In this section, the implemented experimental scenarios used for performance comparison and the corresponding results using the described performance evaluation metrics are described.
6.2.1. Experimental Scenarios
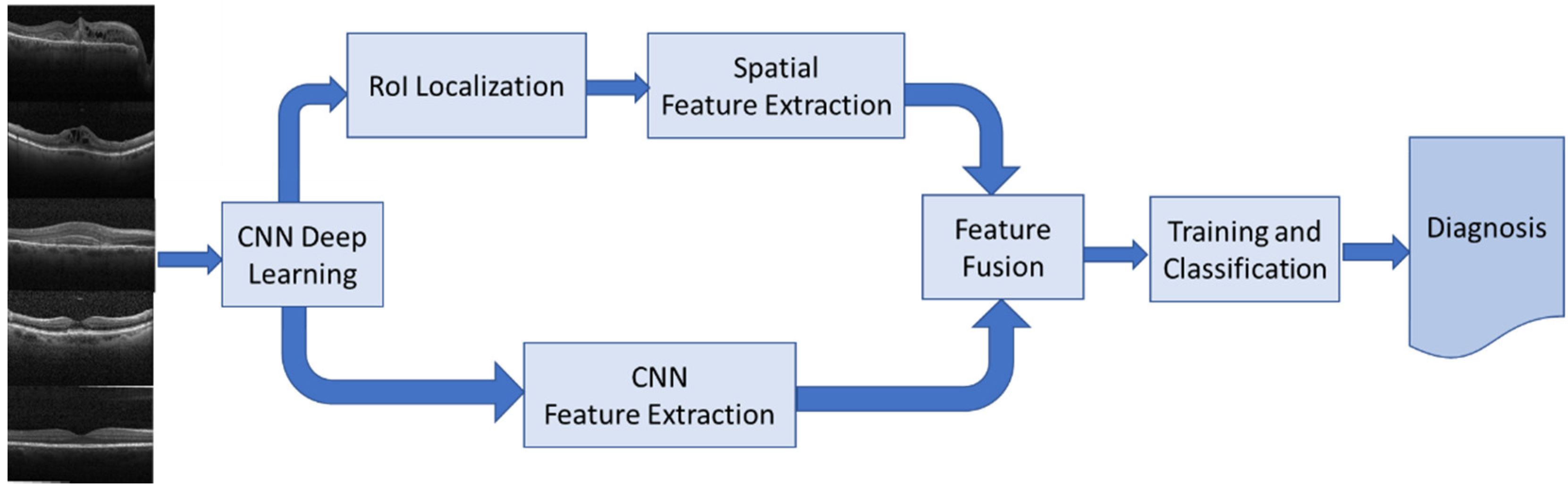
1. HyCAD Architecture
The proposed system architecture presented in
Section 5 is applied to the dataset described in
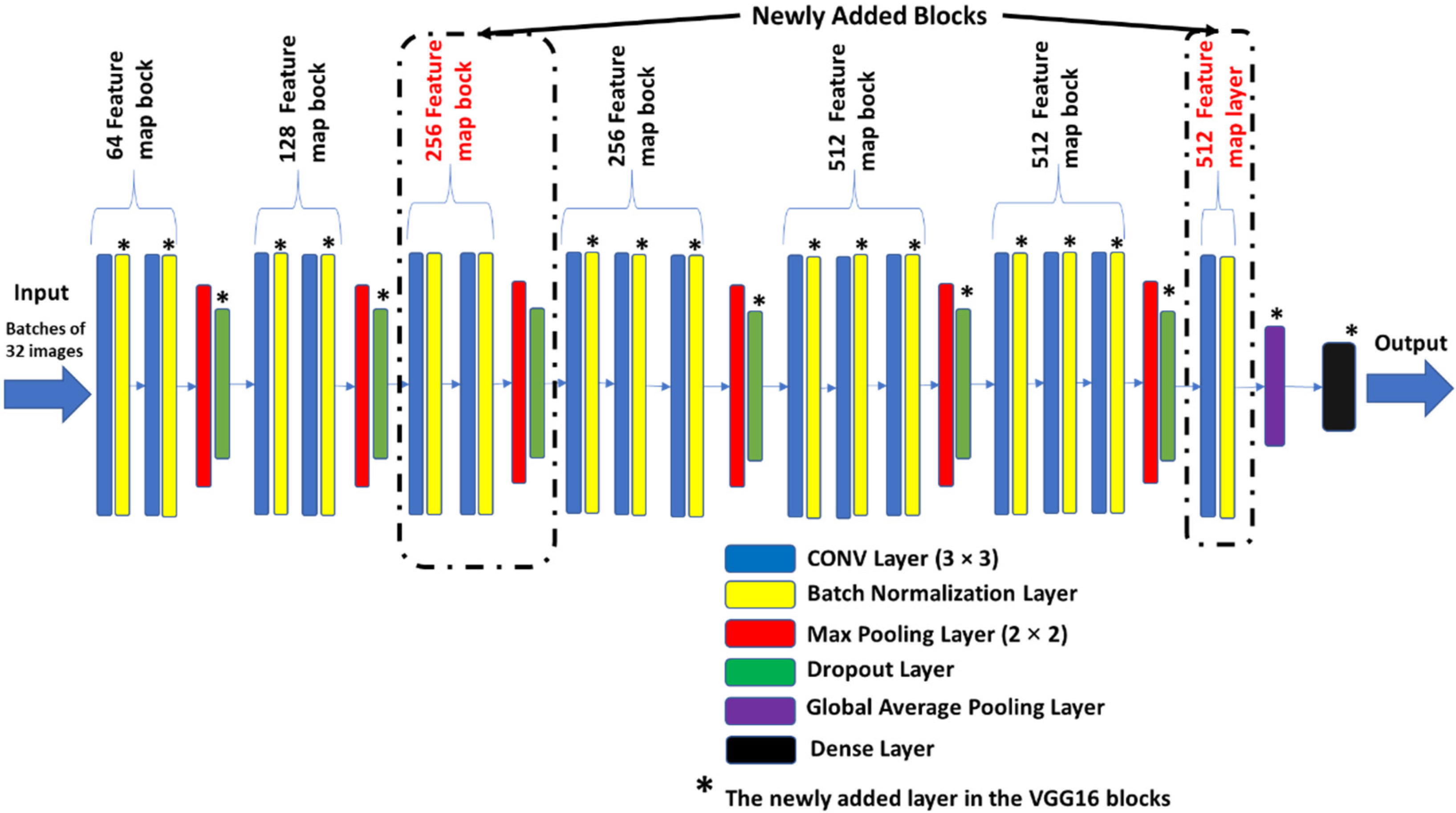
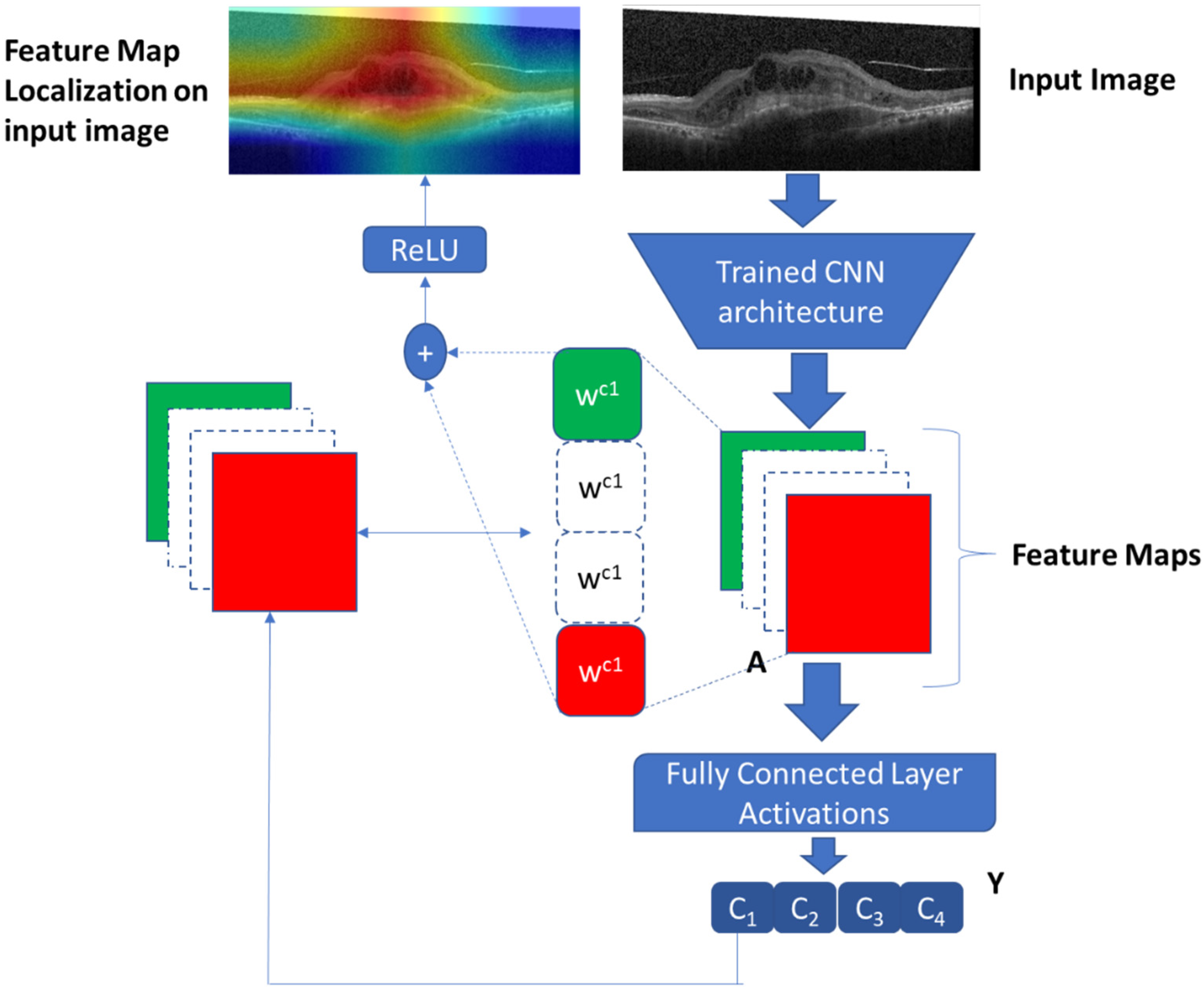
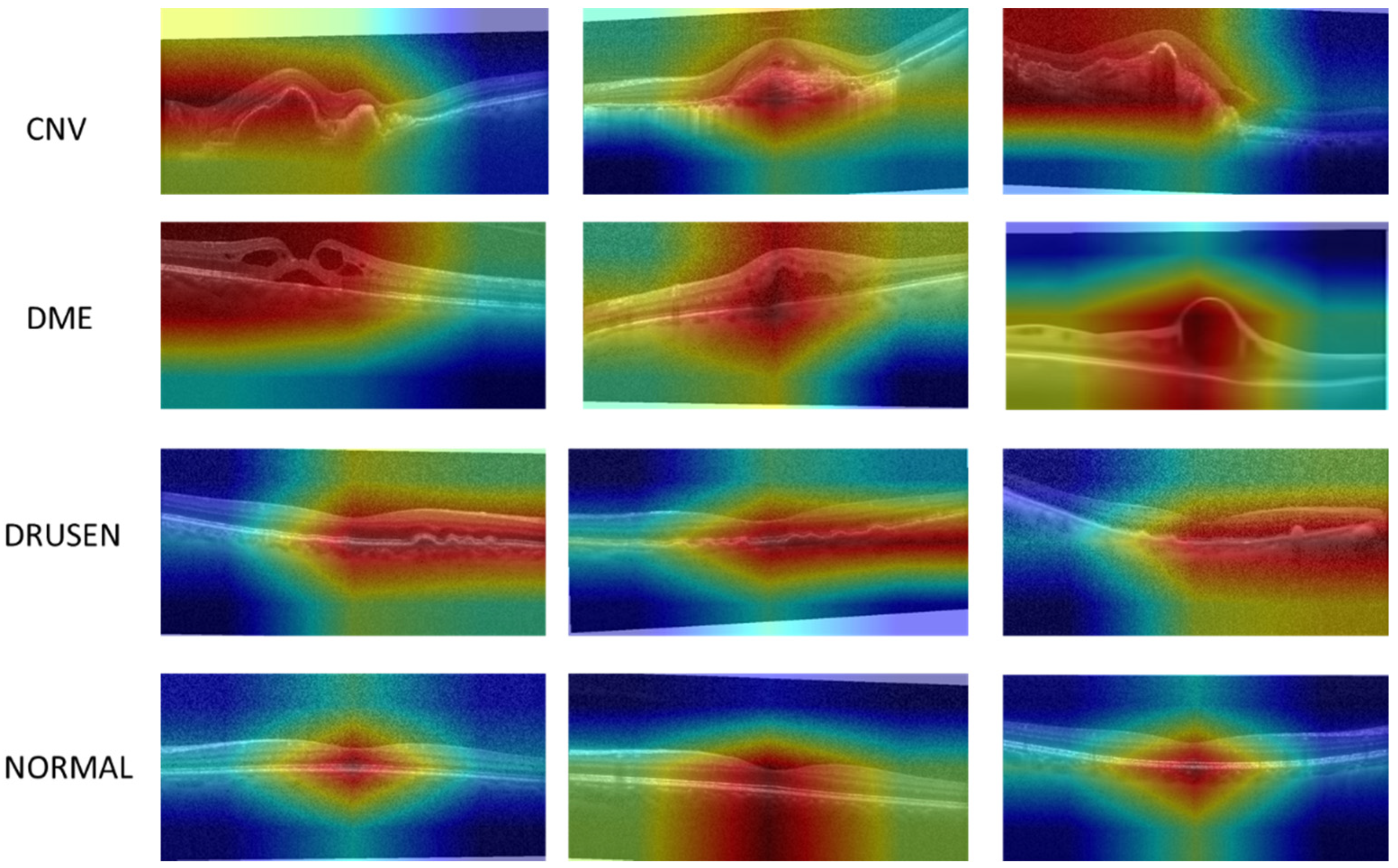
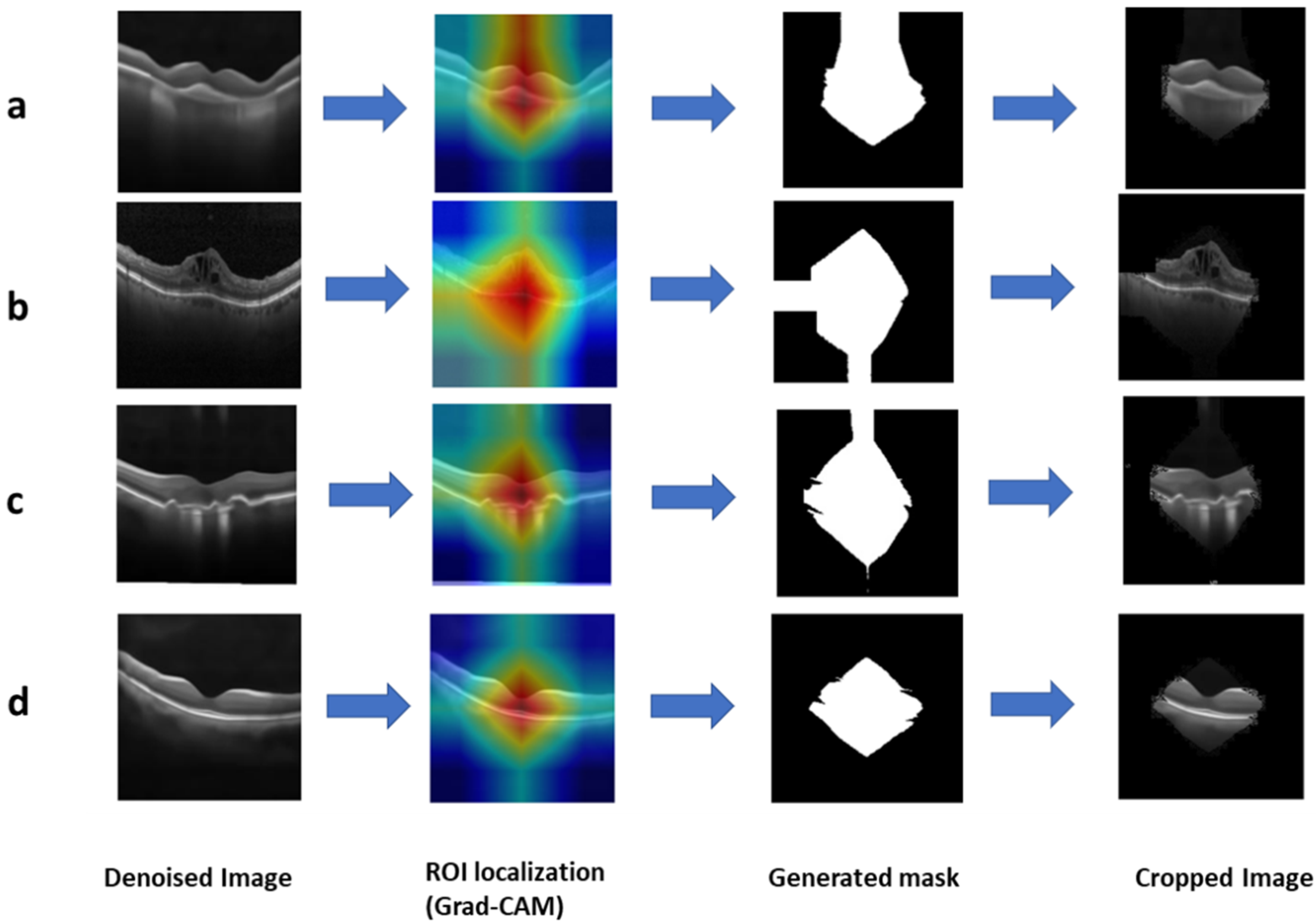
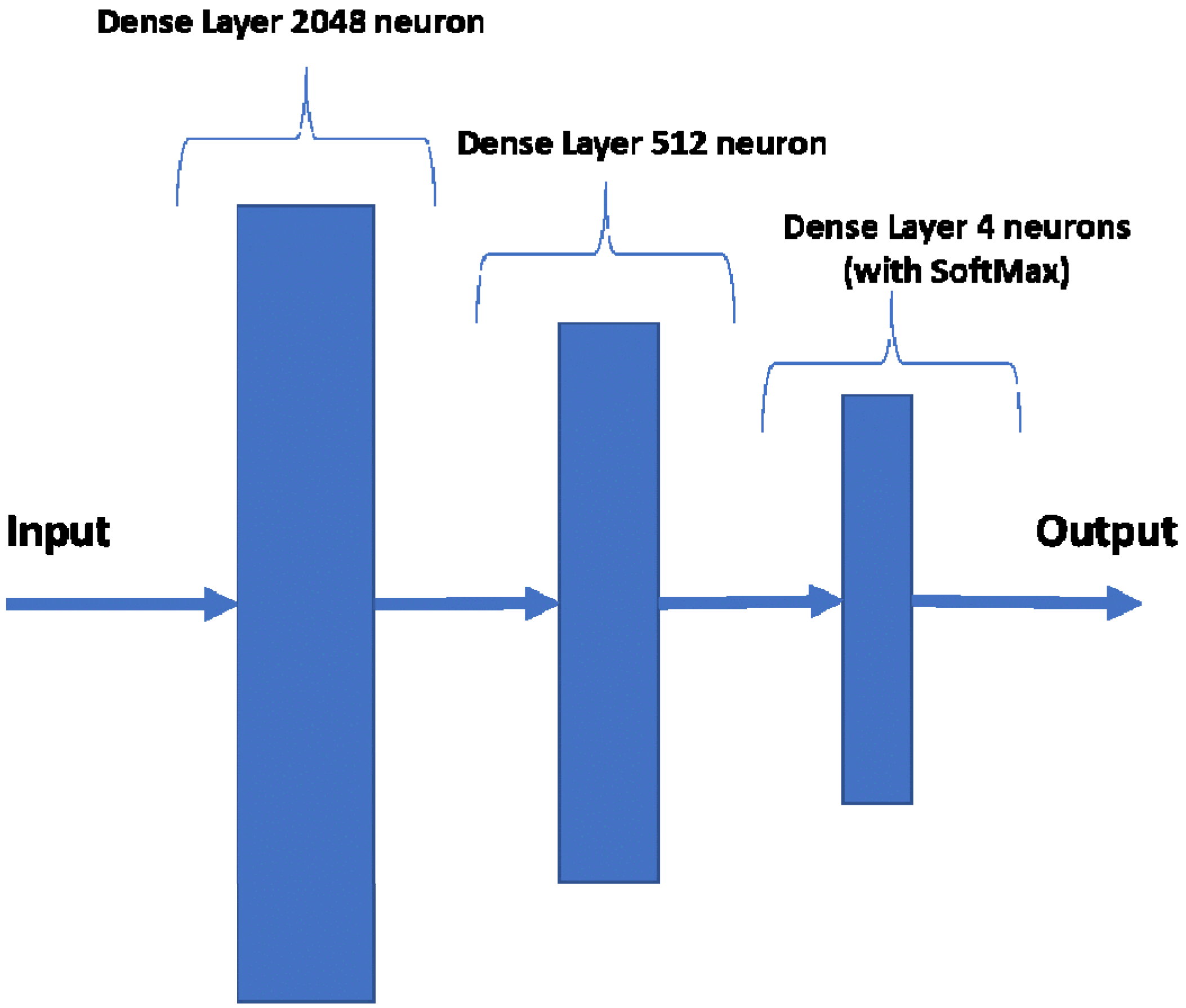
Section 4. Norm-VGG16 integrating kernel regularizer is trained on the dataset from scratch aiming at higher performance metrics. It is used for RoI generation and feature extraction. A set of 512 features are extracted from the global average pooling layer of the CNN network. The hand-crafted feature extraction methods, namely HOG and DAISY, when applied on the segmented RoI generated 8500 features. At the fusion stage of our HyCAD system, all the extracted features are fused and fed into a three sequential dense layer neural network for a classification decision.
2. Norm-VGG16 (kernel regularized) Deep Learning Architecture
In this scenario, the modified Norm-VGG16 Deep Learning architecture is applied on the OCT dataset. The performed classification is based solely on the CNN-based features. This scenario is presented to elucidate the merit of incorporating human articulated features on the performance of the system.
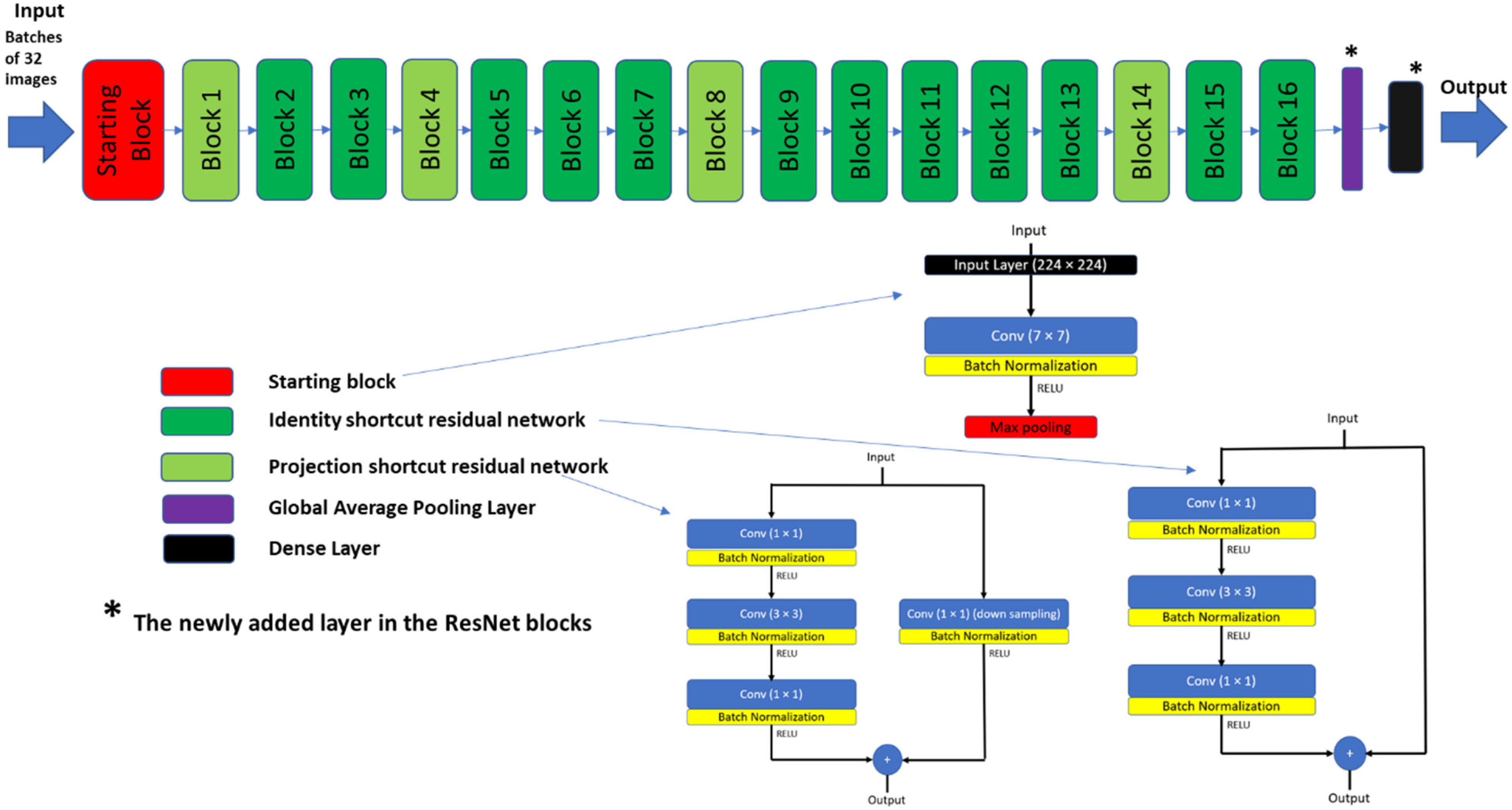
3. ResNet-50 Net (kernel regularized) Deep Learning Architecture
ResNets [
32,
44] can be considered one of the most applied deep learning architectures for image recognition and classification. ResNets include residual blocks which allow deeper network architecture to avoid information loss during training. In addition, it was shown to achieve lower validation loss compared to VGG16 on the ImageNet dataset [
44]. Therefore, ResNet-50 architecture (shown in
Appendix A) is chosen as one of our experimental scenarios, to compare its performance to the proposed HyCAD system. The ResNet-50 best model is modified by adding kernel regularization in the final dense layer.
In addition to these implemented experimental scenarios, the results of HyCAD are compared with the work of Kermany et al. [
4] and Li et al. [
20]. These were chosen as their results were reported on the same dataset using deep learning approaches and attained high results.
6.2.2. Classification Results
Our experimental results are shown in two folds. First, bootstrapping is adopted, and a limited set of results are reported to show the performance of HyCAD across several testing data partitions and investigate its stability relative to Norm-VGG16 and RESNET-50 and to clarify the impact of hand-crafted features’ fusion with deep learning architectures. In the second fold of experiments, elaborate results are reported on the same training and test percentages used by Kermany et al. [
4] and Li et al. [
20]. The results of the best run are displayed to be able to compare to Kermany et al. [
4] and Li et al. [
20].
1. Bootstrapping Experiments Fold
Ten bootstrapping experiments are conducted to evaluate the performance of the models at different boot strapped test partitions. In each experiment, the 109,312 images are shuffled and a random selection of 108,312 images is used as training dataset and the rest of the 1000 images are used as testing dataset. Each new partition tested on our implemented architectures (HyCAD, Norm-VGG16 integrating kernel regularizer and ResNet-50 integrating kernel regularizer) taking into consideration that the testing dataset is partitioned equally between four classes (CNV, DME, DRUSEN and NORMAL).
Table 3 presents the mean values and the standard deviation of overall accuracy and urgent group sensitivity for 10 different bootstrapped partitions. The depicted results reveal the improvement achieved through integrating the handcrafted features with Norm-VGG16 integrating kernel regularizer. The proposed HyCAD architecture attains the highest mean accuracy and mean sensitivity for the critical Urgent referrals compared to Norm-VGG16 integrating kernel regularizer and ResNet-50. In addition, it attains the lowest standard deviation in comparison to the pure CNN architectures. Compared to Norm-VGG16 integrating kernel regularizer, HyCAD achieves a substantial increase of 2.9% and 4.9% in terms of mean accuracy and mean sensitivity of Urgent referrals, respectively. In addition, the HyCAD model has a lower standard deviation relative to the pure deep learning architecture Norm-VGG16 integrating kernel regularizer. Such findings emphasize the positive impact of fusing hand-crafted features with learned features from deep learning architecture.
The Training and Validation losses and accuracies for the two deep learning architecture (Norm-VGG16 kernel regularized and ResNet-50 kernel regularized) for each epoch are shown in
Figure 13. The Norm-VGG16 architecture best model achieves training accuracy of 94.86% and training loss of 15.75%. In addition, it achieves a testing accuracy of 97.3% and testing loss of 8.34%. ResNet-50 achieves a training accuracy of 96.95% and a training loss of 9.02%. In addition, it achieves a testing accuracy of 97% and a testing loss of 8.76%. From the shown learning curves, it is manifest that the performance stabilizes around the 15th epoch, which can lead to reducing the training time considerably.
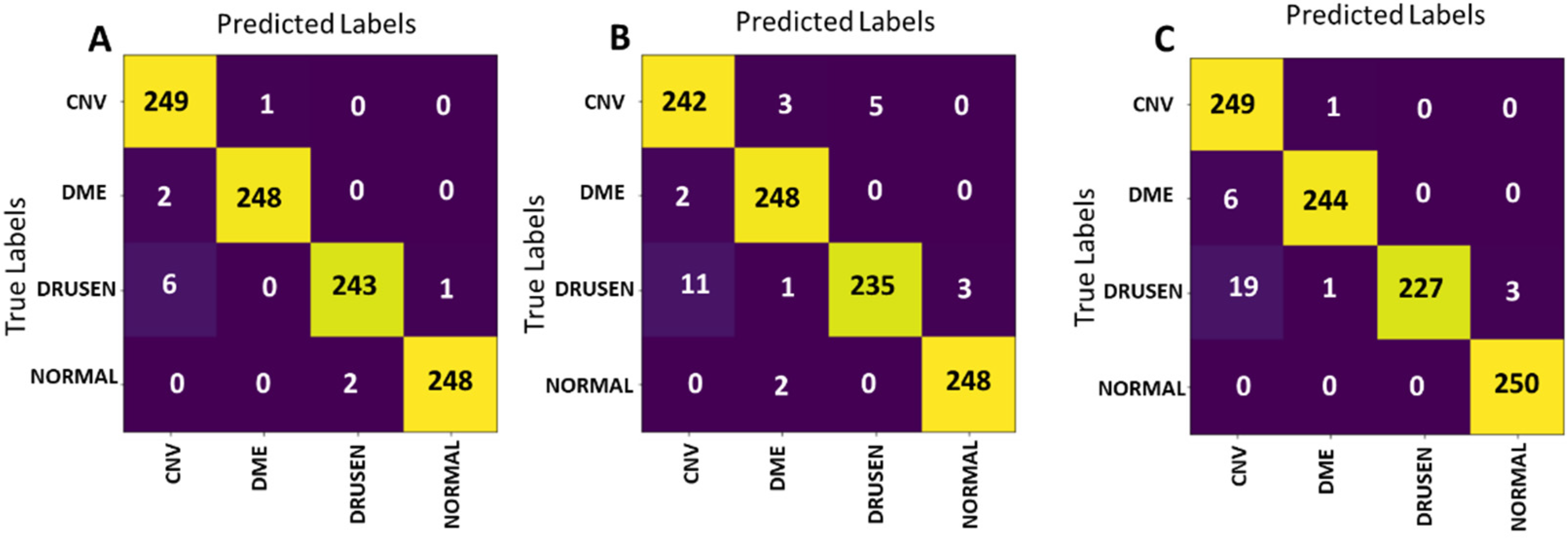
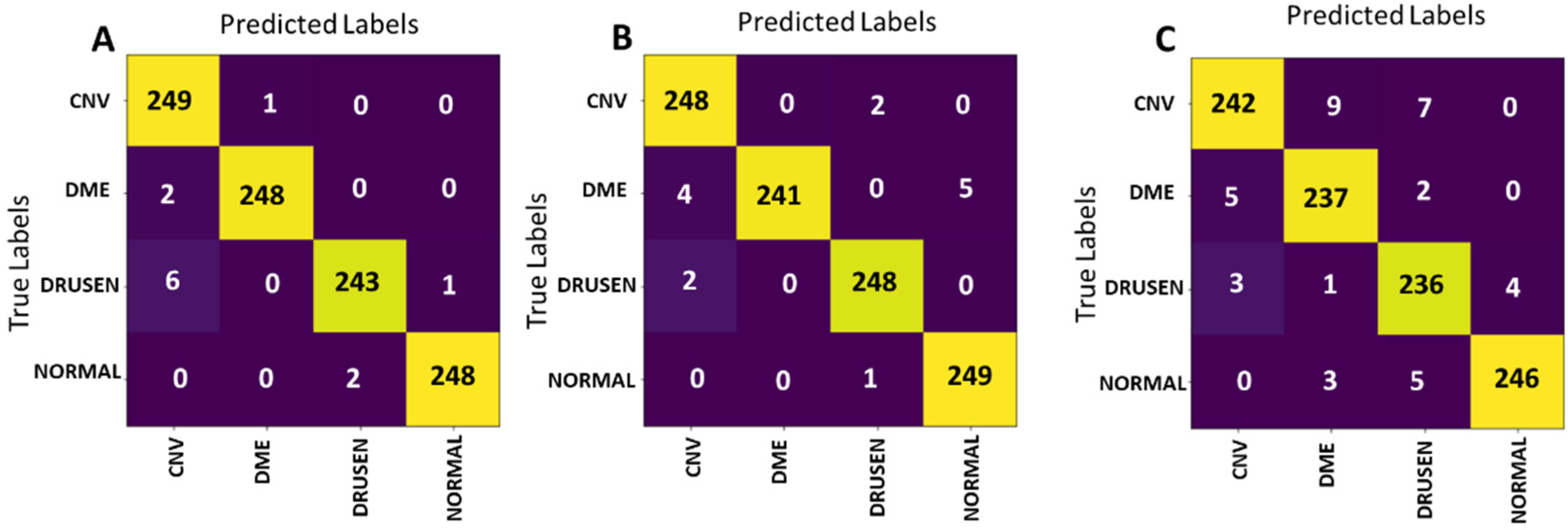
The confusion matrices of the best models of the presented experimental scenarios on the test set are presented in
Figure 14. ResNet-50 (
Figure 14C) achieves the lowest testing accuracy of 97%. The model’s sensitivity for Urgent referral group is 98.6%, while its specificity is 95.4%. The confusion matrix output by applying the best Norm-VGG16 model on the test set is presented in
Figure 14B. The confusion matrix illustrates that 973 out of 1000 testing images were correctly classified. The model’s sensitivity for the Urgent referral group is 98%, while its specificity is 96.6%.
The performance of the models is summarized and compared in
Table 4. From the shown results, it is determined that the best performing model is HyCAD architecture according to its confusion matrix presented in
Figure 14A, scoring an accuracy of 98.8%. In Urgent referrals group, the HyCAD architecture only misclassified 3 images out of 500 and achieves a sensitivity of 99.4% as shown in
Table 4. In the Nonurgent referrals group, the same model misclassified only 9 images out of 500 images and achieves 98.2%. It is worth mentioning that the Norm-VGG16 architecture without Kernel regularization attained a testing accuracy of 96.7% when trained on the dataset from scratch.
2. HyCAD Performance Compared to Pure CNNs Performance and State of the Art
The accuracy per class is calculated and compared with previous models of Kermany et al. [
4] and Li et al. [
20] in
Table 5. The per class accuracy is given by dividing the truly classified image for each class by their total number. It is noticeable from the accuracies in
Table 5 that the lowest accuracy scored by HyCAD is of DRUSEN class, which is explainable due to the fact that it has the lowest percentage in the training set. Nevertheless, HyCAD with the fused hand-crafted features managed to surpass its CNN counterpart Norm-VGG16 in separating the DRUSEN minority class with a difference of 3.2%.
As shown in
Table 5, the proposed HyCAD model achieves a significant increase in accuracy of CNV, DME, DRUSEN by 4.8%, 2.4%, 2.8%, while it attains similar NORMAL accuracy compared to Kermany et al. [
4]. The proposed HyCAD model achieves an increase in accuracies of CNV class by 3.2% compared to Li et al. [
20].
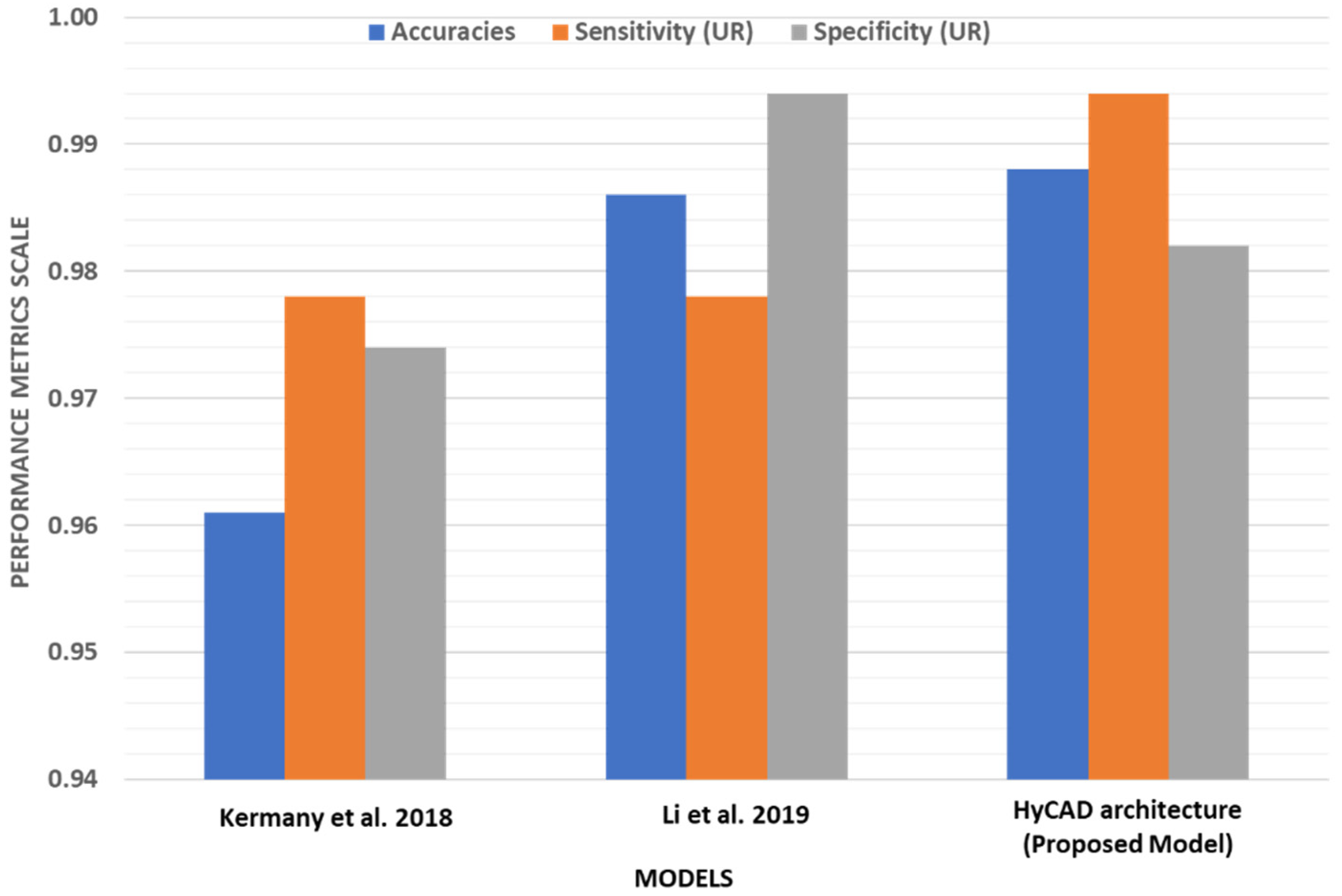
In order to further examine the performance of our best performing model HyCAD architecture relative to the state of the art, its overall performance is compared to the work of Kermany et al. [
4] and Li et al. [
20]. The comparison is depicted in
Table 6 and
Figure 15. The values for Kermany et al. [
4] and Li et al. [
20] are calculated from the best reported confusion matrices as shown in
Figure 16. The HyCAD architecture outperforms the work of Kermany et al. [
4] in terms of accuracy, sensitivity and specificity scoring an increase of 2.5%, 1.6% and 0.8% respectively. In addition, compared to Li et al. [
20], the proposed HyCAD model achieves a noticeable increase in sensitivity by 1.8%, a comparable specificity and a slight increase in accuracy. HyCAD architecture attains the highest sensitivity, scoring an increase of 1.6% compared to the best model of the state of art models [
4,
20] to reach 99.4% for the Urgent referral group. Such a high sensitivity is required for this group as they represent the critical group, which needs immediate attention. This improvement is achieved while maintaining a competitive specificity with the state of the art.
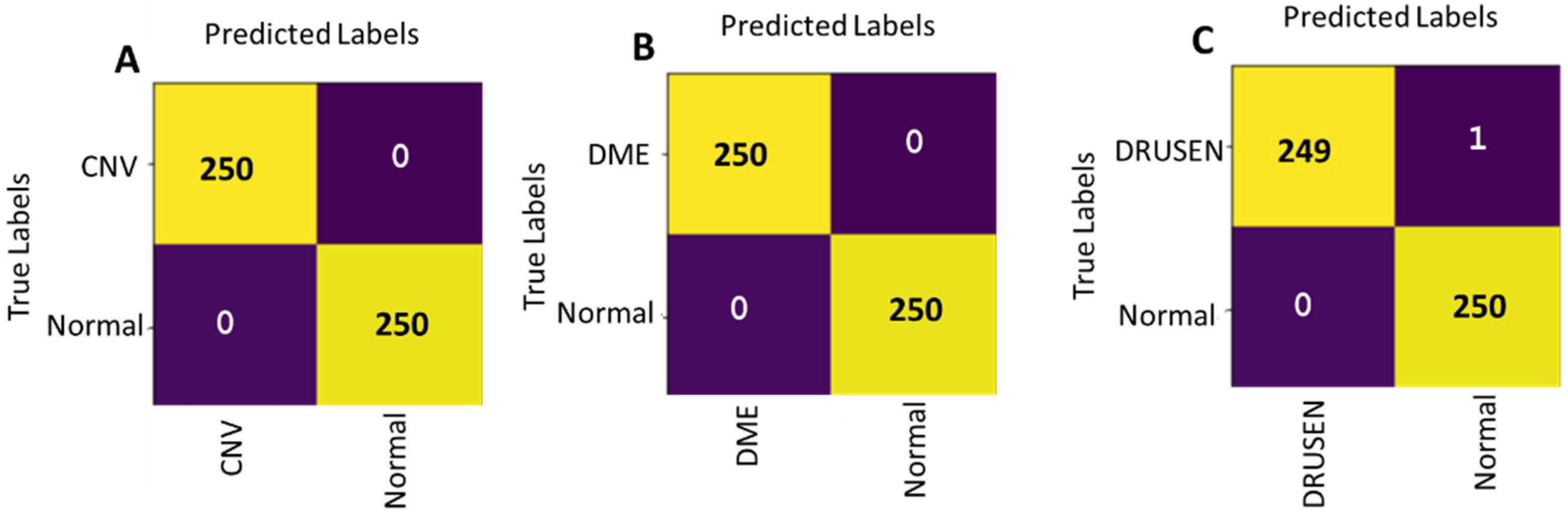
Another important aspect to study is the performance of our HyCAD architecture using hybrid integration of Norm-VGG16 CNN features and hand-crafted features in case of binary classifications. Hence, multiple binary models of CNV vs. NORMAL, DME vs. NORMAL and DRUSEN vs. NORMAL classes are trained and achieve significant results. The respective confusion matrices are shown in
Figure 17 and the results are compared to Kermany et al. [
4] and Li et al. [
20] in
Table 7. The two binary models CNV vs. NORMAL vs. DME and NORMAL achieve an accuracy of 100%, sensitivity of 100% and specificity of 100% without any wrong classification of 500 testing set as can be seen from the confusion matrix in
Figure 17A,B. The binary model between DRUSEN vs. NORMAL achieves an accuracy of 99.79%, sensitivity of 99.6% and specificity of 100% by classifying only one wrong image as shown in
Figure 17C The CNN features are extracted by training Norm-VGG16 for only 15 epochs with learning rate starting with 0.001.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}