Temporal Convolutional Network Connected with an Anti-Arrhythmia Hidden Semi-Markov Model for Heart Sound Segmentation


Abstract
Featured Application
Abstract
1. Introduction
2. Materials and Methods
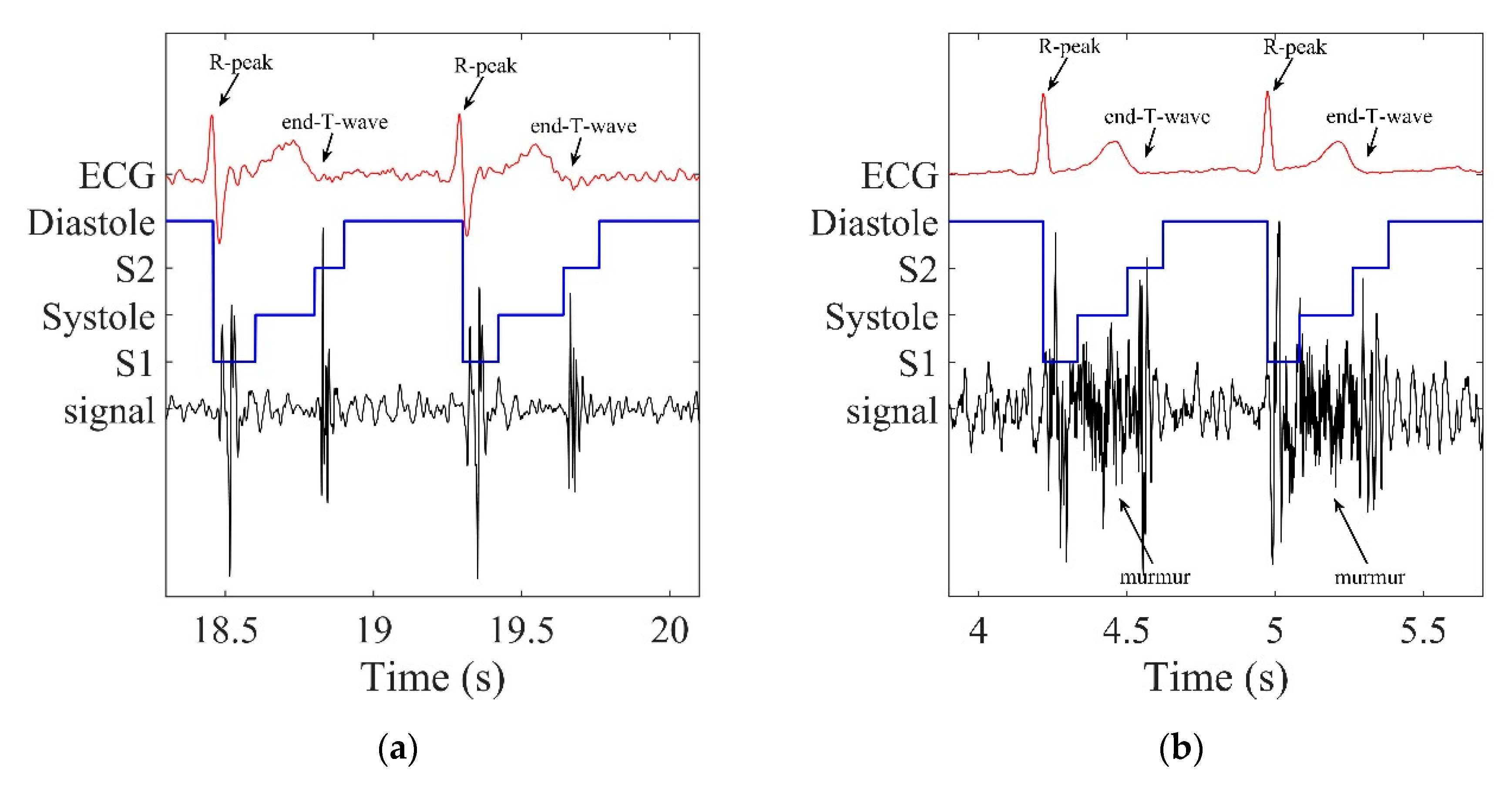
2.1. Dataset
2.2. Metrics
2.3. Feature Extraction
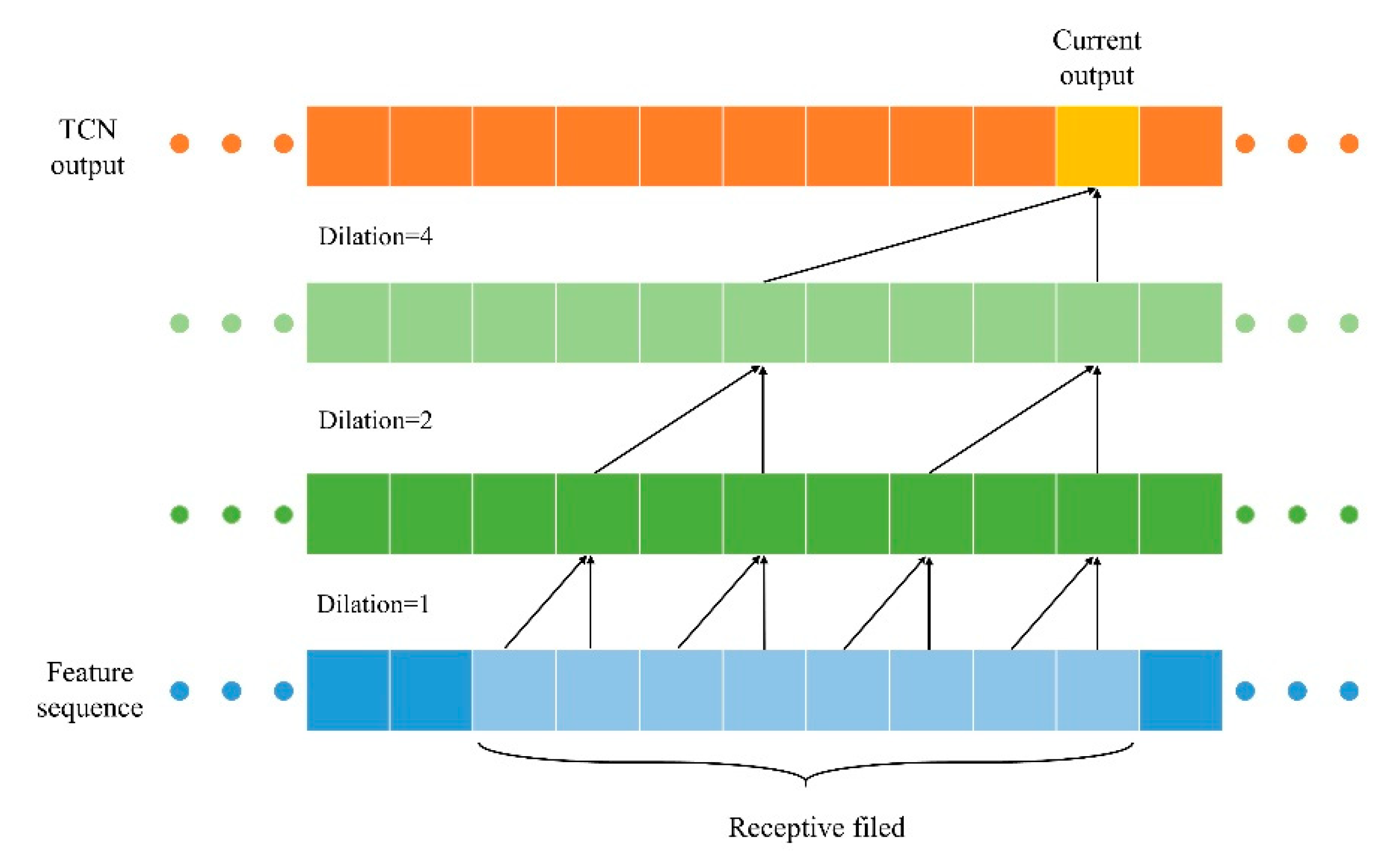
2.4. Feature Classification
2.5. State Annotation
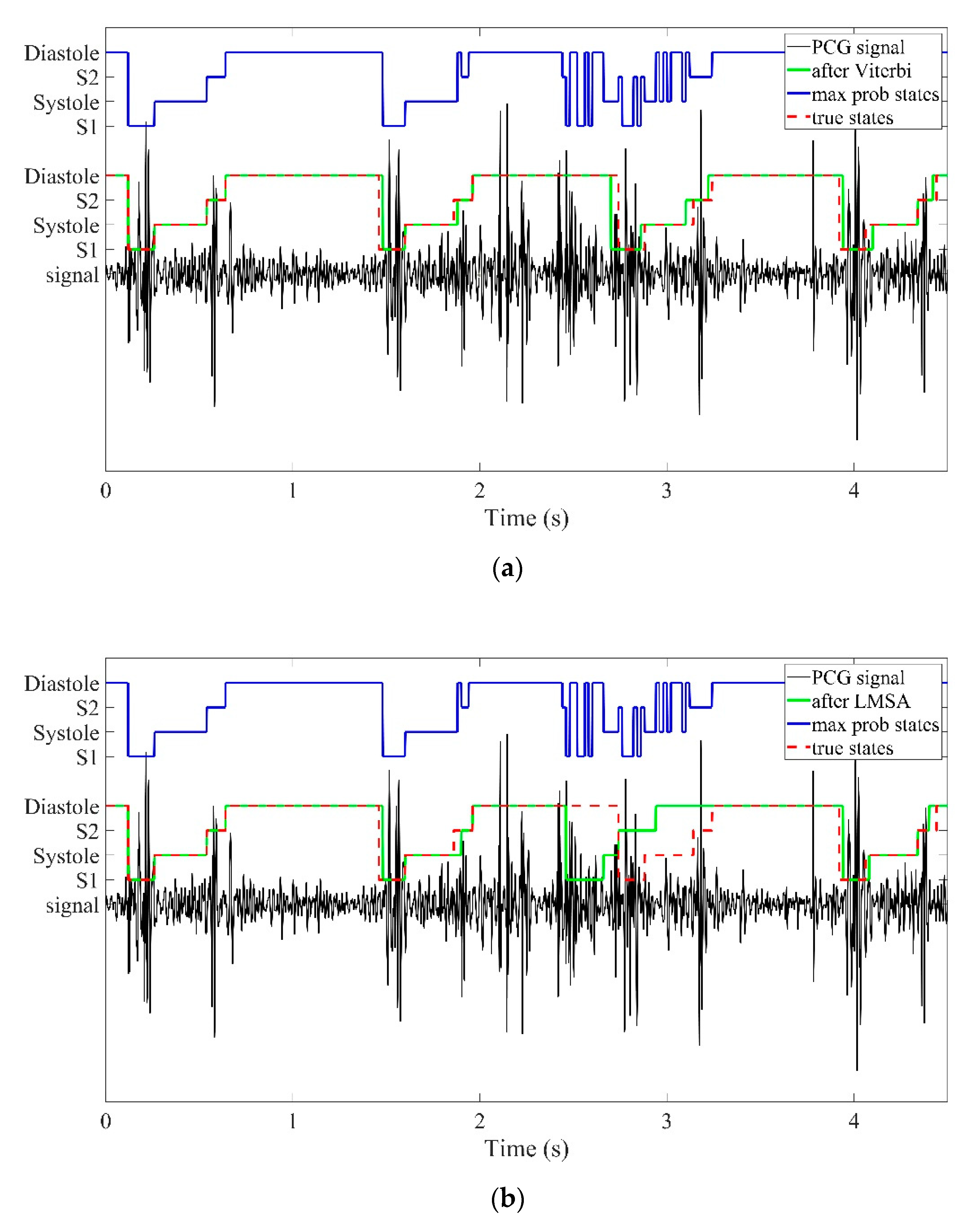
2.5.1. Limited Max Sequential Annotation (LMSA)
2.5.2. Viterbi Algorithm Based on HSMM
- Gaussian distribution:
- Poisson distribution
3. Results
3.1. Parameter Search for LSTM and TCN
3.2. Fixed State Error Correction
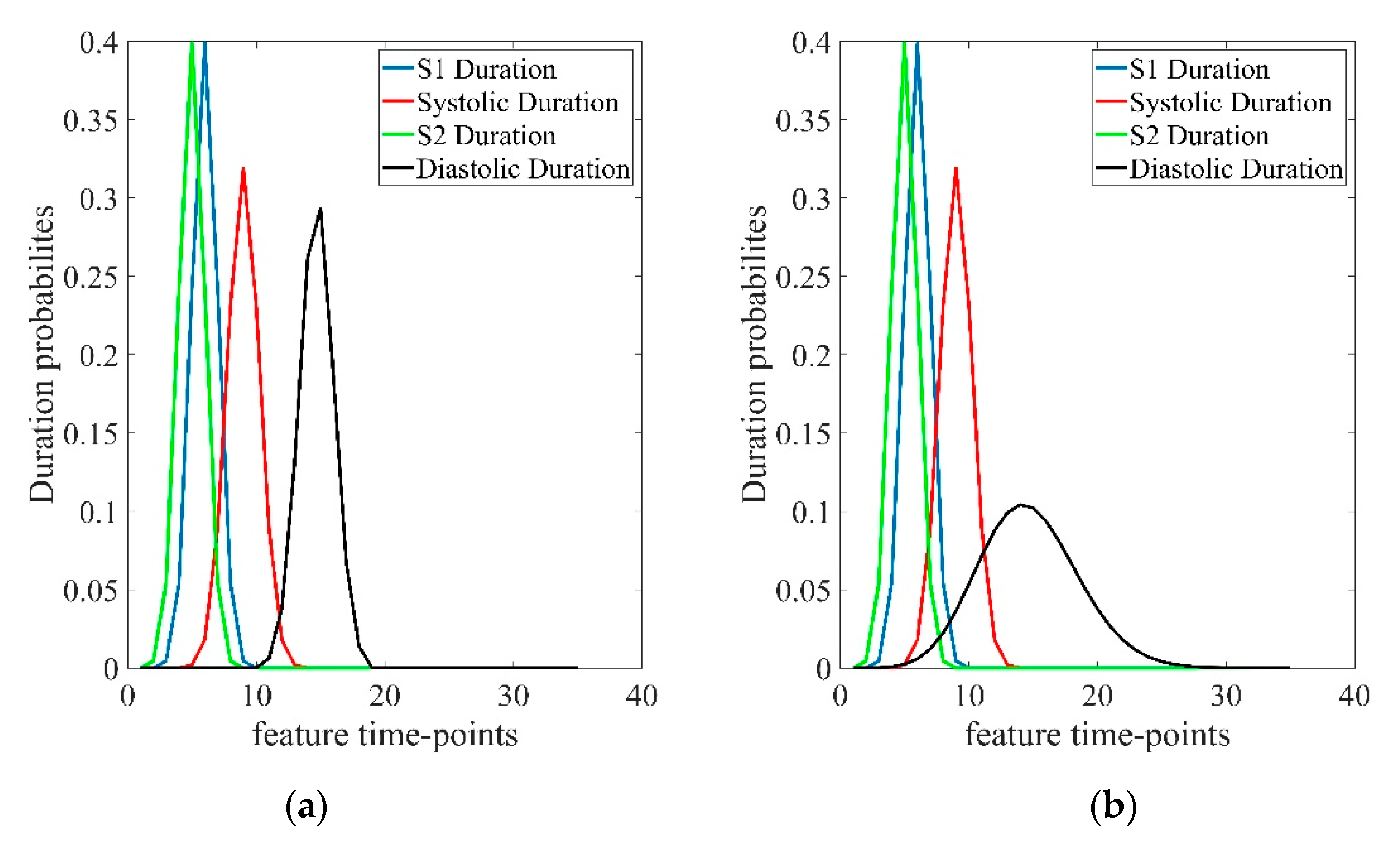
3.3. Arrhythmia Improvement
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shanthi, M. WHO | Global status report on noncommunicable diseases 2014. Women 2015, 47, 2562–2563. [Google Scholar]
- Chauhan, S.; Wang, P.; Chu, S.L.; Anantharaman, V. A computer-aided MFCC-based HMM system for automatic auscultation. Comput. Biol. Med. 2008, 38, 221–233. [Google Scholar] [CrossRef] [PubMed]
- Renna, F.; Oliveira, J.H.; Coimbra, M.T. Deep convolutional neural networks for heart sound segmentation. IEEE J. Biomed. Health Inform. 2019, 23, 2435–2445. [Google Scholar] [CrossRef] [PubMed]
- Clifford, G.D.; Liu, C.; Moody, B.E.; Roig, J.M.; Mark, R.G. Recent advances in heart sound analysis. Physiol. Meas. 2017, 38, E10. [Google Scholar] [CrossRef] [PubMed]
- Delgado-Trejos, E.; Quiceno-Manrique, A.F.; Godino-Llorente, J.I.; Blanco-Velasco, M.; Castellanos-Dominguez, G. Digital auscultation analysis for heart murmur detection. Ann. Biomed. Eng. 2009, 37, 337–353. [Google Scholar] [CrossRef] [PubMed]
- Liang, H.; Lukkarinen, S.; Hartimo, I. Heart sound segmentation algorithm based on heart sound envelogram. In Proceedings of the Computers in Cardiology 1997, Lund, Sweden, 7–10 September 1997; pp. 105–108. [Google Scholar]
- Gupta, C.N.; Palaniappan, R.; Swaminathan, S.; Krishnan, S.M. Neural network classification of homomorphic segmented heart sounds. Appl. Soft Comput. 2007, 7, 286–297. [Google Scholar] [CrossRef]
- Schmidt, S.E.; Holst-Hansen, C.; Graff, C.; Toft, E.; Struijk, J.J. Segmentation of heart sound recordings by a duration-dependent hidden Markov model. Physiol. Meas. 2010, 31, 513–529. [Google Scholar] [CrossRef]
- Sepehri, A.A.; Gharehbaghi, A.; Dutoit, T.; Kocharian, A.; Kiani, A. A novel method for pediatric heart sound segmentation without using the ECG. Comput. Methods Programs Biomed. 2010, 99, 43–48. [Google Scholar] [CrossRef]
- Naseri, H.; Homaeinezhad, M.R. Detection and boundary identification of phonocardiogram sounds using an expert frequency-energy based metric. Ann. Biomed. Eng. 2013, 41, 279–292. [Google Scholar] [CrossRef]
- Moukadem, A.; Dieterlen, A.; Hueber, N.; Brandt, C. A robust heart sounds segmentation module based on S-transform. Biomed. Signal Process. Control 2013, 8, 273–281. [Google Scholar] [CrossRef]
- Papadaniil, C.D.; Hadjileontiadis, L.J. Efficient heart sound segmentation and extraction using ensemble empirical mode decomposition and kurtosis features. IEEE J. Biomed. Health Inform. 2014, 18, 1138–1152. [Google Scholar] [CrossRef] [PubMed]
- Springer, D.B.; Tarassenko, L.; Clifford, G.D. Logistic regression-HSMM-based heart sound segmentation. IEEE Trans. Biomed. Eng. 2016, 63, 822–832. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.-E.; Yang, S.-I.; Ho, L.-T.; Tsai, K.-H.; Chen, Y.-H.; Chang, Y.-F.; Lai, Y.-H.; Wang, S.-S.; Tsao, Y.; Wu, C.-C. S1 and S2 heart sound recognition using deep neural networks. IEEE Trans. Biomed. Eng. 2017, 64, 372–380. [Google Scholar]
- Messner, E.; Zohrer, M.; Pernkopf, F. Heart sound segmentation-an event detection approach using deep recurrent neural networks. IEEE Trans. Biomed. Eng. 2018, 65, 1964–1974. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image computing and computer-assisted intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Thalmayer, A.; Zeising, S.; Fischer, G.; Kirchner, J. A robust and real-time capable envelope-based algorithm for heart sound classification: Validation under different physiological conditions. Sensors 2020, 20, 972. [Google Scholar] [CrossRef]
- Fernando, T.; Ghaemmaghami, H.; Denman, S.; Sridharan, S.; Hussain, N.; Fookes, C. Heart sound segmentation using bidirectional LSTMs with attention. IEEE J. Biomed. Health Inform. 2020, 24, 1601–1609. [Google Scholar] [CrossRef]
- Hornik, K. Approximation capabilities of multilayer feedforward networks. Neural Netw. 1991, 4, 251–257. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Liu, C.Y.; Springer, D.; Li, Q.; Moody, B.; Juan, R.A.; Chorro, F.J.; Castells, F.; Roig, J.M.; Silva, I.; Johnson, A.E.W.; et al. An open access database for the evaluation of heart sound algorithms. Physiol. Meas. 2016, 37, 2181–2213. [Google Scholar] [CrossRef]
- Oord, A.V.D.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Jian, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Yu, S.Z. Hidden semi-Markov models. Artif. Intell. 2010, 174, 215–243. [Google Scholar] [CrossRef]
- Oliveira, J.; Mantadelis, T.; Renna, F.; Gomes, P.; Coimbra, M. On Modifying the Temporal Modeling of HSMMs for Pediatric Heart Sound Segmentation; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Oliveira, J.; Renna, F.; Mantadelis, T.; Coimbra, M. Adaptive sojourn time HSMM for heart sound segmentation. IEEE J. Biomed. Health Inform. 2019, 23, 642–649. [Google Scholar] [CrossRef] [PubMed]
- Kamson, A.P.; Sharma, L.N.; Dandapat, S. Multi-centroid diastolic duration distribution based HSMM for heart sound segmentation. Biomed. Signal Process. Control 2019, 48, 265–272. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. J. Mach. Learn. Res. 2011, 15, 315–323. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Frigo, M.; Johnson, S.G. The design and implementation of FFTW3. Proc. IEEE 2005, 93, 216–231. [Google Scholar] [CrossRef]
- Ker, J.A. The recognition and management of valvular heart disease. Contin. Med. Educ. 2004, 22, 353. [Google Scholar]
- Xu, J.; Durand, L.G.; Pibarot, P. A new, simple, and accurate method for non-invasive estimation of pulmonary arterial pressure. Heart 2002, 88, 76–80. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Feature Extraction | Feature Classification | State Annotation |
|---|---|---|---|
| [6] | Shannon energy envelope | Threshold method for peaks | Larger time intervals are the diastolic period; Corresponding time intervals vary more for diastole |
| [7] | Homomorphic filtering envelope | Peak conditioning process | K-means for time intervals |
| [8] | Homomorphic envelogram and multiple frequency bands | Duration-dependent hidden Markov model (DHMM) | Viterbi algorithm for DHMM |
| [9] | Power spectral density functions | Artificial neural network (ANN) | Corresponding time intervals vary more for diastole |
| [10] | Short-time frequency amplifier and envelope smoothed with a Gaussian smoothing filter | Statistical duration-based assessment methodology | Given directly after S1 and S2 are classified |
| [11] | Optimized S-transform | Three-nearest neighbor classifier based on singular value decomposition | Given directly after S1 and S2 are classified |
| [12] | Ensemble empirical mode decomposition (EEMD) combined with kurtosis features | Threshold based on kurtosis features of peaks | Larger time intervals are the diastolic period |
| [13] | Homomorphic envelope, Hilbert envelope, wavelet envelope, and power spectral density envelope | Logistic regression | Extended Viterbi algorithm |
| [14] | Mel-frequency cepstral coefficients (MFCCs) | K-means algorithm and ANN | Given directly after S1 and S2 are classified |
| [15] | Short-time Fourier transform (STFT), homomorphic envelope, Hilbert envelope, wavelet envelope, power spectral density envelope, and MFCCs | Bidirectional recurrent neural networks | - |
| [3] | Homomorphic envelope, Hilbert envelope, wavelet envelope, and power spectral density envelope | Convolutional neural networks based on U-Net [16] | Sequential max temporal modeling and several different Viterbi algorithms |
| [17] | Hilbert transform and STFT | Threshold method for peaks | Experience of the amplitudes and remove invalid time intervals |
| [18] | Homomorphic envelope, Hilbert envelope, wavelet envelope, power spectral density envelope, and MFCCs | Bidirectional long short-term memory with attention | - |
| Net | Accuracy | Parameter Number | FLOPs | |
|---|---|---|---|---|
| PN-Training-a Testing Set (%) | LH-Training Testing Set (%) | |||
| TCN | 90.98 | 92.48 | 112k | 221k |
| LSTM | 91.26 | 93.13 | 515k | 387k |
| Combination | Database | Accuracy 1 | P+ | Se | F1 |
|---|---|---|---|---|---|
| TCN + LMSA | LH-training | 91.86 ± 0.20 | 96.11 ± 0.25 | 95.44 ± 0.25 | 95.77 ± 0.22 |
| PN-training-a | 89.65 ± 0.23 | 94.81 ± 0.27 | 92.46 ± 0.3 | 93.62 ± 0.26 | |
| TCN + Viterbi (Gaussian, α = 1) | LH-training | 91.23 ± 0.17 | 96.84 ± 0.19 | 96.27 ± 0.18 | 96.56 ± 0.18 |
| PN-training-a | 90.58 ± 0.17 | 96.08 ± 0.17 | 94.61 ± 0.18 | 95.34 ± 0.17 | |
| TCN + Viterbi (Gaussian, α = 0.2) | LH-training | 91.48 ± 0.18 | 96.90 ± 0.21 | 96.75 ± 0.19 | 96.82 ± 0.19 |
| PN-training-a | 90.58 ± 0.18 | 96.25 ± 0.18 | 95.42 ± 0.23 | 95.83 ± 0.19 | |
| TCN + Viterbi (Poisson, α = 1) | LH-training | 91.64 ± 0.17 | 97.25 ± 0.18 | 96.80 ± 0.17 | 97.02 ± 0.17 |
| PN-training-a | 90.59 ± 0.17 | 96.49 ± 0.15 | 94.99 ± 0.21 | 95.74 ± 0.17 | |
| LSTM + LMSA | LH-training | 92.35 ± 0.42 | 96.61 ± 0.31 | 95.78 ± 0.38 | 96.20 ± 0.32 |
| PN-training-a | 89.77 ± 0.74 | 94.33 ± 0.68 | 91.96 ± 0.88 | 93.13 ± 0.76 | |
| LSTM + Viterbi (Gaussian, α = 1) | LH-training | 91.04 ± 0.29 | 96.46 ± 0.28 | 95.90 ± 0.26 | 96.18 ± 0.27 |
| PN-training-a | 89.08 ± 0.59 | 94.01 ± 0.69 | 92.49 ± 0.72 | 93.25 ± 0.70 | |
| LSTM + Viterbi (Gaussian, α = 0.2) | LH-training | 91.56 ± 0.31 | 96.76 ± 0.32 | 96.67 ± 0.28 | 96.72 ± 0.30 |
| PN-training-a | 89.54 ± 0.63 | 94.84 ± 0.65 | 94.08 ± 0.76 | 94.46 ± 0.69 | |
| LSTM + Viterbi (Poisson, α = 1) | LH-training | 91.64 ± 0.31 | 97.05 ± 0.29 | 96.75 ± 0.26 | 96.90 ± 0.27 |
| PN-training-a | 89.50 ± 0.63 | 95.12 ± 0.62 | 93.72 ± 0.76 | 94.41 ± 0.68 |
| Algorithm | Database | Accuracy 1 | P+ | Se | F1 |
|---|---|---|---|---|---|
| [13] | LH-training | 92.52 ± 1.33 | 95.92 ± 0.83 | 95.34 ± 0.88 | 95.63 ± 0.85 |
| [15] | PN-training-all 2 | - | 94.9 | 95.9 | 95.4 |
| [3] | LH-training | 91.7 ± 1.0 | 95.7 ± 1.0 | 95.8 ± 1.0 | 95.7 ± 1.5 |
| [18] | PN-training-all 2 | 96.9 ± 0.13 | 96.3 ± 0.42 | 97.2 ± 0.19 | 96.70 ± 0.17 |
| LSTM + Viterbi (Poisson, α = 1) | LH-training | 91.64 ± 0.17 | 97.25 ± 0.18 | 96.80 ± 0.17 | 97.02 ± 0.17 |
| PN-training-a | 90.59 ± 0.17 | 96.49 ± 0.15 | 94.99 ± 0.21 | 95.74 ± 0.17 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, Y.; Ma, K.; Liu, M. Temporal Convolutional Network Connected with an Anti-Arrhythmia Hidden Semi-Markov Model for Heart Sound Segmentation. Appl. Sci. 2020, 10, 7049. https://doi.org/10.3390/app10207049
Yin Y, Ma K, Liu M. Temporal Convolutional Network Connected with an Anti-Arrhythmia Hidden Semi-Markov Model for Heart Sound Segmentation. Applied Sciences. 2020; 10(20):7049. https://doi.org/10.3390/app10207049
Chicago/Turabian StyleYin, Yibo, Kainan Ma, and Ming Liu. 2020. "Temporal Convolutional Network Connected with an Anti-Arrhythmia Hidden Semi-Markov Model for Heart Sound Segmentation" Applied Sciences 10, no. 20: 7049. https://doi.org/10.3390/app10207049
APA StyleYin, Y., Ma, K., & Liu, M. (2020). Temporal Convolutional Network Connected with an Anti-Arrhythmia Hidden Semi-Markov Model for Heart Sound Segmentation. Applied Sciences, 10(20), 7049. https://doi.org/10.3390/app10207049