Combining Machine Learning and Logical Reasoning to Improve Requirements Traceability Recovery


Abstract
:1. Introduction
- We further investigate the semantics of code constructs and improve our framework by proposing an additional collection of meaningful features.
- We conduct in-depth investigation on the relationships between use cases, based on which we have defined five additional logical reasoning rules to enhance the effectiveness of the second analysis phase.
- We have extensively enriched the evaluation by considering three additional data sets (previously only one data set was used). Correspondingly, we have designed and conducted many more experiments to comprehensively evaluate our proposal.
2. Related Work
2.1. IR-Based Methods
2.2. Hybrid Methods
2.3. Other Studies
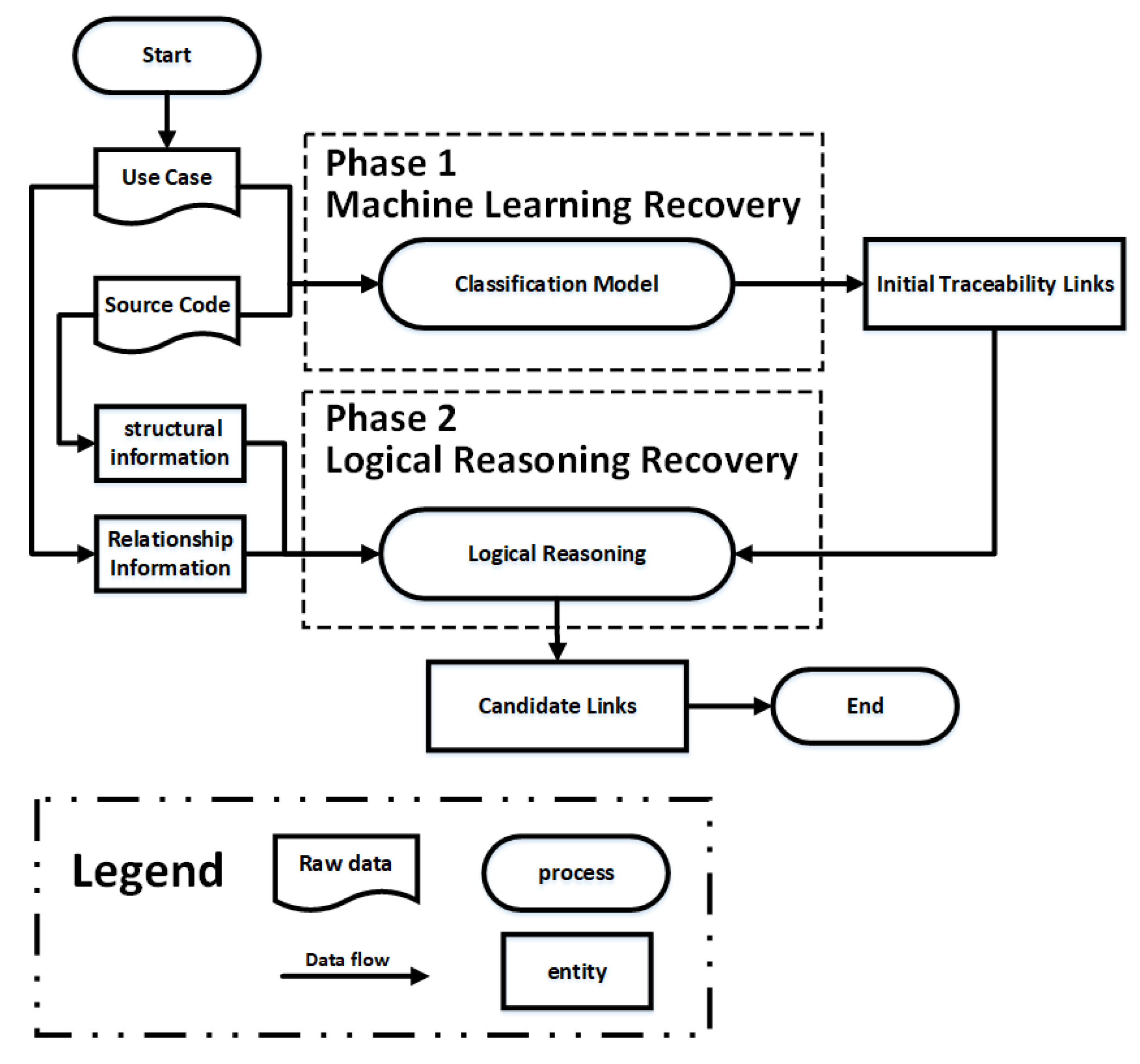
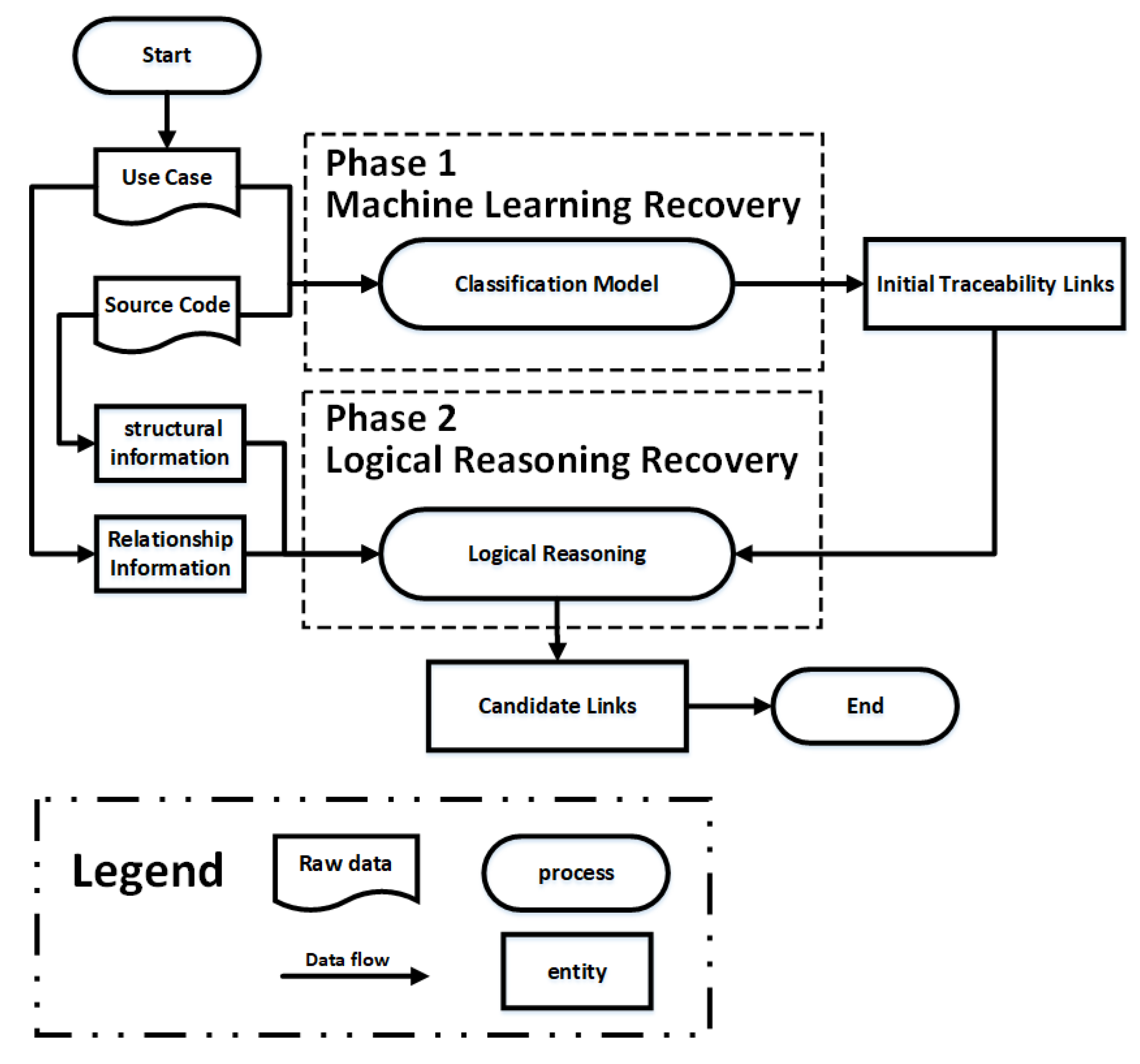
3. A Hybrid Traceability Recovery Approach
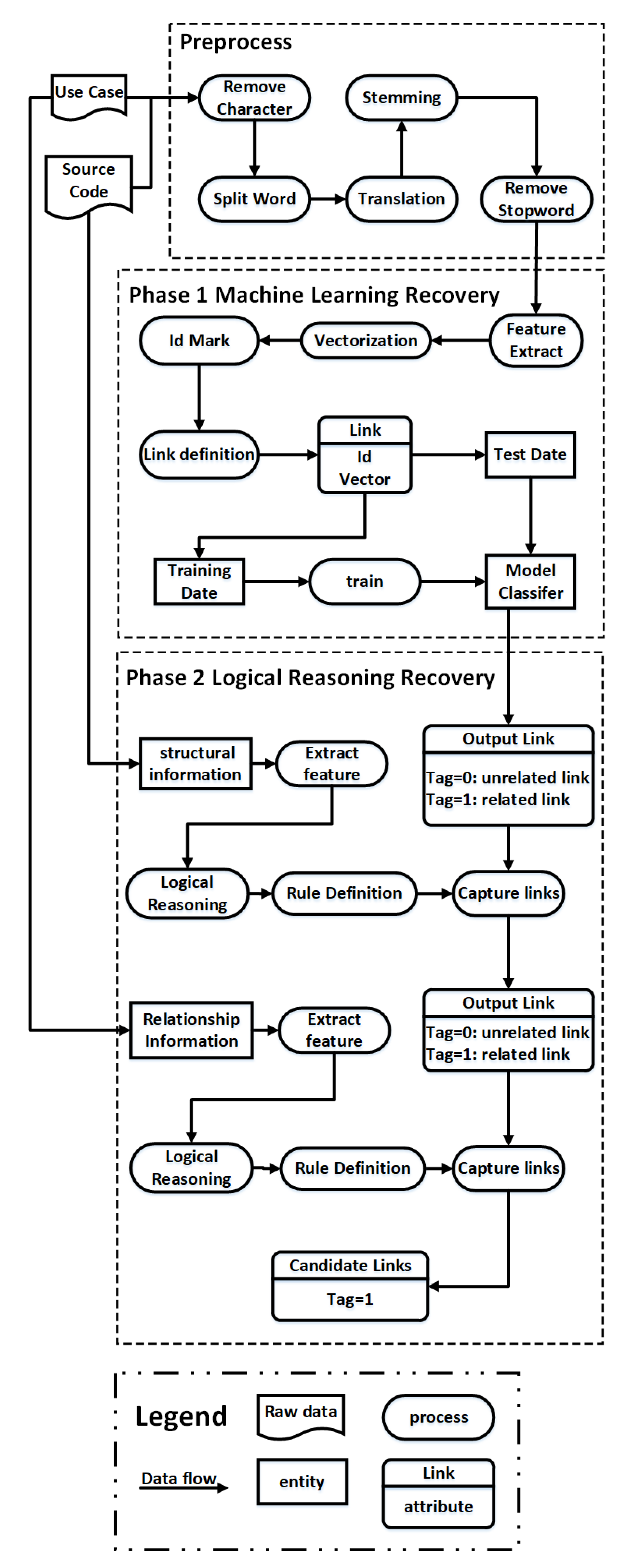
3.1. Preprocessing
- Remove punctuation, numbers, and special characters in software artifacts.
- Extract words in software artifacts by word segmentation. Not that use cases and source code comments are typically written in natural language, while and source code itself is developed with specific programming languages. Since natural language and programming languages are different, we need to deal with them separately. For natural language texts that appear in the content of use cases and comments in source code files, all words are separated by spaces. For source code identifiers, such as class names and method names, we perform word segmentation according to the naming convention adopted in the project, such as the camel-case style and underscore style. It is worth noting that we here assume that the source code should comply with certain naming conventions, otherwise, it cannot be appropriately processed by our segmentation algorithm.
- Since many project repositories are developed and documented in natural languages other than English, it is necessary to translate the content of the software artifacts. To this end, we leverage the advanced translation engine to translate all the documents into English, if they were originally not specified in English. In particular, we used Google Translate APIs in this paper, which would be evolved according to the recent advances in language translation.
- We remove the stop words from the software artifacts (We refer to the stop word list at https://gist.github.com/sebleier/554280). In addition, we also remove Java keywords in source code comments (e.g., static and private).
- We perform lemmatization for all words in order to facilitate natural language analysis, i.e., transforming the verb, noun, adjectives and adverbs into their bases.
3.2. Phase 1 Machine Learning Recovery
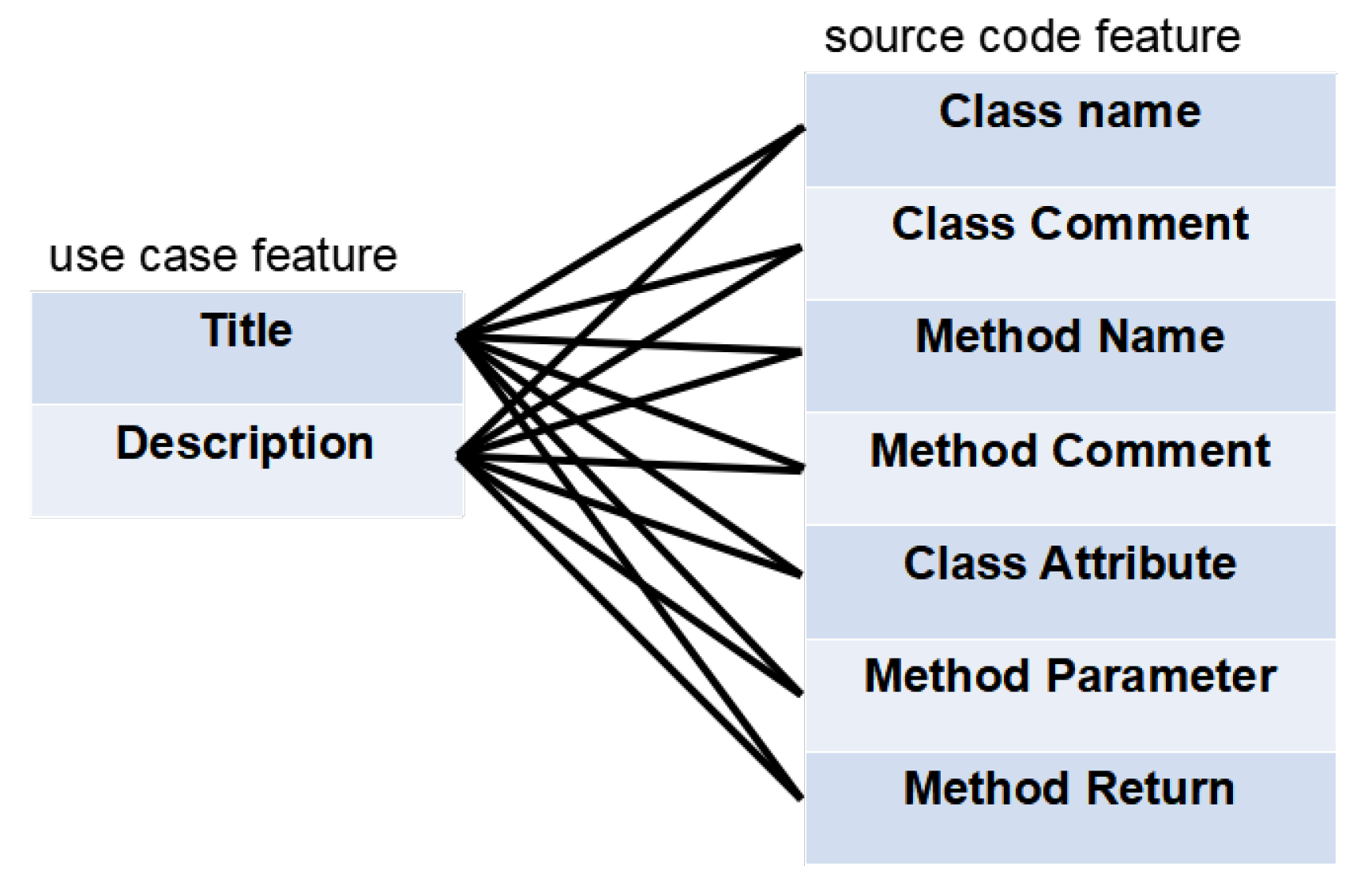
3.2.1. Feature Extraction
3.2.2. Vectorization
3.2.3. Machine Learning Classification
3.3. Phase 2 Logical Reasoning Recovery
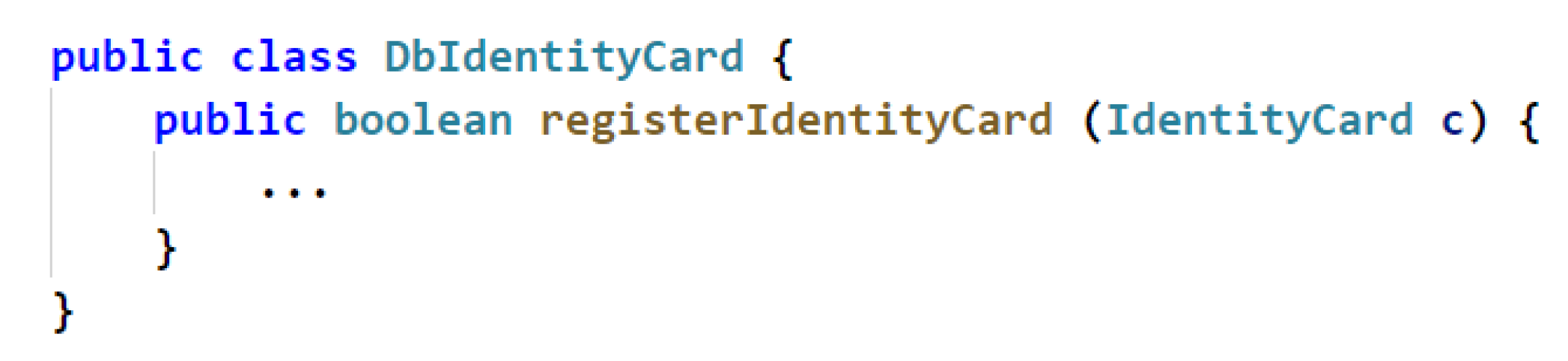
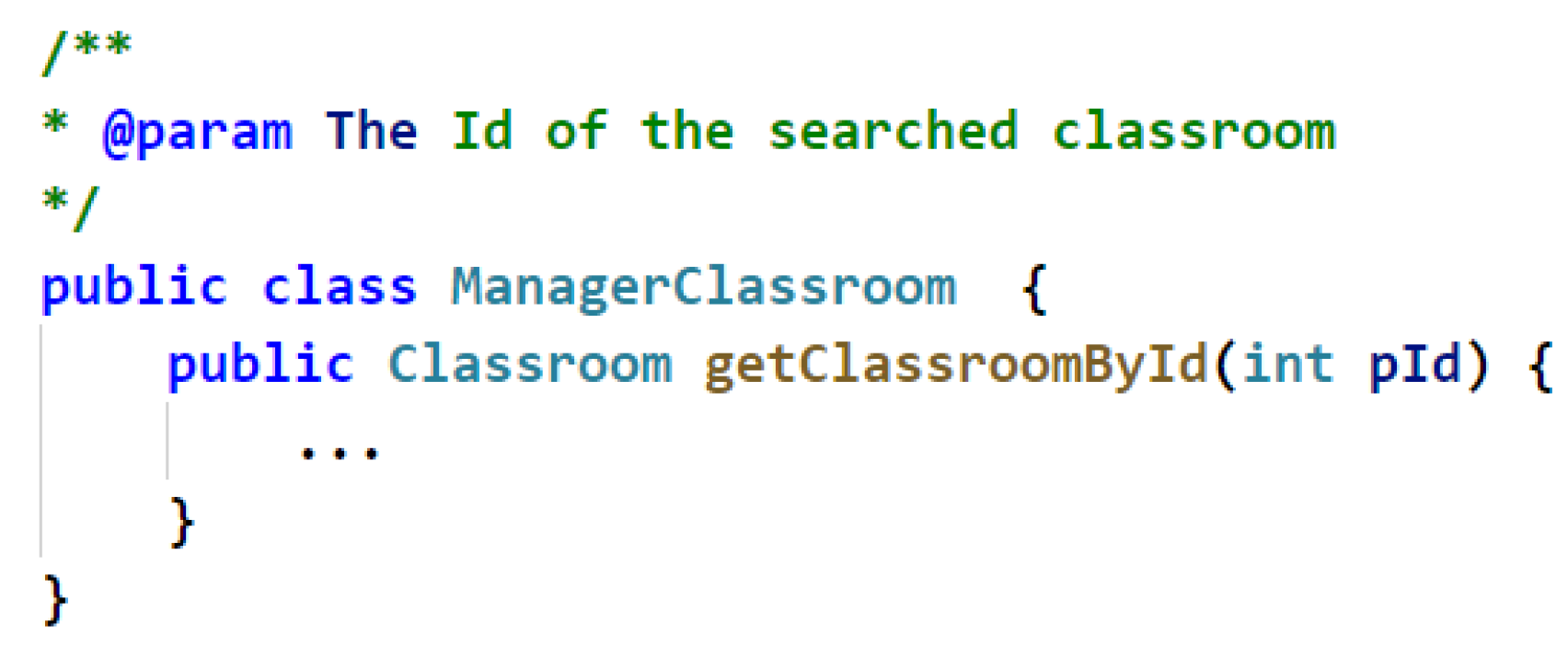
3.3.1. Structural information between Source Code Components
3.3.2. Interrelationships between Use Cases
4. Evaluation
4.1. Datasets
4.2. Metric
4.3. Research Questions
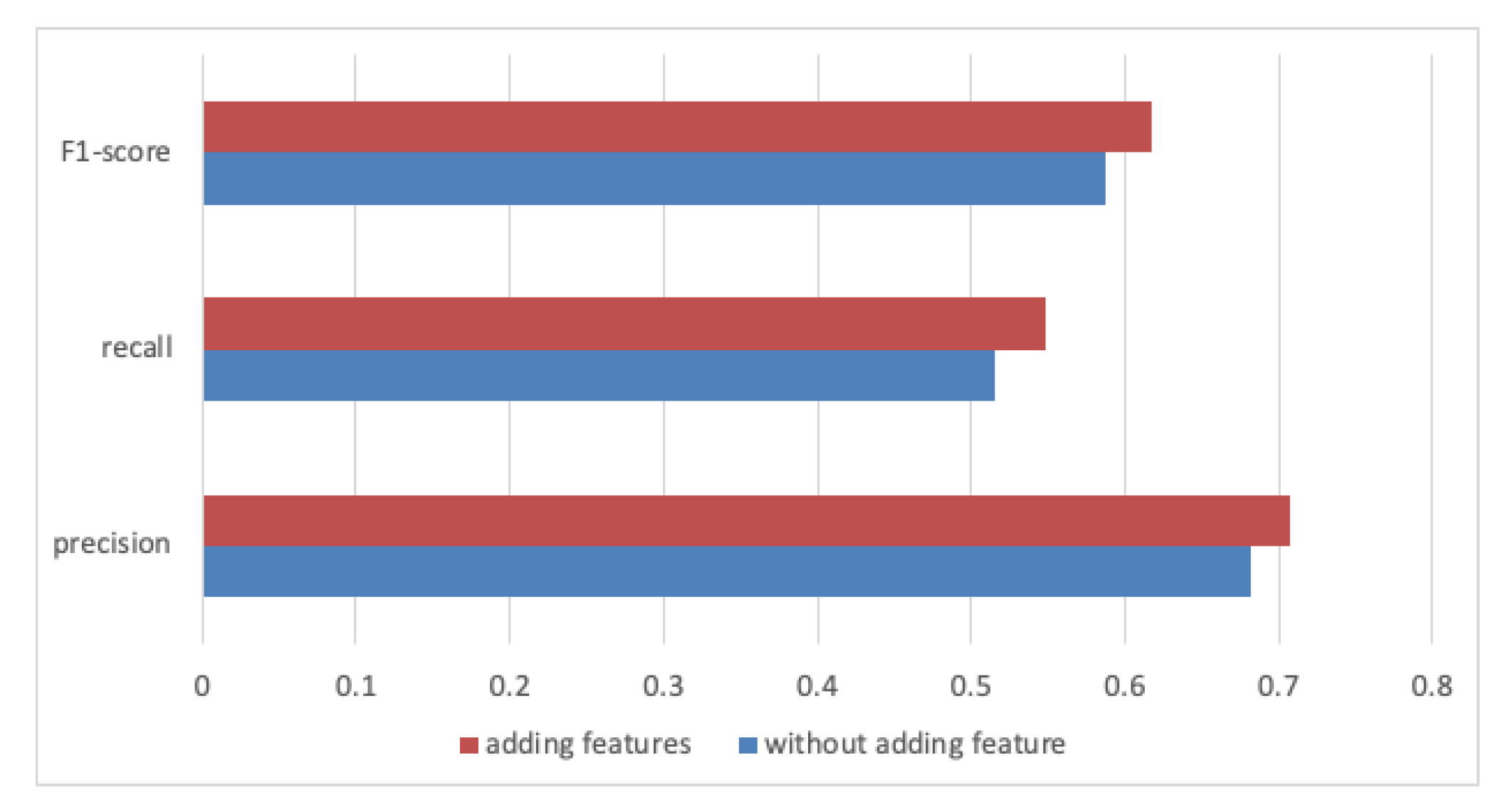
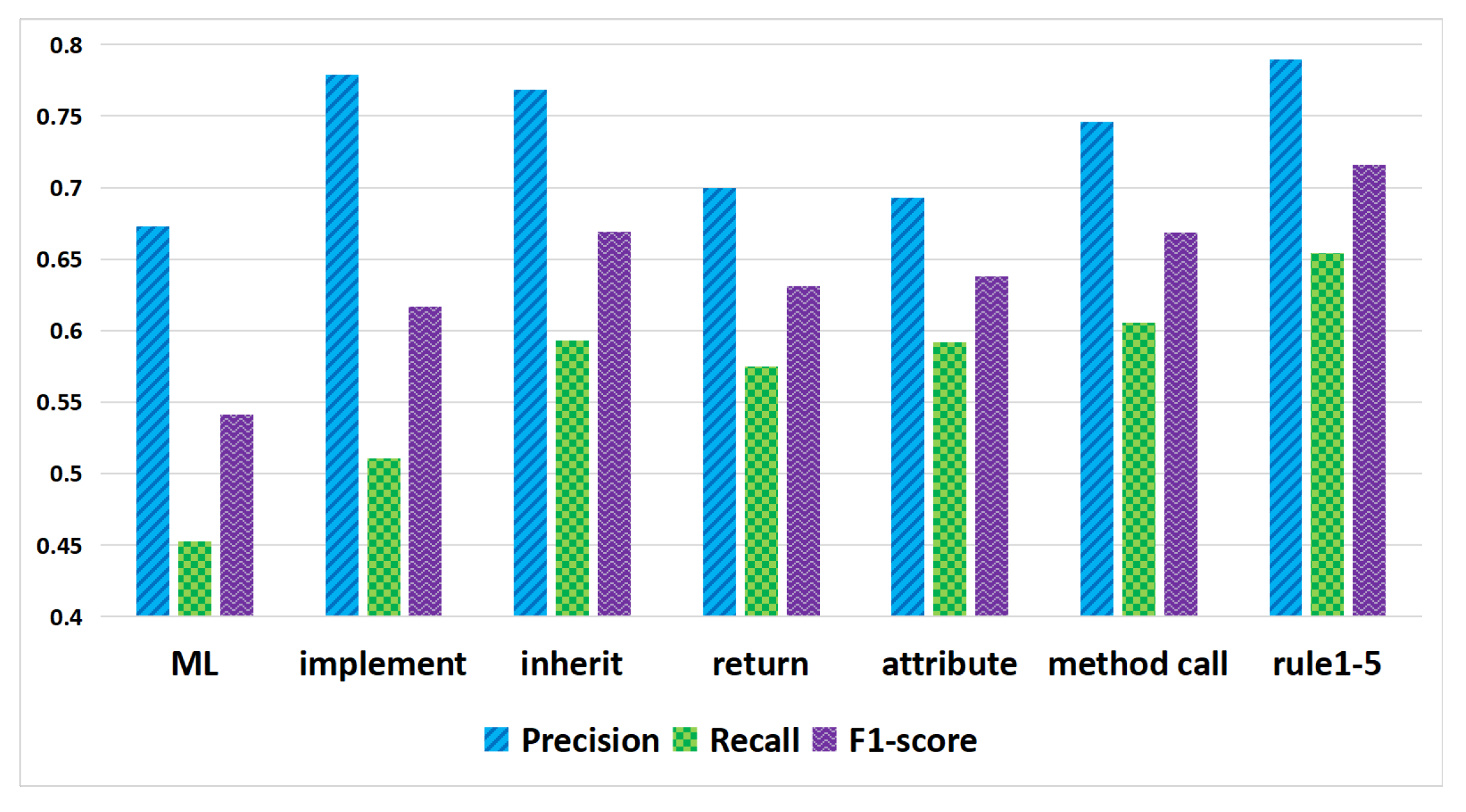
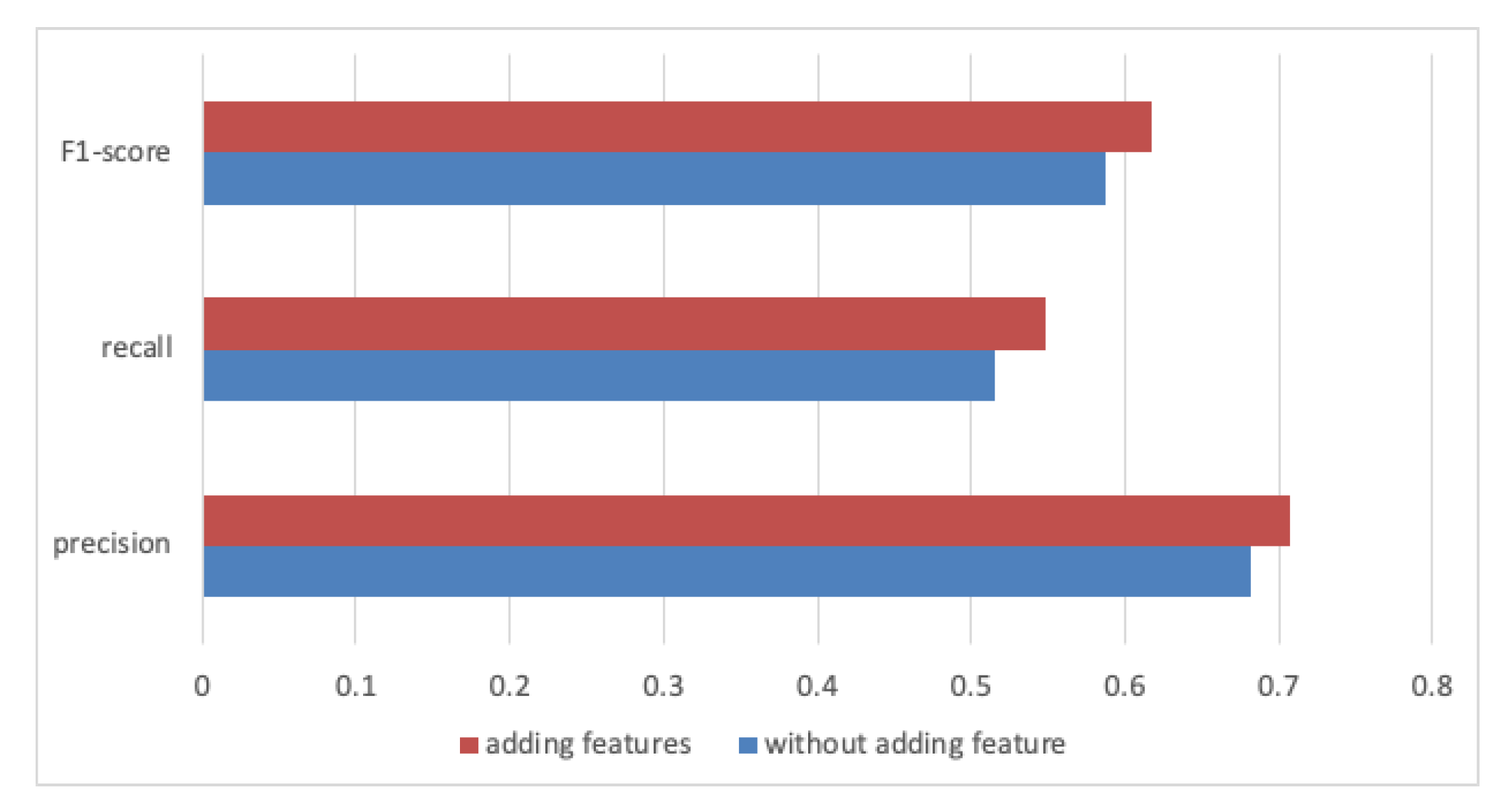
- RQ1: In Phase 1 machine learning recovery, does the addition of the class attribute, method parameter, and method return features to the traceability link vector definition improve traceability recovery?
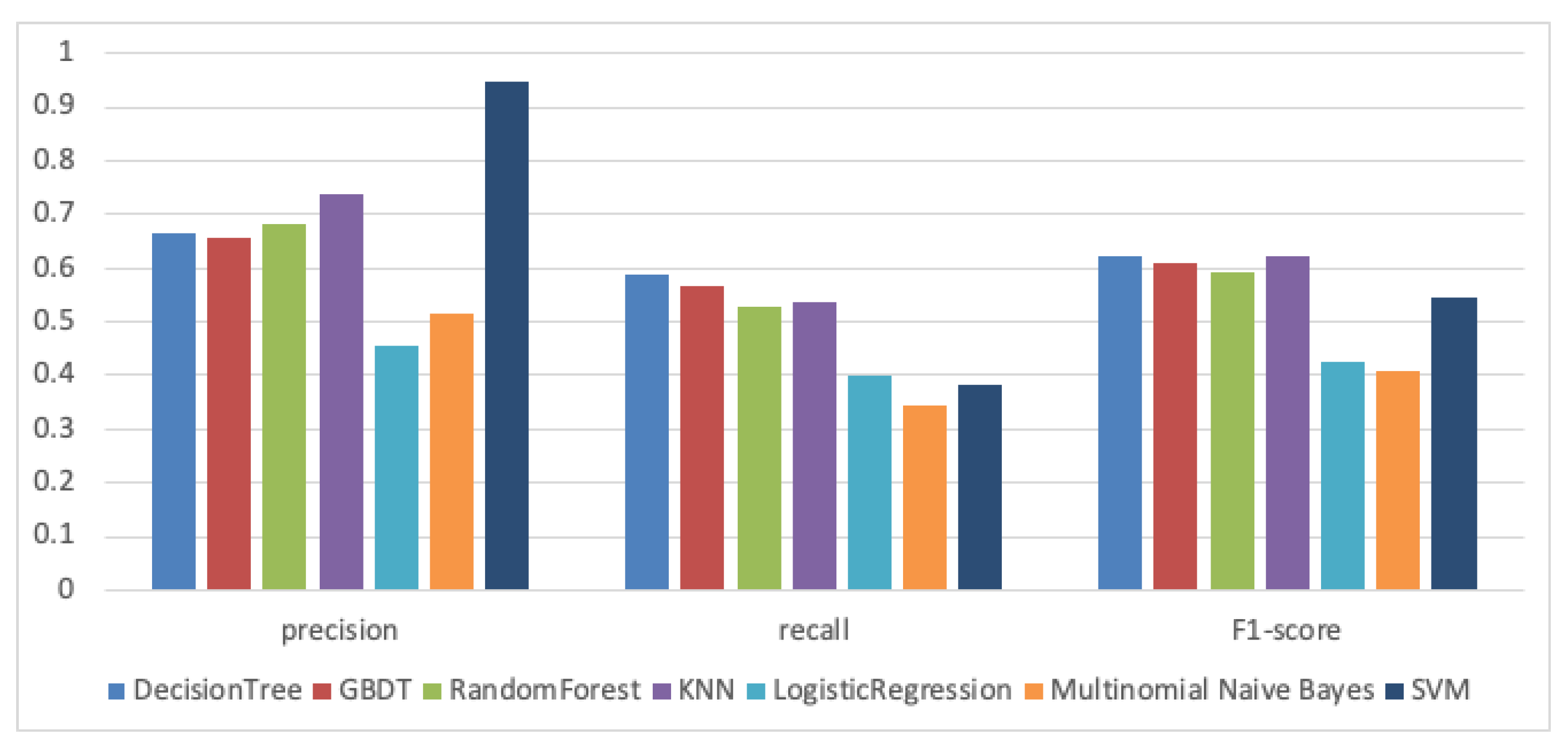
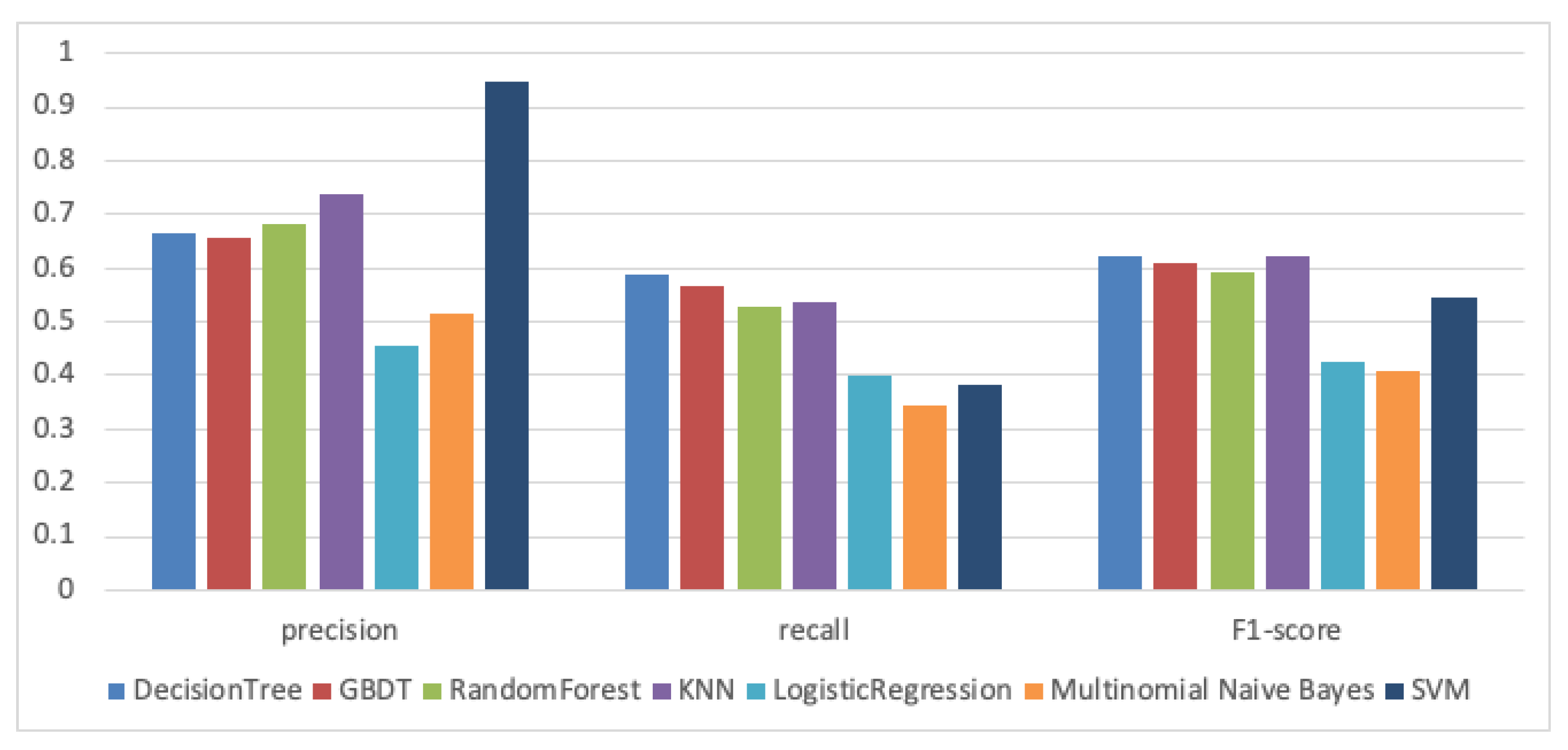
- RQ2: Which is the most appropriate machine learning algorithm for our approach?
- –
- RQ2.1: For the traceability recovery task, which classification algorithm is most effective? Which classification algorithm is most suitable for traceability recovery?
- –
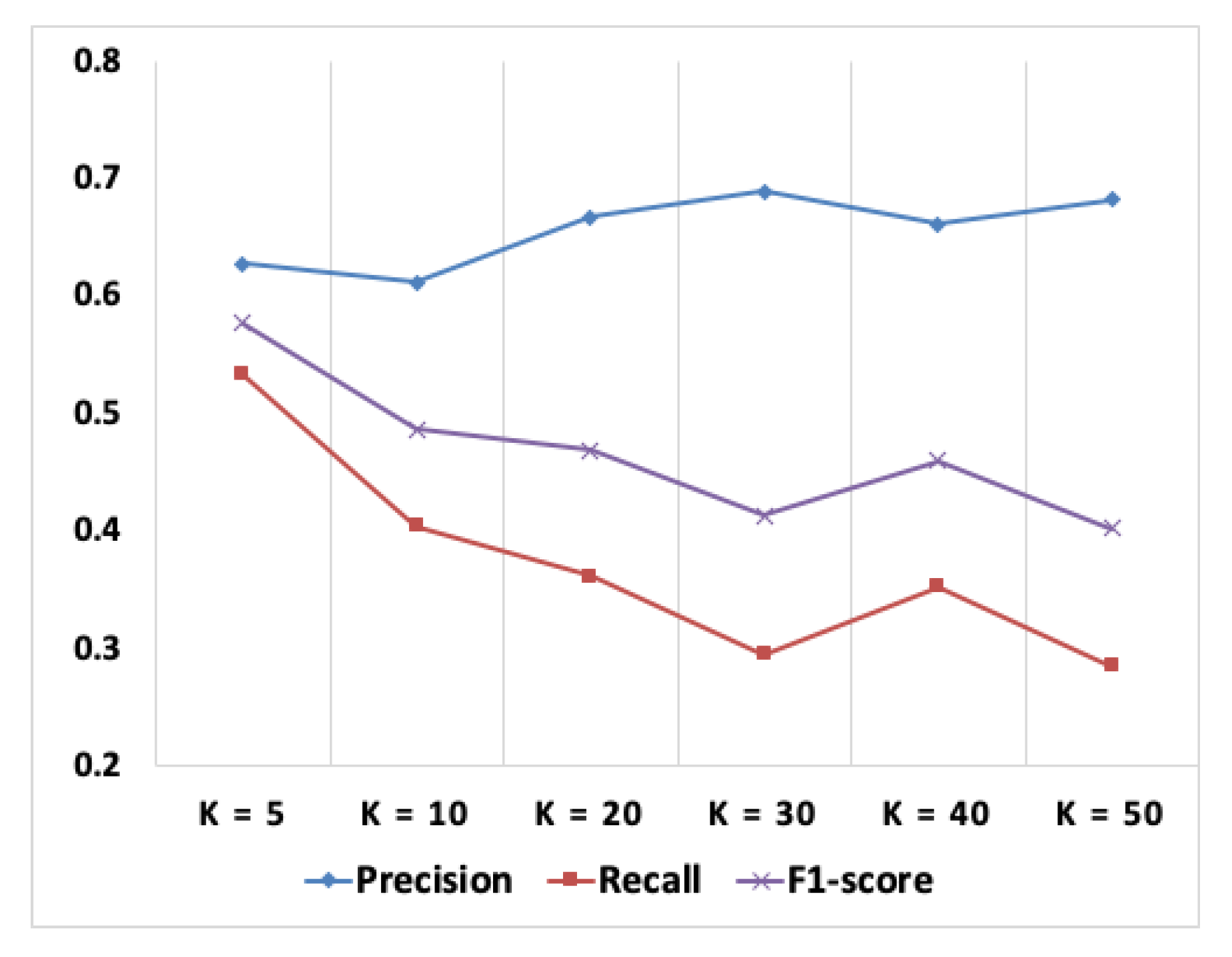
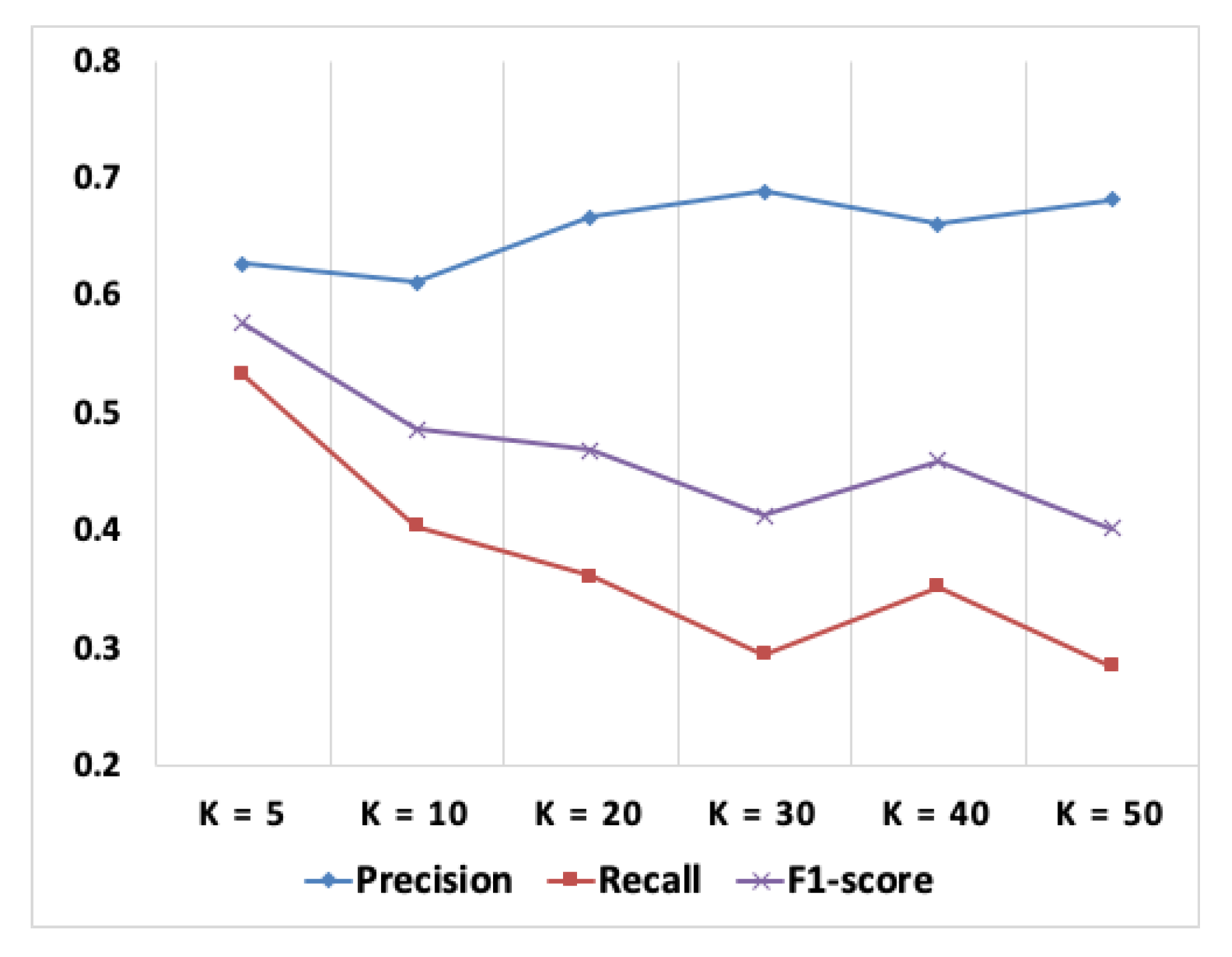
- RQ2.2: What is the most suitable value of parameter k when using the KNN classification algorithm for traceability recovery?
- –
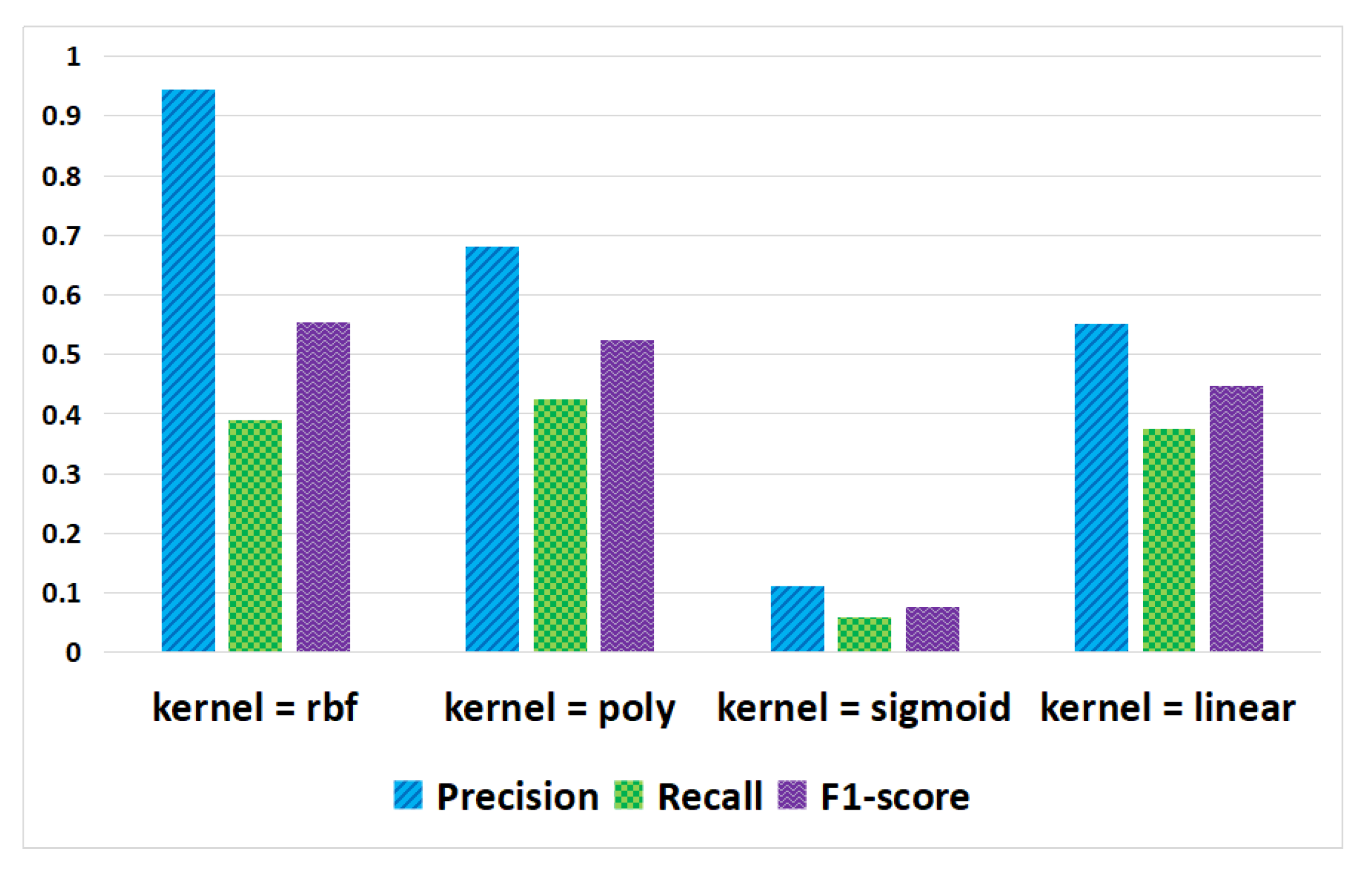
- RQ2.3: When using SVM classification algorithm for traceability recovery, which kernel can obtain better experimental results?
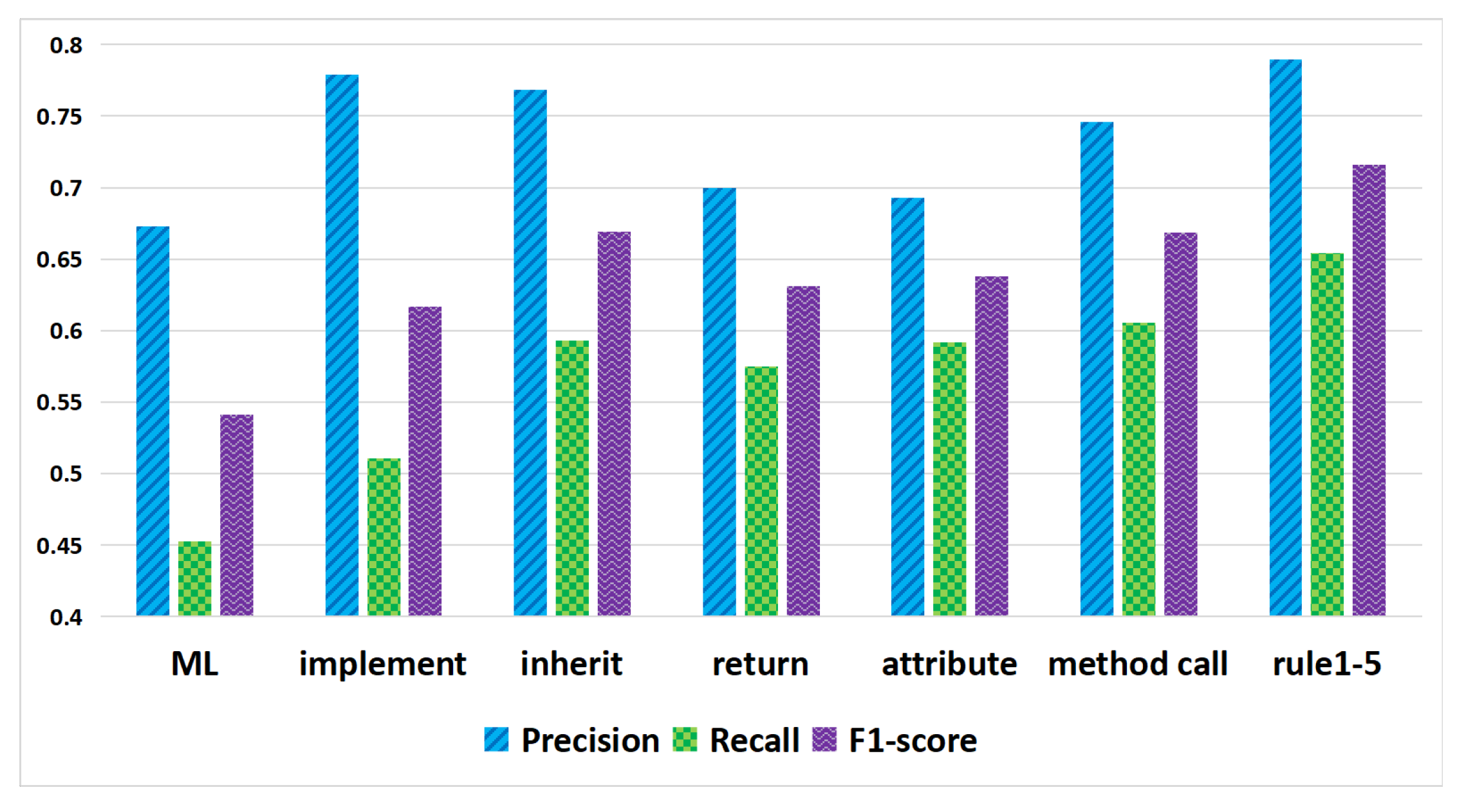
- RQ3: Which structural information features between source code classes are effective for predicting traceability links based on logical reasoning?
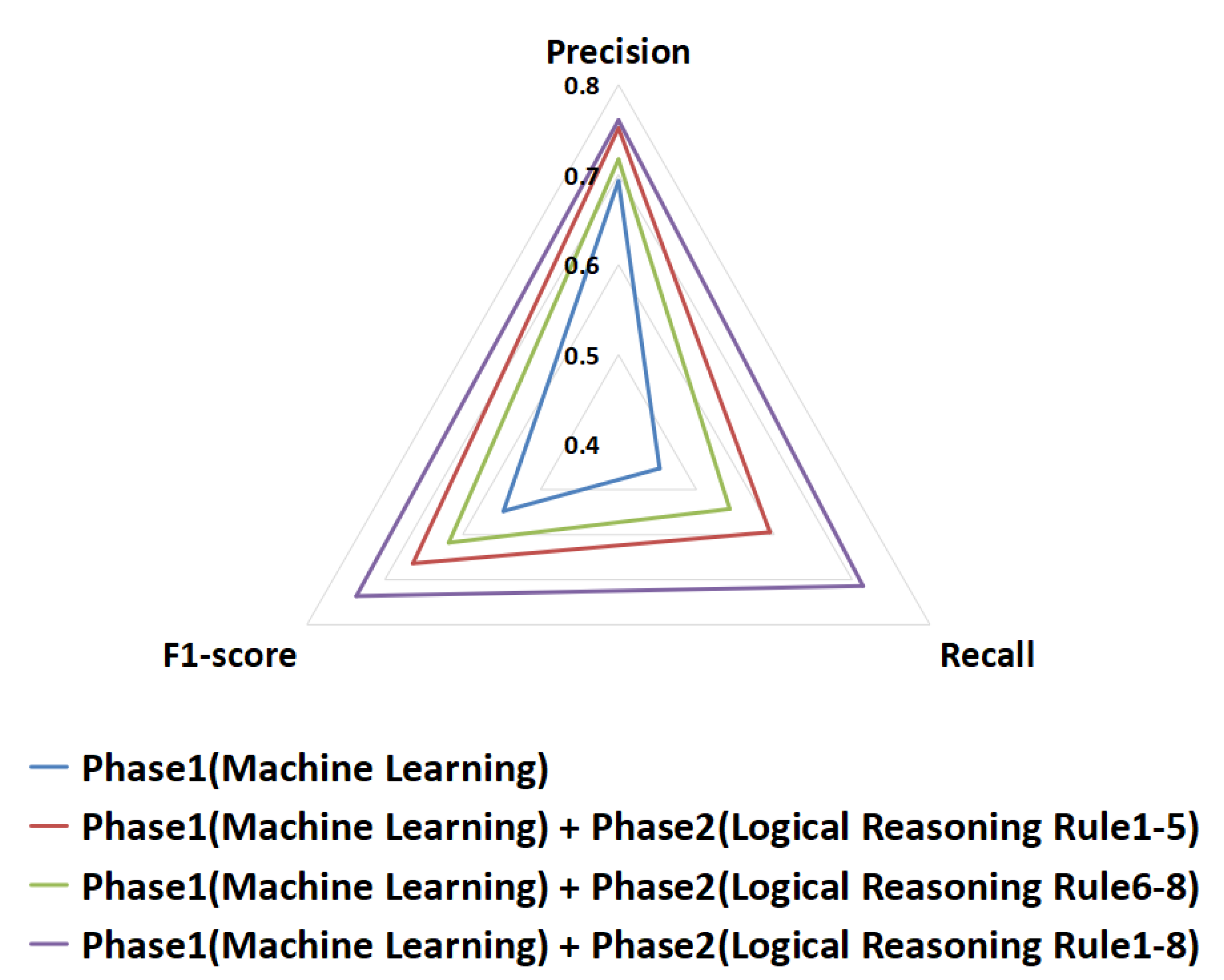
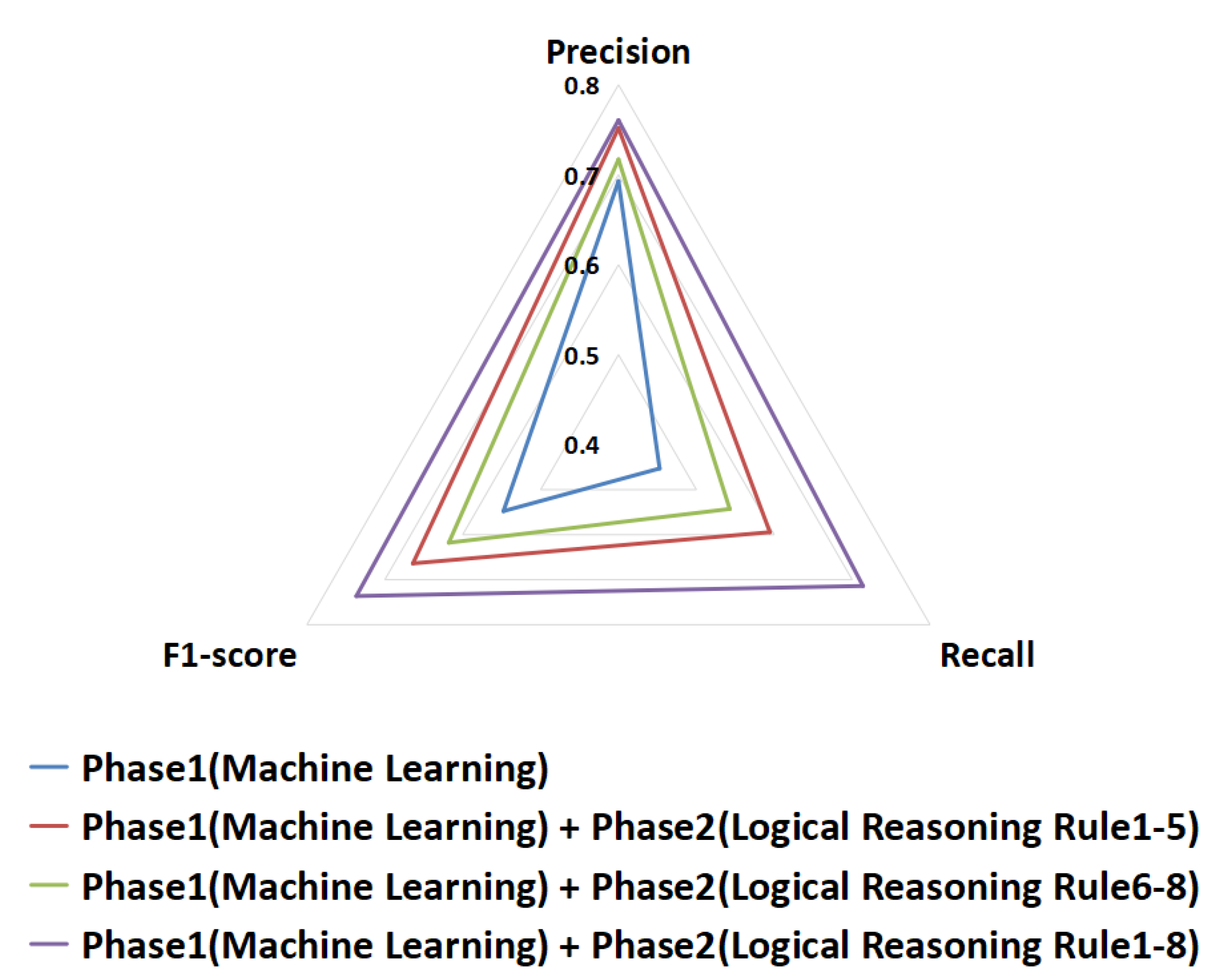
- RQ4: Can using logical reasoning rules based on relationship features between use cases further improve traceability recovery?
- RQ5: What is the interaction between structural information features of source code components and relationship features of use cases?
- –
- RQ5.1: Is the structural information feature of source code components more important than the relationship features of use cases for traceability recovery?
- –
- RQ5.2: Can the combination of source code and use case relationship features further improve traceability recovery?
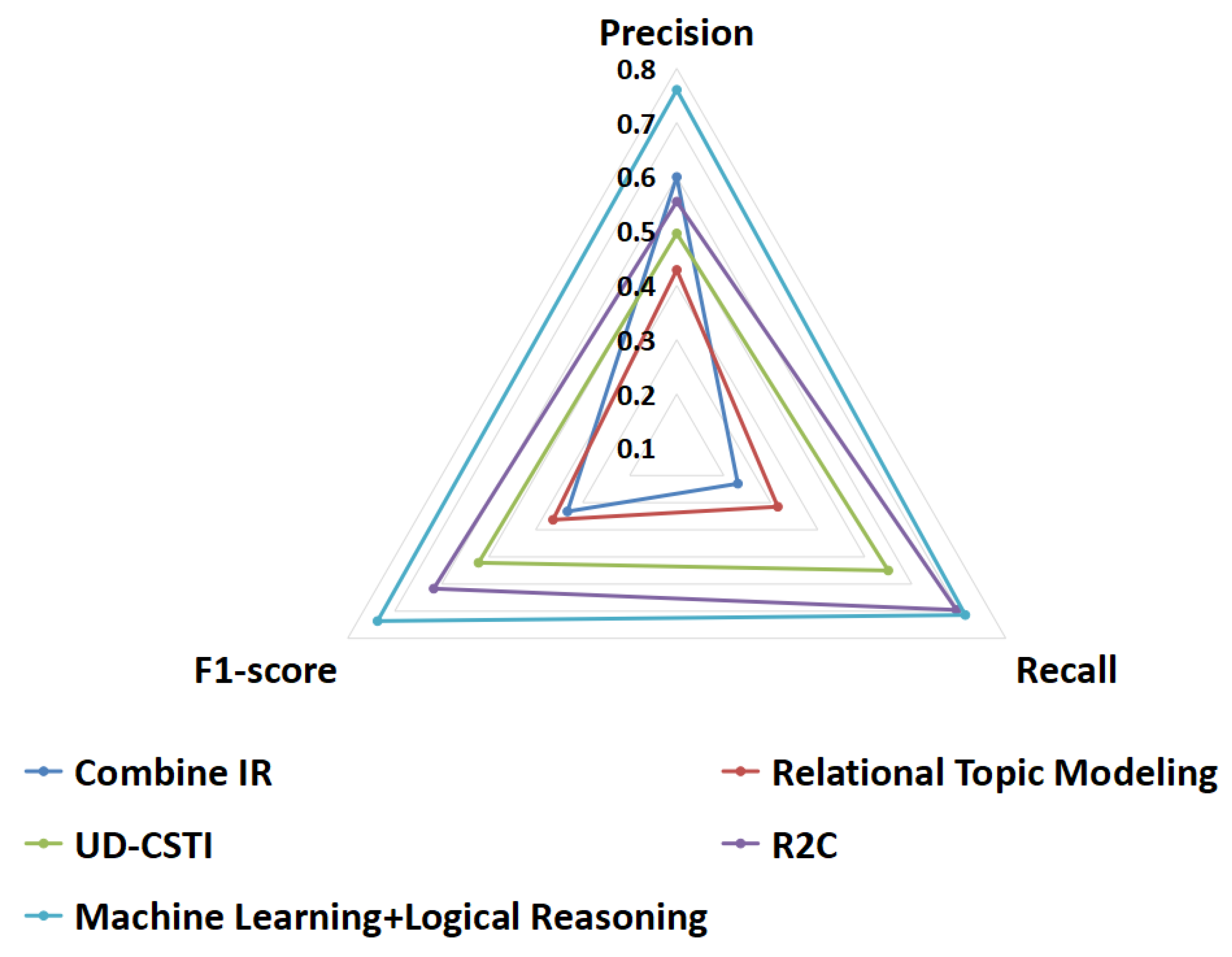
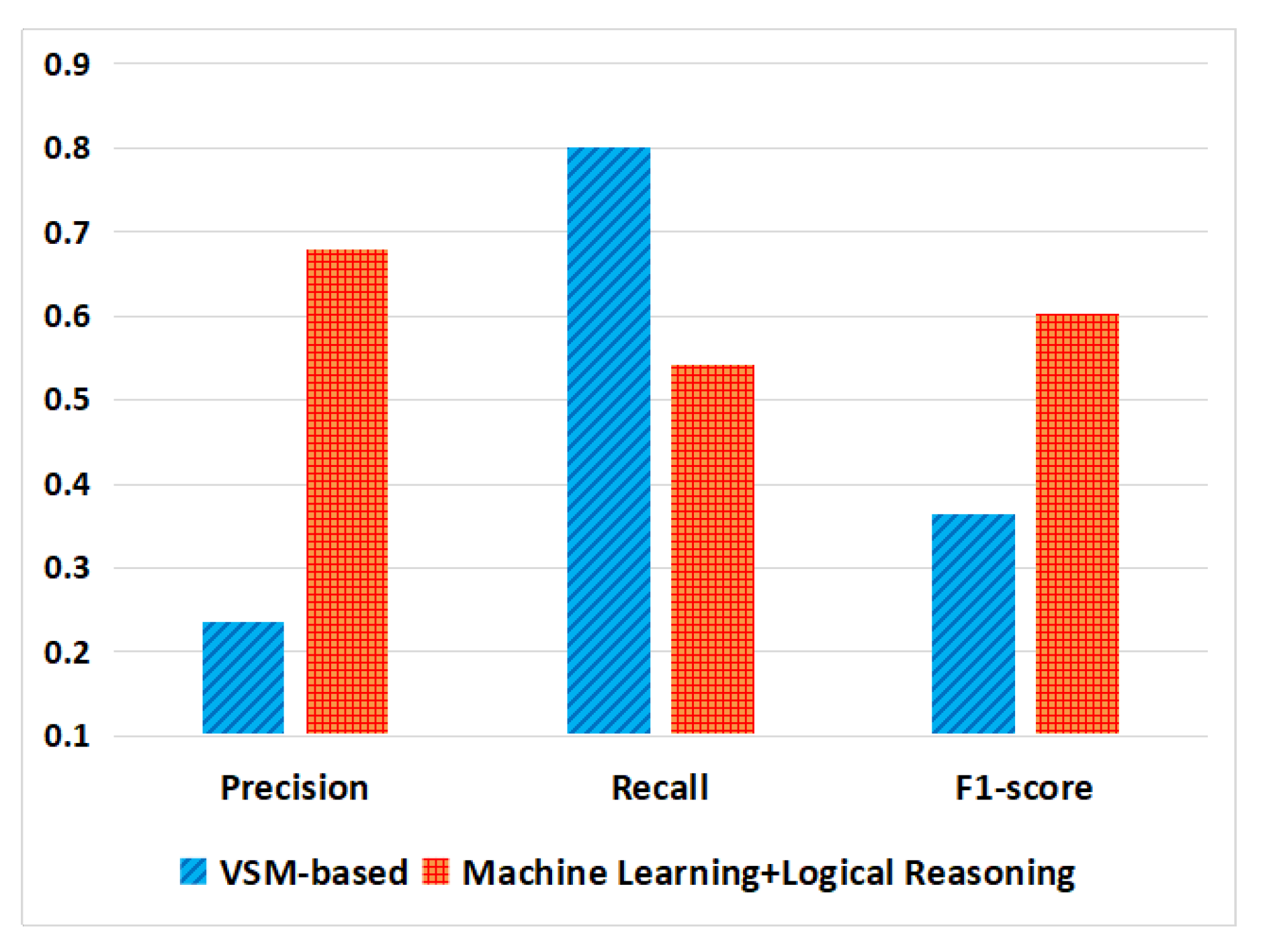
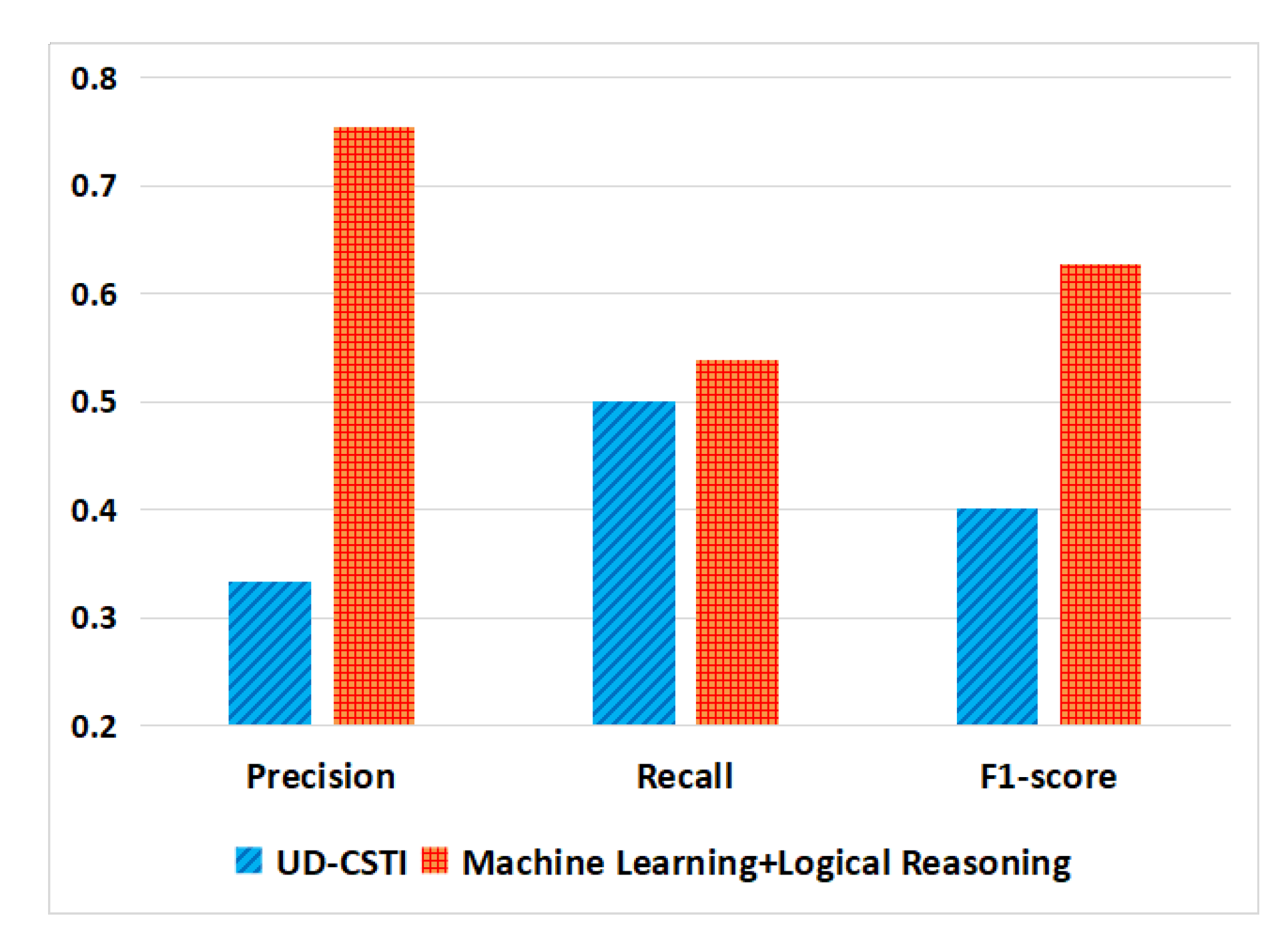
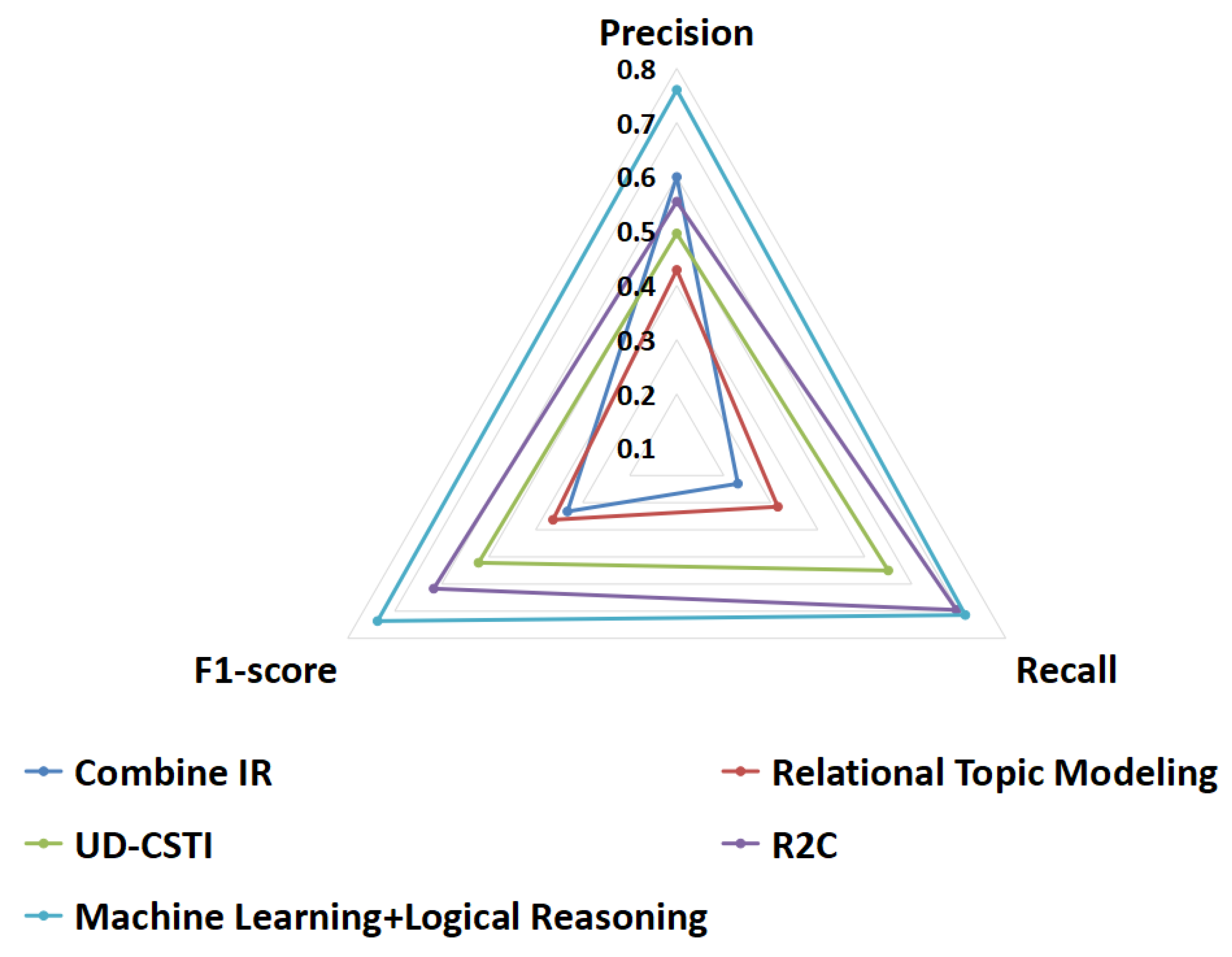
- RQ6: Can our proposal outperform existing traceability link recovery approaches?
4.4. Experiment Design
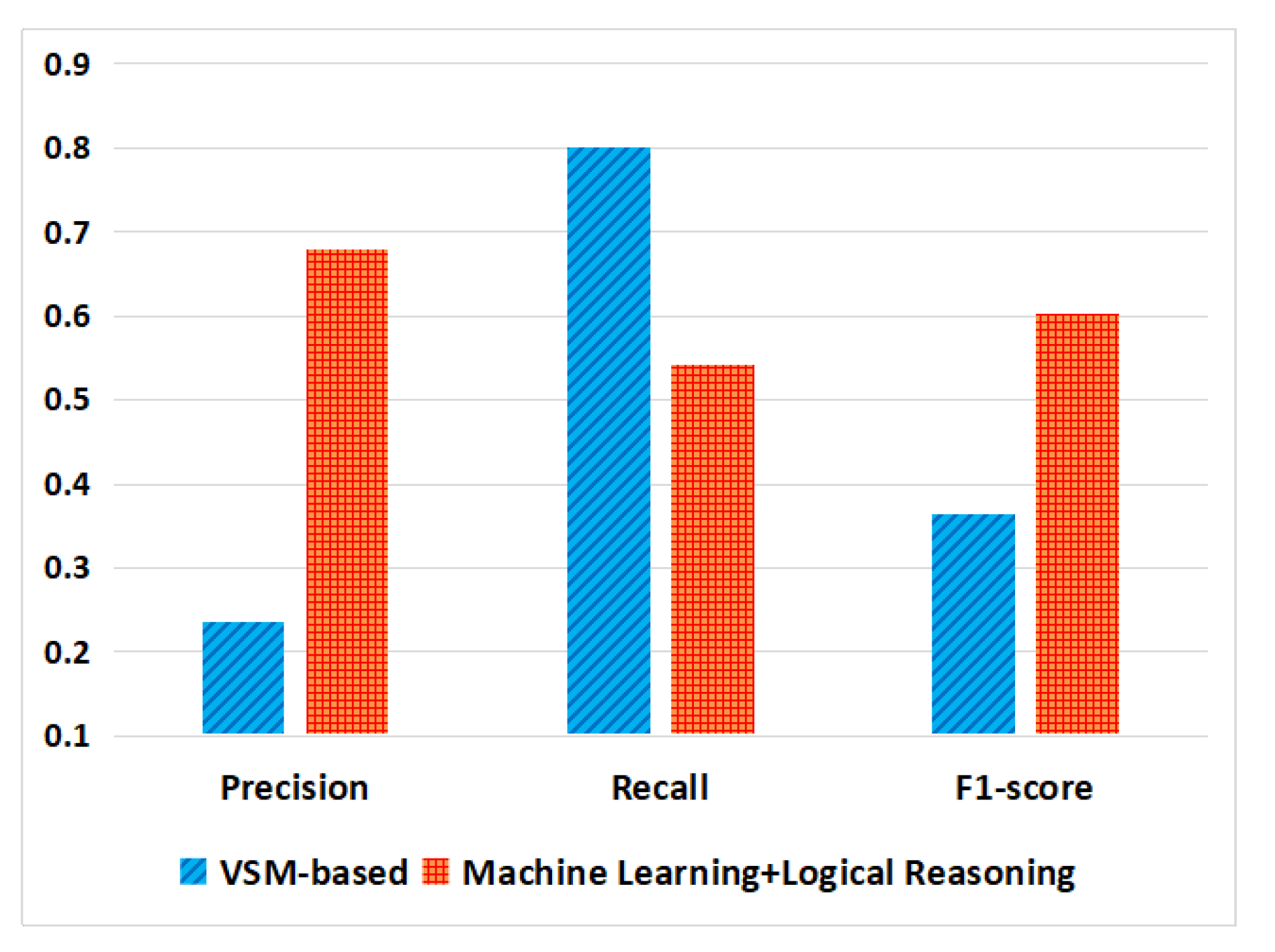
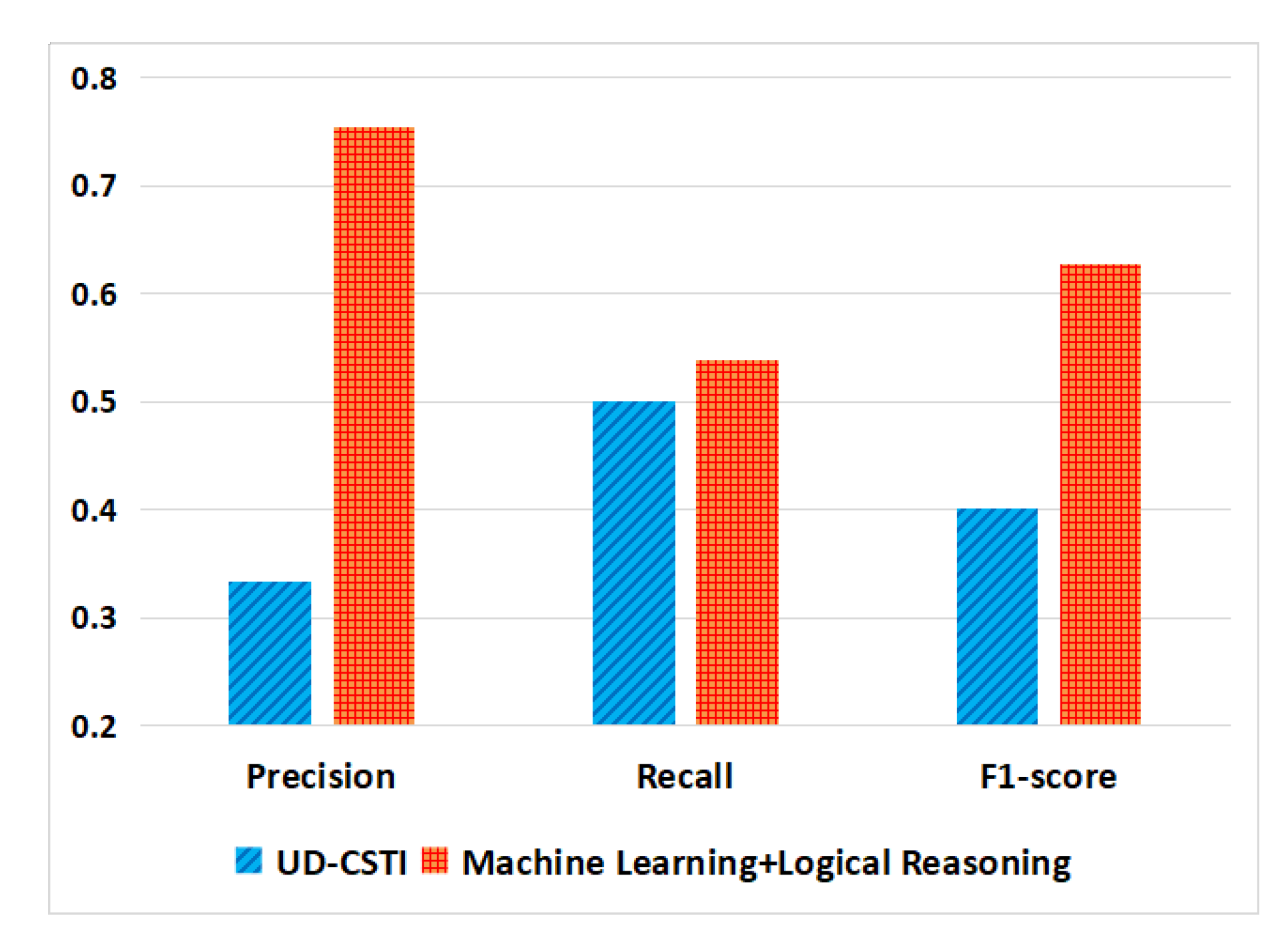
4.5. Results and Analysis
5. Threats to Validity
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Asuncion, H.U.; Asuncion, A.U.; Taylor, R.N. Software traceability with topic modeling. In Proceedings of the 2010 ACM/IEEE 32nd International Conference on Software Engineering, Cape Town, South Africa, 1–8 May 2010; Volume 1, pp. 95–104. [Google Scholar]
- Gethers, M.; Oliveto, R.; Poshyvanyk, D.; De Lucia, A. On integrating orthogonal information retrieval methods to improve traceability recovery. In Proceedings of the 2011 27th IEEE International Conference on Software Maintenance (ICSM), Williamsburg, VA, USA, 25–30 September 2011; pp. 133–142. [Google Scholar]
- Panichella, A.; McMillan, C.; Moritz, E.; Palmieri, D.; Oliveto, R.; Poshyvanyk, D.; De Lucia, A. When and how using structural information to improve ir-based traceability recovery. In Proceedings of the 2013 17th European Conference on Software Maintenance and Reengineering, Genova, Italy, 5–8 March 2013; pp. 199–208. [Google Scholar]
- Zhang, Y.; Wan, C.; Jin, B. An empirical study on recovering requirement-to-code links. In Proceedings of the 2016 17th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Shanghai, China, 30 May–1 June 2016; pp. 121–126. [Google Scholar]
- Capobianco, G.; De Lucia, A.; Oliveto, R.; Panichella, A.; Panichella, S. On the role of the nouns in IR-based traceability recovery. In Proceedings of the 2009 IEEE 17th International Conference on Program Comprehension, Vancouver, BC, Canada, 17–19 May 2009; pp. 148–157. [Google Scholar]
- Asuncion, H.U.; Taylor, R.N. Capturing custom link semantics among heterogeneous artifacts and tools. In Proceedings of the 2009 ICSE Workshop on Traceability in Emerging Forms of Software Engineering, Vancouver, BC, Canada, 18 May 2009; pp. 1–5. [Google Scholar]
- Raghavan, V.V.; Wong, S.M. A critical analysis of vector space model for information retrieval. J. Am. Soc. Inf. Sci. 1986, 37, 279–287. [Google Scholar] [CrossRef]
- Hofmann, T. Probabilistic latent semantic indexing. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Berkeley, CA, USA, 15–19 August 1999; pp. 50–57. [Google Scholar]
- McMillan, C.; Poshyvanyk, D.; Revelle, M. Combining textual and structural analysis of software artifacts for traceability link recovery. In Proceedings of the 2009 ICSE Workshop on Traceability in Emerging Forms of Software Engineering, Vancouver, BC, Canada, 18 May 2009; pp. 41–48. [Google Scholar]
- Wang, S.; Li, T.; Yang, Z. Exploring Semantics of Software Artifacts to Improve Requirements Traceability Recovery: A Hybrid Approach. In Proceedings of the 2019 26th Asia-Pacific Software Engineering Conference (APSEC), Putrajaya, Malaysia, 2–5 December 2019; pp. 39–46. [Google Scholar]
- Hayes, J.H.; Dekhtyar, A.; Osborne, J. Improving requirements tracing via information retrieval. In Proceedings of the 11th IEEE International Requirements Engineering Conference, Monterey Bay, CA, USA, 12 September 2003; pp. 138–147. [Google Scholar]
- Lucia, A.D.; Fasano, F.; Oliveto, R.; Tortora, G. Recovering traceability links in software artifact management systems using information retrieval methods. ACM Trans. Softw. Eng. Methodol. 2007, 16, 13-es. [Google Scholar] [CrossRef]
- De Lucia, A.; Di Penta, M.; Oliveto, R.; Panichella, A.; Panichella, S. Improving ir-based traceability recovery using smoothing filters. In Proceedings of the 2011 IEEE 19th International Conference on Program Comprehension, Kingston, ON, Canada, 22–24 June 2011; pp. 21–30. [Google Scholar]
- Lucia, D. Information retrieval models for recovering traceability links between code and documentation. In Proceedings of the Proceedings 2000 International Conference on Software Maintenance, San Jose, CA, USA, 11–14 October 2000; pp. 40–49. [Google Scholar]
- Topsøe, F. Jenson-shannon divergence and norm-based measures of discrimination and variation. preprint 2003. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Oliveto, R.; Gethers, M.; Poshyvanyk, D.; De Lucia, A. On the equivalence of information retrieval methods for automated traceability link recovery. In Proceedings of the 2010 IEEE 18th International Conference on Program Comprehension, Braga, Portugal, 30 June–2 July 2010; pp. 68–71. [Google Scholar]
- Chang, J.; Blei, D.M. Hierarchical relational models for document networks. Ann. Appl. Stat. 2010, 4, 124–150. [Google Scholar] [CrossRef]
- Capobianco, G.; Lucia, A.D.; Oliveto, R.; Panichella, A.; Panichella, S. Improving IR-based traceability recovery via noun-based indexing of software artifacts. J. Softw. Evol. Process 2013, 25, 743–762. [Google Scholar] [CrossRef]
- Buckner, J.; Buchta, J.; Petrenko, M.; Rajlich, V. JRipples: A tool for program comprehension during incremental change. In Proceedings of the 13th International Workshop on Program Comprehension (IWPC’05), St. Louis, MO, USA, USA, 15–16 May 2005; pp. 149–152. [Google Scholar]
- Rajlich, V.; Gosavi, P. Incremental change in object-oriented programming. IEEE Softw. 2004, 21, 62–69. [Google Scholar] [CrossRef]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- De Marneffe, M.C.; MacCartney, B.; Manning, C.D. Generating typed dependency parses from phrase structure parses. Lrec 2006, 6, 449–454. [Google Scholar]
- Kuang, H.; Nie, J.; Hu, H.; Lü, J. Improving automatic identification of outdated requirements by using closeness analysis based on source code changes. In National Software Application Conference; Springer: Berlin, Germany, 2016; pp. 52–67. [Google Scholar]
- Kuang, H.; Nie, J.; Hu, H.; Rempel, P.; Lü, J.; Egyed, A.; Mäder, P. Analyzing closeness of code dependencies for improving IR-based Traceability Recovery. In Proceedings of the 2017 IEEE 24th International Conference on Software Analysis, Evolution and Reengineering (SANER), Klagenfurt, Austria, 20–24 February 2017; pp. 68–78. [Google Scholar]
- Kuang, H.; Mäder, P.; Hu, H.; Ghabi, A.; Huang, L.; Lü, J.; Egyed, A. Can method data dependencies support the assessment of traceability between requirements and source code? J. Softw. Evol. Process 2015, 27, 838–866. [Google Scholar] [CrossRef]
- Kuang, H.; Mäder, P.; Hu, H.; Ghabi, A.; Huang, L.; Jian, L.; Egyed, A. Do data dependencies in source code complement call dependencies for understanding requirements traceability? In Proceedings of the 2012 28th IEEE International Conference on Software Maintenance (ICSM), Trento, Italy, 23–28 September 2012; pp. 181–190. [Google Scholar]
- Ali, N.; Gueheneuc, Y.G.; Antoniol, G. Trust-based requirements traceability. In Proceedings of the 2011 IEEE 19th International Conference on Program Comprehension, Kingston, ON, Canada, 22–24 June 2011; pp. 111–120. [Google Scholar]
- Diaz, D.; Bavota, G.; Marcus, A.; Oliveto, R.; Takahashi, S.; De Lucia, A. Using code ownership to improve ir-based traceability link recovery. In Proceedings of the 2013 21st International Conference on Program Comprehension (ICPC), San Francisco, CA, USA, 20–21 May 2013; pp. 123–132. [Google Scholar]
- Ali, N.; Sharafl, Z.; Guéhéneuc, Y.G.; Antoniol, G. An empirical study on requirements traceability using eye-tracking. In Proceedings of the 2012 28th IEEE International Conference on Software Maintenance (ICSM), Trento, Italy, 23–28 September 2012; pp. 191–200. [Google Scholar]
- Ali, N.; Sharafi, Z.; Guéhéneuc, Y.G.; Antoniol, G. An empirical study on the importance of source code entities for requirements traceability. Empir. Softw. Eng. 2015, 20, 442–478. [Google Scholar] [CrossRef]
- Lucassen, G.; Dalpiaz, F.; van der Werf, J.M.E.; Brinkkemper, S.; Zowghi, D. Behavior-driven requirements traceability via automated acceptance tests. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference Workshops (REW), Lisbon, Portugal, 4–8 September 2017; pp. 431–434. [Google Scholar]
- Guo, J.; Cheng, J.; Cleland-Huang, J. Semantically enhanced software traceability using deep learning techniques. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), Buenos Aires, Argentina, 20–28 May 2017; pp. 3–14. [Google Scholar]
- Sultanov, H.; Hayes, J.H. Application of reinforcement learning to requirements engineering: Requirements tracing. In Proceedings of the 2013 21st IEEE International Requirements Engineering Conference (RE), Rio de Janeiro, Brazil, 15–19 July 2013; pp. 52–61. [Google Scholar]
- Marcén, A.C.; Lapeña, R.; Pastor, Ó.; Cetina, C. Traceability Link Recovery between Requirements and Models using an Evolutionary Algorithm Guided by a Learning to Rank Algorithm: Train Control and Management Case. J. Syst. Softw. 2020, 163, 110519. [Google Scholar] [CrossRef]
- Opdahl, A.L.; Sindre, G. Experimental comparison of attack trees and misuse cases for security threat identification. Inf. Softw. Technol. 2009, 51, 916–932. [Google Scholar] [CrossRef]
- Holzinger, A. From machine learning to explainable AI. In Proceedings of the 2018 World Symposium on Digital Intelligence for Systems and Machines (DISA), Košice, Slovakia, 23–25 August 2018; pp. 55–66. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Artifact | Feature | Description |
|---|---|---|
| Use Case | Title | The title of use case |
| Description | The description of use case | |
| Source Code | Class Name | The class name |
| Class Comment | The comment associated with a class | |
| Method Name | The method name in a class | |
| Method Comment | The comment associated with a method | |
| Class Attribute | The class attribute (Type, name) | |
| Method Parameter | The method parameter (type, name, Javadoc) | |
| Method Return | The method return (type, name, Javadoc) |
| Attribute | Value | Description |
|---|---|---|
| id | : Use Case, : Source Code | |
| vector | The vector that represents link relationship | |
| tag | 0/1 | 0: unrelated link; 1: related link |
| Artifact | Feature | Description |
|---|---|---|
| Source Code | Class Implementation | The class implementation relationship |
| Class Inheritance | The class inheritance relationship | |
| Method Return | The method return relationship | |
| Class Attribute | The class attribute relationship | |
| Method Call | The method call relationship |
| Artifact | Feature | Description |
|---|---|---|
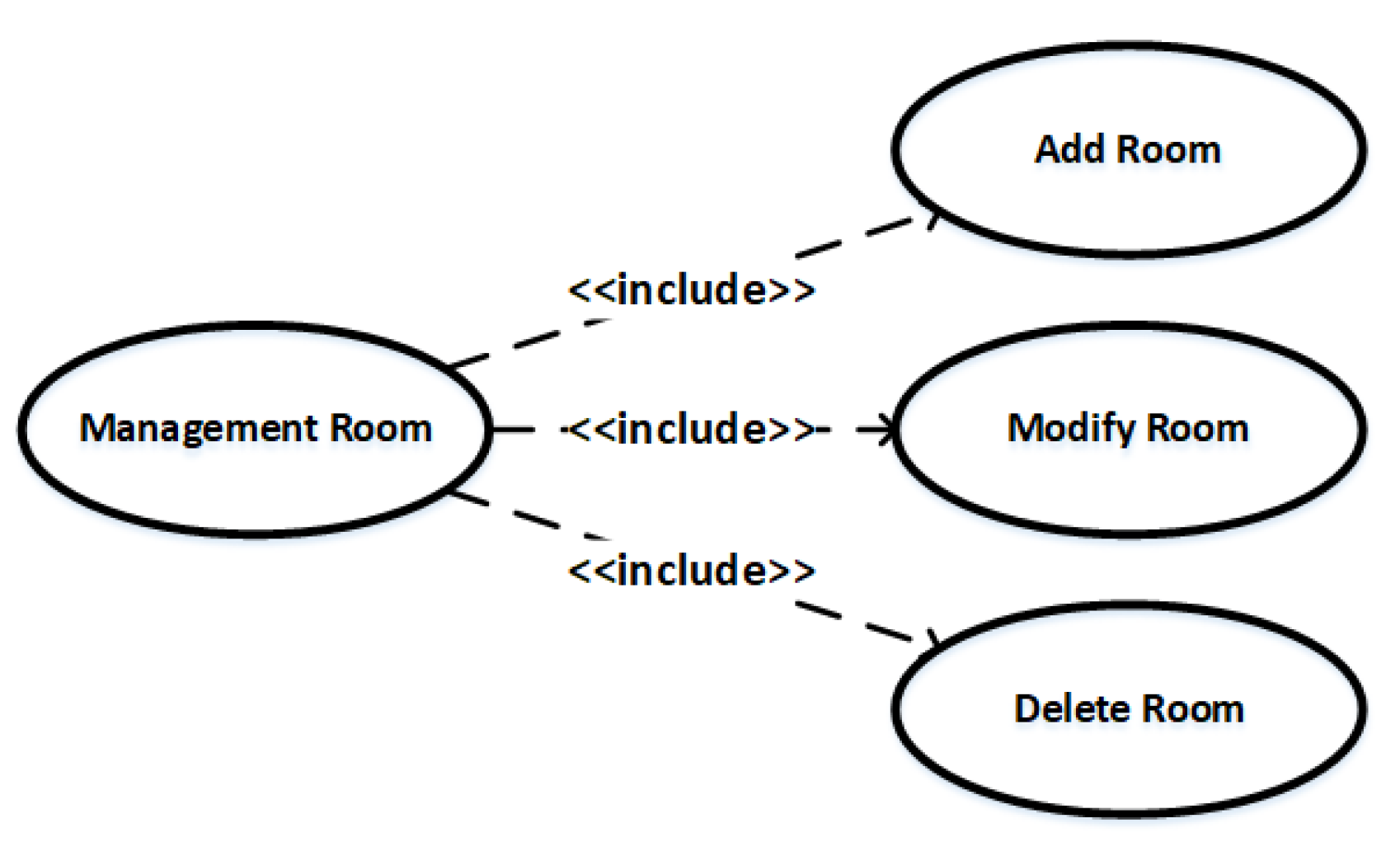
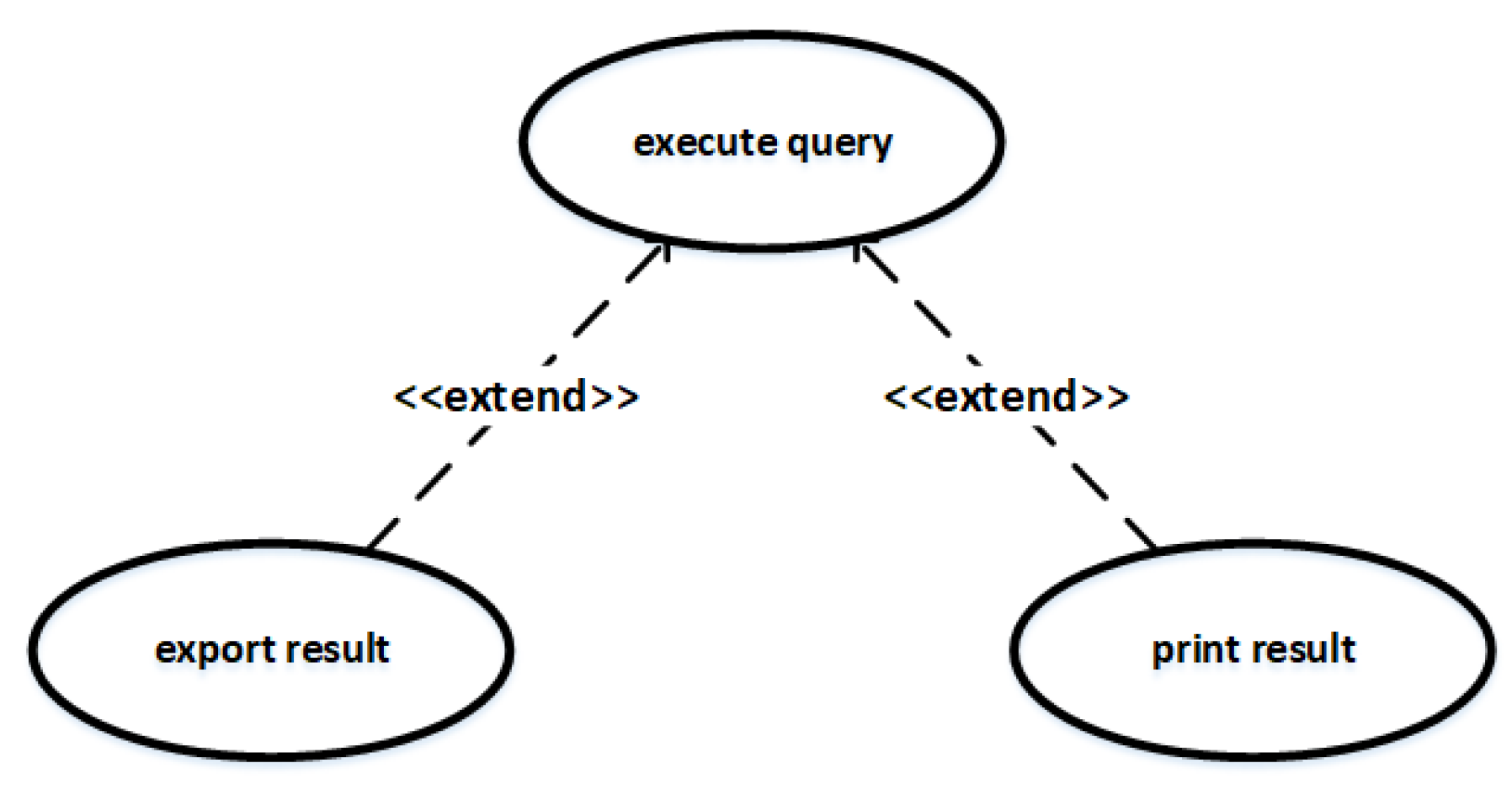
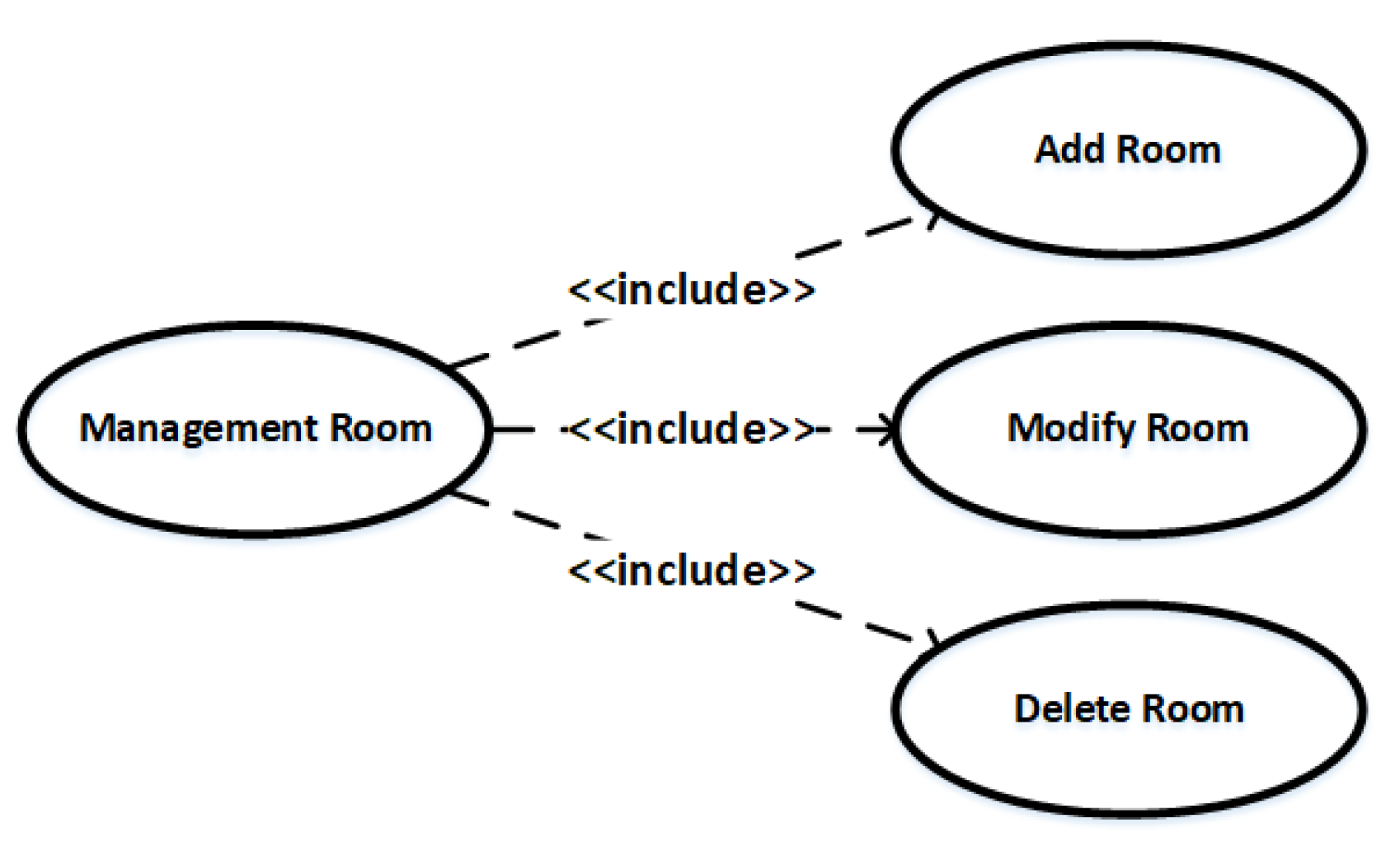
| Use Case | Include | The include relationship between use cases. |
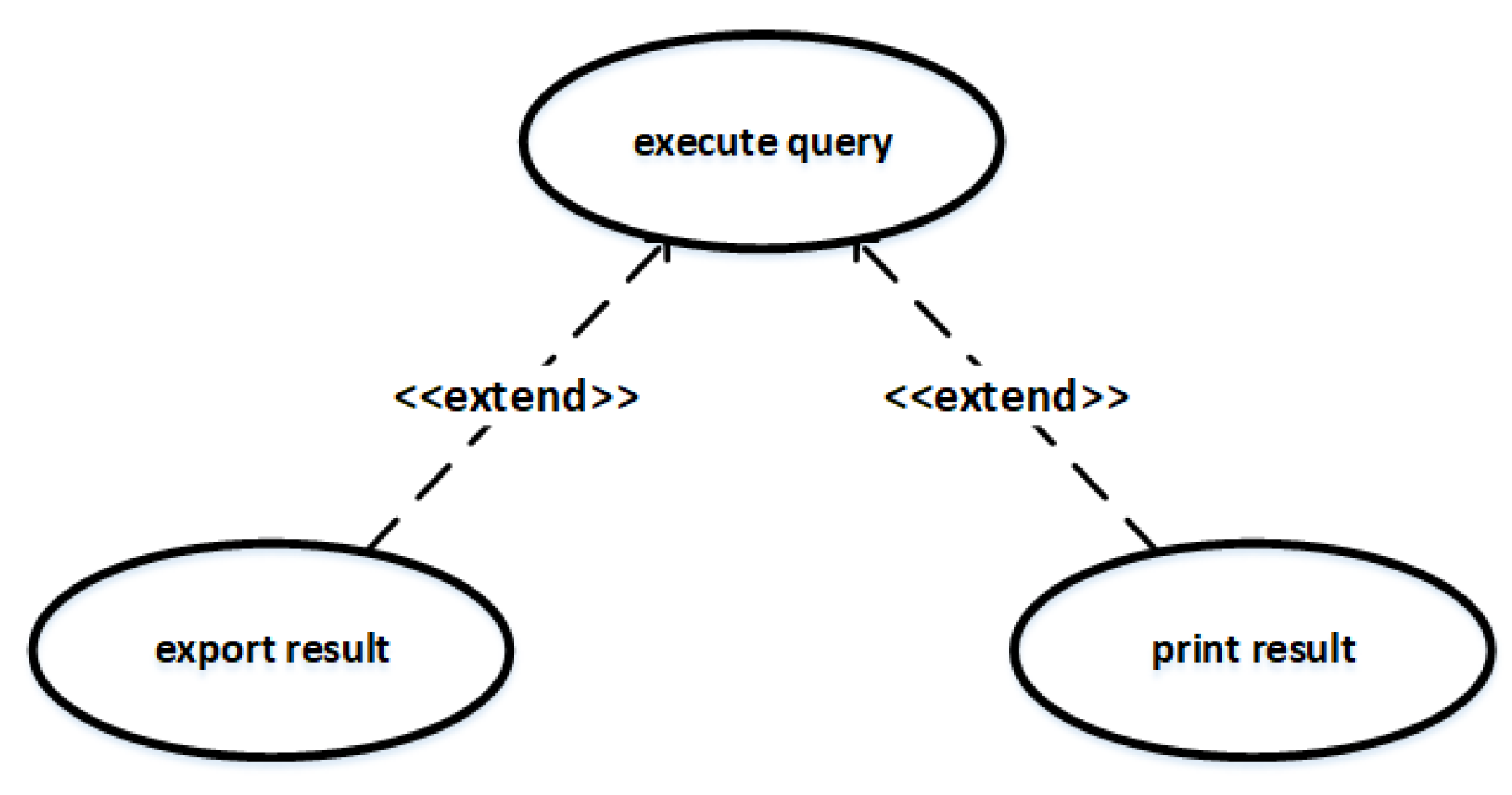
| Extend | The extend relationship between use cases. | |
| Generalize | The generalization relationship between use cases. |
| Project | Source Artifact(#) | Target Artifact(#) | Correct Links | Description |
|---|---|---|---|---|
| eTour | Use cases (58) | Source Code Classes (116) | 336 | An electronic touristic guide system |
| SMOS | Use cases (67) | Source Code Classes (100) | 1045 | High school student monitoring system |
| Albergate | Use cases (17) | Source Code Classes (55) | 54 | Hotel management system |
| eANCI | Use cases (140) | Source Code Classes (55) | 567 | Municipalities management system |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Wang, S.; Lillis, D.; Yang, Z. Combining Machine Learning and Logical Reasoning to Improve Requirements Traceability Recovery. Appl. Sci. 2020, 10, 7253. https://doi.org/10.3390/app10207253
Li T, Wang S, Lillis D, Yang Z. Combining Machine Learning and Logical Reasoning to Improve Requirements Traceability Recovery. Applied Sciences. 2020; 10(20):7253. https://doi.org/10.3390/app10207253
Chicago/Turabian StyleLi, Tong, Shiheng Wang, David Lillis, and Zhen Yang. 2020. "Combining Machine Learning and Logical Reasoning to Improve Requirements Traceability Recovery" Applied Sciences 10, no. 20: 7253. https://doi.org/10.3390/app10207253
APA StyleLi, T., Wang, S., Lillis, D., & Yang, Z. (2020). Combining Machine Learning and Logical Reasoning to Improve Requirements Traceability Recovery. Applied Sciences, 10(20), 7253. https://doi.org/10.3390/app10207253