This section describes the design goals, the periodic polling technique, and the algorithm for determining the optimal polling interval of NetAP.
3.1. Design Goals
The design goals of NetAP include improving deployability and obtaining the optimal polling interval for each VM, which are explained, as follows:
First, to improve deployability, NetAP only modifies the vHost thread of the host system. If we modify the front-end device driver of each guest OS, the user may experience an inconvenience from re-compiling the front-end driver and re-installing the driver module into the guest OS. Therefore, by modifying only the vHost thread of the host OS, we preserve the interface with an unmodified front-end driver.
Second, NetAP tries to obtain the optimal interval for each VM to reflect its individual workload characteristics. A vHost thread is dedicated to its own VM and it fetches network requests from its dedicated shared queue. Because each VM generates and consumes packets at a different speed, each vHost thread needs to have different polling intervals. Therefore, we apply a novel algorithm to determine the polling interval for each vHost thread.
3.2. Periodical Polling for Network Packet Processing
NetAP develops a periodic polling technique in the vHost thread to maximize the utilization of network and CPU resources. The modified vHost thread in NetAP periodically polls the shared queue instead of waiting for a vIRQ from the front-end device driver. At each polling interval, the vHost thread is scheduled, and it processes packets sent from the guest OS. After the vHost thread completes packet processing, it sleeps until the next polling interval. During this sleep time, the guest OS generates packets, and they are buffered into the shared queue. At the next interval, the vHost thread wakes up and processes the buffered packets in the shared queue.
The main difference between NetAP and the original VirtIO is that NetAP frequently monitors the shared queue and proactively handles the buffered packets before a vIRQ is generated from the front-end driver. In original VirtIO, the front-end driver produces packets and inserts them into the shared queue. When the number of buffered packets in the queue is more than a certain threshold, a vIRQ is delivered to the vHost thread to wake up the thread. However, NetAP processes the buffered packets at an appropriate rate with periodic polling before the number of packets exceeds the threshold. Therefore, the front-end driver does not generate vIRQs. This mechanism can prevent expensive VM-Exit and VM-Entry operations and, therefore, improve network performance with efficient CPU use.
3.3. Periodic Polling Algorithm
Algorithm 1 details the periodic polling technique. The core function is , which processes packets in a continuous loop. When the loop is executed once, it processes the packets loaded in the RX and TX queues (line 21 and 22), sleeps for an (line 24), and starts the next loop. Until it sleeps, interrupts are disabled for packet arrivals (line 8 and 23). A is a time unit for observing performance. To adapt NetAP for a given workload, we change the polling interval for each round according to the observed performance for the previous round. Furthermore, is the predetermined length of a round (e.g., one second). Line 14 sets the start time of the next round by adding to , and line 9 checks the time. At the start of a new round, the is updated by running the function on line 10. The parameters are the number of the current round, the size of the packet processed in the round (), and the current interval. The function is explained in detail in the next section.
The algorithm also provides a function to restart adaptation in response to characteristic changes in the workload after adaptation was formerly completed. Line 11 checks whether the size of transferred data changes greater than the predefined ratio , when the interval is no longer updated. Line 17 checks whether the current round exceeds the predefined maximum number of rounds. If one of the two conditions is satisfied, then adaptation is started again by setting the round number to 0. This allows for NetAP to keep tracking the appropriate interval continuously against the changes of workload characteristics within the running VM.
3.4. Adaptation Using Golden-Section Search
We use the golden-section search algorithm to find the near-optimal polling interval for various workloads dynamically. The golden-section search technique searches the maximum or minimum value within a given range in a unimodal function [
25]. The method to find the maximum value for the target function
is as follows: First, we set two x-coordinates
and
to search. We assume that the maximum value is between
and
. Second, we choose
, where
and the
is
R, a reciprocal of the golden ratio (
). These three x-coordinates are golden-section triplets. Third, we set the new x-coordinate,
, where
and the
is
R. Subsequently, we evaluate the
,
,
, and
. If
, then
,
,
are chosen as new triplets, else if
then
,
,
are chosen. Subsequently, we iterate this process until the outer x-coordinates are closer than
, which is the predetermined minimal distance to terminate the algorithm.
The main advantage of the golden-section search algorithm is the efficiency. The evaluation of
requires a considerable time for the real-world workloads. The golden-section algorithm only requires one additional evaluation for each iteration. Moreover, the complexity of the algorithm is logarithmic. The big-O notation of the algorithm is shown in Equation (
1), where
N is the number of iterations required to find the solution [
26,
27].
3.4.1. Considerations for Alternative Algorithms
We choose the golden-section search rather than other line search algorithms, such as the bisection, Newton’s, Quasi-Newton’s, and Nelder-–Mead methods, because Golden-section searching is unconstrained and derivative-free [
28].
First, we need an unconstrained method, because the target function to be searched is not specified. Because NetAP should supports various workloads with different characteristics, we cannot assume any constraints for the searching algorithm. We only assume that the target function is one-dimensional, so we avoid using complex multi-dimensional algorithms, such as the gradient, random search, and Nelder–Mead methods [
29].
Second, we need a derivative-free method, because we do not know the complete function in the mathematical form. We only know few points that are collected from the execution results during the round. In addition, the derivative cannot be correctly calculated in the Linux kernel, because the floating point operations are not allowed in the kernel mode in order to maintain the user context in the floating point unit [
30]. Thus, we avoid algorithms that are based on derivatives, such as the bisection search, Newton’s method, and Quasi-Newton’s method [
31].
| Algorithm 1: Network packet handler with periodical polling |
 |
3.4.2. Preliminary Examination for Golden-Section Search Algorithm
Before we apply the algorithm to solve our problem, there are two requirements to examine: the target function must be unimodal, and a near-optimal value must exist within a range of possible intervals to perform a search. Thus, we demonstrate in advance whether our problem can be solved by the golden-section search algorithm.
We performed a preliminary examination to determine whether a golden-section search can find near-optimal polling intervals. As a result, we made two observations. First, the change in performance over various polling intervals appears as a unimodal function. Second, there is a range of periods that can be commonly applied to various workloads.
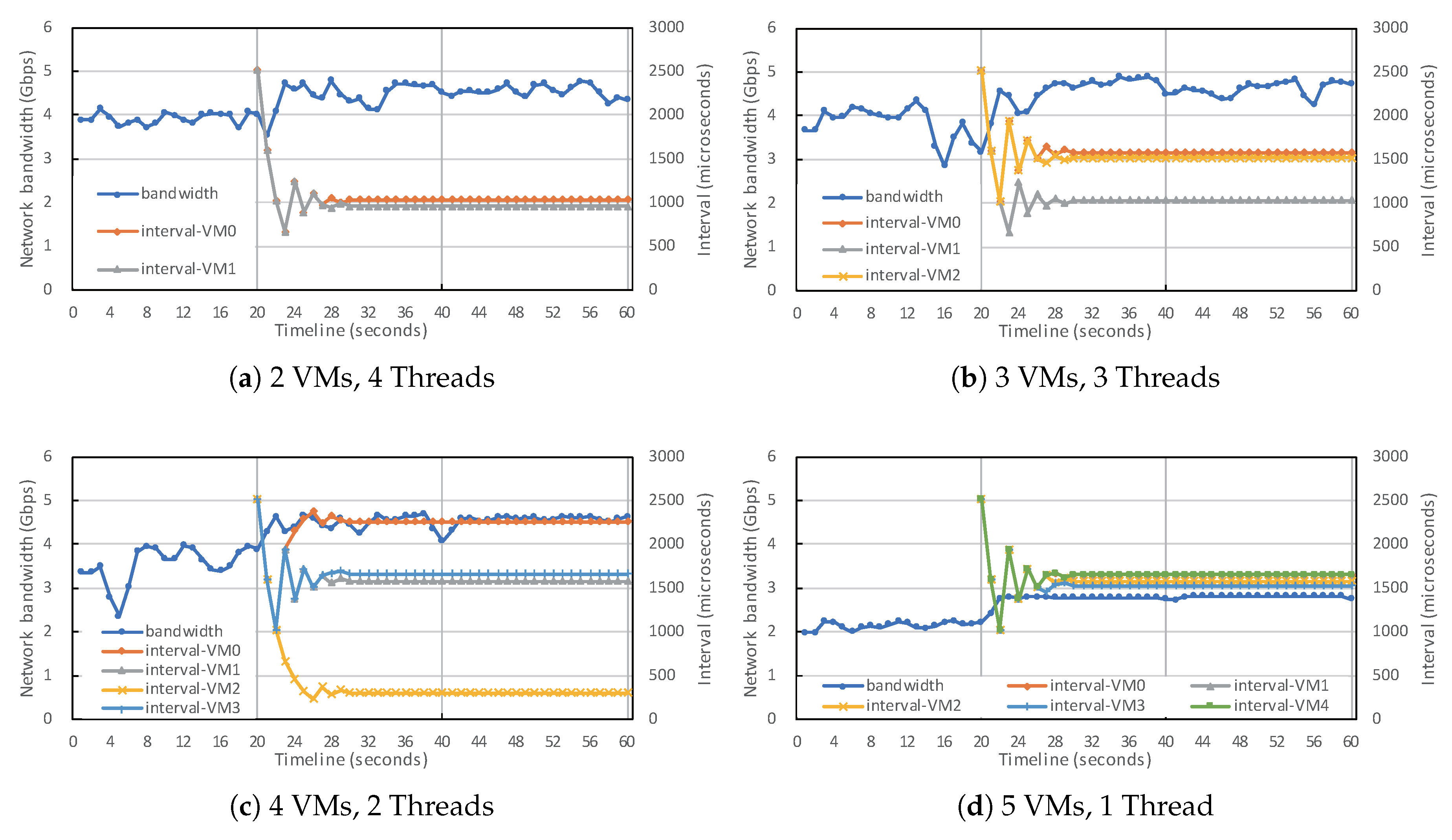
The environment of the experiment is as follows: the host system is equipped with a CPU with six physical cores, 16 GB of memory, and a 10 GbE NIC. Simultaneous multi-threading was disabled, and an additional 1 GbE NIC for controlling the host system was installed to increase the reliability of the experiment. The Linux kernel used corresponded to version v5.1.5, released in May 2019. We ran several VMs on this host system and performed benchmarks on each VM that was connected to a separate Netperf server system. In the experiment, 64B packets were transmitted using TCP, and we measured the aggregated network bandwidth in Mbps.
In this preliminary experiment, We executed one, two, three, and six Netperf threads on each of one, two, three, and six VMs. We increased the polling interval by 500 every 60 s, from 500 us to 5000 us, and observed the performance change that corresponded to each interval for each workload. We did not evaluate each interval separately, but continuously changed the interval. This is to determine how rapidly the effect of changing the polling interval becomes apparent.
Figure 2 shows the result. The first item on the X-axis shows the performance of unmodified VirtIO without applying the periodic polling technique. Furthermore, the figure shows the performance that corresponds to up to 5000 us with gradual increments of 500 us. The performance is shown at five-second intervals. The overall trend forms a unimodal function in every case, and we can find the point where the performance is maximized. As summarized in
Table 1, intervals up to a maximum of 3000 us maximized the performance for all workloads. The bandwidth comparison in
Table 1 is the relative performance of the best network bandwidth as compared to the performance of unmodified VirtIO.
Through the preliminary examination, we determined that the golden-section search algorithm can be applied to find the near-optimal polling interval in NetAP. We also found that the network performance changed immediately after the polling interval was changed.
3.4.3. Golden-Section Search Algorithm
Algorithm 2 obtains the near-optimal interval using golden-section search. First, R is the so-called golden ratio, which is 0.618, and and are the predetermined maximum and minimum intervals, respectively. is a predetermined minimum distance to stop the algorithm.
The function is called by Algorithm 1 with the round, bytes, and previous interval as arguments. In the first and second rounds, and are set using and , respectively, with the same values of , and the performance is collected for a . From the third round, the function checks which value of or achieved higher performance. If has higher performance, is replaced by , and is replaced by ( + ). Conversely, if provides higher performance, is replaced by , and is replaced by ( − ). Subsequently, the updated interval is returned. Furthermore, is decreased by the golden ratio in each round. When is less than , the algorithm terminates, and the previous interval is returned without an update. Through the aforementioned process, we can quickly search for the interval between and that maximizes the performance.
| Algorithm 2: Golden-section search algorithm to find the near-optimal interval |
 |
For the implementation in the Linux kernel, R and were calculated and entered in advance as constant values. This is because floating-point operations cannot be performed within the Linux kernel. and were set to 100 and 4000, respectively. The numbers are chosen according to the results of our preliminary examination, which showed that the near-optimal polling intervals can be found between 500 and 3000 us. In addition, was set to 30, so that the number of searches was limited to 11 iterations. The set of all distances is as follows: . Note that the first distance is used twice, at the first and second rounds.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}