An Effective Optimization Method for Machine Learning Based on ADAM


Abstract
:1. Introduction
2. Cost Function
3. Learning Methods
3.1. Gradient Descent Method
| Algorithm 1: Pseudocode of Gradient Descent Method. |
| : Learning rate |
| : Cost function with parameters w |
| : Initial parameter vector |
| (Initialize time step) |
| not converged |
| (Resulting parameters) |
3.2. ADAM Method
| Algorithm 2: Pseudocode of ADAM Method. |
| : Learning rate |
| : Exponential decay rates for the moment estimates |
| : Cost function with parameters w |
| : Initial parameter vector |
| (Initialize timestep) |
| not converged |
| (Resulting parameters) |
3.3. AdaMax Method
| Algorithm 3: Pseudocode of AdaMax. |
| : Learning rate |
| : Exponential decay rates for the moment estimates |
| : Cost function with parameters w |
| : Initial parameter vector |
| (Initialize time step) |
| not converged |
| (Resulting parameters) |
4. The Proposed Method
Optimization
5. Numerical Tests
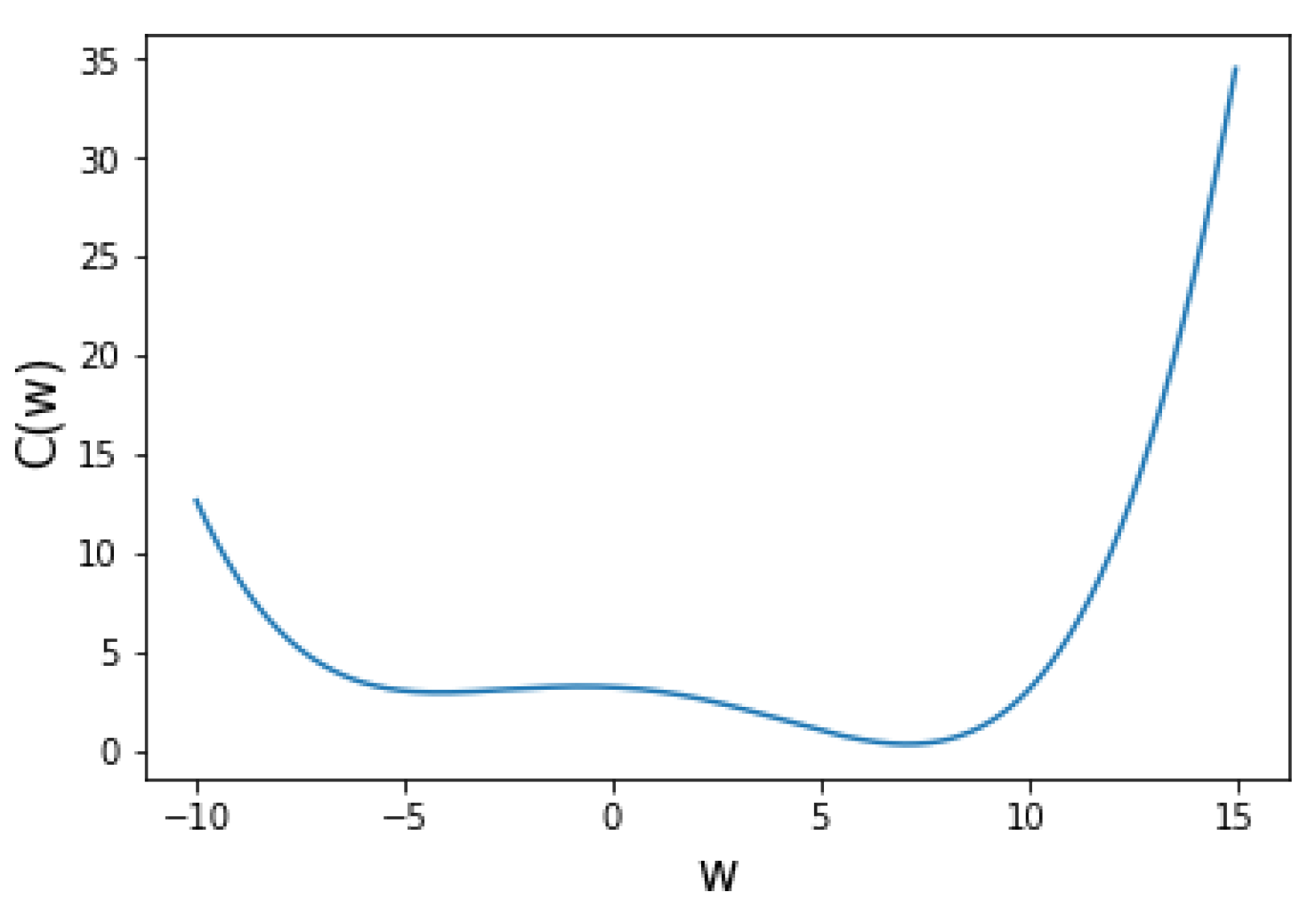
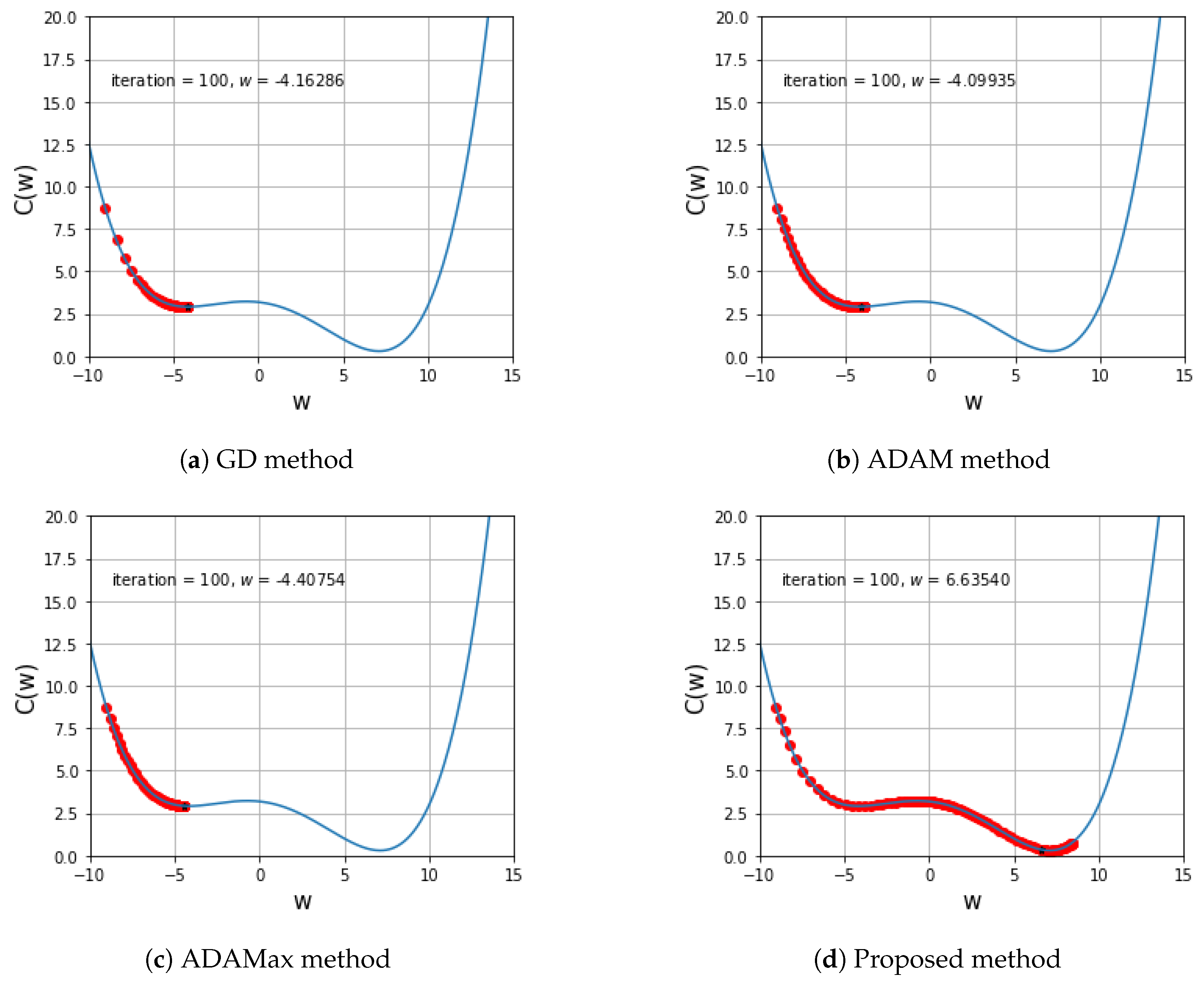
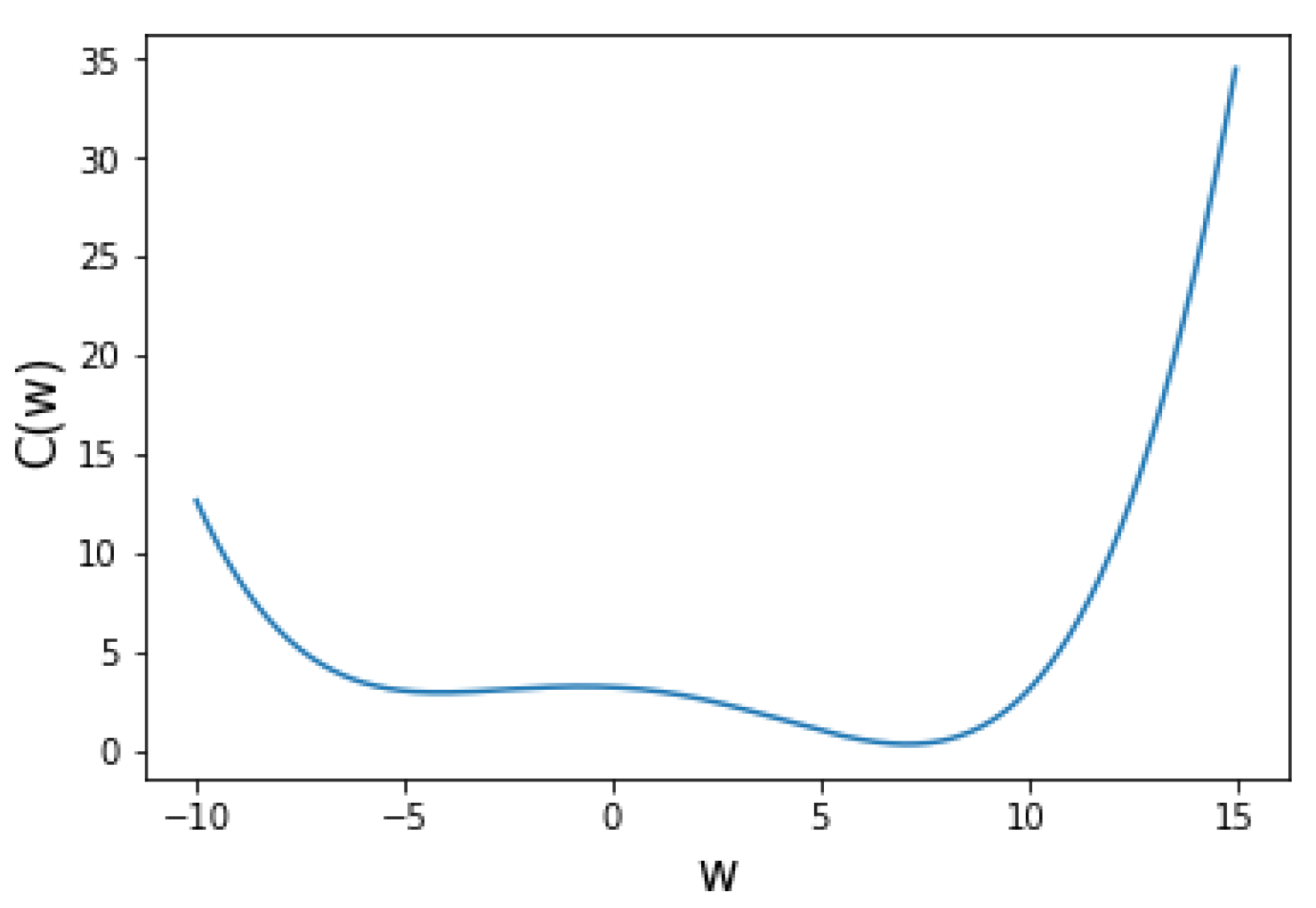
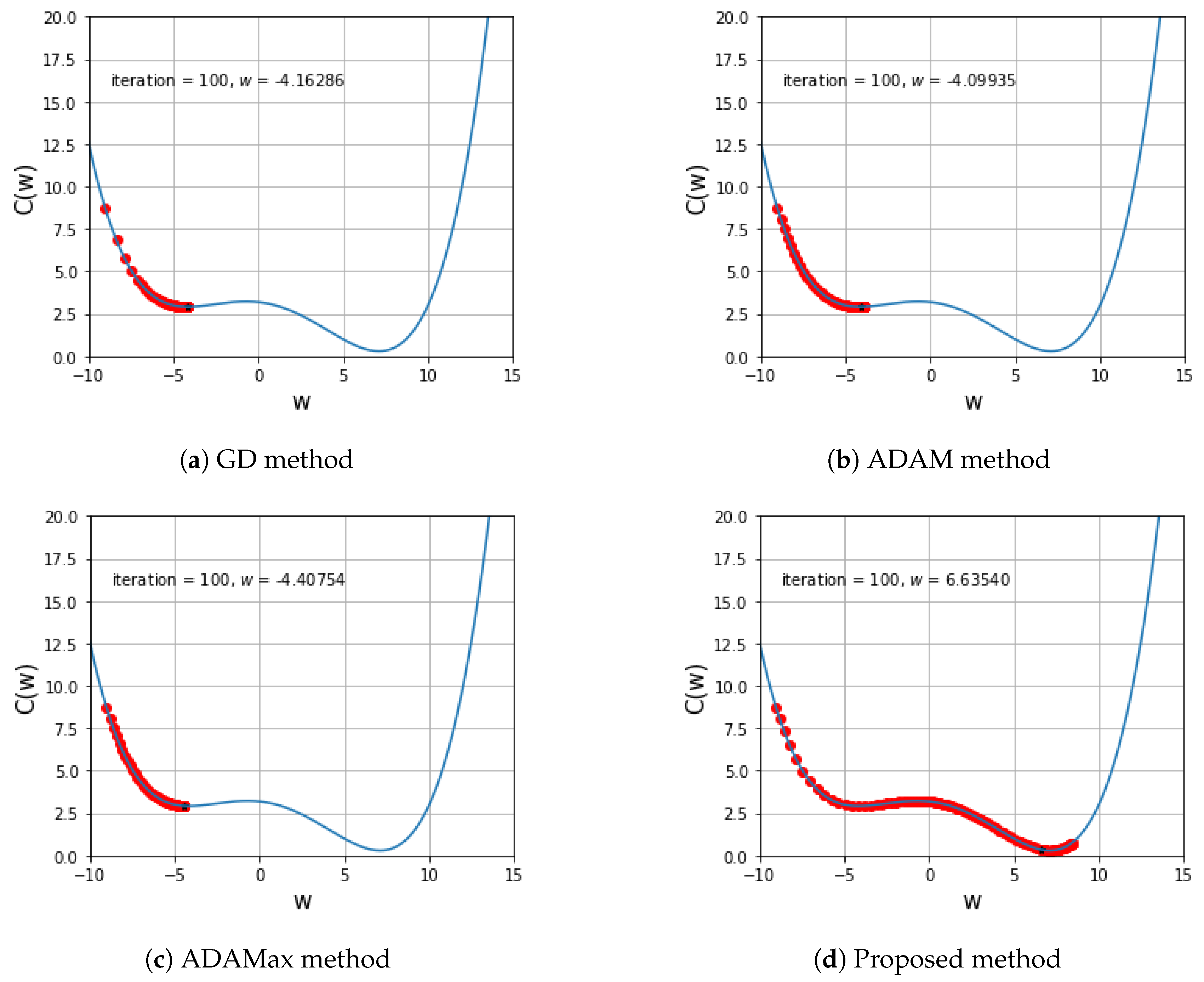
5.1. One Variable Non-Convex Function Test
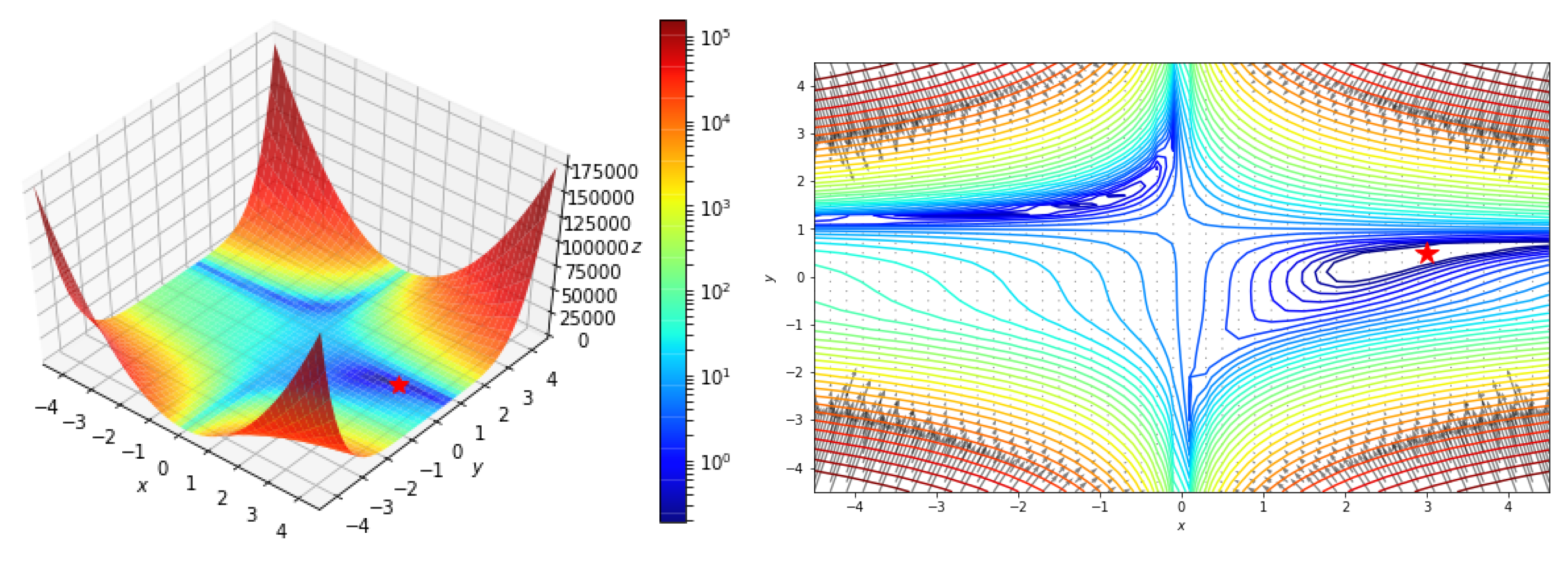
5.2. Two Variables Non-Convex Function Test
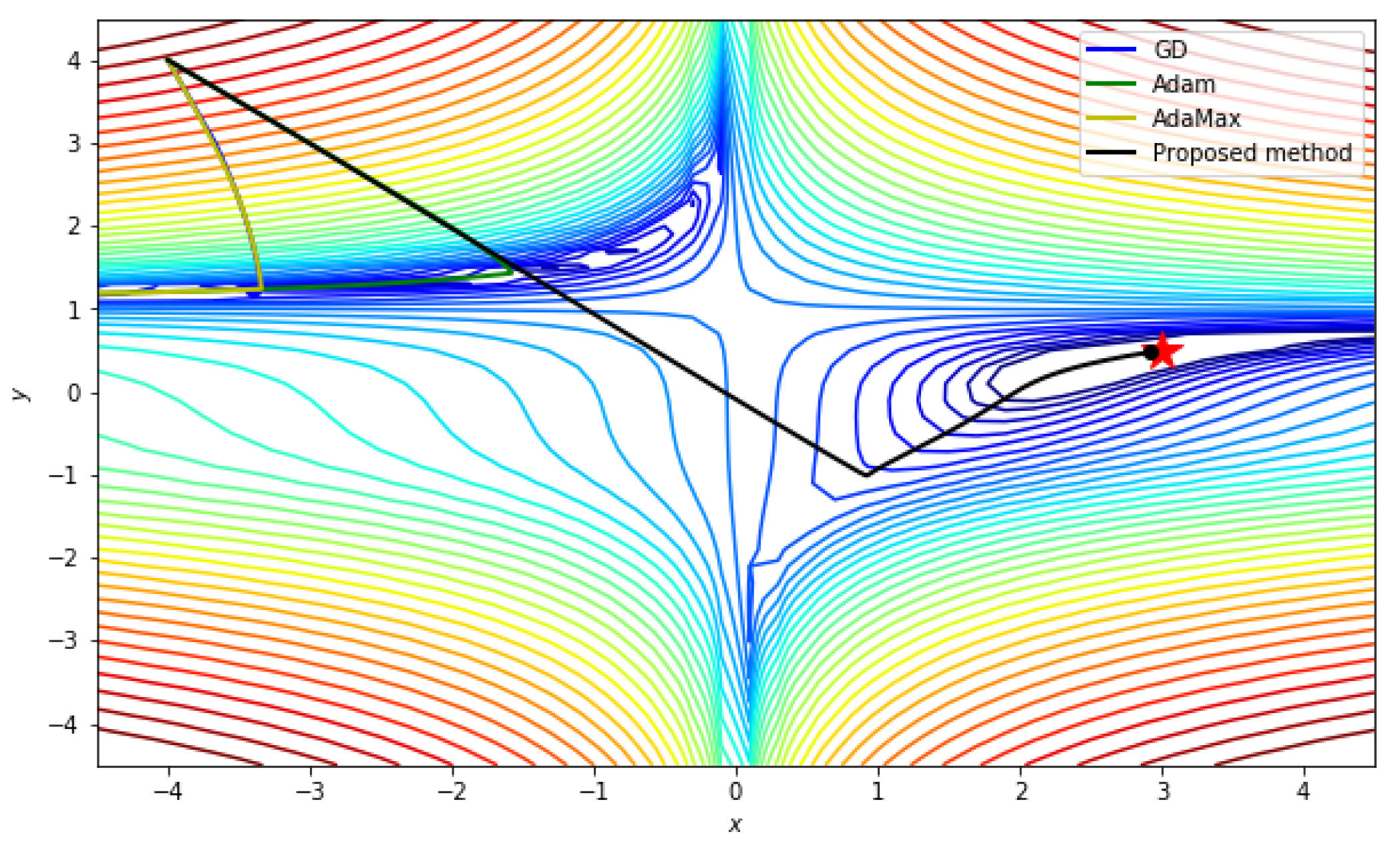
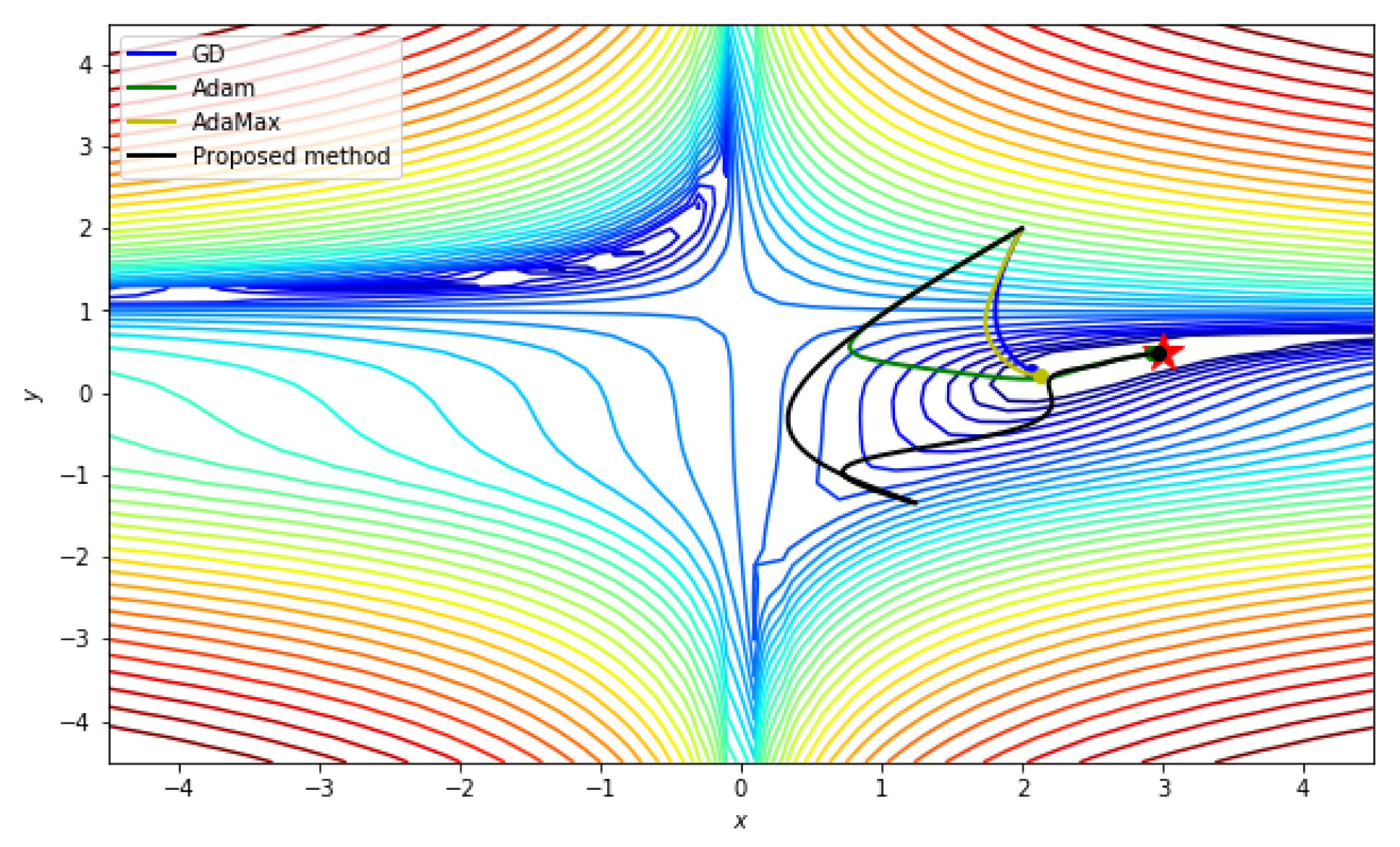
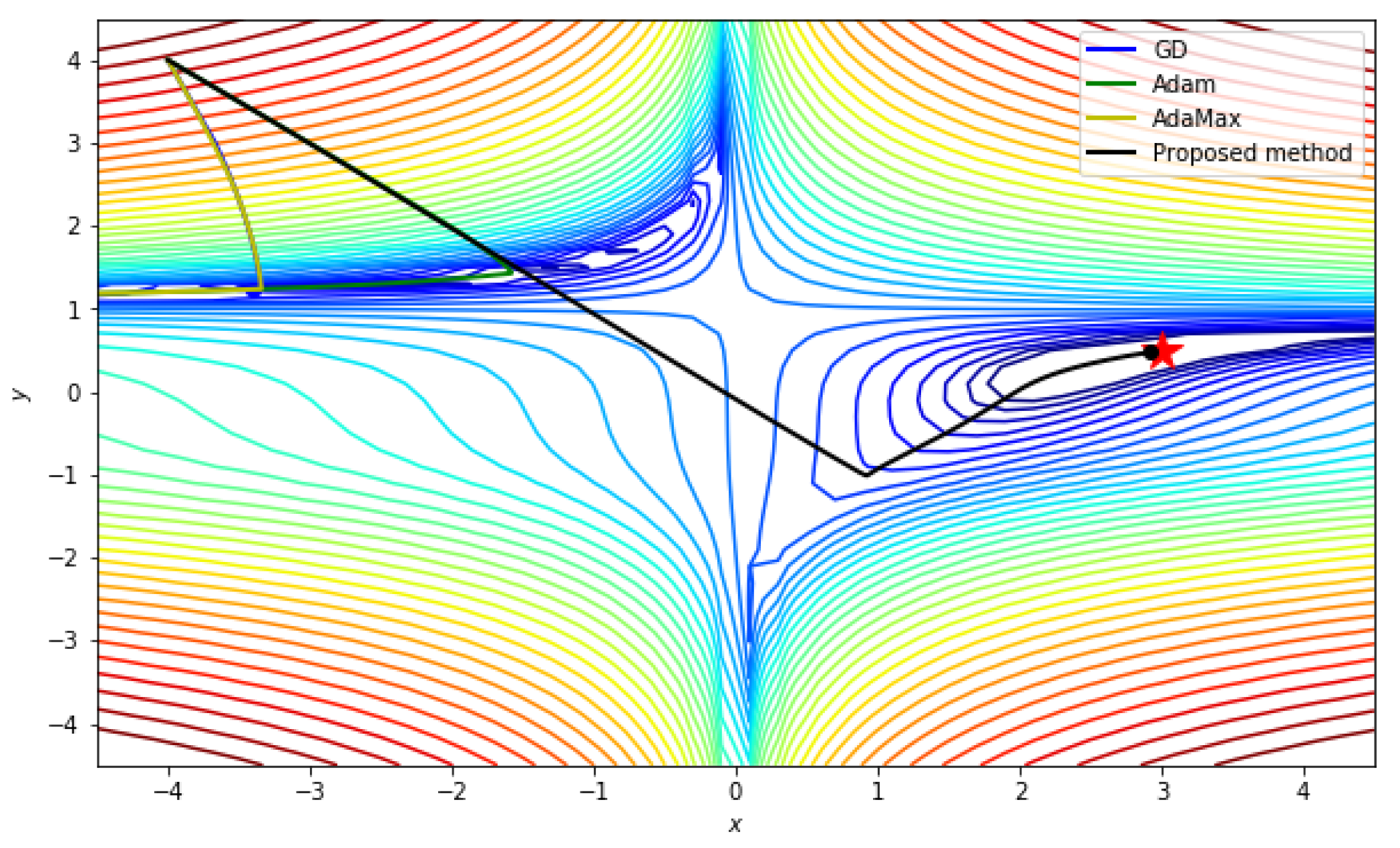
5.2.1. Beale function
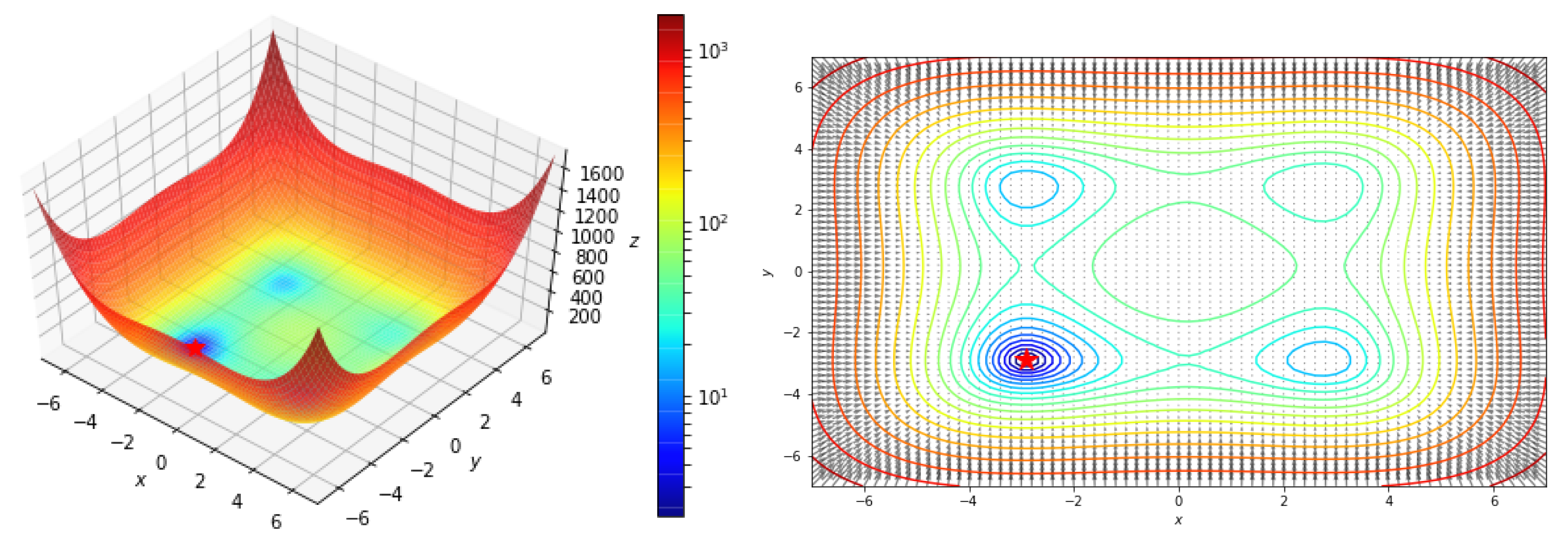
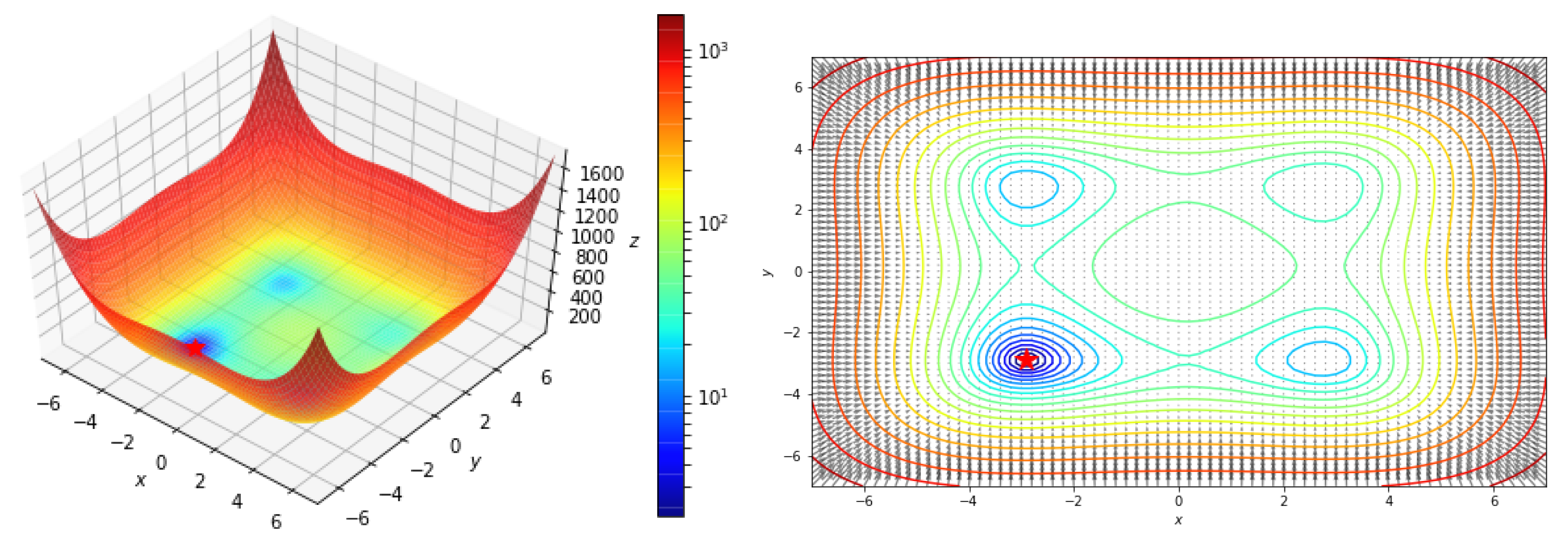
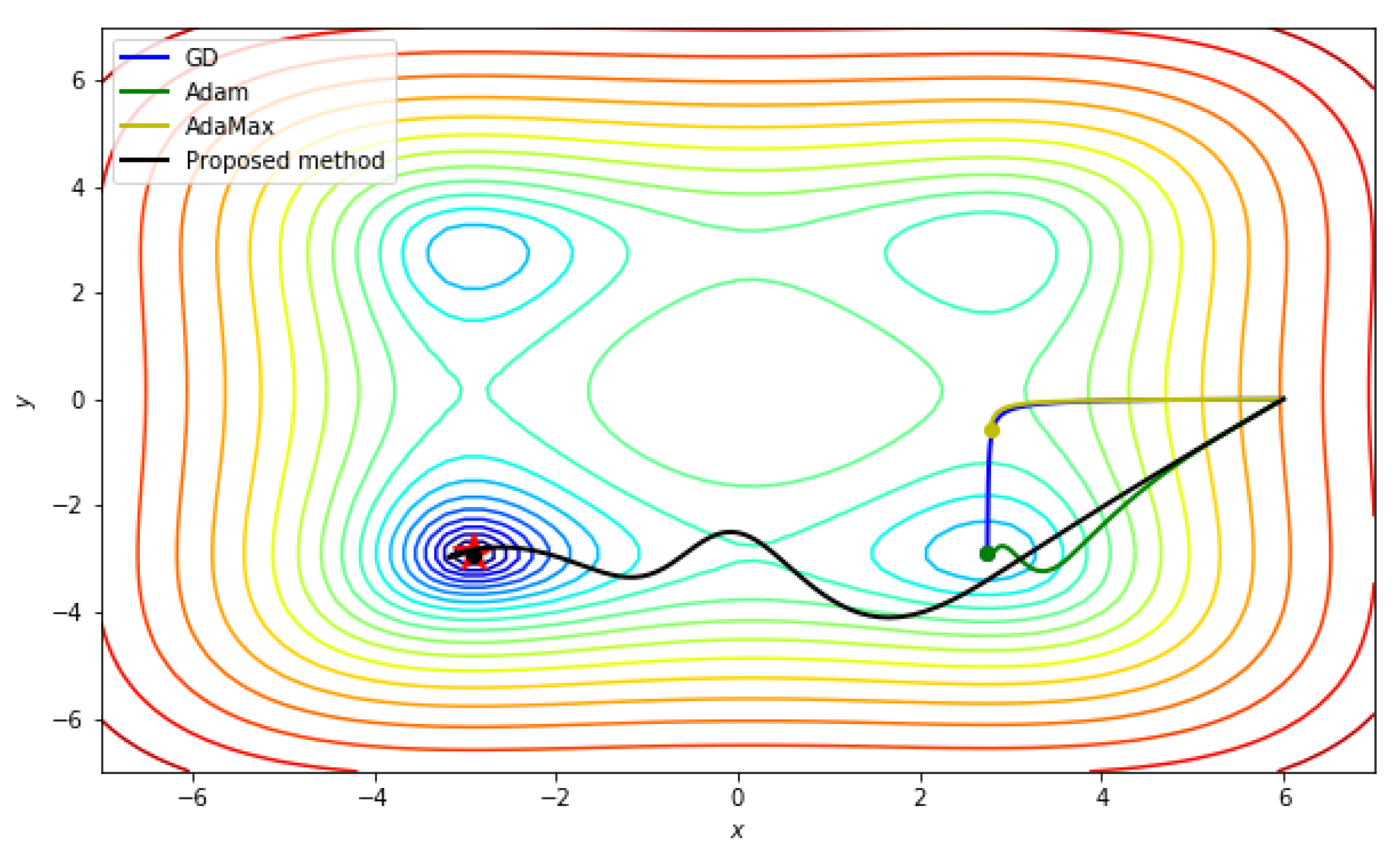
5.2.2. Styblinski–Tang function
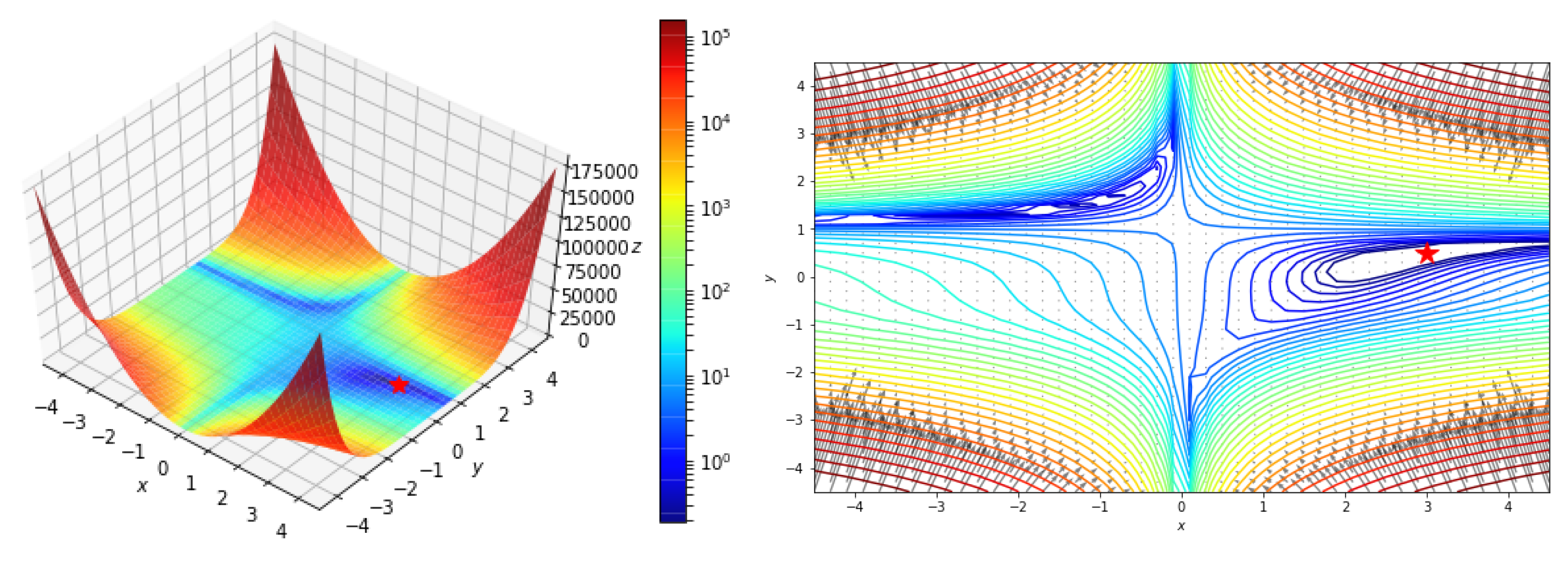
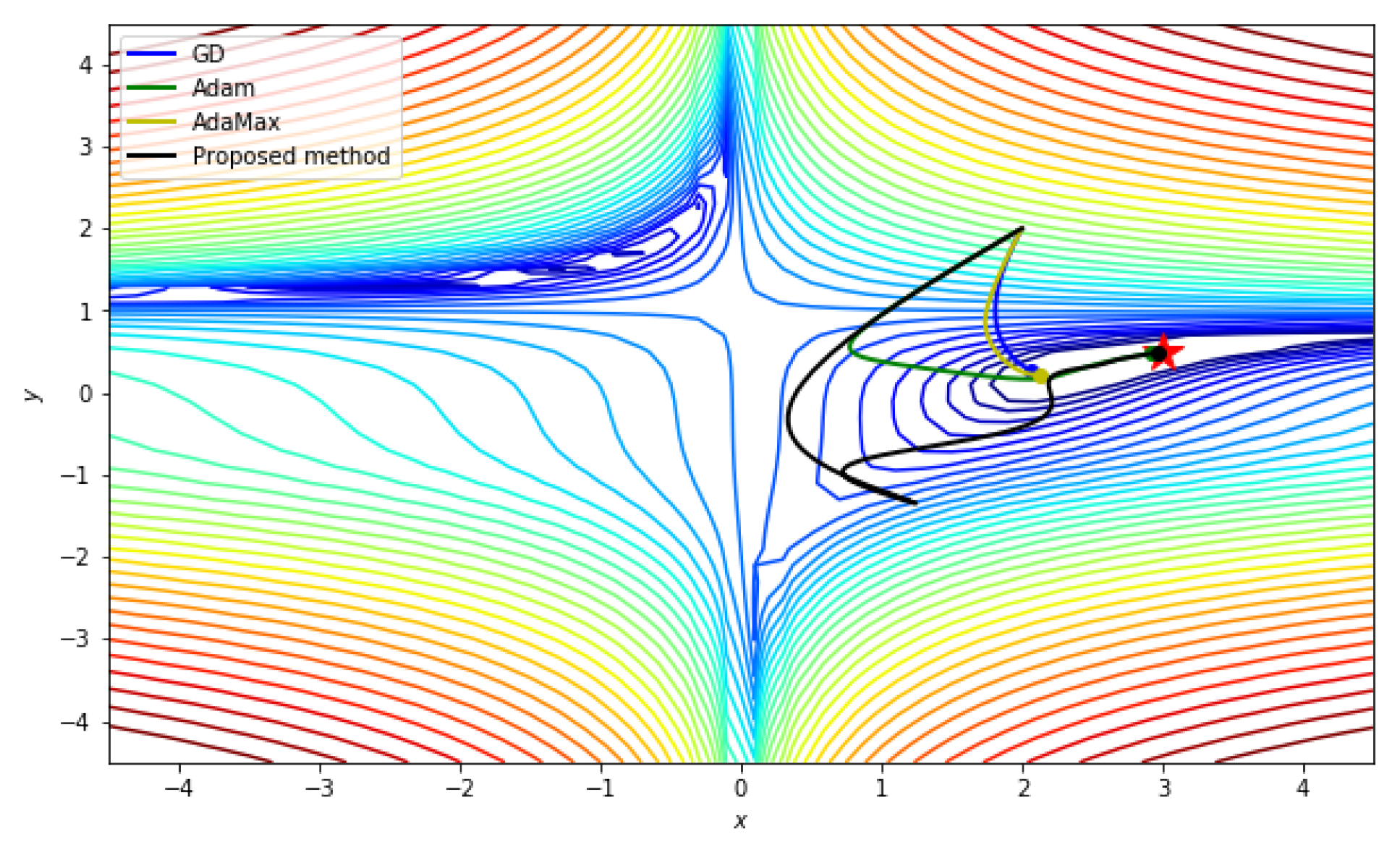
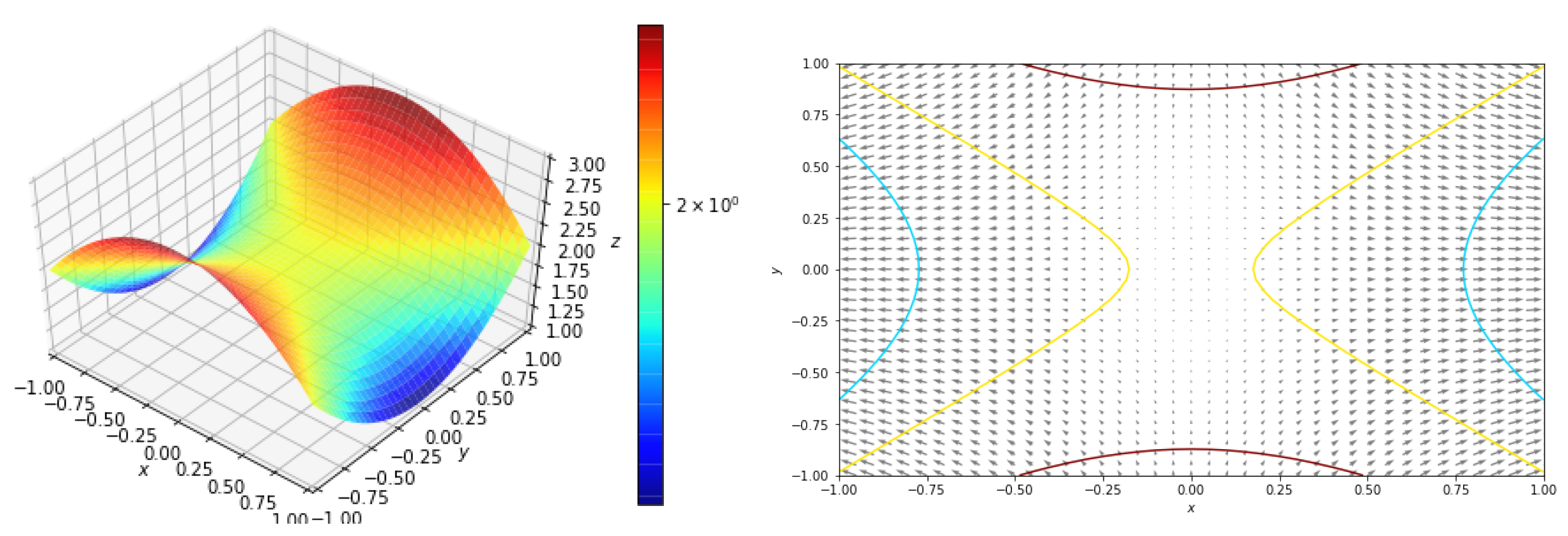
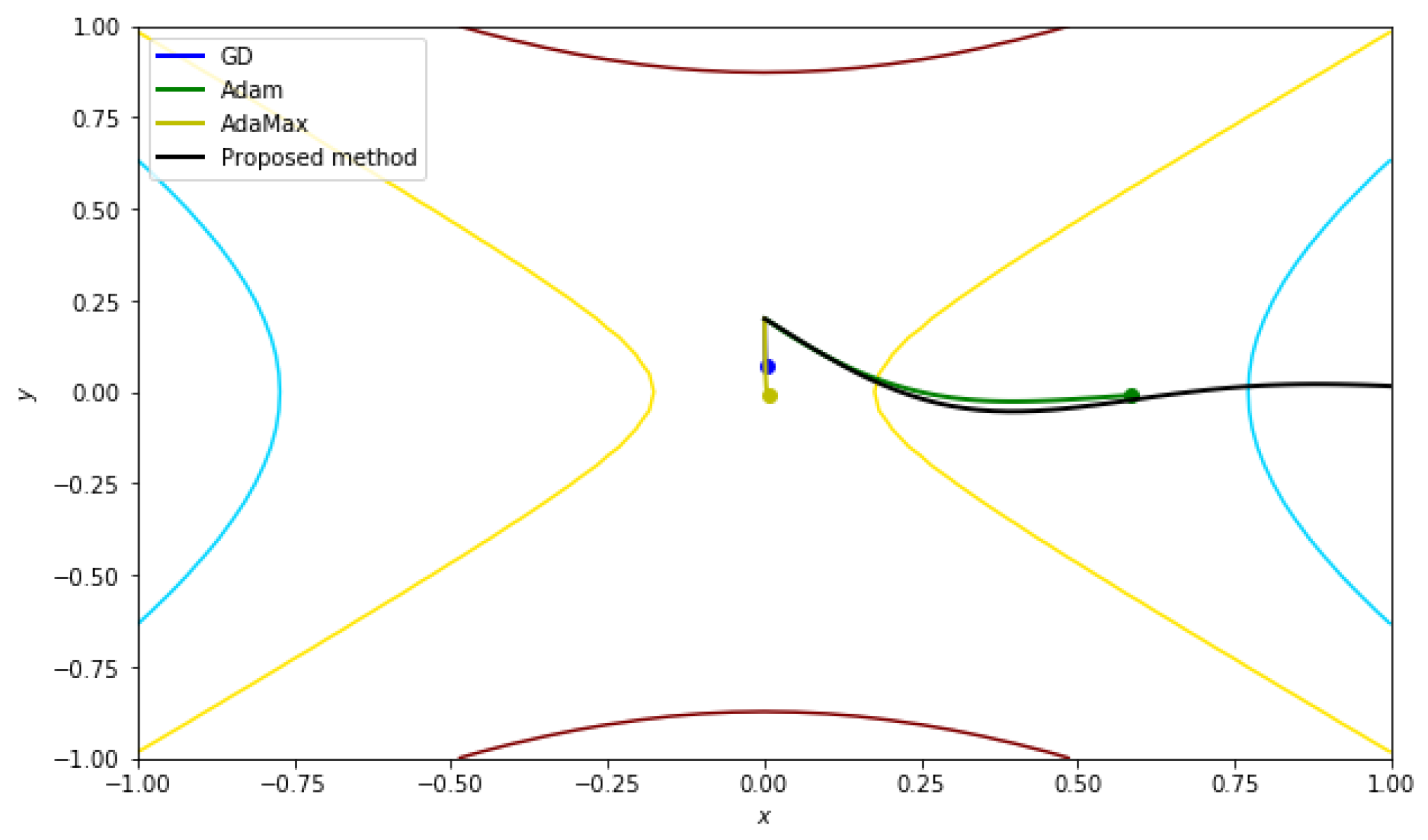
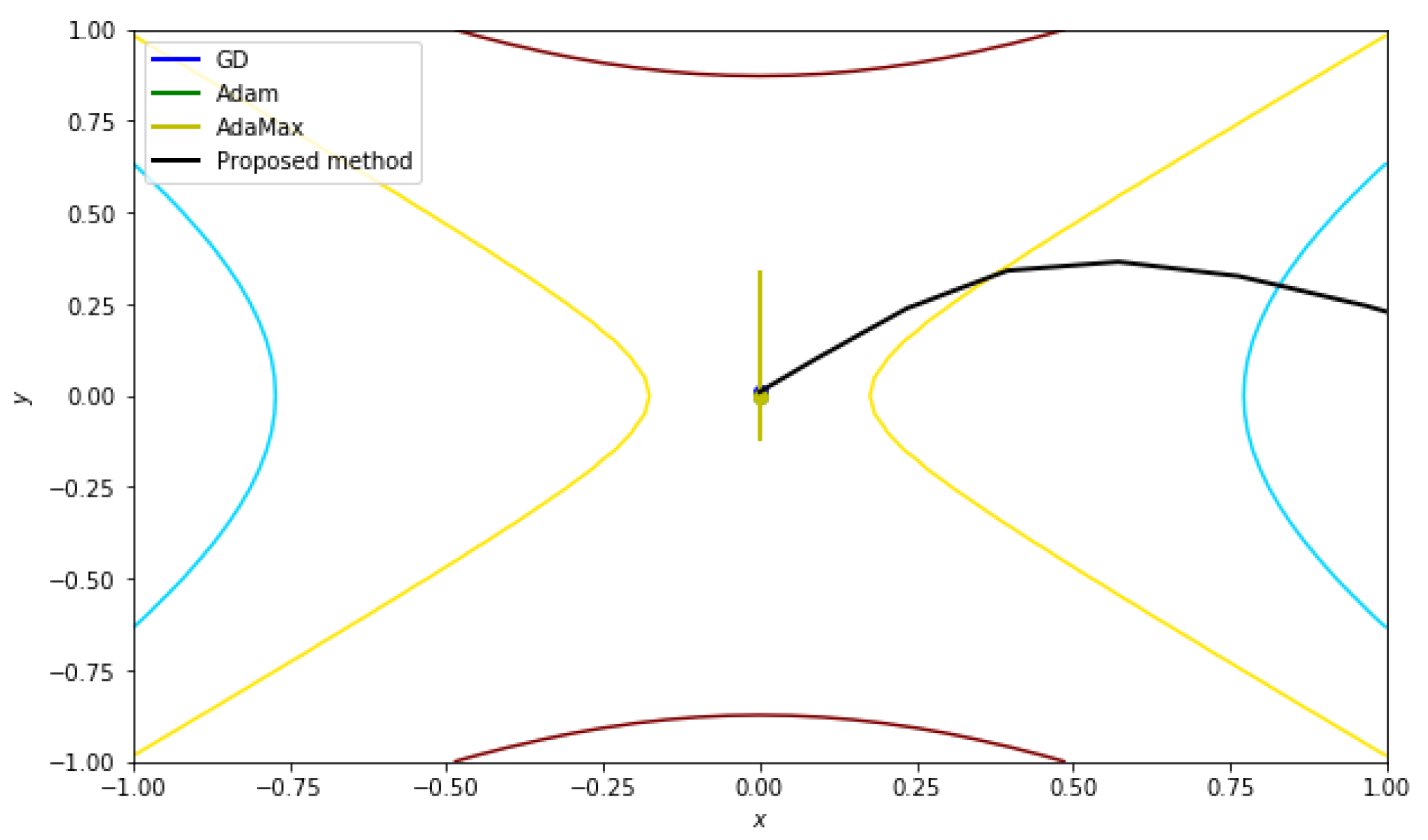
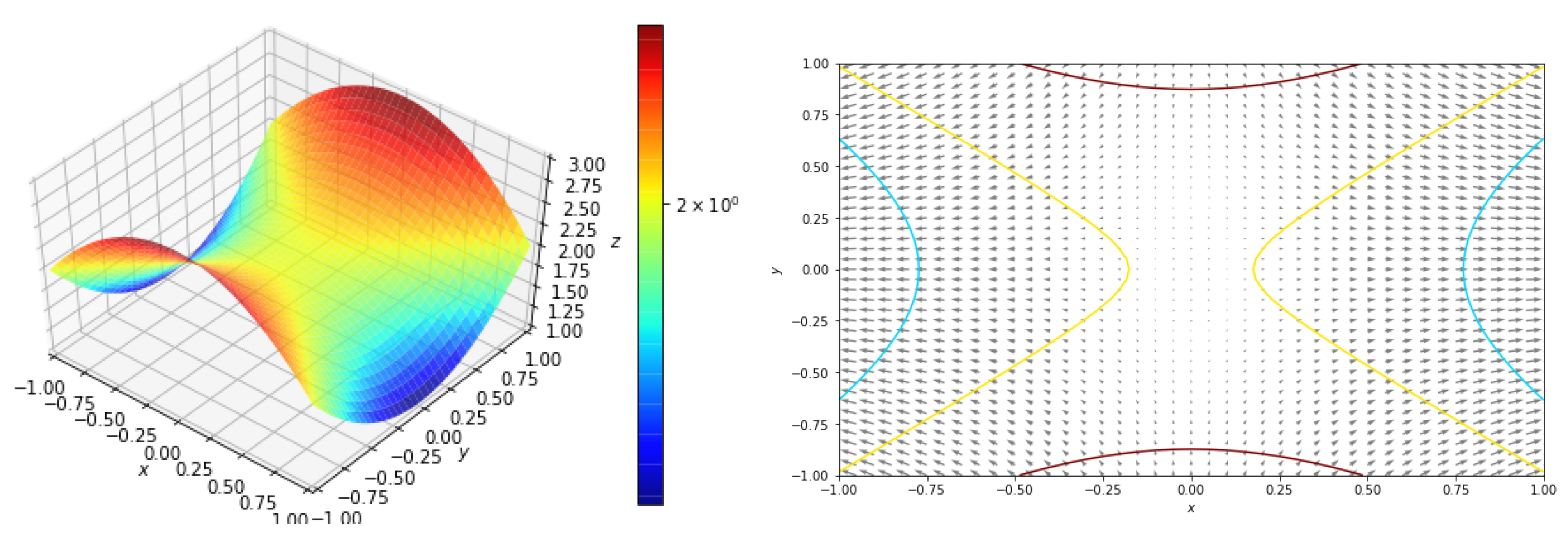
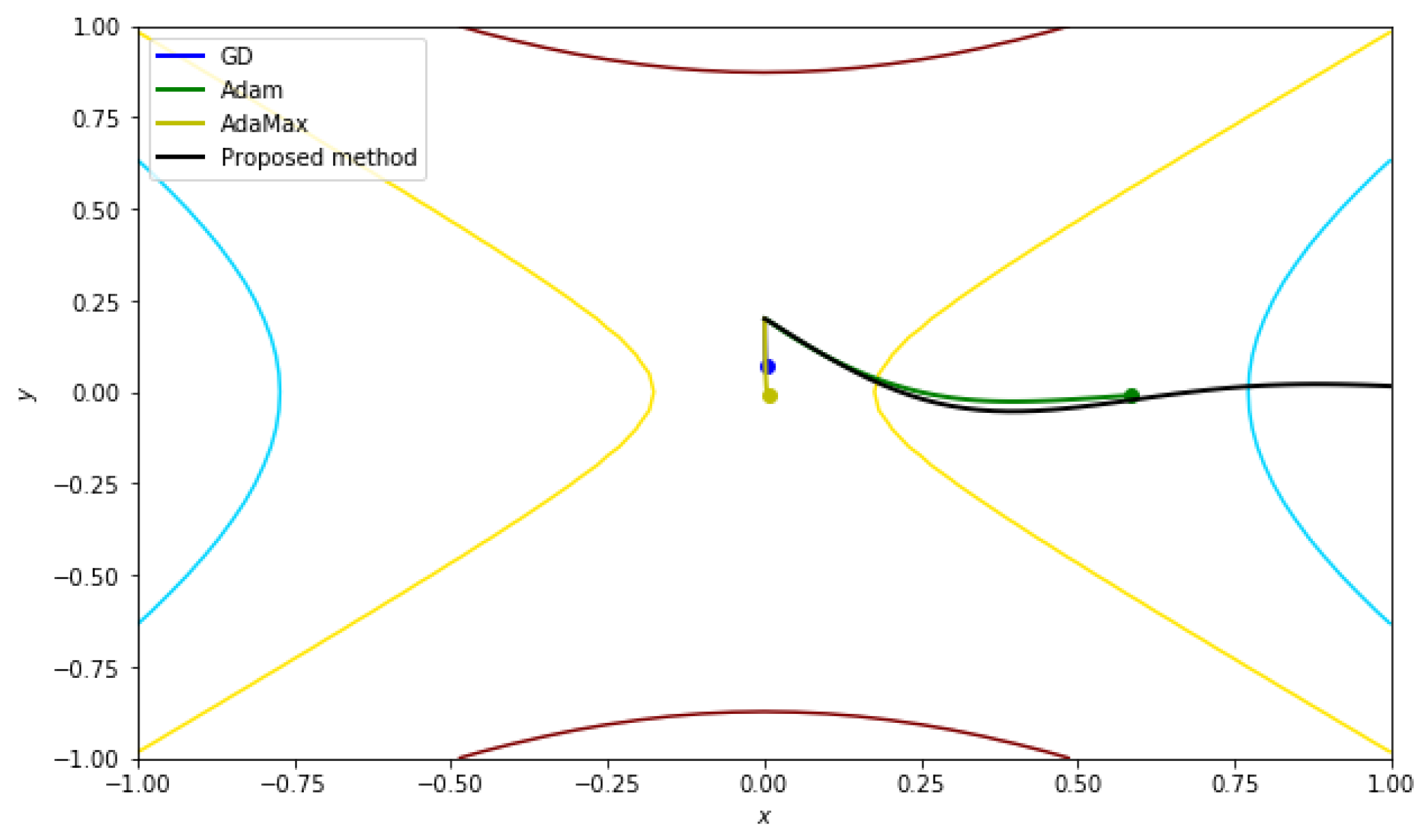
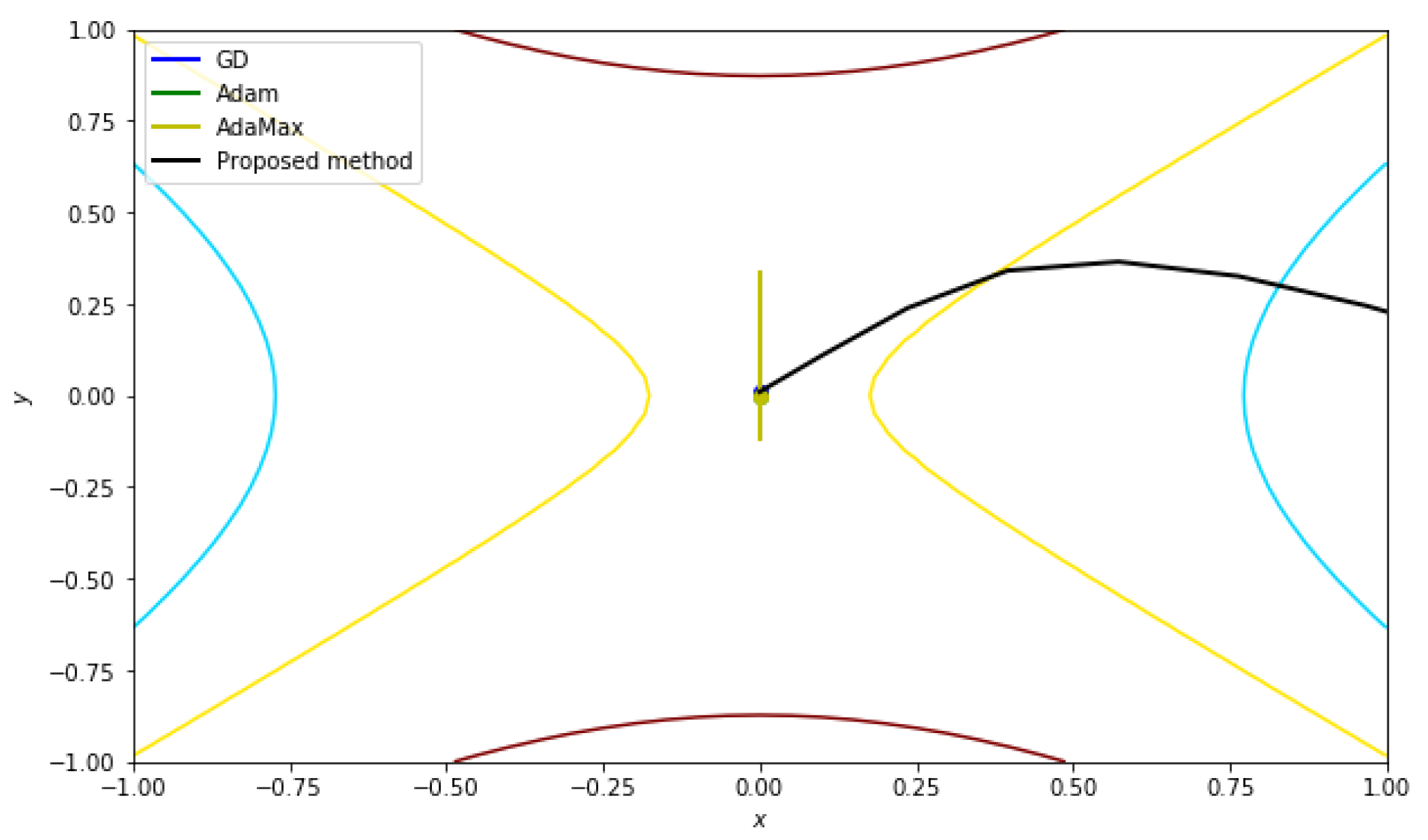
5.2.3. Function with a Saddle Point
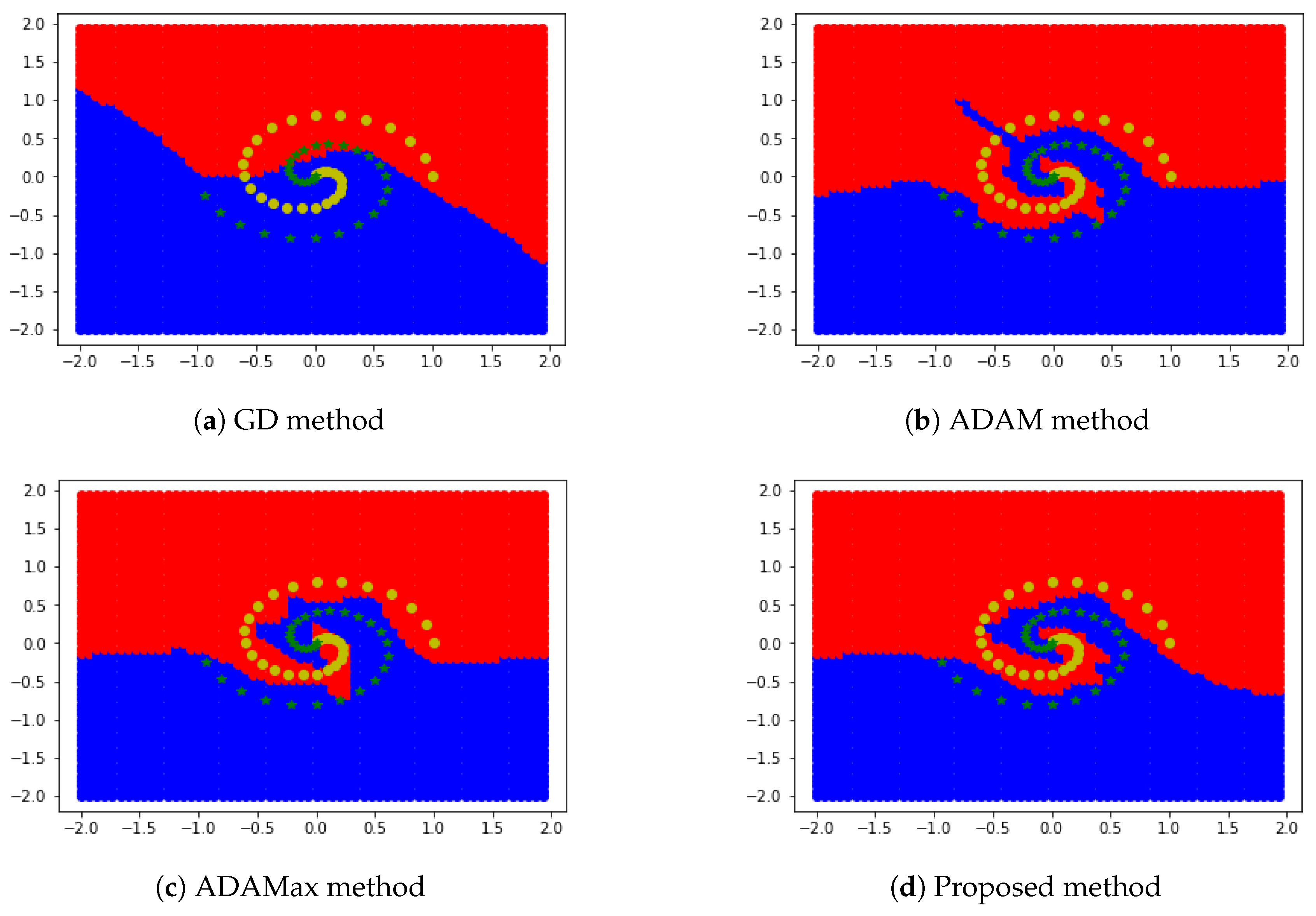
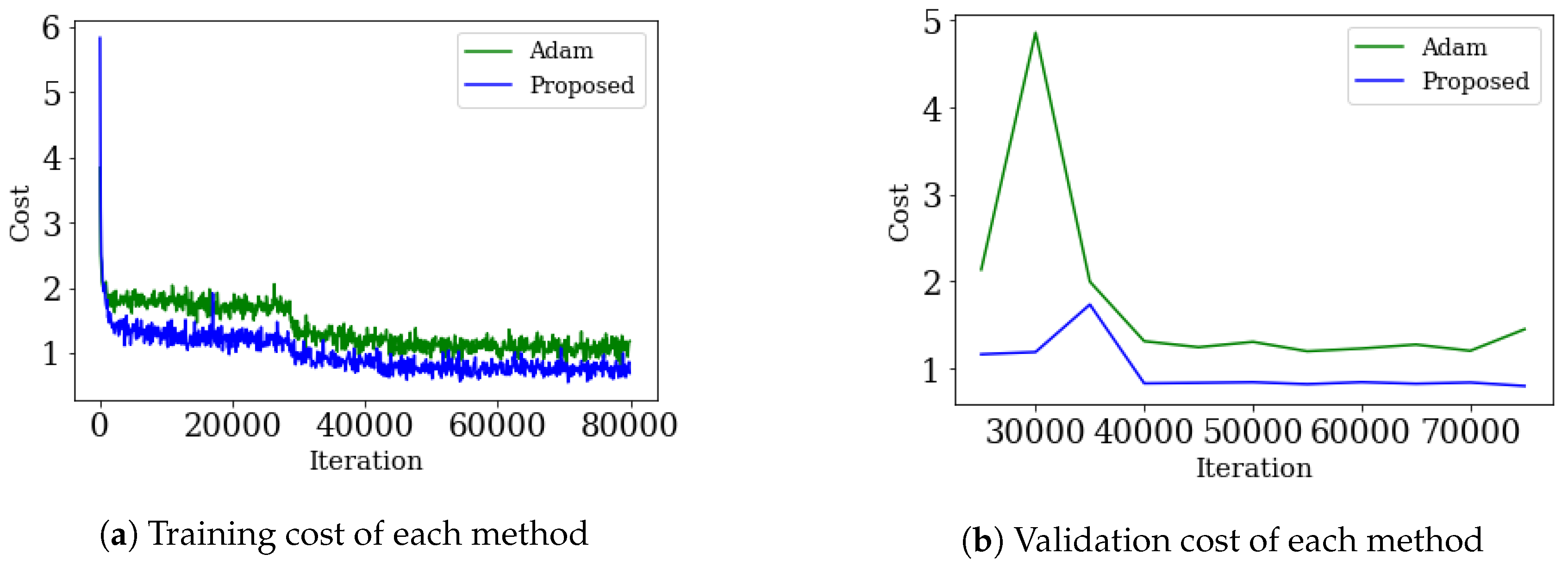
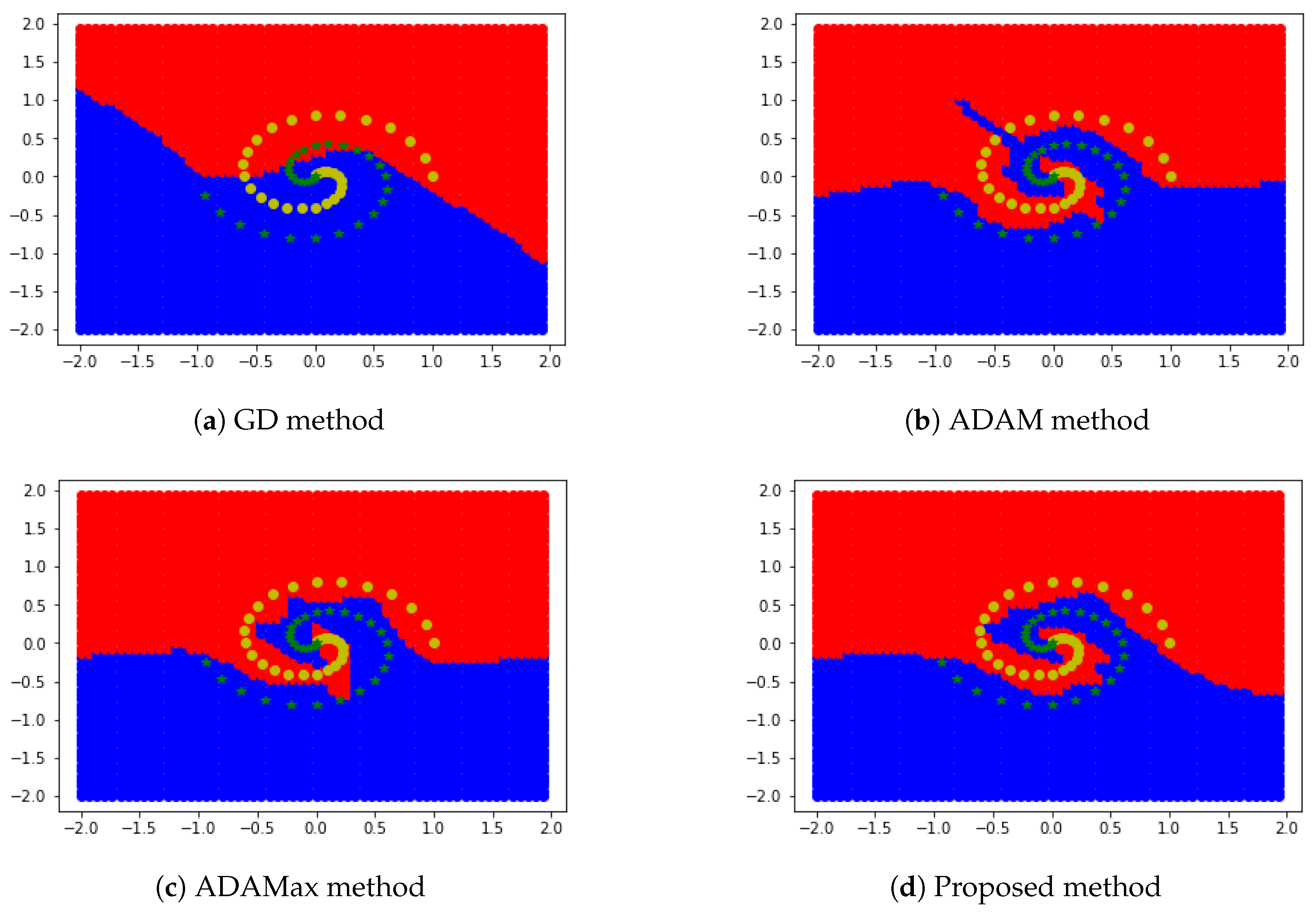
5.3. Two-Dimensional Region Segmentation Test
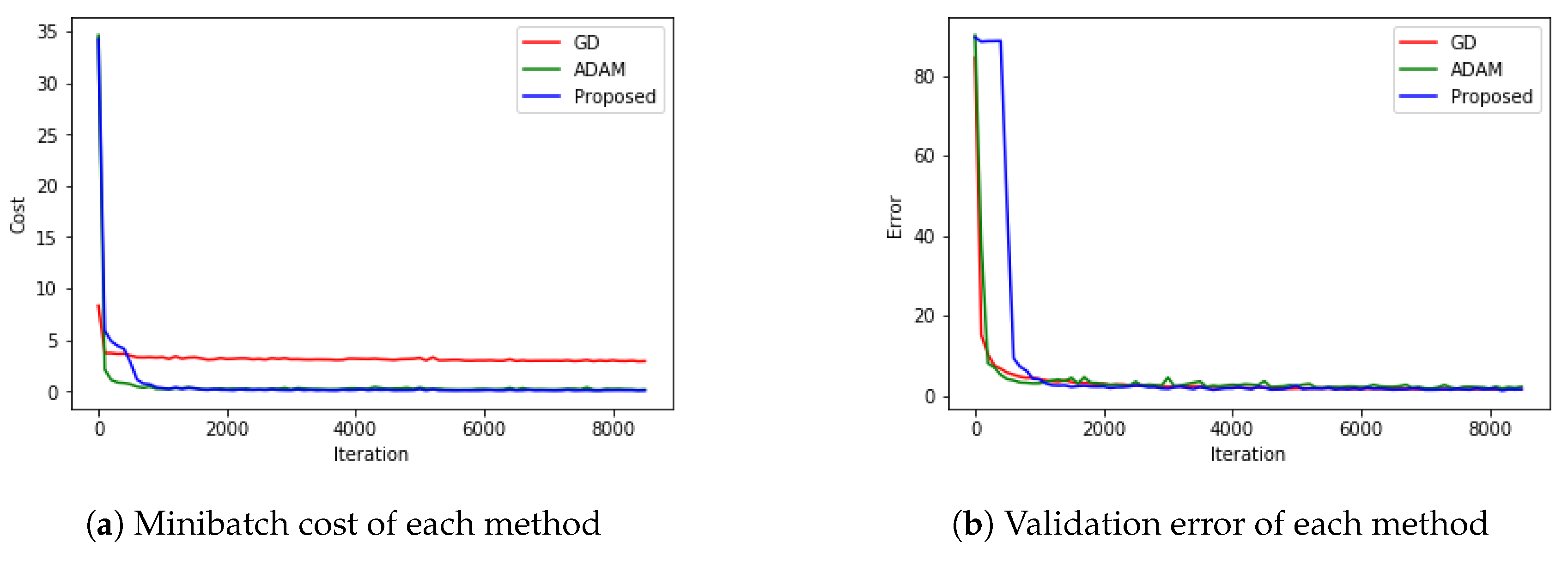
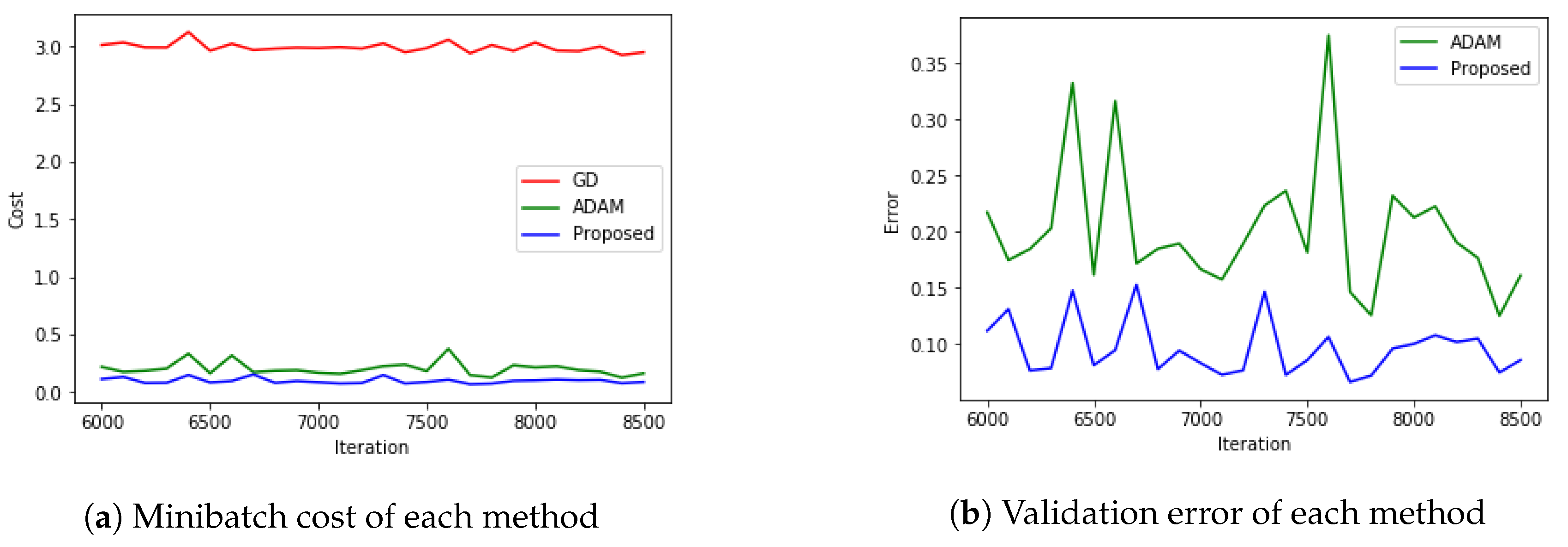
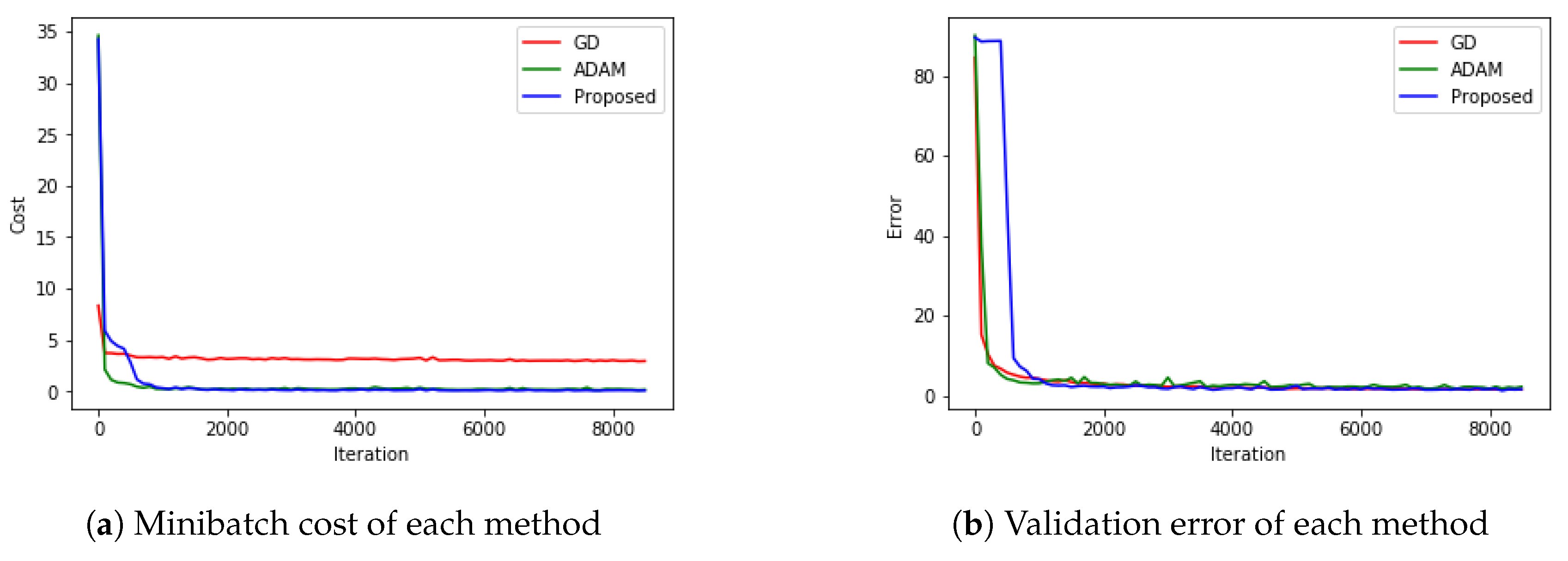
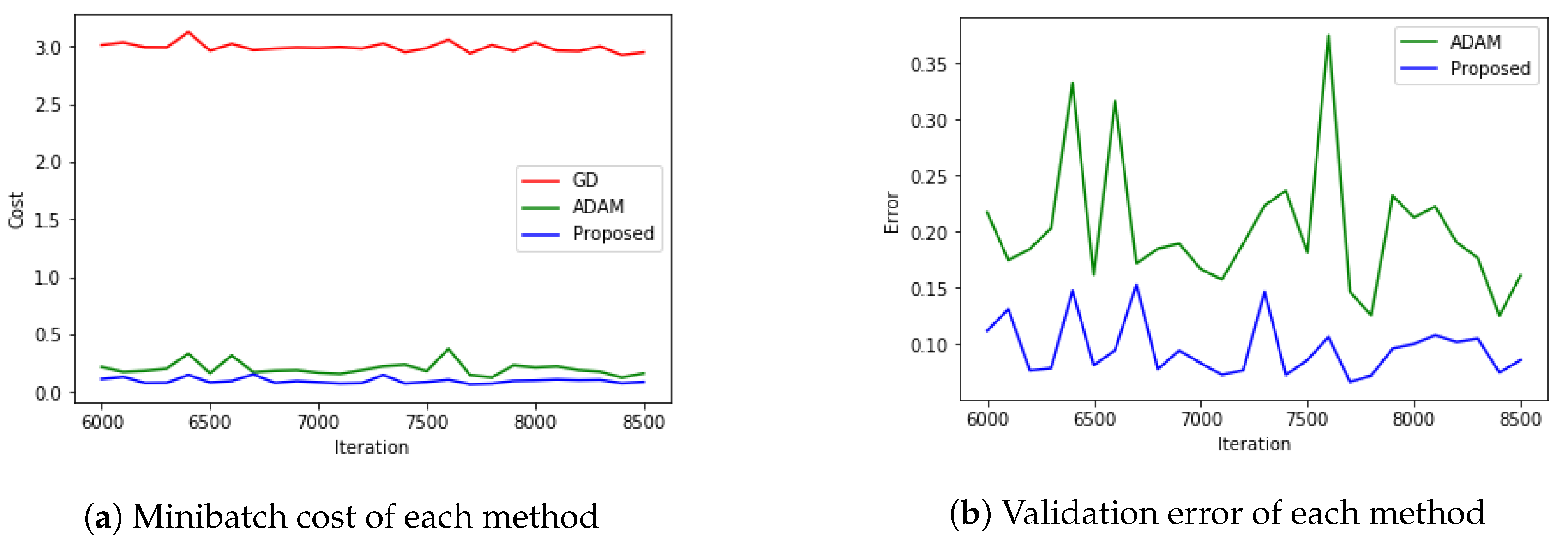
5.4. MNIST with CNN
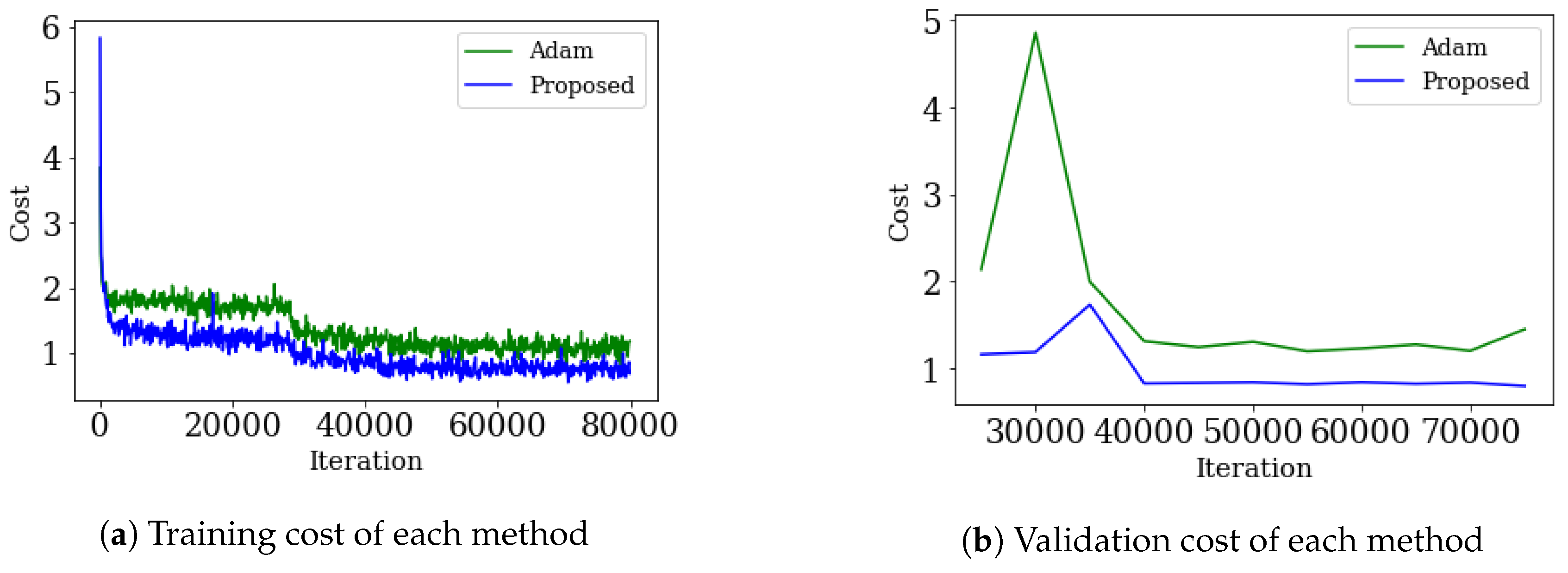
5.5. CIFAR-10 with RESNET
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Deng, L.; Li, J.; Huang, J.; Yao, K.; Yu, D.; Seide, F.; Seltzer, M.L.; Zweig, G.; He, X.; Williams, J.; et al. Recent advances in deep learning for speech research at microsoft. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing—ICASSP 2013, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Graves, A. Generating sequences with recurrent neural networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- Graves, A.; Mohamed, A.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 International Conference on Acoustics, Speech and Signal Processing—ICASSP 2013, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Tieleman, T.; Hinton, G.E. Lecture 6.5—RMSProp, COURSERA: Neural Networks for Machine Learning; Technical Report; COURSERA: Mountain View, CA, USA, 2012. [Google Scholar]
- Dean, J.; Corrado, G.; Monga, R.; Chen, K.; Devin, M.; Le, Q.; Mao, M.; Ranzato, M.; Senior, A.; Tucker, P.; et al. Large scale distributed deep networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems—NIPS 2012, Lake Tahoe, NV, USA, 3 December 2012; pp. 1223–1231. [Google Scholar]
- Jaitly, N.; Nguyen, P.; Senior, A.; Vanhoucke, V. Application of pretrained deep neural networks to large vocabulary speech recognition. In Proceedings of the INTERSPEECH 2012, 13th Annual Conference of the International Speech Communication Association—ISCA 2012, Portland, OR, USA, 9–13 September 2012; pp. 2578–2581. [Google Scholar]
- Amari, S. Natural gradient works efficiently in learning. Neural Comput. 1998, 10, 251–276. [Google Scholar] [CrossRef]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems–NIPS 2012, Lake Tahoe, NV, USA, 3 December 2012; pp. 1097–1105. [Google Scholar]
- Pascanu, R.; Bengio, Y. Revisiting natural gradient for deep networks. arXiv 2013, arXiv:1301.3584. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G.E. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning—ICML 2013, Atlanta, GA, USA, 16–21 Jun 2013; PMLR 28(3). pp. 1139–1147. [Google Scholar]
- Kochenderfer, M.; Wheeler, T. Algorithms for Optimization; The MIT Press Cambridge: London, UK, 2019. [Google Scholar]
- Kingma, D.P.; Ba, J. ADAM: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations—ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Bottou, L.; Curtis, F.E.; Nocedal, J. Optimization Methods for Large-Scale Machine Learning. SIAM Rev. 2018, 60, 223–311. [Google Scholar] [CrossRef]
- Roux, N.L.; Fitzgibbon, A.W. A fast natural newton method. In Proceedings of the 27th International Conference on Machine Learning—ICML 2010, Haifa, Israel, 21–24 June 2010; pp. 623–630. [Google Scholar]
- Sohl-Dickstein, J.; Poole, B.; Ganguli, S. Fast large-scale optimization by unifying stochastic gradient and quasi-newton methods. In Proceedings of the 31st International Conference on Machine Learning—ICML 2014, Beijing, China, 21–24 June 2014; pp. 604–612. [Google Scholar]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Becker, S.; LeCun, Y. Improving the Convergence of Back-Propagation Learning with Second Order Methods; Technical Report; Department of Computer Science, University of Toronto: Toronto, ON, Canada, 1988. [Google Scholar]
- Kelley, C.T. Iterative methods for linear and nonlinear equations. In Frontiers in Applied Mathematics; SIAM: Philadelphia, PA, USA, 1995; Volume 16. [Google Scholar]
- Reddi, S.J.; Kale, S.; Kumar, S. On the Convergence of ADAM and Beyond. arXiv 2019, arXiv:1904.09237. [Google Scholar]
- Ruppert, D. Efficient Estimations from a Slowly Convergent Robbins-Monro Process; Technical Report; Cornell University Operations Research and Industrial Engineering: Ithaca, NY, USA, 1988. [Google Scholar]
- Zinkevich, M. Online Convex Programming and Generalized Infinitesimal Gradient Ascent. In Proceedings of the Twentieth International Conference on Machine Learning—ICML-2003, Washington, DC, USA, 21–24 August 2003; pp. 928–935. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Iteration/Method | GD | ADAM | ADAMax | Proposed Method |
|---|---|---|---|---|
| 0 | [2.0, 2.0] | [2.0, 2.0] | [2.0, 2.0] | [2.0, 2.0] |
| 100 | [1.81, 0.84] | [1.53, 0.24] | [1.75, 0.69] | [2.11, −0.33] |
| 200 | [1.85, 0.63] | [2.20, 0.18] | [1.80, 0.53] | [2.50, 0.32] |
| 300 | [1.89, 0.52] | [2.39, 0.28] | [1.85, 0.42] | [2.72, 0.41] |
| 400 | [1.92, 0.45] | [2.53, 0.34] | [1.90, 0.35] | [2.81, 0.44] |
| 500 | [1.95, 0.39] | [2.64, 0.39] | [1.94, 0.30] | [2.87, 0.46] |
| 600 | [1.98, 0.35] | [2.73, 0.42] | [1.99, 0.26] | [2.91, 0.47] |
| 700 | [2.00, 0.32] | [2.79, 0.44] | [2.03, 0.23] | [2.93, 0.48] |
| 800 | [2.03, 0.30] | [2.84, 0.45] | [2.06, 0.22] | [2.95, 0.48] |
| 900 | [2.05, 0.28] | [2.88, 0.46] | [2.10, 0.21] | [2.96, 0.49] |
| 1000 | [2.06, 0.27] | [2.91, 0.47] | [2.13, 0.21] | [2.97, 0.49] |
| B | GD | ADAM | ADAMax | Proposed Method |
|---|---|---|---|---|
| 0 | ||||
| 10 | ||||
| 20 | ||||
| 30 | ||||
| 40 | ||||
| 50 |
| (a) Image of | (b) Pseudo code of |
 | : empty set for i = 1: 30 put in end for for i = 1: 30 + put in end for return |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, D.; Ahn, J.; Ji, S. An Effective Optimization Method for Machine Learning Based on ADAM. Appl. Sci. 2020, 10, 1073. https://doi.org/10.3390/app10031073
Yi D, Ahn J, Ji S. An Effective Optimization Method for Machine Learning Based on ADAM. Applied Sciences. 2020; 10(3):1073. https://doi.org/10.3390/app10031073
Chicago/Turabian StyleYi, Dokkyun, Jaehyun Ahn, and Sangmin Ji. 2020. "An Effective Optimization Method for Machine Learning Based on ADAM" Applied Sciences 10, no. 3: 1073. https://doi.org/10.3390/app10031073
APA StyleYi, D., Ahn, J., & Ji, S. (2020). An Effective Optimization Method for Machine Learning Based on ADAM. Applied Sciences, 10(3), 1073. https://doi.org/10.3390/app10031073