. Related Work
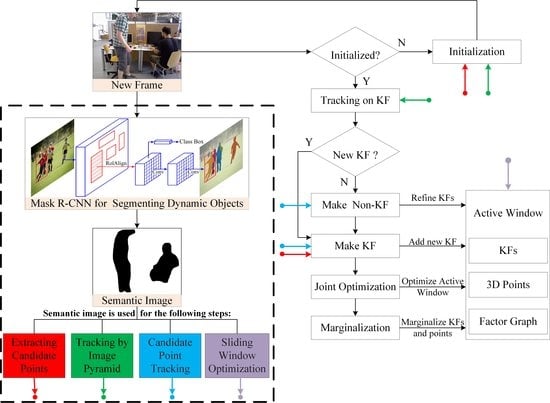
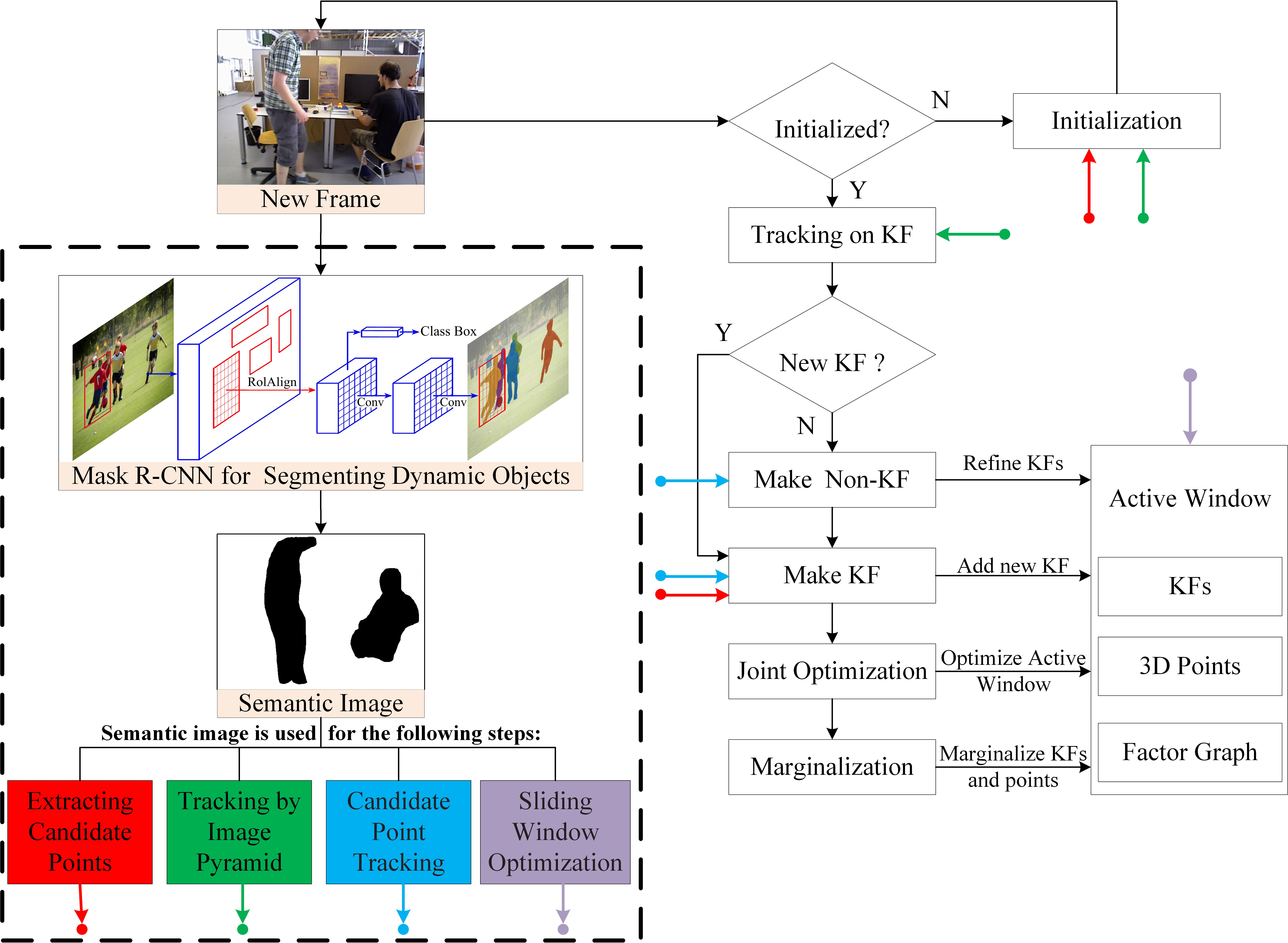
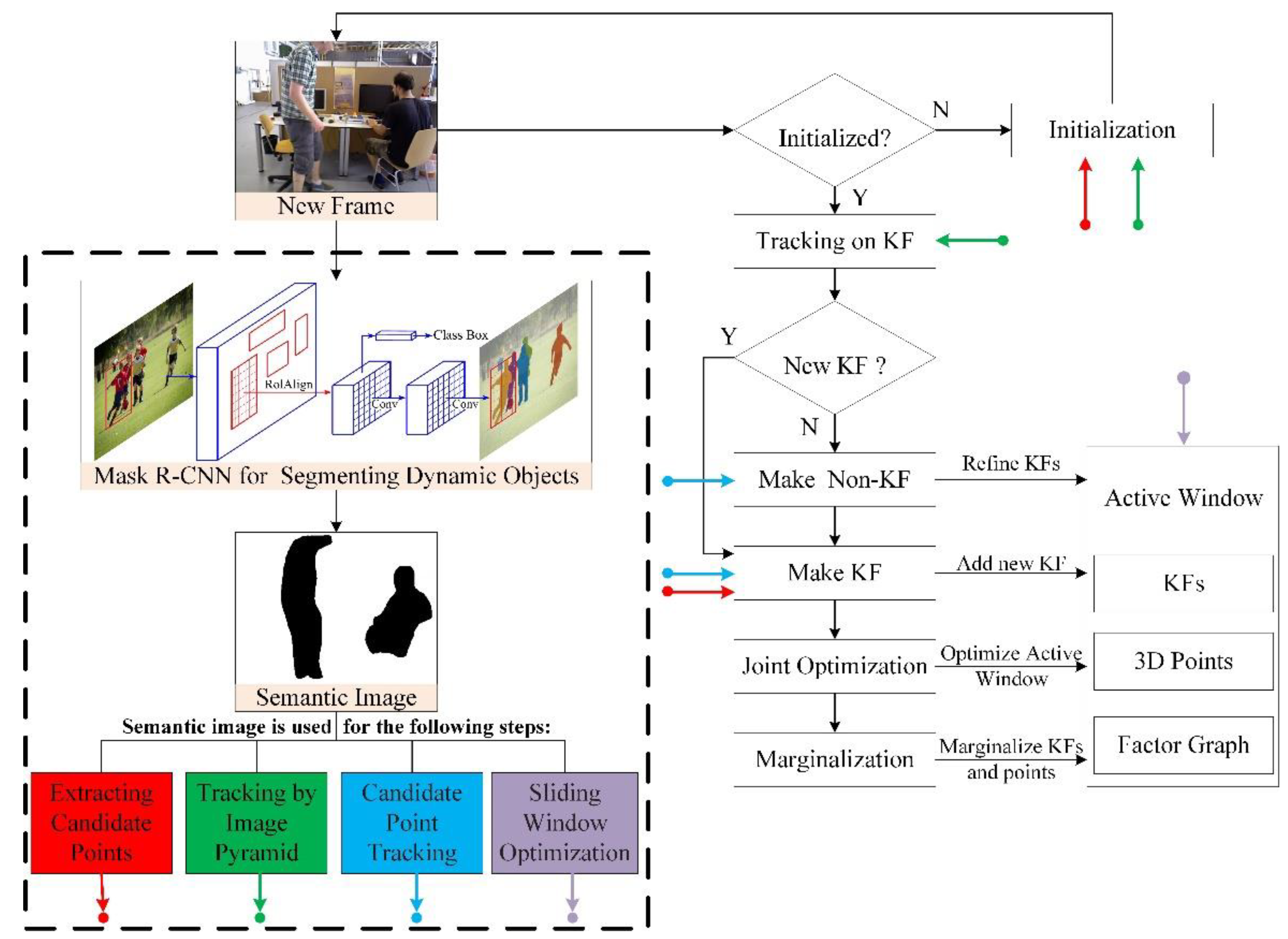
3. Framework of Dynamic-DSO
3.1. Direct Visual Odometry
3.1.1. Front-End
3.1.2. Back-End
4. Methodology
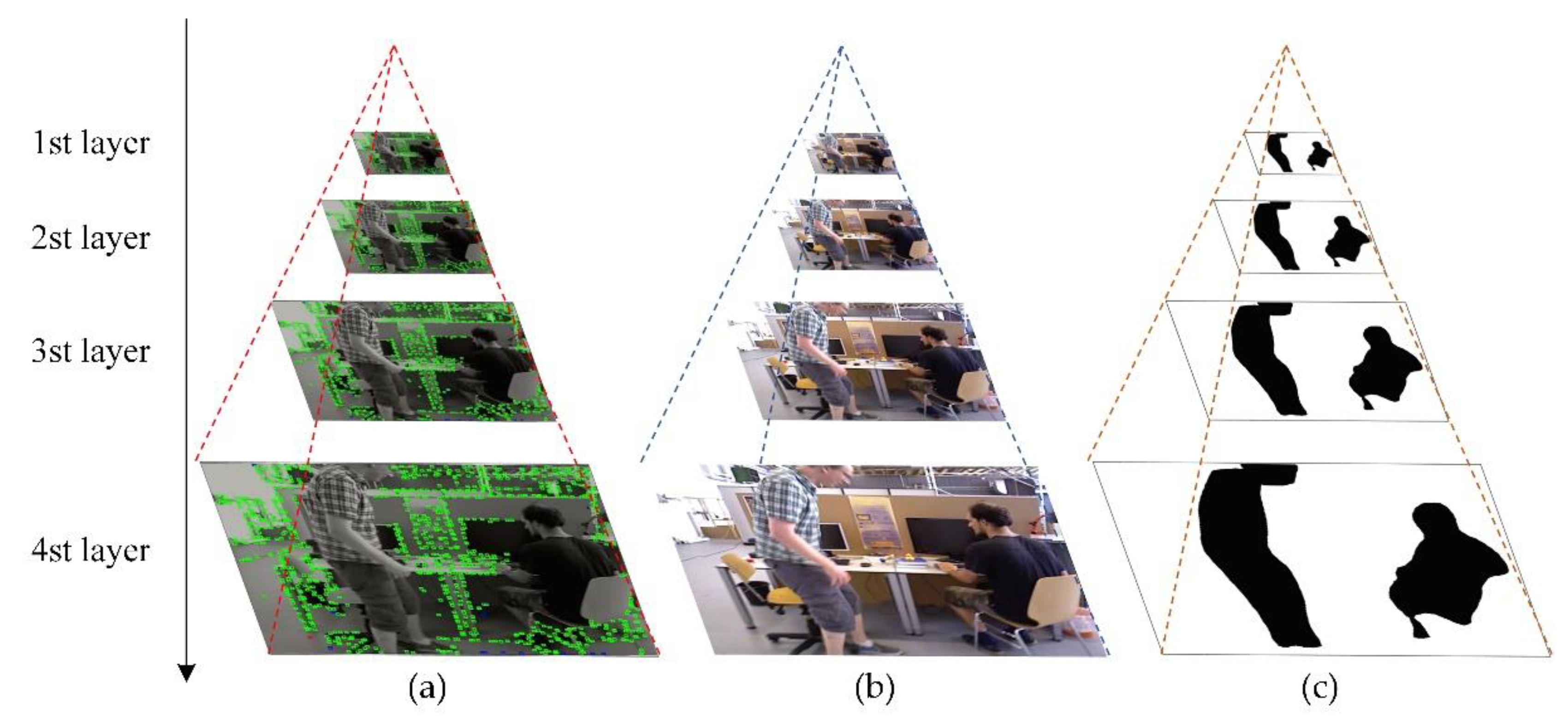
4.1. Candidate Points Extraction Based on Image Semantic Information
4.1.1. Dynamic Objects Segmentation Based on CNNs
4.1.2. Candidate Points Extraction
| Algorithm 1: Candidate points extraction based on image semantic information |
| Input: The original image I, the semantic image Isem, the number of points required: N; |
| Output: The set S of candidate points, the number of selected points Nsel; |
| Initialize: S =, Nsel = 0, k = 1; |
| while Nsel < N do |
| for k <= 4 do |
| Split image I into kd × kd blocks; |
| for each block do |
| Select a point p with the highest gradient which surpass the gradient threshold; |
| if no selected point in this block then |
| Select a point p with the highest gradient which surpass the lower gradient threshold; |
| end if |
| if Isem [p] != 0 then |
| Find the points p1, p2, p3, p4, where they are distributed above, below, left and right at p with the pixel interval D; |
| if (Isem [p1] != 0 && Isem [p2] != 0 && Isem [p3] != 0 && Isem [p4] != 0 ) then |
| Append point p to set S; |
| end if |
| end if |
| end for |
| k = 2 × k; |
| end for |
| Nsel = Nsel + the number of selected points; |
| end while |
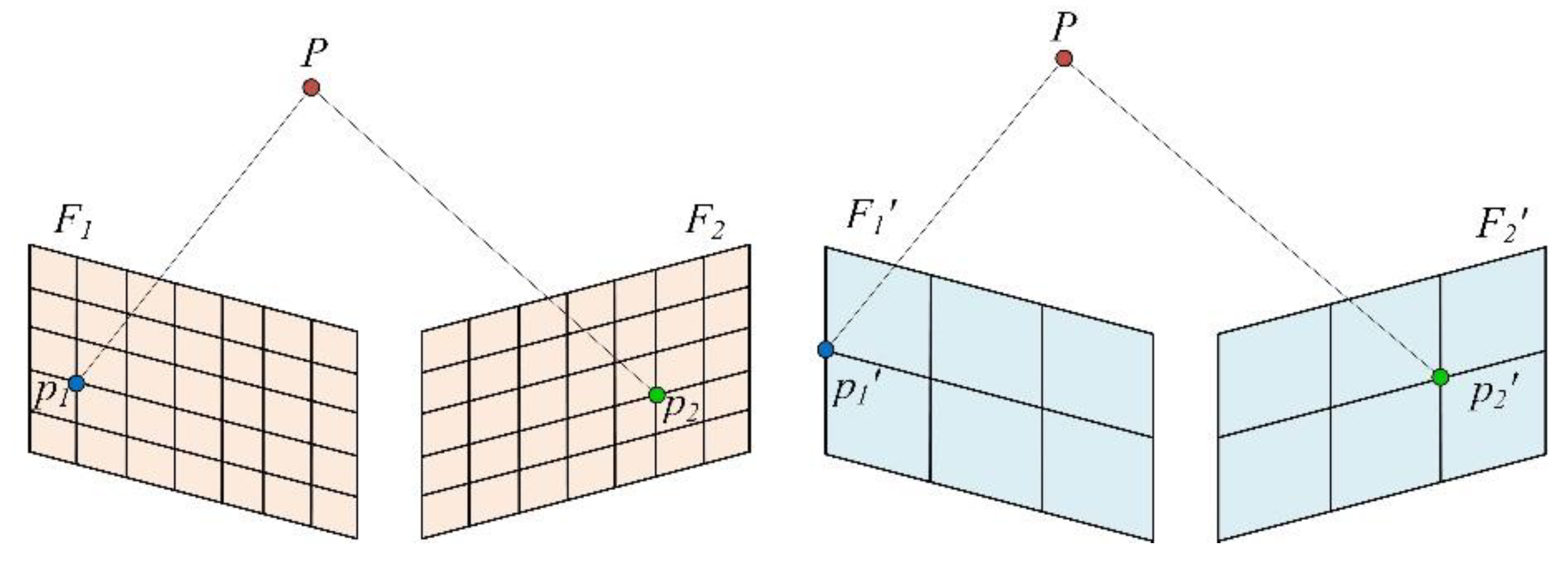
4.2. Pyramid Motion Tracking Model Based on Image Semantic Information
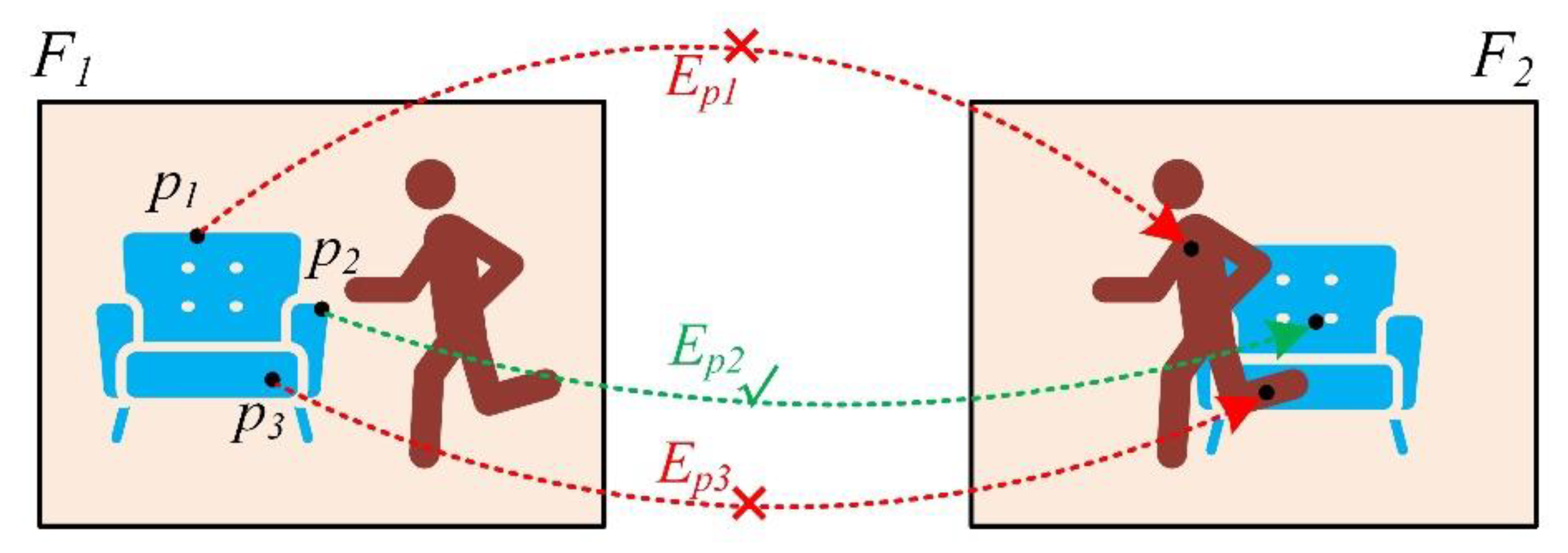
4.3. Candidate Point Tracking Based on Image Semantic Information
4.4. Sliding Window Optimization Based on Image Semantic Information
5. Experiment and Analysis
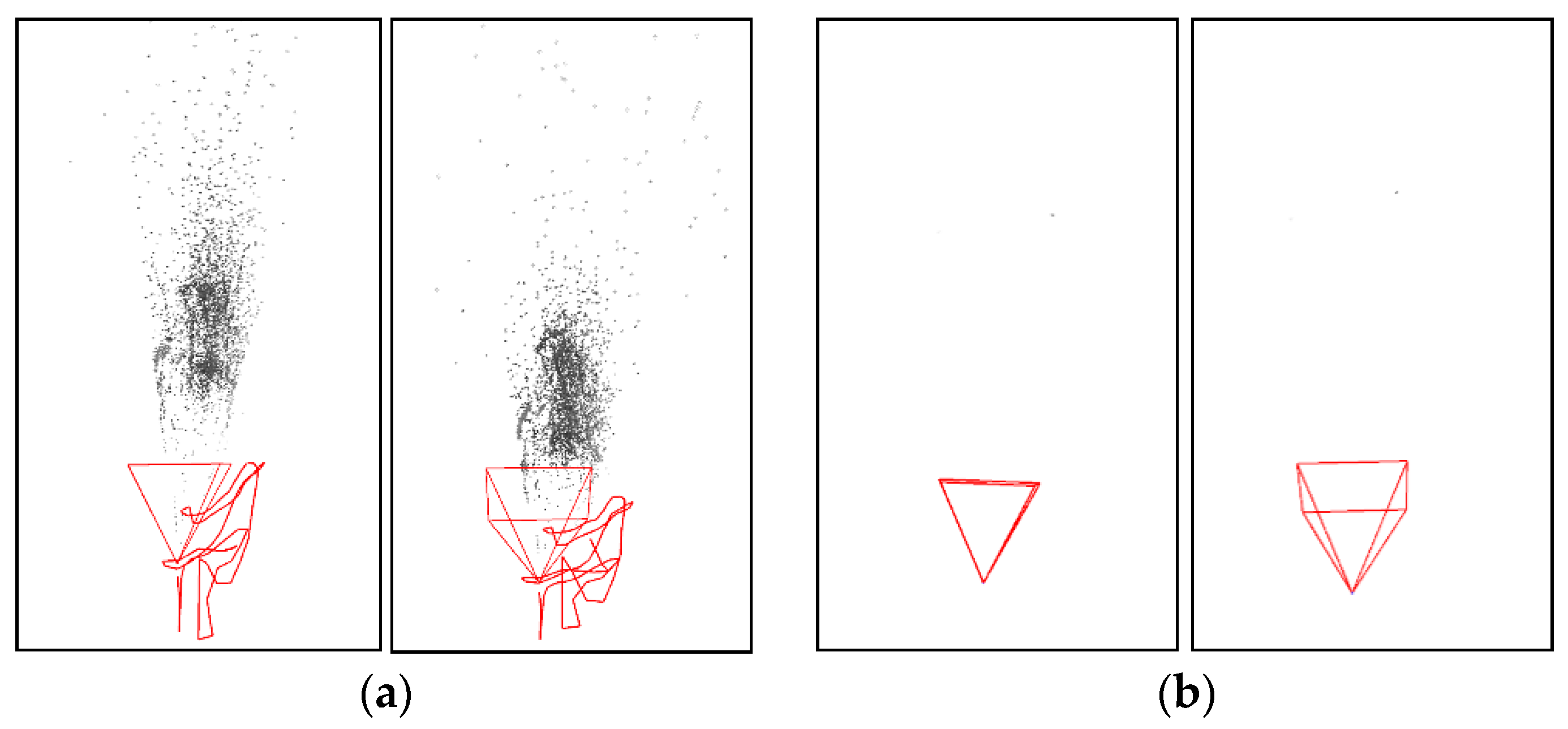
5.1. Evaluation of Candidate Point Extraction
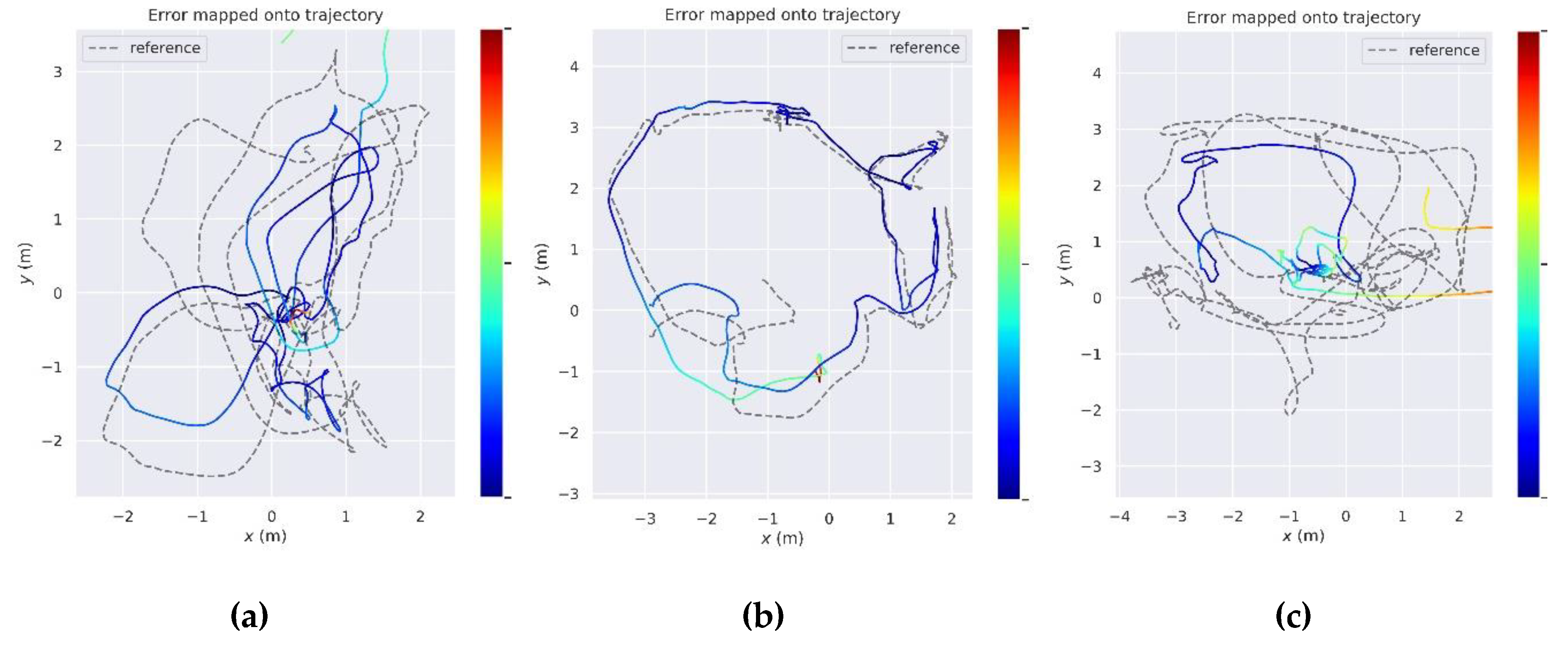
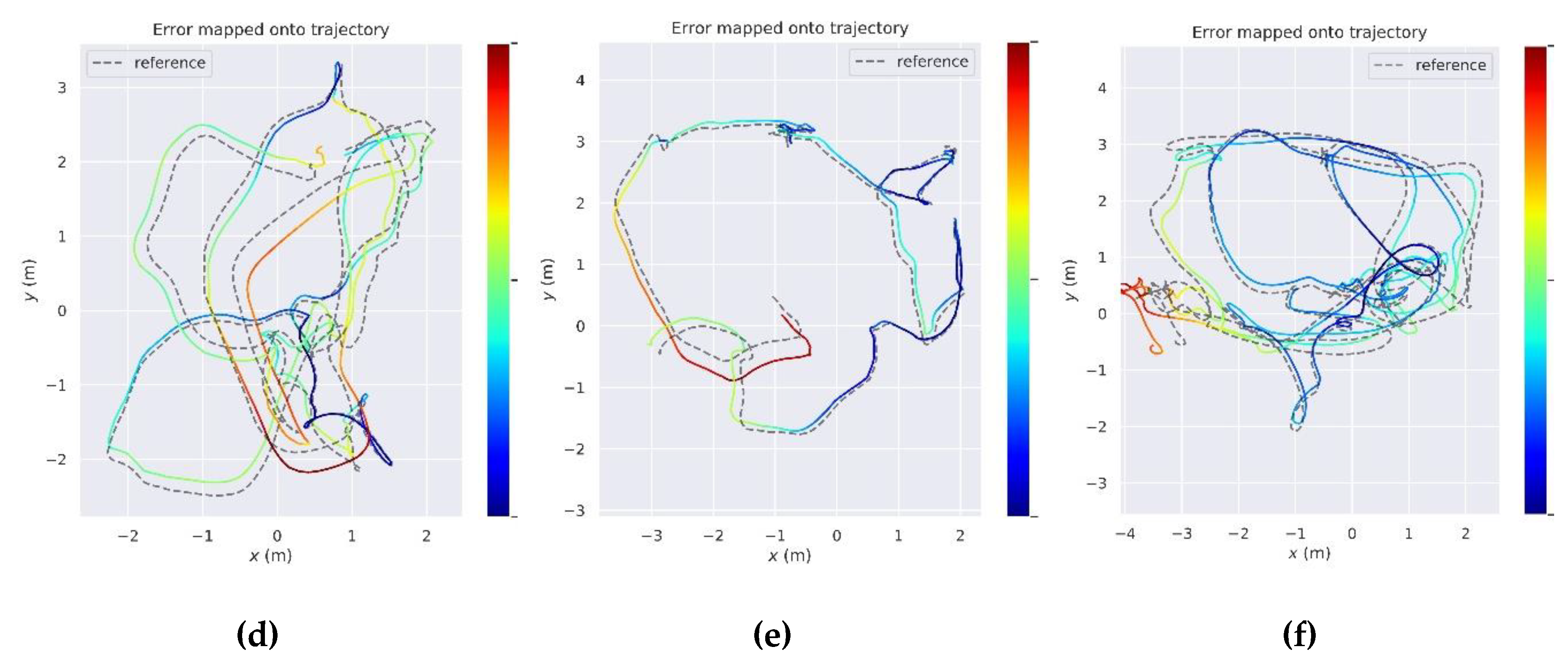
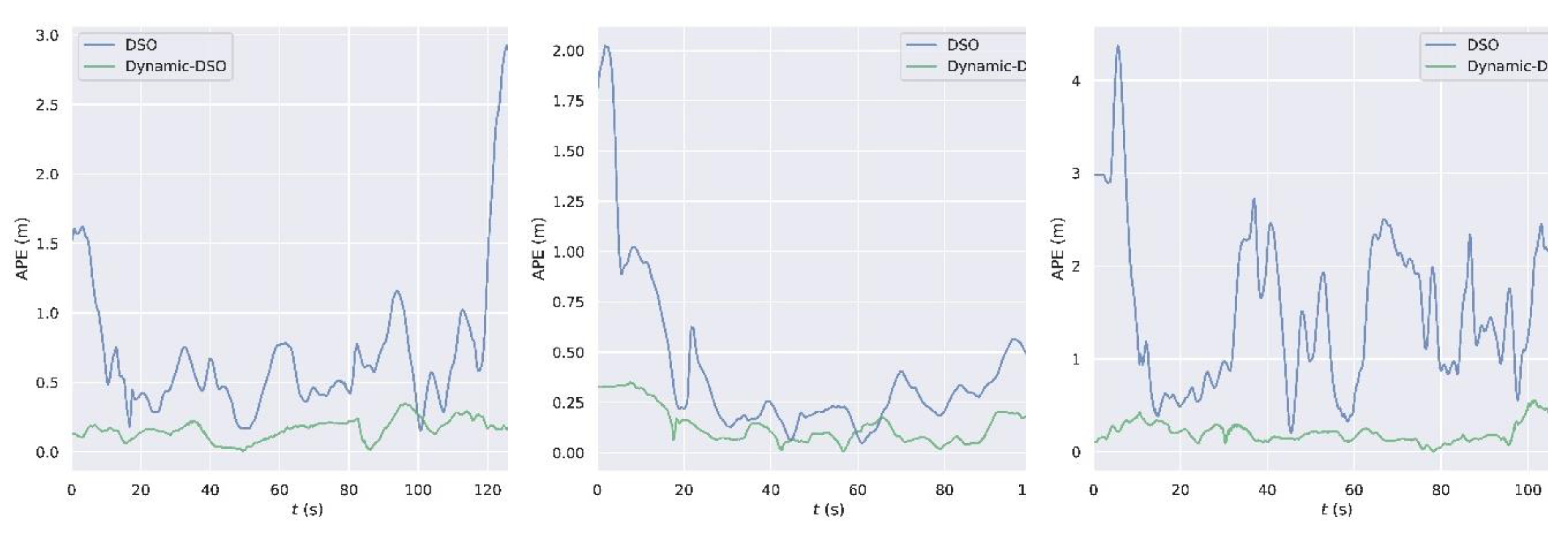
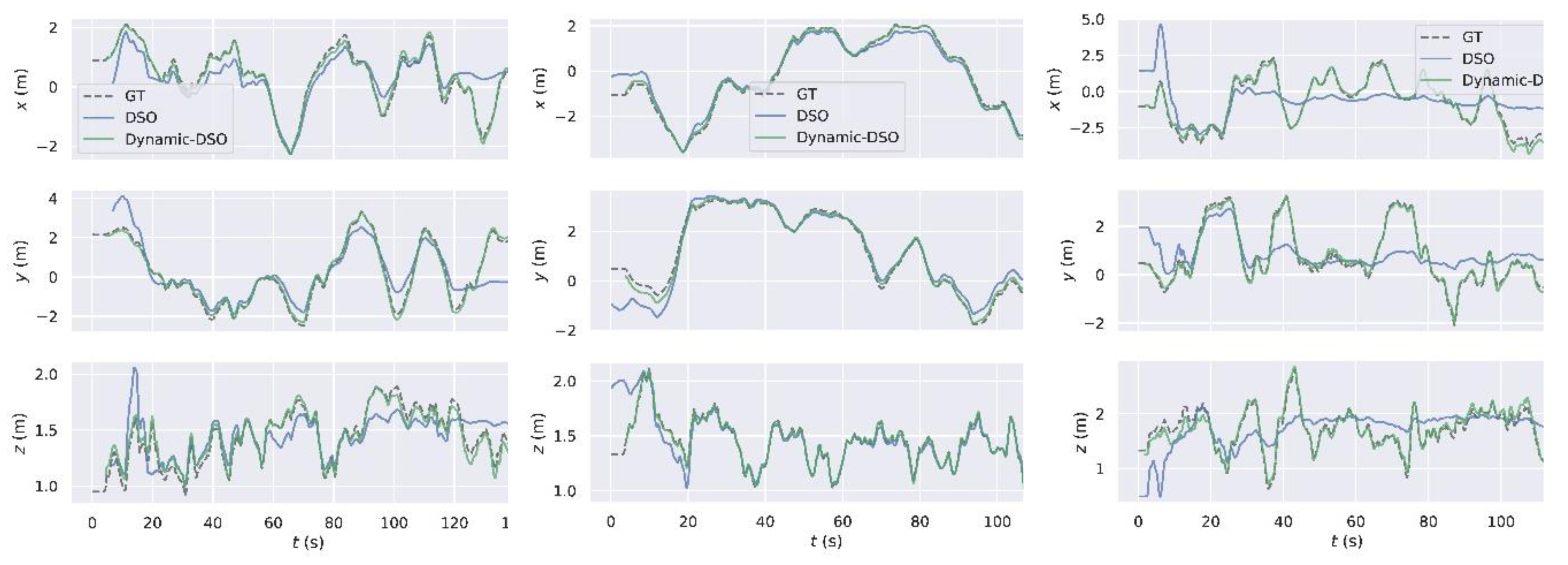
5.2. Evaluation of Position Performance
5.2.1. Evaluation on the Public TUM Dynamic Dataset
5.2.2. Evaluation on the Modified Euroc Dynamic Dataset
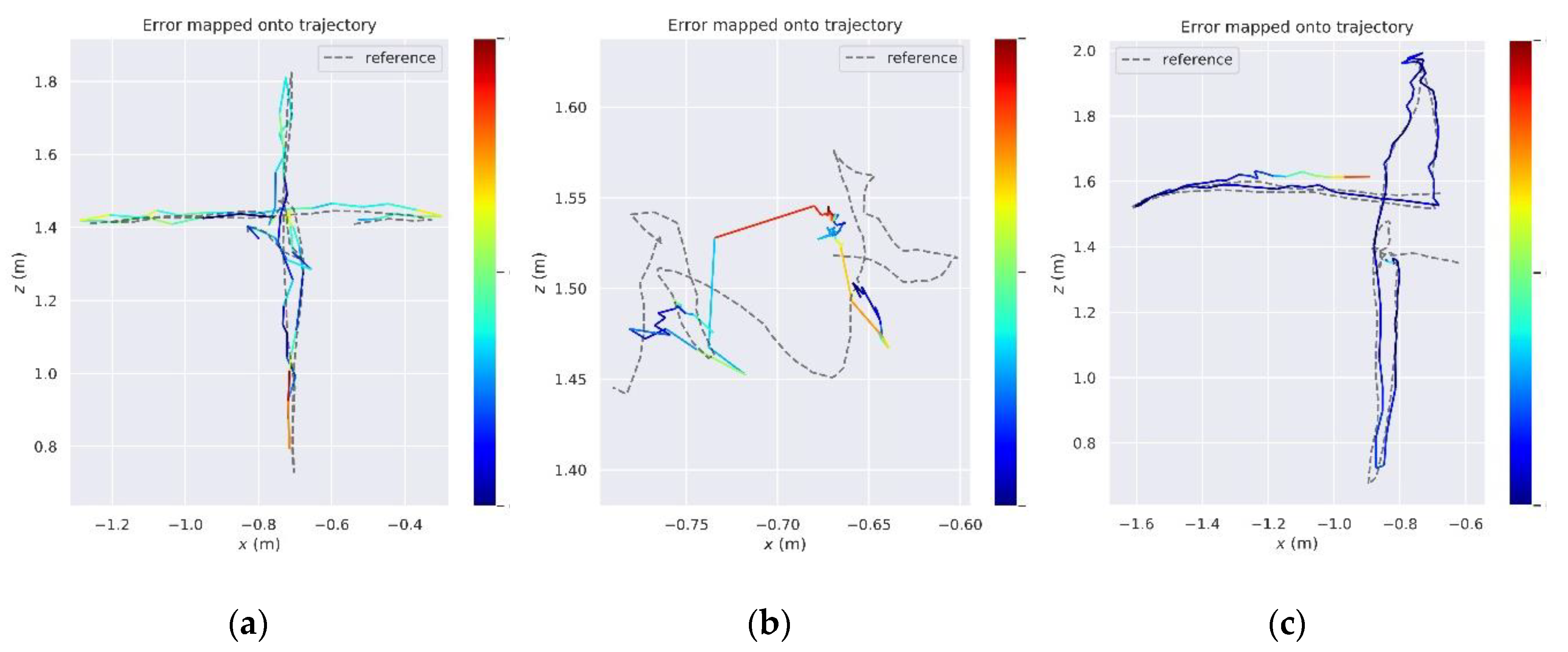
5.2.3. Evaluation on the Self-Collected Sequence
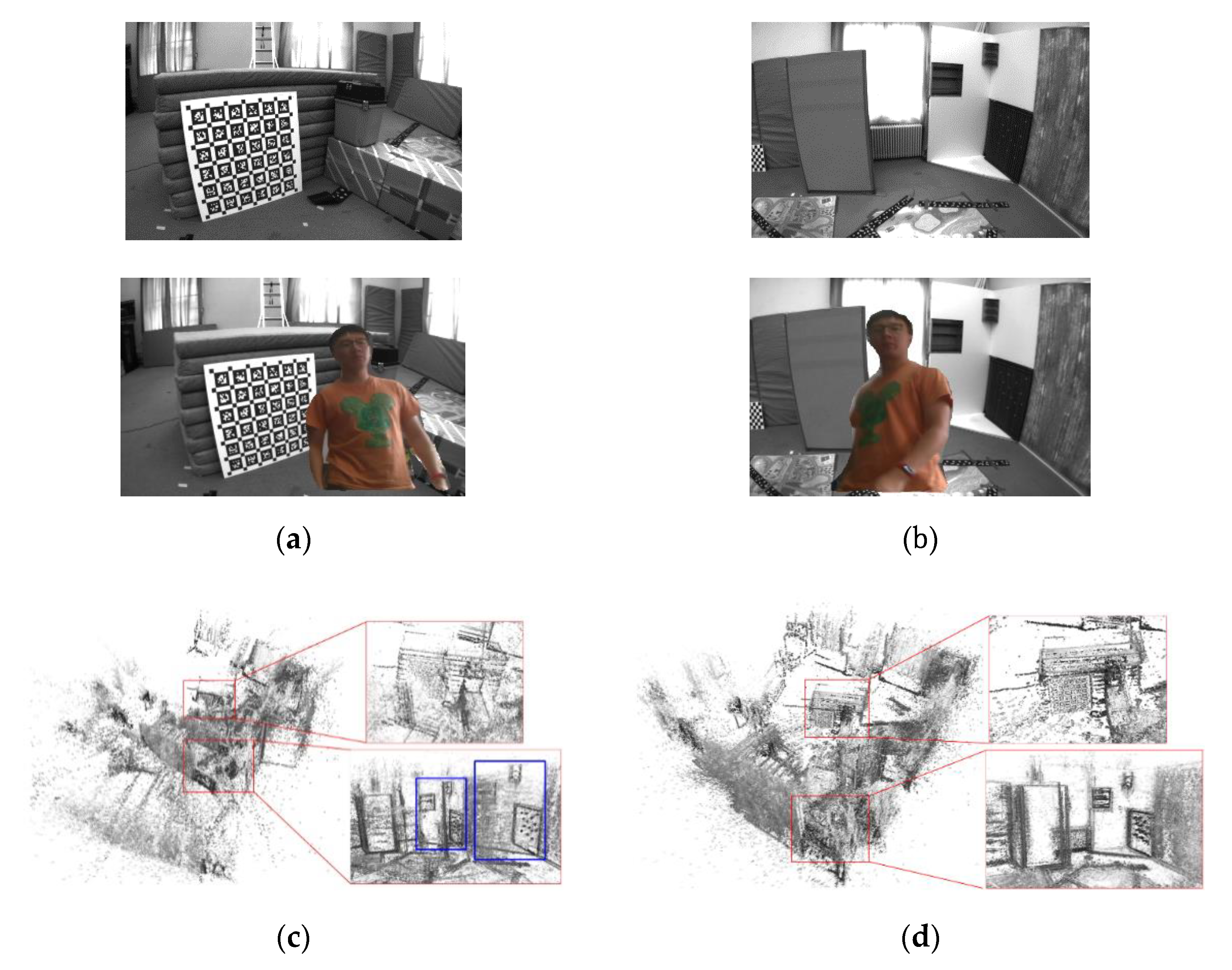
5.3. Evaluation of Mapping Performance
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gu, Z.; Liu, H. A survey of monocular simultaneous localization and mapping. CAAI Trans. Intell. Syst. 2015, 10, 499–507. [Google Scholar]
- Guo, R.; Peng, K.; Fan, W.; Zhai, Y.; Liu, Y. RGB-D SLAM Using Point–Plane Constraints for Indoor Environments. Sensors 2019, 19, 2721. [Google Scholar] [CrossRef] [PubMed]
- Cui, L.; Ma, C. SOF-SLAM: A semantic visual SLAM for Dynamic Environments. IEEE Access 2019, 7, 166528–166539. [Google Scholar] [CrossRef]
- Yousif, K.; Bab-Hadiashar, A.; Hoseinnezhad, R. An overview to visual odometry and visual SLAM: Applications to mobile robotics. Intell. Ind. Syst. 2015, 1, 289–311. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 1–10. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Fang, M.; Liu, Y.-H.; Li, L. Monocular semantic SLAM in dynamic street scene based on multiple object tracking. In Proceedings of the 2017 IEEE International Conference on Cybernetics and Intelligent Systems (CIS) and IEEE Conference on Robotics, Automation and Mechatronics (RAM), Ningbo, China, 19–21 November 2017; pp. 599–604. [Google Scholar]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Z.; Liu, X.-J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. Ds-slam: A semantic visual slam towards dynamic environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Zhang, L.; Wei, L.; Shen, P.; Wei, W.; Zhu, G.; Song, J. Semantic SLAM Based on Object Detection and Improved Octomap. IEEE Access 2018, 6, 75545–75559. [Google Scholar] [CrossRef]
- Xiao, L.H.; Wang, J.G.; Qiu, X.S.; Rong, Z.; Zou, X.D. Dynamic-SLAM: Semantic monocular visual localization and mapping based on deep learning in dynamic environment. Robot. Auton. Syst. 2019, 117, 1–16. [Google Scholar] [CrossRef]
- Bibby, C.; Reid, I. Simultaneous localisation and mapping in dynamic environments (SLAMIDE) with reversible data association. Proc. Robot. Sci. Syst. 2007, 66, 81. [Google Scholar]
- Walcott-Bryant, A.; Kaess, M.; Johannsson, H.; Leonard, J.J. Dynamic pose graph SLAM: Long-term mapping in low dynamic environments. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 1871–1878. [Google Scholar]
- Zou, D.; Tan, P. Coslam: Collaborative visual slam in dynamic environments. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 354–366. [Google Scholar] [CrossRef] [PubMed]
- Kerl, C.; Sturm, J.; Cremers, D. Robust odometry estimation for RGB-D cameras. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 3748–3754. [Google Scholar]
- Bakkay, M.C.; Arafa, M.; Zagrouba, E. Dense 3D SLAM in dynamic scenes using Kinect. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Santiago de Compostela, Spain, 17–19 June 2015; pp. 121–129. [Google Scholar]
- Li, S.; Lee, D. RGB-D SLAM in dynamic environments using static point weighting. IEEE Robot. Autom. Lett. 2017, 2, 2263–2270. [Google Scholar] [CrossRef]
- Bahraini, M.S.; Bozorg, M.; Rad, A.B. SLAM in dynamic environments via ML-RANSAC. Mechatronics 2018, 49, 105–118. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow. Available online: https://github.com/matterport/Mask_RCNN (accessed on 15 October 2019).
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Mal, F.; Karaman, S. Sparse-to-dense: Depth prediction from sparse depth samples and a single image. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| High Dynamic Sequence | Dynamic-SLAM [16] | SOF-SLAM [3] | DS-SLAM [14] | Semantic SLAM [15] | DSO [11] | Dynamic-DSO | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Rmse | Rmse | Rmse | Rmse | Rmse | Mean | Std | Rmse | Mean | Std | |
| fr3_walking_xyz | 0.013 | 0.018 | 0.025 | 0.034 | \ | \ | \ | 0.032 | 0.033 | 0.011 |
| fr3_walking_rpy | 0.060 | 0.027 | 0.444 | - | \ | \ | \ | 0.061 | 0.062 | 0.034 |
| fr3_walking_half | 0.021 | 0.029 | 0.030 | 0.064 | \ | \ | \ | 0.063 | 0.055 | 0.042 |
| High Dynamic Sequence | DSO | Dynamic-DSO | Rmse Improvement | ||||
|---|---|---|---|---|---|---|---|
| Rmse | Mean | Std | Rmse | Mean | Std | ||
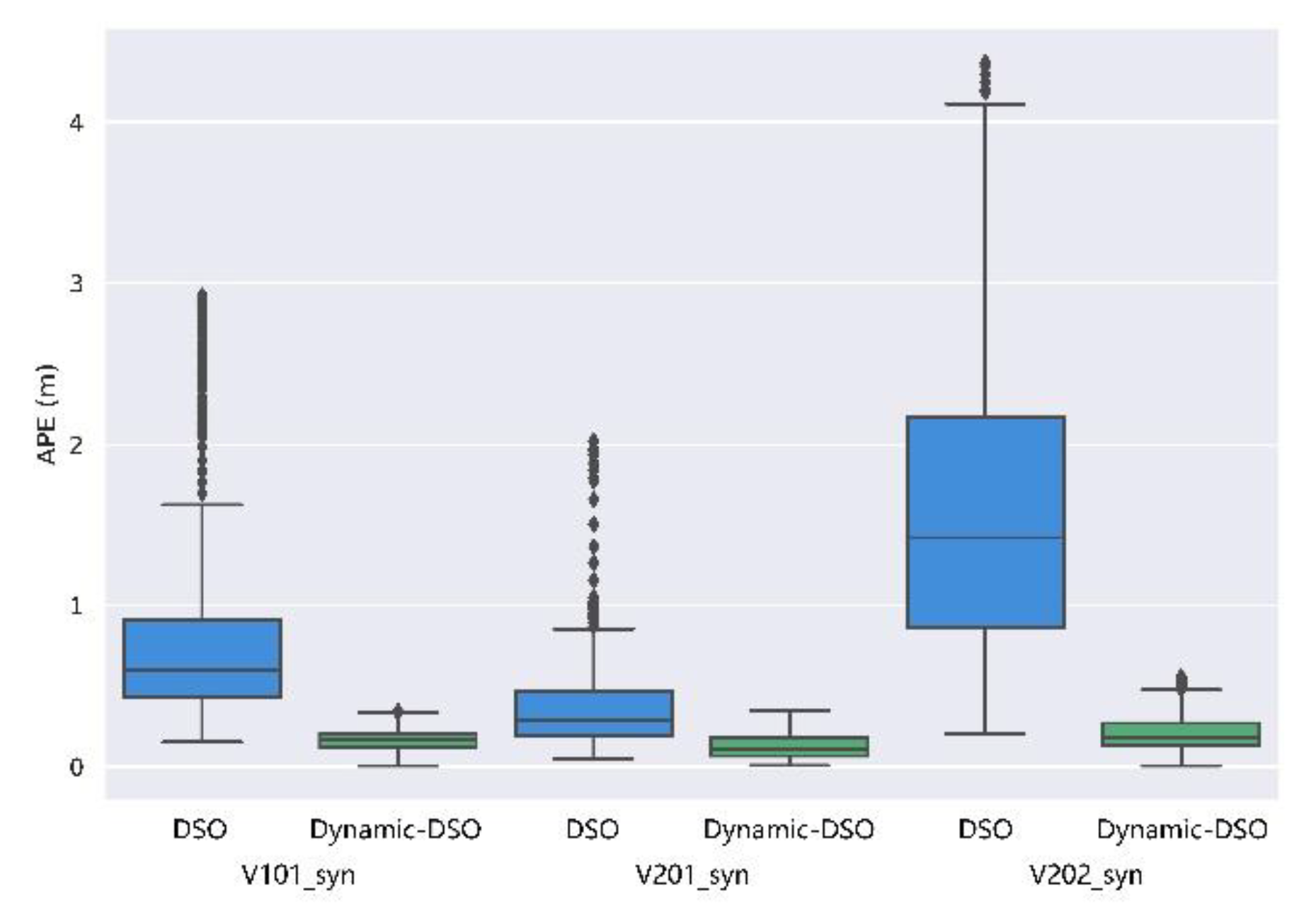
| V101_syn | 1.06 | 0.83 | 0.65 | 0.17 | 0.16 | 0.07 | 84% |
| V201_syn | 0.51 | 0.39 | 0.34 | 0.15 | 0.13 | 0.08 | 71% |
| V202_syn | 1.72 | 1.52 | 0.81 | 0.24 | 0.21 | 0.11 | 86% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheng, C.; Pan, S.; Gao, W.; Tan, Y.; Zhao, T. Dynamic-DSO: Direct Sparse Odometry Using Objects Semantic Information for Dynamic Environments. Appl. Sci. 2020, 10, 1467. https://doi.org/10.3390/app10041467
Sheng C, Pan S, Gao W, Tan Y, Zhao T. Dynamic-DSO: Direct Sparse Odometry Using Objects Semantic Information for Dynamic Environments. Applied Sciences. 2020; 10(4):1467. https://doi.org/10.3390/app10041467
Chicago/Turabian StyleSheng, Chao, Shuguo Pan, Wang Gao, Yong Tan, and Tao Zhao. 2020. "Dynamic-DSO: Direct Sparse Odometry Using Objects Semantic Information for Dynamic Environments" Applied Sciences 10, no. 4: 1467. https://doi.org/10.3390/app10041467
APA StyleSheng, C., Pan, S., Gao, W., Tan, Y., & Zhao, T. (2020). Dynamic-DSO: Direct Sparse Odometry Using Objects Semantic Information for Dynamic Environments. Applied Sciences, 10(4), 1467. https://doi.org/10.3390/app10041467