1. Introduction
The biological structure and behavior of real animal brain neurons has inspired the neural networks [
1], and backpropagation [
2] has evolved to be one of the most effective standard learning rules for artificial neural networks. The supervised learning of neural networks utilize training datasets and a global loss function. The gradient provided by the loss function [
3] is back propagated from the output layer to hidden layers to update the parameters of the network. Many advanced optimizing techniques have been developed for gradient descent [
4], and various neural network models have been proposed and successfully applied for image classification tasks, including the Convolutional Neural Networks (CNN), such as AlexNet [
5] and VGGNet [
6].
Today’s deep learning models can reach human-level accuracy in analyzing and segmenting an image [
7]. These kinds of methods are considered tedious and time-consuming, and require experts in the field, especially in the feature extraction and selection tasks [
8]. Recent studies have shown that machine learning methods can produce promising results on tasks, such as image classification, detection, and segmentation in different fields of computer vision and image processing. Training these deep learning algorithms from scratch to produce accurate results, and avoid overfitting, remain an issue due to the lack of labeled images for experiments [
9]. Apart from these significant achievements, CNNs work very well on large datasets. However, most of the time they fail on small datasets if proper care is not taken. To meet the same level of performance, even on a small dataset, and to classify, we need approaches like transfer learning using pre-trained models trained on source-target architectural techniques. In recent years, some techniques, such as transfer learning and image augmentation, have shown promising opportunities towards increasing the number of training data, overcoming overfitting, and producing robust results [
10]. Another such approach is active transfer learning [
11]. However, these pre-trained networks when trained with domain, which do not contain lots of labeled images related to target domain, lead to poor performance.
To solve this challenge, a transfer learning technique, whose major research focus is how to store the knowledge gained when solving a problem, and apply it to different but related problems, would be needed and desirable to reduce the amount of development and data collection costs and improve the performance of algorithms in the target domain. There are already many examples in knowledge engineering where transfer learning can be truly promising and useful, including object recognition, image classification, and natural language processing [
12,
13,
14].
One of the solutions is proposed by methods such as the Hebbian transfer learning (HTL) algorithm. It will be a valuable contribution, to simplify the difference between the source and target domain problem in transfer learning. The proposed technique can be seen as taking pre-trained systems as backbone and adding high-level functions to the existing architecture. What and how to transfer are vital issues to be addressed, as different methods apply to the different source-target domain. The proposed approach has demonstrated a significant improvement in classification accuracy and performance, making it more suitable for heterogeneous study with less labeled domains, such as medical imaging. The proposed technique will overcome the lack of available training samples issues, improve the pre-trained models accuracy and performance, and will provide a valuable solution to the difference between the source and target domain problem in transfer learning. Transfer learning in the convolutional neural network is the answer to the problem of the need for large data and computing power. The most appropriate TL (“Transfer Learning”) technique, in a situation with deficient datasets, was used due to deficient datasets in research [
15].
Knowledge transfer and transfer learning can reduce the effort of training deep learning models from scratch.
Let us see the problem from the biological perspective. It is a fact that evolutionary learning in the biological brain, over millions of years, is a contribution of the brain’s ability to change existing learning concerning experience gained. The genetic material is responsible for carrying evolutionary information from generation to generations. This explains that a large number of neural connections and their plasticity is learned rather than genetically coded. We see a need where the AI systems and techniques are more influenced by actual brain function, are more flexible, and not just the mathematical formula approach. However, most of the standard transfer learning algorithms are designed to repeat the same method for fine-tuning of the weights on the target domain. However, the human brains mechanism of learning a new complex concept is different from just the repetition of the same method of learning on a different domain.
The Hebbian theory, introduced by Donald Hebb, explains the “discriminative associative learning”. This particular behavior of Hebbian learning makes it a very viable candidate for discriminative learning for the search of the specific feature for the task of object recognition or image classification. The Hebbian rule is both local and incremental. Referring research literature to support the theory that when two neurons fire together, causing the sequenced activations in individual brain cells, commonly called pre- and post-synaptic spikes. Study on the visual cortical circuit, and its relationship to particular learning to induce plasticity, have proved to be of great significance; agents that can learn from experience can be treated as the problem of learning of the learning.
The techniques used in the article give attention to the problem of learning in its entirety. Method is learning how to modify the parameters of the target model and target hyper-parameters as well. However, the concept of plastic-learning for transfer learning, that is, the learning to learn the transfer learning using the synaptic plastic networks in neural networks, is a novel attempt.
The significance of using synaptic plasticity in neural networks as a source of meta-learning has enormous potential. Plasticity at the very local level of a neuron-to-neuron connection, when used as an enhancement to neural network, may learn any independent memory behavior. Learning to discriminate between instances of different classes, over a variable number of classes within the dataset space defined by the task at hand, can be the result-oriented approach for classification problem. HTL technique is a framework that offers comprehensive yet individualized solutions for all the different applied domains. The object in the transfer process has two parts: network structure and weights. Technique transfers both structure and weights of network simultaneously. Our experiment uses significantly smaller source dataset and (relatively) not so large target task dataset. Other transfer learning techniques use larger datasets as source task datasets [
16]. Our study is similar to this approach, to evaluate the effectiveness of transfer learning methods in the repurposed heterogeneous domain [
17].
The need for such method is quite significant, for example: many scenarios where the data set is smaller, or unlabeled data are available and labeled data are much less. In such cases, the technique of transfer learning that is to learn from the available dataset, and using the learned knowledge on a new domain dataset, is very useful. In many cases, the source data and target dataset have different feature space of image data, or different data label space as well. In this situation, the heterogeneous transfer learning plays a significant part, and learning the knowledge from one domain and transferring the knowledge to totally different data domain becomes possible. To increase the ease of transferring knowledge is the purpose of this method.
On the contrary, in absence of such learning, the traditional deep learning techniques use millions and millions of samples of data to learn from existing labeled datasets. Such supervised learning neural network techniques are only possible when we have plenty of labeled data available, and lots of good computer hardware to do all the millions and billions of calculations. However, using the transfer learning with even heterogeneous datasets, the training becomes easier and faster, and needs less cost of computations.
There are many significant applied domains of transfer learning, such as pediatric pneumonia diagnosis, medical imaging, cancer classification using deep neural networks, digital mammographic tumor classification, object classification, and visual categorization [
18,
19,
20,
21,
22,
23]. Transfer learning in deep convolutional neural networks (DCNNs) and unsupervised transfer learning via multi-scale convolutional sparse coding for biomedical applications is an important step in its application to medical imaging tasks. In a non-medical domain, Field Programmable Gate Arrays (FPGAs) can be used for transferring the knowledge from learned neural networks to computer hardware or microcontrollers—hardware, such as FPGAs, where companies are trying to put computer vision on hardware chips is an example of futuristic application. Thus, learned knowledge can be used in small and mobile objects, such as robots, cars, and other vehicles, for example. Transfer learning of deep neural networks in automatic speech recognition systems is also an interesting domain.
The cited pioneer, of transfer learning work in the field of machine learning, is attributed to Lorien pratt, who contributed to the discriminability-based transfer (DBT) algorithm in 1993. Cross-domain transfer learning is a well-proven technique and has been used earlier as well [
24]. However, the mathematical approaches for learning in such neural network models are considerably away from what happens in a real animal brain. Neuroscience suggests that the gradient descent optimization processes are different from the real brain processes [
25].
According to neuroscientists, the biologically inspired rules, such as spike-timing-dependent plasticity (STDP) or the Hebbian learning rules [
26,
27], are more relevant to actual animal brains processes.
About half a century ago, the development and plasticity of the brain was studied by scientists. They investigated/inquired the neuronal response behavior, in general, called plasticity [
28]. The Hebbian learning principle presents how adjacent neurons firing together strengthens the corresponding connection in an animal brain [
29]. This characteristic of neural connection is called the plasticity [
28]. Recent work in neural networks, such as [
30], has demonstrated the implementation of powerful principles of Hebbian plasticity with backpropagation in neural network training. The article discusses the derived analytical expressions for calculating the gradient in neural networks with Hebbian plastic connections and its backpropagation.
As the neural network model is trained using large amount of data, the model parameters are fixed and used to predict outputs of new instances of the same task. If one tries to apply the model to a different task, the parameters must be re-trained using large number of new training instances. Animals and human beings, however, learn new similar task quickly and efficiently with small amount of data (experience). Learning from experience has also been studied in learning to learn domain [
31,
32]. An intelligent way of learning is to extract the knowledge from one or more source tasks, and apply the knowledge to a target task [
33]. There has been much research and surveys on transfer learning [
34], but most of the work has focused on parameter fine-tuning based on error backpropagation, wherein a network model is developed and trained for one task and then used on a second related—or almost similar—task to maximize the accuracy with small amount of training.
Since the Hebbian learning principle addresses the issue of lifetime learning and adaptation through the concept of connection plasticity [
35], introducing the principle into the transfer learning algorithm can improve the efficiency in a better way. Referring to the survey of related work [
34], transfer learning techniques can be classified mainly as instance re-weighting and feature extraction. Based on work on CNN [
36], published work stating the CNNs connection parameter transfer, learning can be implemented either by removing the output layer of a trained network or by implementation of parameter fine-tuning [
37]. Training on one-half and later using the second half. The network, which was fine-tuned, surpasses the performance on randomly initialized one.
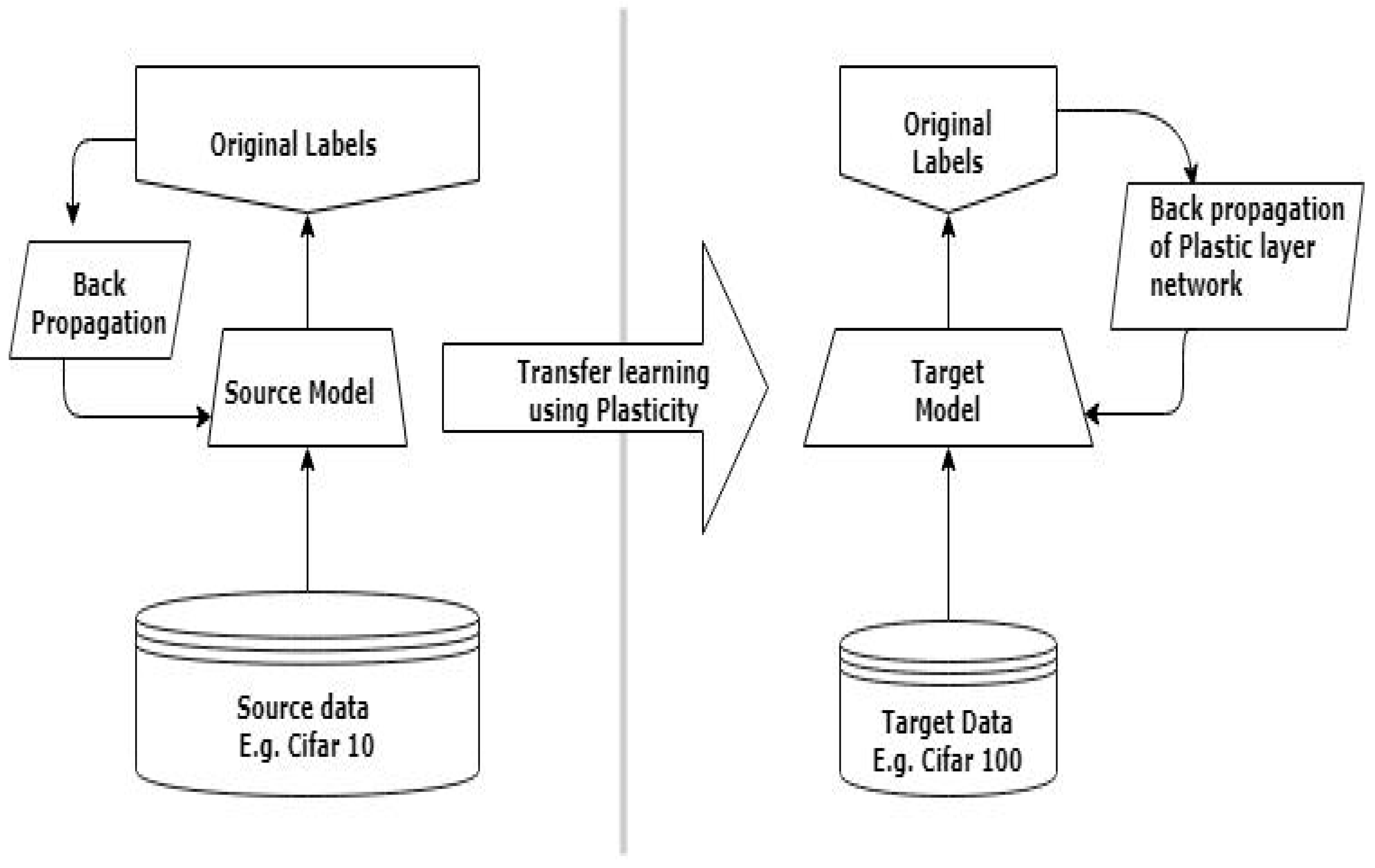
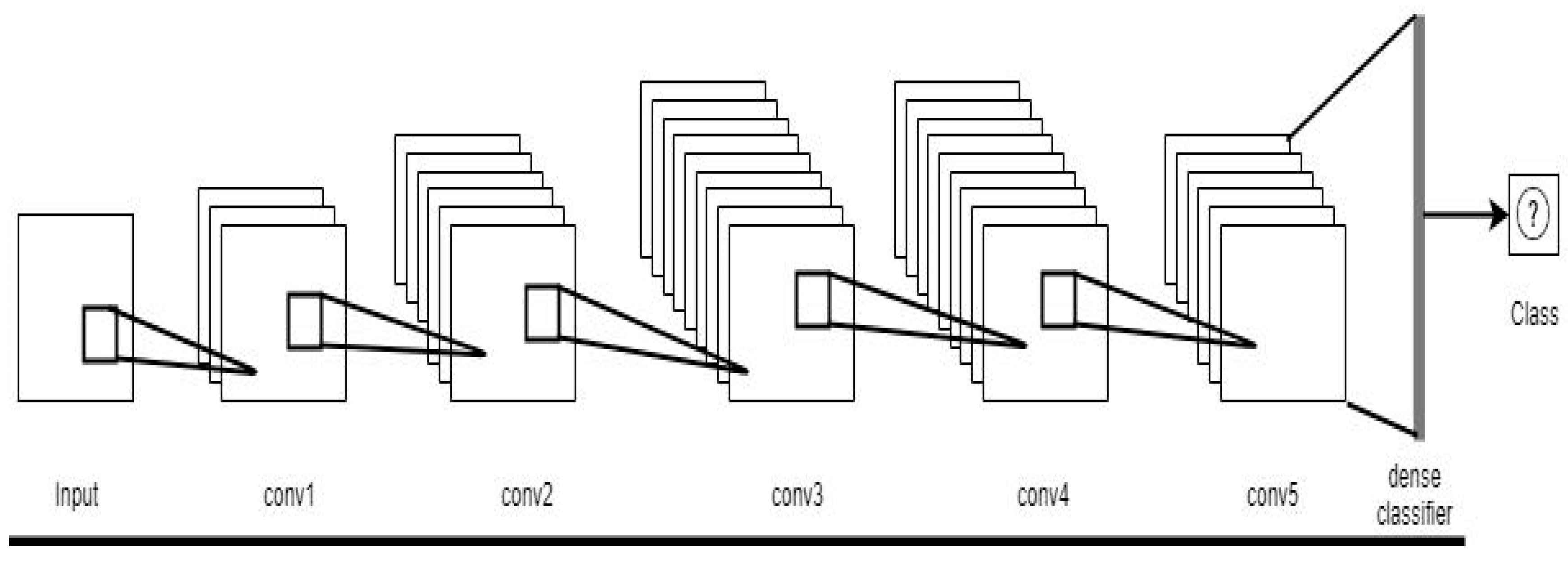
In this paper, we present an algorithm called Hebbian Transfer Learning (HTL), which performs transfer learning on convolutional neural networks with synaptic plasticity in connection weights. It modifies the connection weights and also controls the plasticity coefficients [
38,
39,
40] that are responsible for the flexible nature of each connection weight. By using the flexible nature of the network, we have defined the network layers and connection weights of a convolution neural network in multi-part [
30], a static and dynamic part. The active part can adjust depending upon the input and the plasticity coefficients. Hence, we can say that the network is performing transfer learning to adapt the connection weights as per the given task. These parameters are both learned and updated during the process of training. To check the effectiveness of the proposed algorithm, experiments are performed with publicly available CIFAR-10 (Canadian Institute for Advanced Research) and CIFAR-100 image datasets. The experimental results show that the proposed transfer learning algorithm with Hebbian learning principle outperforms standard transfer learning approach, especially when the source and target domain are heterogeneous.
Main contributions and highlights of the proposed method: the key contribution of this work is to provide a CNN-based hybrid transfer-learning approach using different source pre-trained models to transfer knowledge with the hybrid approach and architecture to accomplish higher accuracy compared to the standard algorithm. The HTL algorithm is the core of the proposed technology. In the proposed method, our aim is to utilize the existing CNN algorithm and do fusion work (e.g., interface work for biology and technology as a research domain). By applying Hebbian learning in transfer learning and deep learning, this method is reusable. It can be used to accelerate the training of neural networks. It is a hybrid CNN architecture.
We propose flexible architecture and algorithms, easy to extend algorithms to other deep learning techniques and domains. First time plasticity is applied in transfer learning. We merge multiple solutions to generated optimal solution using algorithm. These applied methods are well proved biologically by Donald O. Hebb. In larger view, we have made conceptual contribution towards transfer learning in deep learning. In addition, the paper also provides the methodological details of the work, which can be utilized by any research group to take the benefit of this work. Therefore, the motivation of the present study was to utilize the power of Hebbian learning rules and machine learning, and enable better accuracy. The idea of proposed Hebbian learning is to let a new algorithm inherit the knowledge of the existing algorithm. Just as the teacher teaches the student knowledge, the higher level of summary knowledge transfer is undoubtedly the fastest and most efficient.
The rest of the paper is divided in the following section:
Section 2 summarizes related works.
Section 3 describes the methodology used in the study, where the details of the problem definition, proposed algorithm, and technical logics are discussed in detail.
Section 4 provides the experiments, and results of the classification algorithms, describing datasets for training and testing, the comparative performance of training and testing accuracy for both HTL and standard transfer learning (STL) algorithms is studied, and the results with data-plots are discussed in this section, which is followed by a discussion section. Finally, the conclusion is presented in
Section 5.
5. Conclusions
Transfer learning has shown significant benefits in various machine learning tasks, including image classification. The CNN architecture for image classification has feature extraction and classification layers integrated. In general, with machine learning, the training data is the same over many iterations. However, in transfer learning, the network trained with source domain data is to be fine-tuned with new target domain data, and in such situations, a biologically inspired algorithm may significantly improve the learning efficiency.
In this paper, we presented a transfer learning algorithm based on the Hebbian learning principle. The Hebbian learning represents the associative learning where simultaneous activation of brain cells positively affects the increase in synaptic connection strength between the individual cells. We investigate the use of Hebbian plasticity principles using the differentiable plasticity and backpropagation, and applied the principle to the transfer learning. In the Hebbian transfer learning method, we use the last feature extraction layer and reweight the output using a plastic layer in a way that the parameter distribution difference between the old and new training dataset is reduced. We applied HTL to CNN architecture in the experiment, but our algorithm is generic and can be extended to any neural network architecture that has feature extraction and classification layers integrated into one single entity. In this hybrid architecture, where the layers are a combination of feature extraction and plastic layer, the framework requires a minimum percentage of disturbance of weights to fine-tune the network with target dataset.
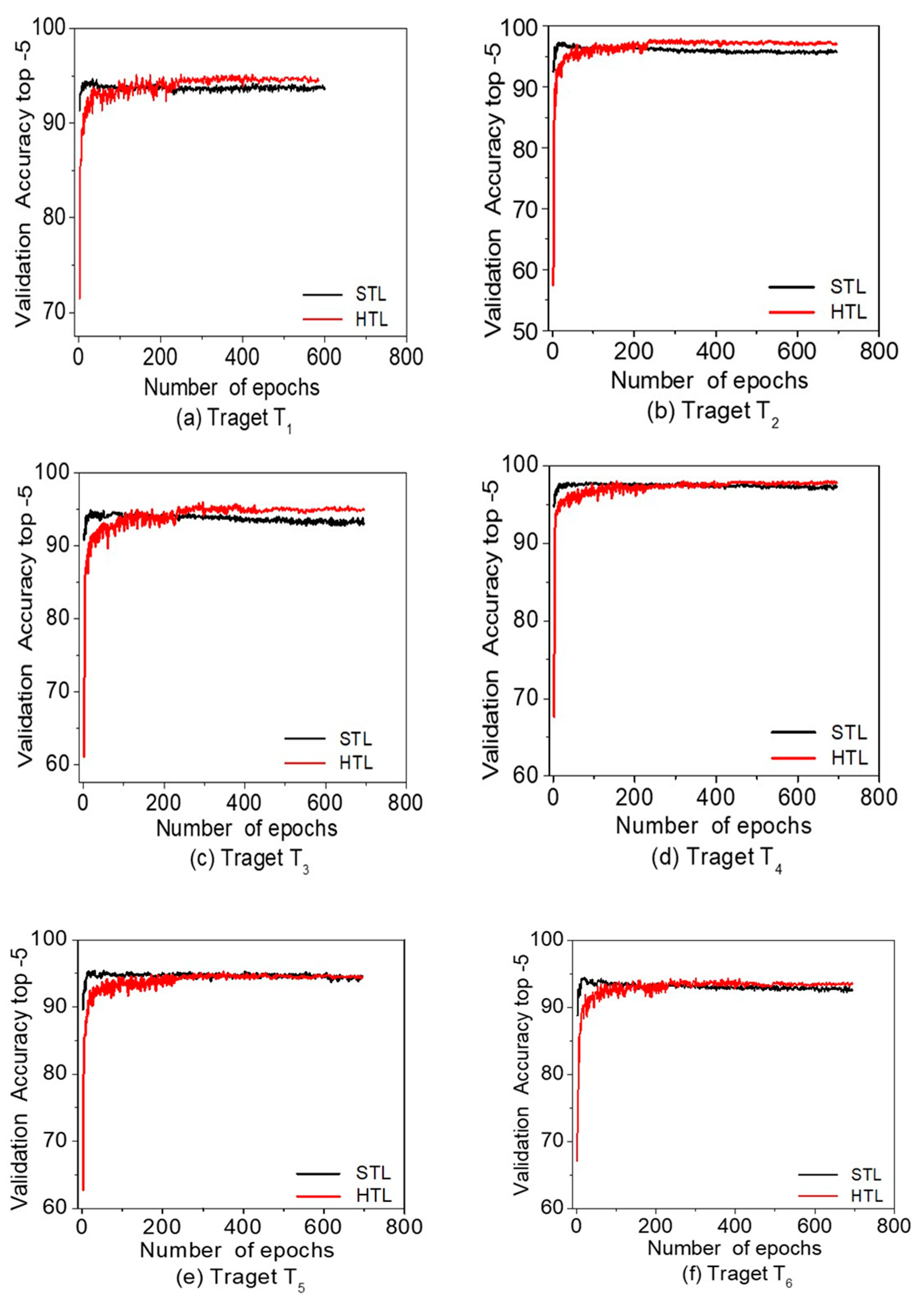
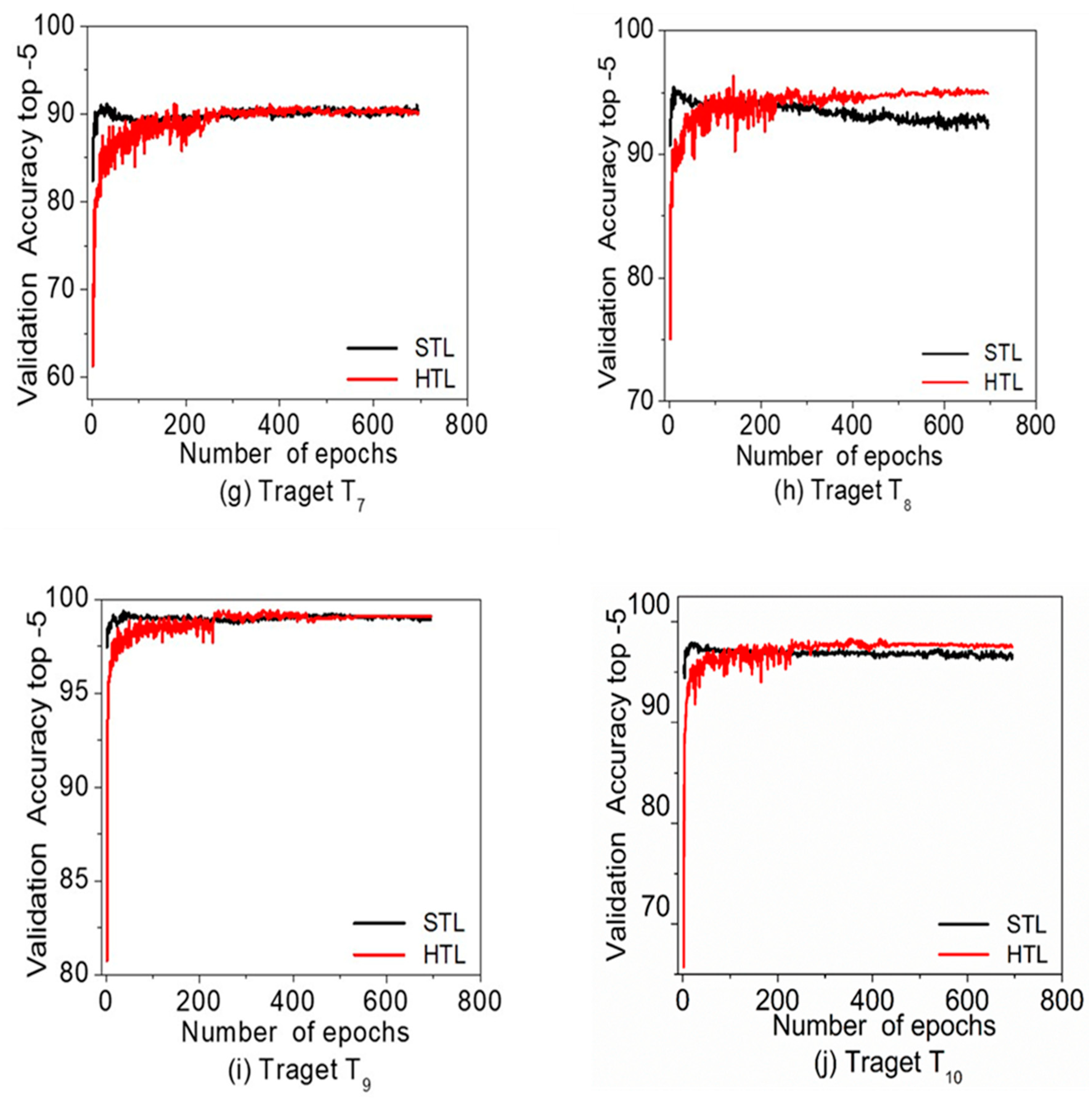
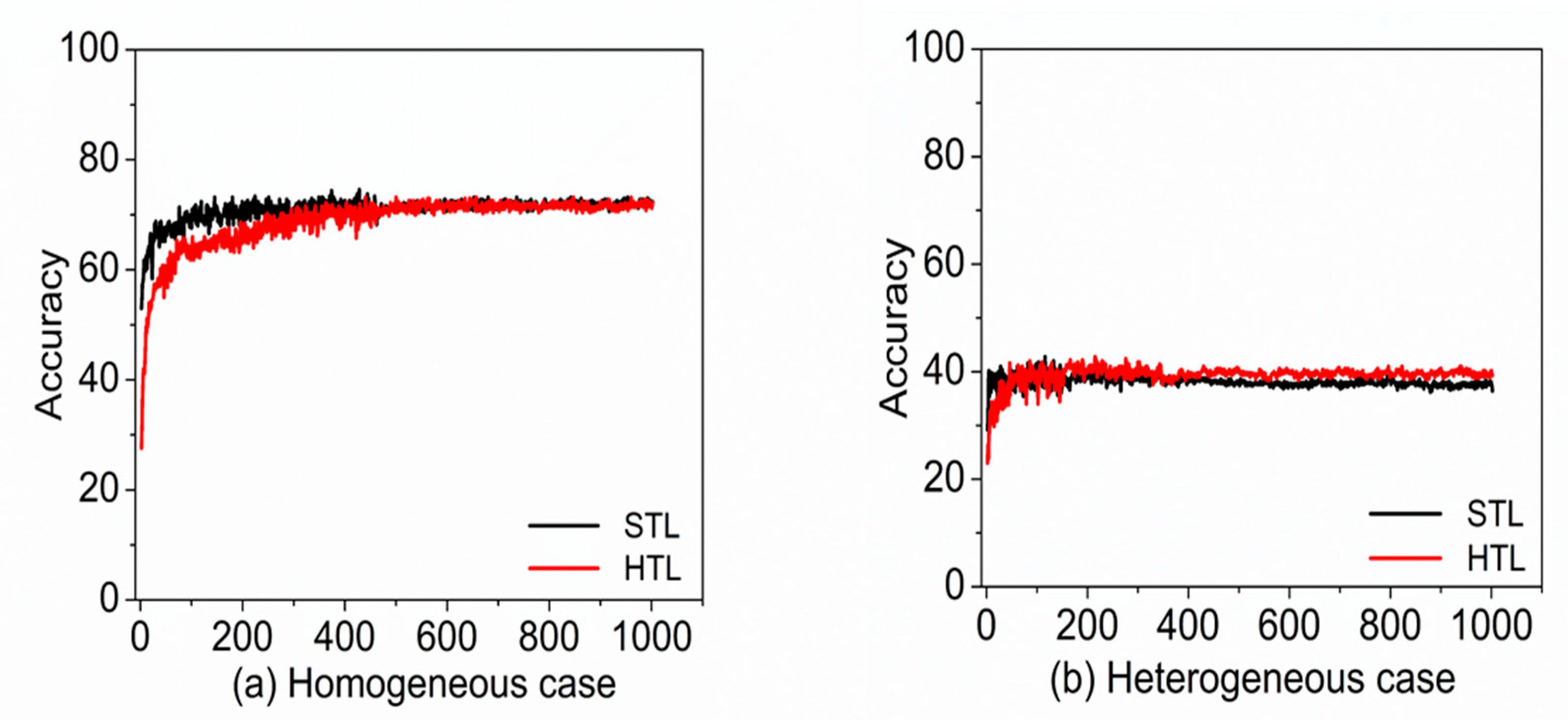
Two experiments were conducted to compare the efficiency of the proposed algorithm with standard transfer learning. The first experiment used CIFAR-10 as source domain and CIFAR-100 as target domain, and the second experiment used subsets of CIFAR-100 as both the source and target domains. The experimental results showed that in both experiments the HTL achieves better accuracy than the STL method. The average top-1 accuracy improvements are +1.19% for first experiment, and +1.80% for the second experiment. In the first experiment, it is observed that the HTL is more effective when the source and target are heterogeneous in terms of their semantic contents. In the second experiment, it is also observed that the HTL is more effective when we try transfer learning from source to heterogeneous target domain. The average top-1 accuracy improvement was +0.13% for homogeneous cases, but it was +1.80% for heterogeneous cases. On the basis of experimental results, we conclude that the proposed Hebbian transfer learning algorithm is significantly competitive to the standard transfer learning algorithm when the homogeneous source and target domain are used, and achieves much better performance when the heterogeneous source and target domain are used.
For future research, the proposed algorithm may be extended by enhancing the positive only weight change in plastic Hebbian learning part. Another possibility would be refining the CNN model by stacking additional layers and adjusting only positive weights on those layers. The algorithm may also be extended by experimenting on larger dataset, such as ImageNet for images and video datasets. Another way to extend this work is working with more advanced—and the latest—architectures, such as Inception, and other larger neural networks, DCCNs. Moreover, we may extend this algorithm to experiment with other machine learning datasets for example NLPs datasets, text datasets. In future, we may experiment with fully plastic architectures for CNNs. We may also investigate the efficiency of transfer learning in imbalanced datasets. We may utilize this quick transfer learning technique for wide range of applications in mobile objects, such as robots, cars, and other mobile vehicles using CNN parameter transfer for object detection, and many more.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}