Improved Single Sample Per Person Face Recognition via Enriching Intra-Variation and Invariant Features



Abstract
1. Introduction
2. Related Work
2.1. Face Recognition with Single Sample Per Person
2.2. Inverse Rendering
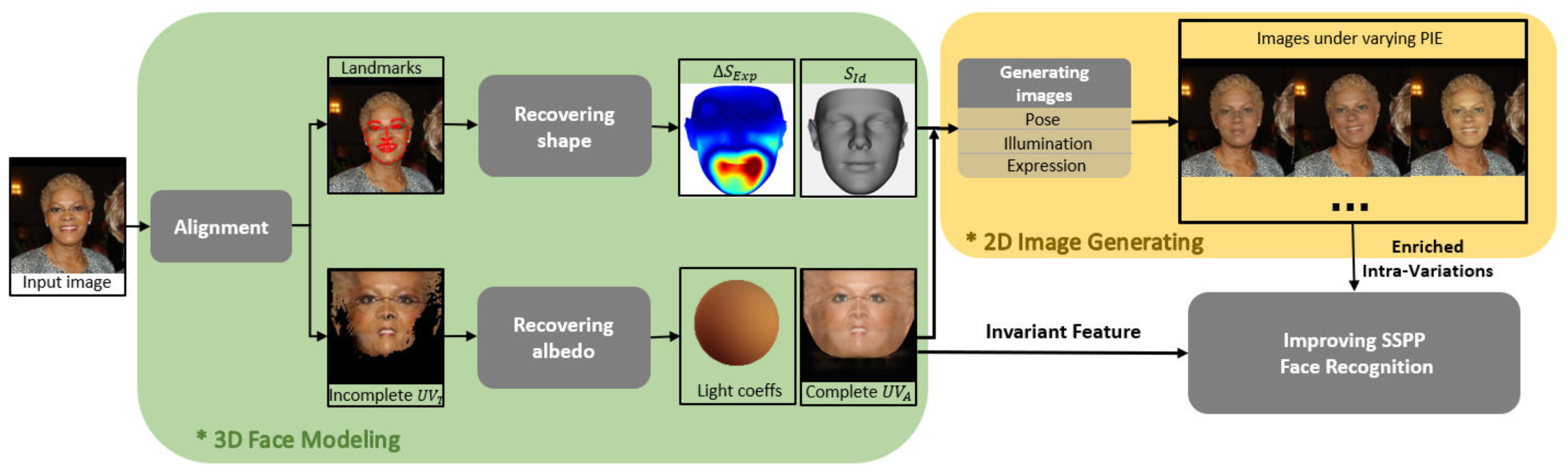
3. Proposed Method
3.1. Overview
3.1.1. Preliminary
3.1.2. Pipeline
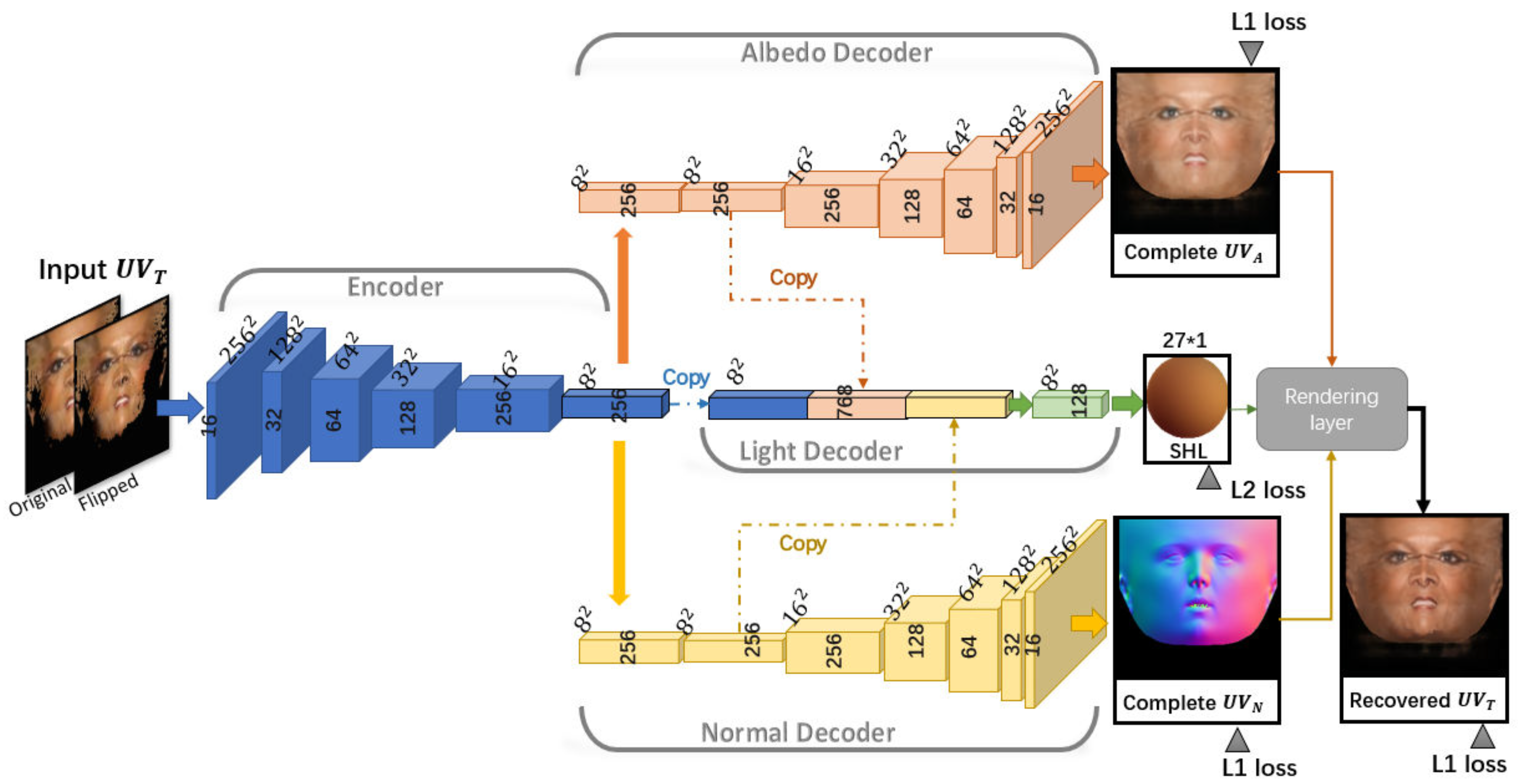
3.2. Albedo Recovery
3.2.1. Network Structure
3.2.2. Loss Functions
3.2.3. Implementation Details
3.3. Shape Recovery
3.4. Data Enrichment
3.5. SSPP FR
3.5.1. Face Recognition via Enriching Intra-Variation
3.5.2. Face Recognition via Enriching both Intra-Variation and Invariant Features
3.5.3. Implementation Details
4. Experiments
4.1. Datasets and Protocols
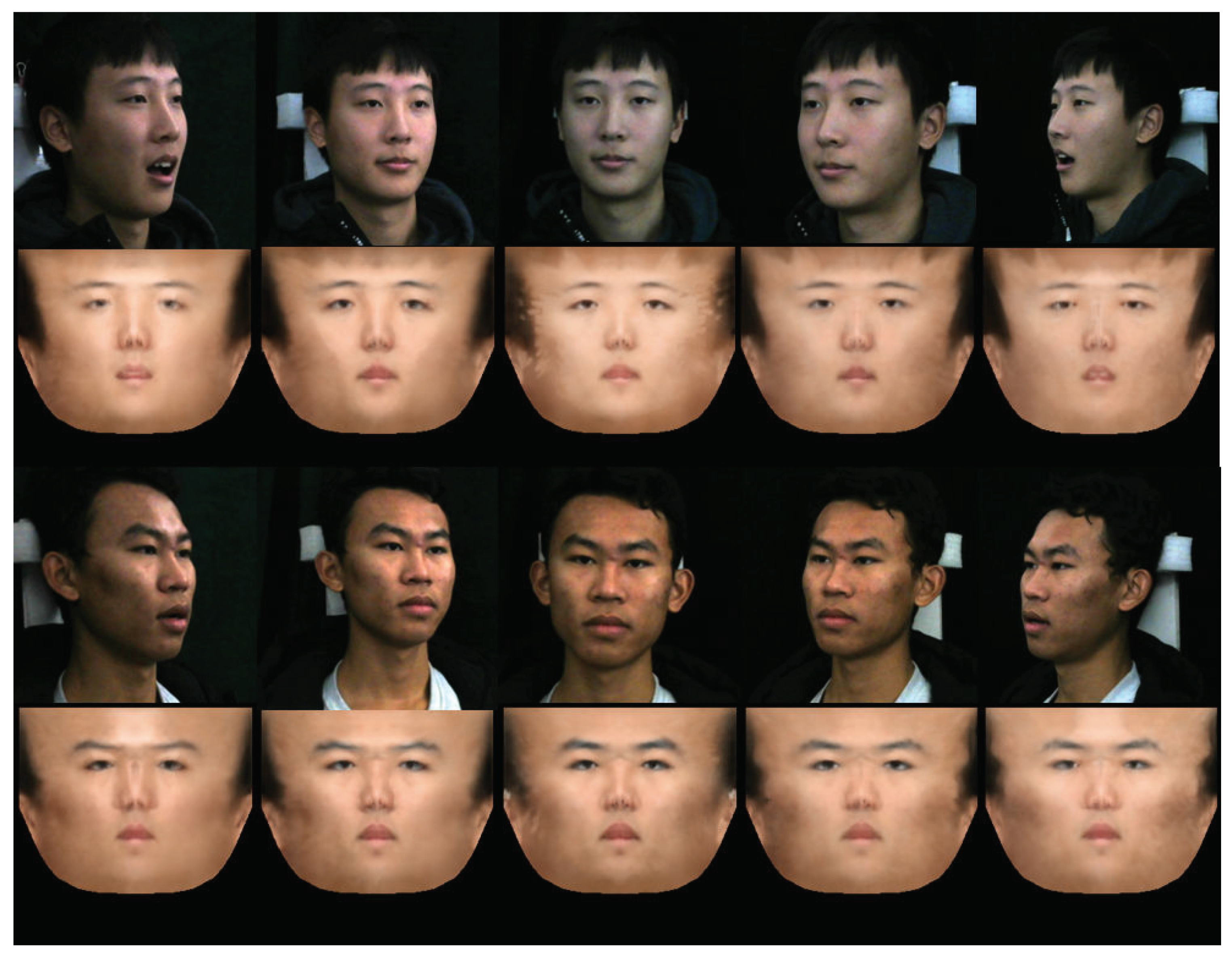
4.2. Visualization of Reconstructed Image Components and Generated Images
4.3. Effectiveness of Enriching Intra-Variation
- We randomly chose one sample per person in CelebA dataset [54] to form the original SSPP training data (denoted as Original). Note that face images in CelebA are in the wild images with varying PIE as well. However, their pose angles are relatively small (mostly within 30 degrees).
- The 3D modeling module was used to recover the intrinsic properties (albedo and shape) and external factors (i.e., PIE) of the face images in Original. We then synthesized images with the same PIE and background as the images in Original to form another training set, named Synthetic.
- With the recovered properties of the images in Original, we further generated another seven face images for each person with varying poses, varying illuminations, varying expressions, varying poses and illuminations, or varying poses, illuminations, and expressions. We call the respective databases of generated images as AugP, AugI, AugE, AugPI, and AugPIE, respectively.
- By combining the above-generated images with the original images, we obtained another five training sets, denoted as Ori + AugP, Ori + AugI, Ori + AugE, Ori + AugPI, and Ori + AugPIE, respectively.
4.4. Effectiveness of Enriching Both Intra-Variation and Invariant Features
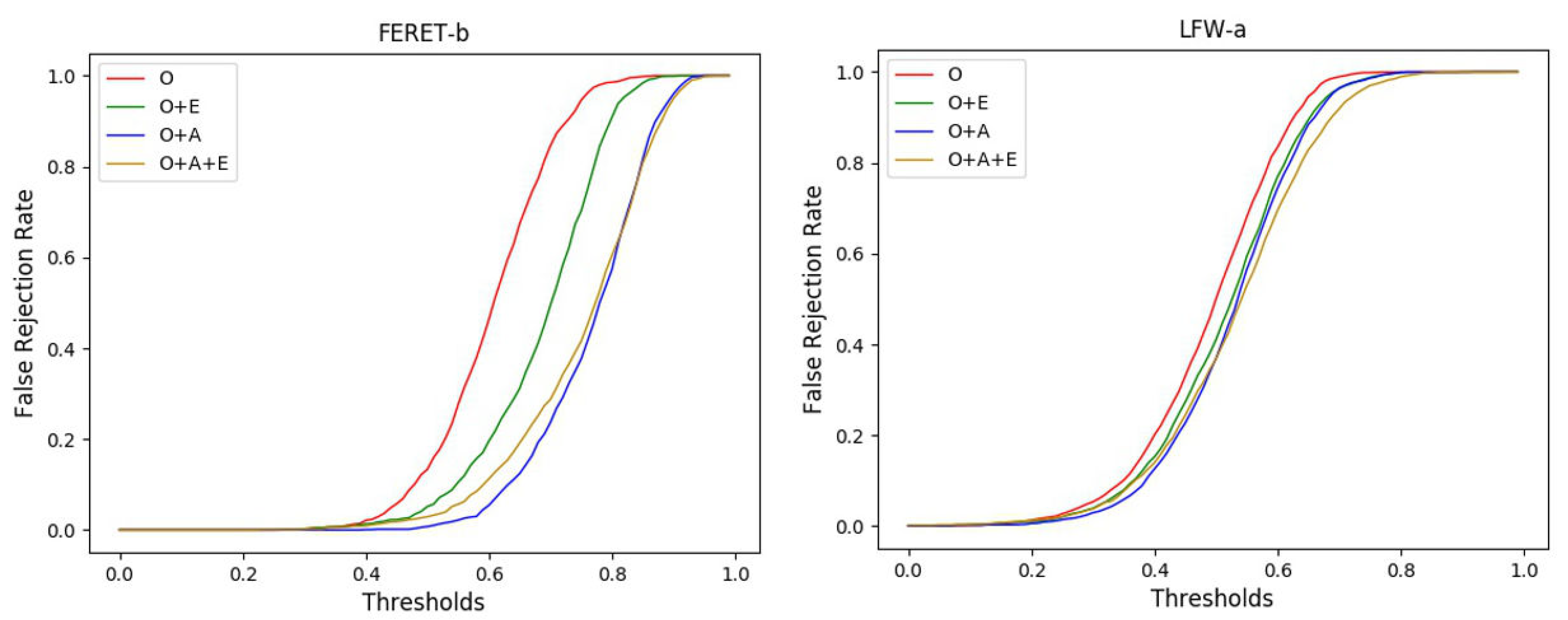
4.4.1. Results on FERET-b Dataset
4.4.2. Results on LFW-a Dataset
4.4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Abate, A.F.; Nappi, M.; Riccio, D.; Sabatino, G. 2D and 3D face recognition: A survey. Pattern Recognit. Lett. 2007, 28, 1885–1906. [Google Scholar] [CrossRef]
- Hassaballah, M.; Aly, S. Face recognition: Challenges, achievements and future directions. IET Comput. Vis. 2015, 9, 614–626. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W. Deep Face Recognition: A Survey. arXiv 2018, arXiv:1804.06655. [Google Scholar]
- Hu, Z.; Gui, P.; Feng, Z.; Zhao, Q.; Fu, K.; Liu, F.; Liu, Z. Boosting Depth-Based Face Recognition from a Quality Perspective. Sensors 2019, 19, 4124. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Wen, C.; Xie, K.; Wen, F.; Sheng, G.; Tang, X. Face Recognition Using the SR-CNN Model. Sensors 2018, 18, 4237. [Google Scholar] [CrossRef]
- Koo, J.H.; Cho, S.W.; Baek, N.R.; Kim, M.; Park, K.R. CNN-Based Multimodal Human Recognition in Surveillance Environments. Sensors 2018, 18, 3040. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 4690–4699. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. CosFace: Large Margin Cosine Loss for Deep Face Recognition. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5265–5274. [Google Scholar] [CrossRef]
- Beymer, D.; Poggio, T.A. Face Recognition from One Example View. In Procedings of the Fifth International Conference on Computer Vision (ICCV 95), Massachusetts Institute of Technology, Cambridge, MA, USA, 20–23 June 1995; pp. 500–507. [Google Scholar] [CrossRef]
- Tan, X.; Chen, S.; Zhou, Z.; Zhang, F. Face recognition from a single image per person: A survey. Pattern Recognit. 2006, 39, 1725–1745. [Google Scholar] [CrossRef]
- Wu, J.; Zhou, Z. Face recognition with one training image per person. Pattern Recognit. Lett. 2002, 23, 1711–1719. [Google Scholar] [CrossRef]
- Yin, H.; Fu, P.; Meng, S. Sampled Two-Dimensional LDA for Face Recognition with One Training Image per Person. In Proceedings of the First International Conference on Innovative Computing, Information and Control (ICICIC 2006), Beijing, China, 30 August–1 September 2006; pp. 113–116. [Google Scholar] [CrossRef]
- Lee, S.; Jung, H.; Hwang, B.; Lee, S. Authenticating corrupted photo images based on noise parameter estimation. Pattern Recognit. 2006, 39, 910–920. [Google Scholar] [CrossRef]
- Lu, J.; Tan, Y.; Wang, G. Discriminative multi-manifold analysis for face recognition from a single training sample per person. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2011, Barcelona, Spain, 6–13 November 2011; pp. 1943–1950. [Google Scholar] [CrossRef]
- Abd-Almageed, W.; Wu, Y.; Rawls, S.; Harel, S.; Hassner, T.; Masi, I.; Choi, J.; Leksut, J.T.; Kim, J.; Natarajan, P.; et al. Face recognition using deep multi-pose representations. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision, WACV 2016, Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Bashbaghi, S.; Granger, E.; Sabourin, R.; Bilodeau, G. Robust watch-list screening using dynamic ensembles of SVMs based on multiple face representations. Mach. Vis. Appl. 2017, 28, 219–241. [Google Scholar] [CrossRef]
- Dadi, H.S.; Pillutla, G.K.M.; Makkena, M.L. Face Recognition and Human Tracking Using GMM, HOG and SVM in Surveillance Videos. Ann. Data Sci. 2018, 5, 157–179. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar] [CrossRef]
- Ahonen, T.; Hadid, A.; Pietikäinen, M. Face Description with Local Binary Patterns: Application to Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Deng, W.; Hu, J.; Guo, J. Extended SRC: Undersampled Face Recognition via Intraclass Variant Dictionary. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1864–1870. [Google Scholar] [CrossRef]
- Deng, W.; Hu, J.; Zhou, X.; Guo, J. Equidistant prototypes embedding for single sample based face recognition with generic learning and incremental learning. Pattern Recognit. 2014, 47, 3738–3749. [Google Scholar] [CrossRef]
- Yang, M.; Gool, L.V.; Zhang, L. Sparse Variation Dictionary Learning for Face Recognition with a Single Training Sample per Person. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2013, Sydney, Australia, 1–8 December 2013; pp. 689–696. [Google Scholar] [CrossRef]
- Su, Y.; Shan, S.; Chen, X.; Gao, W. Adaptive generic learning for face recognition from a single sample per person. In Proceedings of the Twenty-Third IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2010, San Francisco, CA, USA, 13–18 June 2010; pp. 2699–2706. [Google Scholar] [CrossRef]
- Cai, J.; Chen, J.; Liang, X. Single-Sample Face Recognition Based on Intra-Class Differences in a Variation Model. Sensors 2015, 15, 1071–1087. [Google Scholar] [CrossRef] [PubMed]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Shao, C.; Song, X.; Feng, Z.; Wu, X.; Zheng, Y. Dynamic dictionary optimization for sparse-representation- based face classification using local difference images. Inf. Sci. 2017, 393, 1–14. [Google Scholar] [CrossRef]
- Mohammadzade, H.; Hatzinakos, D. Projection into Expression Subspaces for Face Recognition from Single Sample per Person. IEEE Trans. Affect. Comput. 2013, 4, 69–82. [Google Scholar] [CrossRef]
- Zeng, J.; Zhao, X.; Gan, J.; Mai, C.; Zhai, Y.; Wang, F. Deep Convolutional Neural Network Used in Single Sample per Person Face Recognition. Comput. Intell. Neurosci. 2018, 2018, 3803627:1–3803627:11. [Google Scholar] [CrossRef]
- Zhang, Y.; Peng, H. Sample reconstruction with deep autoencoder for one sample per person face recognition. IET Comput. Vis. 2017, 11, 471–478. [Google Scholar] [CrossRef]
- Hong, S.; Im, W.; Ryu, J.; Yang, H.S. SSPP-DAN: Deep domain adaptation network for face recognition with single sample per person. In Proceedings of the 2017 IEEE International Conference on Image Processing, ICIP 2017, Beijing, China, 17–20 September 2017; pp. 825–829. [Google Scholar] [CrossRef]
- Cuculo, V.; D’Amelio, A.; Grossi, G.; Lanzarotti, R.; Lin, J. Robust Single-Sample Face Recognition by Sparsity-Driven Sub-Dictionary Learning Using Deep Features. Sensors 2019, 19, 146. [Google Scholar] [CrossRef] [PubMed]
- Choi, S.; Lee, Y.; Lee, M. Face Recognition in SSPP Problem Using Face Relighting Based on Coupled Bilinear Model. Sensors 2019, 19, 43. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Lei, Z.; Liu, X.; Shi, H.; Li, S.Z. Face Alignment Across Large Poses: A 3D Solution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 146–155. [Google Scholar] [CrossRef]
- Feng, Z.; Hu, G.; Kittler, J.; Christmas, W.J.; Wu, X. Cascaded Collaborative Regression for Robust Facial Landmark Detection Trained Using a Mixture of Synthetic and Real Images With Dynamic Weighting. IEEE Trans. Image Process. 2015, 24, 3425–3440. [Google Scholar] [CrossRef] [PubMed]
- Song, X.; Feng, Z.; Hu, G.; Kittler, J.; Wu, X. Dictionary Integration Using 3D Morphable Face Models for Pose-Invariant Collaborative-Representation-Based Classification. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2734–2745. [Google Scholar] [CrossRef]
- Li, L.; Ge, H.; Tong, Y.; Zhang, Y. Face Recognition Using Gabor-Based Feature Extraction and Feature Space Transformation Fusion Method for Single Image per Person Problem. Neural Process. Lett. 2018, 47, 1197–1217. [Google Scholar] [CrossRef]
- Pan, J.; Wang, X.; Cheng, Y. Single-Sample Face Recognition Based on LPP Feature Transfer. IEEE Access 2016, 4, 2873–2884. [Google Scholar] [CrossRef]
- Min, R.; Xu, S.; Cui, Z. Single-Sample Face Recognition Based on Feature Expansion. IEEE Access 2019, 7, 45219–45229. [Google Scholar] [CrossRef]
- Tran, A.T.; Hassner, T.; Masi, I.; Medioni, G.G. Regressing Robust and Discriminative 3D Morphable Models with a Very Deep Neural Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1493–1502. [Google Scholar] [CrossRef]
- Sengupta, S.; Kanazawa, A.; Castillo, C.D.; Jacobs, D.W. SfSNet: Learning Shape, Reflectance and Illuminance of Faces ‘in the Wild’. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6296–6305. [Google Scholar] [CrossRef]
- Blanz, V.; Vetter, T. Face Recognition Based on Fitting a 3D Morphable Model. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1063–1074. [Google Scholar] [CrossRef]
- Tu, H.; Li, K.; Zhao, Q. Robust Face Recognition with Assistance of Pose and Expression Normalized Albedo Images. In Proceedings of the 2019 5th International Conference on Computing and Artificial Intelligence, ICCAI 2019, Bali, Indonesia, 19–22 April 2019; pp. 93–99. [Google Scholar] [CrossRef]
- Feng, Y.; Wu, F.; Shao, X.; Wang, Y.; Zhou, X. Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; pp. 557–574. [Google Scholar] [CrossRef]
- Ramamoorthi, R. Modeling illumination variation with spherical harmonics—Chapter 12. Face Process. Adv. Model. Methods 2006, 385–424. [Google Scholar]
- Ramamoorthi, R.; Hanrahan, P. A signal-processing framework for reflection. ACM Trans. Graph. 2004, 23, 1004–1042. [Google Scholar] [CrossRef]
- Bas, A.; Huber, P.; Smith, W.A.P.; Awais, M.; Kittler, J. 3D Morphable Models as Spatial Transformer Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops, ICCV Workshops 2017, Venice, Italy, 22–29 October 2017; pp. 895–903. [Google Scholar] [CrossRef]
- Paysan, P.; Knothe, R.; Amberg, B.; Romdhani, S.; Vetter, T. A 3D Face Model for Pose and Illumination Invariant Face Recognition. In Proceedings of the Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance, AVSS 2009, Genova, Italy, 2–4 September 2009; pp. 296–301. [Google Scholar] [CrossRef]
- Cao, C.; Weng, Y.; Zhou, S.; Tong, Y.; Zhou, K. FaceWarehouse: A 3D Facial Expression Database for Visual Computing. IEEE Trans. Vis. Comput. Graph. 2014, 20, 413–425. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar] [CrossRef]
- Liu, F.; Zhao, Q.; Liu, X.; Zeng, D. Joint Face Alignment and 3D Face Reconstruction with Application to Face Recognition. arXiv 2017, arXiv:1708.02734. [Google Scholar] [CrossRef] [PubMed]
- Phillips, P.J.; Moon, H.; Rizvi, S.A.; Rauss, P.J. The FERET Evaluation Methodology for Face-Recognition Algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1090–1104. [Google Scholar] [CrossRef]
- Huang, G.B.; Mattar, M.; Berg, T.L.; Learned-Miller, E.G. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; University of Massachusetts: Amherst, MA, USA, 2007. [Google Scholar]
- Zheng, T.; Deng, W. Cross-pose LFW: A Database for Studying Cross-pose Face Recognition in Unconstrained Environments; Technical Report 18-01; Beijing University of Posts and Telecommunications: Beijing, China, 2018. [Google Scholar]
- Zheng, T.; Deng, W.; Hu, J. Cross-Age LFW: A Database for Studying Cross-Age Face Recognition in Unconstrained Environments. arXiv 2017, arXiv:1708.08197. [Google Scholar]
- Moschoglou, S.; Papaioannou, A.; Sagonas, C.; Deng, J.; Kotsia, I.; Zafeiriou, S. AgeDB: The First Manually Collected, In-the-Wild Age Database. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1997–2005. [Google Scholar] [CrossRef]
- Sengupta, S.; Chen, J.; Castillo, C.D.; Patel, V.M.; Chellappa, R.; Jacobs, D.W. Frontal to profile face verification in the wild. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision, WACV 2016, Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. VGGFace2: A Dataset for Recognising Faces across Pose and Age. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition, FG 2018, Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TrainData\TestData | AgeDB | LFW | CALFW | CPLFW | CFP_FF | CFP_FP | VGGFACE2_FP | FERET-b |
|---|---|---|---|---|---|---|---|---|
| Original | 50.75 | 77.33 | 63.03 | 58.7 | 69.67 | 60.77 | 61.46 | 84.33 |
| Synthetic | 53.35 | 73.77 | 59.05 | 57.52 | 69.09 | 59.74 | 60.28 | 79.96 |
| AugP | 52.12 | 75.95 | 58.82 | 60.08 | 71.46 | 61.89 | 61.66 | 87.54 |
| AugI | 50.28 | 75.45 | 59.27 | 57.58 | 71.7 | 60.87 | 61.46 | 80.17 |
| AugE | 50.43 | 75.05 | 57.47 | 58.10 | 71.09 | 62.49 | 61.44 | 80.04 |
| AugPI | 52.47 | 78.17 | 60.67 | 60.83 | 73.57 | 62.70 | 62.80 | 90.46 |
| AugPIE | 55.18 | 80.08 | 62.78 | 61.90 | 76.59 | 64.37 | 62.94 | 92.08 |
| Ori+AugP | 56.62 | 82.73 | 69.05 | 65.68 | 78.13 | 66.64 | 68.54 | 90.71 |
| Ori+AugI | 52.63 | 77.48 | 60.93 | 58.63 | 70.83 | 62.07 | 62.84 | 81.17 |
| Ori+AugE | 50.93 | 74.85 | 59.02 | 57.53 | 68.36 | 60.51 | 60.54 | 80.20 |
| Ori+AugPI | 58.82 | 86.08 | 72.03 | 67.97 | 81.96 | 70.44 | 71.02 | 94.54 |
| Ori+AugPIE | 58.65 | 85.98 | 71.02 | 67.15 | 82.69 | 70.23 | 70.22 | 95.54 |
| Database\Method | HOG+SVM | CDA | G-FST | FT-LPP | TDL | FaceNet | KCFT | Proposed |
|---|---|---|---|---|---|---|---|---|
| FERET-b | 50.17 | 77.25 | 82.08 | 86.08 | 89.33 | 91.42 | 93.17 | 96.41 |
| LFW-a | 40.98 | 51.12 | 57.95 | 62.49 | 74.01 | 89.04 | 98.83 | 97.25 |
| O | A | E | FERET-b | LFW-a |
|---|---|---|---|---|
| ✓ | 92.25 | 92.46 | ||
| ✓ | ✓ | 96.33 | 97.15 | |
| ✓ | ✓ | 93.17 | 93.53 | |
| ✓ | ✓ | ✓ | 96.41 | 97.25 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tu, H.; Duoji, G.; Zhao, Q.; Wu, S. Improved Single Sample Per Person Face Recognition via Enriching Intra-Variation and Invariant Features. Appl. Sci. 2020, 10, 601. https://doi.org/10.3390/app10020601
Tu H, Duoji G, Zhao Q, Wu S. Improved Single Sample Per Person Face Recognition via Enriching Intra-Variation and Invariant Features. Applied Sciences. 2020; 10(2):601. https://doi.org/10.3390/app10020601
Chicago/Turabian StyleTu, Huan, Gesang Duoji, Qijun Zhao, and Shuang Wu. 2020. "Improved Single Sample Per Person Face Recognition via Enriching Intra-Variation and Invariant Features" Applied Sciences 10, no. 2: 601. https://doi.org/10.3390/app10020601
APA StyleTu, H., Duoji, G., Zhao, Q., & Wu, S. (2020). Improved Single Sample Per Person Face Recognition via Enriching Intra-Variation and Invariant Features. Applied Sciences, 10(2), 601. https://doi.org/10.3390/app10020601