Fast Self-Adaptive Digital Camouflage Design Method Based on Deep Learning

Abstract
1. Introduction
2. Literature Review
3. Methodology
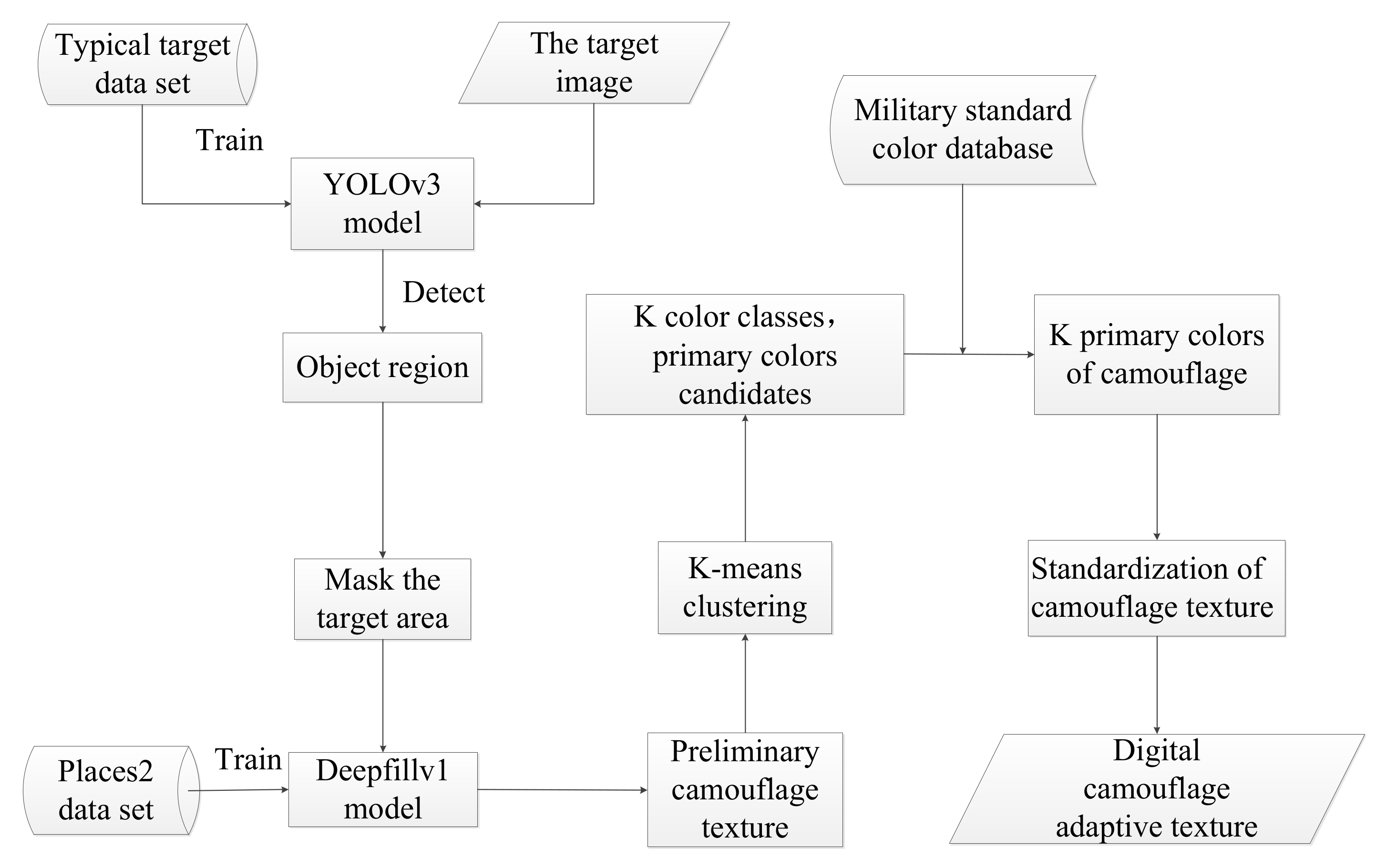
3.1. Outline of Proposed Method
3.2. Dataset
3.3. Military Target Detection Based on YOLOv3
3.4. Preliminary Camouflage Texture Design Based on Deepfillv1
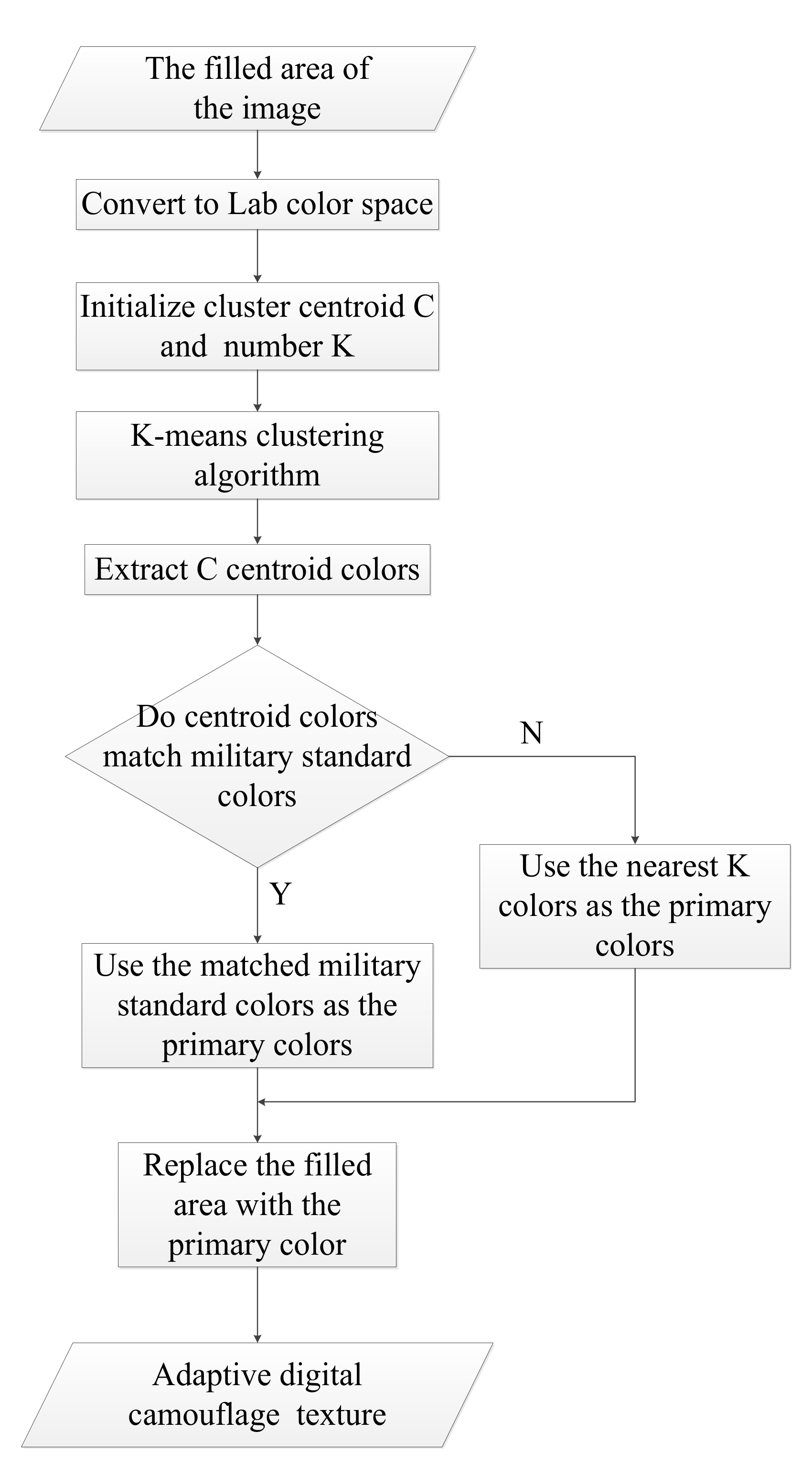
3.5. Standardization of Camouflage Texture based on K-means
- The primary colors should have different brightness so that the camouflage pattern could destroy the shape of the camouflaged target.
- The primary colors should not be too different from the background colors.
4. Results
4.1. Military Target Detection
4.2. Preliminary Camouflage Texture
4.3. Standardization of Camouflage Texture
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Talas, L.; Baddeley, R.J.; Cuthill, I.C. Cultural evolution of military camouflage. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2017, 372, 20160351. [Google Scholar] [CrossRef]
- Merilaita, S.; Scott-Samuel, N.E.; Cuthill, I.C. How camouflage works. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2017, 372, 20160341. [Google Scholar] [CrossRef] [PubMed]
- King, A. The digital revolution: Camouflage in the twenty-first century. Millenn. J. Int. Stud. 2014, 42, 397–424. [Google Scholar] [CrossRef]
- Chu, M.; Tian, S.H. An Extraction Method for Digital Camouflage Texture Based on Human Visual Perception and Isoperimetric Theory. In Proceedings of the 2nd International Conference on Image, Vision and Computing, Chengdu, China, 2–4 June 2017; pp. 158–162. [Google Scholar]
- Xue, F.; Xu, S.; Luo, Y.T.; Jia, W. Design of digital camouflage by recursive overlapping of pattern templates. Neurocomputing 2016, 172, 262–270. [Google Scholar] [CrossRef]
- Zylinski, S.; Darmaillacq, A.S.; Shashar, N. Visual interpolation for contour completion by the European cuttlefish (Sepia officinalis) and its use in dynamic camouflage. Proc. R. Soc. B Biol. Sci. 2012, 279, 2386–2390. [Google Scholar] [CrossRef]
- Kelman, E.J.; Osorio, D.; Baddeley, R.J. A review of cuttlefish camouflage and object recognition and evidence for depth perception. J. Exp. Biol. 2008, 211, 1757–1763. [Google Scholar] [CrossRef]
- Barbosa, A.; Allen, J.J.; Mäthger, L.M.; Hanlon, R.T. Cuttlefish use visual cues to determine arm postures for camouflage. Proc. R. Soc. B Biol. Sci. 2012, 279, 84–90. [Google Scholar] [CrossRef]
- Allen, J.J.; Mäthger, L.M.; Barbosa, A.; Buresch, K.C.; Sogin, E.; Schwartz, J.; Chubb, C.; Hanlon, R.T. Cuttlefish dynamic camouflage: Responses to substrate choice and integration of multiple visual cues. Proc. Biol. Sci. 2010, 277, 1031–1039. [Google Scholar] [CrossRef]
- Teyssier, J.; Saenko, S.V.; Van Der Marel, D.; Milinkovitch, M.C. Photonic crystals cause active colour change in chameleons. Nat. Commun. 2015, 6, 1–7. [Google Scholar] [CrossRef]
- Vigneron, J.P.; Pasteels, J.M.; Windsor, D.M.; Vértesy, Z.; Rassart, M.; Seldrum, T.; Dumont, J.; Deparis, O.; Lousse, V.; Biro, L.P.; et al. Switchable reflector in the Panamanian tortoise beetle Charidotella egregia (Chrysomelidae: Cassidinae). Phys. Rev. E Stat. Nonlin. Soft Matter. Phys. 2007, 76, 031907. [Google Scholar] [CrossRef]
- Zhao, Y.; Xie, Z.; Gu, H.; Zhu, C.; Gu, Z. Bio-inspired variable structural color materials. Chem. Soc. Rev. 2012, 41, 3297–3317. [Google Scholar] [CrossRef] [PubMed]
- Morin, S.A.; Shepherd, R.F.; Kwok, S.W.; Stokes, A.A.; Nemiroski, A.; Whitesides, G.M. Camouflage and display for soft machines. Science 2012, 337, 828–832. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Chen, X.; Liu, S.; Wong, C.; Chu, S. Mechanical Chameleon through Dynamic Real Time-Plasmonic Tuning. Acs Nano 2016, 10, 1788–1794. [Google Scholar] [CrossRef] [PubMed]
- Arsenault, A.C.; Míguez, H.; Kitaev, V.; Ozin, G.A.; Manners, I. Towards photonic ink (P-Ink): A polychrome, fast response metallopolymer gel photonic crystal device. Macromol. Symp. 2003, 196, 63–69. [Google Scholar] [CrossRef]
- Arsenault, A.C.; Puzzo, D.P.; Manners, I.; Ozin, G.A. Photonic-crystal full-colour displays. Nat. Photonics 2007, 1, 468–472. [Google Scholar] [CrossRef]
- Puzzo, D.P.; Arsenault, A.C.; Manners, I.; Ozin, G.A. Electroactive Inverse Opal: A Single Material for All Colors. Angew. Chem. Int. Edit. 2009, 48, 943–947. [Google Scholar] [CrossRef]
- Kim, H.; Ge, J.; Kim, J.; Choi, S.E.; Lee, H.; Lee, H.; Park, W.; Yin, Y.; Kwon, S. Structural colour printing using a magnetically tunable and lithographically fixable photonic crystal. Nat. Photonics 2009, 3, 534–540. [Google Scholar] [CrossRef]
- Yang, H.F.; Yin, J.P. An Adaptive Digital Camouflage Scheme Using Visual Perception and K-Mean Clustering. In Proceedings of the 3rd International Conference on Materials and Products Manufacturing Technology Guangzhou, Guangzhou, China, 25–26 September 2013; pp. 1091–1094. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolution networks for large-scale image recognition. arXiv e-prints 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Liu, Y.; Tao, Z.; Zhang, J.; Hao, H.; Peng, Y.; Hou, J.; Jiang, T. Deep-Learning-Based Active Hyperspectral Imaging Classification Method Illuminated by the Supercontinuum Laser. Appl. Sci. Basel 2020, 10, 17. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Murthy, C.B.; Hashmi, M.F.; Bokde, N.D.; Geem, Z.W. Investigations of Object Detection in Images/Videos Using Various Deep Learning Techniques and Embedded Platforms-A Comprehensive Review. Appl. Sci. Basel 2020, 10, 46. [Google Scholar] [CrossRef]
- Prappacher, N.; Bullmann, M.; Bohn, G.; Deinzer, F.; Linke, A. Defect Detection on Rolling Element Surface Scans Using Neural Image Segmentation. Appl. Sci. Basel 2020, 10, 13. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. Acm T Graphic 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Free-Form Image Inpainting with Gated Convolution. arXiv e-prints 2019, arXiv:1806.03589. [Google Scholar]
- Zhao, D.; Guo, B.L.; Yan, Y.Y. Parallel Image Completion with Edge and Color Map. Appl. Sci. Basel 2019, 9, 29. [Google Scholar] [CrossRef]
- Pezeshkian, N.; Neff, J.D. Adaptive electronic camouflage using texture synthesis. In Proceedings of the Conference on Unmanned Systems Technology XIV, Baltimore, MD, USA, 25–27 April 2012. [Google Scholar]
- Inami, M.; Kawakami, N.; Tachi, S. Optical camouflage using retro-reflective projection technology. In Proceedings of the 2nd IEEE/ACM International Symposium on Mixed and Augmented Reality, Tokyo, Japan, 7–10 October 2003; pp. 348–349. [Google Scholar]
- Uema, Y.; Koizumi, N.; Chang, S.W.; Minamizawa, K.; Sugimoto, M.; Inami, M. Optical Camouflage III: Auto-Stereoscopic and Multiple-View Display System using Retro-Reflective Projection Technology. In Proceedings of the 19th IEEE Virtual Reality Conference, Costa Mesa, CA, USA, 4–8 March 2012; pp. 57–58. [Google Scholar]
- Yu, C.; Li, Y.; Zhang, X.; Huang, X.; Malyarchuk, V.; Wang, S.; Shi, Y.; Gao, L.; Su, Y.; Zhang, Y.; et al. Adaptive optoelectronic camouflage systems with designs inspired by cephalopod skins. Proc. Natl. Acad. Sci. USA 2014, 111, 12998–13003. [Google Scholar] [CrossRef]
- Zhang, Y.; Xue, S.Q.; Jiang, X.J.; Mu, J.Y.; Yi, Y. The Spatial Color Mixing Model of Digital Camouflage Pattern. Def. Technol. 2013, 9, 157–161. [Google Scholar] [CrossRef]
- Jia, Q.; Xu, W.D.; Hu, J.H.; Liu, J.; Yang, X.; Zhu, L.Y. Design and evaluation of digital camouflage pattern by spot combination. Multimed. Tools Appl. 2020, 5, 18. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv e-prints 2018, arXiv:1804.02767. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative Image Inpainting with Contextual Attention. arXiv e-prints 2018, arXiv:1801.07892. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 Million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE-Computer-Society Conference on Computer Vision and Pattern Recognition Workshops, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Joseph, R.; Ali, F. Yolo9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv e-prints 2017, arXiv:1701.07875. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved Training of Wasserstein GANs. arXiv e-prints 2017, arXiv:1704.00028. [Google Scholar]
- Feng, X.; Guoying, C.; Richang, H.; Jing, G. Camouflage texture evaluation using a saliency map. Multimed. Syst. 2015, 21, 169–175. [Google Scholar] [CrossRef]
- Cheng, X.P.; Zhao, D.P.; Yu, Z.J.; Zhang, J.H.; Bian, J.T.; Yu, D.B. Effectiveness evaluation of infrared camouflage using image saliency. Infrared. Phys. Technol. 2018, 95, 213–221. [Google Scholar] [CrossRef]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned Salient Region Detection. In Proceedings of the IEEE-Computer-Society Conference on Computer Vision and Pattern Recognition Workshops, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Training Set | Test Set |
|---|---|---|
| Airships | 459 | 50 |
| Aircraft Carriers | 455 | 50 |
| Tanks | 496 | 55 |
| Uniformed Soldiers | 560 | 62 |
| Total | 1970 | 217 |
| Type | Filters | Size/Stride | Output | |
|---|---|---|---|---|
| Convolutional | 32 | 3 × 3 | 416 × 416 | |
| Convolutional | 64 | 3 × 3/2 | 208 × 208 | |
| 1× | Convolutional | 32 | 1 × 1 | |
| Convolutional | 64 | 3 × 3 | ||
| Residual | 208 × 208 | |||
| Convolutional | 128 | 3 × 3/2 | 104 × 104 | |
| 2× | Convolutional | 64 | 1 × 1 | |
| Convolutional | 128 | 3 × 3 | ||
| Residual | 104 × 104 | |||
| Convolutional | 256 | 3 × 3/2 | 52 × 52 | |
| 8× | Convolutional | 128 | 1 × 1 | |
| Convolutional | 256 | 3 × 3 | ||
| Residual | 52 × 52 | |||
| Convolutional | 512 | 3 × 3/2 | 26 × 26 | |
| 8× | Convolutional | 256 | 1 × 1 | |
| Convolutional | 512 | 3 × 3 | ||
| Residual | 26 × 26 | |||
| Convolutional | 1024 | 3 × 3/2 | 13 × 13 | |
| 4× | Convolutional | 512 | 1 × 1 | |
| Convolutional | 1024 | 3 × 3 | ||
| Residual | 13 × 13 | |||
| Avgpool | Global | |||
| Connected | 1000 | |||
| Softmax |
| Variable | Value | Variable | Value |
|---|---|---|---|
| 0.5 | 1 α 10−4 | ||
| Batch_size | 6 | 1 α 10−6 | |
| Input_size | [320, 352, 384, 416, 448, 480, 512, 544, 576, 608] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, H.; Qu, Z.; Lv, M.; Jiang, Y.; Wang, C.; Qin, R. Fast Self-Adaptive Digital Camouflage Design Method Based on Deep Learning. Appl. Sci. 2020, 10, 5284. https://doi.org/10.3390/app10155284
Xiao H, Qu Z, Lv M, Jiang Y, Wang C, Qin R. Fast Self-Adaptive Digital Camouflage Design Method Based on Deep Learning. Applied Sciences. 2020; 10(15):5284. https://doi.org/10.3390/app10155284
Chicago/Turabian StyleXiao, Houdi, Zhipeng Qu, Mingyun Lv, Yi Jiang, Chuanzhi Wang, and Ruiru Qin. 2020. "Fast Self-Adaptive Digital Camouflage Design Method Based on Deep Learning" Applied Sciences 10, no. 15: 5284. https://doi.org/10.3390/app10155284
APA StyleXiao, H., Qu, Z., Lv, M., Jiang, Y., Wang, C., & Qin, R. (2020). Fast Self-Adaptive Digital Camouflage Design Method Based on Deep Learning. Applied Sciences, 10(15), 5284. https://doi.org/10.3390/app10155284