Preliminary Results on Different Text Processing Tasks Using Encoder-Decoder Networks and the Causal Feature Extractor



Abstract
1. Introduction
2. Materials and Methods
2.1. Encoder-Decoder Architecture
2.2. Causal Feature Extractor
- First, in order to extend the receptive field of the convolutions without requiring large kernels, several convolutional neural layers are stacked, and each one has two times the dilation of the previous one. That is, in the first layer, the convolution for position t depends on ; in the second layer, it depends on ; in the third layer, , and so on.
- Second, with the aim of making a better use of the attention mechanisms in comparison with CNNs, these stacked convolutional layers are turned into causal convolutions, meaning that the output at one position will depend on the inputs previous or next to that position, but never both. This is the same idea as the Causal CNN proposed by Oord et al. [9].
- Third, considering that the use of causal layers means the misuse of one part of the input, two stacks of causal convolution layers are used, each one taking into account a different direction of the input (the previous or the subsequent input values). The same idea of bidirectionality has also been applied to LSTMs [21].
2.3. Language Processing Tasks
- Text translation or bilingual translation. This is one of the first and most studied problems in machine NLP, so it is an interesting test bed for the proposed method. Given a text in one language, the output is an equivalent phrase in another language. The difficulty of this task is that there may be words and idioms that do not have a direct translation, or phrases that can be translated into different ways, being all of them valid. The state-of-the-art system used for comparison is given by the Transformer model introduced by Vaswani et al. [2] which overcame the results of other popular machine translation systems such as the GMT model (used in Google Translate). It uses an encoder-decoder architecture and new iterations and improvements of the attention mechanism. We also included in the comparison an encoder-decoder model with LSTM networks in the decoder.In the experiments, we used the dataset for the translation from English to German provided in the ACL 2016 Conference on Machine Translation (http://www.statmt.org/wmt16/). The training set of this resource contains near two million parallel sentences (English-German), with a total about 48 million words in English and 45 million words in German. The validation set contains 3000 sentences, and the test set also 3000 sentences. The parameter used to measure the quality of the result is the well-known Bilingual Evaluation Understudy (BLEU) [22]. Another interesting parameter is the perplexity [23], that is used during the training process in the validation set to check the network progress. It is defined as 2 raised to the cross entropy of the empirical distribution of the actual data and the distribution of the predicted values, so that a lower value indicates a better result.
- LaTeX decompilation. This problem, which is useful in tasks such as digitization of scientific texts, can also be seen as a particular case of automatic translation. In this case, the input is an image containing a mathematical formula, and the output is a LaTeX command that must produce the same formula as generated by a LaTeX engine. It combines computer vision and neural machine translation, so it is interesting for studying the effectiveness of the proposed CFE model into images. As before, the solution is not necessarily unique, since multiple LaTeX commands can produce the same result.The current state-of-the-art model used for comparison is the system presented by Deng et al. [6]. Again, it is based on an encoder-decoder architecture; the encoder consists of two steps, a CNN and a recurrent network, while the decoder is a recurrent network. The method introduces a specific attention mechanism called coarse-to-fine attention. The experiments have been done with the dataset available in [6], which contains over 103,000 training samples, 9300 validation samples and 10,300 test samples. Some of these samples are shown in Figure 2. The accuracy measures are also the BLUE and the perplexity.
- Audio transcription. The task of audio transcription is another well studied problem, which can also be understood as a type of translation, from audio to text. In this way, the main types of input have been analyzed: text, audio, and images. This problem is used both in online services and in out-of-line transcription of multimedia content. The defining characteristic, with respect to the other problems, is the possible existence of noise in the audio.The state of the art of this problem is given by models that do not follow an encoder-decoder architecture, but techniques based on hidden Markov models. Nevertheless, there are good encoder-decoder transcription systems which can be used for comparison. In particular, we used the Listen-Attend-Spell model from Chan et al. [12] to compare the results of the proposed CFE. The dataset is the AN4 set from CMU (http://www.speech.cs.cmu.edu/databases/an4/), which contains more than 1000 recordings of dates, names, numbers, etc. Concreting, the training set includes 1018 samples and the test set 140. The accuracy measures are the word error rate (WER) defined as the correctly identified words over the total, and the perplexity.
3. Results and Discussion
3.1. Experimental Setup
3.2. Accuracy Performance Results
3.3. Discussion of the Results
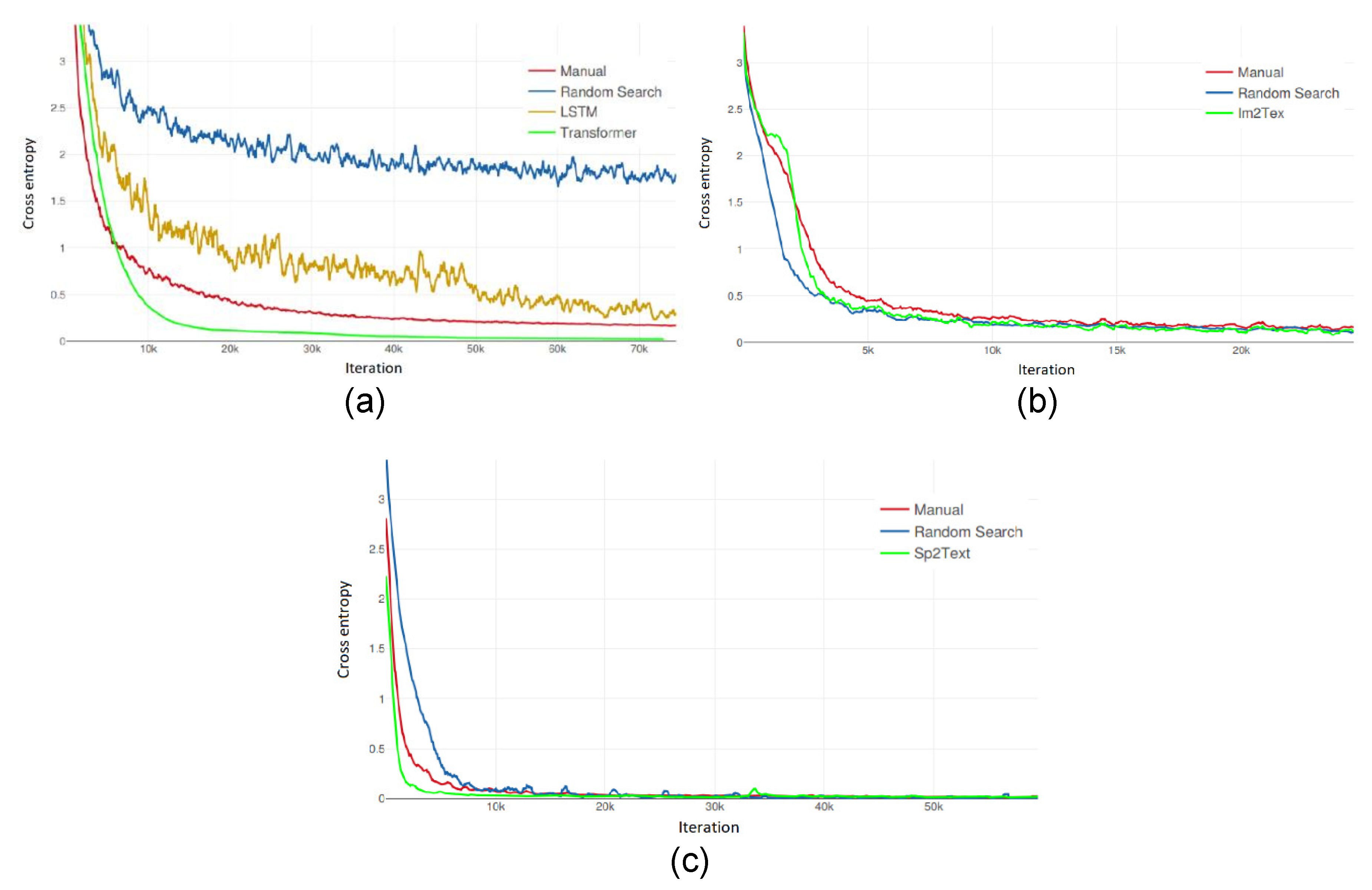
- The proposed CFE models are not able to overcome the results of the state-of-the-art methods used for comparison, as it can be seen in Table 2, although they are very close in many cases. These differences between methods have been confirmed by the approximate randomization tests, indicating that the differences of the predictors are statistically significant. However, it must be observed that these alternative methods are specifically designed for each problem, while the proposed method has shown to be generic, being able to work with text, audio and images, with minimal adaptations for each problem.
- In all the experiments, the number of iterations of the learning process was fixed for each problem (as indicated in Table 2). However, it has to be considered that the average time per iteration is not the same for all the methods. In fact, the proposed CFE encoder is approximately 1.7 times faster than the other alternatives. Thus, for a fixed learning time, the proposed solution could overcome the other methods in some cases. This can be observed in the validation measures (ACC and PER). For example, using the same learning time in the LaTeX decompilation task, CFE achieves an ACC of 96.5%, while Im2Text achieves 96.1%. In other words, Im2Text method needs around 70% more time to achieve its optimum result. A special case is the Transformer method for the problem of bilingual translation, whose average time per iteration is 4 times greater than the time of CFE; so, for the same training time, the performance achieved by CFE would be higher.
- It was observed that the proposed CFE encoder makes a better usage of the attention mechanisms [8]. The attention matrices obtained by CFE are sharper than those obtained for the other methods, i.e., they present a bigger different between the elements of interest and those that are not interesting for the decoder. This effect can be observed in the attention matrices shown in Figure 4 for the bilingual translation problem. This is a very positive aspect, since it indicates that future improvements of the proposed method could benefit more from the attention mechanisms.
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ACC | Accuracy |
| BLEU | Bilingual evaluation understudy |
| CFE | Causal feature encoder |
| CNN | Convolutional neural networks |
| FCNN | Fully connected neural network |
| LSTM | Long short-term memory |
| MNT | Machine neural translation |
| NLP | Natural language processing |
| PER | Perplexity |
| WER | Word error rate |
| RNN | Recurrent neural network |
References
- Yang, S.; Wang, Y.; Chu, X. A Survey of Deep Learning Techniques for Neural Machine Translation. arXiv 2020, arXiv:2002.07526. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. arXiv 2017, arXiv:1705.03122. [Google Scholar]
- Kameoka, H.; Tanaka, K.; Kwaśny, D.; Kaneko, T.; Hojo, N. ConvS2S-VC: Fully Convolutional Sequence-to- Sequence Voice Conversion. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1849–1863. [Google Scholar] [CrossRef]
- Daudaravicius, V. Textual and Visual Characteristics of Mathematical Expressions in Scholar Documents. In Proceedings of the Workshop on Extracting Structured Knowledge from Scientific Publications (ESSP), Minneapolis, MN, USA, 6 June 2019; pp. 72–81. [Google Scholar]
- Deng, Y.; Kanervisto, A.; Ling, J.; Rush, A.M. Image-to-markup generation with coarse-to-fine attention. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, Australia, 7–9 August 2017; pp. 980–989. [Google Scholar]
- Lipton, Z.C.; Steinhardt, J. Troubling trends in machine learning scholarship. Queue 2019, 17, 45–77. [Google Scholar]
- Javaloy, A.; García-Mateos, G. Text Normalization Using Encoder–Decoder Networks Based on the Causal Feature Extractor. Appl. Sci. 2020, 10, 4551. [Google Scholar] [CrossRef]
- Oord, A.v.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Shrestha, A.; Mahmood, A. Review of deep learning algorithms and architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar]
- Galassi, A.; Lippi, M.; Torroni, P. Attention, please! a critical review of neural attention models in natural language processing. arXiv 2019, arXiv:1902.02181. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Baldi, P.; Sadowski, P. The dropout learning algorithm. Artif. Intell. 2014, 210, 78–122. [Google Scholar] [CrossRef] [PubMed]
- Salimans, T.; Kingma, D.P. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; pp. 901–909. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning (ICML), Atlanta, GA, USA, 16–21 June 2013; pp. 1310–1318. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- LeCun, Y.; Haffner, P.; Bottou, L.; Bengio, Y. Object recognition with gradient-based learning. In Shape, Contour and Grouping in Computer Vision; Springer: Berlin/Heidelberg, Germany, 1999; pp. 319–345. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; pp. 207–212. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Nabhan, A.R.; Rafea, A. Tuning statistical machine translation parameters using perplexity. In Proceedings of the IRI-2005 IEEE International Conference on Information Reuse and Integration, Las Vegas, NV, USA, 15–17 August 2005; pp. 338–343. [Google Scholar]
- Riezler, S.; Maxwell, J.T. On some pitfalls in automatic evaluation and significance testing for MT. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 57–64. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Text Translation | LaTeX Decompilation | Audio Transcription | |||
|---|---|---|---|---|---|---|
| Method | Manual | Random | Manual | Random | Manual | Random |
| Bridge | no | yes | no | yes | no | yes |
| Global attention | general | concat | general | dot | general | dot |
| Position encoding | no | yes | no | no | yes | no |
| RNN layers | 3 | 4 | 2 | 1 | 2 | 1 |
| RNN size | 512 | 238 | 500 | 414 | 500 | 126 |
| CNN kernel width | 5 | 3 | 5 | 11 | 5 | 7 |
| Receptive field | 20 | 13 | 20 | 16 | 20 | 17 |
| Normalization | tokens | sents | sents | sents | sents | tokens |
| Batch size | 64 | 16 | 20 | 12 | 16 | 9 |
| Max grad. norm. | 1 | 14.12 | 20 | 28.68 | 20 | 3.79 |
| Dropout | 0.3 | 0.71 | 0.3 | 0.2 | 0.3 | 0.52 |
| Learning rate decay | 0.5 | 0.654 | 0.5 | 0.576 | 0.5 | 0.465 |
| Problem | Method | BLEU/WER % | ACC % | PER |
|---|---|---|---|---|
| Text translation | CFE Manual | 23.34 | 62.73 | 13.59 |
| 75,000 iterations | CFE Random | 27.80 | 63.02 | 13.39 |
| LSTM | 36.48 | 69.64 | 11.52 | |
| Transformer | 34.95 | 67.78 | 14.30 | |
| LaTeX decompilation | CFE Manual | 77.57 | 96.55 | 1.24 |
| 25,000 iterations | CFE Random | 75.82 | 96.56 | 1.24 |
| Im2Text | 80.46 | 96.78 | 1.13 | |
| Audio transcription | CFE Manual | 53.12 | 60.13 | 8.84 |
| 60,000 iteration | CFE Random | 55.05 | 59.13 | 22.4 |
| Lis.-Att.-Spell | 43.14 | 70.98 | 5.37 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Javaloy, A.; García-Mateos, G. Preliminary Results on Different Text Processing Tasks Using Encoder-Decoder Networks and the Causal Feature Extractor. Appl. Sci. 2020, 10, 5772. https://doi.org/10.3390/app10175772
Javaloy A, García-Mateos G. Preliminary Results on Different Text Processing Tasks Using Encoder-Decoder Networks and the Causal Feature Extractor. Applied Sciences. 2020; 10(17):5772. https://doi.org/10.3390/app10175772
Chicago/Turabian StyleJavaloy, Adrián, and Ginés García-Mateos. 2020. "Preliminary Results on Different Text Processing Tasks Using Encoder-Decoder Networks and the Causal Feature Extractor" Applied Sciences 10, no. 17: 5772. https://doi.org/10.3390/app10175772
APA StyleJavaloy, A., & García-Mateos, G. (2020). Preliminary Results on Different Text Processing Tasks Using Encoder-Decoder Networks and the Causal Feature Extractor. Applied Sciences, 10(17), 5772. https://doi.org/10.3390/app10175772