1. Introduction
A key-value data structure that returns a value corresponding to an input key has been used in many fields [
1,
2,
3]. Various network applications, such as Internet Protocol (IP) address lookup, packet classification, name lookup in Named Data Networking (NDN), traffic classification in Software-Defined Networking (SDN), and cloud computing [
4,
5,
6,
7,
8], use key-value structures for data storage. For example, in performing a Pending Interest Table (PIT) lookup in the NDN, a content name is used as a key, and the input faces of each
Interest packet are returned as the value corresponding to the key [
9,
10,
11,
12].
As a representative key-value data structure, hashing has been popularly applied to various applications [
13,
14,
15,
16]. Hashing converts an input key string to an index, which can be used to point an entry in a hash table. The pointed entry stores both the key itself (or the signature of the key) and a return value. Collision in hash indexes is an intrinsic problem of hash-based data structures. Elements that could not be stored in a hash table because of hash collisions cause failures in search process. To reduce the number of hash collisions, several variant structures have been studied such as multi-hashing, cuckoo hashing, and
d-left hashing [
17,
18,
19]. In order to avoid an excessive number of hash collisions, the load factor of a hash table, which indicates the ratio of the number of stored elements compared to the number of entries in a hash table, should be small enough.
A functional Bloom filter satisfies the key-value operation required in various applications [
20,
21,
22,
23,
24,
25]. Unlike a hash table, a functional Bloom filter does not require to store input keys, as different combinations of Bloom filter indexes for each input key can work as the signature of the input key.
Even though modern hardware equipments have a sufficient amount of internal memory to accommodate large hash tables, an efficient use of the memory, which is a limited resource, is required to provide scalability. For example, according to Cisco’s annual Internet report [
26], IoT devices will account for 50 percent of all networked devices by 2023, and a 5G connection will generate nearly three times more traffic than the 4G connection of 2018 because there will be 29.3 billion networked devices by 2023, up from 18.4 billion of 2018. In order to keep up with the ever-increasing network traffic, it is necessary to build effective data structures which utilize limited memory resources efficiently [
27,
28,
29].
In this paper, we claim that a functional Bloom filter provides a lower search failure rate than hash-based data structures in storing a large amount of data to a limited size of memory. The search failure is the most important criterion for evaluating the performance of key-value structures. Therefore, as a key-value structure, the FBF can effectively replace hash tables. The basic idea of this paper was briefly introduced in [
30], and we provide a thorough theoretical analysis and compare each data structure in their search failure probabilities in this paper. Our theoretical analysis is validated by simulation results for each structure.
The remainder of this paper is organized as follows.
Section 2 describes the Bloom filter and hash table as related works. In
Section 3, we explain and compare four data structures: a multi-hash table, a cuckoo hash table, a
d-left hash table, and a functional Bloom filter.
Section 4 theoretically analyzes the probability of signature collision and the probability of search failure for each structure.
Section 5 evaluates and compares the performance of each data structure, and
Section 6 concludes the paper.
3. Hash-Based Key-Value Data Structures
A
key-value data structure stores a key and a corresponding value in pairs, and returns the value when a given input matches the key. In other words, assuming that set
is stored in a hash table using hash function
,
(for
) is stored in
. In searching
y, if
in
is equal to
y,
is returned.
Figure 1 shows the hash-based key-value data structures considered in this paper: a multi-hash table, a cuckoo hash table, a
d-left hash table, and a functional Bloom filter. The basic idea of this paper was briefly introduced in [
30]. This paper additionally provides theoretical analysis and compares each data structure in their search failure rates. We assume that hash tables store a fixed-length signature (instead of a variable-length key) and a value corresponding to each key.
Table 1 represents notations and definitions used in key-value data structures.
3.1. Multi-Hash Table
A multi-hash table [
17] uses multiple hash functions instead of a single hash function for each key to reduce the number of collisions.
Figure 1a shows a multi-hash table with two hash functions and two entries per bucket. For given set
, in inserting element
to the multi-hash table in
Figure 1a, among the two buckets pointed by two hash indexes, the signature of
and return value
are stored in the bucket with a smaller number of loads. In this way, a multi-hash table distributes a number of loads more evenly. If there is no empty entry in both buckets,
cannot be stored (i.e., overflow).
In searching, the first and second buckets are checked in turn, if there is no matching entry in the first bucket. If an element could not be stored because of hash collision, searching for this element causes a false negative. In this case, a search failure occurs for this specific input. Assuming that a bucket of a multi-hash table has two entries, where n is the number of elements in a given set and is a load factor, the number of buckets () in the multi-hash table is . The amount of the memory () is , where the signature of a key has bits and a return value has L bits.
3.2. Cuckoo Hash Table
A cuckoo hash table shown in
Figure 1b uses two hash tables, and each bucket of a cuckoo hash table stores a signature and a return value. Therefore, if the same amount of memory is used as a multi-hash table, the number of buckets (
) in a cuckoo hash table is the same as
.
Each element uses a single index per table. When a new element is inserted, cuckoo hashing [
18] solves hash collision by pushing the preoccupied element to the other table. In
Figure 1b, when inserting
, if there is a collision in the bucket of the first table (i.e.,
),
is stored in the bucket and element
(of which bucket is taken away) is pushed to the second table (i.e.,
). If a collision also occurs in the second table, this procedure is repeated until the pushed element finds an empty bucket (i.e.,
in
Figure 1b. Therefore, in inserting an element, even though each element uses only one hash index for each table, more entries can be examined in the cuckoo hashing by involving other elements already stored in the table. As will be shown in
Section 4.2.2, if there occur two loops in inserting an element, the element cannot be saved. The unsaved element, due to an overflow in insertion procedure, causes a false negative in search procedure, and it is classified as a search failure.
In searching, only two buckets pointed by two hash indexes for each given input are checked. Therefore, the number of bucket accesses in searching an input is always two, even though the number of accesses in inserting a key can be large as the load factor increases.
3.3. d-Left Hash Table
In inserting
, the
d-left hash table [
19] uses
d hash functions and stores
in the bucket with the smallest number of loads.
Figure 1c shows a
d-left hash table, where each bucket includes a single entry and the number of hash functions is
d. As we assume the
d-left hash table with a single entry per bucket,
is stored in the topmost empty bucket (i.e.,
in
Figure 1c. If collisions occur in all
d entries,
cannot be saved. The unsaved element, due to an overflow in insertion procedure, causes a false negative in the search procedure, and it is classified as a search failure.
In searching an input, each bucket is checked from the topmost bucket to the bucket until the input has a match. If the same amount of memory is used as a multi-hash table, the number of buckets () in a d-left hash table is equal to , as each bucket stores a signature and a return value.
3.4. Functional Bloom Filter
A functional Bloom filter (FBF) [
20,
21,
22] is a variant of a standard Bloom filter that returns a value corresponding to a key as well as its membership.
Figure 1d shows a functional Bloom filter with
m cells and
k hash indexes. As each cell is composed of
L bits, each cell can have a value with range
. In a functional Bloom filter, the signature of each key is not stored and only a value corresponding to each key is stored in each cell, as various combinations of
k hash indexes can serve as the signatures.
Every cell in an FBF is initialized to 0. To program set to an FBF, in inserting element , k independent hash functions are used. The FBF is programmed by setting return value of in all cells pointed by s for . Key is used to obtain hash indexes to access k cells but not stored, and the return value is only stored.
An important issue when dealing with a functional Bloom filter is how to resolve collision because a cell cannot store two or more different return values. Collided cells are not used in returning a value in a functional Bloom filter. In other words, in storing an element, if a value different from the return value of the element is already stored in an accessed cell, the cell is set to the maximum value
to represent the collision. Cells with the maximum value are named
conflict cells, denoted with
in
Figure 1d. Thus, each cell can represent
return values in a functional Bloom filter, and values in conflict cells are not used in querying.
In querying, a functional Bloom filter returns three types of results: negative, positive, and indeterminable. For input y, if there exists at least one cell with for , it obviously means , which is termed negative. Additionally, for cells with values other than conflict, if there are any cells with for , it is also , as these cells are programmed by different keys other than y. For cells with values other than conflict, if all s are the same, it would be and the FBF returns , which is termed positive. It should be noted that, as in a standard BF, an FBF can return a false positive. For , if all = , which means that conflicts occur in every cell, the FBF fails to return a value, and it is termed indeterminable. Search failure of a functional Bloom filter is defined by false positive and indeterminable results.
If the same amount of memory is used as a multi-hash table, the number of cells (m) in a functional Bloom filter is calculated by , as each cell only stores a return value without the signature of a key. As described in the querying procedure, by comparing the values of multiple cells pointed by an input, a functional Bloom filter can determine the return value without storing key (or the signature of ).
4. Theoretical Analysis
A theoretical analysis of hash collisions inevitably occurring in hash-based structures has been studied [
15,
16,
44,
45]. We theoretically analyze signature collision and search failure probabilities for the hash-based key-value data structures described in
Section 3.
4.1. Signature Collision
A key with a variable length needs to be converted to a fixed-length signature to be stored in a fixed-width hash entry. Since a signature is generated by hashing, signature collision can also occur, in which two or more different keys are mapped to the same signature. The number of bits for a signature is set as in this work, where n is the number of elements stored in a hash table.
In a hash table, a signature collision can cause two types of search failures: false result and false positive. A false result occurs for elements included in a given set if two or more different keys which have the same signature but different return values are mapped to the same entry in a hash table in insertion procedure. In this case, if the key which could not be stored because of entry collision is given as an input, a wrong value can be returned in search procedure, as the signature of the key matches the stored signature.
False positive occurs for an input not included in a given set if the input has the same signature as an element included in the set and the hash index of the input is mapped to the entry, where the signature of the element is stored. In search procedure, the input is recognized as the element that has been stored in insertion procedure.
The probabilities of false result and false positive caused by signature collision can be derived as follows. Let r represent the number of available signatures. If the number of bits of a signature is set as , then . Probability that a signature value is unused after one element is mapped to a signature by hashing is . Thus, probability that a signature is unused after n elements are mapped by hashing is .
Let
be the expected number of unused signatures.
Let
be the expected number of used signatures.
Each used signature would contain one key (element) that has not been collided in the process of signature mapping. Therefore, the number of collisions would be
n minus the number of used signatures. Let
represent the expected number of collisions in signature mapping.
We can numerically show that
in Label (
6) converges to 0.5 as
n becomes large.
Let
represent the probability that an element are collided in the process of signature mapping.
If an element is mapped to a bucket, where another element with the same signature was already stored, the element that has been collided in signature mapping cannot be stored because the element is considered to be already stored. Therefore, when both signature collision and bucket collision occur in an insertion procedure, a false result occurs in the search procedure. Let
B represent the number of buckets in a hash table and
represent the probability of false results. In other words,
represents the probability that an element is mapped to the bucket where another element with the same signature as itself is stored.
Let
represent the probability that a non-programmed input (which is not included in the insertion set) is mapped to a used signature. As there are
r possible signatures,
A false positive occurs in search procedure, when a non-programmed input is mapped to a specific used signature and its hash index is mapped to the bucket, where the specific used signature is stored. Let
represent the probability of false positives.
As shown in Labels (
8) and (
10), the probabilities of false result and false positive occurring in search procedure due to signature collision are very small, and therefore it proves that
bits are enough for signature length. Therefore, signature collision is not considered when analyzing search failure probability in the next section. The functional Bloom filter does not have a signature collision problem because it stores return value only without storing signature at all.
4.2. Search Failure Probability
Search failure probability of a hash table is equal to false negative probability, which occurs when an element could not be inserted to a hash table because of index collision. Search failure probability of the functional Bloom filter is the summation of false positive and indeterminable probabilities. The false positive occurs when a value is returned for a non-programmed input. The indeterminable occurs when every cell pointed by an input has a conflict value. The indeterminable means that the result cannot be determined by the functional Bloom filter. For theoretical analysis, we assume that the number of inputs in searching set U is , i.e., , , and .
4.2.1. Multi-Hash Table
In inserting an element to a multi-hash table shown in
Figure 1a, if four entries in two buckets were already occupied, the element cannot be stored. When
elements were stored, the number of buckets where both entries are occupied is
. The
element cannot be inserted when each of the two hash indexes of the
element is mapped to one of the
occupied buckets. Let
be the probability that an overflow occurs for the
element. Then,
has the upper bound as follows.
Let
be the probability that an element cannot be stored when
n elements are inserted in a multi-hash table. Then, from Label (
11),
is derived as follows.
As
in a multi-hash table, and assuming that
n is very large, Label (
13) can be formulated as follows,
where
is the load factor of a multi-hash table. When
n is odd, the same result is obtained.
Let
represent the
false negative probability of a multi-hash table. It can be formulated as
where
and
represent the probability that input
y is included in
S and
, respectively, and
and
. For
inputs,
and
. Among
n elements in
S,
false negatives occur for the elements that could not be stored, and
as any element in
does not produce false negatives. Therefore,
has the following upper bound.
Labels (
14) and (
16) hold true when
. In case of
, the number of elements is more than the number of entries in a hash table (i.e.,
). Assuming that no empty entry exists in a hash table when the number of programmed elements is
, the
element cannot be inserted in the table for
. In other words, in calculating
for
, the probability that the
element cannot be inserted is 1, which means that the collision unavoidably occurs. Thus, for
,
is derived as follows.
Therefore,
for
has the following upper bound.
4.2.2. Cuckoo Hash Table
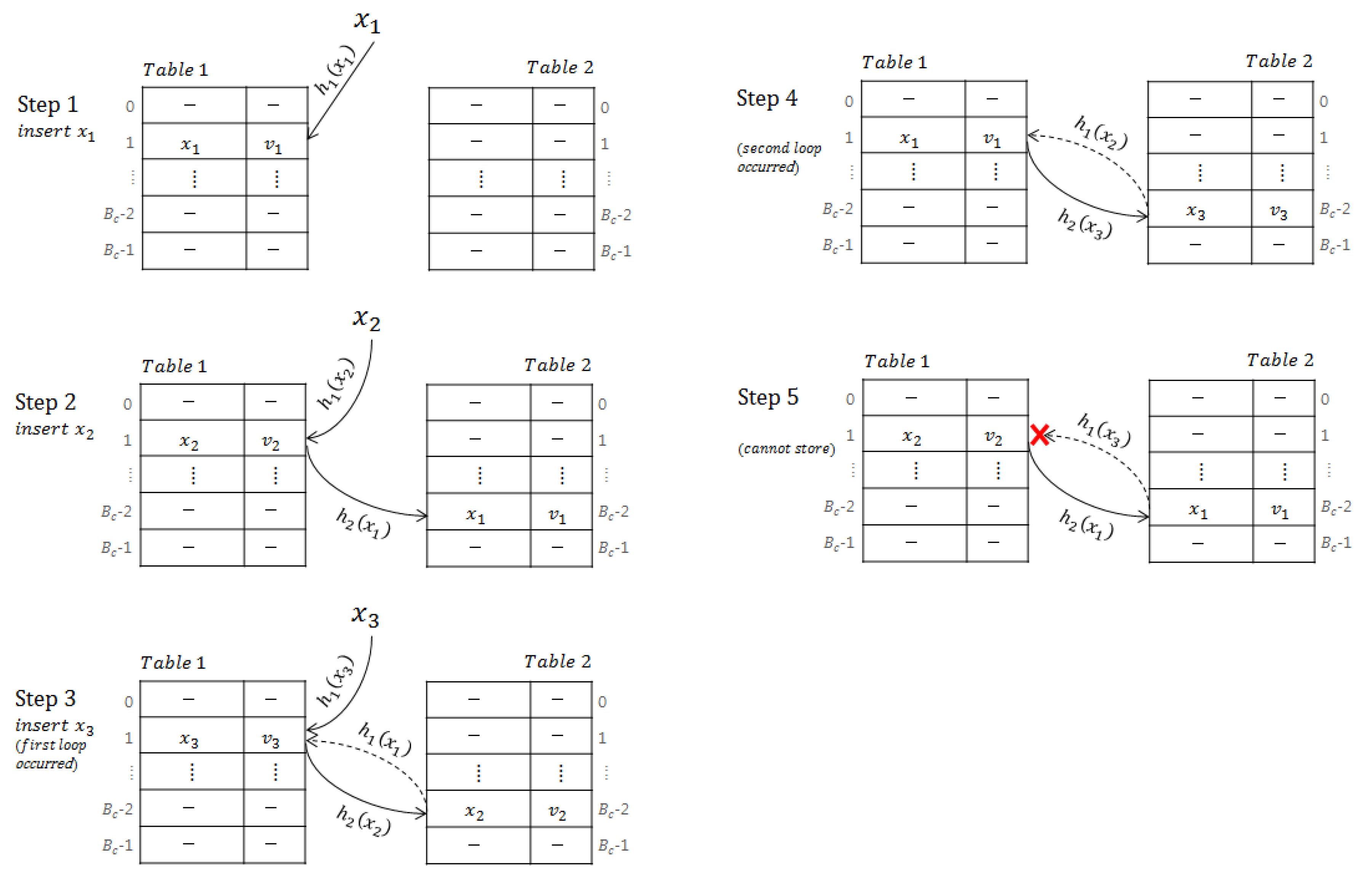
A false negative that results in search failure in a cuckoo hash table also occurs when searching an element that could not be inserted.
Figure 2 shows a case where an element cannot be stored in a cuckoo hash table. In inserting 3 elements,
,
, and
, in sequence, if
=
=
and
=
=
, element
cannot be stored, as two loops occur. The insertion procedure should stop; otherwise, the insertion procedure will repeat infinitely.
To find the upper bound of probability that an element cannot be stored in a cuckoo hash table because of two loops, assume that the
indexes of
elements are mapped to only
buckets and elements are evenly distributed to both tables (the difference between the number of occupied buckets in the first table and the second table is equal to 0 or 1). When the
element needs to be inserted, if the
element selects two (one in each table) of the
buckets, two loops occur. Let
represent the probability that an element cannot be stored in a cuckoo hash table because of two loops. Assuming that
n is even, then
is formulated as follows.
As
has to be handled depending on whether the
element is an odd-numbered or an even-numbered element, the summation in Label (
19) consists of two types of sequences for
j. Because
, and assuming that
n is very large, Label (
19) can be formulated as follows.
where
is the load factor of a multi-hash table. When
n is odd, the same result is also obtained.
Let
represent the
false negative probability of a cuckoo hash table. For
inputs, as
, the
has the following upper bound.
Labels (
20) and (
21) hold true when
. In case of
, the number of elements is more than the number of entries in a hash table (i.e.,
). Assuming that no empty entry exists in a hash table when the number of programmed elements is
, the
element cannot be inserted in the table for
. In other words, in calculating
for
, the probability that the
element cannot be inserted is 1, which means collision unavoidably occurs. Thus, for
,
is derived as follows.
Therefore,
for
has the following upper bound.
4.2.3. d-Left Hash Table
The
d-left hash table is assumed to have only one entry per bucket in this work. If collisions occur in all
d buckets, an element cannot be stored. When searching an element that could not be inserted, search failure occurs due to false negative. Let
represent the probability that an element cannot be stored in a
d-left hash table because of collisions in all
d buckets. Then,
is formulated as follows.
Let
represent the
false negative probability of a
d-left hash table. For
inputs, since
,
is as follows.
Labels (
24) and (
25) hold true when
. In case of
, the number of elements is more than the number of entries in a hash table (i.e.,
). Assuming that no empty entry exists in a hash table when the number of programmed elements is
, the
element cannot be inserted in the table for
. In other words, in calculating
for
, the probability that the
element cannot be inserted is 1, which means collision unavoidably occurs. Thus, for
,
is formulated as follows.
Therefore,
for
is as follows.
4.2.4. Functional Bloom Filter
Based on the analysis of a functional Bloom filter (FBF) in [
22], we compare search failure probability with other hash-based data structures in this paper. Let
represent the
search failure probability of a functional Bloom filter. As the search failure of an FBF is caused by
indeterminable or
false positive,
can be formulated as follows.
where
represents the probability of
indeterminables and
represents the probability of false positives in a functional Bloom filter.
Let L represent the number of bits in a cell of an FBF. Among possible values in a cell, value is reserved to represent conflict. Value 0 is reserved for the initial before programming. Therefore, a functional Bloom filter can have return values. Let represent the set of elements whose return value is q with (), where . Assuming that return values are uniformly distributed, let be the number of elements in for .
In the querying procedure, if all the return values of k cells for input y are set as , i.e., conflict, then the functional Bloom filter cannot return a value, termed an indeterminable. Conflict occurs when a specific cell that was hashed by any element in is hashed at least once by any other element in .
The probability of
indeterminable,
, can be formulated as
In Label (
29),
and
represent the probability that an input
y is included in
S and
, respectively, where
and
.
Consider
first. If input
y is included in
S (
), input
y would be included in one of
among
. Consider a specific cell that is hashed by
. If the specific cell is hashed at least once by any other element in
, then the cell would set conflict. The probability that the specific cell is not selected (hashed) by
elements in
with
k hash functions is
. Let
represent the probability of conflict for an element in set
S, which is the event that the specific cell is hashed at least once by
elements with
k hash functions.
There would be
k cells that are hashed by the specific input
y with
k hash functions. An indeterminable event occurs when all
k cells hashed by
y get conflict.
Now we consider
. Let
represent the probability of conflict for input
y which is not in set
S (
). Consider a specific cell that is hashed by
y. If the specific cell was hashed by any element in
and it was also hashed at least once by any other element in
in programming, then the specific cell is in conflict. The numbers of elements in
and
are
and
, respectively.
is calculated as follows.
is calculated avoiding duplications for
. An indeterminable event occurs when all
k cells hashed by
y with
k hash functions get conflict.
For
inputs (with
n elements in
S and with
elements in
), then
and
. Therefore, from Label (
29)
A false positive that results in a search failure can occur for input
only. In other words,
, which means that inputs included in set
S do not cause false positives. Therefore, the probability of false positives in a functional Bloom filter,
, can be formulated as
We need to consider
. Let
represent the positive probability for input
y which is not in set
S (
). Consider a specific cell that is hashed by
y. If the specific cell was hashed by any element in
and it was not hashed by any other element in
in programming, then the specific cell has value
q for
. The probability that the specific cell is not hashed by
elements in
with
k hash functions is
.
The false positive event occurs when all of the cells other than conflict cells among
k cells hashed by
y have the same value. Note that there can be
Q cases with equal probability for
.
For
inputs, as
,
is as follows.
From Labels (
28), (
29), and (
35), the search failure probability of a functional Bloom filter,
, can be formulated as follows.
We have an interesting question here of whether false positive or indeterminable is more harmful to raise search failure. While some of the indeterminables are caused by positive inputs, which are the elements included in the programming set, every false positive is caused by negative inputs, which are not included in the programming set. It has been recently shown that the indeterminables caused by positive inputs can be identified and resolved in the programming procedure by constructing an additional functional Bloom filter [
46]. Therefore, false positives are more harmful to raise the search failures.
5. Performance Evaluation
In this section, we evaluate and compare the performance of four hash-based data structures described in the previous section using a specific example of name lookup in Named Data Networking (NDN), which uses a key-value data structure. In this application, keys are URLs and values are their output faces. As an FBF stores values only, the number of bits in an FBF cell is allocated according to the number of output faces; however, hash tables store the signature of a key and a corresponding value in pairs. Simulations are carried out using random URLs provided by Web Information Company ALEXA [
47]. For simulation, we have randomly selected and made three experimental sets.
Table 2 shows experimental data sets. Set
S is stored to hash tables and to a functional Bloom filter. The number of URLs in input set
U used in searching is three times the number of URLs of set
S. One-third of set
U is the same as set
S, which means that these inputs should have a match from hash tables and from the functional Bloom filter. The remaining two-thirds is included in set
, which means that these inputs do not have a match. We assume 14 kinds of return values, and therefore the size of a return value is 4 bits.
In our simulation, search failure performance is evaluated in various load factors, and load factors are controlled by adjusting the size of a hash table instead of the number of stored elements. In other words, the number of elements to be inserted in a hash table is fixed, and the load factor is increased by reducing hash table sizes. We first construct a multi-hash table with load factors () of 0.6, 0.8, 1, 1.2, and 1.4, and then measure the required amount of memory for each multi-hash table according to . We then construct a cuckoo hash table, a d-left hash table, and a functional Bloom filter, using the same amount of memory as the multi-hash table. We assume that the number of hash functions d in a d-left hash table is equal to k, which is the optimal number of hash indexes of a functional Bloom filter.
A 64-bit cyclic redundancy check (CRC) generator is used as a hash function for our simulation. A number of hash indexes were extracted by combining a variable number of bits of a CRC code generated by a key or an input. Therefore, even if multiple hash indexes are required, there is almost no difference in the amount of computational overhead, once a CRC code is obtained.
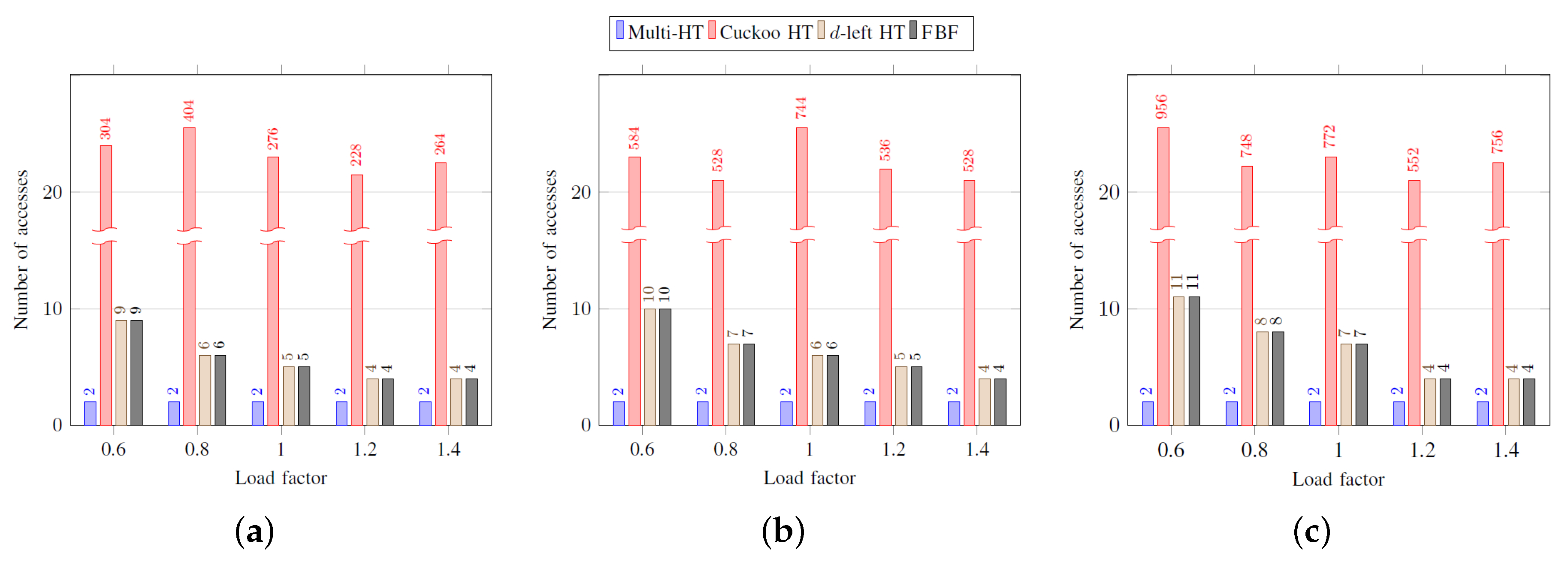
Figure 3 shows the average number of memory accesses in inserting an element according to load factors. As the load factor increases, the cuckoo hash table requires a large number of accesses because many buckets are affected until an empty entry is found. The multi-hash table shows the best performance in most cases, as elements can be inserted if an empty entry is found even before two accesses. However, it is worth noting that the multi-hash table, the
d-left hash table, and the functional Bloom filter have the performance proportional to
. The average number of memory accesses for the functional Bloom filter is always
k obtained from Label (
1). As the load factor increases,
k decreases, as
in Label (
1) decreases.
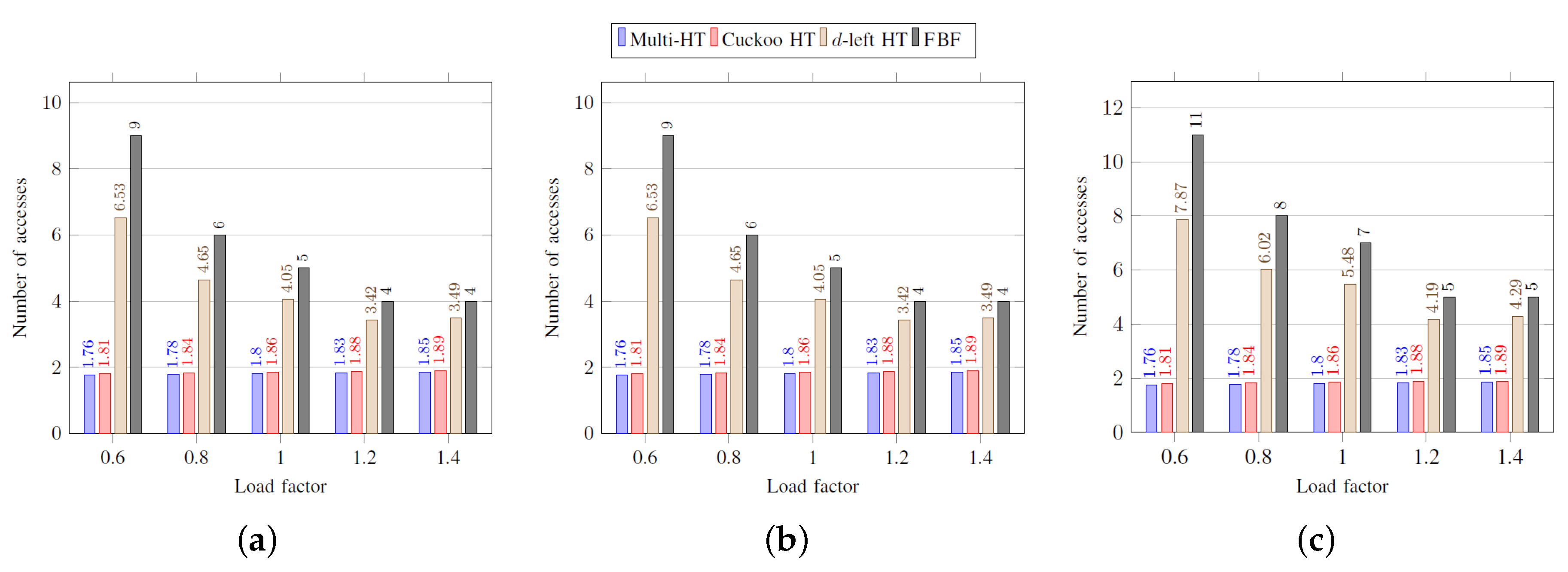
Figure 4 shows the worst-case number of memory accesses in inserting an element according to load factors. As shown, the multi-hash table, the
d-left hash table, and the functional Bloom filter show better performance than the cuckoo hash table, and these structures have a performance proportional to
. The worst-case performance of the cuckoo hash table is not acceptable as shown. For the functional Bloom filter, the average and the worst-case number of accesses are the same as the number of memory accesses is always equal to
k.
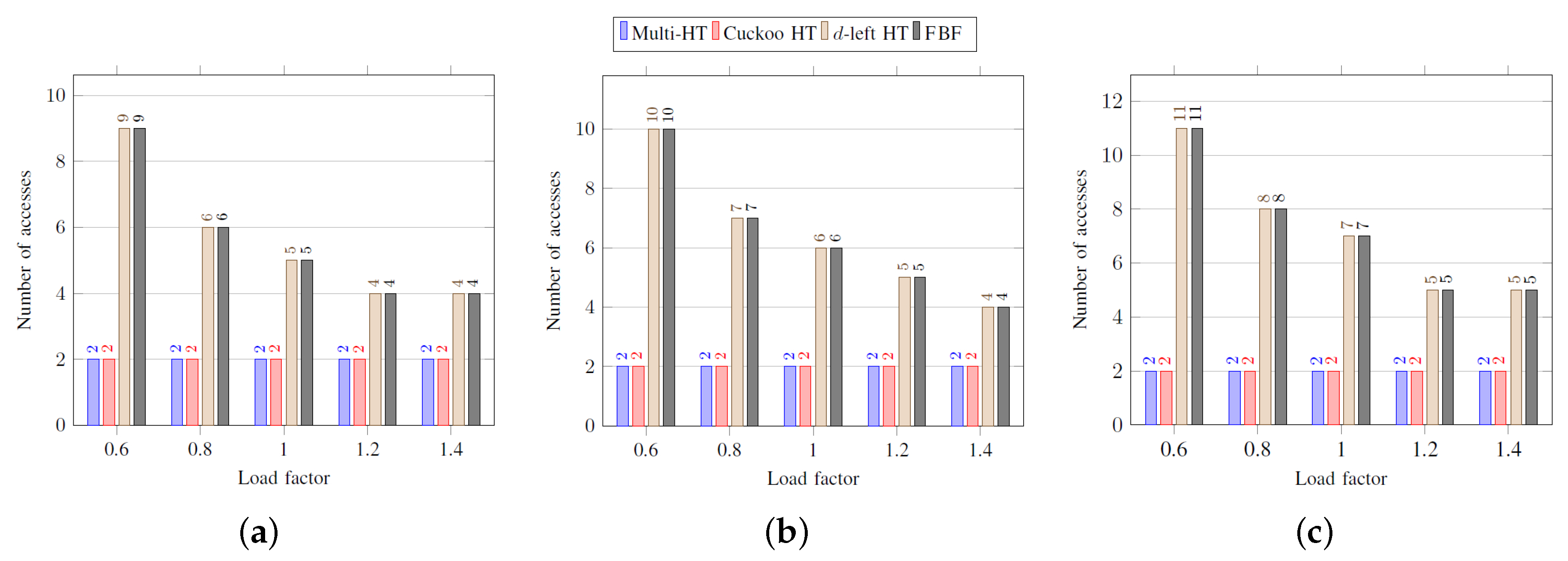
Figure 5 and
Figure 6 show the average and the worst-case number of memory accesses during search procedure, respectively. Unlike insertion performance, the cuckoo hash table practically has the same performance as the multi-hash table because two hash functions for each element are used, and therefore each of the search procedure is completed within two accesses. In case of the
d-left hash table, as the number of hash functions
d is equal to
k, the search procedure is completed within
k accesses. The search performance of the functional Bloom filter is also
k accesses as the same as insertion performance.
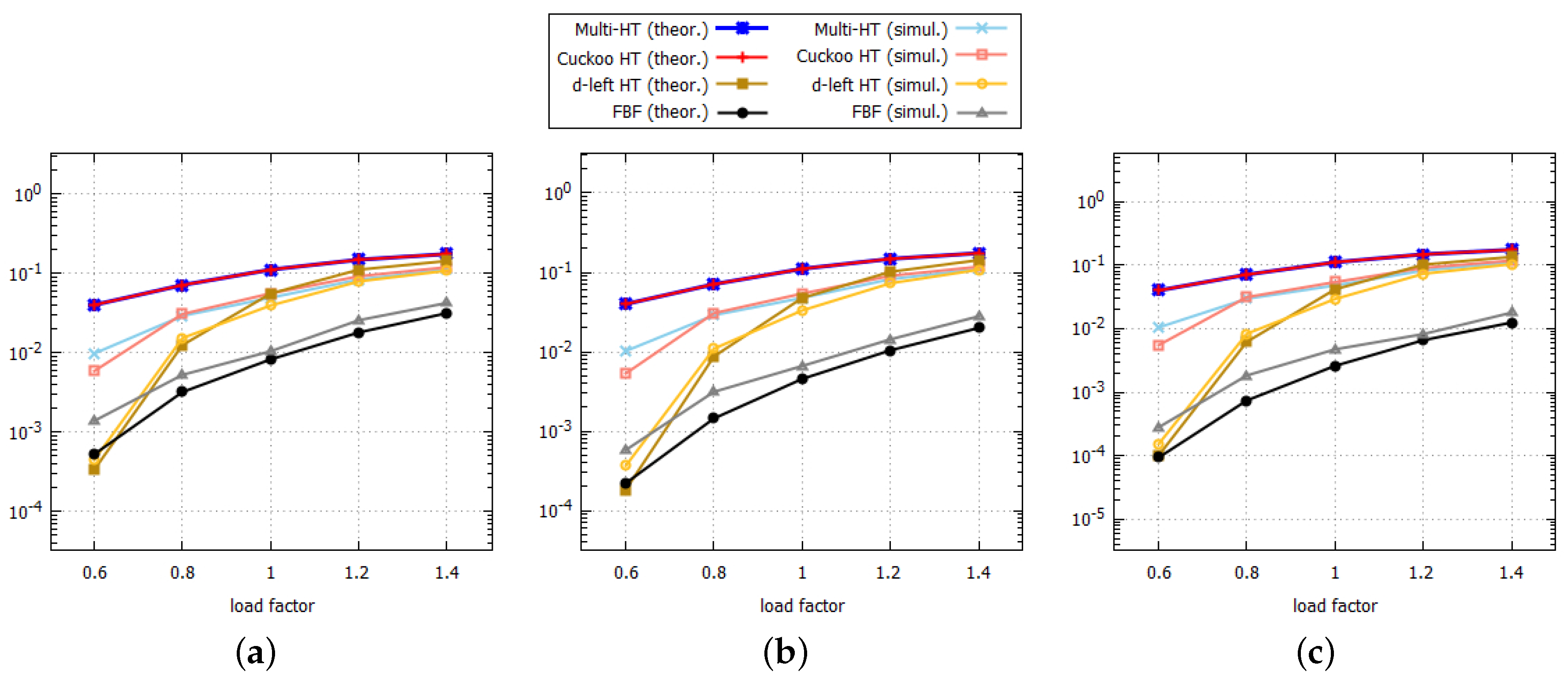
Figure 7 shows the comparison on search failure rates between theoretical and simulation results as the load factor increases. It is shown that the theoretical and simulation results become similar as the load factor increases. For the theoretical results of hash tables, Labels (
16), (
21), and (
25) are used for
, and Labels (
18), (
23), and (
27) are used for
. In cases of the multi-hash table and the cuckoo hash table, parameters determining the performance of a data structure, such as the number of buckets and the number of hash functions, are the same, and therefore these tables have almost the same theoretical upper bounds. In evaluating the performance of data structures, the worst-case performance is the most critical, and thus the upper bound is important. It is shown that simulation results are less than the upper bound, as the worst case was assumed in calculating the upper bounds for these structures. Because a cuckoo hash table can access more buckets in inserting an element than a multi-hashing table, it has a better search failure rate when the load factor is 0.6, but no meaningful difference when the load factor is larger than 0.6.
In cases of the
d-left hash table and the functional Bloom filter, simulation results show very similar patterns to their theoretical results. As shown in
Figure 7, the functional Bloom filter shows the best search failure rate when
increases. More specifically, in terms of the simulation result for 130k at
shown in
Figure 7c, the search failure rate of the Multi-HT is 5%, and it is ten times larger than that of the FBF, which is 0.5%. Note that the search failure rate of the FBF decreases slightly as the number of elements increases, as
for the FBF increases as the number of elements increases. Therefore, the functional Bloom filter is the most efficient structure which can replace hash tables, when the search failure rate is the most concern in storing a large set of elements to a limited size of memory.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}