Assessment of Landslide Susceptibility Combining Deep Learning with Semi-Supervised Learning in Jiaohe County, Jilin Province, China


Abstract
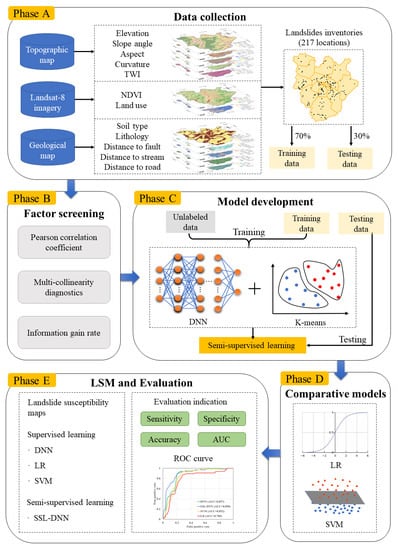
1. Introduction
2. Study Area
3. Materials and Methods
3.1. Data Preparation
3.2. Impact Factors
3.3. The Framework of Semi-Supervised Deep Learning
3.3.1. SSL-DNN for LSM
3.3.2. Pre-Training DNN Architecture
3.3.3. Training with Loss Function
3.3.4. Pseudo-Labeling via Clustering K-Means
3.4. Comparative Models
3.4.1. Support Vector Machine
3.4.2. Logistic Regression
3.5. Feature Metrics
3.6. Model Metrics
4. Results
4.1. The Analysis of Impact Factors
4.2. Landslides Susceptibility Assessment
4.3. Model Comparison and Validation
5. Discussion
5.1. Impact Factor on Control of Landslide
5.2. Susceptibility in SSL-DNN
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kjekstad, O.; Highland, L. Economic and Social Impacts of Landslides; Springer: Berlin, Germany, 2009. [Google Scholar]
- Caine, N. The Rainfall Intensity-Duration Control of Shallow Landslides and Debris Flows. Geogr. Ann. Ser. Phys. Geogr. 1980, 62, 23–27. [Google Scholar] [CrossRef]
- Iverson, R.M. Landslide triggering by rain infiltration. Water Resour. Res. 2000, 36, 1897–1910. [Google Scholar] [CrossRef]
- Peng, L.; Xu, D.; Wang, X. Vulnerability of rural household livelihood to climate variability and adaptive strategies in landslide-threatened western mountainous regions of the Three Gorges Reservoir Area, China. Clim. Dev. 2019, 11, 469–484. [Google Scholar] [CrossRef]
- van Westen, C.J.; van Asch, T.W.J.; Soeters, R. Landslide hazard and risk zonation—Why is it still so difficult? Bull. Eng. Geol. Environ. 2006, 65, 167–184. [Google Scholar] [CrossRef]
- Guzzetti, F.; Peruccacci, S.; Rossi, M.; Stark, C.P. The rainfall intensity-duration control of shallow landslides and debris flows: An update. Landslides 2008, 5, 3–17. [Google Scholar] [CrossRef]
- Papathoma-Koehle, M.; Kappes, M.; Keiler, M.; Glade, T. Physical vulnerability assessment for alpine hazards: State of the art and future needs. Nat. Hazards 2011, 58, 645–680. [Google Scholar] [CrossRef]
- Dai, F.C.; Lee, C.F.; Ngai, Y.Y. Landslide risk assessment and management: An overview. Eng. Geol. 2002, 64, 65–87. [Google Scholar] [CrossRef]
- Ayalew, L.; Yamagishi, H.; Marui, H.; Kanno, T. Landslides in Sado Island of Japan: Part II. GIS-based susceptibility mapping with comparisons of results from two methods and verifications. Eng. Geol. 2005, 81, 432–445. [Google Scholar] [CrossRef]
- Chen, W.; Peng, J.; Hong, H.; Shahabi, H.; Pradhan, B.; Liu, J.; Zhu, A.X.; Pei, X.; Duan, Z. Landslide susceptibility modelling using GIS-based machine learning techniques for Chongren County, Jiangxi Province, China. Sci. Total Environ. 2018, 626, 1121–1135. [Google Scholar] [CrossRef]
- Guzzetti, F.; Mondini, A.C.; Cardinali, M.; Fiorucci, F.; Santangelo, M.; Chang, K.-T. Landslide inventory maps: New tools for an old problem. Earth-Sci. Rev. 2012, 112, 42–66. [Google Scholar] [CrossRef]
- Santangelo, M.; Marchesini, I.; Bucci, F.; Cardinali, M.; Fiorucci, F.; Guzzetti, F. An approach to reduce mapping errors in the production of landslide inventory maps. Nat. Hazards Earth Syst. Sci. 2015, 15, 2111–2126. [Google Scholar] [CrossRef]
- Hong, H.; Pradhan, B.; Xu, C.; Tien Bui, D. Spatial prediction of landslide hazard at the Yihuang area (China) using two-class kernel logistic regression, alternating decision tree and support vector machines. Catena 2015, 133, 266–281. [Google Scholar] [CrossRef]
- Dieu Tien, B.; Tsangaratos, P.; Viet-Tien, N.; Ngo Van, L.; Phan Trong, T. Comparing the prediction performance of a Deep Learning Neural Network model with conventional machine learning models in landslide susceptibility assessment. Catena 2020, 188, 104426. [Google Scholar] [CrossRef]
- Saha, S.; Saha, A.; Hembram, T.K.; Pradhan, B.; Alamri, A.M. Evaluating the Performance of Individual and Novel Ensemble of Machine Learning and Statistical Models for Landslide Susceptibility Assessment at Rudraprayag District of Garhwal Himalaya. Appl. Sci. 2020, 10, 3772. [Google Scholar] [CrossRef]
- Dieu Tien, B.; Tran Anh, T.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar] [CrossRef]
- Elkadiri, R.; Sultan, M.; Youssef, A.M.; Elbayoumi, T.; Chase, R.; Bulkhi, A.B.; Al-Katheeri, M.M. A Remote Sensing-Based Approach for Debris-Flow Susceptibility Assessment Using Artificial Neural Networks and Logistic Regression Modeling. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2014, 7, 4818–4835. [Google Scholar] [CrossRef]
- Catani, F.; Lagomarsino, D.; Segoni, S.; Tofani, V. Landslide susceptibility estimation by random forests technique: Sensitivity and scaling issues. Nat. Hazards Earth Syst. Sci. 2013, 13, 2815–2831. [Google Scholar] [CrossRef]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Md Abul Ehsan, B.; Begum, F.; Ilham, S.J.; Khan, R.S. Advanced wind speed prediction using convective weather variables through machine learning application. Appl. Computing Geosci. 2019, 1, 100002. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, H.; Mei, H.; Xiao, D.; Li, Y.; Li, M. Landslide Susceptibility Mapping Using the Stacking Ensemble Machine Learning Method in Lushui, Southwest China. Appl. Sci. 2020, 10, 4016. [Google Scholar] [CrossRef]
- Choubin, B.; Zehtabian, G.; Azareh, A.; Rafiei-Sardooi, E.; Sajedi-Hosseini, F.; Kisi, O. Precipitation forecasting using classification and regression trees (CART) model: A comparative study of different approaches. Environ. Earth Sci. 2018, 77, 314. [Google Scholar] [CrossRef]
- Yang, F.F.; Wanik, D.W.; Cerrai, D.; Bhuiyan, M.A.; Anagnostou, E.N. Quantifying Uncertainty in Machine Learning-Based Power Outage Prediction Model Training: A Tool for Sustainable Storm Restoration. Sustainability 2020, 12, 1525. [Google Scholar] [CrossRef]
- Huang, F.; Yao, C.; Liu, W.; Li, Y.; Liu, X. Landslide susceptibility assessment in the Nantian area of China: A comparison of frequency ratio model and support vector machine. Geomat. Nat. Hazards Risk 2018, 9, 919–938. [Google Scholar] [CrossRef]
- Zhu, L.; Huang, L.; Fan, L.; Huang, J.; Huang, F.; Chen, J.; Zhang, Z.; Wang, Y. Landslide Susceptibility Prediction Modeling Based on Remote Sensing and a Novel Deep Learning Algorithm of a Cascade-Parallel Recurrent Neural Network. Sensors 2020, 20, 1576. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Merghadi, A.; Shirzadi, A.; Hoang, N.; Hussain, Y.; Avtar, R.; Chen, Y.; Binh Thai, P.; Yamagishi, H. Different sampling strategies for predicting landslide susceptibilities are deemed less consequential with deep learning. Sci. Total Environ. 2020, 720, 137320. [Google Scholar] [CrossRef]
- Viet-Ha, N.; Nhat-Duc, H.; Hieu, N.; Phuong Thao Thi, N.; Tinh Thanh, B.; Pham Viet, H.; Samui, P.; Dieu Tien, B. Effectiveness assessment of Keras based deep learning with different robust optimization algorithms for shallow landslide susceptibility mapping at tropical area. Catena 2020, 188, 104458. [Google Scholar] [CrossRef]
- Wu, H.; Prasad, S. Semi-Supervised Deep Learning Using Pseudo Labels for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 1259–1270. [Google Scholar] [CrossRef]
- Ito, R.; Nakae, K.; Hata, J.; Okano, H.; Ishii, S. Semi-supervised deep learning of brain tissue segmentation. Neural Netw. 2019, 116, 25–34. [Google Scholar] [CrossRef]
- Nartey, O.T.; Yang, G.; Asare, S.K.; Wu, J.; Frempong, L.N. Robust Semi-Supervised Traffic Sign Recognition via Self-Training and Weakly-Supervised Learning. Sensors 2020, 20, 2684. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Wang, X.; Cheng, Y.; Zhang, L. Tumor gene expression data classification via sample expansion-based deep learning. Oncotarget 2017, 8, 109646–109660. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Zhou, Y.; Liu, X.; Dong, F.; Wang, C.; Wang, Z. Wasserstein GAN-Based Small-Sample Augmentation for New-Generation Artificial Intelligence: A Case Study of Cancer-Staging Data in Biology. Engineering 2019, 5, 156–163. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Peng, D.; Xu, L. Assessment of urban flood susceptibility using semi-supervised machine learning model. Sci. Total Environ. 2019, 659, 940–949. [Google Scholar] [CrossRef]
- Chang, Z.L.; Du, Z.; Zhang, F.; Huang, F.M.; Chen, J.W.; Li, W.B.; Guo, Z.Z. Landslide Susceptibility Prediction Based on Remote Sensing Images and GIS: Comparisons of Supervised and Unsupervised Machine Learning Models. Remote Sens. 2020, 12, 502. [Google Scholar] [CrossRef]
- Huang, G.; Song, S.J.; Gupta, J.N.D.; Wu, C. Semi-Supervised and Unsupervised Extreme Learning Machines. IEEE T. Cybern. 2014, 44, 2405–2417. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Bandos, T.V.; Zhou, D. Semi-supervised graph-based hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3044–3054. [Google Scholar] [CrossRef]
- Wu, D.; Pigou, L.; Kindermans, P.-J.; Nam Do-Hoang, L.; Shao, L.; Dambre, J.; Odobez, J.-M. Deep Dynamic Neural Networks for Multimodal Gesture Segmentation and Recognition. IEEE Trans. Pattern Anal. Machine Intell. 2016, 38, 1583–1597. [Google Scholar] [CrossRef]
- Kiran, B.R.; Thomas, D.M.; Parakkal, R. An Overview of Deep Learning Based Methods for Unsupervised and Semi-Supervised Anomaly Detection in Videos. J. Imaging 2018, 4, 36. [Google Scholar] [CrossRef]
- Lee, H.-W.; Kim, N.-R.; Lee, J.-H. Deep Neural Network Self-training Based on Unsupervised Learning and Dropout. Int. J. Fuzzy Log. Intell. Syst. 2017, 17, 1–9. [Google Scholar] [CrossRef]
- Rasmus, A.; Valpola, H.; Honkala, M.; Berglund, M.; Raiko, T. Semi-Supervised Learning with Ladder Networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Zhou, S.; Chen, Q.; Wang, X. Active deep learning method for semi-supervised sentiment classification. Neurocomputing 2013, 120, 536–546. [Google Scholar] [CrossRef]
- Zhu, X.; Goldberg, A.B.; Khot, T. Some New Directions in Graph-Based Semi-Supervised Learning. In Proceedings of the 2009 IEEE International Conference on Multimedia and Expo, New York, NY, USA, 28 June–3 July 2009; Volumes 1–3, pp. 1504–1507. [Google Scholar]
- Yang, J.; Parikh, D.; Batra, D. Joint Unsupervised Learning of Deep Representations and Image Clusters. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5147–5156. [Google Scholar]
- Fang, B.; Li, Y.; Zhang, H.; Chan, J.C.-W. Collaborative learning of lightweight convolutional neural network and deep clustering for hyperspectral image semi-supervised classification with limited training samples. ISPRS-J. Photogramm. Remote Sens. 2020, 161, 164–178. [Google Scholar] [CrossRef]
- Chapelle, O.; Sindhwani, V.; Keerthi, S.S. Optimization techniques for semi-supervised support vector machines. J. Mach. Learn. Res. 2008, 9, 203–233. [Google Scholar]
- Qiao, S.; Qin, S.; Chen, J.; Hu, X.; Ma, Z. The Application of a Three-Dimensional Deterministic Model in the Study of Debris Flow Prediction Based on the Rainfall-Unstable Soil Coupling Mechanism. Processes 2019, 7, 99. [Google Scholar] [CrossRef]
- Quoc Cuong, T.; Duc Do, M.; Jaafari, A.; Al-Ansari, N.; Duc Dao, M.; Duc Tung, V.; Duc Anh, N.; Trung Hieu, T.; Lanh Si, H.; Duy Huu, N.; et al. Novel Ensemble Landslide Predictive Models Based on the Hyperpipes Algorithm: A Case Study in the Nam Dam Commune, Vietnam. Appl. Sci. 2020, 10, 3710. [Google Scholar] [CrossRef]
- Ercanoglu, M.; Gokceoglu, C. Assessment of landslide susceptibility for a landslide-prone area (north of Yenice, NW Turkey) by fuzzy approach. Environ. Geol. 2002, 41, 720–730. [Google Scholar] [CrossRef]
- Conforti, M.; Pascale, S.; Robustelli, G.; Sdao, F. Evaluation of prediction capability of the artificial neural networks for mapping landslide susceptibility in the Turbolo River catchment (northern Calabria, Italy). Catena 2014, 113, 236–250. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Prakash, I. Bagging based Support Vector Machines for spatial prediction of landslides. Environ. Earth Sci. 2018, 77, 17. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth-Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Gupta, V.K.; Mantilla, R.; Troutman, B.M.; Dawdy, D.; Krajewski, W.F. Generalizing a nonlinear geophysical flood theory to medium-sized river networks. Geophys. Res. Lett. 2010, 37. [Google Scholar] [CrossRef]
- Merghadi, A.; Abderrahmane, B.; Dieu Tien, B. Landslide Susceptibility Assessment at Mila Basin (Algeria): A Comparative Assessment of Prediction Capability of Advanced Machine Learning Methods. Isprs Int. J. Geo-Inf. 2018, 7, 268. [Google Scholar] [CrossRef]
- Belkin, M.; Niyogi, P. Semi-supervised learning on Riemannian manifolds. Mach. Learn. 2004, 56, 209–239. [Google Scholar] [CrossRef]
- Wang, J.; Kumar, S.; Chang, S.-F. Semi-Supervised Hashing for Large-Scale Search. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2393–2406. [Google Scholar] [CrossRef] [PubMed]
- Esfahani, M.S.; Dougherty, E.R. Effect of separate sampling on classification accuracy. Bioinformatics 2014, 30, 242–250. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Sameen, M.I.; Pradhan, B.; Lee, S. Application of convolutional neural networks featuring Bayesian optimization for landslide susceptibility assessment. Catena 2020, 186, 104249. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, X.; Trmal, J.; Povey, D.; Khudanpur, S. Improving Deep Neural Network Acoustic Models Using Generalized Maxout Networks. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing, Florence, Italy, 4–9 May 2014. [Google Scholar]
- Zhang, Y.-D.; Pan, C.; Sun, J.; Tang, C. Multiple sclerosis identification by convolutional neural network with dropout and parametric ReLU. J. Comput. Sci. 2018, 28, 1–10. [Google Scholar] [CrossRef]
- Sharma, A. Guided Stochastic Gradient Descent Algorithm for inconsistent datasets. Appl. Soft Comput. 2018, 73, 1068–1080. [Google Scholar] [CrossRef]
- Dahl, G.E.; Sainath, T.N.; Hinton, G.E. Improving Deep Neural Networks for Lvcsr Using Rectified Linear Units and Dropout. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8609–8613. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.-R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Patrick, N.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Otto, C.; Wang, D.; Jain, A.K. Clustering Millions of Faces by Identity. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 289–303. [Google Scholar] [CrossRef]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Suykens, J.A.K.; Vandewalle, J. Least squares support vector machine classifiers. Neural Processing Letters 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Mansor, S.; Ahmad, N. Flood susceptibility assessment using GIS-based support vector machine model with different kernel types. Catena 2015, 125, 91–101. [Google Scholar] [CrossRef]
- Hsieh, F.Y.; Bloch, D.A.; Larsen, M.D. A simple method of sample size calculation for linear and logistic regression. Stat. Med. 1998, 17, 1623–1634. [Google Scholar] [CrossRef]
- Fagerland, M.W.; Hosmer, D.W. A generalized Hosmer-Lemeshow goodness-of-fit test for multinomial logistic regression models. Stata J. 2012, 12, 447–453. [Google Scholar] [CrossRef]
- O’Brien, R.M. A caution regarding rules of thumb for variance inflation factors. Qual. Quant. 2007, 41, 673–690. [Google Scholar] [CrossRef]
- Iwata, K.; Ikeda, K.; Sakai, H. A new criterion using information gain for action selection strategy in reinforcement learning. IEEE Trans. Neural Netw. 2004, 15, 792–799. [Google Scholar] [CrossRef]
- Binh Thai, P.; Prakash, I.; Dou, J.; Singh, S.K.; Phan Trong, T.; Hieu Trung, T.; Tu Minh, L.; Tran Van, P.; Khoi, D.K.; Shirzadi, A.; et al. A novel hybrid approach of landslide susceptibility modelling using rotation forest ensemble and different base classifiers. Geocarto Int. 2019, 1–25. [Google Scholar] [CrossRef]
- Mason, S.J.; Graham, N.E. Areas beneath the relative operating characteristics (ROC) and relative operating levels (ROL) curves: Statistical significance and interpretation. Q. J. R. Meteorol. Soc. 2002, 128, 2145–2166. [Google Scholar] [CrossRef]
- Fagerland, M.W.; Sandvik, L. The Wilcoxon-Mann-Whitney test under scrutiny. Stat. Med. 2009, 28, 1487–1497. [Google Scholar] [CrossRef] [PubMed]
- Feng, S.; Zhou, H.; Dong, H. Using deep neural network with small dataset to predict material defects. Mater. Des. 2019, 162, 300–310. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. In Proceedings of the 27th International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Volume 11141, pp. 270–279. [Google Scholar]
- Prakash, N.; Manconi, A.; Loew, S. Mapping Landslides on EO Data: Performance of Deep Learning Models vs. Traditional Machine Learning Models. Remote Sens. 2020, 12, 346. [Google Scholar] [CrossRef]
- Dong Van, D.; Jaafari, A.; Bayat, M.; Mafi-Gholami, D.; Qi, C.; Moayedi, H.; Tran Van, P.; Hai-Bang, L.; Tien-Thinh, L.; Phan Trong, T.; et al. A spatially explicit deep learning neural network model for the prediction of landslide susceptibility. Catena 2020, 188, 104451. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Layers | Spatial Resolution | Source | Techniques |
|---|---|---|---|
| Elevation | Topographic map | DEM | |
| Slope angle | Topographic map | The slope angle depends on the rate of change (increment) of the surface in the horizontal and vertical directions starting from the central pixel. | |
| Aspect | Topographic map | ||
| Curvature | Topographic map | DEM | |
| TWI | Topographic map | Where refers to the upstream catchment area and represents the slope angle of a certain grid cell. | |
| NDVI | Landsat-8 | where is near inferred band or band 4 and is the infrared band or band 3. | |
| Land use | 1:250,000 | Landsat-8 | Supervised classification (Maximum likelihood) |
| Soil type | 1:250,000 | Geological map | Digitization process |
| Lithology | 1:250,000 | Geological map | Digitization process |
| Distance to fault | 1:250,000 | Geological map | Euclidian distance buffering |
| Distance to stream | 1:250,000 | Geological map | Euclidian distance buffering |
| Distance to road | 1:250,000 | Geological map | Digitization process |
| NO. | Impact Factors | Collinearity Statistics | IGR | |
|---|---|---|---|---|
| TOL | VIF | |||
| 1 | Elevation | 0.602 | 1.661 | 0.146 |
| 2 | Slope angle | 0.612 | 1.634 | 0.020 |
| 3 | Aspect | 0.930 | 1.076 | 0.019 |
| 4 | Curvature | 0.881 | 1.135 | 0.060 |
| 5 | TWI | 0.729 | 1.372 | 0.016 |
| 6 | NDVI | 0.578 | 1.730 | 0.301 |
| 7 | Land use | 0.615 | 1.625 | 0.205 |
| 8 | Soil type | 0.956 | 1.046 | 0.026 |
| 9 | Lithology | 0.948 | 1.055 | 0.084 |
| 10 | Distance to fault | 0.930 | 1.075 | 0.028 |
| 11 | Distance to stream | 0.747 | 1.338 | 0.086 |
| 12 | Distance to road | 0.650 | 1.539 | 0.263 |
| Method | DNN | SSL-DNN | |
|---|---|---|---|
| Parameters | |||
| Epochs | 300 | 300 | |
| Dropout | 0.5 | 0.5 | |
| Learning rate | 0.001 | 0.001 | |
| Number of hidden layers | 3 | 3 | |
| Dense connection | 16 | 64 | |
| Activation function | ReLU | ReLU | |
| Optimizer | Adam | Adam | |
| Loss function | Binary cross-entropy | Binary cross-entropy | |
| Models | TP | TN | FP | FN | PPV | NPV | Sensitivity | Specificity | ACC | AUC |
|---|---|---|---|---|---|---|---|---|---|---|
| DNN | 52 | 54 | 13 | 11 | 0.800 | 0.831 | 0.806 | 0.857 | 0.815 | 0.857 |
| SSL-DNN | 57 | 54 | 8 | 11 | 0.877 | 0.831 | 0.871 | 0.794 | 0.854 | 0.898 |
| SVM | 54 | 52 | 13 | 11 | 0.831 | 0.800 | 0.825 | 0.776 | 0.815 | 0.852 |
| LR | 50 | 48 | 15 | 17 | 0.769 | 0.738 | 0.762 | 0.716 | 0.754 | 0.780 |
| Pairwise Model | p-Value | z-Value |
|---|---|---|
| SSL-DNN vs. DNN | 0.000 | −5.925 |
| SSL-DNN vs. SVM | 0.000 | −4.752 |
| SSL-DNN vs. LR | 0.000 | −4.888 |
| DNN vs. SVM | 0.000 | −8.146 |
| DNN vs. LR | 0.000 | −9.097 |
| SVM vs.LR | 0.001 | −4.616 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, J.; Qin, S.; Qiao, S.; Che, W.; Chen, Y.; Su, G.; Miao, Q. Assessment of Landslide Susceptibility Combining Deep Learning with Semi-Supervised Learning in Jiaohe County, Jilin Province, China. Appl. Sci. 2020, 10, 5640. https://doi.org/10.3390/app10165640
Yao J, Qin S, Qiao S, Che W, Chen Y, Su G, Miao Q. Assessment of Landslide Susceptibility Combining Deep Learning with Semi-Supervised Learning in Jiaohe County, Jilin Province, China. Applied Sciences. 2020; 10(16):5640. https://doi.org/10.3390/app10165640
Chicago/Turabian StyleYao, Jingyu, Shengwu Qin, Shuangshuang Qiao, Wenchao Che, Yang Chen, Gang Su, and Qiang Miao. 2020. "Assessment of Landslide Susceptibility Combining Deep Learning with Semi-Supervised Learning in Jiaohe County, Jilin Province, China" Applied Sciences 10, no. 16: 5640. https://doi.org/10.3390/app10165640
APA StyleYao, J., Qin, S., Qiao, S., Che, W., Chen, Y., Su, G., & Miao, Q. (2020). Assessment of Landslide Susceptibility Combining Deep Learning with Semi-Supervised Learning in Jiaohe County, Jilin Province, China. Applied Sciences, 10(16), 5640. https://doi.org/10.3390/app10165640