Application of Support Vector Machine (SVM) in the Sentiment Analysis of Twitter DataSet



Abstract
1. Introduction
1.1. Kernel Function
1.2. LSA & PLSA
2. Materials and Methods
2.1. Fisher Kernel Function
2.2. Topical Features by PLSA Model
2.3. Improved Fisher Kernel Function
2.4. Convergence Based on Fisher Kernel Support Vector Machine
3. Results
3.1. Twitter Data Set
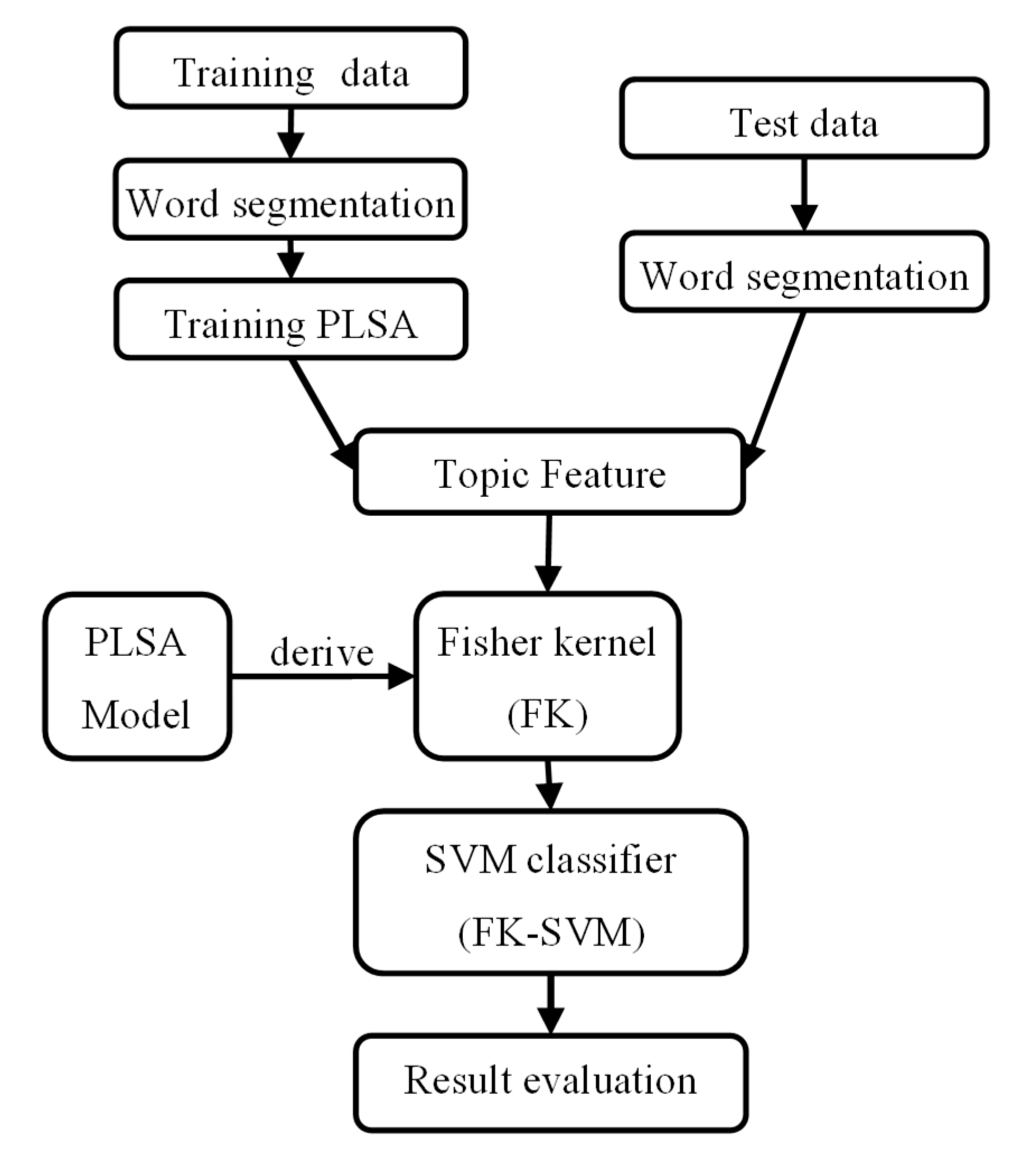
3.2. Text Sentiment Analysis Experiment Based on FK-SVM
- Pre-process emotional detection data;
- Extract the characteristics of the preprocessed data;
- Pass the extracted features to a linear support vector machine for training and recognition;
- Output classification results.
3.3. Experimental Design and Algorithm Evaluation Criteria
- Prepare the training data set;
- Data preprocessing;
- Train the PLSA model;
- Derive the Fisher kernel function through the PLSA model for use in SVM methods supporting kernel functions;
- Train and classify the SVM classifier. The emotional theme vector, namely, the Z vector in the PLSA, is used as the feature of the document and delivered to the SVM based on the Fisher kernel function for binary classification.
- Documents that are relevant and retrieved by the system (TP);
- Documents that are irrelevant and retrieved by the system (FP);
- Documents that are relevant but not retrieved by the system (FN);
- Documents that are irrelevant but not retrieved by the system (TN);
3.4. Experimental Results of FK-SVM, HIST-SVM and PLSA-SVM
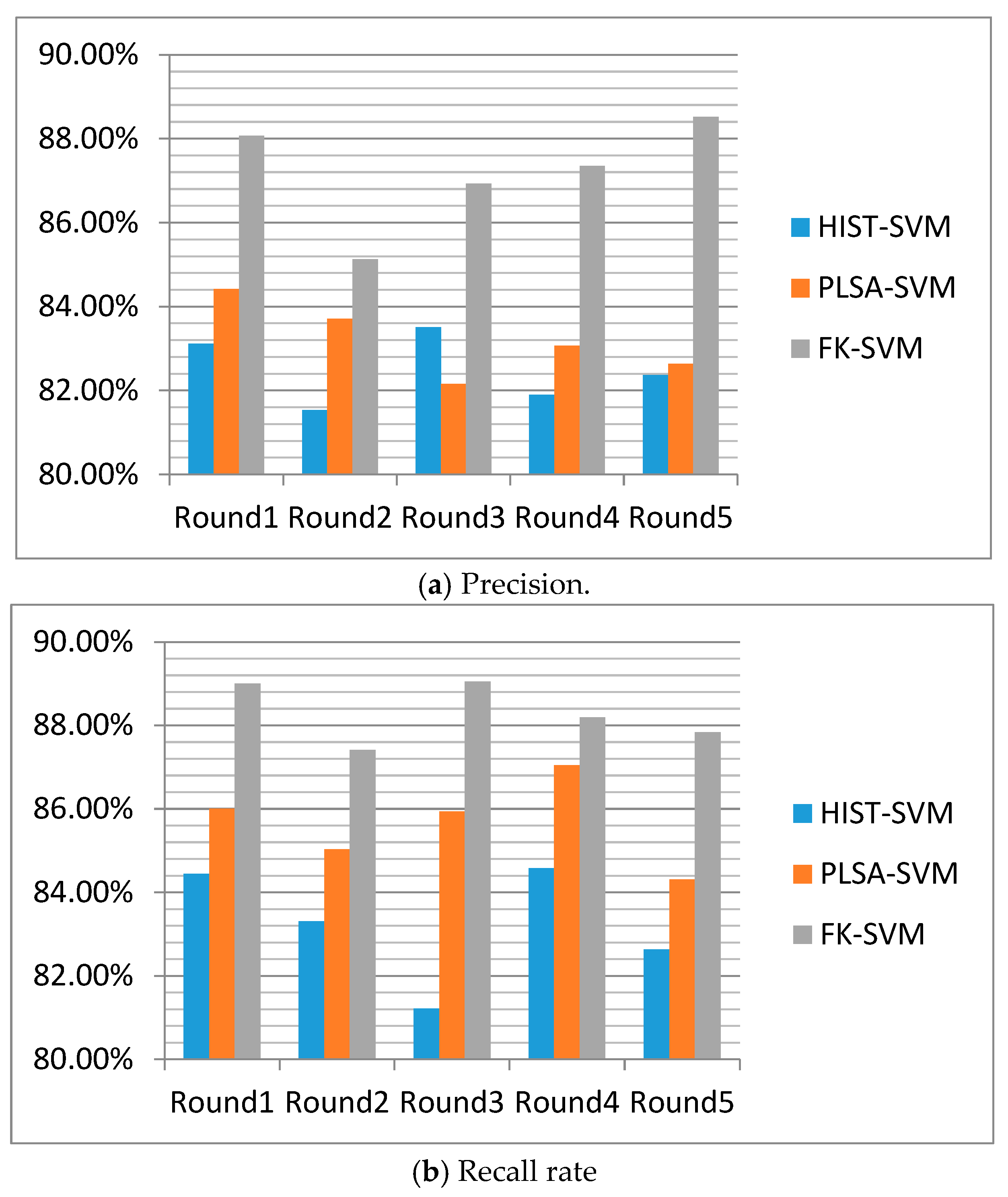
- On the twitter data set, five rounds of cross-validation training and testing are carried out for FK-SVM method, HIST-SVM method and PLSA-SVM method, followed by the obtaining and comparison of the accuracy, recall rate and corresponding average value of each round.
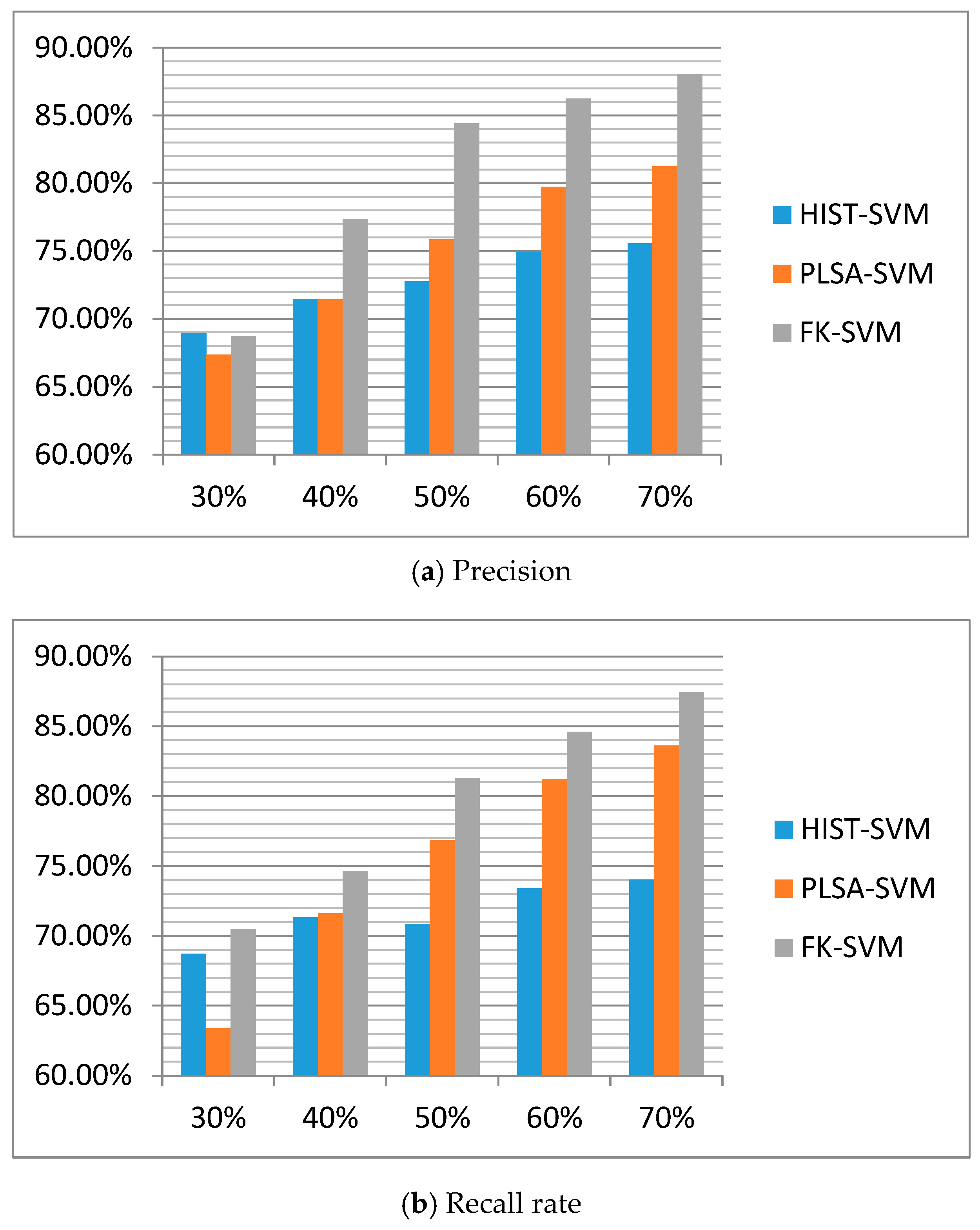
- On the twitter data set, FK-SVM, HIST-SVM method and PLSA-SVM methods are trained and tested in 5 rounds with different proportions of training samples, followed by the obtaining and comparison of the accuracy, recall rate and corresponding average value of each round.
4. Discussion
4.1. Experiment Analysis of Experiment 1
- 1
- Comparison between FK-SVM and HIST-SVM:
- 2
- Comparison between FK-SVM and PLSA-SVM:
4.2. Experiment Analysis of Experiment 2
- 1.
- Comparison between FK-SVM and HIST-SVM:
- 2.
- Comparison between FK-SVM and PLSA-SVM:
5. Conclusions
- A Fisher kernel function based on Probabilistic Latent Semantic Analysis is proposed in this paper. More specifically, the Fisher kernel function based on probability latent semantic analysis can be deduced by using Fisher function to measure the similarity between two objects on the generated model set and the statistical model set. By means of this method, latent semantic information involving the probability features can be used as the classification features, which also improves the effect of classification for support vector machine, and helps address the problem of ignoring the latent semantic features in text sentiment analysis.
- FK-SVM method is proposed and compared with HIST-SVM and PLSA-SVM. The classification accuracy of the proposed method is verified by using Twitter data set, along with the comparison between the results of the experiment to verify the effect of the sentiment analysis method. The experimental results show that the average accuracy of the FK-SVM method on the Twitter sentiment corpus is 87.20%, a great improvement on the basis of the HIST-SVM and the PLSA-SVM method.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tran, T.K.; Phan, T.T. Deep Learning Application to Ensemble Learning-The Simple, but Effective, Approach to Sentiment Classifying. Appl. Sci. 2019, 9, 2760. [Google Scholar] [CrossRef]
- Coşkun, M.; Ozturan, M. europehappinessmap: A Framework for Multi-Lingual Sentiment Analysis via Social Media Big Data (A Twitter Case Study). Information 2018, 9, 102. [Google Scholar] [CrossRef]
- Wang, Y.-L.; Youn, H.Y. Feature Weighting Based on Inter-Category and Intra-Category Strength for Twitter Sentiment Analysis. Appl. Sci. 2019, 9, 92. [Google Scholar] [CrossRef]
- Koltcov, S.; Ignatenko, V.; Koltsova, O. Estimating Topic Modeling Performance with Sharma–Mittal Entropy. Entropy 2019, 21, 660. [Google Scholar] [CrossRef]
- Hofmann, T. Unsupervised Learning by Probabilistic Latent Semantic Analysis. Mach. Learn. 2001, 42, 177. [Google Scholar] [CrossRef]
- Ren, W.-J.; Han, K.-X. Sentiment Detection of Web Users Using Probabilistic Latent Semantic Analysis. J. Multimed. 2014, 10, 863–870. [Google Scholar] [CrossRef]
- Liu, H.-F. Some Properties of Support Vector Machines Mercer’s Nuclear. J. Beijing Union Univ. Nat. Sci. 2005, 19, 45–46. [Google Scholar]
- Burges, J.C. Geometry and Invariance in Kernel based methods. In Advances in Kernel Methods-Support Vector Learning; MIT Press: Cambridge, UK, 1999; pp. 89–116. [Google Scholar]
- Wu, T.; He, H.-G.; He, M.-K. Interpolation Based Kernel Function’s Construction. Chin. J. Comput. 2003, 26, 990–996. [Google Scholar]
- Amari, S.; WU, S. Improving support vector machine classifiers by modifying kernel function. Neural Netw. 1999, 12, 783–789. [Google Scholar] [CrossRef]
- Liu, C.-W.; Luo, J.-X. A PSO-SVM Classifier Based on Hybrid Kernel Function. J. East China Univ. Sci. Technol. Nat. Sci. Ed. 2014, 1, 96–101. [Google Scholar]
- Jia, F.-T.; Song, Z.-L. A New Algorithm Based on SVM Parameter Optimization. Math. Pract. Theory 2014, 1, 200–204. [Google Scholar]
- Smits, G.F.; Jordaan, E.M. Improved SVM Regression using Mixtures of Kernel. In Proceedings of the 2002 International Joint Conference on Neural Networks, Honolulu, HI, USA, 12–17 May 2002. [Google Scholar]
- Liu, H.-F.; Wang, Y.-Y.; Zhang, X.-R.; Liu, S.-S. A Method of Reducing Text Features Based on the Combing of Features Clustering and LSA. J. Inf. 2008, 2, 3–6. [Google Scholar]
- Langerak, T.R.; Berendsen, F.F.; Van der Heide, U.A.; Kotte, A.N.T.J.; Pluim, J.P.W. Multiatlas-based segmentation with preregistration atlas selection. Med. Phys. 2013, 409, 091701. [Google Scholar] [CrossRef] [PubMed]
- Shah-Hosseini, A.; Knapp, G.M. Semantic Image Retrieval Based on Probabilistic Latent Semantic Analysis; ACM: New York, NY, USA, 2006. [Google Scholar]
- Wang, Z.-H.; Wang, L.-Y.; Dang, H. Web clustering based on hybrid probabilistic latent semantic analysis model. J. Comput. Appl. 2012, 11, 3018–3022. [Google Scholar] [CrossRef]
- Zhang, W.; Huang, W.; Xia, L.-M. Recommendation research based on general content probabilistic latent semantic analysis model. J. Comput. Appl. 2013, 5, 1330–1333. [Google Scholar] [CrossRef]
- Zhang, Y.-F.; He, C. Research on Text Categorization Model Based on Latent Semantic Analysis and HS-SVM. Information Studies. Theory Appl. 2010, 7, 104–107. [Google Scholar]
- Perronnin, F.; Rodriguez-Serrano, J.A. Fisher kernels for hand-written word-spotting. In Proceedings of the 10th International Confere- nce on Document Analysis and Recognition, Beijing, China, 10–15 November 2009. [Google Scholar]
- Travieso, C.M.; Briceño, J.C.; Ferrer, M.A.; Alonso, J.B. Using Fisher kernel on 2D-shape identification. In Proceedings of the Computer Aided Systems Theory-EUROCAST 2007, LNCS 4739, Berlin, Germany, 12–16 February 2007; pp. 740–746. [Google Scholar]
- Won, C.; Saunders, A. Prügel-Bennett. Evolving fisher kernels for biological sequence classification. Evol. Comput. 2011, 21, 83–105. [Google Scholar] [CrossRef] [PubMed]
- Inokuchi, R.; Miyamoto, S. Nonparametric fisher kernel using fuzzy clustering. In Knowledge-Based Intelligent Information and Engineering Systems; LNCS4252; Springer: Berlin/Heidelberg, Germany, 2006; pp. 78–85. [Google Scholar]
- Salvador, D.-B.; Thomas, W.; Susan, L.D. Top-down feedback in an HMAX-like cortical model of object perception based on hierarchical Bayesian networks and belief propagation. PLoS ONE 2012, 7, e48216. [Google Scholar]
- The Corpus Used in this Paper is from Stanford University’s “Sentiment140”. Available online: http://help.sentiment140.com/for-students/ (accessed on 9 September 2019).




{kind=link}
{kind=link}
{kind=link}
| Experimental Round | HIST-SVM | PLSA-SVM | FK-SVM |
|---|---|---|---|
| Round 1 | 83.12% | 84.42% | 88.07% |
| Round 2 | 81.53% | 83.71% | 85.13% |
| Round 3 | 83.51% | 82.16% | 86.93% |
| Round 4 | 81.89% | 83.07% | 87.35% |
| Round 5 | 82.37% | 82.64% | 88.52% |
| Average | 82.49% | 83.20% | 87.20% |
| (a) | |||
| Round 1 | 84.45% | 86.01% | 89.00% |
| Round 2 | 83.31% | 85.03% | 87.41% |
| Round 3 | 81.22% | 85.94% | 89.05% |
| Round 4 | 84.58% | 87.05% | 88.19% |
| Round 5 | 82.63% | 84.31% | 87.83% |
| Average | 83.24% | 85.67% | 88.30% |
| (b) | |||
| Experimental Round | HIST-SVM | PLSA-SVM | FK-SVM |
|---|---|---|---|
| 30% | 68.93% | 67.37% | 68.71% |
| 40% | 71.46% | 71.43% | 77.37% |
| 50% | 72.77% | 75.86% | 84.42% |
| 60% | 74.92% | 79.75% | 86.25% |
| 70% | 75.56% | 81.24% | 88.04% |
| Average | 72.73% | 75.13% | 80.96% |
| (a) | |||
| 30% | 68.72% | 63.38% | 70.47% |
| 40% | 71.33% | 71.61% | 74.63% |
| 50% | 70.86% | 76.83% | 81.25% |
| 60% | 73.39% | 81.22% | 84.59% |
| 70% | 74.03% | 83.63% | 87.45% |
| Average | 71.67% | 75.33% | 79.68% |
| (b) | |||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, K.-X.; Chien, W.; Chiu, C.-C.; Cheng, Y.-T. Application of Support Vector Machine (SVM) in the Sentiment Analysis of Twitter DataSet. Appl. Sci. 2020, 10, 1125. https://doi.org/10.3390/app10031125
Han K-X, Chien W, Chiu C-C, Cheng Y-T. Application of Support Vector Machine (SVM) in the Sentiment Analysis of Twitter DataSet. Applied Sciences. 2020; 10(3):1125. https://doi.org/10.3390/app10031125
Chicago/Turabian StyleHan, Kai-Xu, Wei Chien, Chien-Ching Chiu, and Yu-Ting Cheng. 2020. "Application of Support Vector Machine (SVM) in the Sentiment Analysis of Twitter DataSet" Applied Sciences 10, no. 3: 1125. https://doi.org/10.3390/app10031125
APA StyleHan, K.-X., Chien, W., Chiu, C.-C., & Cheng, Y.-T. (2020). Application of Support Vector Machine (SVM) in the Sentiment Analysis of Twitter DataSet. Applied Sciences, 10(3), 1125. https://doi.org/10.3390/app10031125