A Response-Adaptive Method for Design of Validation Experiments in Computational Mechanics



Abstract
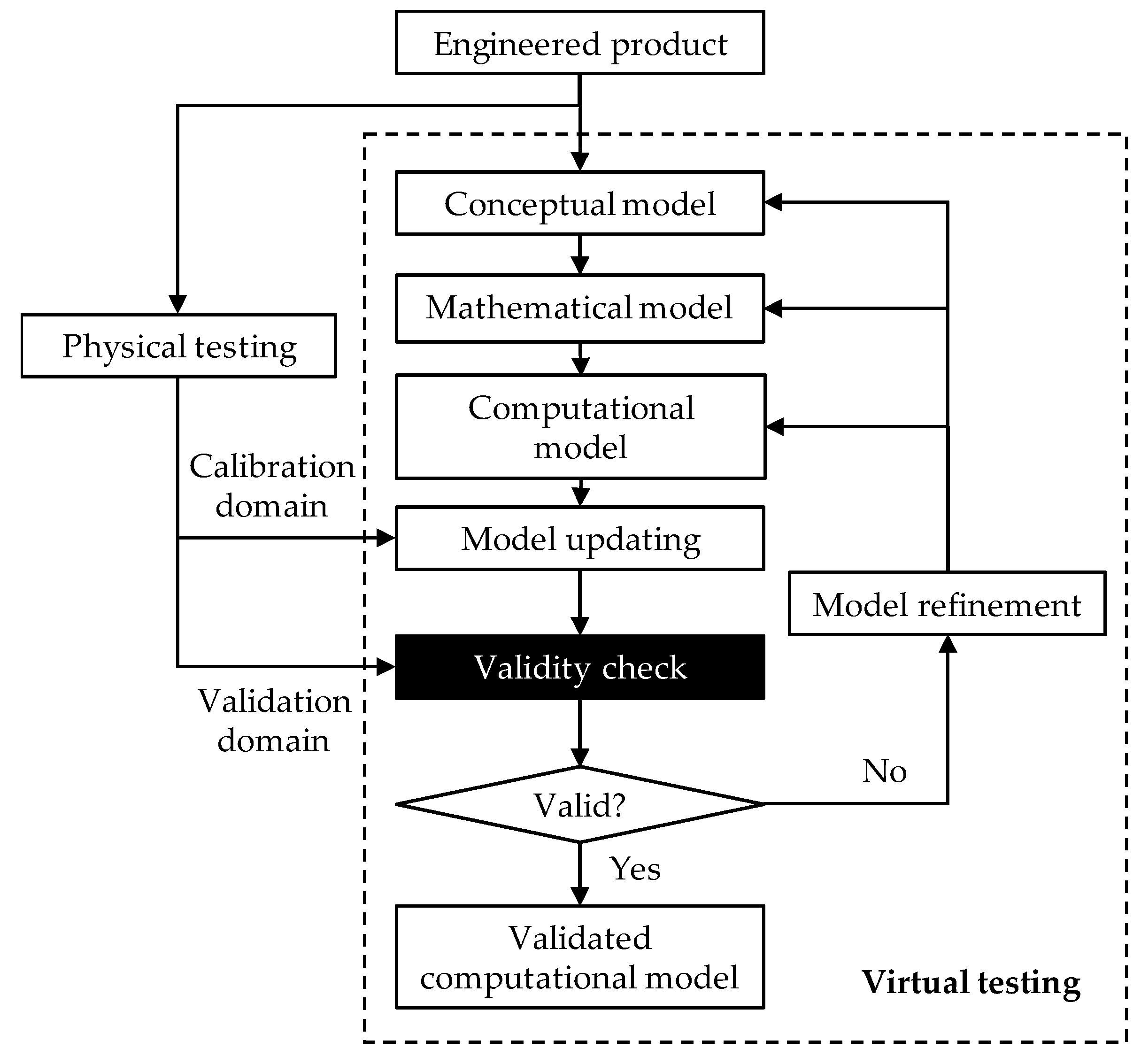
1. Introduction
2. Hypothesis Test for Validity Check
3. Response-Adaptive Experiment Design
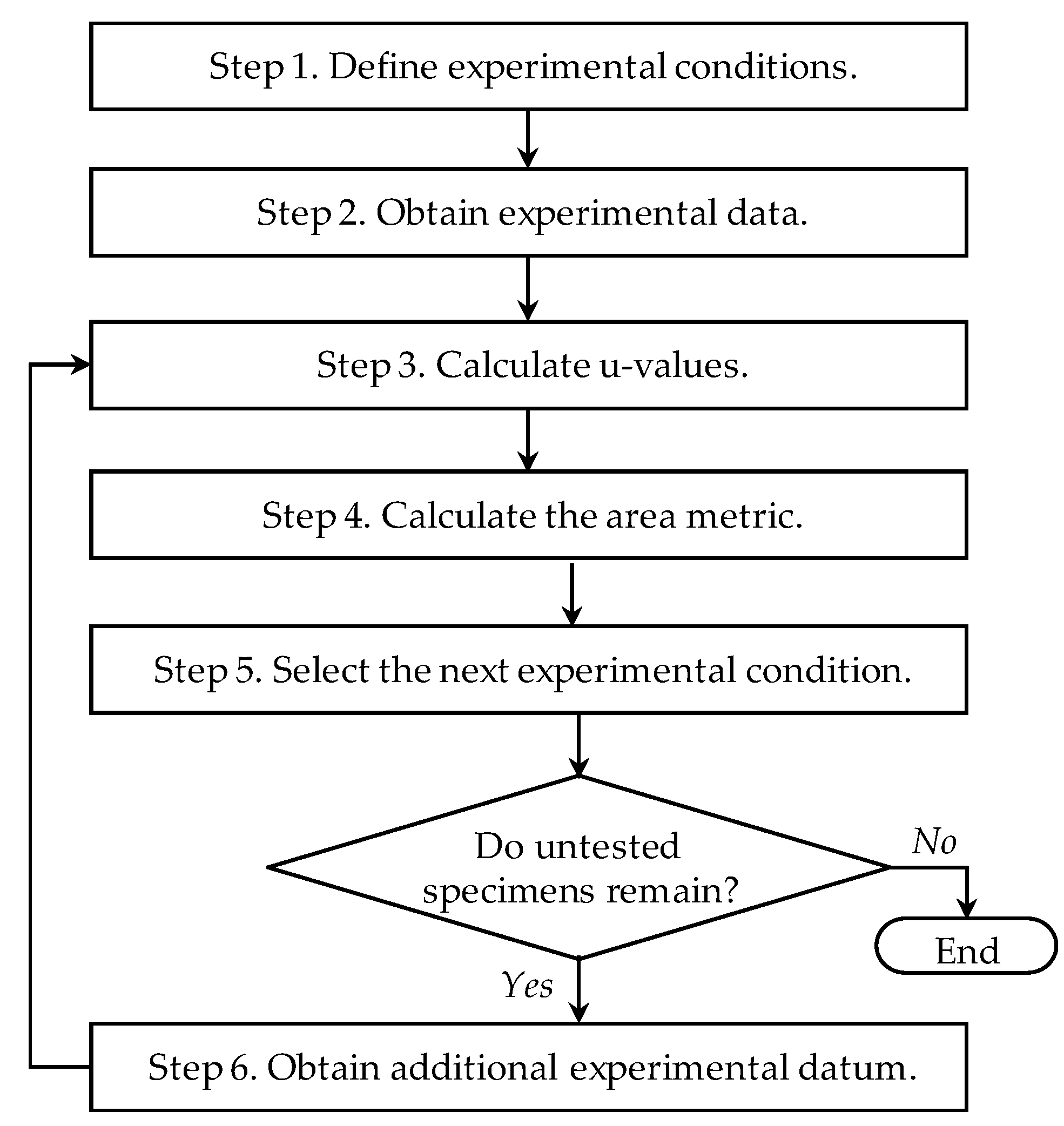
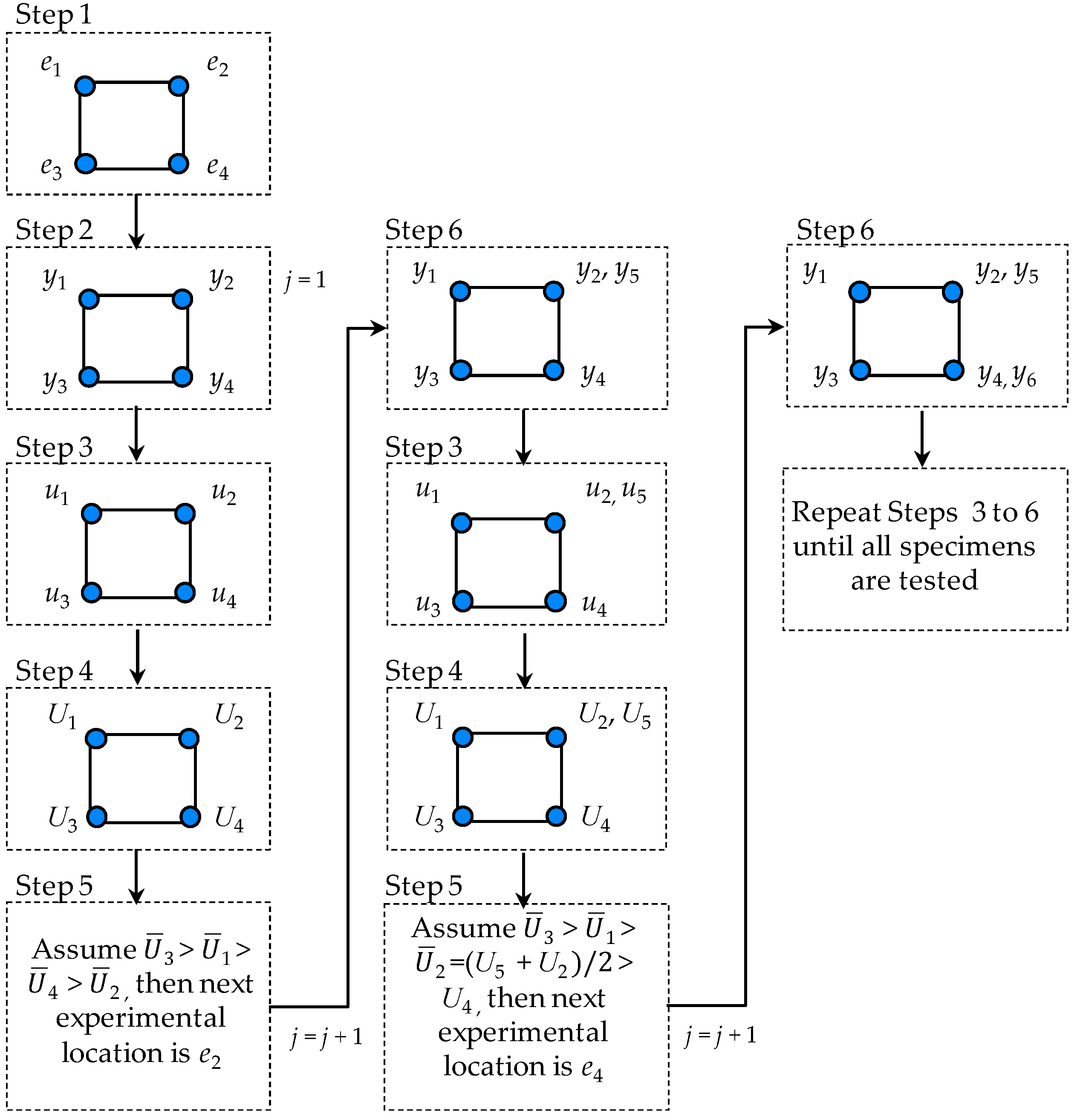
3.1. Procedure of Experimental Design
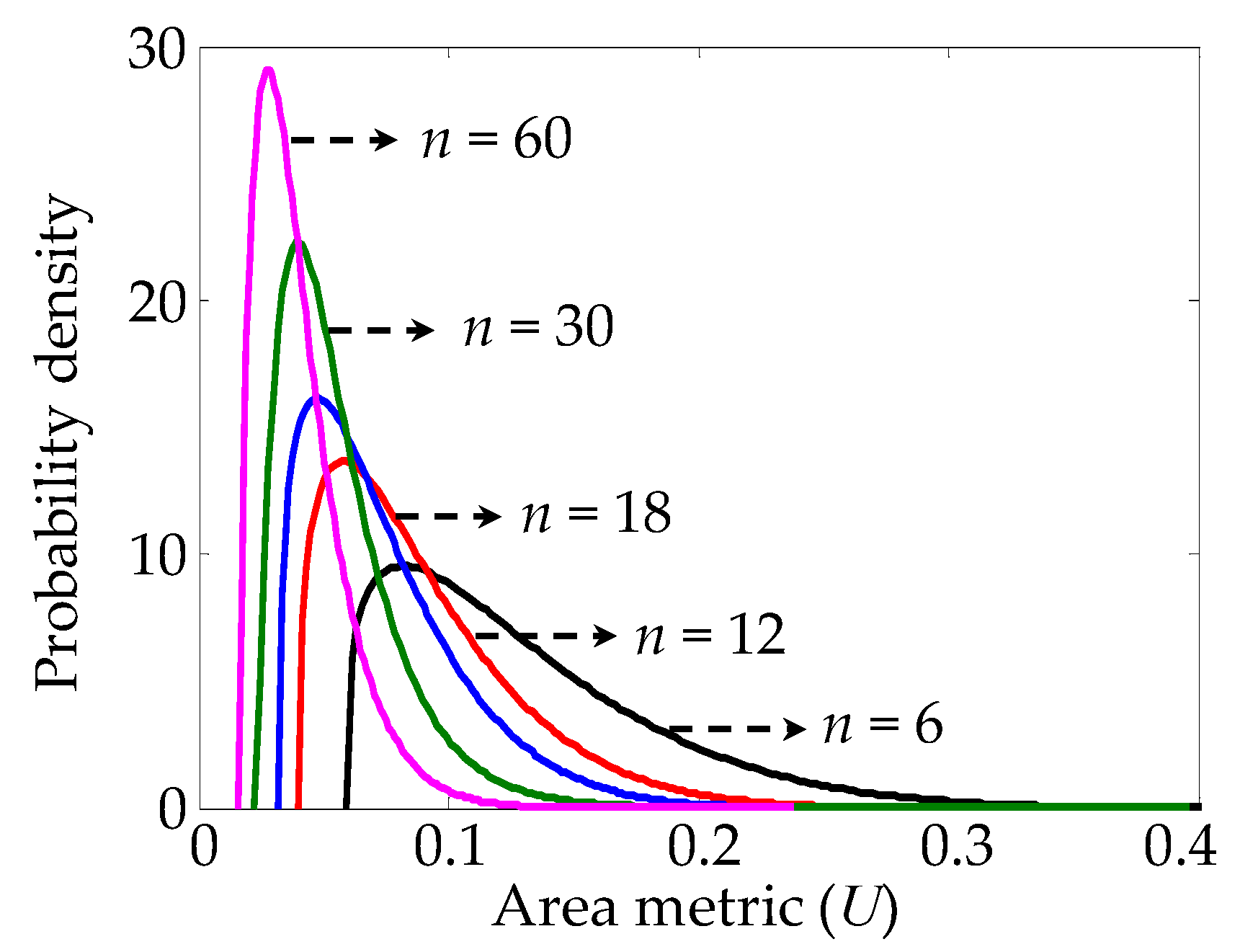
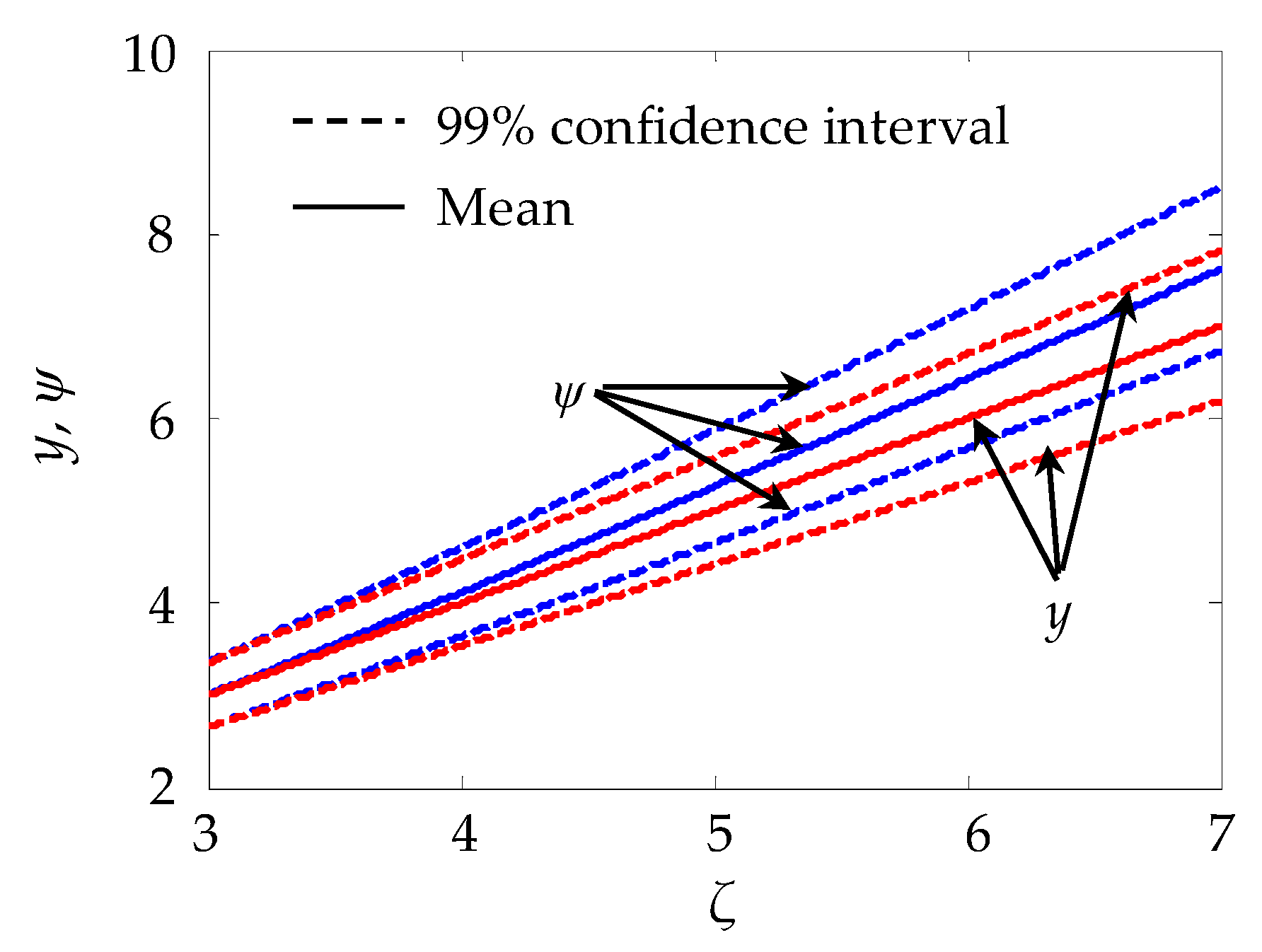
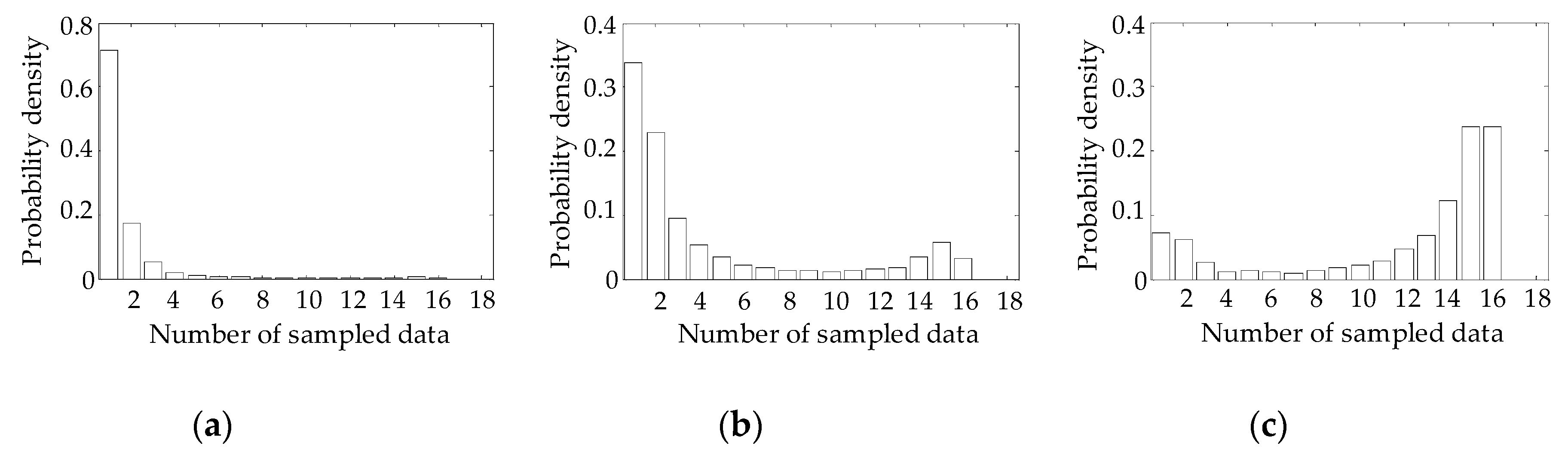
3.2. Experimental Design for Reduction of Type II Error
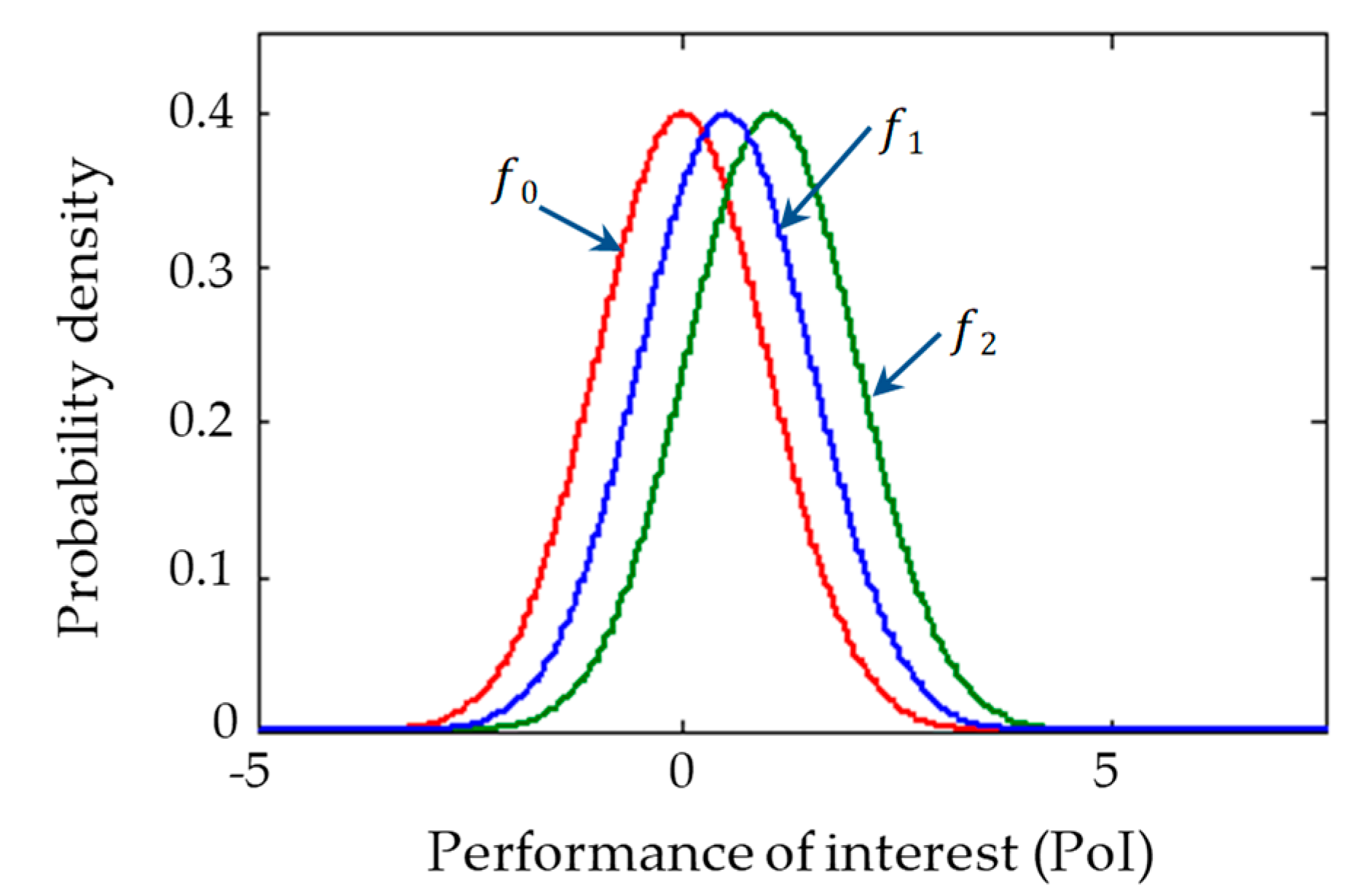
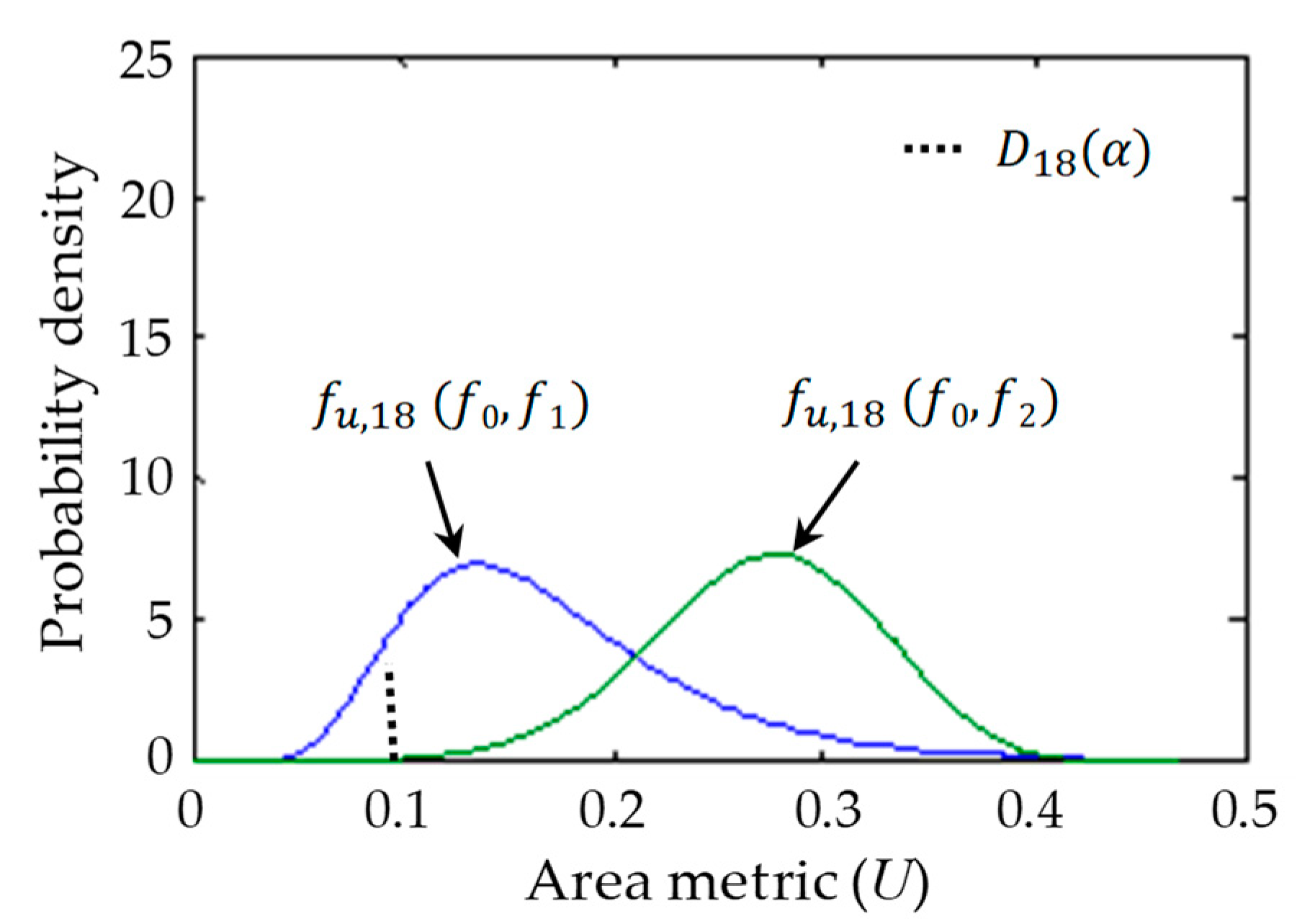
4. Case Study
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Park, J.; Ha, J.M.; Oh, H.; Youn, B.D.; Choi, J.; Kim, N.H. Model-based fault diagnosis of a planetary gear: A novel approach using transmission error. IEEE Trans. Reliab. 2016, 65, 1830–1841. [Google Scholar] [CrossRef]
- Oh, H.; Choi, H.; Jung, J.H.; Youn, B.D. A robust and convex metric for unconstrained optimization in statistical model calibration—Probability residual (PR). Struct. Multidiscip. Optim. 2019, 60, 1171–1187. [Google Scholar] [CrossRef]
- IEEE. IEEE Standard for Software Verfication and Validation; Institute of Electrical and Electronic Engineers: New York, NY, USA, 1998; pp. 1–80. [Google Scholar]
- ASME. Guide for Verification and Validation in Computational Solid Mechanics; American Society of Mechanical Engineers: New York, NY, USA, 2006; pp. 1–36. [Google Scholar]
- Oberkampf, W.L.; Trucano, T.G.; Hirsch, C. Verification, validation, predictive capability in computational engineering and physics. Appl. Mech. Rev. 2004, 57, 345–384. [Google Scholar] [CrossRef]
- Thacker, B.H.; Doebling, S.W.; Hemez, F.M.; Anderson, M.C.; Pepin, J.E.; Rodriguez, E.A. Concepts of Model Verification and Validation; Los Alamos National Laboratory: Los Alamos, NM, USA, 2004; pp. 1–27. [Google Scholar]
- Oberkampf, W.L.; Barone, M.F. Measures of agreement between computation and experiment: Validation metrics. J. Comput. Phys. 2006, 217, 5–36. [Google Scholar] [CrossRef]
- Youn, B.D.; Jung, B.C.; Xi, Z.; Kim, S.B.; Lee, W.R. A hierarchical framework for statistical model calibration in engineering product development. Comput. Methods Appl. Mech. Eng. 2011, 200, 1421–1431. [Google Scholar] [CrossRef]
- Zhang, R.X.; Mahadevan, S. Bayesian methodology for reliability model acceptance. Reliab. Eng. Syst. Saf. 2003, 80, 95–103. [Google Scholar] [CrossRef]
- Chen, W.; Tsui, K.; Wang, S. A design-driven validation approach using Bayesian prediction models. J. Mech. Des. 2008, 140, 021101. [Google Scholar] [CrossRef]
- Liu, F.; Bayarri, M.J.; Berger, J.O.; Paulo, R.; Sacks, J. A Bayesian analysis of the thermal challenge problem. Comput. Methods Appl. Mech. Eng. 2008, 197, 2457–2466. [Google Scholar] [CrossRef]
- Jung, B.C.; Park, J.; Oh, H.; Kim, J.; Youn, B.D. A framework of model validation and virtual product qualification with limited experimental data based on statistical inference. Struct. Multidiscip. Optim. 2015, 51, 573–583. [Google Scholar] [CrossRef]
- Mohammadi, F.; Zheng, C. A precise SVM classification model for predictions with missing data. In Proceedings of the 4th National Conference on Applied Research in Electrical, Mechanical Computer and IT Engineering, Tehran, Iran, 4 October 2018; pp. 3594–3606. [Google Scholar]
- Angus, J.E. The probability integral transform and related results. SIAM Rev. 1994, 36, 652–654. [Google Scholar] [CrossRef]
- Ferson, S.; Oberkampf, W.L.; Ginzburg, L. Model validation and predictive capability for the thermal challenge problem. Comput. Methods Appl. Mech. Eng. 2008, 197, 2408–2430. [Google Scholar] [CrossRef]
- Tavoosi, J.; Mohammadi, F. Design a New Intelligent Control for a Class of Nonlinear Systems. In Proceedings of the 6th International Conference on Control, Instrumentation, and Automation (ICCIA 2019), Kordestan, Iran, 30–31 October 2019. [Google Scholar]
- Karimi, H.; Ghasemi, R.; Mohammadi, F. Adaptive Neural Observer-Based Nonsingular Terminal Sliding Mode Controller Design for a Class of Nonlinear Systems. In Proceedings of the 6th International Conference on Control, Instrumentation, and Automation (ICCIA 2019), Kordestan, Iran, 30–31 October 2019. [Google Scholar]
- Oh, H.; Kim, J.; Son, H.; Youn, B.D.; Jung, B.C. A systematic approach for model refinement considering blind and recognized uncertainties in engineered product development. Struct. Multidiscip. Optim. 2016, 54, 1527–1541. [Google Scholar] [CrossRef]
- Youn, B.D.; Xi, Z.; Wang, P. Eigenvector dimension reduction (EDR) method for sensitivity-free probability analysis. Struct. Multidiscip. Optim. 2008, 37, 13–28. [Google Scholar] [CrossRef]
- Rebenda, J.; Smarda, Z.; Khan, Y. A new semi-analytical approach for numerical solving of Cauchy problem for differential equations with delay. Filomat 2017, 31, 4725–4733. [Google Scholar] [CrossRef]
- Fazio, R.; Jannelli, A.; Agreste, S. A finite difference method on non-uniform meshes for time-fractional advection—Diffusion equations with a source term. Appl. Sci. 2018, 8, 960. [Google Scholar] [CrossRef]
- Ruggieri, M.; Speciale, M.P. Similarity reduction and closed form solutions for a model derived from two-layer fluids. Adv. Differ. Equ. 2013, 2013, 355. [Google Scholar] [CrossRef][Green Version]
- Ruggieri, M. Kink solutions for a class of generalized dissipative equations. Abstr. Appl. Anal. 2012, 2012, 7. [Google Scholar] [CrossRef]
- Ruggieri, M.; Valenti, A. Approximate symmetries in nonlinear viscoelastic media. Bound. Value Probl. 2013, 2013, 143. [Google Scholar] [CrossRef]
- Cho, J.C.; Jung, B.C. Prediction of tread pattern wear by an explicit finite element model. Tire Sci. Technol. 2007, 35, 276–299. [Google Scholar] [CrossRef]
- Oh, H.; Wei, H.P.; Han, B.; Youn, B.D. Probabilistic lifetime prediction of electronic packages using advanced uncertainty propagation analysis and model calibration. IEEE Trans. Compon. Packag. Manuf. Technol. 2016, 6, 238–248. [Google Scholar] [CrossRef]
- Dowding, K.J.; Pilch, M.; Hills, R.G. Formulation of the thermal problem. Comput. Methods Appl. Mech. Eng. 2008, 197, 2385–2389. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | Mean | Standard Deviation | Skewness | Kurtosis |
|---|---|---|---|---|
| 6 | 0.1296 | 0.0535 | 1.1326 | 4.2585 |
| 12 | 0.0914 | 0.0389 | 1.2337 | 4.7938 |
| 18 | 0.0741 | 0.0319 | 1.2177 | 4.6966 |
| 30 | 0.0569 | 0.0247 | 1.4871 | 6.3728 |
| 60 | 0.0407 | 0.0178 | 1.3245 | 5.3782 |
| Cases | Type II Error |
|---|---|
| Condition I | 0.35 |
| Condition II | 0.00 |
| Experimental Design | Mean | Standard Deviation | Skewness | Kurtosis | Pearson System Type | Type II Error |
|---|---|---|---|---|---|---|
| Design A | 0.2190 | 0.0542 | −0.0566 | 2.8346 | Type I | 0.068 |
| Design B | 0.2390 | 0.0562 | −0.1761 | 2.8332 | Type I | 0.040 |
| Design C | 0.3206 | 0.0675 | −1.0643 | 4.6404 | Type I | 0.016 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, B.C.; Shin, Y.-H.; Lee, S.H.; Huh, Y.C.; Oh, H. A Response-Adaptive Method for Design of Validation Experiments in Computational Mechanics. Appl. Sci. 2020, 10, 647. https://doi.org/10.3390/app10020647
Jung BC, Shin Y-H, Lee SH, Huh YC, Oh H. A Response-Adaptive Method for Design of Validation Experiments in Computational Mechanics. Applied Sciences. 2020; 10(2):647. https://doi.org/10.3390/app10020647
Chicago/Turabian StyleJung, Byung C., Yun-Ho Shin, Sang Hyuk Lee, Young Cheol Huh, and Hyunseok Oh. 2020. "A Response-Adaptive Method for Design of Validation Experiments in Computational Mechanics" Applied Sciences 10, no. 2: 647. https://doi.org/10.3390/app10020647
APA StyleJung, B. C., Shin, Y.-H., Lee, S. H., Huh, Y. C., & Oh, H. (2020). A Response-Adaptive Method for Design of Validation Experiments in Computational Mechanics. Applied Sciences, 10(2), 647. https://doi.org/10.3390/app10020647