In-Silico Evaluation of Glucose Regulation Using Policy Gradient Reinforcement Learning for Patients with Type 1 Diabetes Mellitus

 and
and 
Abstract
1. Introduction
1.1. Related Work
1.2. Structure of Paper
2. Theoretical Background
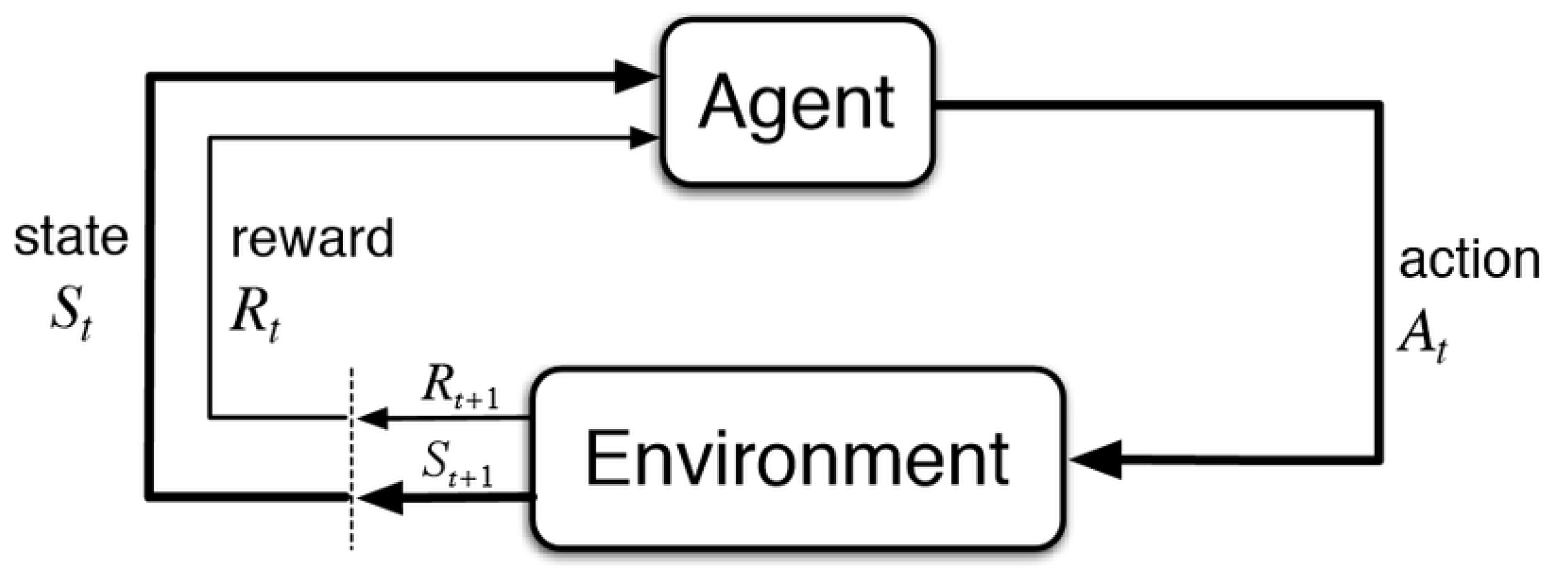
2.1. Reinforcement Learning
2.2. Policy Gradient Methods
| Algorithm 1 REINFORCE |
|
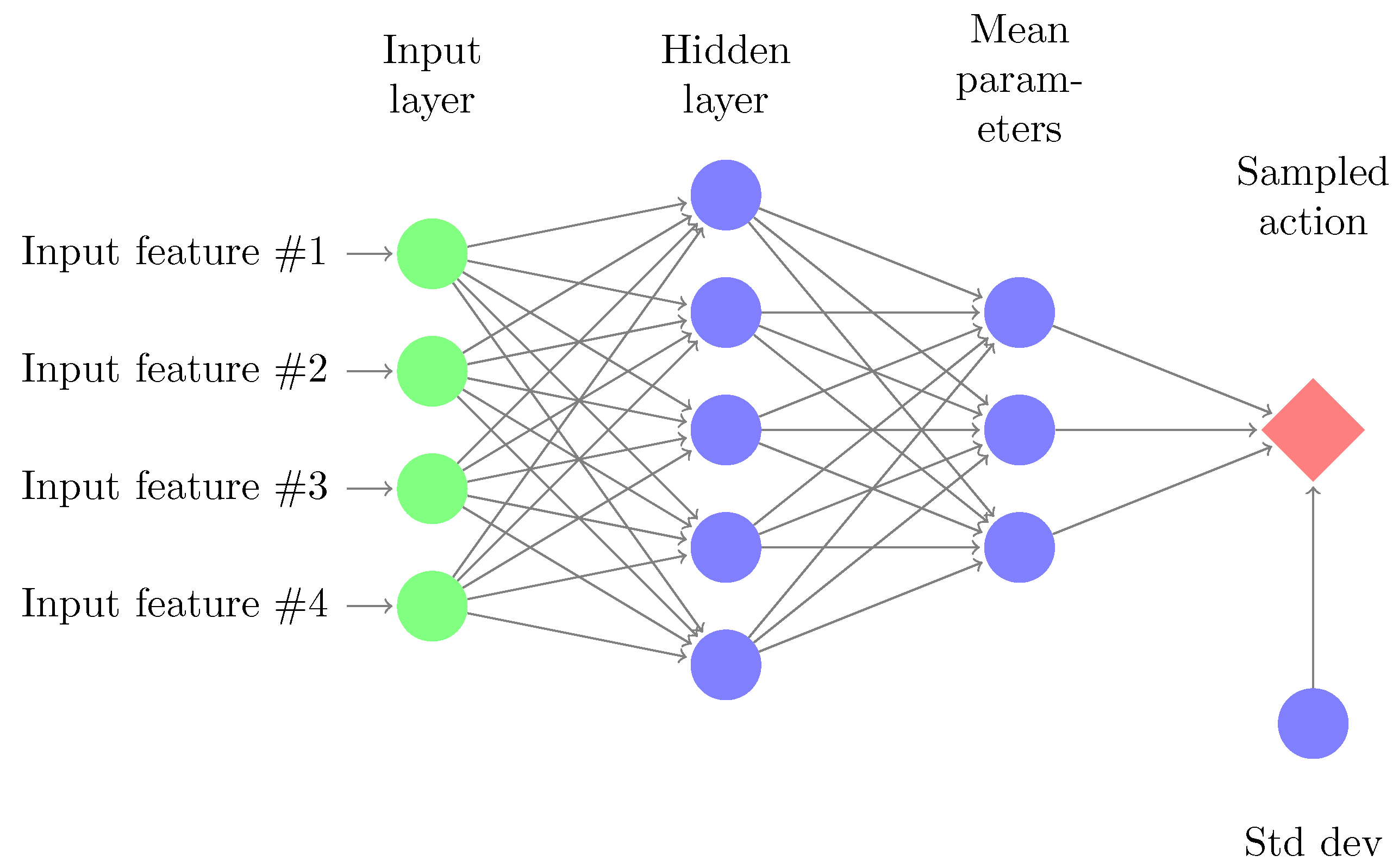
2.3. Parameterized Policies
2.4. Model Predictive Control
3. In-Silico Simulation
3.1. Simulator
- Patient weight is sampled from a uniform distribution between 55–95 kg.
- When the basal rate is delivered and the patient is in fasting conditions, glucose levels are constant and are between 110–180 mg/dL.
- The patient’s basal rates were sampled from a uniform distribution between 0.2–2.5 U.
- The patient’s carbohydrate ratios were sampled from a uniform distribution between 3–30 g/U.
- Each patient is characterized with a unique insulin sensitivity factor () mg/dL/U, i.e., if an insulin bolus of size 1 U is delivered, glucose levels will drop by mg/dL.
- The patient’s insulin sensitivities were sampled from a uniform distribution between 0.5–6.5 mmol/L.
- A theoretical total daily dose () of insulin is computed assuming a daily diet of carbohydrates between 70–350 g. This value is then compared to sampled insulin sensitivity to ensure that the 1800 rule holds: .
- A theoretical total fraction of basal insulin is computed and is compared to to ensure that the proportion of basal insulin is between 25–75% of .
- All Hovorka’s parameters, [62], are sampled using a log-normal distribution (to avoid negative values) around published parameters.
3.2. Reinforcement Learning, T1DM and the Artificial Pancreas
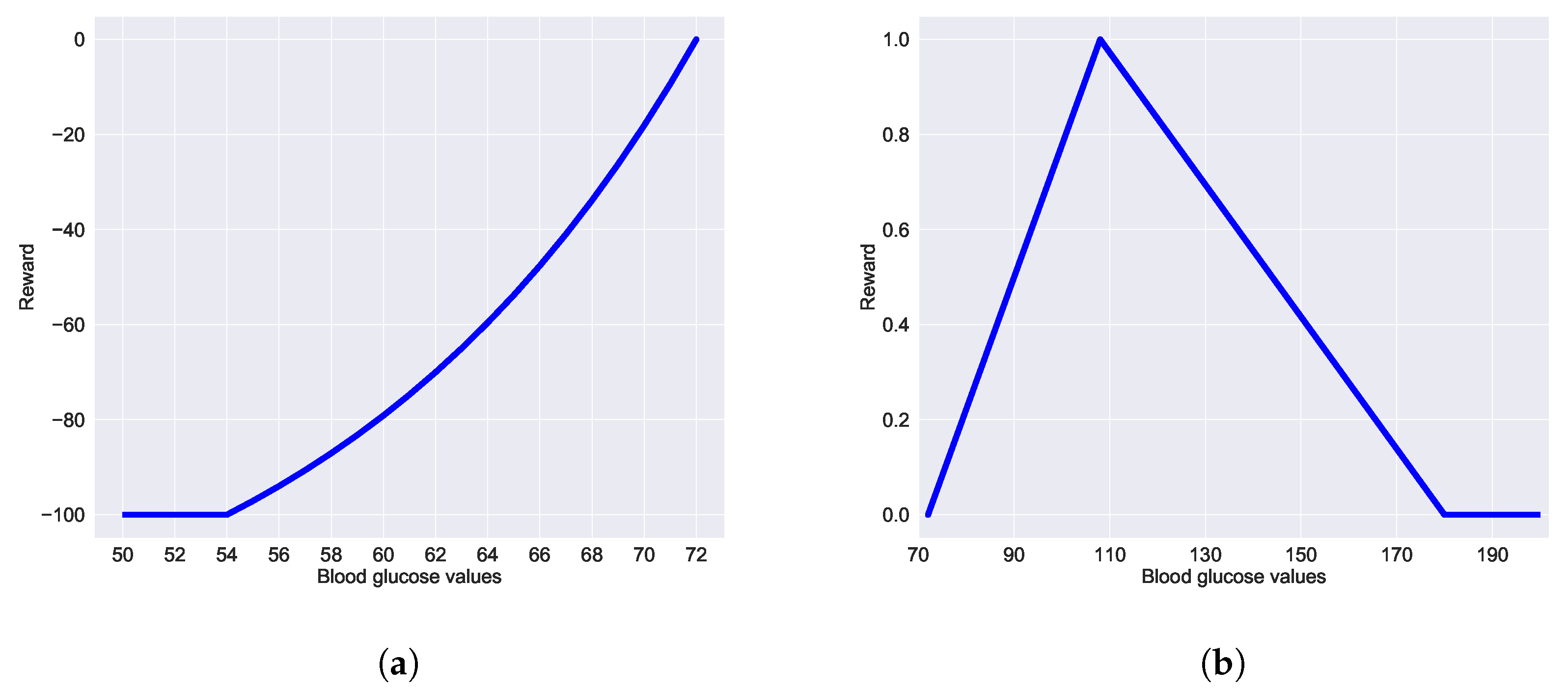
3.3. Experiment Setup
4. Results
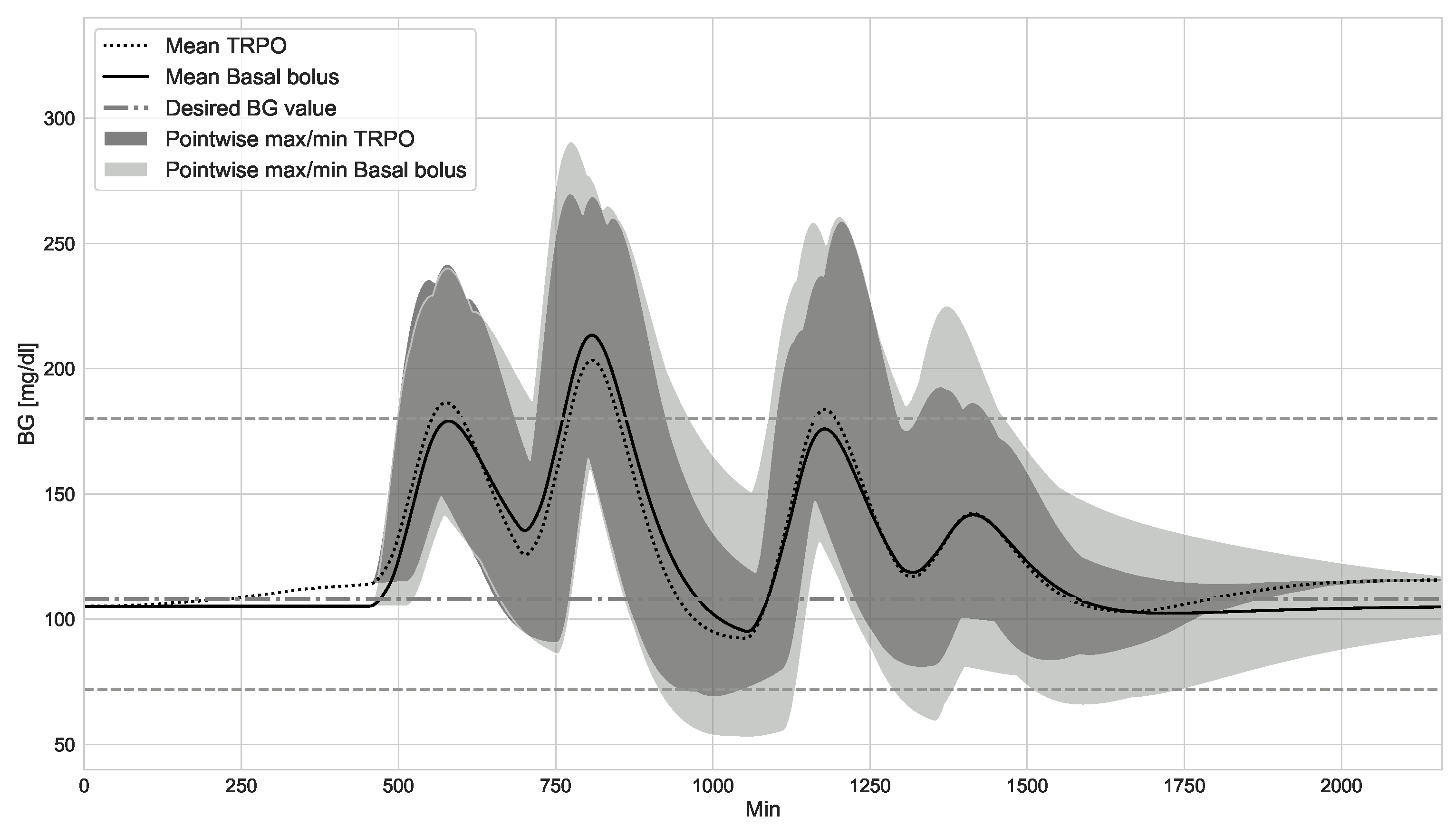
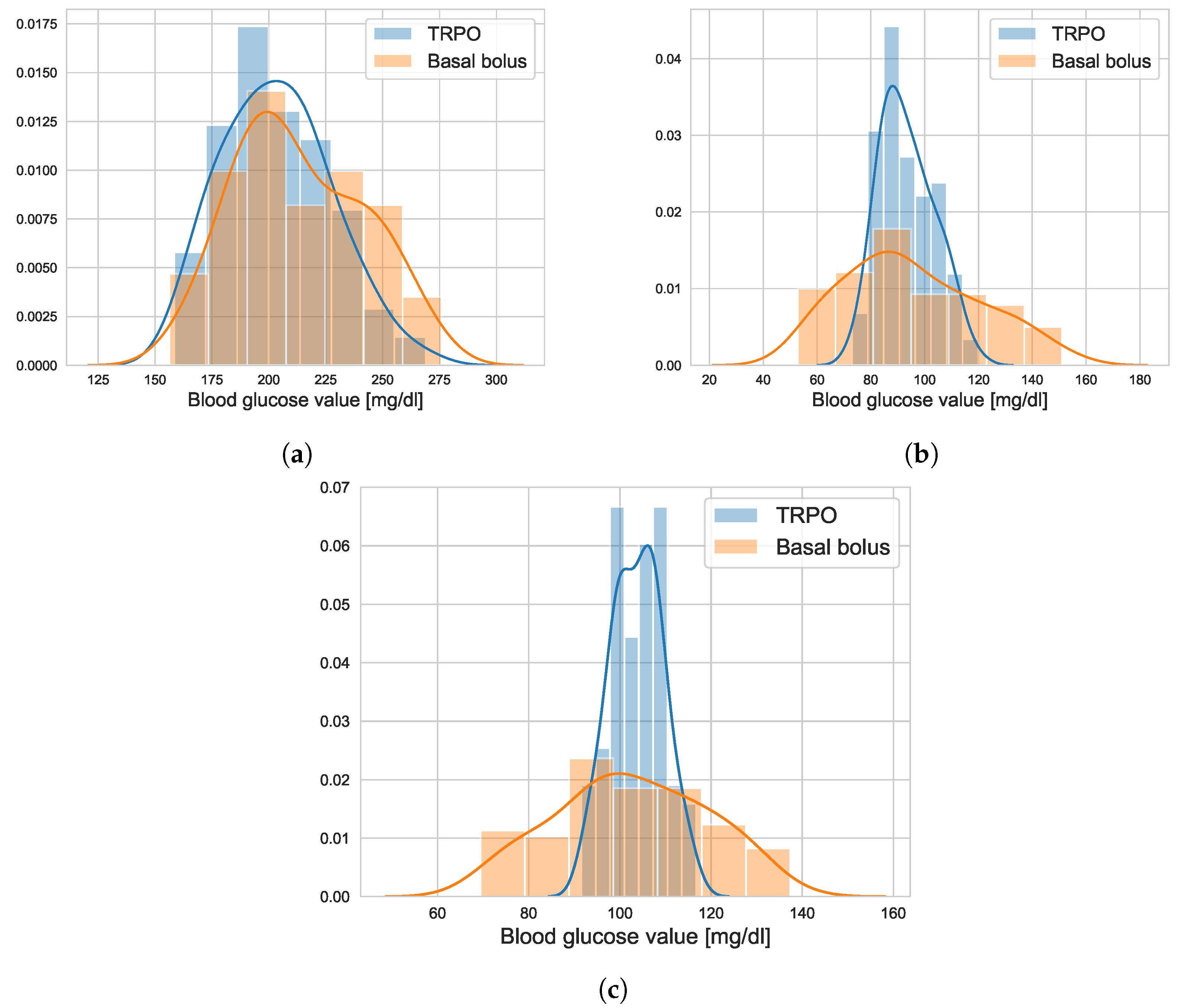
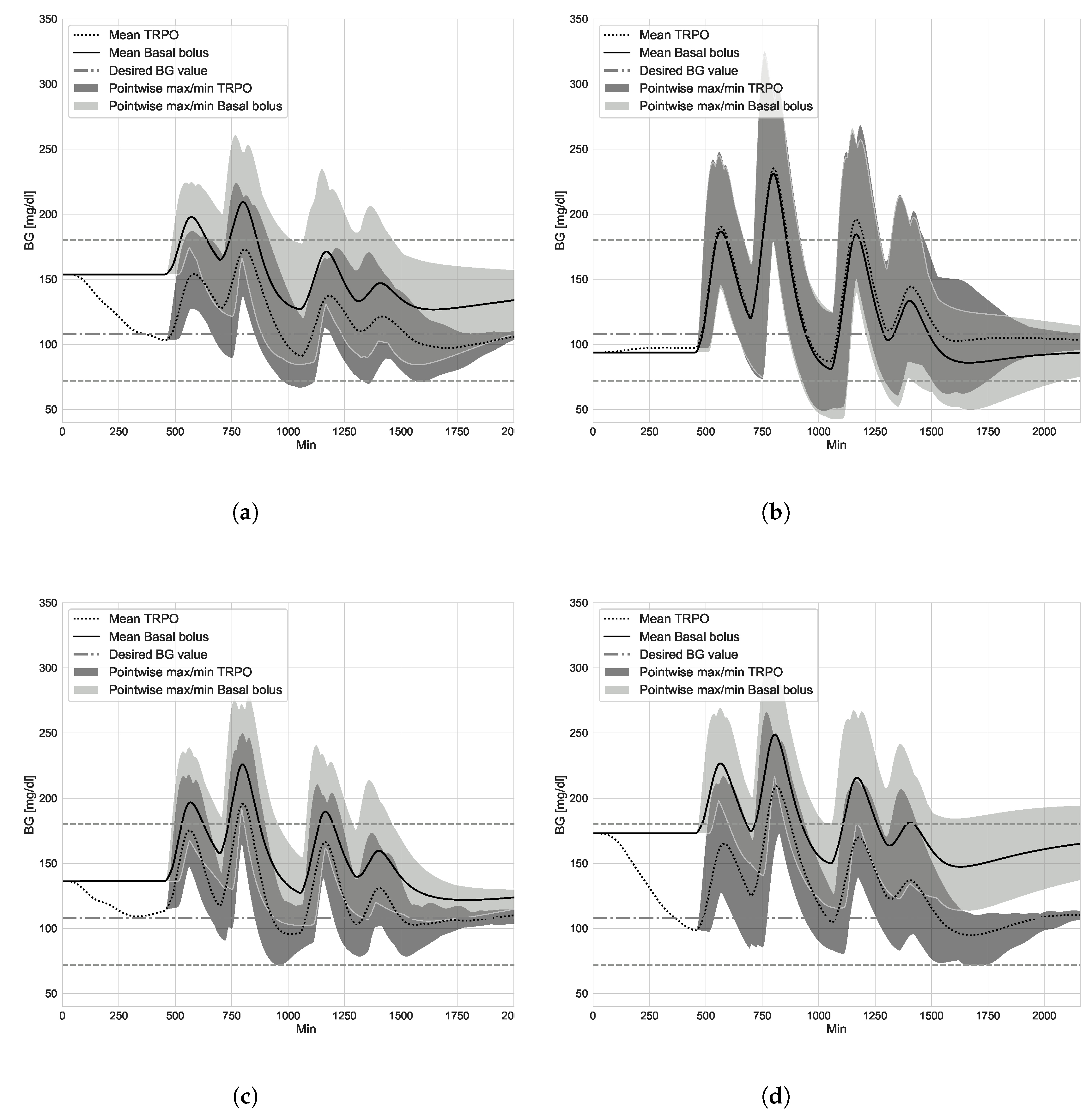
4.1. TRPO versus Open Loop Basal-Bolus Treatment–Hovorka Patient and Carbohydrate Counting Errors
4.2. Virtual Population Experiment: Undertreated Patients
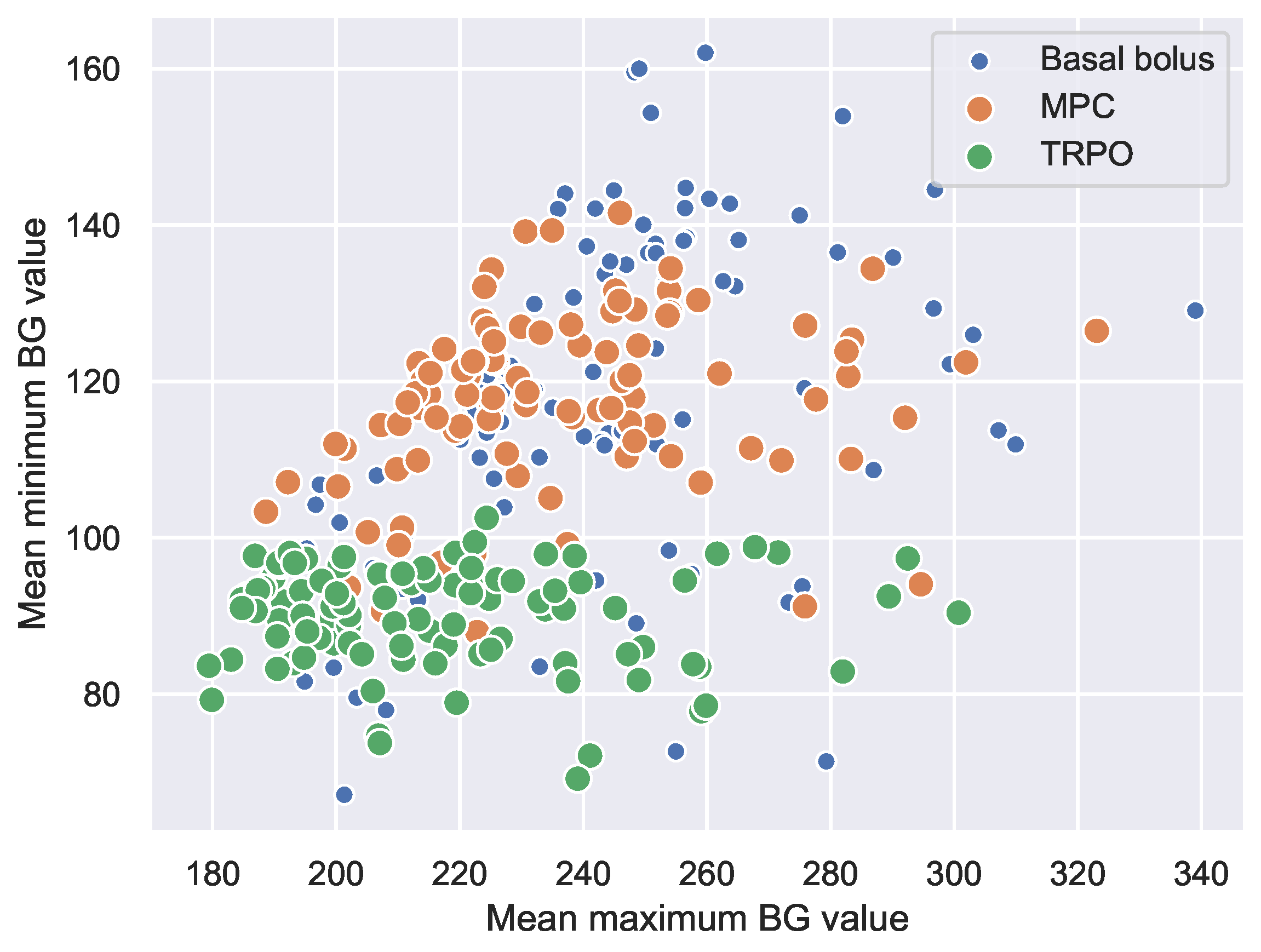
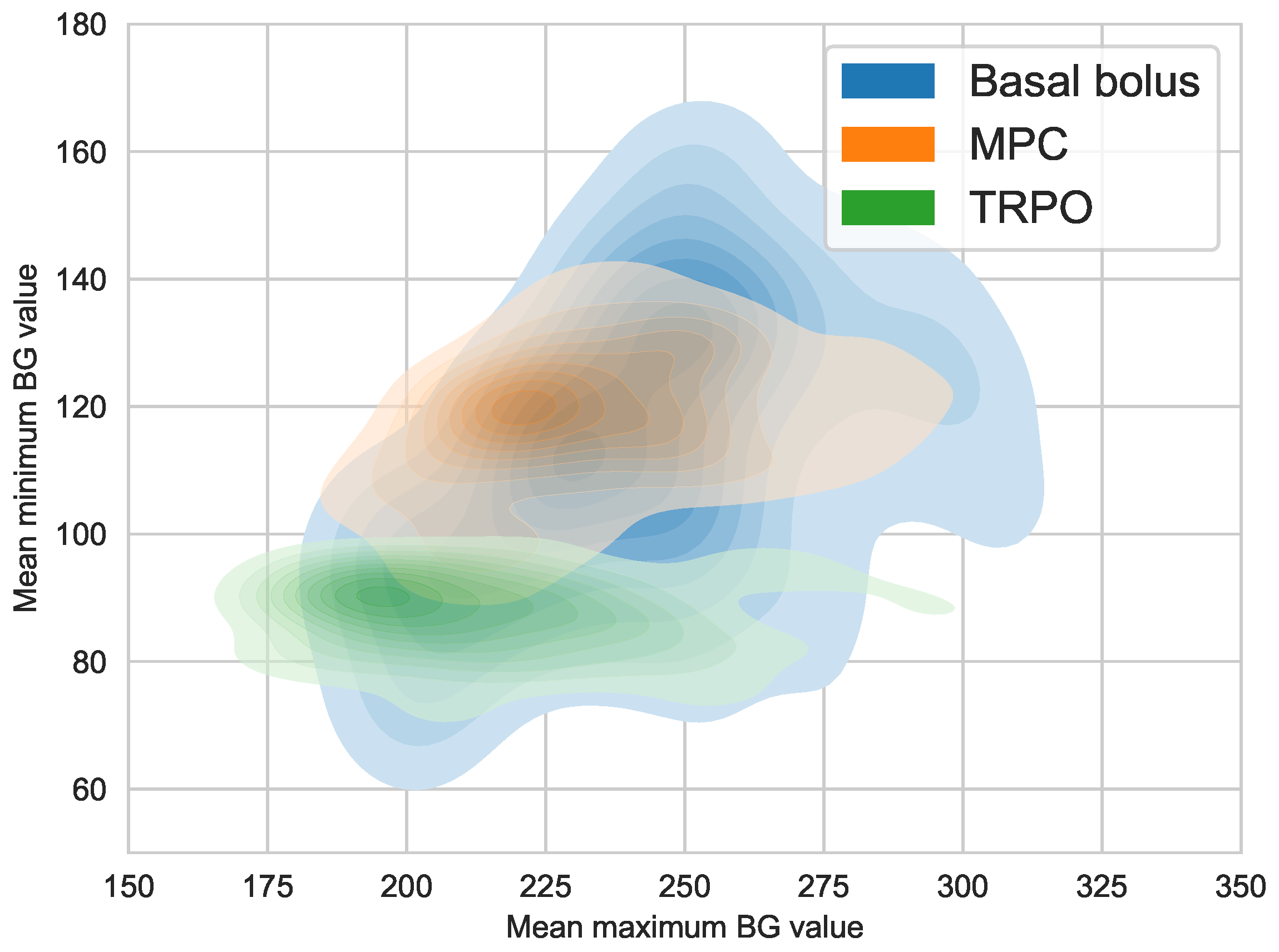
4.3. Virtual Population Experiment: TRPO versus Model Predictive Control
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- WHO. Diabetes. 2017. Available online: http://www.webcitation.org/719KGYXpa (accessed on 8 August 2018).
- What is Insulin? Available online: https://www.endocrineweb.com/conditions/type-1-diabetes/what-insulin (accessed on 23 January 2020).
- Diabetes Control and Complications Trial Research Group; The relationship of glycemic exposure (HbA1c) to the risk of development and progression of retinopathy in the diabetes control and complications trial. Diabetes 1995, 44, 968–983. [CrossRef]
- Misso, M.L.; Egberts, K.J.; Page, M.; O’Connor, D.; Shaw, J. Continuous subcutaneous insulin infusion (CSII) versus multiple insulin injections for type 1 diabetes mellitus. Cochrane Database Syst. Rev. 2010, 20, CD005103. [Google Scholar]
- Juvenile Diabetes Research Foundation Continuous Glucose Monitoring Study Group. Continuous glucose monitoring and intensive treatment of type 1 diabetes. N. Engl. J. Med. 2008, 359, 1464–1476. [Google Scholar] [CrossRef]
- El Fathi, A.; Smaoui, M.R.; Gingras, V.; Boulet, B.; Haidar, A. The artificial pancreas and meal control: An overview of postprandial glucose regulation in type 1 diabetes. IEEE Control. Syst. Mag. 2018, 38, 67–85. [Google Scholar]
- ADA. Diabetes. Available online: https://www.diabetes.org/newsroom/press-releases/2019/new-recommendations-for (accessed on 16 September 2019).
- Hovorka, R. Closed-loop insulin delivery: From bench to clinical practice. Nat. Rev. Endocrinol. 2011, 7, 385–395. [Google Scholar] [CrossRef] [PubMed]
- Cinar, A. Artificial pancreas systems: An introduction to the special issue. IEEE Control. Syst. Mag. 2018, 38, 26–29. [Google Scholar]
- Basu, R.; Johnson, M.L.; Kudva, Y.C.; Basu, A. Exercise, Hypoglycemia, and Type 1 Diabetes. Diabetes Technol. Ther. 2014, 16, 331–337. [Google Scholar] [CrossRef] [PubMed]
- Messer, L.H.; Forlenza, G.P.; Sherr, J.L.; Wadwa, R.P.; Buckingham, B.A.; Weinzimer, S.A.; Maahs, D.M.; Slover, R.H. Optimizing hybrid closed-loop therapy in adolescents and emerging adults using the MiniMed 670G system. Diabetes Care 2018, 41, 789–796. [Google Scholar] [CrossRef] [PubMed]
- Petruzelkova, L.; Soupal, J.; Plasova, V.; Jiranova, P.; Neuman, V.; Plachy, L.; Pruhova, S.; Sumnik, Z.; Obermannova, B. Excellent glycemic control maintained by open-source hybrid closed-loop AndroidAPS during and after sustained physical activity. Diabetes Technol. Ther. 2018, 20, 744–750. [Google Scholar] [CrossRef] [PubMed]
- Chase, H.P.; Doyle, F.J., III; Zisser, H.; Renard, E.; Nimri, R.; Cobelli, C.; Buckingham, B.A.; Maahs, D.M.; Anderson, S.; Magni, L.; et al. Multicenter closed-loop/hybrid meal bolus insulin delivery with type 1 diabetes. Diabetes Technol. Ther. 2014, 16, 623–632. [Google Scholar] [CrossRef]
- Reiterer, F.; Freckmann, G.; del Re, L. Impact of Carbohydrate Counting Errors on Glycemic Control in Type 1 Diabetes. IFAC-PapersOnLine 2018, 51, 186–191. [Google Scholar] [CrossRef]
- Deeb, A.; Al Hajeri, A.; Alhmoudi, I.; Nagelkerke, N. Accurate carbohydrate counting is an important determinant of postprandial glycemia in children and adolescents with type 1 diabetes on insulin pump therapy. J. Diabetes Sci. Technol. 2017, 11, 753–758. [Google Scholar] [CrossRef] [PubMed]
- Vasiloglou, M.; Mougiakakou, S.; Aubry, E.; Bokelmann, A.; Fricker, R.; Gomes, F.; Guntermann, C.; Meyer, A.; Studerus, D.; Stanga, Z. A comparative study on carbohydrate estimation: GoCARB vs. Dietitians. Nutrients 2018, 10, 741. [Google Scholar] [CrossRef] [PubMed]
- Kawamura, T.; Takamura, C.; Hirose, M.; Hashimoto, T.; Higashide, T.; Kashihara, Y.; Hashimura, K.; Shintaku, H. The factors affecting on estimation of carbohydrate content of meals in carbohydrate counting. Clin. Pediatr. Endocrinol. 2015, 24, 153–165. [Google Scholar] [CrossRef] [PubMed]
- Kovatchev, B.; Cheng, P.; Anderson, S.M.; Pinsker, J.E.; Boscari, F.; Buckingham, B.A.; Doyle, F.J., III; Hood, K.K.; Brown, S.A.; Breton, M.D.; et al. Feasibility of long-term closed-loop control: A multicenter 6-month trial of 24/7 automated insulin delivery. Diabetes Technol. Ther. 2017, 19, 18–24. [Google Scholar] [CrossRef]
- Boughton, C.K.; Hovorka, R. Advances in artificial pancreas systems. Sci. Transl. Med. 2019, 11, 4949. [Google Scholar] [CrossRef]
- Turksoy, K.; Hajizadeh, I.; Samadi, S.; Feng, J.; Sevil, M.; Park, M.; Quinn, L.; Littlejohn, E.; Cinar, A. Real-time insulin bolusing for unannounced meals with artificial pancreas. Control. Eng. Pract. 2017, 59, 159–164. [Google Scholar] [CrossRef]
- Steil, G.M.; Rebrin, K.; Darwin, C.; Hariri, F.; Saad, M.F. Feasibility of automating insulin delivery for the treatment of type 1 diabetes. Diabetes 2006, 55, 3344–3350. [Google Scholar] [CrossRef]
- Hovorka, R.; Canonico, V.; Chassin, L.J.; Haueter, U.; Massi-Benedetti, M.; Federici, M.O.; Pieber, T.R.; Schaller, H.C.; Schaupp, L.; Vering, T.; et al. Nonlinear model predictive control of glucose concentration in subjects with type 1 diabetes. Physiol. Meas. 2004, 25, 905. [Google Scholar] [CrossRef]
- Harvey, R.A.; Dassau, E.; Bevier, W.C.; Seborg, D.E.; Jovanovič, L.; Doyle, F.J., III; Zisser, H.C. Clinical evaluation of an automated artificial pancreas using zone-model predictive control and health monitoring system. Diabetes Technol. Ther. 2014, 16, 348–357. [Google Scholar] [CrossRef]
- Boiroux, D.; Duun-Henriksen, A.K.; Schmidt, S.; Nørgaard, K.; Poulsen, N.K.; Madsen, H.; Jørgensen, J.B. Assessment of model predictive and adaptive glucose control strategies for people with type 1 diabetes. IFAC Proc. Vol. 2014, 47, 231–236. [Google Scholar] [CrossRef]
- Bothe, M.K.; Dickens, L.; Reichel, K.; Tellmann, A.; Ellger, B.; Westphal, M.; Faisal, A.A. The use of reinforcement learning algorithms to meet the challenges of an artificial pancreas. Biomed. Signal Process. Control. 2013, 10, 661–673. [Google Scholar] [CrossRef] [PubMed]
- Atlas, E.; Nimri, R.; Miller, S.; Grunberg, E.A.; Phillip, M. MD-logic artificial pancreas system: A pilot study in adults with type 1 diabetes. Diabetes Care 2010, 33, 1072–1076. [Google Scholar] [CrossRef] [PubMed]
- Aiello, E.M.; Lisanti, G.; Magni, L.; Musci, M.; Toffanin, C. Therapy-driven Deep Glucose Forecasting. Eng. Appl. Artif. Intell. 2020, 87, 103255. [Google Scholar] [CrossRef]
- Li, K.; Liu, C.; Zhu, T.; Herrero, P.; Georgiou, P. GluNet: A deep learning framework for accurate glucose forecasting. IEEE J. Biomed. Health Inform. 2019, 24, 414–423. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Ngo, P.D.; Wei, S.; Holubová, A.; Muzik, J.; Godtliebsen, F. Reinforcement-learning optimal control for type-1 diabetes. In Proceedings of the 2018 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), Las Vegas, NV, USA, 4–7 March 2018; pp. 333–336. [Google Scholar]
- Bastani, M. Model-Free Intelligent Diabetes Management Using Machine Learning. Master’s Thesis, University of Alberta Libraries, Edmonton, AB, Canada, 2014. [Google Scholar]
- Myhre, J.N.; Launonen, I.K.; Wei, S.; Godtliebsen, F. Controlling Blood Glucose Levels in Patients with Type 1 Diabetes Using Fitted Q-Iterations and Functional Features. In Proceedings of the 2018 IEEE 28th International Workshop on Machine Learning for Signal Processing (MLSP), Aalborg, Denmark, 17–20 September 2018; pp. 1–6. [Google Scholar]
- Fox, I.; Wiens, J. Reinforcement Learning for Blood Glucose Control: Challenges and Opportunities. In Proceedings of the Reinforcement Learning for Real Life (RL4RealLife) Workshop in the 36th International Conference on Machine Learning, Long Beach, CA, USA, 30 May 2019. [Google Scholar]
- Daskalaki, E.; Diem, P.; Mougiakakou, S.G. An Actor–Critic based controller for glucose regulation in type 1 diabetes. Comput. Methods Programs Biomed. 2013, 109, 116–125. [Google Scholar] [CrossRef] [PubMed]
- Sun, Q.; Jankovic, M.V.; Mougiakakou, S.G. Reinforcement learning-based adaptive insulin advisor for individuals with type 1 diabetes patients under multiple daily injections therapy. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 3609–3612. [Google Scholar]
- Yasini, S.; Naghibi-Sistani, M.; Karimpour, A. Agent-based simulation for blood glucose control in diabetic patients. Int. J. Appl. Sci. Eng. Technol. 2009, 5, 40–49. [Google Scholar]
- Sun, Q.; Jankovic, M.V.; Budzinski, J.; Moore, B.; Diem, P.; Stettler, C.; Mougiakakou, S.G. A dual mode adaptive basal-bolus advisor based on reinforcement learning. IEEE J. Biomed. Health Inform. 2018, 23, 2633–2641. [Google Scholar] [CrossRef]
- Zhu, T.; Li, K.; Herrero, P.; Georgiou, P. Basal Glucose Control in Type 1 Diabetes using Deep Reinforcement Learning: An In Silico Validation. arXiv 2020, arXiv:2005.09059. [Google Scholar]
- Lee, S.; Kim, J.; Park, S.W.; Jin, S.M.; Park, S.M. Toward a fully automated artificial pancreas system using a bioinspired reinforcement learning design: In silico validation. IEEE J. Biomed. Health Inform. 2020. [Google Scholar] [CrossRef]
- Tejedor, M.; Woldaregay, A.Z.; Godtliebsen, F. Reinforcement learning application in diabetes blood glucose control: A systematic review. Artif. Intell. Med. 2020, 104, 101836. [Google Scholar] [CrossRef] [PubMed]
- Tesauro, G. TD-Gammon, a self-teaching backgammon program, achieves master-level play. Neural Comput. 1994, 6, 215–219. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484. [Google Scholar] [CrossRef] [PubMed]
- Duan, Y.; Chen, X.; Houthooft, R.; Schulman, J.; Abbeel, P. Benchmarking Deep Reinforcement Learning for Continuous Control. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1329–1338. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Nachum, O.; Norouzi, M.; Xu, K.; Schuurmans, D. Bridging the gap between value and policy based reinforcement learning. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 2775–2785. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press: Cambridge, MA, USA, 1998; Volume 135. [Google Scholar]
- Kakade, S.M. A natural policy gradient. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2002; pp. 1531–1538. [Google Scholar]
- Shi, D.; Dassau, E.; Doyle, F.J. Adaptive Zone Model Predictive Control of Artificial Pancreas Based on Glucose-and Velocity-Dependent Control Penalties. IEEE Trans. Biomed. Eng. 2019, 66, 1045–1054. [Google Scholar] [CrossRef] [PubMed]
- Del Favero, S.; Place, J.; Kropff, J.; Messori, M.; Keith-Hynes, P.; Visentin, R.; Monaro, M.; Galasso, S.; Boscari, F.; Toffanin, C.; et al. Multicenter outpatient dinner/overnight reduction of hypoglycemia and increased time of glucose in target with a wearable artificial pancreas using modular model predictive control in adults with type 1 diabetes. Diabetes Obes. Metab. 2015, 17, 468–476. [Google Scholar] [CrossRef]
- Incremona, G.P.; Messori, M.; Toffanin, C.; Cobelli, C.; Magni, L. Model predictive control with integral action for artificial pancreas. Control. Eng. Pract. 2018, 77, 86–94. [Google Scholar] [CrossRef]
- Brown, S.A.; Kovatchev, B.P.; Raghinaru, D.; Lum, J.W.; Buckingham, B.A.; Kudva, Y.C.; Laffel, L.M.; Levy, C.J.; Pinsker, J.E.; Wadwa, R.P.; et al. Six-month randomized, multicenter trial of closed-loop control in type 1 diabetes. N. Engl. J. Med. 2019, 381, 1707–1717. [Google Scholar] [CrossRef]
- Camacho, E.F.; Bordons, C.; Johnson, M. Model Predictive Control. Advanced Textbooks in Control and Signal Processing; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Toffanin, C.; Aiello, E.; Del Favero, S.; Cobelli, C.; Magni, L. Multiple models for artificial pancreas predictions identified from free-living condition data: A proof of concept study. J. Process. Control 2019, 77, 29–37. [Google Scholar] [CrossRef]
- Cameron, F.; Niemeyer, G.; Wilson, D.M.; Bequette, B.W.; Benassi, K.S.; Clinton, P.; Buckingham, B.A. Inpatient trial of an artificial pancreas based on multiple model probabilistic predictive control with repeated large unannounced meals. Diabetes Technol. Ther. 2014, 16, 728–734. [Google Scholar] [CrossRef] [PubMed]
- Turksoy, K.; Quinn, L.; Littlejohn, E.; Cinar, A. Multivariable adaptive identification and control for artificial pancreas systems. IEEE Trans. Biomed. Eng. 2013, 61, 883–891. [Google Scholar] [CrossRef] [PubMed]
- Bergman, R.N. Toward physiological understanding of glucose tolerance: Minimal-model approach. Diabetes 1989, 38, 1512–1527. [Google Scholar] [CrossRef] [PubMed]
- Dalla Man, C.; Rizza, R.A.; Cobelli, C. Meal simulation model of the glucose-insulin system. IEEE Trans. Biomed. Eng. 2007, 54, 1740–1749. [Google Scholar] [CrossRef]
- Kanderian, S.S.; Weinzimer, S.A.; Steil, G.M. The identifiable virtual patient model: Comparison of simulation and clinical closed-loop study results. J. Diabetes Sci. Technol. 2012, 6, 371–379. [Google Scholar] [CrossRef]
- Wilinska, M.E.; Hovorka, R. Simulation models for in silico testing of closed-loop glucose controllers in type 1 diabetes. Drug Discov. Today Dis. Model. 2008, 5, 289–298. [Google Scholar] [CrossRef]
- Wilinska, M.E.; Chassin, L.J.; Acerini, C.L.; Allen, J.M.; Dunger, D.B.; Hovorka, R. Simulation environment to evaluate closed-loop insulin delivery systems in type 1 diabetes. J. Diabetes Sci. Technol. 2010, 4, 132–144. [Google Scholar] [CrossRef]
- Walsh, J.; Roberts, R. Pumping Insulin: Everything You Need for Success on a Smart Insulin Pump; Torrey Pines Press: San Diego, CA, USA, 2006. [Google Scholar]
- Gingras, V.; Taleb, N.; Roy-Fleming, A.; Legault, L.; Rabasa-Lhoret, R. The challenges of achieving postprandial glucose control using closed-loop systems in patients with type 1 diabetes. Diabetes Obes. Metab. 2018, 20, 245–256. [Google Scholar] [CrossRef]
- Schmelzeisen-Redeker, G.; Schoemaker, M.; Kirchsteiger, H.; Freckmann, G.; Heinemann, L.; del Re, L. Time delay of CGM sensors: Relevance, causes, and countermeasures. J. Diabetes Sci. Technol. 2015, 9, 1006–1015. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Tejedor, M.; Myhre, J.N. Controlling Blood Glucose For Patients With Type 1 Diabetes Using Deep Reinforcement Learning—The Influence Of Changing The Reward Function. Proc. North. Light. Deep. Learn. Workshop 2020, 1, 1–6. [Google Scholar]
- Danne, T.; Nimri, R.; Battelino, T.; Bergenstal, R.M.; Close, K.L.; DeVries, J.H.; Garg, S.; Heinemann, L.; Hirsch, I.; Amiel, S.A.; et al. International consensus on use of continuous glucose monitoring. Diabetes Care 2017, 40, 1631–1640. [Google Scholar] [CrossRef] [PubMed]
- Suh, S.; Kim, J.H. Glycemic variability: How do we measure it and why is it important? Diabetes Metab. J. 2015, 39, 273–282. [Google Scholar] [CrossRef] [PubMed]
- Clarke, W.; Kovatchev, B. Statistical tools to analyze continuous glucose monitor data. Diabetes Technol. Ther. 2009, 11, S-45–S-54. [Google Scholar] [CrossRef] [PubMed]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Magni, L.; Raimondo, D.M.; Dalla Man, C.; Breton, M.; Patek, S.; De Nicolao, G.; Cobelli, C.; Kovatchev, B.P. Evaluating the Efficacy of Closed-Loop Glucose Regulation via Control-Variability Grid Analysis. J. Diabetes Sci. Technol. 2008, 2, 630–635. [Google Scholar] [CrossRef]
- Gu, S.; Lillicrap, T.; Sutskever, I.; Levine, S. Continuous deep q-learning with model-based acceleration. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2829–2838. [Google Scholar]
- Berkenkamp, F.; Turchetta, M.; Schoellig, A.; Krause, A. Safe model-based reinforcement learning with stability guarantees. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 908–918. [Google Scholar]
- Ho, J.; Ermon, S. Generative adversarial imitation learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4565–4573. [Google Scholar]
- Garcia, J.; Fernandez, F. A Comprehensive Survey on Safe Reinforcement Learning. J. Mach. Learn. Res. 2015, 16, 1437–1480. [Google Scholar]
- Bacon, P.L.; Harb, J.; Precup, D. The option-critic architecture. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Treatment | Time-in-Range | -Hypo | -Hyper | LBGI | HBGI | RI | Std | CoV |
|---|---|---|---|---|---|---|---|---|
| Basal-bolus | 83.45 | 2.42 | 14.13 | 0.87 | 4.62 | 5.5 | 40.35 | 0.3 |
| TRPO | 86.12 | 0.1 | 13.78 | 0.46 | 3.17 | 3.62 | 36.55 | 0.27 |
| TRPOe w/ 300 itrs | 86.33 | 0.49 | 13.18 | 0.42 | 4.14 | 4.56 | 36.71 | 0.28 |
| Random skipped boluses: | ||||||||
| Basal-bolus | 79.59 | 2.27 | 18.13 | 0.85 | 5.8 | 6.65 | 50.35 | 0.36 |
| TRPO | 82.91 | 0.0 | 17.09 | 0.2 | 5.55 | 5.75 | 41.06 | 0.29 |
| TRPOe w/ 300 itrs | 84.68 | 0.49 | 14.84 | 0.43 | 4.68 | 5.11 | 40.36 | 0.3 |
| Treatment | Time-in-Range | -Hypo | LBGI | HBGI | RI | Std | CoV |
|---|---|---|---|---|---|---|---|
| Basal-bolus | 73.67 | 0.30 | 0.51 | 6.12 | 6.63 | 32.73 | 0.21 |
| TRPO | 88.72 | 0.50 | 0.78 | 3.80 | 4.57 | 32.75 | 0.24 |
| MPC | 79.25 | 0.003 | 0.13 | 5.14 | 5.27 | 30.11 | 0.19 |
| Best and worst cases: | Best TIR | Worst TIR | Worst TIH | ||||
| Basal-bolus | 95.59 | 43.80 | 7.11 | ||||
| TRPO | 97.18 | 63.63 | 5.01 | ||||
| MPC | 96.02 | 55.27 | 0.15 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nordhaug Myhre, J.; Tejedor, M.; Kalervo Launonen, I.; El Fathi, A.; Godtliebsen, F. In-Silico Evaluation of Glucose Regulation Using Policy Gradient Reinforcement Learning for Patients with Type 1 Diabetes Mellitus. Appl. Sci. 2020, 10, 6350. https://doi.org/10.3390/app10186350
Nordhaug Myhre J, Tejedor M, Kalervo Launonen I, El Fathi A, Godtliebsen F. In-Silico Evaluation of Glucose Regulation Using Policy Gradient Reinforcement Learning for Patients with Type 1 Diabetes Mellitus. Applied Sciences. 2020; 10(18):6350. https://doi.org/10.3390/app10186350
Chicago/Turabian StyleNordhaug Myhre, Jonas, Miguel Tejedor, Ilkka Kalervo Launonen, Anas El Fathi, and Fred Godtliebsen. 2020. "In-Silico Evaluation of Glucose Regulation Using Policy Gradient Reinforcement Learning for Patients with Type 1 Diabetes Mellitus" Applied Sciences 10, no. 18: 6350. https://doi.org/10.3390/app10186350
APA StyleNordhaug Myhre, J., Tejedor, M., Kalervo Launonen, I., El Fathi, A., & Godtliebsen, F. (2020). In-Silico Evaluation of Glucose Regulation Using Policy Gradient Reinforcement Learning for Patients with Type 1 Diabetes Mellitus. Applied Sciences, 10(18), 6350. https://doi.org/10.3390/app10186350