A Comparison of Human against Machine-Classification of Spatial Audio Scenes in Binaural Recordings of Music





Abstract
1. Introduction
2. Background
2.1. Binaural Perception by Humans and Machines
2.2. The State-of-the-Art Models
2.3. Related Work
3. Repository of Binaural Audio Recordings
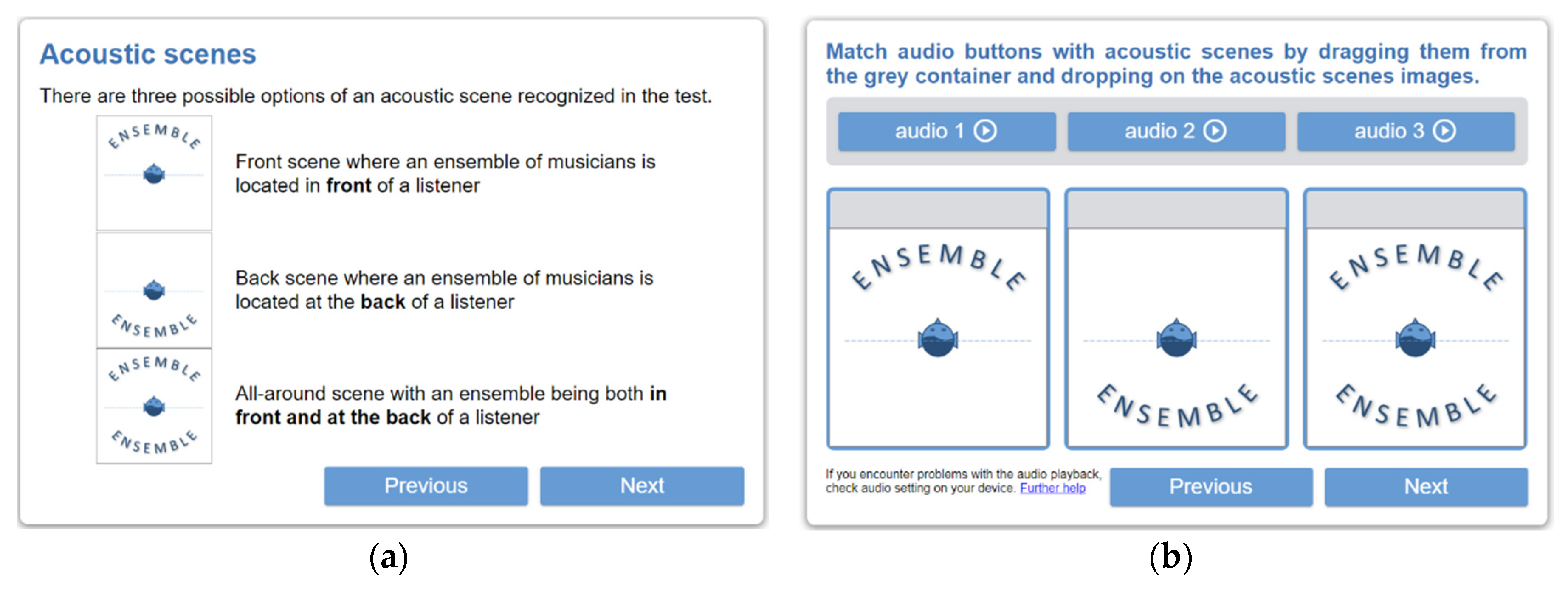
- Foreground–Background (FB) scene—foreground content (music ensemble) located in front of a listener and background content, such as reverberations and room reflections, arriving from the back of a listener. This is a conventional “stage-audience” scenario [33], often used in jazz and classical music recordings.
- Background–Foreground (BF) scene—background content in front of a listener with foreground content perceived from the back (a reversed stage-audio scenario). While it is infrequently used in music recordings, it was included in this study for completeness, as a symmetrically “flipped” counterpart of the previous scene.
- Foreground–Foreground (FF) scene—foreground content both in front of and behind a listener, surrounding a listener in a horizontal plane. This scene is often used in binaural music recordings, e.g., in electronica, dance, and pop music (360° source scenario [33]).
4. Human-Performed Classification
4.1. Stimuli
4.2. Listeners
4.3. Acoustical Conditions
- a mechanism supporting head movements was not incorporated in the playback system (no head-tracking devices used),
- no headphones frequency-response compensation was applied,
- no individualized HRTFs were incorporated.
4.4. Classification Method
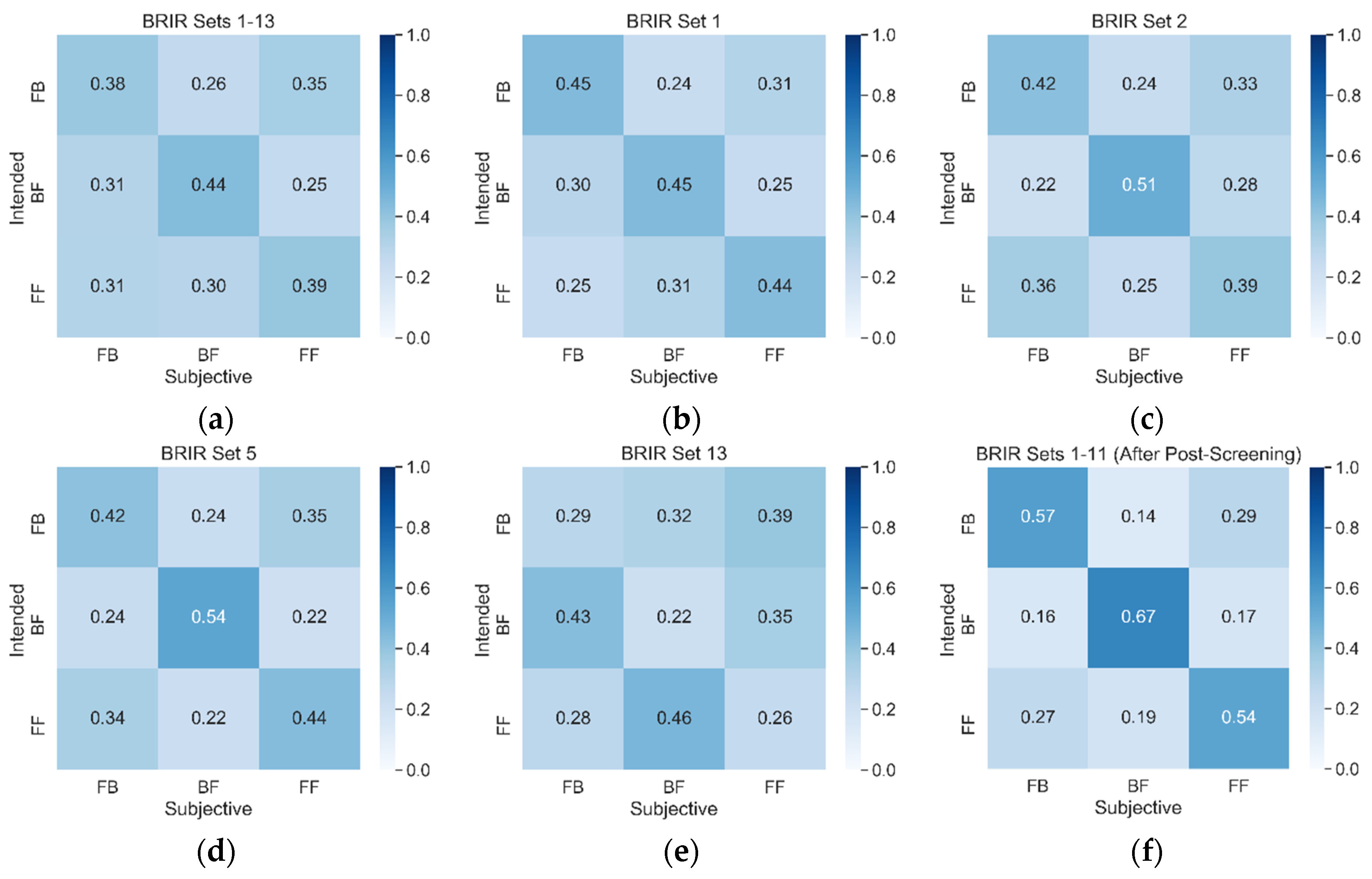
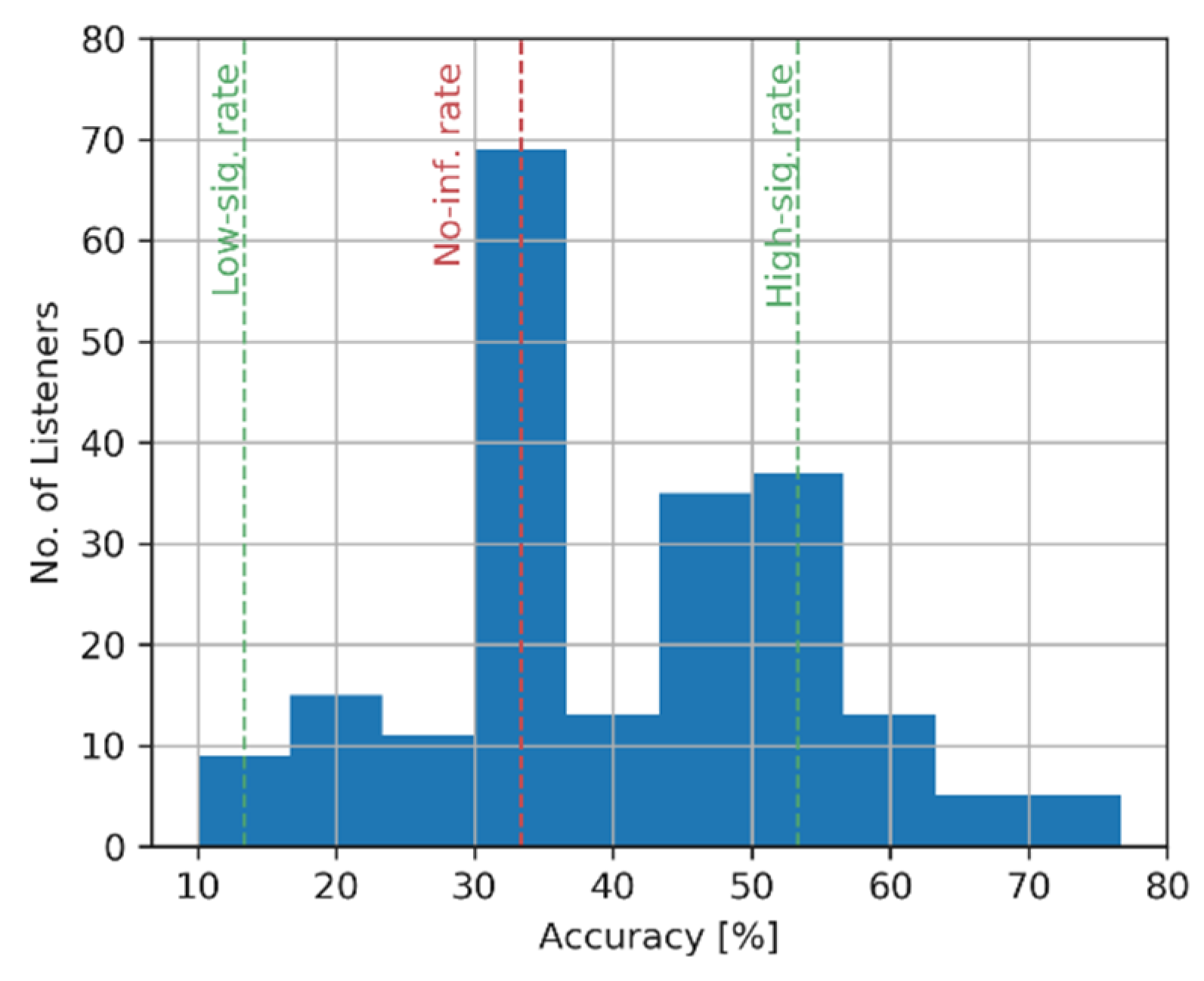
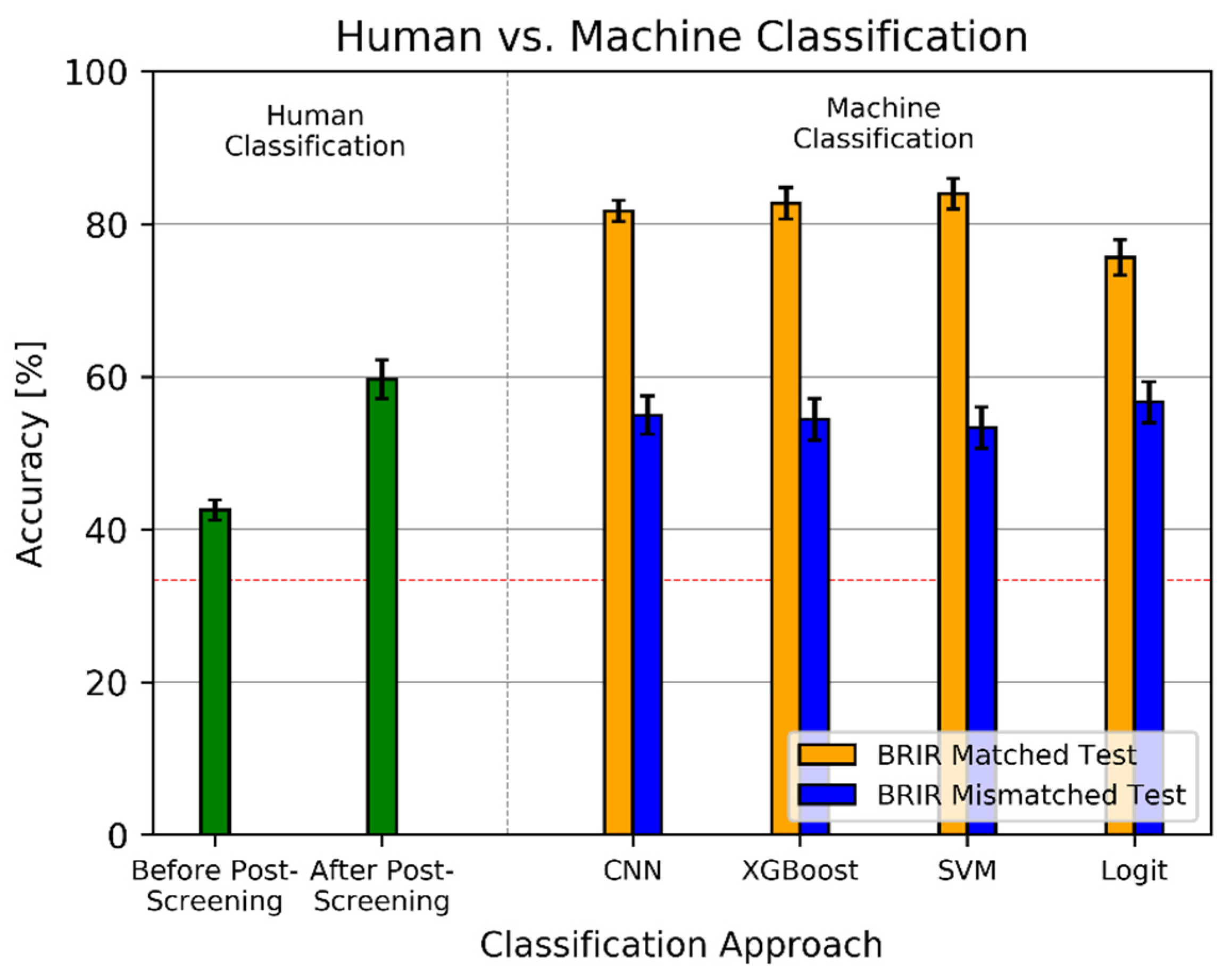
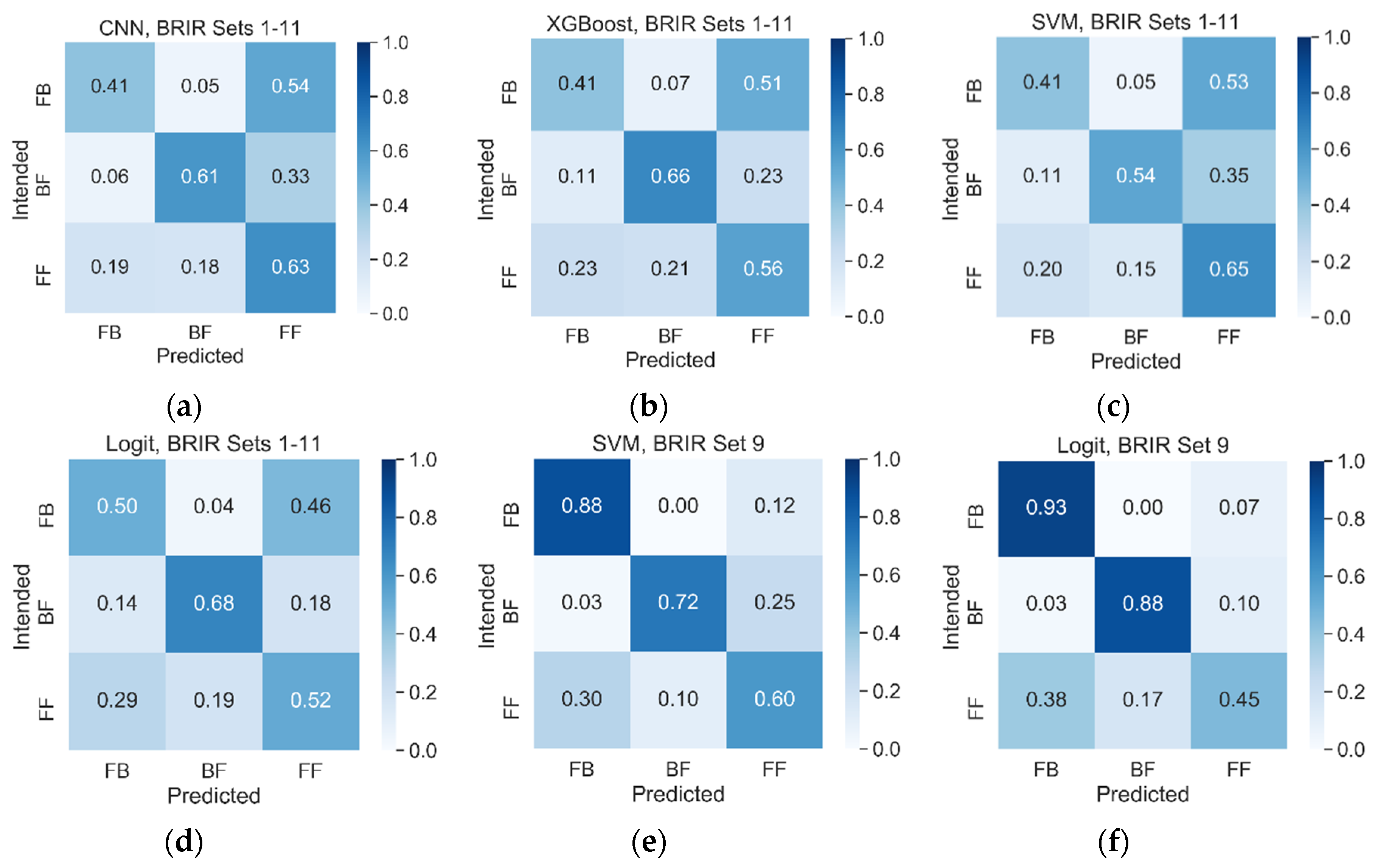
4.5. Listening Test Results
4.6. Post-Screening
- removing the data obtained using BRIR sets 12 and 13 (as a result, the accuracy increased from 40.6% to 42.5%),
- retaining the data obtained only from the listeners whose accuracy scores were no less than the statistical significance threshold of 53.3%, resulting in the further accuracy rise to 59.7%.
5. Classification Performed by Machine Learning Algorithms
5.1. Selection of the Algorithms
5.2. Development and Test Datasets
5.3. Convolutional Neural Network
5.3.1. Spectrograms extraction
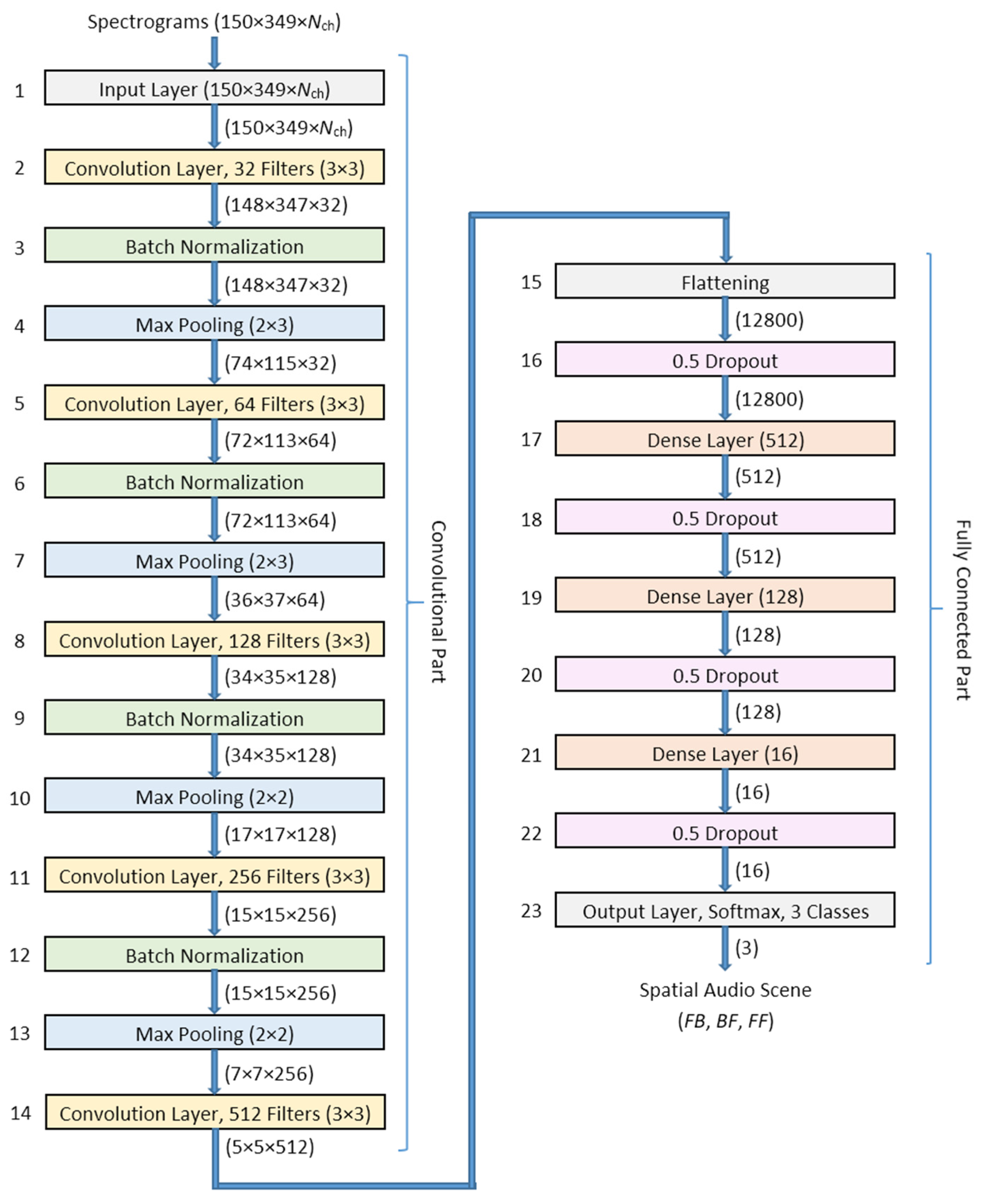
5.3.2. Convolutional Neural Network Topology
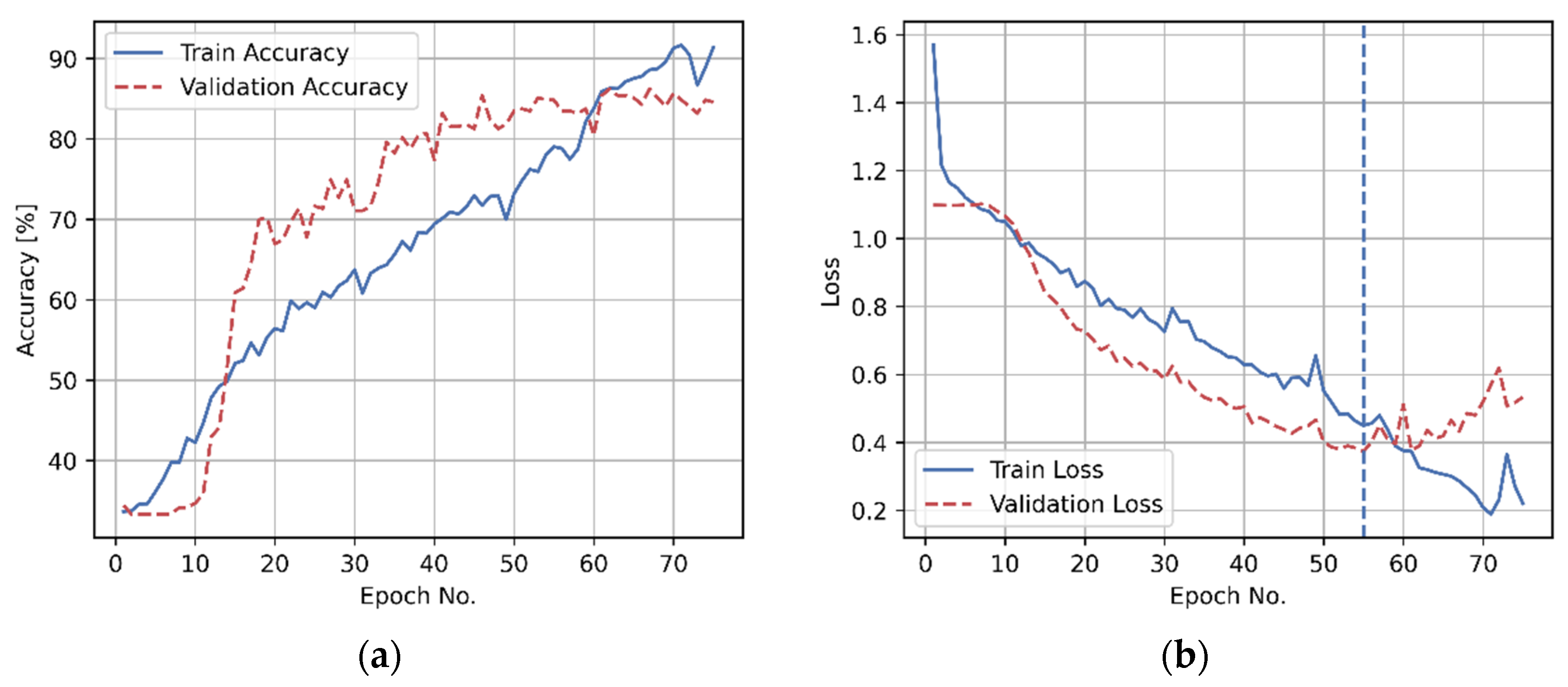
5.3.3. Convolutional Neural Network Training
5.4. Traditional Machine Learning Algorithms
5.4.1. Feature Extraction
5.4.2. Hyper-Parameters and Training
5.5. Testing Procedure
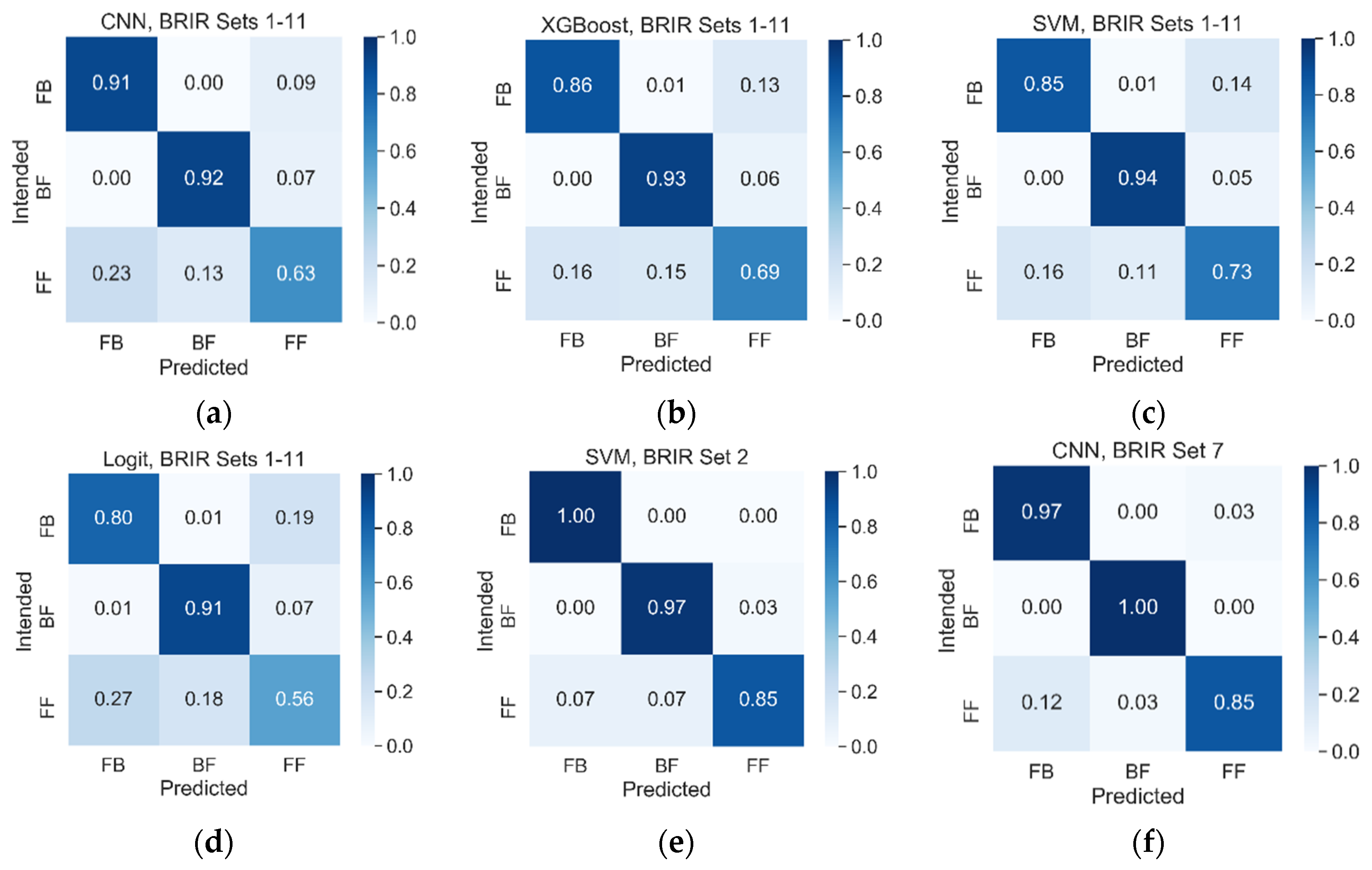
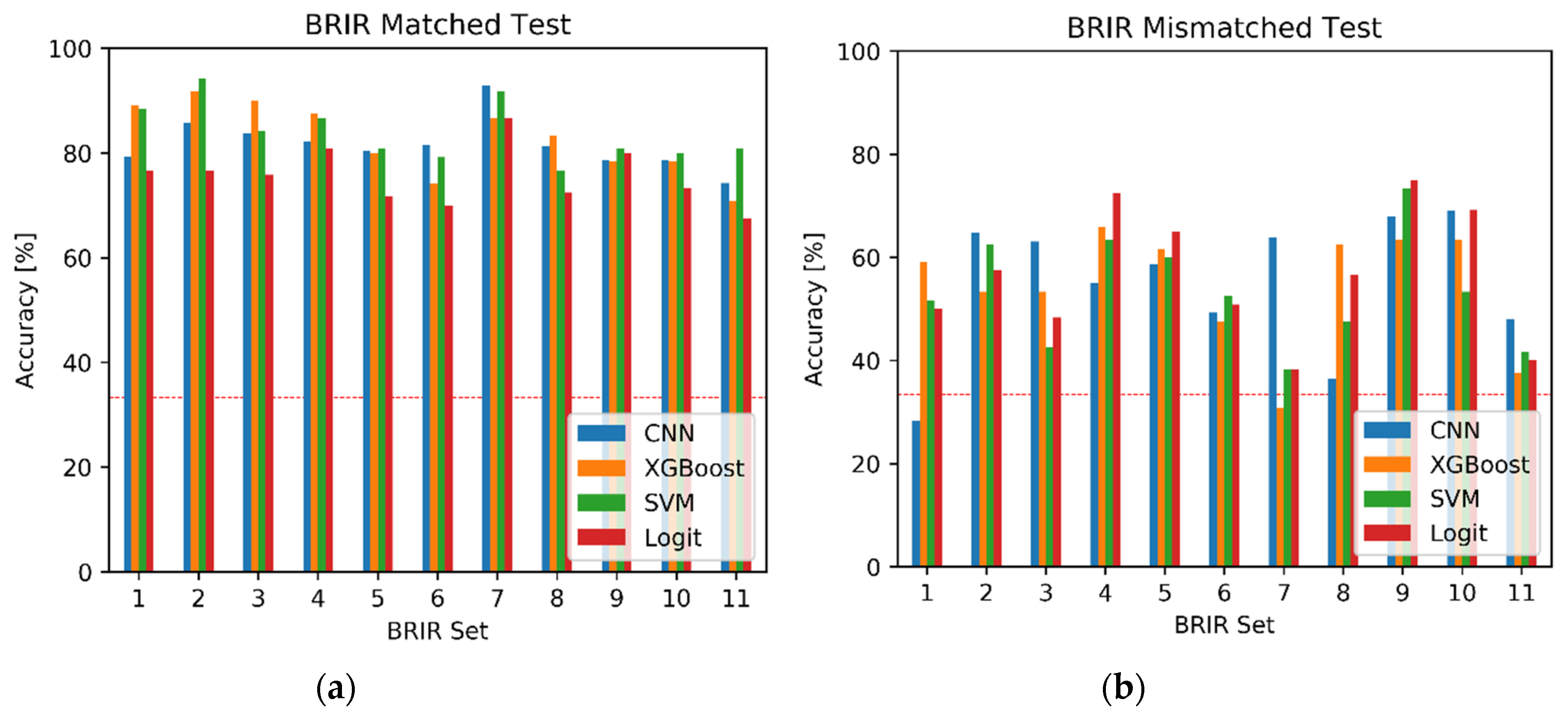
5.6. Results from Machine Learning Algorithms
5.7. Comparison with the Listening Test Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Examples of The Headphones Models Used in the Listening Test
- AKG (K240 Monitor, K240 Studio, K272 HD, K550, K701, K712 Pro)
- Apple (EarPods with lighting connection)
- Asus (Cerberus)
- Audio-Technica (ATH-M50, ATH-R70x)
- Beyerdynamic (Custom One Pro, DT 331, DT-770 Pro 250 Ohm, DT-990 Pro 250 Ohm, T5p, Soul Byrd)
- Bloody (G501)
- Bose (QC25)
- Canford Level Limited Headphones (HD480 88dBA)
- Corsair (HS50, HS60)
- Creative SoundBlaster (JAM)
- Focal (Spirit Professional)
- Genesis (Argon 200, H44, HM67, Radon 720)
- HTC (HS S260)
- Huawei (AM116)
- HyperX (Cloud Alpha, Cloud 2)
- ISK (HD9999)
- Jabra Elite (65t)
- JBL (E65BTNC, T110, T450BT, T460BT)
- Klipsch Reference On-Ear Bluetooth Headophones, Koss (KSC75)
- Logitech (G633, G933)
- Mad Dog (GH702)
- Nokia (WH-108)
- Panasonic (RP-HJE125E-K, RP-HT161)
- Philips (SHL3060BK)
- Pioneer (SE-M531, SE-M521)
- Razer (Kraken 7.1 Chroma, Kraken Pro v2, Thresher Tournament Edition)
- Roccat Syva (ROC-14-100)
- Samsung (EHS61)
- Sennheiser (CX 300-II, HD 201, HD 215, HD 228, HD 280 PRO, HD 380 Pro, HD 4.40, HD 555, HD 559, HD 598)
- Skullcandy (Uprock)
- SMS (Studio Street by 50 Cent Wireless OverEar)
- Snab Overtone (EP-101m)
- Sony (MDR-AS200, MDR-EX110LPB.AE, MDR-E9LPB, MDR-NC8, MDR-ZX110B, MDR-XB550, MDR-XB950B1, WH-1000XM3)
- SoundMagic (E10, E11)
- Stax (404 LE)
- Superlux (HD660, HD669, HD681)
- Takstar (HD2000)
- Thinksound (MS02)
- Tracer (Gamezone Thunder 7.1, Dragon TRASLU 44893)
- Urbanears, QCY (T2C)
Appendix B. Overview of the Hyper-Parameters in Traditional Machine Learning Algorithms

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification Algorithm | Hyper-Parameters |
|---|---|
| XGBoost | number of estimators n = {100, 200, 500} |
| SVM | number of features 1 k = {500, 700, 1376} C = {1, 10, 100} γ = {7.27 × 10−3, 7.27 × 10−4, 7.27 × 10−5} |
| Logit | C = {0.01, 0.1, 1} |
| Classification Algorithm | Hyper-Parameters |
|---|---|
| XGBoost | n = 100 |
| SVM | k = 700, C = 100, γ = 7.27 × 10−4 |
| Logit | C = 0.1 |
| Classification Algorithm | Hyper-Parameter | BRIR Set Left Out during the Training | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | ||
| XGBoost | n | 500 | 500 | 500 | 500 | 500 | 500 | 500 | 500 | 100 | 500 | 500 |
| SVM | k | 500 | 500 | 500 | 500 | 500 | 500 | 700 | 500 | 700 | 700 | 500 |
| C | 100 | 100 | 10 | 100 | 100 | 100 | 100 | 10 | 100 | 10 | 100 | |
| γ = 7.27× | 10−4 | 10−4 | 10−4 | 10−4 | 10−4 | 10−4 | 10−4 | 10−4 | 10−4 | 10−4 | 10−4 | |
| Logit | C | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
References
- Begault, D.R. 3-D Sound for Virtual Reality and Multimedia; NASA Center for AeroSpace Information: Hanover, MD, USA, 2000.
- Blauert, J. The Technology of Binaural Listening; Springer: Berlin, Germany, 2013. [Google Scholar]
- Roginska, A. Binaural Audio through Headphones. In Immersive Sound. The Art and Science of Binaural and Multi-Channel Audio, 1st ed.; Routledge: New York, NY, USA, 2017. [Google Scholar]
- Parnell, T. Binaural Audio at the BBC Proms, BBC R&D. Available online: https://www.bbc.co.uk/rd/blog/2016-09-binaural-proms (accessed on 14 July 2017).
- Firth, M. Developing Tools for Live Binaural Production at the BBC Proms, BBC R&D. Available online: https://www.bbc.co.uk/rd/blog/2019-07-proms-binaural (accessed on 7 February 2020).
- Kelion, L. YouTube Live-Streams in Virtual Reality and adds 3D Sound, BBC News. Available online: http://www.bbc.com/news/technology-36073009 (accessed on 18 April 2016).
- Zieliński, S.; Rumsey, F.; Kassier, R. Development and Initial Validation of a Multichannel Audio Quality Expert System. J. Audio Eng. Soc. 2005, 53, 4–21. [Google Scholar]
- MacPherson, E.A.; Sabin, A.T. Binaural weighting of monaural spectral cues for sound localization. J. Acoust. Soc. Am. 2007, 121, 3677–3688. [Google Scholar] [CrossRef] [PubMed]
- Benaroya, E.L.; Obin, N.; Liuni, M.; Roebel, A.; Raumel, W.; Argentieri, S.; Benaroya, L. Binaural Localization of Multiple Sound Sources by Non-Negative Tensor Factorization. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1072–1082. [Google Scholar] [CrossRef]
- Rumsey, F. Spatial quality evaluation for reproduced sound: Terminology, meaning, and a scene-based paradigm. J. Audio Eng. Soc. 2002, 50, 651–666. [Google Scholar]
- Zieliński, S.K. Spatial Audio Scene Characterization (SASC). Automatic Classification of Five-Channel Surround Sound Recordings According to the Foreground and Background Content. In Multimedia and Network Information Systems, Proceedings of the MISSI 2018; Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Zielinski, S.; Lee, H. Feature Extraction of Binaural Recordings for Acoustic Scene Classification. In Proceedings of the 2018 Federated Conference on Computer Science and Information Systems; Polish Information Processing Society PTI: Warszawa, Poland, 2018; Volume 15, pp. 585–588. [Google Scholar]
- Zieliński, S.K.; Lee, H. Automatic Spatial Audio Scene Classification in Binaural Recordings of Music. Appl. Sci. 2019, 9, 1724. [Google Scholar] [CrossRef]
- Zielinski, S. Improving Classification of Basic Spatial Audio Scenes in Binaural Recordings of Music by Deep Learning Approach. In Proceedings of the Bioinformatics Research and Applications; Springer Science and Business Media LLC: New York, NY, USA, 2020; pp. 291–303. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef]
- Zonoz, B.; Arani, E.; Körding, K.P.; Aalbers, P.A.T.R.; Celikel, T.; Van Opstal, A.J. Spectral Weighting Underlies Perceived Sound Elevation. Nat. Sci. Rep. 2019, 9, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Blauert, J. Spatial Hearing. The Psychology of Human Sound Localization; The MIT Press: London, UK, 1974. [Google Scholar]
- Begault, D.R.; Wenzel, E.M.; Anderson, M.R. Direct Comparison of the Impact of Head Tracking, Reverberation, and Individualized Head-Related Transfer Functions on the Spatial Perception of a Virtual Speech Source. J. Audio Eng. Soc. 2001, 49, 904–916. [Google Scholar] [PubMed]
- Jeffress, L.A. A place theory of sound localization. J. Comp. Physiol. Psychol. 1948, 41, 35–39. [Google Scholar] [CrossRef] [PubMed]
- Breebaart, J.; van de Par, S.; Kohlrausch, A. Binaural processing model based on contralateral inhibition. I. Model structure. J. Acoust. Soc. Am. 2001, 110, 1074–1088. [Google Scholar] [CrossRef] [PubMed]
- May, T.; Ma, N.; Brown, G.J. Robust localisation of multiple speakers exploiting head movements and multi-conditional training of binaural cues. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Institute of Electrical and Electronics Engineers (IEEE), Brisbane, Australia, 19–24 April 2015; pp. 2679–2683. [Google Scholar]
- Ma, N.; Brown, G.J. Speech localisation in a multitalker mixture by humans and machines. In Proceedings of the INTERSPEECH 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 3359–3363. [Google Scholar] [CrossRef]
- Ma, N.; May, T.; Brown, G.J. Exploiting Deep Neural Networks and Head Movements for Robust Binaural Localization of Multiple Sources in Reverberant Environments. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2444–2453. [Google Scholar] [CrossRef]
- Ma, N.; Gonzalez, J.A.; Brown, G.J. Robust Binaural Localization of a Target Sound Source by Combining Spectral Source Models and Deep Neural Networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 2122–2131. [Google Scholar] [CrossRef]
- Wang, J.; Wang, J.; Qian, K.; Xie, X.; Kuang, J. Binaural sound localization based on deep neural network and affinity propagation clustering in mismatched HRTF condition. EURASIP J Audio Speech Music Process. 2020, 4. [Google Scholar] [CrossRef]
- Vecchiotti, P.; Ma, N.; Squartini, S.; Brown, G.J. End-to-end binaural sound localisation from the raw waveform. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 April 2019; pp. 451–455. [Google Scholar]
- Han, Y.; Park, J.; Lee, K. Convolutional neural networks with binaural representations and background subtraction for acoustic scene classification. In Proceedings of the Conference on Detection and Classification of Acoustic Scenes and Events 2017, Munich, Germany, 16 November 2017; pp. 1–5. [Google Scholar]
- Raake, A. A Computational Framework for Modelling Active Exploratory Listening that Assigns Meaning to Auditory Scenes—Reading the World with Two Ears. Available online: http://twoears.eu (accessed on 8 March 2019).
- Szabó, B.T.; Denham, S.L.; Winkler, I. Computational models of auditory scene analysis: A review. Front. Neurosci. 2016, 10, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Barchiesi, D.; Giannoulis, D.; Stowell, D.; Plumbley, M.D. Acoustic scene classification: Classifying environments from the sounds they produce. IEEE Signal. Process. Mag. 2015, 32, 16–34. [Google Scholar] [CrossRef]
- Wu, Y.; Lee, T. Enhancing Sound Texture in CNN-based Acoustic Scene Classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 815–819. [Google Scholar]
- Woodcock, J.; Davies, W.J.; Cox, T.J.; Melchior, F. Categorization of Broadcast Audio Objects in Complex Auditory Scenes. J. Audio Eng. Soc. 2016, 64, 380–394. [Google Scholar] [CrossRef]
- Lee, H.; Millns, C. Microphone Array Impulse Response (MAIR) Library for Spatial Audio Research. In Proceedings of the 143rd AES Convention, New York, NY, USA, 8 October 2017. [Google Scholar]
- Zieliński, S.K.; Lee, H. Database for Automatic Spatial Audio Scene Classification in Binaural Recordings of Music. Zenodo. Available online: https://zenodo.org (accessed on 7 April 2020).
- Satongar, D.; Lam, Y.W.; Pike, C.H. Measurement and analysis of a spatially sampled binaural room impulse response dataset. In Proceedings of the 21st International Congress on Sound and Vibration, Beijing, China, 13–17 July 2014; pp. 13–17. [Google Scholar]
- Stade, P.; Bernschütz, B.; Rühl, M. A Spatial Audio Impulse Response Compilation Captured at the WDR Broadcast Studios. In Proceedings of the 27th Tonmeistertagung—VDT International Convention, Cologne, Germany, 20 November 2012. [Google Scholar]
- Wierstorf, H. Binaural Room Impulse Responses of a 5.0 Surround Setup for Different Listening Positions. Zenodo. Available online: https://zenodo.org (accessed on 14 October 2016).
- Werner, S.; Voigt, M.; Klein, F. Dataset of Measured Binaural Room Impulse Responses for Use in an Position-Dynamic Auditory Augmented Reality Application. Zenodo. Available online: https://zenodo.org (accessed on 26 July 2018).
- Klein, F.; Werner, S.; Chilian, A.; Gadyuchko, M. Dataset of In-The-Ear and Behind-The-Ear Binaural Room Impulse Responses used for Spatial Listening with Hearing Implants. In Proceedings of the 142nd AES Convention, Berlin, Germany, 20–23 May 2017. [Google Scholar]
- Erbes, V.; Geier, M.; Weinzierl, S.; Spors, S. Database of single-channel and binaural room impulse responses of a 64-channel loudspeaker array. In Proceedings of the 138th AES Convention, Warsaw, Poland, 7–10 May 2015. [Google Scholar]
- Zieliński, S.K. On Some Biases Encountered in Modern Audio Quality Listening Tests (Part 2): Selected Graphical Examples and Discussion. J. Audio Eng. Soc. 2016, 64, 55–74. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning with Applications in R; Springer: London, UK, 2017. [Google Scholar]
- Abeßer, J. A Review of Deep Learning Based Methods for Acoustic Scene Classification. Appl. Sci. 2020, 10, 2020. [Google Scholar] [CrossRef]
- Rakotomamonjy, A. Supervised Representation Learning for Audio Scene Classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1253–1265. [Google Scholar] [CrossRef]
- Brookes, M. VOICEBOX: Speech Processing Toolbox for MATLAB. Available online: http://www.ee.ic.ac.uk/hp/staff/dmb/voicebox/voicebox.html (accessed on 17 April 2020).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. Available online: https://arxiv.org/abs/1412.6980 (accessed on 26 August 2020).
- Chollet, F. Deep Learning with Python; Manning Publications: Shelter Island, NY, USA, 2020. [Google Scholar]










| Destination | No. of Multitrack Recordings | No. of BRIR Sets | No. of Binaural Excerpts |
|---|---|---|---|
| Training | 112 | 13 | 4368 |
| Testing | 40 | 13 | 1560 |
| No. | Description | Dummy Head | RT60 (s) |
|---|---|---|---|
| 1 | Salford, British Broadcasting Corporation (BBC)—Listening Room [35] | B&K HATS Type 4100 | 0.27 |
| 2 | Huddersfield—Concert Hall [33] | Neumann KU100 | 2.1 |
| 3 | Westdeutscher Rundfunk (WDR) Broadcast Studios—Control Room 1 [36] | Neumann KU100 | 0.23 |
| 4 | WDR Broadcast Studios—Control Room 7 [36] | Neumann KU100 | 0.27 |
| 5 | WDR Broadcast Studios—Small Broadcast Studio (SBS) [36] | Neumann KU100 | 1.0 |
| 6 | WDR Broadcast Studios—Large Broadcast Studio (LBS) [36] | Neumann KU100 | 1.8 |
| 7 | Technische Universität (TU) Berlin—Calypso Room [37] | KEMAR 45BA | 0.17 |
| 8 | TU Ilmenau—TV Studio (distance of 3.5 m) [38] | KEMAR 45BA | 0.7 |
| 9 | TU Ilmenau—TV Studio (distance of 2 m) [39] | KEMAR 45BA | 0.7 |
| 10 | TU Ilmenau—Listening Laboratory [39] | KEMAR 45BA | 0.3 |
| 11 | TU Ilmenau—Rehabilitation Laboratory [39] | KEMAR 45BA | NA |
| 12 | University of Rostock—Audio Laboratory (additional absorbers) [40] | KEMAR 45BA | 0.25 |
| 13 | University of Rostock—Audio Laboratory (all broadband absorbers) [40] | KEMAR 45BA | 0.31 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zieliński, S.K.; Lee, H.; Antoniuk, P.; Dadan, O. A Comparison of Human against Machine-Classification of Spatial Audio Scenes in Binaural Recordings of Music. Appl. Sci. 2020, 10, 5956. https://doi.org/10.3390/app10175956
Zieliński SK, Lee H, Antoniuk P, Dadan O. A Comparison of Human against Machine-Classification of Spatial Audio Scenes in Binaural Recordings of Music. Applied Sciences. 2020; 10(17):5956. https://doi.org/10.3390/app10175956
Chicago/Turabian StyleZieliński, Sławomir K., Hyunkook Lee, Paweł Antoniuk, and Oskar Dadan. 2020. "A Comparison of Human against Machine-Classification of Spatial Audio Scenes in Binaural Recordings of Music" Applied Sciences 10, no. 17: 5956. https://doi.org/10.3390/app10175956
APA StyleZieliński, S. K., Lee, H., Antoniuk, P., & Dadan, O. (2020). A Comparison of Human against Machine-Classification of Spatial Audio Scenes in Binaural Recordings of Music. Applied Sciences, 10(17), 5956. https://doi.org/10.3390/app10175956