An Overview of Reinforcement Learning Methods for Variable Speed Limit Control





Abstract
1. Introduction
- In this study, the systematic literature review approach is applied. A keyword-based search was used, and 12 primary studies were systematically identified from search results.
- Traffic management studies on motorways focused on RL approaches to solve the VSL optimization problem are covered by this study.
- Unlike existing studies such as [31], which focus on summarizing the approaches of VSLs traffic management systems, this study tries to assess how well the present RL-VSL approaches work based on the provided results. First, the objectives of the approaches, such as improving efficiency or safety, were identified and categorized. Then, different approaches were compared on how well they meet a specific goal. In addition, the RL methods used to solve VSL and how the VSL problem is being modeled for a particular objective for intelligent traffic management on motorways were identified and summarized.
2. Application of RL in VSL Control
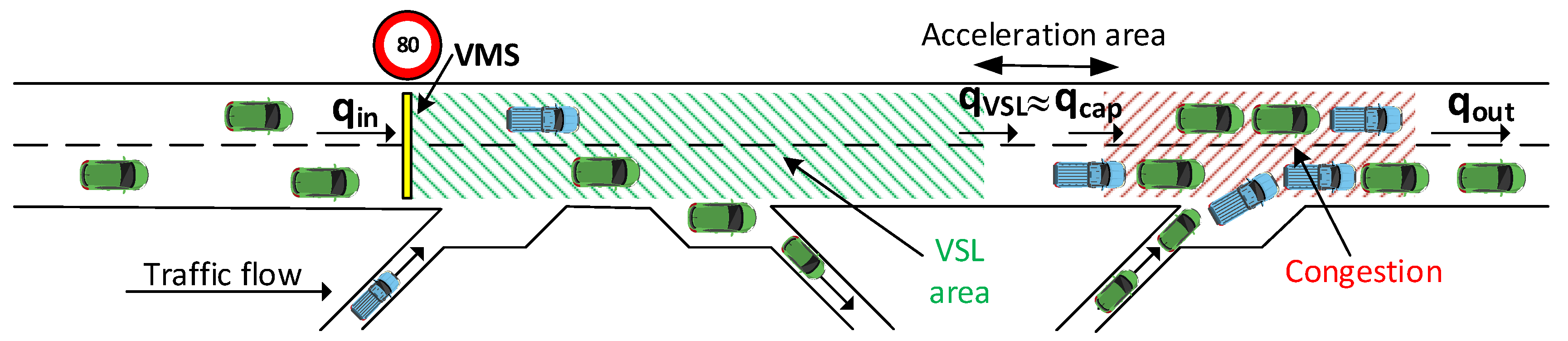
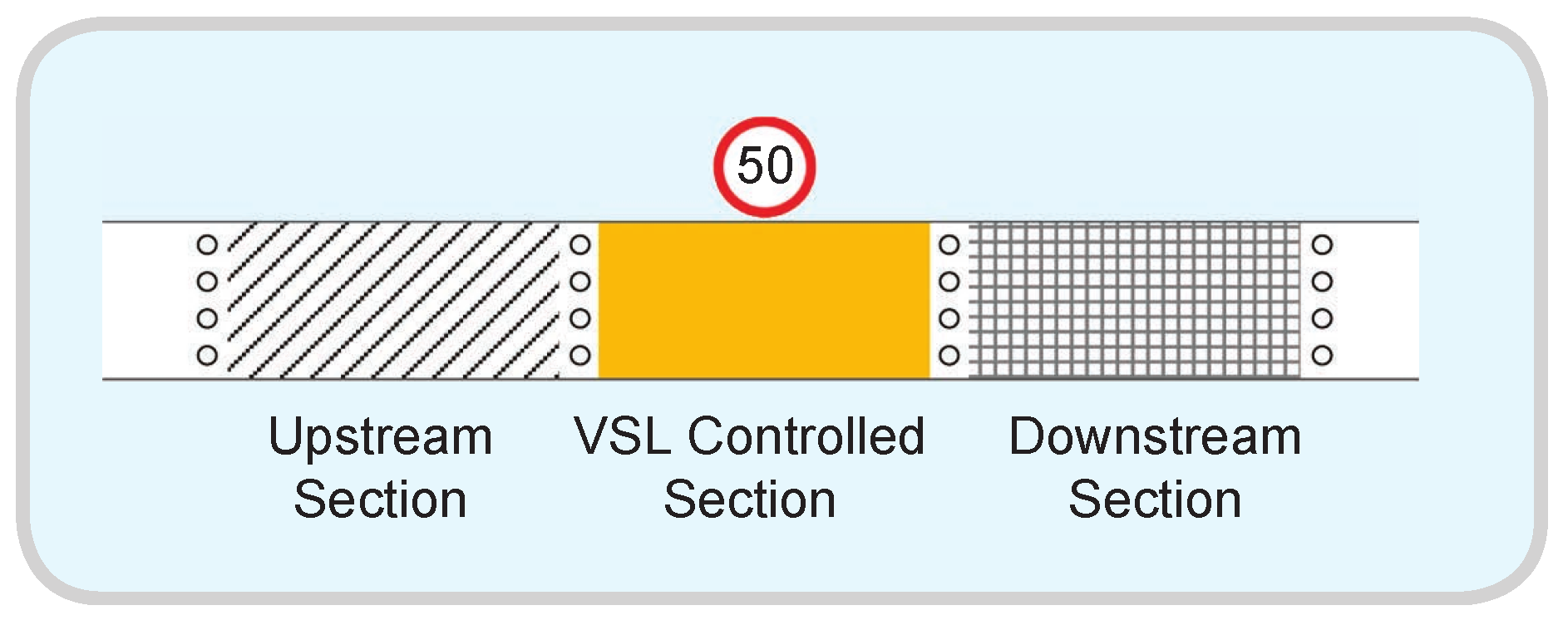
2.1. Variable Speed Limit Control
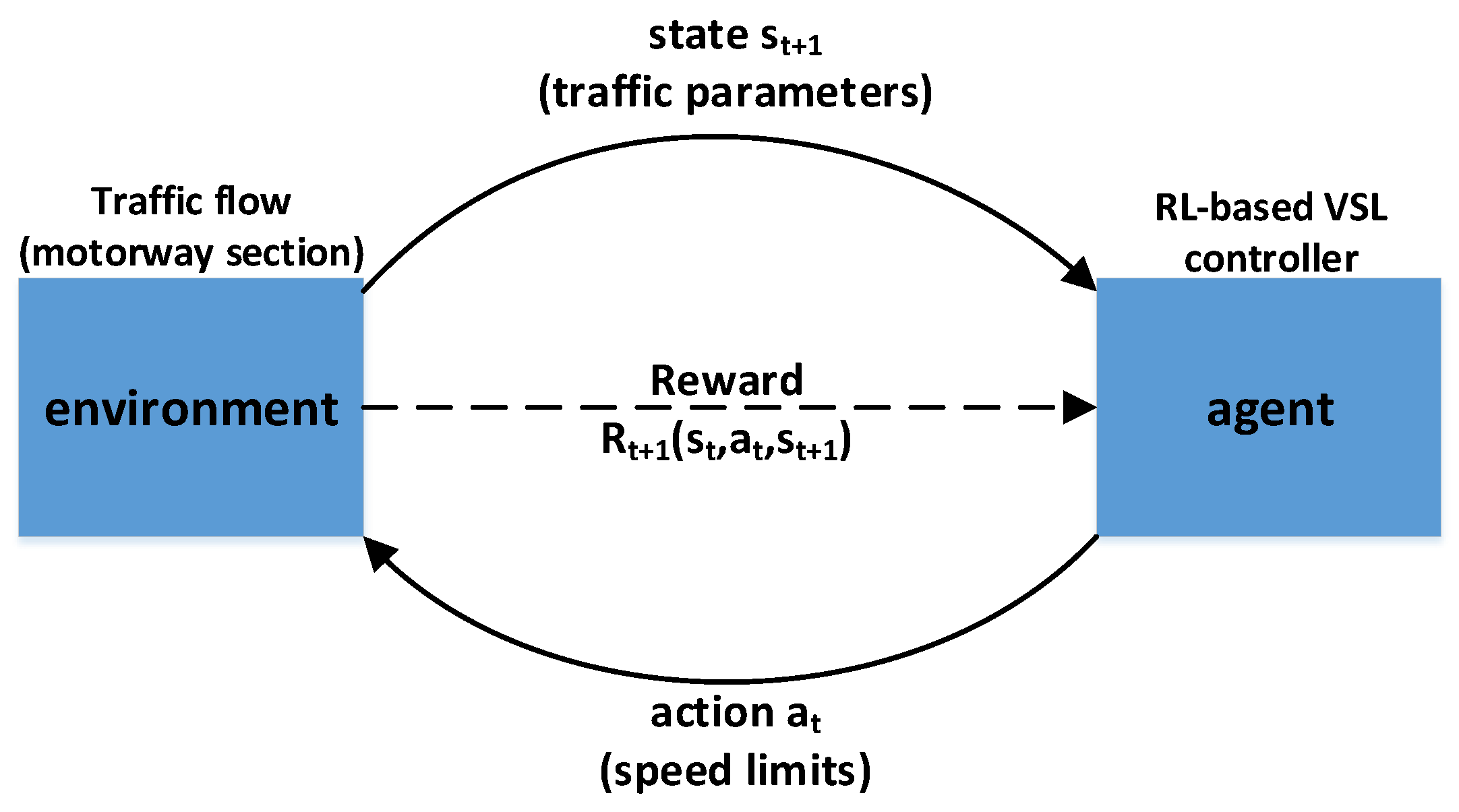
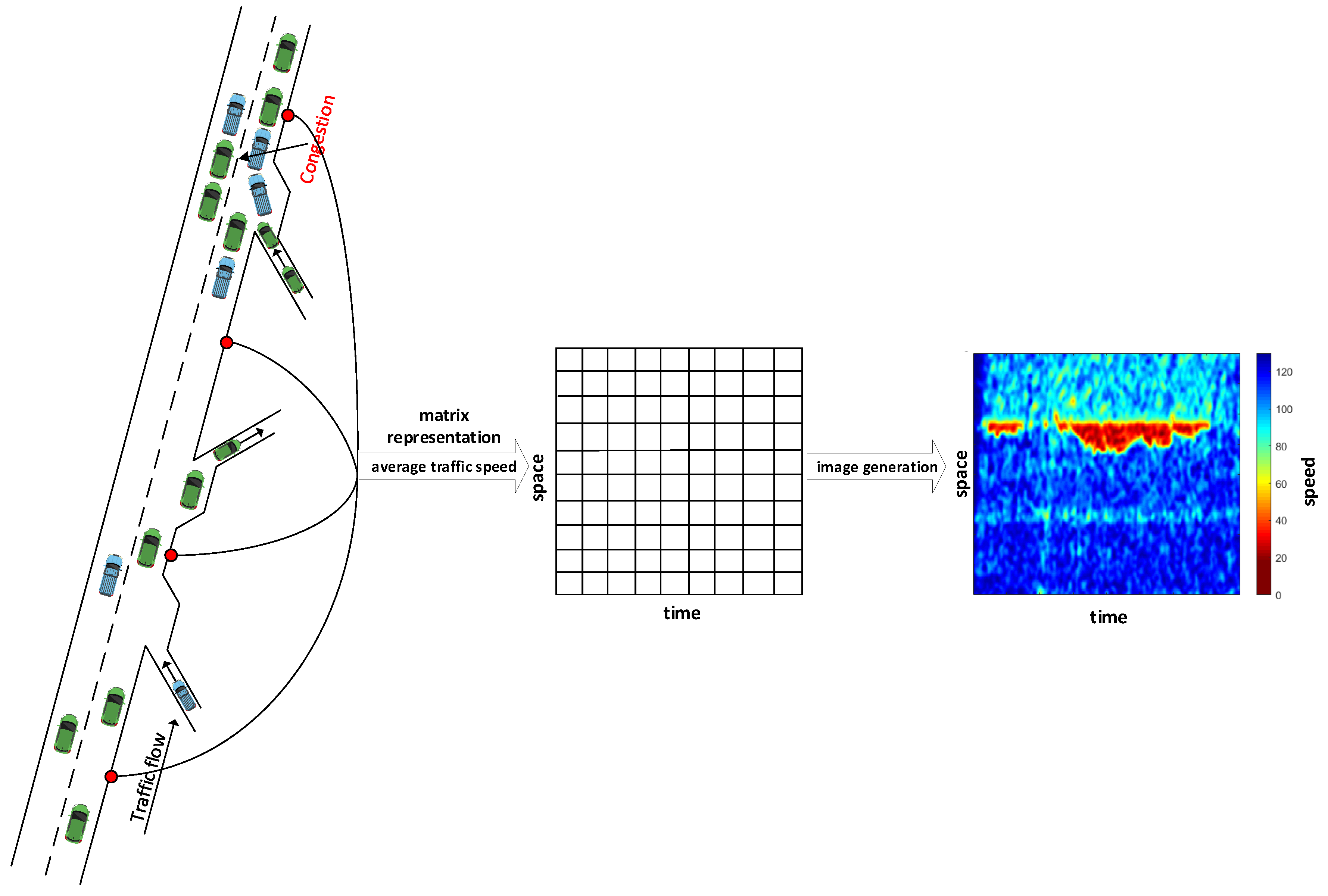
Reinforcement Learning
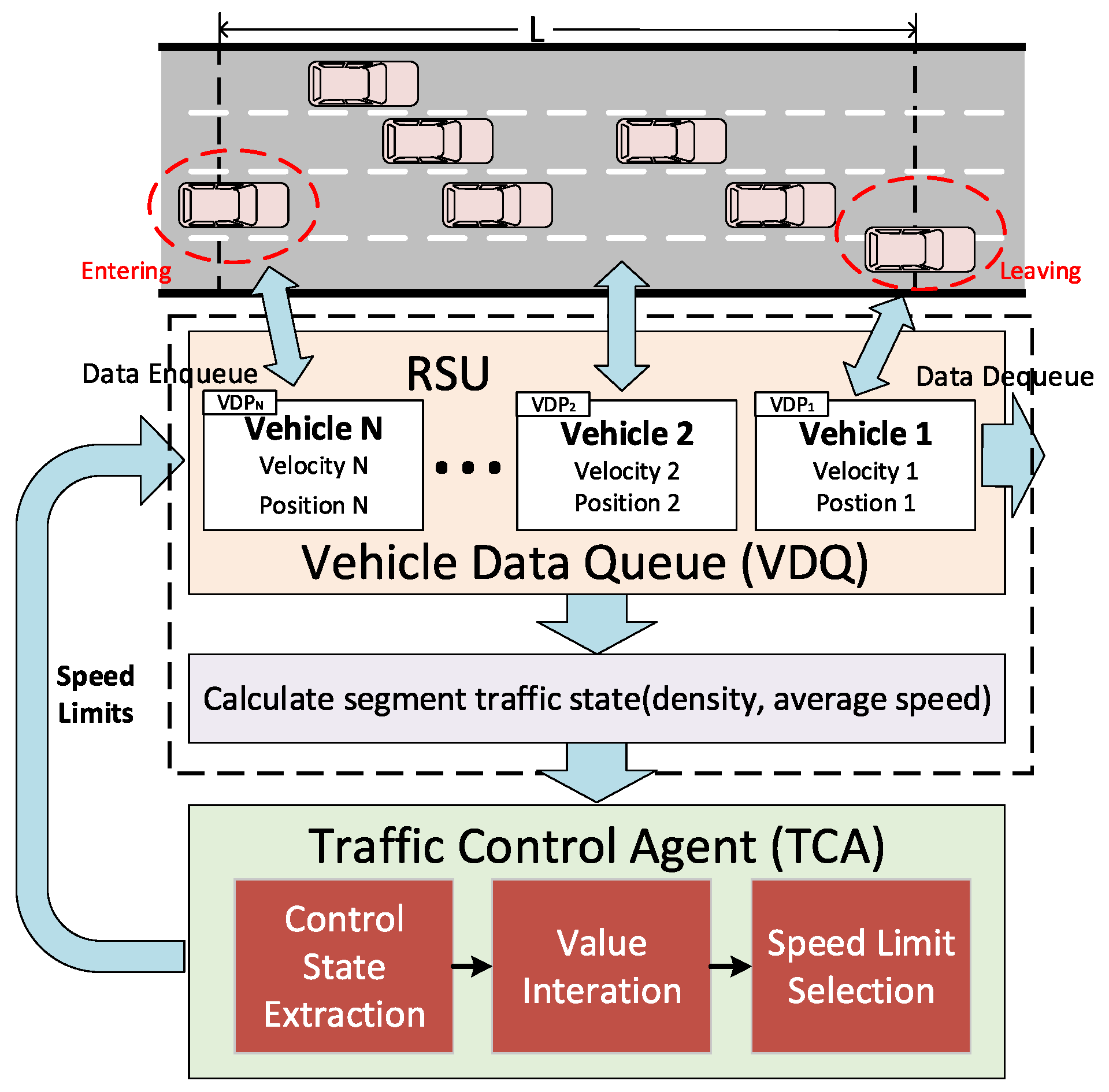
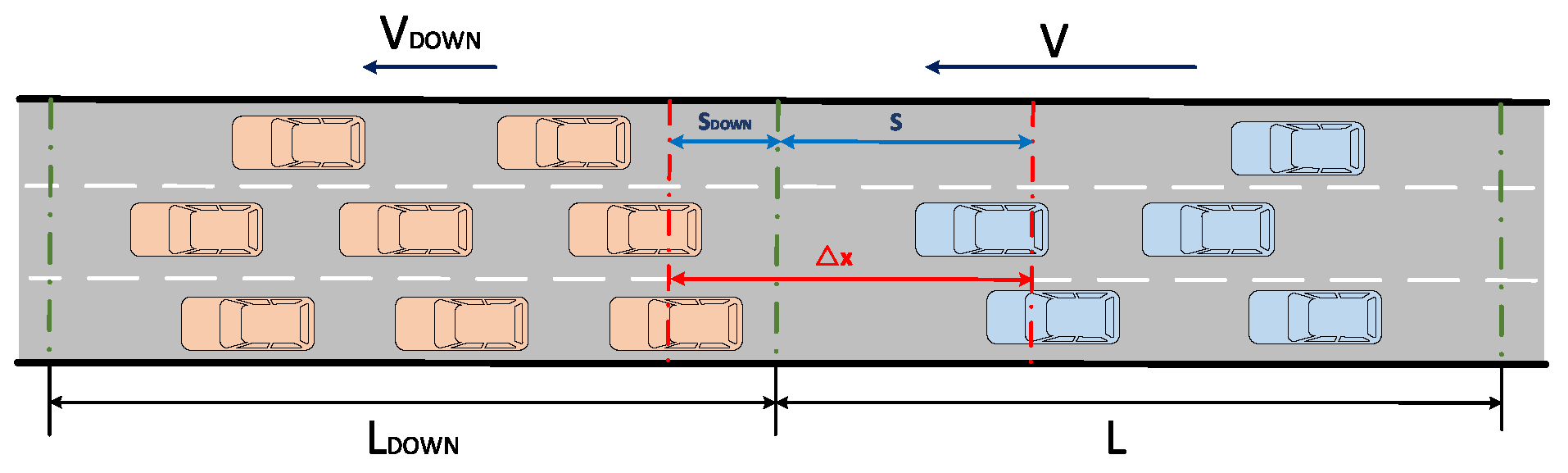
3. Research and Implementation
3.1. Research Method and Research Questions
- RQ1. What factors address speed limit management studies in terms of utilizing RL to solve the VSL problem?
- RQ2. What kinds of methodologies have been proposed to address the potential problems related to intelligent VSL systems?
- –
- RQ2.1. What kinds of RL algorithms have been proposed for VSL when traffic flow is consisting of only AVs?
- –
- RQ2.2. What kinds of RL algorithms have been proposed for VSL when traffic flow consists of a mixture of autonomous and human-driven vehicles?
- RQ3. What challenges and open questions arise?
- Scopus;
- IEEE;
- Web of Science (WoS).
3.2. Conducting the Review
3.3. Results of Research Questions
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| AV | Autonomous Vehicles |
| CAV | Connected Autonomous Vehicles |
| CTM | Cell Transmission traffic flow Model |
| CNN | Convolutional Neural Network |
| DDPG | Deep Deterministic Policy Gradient |
| DL | Deep Learning |
| DRL | Deep Reinforcement Learning |
| DQL | Deep Q-Learning |
| DVSL | Differential Variable Speed Limit |
| GRU | Gated Recurrent Unit Neural Net |
| ETRL | Eligibility Traces based Reinforcement Learning |
| FB-VLS | Feedback Variable Speed Limit |
| ITS | Intelligent Transportation Systems |
| kNN | k-Nearest Neighbors |
| LSTM | Long-Short Term Memory |
| ML | Machine learning |
| MDP | Markov Decision Processes |
| QL | Q-Learning |
| RL | Reinforcement Learning |
| R-MART | Reinforcement-Mark Average Reward Technique |
| RM | Ramp Metering |
| RNN | Recurrent Neural Network |
| TCA | Traffic Control Agent |
| Total Travel Time | |
| Total Time Spent | |
| VMS | Variable Message Signs |
| VSL | Variable Speed Limit |
| WoS | Web of Science |
References
- Gregurić, M.; Vujić, M.; Alexopoulos, C.; Miletić, M. Application of Deep Reinforcement Learning in Traffic Signal Control: An Overview and Impact of Open Traffic Data. Appl. Sci. 2020, 10, 4011. [Google Scholar] [CrossRef]
- European Environment Agency. Greenhouse Gas Emissions from Transport in Europe; Technical Report; EEA: Copenhagen, Denmark, 2019.
- Noland, R. Relationships between highway capacity and induced vehicle travel. Transp. Res. Part A Policy Pract. 2001, 35, 47–72. [Google Scholar] [CrossRef]
- Braess, D. Über ein Paradoxon aus der Verkehrsplanung. Unternehmensforschung 1968, 12, 258–268. (In German) [Google Scholar] [CrossRef]
- Lu, X.Y.; Shladover, S.E. Review of Variable Speed Limits and Advisories: Theory, Algorithms, and Practice. Transp. Res. Rec. 2014, 2423, 15–23. [Google Scholar] [CrossRef]
- Papageorgiou, M.; Kotsialos, A. Freeway ramp metering: An overview. IEEE Trans. Intell. Transp. Syst. 2002, 3, 271–281. [Google Scholar] [CrossRef]
- Castro, Á.G.; de Cáceres, A.M. Variable Speed Limits. Review and development of an aggregate indicator based on floating car data. In Proceedings of the 13th International Conference “Reliability and Statistics in Transportation and Communication” (RelStat’13), Riga, Latvia, 16–19 October 2013; Transport and Telecommunication Institute: Riga, Latvia; pp. 117–127. [Google Scholar]
- Strömgren, P.; Lind, G. Harmonization with Variable Speed Limits on Motorways. Transp. Res. Procedia 2016, 15, 664–675. [Google Scholar] [CrossRef]
- Van den Hoogen, E.; Smulders, S. Control by variable speed signs: Results of the Dutch experiment. In Proceedings of the Seventh International Conference on ‘Road Traffic Monitoring and Control’, London, UK, 26–28 April 1994; pp. 145–149. [Google Scholar] [CrossRef]
- Gao, C.; Xu, J.; Li, Q.; Yang, J. The Effect of Posted Speed Limit on the Dispersion of Traffic Flow Speed. Sustainability 2019, 11, 3594. [Google Scholar] [CrossRef]
- Müller, E.R.; Carlson, R.C.; Kraus, W.; Papageorgiou, M. Microsimulation Analysis of Practical Aspects of Traffic Control with Variable Speed Limits. IEEE Trans. Intell. Transp. Syst. 2015, 16, 512–523. [Google Scholar] [CrossRef]
- Jeon, S.; Park, C.; Seo, D. The Multi-Station Based Variable Speed Limit Model for Realization on Urban Highway. Electronics 2020, 9, 801. [Google Scholar] [CrossRef]
- Dadashzadeh, N.; Ergun, M. An Integrated Variable Speed Limit and ALINEA Ramp Metering Model in the Presence of High Bus Volume. Sustainability 2019, 11, 6326. [Google Scholar] [CrossRef]
- Lighthill, M.J.; Whitham, G.B. On kinematic waves II. A theory of traffic flow on long crowded roads. Proc. R. Soc. Lond. Ser. A Math. Phys. Sci. 1955, 229, 317–345. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H. Learning from Delayed Rewards. Ph.D. Thesis, King’s College, Cambridge, UK, 1989. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; A Bradford Book; The MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Zhu, F.; Ukkusuri, S.V. Accounting for dynamic speed limit control in a stochastic traffic environment: A reinforcement learning approach. Transp. Res. Part C Emerg. Technol. 2014, 41, 30–47. [Google Scholar] [CrossRef]
- Walraven, E.; Spaan, M.T.; Bakker, B. Traffic flow optimization: A reinforcement learning approach. Eng. Appl. Artif. Intell. 2016, 52, 203–212. [Google Scholar] [CrossRef]
- Schmidt-Dumont, T.; van Vuuren, J.H. A case for the adoption of decentralised reinforcement learning for the control of traffic flow on South African highways. J. S. Afr. Inst. Civ. Eng. 2019, 61, 7–19. [Google Scholar] [CrossRef]
- Kušić, K.; Ivanjko, E.; Gregurić, M. A Comparison of Different State Representations for Reinforcement Learning Based Variable Speed Limit Control. In Proceedings of the MED 2018—26th Mediterranean Conference on Control and Automation, Zadar, Croatia, 19–22 June 2018; pp. 266–271. [Google Scholar]
- Li, Z.; Liu, P.; Xu, C.; Duan, H.; Wang, W. Reinforcement Learning-Based Variable Speed Limit Control Strategy to Reduce Traffic Congestion at Freeway Recurrent Bottlenecks. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3204–3217. [Google Scholar] [CrossRef]
- Tabadkani Aval, S.S.; Shojaee Ghandeshtani, N.; Akbari, P.; Eghbal, N.; Noori, A. An Eligibility Traces based Cooperative and Integrated Control Strategy for Traffic Flow Control in Freeways. In Proceedings of the 2019 9th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 24–25 October 2019; pp. 40–45. [Google Scholar]
- Vinitsky, E.; Parvate, K.; Kreidieh, A.; Wu, C.; Bayen, A. Lagrangian Control through Deep-RL: Applications to Bottleneck Decongestion. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 759–765. [Google Scholar] [CrossRef]
- Lu, C.; Huang, J.; Gong, J. Reinforcement Learning for Ramp Control: An Analysis of Learning Parameters. Promet—Traffic Transp. 2016, 28, 371–381. [Google Scholar] [CrossRef]
- Dusparic, I.; Monteil, J.; Cahill, V. Towards autonomic urban traffic control with collaborative multi-policy reinforcement learning. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 2065–2070. [Google Scholar]
- Guériau, M.; Dusparic, I. SAMoD: Shared Autonomous Mobility-on-Demand using Decentralized Reinforcement Learning. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 1558–1563. [Google Scholar]
- Hsu, R.C.; Liu, C.; Chan, D. A Reinforcement-Learning-Based Assisted Power Management with QoR Provisioning for Human–Electric Hybrid Bicycle. IEEE Trans. Ind. Electron. 2012, 59, 3350–3359. [Google Scholar] [CrossRef]
- Lee, J.; Jiang, J. Enhanced fuzzy-logic-based power-assisted control with user-adaptive systems for human-electric bikes. IET Intell. Transp. Syst. 2019, 13, 1492–1498. [Google Scholar] [CrossRef]
- Schumann, R.; Taramarcaz, C. Towards systematic testing of complex interacting systems. In Proceedings of the First Workshop on Systemic Risks in Global Networks co-located with 14. Internationale Tagung Wirtschaftsinformatik (WI 2019), Siegen, Germany, 24 February 2019; pp. 55–63. [Google Scholar]
- Zambrano-Martinez, J.L.; Calafate, C.T.; Soler, D.; Cano, J.C. Towards Realistic Urban Traffic Experiments Using DFROUTER: Heuristic, Validation and Extensions. Sensors 2017, 17, 2921. [Google Scholar] [CrossRef]
- Khondaker, B.; Kattan, L. Variable speed limit: An overview. Transp. Lett. 2015, 7, 264–278. [Google Scholar] [CrossRef]
- Wang, W.; Yang, Z.S.; Zhao, D.X. Control model of variable speed limit based on finite horizon Markov decision-making. Jiaotong Yunshu Gongcheng Xuebao/J. Traffic Transp. Eng. 2011, 11, 109–114. [Google Scholar]
- Fares, A.; Gomaa, W.; Khamis, M.A. MARL-FWC: Optimal Coordination of Freeway Traffic Control Measures. arXiv 2018, arXiv:1808.09806. Available online: http://xxx.lanl.gov/abs/1808.09806 (accessed on 20 June 2020).
- Wang, C.; Zhang, J.; Xu, L.; Li, L.; Ran, B. A New Solution for Freeway Congestion: Cooperative Speed Limit Control Using Distributed Reinforcement Learning. IEEE Access 2019, 7, 41947–41957. [Google Scholar] [CrossRef]
- Li, Z.; Xu, C.; Pu, Z.; Guo, Y.; Liu, P. Reinforcement Learning-Based Variable Speed Limits Control to Reduce Crash Risks near Traffic Oscillations on Freeways. IEEE Intell. Transp. Syst. Mag. 2020. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, H.; Jiang, Z.; Ran, B. ES-CTC: A Deep Neuroevolution Model for Cooperative Intelligent Freeway Traffic Control. arXiv 2019, arXiv:1905.04083. Available online: http://xxx.lanl.gov/abs/1905.04083 (accessed on 20 June 2020).
- Wu, Y.; Tan, H.; Ran, B. Differential Variable Speed Limits Control for Freeway Recurrent Bottlenecks via Deep Reinforcement learning. arXiv 2018, arXiv:1810.10952. Available online: http://xxx.lanl.gov/abs/1810.10952 (accessed on 20 June 2020).
- Smulders, S. Control of freeway traffic flow by variable speed signs. Transp. Res. Part B 1990, 24, 111–132. [Google Scholar] [CrossRef]
- Allaby, P.; Hellinga, B.; Bullock, M. Variable speed limits: Safety and operational impacts of a candidate control strategy for freeway applications. IEEE Trans. Intell. Transp. Syst. 2007, 8, 671–680. [Google Scholar] [CrossRef]
- Pauw, E.; Daniels, S.; Franckx, L.; Mayeres, I. Safety effects of dynamic speed limits on motorways. Accid. Anal. Prev. 2017, 114. [Google Scholar] [CrossRef]
- Ziolkowski, R. Effectiveness of Automatic Section Speed Control System Operating on National Roads in Poland. Promet—Traffic Transp. 2019, 31, 435–442. [Google Scholar]
- Iordanidou, G.; Roncoli, C.; Papamichail, I.; Papageorgiou, M. Feedback-Based Mainstream Traffic Flow Control for Multiple Bottlenecks on Motorways. IEEE Trans. Intell. Transp. Syst. 2015, 16, 610–621. [Google Scholar] [CrossRef]
- Lu, X.Y.; Varaiya, P.; Horowitz, R.; Su, D.; Shladover, S.E. A new approach for combined freeway variable speed limits and coordinated ramp metering. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, ITSC 2010, Funchal, Portugal, 19–22 September 2010; pp. 491–498. [Google Scholar]
- Hegyi, A.; De Schutter, B.; Hellendoorn, J. Optimal coordination of variable speed limits to suppress shock waves. IEEE Trans. Intell. Transp. Syst. 2005, 6, 102–112. [Google Scholar] [CrossRef]
- Papageorgiou, M.; Kosmatopoulos, E.; Papamichail, I. Effects of Variable Speed Limits on Motorway Traffic Flow. Transp. Res. Rec. J. Transp. Res. Board 2008, 37–48. [Google Scholar] [CrossRef]
- Bae, H.; Kim, G.; Kim, J.; Qian, D.; Lee, S. Multi-Robot Path Planning Method Using Reinforcement Learning. Appl. Sci. 2019, 9, 3057. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Benuwa, B.B.; Zhan, Y.Z.; Ghansah, B.; Wornyo, D.K.; Banaseka Kataka, F. A Review of Deep Machine Learning. Int. J. Eng. Res. Afr. 2016, 24, 124–136. [Google Scholar] [CrossRef]
- Kušić, K.; Dusparic, I.; Guériau, M.; Gregurić, M.; Ivanjko, E. Extended Variable Speed Limit control using Multi-agent Reinforcement Learning. In Proceedings of the 23rd IEEE International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 22–23 September 2020. [Google Scholar]
- Messmer, A.; Papageorgiou, M. METANET: A macroscopic simulation program for motorway networks. Traffic Eng. Control 1990, 31, 466–470. [Google Scholar]
- Belletti, F.; Haziza, D.; Gomes, G.; Bayen, A.M. Expert Level Control of Ramp Metering Based on Multi-Task Deep Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1198–1207. [Google Scholar] [CrossRef]
- Martin H, J.A.; Asiaín, J.; Maravall, D. Robust high performance reinforcement learning through weighted k-nearest neighbors. Neurocomputing 2011, 74, 1251–1259. [Google Scholar] [CrossRef]
- Nair, R.; Varakantham, P.; Tambe, M.; Yokoo, M. Networked distributed POMDPs: A synthesis of distributed constraint optimization and POMDPs. Proc. Natl. Conf. Artif. Intell. 2005, 1, 133–139. [Google Scholar]
- El-Tantawy, S.; Abdulhai, B.; Abdelgawad, H. Multiagent Reinforcement Learning for Integrated Network of Adaptive Traffic Signal Controllers (MARLIN-ATSC): Methodology and Large-Scale Application on Downtown Toronto. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1140–1150. [Google Scholar] [CrossRef]
- Humphrys, M. Action Selection Methods Using Reinforcement Learning. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 1996. [Google Scholar]
- Li, Z.; Ahn, S.; Chung, K.; Ragland, D.R.; Wang, W.; Yu, J.W. Surrogate safety measure for evaluating rear-end collision risk related to kinematic waves near freeway recurrent bottlenecks. Accid. Anal. Prev. 2014, 64, 52–61. [Google Scholar] [CrossRef] [PubMed]
- Han, Z.; Zhao, J.; Leung, H.; Ma, K.F.; Wang, W. A Review of Deep Learning Models for Time Series Prediction. IEEE Sens. J. 2019. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. Available online: http://xxx.lanl.gov/abs/1406.1078 (accessed on 20 June 2020).
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Barto, A.G.; Sutton, R.S.; Anderson, C.W. Neuronlike adaptive elements that can solve difficult learning control problems. IEEE Trans. Syst. Man Cybern. 1983, SMC-13, 834–846. [Google Scholar] [CrossRef]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. arXiv 2015, arXiv:1511.05952. Available online: http://xxx.lanl.gov/abs/1511.05952 (accessed on 20 June 2020).
- Ma, X.; Dai, Z.; He, Z.; Wang, Y. Learning Traffic as Images: A Deep Convolution Neural Network for Large-scale Transportation Network Speed Prediction. arXiv 2017, arXiv:1701.04245. Available online: http://xxx.lanl.gov/abs/1701.04245 (accessed on 20 June 2020).
- Ma, X.; Tao, Z.; Wang, Y.; Yu, H.; Wang, Y. Long short-term memory neural network for traffic speed prediction using remote microwave sensor data. Transp. Res. Part C Emerg. Technol. 2015, 54. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Year | RL Method | Compared against | Control Strategy | Improvements |
|---|---|---|---|---|---|
| [35] | 2020 | Q-Learning | no-control | VSL | lower crash risk |
| [49] | 2020 | W-Learning | no-control, single and independent VSL agents | multi-agent VSL | lower bottleneck density |
| [34] | 2019 | Distributed Q-Learning (kNN-TD) | no-control | multi-agent VSL | lower |
| [19] | 2019 | Maximax MARL | no-control, feedback, independent, hierarchical MARL | multi-agent RM and VSL | lower |
| [23] | 2018 | Deep-RL (GRU) | no-control, feedback RM | centralized agent VSL to AVs | higher bottleneck throughput |
| [20] | 2018 | Q-Learning linear approx. | no-control, Q-tabular, (Tile, Coarse, RBF) | VSL | lower overall |
| [21] | 2017 | Q-Learning (kNN-TD) | no-control, FB-VSL | VSL | lower |
| [18] | 2016 | O-Learning (ANN) | no-control, certain fixed amount of VSL | VSL | lower |
| [17] | 2014 | R-MART | no-control | VSL | lower |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kušić, K.; Ivanjko, E.; Gregurić, M.; Miletić, M. An Overview of Reinforcement Learning Methods for Variable Speed Limit Control. Appl. Sci. 2020, 10, 4917. https://doi.org/10.3390/app10144917
Kušić K, Ivanjko E, Gregurić M, Miletić M. An Overview of Reinforcement Learning Methods for Variable Speed Limit Control. Applied Sciences. 2020; 10(14):4917. https://doi.org/10.3390/app10144917
Chicago/Turabian StyleKušić, Krešimir, Edouard Ivanjko, Martin Gregurić, and Mladen Miletić. 2020. "An Overview of Reinforcement Learning Methods for Variable Speed Limit Control" Applied Sciences 10, no. 14: 4917. https://doi.org/10.3390/app10144917
APA StyleKušić, K., Ivanjko, E., Gregurić, M., & Miletić, M. (2020). An Overview of Reinforcement Learning Methods for Variable Speed Limit Control. Applied Sciences, 10(14), 4917. https://doi.org/10.3390/app10144917