Towards Robust Word Embeddings for Noisy Texts




Abstract
1. Introduction
2. Towards Noise-Resistant Word Embeddings
2.1. Modified Skipgram Model
3. Evaluation
3.1. Word Embedding Training
3.2. Intrinsic Tasks: Word Similarity and Outlier Detection
3.3. Extrinsic Tasks: The Senteval Benchmark and Twitter SA
3.4. Dataset De-Normalization
3.5. Results
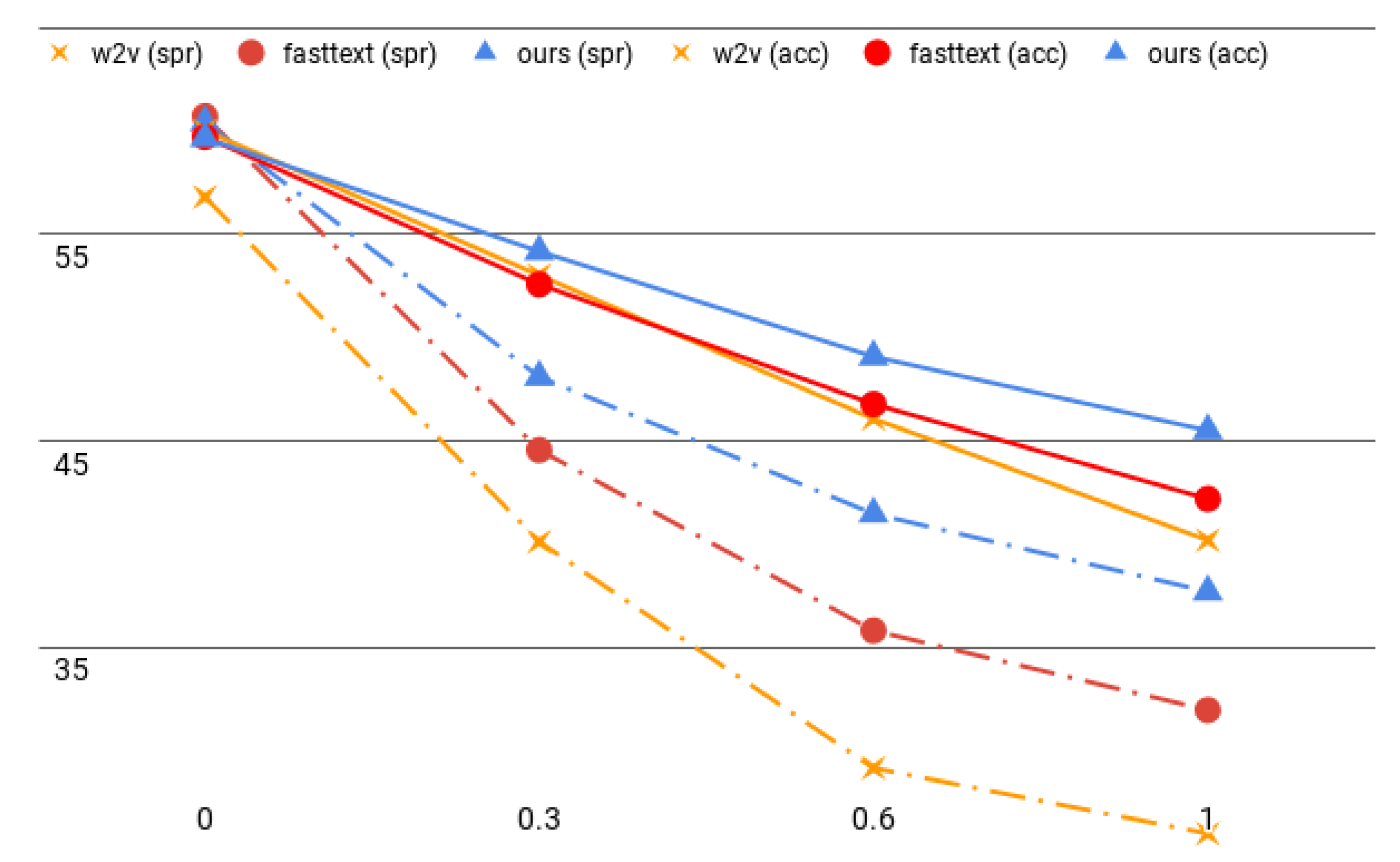
3.5.1. Intrinsic Evaluation
3.5.2. Extrinsic Evaluation
4. Related Work
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
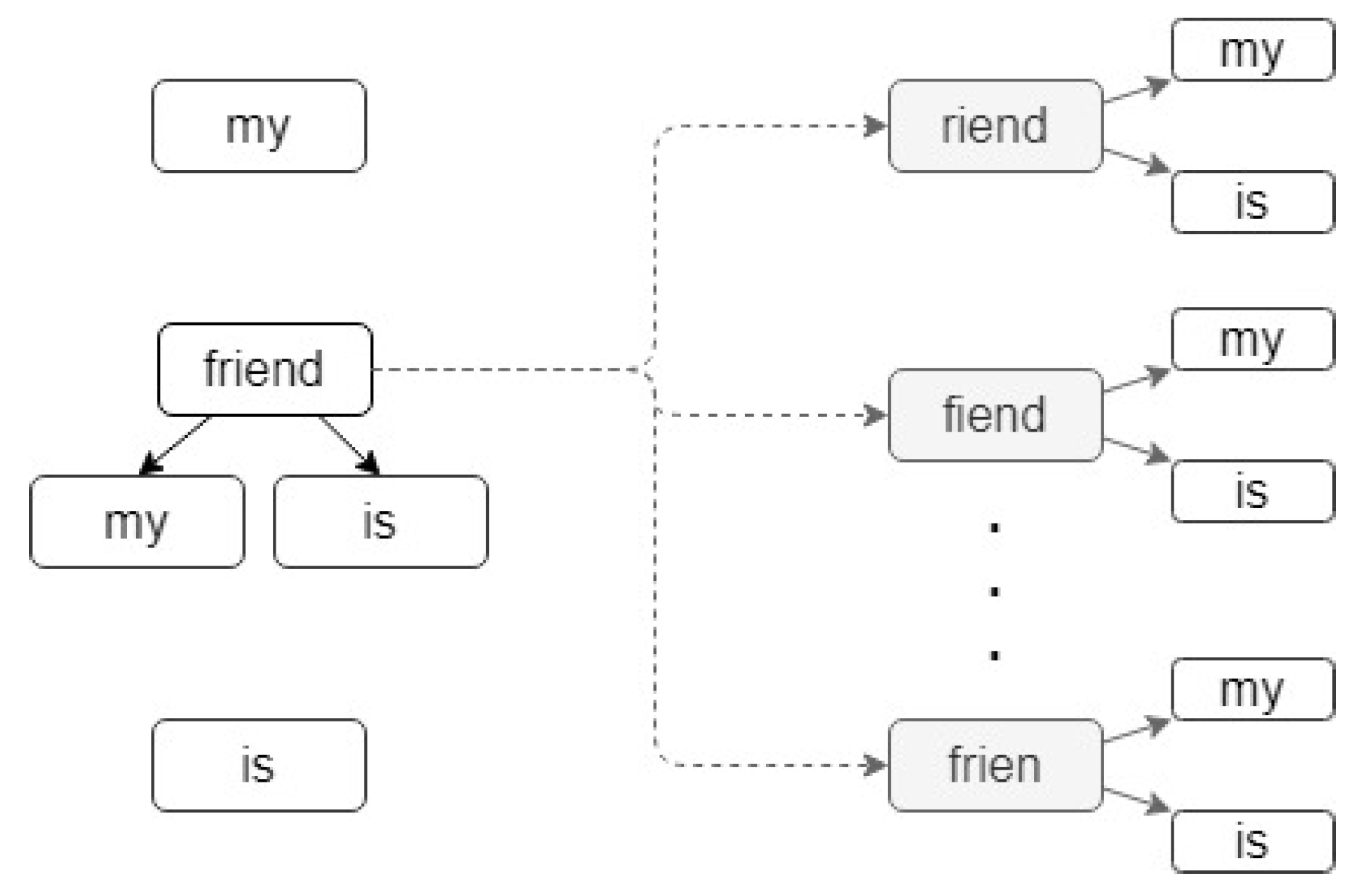
Appendix A. The Importance of Word Segmentation

{kind=link}
{kind=link}
| Join | Split | |
|---|---|---|
| word2vec | 11.0 | 18.3 |
| fastText | 39.2 | 18.7 |
| ours | 39.2 | 17.2 |
References
- Bansal, M.; Gimpel, K.; Livescu, K. Tailoring Continuous Word Representations for Dependency Parsing. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 22–27 June 2014; Association for Computational Linguistics: Baltimore, MD, USA, 2014; pp. 809–815. [Google Scholar] [CrossRef]
- Vulić, I.; Moens, M.F. Monolingual and Cross-Lingual Information Retrieval Models Based on (Bilingual) Word Embeddings. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval—SIGIR ’15, Santiago, Chile, 11–15 August 2015; pp. 363–372. [Google Scholar] [CrossRef]
- Kutuzov, A.; Velldal, E.; Øvrelid, L. Redefining part-of-speech classes with distributional semantic models. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 115–125. [Google Scholar] [CrossRef]
- Xiong, S.; Lv, H.; Zhao, W.; Ji, D. Towards Twitter sentiment classification by multi-level sentiment-enriched word embeddings. Neurocomputing 2018, 275, 2459–2466. [Google Scholar] [CrossRef]
- Lampos, V.; Zou, B.; Cox, I.J. Enhancing Feature Selection Using Word Embeddings: The Case of Flu Surveillance. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 May 2017; ACM: Perth, Australia, 2017; pp. 695–704. [Google Scholar] [CrossRef]
- Yang, X.; Macdonald, C.; Ounis, I. Using word embeddings in Twitter election classification. Inf. Retr. J. 2018, 21, 183–207. [Google Scholar] [CrossRef]
- Liang, S.; Zhang, X.; Ren, Z.; Kanoulas, E. Dynamic Embeddings for User Profiling in Twitter. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD, London, UK, 19–23 August 2018; ACM: London, UK, 2018; pp. 1764–1773. [Google Scholar] [CrossRef]
- Mikolov, T.; Corrado, G.; Chen, K.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the 1st International Conference on Learning Representations, Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Sumbler, P.; Viereckel, N.; Afsarmanesh, N.; Karlgren, J. Handling Noise in Distributional Semantic Models for Large Scale Text Analytics and Media Monitoring. In Proceedings of the Abstract in the Fourth Workshop on Noisy User—Generated Text (W-NUT 2018), Brussels, Belgium, 1 November 2018. [Google Scholar]
- Eisenstein, J. What to do about bad language on the internet. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; Association for Computational Linguistics: Atlanta, GA, USA, 2013; pp. 359–369. [Google Scholar]
- Chrupała, G. Normalizing tweets with edit scripts and recurrent neural embeddings. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 22–27 June 2014; Association for Computational Linguistics: Baltimore, MD, USA, 2014; pp. 680–686. [Google Scholar] [CrossRef]
- Van der Goot, R.; van Noord, G. MoNoise: Modeling Noise Using a Modular Normalization System. Comput. Linguist. Neth. J. 2017, 7, 129–144. [Google Scholar]
- Bordes, A.; Boureau, Y.; Weston, J. Learning End-to-End Goal-Oriented Dialog. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A. OpenNMT: Open-Source Toolkit for Neural Machine Translation. In Proceedings of the ACL 2017, System Demonstrations, Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 67–72. [Google Scholar]
- Schmitt, M.; Steinheber, S.; Schreiber, K.; Roth, B. Joint Aspect and Polarity Classification for Aspect-based Sentiment Analysis with End-to-End Neural Networks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1109–1114. [Google Scholar]
- van der Goot, R.; Plank, B.; Nissim, M. To normalize, or not to normalize: The impact of normalization on Part-of-Speech tagging. In Proceedings of the 3rd Workshop on Noisy User-generated Text, Copenhagen, Denmark, 7 September 2017; pp. 31–39. [Google Scholar]
- Costa Bertaglia, T.F.; Volpe Nunes, M.D.G. Exploring Word Embeddings for Unsupervised Textual User-Generated Content Normalization. In Proceedings of the 2nd Workshop on Noisy User-generated Text (WNUT), Osaka, Japan, 19 November 2020; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 112–120. [Google Scholar]
- Ansari, S.A.; Zafar, U.; Karim, A. Improving Text Normalization by Optimizing Nearest Neighbor Matching. arXiv 2017, arXiv:1712.09518. [Google Scholar]
- Sridhar, V.K.R. Unsupervised text normalization using distributed representations of words and phrases. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, Denver, CO, USA, 31 May–5 June 2015; pp. 8–16. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; Volume 1, (Long and Short Papers). pp. 4171–4186. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Camacho-Collados, J.; Navigli, R. Find the word that does not belong: A Framework for an Intrinsic Evaluation of Word Vector Representations. In Proceedings of the 1st Workshop on Evaluating Vector-Space Representations for NLP, Berlin, Germany, 12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 43–50. [Google Scholar] [CrossRef]
- Conneau, A.; Kiela, D. SentEval: An Evaluation Toolkit for Universal Sentence Representations. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; European Language Resources Association (ELRA): Miyazaki, Japan, 2018. [Google Scholar]
- Han, L.; Kashyap, A.L.; Finin, T.; Mayfield, J.; Weese, J. UMBC_EBIQUITY-CORE: Semantic Textual Similarity Systems. In Second Joint Conference on Lexical and Computational Semantics (*SEM), Volume 1: Proceedings of the Main Conference and the Shared Task: Semantic Textual Similarity; Association for Computational Linguistics: Atlanta, GA, USA, 2013; pp. 44–52. [Google Scholar]
- Finkelstein, L.; Evgeniy, G.; Yossi, M.; Ehud, R.; Zach, S.; Gadi, W.; Eytan, R. Placing Search in Context: The Concept Revisited. ACM Trans. Inf. Syst. 2002, 20, 116–131. [Google Scholar]
- Huang, E.; Socher, R.; Manning, C.; Ng, A. Improving Word Representations via Global Context and Multiple Word Prototypes. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Jeju Island, Korea, 8–14 July 2012; Association for Computational Linguistics: Jeju Island, Korea, 2012; pp. 873–882. [Google Scholar]
- Hill, F.; Reichart, R.; Korhonen, A. SimLex-999: Evaluating Semantic Models With (Genuine) Similarity Estimation. Comput. Linguist. 2015, 41, 665–695. [Google Scholar] [CrossRef]
- Camacho-Collados, J.; Pilehvar, M.T.; Collier, N.; Navigli, R. SemEval-2017 Task 2: Multilingual and Cross-lingual Semantic Word Similarity. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 15–26. [Google Scholar] [CrossRef]
- Blair, P.; Merhav, Y.; Barry, J. Automated Generation of Multilingual Clusters for the Evaluation of Distributed Representations. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Faruqui, M.; Tsvetkov, Y.; Rastogi, P.; Dyer, C. Problems With Evaluation of Word Embeddings Using Word Similarity Tasks. In Proceedings of the 1st Workshop on Evaluating Vector-Space Representations for NLP, Berlin, Germany, 12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 30–35. [Google Scholar] [CrossRef]
- Chiu, B.; Korhonen, A.; Pyysalo, S. Intrinsic Evaluation of Word Vectors Fails to Predict Extrinsic Performance. In Proceedings of the 1st Workshop on Evaluating Vector-Space Representations for NLP, Berlin, Germany, 12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Conneau, A.; Kiela, D.; Schwenk, H.; Barrault, L.; Bordes, A. Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 670–680. [Google Scholar]
- Subramanian, S.; Trischler, A.; Bengio, Y.; Pal, C.J. Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–16. [Google Scholar]
- Nakov, P.; Rosenthal, S.; Kozareva, Z.; Stoyanov, V.; Ritter, A.; Wilson, T. SemEval-2013 Task 2: Sentiment Analysis in Twitter. In Proceedings of the 7th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2013, Atlanta, GA, USA, 14–15 June 2013; Association for Computational Linguistics: Atlanta, GA, USA, 2013; pp. 312–320. [Google Scholar]
- Rosenthal, S.; Ritter, A.; Nakov, P.; Stoyanov, V. SemEval-2014 Task 9: Sentiment Analysis in Twitter. In Proceedings of the 8th International Workshop on Semantic Evaluation, SemEval@COLING 2014, Dublin, Ireland, 23–24 August 2014; pp. 73–80. [Google Scholar]
- Nakov, P.; Ritter, A.; Rosenthal, S.; Sebastiani, F.; Stoyanov, V. SemEval-2016 Task 4: Sentiment Analysis in Twitter. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016); Association for Computational Linguistics: San Diego, CA, USA, 2016; pp. 1–18. [Google Scholar] [CrossRef]
- Baldwin, T.; de Marneffe, M.C.; Han, B.; Kim, Y.B.; Ritter, A.; Xu, W. Shared tasks of the 2015 workshop on noisy user-generated text: Twitter lexical normalization and named entity recognition. In Proceedings of the Workshop on Noisy User—-Generated Text, Beijing, China, 31 July 2015; pp. 126–135. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533. [Google Scholar] [CrossRef]
- Luong, T.; Socher, R.; Manning, C. Better Word Representations with Recursive Neural Networks for Morphology. In Proceedings of the 17th Conference on Computational Natural Language Learning, Sofia, Bulgaria, 8–9 August 2013; Association for Computational Linguistics: Sofia, Bulgaria, 2013; pp. 104–113. [Google Scholar]
- Ling, W.; Dyer, C.; Black, A.W.; Trancoso, I.; Fermandez, R.; Amir, S.; Marujo, L.; Luís, T. Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 5 June 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 1520–1530. [Google Scholar] [CrossRef]
- Kim, Y.; Jernite, Y.; Sontag, D.A.; Rush, A.M. Character-Aware Neural Language Models. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; AAAI Press: Phoenix, AZ, USA, 2016; pp. 2741–2749. [Google Scholar]
- Wieting, J.; Bansal, M.; Gimpel, K.; Livescu, K. Charagram: Embedding Words and Sentences via Character n-grams. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; Association for Computational Linguistics: Austin, TX, USA, 2016; pp. 1504–1515. [Google Scholar] [CrossRef]
- Malykh, V.; Logacheva, V.; Khakhulin, T. Robust Word Vectors: Context-Informed Embeddings for Noisy Texts. In Proceedings of the 2018 EMNLP Workshop W-NUT: The 4th Workshop on Noisy User—Generated Text, Brussels, Belgium, 9–15 September 2018; pp. 54–63. [Google Scholar]
- Luong, T.; Pham, H.; Manning, C.D. Bilingual Word Representations with Monolingual Quality in Mind. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, Denver, CO, USA, 5 June 2015; Association for Computational Linguistics: Denver, CO, USA, 2015; pp. 151–159. [Google Scholar] [CrossRef]
- Philips, L. Hanging on the metaphone. Comput. Sci. 1990, 7, 39–43. [Google Scholar]
- Mikolov, T.; Grave, E.; Bojanowski, P.; Puhrsch, C.; Joulin, A. Advances in Pre-Training Distributed Word Representations. In Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; European Language Resources Association (ELRA): Miyazaki, Japan, 2018. [Google Scholar]
- Doval, Y.; Gómez-Rodríguez, C. Comparing neural-and N-gram-based language models for word segmentation. J. Assoc. Inf. Sci. Technol. 2019, 70, 187–197. [Google Scholar] [CrossRef] [PubMed]
- Doval, Y.; Gómez-Rodríguez, C.; Vilares, J. Spanish word segmentation through neural language models. Proces. Del Leng. Nat. 2016, 57, 75–82. [Google Scholar]
- Meng, Y.; Li, X.; Sun, X.; Han, Q.; Yuan, A.; Li, J. Is Word Segmentation Necessary for Deep Learning of Chinese Representations? In Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3242–3252. [Google Scholar]


| Standard | ||||
|---|---|---|---|---|
| SCWS | WS353 | SL999 | Sem17 | |
| word2vec | 64.7 | 69.1 | 32.2 | 68.2 |
| fastText | 65.4 | 72.7 | 33.5 | 70.3 |
| ours | 65.1 | 73.1 | 33.8 | 70.4 |
| Noisy | ||||
| SCWS | WS353 | SL999 | Sem17 | |
| word2vec | 13.0 | 13.7 | −10.9 | 11.2 |
| fastText | 35.2 | 38.1 | 7.3 | 37.2 |
| ours | 42.1 | 44.2 | 16.4 | 43.1 |
| Standard | Noisy | |||
|---|---|---|---|---|
| 8-8-8 | wiki | 8-8-8 | wiki | |
| word2vec | 59.4 | 53.8 | 22.8 | 39.3 |
| fastText | 65.6 | 49.0 | 31.7 | 41.1 |
| ours | 67.2 | 47.8 | 33.3 | 41.1 |
| Standard | Noisy | Standard | Noisy | |||||
|---|---|---|---|---|---|---|---|---|
| Low | Mid | High | Low | Mid | High | |||
| Semantic sim. & rel. | Binary classification | |||||||
| word2vec | 56.8 | 40.1 | 29.2 | 26.0 | 81.5 | 78.8 | 76.1 | 71.4 |
| fastText | 60.7 | 44.6 | 35.8 | 32.0 | 81.8 | 79.0 | 75.8 | 72.1 |
| ours | 60.4 | 48.1 | 41.5 | 37.7 | 81.6 | 79.4 | 77.7 | 74.1 |
| Sentiment analysis | Entailment | |||||||
| word2vec | 57.9 | 55.4 | 50.5 | 42.8 | 66.3 | 54.9 | 48.8 | 35.8 |
| fastText | 58.8 | 55.8 | 52.6 | 47.0 | 66.2 | 54.0 | 50.0 | 40.2 |
| ours | 59.3 | 56.9 | 54.6 | 51.1 | 66.3 | 55.1 | 51.4 | 48.1 |
| Question-type classification | Paraphrase detection | |||||||
| word2vec | 79.4 | 65.6 | 53.3 | 35.0 | 72.6 | 67.0 | 61.2 | 65.5 |
| fastText | 74.8 | 62.5 | 52.1 | 41.8 | 72.3 | 62.7 | 57.1 | 56.8 |
| ours | 73.4 | 67.5 | 59.4 | 49.5 | 72.9 | 66.9 | 60.2 | 56.3 |
| Probing tasks | ||||||||
| word2vec | 58.2 | 51.5 | 45.3 | 39.3 | ||||
| fastText | 57.8 | 51.2 | 45.9 | 41.0 | ||||
| ours | 57.7 | 52.8 | 48.4 | 43.6 | ||||
| SE13 B | SE14 B | SE16 BD | SE16 CE | |
|---|---|---|---|---|
| word2vec | 84.3 | 88.3 | 77.4 | 35.1 |
| fastText | 83.3 | 88.1 | 76.5 | 33.7 |
| ours | 84.8 | 88.6 | 78.4 | 35.5 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Doval, Y.; Vilares, J.; Gómez-Rodríguez, C. Towards Robust Word Embeddings for Noisy Texts. Appl. Sci. 2020, 10, 6893. https://doi.org/10.3390/app10196893
Doval Y, Vilares J, Gómez-Rodríguez C. Towards Robust Word Embeddings for Noisy Texts. Applied Sciences. 2020; 10(19):6893. https://doi.org/10.3390/app10196893
Chicago/Turabian StyleDoval, Yerai, Jesús Vilares, and Carlos Gómez-Rodríguez. 2020. "Towards Robust Word Embeddings for Noisy Texts" Applied Sciences 10, no. 19: 6893. https://doi.org/10.3390/app10196893
APA StyleDoval, Y., Vilares, J., & Gómez-Rodríguez, C. (2020). Towards Robust Word Embeddings for Noisy Texts. Applied Sciences, 10(19), 6893. https://doi.org/10.3390/app10196893