Decoding Visual Motions from EEG Using Attention-Based RNN


Abstract
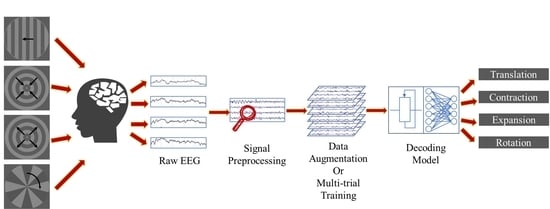
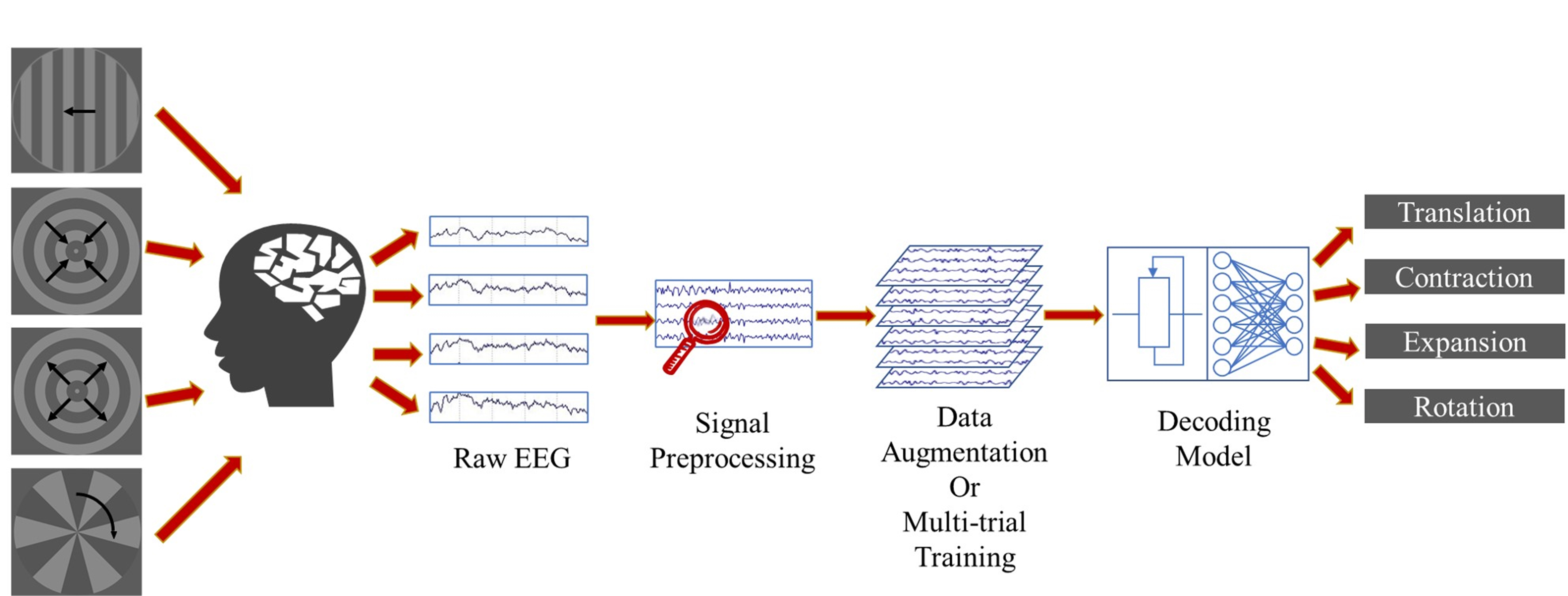
1. Introduction
2. Related Work
2.1. DL Methods for Classifying EEG Signals Evoked by Visual Stimuli
2.2. Motion Stimuli for BCI Systems
2.3. Attention-Based RNNs
2.4. Data Augmentation for EEG Signals
3. Materials
3.1. Participants
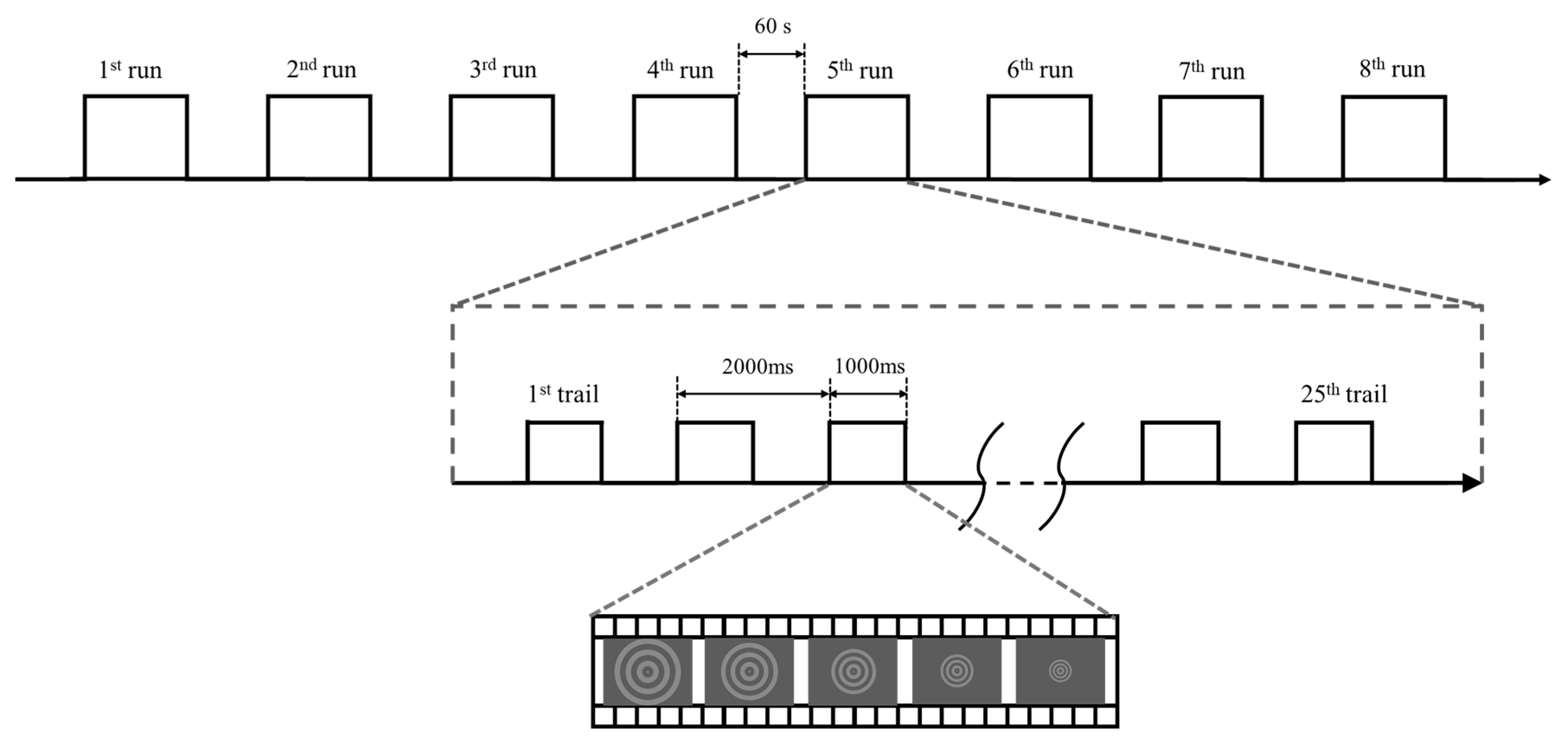
3.2. Experimental Protocol
3.3. Data Acquisition
3.4. Data Preprocessing
4. Methods
4.1. Stacked GRU with Skip Connections
4.2. Attention-Based GRU
4.3. Data Augmentation by Randomly Averaging
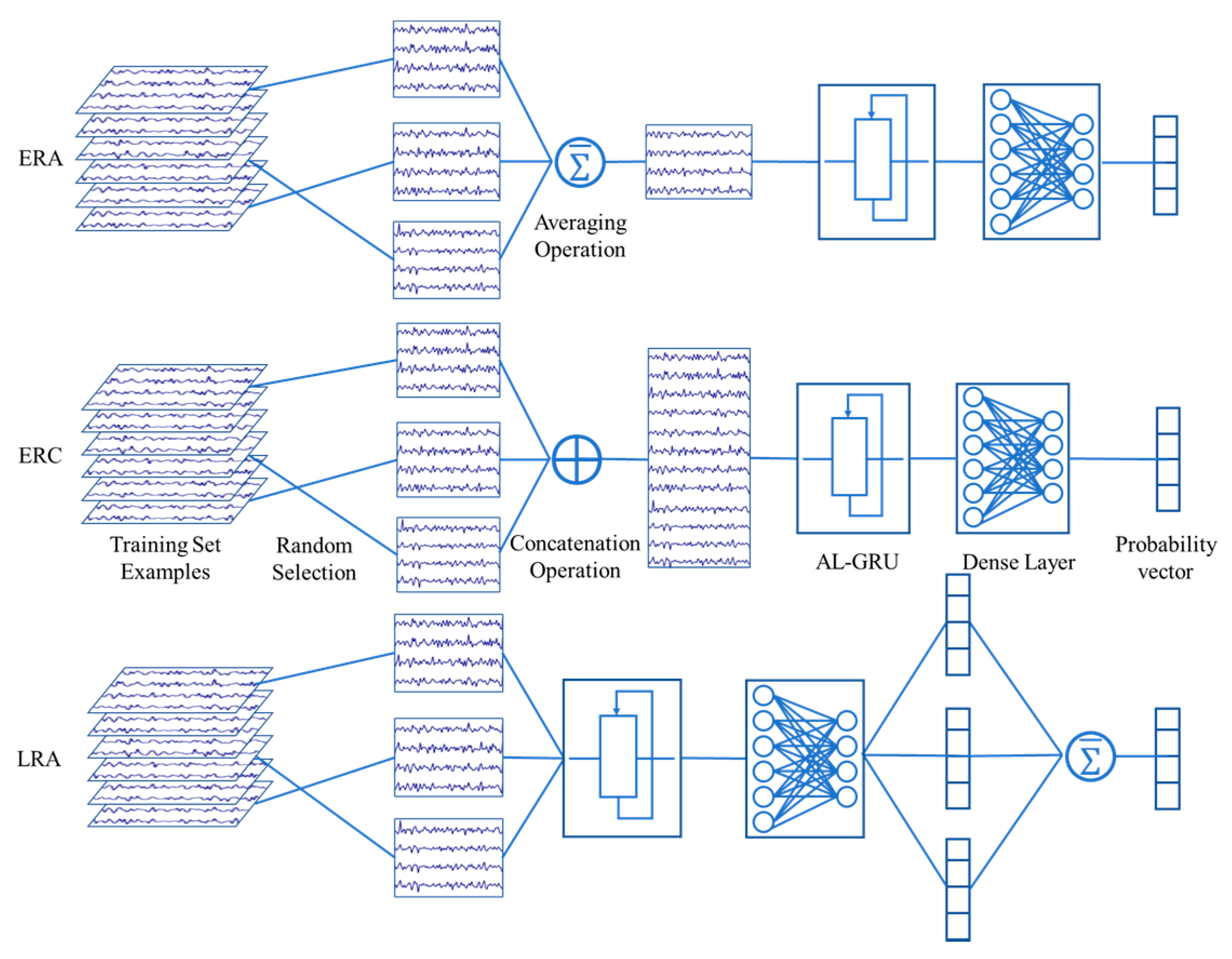
4.4. Multi-Trial Combination Strategies
4.5. Model Configuration and Training
4.6. Model Configuration and Training
5. Results and Discussion
5.1. Reaction Times for Each Motion
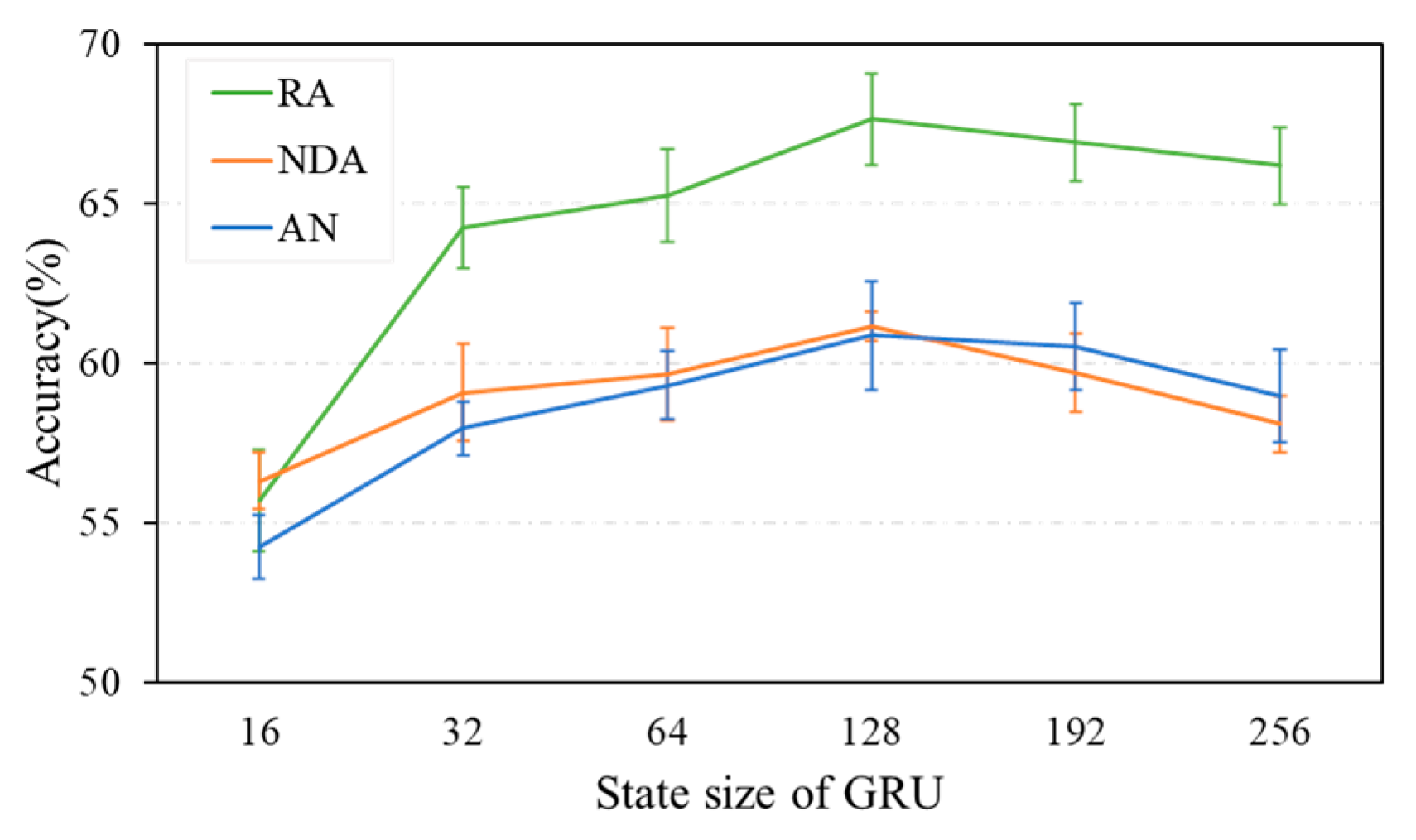
5.2. Performance of Attention-Based GRU with Skip Connections
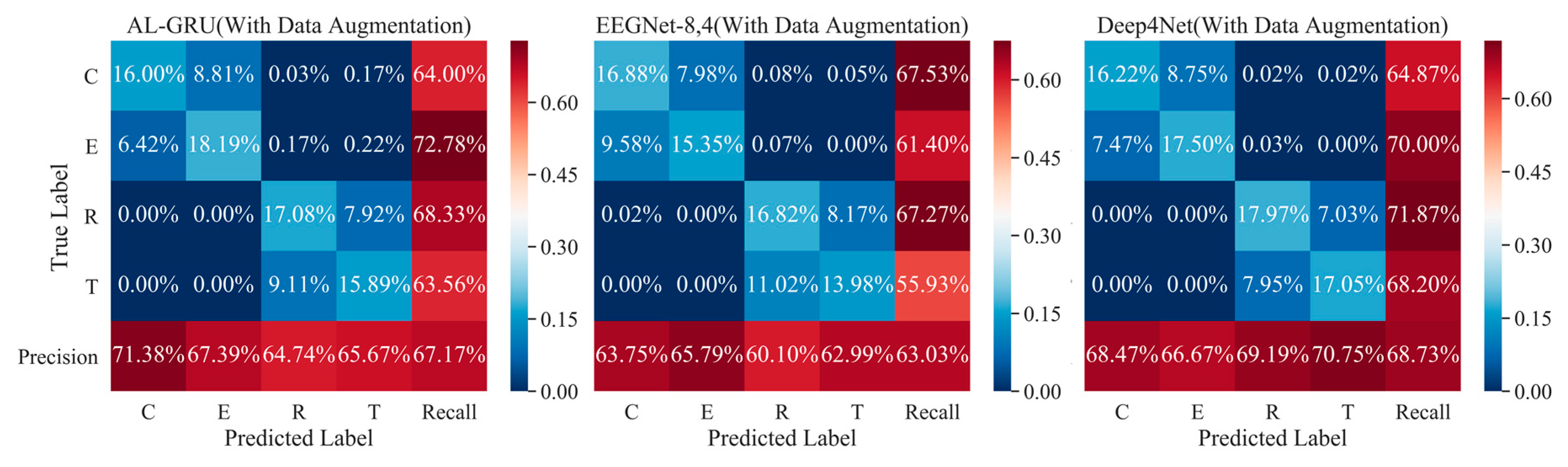
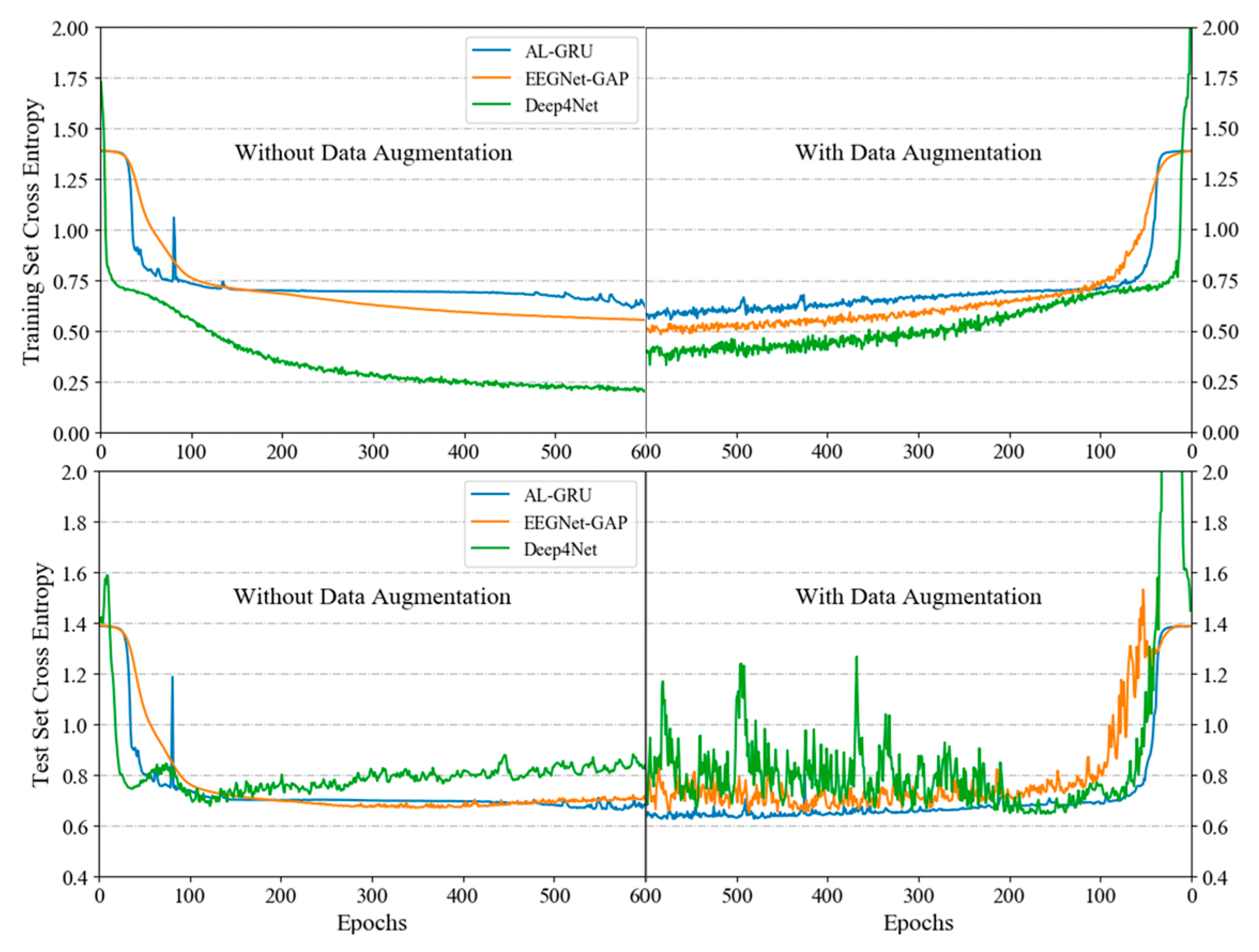
5.3. Performance of Data Augmentation by Randomly Averaging
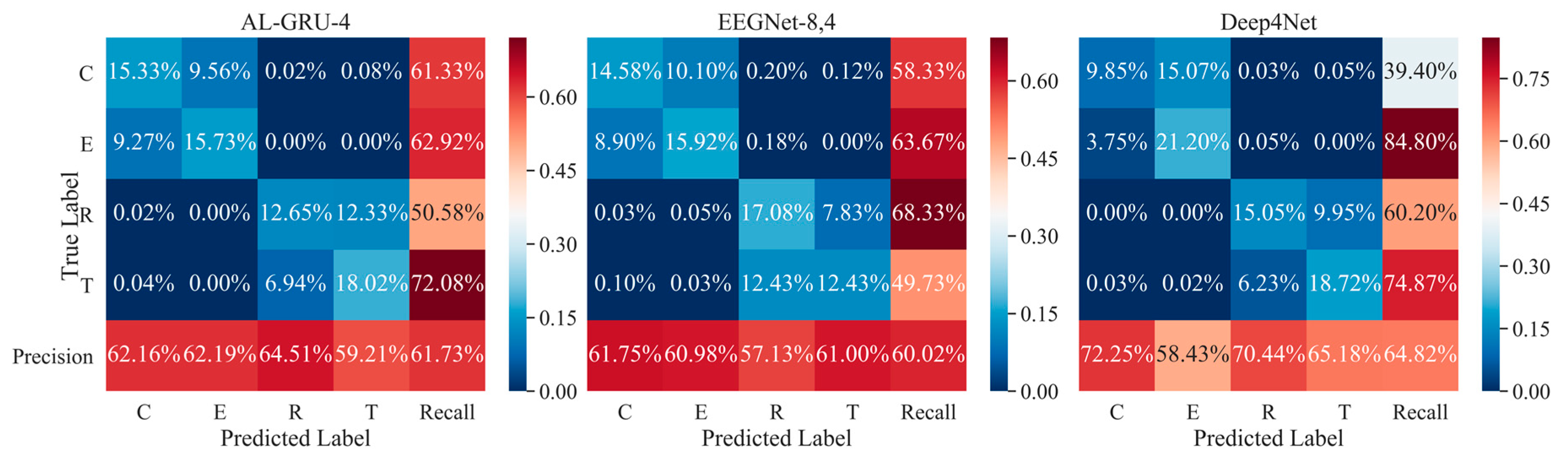
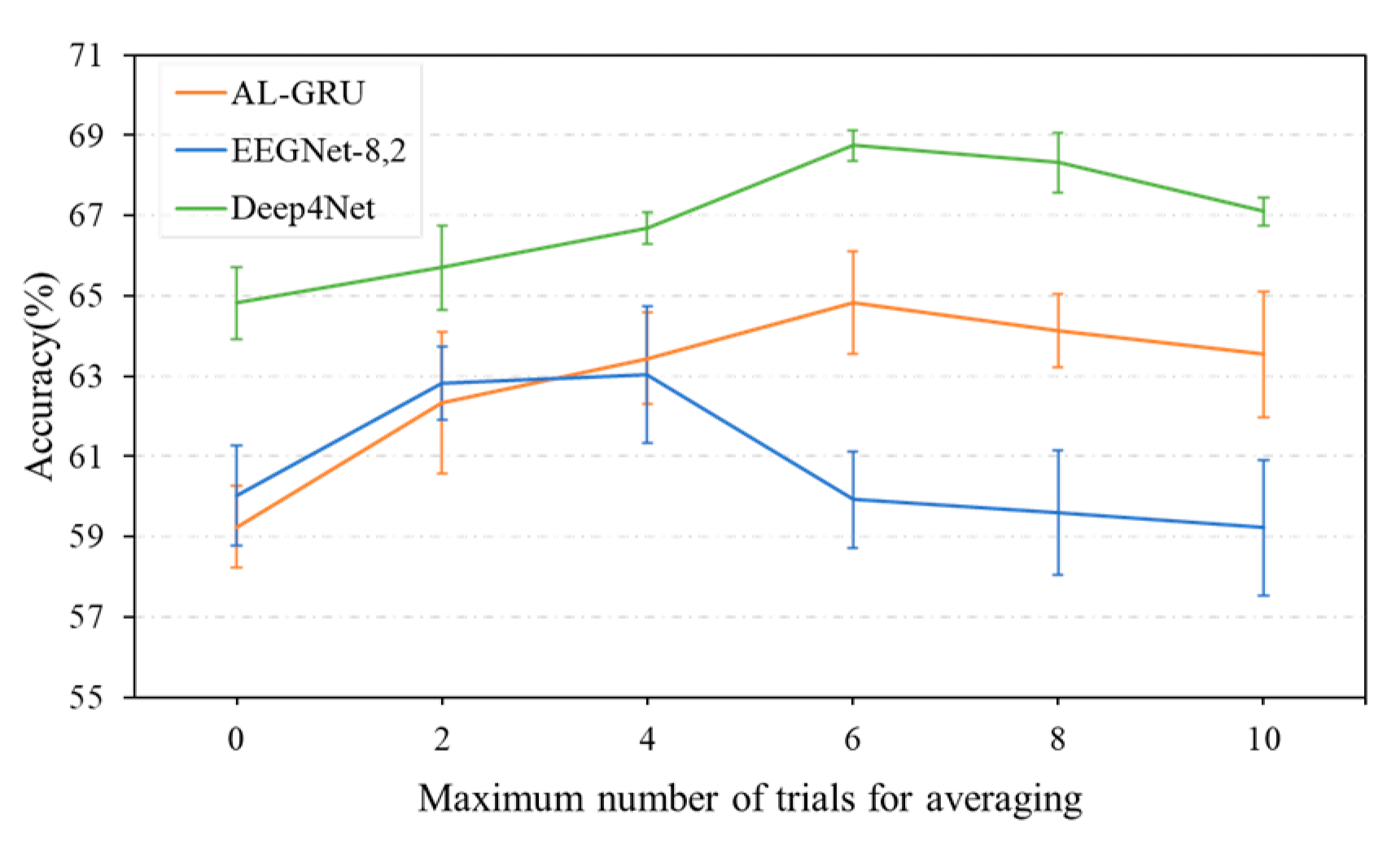
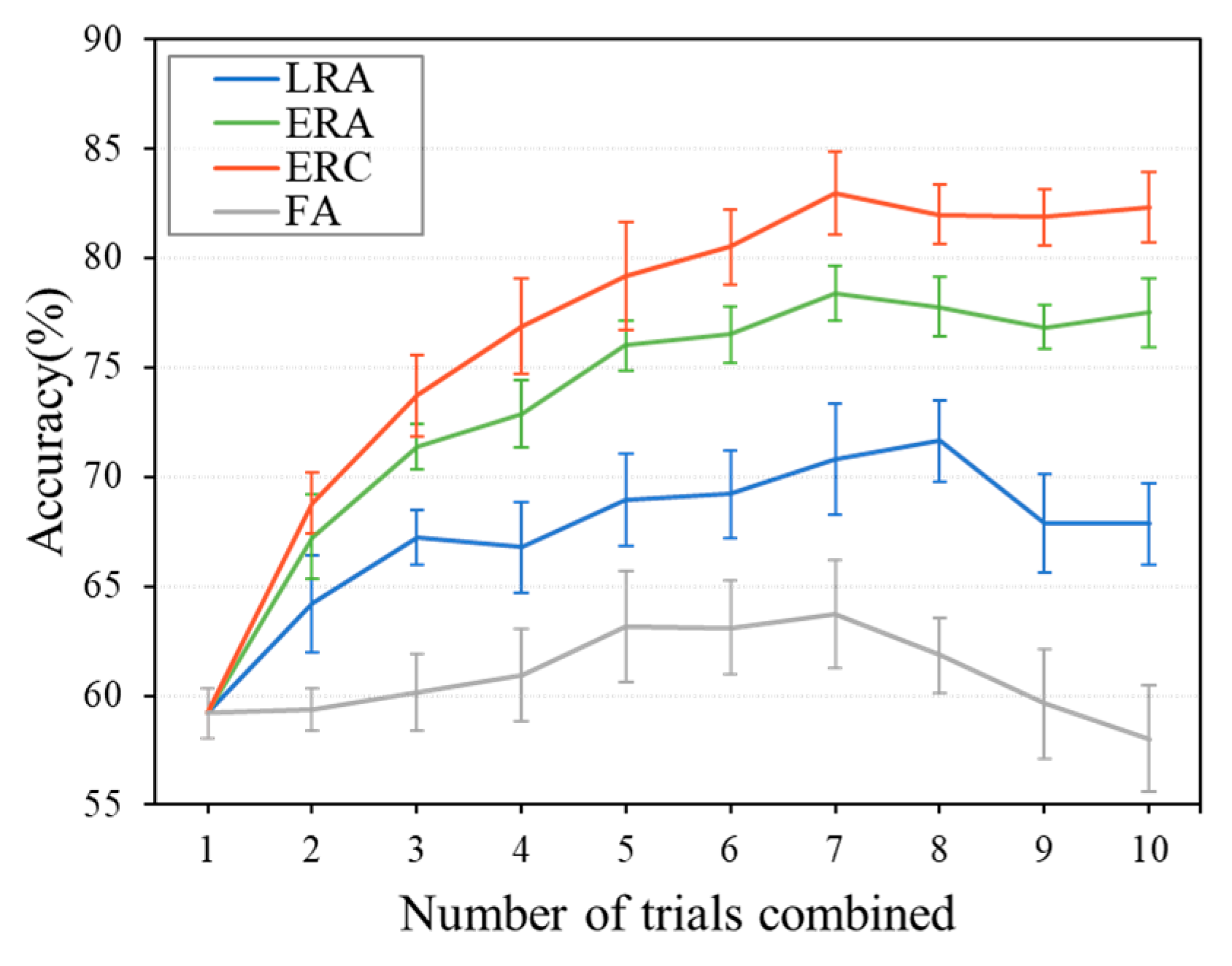
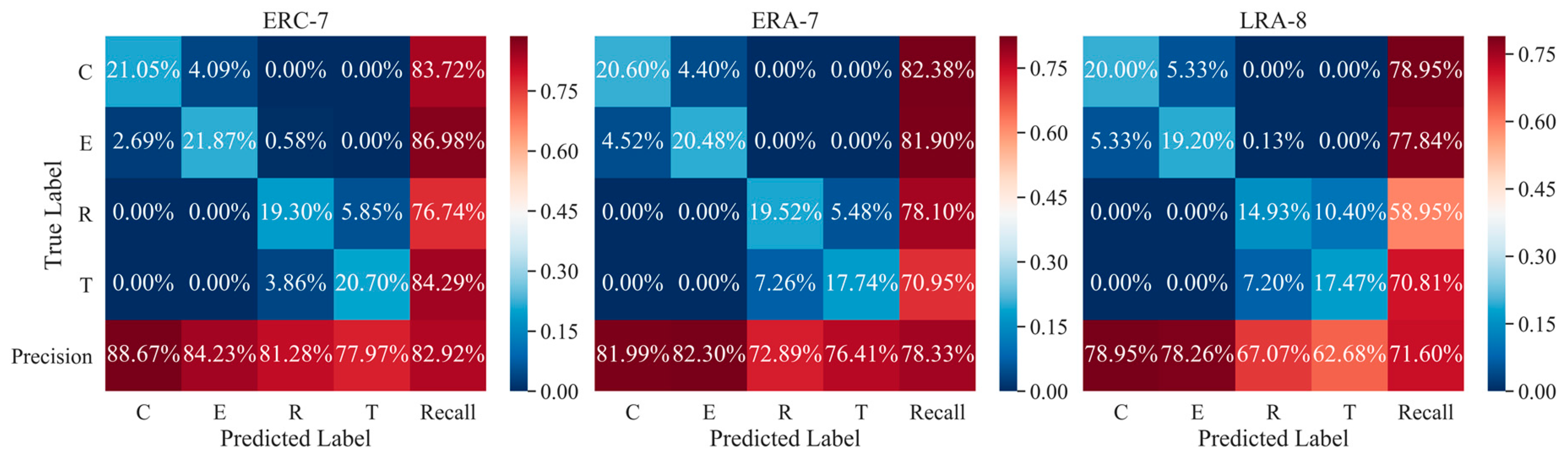
5.4. Performance of Combination Strategies for Multi-Trial EEG Decoding
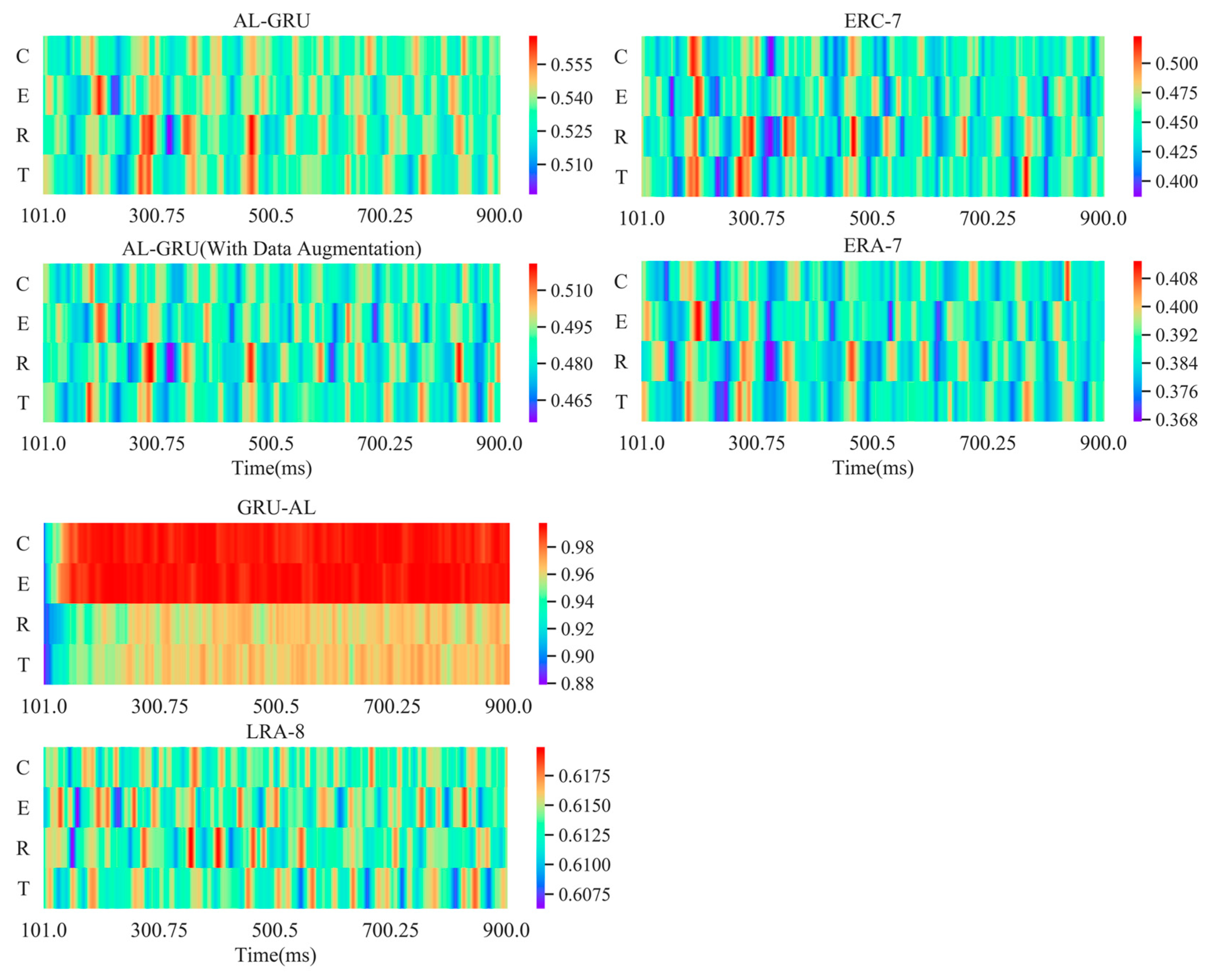
5.5. Attention Weights Visualization
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Padfield, N.; Zabalza, J.; Zhao, H.; Masero, V.; Ren, J. EEG-Based Brain-Computer Interfaces Using Motor-Imagery: Techniques and Challenges. Sensers 2019, 19, 1423. [Google Scholar] [CrossRef] [PubMed]
- Schreuder, M.; Blankertz, B.; Tangermann, M. A New Auditory Multi-Class Brain-Computer Interface Paradigm: Spatial Hearing as an Informative Cue. PLoS ONE 2010, 5, e9813. [Google Scholar] [CrossRef] [PubMed]
- Fazel-Rezai, R.; Allison, B.Z.; Guger, C.; Sellers, E.W.; Kleih, S.C.; Kübler, A. P300 brain computer interface: Current challenges and emerging trends. Front. Neuroeng. 2012, 5, 14. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.-J.; Chen, S.-C.; Zaeni, I.A.E.; Wu, C.-M. Fuzzy Tracking and Control Algorithm for an SSVEP-Based BCI System. Appl. Sci. 2016, 6, 270. [Google Scholar] [CrossRef]
- Liu, Y.-H.; Wang, S.-H.; Hu, M.-R. A Self-Paced P300 Healthcare Brain-Computer Interface System with SSVEP-Based Switching Control and Kernel FDA + SVM-Based Detector. Appl. Sci. 2016, 6, 142. [Google Scholar] [CrossRef]
- Morrone, M.C.; Tosetti, M.; Montanaro, D.; Fiorentini, A.; Cioni, G.; Burr, D.C. A cortical area that responds specifically to optic flow, revealed by fMRI. Nat. Neurosci. 2000, 3, 1322–1328. [Google Scholar] [CrossRef]
- McKeefry, D.J.; Watson, J.D.; Frackowiak, R.S.; Fong, K.; Zeki, S. The activity in human areas V1/V2, V3, and V5 during the perception of coherent and incoherent motion. Neuroimage 1997, 5, 1–12. [Google Scholar] [CrossRef]
- Delon-Martin, C.; Gobbelé, R.; Buchner, H.; Haug, B.A.; Antal, A.; Darvas, F.; Paulus, W. Temporal pattern of source activities evoked by different types of motion onset stimuli. Neuroimage 2006, 31, 1567–1579. [Google Scholar] [CrossRef]
- Hong, B.; Guo, F.; Liu, T.; Gao, X.; Gao, S. N200-speller using motion-onset visual response. Clin. Neurophysiol. 2009, 120, 1658–1666. [Google Scholar] [CrossRef]
- Xie, J.; Xu, G.; Wang, J.; Li, M.; Han, C.; Jia, Y. Effects of Mental Load and Fatigue on Steady-State Evoked Potential Based Brain Computer Interface Tasks: A Comparison of Periodic Flickering and Motion-Reversal Based Visual Attention. PLoS ONE 2016, 11, e0163426. [Google Scholar] [CrossRef]
- Gao, Z.; Yuan, T.; Zhou, X.; Ma, C.; Ma, K.; Hui, P. A Deep Learning Method for Improving the Classification Accuracy of SSMVEP-based BCI. IEEE Trans. Circuits Syst. Ii Express Briefs 2020. [Google Scholar] [CrossRef]
- Yan, W.; Xu, G.; Xie, J.; Li, M.; Dan, Z. Four Novel Motion Paradigms Based on Steady-State Motion Visual Evoked Potential. IEEE Trans. Biomed. Eng. 2018, 65, 1696–1704. [Google Scholar] [CrossRef] [PubMed]
- Park, S.; Cha, H.; Im, C. Development of an Online Home Appliance Control System Using Augmented Reality and an SSVEP-Based Brain–Computer Interface. IEEE Access 2019, 7, 163604–163614. [Google Scholar] [CrossRef]
- Ma, T.; Li, H.; Yang, H.; Lv, X.; Li, P.; Liu, T.; Yao, D.; Xu, P. The extraction of motion-onset VEP BCI features based on deep learning and compressed sensing. J. Neurosci. Methods 2017, 275, 80–92. [Google Scholar] [CrossRef]
- Carvalho, S.R.; Filho, I.C.; Resende, D.O.D.; Siravenha, A.C.; Souza, C.R.B.D.; Debarba, H.; Gomes, B.D.; Boulic, R. A Deep Learning Approach for Classification of Reaching Targets from EEG Images. In Proceedings of the 2017 30th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Niterói, Brazil, 17–20 October 2017; pp. 178–184. [Google Scholar]
- Zhang, G.; Davoodnia, V.; Sepas-Moghaddam, A.; Zhang, Y.; Etemad, A. Classification of Hand Movements From EEG Using a Deep Attention-Based LSTM Network. IEEE Sens. J. 2020, 20, 3113–3122. [Google Scholar] [CrossRef]
- Roy, Y.; Banville, H.; Albuquerque, I.; Gramfort, A.; Falk, T.H.; Faubert, J. Deep learning-based electroencephalography analysis: A systematic review. J. Neural Eng. 2019, 16. [Google Scholar] [CrossRef]
- Xing, X.; Li, Z.; Xu, T.; Shu, L.; Hue, B.; Xu, X. SAE plus LSTM: A New Framework for Emotion Recognition From Multi-Channel EEG. Front. Neurorobotics 2019, 13. [Google Scholar] [CrossRef]
- Liu, J.; Su, Y.; Liu, Y. Multi-modal Emotion Recognition with Temporal-Band Attention Based on LSTM-RNN. In Advances in Multimedia Information Processing-Pcm 2017, Pt I; Zeng, B., Huang, Q., ElSaddik, A., Li, H., Jiang, S., Fan, X., Eds.; Springer: Cham, Switzerland, 2018; Volume 10735, pp. 194–204. [Google Scholar]
- Zhang, X.; Yao, L.; Kanhere, S.S.; Liu, Y.; Gu, T.; Chen, K. MindID: Person Identification from Brain Waves through Attention-based Recurrent Neural Network. Proc. Acm Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 149. [Google Scholar] [CrossRef]
- Wang, B.; Liu, K.; Zhao, J. Inner Attention based Recurrent Neural Networks for Answer Selection. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; ACL: Beijing, China, 2016; pp. 1288–1297. [Google Scholar]
- Bashivan, P.; Rish, I.; Yeasin, M.; Codella, N. Learning representations from EEG with deep recurrent-convolutional neural networks. arXiv 2015, arXiv:1511.06448. [Google Scholar]
- Arvidsson, I.; Overgaard, N.C.; Åström, K.; Heyden, A. Comparison of Different Augmentation Techniques for Improved Generalization Performance for Gleason Grading. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 923–927. [Google Scholar]
- Wang, F.; Zhong, S.-h.; Peng, J.; Jiang, J.; Liu, Y. Data Augmentation for EEG-Based Emotion Recognition with Deep Convolutional Neural Networks. In Multimedia Modeling, Mmm 2018, Pt Ii; Schoeffmann, K., Chalidabhongse, T.H., Ngo, C.W., Aramvith, S., Oconnor, N.E., Ho, Y.S., Gabbou, M., Elgammal, A., Eds.; Springer: Cham, Switzerland, 2018; Volume 10705, pp. 82–93. [Google Scholar]
- Krell, M.M.; Kim, S.K.; IEEE. Rotational Data Augmentation for Electroencephalographic Data. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Seogwipo, Korea, 11–15 July 2017; pp. 471–474. [Google Scholar]
- Schirrmeister, R.T.; Springenberg, J.T.; Fiederer, L.D.J.; Glasstetter, M.; Eggensperger, K.; Tangermann, M.; Hutter, F.; Burgard, W.; Ball, T. Deep Learning With Convolutional Neural Networks for EEG Decoding and Visualization. Hum. Brain Mapp. 2017, 38, 5391–5420. [Google Scholar] [CrossRef]
- Luo, Y.; Lu, B.-L. EEG Data Augmentation for Emotion Recognition Using a Conditional Wasserstein GAN. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; Volume 2018, pp. 2535–2538. [Google Scholar] [CrossRef]
- Vidal, J.J. Real-time detection of brain events in EEG. Proc. IEEE 1977, 65, 633–641. [Google Scholar] [CrossRef]
- Kalunga, E.; Chevallier, S.; Barthélemy, Q. Data augmentation in Riemannian space for Brain-Computer Interfaces. In Proceedings of the STAMLINS, Lille, France, 6–11 July 2015. [Google Scholar]
- Baltatzis, V.; Bintsi, K.-M.; Apostolidis, G.K.; Hadjileontiadis, L.J. Bullying incidences identification within an immersive environment using HD EEG-based analysis: A Swarm Decomposition and Deep Learning approach. Sci. Rep. 2017, 7, 17292. [Google Scholar] [CrossRef] [PubMed]
- Behncke, J.; Schirrmeister, R.T.; Burgard, W.; Ball, T. The signature of robot action success in EEG signals of a human observer: Decoding and visualization using deep convolutional neural networks. In Proceedings of the 2018 6th International Conference on Brain-Computer Interface (BCI), GangWon, Korea, 15–17 January 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Teo, J.; Hou, C.L.; Mountstephens, J. Deep learning for EEG-Based preference classification. In Proceedings of AIP Conference Proceedings; AIP: New York, NY, USA, 2017; p. 020141. [Google Scholar]
- Liu, D.; Liu, C.; Hong, B. Bi-directional Visual Motion Based BCI Speller. In Proceedings of the 2019 9th International IEEE/EMBS Conference on Neural Engineering (NER), San Francisco, CA, USA, 20–23 March 2019; pp. 589–592. [Google Scholar]
- Chai, X.; Zhang, Z.; Guan, K.; Zhang, T.; Xu, J.; Niu, H. Effects of fatigue on steady state motion visual evoked potentials: Optimised stimulus parameters for a zoom motion-based brain-computer interface. Comput. Methods Programs Biomed. 2020, 196, 105650. [Google Scholar] [CrossRef] [PubMed]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Righi, G.; Vettel, J. Dorsal Visual Pathway. In Encyclopedia of Clinical Neuropsychology; Kreutzer, J.S., DeLuca, J., Caplan, B., Eds.; Springer: New York, NY, USA, 2011; pp. 887–888. [Google Scholar] [CrossRef]
- Schalk, G.; McFarland, D.J.; Hinterberger, T.; Birbaumer, N.; Wolpaw, J.R. BCI2000: A general-purpose brain-computer interface (BCI) system. IEEE Trans. Biomed. Eng. 2004, 51, 1034–1043. [Google Scholar] [CrossRef]
- Niedermeyer, E.; da Silva, F.L. Electroencephalography: Basic Principles, Clinical Applications, and Related Fields; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2005; pp. 179–190. [Google Scholar]
- Wallstrom, G.L.; Kass, R.E.; Miller, A.; Cohn, J.F.; Fox, N.A. Automatic correction of ocular artifacts in the EEG: A comparison of regression-based and component-based methods. Int. J. Psychophysiol. 2004, 53, 105–119. [Google Scholar] [CrossRef]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.107. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A multimodal database for affect recognition and implicit tagging. IEEE Trans. Affect. Comput. 2011, 3, 42–55. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, NIPS, Vancouver, BC, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef]
- Li, X.; Chen, S.; Hu, X.; Yang, J. Understanding the disharmony between dropout and batch normalization by variance shift. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2682–2690. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Bénar, C.G.; Papadopoulo, T.; Torrésani, B.; Clerc, M. Consensus matching pursuit for multi-trial EEG signals. J. Neurosci. Methods 2009, 180, 161–170. [Google Scholar] [CrossRef]
- Patel, S.H.; Azzam, P.N. Characterization of N200 and P300: Selected studies of the event-related potential. Int. J. Med. Sci. 2005, 2, 147. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Motion | Contraction | Expansion | Rotation | Translation | ||||
|---|---|---|---|---|---|---|---|---|
| RTs (ms) | 346.88 ± 66.53 | 338.95 ± 65.03 | 328.66 ± 67.86 | 341.72 ± 59.16 | ||||
| p-VALUES | C-E | 1.00 | E-C | 1.00 | R-C | 0.076 | T-C | 1.00 |
| C-R | 0.076 | E-R | 0.898 | R-E | 0.898 | T-E | 1.00 | |
| C-T | 1.00 | E-T | 1.00 | R-T | 0.434 | T-R | 0.434 | |
| Layers | GRU | SC-GRU | AL-GRU | GRU-AL | EEGNet-8,4 | DeepConvNet |
|---|---|---|---|---|---|---|
| 1 | 57.08 ± 0.11 | 59.44 ± 1.02 | 58.60 ± 0.37 | 60.02 ± 1.84 | 64.82 ± 0.89 | |
| 2 | 57.16 ± 0.58 | 58.04 ± 0.99 | 59.90 ± 0.18 | 59.68 ± 0.75 | ||
| 3 | 54.66 ± 1.86 | 59.20 ± 1.30 | 60.76 ± 1.39 | 59.86 ± 1.45 | ||
| 4 | 55.04 ± 2.20 | 60.36 ± 1.99 | 61.74 ± 1.86 | 61.24 ± 1.80 | ||
| 5 | 53.84 ± 0.70 | 59.62 ± 0.91 | 59.80 ± 1.22 | 59.68 ± 0.52 | ||
| 6 | 53.52 ± 2.03 | 59.46 ± 2.02 | 59.98 ± 1.03 | 59.18 ± 1.98 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, D.; Liu, Y.; Zhou, Z.; Yu, Y.; Liang, X. Decoding Visual Motions from EEG Using Attention-Based RNN. Appl. Sci. 2020, 10, 5662. https://doi.org/10.3390/app10165662
Yang D, Liu Y, Zhou Z, Yu Y, Liang X. Decoding Visual Motions from EEG Using Attention-Based RNN. Applied Sciences. 2020; 10(16):5662. https://doi.org/10.3390/app10165662
Chicago/Turabian StyleYang, Dongxu, Yadong Liu, Zongtan Zhou, Yang Yu, and Xinbin Liang. 2020. "Decoding Visual Motions from EEG Using Attention-Based RNN" Applied Sciences 10, no. 16: 5662. https://doi.org/10.3390/app10165662
APA StyleYang, D., Liu, Y., Zhou, Z., Yu, Y., & Liang, X. (2020). Decoding Visual Motions from EEG Using Attention-Based RNN. Applied Sciences, 10(16), 5662. https://doi.org/10.3390/app10165662