Learning Collision Situation to Convolutional Neural Network Using Collision Grid Map Based on Probability Scheme

Abstract
1. Introduction
2. Collision Grid Map Scheme and Convolutional Neural Network
2.1. Collision Grid Map Scheme
2.2. Convolutional Neural Network Algorithm Using the Collision Grid Map
3. Experimental Results
3.1. Experimental Setup
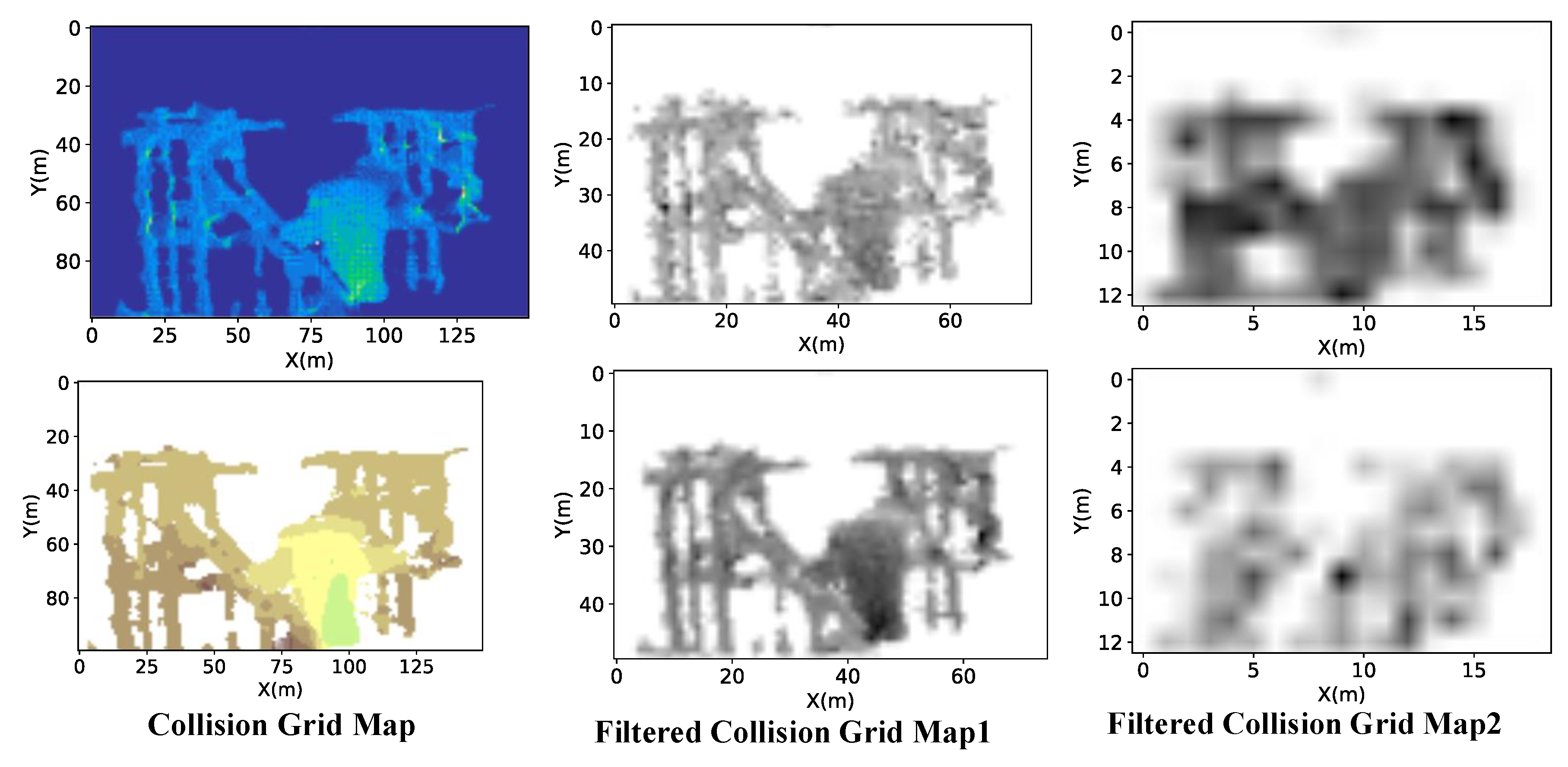
3.2. Result of the Collision Grid Map
3.3. Convolutional Neural Network Algorithm Using the Collision Grid Map
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Banhazi, T.M.; Babinszky, L.; Halas, V.; Tscharke, M. Precision livestock farming: Precision feeding technologies and sustainable livestock production. Int. J. Agric. Biol. Eng. 2012, 5, 54–61. [Google Scholar]
- Lehmann, R.J.; Reiche, R.; Schiefer, G. Future internet and the agri-food sector: State-of-the-art in literature and research. Comput. Electron. Agric. 2012, 89, 158–174. [Google Scholar] [CrossRef]
- Barbaros, F.; Gül, A.; Harmancİoğlu, N. An Earth observation assisted tool for irrigation water management. Fresenius Environ. Bull. 2013, 22, 705–713. [Google Scholar]
- Mutchek, M.A.; Williams, E.D. Design space characterization for meeting cost and carbon reduction goals: Smart irrigation controllers in the southwestern United States. J. Ind. Ecol. 2010, 14, 727–739. [Google Scholar] [CrossRef]
- Chen, J.H.; Song, K.T. Collision-Free Motion Planning for Human-Robot Collaborative Safety under Cartesian Constraint. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation, Brisbane, QLD, Australia, 21–25 May 2018. [Google Scholar]
- Flacco, F.; Kröger, T.; De Luca, A.; Khatib, O. A depth space approach to human-robot collision avoidance. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012. [Google Scholar]
- Flacco, F.; Kroeger, T.; De Luca, A.; Khatib, O. A depth space approach for evaluating distance to objects. J. Intell. Robot. Syst. 2015, 80, 7–22. [Google Scholar] [CrossRef]
- Fetzner, A.; Frese, C.; Frey, C. A 3D representation of obstacles in the robots reachable area considering occlusions. In Proceedings of the ISR/Robotik 2014 41st International Symposium on Robotics, Munich, Germany, 2–3 June 2014; pp. 1–8. [Google Scholar]
- Xu, H.; Zhou, J.; G Asteris, P.; Jahed Armaghani, D.; Tahir, M.M. Supervised machine learning techniques to the prediction of tunnel boring machine penetration rate. Appl. Sci. 2019, 9, 3715. [Google Scholar] [CrossRef]
- Huang, L.; Asteris, P.G.; Koopialipoor, M.; Armaghani, D.J.; Tahir, M.M. Invasive weed optimization technique-based ANN to the prediction of rock tensile strength. Appl. Sci. 2019, 9, 5372. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Oh, E.; Lee, H. Development of a Convolution-Based Multi-Directional and Parallel Ant Colony Algorithm Considering a Network with Dynamic Topology Changes. Appl. Sci. 2019, 9, 3646. [Google Scholar] [CrossRef]
- Nam, G.; Choi, H.; Cho, J.; Kim, I.J. PSI-CNN: A pyramid-based scale-invariant CNN architecture for face recognition robust to various image resolutions. Appl. Sci. 2018, 8, 1561. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and multi-view cnns for object classification on 3d data. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5648–5656. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Masci, J.; Boscaini, D.; Bronstein, M.; Vandergheynst, P. Geodesic convolutional neural networks on riemannian manifolds. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 37–45. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5099–5108. [Google Scholar]
- Wang, D.Z.; Posner, I. Voting for Voting in Online Point Cloud Object Detection. Robot. Sci. Syst. 2015, 1, 10–15607. [Google Scholar]
- Engelcke, M.; Rao, D.; Wang, D.Z.; Tong, C.H.; Posner, I. Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1355–1361. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Moravec, H.; Elfes, A. High resolution maps from wide angle sonar. In Proceedings of the 1985 IEEE International Conference on Robotics and Automation, St. Louis, MO, USA, 25–28 March 1985; Volume 2, pp. 116–121. [Google Scholar]
- Thrun, S. Learning occupancy grid maps with forward sensor models. Auton. Robot. 2003, 15, 111–127. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Size (KB) |
|---|---|
| Raw point cloud | 4508.9 |
| Vox grid data | 8.0 |
| Collision Grid Map | 5.7 |
| Method | Accuracy (%) |
|---|---|
| Vox grid data | 73.9 |
| Collision Grid Map | 93.1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jo, J.H.; Moon, C.-b. Learning Collision Situation to Convolutional Neural Network Using Collision Grid Map Based on Probability Scheme. Appl. Sci. 2020, 10, 617. https://doi.org/10.3390/app10020617
Jo JH, Moon C-b. Learning Collision Situation to Convolutional Neural Network Using Collision Grid Map Based on Probability Scheme. Applied Sciences. 2020; 10(2):617. https://doi.org/10.3390/app10020617
Chicago/Turabian StyleJo, Jun Hyeong, and Chang-bae Moon. 2020. "Learning Collision Situation to Convolutional Neural Network Using Collision Grid Map Based on Probability Scheme" Applied Sciences 10, no. 2: 617. https://doi.org/10.3390/app10020617
APA StyleJo, J. H., & Moon, C.-b. (2020). Learning Collision Situation to Convolutional Neural Network Using Collision Grid Map Based on Probability Scheme. Applied Sciences, 10(2), 617. https://doi.org/10.3390/app10020617