1. Introduction
In the biosciences, with the escalating numbers of studies involving many variables and subjects, there is a belief between non-biostatistician scientists that the amount of data will simply reveal all there is to understand from it. Unfortunately, this is not always true. Data analysis can be significantly simplified when the variable of interest has a symmetric distribution (preferably normal distribution) across subjects, but usually, this is not the case. The need for this desirable property can be avoided by using very complex modeling that might give results that are harder to interpret and inconvenient for generalizing—so the need for a high level of expertise in data analysis is a necessity.
As biostatisticians with the main responsibility for collaborative research in many biosciences’ fields, we are commonly asked the question of whether skewed data should be dealt with using transformation and parametric tests or using nonparametric tests. In this paper, the Monte Carlo simulation is used to investigate this matter in the case of comparing means from two groups.
Monte Carlo simulation is a systematic method of doing what-if analysis that is used to measure the reliability of different analyses’ results to draw perceptive inferences regarding the relationship between the variation in conclusion criteria values and the conclusion results [
1]. Monte Carlo simulation, which is a handy statistical tool for analyzing uncertain scenarios by providing evaluations of multiple different scenarios in-depth, was first used by Jon von Neumann and Ulam in the 1940s. Nowadays, Monte Carlo simulation describes any simulation that includes repeated random generation of samples and studying the performance of statistical methods’ overpopulation samples [
2]. Information obtained from random samples is used to estimate the distributions and obtain statistical properties for different situations. Moreover, simulation studies, in general, are computer experiments that are associated with creating data by pseudo-random sampling. An essential asset of simulation studies is the capability to understand and study the performance of statistical methods because parameters of distributions are known in advance from the process of generating the data [
3]. In this paper, the Monte Carlo simulation approach is applied to find the Type I error and power for both statistical methods that we are comparing.
Now, it is necessary to explain the aspects of the problem we are investigating. First, the normal distribution holds a central place in statistics, with many classical statistical tests and methods requiring normally or approximately normally distributed measurements, such as t-test, ANOVA, and linear regression. As such, before applying these methods or tests, the measurement normality should be assessed using visual tools like the Q–Q plot, P–P plot, histogram, boxplot, or statistical tests like the Shapiro–Wilk, Kolmogrov–Smirnov, or Anderson–Darling tests. Some work has been done to compare between formal statistical tests and a Q–Q plot for visualization using simulations [
4,
5].
When testing the difference between two population means with a two-sample
t-test, normality of the data is assumed. Therefore, actions improve the normality of such data that must occur before utilizing the
t-test. One suggested method for right-skewed measurements is the logarithmic transformation [
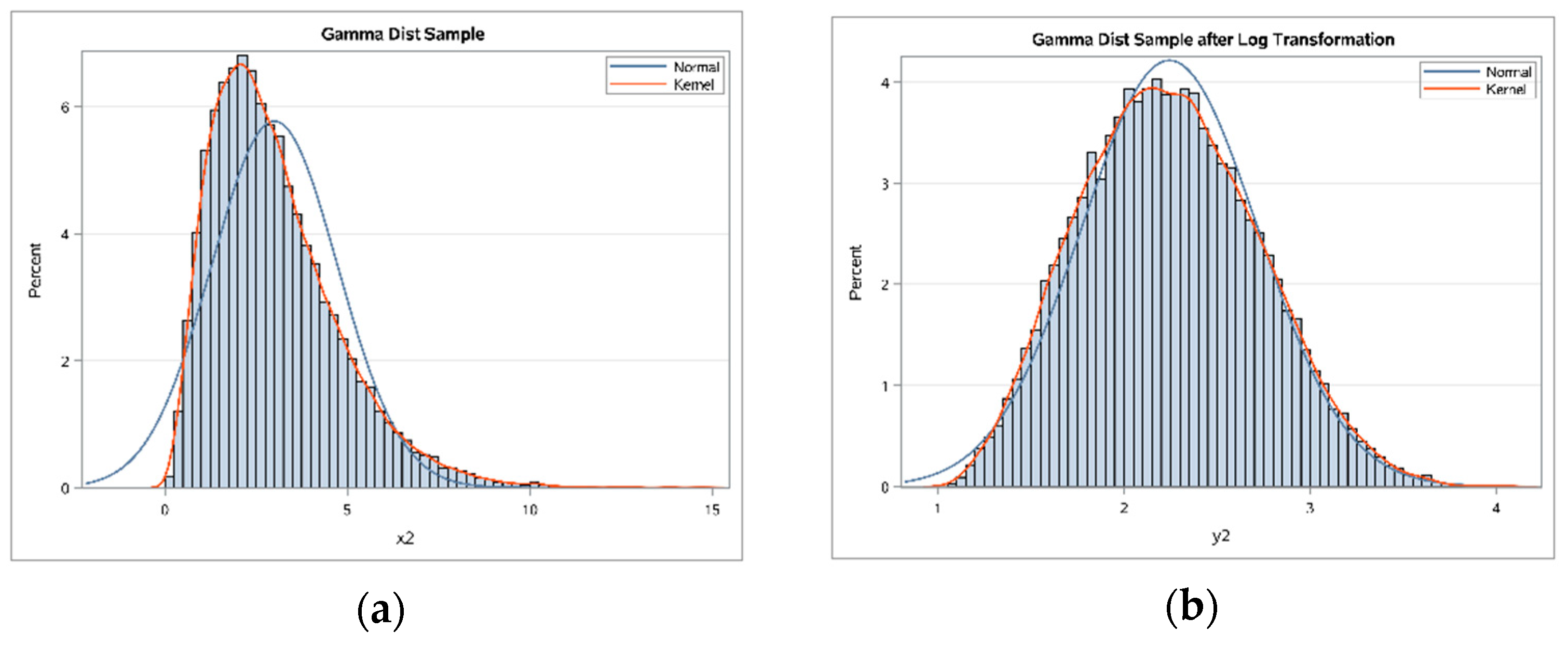
6]. For example, measurements in biomedical and psychosocial research can often be modelled with log-normal distributions, meaning the values are normally distributed after log transformation. Such log transformations can help to meet the normality assumptions of parametric statistical tests, which can also improve graphical presentation and interpretability (
Figure 1a,b). The log transformation is simple to implement, requires minimal expertise to perform, and is available in basic statistical software [
6].
However, while the log transformation can decrease skewness, log-transformed data are not guaranteed to satisfy the normality assumption [
7]. Thus, the normality of the data should also be checked after transformation. In addition, the use of log transformations can lead to mathematical errors and misinterpretation of results [
6,
8].
Similarly, the attitudes of regulatory authorities profoundly influence the trials performed by pharmaceutical companies; Food and Drug Administration (FDA) guidelines state that unnecessary data transformation should be avoided, raising doubts about using transformations. If data transformation is performed, a justification for the optimal data transformation, aside from the interpretation of the estimates of treatment effects based on transformed data, should be given. An industry statistician should not analyze the data using several transformations and choose the transformation that yields the most satisfactory results. Unfortunately, the guideline includes the log transformation with all other kinds of transformation and gives it no special status [
9].
An alternative approach is the generalized linear model (GLM), which does not require the normality of data to test for differences between two populations. The GLM is a wide range of models first promoted by Nelder and Wedderburn in 1972 and then by McCullagh and Nelder in 1989 [
10,
11]. The GLM was presented as a general framework for dealing with a variety of standard statistical models for both normal and non-normal data, like ANOVA, logistic regression, multiple linear regression, log-linear models, and Poisson regression. The GLM can be considered as a flexible generalization of ordinary linear regression, which extends the linear modeling framework to response variables that have non-normal error distributions [
12]. It generalizes linear regression by connecting the linear model to the response variable via a link function, and by permitting the magnitude of the variance of each measurement to be a function of its expected value [
10].
The GLM consists of:
- i
A linear predictor
where
, is a set of independent random variables called response variables, where each
is a linear function of explanatory variables
.
- ii
A link function that defines how
which is the mean or expected value of the outcome
, depends on the linear predictor,
, where
is a monotone, differentiable function. The mean
is thus made a smooth and invertible function of the linear predictor:
- iii
A variance function that defines how the variance, , depends on the mean , where the dispersion parameter is a constant. Replacing the in with also makes the variance a function of the linear predictor.
In the GLM, the form of
and
are determined by the distribution of the dependent variable
and the link function
. Furthermore, no normality assumption is required [
13,
14]. All the major statistical software platforms such as STATA, SAS, R and SPSS include facilities for fitting GLMs to data [
15].
Because finding appropriate transformations that simultaneously provide constant variance and approximate normality can be challenging, the GLM becomes a more convenient choice, since the choice of the link function and the random component (which specifies the probability distribution for response variable (
) are separated. If a link function is convenient in the sense that the inverse-linked linear model of explanatory variables adheres to the support for the expected value for that outcome, it does not further need to stabilize variance or produce normality; this is because the fitting process maximizes the likelihood for the choice of the probability distribution for
, and that choice is not limited to normality [
16]. Alternatively, the transformations used on data are often undefined on the boundary of the sample space, like the log transformation with a zero-valued count or a proportion. Generalized linear models are now pervasive in much of applied statistics and are valuable in environmetrics, where we meet non-normal data frequently, as counts or skewed frequency distributions [
17].
Lastly, it is worth mentioning that the two methods discussed here are not the only methods available to handle skewed data. Many nonparametric tests can be used, though their use requires the researcher to re-parameterize or reformat the null and alternative hypotheses. For example, The Wilcoxon–Mann–Whitney (WMW) test is an alternative to a
t-test. Yet, the two have quite different hypotheses; whereas
t-test compares population means under the assumption of normality, the WMW test compares medians, regardless of the underlying distribution of the outcome; the WMW test can also be thought of as comparing distributions transformed to the rank-order scale [
18]. Although the WMW and other tests are valid alternatives to the two-sample
t-test, we will not consider them further here.
In this work, the two-group t-test on log-transformed measures and the generalized linear model (GLM) on the un-transformed measures are compared. Through simulation, we study skewed data from three different sampling distributions to test the difference between two-group means.
2. Materials and Methods
Using Monte Carlo simulations, we simulated continuous skewed data for two groups. We then tested for differences between group means using two methods: a two-group t-test for the log-transformed data and a GLM model for the untransformed skewed data. All skewed data were simulated from three different continuous distributions: gamma, exponential, or beta distributions. For each simulated data set, we tested the null hypothesis () of no difference between the two groups means against the alternative hypothesis ( that there was a difference between the two groups means. The significance level was fixed at . Three sample sizes () were considered. The Shapiro–Wilk test was used to test the normality of the simulated data before and after the application of the log transformation. We applied two conditions (filters) on the data: it was only accepted if it was not normal in the beginning, and then it became normal after log transformation. The only considered scenarios were the ones with more than 10,000 data sets after applying the two conditions and the number of accepted simulated samples = T. We chose T to be greater than 10,000 to overcome minor variations attributable changing the random seed in the SAS code.
Afterward, a t-test was applied to transformed data, while a GLM model was fitted to untransformed skewed data. We used the logit link function when the data were simulated from a beta distribution, and we used the log link function when the data were simulated from the exponential distribution or gamma distributions. In each case, a binary indicator of group membership was included as the only covariate.
The two methods were compared regarding Type I error, power rates, and bias. To assess the Type I error rate, which is the probability of rejecting when is true, we simulated the two samples from the same distribution with the same parameters. The same parameters guaranteed statistically equal variances between groups, and thus we used the equal-variance two-sample t-test. In addition, the GLM method with an appropriate link function was used. If the p-value was less than the two-sided 5% significance level, then was rejected and a Type I error was committed (since was true). The Type I error rate is then the number of times was rejected (K for t-test and KGLM for GLM) divided by the total number of accepted simulated samples (K/T or KGLM/T).
To assess the power rate, which is the probability of rejecting
when
is true and it is the complement of the Type II error rate, we assumed different mean values for the two groups by simulating the two groups from distributions with different parameters. In this case, since the variances are functions of the mean parameter as well, the unequal variance two-sample
t-test was used. In these situations, if the
p-value was less than the 5% significance level, then we rejected
knowing that
is true. If the
p-value was larger than the significance level, we failed to reject
and concluded that a Type II error was committed (because
was true). Then, the power rate is the number of times
was rejected (K for
t-test and K
GLM for GLM) divided by the total number of accepted simulated samples (K/T or K
GLM/T). Each case (sample size, distribution, mean relationship) was repeated five million times (denoted as T
0). The diagram of testing the Type I error algorithm is shown in
Figure 2.
Regarding the difference estimates, other methods work on the response differently. The log transformation changes each response value, while the GLM transforms only the mean response through the link function. Researchers tend to transform back estimates after using a t-test with transformed data or after using GLM. We wanted to test which method gives a closer estimate to the actual difference estimates. So, while testing Type I error, we transformed back the estimates of the mean difference of the log-transformed data and the GLM-fitted data. Then we compared it with the means difference of the original untransformed data (which should be close to zero under (H0) to see which of the two methods gave mean difference estimates that are not significantly different from the estimates of the actual mean difference. We also compared the estimates of the difference of the standard deviations between the log-transformed and the original data under the assumption that H0 is true (while testing Type I error), so we could use pooled standard deviation.
In three applications to real-life data, we applied the two methods to determine whether the methods give consistent or contradicting results. By using visual inspection for this simulation study, Q–Q plots were used to test the normality of the data before and after the application of the log transformation to make sure that targeted variables were not normal before transformation and then became normal after transformation. After that, we used the
t-test. Then, we used the bias-corrected Akaike information criterion (AICc) after fitting different continuous distributions to determine which distribution and link function to use with the GLM model [
19,
20]. Finally, we compared the results from both models. We generated all simulated data and performed all procedures using SAS codes. Moreover, the data that support the findings in the real-life applications of this study are openly available from the JMP software.
4. Discussion
In this work, we compared the use of a t-test on log-transformed data and the use of GLM on untransformed skewed data. The log transformation was studied because it is one of the most common transformations used in biosciences research. If such an approach is used, the scientist must be careful about its limitations; especially when interpreting the significance of the analysis of transformed data for the hypothesis of interest about the original data. Moreover, a researcher who uses log transformation should know how to facilitate log-transformed data to give inferences concerning the original data. Furthermore, log transformation does not always help make data less variable or more normal and may, in some situations, make data more variable and more skewed. For that, the variability and normality should always be examined after applying the log transformation.
On the other hand, GLM was used because other nonparametric tests’ inferences concern medians and not means. In addition, GLM models deal differently with response variables depending on their population distributions, which provides the scientist with flexibility in modeling; GLM allows for response variables to have different distributions, and each distribution has an appropriate link function to vary linearly with the predicted values.
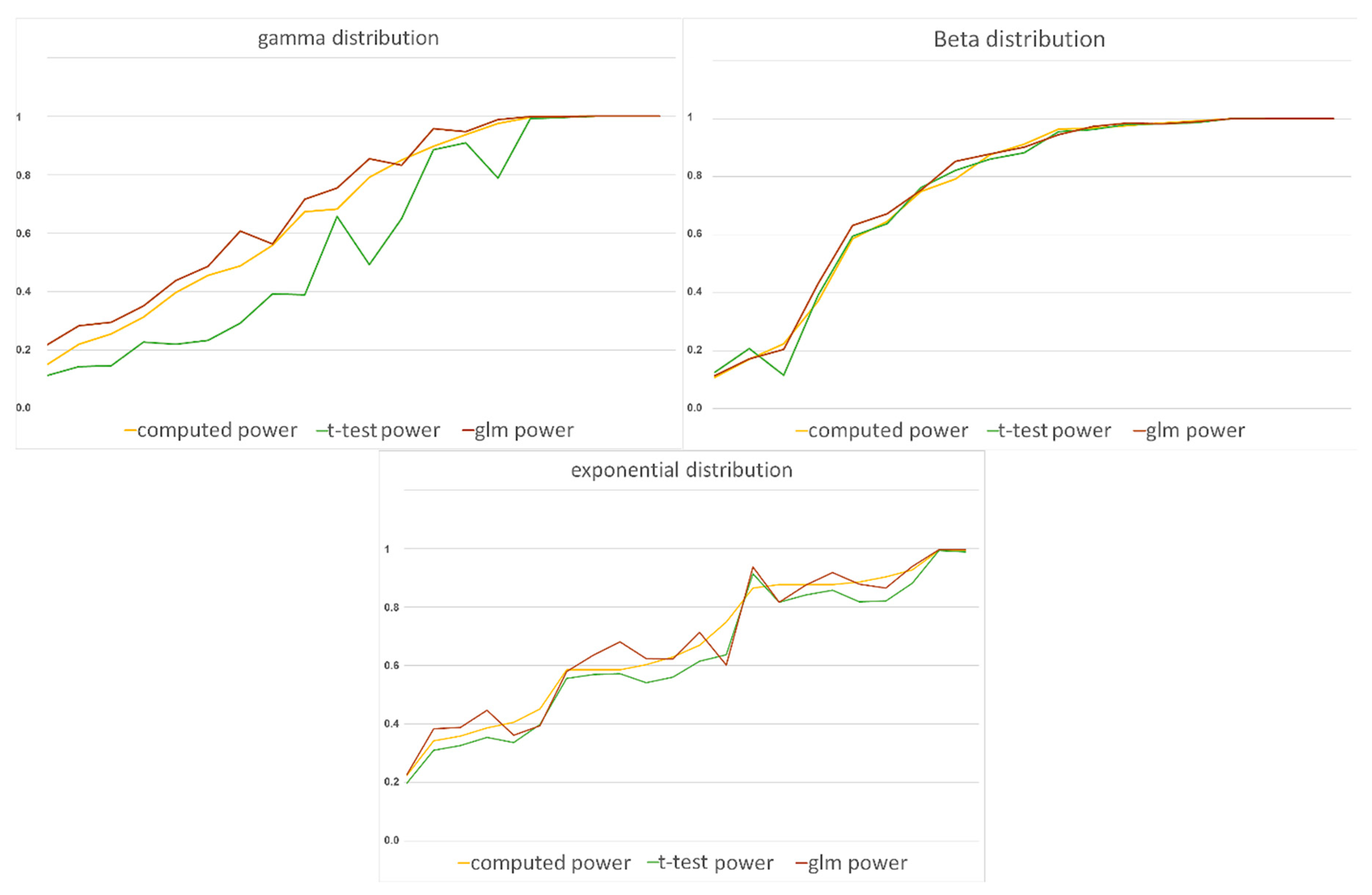
Each comparison was made for two simulated groups from several sampling distributions with varying sample sizes. The comparisons regarded Type I error rates, power rates and estimates of the means. Overall, the t-test method with transformed data produced smaller Type I error rates and closer estimations. The GLM method, however, produced a higher power rate compared to t-test methods, though both reported acceptable power rates.
For gamma distribution, Type I error rates in the t-test case were very close to 0.05 (0.0497 to 0.0504), while the Type I error rates of the GLM method had a wider range (0.0490 to 0.0577). For most examples in the gamma-distributed data, the Type I error rates of the t-test method were smaller than the respective rates in the GLM method. Regarding power, the GLM rates were higher in about 85% of the settings than the ones using the t-test, with absolute values of differences, ranging from 0.000 to 0.363.
The back-transformed estimates of the mean differences in the t-test case were not significantly different from the estimates of the original data mean differences in the t-test method. The GLM estimates, in contrast, were significantly different from the estimates of the original data. So, if we are looking for lower Type I error and closer estimates, we can use the t-test method with transformed data. However, if we are looking for a method with higher power rates, we recommend choosing the GLM method.
In the exponentially distributed data, the GLM method has achieved a noticeably lower Type I error rate and higher power in most of the settings than the t-test method. Regarding the estimates, the t-test method gave closer estimates. Despite the closer estimates for the t-test method, our advice is to use the GLM method.
For beta distributed data, Type I error rates seem to favor the
t-test method with transformed data. The power rates of the GLM method were higher than the power rates in the
t-test method, with absolute values of differences ranging from 0 to 0.0884. Furthermore, by looking at
Figure 4, we can see that the two methods have very close power rates. So, both methods seem to be good enough in this matter. Nevertheless, since the
t-test method has lower Type I rates and closer estimates in the beta distributed data, we recommend it over GLM.
The missing rates for some of the parameters’ combinations, especially in calculating power rates, are due to two reasons. First, in most cases, rates were not missing, but the counts for accepted simulated samples were less than 10,000. That caused the setting to be rejected. Particularly in the case of calculating power rates, the two groups are from the same distribution with different parameters, which made it harder to apply the two filters (both groups should not be normally distributed before the use of log transformation and normally distributed after the application of log transformation). Although being less than 10,000 caused the estimates to vary as a response to changing the random seed, it gave the same conclusion. For example, if the GLM had a higher power rate in one sitting of parameters, it kept having a higher power rate even if we changed the seed. Yet, we preferred not to include these settings because we needed the estimates to be reproducible.
Second, in rare cases, none of the samples’ normality issues were resolved with log transformation, so we had zero accepted simulated samples. As a result, our comparison does not apply to that parameter combination. In conclusion, we did not consider missing rates as an issue since GLM had a higher power rate, as well as the t-test had closer mean difference estimates in all other accepted settings.
Our results were consistent across parameter settings and sample sizes (), so we expect that the difference in sample sizes will not affect the method choice no matter what the sample size effect is over the method performance itself.
After analyzing the data from our real-life examples, we recommend reporting the results from the t-test with log-transformed data for the lipid data example and catheters data example, since the best fit for both examples was a gamma distribution. Because the catheters data example had larger sample size (n = 592) than used in our simulations, we conducted additional simulations with sample size of 296 per group. Though not reported, these results concurred with our reported findings at lower sample sizes.
We followed the same steps for the third example (the pharmaceutical and computer data example), which had the exponential fit as the best fit. We conducted additional (though not reported) simulations with 16 subjects per group, and again observed results that agreed with our reported findings. Thus, our recommendation is to report the GLM method results.
Therefore, for any Bio-application research, studying the appropriate statistical distribution that fits the dependent variable can help us to determine if a parametric model can reasonably test the data after log transformation is used. Alternatively, it would probably be better to abandon the classic approach and switch to the GLM method.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}