An Auditory-Perceptual and Pupillometric Study of Vocal Strain and Listening Effort in Adductor Spasmodic Dysphonia

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Listening Effort
1.2. Pupillometry
- Do normal hearing adult listeners expend effort while listening to intelligible speech samples from talkers with different degrees of AdSD severity?
- Is there a relationship between the auditory-perceptual ratings of vocal strain and listening effort for these AdSD talker samples?
- What is the relationship between the pupillometric measures of listening effort and perceived vocal strain and listening effort ratings, when listeners are presented with AdSD speech samples?
2. Materials and Methods
2.1. Participants
2.2. Auditory Stimuli
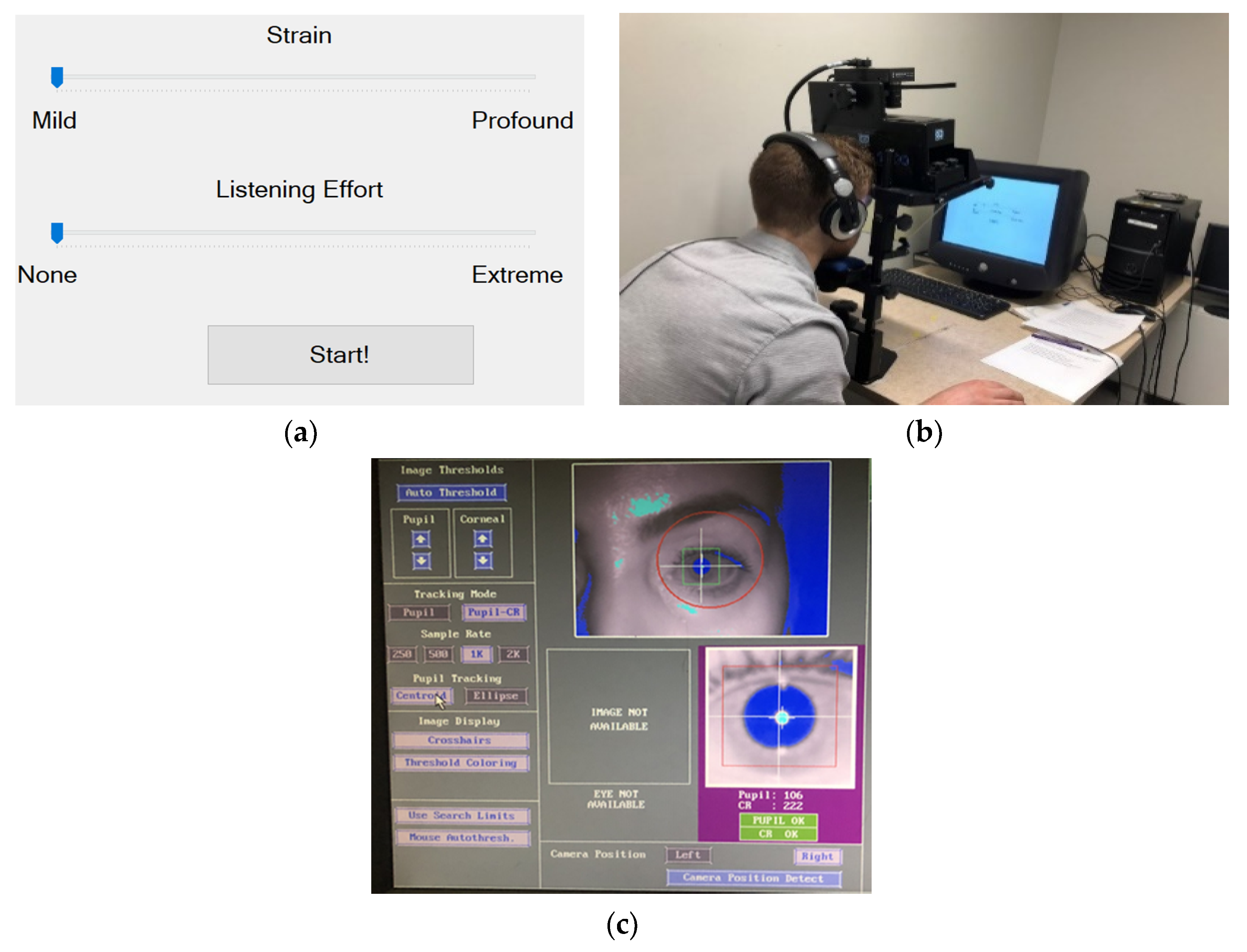
2.3. Assessment of Strain and Listening Effort
2.4. Pupillometry Data Recording
2.5. Procedure
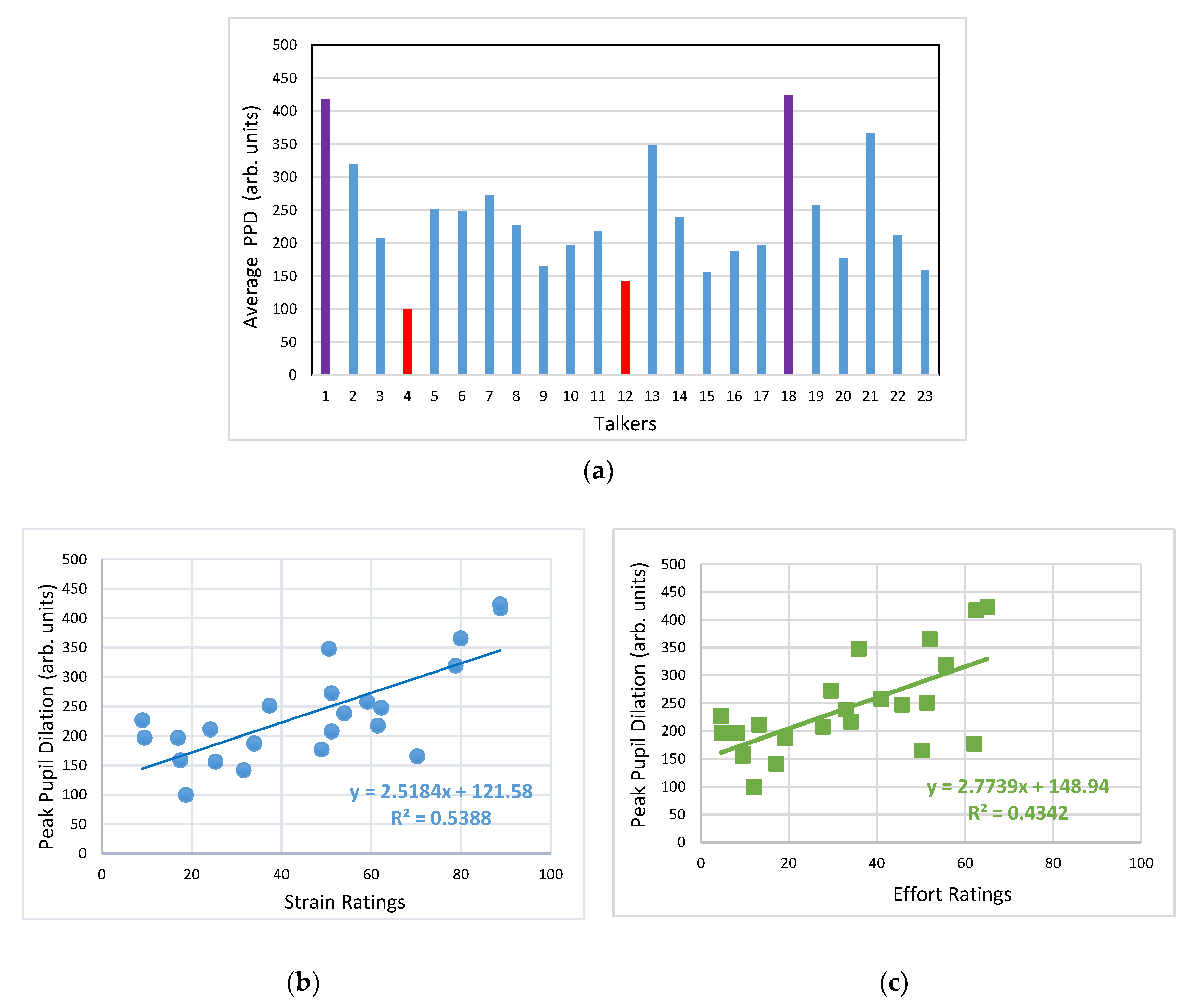
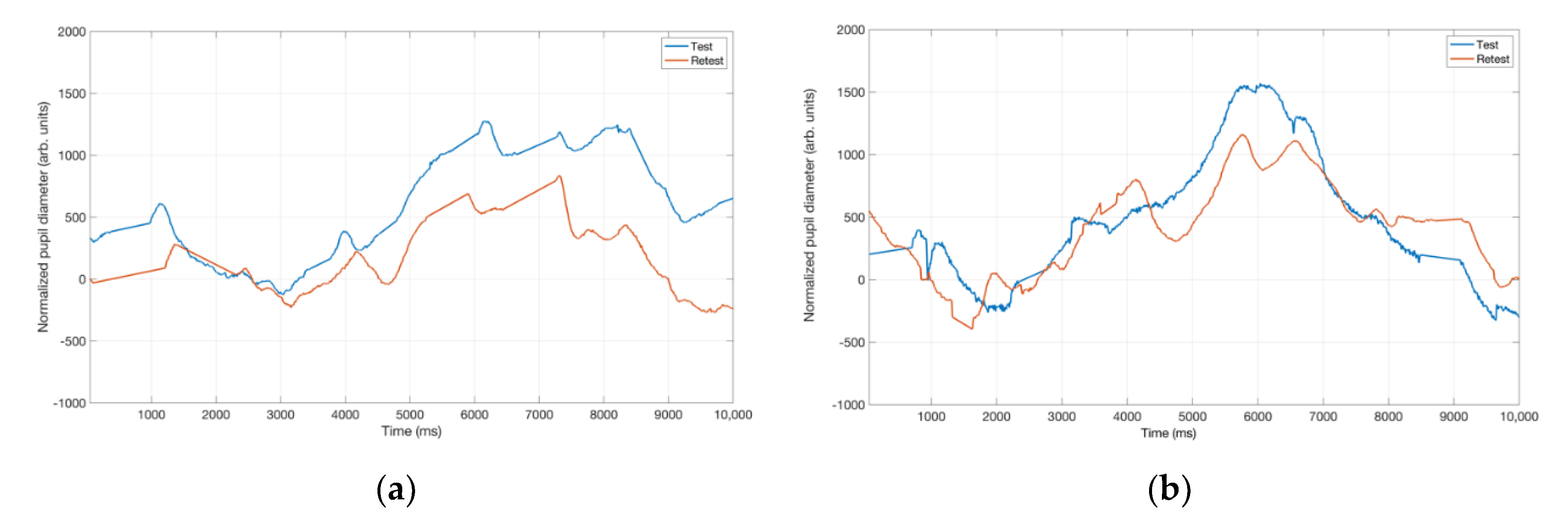
3. Results
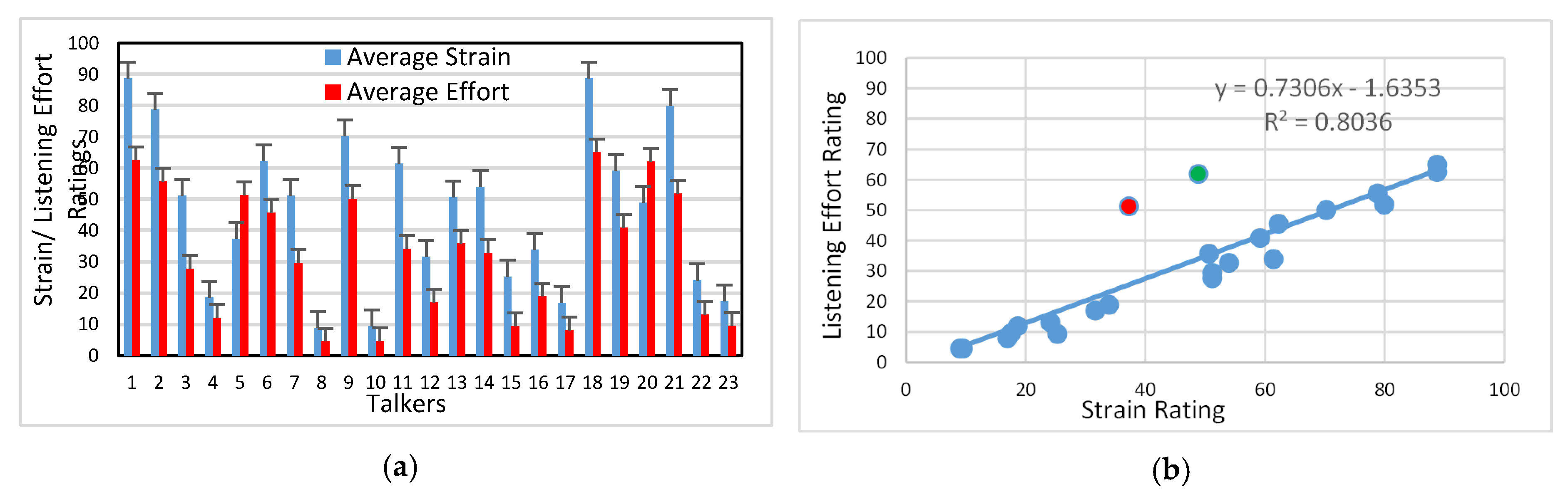
3.1. Auditory-Perceptual Data
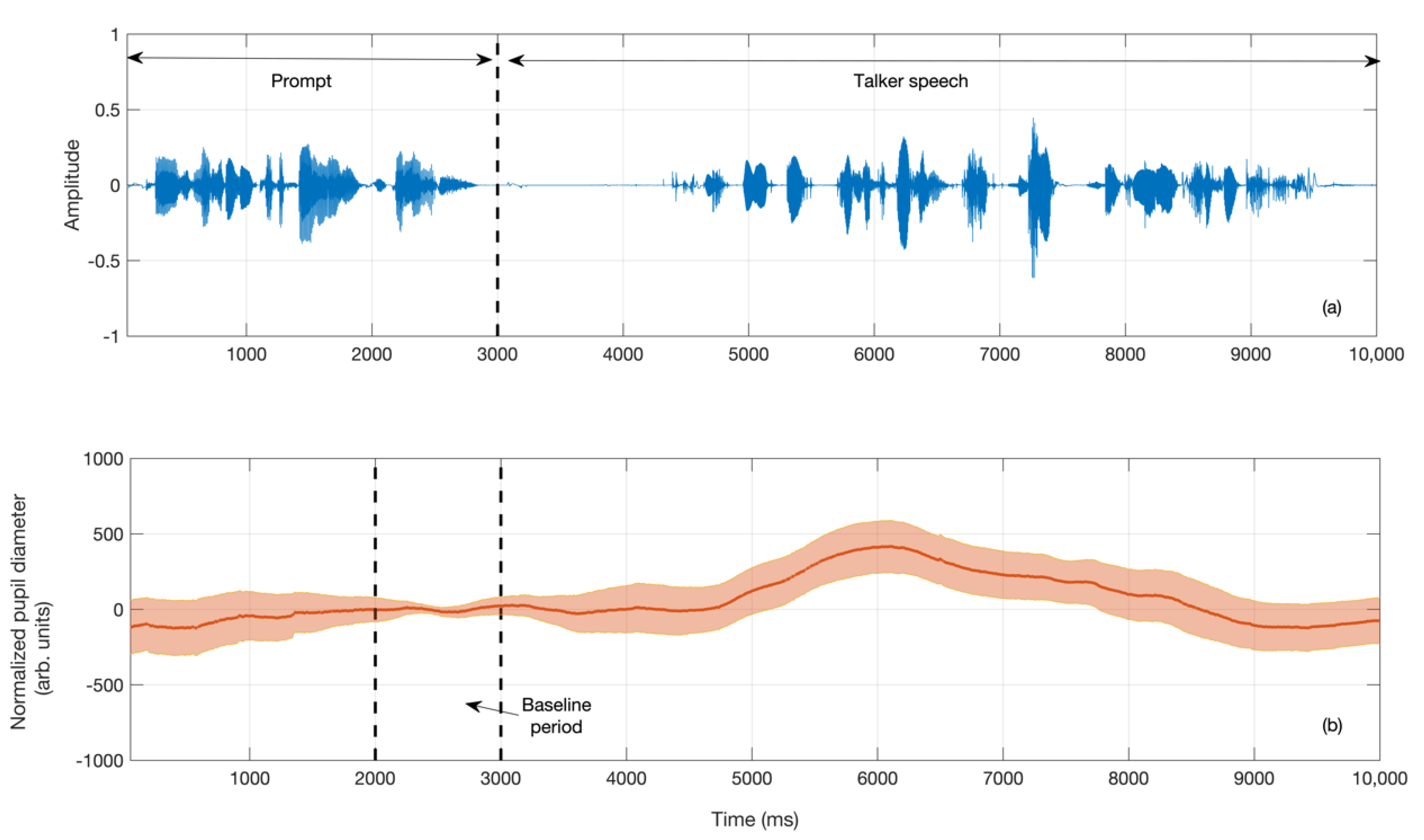
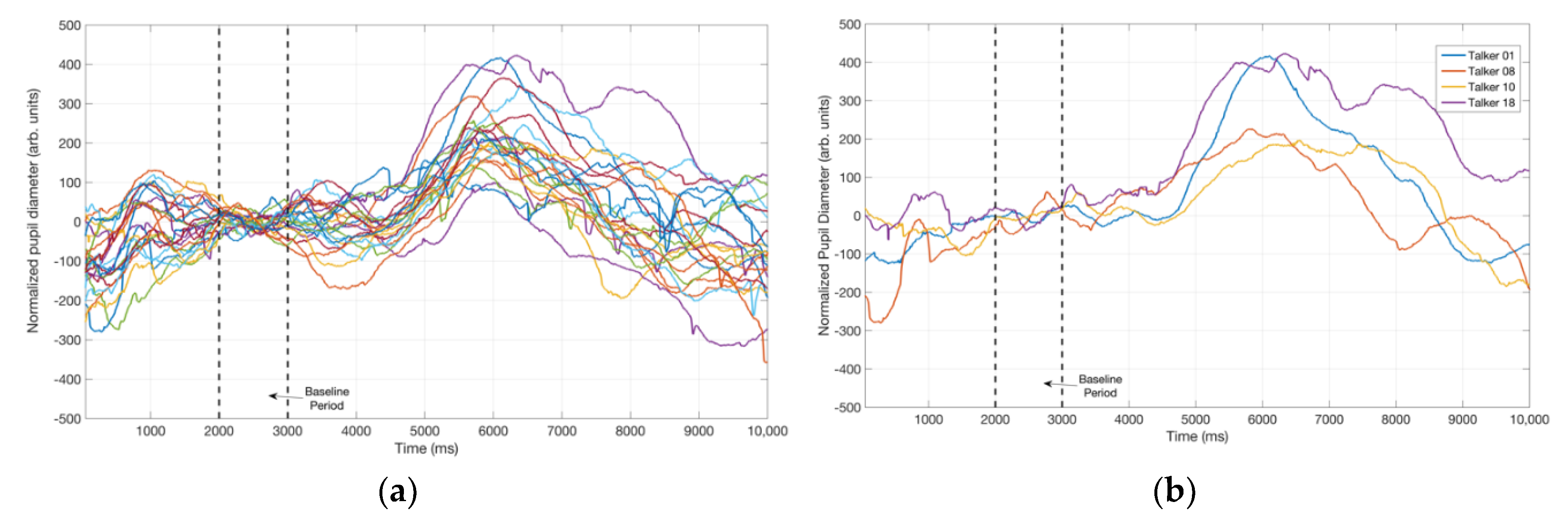
3.2. Pupillometry Data
4. Discussion
4.1. Listener Ratings of Strain and Effort
4.2. Pupil Dialation in Response to Vocal Samples
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- The Use of Voice Therapy in the Treatment of Dysphonia. Available online: https://www.asha.org/policy/tr2005-00158/ (accessed on 17 January 2020).
- Yeung, J.C.; Fung, K.; Davis, E.; Rai, S.K.; Day, A.M.; Dzioba, A.; Bornbaum, C.; Doyle, P.C. Longitudinal variations of laryngeal overpressure and voice-related quality of life in spasmodic dysphonia. Laryngoscope 2015, 125, 661–666. [Google Scholar] [CrossRef] [PubMed]
- Cannito, M.P.; Doiuchi, M.; Murry, T.; Woodson, G.E. Perceptual structure of adductor spasmodic dysphonia and its acoustic correlates. J. Voice 2012, 26, 818.e5–818.e13. [Google Scholar] [CrossRef]
- Cannito, M.P.; Burch, A.R.; Watts, C.; Rappold, P.W.; Hood, S.B.; Sherrard, K. Disfluency in spasmodic dysphonia: A multivariate analysis. J. Speech Lang. Hear. Res. 1997, 40, 627–641. [Google Scholar] [CrossRef]
- Eadie, T.L.; Nicolici, C.; Baylor, C.; Almand, K.; Waugh, P.; Maronian, N. Effect of experience on judgments of adductor spasmodic dysphonia. Ann. Otol. Rhinol. Laryngol. 2007, 116, 695–701. [Google Scholar] [CrossRef] [PubMed]
- Isetti, D.; Xuereb, L.; Eadie, T.L. Inferring speaker attributes in adductor spasmodic dysphonia: Ratings from unfamiliar listeners. Am. J. Speech Lang. Pathol. 2014, 23, 134–145. [Google Scholar] [CrossRef] [PubMed]
- Ludlow, C.L.; Naunton, R.F.; Terada, S.; Anderson, B.J. Successful treatment of selected cases of abductor spasmodic dysphonia using botulinum toxin injection. Otolaryngol. Head Neck Surg. 1991, 104, 849–855. [Google Scholar] [CrossRef]
- Kreiman, J.; Gerratt, B.R.; Kempster, G.B.; Erman, A.; Berke, G.S. Perceptual evaluation of voice quality: Review, tutorial, and a framework for future research. J. Speech Lang. Hear. Res. 1993, 36, 21–40. [Google Scholar] [CrossRef]
- Johnsrude, I.S.; Rodd, J.M. Factors that increase processing demands when listening to speech. In Neurobiology of Language; Academic Press: Cambridge, MA, USA, 2016; pp. 491–502. [Google Scholar]
- Doyle, P.C. Documenting voice and speech outcomes in alaryngeal speakers. In Clinical Care and Rehabilitation in Head and Neck Cancer; Doyle, P.C., Ed.; Springer: New York, NY, USA, 2019; pp. 281–297. [Google Scholar]
- Lindblom, B. On the communication process: Speaker-listener interaction and the development of speech. Augment. Altern. Commun. 1990, 6, 220–230. [Google Scholar] [CrossRef]
- Kramer, S.E.; Lorens, A.; Coninx, F.; Zekveld, A.A.; Piotrowska, A.; Skarzynski, H. Processing load during listening: The influence of task characteristics on the pupil response. Lang. Cogn. Proc. 2013, 28, 426–442. [Google Scholar] [CrossRef]
- Pichora-Fuller, M.K.; Kramer, S.E.; Eckert, M.A.; Edwards, B.; Hornsby, B.W.; Humes, L.E.; Lemke, U.; Lunner, T.; Matthen, M.; Mackersie, C.L.; et al. Hearing impairment and cognitive energy: The framework for understanding effortful listening (FUEL). Ear Hear. 2016, 37, 5S–27S. [Google Scholar] [CrossRef]
- Nagle, K.F.; Eadie, T.L. Listener effort for highly intelligible tracheoesophageal speech. J. Commun. Disord. 2012, 45, 235–245. [Google Scholar] [CrossRef] [PubMed]
- Imhof, M.; Välikoski, T.R.; Laukkanen, A.M.; Orlob, K. Cognition and interpersonal communication: The effect of voice quality on information processing and person perception. Stud. Commun. Sci. 2014, 14, 37–44. [Google Scholar] [CrossRef]
- Nagle, K.F.; Eadie, T.L. Perceived listener effort as an outcome measure for disordered speech. J. Commun. Disord. 2018, 73, 34–49. [Google Scholar] [CrossRef] [PubMed]
- Zekveld, A.A.; Koelewijn, T.; Kramer, S.E. The pupil dilation response to auditory stimuli: Current state of knowledge. Trends Hear. 2018, 22. [Google Scholar] [CrossRef]
- Kahneman, D. Attention and Effort; Prentice-Hall: Englewood Cliffs, NJ, USA, 1973. [Google Scholar]
- Fairbanks, G. The rainbow passage. In Voice and Articulation Drillbook, 2nd ed.; Harper & Row: New York, NY, USA, 1960. [Google Scholar]
- Winn, M.B.; Wendt, D.; Koelewijn, T.; Kuchinsky, S.E. Best practices and advice for using pupillometry to measure listening effort: An introduction for those who want to get started. Trends Hear. 2018, 22. [Google Scholar] [CrossRef]
- Whitehill, T.L.; Wong, C.C. Contributing factors to listening effort for dysarthric speech. J. Med. Speech Lang. Pathol. 2006, 14, 335–342. [Google Scholar]
- Brown, G.G.; Kindermann, S.S.; Siegle, G.J.; Granholm, E.; Wong, E.C.; Buxton, R.B. Brain activation and pupil response during covert performance of the Stroop Color Word task. J. Int. Neuropsychol. Soc. 1999, 5, 308–319. [Google Scholar] [CrossRef]
- Hyönä, J.; Tommola, J.; Alaja, A.M. Pupil dilation as a measure of processing load in simultaneous interpretation and other language tasks. Q. J. Exp. Psychol. 1995, 48, 598–612. [Google Scholar] [CrossRef]
- Wendt, D.; Dau, T.; Hjortkjær, J. Impact of background noise and sentence complexity on processing demands during sentence comprehension. Front. Psychol. 2016, 7, 345. [Google Scholar] [CrossRef]
- Pichora-Fuller, M.K.; Singh, G. Effects of age on auditory and cognitive processing: Implications for hearing aid fitting and audiologic rehabilitation. Trends Amplif. 2006, 10, 29–59. [Google Scholar] [CrossRef]
- Rabbitt, P.M. Channel-capacity, intelligibility and immediate memory. Q. J. Exp. Psychol. 1968, 20, 241–248. [Google Scholar] [CrossRef] [PubMed]
- Zekveld, A.A.; Kramer, S.E.; Festen, J.M. Pupil response as an indication of effortful listening: The influence of sentence intelligibility. Ear Hear. 2010, 31, 480–490. [Google Scholar] [CrossRef] [PubMed]
- Kramer, S.E.; Kapteyn, T.S.; Festen, J.M.; Kuik, D.J. Assessing aspects of auditory handicap by means of pupil dilation. Audiology 1997, 36, 155–164. [Google Scholar] [CrossRef]
- Antonenko, P.; Paas, F.; Grabner, R.; Van Gog, T. Using electroencephalography to measure cognitive load. Educ. Psychol. Rev. 2010, 22, 425–438. [Google Scholar] [CrossRef]
- Francis, A.L.; Love, J. Listening effort: Are we measuring cognition or affect, or both? Wires Cogn. Sci. 2020, 11, e1514. [Google Scholar] [CrossRef] [PubMed]
- Damsma, A.; van Rijn, H. Pupillary response indexes the metrical hierarchy of unattended rhythmic violations. Brain Cogn. 2017, 111, 95–103. [Google Scholar] [CrossRef]
- Marois, A.; Labonté, K.; Parent, M.; Vachon, F. Eyes have ears: Indexing the orienting response to sound using pupillometry. Int. J. Psychophysiol. 2018, 123, 152–162. [Google Scholar] [CrossRef]
- Dahlman, J.; Sjörs, A.; Lindström, J.; Ledin, T.; Falkmer, T. Performance and autonomic responses during motion sickness. Hum. Factors 2009, 51, 56–66. [Google Scholar] [CrossRef]
- Raman, S.; Serrano, L.; Winneke, A.; Navas, E.; Hernaez, I. Intelligibility and listening effort of Spanish oesophageal speech. Appl. Sci. 2019, 9, 3233. [Google Scholar] [CrossRef]






© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farahani, M.; Parsa, V.; Herrmann, B.; Kadem, M.; Johnsrude, I.; Doyle, P.C. An Auditory-Perceptual and Pupillometric Study of Vocal Strain and Listening Effort in Adductor Spasmodic Dysphonia. Appl. Sci. 2020, 10, 5907. https://doi.org/10.3390/app10175907
Farahani M, Parsa V, Herrmann B, Kadem M, Johnsrude I, Doyle PC. An Auditory-Perceptual and Pupillometric Study of Vocal Strain and Listening Effort in Adductor Spasmodic Dysphonia. Applied Sciences. 2020; 10(17):5907. https://doi.org/10.3390/app10175907
Chicago/Turabian StyleFarahani, Mojgan, Vijay Parsa, Björn Herrmann, Mason Kadem, Ingrid Johnsrude, and Philip C. Doyle. 2020. "An Auditory-Perceptual and Pupillometric Study of Vocal Strain and Listening Effort in Adductor Spasmodic Dysphonia" Applied Sciences 10, no. 17: 5907. https://doi.org/10.3390/app10175907
APA StyleFarahani, M., Parsa, V., Herrmann, B., Kadem, M., Johnsrude, I., & Doyle, P. C. (2020). An Auditory-Perceptual and Pupillometric Study of Vocal Strain and Listening Effort in Adductor Spasmodic Dysphonia. Applied Sciences, 10(17), 5907. https://doi.org/10.3390/app10175907