A Comparative Study of Different Machine Learning Algorithms in Predicting the Content of Ilmenite in Titanium Placer

 , , ,
, , ,  ,
,  and
and
Abstract
1. Introduction
2. Background of Artificial Intelligence Techniques Used
2.1. Random Forest
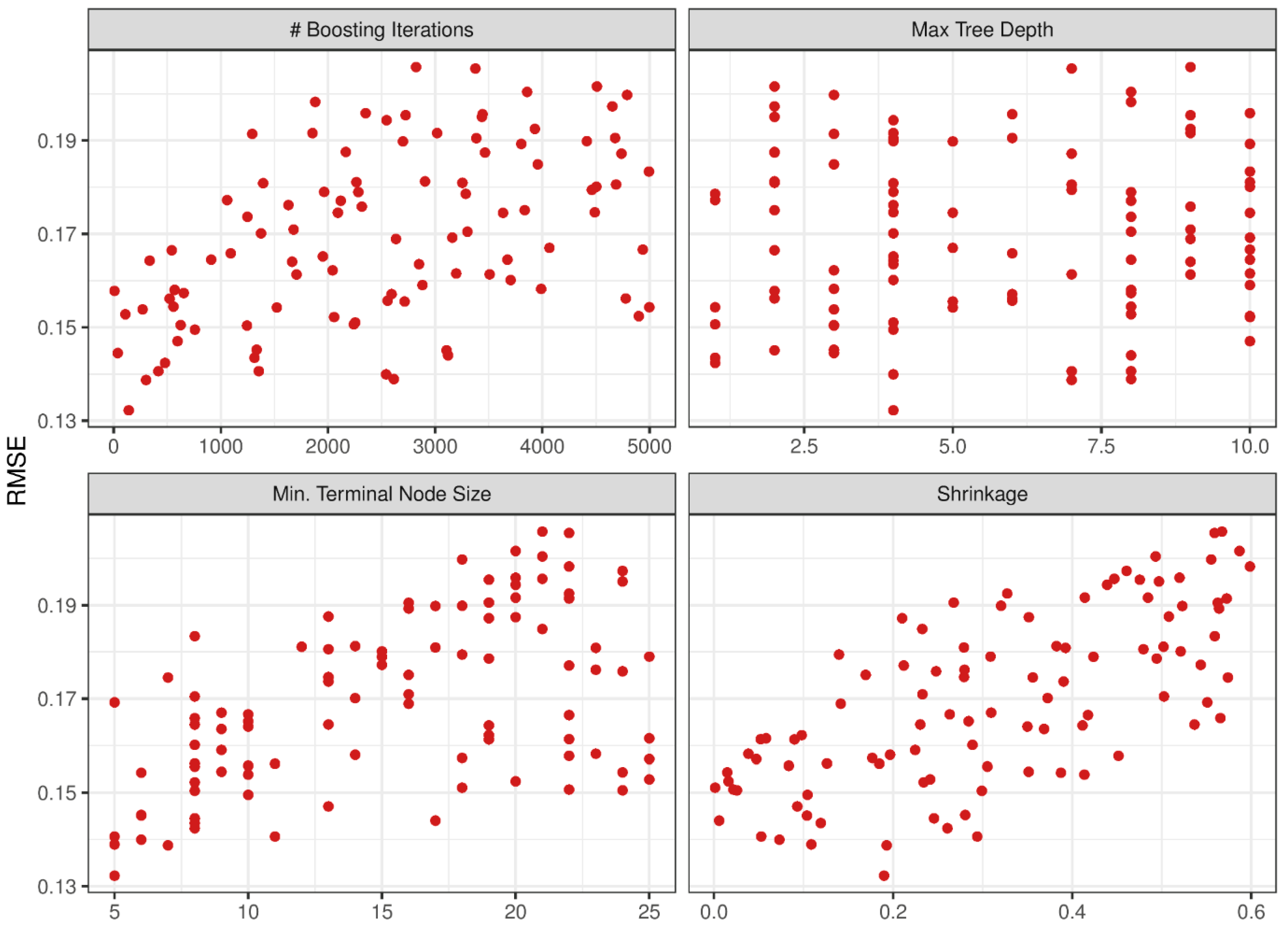
2.2. Stochastic Gradient Boosting
2.3. CART
2.4. SVM
2.5. Cubist
2.6. The k-Nearest Neighbors
2.7. ANN
- Step 1: The input neurons receive signals from the external environment (the weight percent of each heavy mineral: Rutile, anatase, leucoxene, zircon, and monazite).
- Step 2: Calculate weights and biases.
- Step 3: Send information that has been preprocessed to the first hidden layer. Transfer functions can be enabled to transmit information between layers.
- Step 4: Perform learning and calculation in the first hidden layer.
- Step 5: Recalculate weights and biases after learning in the first hidden layer.
- Step 6: Send the results to the second hidden layer,
- Step 7: Perform the same actions as done in the first hidden layer.
- Step 8: Send the calculation results, weights, and biases in the second hidden layer to the output layer.
- Step 9: Repeat the same calculations for the next hidden layer.
- Step 10: Estimate the ilmenite content and produce the final result.
3. Data Collection
4. Development of the Model
4.1. RF Model
4.2. SGB Model
4.3. CART Model
4.4. SVM Model
4.5. Cubist Model
4.6. The kNN Model
4.7. ANN Model
5. Performance Indicators for Evaluating the Soft Computing Techniques
6. Results and Discussions
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lasheen, T. Chemical benefication of Rosetta ilmenite by direct reduction leaching. Hydrometallurgy 2005, 76, 123–129. [Google Scholar] [CrossRef]
- Nayl, A.; Awwad, N.; Aly, H. Kinetics of acid leaching of ilmenite decomposed by KOH: Part 2. Leaching by H2SO4 and C2H2O4. J. Hazard. Mater. 2009, 168, 793–799. [Google Scholar] [CrossRef] [PubMed]
- Nayl, A.; Ismail, I.; Aly, H. Ammonium hydroxide decomposition of ilmenite slag. Hydrometallurgy 2009, 1, 196–200. [Google Scholar] [CrossRef]
- Mehdilo, A.; Irannajad, M.; Rezai, B. Applied mineralogical characterization of ilmenite from Kahnuj placer deposit, Southern Iran. Period. Mineral. 2015, 84, 289–302. [Google Scholar]
- Kušnír, I. Mineral resources of Vietnam. Acta Montan. Slovaca 2000, 2, 165–172. [Google Scholar]
- Dung, N.T.; Bac, B.H.; Van Anh, T.T. Distribution and Reserve Potential of Titanium-Zirconium Heavy Minerals in Quang an Area, Thua Thien Hue Province, Vietnam. In Proceedings of the International Conference on Geo-Spatial Technologies and Earth Resources, Hanoi, Vietnam, 5–6 October 2017; pp. 326–339. [Google Scholar]
- Lalomov, A.; Platonov, M.; Tugarova, M.; Bochneva, A.; Chefranova, A. Rare metal–titanium placer metal potential of Cambrian–Ordovician sandstones in the northwestern Russian Plate. Lithol. Miner. Resour. 2015, 50, 501–511. [Google Scholar] [CrossRef]
- Force, E.R. Geology of Titanium-Mineral Deposits; Geological Society of America: McLean, Vietnam, 1991; Volume 259. [Google Scholar]
- Dill, H.; Melcher, F.; Fuessl, M.; Weber, B. The origin of rutile-ilmenite aggregates (“nigrine”) in alluvial-fluvial placers of the Hagendorf pegmatite province, NE Bavaria, Germany. Mineral. Petrol. 2007, 89, 133–158. [Google Scholar] [CrossRef]
- Gázquez, M.J.; Bolívar, J.P.; Garcia-Tenorio, R.; Vaca, F. A review of the production cycle of titanium dioxide pigment. Mater. Sci. Appl. 2014, 5, 441. [Google Scholar] [CrossRef]
- Mwase Malumbo, J.; Gaydardzhiev, S.; Guillet, A.; Stefansecu, E.; Sehner, E. Investigation on Ilmenite Placer Ore as a Precursor for Synthetic Rutile. In Proceedings of the EMPRC 2018 European Mineral Processing and Recycling Congress, Clausthal-Zellerfeld, Germany, 25–26 June 2018. [Google Scholar]
- Korneliussen, A.; McENROE, S.A.; Nilsson, L.P.; Schiellerup, H.; Gautneb, H.; Meyer, G.B.; Storseth, L. An overview of titanium deposits in Norway. Nor. Geol. Unders. 2000, 436, 27–38. [Google Scholar]
- Samal, S.; Mohapatra, B.; Mukherjee, P.; Chatterjee, S. Integrated XRD, EPMA and XRF study of ilmenite and titania slag used in pigment production. J. Alloys Compd. 2009, 474, 484–489. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, S.; Ma, W.; Dai, Y. Review of TiO2-Rich Materials Preparation for the Chlorination Process. In TMS Annual Meeting & Exhibition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 225–234. [Google Scholar]
- Perks, C.; Mudd, G. Titanium, zirconium resources and production: A state of the art literature review. Ore Geol. Rev. 2019, 107, 629–646. [Google Scholar] [CrossRef]
- Achieng, K.O. Modelling of soil moisture retention curve using machine learning techniques: Artificial and deep neural networks vs support vector regression models. Comput. Geosci. 2019, 133, 104320. [Google Scholar] [CrossRef]
- Conway, D.; Alexander, B.; King, M.; Heinson, G.; Kee, Y. Inverting magnetotelluric responses in a three-dimensional earth using fast forward approximations based on artificial neural networks. Comput. Geosci. 2019, 127, 44–52. [Google Scholar] [CrossRef]
- Johnson, L.M.; Rezaee, R.; Kadkhodaie, A.; Smith, G.; Yu, H. Geochemical property modelling of a potential shale reservoir in the Canning Basin (Western Australia), using Artificial Neural Networks and geostatistical tools. Comput. Geosci. 2018, 120, 73–81. [Google Scholar] [CrossRef]
- Souza, J.; Santos, M.; Magalhães, R.; Neto, E.; Oliveira, G.; Roque, W. Automatic classification of hydrocarbon “leads” in seismic images through artificial and convolutional neural networks. Comput. Geosci. 2019, 132, 23–32. [Google Scholar] [CrossRef]
- Trépanier, S.; Mathieu, L.; Daigneault, R.; Faure, S. Precursors predicted by artificial neural networks for mass balance calculations: Quantifying hydrothermal alteration in volcanic rocks. Comput. Geosci. 2016, 89, 32–43. [Google Scholar] [CrossRef]
- Juliani, C.; Ellefmo, S.L. Prospectivity Mapping of Mineral Deposits in Northern Norway Using Radial Basis Function Neural Networks. Minerals 2019, 9, 131. [Google Scholar] [CrossRef]
- Chen, Y.; An, A. Application of ant colony algorithm to geochemical anomaly detection. J. Geochem. Explor. 2016, 164, 75–85. [Google Scholar] [CrossRef]
- Mlynarczuk, M.; Skiba, M. The application of artificial intelligence for the identification of the maceral groups and mineral components of coal. Comput. Geosci. 2017, 103, 133–141. [Google Scholar] [CrossRef]
- Maepa, F.; Smith, R. Predictive mapping of the gold mineral potential in the Swayze Greentone Belt, ON, Canada. In SEG Technical Program Expanded Abstracts 2017; Society of Exploration Geophysicists: Tulsa, OK, USA, 2017; pp. 2456–2460. [Google Scholar]
- Zuo, R.; Xiong, Y. Big data analytics of identifying geochemical anomalies supported by machine learning methods. Nat. Resour. Res. 2018, 27, 5–13. [Google Scholar] [CrossRef]
- Zuo, R.; Xiong, Y.; Wang, J.; Carranza, E.J.M. Deep learning and its application in geochemical mapping. Earth Sci. Rev. 2019, 192, 1–14. [Google Scholar] [CrossRef]
- Chen, Y.; Lu, L.; Li, X. Application of continuous restricted Boltzmann machine to identify multivariate geochemical anomaly. J. Geochem. Explor. 2014, 140, 56–63. [Google Scholar] [CrossRef]
- Ekbia, H.; Mattioli, M.; Kouper, I.; Arave, G.; Ghazinejad, A.; Bowman, T.; Suri, V.R.; Tsou, A.; Weingart, S.; Sugimoto, C.R. Big data, bigger dilemmas: A critical review. J. Assoc. Inf. Sci. Technol. 2015, 66, 1523–1545. [Google Scholar] [CrossRef]
- Gonbadi, A.M.; Tabatabaei, S.H.; Carranza, E.J.M. Supervised geochemical anomaly detection by pattern recognition. J. Geochem. Explor. 2015, 157, 81–91. [Google Scholar] [CrossRef]
- Liu, Y.; Ma, S.; Zhu, L.; Sadeghi, M.; Doherty, A.L.; Cao, D.; Le, C. The multi-attribute anomaly structure model: An exploration tool for the Zhaojikou epithermal Pb-Zn deposit, China. J. Geochem. Explor. 2016, 169, 50–59. [Google Scholar] [CrossRef]
- Nykänen, V.; Niiranen, T.; Molnár, F.; Lahti, I.; Korhonen, K.; Cook, N.; Skyttä, P. Optimizing a knowledge-driven prospectivity model for gold deposits within Peräpohja Belt, Northern Finland. Nat. Resour. Res. 2017, 26, 571–584. [Google Scholar] [CrossRef]
- Parsa, M.; Maghsoudi, A.; Yousefi, M. A receiver operating characteristics-based geochemical data fusion technique for targeting undiscovered mineral deposits. Nat. Resour. Res. 2018, 27, 15–28. [Google Scholar] [CrossRef]
- Hronsky, J.M.; Kreuzer, O.P. Applying Spatial Prospectivity Mapping to Exploration Targeting: Fundamental Practical issues and Suggested Solutions for the Future. Ore Geol. Rev. 2019, 107, 647–653. [Google Scholar] [CrossRef]
- Wang, Z.; Zuo, R.; Dong, Y. Mapping Geochemical Anomalies Through Integrating Random Forest and Metric Learning Methods. Nat. Resour. Res. 2019, 28, 1285–1298. [Google Scholar] [CrossRef]
- Khang, L.Q. Report on Exploration of Titan-Zircon Heavy Minerals at South Suoi Nhum, Ham Thuan Nam District, Binh Thuan Province; Center for Information and Archives of Geology: Hanoi, Vietnam, 2011.
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Vigneau, E.; Courcoux, P.; Symoneaux, R.; Guérin, L.; Villière, A. Random forests: A machine learning methodology to highlight the volatile organic compounds involved in olfactory perception. Food Qual. Prefer. 2018, 68, 135–145. [Google Scholar] [CrossRef]
- Matin, S.; Farahzadi, L.; Makaremi, S.; Chelgani, S.C.; Sattari, G. Variable selection and prediction of uniaxial compressive strength and modulus of elasticity by random forest. Appl. Soft Comput. 2018, 70, 980–987. [Google Scholar] [CrossRef]
- Cánovas-García, F.; Alonso-Sarría, F.; Gomariz-Castillo, F.; Oñate-Valdivieso, F. Modification of the random forest algorithm to avoid statistical dependence problems when classifying remote sensing imagery. Comput. Geosci. 2017, 103, 1–11. [Google Scholar] [CrossRef]
- Anderson, G.; Pfahringer, B. Random Relational Rules. Ph.D. Thesis, Department of Computer Science, University of Waikato, Hamilton, New Zealand, 2009. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Czajkowski, M.; Kretowski, M. The role of decision tree representation in regression problems–An evolutionary perspective. Appl. Soft Comput. 2016, 48, 458–475. [Google Scholar] [CrossRef]
- Hamze-Ziabari, S.; Bakhshpoori, T. Improving the prediction of ground motion parameters based on an efficient bagging ensemble model of M5′ and CART algorithms. Appl. Soft Comput. 2018, 68, 147–161. [Google Scholar] [CrossRef]
- Choubin, B.; Moradi, E.; Golshan, M.; Adamowski, J.; Sajedi-Hosseini, F.; Mosavi, A. An Ensemble prediction of flood susceptibility using multivariate discriminant analysis, classification and regression trees, and support vector machines. Sci. Total Environ. 2019, 651, 2087–2096. [Google Scholar] [CrossRef]
- Kantardzic, M. Data Mining: Concepts, Models, Methods, and Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Larose, D.T.; Larose, C.D. Discovering Knowledge in Data: An Introduction to Data Mining; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- De’ath, G.; Fabricius, K.E. Classification and regression trees: A powerful yet simple technique for ecological data analysis. Ecology 2000, 81, 3178–3192. [Google Scholar] [CrossRef]
- Steinberg, D.; Colla, P. CART: Classification and regression trees. In The Top Ten Algorithms in Data Mining; Chapman and Hall/CRC: New York, NY, USA, 2009; pp. 193–216. [Google Scholar]
- Timofeev, R. Classification and Regression Trees (CART) Theory and Applications; Humboldt University: Berlin, Germany, 2004. [Google Scholar]
- Breiman, L. Classification and Regression Trees, 1st ed.; Routledge: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Wang, G.; Carr, T.R.; Ju, Y.; Li, C. Identifying organic-rich Marcellus Shale lithofacies by support vector machine classifier in the Appalachian basin. Comput. Geosci. 2014, 64, 52–60. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support vector machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Dohare, A.K.; Kumar, V.; Kumar, R. Detection of myocardial infarction in 12 lead ECG using support vector machine. Appl. Soft Comput. 2018, 64, 138–147. [Google Scholar] [CrossRef]
- Zendehboudi, A.; Baseer, M.; Saidur, R. Application of support vector machine models for forecasting solar and wind energy resources: A review. J. Clean. Prod. 2018, 199, 272–285. [Google Scholar] [CrossRef]
- Nguyen, H. Support vector regression approach with different kernel functions for predicting blast-induced ground vibration: A case study in an open-pit coal mine of Vietnam. SN Appl. Sci. 2019, 1, 283. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Shi, X. Long-term prediction model of rockburst in underground openings using heuristic algorithms and support vector machines. Saf. Sci. 2012, 50, 629–644. [Google Scholar] [CrossRef]
- Hemmati-Sarapardeh, A.; Shokrollahi, A.; Tatar, A.; Gharagheizi, F.; Mohammadi, A.H.; Naseri, A. Reservoir oil viscosity determination using a rigorous approach. Fuel 2014, 116, 39–48. [Google Scholar] [CrossRef]
- Tian, Y.; Fu, M.; Wu, F. Steel plates fault diagnosis on the basis of support vector machines. Neurocomputing 2015, 151, 296–303. [Google Scholar] [CrossRef]
- Bui, X.N.; Nguyen, H.; Le, H.A.; Bui, H.B.; Do, N.H. Prediction of Blast-induced Air Over-pressure in Open-Pit Mine: Assessment of Different Artificial Intelligence Techniques. Nat. Resour. Res. 2019. [Google Scholar] [CrossRef]
- Nguyen, H.; Drebenstedt, C.; Bui, X.-N.; Bui, D.T. Prediction of Blast-Induced Ground Vibration in an Open-Pit Mine by a Novel Hybrid Model Based on Clustering and Artificial Neural Network. Nat. Resour. Res. 2019. [Google Scholar] [CrossRef]
- Gonzalez-Abril, L.; Angulo, C.; Nuñez, H.; Leal, Y. Handling binary classification problems with a priority class by using Support Vector Machines. Appl. Soft Comput. 2017, 61, 661–669. [Google Scholar] [CrossRef][Green Version]
- De Almeida, B.J.; Neves, R.F.; Horta, N. Combining Support Vector Machine with Genetic Algorithms to optimize investments in Forex markets with high leverage. Appl. Soft Comput. 2018, 64, 596–613. [Google Scholar] [CrossRef]
- Quinlan, J.R. Learning with continuous classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence, Hobart, Australia, 16–18 November 1992; pp. 343–348. [Google Scholar]
- Rulequest. Data Mining with Cubist. RuleQuest Research Pty Ltd., St. Ives, NSW, Australia. Available online: https://wwwrulequestcom/cubist-infohtml (accessed on 15 November 2019).
- Wang, Y.; Witten, I.H. Induction of model trees for predicting continuous classes. Presented at the Ninth European Conference on Machine Learning, Prague, Czech Republic, 23–25 April 1997. [Google Scholar]
- Butina, D.; Gola, J.M. Modeling aqueous solubility. J. Chem. Inf. Comput. Sci. 2003, 43, 837–841. [Google Scholar] [CrossRef]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Rezaei, Z.; Selamat, A.; Taki, A.; Rahim, M.S.M.; Kadir, M.R.A. Automatic plaque segmentation based on hybrid fuzzy clustering and k nearest neighborhood using virtual histology intravascular ultrasound images. Appl. Soft Comput. 2017, 53, 380–395. [Google Scholar] [CrossRef]
- Silva-Ramírez, E.-L.; Pino-Mejías, R.; López-Coello, M. Single imputation with multilayer perceptron and multiple imputation combining multilayer perceptron and k-nearest neighbours for monotone patterns. Appl. Soft Comput. 2015, 29, 65–74. [Google Scholar] [CrossRef]
- Pu, Y.; Zhao, X.; Chi, G.; Zhao, S.; Wang, J.; Jin, Z.; Yin, J. Design and implementation of a parallel geographically weighted k-nearest neighbor classifier. Comput. Geosci. 2019, 127, 111–122. [Google Scholar] [CrossRef]
- Tkáč, M.; Verner, R. Artificial neural networks in business: Two decades of research. Appl. Soft Comput. 2016, 38, 788–804. [Google Scholar] [CrossRef]
- Crowder, J.A.; Carbone, J.; Friess, S. Artificial Creativity and Self-Evolution: Abductive Reasoning in Artificial Life Forms. In Artificial Psychology: Psychological Modeling and Testing of AI Systems; Springer International Publishing: Cham, Switzerland, 2020; pp. 65–74. [Google Scholar] [CrossRef]
- Karayiannis, N.; Venetsanopoulos, A.N. Artificial Neural Networks: Learning Algorithms, Performance Evaluation, and Applications; Springer Science & Business Media: New York, NY, USA, 2013; Volume 209. [Google Scholar]
- Mocanu, D.C.; Mocanu, E.; Stone, P.; Nguyen, P.H.; Gibescu, M.; Liotta, A. Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science. Nat. Commun. 2018, 9, 2383. [Google Scholar] [CrossRef]
- Mishra, A.; Chandra, P.; Ghose, U.; Sodhi, S.S. Bi-modal derivative adaptive activation function sigmoidal feedforward artificial neural networks. Appl. Soft Comput. 2017, 61, 983–994. [Google Scholar] [CrossRef]
- Chatfield, C. Introduction to Multivariate Analysis, 1st ed.; Routledge: New York, NY, USA, 1980. [Google Scholar] [CrossRef]
- Moayedi, H.; Armaghani, D.J. Optimizing an ANN model with ICA for estimating bearing capacity of driven pile in cohesionless soil. Eng. Comput. 2018, 34, 347–356. [Google Scholar] [CrossRef]
- Nguyen, H.; Bui, X.-N.; Tran, Q.-H.; Mai, N.-L. A new soft computing model for estimating and controlling blast-produced ground vibration based on hierarchical K-means clustering and cubist algorithms. Appl. Soft Comput. 2019, 77, 376–386. [Google Scholar] [CrossRef]
- Nguyen, H.; Bui, X.-N. Predicting Blast-Induced Air Overpressure: A Robust Artificial Intelligence System Based on Artificial Neural Networks and Random Forest. Nat. Resour. Res. 2019, 28, 893–907. [Google Scholar] [CrossRef]
- Olatomiwa, L.; Mekhilef, S.; Shamshirband, S.; Mohammadi, K.; Petković, D.; Sudheer, C. A support vector machine–firefly algorithm-based model for global solar radiation prediction. Sol. Energy 2015, 115, 632–644. [Google Scholar] [CrossRef]
- Qian, X.; Yang, M.; Wang, C.; Li, H.; Wang, J. Leaf magnetic properties as a method for predicting heavy metal concentrations in PM2.5 using support vector machine: A case study in Nanjing, China. Environ. Pollut. 2018, 242, 922–930. [Google Scholar]
- Nguyen, H.; Bui, X.-N.; Bui, H.-B.; Mai, N.-L. A comparative study of artificial neural networks in predicting blast-induced air-blast overpressure at Deo Nai open-pit coal mine, Vietnam. Neural Comput. Appl. 2018, 1–17. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | Rutile | Anatase | Leucoxene | Zircon | Monazite | Ilmenite |
|---|---|---|---|---|---|---|
| Min.: | 0.000 | 0.000 | 0.000 | 0.013 | 0.001 | 0.188 |
| 1st Qu.: | 0.001 | 0.0001 | 0.003 | 0.030 | 0.001 | 0.306 |
| Median: | 0.001 | 0.0001 | 0.005 | 0.052 | 0.001 | 0.424 |
| Mean: | 0.001343 | 0.0001573 | 0.008 | 0.064 | 0.003 | 0.467 |
| 3rd Qu.: | 0.002 | 0.0002 | 0.012 | 0.080 | 0.002 | 0.538 |
| Max.: | 0.009 | 0.0007 | 0.032 | 0.306 | 0.058 | 2.246 |
| Rutile | Anatase | Leucoxene | Zircon | Monazite | Ilmenite | |
|---|---|---|---|---|---|---|
| Rutile | 1 | |||||
| Anatase | 0.659115 | 1 | ||||
| Leucoxene | 0.516591 | 0.447161 | 1 | |||
| Zircon | 0.65455 | 0.632258 | 0.326362 | 1 | ||
| Monazite | 0.101687 | 0.037384 | 0.084057 | 0.052774 | 1 | |
| Ilmenite | 0.476926 | 0.650812 | 0.04358 | 0.668171 | −0.00484 | 1 |
| Model | RMSE | R2 | Rank for RMSE | Rank for R2 | Total Ranking Score | Sort |
|---|---|---|---|---|---|---|
| SVM | 0.134 | 0.692 | 2 | 2 | 4 | 6 |
| CART | 0.147 | 0.675 | 1 | 1 | 2 | 7 |
| kNN | 0.122 | 0.747 | 6 | 6 | 12 | 2 |
| RF | 0.127 | 0.737 | 5 | 5 | 10 | 3 |
| SGB | 0.132 | 0.716 | 3 | 3 | 6 | 5 |
| Cubist | 0.128 | 0.720 | 4 | 4 | 8 | 4 |
| ANN | 0.091 | 0.860 | 7 | 7 | 14 | 1 |
| Model | RMSE | R2 | Rank for RMSE | Rank for R2 | Total Ranking Score | Sort |
|---|---|---|---|---|---|---|
| SVM | 0.092 | 0.780 | 1 | 3 | 4 | 5 |
| CART | 0.082 | 0.817 | 4 | 4 | 8 | 4 |
| kNN | 0.092 | 0.766 | 1 | 1 | 2 | 7 |
| RF | 0.080 | 0.824 | 6 | 6 | 12 | 2 |
| SGB | 0.081 | 0.818 | 5 | 5 | 10 | 3 |
| Cubist | 0.078 | 0.830 | 7 | 7 | 14 | 1 |
| ANN | 0.092 | 0.774 | 1 | 2 | 3 | 6 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
LV, Y.; Le, Q.-T.; Bui, H.-B.; Bui, X.-N.; Nguyen, H.; Nguyen-Thoi, T.; Dou, J.; Song, X. A Comparative Study of Different Machine Learning Algorithms in Predicting the Content of Ilmenite in Titanium Placer. Appl. Sci. 2020, 10, 635. https://doi.org/10.3390/app10020635
LV Y, Le Q-T, Bui H-B, Bui X-N, Nguyen H, Nguyen-Thoi T, Dou J, Song X. A Comparative Study of Different Machine Learning Algorithms in Predicting the Content of Ilmenite in Titanium Placer. Applied Sciences. 2020; 10(2):635. https://doi.org/10.3390/app10020635
Chicago/Turabian StyleLV, Yingli, Qui-Thao Le, Hoang-Bac Bui, Xuan-Nam Bui, Hoang Nguyen, Trung Nguyen-Thoi, Jie Dou, and Xuan Song. 2020. "A Comparative Study of Different Machine Learning Algorithms in Predicting the Content of Ilmenite in Titanium Placer" Applied Sciences 10, no. 2: 635. https://doi.org/10.3390/app10020635
APA StyleLV, Y., Le, Q.-T., Bui, H.-B., Bui, X.-N., Nguyen, H., Nguyen-Thoi, T., Dou, J., & Song, X. (2020). A Comparative Study of Different Machine Learning Algorithms in Predicting the Content of Ilmenite in Titanium Placer. Applied Sciences, 10(2), 635. https://doi.org/10.3390/app10020635