Application of Machine Learning Techniques to Delineate Homogeneous Climate Zones in River Basins of Pakistan for Hydro-Climatic Change Impact Studies


 , , ,
, , ,  and
and 
Abstract
1. Introduction
- comparing the observational and GCM data at each grid point [21,31,32] and then selecting the GCM in the entire study area using different filtering approaches, such as clustering hierarchy [33,34], Bayesian weighting [35], weighted skill score [15,36] and spectral analysis [37]; however, such selection processes do not cater to the area-specific efficiencies of the climate models because this efficiency varies amongst models and regions [4,27]. Several studies [21,31,32] have shown that the evaluated GCMs only account for some grid points over the entire study region. However, these studies have overlooked the ability of GCM to reproduce spatial climatic patterns. The drivers of this spatial variability are atmospheric circulation patterns that depend on the geographical location of the area. The capacity of the GCMs to reproduce the patterns of climate parameters spatially, in the baseline/historical period is, therefore, imperative [7,21]. The GCM or ensemble of GCMs selected, via the aforementioned comparative analysis of spatio-temporal averages and filtering techniques, may be appropriate for simulating the spatial climatic patterns for some percentage of the entire study area but not all, thus enhancing the uncertainties in projecting the climate. To narrow this uncertainty in projecting the climate variables (precipitation) trends, we propose a different method of the selection of GCMs by first identifying the climatologically homogeneous zones and then selecting the GCM in each zone through past performance assessment. These homogeneous sub-regions are based on similar spatial and temporal climate patterns, as depicted by the highly resolved observation data. Following the philosophy of McSweeny et al. [4] for the regional suitability of the GCMs, we selected the GCMs in every homogeneous precipitation region and validated our selection through the comparative analysis with Simple Composite Method (SCM). The SCM is broadly used for generating the multi-model ensemble that is, to obtain the equally weighted mean of all the ensemble members data at each grid point [7].
2. Study Area and Data
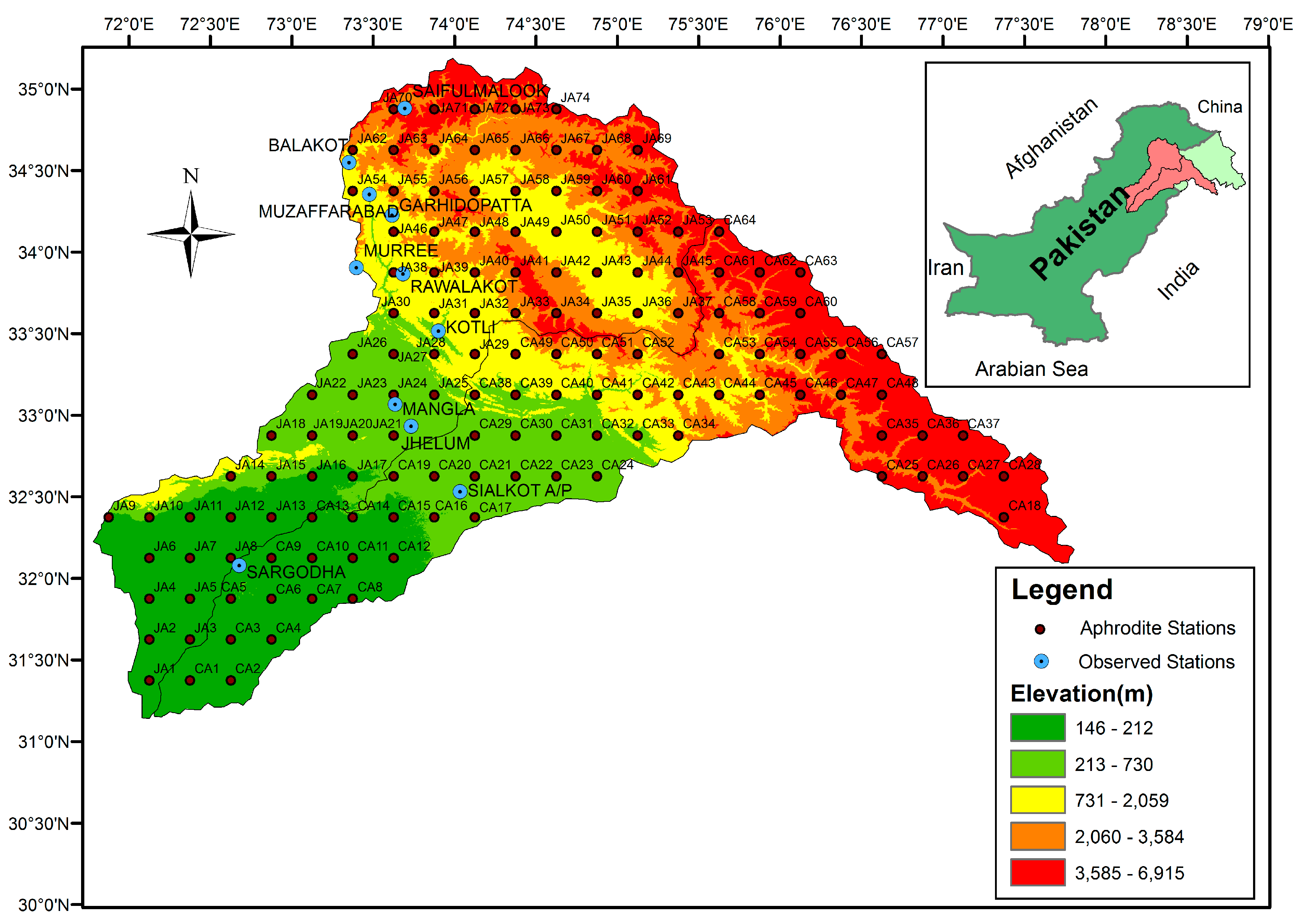
2.1. Study Area
2.2. APHRODITE Data
2.3. NEX-GDDP-GCMs-CMIP5 Data
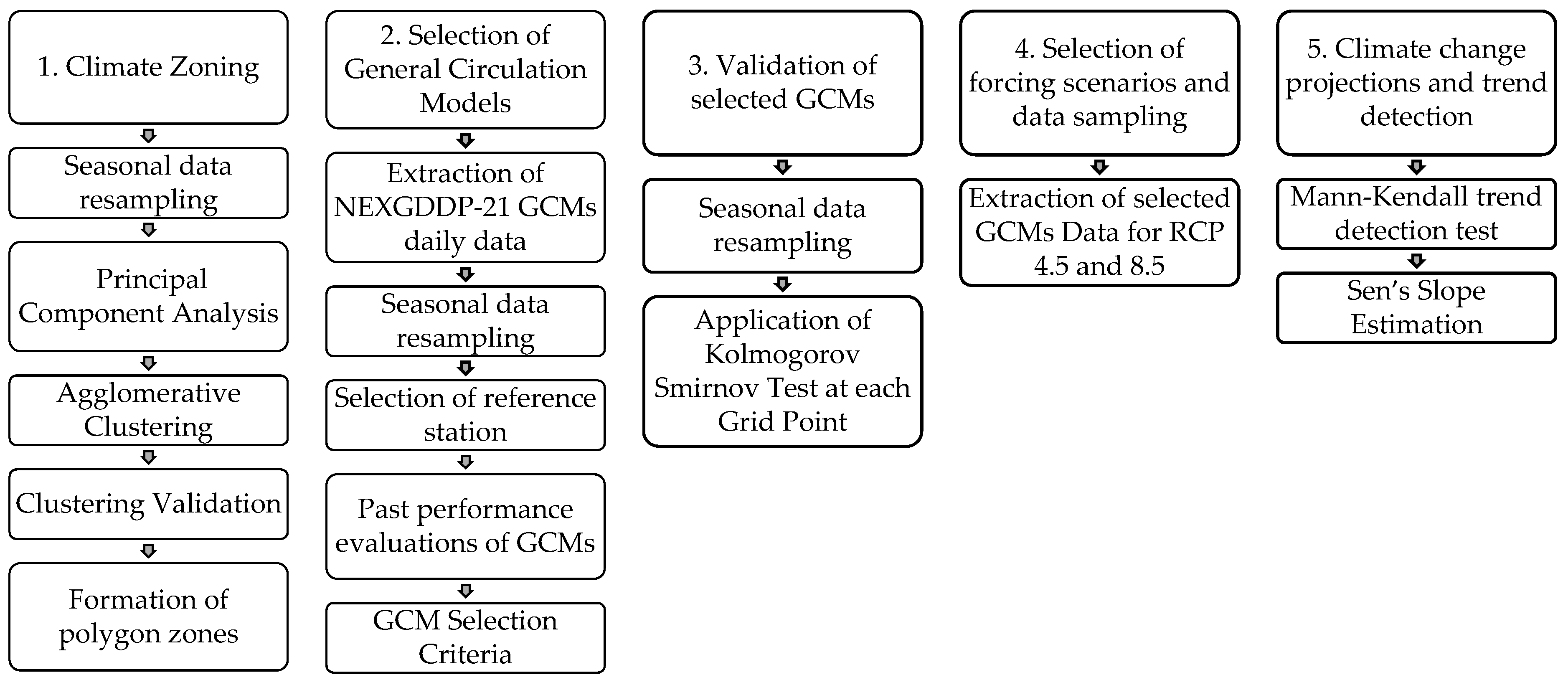
3. Methodology
3.1. Climate Zoning
3.1.1. Seasonal Data Resampling
3.1.2. Principal Component Analysis (PCA)
3.1.3. Agglomerative Hierarchical Clustering
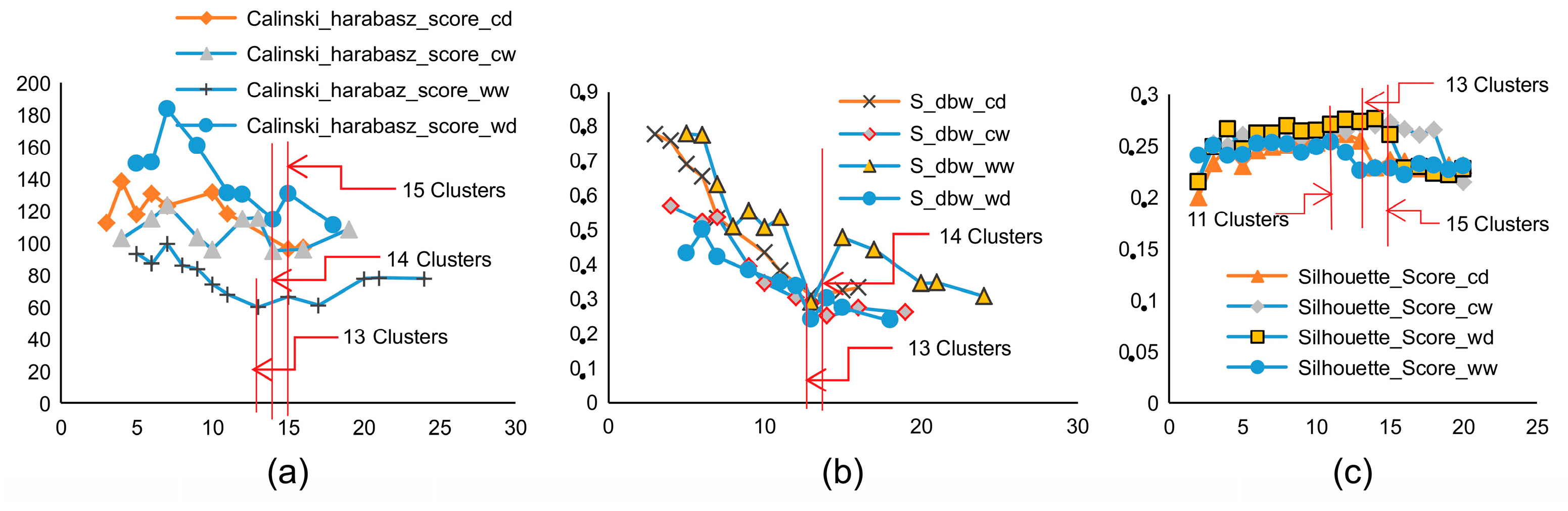
3.1.4. Optimal Clustering and Climate zone Formation
Silhouette Score
S Dbw Validity Index
Calinski–Harabasz Index
3.1.5. Climate Zone Polygon Formation
3.2. GCM Selection
3.3. Validation of Selected GCMs
3.3.1. Seasonal Data Sampling
3.3.2. Kolmogorov–Smirnov Test
3.4. Selection of Forcing Scenarios
Extraction of Selected GCMs Data for RCP 4.5 and 8.5
3.5. Climate Change Projections and Trend Detection
3.5.1. Mann-Kendall Test (MK Test)
3.5.2. Sen’s Slope Evaluation
4. Results and Discussion
4.1. Climate Zones
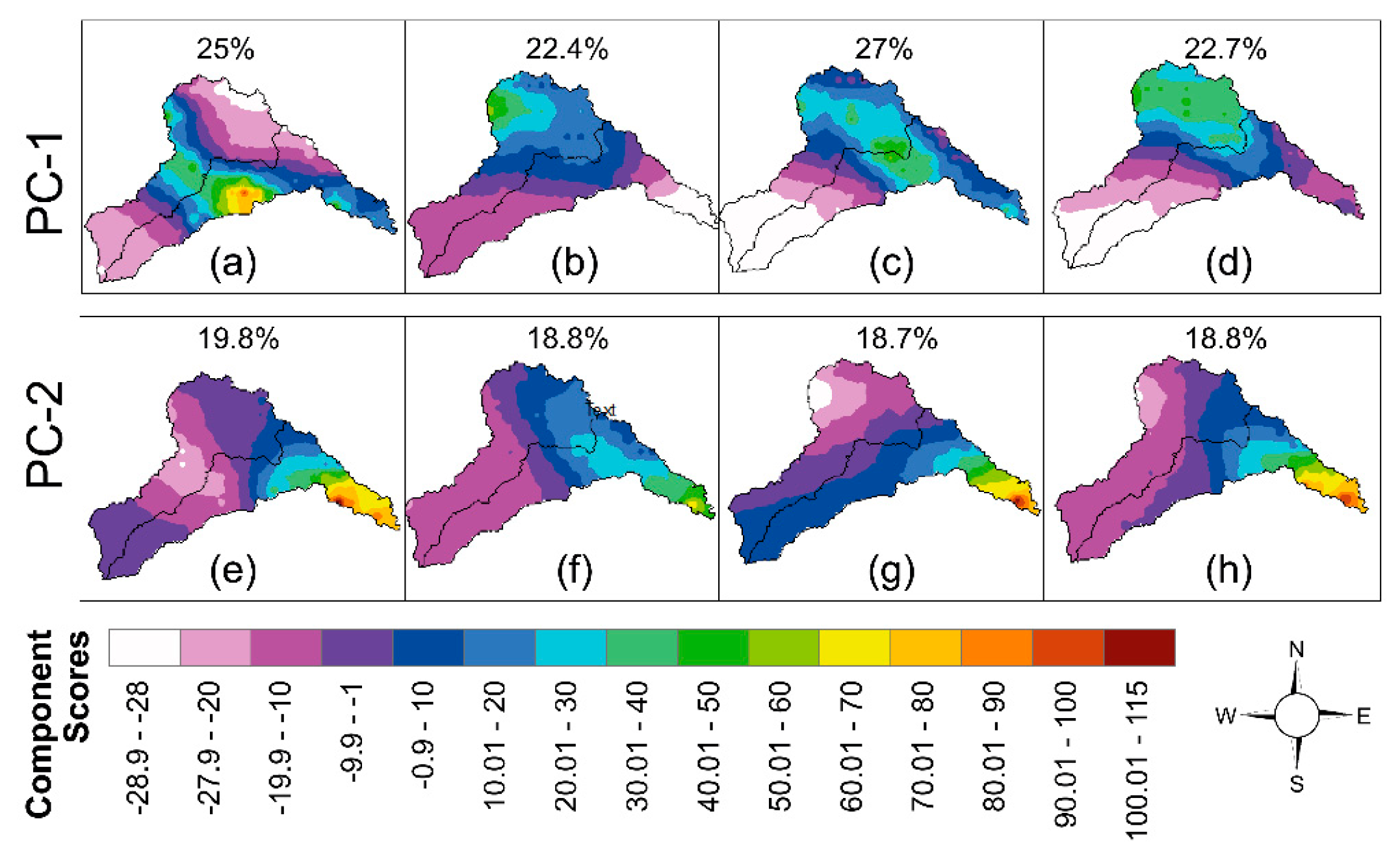
4.1.1. Principal Component Analysis
4.1.2. Agglomerative Hierarchical Clustering (AHC)
4.1.3. Climate Zones and Reference site
4.2. GCM Selection
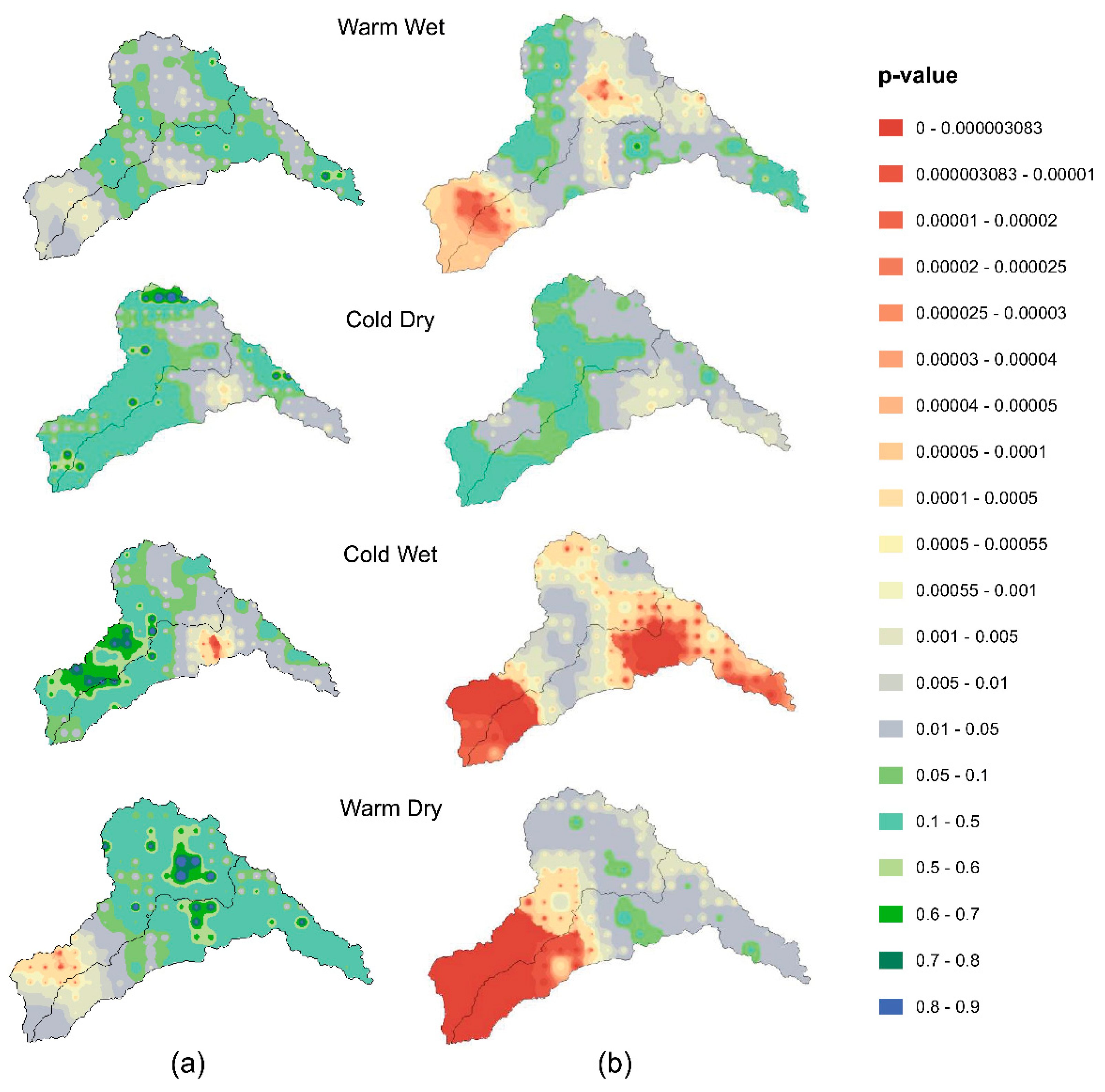
4.3. Validation of Selected GCMs
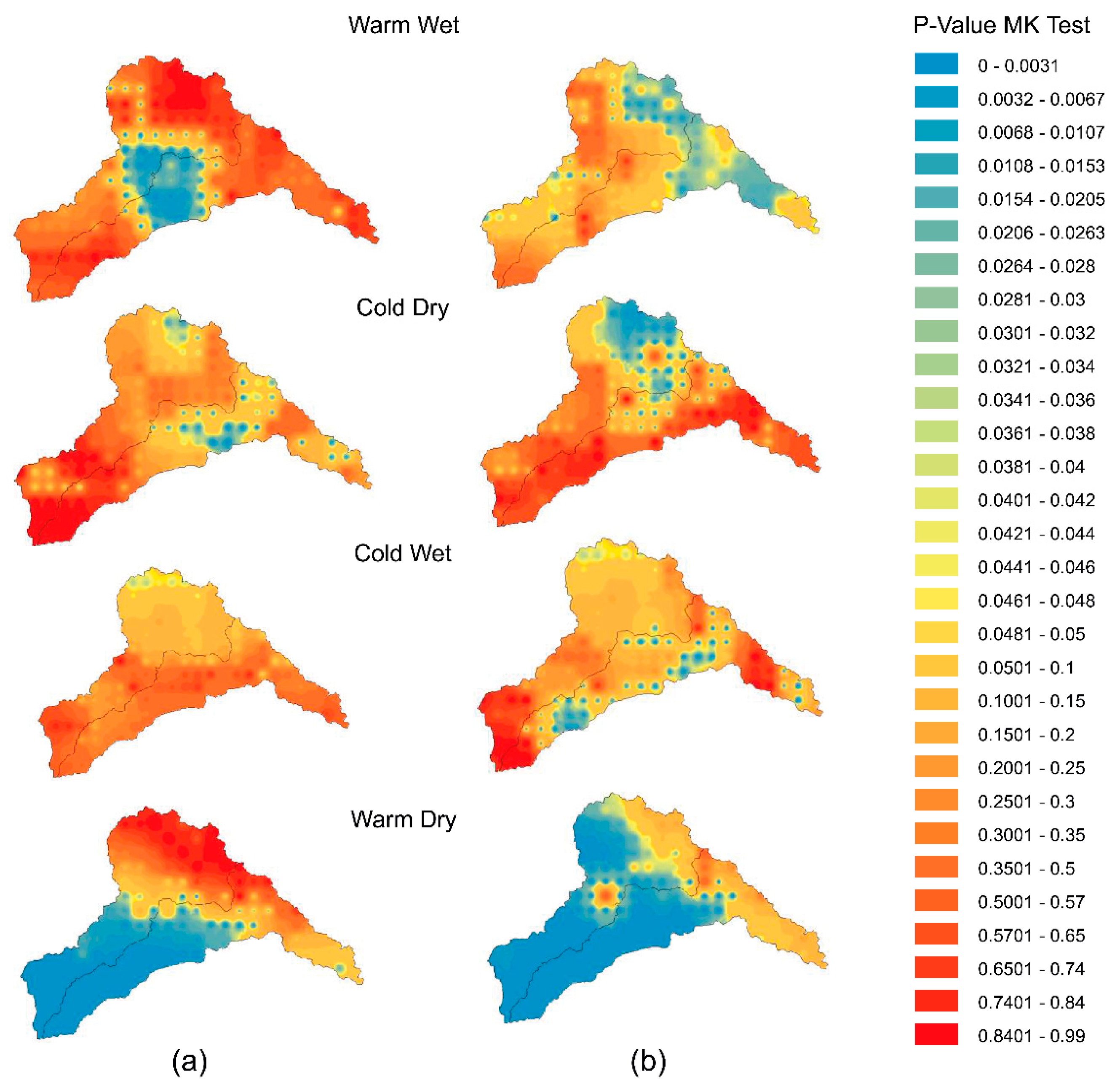
4.4. Seasonal Precipitation Trend Projection
5. Conclusions
- 1)
- Due to its highly volatile hydroclimatic conditions, this area of Pakistan poses major scientific challenges; hence, investigations require complex methods. Multivariate techniques, such as PCA and Agglomerative Hierarchical Clustering (AHC) algorithms, are used to develop decisive precipitation statistics and delineate homogeneous precipitation regions, respectively. The entire study area was divided into 13 homogeneous precipitation regions for the warm-wet season, 13 homogeneous precipitation regions for the cold-dry season, 14 homogeneous precipitation regions for the cold-wet season and 13 homogeneous precipitation regions for the warm-dry season. The reference station, which is representative of the respective homogeneous precipitation regions, was obtained in each homogeneous precipitation region for GCM selection. Seasonal rainfall characteristics were incorporated to define the homogeneous climate regions to design the climate zones in the river basins of Pakistan. Representative rainfall station/grid points were selected in each climate zone for the climate change impact assessment. This study provides an objective demarcation structure for homogeneous precipitation regions based on the statistical characteristics of seasonal precipitation.
- 2)
- The best-correlated GCM was identified in each climate zone in the Jhelum and Chenab river basins, followed by data extraction. This selection was validated and compared spatially with the KS test. Two schemes of the daily precipitation data were derived: (1) the precipitation data sampled from the selected GCMs based on this framework and (2) the precipitation data from the MME mean (21 models of the CMIP5 mean). The KS test was used to measure the compatibility of the observed data with data from scheme 1 and then the data from scheme 2. The results clearly show the improved performance of the present framework for the selected GCMs compared with the conventional method involving the equally weighted means of all the available GCMs.
- 3)
- The precipitation pattern can represent the climatic dynamics because the atmospheric circulation covariates have a strong correlation with the precipitation patterns in the region [2]. The daily projected precipitation data (2006–2099), synthesized for the regions of the Jhelum and Chenab river basins, are publicly available. The creation of homogeneous climatic zones accommodates a deeper understanding of the dynamic spatio-temporal precipitation variability over a given region. Infrastructure development and climate forecasting are based on effective regionalization using reliable estimates of climate variables. The region should be conditionally considered as climatically homogeneous to proceed with the selection of GCMs for the climate change impact assessments.
- 4)
- The projections of the changes in the precipitation trends were presented based on two scenarios, that is, RCP 4.5 and RCP 8.5. For the RCP 4.5, a significant positive precipitation trend was observed for the warm-dry season, while insignificant positive trends were observed for the cold dry and cold wet seasons. A negative precipitation trend was observed throughout the entire study area, in which 40% of the area had a significant negative trend for the warm-wet season. For the RCP 8.5, the warm-dry season again exhibited a significant positive precipitation trend, whereas insignificant positive trends were observed for the warm-wet, cold-dry and cold-wet seasons. The effect of the precipitation change trends may have greater implications on water resources and its management. This unique study provides spatial changes in patterns, as well as temporal changes. Strong increasing and decreasing signals occurred during the warm-dry season for both scenarios in the river basins. Precipitation trends were detected within this framework, which were mapped spatially across the entire study region.
- 5)
- Future studies should redefine the homogeneous precipitation region and change detection using the projected data to obtain the hydrological response in a basin using this projected input data for the rainfall. The same framework, with a set of machine learning modules, can be employed to select and detect precipitation trends using the next generation of GCMs. More than 125 years of precipitation data of daily scale, were used for the analyses in this study, which depicts the strength of machine learning.
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Jamro, S.; Channa, F.N.; Dars, G.H.; Ansari, K.; Krakauer, N.Y. Exploring the Evolution of Drought Characteristics in Balochistan, Pakistan. Appl. Sci. 2020, 10, 913. [Google Scholar] [CrossRef]
- Asong, Z.E.; Khaliq, M.N.; Wheater, H.S. Regionalization of Precipitation Characteristics in the Canadian Prairie Provinces Using Large-scale Atmospheric Covariates and Geophysical Attributes. Stoch. Environ. Res. Risk Assess. 2015, 29, 875–892. [Google Scholar] [CrossRef]
- Christensen, J.; Kanikicharla, K.; Aldrian, E.; An, S.-I.; Fonseca, I.; Castro, M.; Dong, W.; Goswami, P.; Hall, A.; Kanyanga, J.K.; et al. Climate Phenomena and Their Relevance for Future Regional Climate Change; IPCC: Geneva, Switzerland, 2013; pp. 1–92. [Google Scholar]
- McSweeney, C.F.; Jones, R.G.; Lee, R.W.; Rowell, D.P. Selecting CMIP5 GCMs for downscaling over multiple regions. Clim. Dyn. 2015, 44, 3237–3260. [Google Scholar] [CrossRef]
- Ahmed, K.; Shahid, S.; Chung, E.-S.; Wang, X.; Harun, S.B. Climate Change Uncertainties in Seasonal Drought Severity-Area-Frequency Curves: Case of Arid Region of Pakistan. J. Hydrol. 2019, 570, 473–485. [Google Scholar] [CrossRef]
- Wu, C.; Huang, G.; Yu, H.; Chen, Z.; Ma, J. Impact of Climate Change on Reservoir Flood Control in the Upstream Area of the Beijiang River Basin, South China. J. Hydrometeor. 2014, 15, 2203–2218. [Google Scholar] [CrossRef]
- Ahmed, K.; Sachindra, D.A.; Shahid, S.; Demirel, M.C.; Chung, E.S. Selection of multi-model ensemble of general circulation models for the simulation of precipitation and maximum and minimum temperature based on spatial assessment metrics. Hydrol. Earth Syst. Sci. 2019, 23, 4803–4824. [Google Scholar] [CrossRef]
- Ismail, H.; Kamal, M.R.; Abdullah, A.F.B.; Jada, D.T.; Sai Hin, L. Modeling Future Streamflow for Adaptive Water Allocation under Climate Change for the Tanjung Karang Rice Irrigation Scheme Malaysia. Appl. Sci. 2020, 10, 4885. [Google Scholar] [CrossRef]
- Uamusse, M.M.; Tussupova, K.; Persson, K.M. Climate Change Effects on Hydropower in Mozambique. Appl. Sci. 2020, 10, 4842. [Google Scholar] [CrossRef]
- Touseef, M.; Chen, L.; Masud, T.; Khan, A.; Yang, K.; Shahzad, A.; Wajid Ijaz, M.; Wang, Y. Assessment of the Future Climate Change Projections on Streamflow Hydrology and Water Availability over Upper Xijiang River Basin, China. Appl. Sci. 2020, 10, 3671. [Google Scholar] [CrossRef]
- Yu, Z.; Man, X.; Duan, L.; Cai, T. Assessments of Impacts of Climate and Forest Change on Water Resources Using SWAT Model in a Subboreal Watershed in Northern Da Hinggan Mountains. Water 2020, 12, 1565. [Google Scholar] [CrossRef]
- Dikshit, A.; Pradhan, B.; Alamri, A.M. Short-Term Spatio-Temporal Drought Forecasting Using Random Forests Model at New South Wales, Australia. Appl. Sci. 2020, 10, 4254. [Google Scholar] [CrossRef]
- Zhao, Q.; Ma, X.; Liang, L.; Yao, W. Spatial–Temporal Variation Characteristics of Multiple Meteorological Variables and Vegetation over the Loess Plateau Region. Appl. Sci. 2020, 10, 1000. [Google Scholar] [CrossRef]
- McMahon, T.A.; Peel, M.C.; Karoly, D.J. Assessment of Precipitation and Temperature Data from CMIP3 Global Climate Models for Hydrologic Simulation. Hydrol. Earth Syst. Sci. 2015, 19, 361–377. [Google Scholar] [CrossRef]
- Maxino, C.C.; McAvaney, B.J.; Pitman, A.J.; Perkins, S.E. Ranking the AR4 Climate Models over the Murray-Darling Basin Using Simulated Maximum Temperature, Minimum Temperature and Precipitation. Int. J. Climatol. 2008, 28, 1097–1112. [Google Scholar] [CrossRef]
- Lorenz, E.N. Predictability: A Problem Partly Solved. In Proceedings of the Seminar on Predictability, Shinfield Park, Reading, UK, 4–8 September 1995. [Google Scholar]
- Hawkins, E.; Sutton, R. The Potential to Narrow Uncertainty in Projections of Regional Precipitation Change. Clim. Dyn. 2011, 37, 407–418. [Google Scholar] [CrossRef]
- Baker, N.; Taylor, P. A Framework for Evaluating Climate Model Performance Metrics. J. Clim. 2016, 29, 1773–1782. [Google Scholar] [CrossRef]
- Chhin, R.; Yoden, S. Ranking CMIP5 GCMs for Model Ensemble Selection on Regional Scale: Case Study of the Indochina Region. J. Geophys. Res. Atmos. 2018, 123, 8949–8974. [Google Scholar] [CrossRef]
- Wilcke, R.A.I.; Bärring, L. Selecting Regional Climate Scenarios for Impact Modelling Studies. Environ. Model. Softw. 2016, 78, 191–201. [Google Scholar] [CrossRef]
- Salman, S.A.; Shahid, S.; Ismail, T.; Ahmed, K.; Wang, X.-J. Selection of Climate Models for Projection of Spatiotemporal Changes in Temperature of Iraq with Uncertainties. Atmos. Res. 2018, 213, 509–522. [Google Scholar] [CrossRef]
- Lutz, A.F.; ter Maat, H.W.; Biemans, H.; Shrestha, A.B.; Wester, P.; Immerzeel, W.W. Selecting Representative Climate Models for Climate Change Impact Studies: An Advanced Envelope-Based Selection Approach. Int. J. Climatol. 2016, 36, 3988–4005. [Google Scholar] [CrossRef]
- Cannon, A.J. Selecting GCM Scenarios that Span the Range of Changes in a Multimodel Ensemble: Application to CMIP5 Climate Extremes Indices. J. Clim. 2015, 28, 1260–1267. [Google Scholar] [CrossRef]
- Azmat, M.; Qamar, M.U.; Huggel, C.; Hussain, E. Future Climate and Cryosphere Impacts on the Hydrology of a Scarcely Gauged Catchment on the Jhelum River Basin, Northern Pakistan. Sci. Total Environ. 2018, 961–976. [Google Scholar] [CrossRef] [PubMed]
- Mahmood, R.; Jia, S.; Tripathi, N.K.; Shrestha, S. Precipitation Extended Linear Scaling Method for Correcting GCM Precipitation and Its Evaluation and Implication in the Transboundary Jhelum River Basin. Atmosphere 2018, 9, 160. [Google Scholar] [CrossRef]
- Kim, J.-B.; So, J.-M.; Bae, D.-H. Global Warming Impacts on Severe Drought Characteristics in Asia Monsoon Region. Water 2020, 12, 1360. [Google Scholar] [CrossRef]
- Gu, H.; Yu, Z.; Wang, J.; Wang, G.; Yang, T.; Ju, Q.; Yang, C.; Xu, F.; Fan, C. Assessing CMIP5 General Circulation Model Simulations of Precipitation and Temperature over China. Int. J. Climatol. 2015, 35, 2431–2440. [Google Scholar] [CrossRef]
- Fu, G.; Charles, S.P.; Kirshner, S. Daily Rainfall Projections from General Circulation Models with a Downscaling Nonhomogeneous Hidden Markov Model (NHMM) for South-Eastern Australia. Hydrol. Process. 2013, 27, 3663–3673. [Google Scholar] [CrossRef]
- Johnson, F.; Sharma, A. Measurement of GCM Skill in Predicting Variables Relevant for Hydroclimatological Assessments. J. Clim. 2009, 22, 4373–4382. [Google Scholar] [CrossRef]
- Schaeffer, M.; Selten, F.M.; Opsteegh, J.D. Shifts of Means Are Not a Proxy for Changes in Extreme Winter Temperatures in Climate Projections. Clim. Dyn. 2005, 25, 51–63. [Google Scholar] [CrossRef]
- Srinivasa Raju, K.; Sonali, P.; Nagesh Kumar, D. Ranking of CMIP5-based global climate models for India using compromise programming. Theor. Appl. Climatol. 2017, 128, 563–574. [Google Scholar] [CrossRef]
- Khan, N.; Shahid, S.; Ahmed, K.; Ismail, T.; Nawaz, N.; Son, M. Performance Assessment of General Circulation Model in Simulating Daily Precipitation and Temperature Using Multiple Gridded Datasets. Water 2018, 10, 1793. [Google Scholar] [CrossRef]
- Knutti, R.; Masson, D.; Gettelman, A. Climate Model Genealogy: Generation CMIP5 and How We Got There. Geophys. Res. Lett. 2013, 40, 1194–1199. [Google Scholar] [CrossRef]
- Yokoi, S.; Takayabu, Y.N.; Nishii, K.; Nakamura, H.; Endo, H.; Ichikawa, H.; Inoue, T.; Kimoto, M.; Kosaka, Y.; Miyasaka, T.; et al. Application of Cluster Analysis to Climate Model Performance Metrics. J. Appl. Meteorol. Climatol. 2011, 50, 1666–1675. [Google Scholar] [CrossRef]
- Min, S.-K.; Hense, A. A Bayesian Approach to Climate Model Evaluation and Multi-Model Averaging with an Application to Global Mean Surface Temperatures from IPCC AR4 Coupled Climate Models. Geophys. Res. Lett. 2006, 33, Ar.4. [Google Scholar] [CrossRef]
- Perkins, S.E.; Pitman, A.J.; Holbrook, N.J.; McAneney, J. Evaluation of the AR4 Climate Models’ Simulated Daily Maximum Temperature, Minimum Temperature, and Precipitation over Australia Using Probability Density Functions. J. Clim. 2007, 20, 4356–4376. [Google Scholar] [CrossRef]
- Jiang, X.; Waliser, D.E.; Xavier, P.K.; Petch, J.; Klingaman, N.P.; Woolnough, S.J.; Guan, B.; Bellon, G.; Crueger, T.; DeMott, C.; et al. Vertical Structure and Physical Processes of the Madden-Julian Oscillation: Exploring Key Model Physics in Climate Simulations. J. Geophys. Res. Atmos. 2015, 120, 4718–4748. [Google Scholar] [CrossRef]
- Immerzeel, W.W.; Wanders, N.; Lutz, A.F.; Shea, J.M.; Bierkens, M.F.P. Reconciling High-Altitude Precipitation in the Upper Indus Basin with Glacier Mass Balances and Runoff. Hydrol. Earth Syst. Sci. 2015, 19, 4673–4687. [Google Scholar] [CrossRef]
- Lutz, A.; Immerzeel, W.; Kraaijienbrink, P.D.A. Gridded Meteorological Datasets and Hydrological Modelling in the Upper Indus Basin; Future Water: Wageningen, The Netherlands, 2014; p. 83. [Google Scholar]
- Yatagai, A.; Kamiguchi, K.; Arakawa, O.; Hamada, A.; Yasutomi, N.; Kitoh, A. APHRODITE: Constructing a Long-Term Daily Gridded Precipitation Dataset for Asia Based on a Dense Network of Rain Gauges. Bull. Am. Meteorol. Soc. 2012, 93, 1401–1415. [Google Scholar] [CrossRef]
- Lutz, A.; Immerzeel, W. Water Availability Analysis for the Upper Indus, Ganges and Brahmaputra River Basins; Future Water: Wageningen, The Netherlands, 2013; p. 85. [Google Scholar]
- ECMWF. European Reanalysis Dataset (ERA5). 2020. Available online: http://climate.copernicus.eu/climate-reanalysis (accessed on 9 September 2020).
- Global Meteorological Forcing Dataset for Land Surface Modeling. Research Data Archive at the National Center for Atmospheric Research; Computational and Information Systems Laboratory: Boulder, CO, USA, 2006. [Google Scholar] [CrossRef]
- Taylor, E.K.; Ronald, S.; Meehl, G. An Overview of CMIP5 and the Experiment Design. Bull. Am. Meteorol. Soc. 2011, 93, 485–498. [Google Scholar] [CrossRef]
- Thrasher, B.; Maurer, E.; McKellar, C.; Duffy, P.B. Technical Note: Bias Correcting Climate Model Simulated Daily Temperature Extremes with Quantile Mapping. Hydrol. Earth Syst. Sci. 2012, 16, 3309–3314. [Google Scholar] [CrossRef]
- Sheffield, J.; Goteti, G.; Wood, E.F. Development of a 50-Year High-Resolution Global Dataset of Meteorological Forcings for Land Surface Modeling. J. Clim. 2006, 19, 3088–3111. [Google Scholar] [CrossRef]
- Chen, H.-P.; Sun, J.-Q.; Li, H.-X. Future changes in precipitation extremes over China using the NEX-GDDP high-resolution daily downscaled data-set. Atmos. Ocean. Sci. Lett. 2017, 10, 403–410. [Google Scholar] [CrossRef]
- Carter, T.R. General Guidelines on the Use of Scenario Data for Climate Impact and Adaptation Assessment, 2nd ed.; Task Group on Data and Scenario Support for Impact and Climate Assessment (TGICA); Intergovernmental Panel on Climate Change (IPCC): Helsinki, Finland, 2007; p. 66. [Google Scholar]
- Gabriele, S.; Chiaravalloti, F. Searching Regional Rainfall Homogeneity Using Atmospheric Fields. Adv. Water Resour. 2013, 53, 163–174. [Google Scholar] [CrossRef]
- Irwin, S.; Srivastav, R.K.; Simonovic, S.P.; Burn, D.H. Delineation of Precipitation Regions Using Location and Atmospheric Variables in Two Canadian Climate Regions: The Role of Attribute Selection. Hydrol. Sci. J. 2017, 62, 191–204. [Google Scholar] [CrossRef]
- Nam, W.; Shin, H.; Jung, Y.; Joo, K.; Heo, J.-H. Delineation of the Climatic Rainfall Regions of South Korea Based on a Multivariate Analysis and Regional Rainfall Frequency Analyses. Int. J. Climatol. 2015, 35, 777–793. [Google Scholar] [CrossRef]
- Rasheed, A.; Egodawatta, P.; Goonetilleke, A.; McGree, J. A Novel Approach for Delineation of Homogeneous Rainfall Regions for Water Sensitive Urban Design—A Case Study in Southeast Queensland. Water 2019, 11, 570. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hosking, J.R.M.; Wallis, J.R. Frontmatter. In Regional Frequency Analysis: An Approach Based on L-Moments; Hosking, J.R.M., Wallis, J.R., Eds.; Cambridge University Press: Cambridge, UK, 1997; pp. i–vi. [Google Scholar]
- Liu, M.; Huang, Y.; Li, Z.; Tong, B.; Liu, Z.; Sun, M.; Jiang, F.; Zhang, H. The Applicability of LSTM-KNN Model for Real-Time Flood Forecasting in Different Climate Zones in China. Water 2020, 12, 440. [Google Scholar] [CrossRef]
- Zeraatpisheh, M.; Bakhshandeh, E.; Emadi, M.; Li, T.; Xu, M. Integration of PCA and Fuzzy Clustering for Delineation of Soil Management Zones and Cost-Efficiency Analysis in a Citrus Plantation. Sustainability 2020, 12, 5809. [Google Scholar] [CrossRef]
- Chen, Y.; Zheng, B.; Hu, Y. Mapping Local Climate Zones Using ArcGIS-Based Method and Exploring Land Surface Temperature Characteristics in Chenzhou, China. Sustainability 2020, 12, 2974. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, C.; Li, H. Quality Assessment by Region and Land Cover of Sharpening Approaches Applied to GF-2 Imagery. Appl. Sci. 2020, 10, 3673. [Google Scholar] [CrossRef]
- Hsu, K.-C.; Li, S.-T. Clustering Spatial–Temporal Precipitation Data Using Wavelet Transform and Self-Organizing Map Neural Network. Adv. Water Resour. 2010, 33, 190–200. [Google Scholar] [CrossRef]
- Benestad, R.E.; Chen, D.; Mezghani, A.; Fan, L.; Parding, K. On Using Principal Components to Represent Stations in Empirical–Statistical Downscaling. Tellus A 2015, 67, 28326. [Google Scholar] [CrossRef]
- Mendlik, T.; Gobiet, A. Selecting Climate Simulations for Impact Studies Based on Multivariate Patterns of Climate Change. Clim. Chang. 2016, 135, 381–393. [Google Scholar] [CrossRef]
- Carvalho, M.J.; Melo-Gonçalves, P.; Teixeira, J.C.; Rocha, A. Regionalization of Europe Based on a K-Means Cluster Analysis of the Climate Change of Temperatures and Precipitation. Phys. Chem. Earth Parts A B C 2016, 94, 22–28. [Google Scholar] [CrossRef]
- Cowpertwait, P.S.P. A Regionalization Method Based on a Cluster Probability Model. Water Resour. Res. 2011, 47. [Google Scholar] [CrossRef]
- Huth, R.; Beck, C.; Philipp, A.; Demuzere, M.; Ustrnul, Z.; Cahynová, M.; Kyselý, J.; Tveito, O.E. Classifications of Atmospheric Circulation Patterns: Recent Advances and Applications. Ann. N. Y. Acad. Sci. 2008, 1146, 105–152. [Google Scholar] [CrossRef] [PubMed]
- Mimmack, G.M.; Mason, S.J.; Galpin, J.S. Choice of Distance Matrices in Cluster Analysis: Defining Regions. J. Clim. 2001, 14, 2790–2797. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Halkidi, M.; Batistakis, Y.; Vazirgiannis, M. On Clustering Validation Techniques. J. Intell. Inf. Syst. 2001, 17, 107–145. [Google Scholar] [CrossRef]
- Caliński, T.; Harabasz, J. A Dendrite Method for Cluster Analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Arbelaitz, O.; Gurrutxaga, I.; Muguerza, J.; Pérez, J.M.; Perona, I. An Extensive Comparative Study of Cluster Validity Indices. Pattern Recognit. 2013, 46, 243–256. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.; Xiong, H.; Gao, X.; Wu, J. Understanding of Internal Clustering Validation Measures. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 911–916. [Google Scholar]
- Aghakhani, A.A.; Hasanzadeh, Y.; Besalatpour, A.A.; Pourreza-Bilondi, M. Climate Change Forecasting in a Mountainous Data Scarce Watershed Using CMIP5 Models under Representative Concentration Pathways. Theor. Appl. Climatol. 2017, 129, 683–699. [Google Scholar] [CrossRef]
- Xuan, W.; Ma, C.; Kang, L.; Gu, H.; Pan, S.; Xu, Y.-P. Evaluating Historical Simulations of CMIP5 GCMs for Key Climatic Variables in Zhejiang Province, China. Theor. Appl. Climatol. 2017, 128, 207–222. [Google Scholar] [CrossRef]
- Latif, M.; Hannachi, A.; Syed, F.S. Analysis of Rainfall Trends over Indo-Pakistan Summer Monsoon and Related Dynamics Based on CMIP5 Climate Model Simulations. Int. J. Climatol. 2018, 38, e577–e595. [Google Scholar] [CrossRef]
- Wang, W.; Chen, X.; Shi, P.; van Gelder, P.H.A.J.M. Detecting Changes in Extreme Precipitation and Extreme Streamflow in the Dongjiang River Basin in Southern China. Hydrol. Earth Syst. Sci. 2008, 12, 207–221. [Google Scholar] [CrossRef]
- Van Vuuren, D.P.; Edmonds, J.; Kainuma, M.; Riahi, K.; Thomson, A.; Hibbard, K.; Hurtt, G.C.; Kram, T.; Krey, V.; Lamarque, J.-F.; et al. The Representative Concentration Pathways: An Overview. Clim. Chang. 2011, 109, 5–31. [Google Scholar] [CrossRef]
- Mann, H.B. Nonparametric Tests against Trend. Econometrica 1945, 13, 245–259. [Google Scholar] [CrossRef]
- Sen, P.K. Estimates of the Regression Coefficient Based on Kendall’s Tau. J. Am. Stat. Assoc. 1968, 63, 1379–1389. [Google Scholar] [CrossRef]
- Smith, I.; Chandler, E. Refining Rainfall Projections for the Murray Darling Basin of South-East Australia—The Effect of Sampling Model Results Based on Performance. Clim. Chang. 2010, 102, 377–393. [Google Scholar] [CrossRef]
- Behnke, R.; Vavrus, S.; Allstadt, A.; Albright, T.; Thogmartin, W.E.; Radeloff, V.C. Evaluation of Downscaled, Gridded Climate Data for the Conterminous United States. Ecol. Appl. 2016, 26, 1338–1351. [Google Scholar] [CrossRef]
- Xu, C.-Y.; Widén, E.; Halldin, S. Modelling Hydrological Consequences of Climate Change—Progress and Challenges. Adv. Atmos. Sci. 2005, 22, 789–797. [Google Scholar] [CrossRef]
- Kay, A.L.; Davies, H.N.; Bell, V.A.; Jones, R.G. Comparison of Uncertainty Sources for Climate Change Impacts: Flood Frequency in England. Clim. Chang. 2009, 92, 41–63. [Google Scholar] [CrossRef]
- Woldemeskel, F.M.; Sharma, A.; Sivakumar, B.; Mehrotra, R. An Error Estimation Method for Precipitation and Temperature Projections for Future Climates. J. Geophys. Res. 2012, 117. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, Y.-P.; Fu, G. Uncertainties in SWAT Extreme Flow Simulation under Climate Change. J. Hydrol. 2014, 515, 205–222. [Google Scholar] [CrossRef]
- Solomon, S.; Qin, D.; Manning, M.; Chen, Z.; Marquis, M.; Averyt, K.B.; Tignor, M.; Miller, H.L. Climate Change 2007: Working Group I: The Physical Science Basis; Intergovernmental Panel on Climate Change: Geneva, Switzerland, 2007. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gauging Stations | Time Period | Correlation Coefficient | p-Value, KS Test | |||||
|---|---|---|---|---|---|---|---|---|
| Elevation (m) | APHRODITE | ERA5 | GMFD | APHRODITE | ERA5 | GMFD | ||
| Astore | 1979–2005 | 2546 | 0.90 | 0.65 | 0.08 | 0.0001 | 0.000 | 0.001 |
| Balakot | 1979–2005 | 1088 | 0.91 | 0.77 | 0.17 | 0.018 | 0.069 | 0.000 |
| GarhiDopatta | 1979–2005 | 819 | 0.90 | 0.71 | 0.25 | 0.0001 | 0.336 | 0.000 |
| Jhelum | 1979–2005 | 234 | 0.99 | 0.79 | 0.31 | 0.99 | 0.000 | 0.238 |
| Kotli | 1979–2005 | 608 | 0.91 | 0.83 | 0.26 | 0.29 | 0.568 | 0.079 |
| Mangla | 1996–2005 | 605 | 0.96 | 0.77 | 0.40 | 0.74 | 0.519 | 0.060 |
| Muzaffarabad | 1979–2005 | 737 | 0.92 | 0.71 | 0.28 | 0.92 | 0.248 | 0.000 |
| Rawalakot | 2003–2005 | 1638 | 0.95 | 0.75 | 0.10 | 0.11 | 0.199 | 0.024 |
| Saifulmaluk | 1996–2005 | 3224 | 0.37 | 0.52 | 0.13 | 0.0006 | 0.00 | 0.069 |
| Sargodha | 1979–2005 | 190 | 0.78 | 0.75 | 0.26 | 0.0002 | 0.000 | 0.002 |
| Sialkot | 1979–2005 | 256 | 0.91 | 0.79 | 0.35 | 0.29 | 0.014 | 0.201 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nusrat, A.; Gabriel, H.F.; Haider, S.; Ahmad, S.; Shahid, M.; Ahmed Jamal, S. Application of Machine Learning Techniques to Delineate Homogeneous Climate Zones in River Basins of Pakistan for Hydro-Climatic Change Impact Studies. Appl. Sci. 2020, 10, 6878. https://doi.org/10.3390/app10196878
Nusrat A, Gabriel HF, Haider S, Ahmad S, Shahid M, Ahmed Jamal S. Application of Machine Learning Techniques to Delineate Homogeneous Climate Zones in River Basins of Pakistan for Hydro-Climatic Change Impact Studies. Applied Sciences. 2020; 10(19):6878. https://doi.org/10.3390/app10196878
Chicago/Turabian StyleNusrat, Ammara, Hamza Farooq Gabriel, Sajjad Haider, Shakil Ahmad, Muhammad Shahid, and Saad Ahmed Jamal. 2020. "Application of Machine Learning Techniques to Delineate Homogeneous Climate Zones in River Basins of Pakistan for Hydro-Climatic Change Impact Studies" Applied Sciences 10, no. 19: 6878. https://doi.org/10.3390/app10196878
APA StyleNusrat, A., Gabriel, H. F., Haider, S., Ahmad, S., Shahid, M., & Ahmed Jamal, S. (2020). Application of Machine Learning Techniques to Delineate Homogeneous Climate Zones in River Basins of Pakistan for Hydro-Climatic Change Impact Studies. Applied Sciences, 10(19), 6878. https://doi.org/10.3390/app10196878