A Machine Learning Approach to Predicting Readmission or Mortality in Patients Hospitalized for Stroke or Transient Ischemic Attack



Abstract
1. Introduction
2. Materials and Methods
2.1. Study Population
2.2. Variables
2.3. Machine Learning Techniques
2.4. Experiments
2.5. Evaluation Metrics and Statistical Analysis
3. Results
3.1. Important Features
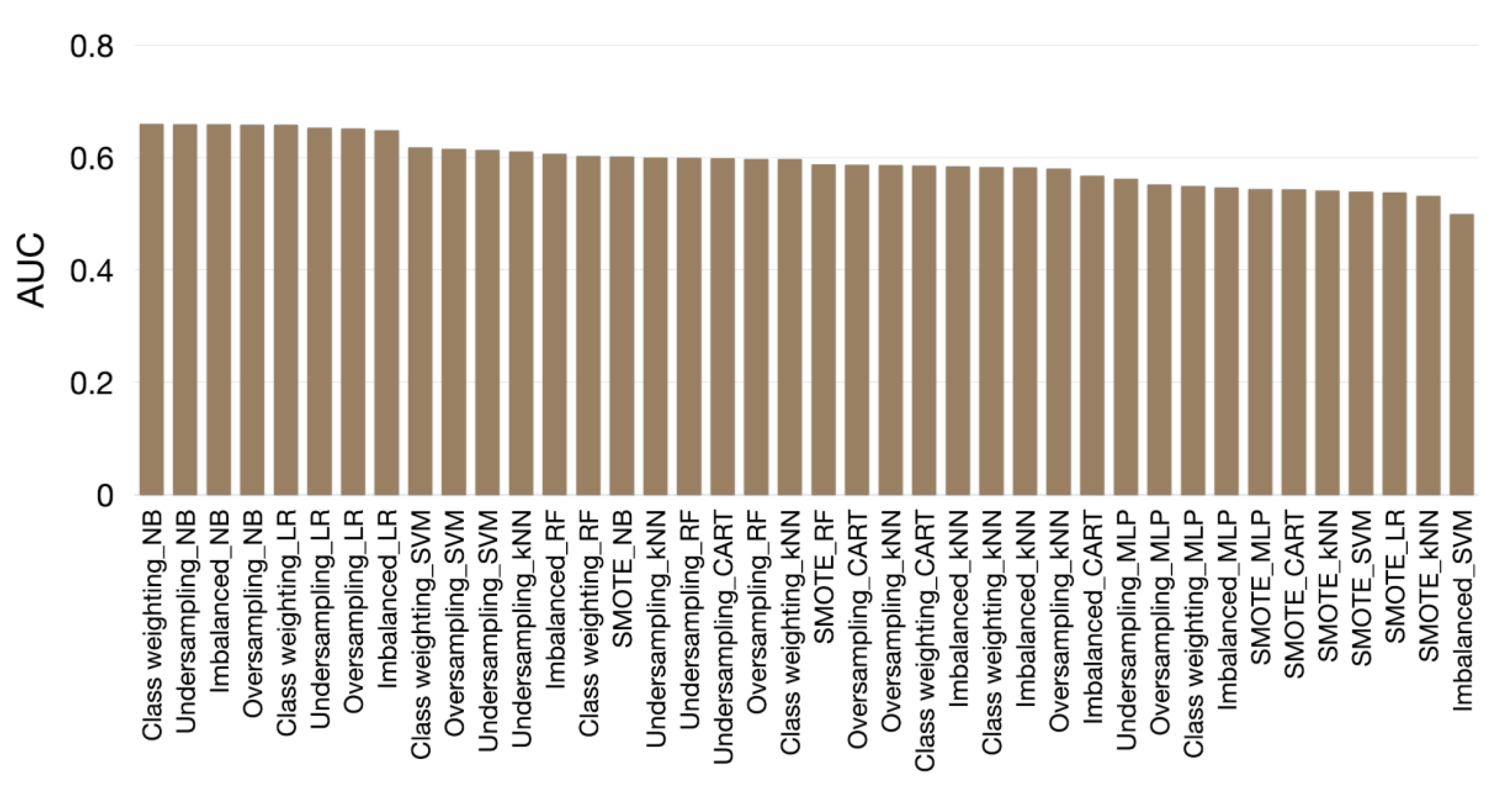
3.2. Evaluation Results
4. Discussion
4.1. Principal Findings
4.2. Comparisons with Past Studies
4.3. Clinical Implications and Applications in Real-World Settings
4.4. Future Directions
4.5. Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Roth, G.A.; Abate, D.; Abate, K.H.; Abay, S.M.; Abbafati, C.; Abbasi, N.; Abbastabar, H.; Abd-Allah, F.; Abdela, J.; Abdelalim, A.; et al. Global, regional, and national age-sex-specific mortality for 282 causes of death in 195 countries and territories, 1980–2017: A systematic analysis for the Global Burden of Disease Study 2017. Lancet 2018, 392, 1736–1788. [Google Scholar] [CrossRef]
- Kyu, H.H.; Abate, D.; Abate, K.H.; Abay, S.M.; Abbafati, C.; Abbasi, N.; Abbastabar, H.; Abd-Allah, F.; Abdela, J.; Abdelalim, A.; et al. Global, regional, and national disability-adjusted life-years (DALYs) for 359 diseases and injuries and healthy life expectancy (HALE) for 195 countries and territories, 1990–2017: A systematic analysis for the Global Burden of Disease Study 2017. Lancet 2018, 392, 1859–1922. [Google Scholar] [CrossRef]
- Johnson, C.O.; Nguyen, M.; Roth, G.A.; Nichols, E.; Alam, T.; Abate, D.; Abd-Allah, F.; Abdelalim, A.; Abraha, H.N.; Abu-Rmeileh, N.M.; et al. Global, regional, and national burden of stroke, 1990–2016: A systematic analysis for the Global Burden of Disease Study 2016. Lancet Neurol. 2019, 18, 439–458. [Google Scholar] [CrossRef]
- Bergström, L.; Irewall, A.-L.; Söderström, L.; Ögren, J.; Laurell, K.; Mooe, T. One-Year Incidence, Time Trends, and Predictors of Recurrent Ischemic Stroke in Sweden From 1998 to 2010. Stroke 2017, 48, 2046–2051. [Google Scholar] [CrossRef]
- Hsieh, C.-Y.; Wu, D.P.; Sung, S.-F. Trends in vascular risk factors, stroke performance measures, and outcomes in patients with first-ever ischemic stroke in Taiwan between 2000 and 2012. J. Neurol. Sci. 2017, 378, 80–84. [Google Scholar] [CrossRef]
- Kumar, S.; Selim, M.H.; Caplan, L.R. Medical complications after stroke. Lancet Neurol. 2010, 9, 105–118. [Google Scholar] [CrossRef]
- Li, H.-W.; Yang, M.-C.; Chung, K.-P. Predictors for readmission of acute ischemic stroke in Taiwan. J. Formos. Med Assoc. 2011, 110, 627–633. [Google Scholar] [CrossRef]
- Lin, H.-J.; Chang, W.-L.; Tseng, M.-C. Readmission after stroke in a hospital-based registry: Risk, etiologies, and risk factors. Neurology 2011, 76, 438–443. [Google Scholar] [CrossRef]
- Lee, H.-C.; Chang, K.-C.; Huang, Y.-C.; Hung, J.-W.; Chiu, H.-H.E.; Chen, J.-J.; Lee, T.-H. Readmission, mortality, and first-year medical costs after stroke. J. Chin. Med Assoc. 2013, 76, 703–714. [Google Scholar] [CrossRef]
- Hsieh, C.-Y.; Lin, H.-J.; Hu, Y.-H.; Sung, S.-F. Stroke severity may predict causes of readmission within one year in patients with first ischemic stroke event. J. Neurol. Sci. 2017, 372, 21–27. [Google Scholar] [CrossRef]
- Kind, A.; Smith, M.; Liou, J.-I.; Pandhi, N.; Frytak, J.R.; Finch, M.D. The price of bouncing back: One-year mortality and payments for acute stroke patients with 30-day bounce-backs. J. Am. Geriatr. Soc. 2008, 56, 999–1005. [Google Scholar] [CrossRef] [PubMed]
- Bjerkreim, A.T.; Thomassen, L.; Brøgger, J.C.; Waje-Andreassen, U.; Næss, H. Causes and Predictors for Hospital Readmission after Ischemic Stroke. J. Stroke Cerebrovasc. Dis. 2015, 24, 2095–2101. [Google Scholar] [CrossRef] [PubMed]
- Fonarow, G.C.; Smith, E.E.; Reeves, M.J.; Pan, W.; Olson, D.; Hernandez, A.F.; Peterson, E.D.; Schwamm, L.; for the Get With the Guidelines Steering Committee and Hospitals. Hospital-Level Variation in Mortality and Rehospitalization for Medicare Beneficiaries With Acute Ischemic Stroke. Stroke 2011, 42, 159–166. [Google Scholar] [CrossRef] [PubMed]
- Axon, R.N.; Williams, M.V. Hospital Readmission as an Accountability Measure. JAMA 2011, 305, 504–505. [Google Scholar] [CrossRef] [PubMed]
- Daras, L.C.; Ingber, M.J.; Carichner, J.; Barch, D.; Deutsch, A.; Smith, L.M.; Levitt, A.; Andress, J. Evaluating Hospital Readmission Rates After Discharge From Inpatient Rehabilitation. Arch. Phys. Med. Rehabilitation 2018, 99, 1049–1059. [Google Scholar] [CrossRef]
- Lichtman, J.H.; Leifheit-Limson, E.C.; Jones, S.B.; Wang, Y.; Goldstein, L.B. Preventable Readmissions Within 30 Days of Ischemic Stroke Among Medicare Beneficiaries. Stroke 2013, 44, 3429–3435. [Google Scholar] [CrossRef]
- Fisher, S.R.; Graham, J.E.; Krishnan, S.; Ottenbacher, K.J. Predictors of 30-Day Readmission Following Inpatient Rehabilitation for Patients at High Risk for Hospital Readmission. Phys. Ther. 2016, 96, 62–70. [Google Scholar] [CrossRef]
- Chiu, W.-T.; Yang, C.-M.; Lin, H.-W.; Chu, T.-B. Development and implementation of a nationwide health care quality indicator system in Taiwan. Int. J. Qual. Heal. Care 2006, 19, 21–28. [Google Scholar] [CrossRef]
- Shah, S.V.; Corado, C.; Bergman, D.; Curran, Y.; Bernstein, R.A.; Naidech, A.M.; Prabhakaran, S. Impact of Poststroke Medical Complications on 30-Day Readmission Rate. J. Stroke Cerebrovasc. Dis. 2015, 24, 1969–1977. [Google Scholar] [CrossRef]
- Hsieh, F.-I.; Lien, L.-M.; Chen, S.-T.; Bai, C.-H.; Sun, M.-C.; Tseng, H.-P.; Chen, Y.-W.; Chen, C.-H.; Jeng, J.-S.; Tsai, C.-F.; et al. Get With The Guidelines-Stroke Performance Indicators: Surveillance of Stroke Care in the Taiwan Stroke Registry: Get With The Guidelines-Stroke in Taiwan. Circulation 2010, 122, 1116–1123. [Google Scholar] [CrossRef]
- Slocum, C.; Gerrard, P.; Black-Schaffer, R.; Goldstein, R.; Singhal, A.; Divita, M.A.; Ryan, C.M.; Mix, J.; Purohit, M.; Niewczyk, P.; et al. Functional Status Predicts Acute Care Readmissions from Inpatient Rehabilitation in the Stroke Population. PLoS ONE 2015, 10, e0142180. [Google Scholar] [CrossRef] [PubMed]
- Fehnel, C.R.; Lee, Y.; Wendell, L.C.; Thompson, B.B.; Potter, N.S.; Mor, V. Post–Acute Care Data for Predicting Readmission After Ischemic Stroke: A Nationwide Cohort Analysis Using the Minimum Data Set. J. Am. Hear. Assoc. 2015, 4, e002145. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Yang, X.; Huang, H.; Peng, C.; Ge, Y.; Wu, H.; Wang, J.; Xiong, G.; Yi, Y. Extreme Gradient Boosting Model Has a Better Performance in Predicting the Risk of 90-Day Readmissions in Patients with Ischaemic Stroke. J. Stroke Cerebrovasc. Dis. 2019, 28, 104441. [Google Scholar] [CrossRef]
- Kilkenny, M.F.; Dalli, L.L.; Kim, J.; Sundararajan, V.; Andrew, N.E.; Dewey, H.M.; Johnston, T.; Alif, S.M.; Lindley, R.I.; Jude, M.; et al. Factors Associated With 90-Day Readmission After Stroke or Transient Ischemic Attack. Stroke 2020, 51, 571–578. [Google Scholar] [CrossRef]
- Chu, N.-F. Prevalence of obesity in Taiwan. Obes. Rev. 2005, 6, 271–274. [Google Scholar] [CrossRef]
- Rao, R.R.; Makkithaya, K. Learning from a Class Imbalanced Public Health Dataset: A Cost-based Comparison of Classifier Performance. Int. J. Electr. Comput. Eng. (IJECE) 2017, 7, 2215. [Google Scholar] [CrossRef]
- Chen, J.; Lalor, J.; Liu, W.; Druhl, E.; Granillo, E.; Vimalananda, V.G.; Yu, H.; Cronin, R.; Sulieman, L. Detecting Hypoglycemia Incidents Reported in Patients’ Secure Messages: Using Cost-Sensitive Learning and Oversampling to Reduce Data Imbalance. J. Med. Internet Res. 2019, 21, e11990. [Google Scholar] [CrossRef]
- Hall, M.A. Correlation-based feature selection for machine learning. Ph.D. Thesis, The University of Waikato, Hamilton, New Zealand, April 1999. [Google Scholar]
- Ottenbacher, K.J.; Graham, J.E.; Lee, J.; Al Snih, S.; Karmarkar, A.; Reistetter, T.; Ostir, G.V.; Ottenbacher, A.J. Hospital Readmission in Persons With Stroke Following Postacute Inpatient Rehabilitation. J. Gerontol. Ser. A Boil. Sci. Med. Sci. 2012, 67, 875–881. [Google Scholar] [CrossRef]
- Andrews, A.W.; Li, D.; Freburger, J.K. Association of Rehabilitation Intensity for Stroke and Risk of Hospital Readmission. Phys. Ther. 2015, 95, 1660–1667. [Google Scholar] [CrossRef]
- Ottenbacher, K.J.; Smith, P.M.; Illig, S.B.; Linn, R.T.; Fiedler, R.C.; Granger, C.V. Comparison of logistic regression and neural networks to predict rehospitalization in patients with stroke. J. Clin. Epidemiology 2001, 54, 1159–1165. [Google Scholar] [CrossRef]
- Hu, J.; Gonsahn, M.D.; Nerenz, D.R. Socioeconomic Status and Readmissions: Evidence From An Urban Teaching Hospital. Heal. Aff. 2014, 33, 778–785. [Google Scholar] [CrossRef] [PubMed]
- Kansagara, D.; Englander, H.; Salanitro, A.; Kagen, D.; Theobald, C.; Freeman, M.; Kripalani, S. Risk Prediction Models for Hospital Readmission. JAMA 2011, 306, 1688. [Google Scholar] [CrossRef] [PubMed]
- Frizzell, J.D.; Liang, L.; Schulte, P.J.; Yancy, C.W.; Heidenreich, P.A.; Hernandez, A.F.; Bhatt, D.L.; Fonarow, G.C.; Laskey, W.K. Prediction of 30-Day All-Cause Readmissions in Patients Hospitalized for Heart Failure: Comparison of Machine Learning and Other Statistical Approaches. JAMA Cardiol. 2017, 2, 204–209. [Google Scholar] [CrossRef]
- Vahidy, F.; Donnelly, J.; McCullough, L.D.; Tyson, J.E.; Miller, C.C.; Boehme, A.K.; Savitz, S.I.; Albright, K.C. Nationwide Estimates of 30-Day Readmission in Patients With Ischemic Stroke. Stroke 2017, 48, 1386–1388. [Google Scholar] [CrossRef]
- Henke, R.M.; Karaca, Z.; Jackson, P.; Marder, W.D.; Wong, H.S. Discharge Planning and Hospital Readmissions. Med. Care Res. Rev. 2016, 74, 345–368. [Google Scholar] [CrossRef] [PubMed]
- Kripalani, S.; Theobald, C.; Anctil, B.; Vasilevskis, E.E. Reducing hospital readmission rates: Current strategies and future directions. Annu. Rev. Med. 2013, 65, 471–485. [Google Scholar] [CrossRef]
- Leppert, M.; Sillau, S.; Lindrooth, R.C.; Poisson, S.N.; Campbell, J.D.; Simpson, J.R. Relationship between early follow-up and readmission within 30 and 90 days after ischemic stroke. Neurology 2020, 94, e1249–e1258. [Google Scholar] [CrossRef]
- Hong, I.; Knox, S.; Pryor, L.; Mroz, T.M.; Graham, J.; Shields, M.F.; Reistetter, T.A. Is Referral to Home Health Rehabilitation Following Inpatient Rehabilitation Facility Associated With 90-Day Hospital Readmission for Adult Patients With Stroke? Am. J. Phys. Med. Rehabilitation 2020. [Google Scholar] [CrossRef]
- Bates, D.W.; Saria, S.; Ohno-Machado, L.; Shah, A.; Escobar, G. Big Data In Health Care: Using Analytics To Identify And Manage High-Risk And High-Cost Patients. Heal. Aff. 2014, 33, 1123–1131. [Google Scholar] [CrossRef]
- He, D.; Mathews, S.C.; Kalloo, A.N.; Hutfless, S.M. Mining high-dimensional administrative claims data to predict early hospital readmissions. J. Am. Med Informatics Assoc. 2014, 21, 272–279. [Google Scholar] [CrossRef]
- Navathe, A.S.; Zhong, F.; Lei, V.J.; Chang, F.Y.; Sordo, M.; Topaz, M.; Navathe, S.B.; Rocha, R.A.; Zhou, L. Hospital Readmission and Social Risk Factors Identified from Physician Notes. Heal. Serv. Res. 2017, 53, 1110–1136. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Techniques | Hyperparameters | Range | Increment |
|---|---|---|---|
| NB | NA | NA | NA |
| LR | Ridge value | Default | NA |
| RF | Number of trees | 10–200 | 10 |
| kNN | Number of neighbors | 1–20 | 1 |
| SVM | Complexity | 0.5–1.0 | 0.5 |
| Kernel | PolyKernel, RBFKernel | NA | |
| C4.5 | Confidence factor | 0.20–0.45 | 0.05 |
| Minimum of number of instances per leaf | 2–20 | 1 | |
| CART | Minimum number of instances per leaf | 2–20 | 1 |
| MLP | Learning rate | 0.1–0.5 | 0.2 |
| Momentum | 0.1–0.3 | 0.1 |
| Clinical Feature | Total (n = 3422) | Readmission or Mortality within 90 Days (n = 602) | No Readmission or Mortality within 90 Days (n = 2820) | p |
|---|---|---|---|---|
| Age, years, mean (SD) | 68.3 (12.6) | 71.3 (12.3) | 67.7 (12.6) | <0.001 |
| Female, n (%) | 1366 (39.9) | 264 (43.9) | 1102 (39.1) | 0.030 |
| Stroke type, n (%) | 0.924 | |||
| Ischemic stroke | 2622 (76.6) | 465 (77.2) | 2157 (76.5) | |
| TIA | 467 (13.7) | 80 (13.3) | 387 (13.7) | |
| ICH | 333 (9.7) | 57 (9.5) | 276 (9.8) | |
| NIHSS, median (IQR) | 4 (2–9) | 6 (3–14) | 4 (2–8) | <0.001 |
| Features | Selection Times (out of 30) |
|---|---|
| Age | 30 |
| Prior ED visits within one year | 30 |
| Pre-stroke mRS | 30 |
| NIHSS | 30 |
| BMI group | 30 |
| GCS group | 30 |
| Use of nasogastric tube | 30 |
| Failed dysphagia screening test | 29 |
| CAD | 29 |
| Cancer | 29 |
| Heart failure | 28 |
| Atrial fibrillation | 27 |
| Recent infection | 25 |
| Prior hospitalization within one year | 23 |
| eCCr stage | 22 |
| Use of Foley catheter | 22 |
| Hematocrit | 18 |
| ESRD | 18 |
| Hemoglobin | 18 |
| Diabetes mellitus | 7 |
| ED arrival mode | 4 |
| Occupation | 2 |
| Cared by attendant | 2 |
| Education | 1 |
| Use of birth control pill | 1 |
| AUC | Sensitivity | Specificity | Accuracy | |
|---|---|---|---|---|
| Imbalanced | ||||
| C4.5 | 0.583 | 0.097 | 0.960 | 0.808 |
| CART | 0.568 | 0.071 | 0.965 | 0.808 |
| kNN | 0.585 | 0.044 | 0.980 | 0.815 |
| LR | 0.649 | 0.075 | 0.983 | 0.823 |
| MLP | 0.547 | 0.188 | 0.884 | 0.762 |
| NB | 0.660 | 0.328 | 0.868 | 0.773 |
| RF | 0.607 | 0.070 | 0.956 | 0.800 |
| SVM | 0.500 | 0.000 | 1.000 | 0.824 |
| Undersampling | ||||
| C4.5 | 0.600 | 0.531 | 0.642 | 0.623 |
| CART | 0.599 | 0.526 | 0.657 | 0.634 |
| kNN | 0.611 | 0.434 | 0.740 | 0.686 |
| LR | 0.653 | 0.553 | 0.680 | 0.657 |
| MLP | 0.563 | 0.494 | 0.621 | 0.599 |
| NB | 0.660 | 0.503 | 0.742 | 0.700 |
| RF | 0.599 | 0.578 | 0.575 | 0.575 |
| SVM | 0.614 | 0.465 | 0.763 | 0.711 |
| Oversampling | ||||
| C4.5 | 0.581 | 0.472 | 0.656 | 0.624 |
| CART | 0.588 | 0.516 | 0.643 | 0.620 |
| kNN | 0.587 | 0.482 | 0.646 | 0.617 |
| LR | 0.652 | 0.550 | 0.688 | 0.663 |
| MLP | 0.552 | 0.395 | 0.708 | 0.653 |
| NB | 0.659 | 0.511 | 0.739 | 0.699 |
| RF | 0.598 | 0.346 | 0.772 | 0.697 |
| SVM | 0.616 | 0.484 | 0.748 | 0.701 |
| SMOTE | ||||
| C4.5 | 0.542 | 0.238 | 0.796 | 0.698 |
| CART | 0.544 | 0.263 | 0.780 | 0.689 |
| kNN | 0.532 | 0.313 | 0.724 | 0.652 |
| LR | 0.539 | 0.369 | 0.696 | 0.638 |
| MLP | 0.545 | 0.291 | 0.774 | 0.689 |
| NB | 0.602 | 0.431 | 0.740 | 0.686 |
| RF | 0.588 | 0.162 | 0.870 | 0.745 |
| SVM | 0.540 | 0.397 | 0.682 | 0.632 |
| Class weighting | ||||
| C4.5 | 0.584 | 0.486 | 0.657 | 0.627 |
| CART | 0.586 | 0.502 | 0.636 | 0.613 |
| kNN | 0.598 | 0.488 | 0.660 | 0.630 |
| LR | 0.659 | 0.558 | 0.693 | 0.669 |
| MLP | 0.550 | 0.364 | 0.738 | 0.673 |
| NB | 0.661 | 0.499 | 0.744 | 0.701 |
| RF | 0.603 | 0.239 | 0.844 | 0.737 |
| SVM | 0.618 | 0.486 | 0.751 | 0.704 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hung, L.-C.; Sung, S.-F.; Hu, Y.-H. A Machine Learning Approach to Predicting Readmission or Mortality in Patients Hospitalized for Stroke or Transient Ischemic Attack. Appl. Sci. 2020, 10, 6337. https://doi.org/10.3390/app10186337
Hung L-C, Sung S-F, Hu Y-H. A Machine Learning Approach to Predicting Readmission or Mortality in Patients Hospitalized for Stroke or Transient Ischemic Attack. Applied Sciences. 2020; 10(18):6337. https://doi.org/10.3390/app10186337
Chicago/Turabian StyleHung, Ling-Chien, Sheng-Feng Sung, and Ya-Han Hu. 2020. "A Machine Learning Approach to Predicting Readmission or Mortality in Patients Hospitalized for Stroke or Transient Ischemic Attack" Applied Sciences 10, no. 18: 6337. https://doi.org/10.3390/app10186337
APA StyleHung, L.-C., Sung, S.-F., & Hu, Y.-H. (2020). A Machine Learning Approach to Predicting Readmission or Mortality in Patients Hospitalized for Stroke or Transient Ischemic Attack. Applied Sciences, 10(18), 6337. https://doi.org/10.3390/app10186337