Towards Semi-Automatic Generation of a Steady State Digital Twin of a Brownfield Process Plant

 ,
,  ,
,
Abstract
Featured Application
Abstract
1. Introduction
- It accurately captures aspects of the plant relevant to the retrofit
- It can be generated from source information commonly available at brownfield plants
- Minimal manual engineering effort should be involved
2. Literature Review
2.1. Steady State Simulation
2.2. Digital Twins for Brownfield Process Plants
2.3. Automatic Generation of Digital Twins
3. Proposed Methodology
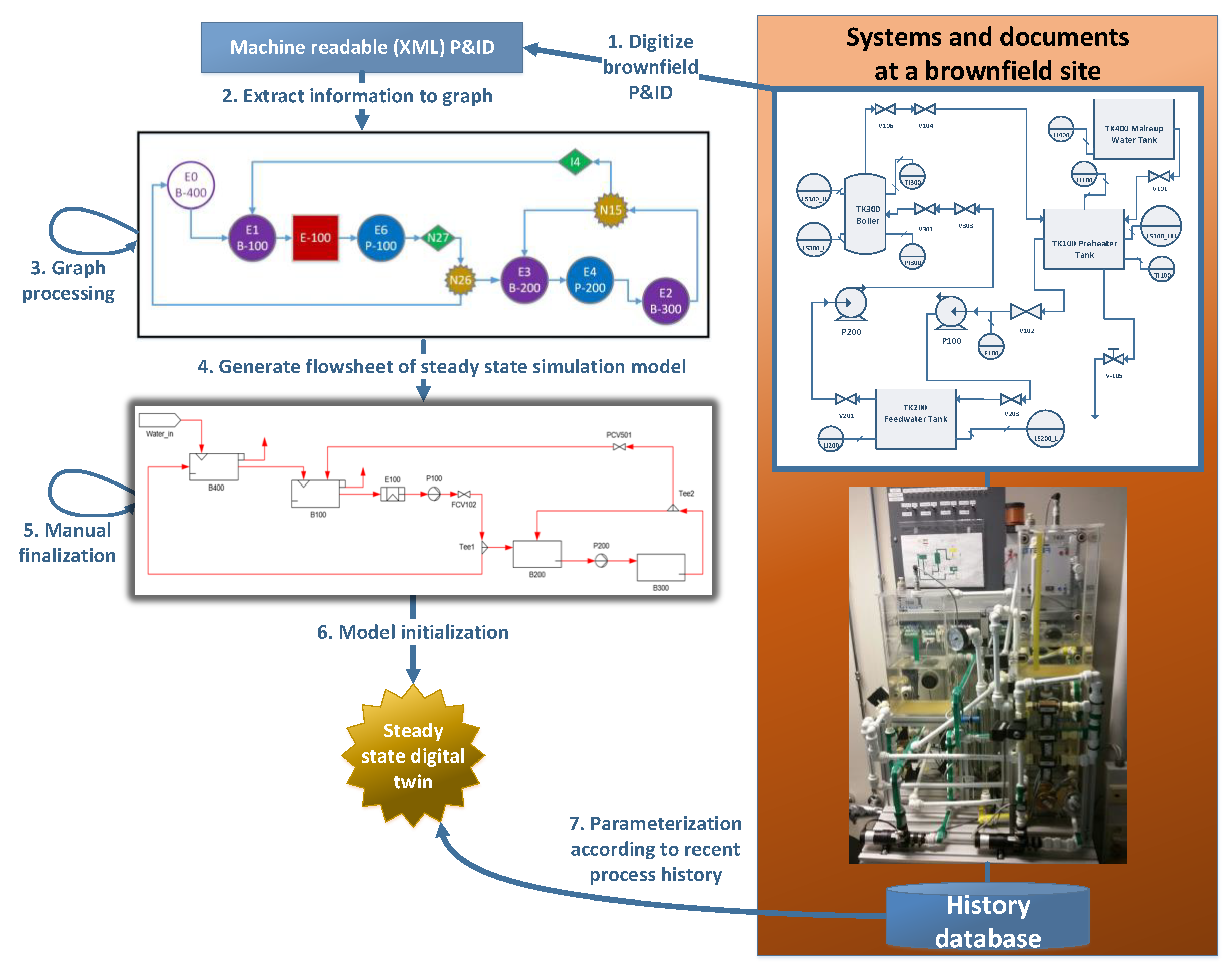
3.1. Methodology Overview
- The main process design document that is generally available at a brownfield process plant is a P&ID. Some leading P&ID CAD vendor’s tools are able to export P&IDs in a machine readable format according to the standardized Proteus XML schema, but this capability is present only in the most recent tool versions and is thus not applicable to brownfield plants [6,59]. In general, the P&IDs at a brownfield plant are paper documents that have been scanned to pdf-format, so various image recognition techniques are needed to extract information from them [12,48,60,61].
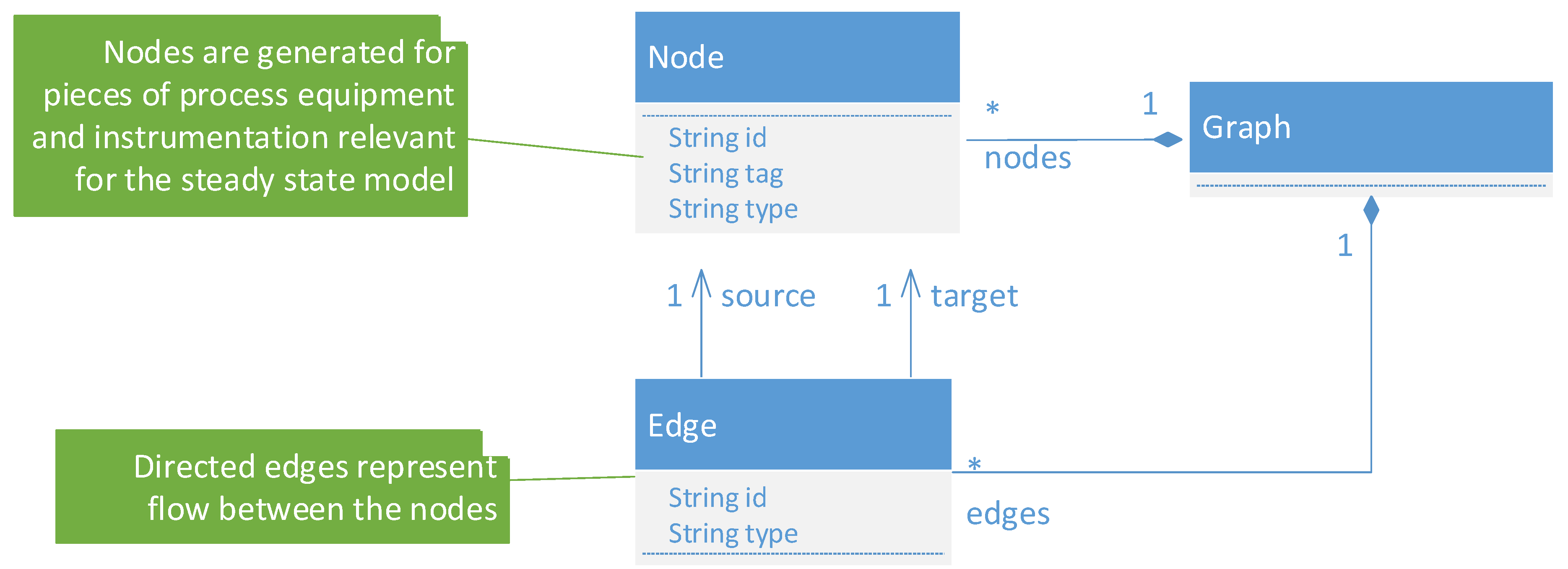
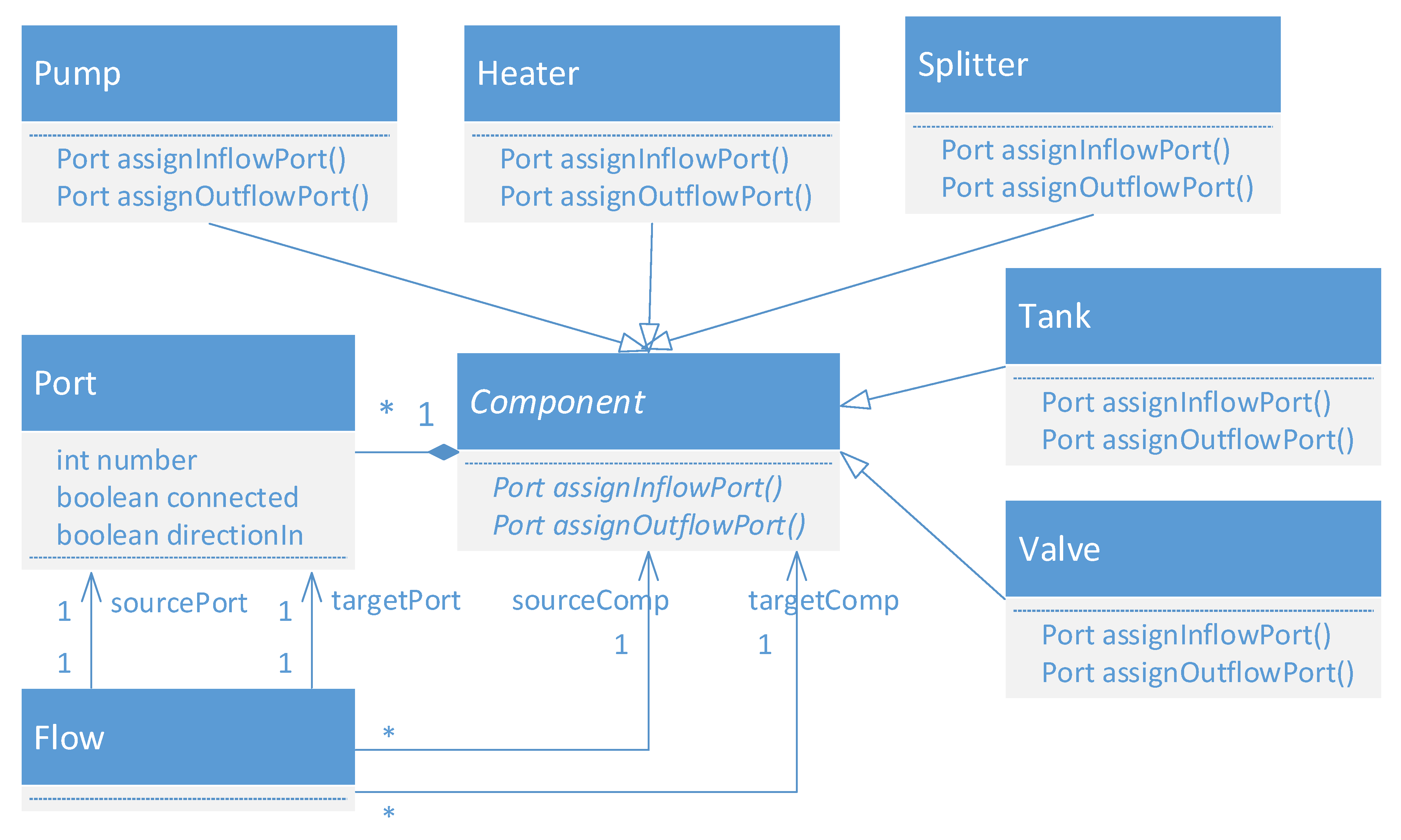
- Graphs have emerged as an intermediate format for abstracting key information from a process plant design [6,54,55,56]. The information that is relevant for building a steady state simulation model is extracted from the digitalized P&ID into a directed graph, as described in [6]. If Proteus XML is used as the digitalized P&ID format, the methodology will be able to support also modern plants for which the P&ID could be exported directly into this format. However, if the compatibility is not required, any proprietary format for a digitalized P&ID can be used as long as the graph is generated according to the following guidelines. Process equipment such as tanks, pumps, and valves are represented with nodes, and node labels capture the type of the component as well as the tag. Flows are represented with directed edges between the components, and the type of flow (e.g., water or broke) is captured by the edge label.
- The graph should be transformed until it is at a level of abstraction in which the steady state model can be generated by performing a one-to-one mapping from the graph nodes and edges to the equipment and flows of a steady state model.
- Simulation tool specific rules should be defined and implemented for generating a flowsheet of the steady state model automatically from the graph generated in step 3. The rules should be implemented by a custom software tool that writes its output into a format that can be imported to the selected simulation tool.
- A steady state modelling expert should manually finalize the flowsheet of the generated steady state model, using his or her expert modelling knowledge that could not be formalized as rules in step 4.
- A steady state modelling expert should manually initialize the steady state simulation model by defining the chemical components (i.e., water, pulp, air, steam, etc.) and selecting the calculation modules for each process equipment using his or her expert modelling knowledge that could not be formalized as rules in step 4. Further research could try to automate this step.
- The selected calculation module defines the needed input values for parameterizing the process equipment. The steady state modelling expert performs the parameterization manually. Further research could try to automate this step. If the parameterization is performed according to recent sensor data from the process, the steady state model may be considered as a digital twin.
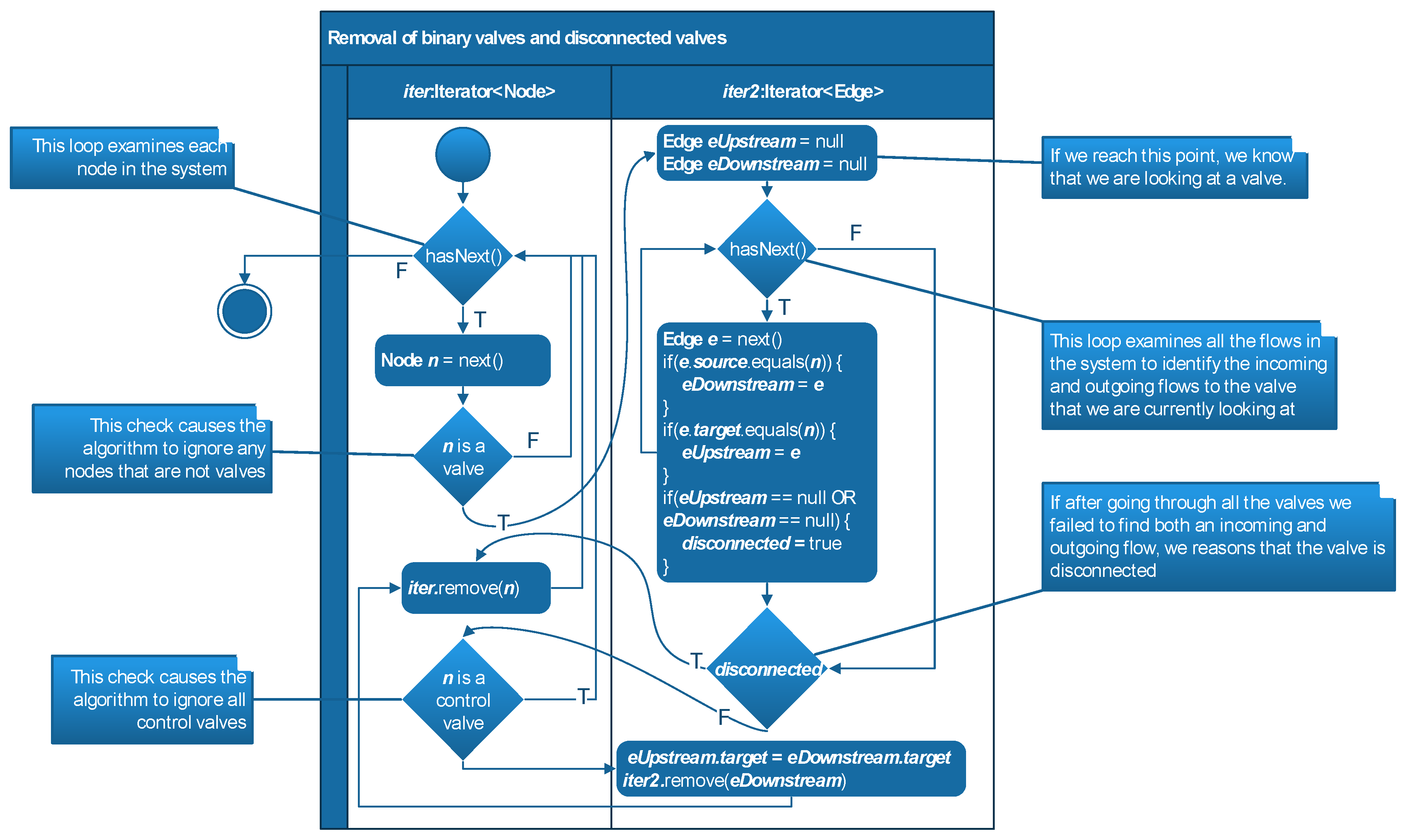
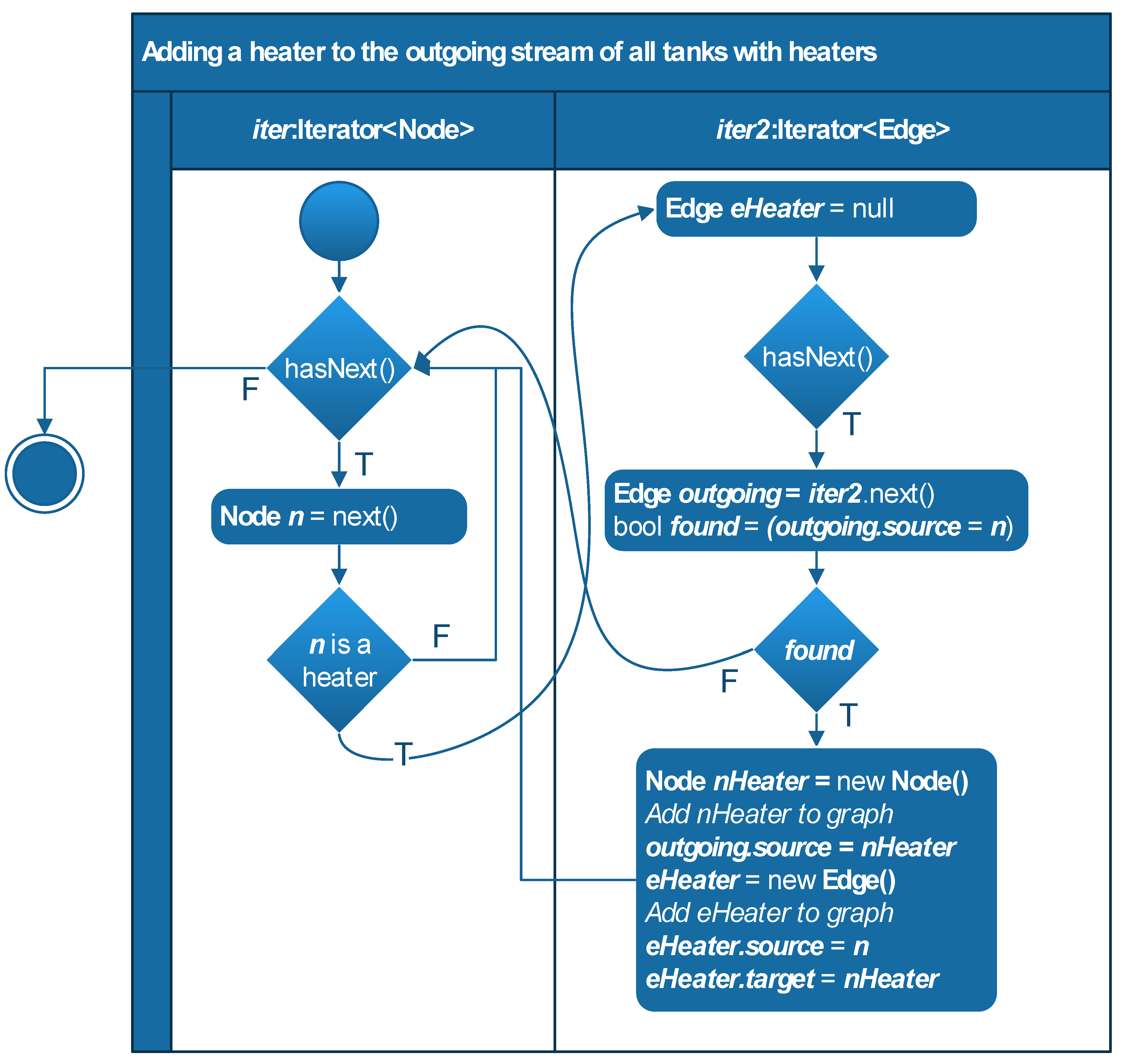
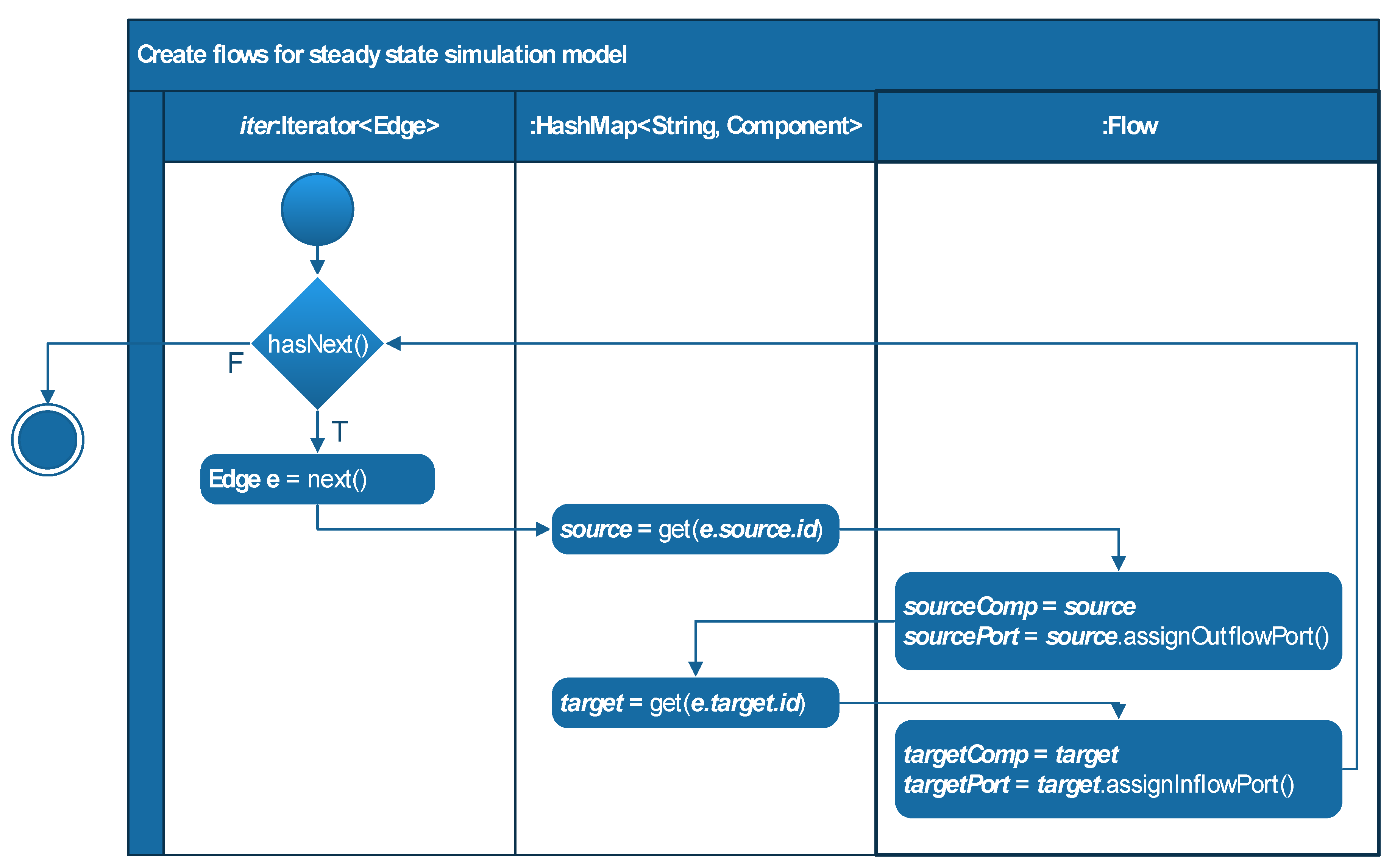
3.2. Graph processing
3.3. Generating a Flowsheet of the Steady State Model
3.4. Implementation of the Design
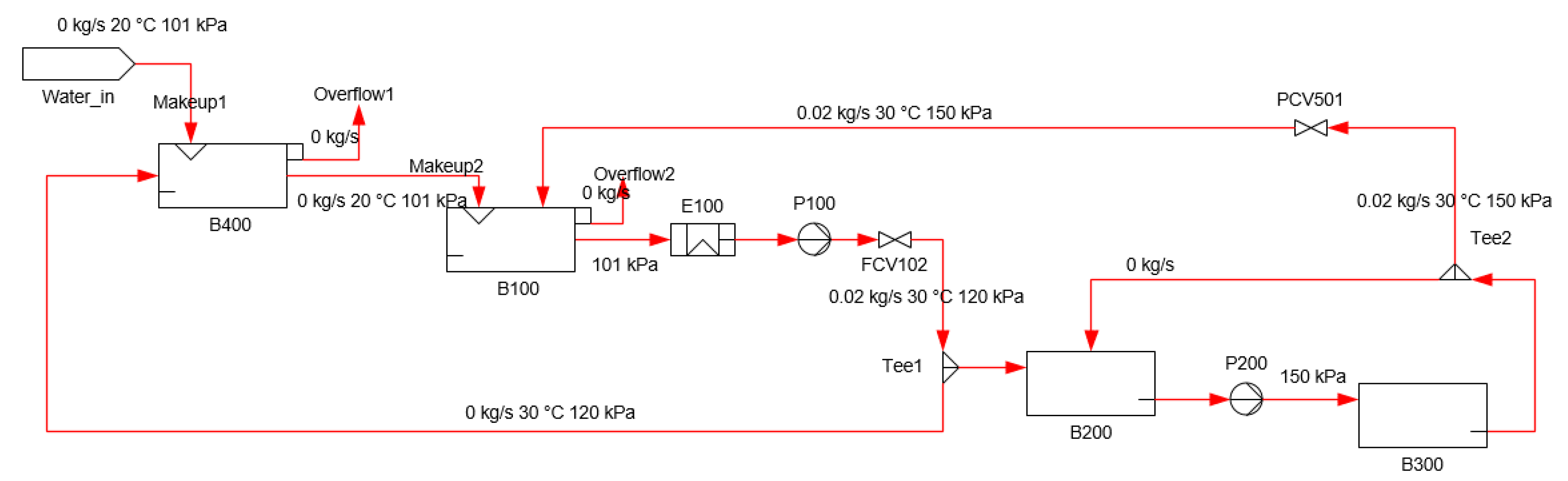
4. Case Study
5. Results
6. Discussion
7. Conclusion and Further Work
7.1. Limitations
7.2. Summary of Results and Further Work
Author Contributions
Funding
Conflicts of Interest
References
- Pinto-Varela, T.; Barbosa-Póvoa, A.P.F.D.; Carvalho, A. Sustainable batch process retrofit design under uncertainty—An integrated methodology. Comput. Chem. Eng. 2017, 102, 226–237. [Google Scholar] [CrossRef]
- Wang, B.; Klemeš, J.J.; Varbanov, P.S.; Chin, H.H.; Wang, Q.-W.; Zeng, M. Heat exchanger network retrofit by a shifted retrofit thermodynamic grid diagram-based model and a two-stage approach. Energy 2020, 198, 117338. [Google Scholar] [CrossRef]
- Min, K.-J.; Binns, M.; Oh, S.-Y.; Cha, H.-Y.; Kim, J.-K.; Yeo, Y.-K. Screening of site-wide retrofit options for the minimization of CO2 emissions in process industries. Appl. Therm. Eng. 2015, 90, 335–344. [Google Scholar] [CrossRef]
- Faria, D.C.; Bagajewicz, M.J. Profit-based grassroots design and retrofit of water networks in process plants. Comput. Chem. Eng. 2009, 33, 436–453. [Google Scholar] [CrossRef]
- Wen, M.; Wu, Q.; Li, G.; Wang, S.; Li, Z.; Tang, Y.; Xu, L.; Liu, T. Impact of ultra-low emission technology retrofit on the mercury emissions and cross-media transfer in coal-fired power plants. J. Hazard. Mater. 2020, 396, 122729. [Google Scholar] [CrossRef] [PubMed]
- Sierla, S.; Azangoo, M.; Vyatkin, V.; Fay, A.; Papakonstantinou, N. Integrating 2D and 3D Digital Plant Information towards Automatic Generation of Digital Twins. In Proceedings of the 29th IEEE International Symposium on Industrial Electronics, Delft, The Netherlands, 17–19 June 2020. [Google Scholar]
- Chen, B.; Wan, J.; Shu, L.; Li, P.; Mukherjee, M.; Yin, B. Smart Factory of Industry 4.0: Key Technologies, Application Case, and Challenges. IEEE Access 2018, 6, 6505–6519. [Google Scholar] [CrossRef]
- Schluse, M.; Priggemeyer, M.; Atorf, L.; Roßmann, J.; Romann, J. Experimentable Digital Twins—Streamlining Simulation-Based Systems Engineering for Industry 4.0. IEEE Trans. Ind. Inform. 2018, 14, 1722–1731. [Google Scholar] [CrossRef]
- Martinez, G.S.; Karhela, T.A.; Ruusu, R.J.; Sierla, S.; Vyatkin, V. An Integrated Implementation Methodology of a Lifecycle-Wide Tracking Simulation Architecture. IEEE Access 2018, 6, 15391–15407. [Google Scholar] [CrossRef]
- Martinez, G.S.; Sierla, S.; Karhela, T.; Lappalainen, J.; Vyatkin, V. Automatic Generation of a High-Fidelity Dynamic Thermal-Hydraulic Process Simulation Model from a 3D Plant Model. IEEE Access 2018, 6, 45217–45232. [Google Scholar] [CrossRef]
- Martínez, G.S.; Sierla, S.; Karhela, T.; Vyatkin, V. Automatic Generation of a Simulation-Based Digital Twin of an Industrial Process Plant. In Proceedings of the 44th Annual Conference of the IEEE Industrial Electronics Society IECON 2018, Washington, DC, USA, 21–23 October 2018; pp. 3084–3089. [Google Scholar] [CrossRef]
- Arroyo, E.; Hoernicke, M.; Rodríguez, P.; Fay, A. Automatic derivation of qualitative plant simulation models from legacy piping and instrumentation diagrams. Comput. Chem. Eng. 2016, 92, 112–132. [Google Scholar] [CrossRef]
- Shellshear, E.; Berlin, R.; Carlson, J.S. Maximizing Smart Factory Systems by Incrementally Updating Point Clouds. IEEE Comput. Graph. Appl. 2015, 35, 62–69. [Google Scholar] [CrossRef] [PubMed]
- Emerson. Understanding and Applying Simulation Fidelity to the Digital Twin. White Paper 2018. Available online: emerson.com/documents/automation/understanding-applying-simulation-fidelity-to-digital-twin-en-5079366 (accessed on 2 October 2020).
- Matzopoulos, M. Dynamic Process Modeling: Combining Models and Experimental Data to Solve Industrial Problems. In Process Systems Engineering: Volume 7 Dynamic Process Modeling; Georgiadis, M.C., Banga, J.R., Pistikopoulos, E.N., Eds.; Wiley-VCH: Weinheim, Germany, 2010; pp. 1–33. [Google Scholar] [CrossRef]
- Leiviskä, K. Simulation in Pulp and Paper Industry; University of Oulu, Control Engineering Laboratory: Oulu, Finland, 1996; Report A, 2; pp. 1–58. [Google Scholar]
- Blanco, A.; Dahlquist, E.; Kappen, J.; Manninen, J.; Negro, C.; Ritala, R. Use of modelling and simulation in the pulp and paper industry. Math. Comput. Model. Dyn. Syst. 2009, 15, 409–423. [Google Scholar] [CrossRef]
- Bezzo, F.; Bernardi, R.; Cremonese, G.; Finco, M.; Barolo, M. Using Process Simulators for Steady-State and Dynamic Plant Analysis. Chem. Eng. Res. Des. 2004, 82, 499–512. [Google Scholar] [CrossRef]
- Enaasen, N.; Tobiesen, A.; Kvamsdal, H.M.; Hillestad, M. Dynamic Modeling of the Solvent Regeneration Part of a CO2 Capture Plant. Energy Procedia 2013, 37, 2058–2065. [Google Scholar] [CrossRef][Green Version]
- Măluțan, T.; Mǎluţan, C. Simulation of Processes in Papermaking by WinGEMS Software. Environ. Eng. Manag. J. 2013, 12, 1645–1647. [Google Scholar] [CrossRef]
- Turon, X.; Labidi, J.; Paris, J. Simulation and optimisation of a high grade coated paper mill. J. Clean. Prod. 2005, 13, 1424–1433. [Google Scholar] [CrossRef]
- Cardoso, M.; De Oliveira, K.D.; Costa, G.A.A.; Passos, M.L. Chemical process simulation for minimizing energy consumption in pulp mills. Appl. Energy 2009, 86, 45–51. [Google Scholar] [CrossRef]
- Atkins, M.; Morrison, A.; Walmsley, M.; Riley, J. WinGEMS Modelling and Pinch Analysis of a Paper Machine for Utility Reduction. Appita J. 2010, 63, 281–287. [Google Scholar]
- Jönsson, J.; Ruohonen, P.; Michel, G.; Berntsson, T. The potential for steam savings and implementation of different biorefinery concepts in Scandinavian integrated TMP and paper mills. Appl. Therm. Eng. 2011, 31, 2107–2114. [Google Scholar] [CrossRef][Green Version]
- Clement, S.; Gouiller, A.; Ottenio, P.; Nivelon, S.; Huber, P.; Nortier, P. Speciation and supersaturation model in papermaking streams. Process. Saf. Environ. Prot. 2011, 89, 67–73. [Google Scholar] [CrossRef]
- Huber, P.; Nivelon, S.; Ottenio, P.; Nortier, P. Coupling a Chemical Reaction Engine with a Mass Flow Balance Process Simulation for Scaling Management in Papermaking Process Waters. Ind. Eng. Chem. Res. 2012, 52, 421–429. [Google Scholar] [CrossRef]
- Kangas, P.; Kaijaluoto, S.; Määttänen, M. Evaluation of future pulp mill concepts—Reference model of a modern Nordic kraft pulp mill. Nord. Pulp Pap. Res. J. 2014, 29, 620–634. [Google Scholar] [CrossRef]
- Barbera, E.; Menegon, S.; Banzato, D.; D’Alpaos, C.; Bertucco, A. From biogas to biomethane: A process simulation-based techno-economic comparison of different upgrading technologies in the Italian context. Renew. Energy 2019, 135, 663–673. [Google Scholar] [CrossRef]
- Kautto, J.; Realff, M.J.; Ragauskas, A.J. Design and simulation of an organosolv process for bioethanol production. Biomass Convers. Biorefinery 2013, 3, 199–212. [Google Scholar] [CrossRef]
- Søtoft, L.F.; Rong, B.-G.; Christensen, K.; Norddahl, B. Process simulation and economical evaluation of enzymatic biodiesel production plant. Bioresour. Technol. 2010, 101, 5266–5274. [Google Scholar] [CrossRef]
- Cheah, K.W.; Yusup, S.; Singh, H.K.G.; Uemura, Y.; Lam, H.L.; Wai, C.K. Process simulation and techno economic analysis of renewable diesel production via catalytic decarboxylation of rubber seed oil—A case study in Malaysia. J. Environ. Manag. 2017, 203, 950–961. [Google Scholar] [CrossRef]
- Barbosa, L.D.S.N.S.; Hytönen, E.; Vainikka, P. Carbon mass balance in sugarcane biorefineries in Brazil for evaluating carbon capture and utilization opportunities. Biomass Bioenergy 2017, 105, 351–363. [Google Scholar] [CrossRef]
- Hytönen, E.; Stuart, P.R. Biofuel Production in an Integrated Forest Biorefinery—Technology Identification under Uncertainty. J. Biobased Mater. Bioenergy 2010, 4, 58–67. [Google Scholar] [CrossRef]
- Nabgan, B.; Abdullah, T.A.T.; Nabgan, W.; Ahmad, A.; Saeh, I.; Moghadamian, K. Process Simulation for Removing Impurities from Wastewater Using Sour Water 2-Strippers system via Aspen Hysys. Chem. Prod. Process. Model. 2016, 11, 315–321. [Google Scholar] [CrossRef]
- Miltner, A.; Wukovits, W.; Pröll, T.; Friedl, A. Renewable hydrogen production: A technical evaluation based on process simulation. J. Clean. Prod. 2010, 18, S51–S62. [Google Scholar] [CrossRef]
- Zhang, Y.; Cruz, J.; Zhang, S.; Lou, H.H.; Benson, T.J. Process simulation and optimization of methanol production coupled to tri-reforming process. Int. J. Hydrogen Energy 2013, 38, 13617–13630. [Google Scholar] [CrossRef]
- Michaux, B.; Rudolph, M.; Reuter, M.A.; Reuter, M.A. Study of process water recirculation in a flotation plant by means of process simulation. Miner. Eng. 2020, 148, 106181. [Google Scholar] [CrossRef]
- McNulty, M.J.; Gleba, Y.; Tusé, D.; Hahn-Löbmann, S.; Giritch, A.; Nandi, S.; McDonald, K.A. Techno-economic analysis of a plant-based platform for manufacturing antimicrobial proteins for food safety. Biotechnol. Prog. 2019, 36, e2896. [Google Scholar] [CrossRef] [PubMed]
- Bon, J.; Clemente, G.; Váquiro, H.; Mulet, A. Simulation and optimization of milk pasteurization processes using a general process simulator (ProSimPlus). Comput. Chem. Eng. 2010, 34, 414–420. [Google Scholar] [CrossRef]
- Koulamas, C.; Kalogeras, A.P. Cyber-Physical Systems and Digital Twins in the Industrial Internet of Things. Computer 2018, 51, 95–98. [Google Scholar] [CrossRef]
- Tao, F.; Zhang, M. Digital Twin Shop-Floor: A New Shop-Floor Paradigm towards Smart Manufacturing. IEEE Access 2017, 5, 20418–20427. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, Q.; Chen, X.; Zhang, D.; Leng, J. A Digital Twin-Based Approach for Designing and Multi-Objective Optimization of Hollow Glass Production Line. IEEE Access 2017, 5, 26901–26911. [Google Scholar] [CrossRef]
- Wan, J.; Tang, S.; Li, D.; Imran, M.; Zhang, C.; Liu, C.; Pang, Z. Reconfigurable Smart Factory for Drug Packing in Healthcare Industry 4.0. IEEE Trans. Ind. Inform. 2018, 15, 507–516. [Google Scholar] [CrossRef]
- Schmidt, N.; Lüder, A. The Flow and Reuse of Data: Capabilities of Automation ML in the Production System Life Cycle. IEEE Ind. Electron. Mag. 2018, 12, 59–63. [Google Scholar] [CrossRef]
- Hartmann, B.; Török, S.; Börcsök, E.; Groma, V.O. Multi-objective method for energy purpose redevelopment of brownfield sites. J. Clean. Prod. 2014, 82, 202–212. [Google Scholar] [CrossRef]
- Sørensen, D.; Brunoe, T.D.; Nielsen, K. Brownfield Development of Platforms for Changeable Manufacturing. Procedia CIRP 2019, 81, 986–991. [Google Scholar] [CrossRef]
- Illa, P.K.; Padhi, N. Practical Guide to Smart Factory Transition Using IoT, Big Data and Edge Analytics. IEEE Access 2018, 6, 55162–55170. [Google Scholar] [CrossRef]
- Barth, M.; Fay, A. Automated generation of simulation models for control code tests. Control. Eng. Pract. 2013, 21, 218–230. [Google Scholar] [CrossRef]
- Stojanovic, N.; Milenovic, D. Data-driven Digital Twin approach for process optimization: An industry use case. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 4202–4211. [Google Scholar]
- Makarov, V.; Frolov, Y.; Parshina, I.S.; Ushakova, M. The Design Concept of Digital Twin. In Proceedings of the 2019 Twelfth International Conference “Management of large-scale system development” (MLSD), Moscow, Russia, 1–3 October 2019; pp. 1–4. [Google Scholar]
- Kychkin, A.; Nikolaev, A. IoT-based Mine Ventilation Control System Architecture with Digital Twin. In Proceedings of the 2020 International Conference on Industrial Engineering, Applications and Manufacturing (ICIEAM), Sochi, Russia, 18–22 May 2020; pp. 1–5. [Google Scholar]
- Barth, M.; Strube, M.; Fay, A.; Weber, P.; Greifeneder, J. Object-oriented engineering data exchange as a base for automatic generation of simulation models. In Proceedings of the 2009 35th Annual Conference of IEEE Industrial Electronics, Porto, Portugal, 3–5 November 2009; pp. 2465–2470. [Google Scholar]
- Campos, J.G.; López, J.S.; Quiroga, J.I.A.; Seoane, A.M.E. Automatic generation of digital twin industrial system from a high level specification. Procedia Manuf. 2019, 38, 1095–1102. [Google Scholar] [CrossRef]
- Sierla, S.; Azangoo, M.; Vyatkin, V. Generating an Industrial Process Graph from 3D Pipe Routing Information. In Proceedings of the 25th IEEE International Conference on Emerging Technologies and Factory Automation, ETFA 2020, Vienna, Austria, 8–11 September 2020. [Google Scholar]
- Wen, R.; Tang, W.; Su, Z. Topology based 2D engineering drawing and 3D model matching for process plant. Graph. Model. 2017, 92, 1–15. [Google Scholar] [CrossRef]
- Rantala, M.; Niemistö, H.; Karhela, T.; Sierla, S.; Vyatkin, V. Applying graph matching techniques to enhance reuse of plant design information. Comput. Ind. 2019, 107, 81–98. [Google Scholar] [CrossRef]
- Son, H.; Kim, C.; Kim, C. 3D reconstruction of as-built industrial instrumentation models from laser-scan data and a 3D CAD database based on prior knowledge. Autom. Constr. 2015, 49, 193–200. [Google Scholar] [CrossRef]
- Lee, J.; Son, H.; Kim, C.; Kim, C. Skeleton-based 3D reconstruction of as-built pipelines from laser-scan data. Autom. Constr. 2013, 35, 199–207. [Google Scholar] [CrossRef]
- Papakonstantinou, N.; Karttunen, J.; Sierla, S.; Vyatkin, V. Design to automation continuum for industrial processes: ISO 15926–IEC 61131 versus an industrial case. In Proceedings of the 2019 24th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Zaragoza, Spain, 10–13 September 2019; pp. 1207–1212. [Google Scholar]
- Sinha, A.; Bayer, J.; Bukhari, S.S. Table Localization and Field Value Extraction in Piping and Instrumentation Diagram Images. In Proceedings of the 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW), Sydney, Australia, 20–25 September 2019; Volume 1, pp. 26–31. [Google Scholar]
- Nurminen, J.K.; Rainio, K.; Numminen, J.P.; Syrjänen, T.; Paganus, N.; Honkoila, K. Object Detection in Design Diagrams with Machine Learning. In Advances in Intelligent Systems and Computing; Springer: Cham, Germany, 2020; Volume 977, pp. 27–36. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Graph Structure | Mapping to Balas® |
|---|---|
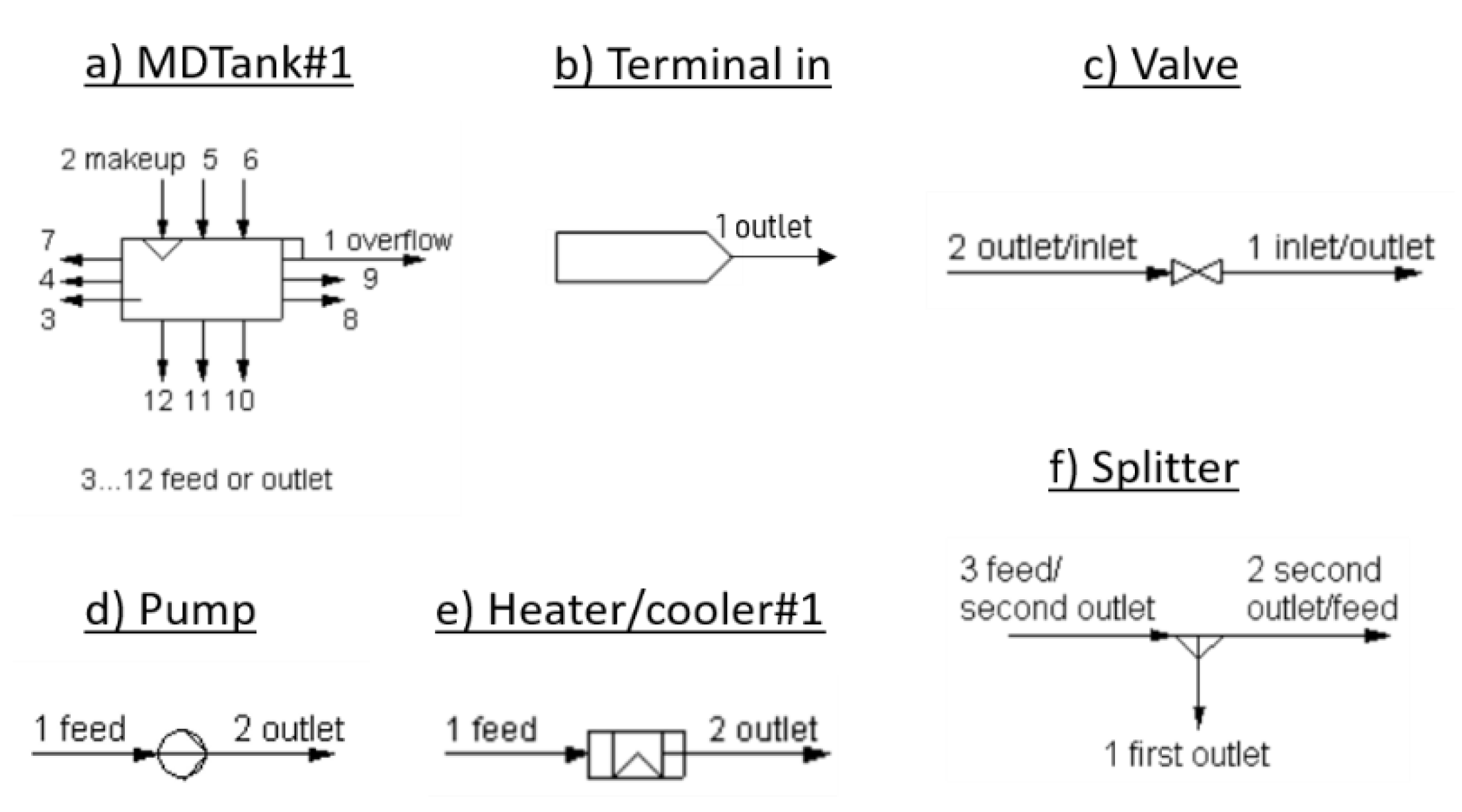
| A node of type tank, with one outgoing edge and one or more incoming edges | Replace all tank nodes with a symbol “MDTank#1” (See Figure 5a). Add a stream from port#1 of symbol “Terminal in” (See Figure 5b) to port #2 of symbol “MDTank#1”. From port #1 of symbol “MDTank#1”, add a stream to nowhere. Ports #3-#12 of the symbol “MDTank#1” can be used either for feed or outlet. |
| A node of type valve, pump or heater with one incoming and one outgoing edge | The relevant symbols are “Valve” (See Figure 5c), “Pump” (See Figure 5d), “Heater/cooler#1” (See Figure 5e). For each of these symbols, port #1 is for inlet and port #2 is for outlet. |
| A node of type tee with one incoming and two outgoing edges | Replace tees with symbol “Splitter” (See Figure 5f) with port #3 for inlet and ports #1 and #2 for outlet. |
| NodeName | Symbol |
|---|---|
| B-400 | MDTank#1 |
| Source1 | Terminal in |
| B-100 | MDTank#1 |
| Source2 | Terminal in |
| B-300 | MDTank#1 |
| Source3 | Terminal in |
| B-200 | MDTank#1 |
| Source4 | Terminal in |
| P-200 | Pump |
| P-100 | Pump |
| I4 | Valve |
| ES-E100 | Heater/cooler#1 |
| N15 | Splitter |
| N26 | Splitter |
| N27 | Valve |
| Source | SourcePort | Target | TargetPort |
|---|---|---|---|
| Source1 | 1 | B-400 | 2 |
| B-400 | 1 | drain | 0 |
| Source2 | 1 | B-100 | 2 |
| B-100 | 1 | drain | 0 |
| Source3 | 1 | B-300 | 2 |
| B-300 | 1 | drain | 0 |
| Source4 | 1 | B-200 | 2 |
| B-200 | 1 | drain | 0 |
| B-200 | 3 | P-200 | 1 |
| B-400 | 3 | B-100 | 3 |
| I4 | 2 | B-100 | 4 |
| N15 | 1 | I4 | 1 |
| B-300 | 3 | N15 | 3 |
| N15 | 2 | B-200 | 4 |
| P-100 | 2 | N27 | 1 |
| N27 | 2 | N26 | 3 |
| N26 | 1 | B-200 | 5 |
| N26 | 2 | B-400 | 4 |
| ES-E100 | 2 | P-100 | 1 |
| P-200 | 2 | B-300 | 4 |
| B-100 | 5 | ES-E100 | 1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sierla, S.; Sorsamäki, L.; Azangoo, M.; Villberg, A.; Hytönen, E.; Vyatkin, V. Towards Semi-Automatic Generation of a Steady State Digital Twin of a Brownfield Process Plant. Appl. Sci. 2020, 10, 6959. https://doi.org/10.3390/app10196959
Sierla S, Sorsamäki L, Azangoo M, Villberg A, Hytönen E, Vyatkin V. Towards Semi-Automatic Generation of a Steady State Digital Twin of a Brownfield Process Plant. Applied Sciences. 2020; 10(19):6959. https://doi.org/10.3390/app10196959
Chicago/Turabian StyleSierla, Seppo, Lotta Sorsamäki, Mohammad Azangoo, Antti Villberg, Eemeli Hytönen, and Valeriy Vyatkin. 2020. "Towards Semi-Automatic Generation of a Steady State Digital Twin of a Brownfield Process Plant" Applied Sciences 10, no. 19: 6959. https://doi.org/10.3390/app10196959
APA StyleSierla, S., Sorsamäki, L., Azangoo, M., Villberg, A., Hytönen, E., & Vyatkin, V. (2020). Towards Semi-Automatic Generation of a Steady State Digital Twin of a Brownfield Process Plant. Applied Sciences, 10(19), 6959. https://doi.org/10.3390/app10196959