1. Introduction
During recent years, much research has been conducted on two-phase inside microchannels to survey transport phenomena. There are many examples for the process involving two-phase flow in microchannels: microreactors, miniature heat exchangers, fuel injection in internal combustion equipment, miniature refrigeration systems, cooling of high-powered electronic systems, fusion reactors for cooling plasma-facing components, and fuel cells with evaporator components [
1,
2,
3,
4].
Nevertheless, two-phase flows inside microchannels come with disadvantages, too. They impose a higher pressure drop through the fluid flow passing through narrow channels. Hence, both pressure drop and heat transfer considerations should simultaneously be taken into account during the design process of these miniaturized heat exchangers.
Numerous experimental datasets have been collected and studied by scholars, to investigate inside two-phase flow microchannels [
5,
6,
7,
8]. For instance, there are published experimental works that explore fluid characteristics inside microchannels with a two-phase flow of nitrogen, R12, R32, R134a, R236ea, R245fa, R404a, R410a, and R422 with different qualities and mass fluxes at different channel hydraulic diameters [
9,
10,
11].
Harirchian and Garimella [
12] considered a boiling of the dielectric liquid fluorinert FC-77 in parallel microchannels to investigate heat transfer coefficients and pressure. They studied the flow and boiling phenomena for a comprehensive range of channels in four distinct flow regimes, including slug, annular, bubbly, and alternating churn/annular/wispy-annular flow regimes.
Pan et al. [
13] experimentally examined the characteristics of flow boiling of deionized water inside a microchannel consisting of 14 parallel channels with 0.15 × 0.25 mm rectangular shape. They selected the heat flux, mass flux, and inlet temperature as significant factors for the variation of pressure drop. Based on the experiment results, they concluded from the pressure drop trend that with the increasing quality of vapor, instability will be increased.
Meanwhile, researchers have tried to validate the adiabatic pressure drop correlations of two-phase flow inside microchannels for different conditions by comparing them with the comprehensive databases at hand. Some researchers [
14,
15,
16,
17,
18] have studied the heat transfer coefficient for flow boiling of oxygen-free streams inside copper microchannel heat sinks. The experimental results are in good agreement with the corresponding numerical predictions. Maher et al. [
19] proposed a set of new equations to describe a two-phase pressure drop, along with the homogeneous flow of different working fluids at different tube diameters and fluid flux values.
Although many correlations are provided by researchers for predicting pressure drops, having a comprehensive correlation for an extensive range of factors for linear multivariate modeling is too difficult. A common way to obtain a comprehensive correlation is to use non-linear empirical modeling techniques, such as artificial neural network (ANN), which is developed based on the brain’s biological neuron network function [
20,
21,
22,
23].
The artificial neural network method has been increasingly used to solve engineering problems. Using an appropriate form of the algorithm to train and test the network configurations would be followed by the successful application of ANN. Picanco et al. [
24] suggested that the functional relations between the pertinent dimensionless numbers in nucleate boiling can be correlated to convective heat transfer through a genetic algorithm. The flow pattern of two-phase water and air stream was presented by Mehta et al. [
25]. They found predictor correlations by means of applying the ANN method on a circular Y-junction minichannel with a 2.1 mm diameter.
According to the literature, there has been limited effort focused on evaluating the pressure drop by means of the ANN technique. Therefore, in this study, in addition to the use of conventional neural networks in engineering sciences to achieve higher levels of accuracy, we have integrated these models using the concept of committee neural network. As such, different neural network models were employed, and then a committee neural network was generated, based on a genetic algorithm to integrate the neural networks.
2. Methods
2.1. Artificial Neural Networks
Artificial Neural Network (ANN) is a system of data processing, describing, predicting, and clustering which is inspired by the biological nervous system [
26]. The nerve cell is the smallest component of this system. The data gained from experiments, or the measurements, are inputs of this system. The relative importance of the inputs is assigned by weights, and the weighted input values are combined by the summing function. Evaluation of information takes place by processing the obtained data from the summing function and the outputs of the activation unit. The nature of the relationship between artificial neural cells and biological neurons is illustrated in
Figure 1. As shown in this figure, a similar manner of processing collected data from the outside world exists for both an artificial neural cell and a biological neuron.
For this purpose, the input layer takes variables from resources like experimental data to do some mathematical operations. Then these values are sent to the hidden layers, in which the number of hidden layers can be specified regarding the complexity of problems. The estimation of output value for all ANN structures can be provided as below:
where the output value (
) is computed using a function
f and the summation of the multiplication of weight
and input
to the bias
b.
In general, ANN models predict the output parameters according to the following procedure:
Training trends are determined based on datasets.
The architecture of the neural network is defined.
The network parameters are determined.
The feedforward back-propagation program is run.
Data are compared and analyzed.
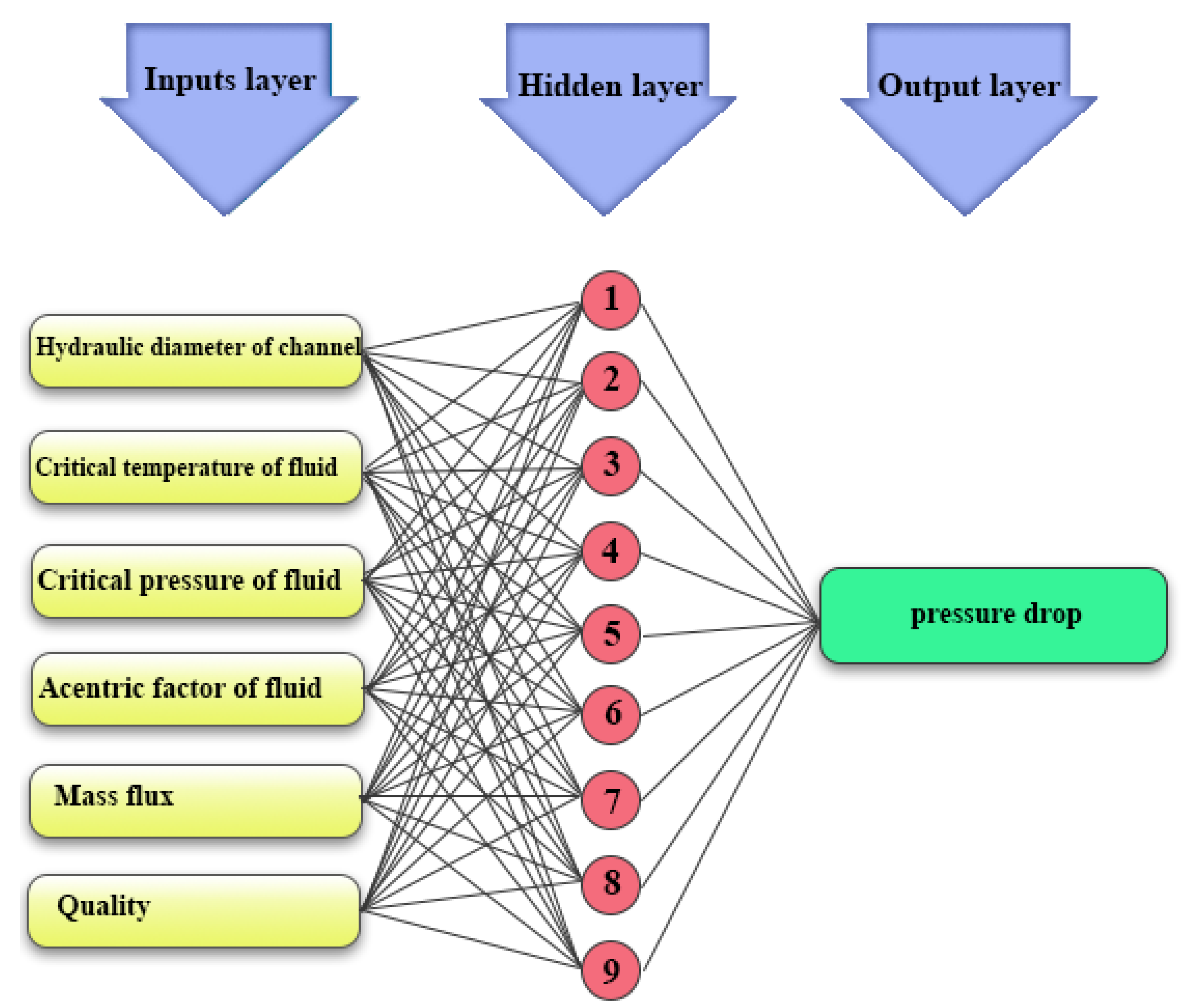
In this study, the pressure drop, as the output, is essentially the target, and is predicted by compiling the testing inputs data. Inputs 1 to 6 are hydraulic diameter of channel, critical temperature of fluid, critical pressure of fluid, acentric factor of fluid (a concept referring to the molecule’s shape), mass flux, and quality (the mass fraction of vapor in a saturated mixture), respectively.
Table 1 presents the values of these input parameters.
Various models of the artificial neural network can be utilized in the prediction and comparison of experimental data results. Classification of these networks is dependent on their application. In this paper, four specific types of neural networks, such as multilayer perceptron, radial basis function, cascade feedforward, and general regression, are employed for estimations.
2.1.1. Multilayer Perceptron (MLP)
Multilayer perceptron (MLP) was developed in 1986, and it has become the most commonly used type of artificial neural network to solve problems by estimation [
27]. These networks have a number of layers between their input and output layers, and their learning algorithm is essentially based on a gradient descent technique, which is basically a back-propagation algorithm. The back-propagation networks aim to approximate the network outputs according to the desired output, with the aim of reducing error. Ultimately, error reduction is achieved by setting the network weight values in the subsequent iteration.
2.1.2. Radial Basis Function (RBF)
Broomhead and Lowe developed a type of feedforward neural network named the radial basis function neural network [
28]. The main difference between MLP and RBF methodologies is that the RBF method includes hidden layers containing radial basis activation functions.
2.1.3. Cascade Feedforward (CF)
Feedforward and cascade forward networks make use of the back-propagation algorithm regardless of the connection between neurons in each layer. In cascade forward networks, neurons are connected to both the neurons in the previous layers, as well as all the neurons in the same layer [
29]. Similar to feedforward back-propagation networks, the back-propagation algorithm is also used by cascade networks for updating weights. The main feature of a cascade neural network is that in each layer, neurons are associated with all neurons in the previous layer.
2.1.4. General Regression (GR)
The general regression neural network is used for estimation of a continuous variable, similar to the standard regression technique. However, GR is superior with regards to fast learning and converging into optimal regression [
30]. GR is structured by four layers: input, pattern, output, and summation layers. GR might be recognized as a fully connected network, since its layers are linked to the following layer through weighting vectors between neurons. This method is used to determine the nonlinear relationship between variables.
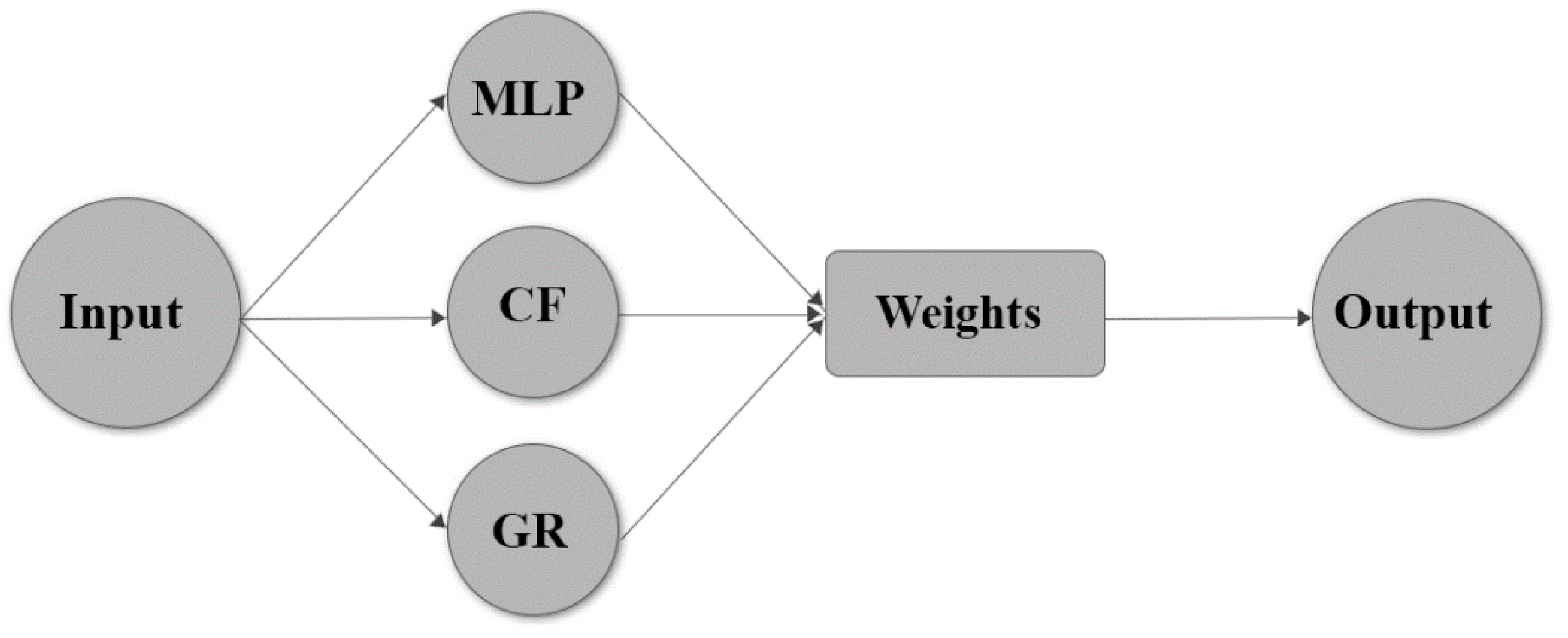
2.1.5. Committee Neural Network (CNN)
In general, a set of neural networks is making up the committee neural network, and it offers the benefits of the whole work by integrating the product of individual systems. Therefore, a model can act better than the finest individual network. CNN is used as an optimization method to reach the final result through a combination of the outputs of different models [
31,
32].
Figure 2 shows a schematic representation of a committee neural network. A combiner integrates the models in various ways; the most common way is the simple averaging of the group. Meanwhile, the genetic algorithm (GA) can help properly combine the weight (contribution) of each neural network in CNN. This approximation method incorporates the principles of genetics and natural selection. Therefore, a set of networks makes up CNN, and it incorporates the benefits of the whole work by means of integrating the product of each individual mode.
2.2. Experimental Database
In this study, the databank obtained from different experimental studies [
33,
34,
35,
36,
37,
38] was used for the investigation of pressure drop. Available experimental results in the literature demonstrate that the pressure drop in microchannels is influenced by the vapor quality and other fluid properties. Therefore, as reported in
Table 2, a total of 329 empirical data points was selected for modeling, and various neural networks were examined for data training purposes. The collected experimental data covers the quality ranging from 0.007 to 0.96, mass flux of 196.8–1400 kg·m
−2·s
−1, acentric factor from 0.152 to 0.33, critical pressure of 3.73–11.3 MPa, critical temperature of 345–419 K, and hydraulic diameter values ranging from 0.078 to 6.2.
2.3. Scaling Database and Transformation
The provision for employing the ANN method is that there should not be any units when training begins. The reason is that the limit for the neuron output to be in the range [0, 1] is imposed by non-linear activation functions, such as a hyperbolic or logistical tangent. The standardization of data for ANN computations was done by the statistical normalization rule. After calculation completion, the output data from the network were reverse converted to their original representation. To improve the efficiency of the training step in the ANN calculations, Equation (2) was used to normalize the inputs and target values.
In this equation, V signifies the variables, whether they be dependent or independent, and Vnormal represents the normal value. The maximum and minimum values of each variable are shown by Vmax and Vmin, respectively.
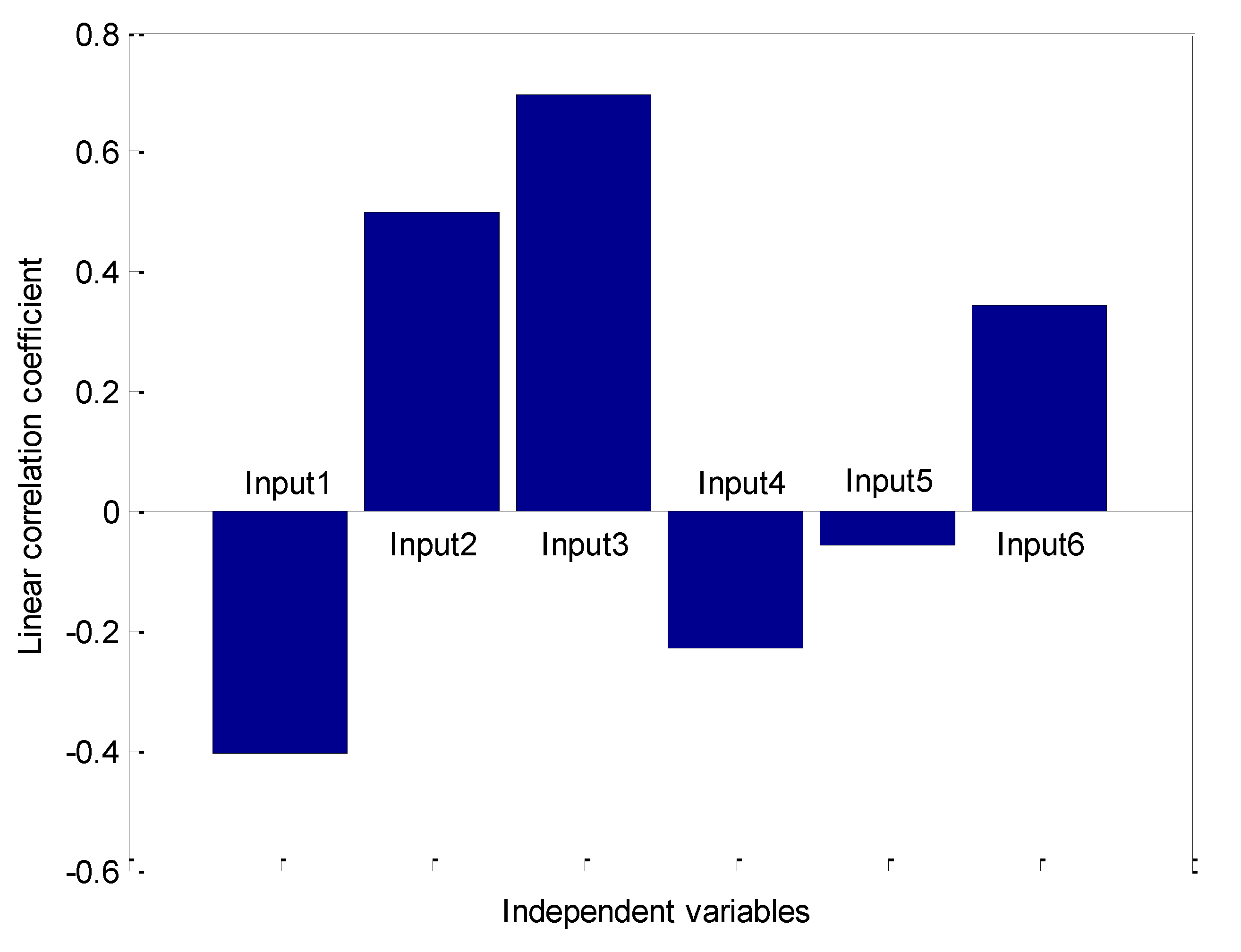
The process of selecting suitable inputs for ANN is accomplished by means of the Pearson correlation coefficient, which is a measure for variable rating. The connection type and intensity between sets of variables are determined by the Pearson correlation coefficient. This coefficient takes the values in a range between −1 and +1, which respectively correspond to the highest reverse and direct association cases. This coefficient is equal to 0 if there is no association between variables. The most important variables are the absolute averaged ones, since they have an imperative close interaction. Thus, the relationship between independent and dependent variables would be most credible when the maximization of average absolute Pearson’s coefficient (AAPC) is performed for a particular dependent variable transformation. The Pearson correlation coefficient values between each pair of variables are represented in
Figure 3.
It is evident from this figure that the most influential direct and indirect relationships belong to critical temperature of fluid and hydraulic diameter of the channel, respectively. This is while mass flux has the least linearity with pressure drop in the microchannel.
Table 3 contains the inputs and different transformations. This figure indicates that the best possible outcome for pressure drop is obtained from the output to the power of 0.5. Eventually, the transformation should be reversed to reach the modeling dependent variables and enable its comparison with the actual values.
3. Results and Discussion
3.1. Performance Analysis of Models
To compare the precision of the model, various statistical indexes, such as absolute average relative deviation percent (AARD%), mean square error (MSE), the regression coefficient (R
2), and root mean square error (RMSE), have been utilized. These indexes are introduced as follows:
where
,
, and
represent the real values, the mean of real values, and values of predicted pressure drop, respectively. Moreover,
N indicates the dataset’s number.
3.2. Selecting the Configuration of ANNs
According to the literature, the dataset was divided into testing and training portions, comprising 15% and 85% of the entire experimental dataset, respectively; this is done to confirm the consistency of expected models. Determination of weights and topology of a network is called the optimization process, and results in the optimum function when specific performance equations are utilized. The determination of the number of optimal neurons contained in the hidden layer is of great importance. The number of inputs, outputs, the architecture of the network, and the algorithm used for training can all affect the optimum number of neurons in a hidden layer. As expressed by Ayoub and Demiral [
39], determining the optimum number of hidden neurons is not simple, and cannot be performed without training, and solely by examining different numbers of them to estimate each generalization error. Bar and Das [
40] demonstrated that a single hidden layer having enough number of processing units would have an acceptable performance. As such, we chose a single hidden layer with multiple processing neurons in this study.
The trial and error method was used to develop a successful model. The dominant statistical parameters, such as the average absolute relative error, correlation coefficient, and root mean squared errors, were examined for all of the topologies. This provided the opportunity for careful inspection and visualization of the cross-validation or generalization error of each network design.
As mentioned before, the optimization of the MLP was done by changing the neuron content of the hidden layer while the statistical indexes were monitored. The minimum number of data needed for training is 2–11 times of weight and bias. Hence, for an MLP that has one dependent and six independent variables, the number of hidden neurons were computed as follows:
The best outcomes of the MLP network for the number of hidden neurons are presented in
Table 4.
Considering the minimum MSE value and the maximum R-squared value, eleven hidden neurons in MLP networks are optimum. The efficiencies of different types of ANNs were compared to find a suitable model for pressure drop prediction. Hence, a comparison was performed between the optimum MLP network structure and other ANN models, such as CF, RBF, and GR. The exactness of sensitivity for finding the optimum hidden neurons number is listed in
Table 5,
Table 6 and
Table 7. It should be noted that the determination of the number of hidden neurons is similar in all kinds of ANNs and has regulations similar to MLP.
The hidden neurons were not significant in the GR, therefore the spread value needed to be modified to reach the significant hidden neurons in GR. Accordingly, one hundred statistical indicators of various GRs were compared with regards to the spread value changes within 0.1–10, with 0.1 interval steps.
Table 8 lists the values of AARD%, MSE, RMSE, and R
2 obtained from different ANN models with the best topology.
Rationally, the AARD% values of the best models are minimum. As indicated in
Table 8, the best prediction of the pressure drop belongs to the GR model, compared to other models. By considering the values obtained as the statistical error of pressure drop, the AARD% of the GR model (with the error value of 7.63) yielded the best prediction, compared with other ANN models of MLP (10.89), RBF (59.16), and CF (10.65).
It should be noted that the statistical indices of R2, MSE, RMSE, and AARD% served as the basis for choosing this model amongst a set of 1620 distinct models (1100 RBF models, 200 CF models, 100 GR models, 220 MLP models).
3.3. Comparison of CNN with Other Neural Networks
As mentioned before, the CNN method is made up of two steps for predicting pressure drop parameters. The first is by applying it in committee neural network methodology to determine pressure drop parameters, and the second one is implementing it in a genetic algorithm to find the share (weight) of each algorithm in building CNN.
By joining the outputs of the three models MLP, GR, and CF, the microchannel pressure drop was predicted in more precision. It should be noted that, due to the high error of the RBF method, the predicted data from this model has not been used in the CNN model. To describe the coefficient of every single model, GA is merged as follows:
where calculated values of
,
,
and
are 0.0534, 0.9281, 0.01725, and −0.1574, respectively.
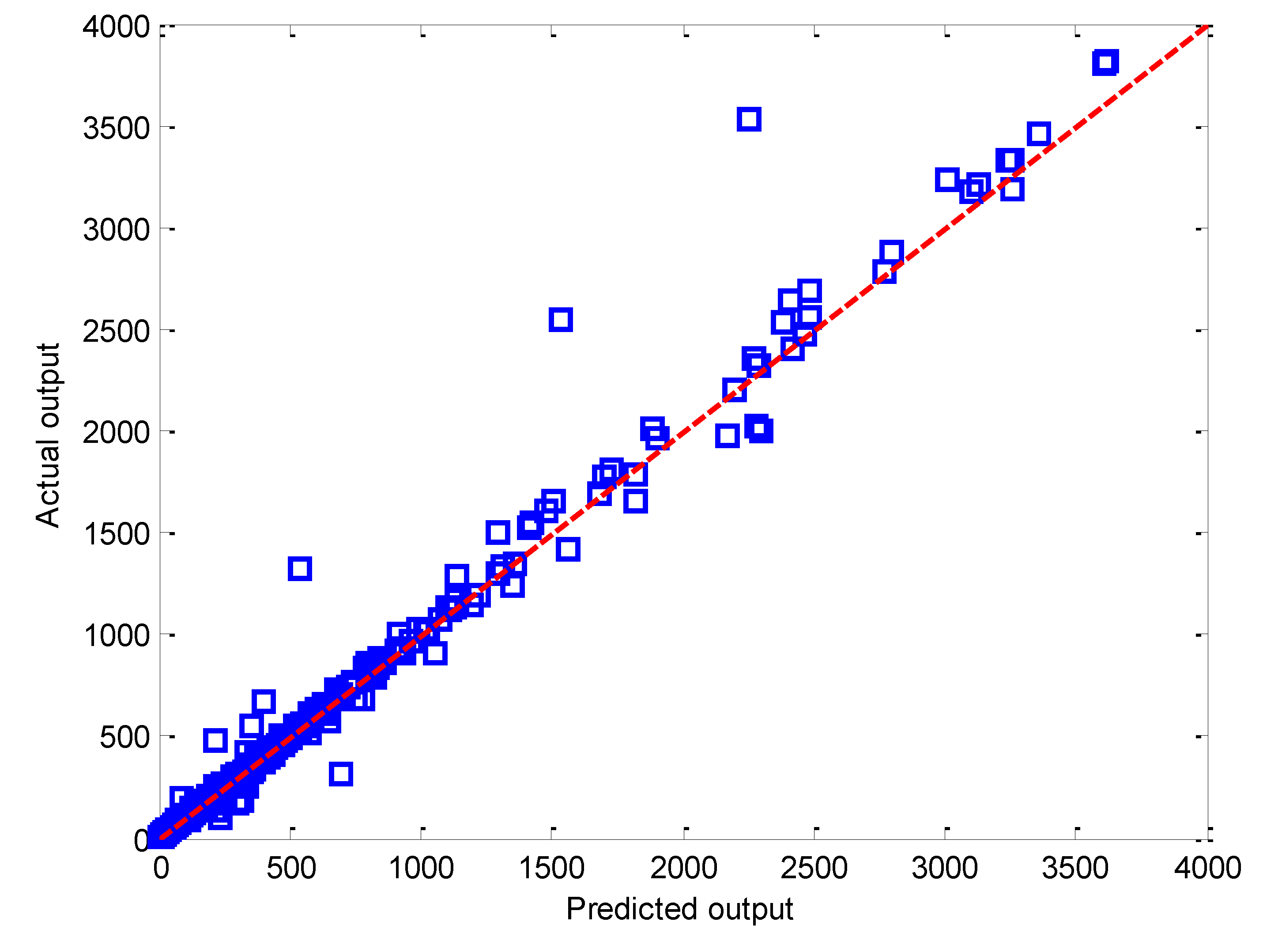
Figure 4 illustrates the actual outputs versus the values of predicted outputs by CNN for the entire dataset of pressure drop. It is evident that the CNN model is remarkably capable of forecasting results for the whole dataset, as the concentration of symbols around the solid 45° line confirms this.
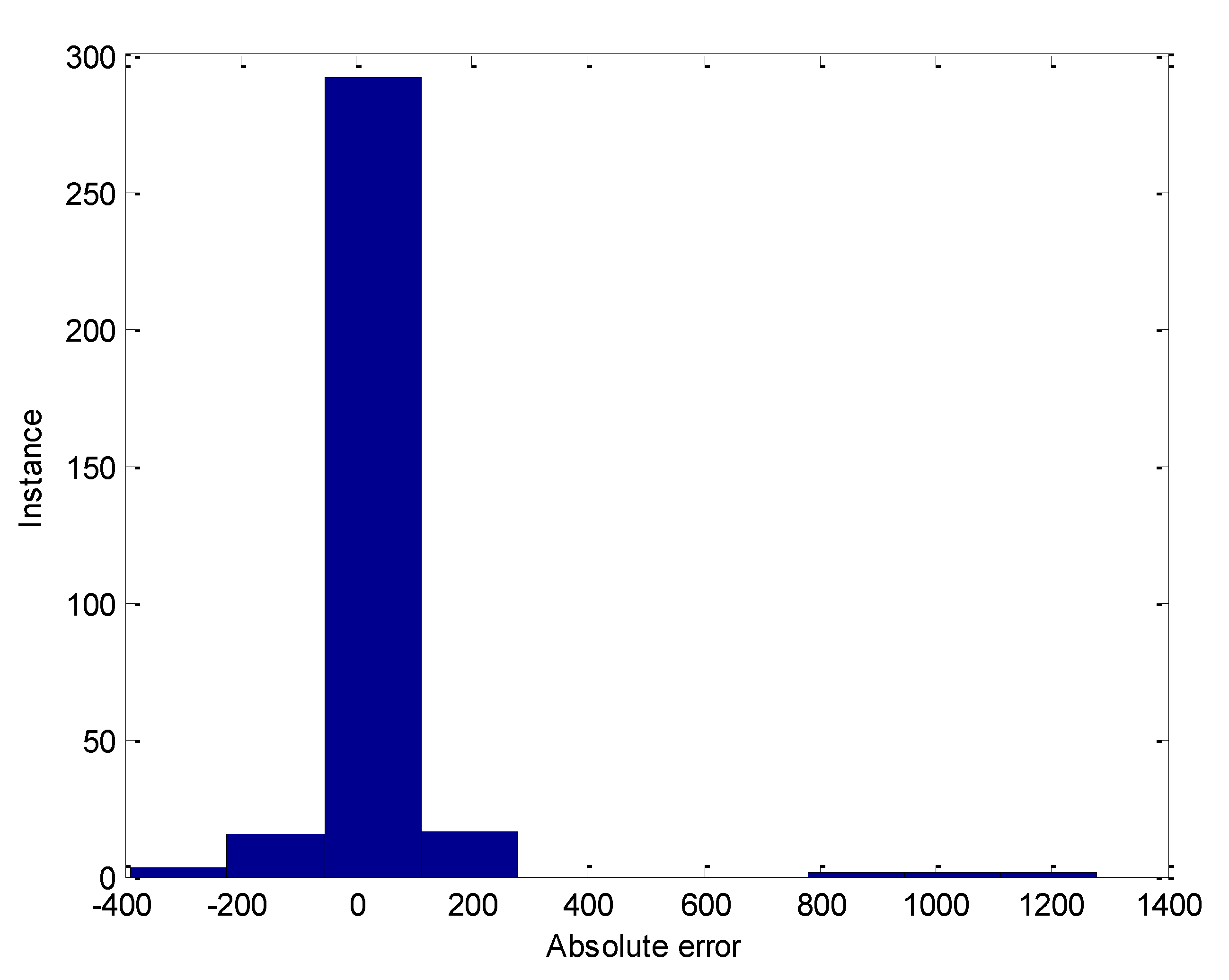
The absolute error histogram for the entire data by the CNN network is presented in
Figure 5, which is an approximately normal distribution. As shown, it can be seen that the absolute error distribution histogram is stable, and most of the prediction errors belong to the −200 to 200 absolute error intervals.
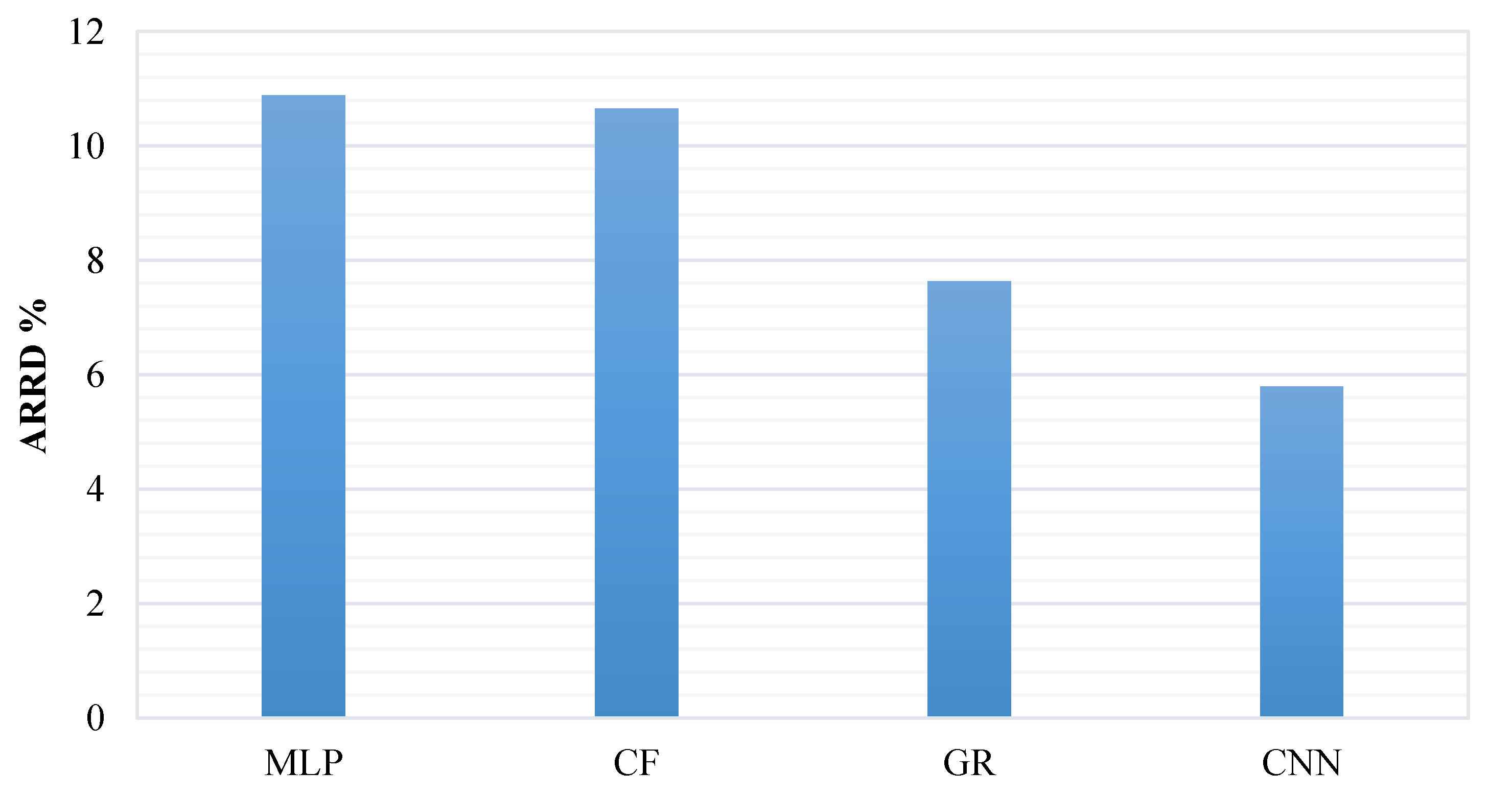
The comparison between the suggested CNN model and the three other models of MLP, CF, and GR are presented in
Figure 6, based on the statistical indices of AARD%. This figure indicates the performance superiority of the CNN model, compared with the other models. In other words, it depicts the capability of CNN to increase the accuracy of the prediction.
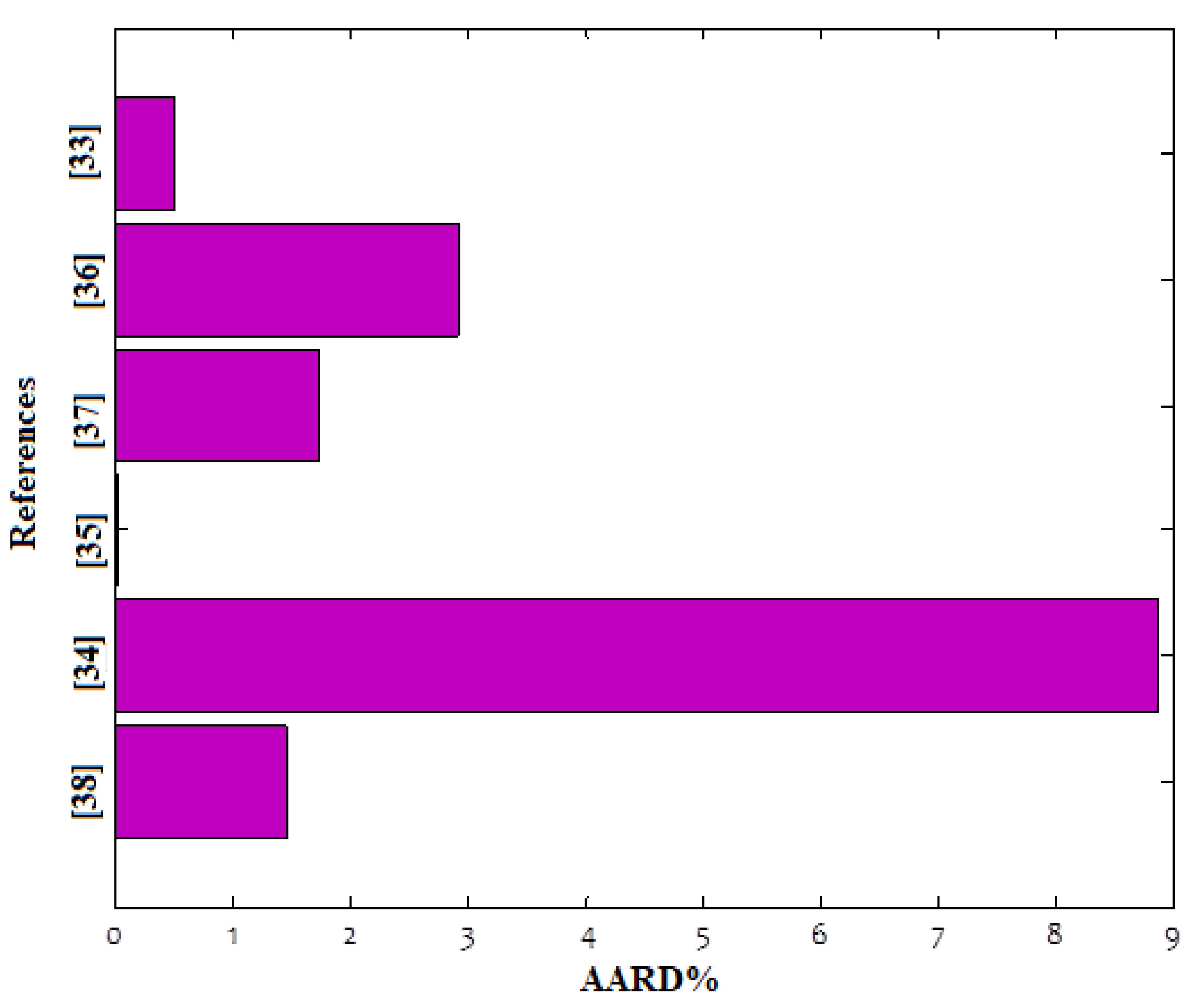
Finally, the predicted values from the CNN model representing microchannel pressure drop prediction were evaluated for different experimental datasets. The AARD% values in
Figure 7 were obtained to compare the predicted values and experimental datasets. As can be seen, the CNN model can predict all experimental data with great accuracy. However, the predictive precision of the CNN model can slightly depend on the distribution pattern of the data, as expected. This is consistent with the recent data of [
41].
4. Conclusions
In this study, the pressure drop was predicted using a committee neural network (CNN). As such, a total number of 329 empirical data points were selected to model the pressure drop in microchannels at various conditions. The results reveal that despite the low dependency of the pressure drop on the mass flux, it is highly dependent on the properties of the fluid. Nevertheless, the plot of the pressure drop as a function of variables revealed its dependency on the hydraulic diameter of the channel and vapor quality. The weight coefficient of each network in CNN was determined using a genetic algorithm and a simple averaging method. The minimum AARD% is achieved when using a simple averaging procedure for combining MLP, GR, and CF algorithms. The finest value of AARD% (5.79) is obtained by combining all algorithms using the weighted averaging method. The values of 0.0534, 0.9281, and 0.01725 were obtained as the derived weights of GA for MLP, GR, and CF, respectively. This study demonstrates that CNN results are more precise when there are various techniques to solve a problem, therefore the superior results, compared to the other methods, indicate a high potential for prediction in different fields of applied science.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}