Object Semantic Grid Mapping with 2D LiDAR and RGB-D Camera for Domestic Robot Navigation


Abstract
1. Introduction
- An object semantic grid mapping system with 2D LiDAR and RGB-D sensors for domestic robot navigation is proposed.
- A method for extracting the dominant directions of the room to generate OOMBRs for objects is proposed.
- Object goal spaces are created for robot goal point selection conveniently and socially.
- The effectiveness of the system on a home dataset is verified.
2. System Overview
3. Front-End
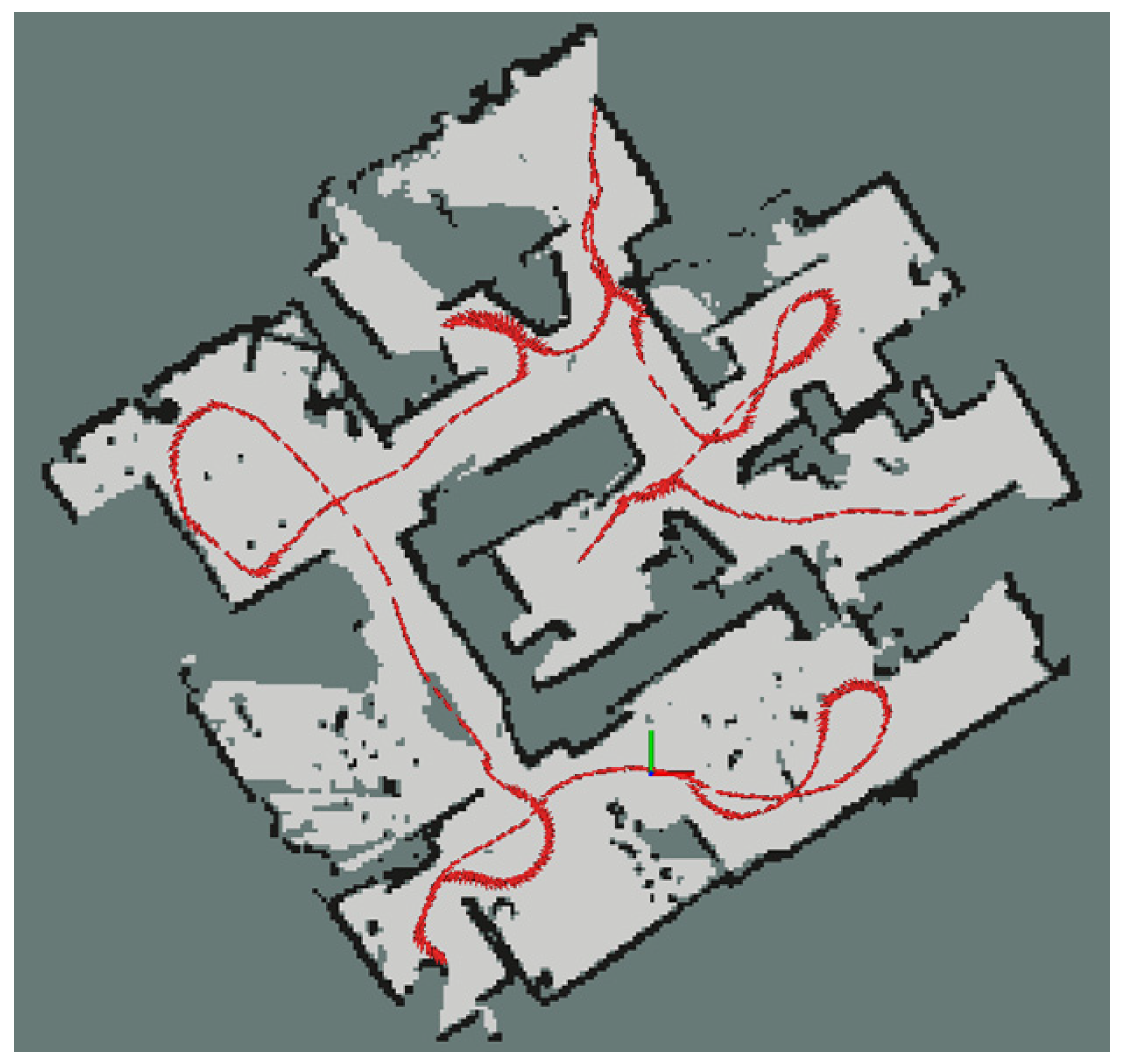
3.1. Laser-Based SLAM
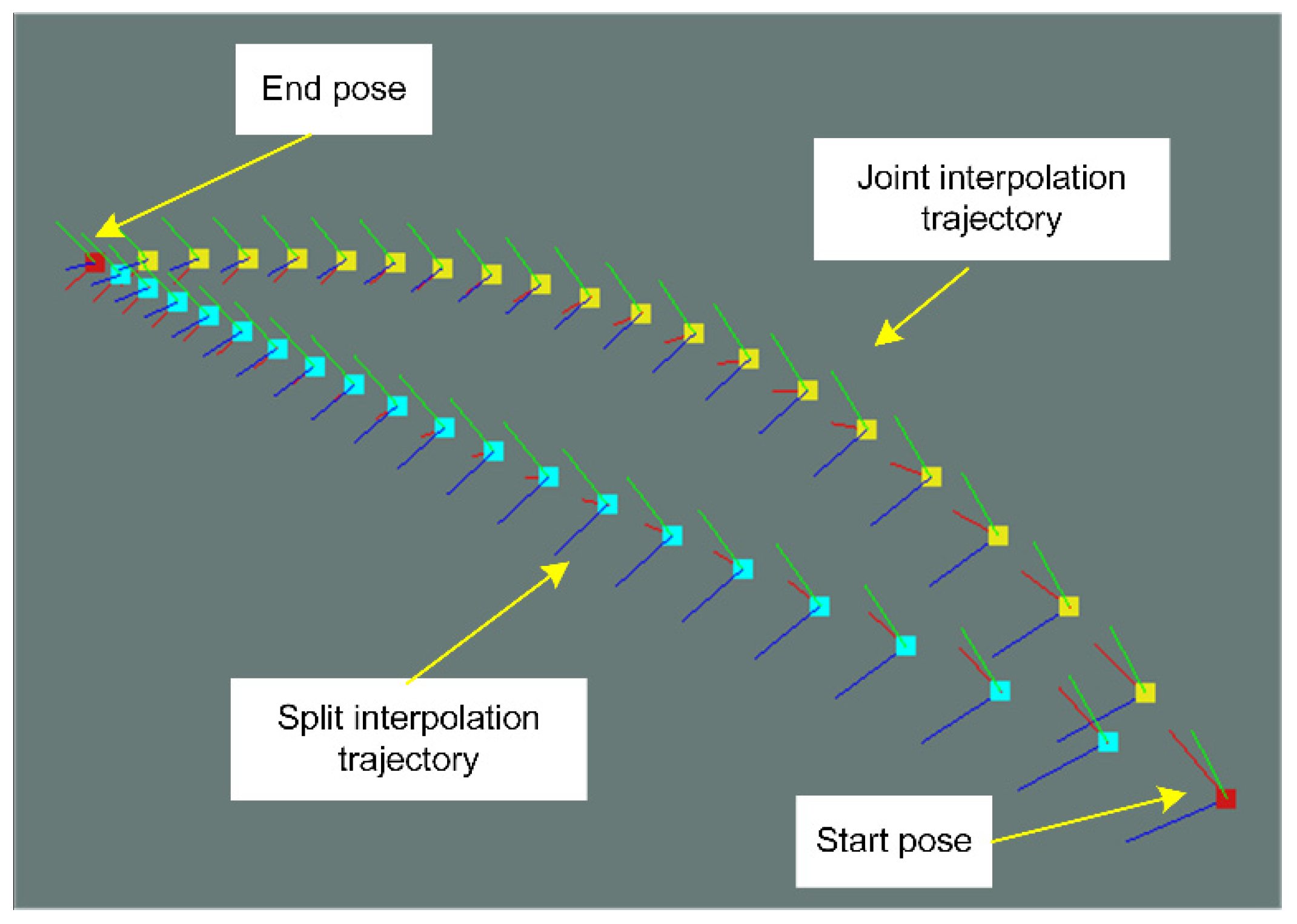
3.2. Camera Pose Interpolation
3.3. Object Detection
4. Back-End
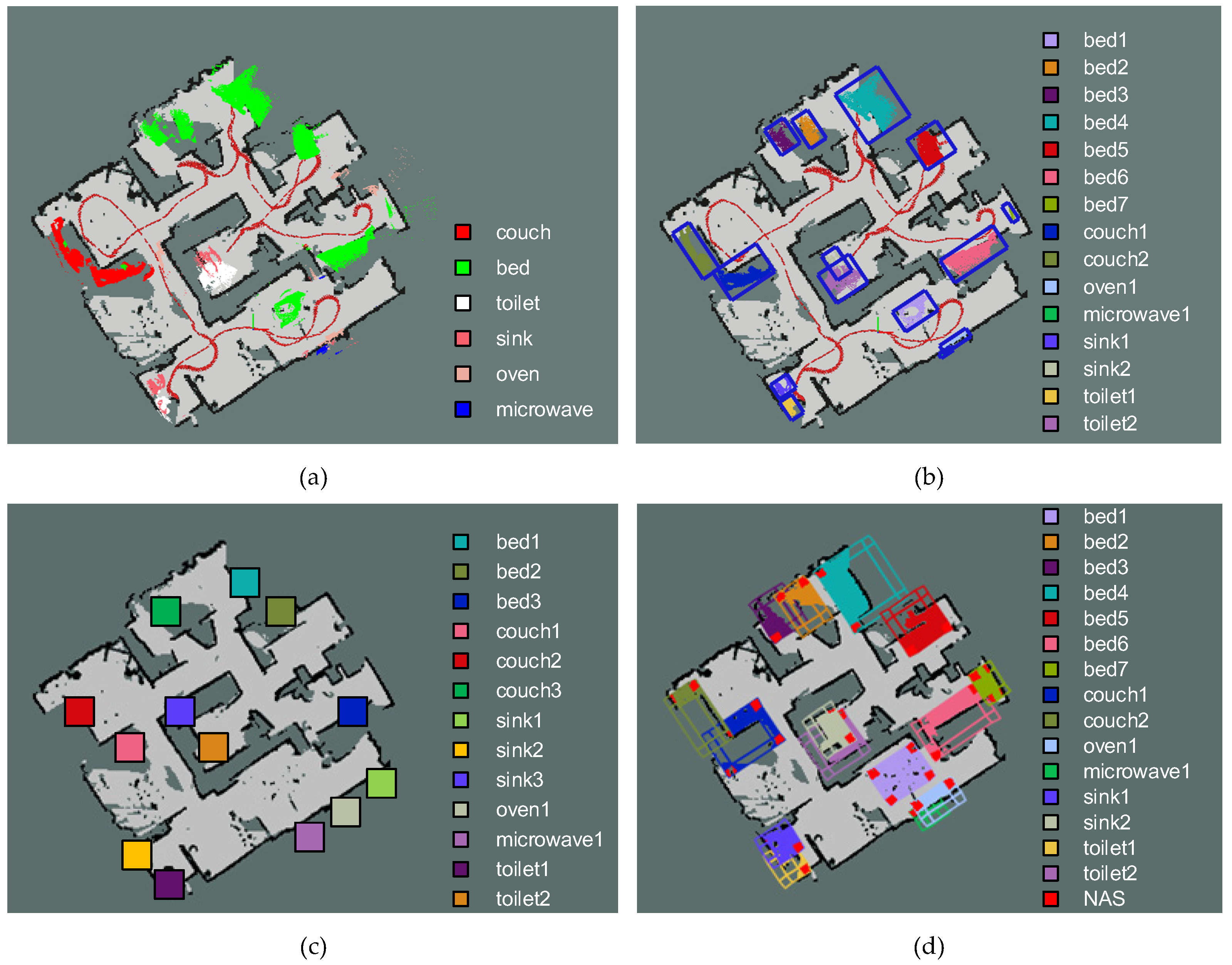
4.1. Object Point Cloud
4.2. Room Dominant Direction Detection
4.3. Object Goal Space Generation
5. Experimental Results and Discussion
5.1. Experimental Setup
5.2. Results
5.3. Discussion
- (1)
- The object detection algorithm generates many wrong results as we directly employ an instance of Mask R-CNN pretrained with the COCO dataset.
- (2)
- There are many insufficient observations of objects, resulting in the corresponding object point clouds being sparse and removed by the point cloud filter algorithm.
- (3)
- An object is instantiated into two, as the camera interpolation method cannot refine some camera poses.
- (1)
- Since the object goal space depends on the OOMBR, it may not be accurate enough.
- (2)
- The object goal space may be defined through the walls and in other rooms.
- (1)
- To make the object detection more accurate, we can retrain the neural network model for domestic environments. As precision is related to the number of correctly instantiated objects, we can obviously improve it.
- (2)
- To obtain sufficient observations of the objects, the robot should approach the detected objects to achieve more complete observations and generate dense object point clouds. Based on (1), we can correctly instantiate more objects and improve the recall significantly.
- (3)
- To further improve the precision and recall scores and make the object goal spaces more in-line with the actual objects, we can apply a bundle adjustment-like method over all the estimated camera poses and depth maps to improve their accuracy.
- (4)
- As the object we detect can only be located in one room, we will use a room segmentation algorithm to solve the problem that part of the goal space is located in another room.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Vicentini, F.; Pedrocchi, N.; Beschi, M.; Giussani, M.; Iannacci, N.; Magnoni, P.; Pellegrinelli, S.; Roveda, L.; Villagrossi, E.; Askarpour, M.; et al. PIROS: Cooperative, safe and reconfigurable robotic companion for cnc pallets load/unload stations. In Bringing Innovative Robotic Technologies from Research Labs to Industrial End-Users; Caccavale, F., Ott, C., Winkler, B., Taylor, Z., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; pp. 57–96. [Google Scholar]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Roveda, L. Adaptive interaction controller for compliant robot base applications. IEEE Access 2018, 7, 6553–6561. [Google Scholar] [CrossRef]
- Qi, X.; Wang, W.; Guo, L.; Li, M.; Zhang, X.; Wei, R. Building a plutchik’s wheel inspired affective model for social robots. J. Bionic. Eng. 2019, 16, 209–221. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, X. Building 3D semantic maps for mobile robots using RGB-D camera. Intel. Serv. Robot. 2016, 9, 297–309. [Google Scholar] [CrossRef]
- Cao, H.L.; Esteban, P.G.; Albert, D.B.; Ramona, S.; Van de Perre, G.; Lefeber, D.; Vanderborght, B. A Collaborative Homeostatic-Based Behavior Controller for Social Robots in Human—Robot Interaction Experiments. Int. J. Soc. Robot. 2017, 9, 675–690. [Google Scholar] [CrossRef]
- Thrun, S. Learning metric-topological maps for indoor mobile robot navigation. Artif. Intell. 1998, 99, 21–71. [Google Scholar] [CrossRef]
- Kostavelis, I.; Gasteratos, A. Semantic mapping for mobile robotics tasks: A survey. Robot. Auton. Syst. 2015, 66, 86–103. [Google Scholar] [CrossRef]
- Qi, X.; Wang, W.; Yuan, M.; Wang, Y.; Li, M.; Xue, L.; Sun, Y. Building semantic grid maps for domestic robot navigation. Int. J. Adv. Robot. Syst. 2020, 2020, 1–12. [Google Scholar] [CrossRef]
- Landsiedel, C.; Rieser, V.; Walter, M.; Wollherr, D. A review of spatial reasoning and interaction for real-world robotics. Adv. Robot. 2017, 31, 222–242. [Google Scholar] [CrossRef]
- Kohlbrecher, S.; von Stryk, O.; Meyer, J.; Klingauf, U. A flexible and scalable slam system with full 3d motion estimation. In Proceedings of the 2011 IEEE International Symposium on Safety, Security, and Rescue Robotics, Kyoto, Japan, 1–5 November 2011; pp. 155–160. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved techniques for grid mapping with rao-blackwellized particle filters. IEEE Trans. Robot. 2007, 23, 34–46. [Google Scholar] [CrossRef]
- Vincent, R.; Limketkai, B.; Eriksen, M. Comparison of indoor robot localization techniques in the absence of GPS. In Detection and Sensing of Mines, Explosive Objects, and Obscured Targets XV; International Society for Optics and Photonics: Bellingham, WA, USA, 2010; p. 76641Z. [Google Scholar]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-time loop closure in 2d lidar slam. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 1–10. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Bartoli, A.; Sturm, P. Structure-from-motion using lines: Representation triangulation and bundle adjustment. Comput. Vis. Image Underst. 2005, 100, 416–441. [Google Scholar] [CrossRef]
- Gomez-Ojeda, R.; Moreno, F.A.; Zuniga-Noel, D.; Scaramuzza, D.; Gonzalez-Jimenez, J. Pl-slam: A stereo slam system through the combination of points and line segments. IEEE Trans. Robot. 2019, 35, 734–746. [Google Scholar] [CrossRef]
- Guo, R.; Peng, K.; Fan, W.; Zhai, Y.; Liu, Y. Rgb-d slam using point-plane constraints for indoor environments. Sensors 2019, 19, 2721. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, W.; Qi, X.; Liao, Z.; Ran, W. Point-plane slam using supposed planes for indoor environments. Sensors 2019, 19, 3795. [Google Scholar] [CrossRef]
- Mozos, O.M.; Triebel, R.; Jensfelt, P.; Rottmann, A.; Burgard, W. Supervised semantic labeling of places using information extracted from sensor data. Robot. Auton. Syst. 2007, 55, 391–402. [Google Scholar] [CrossRef]
- Goerke, N.; Braun, S. Building Semantic Annotated Maps by Mobile Robots. In Proceedings of the Towards Autonomous Robotic Systems, Londonderry, UK, 25–27 July 2018. [Google Scholar]
- Brunskill, E.; Kollar, T.; Roy, N. Topological mapping using spectral clustering and classification. In Proceedings of the IEEE/RSJ Conference on Robots and Systems, San Diego, CA, USA, 20 October–2 November 2007. [Google Scholar]
- Friedman, S.; Pasula, H.; Fox, D. Voronoi random fields: Extracting the topological structure of indoor environments via place labeling. In Proceedings of the International Joint Conference on Artificial Intelligence, Hyderabad, India, 6–12 January 2007. [Google Scholar]
- Goeddel, R.; Olson, E. Learning semantic place labels from occupancy grids using cnns. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 3999–4004. [Google Scholar]
- Fernadez-Chaves, D.; Ruiz-Sarmiento, J.; Petkov, N.; González-Jiménez, J. From object detection to room categorization in robotics. In Proceedings of the 3rd International Conference on Applications of Intelligent Systems, Las Palmas, Spain, 7–12 January 2020; pp. 1–6. [Google Scholar]
- Rusu, R.B. Semantic 3D object maps for everyday manipulation in human living environments. Kunstl. Intell. 2010, 24, 345–348. [Google Scholar] [CrossRef]
- Tateno, K.; Tombari, F.; Laina, I.; Navab, N. Cnn-slam: Real-time dense monocular slam with learned depth prediction. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6565–6574. [Google Scholar]
- Sunderhauf, N.; Dayoub, F.; McMahon, S.; Talbot, B.; Schulz, R.; Corke, P.; Wyeth, G.; Upcroft, B.; Milford, M. Place categorization and semantic mapping on a mobile robot. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5729–5736. [Google Scholar]
- Liu, Z.; Wichert, G.V. Extracting semantic indoor maps from occupancy grids. Robot. Auton. Syst. 2014, 62, 663–674. [Google Scholar] [CrossRef]
- Salas-Moreno, R.F.; Strasdat, H.; Kelly, P.H.J.; Davison, A.J. Slam++: Simultaneous localization and mapping at the level of objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 25–27 June 2013; pp. 1352–1359. [Google Scholar]
- Gunthe, M.; Wiemann, T.; Albrecht, S.; Hertzberg, J. Model-based furniture recognition for building semantic object maps. Artif. Intell. 2017, 247, 336–351. [Google Scholar] [CrossRef]
- Gemignani, G.; Capobianco, R.; Bastianelli, E.; Bloisi, D.D.; Iocchi, L.; Nardi, D. Living with robots: Interactive environmental knowledge acquisition. Robot. Auton. Syst. 2016, 78, 1–16. [Google Scholar] [CrossRef]
- Walter, M.R.; Hemachandra, S.M.; Homberg, B.S.; Tellex, S.; Teller, S. A framework for learning semantic maps from grounded natural language descriptions. Int. J. Robot. Res. 2014, 33, 1167–1190. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Visual-inertial monocular SLAM with map reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef]
- Yang, D.; Bi, S.; Wang, W.; Yuan, C.; Wang, W.; Qi, X.; Cai, Y. Dre-slam: Dynamic rgb-d encoder slam for a differential-drive robot. Remote Sens. 2019, 11, 380. [Google Scholar] [CrossRef]
- Haarbach, A.; Birdal, T.; Ilic, S. Survey of higher order rigid body motion interpolation methods for keyframe animation and continuous-time trajectory estimation. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 381–389. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster RCNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2017, 39, 1137–1149. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask RCNN. arXiv e-prints, Article. arXiv 2017, arXiv:1703.06870. [Google Scholar]
- Rusu, R.B.; Marton, Z.C.; Blodow, N.; Dolha, M.; Beetz, M. Towards 3d point cloud based object maps for household environments. Robot. Auton. Syst. 2008, 56, 927–941. [Google Scholar] [CrossRef]
- Rusu, R.B.; Cousins, S. 3D is here: Point cloud library (PCL). In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Rios-Martinez, J.; Spalanzani, A.; Laugier, C. From Proxemics Theory to Socially-Aware Navigation: A Survey. Int. J. Soc. Robot. 2015, 7, 137–153. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Yi, C.; Suh, I.H.; Lim, G.H.; Choi, B.-U. Bayesian robot localization using spatial object contexts. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; pp. 3467–3473. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Ruiz-Sarmiento, J.R.; Galindo, C.; Gonzalez-Jimenez, J. Robot@Home, a robotic dataset for semantic mapping of home environments. Int. J. Robot. Res. 2017, 36, 131–141. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Bed | Couch | Sink | Toilet | Microwave | Oven | Total |
|---|---|---|---|---|---|---|---|
| #ground truth | 2 | 2 | 2 | 1 | 1 | 0 | 8 |
| #instance | 2 | 1 | 1 | 0 | 1 | 0 | 5 |
| #correct instance | 2 | 1 | 1 | 0 | 0 | 0 | 4 |
| precision (%) | 100 | 100 | 100 | - | 0 | - | 80 |
| recall (%) | 100 | 50 | 50 | 0 | 0 | - | 50 |
| Index | Bed | Couch | Sink | Toilet | Microwave | Oven | Total |
|---|---|---|---|---|---|---|---|
| #ground truth | 1 | 1 | 2 | 1 | 0 | 0 | 5 |
| #instance | 3 | 1 | 1 | 1 | 0 | 0 | 6 |
| #correct instance | 1 | 1 | 1 | 1 | 0 | 0 | 4 |
| precision (%) | 33.33 | 100 | 100 | 100 | - | - | 66.67 |
| recall (%) | 100 | 100 | 50 | 100 | - | - | 80 |
| Index | Bed | Couch | Sink | Toilet | Microwave | Oven | Total |
|---|---|---|---|---|---|---|---|
| #ground truth | 3 | 3 | 3 | 2 | 1 | 1 | 13 |
| #instance | 7 | 2 | 2 | 2 | 1 | 1 | 15 |
| #correct instance | 3 | 2 | 2 | 2 | 1 | 1 | 11 |
| precision (%) | 42.86 | 100 | 100 | 100 | 100 | 100 | 73.33 |
| recall (%) | 100 | 66.67 | 66.67 | 100 | 100 | 100 | 84.62 |
| Index | Bed | Couch | Sink | Toilet | Microwave | Oven | Total |
|---|---|---|---|---|---|---|---|
| #ground truth | 3 | 4 | 3 | 2 | 1 | 1 | 14 |
| #instance | 4 | 1 | 1 | 1 | 1 | 4 | 12 |
| #correct instance | 3 | 0 | 1 | 1 | 1 | 1 | 7 |
| precision (%) | 75 | 0 | 100 | 100 | 100 | 25 | 58.33 |
| recall (%) | 100 | 0 | 33.33 | 50 | 100 | 100 | 50 |
| Index | Bed | Couch | Sink | Toilet | Microwave | Oven | Total |
|---|---|---|---|---|---|---|---|
| #ground truth | 9 | 10 | 10 | 6 | 3 | 2 | 40 |
| #instance | 16 | 5 | 5 | 4 | 3 | 5 | 38 |
| #correct instance | 9 | 4 | 5 | 4 | 2 | 2 | 26 |
| precision (%) | 56.25 | 80 | 100 | 100 | 66.67 | 40 | 68.42 |
| recall (%) | 100 | 40 | 50 | 66.67 | 66.67 | 100 | 65 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, X.; Wang, W.; Liao, Z.; Zhang, X.; Yang, D.; Wei, R. Object Semantic Grid Mapping with 2D LiDAR and RGB-D Camera for Domestic Robot Navigation. Appl. Sci. 2020, 10, 5782. https://doi.org/10.3390/app10175782
Qi X, Wang W, Liao Z, Zhang X, Yang D, Wei R. Object Semantic Grid Mapping with 2D LiDAR and RGB-D Camera for Domestic Robot Navigation. Applied Sciences. 2020; 10(17):5782. https://doi.org/10.3390/app10175782
Chicago/Turabian StyleQi, Xianyu, Wei Wang, Ziwei Liao, Xiaoyu Zhang, Dongsheng Yang, and Ran Wei. 2020. "Object Semantic Grid Mapping with 2D LiDAR and RGB-D Camera for Domestic Robot Navigation" Applied Sciences 10, no. 17: 5782. https://doi.org/10.3390/app10175782
APA StyleQi, X., Wang, W., Liao, Z., Zhang, X., Yang, D., & Wei, R. (2020). Object Semantic Grid Mapping with 2D LiDAR and RGB-D Camera for Domestic Robot Navigation. Applied Sciences, 10(17), 5782. https://doi.org/10.3390/app10175782