1. Introduction
Micro-blogs have become widely-used online platforms for sharing ideas, political views, emotions and so on. One very famous micro-blog is
Twitter: it is an online social network that allows users to publish short sentences; every day, millions of messages (also called
tweets) concerning a very large variety of topics are published (or
posted) by users. According to [
1], Twitter is a famous micro-blogging site where more than 313 million users from all over the world are active monthly.
Due to the importance it has gained, Twitter inspired novel researches concerned with many areas of computer science, in particular data mining [
2], sentiment analysis [
3], text mining [
4], discovering mobility of people [
5,
6,
7] and so on. For example, tweets are analyzed to find out political friends [
8], so this implies that texts are analyzed to detect their political polarity. Another interesting application is detecting communities from networks of users [
9], in which sentiment analysis plays an important role; sentiment analysis and opinion mining can be also adopted to study the general sentiment of a given country [
10], in order to detect the degree of support to terrorists. We can summarize that most of works concerned with the analysis of tweets are focused on sentiment analysis and opinion extraction; thus, the common perspective is that tweets posted by users are collected and queried to provide useful information about users. We can say that users are analyzed from outside the micro-blog; the results of the analysis are not used to provide a service or a functionality to users of the micro-blog itself.
Nevertheless, many users post a lot of messages, because they wish to influence other users. In fact, when a followed user posts a new tweet, all her/his followers receive it. Typically, users post many messages because they would like to be recognized as influencers in a specific topic. This goal requires a user to have many followers, that are interested in the same topic. Consequently, it is critical, for an influencer, to be interesting for other users and easily found by them. On the contrary, non influencer users would like to easily find interesting influencers to follow.
How to find users to follow? The reasons to decide to follow other users can be various; typically, one reason is affinity of interests: a user would like to follow other users with similar interests. However, currently it is quite hard to find out users that show the same interests, because micro-blog platforms in general (and Twitter in particular) do not provide any end-user functionality or service that recommends users with similar interests; consequently, we are envisioning a new scenario for micro-blog platforms.
This new scenario can become reality only if it is technically possible to realize it. This is the goal of this paper, i.e., addressing the basic problem at the basis of the envisioned functionality: we show that it is effective and efficient to classify messages with topics they talk about. In practice, we demonstrate that it is possible to define a technique that allows for characterizing user interests (in terms of topics) by analyzing their posted messages, that will open the way to build a sort of recommender system that recommends one user with other users having similar interests. At the best of our knowledge, very limited work has appeared in literature concerning this topic.
In this paper, we investigate the definition of an approach based on supervised learning, to discover topics that messages posted by micro-blog users talk about. To this end, we devised an investigation framework whose goal is to apply various combinations of feature patterns (extracted from within posted messages) and classification techniques: this framework has enabled us to identify the best combination to address the problem. In this work, basic and combined n-grams, weighted with a “Term Frequency-Inverse Document Frequency” (TF-IDF)-like metric, are used to extract features from messages to train four of the mostly-used classifiers for text classification, i.e., Naive Bayes (NB), Support Vector Machine (SVM), K- Nearest Neighbors (kNN) and Random Forest (RF). By means of the investigation framework, we performed a comparative analysis of accuracy and execution times; to identify the most suitable solution, we defined a cost-benefit function called Suitability, able to balance the benefit of a technique in terms of accuracy with the computational cost of using that technique. We will show that the comparative analysis yielded the solution that we think suitable for discovering topics messages talk about: this is the preliminary step to extend micro-blog user interfaces with functionalities able to suggest influencers to follow. This comparative analysis, that considers both accuracy and execution time, is the distinctive contribution of this paper: in fact, at the best of our knowledge, a similar approach has not been proposed yet.
The rest of the paper is organized as follows.
Section 2 gives a brief review of the existing approaches used for text mining applications on micro-blog data sets.
Section 3 depicts the envisioned application scenario and defines the specific problem addressed by the paper.
Section 4 presents the investigation framework, by discussing the dimensions of the investigation.
Section 5 reports about the experimental analysis conducted by means of the investigation framework; by means of results, we perform a comparative analysis of techniques, by considering both their effectiveness (in terms of accuracy) and their computational cost. By means of the cost-benefit function called Suitability, we rank the techniques and we identify the most suitable solution for the application scenario depicted in
Section 3. Finally,
Section 6 draws the conclusions.
2. Literature Review
To the best of our knowledge, the problem of discovering topics from messages in micro-blogs has not been significantly addressed yet, specifically if the goal is to introduce new functionalities in the micro-blogs interface. Nevertheless, micro-blogs have become precious for many application fields, and many techniques have been developed. In this sense, the related literature is so vast that it is impossible to be exhaustive. In the rest of this section, we propose a brief overview of techniques developed for application areas that are somehow related to our paper.
2.1. Sentiment Analysis and Opinion Mining
Topic discovery is somewhat close to sentiment analysis and opinion mining. Various approaches to perform sentiment analysis and opinion mining on micro-blogs (and Twitter in particular) have been proposed. Their application context is very different with respect to the context and the goal considered in this paper. Nevertheless, it is useful to give an overview of these techniques.
Kanavos et al. [
11] proposed an algorithm to exploit the emotions of Twitter users by considering a very large data-set of tweets for sentiment analysis. They proposed a distributed framework to perform sentiment classification. They used Apache Hadoop and Apache Spark to take the benefits of big data technology. They partitioned tweets into three classes, i.e., positive, negative and neutral tweets. The proposed framework is composed of four stages: (i) feature extraction (ii) feature vector construction (iii) distance computation, and (iv) sentiment classification. They utilized hashtags and emoticons as sentiment labels, while they performed classification by adopting the AkNN method (specifically designed for Map-Reduce frameworks).
The study [
12] by Hassan et al. evaluated the impact of research articles on individuals, based on the sentiments expressed on them within tweets citing scientific papers. The authors defined three categories of tweets, i.e., positive, negative, and neutral. They observed that articles which were cited in positive or neutral tweets have more impact if compared to articles cited in negative tweets or not cited at all. To perform sentiment analysis, a data-set of 6,482,260 tweets linking to 1,083,535 publications was used.
Twitter data are also very important for companies, so as to exploit them to improve their understanding about the perception by customers of the quality of their products. In [
13] authors proposed an approach to process the comments of the customers about a popular food brand, by using tweets from customers. A Binary Tree Classifier was used for discovering the polarity lexicon of English tweets, i.e., positive or negative. To group similar words in tweets, a K-means clustering algorithm was employed.
2.2. Sociological Analysis
The area of sociological analysis is the target of many classification techniques on micro-blog messages.
The paper [
14] presents a technique to understand the emotional reactions of supporters of two Super Bowl 50 teams, i.e., Panthers and Broncos. The author applied a lexicon-based text mining approach. About 328,000 tweets were posted during the match by supporters, in which they expressed their emotions regarding different events during the match. For instance, supporters expressed positive emotions when their team scored; on the other hand, they expressed negative emotions when their team conceded a goal. It was concluded that results supported sociological theories of affective disposition and opponent process.
The work [
15] shows how the authors used tweets to monitor the opinion of citizens regarding vaccination in Italy, i.e., in favor, not in favor and neutral. For improving the proposed system, different combinations of text representations and classification approaches were used, and the best accuracy was achieved by the combination scheme of bag-of-words, with stemmed n-grams as tokens, and Support Vector Machines (SVM) for classification. The proposed approach fetched and pre-processed tweets related to vaccine and applied SVM to perform classification of tweets and achieved an accuracy of 64.84%, that is acceptable but not very good. The investigation approach is similar to the one adopted in our research, i.e., various combinations of techniques are tested to find the most effective combination.
Geetha et al. [
16] aimed to analyze the state of mind expressed on Twitter through emoticons and text in tweets. They developed FPAEC—Future Prediction Architecture Based on Efficient Classification; it incorporates different classification algorithms, including Fisher’s linear discriminant classifier, artificial neural networks, Support Vector Machines (SVM), Naive Bayes and balanced iterative reducing; it also incorporates a hierarchical clustering algorithm. In fact, they propose a two-step approach, where clustering follows a preliminary classification step, to aggregate classified data.
2.3. Politics
Politics is an interesting application field of sentiment analysis and opinion mining on micro-blogs. Here, we report a few works.
In [
17], the authors proposed a framework to predict the popularity of political parties in Pakistan in 2013 public election, by finding the sentiments of Twitter users. The proposed framework is based on the following steps: (1) collection of tweets; (2) pre-processing of tweets; (3) manual annotation of the corpus. Then, to perform sentiment classification, supervised machine learning techniques such as Naive Bayes (NB), k Nearest Neighbors (kNN), Support Vector Machines (SVM) and Naive Bayes Multinomial (NBMN) were used to categorize the tweets into the predefined labels.
In [
18], authors utilized tweets to reveal the views of the leaders of two democratic parties in India. The tweet data-set was collected by using the public twitter accounts, and Opinion Lexicon [
19] was used to compute the number of positive, negative and neutral tweets. They proposed a “Twitter Sentiment Analysis” framework, which, after pre-processing of the crawled data-set from Twitter, accumulated opinion lexicon along with classification of tweets into three classes, i.e., positive, negative and neutral, for the evaluation of sentiments of users.
To discover the sentiments of Twitter users, with the aim of exploring their opinions regarding political activities during election days, the authors of [
20] proposed a methodology and compared the performance of three sentiment lexicons, i.e., W-WSD, SentiWordNet, TextBlob and two well known machine learning classifiers, i.e., Support Vector Machines (SVM) and Naive Bayes. They achieved better classification results with the W-WSD sentiment lexicon.
In [
10], authors utilized tweets to predict the sentiment about Islamic State of Iraq and Syria (ISIS); opinions are organized based on their geographical location. To perform the experimental evaluation, they collected tweets for a period of three days and used Jeffrey Breen’s algorithm with data mining algorithms such as Support Vector Machine, Random Forest, Bagging, Decision Trees and Maximum Entropy to classify tweets related to ISIS.
The paper [
8] presents a study where the authors exploit tweets to find out political friends. They named their approach a “Politic Ally” which identifies the friends having the same political interest.
2.4. Phishing and Spamming
Aspects related to phishing and spamming can be addressed by analyzing micro-blogs as well, and are close to the problem of topic discovery.
The work [
21] proposed an effective security alert mechanism to contrast phishing attacks which targeted users on social networks such as Twitter, Facebook and so on. The proposed methodology is based on a supervised machine learning technique. Eleven critical features in messages were identified: URL length, SSL connection, Hexadecimal, Alexa rank, Age of domain-Year, Equal Digit in host, Host length, Path length, Registrar and Number of dots in host name. Based on these features, messages were classified, to build a classification model able to identify phishing.
Similarly, to deal with spam content being shared on twitter by spammers, Washha et al. [
22] introduced a framework called Spam Drift, which combined various classification algorithms, such as Random Forest, Support Vector Machines (SVM) and J48 [
23]. In short, they developed an unsupervised framework that dynamically retrains classifiers, used during the on-line classification of new tweets to detect spam.
2.5. Frameworks for Topic Discovery (Interest Mining)
As far as topic discovery (or user interest mining) is concerned, the work [
24] proposed a framework for “Tweets Classification, Hashtags Suggestion and Tweet Linking”. The framework performs seven activities: (i) data-set selection; (ii) pre-processing of data-set; (iii) separation of hashtags; (iv) finding relevant domain of tweets; (v) suggestion of possible interesting hashtags; (vi) indexing of tweets; (vii) linking of tweets. Thus, topics are represented by hashtags, that are suggested to users. With respect to our approach, discovered topics are very fine grained (at the level of hashtags), because the idea is to suggest hashtags to follow, not users.
In a similar study [
25], to detect user interests by automatically categorizing data on the basis of data collected from Twitter and Reddit, authors proposed a methodology comprised of two steps. (i) multi-label text classification model by using Word2vec [
26], a predictive model and (ii) topic detection by using Latent Dirichlet Allocation (LDA) [
27], a statistical topic detection model based on counting word frequency from a set of documents. A pool of 42,100 documents collected from Redit and manually labeled was used to train the model; then, a pool of 1,573,000 tweets (posted by 1573 users) was used as training set. This work is interesting because it uses Reddit to build the classification model to classify unlabeled tweets from Twitter. However, the scenario is quite different with respect to our paper: in fact, we propose that users wishing to be influencers voluntarily label their posts, with the goal to be recognized as influencers.
The work [
28] presents a web-based application to classify tweets into predefined categories of interest. These classes are related to health, music, sport, and technology. The system performs various activities. First of all, they fetch tweets from Twitter and pre-process them; second of all, feature selection from texts is performed; finally, the machine learning algorithm is applied. Although, from a general point of view, it is an interesting system, it is designed to perform analysis of messages from outside the micro-blog. In contrast, our goal is to find out the best technique suitable to discover topics within the micro-blog application.
So, we can say that our envisioned application scenario is quite novel; furthermore, the specific goal of the investigation framework presented in this paper is not to be the end-user solution, but a tool to discover the technique that is most suitable to be executed within the micro-blog application to discover topics.
2.6. Recommendation Techniques
Recommendation techniques have been proposed in the social network world by a multitude of papers. They are so many that it is impossible to report them all. Hereafter, we report those that we consider representative of most recent developments.
The Reference [
29] proposed a Recommendation System for Podcast (RSPOD). The system recommends podcasts, i.e., audios, to listen to. The system utilizes the intimacy between social network users, i.e., how well they virtually communicate with each other. RSPOD works (i) by crawling podcast information, (ii) by extracting data from social network services and (iii) by applying a recommendation module for podcasts.
To predict user’s rating for several items, [
30] considers social trust and user influence. In fact, it is argued that social trust and influence of users can play a vital role to overcome the negative impact on the quality of recommendation caused by sparsity of data. The phenomenon of social trust is based on the sociology theory called “Six Degrees of Separation” [
31]: the authors proposed a framework that jointly adopts user similarity, trust and influence, by balancing preferences of users, trust between them and ratings from influential users for recommending shops, hotels and other services. The proposed framework was applied on a data set collected from
dianping.com, a Chinese platform that allows users to rate the aforementioned services.
According to Chen et al. [
32], previous recommendation systems mainly focus on recommendations based on users’ preference and overlook the significance of users’ attention. Influence of trust relation dwells more on users’ attention rather than users’ preference. Therefore, an item of a user’s interest can be skipped if it does not get his attention. To counter this, they proposed a probabilistic model called Hierarchical Trust-Based Poisson Factorization, which utilizes both users’ attention and preferences for social recommendation of movies, music, software, television shows and so on.
Similarly, [
33] aimed at accurately predicting users’ preferences and relevant products recommendation on social networks by integrating interaction, trust relationships and popularity of products. The key focus of the proposed model is on performing analysis of users’ interaction behavior to infer users’ latent interaction relationships, based on product ratings and comments. Moreover, the popularity of product is considered as well, to help support decision making for purchasing products.
By emphasizing on the importance of social interaction on recommendation systems [
34], presented an approach based on mapping the weighted social interaction for representing interactions among users of a social network, by including historical information about users’ behavior. This information is further mined by using an algorithm called Complete Path Mining, which helps find similar social neighbors possessing similar tastes as of the target user. To predict the final ratings of unrated items (such as software, music, movie and so on), the proposed model uses social similar tendencies of the users on complete paths.
To summarize, the reader can see that recommendation techniques are thought to recommend single items (such as posts, podcasts or products) to users, based on the existing relationships among users. Li et al. [
35] address the same general problem that we envision in our application scenario, i.e., recommending users to follow: they propose a framework to recommend the 50 users that are more similar to a specific user; they jointly exploit user features (such as ID, gender, region, job, education and so on) and user relationships. In contrast, in our envisioned scenario, we propose a different approach, i.e., recommending other users to establish a relationship with (e.g., to follow) on the basis topics their posts talk about. At the best of our knowledge, this problem has not been addressed yet in literature.
3. Scenario and Problem Statement
In this section, we illustrate the application scenario we are considering, in order to define the problem we address in the rest of the paper.
Suppose a user of a micro-blog platform wants to look for other users to follow, in order to receive their posts. How to find them? Currently, both micro-blog apps and the web sites provide a search functionality to search for users on the basis of a keyword-based search. So, the activity a user has to perform to find out interesting users to follow, that is depicted in the right-hand side of
Figure 1 (the block titled
Current Scenario), can be summarized as follows.
User performs a keyword-based search, hoping that the specified keywords find out actually interesting users. The search provides the list of users denoted as .
For each user (or for many of them), user opens ’s profile and looks at it and at messages posted by ; if finds that is interesting, asks to follow .
Such a process is quite tedious and boring, so probably user could miss interesting users to follow.
In contrast, we envision a novel functionality for micro-blog apps and web sites: suggesting users based on similar interests. Let us clarify our vision:
User starts posting some messages, possibly re-posting messages received from followed users.
At a given time, the application suggests with a list of users potentially having the same interests.
User looks at the profile of some user and, if finds that is interesting, decides to start following .
Clearly, it is necessary to devise a technique able to learn about user interests. This must necessarily be a multi-label classification technique, that based on the analysis of features extracted from posted messages, builds a model of user interests on the basis of these features.
So, the application scenario we envision, that is illustrated in the left-hand side of
Figure 1 (the block titled
Proposed Scenario), can be described as follows.
Mobile app and web site of a micro-blog should be extended, in order to provide two new functionalities: Associating Topics to Posted Messages and Suggesting Users with Similar Interests.
The functionality named Associating Topics to Posted Messages should allow users to associate topics to each single post, at the moment they are posting it. A topic will play the role of classification label for the post. This functionality should be not mandatory, and could be appreciated by influencers, i.e., users that are able to (or would like to) influence other users.
A classification model for topics should be built by analyzing posts that are labeled with topics, on the basis of features extracted from within posted messages.
The functionality named Suggesting Users with Similar Interests applies the classification model to unlabeled messages posted by a user, in order to automatically associate topics to unlabeled messages. Once the most frequent topics in unlabeled messages posted by user are collected, the application suggests the list of users possibly posting messages concerning the same topics of interest for .
User can inspect the profiles of users in S and choose the ones to follow, if any.
In order to avoid misunderstandings, we clearly state that we do not consider two different types of users, i.e., influencers and regular users: any user is equal to other users. However, if a users wishes to be recognized as an influencer, she/he can better succeed if the micro-blog platform provides a tool that helps achieve this aim. In fact, the basic condition for a user to be considered as an influencer is that the number of followers is significantly high; thus, a tool that recommends potential interesting users is the solution. Such a tool could integrate classical text-based search: in fact, we can envision that the micro-blog platform is pro-active in suggesting users; furthermore, text search could be too fine grained to be successful. In other words, we explore the possibility to improve the service provided by micro-blog platforms to users, both those who wish to become influencers and those who wish to find out possibly interesting and emerging influencers.
Clearly, the basic brick to be able to develop the envisioned functionalities is to be able to assign the proper topic to unlabeled messages. The main goal of this paper is to investigate if there exists a classification technique that is suitable for this task, both in terms of effectiveness and in terms of efficiency. The specific problem that must be addressed by the wished technique is defined as follows.
Problem 1. Consider a setof labeled posts; eachdenotes a labeled post, whereis the message text andis the assigned topic.
Consider a second setof unlabeled messages. Based on the set of labeled posts, a classification modelmust be built, such that given a message text,, i.e., the classification model C provides the topicof themessage.
In the rest of the paper, we will address Problem 1, looking for the technique based on text classification that provides the best compromise between accuracy (as far as topic detection is concerned) and efficiency. In fact, if we are able to demonstrate that there exists a technique suitable to solve Problem 1, the way to further investigate how to rank influencers to suggest to users can be taken.
4. The Investigation Framework
In this section, we introduce the framework we built to investigate how to discover topics messages talk about, as reported in Problem 1. First of all, we discuss the dimensions of investigation we considered (
Section 4.1); then, we present technical aspects of the framework in details.
4.1. Dimensions of the Investigation
Problem 1 is a multi-label text classification problem. Thus, through the investigation framework, two dimensions must be investigated.
Feature extraction. Message texts must be represented by means of a pool of features, that denote texts at a level of granularity that makes the classifier effective. However, many patterns of features can be adopted to represent texts: so effectiveness and efficiency of classifiers are significantly affected by the specific feature pattern adopted to represent texts.
Classification technique. Different classification techniques behave differently, so it is necessary to evaluate the behavior of a pool of classification techniques.
Figure 2 graphically reports the dimensions of the investigation: the reader can see that the two dimensions are orthogonal. Thus, the goal of the investigation framework is to experiment all combinations, in order to find the best one to solve Problem 1. Hereafter, we separately discuss each dimension.
4.1.1. Feature Extraction
In order to apply the classification technique, we need to extract features to classify from texts, in order to obtain a different representation of texts. We decided to adopt the n-gram model, that is widely adopted in text classification.
Hereafter, we shortly introduce the four basic n-gram patterns we adopted in our investigation.
Uni-gram patterns. In our model, a uni-gram is a single word (or token) that is present in the text. Uni-gram patterns are singleton patterns, i.e., a single word is a pattern itself (i.e., n-grams with ).
Uni-gram patterns do not consider the relative position of words in the text.
Bi-gram patterns. A bi-gram is a sequence of two consecutive uni-grams (n-grams with ), i.e., two consecutive words in the text.
Tri-gram patterns. A tri-gram is a sequence of three consecutive uni-grams (n-grams with ), i.e., three consecutive words in the text.
Quad-gram patterns. A quad-gram is a sequence of four consecutive uni-grams (n-grams with ), i.e., four consecutive words in the text.
With these premises, we can represent a document d (a message text, in our context) as a vector of terms, i.e., is the j-th term in the document. When we consider n-grams, the document is represented as a vector of n-grams, i.e., is the n-gram whose first word is in position j in the original document (of course, if , the vector of uni-grams and the vector of words coincide.).
Table 1 reports four different ways of representing a sample document, based on uni-grams, bi-grams, tri-grams and quad-grams, by reporting the different vectors that represent the same document. For example, if we consider the case
in
Table 1,
d contains only two items, i.e.,
and
.
Moving from the methodology proposed in [
36], we consider also combined features, i.e., features obtained by combining basic features (i.e., uni-grams, bi-grams, tri-grams and quad-grams).
Given z sets of basic features , with , a set of complex features is obtained by means of the Cartesian product of sets , i.e., . Thus, a feature in is a tuple of z basic features (n-grams).
As an example, consider
Table 1. A feature obtained by combining a uni-gram and a bi-gram is the tuple
.
In our framework, we considered the four basic feature patterns and five complex feature patterns. In
Table 2, we report them and the corresponding abbreviation we will use throughout the paper.
Feature weight. In order to help the construction of the classification model, features are weighted. Typically, in text classification the most-frequently adopted metric is
Term Frequency-Inverse Document Frequency (TF-IDF) [
37]. It is a numerical score which denotes the importance of a term in a collection of documents. TF-IDF is the combination of two scores which are called
Term Frequency and
Inverse Document Frequency. The comparative analysis in [
38] demonstrated that TF-IDF significantly improves the effectiveness of classifiers.
The score balances the importance of a term for a given document with respect to its capability of characterizing a small number of documents. The rationale is that if a term is highly frequent in the collection, it does not characterize a subset of documents; thus, terms that appear in many documents cannot be considered relevant features for any document.
Consider a set
of documents, where each document
is a vector of terms (in the broadest sense, i.e., terms can be either n-grams or tuples of n-grams). The Term Frequency
) of a term
t in a document
d is the number of times
t appears within
d on the total number of terms in
d (see [
39]). It is defined as:
The Inverse Document Frequency
) of a term
t in the collection (of documents)
D measures the capability of
t of denoting a small set of documents in
D: the lower the number of documents in which
t appears, the greater its
score [
39]. It is defined as:
By combining
and
, we obtain the overall
score of a term
t within a document
d belonging to a collection of documents
D, as follows:
In our model, terms are either basic n-grams (basic feature patterns denoted as
U,
B,
T and
Q), or combined n-grams, such as
U,B and so on (see
Table 2): thus, we apply the
metric to rank these features. However, we do not compute TF-IDF on a document basis, but on a class basis: the frequency of a term is the number of documents in the class that contain the term; the inverse document frequency should be properly called
Inverse Class Frequency, because we count the number of classes that contain the term on the total number of classes. Formula
1 formally defines the weight.
in other words, the weight of a term
t in a class
is the frequency of
t within the documents that belong to that class, multiplied by the inverse frequency of
t among all classes in
C. Notice that with
we denote the class which document
d belongs to.
In
Section 5.2, we perform experiments with the full set of features and with the strongest 80%, 65% and 50% features, on the basis of function
defined in Formula
1.
4.1.2. Classification Techniques
The second dimension of investigation is to find out the classification technique that demonstrates to be more suitable for the application scenario. Recall from Problem 1 that the classifier has to discover the topic that an unlabeled message talks about. Hereafter, we briefly introduce the four classification techniques we considered in our investigation framework.
Naive Bayes (NB). The Naive Bayes classifier [
40] is a simple, fast, efficient, easy to implement and popular classification technique for texts: in fact, this technique is quite efficient as far as computation time is concerned; however, it performs well when features behave as statistically independent variables.
In short, it is a probabilistic classification technique, which completely depends on the probabilistic value of features. For each single feature, the probability that it falls into a given class is calculated.
It is widely used to address many different problems, such as for predicting social events, for denoting personality traits, for analyzing social crime, and so on.
Support Vector Machine (SVM). Support Vector Machine classifiers are widely used for classification of short texts. This classification technique is based on the principle of structured risk minimization [
41]: given the hyper-space of features, in which each point represents a document, it creates a hyper-plane
h that divides the data into two sets (i.e., the hyper-space is divided into two semi-spaces by the hyper-place); the algorithm tries to identify the hyper-plane that maximizes the distance from each point (the distance is called
margin) because the greater the margin, the lower the risk that a point falls into the wrong semi-space. In the test phase, a data point is categorized depending on the semi-space it falls into. The technique has been extended and adapted to support multi-label classification [
42].
K-Nearest Neighbors (kNN). K-Nearest Neighbors (kNN) classifiers are widely used for classification of short texts. During the test phase, given a new document
, the distance between document
and all the documents in the training corpus is measured, by employing a similarity or a dissimilarity measure. Then, the set
that contains the
K nearest neighbors among the entire training corpus is obtained; the class label having the largest number of documents in
becomes the class of
[
43]. For example, if
contains 15 nearest neighbors to document
, where seven documents are labeled with the
"politics" class, four documents are labeled with the
"sports" class, three documents are labeled with the
"weather" class and one document is labeled with the
"health" class, then
is labeled with the
"politics" class.
Random Forest (RF). It is a known supervised learning method for classification devised by Ho [
44]. It is an evolution of classical tree-based classifiers. The name of the technique is motivated by the fact that, during the training phase, many classification trees are generated: we can say that the classification model is a
forest of classification trees. During the test phase, all the classification tress are independently used to classify the unclassified case: the class assigned by the majority of trees is chosen as class label assigned to the unclassified case.
This technique is very general and widely used in many application contexts, not only for text classification [
45].
4.2. Framework Overview
The investigation framework is composed of many modules. First of all, we give a high-level overview of them, describing the task performed by each single module.
Module M1-Pre-processor. The module named Pre-processor performs many pre-processing activities on the data set, i.e., the set of labeled messages that constitutes the input data set for the investigation framework. Specifically, it performs tokenization, stop-word removal, special symbol elimination, and stemming (that are typical pre-processing techniques adopted in information retrieval). Specifically, stemming is important to reduce dimensionality of features: in fact, natural languages provide many different forms for the same word (for instance, singular and plural); stemming reduces words to the root form.
The result of the Pre-processor module is the corpus of messages, where each document is represented as an array of stems.
Module M2-Feature Extractor. After the
Pre-processor is executed, the module named
Feature Extractor extracts features that represent messages. In this module, messages are translated into vectors of basic and combined feature patterns, as reported in
Table 2. The
score defined in Formula
1 is computed for each term (i.e., feature) belonging to the training set.
Module M3-Multi-Classifier. The final module is called
Multi-Classifier, because it has to apply all the four different classification techniques we discussed in
Section 4.1.2. In fact, the goal of the investigation framework is to understand which is the best combination of feature pattern and classification technique (recall
Figure 2). Thus, for each feature pattern, the module builds four classification models and tests them to evaluate the accuracy of classification.
Figure 3 reports the organization of the framework, by illustrating data flows between and inside modules. They are discussed in details hereafter.
The framework is implemented in the Python programming languages, by exploiting the libraries nltk for pre-processing, sklearn for feature extraction, generation of n-gram combinations, training and testing of classifiers.
4.2.1. External Module EM1-Message Collector
This module is responsible to gather messages from the source micro-blog (in our case, Twitter) and support researchers to label messages with class labels denoting topics.
Since our investigation framework is designed to be independent of the specific source micro-blog, we decided to consider it as an external module that can be replaced with a different one, suitable to gather data from a different micro-blog.
4.2.2. Module M1-Pre-Processor in Details
When users write messages, they write punctuation, single characters and stop-words that are not useful for topic classification (and even decrease the accuracy of classification). So, before features are extracted, messages must be pre-processed in order to be cleaned from noise. Specifically, module Pre-processor performs text tokenization, special symbol removal, stop-words filtering and stemming. Hereafter, we describe these activities in more details.
Let us denote the input data set as , where each is a labeled message, such that , i.e., is the message text and is the label class or topic associated to the message.
For each message , on its message text the module performs the following processing steps, in order to generate the set of pre-processed messages.
The message is tokenized, in order to represent it as a vector of terms, where a term is a token found within the message text.
From vector , we obtain vector by removing special symbols, punctuation marks, numbers and special characters.
Stop-word removal is performed, by comparing each term in
with
[
46], a static list of stop-words. We formalize this process by defining the recursive function
hereafter.
where
d is the message represented as a vector of terms,
is the size of the vector,
denotes a position index,
denotes the term (string within vector
d in position
),
denotes the length of the term (string) in position
in vector
d. Furthermore,
is the list of stop-words, while function
removes the item in position
from vector
d. The function is defined by the following formula.
where with
we denote the sub-vector with items from position
i to position
j and the • denotes an operator that concatenates two vectors.
The vector representing the message without stop-words is obtained by calling the function as .
After stop-word removal, stemming is performed on vector
by applying the
Porter stemming algorithm [
47]; we obtain the final
vector, i.e., the vector of terms that represent the
message text after pre-processing. The
vector is paired with the class label
, obtaining the pair
that is inserted into
, the set of pre-processed messages.
is the final output of this module: the source data set T has been transformed into , where instead of strings, message texts are represented by vectors of terms.
4.2.3. External Module EM2-Data Splitter
The pre-processed data set is now split into training set and test set . The training set becomes the input of module M2-Feature Extractor, while the test set will be used by module M3-Multi-classifier, for computing the accuracy. Notice that contains labeled messages: this is necessary for validating classification and compute the accuracy, by computing true positives, false positives, true negatives and false negatives simply by comparing the topic assigned by the classifier to the message and the label originally associated with the message.
This is an external module of the investigation framework, if compared to modules M1, M2 and M3, that are the core modules of the framework. This choice is motivated by the need for flexibility. In fact, different techniques for splitting could be used; this way, the investigation framework is parametric with respect to data splitting.
4.2.4. Module M2-Feature Extractor in Details
Module
M2-Feature Extractor receives the training set
extracted from the overall set of pre-processed messages
. Its goal is to give different representations of each labeled message
, based on the basic and combined feature patterns reported in
Table 2.
The module generates nine different versions of the training set
, one for each feature pattern, denoted as
,
,
,
,
,
,
,
and
. These are intermediate results, necessary to generate the actual output of the module, i.e., a pool of feature vectors
(where
denotes the feature pattern, as in
Table 2): each
contains a feature vector for each topical class. Let us start by describing the generation of
First, , because uni-grams coincide with single terms in vectors representing message texts (i.e., ).
Each derives from the corresponding basic version , where is a vector of bi-grams.
Similarly, training sets and contains descriptions and of messages whose vectors and are vectors of tri-grams and quad-grams, respectively.
Training sets based on combined feature patterns are derived from training sets based on basic patterns.
Given a message , its representations based on combined feature patterns are obtained as follows:
- –
for , ;
- –
for , ;
- –
for , ;
- –
for , ;
- –
for , .
Once the training sets are prepared, for each of them (that generically we will denote as ) the module performs the following activities.
For each message
, a set of terms
is derived from the vector of terms
:
so that duplicate occurrences of a term in
becomes a unique occurrence in
.
The frequency matrix
is built, where
t is a term and
c is a class (or topic). To obtain the
matrix, first of all the module builds
, a set of (term, class, message identifier) triples
obtained as
that is, by performing the Cartesian product among the set
of terms in the message, the singleton set of the class label (topic)
associated to the message and the singleton set containing
i (i.e., the identifier of the message). All the
sets are united into the
set, i.e.,
.
Each single item of the
matrix is then computed as follows:
where we count, for each term
t and each class
c, the number of different documents, associated to class
c, which term
t occurs in (the third element
in triples is necessary to distinguish term occurrences coming from different messages).
For each term
t in each class
c, the module computes the
score (defined in Formula
1), where
C is the set of all class labels. We denote the weight for the feature pattern
as
; it is defined as:
where
C is the overall set of class labels. In the product on the right-hand side of the formula, the first operand is the term frequency, while the second operand is the inverse document frequency.
Finally, for each class , the feature vector for the given feature pattern is built, where each item is a pair , where t is the term and is the weight.
The sets
of feature vectors
, where
denotes the feature pattern (as in
Table 2), are the final output of module M2.
4.2.5. Module M3-Multi-Classifier in Details
Module
M3-Multi-classifier performs the last step of the investigation process, i.e., it builds the classification models by training the classifiers, then exploits the classification models to label the test set. It is called
multi-classifier because it uses all the four classification techniques shortly presented in
Section 4.1.2, to train a classification model and label the test set.
Let us describe the process performed by Module M3 in details. The module receives two inputs: the pool of feature vector sets , , , , , , , and , generated by module M2, and the test set , generated by the external module EM2. For each one of the training sets and for each one of the classification techniques, the module performs the following activities.
The specific classification technique (Naive Bayes, SVM, kNN and Random Forest) is applied, to obtain a classification model (where is the feature pattern and is the classification technique) for each feature pattern, using the corresponding as training set.
For each classification model , the messages in the test set are labeled accordingly. The classified test sets so far obtained contain both the labels provided by the classifier and the labels assigned by humans that prepared the overall data set.
At this point, the module performs the accuracy evaluation, i.e, it evaluates accuracy of classification for all the classified test sets, in order to produce a final report, that is the outcome of the investigation framework.
5. Experimental Evaluation
The investigation framework was run on a data set specifically collected. In
Section 5.1, we present both the way we collected and prepared the data set, as well as the metrics we adopted to evaluate the classification results. In
Section 5.2, we present the experiments and discuss the results, as far as the effectiveness of classification is concerned, while in
Section 5.3 we present the sensitivity analysis of classifiers.. Then,
Section 5.4 considers execution times and introduces the metric called
Suitability.
5.1. Data Preparation and Evaluation Metrics
To perform the experimental evaluation through the proposed investigation framework, we performed data collection and labeling. Data collection is the process of collecting messages (from Twitter) that are relevant to the problem domain. It is a crucial step, because it strongly determines the results obtained by classifiers. Messages were collected from Twitter by using Tweepy API [
48]; 133,306 messages were collected from different accounts.
The next step was to manually label the messages with a pool of predefined topics. In this process, we involved five volunteer students of the Masters degree at University of Sialkot (Pakistan), to label messages. Each message was labeled by two different students, that worked separately: in the case two different labels were assigned to the same message, the message was discarded from the data set. This way, only messages labeled with the same class by two different students were considered: messages that did not clearly talk about one of the selected topics were not considered.
Hereafter, we list the topics considered as classes and the criteria adopted for labeling messages with each single topic.
Business: Messages talk about stocks, business activities, oil prices, Wall Street and companies’ shares.
Health: Messages that talk about disease, medicine, surgeries, viruses, hospitals and related arguments are included in this topic.
Politics: Messages regarding elections, democracy, government and its policies are included in this topic.
Entertainment: Messages regarding show business, movies, music, TV shows and similar arguments belong to this topic.
Sports: Messages regarding all kinds of sports, athletes, matches and sports tournaments belong to this topic.
Technology: Messages talk about new tech, gadgets, software and related information.
Weather: Messages talk about weather, rains, storms and weather forecasting.
The list of topics was inspired by [
49], that proposed a list of categories for classifying sensitive tweets; we did not consider all the list proposed in [
49], because some of the proposed categories did not denote topics that users would use to label messages (e.g., racism); we selected and integrated those that, presumably, could be often used by users.
Table 3 provides a sample message for each one of the topical classes.
In order to have a homogeneous distribution among classes, the training set contained 3500 messages for each class, while the test set contained 1500 messages for each class. Consequently, the training set contained 24,500 messages, while the test set contained 10,500 messages; the total number of messages was 35,000, that constitute the input for the investigation framework. All messages were written in English.
Remember that messages in the test set were labeled by hand as well, in order to allow module M3 to automatically compute accuracy.
To evaluate the results, the investigation framework computed accuracy, precision, recall and F1-measure. These measures are typical metrics adopted in information retrieval. Since we operated in a context of multi-label classification, we adopted the definitions reported in [
50,
51].
Given a set of class labels, for each class we define the following counts:
(true positives) is the number of items correctly assigned to class ;
(false positives) is the number of items incorrectly assigned to class ;
(false negatives) is the number of items incorrectly not assigned to class ;
(true negatives) is the number of items correctly not assigned to class .
For each class , we can define the four above-mentioned metrics.
Accuracy is the number of messages properly associated and properly not associated with class on the total number of messages, i.e., .
Precision is the fraction of messages correctly labeled with class on the total number of messages labeled with by the classifier, i.e., .
Recall is the fraction of messages properly labeled with class on the total number of messages that have to be labeled with , i.e., .
F1-measure is a synthetic measure that combines precision and recall, i.e., F1-measure.
Since we are in a context of multi-label classification, we have to compute a general global version of each measure. This is usually done by averaging the values computed for each class. Consequently, , , , F1-measure.
We are now ready to discuss the results of our investigation, based on the two dimensions discussed in
Section 4.1.
5.2. Experiments and Comparison of Classifiers
Based on the dimensions of investigation discussed in
Section 4.1, we performed a large number of experiments, that involved the four classification techniques presented in
Section 4.1.2.
Let us start considering the results obtained by the Naive Bayes classifier.
Table 4 is organized as follows: for each basic n-gram pattern, i.e.,
U,
B,
T and
Q, as well as for each combined feature pattern
U,B,
B,T,
T,Q,
U,B,T and
U,B,T,Q, the full set of features (100%) and the most relevant 80%, 65% and 50% of features, on the basis of their weight defined in Formula
1 are used to perform experiments.
Similarly,
Table 5 shows the results obtained by applying the kNN classification technique to the same feature patterns previously discussed; in the same way, we report the sensitivity analysis for each feature pattern.
Table 6 reports the results obtained by applying the SVM classification technique, while
Table 7 reports the results obtained by applying the Random-Forest classification technique.
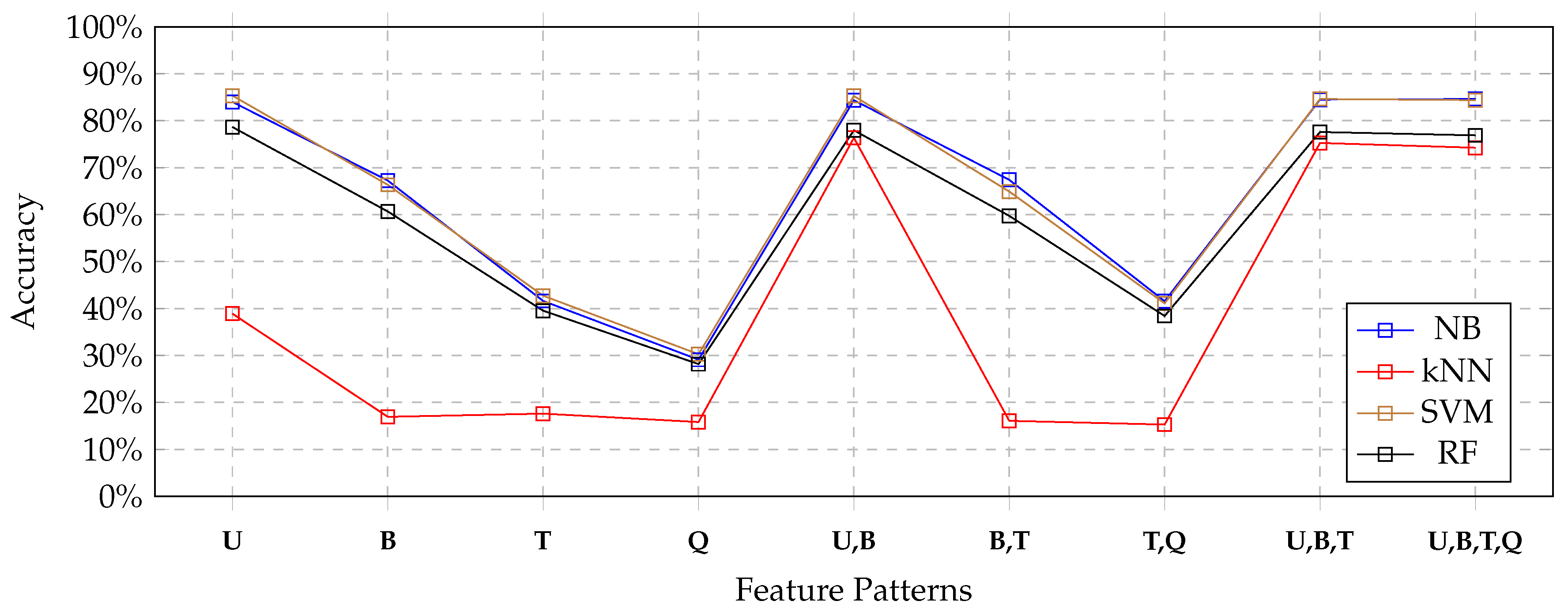
Figure 4 depicts the results obtained by each classifier for all feature patterns by using the full set of features extracted from the training set. The blue line depicts the results obtained by the Naïve Bayes classifier; the red line depicts the results obtained by the kNN classifier; the brown line depicts the results obtained by the SVM classifier, the black line depicts the results obtained by the Random-Forest classifier.
We can notice that the Naïve Bayes classifier (blue line) always performed as the best classifier, always obtaining the highest accuracy. The SVM classifier (brown line) performed only a little bit worse, but results were comparable. The Random Forest classifier still showed comparable accuracy, even though a little bit less than Naïve Bayes and SVM classifiers.
In contrast, the inability of the kNN classifier to exploit most of feature patterns was evident. In details, we noticed that for U, U,B, U,B,T and U,B,T,Q feature patterns, the kNN classifiers obtained results that were comparable with the other classifiers. Instead, for feature patterns that did not include uni-grams, the kNN classifier obtained very poor results.
Nevertheless, notice that the other three tested classification techniques suffered for the absence of uni-grams in the feature sets as well, even though they behaved better than the kNN classifier.
If we focus on results obtained by each classifier for feature patterns that contain uni-grams, it clearly appears that no advantage was obtained by combining uni-grams with other features. Looking at
Table 4, we see that the Naïve Bayes classifier obtained a very slight improvement; in contrast, looking at
Table 5,
Table 6 and
Table 7, we can see a slight deterioration of accuracy, when comparing the
U pattern with
U,B,
U,B,T and
U,B,T,Q combined patterns.
5.3. Sensitivity Analysis
We can now consider the sensitivity analysis we performed. Recall that, apart from the full set of features, we also considered the best 80%, 65% and 50% of features, on the basis of the weight defined in Formula
1.
Figure 5,
Figure 6 and
Figure 7 depict the results so far obtained, respectively, with the 80%, 65% and 50% of features. In the 80% case (
Figure 5), no significant variations appeared: the performances obtained by all classifiers were, more or less the same. This is also confirmed by looking at the tables, that show very small reductions of accuracy. Nevertheless, the general behavior of the four classifiers remained exactly the same as for the full set of features. Consequently, we could argue that it was not the case to use the full set of features for training the classifiers, so as to save time and computational power.
Considering the 65% case (depicted in
Figure 6), and the 50% case (depicted i
Figure 7), we still observed a very slight reduction of accuracy. Only the kNN classifier behaved significantly worse with uni-gram patterns in the 50% case; nevertheless, looking at
Figure 7, we notice that with patterns
U,B,T and
U,B,T,Q, the combined feature patterns that contained uni-grams helped the classifier to obtain good results.
In effect, looking at
Table 5, we can see that both precision and recall strongly penalized the kNN classifier, with respect to the other competitors. This happened with all feature patterns.
5.4. Execution Times and Suitability Metric
Based on accuracy, the kNN classifier was not suitable for the investigated application context, while the other classifiers showed comparable performance. However, the cost of computation is an important issue, thus we also gathered execution times both for training and testing.
We performed experiments on a PC powered by Processor Intel(R) Core(TM) i7-5600U, with clock frequency of 2.60 GHz, equipped with 8 GB RAM; the operating system was Windows 10 Pro (64 bit).
Table 8 reports the execution times shown by the four classifiers on the full set of features, for the most promising feature patterns, i.e.,
U,
U,B,
U,B,T and
U,B,T,Q. Specifically, we evaluated execution times during the training phase and during the test phase; notice that we also measured the execution times concerned with feature extraction, so as to understand how heavy the computation of Cartesian products of features was.
The first thing we can notice is that feature extraction was performed in a negligible time, if compared with the actual training performed by the classifier; even in the case of the most complicated feature pattern (i.e., U,B,T,Q), this time was negligible. Nonetheless, to obtain a given feature pattern, experiments confirmed that the library we adopted was deterministic, since the execution time was independent of the specific attempt.
In contrast, looking at the execution time for model building, the reader can see that there were significant differences. Consequently, in order to choose the best classifier, the cost of computation should be considered. For this reason, we defined a cost-benefit metric, in such a way accuracy represents the benefit, while execution time represents the cost. We called this metric Suitability, because by means of it we wanted to rank classifiers in order to find out the one that was suitable for our context.
Consider a pool of experiments
, where for an experiment
we refer to its accuracy as
, to its training execution times as
(the execution time shown during the training phase) and to the test execution times as
(the execution time shown during the test phase). The
Training Suitability of an experiment is defined as
where
(i.e., the minimum training execution time).
is a importance weight of the difference between the training execution time of the
experiment and the minimum training execution time; we decided to set it to
, in order to mitigate the effect of execution times on the final score; in fact, with
, the penalty effect would be excessive.
Similarly, we can define the
Testing Suitability, defined in Formula
4.
where
(i.e., the minimum testing execution time among the experiments). Similarly to
,
is the relevance of the difference between execution time of the
experiment and the minimum testing time. We decided to set it to
as well.
Training Suitability and Testing Suitability ranked experiments by keeping the two phases (training and testing) separated.
In Formula
5, we propose a unified
Suitability metric.
i.e., the unified suitability is the weighted average of
Training Suitability and
Testing Suitability, where
balances the two contributions.
Table 9 reports the values of training suitability, testing suitability and unified suitability for the same experiments considered in
Table 8.
Figure 8 depicts the results, by using the same convention as in
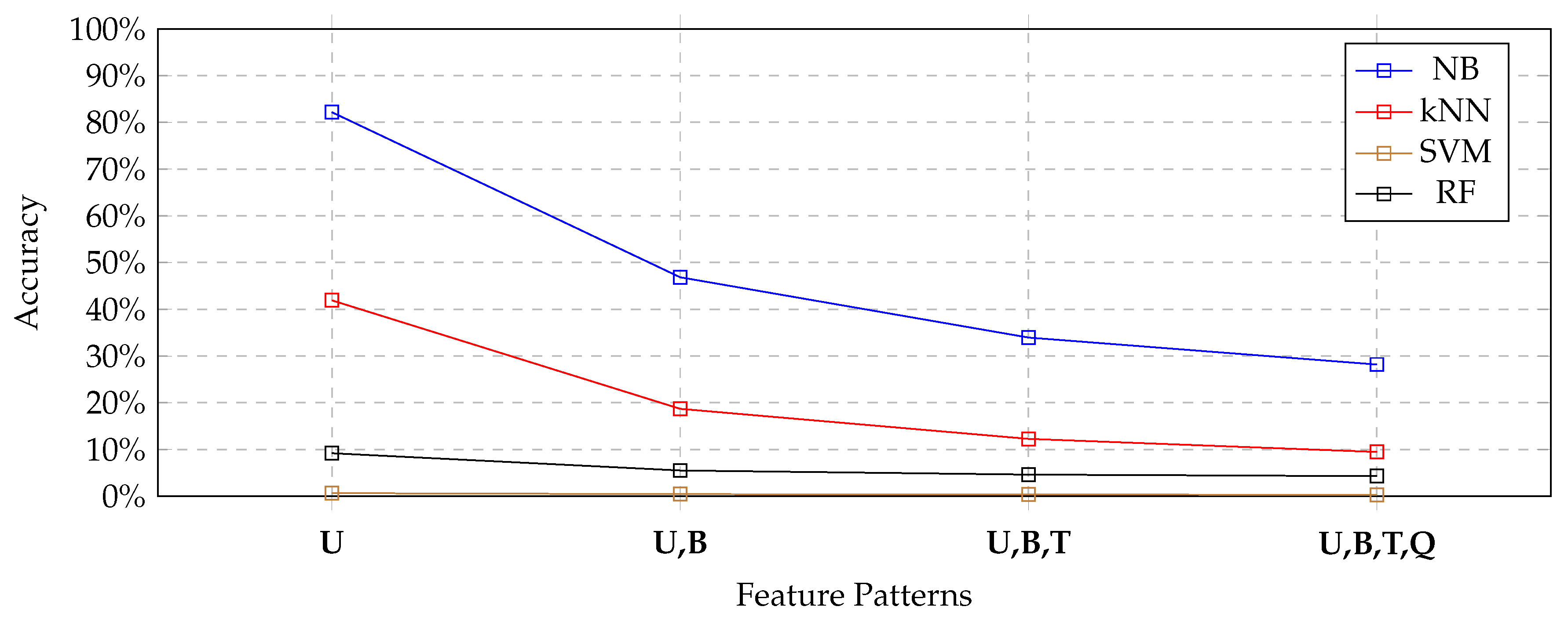
Figure 4, by using the unified suitability. The reader can see that the Naive Bayes classifier had the highest suitability values, due to its ability to combine high accuracy and very low execution times. Surprisingly, the kNN classifier obtained the second position; in fact, in spite of the fact that it obtained the worst accuracy values, it obtained the lowest execution times. Finally, the SVM classifier and the Random-Forest classifier were strongly penalized by their execution times.
Consequently, on the basis of
Table 9 and
Figure 8, we can clearly say that the Naive Bayes classifier applied to the feature pattern of uni-grams clearly emerged as the most suitable solution for our application context (presented in
Section 3) and specifically to solve Problem 1.
6. Conclusions and Future Work
In this paper, we have posed the basic brick towards the extension of micro-blog user interfaces with a new functionality: a tool to recommend users with other users to follow (influencers) on the basis of topics their message talk about. The basic brick is a text classification technique applied to a given feature pattern that provides good accuracy by requiring limited execution times. To identify it, we built an investigation framework, that allowed us to perform experiments, by measuring effectiveness (accuracy) and execution times. A cost-benefit function, called Suitability, has been defined: by means of it, we discovered that the best solution to address the problem is to apply a Naive Bayes classifier to uni-grams extracted from within messages, both to train the model and to classify unlabeled messages. We considered execution times because, in our opinion, the envisioned application scenario asks for fast functionalities; thus execution times emerge as critical factors. At the best of our knowledge, this comparative study of performances shown by classifiers, based on both accuracy and execution times, is a unique contribution of this paper.
The next steps towards the more ambitions goal of building a recommender system for influencers is to develop the surrounding methodology that actually enables to recommend influencers: in fact, once messages are labeled with topics, it is necessary to rank potential influencers, on the basis of the frequency with which they post messages about a given topic. This methodology will be the next step of our work.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}