Ocular Biometrics Recognition by Analyzing Human Exploration during Video Observations

 ,
, 




Abstract
1. Introduction
- it analyzes gaze patterns by using a computer vision-based pipeline to prove the correlation between visual exploration and user identity. This correlation is robustly computed in a free exploration scenario, not biased by wearable device and constrained to a prior personalized calibration;
- it introduces a novel public dataset that can be used as a benchmark to improve knowledge about this challenging research topic. It is the first dataset that directly provides images framing the faces of the involved subjects instead of their gaze tracks extracted by an eye tracker (unlike all the available datasets aimed at improving biometric analysis of gaze patterns).
2. Related Work
3. Proposed Method
3.1. Face Detection
3.2. Gaze Vector Estimation
3.3. Data Aggregation and FIR Smoothing
- the subject i, where is the total number of participants;
- the j-th video, where is the total number of different videos;
- the k-th session, where is the total number of session performed by the subjects.
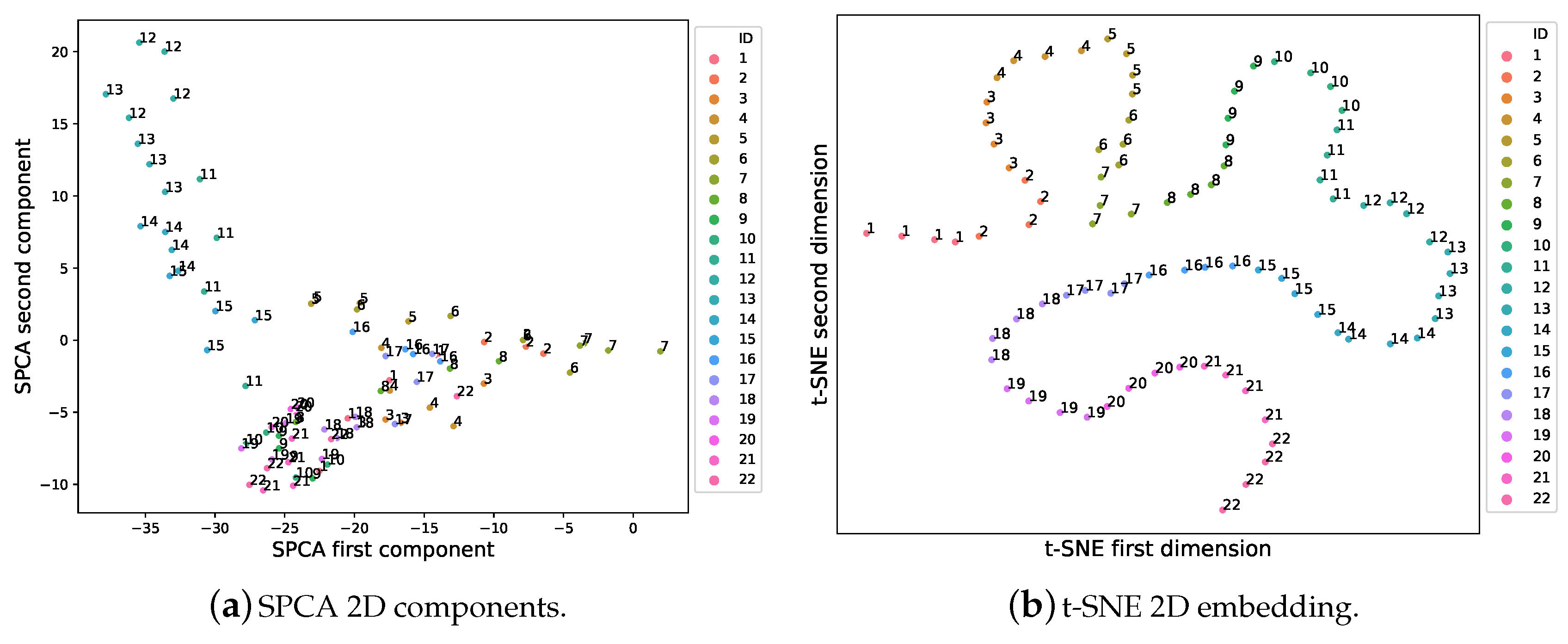
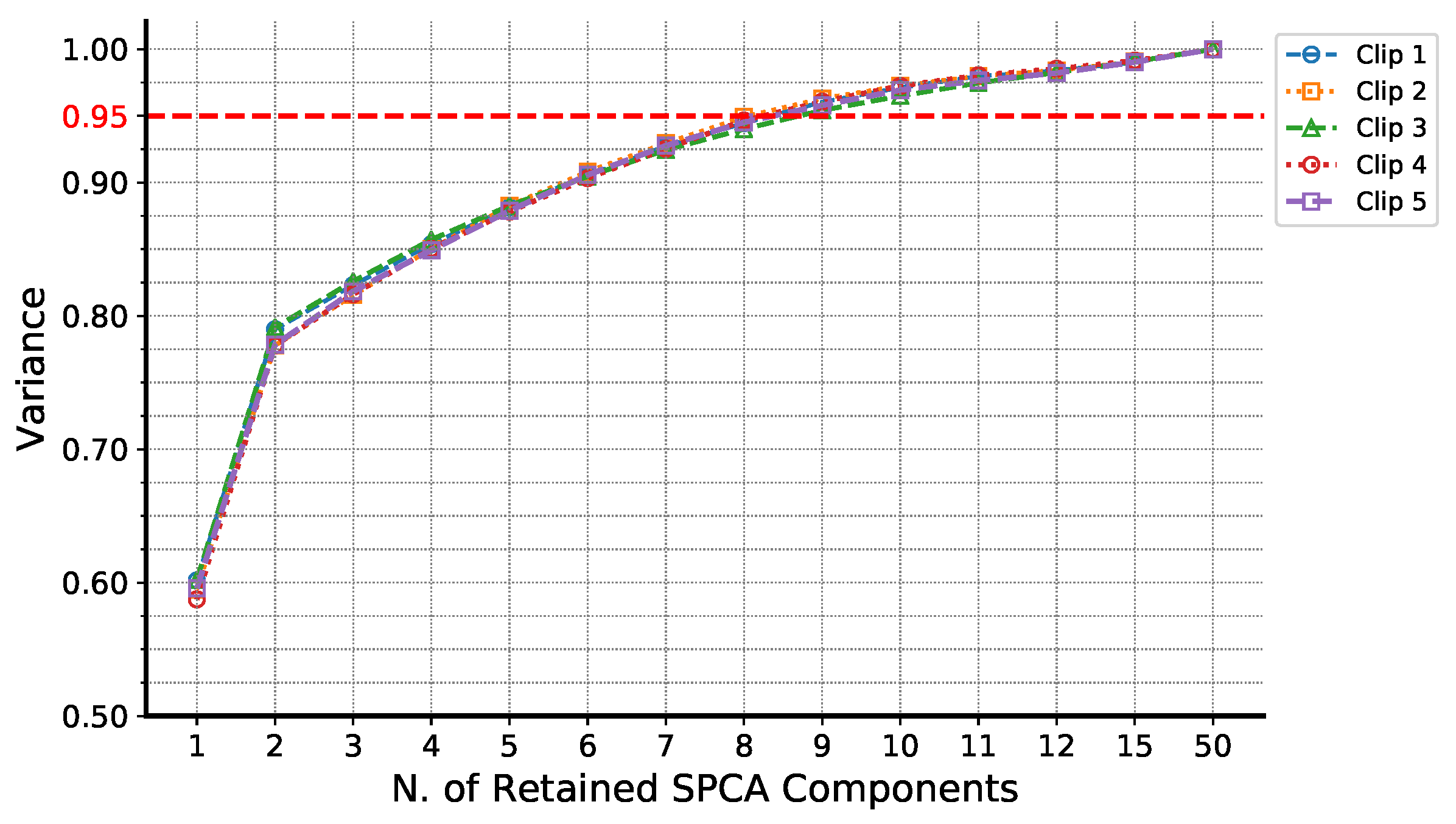
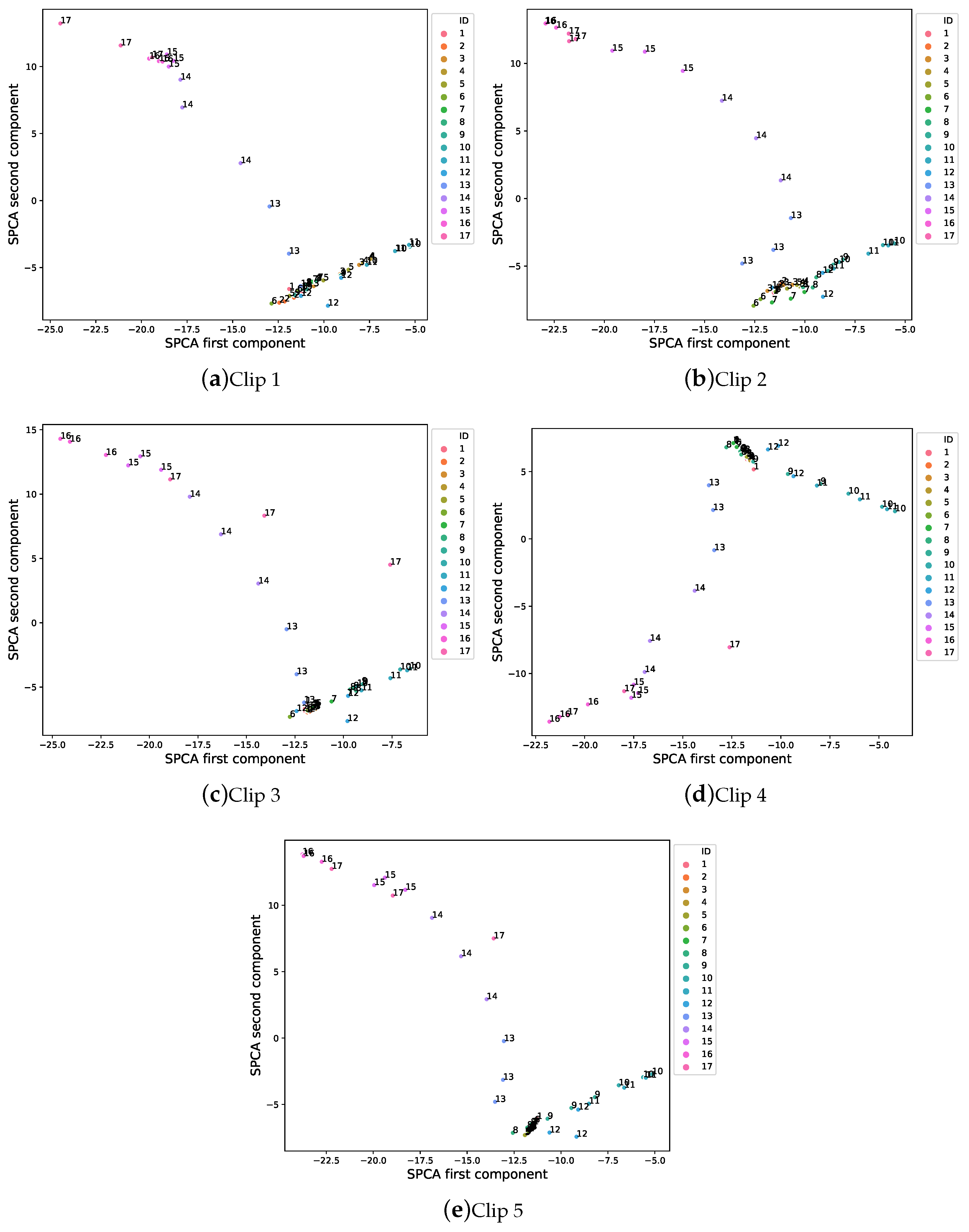
3.4. Sparse Principal Component Analysis
3.5. k-Nearest Neighbors
4. Dataset
- Column 1: name of the file video;
- Column 2: age of the participant;
- Column 3: gender of the participant (M/F);
- Column 4: user ID;
- Column 5: session number;
- Column 6: clip number;
- Column 7-END: vector (composed as described in Section 3.3).
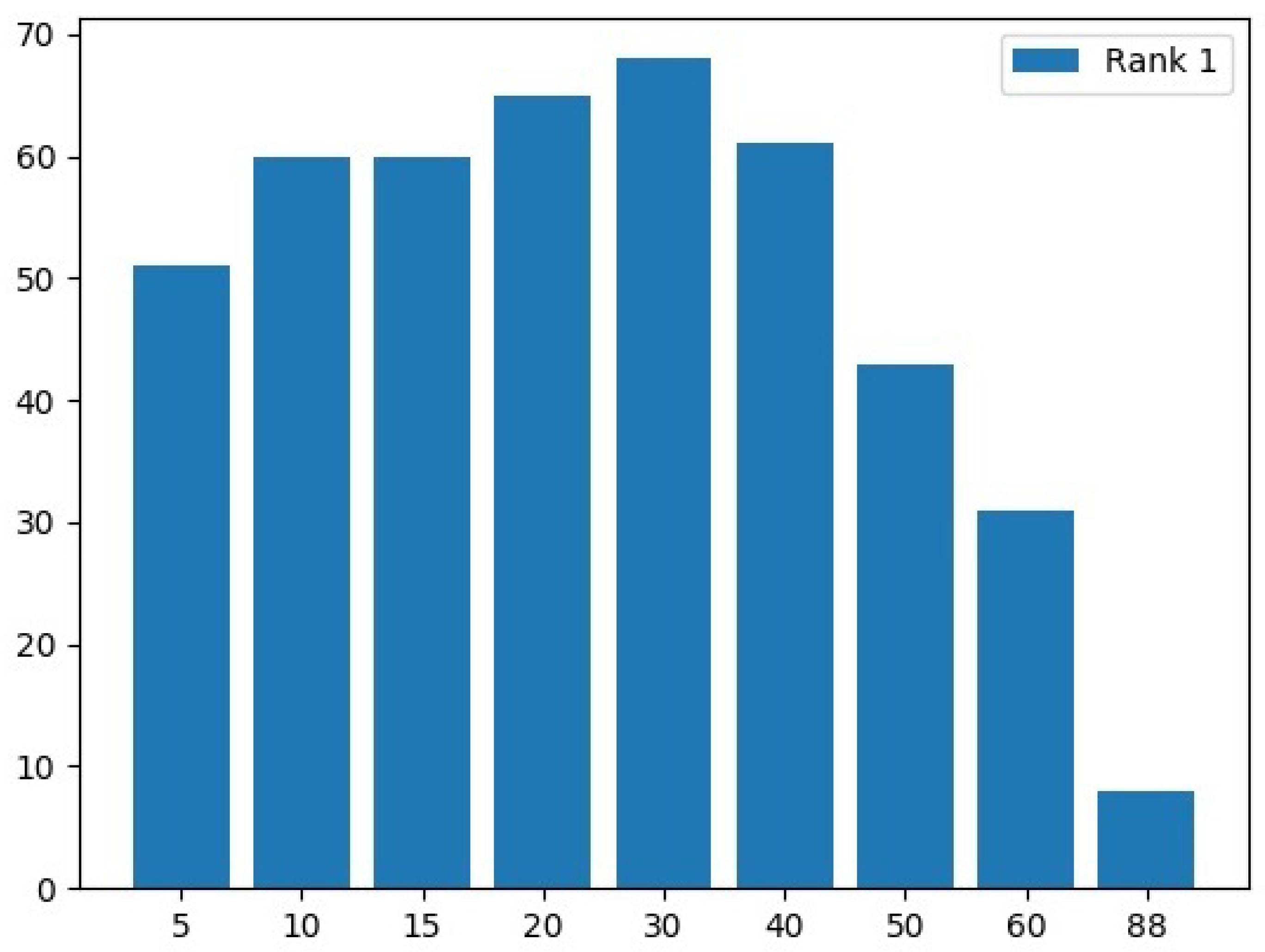
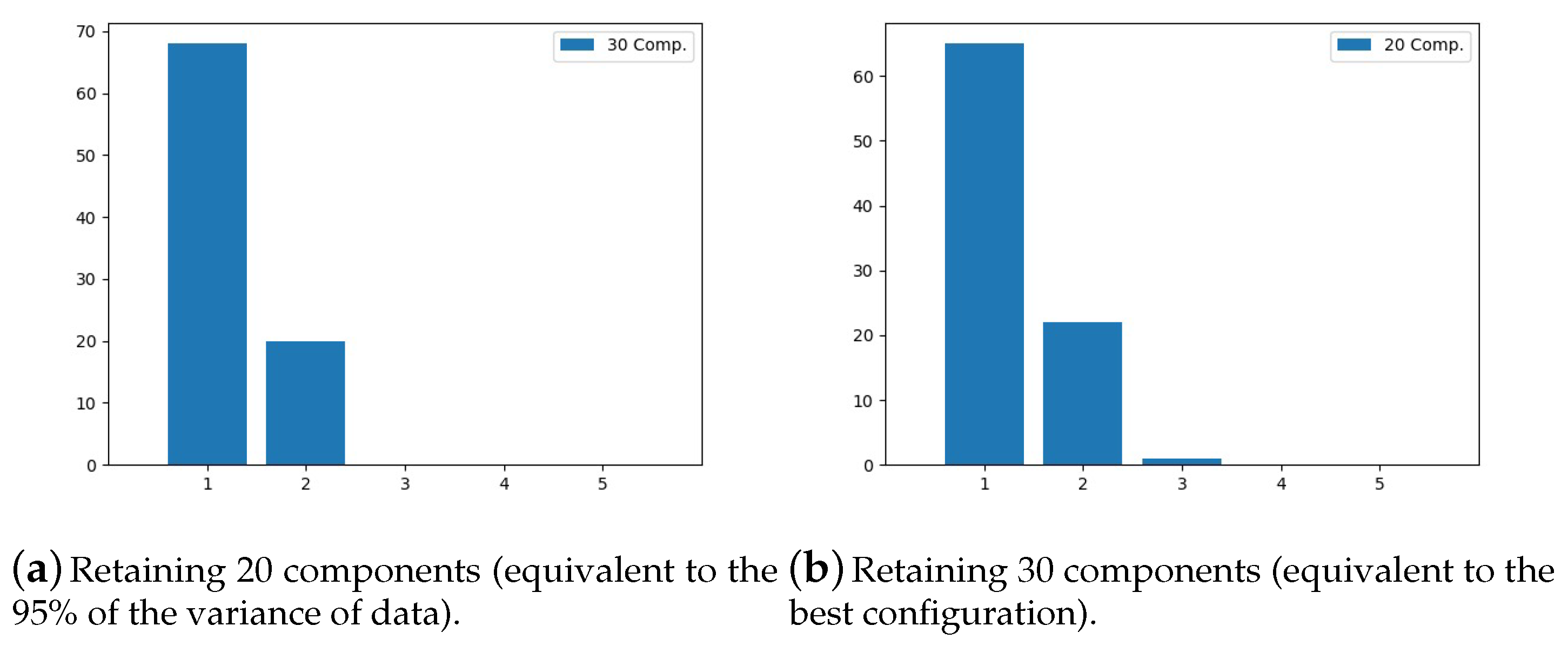
5. Experiments and Results
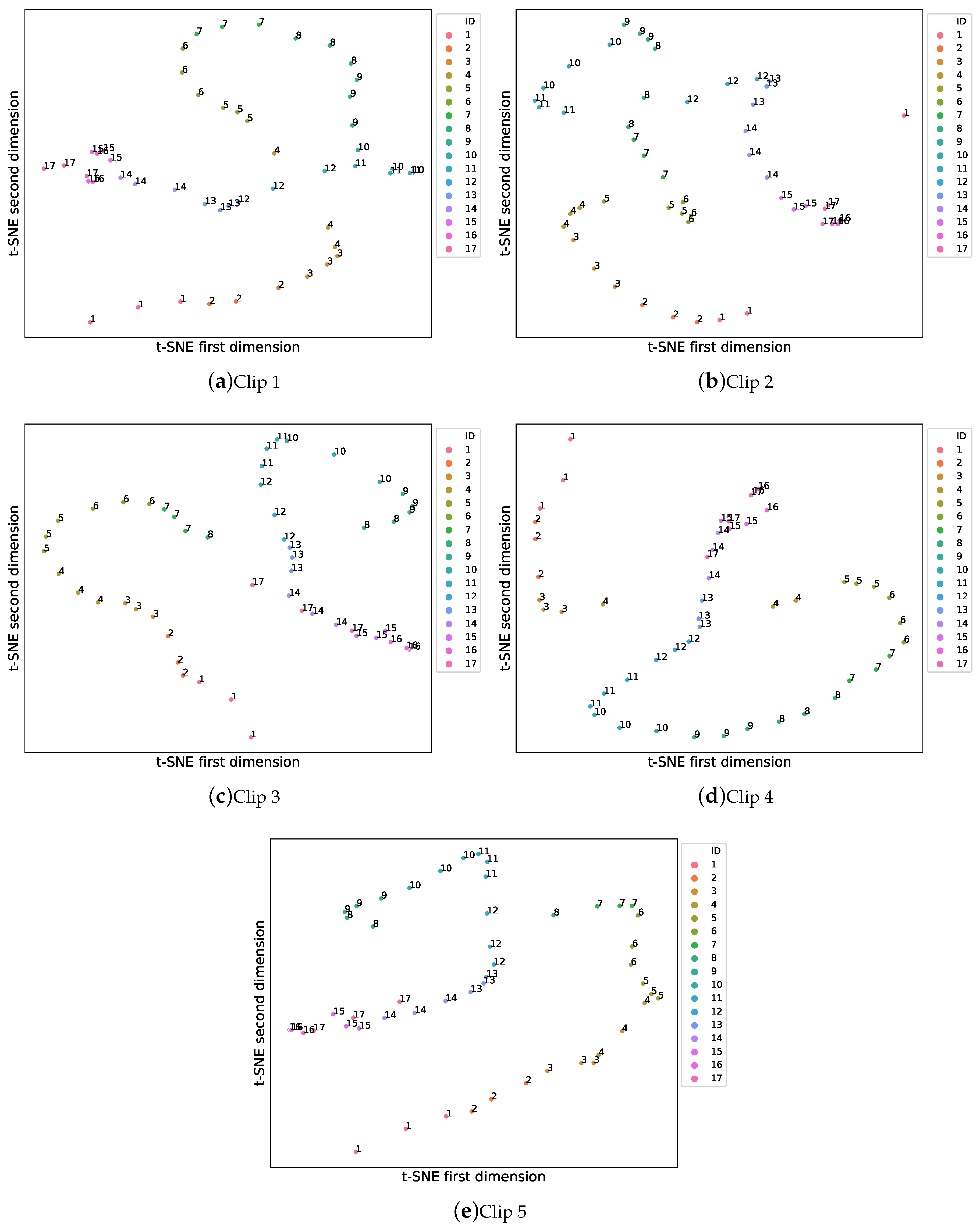
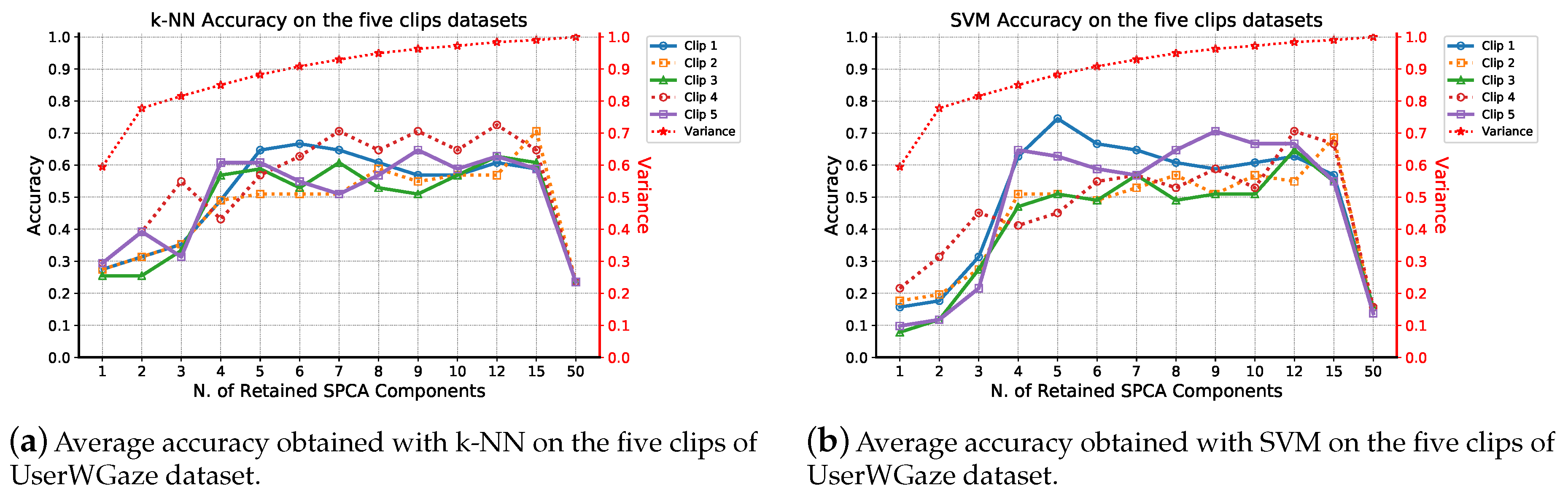
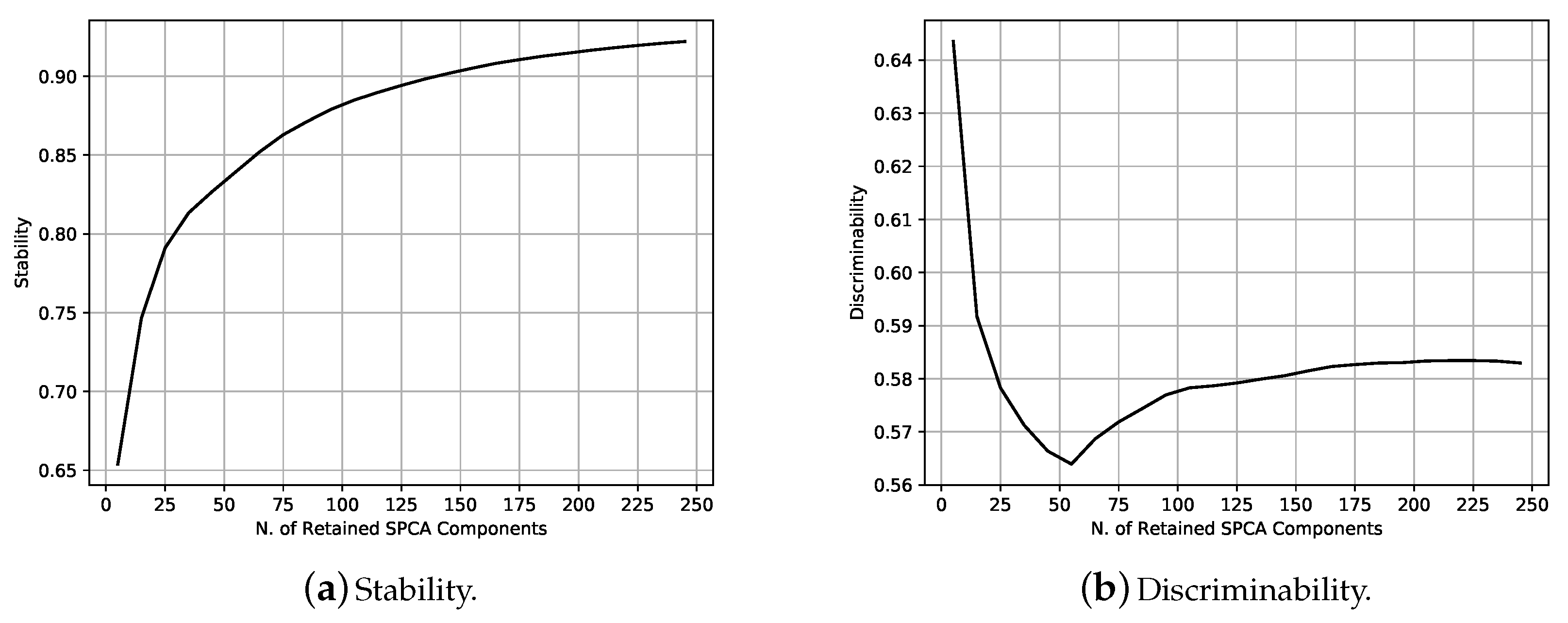
5.1. Experimental Phase #1: System Validation
5.2. Experimental Phase #2: Soft-Biometrics Identification
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bertillon, A.; Müller, G. Instructions for Taking Descriptions for the Identification Of Criminals and Others by the Means of Anthropometric Indications; Kessinger Publishing: Whitefish, MT, USA, 1889. [Google Scholar]
- Rhodes, H.T.F. Alphonse Bertillon, Father of Scientific Detection; Abelard-Schuman: London, UK, 1956. [Google Scholar]
- Jain, A.K.; Dass, S.C.; Nandakumar, K. Soft biometric traits for personal recognition systems. In Proceedings of the International Conference on Biometric Authentication, Hong Kong, China, 15–17 July 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 731–738. [Google Scholar]
- Dantcheva, A.; Velardo, C.; D’angelo, A.; Dugelay, J.L. Bag of soft biometrics for person identification. Multimed. Tools Appl. 2011, 51, 739–777. [Google Scholar] [CrossRef]
- Jaha, E.S.; Nixon, M.S. Soft biometrics for subject identification using clothing attributes. In Proceedings of the IEEE International Joint Conference on Biometrics, Clearwater, FL, USA, 29 September–2 October 2014; pp. 1–6. [Google Scholar]
- Reid, D.A.; Samangooei, S.; Chen, C.; Nixon, M.S.; Ross, A. Soft biometrics for surveillance: An overview. In Handbook of Statistics; Elsevier: Amsterdam, The Netherlands, 2013; Volume 31, pp. 327–352. [Google Scholar]
- Abdelwhab, A.; Viriri, S. A Survey on Soft Biometrics for Human Identification. Mach. Learn. Biom. 2018, 37. [Google Scholar] [CrossRef]
- Zewail, R.; Elsafi, A.; Saeb, M.; Hamdy, N. Soft and hard biometrics fusion for improved identity verification. In Proceedings of the 2004 47th Midwest Symposium on Circuits and Systems, Hiroshima, Japan, 25–28 July 2004. [Google Scholar] [CrossRef]
- Jaha, E.S. Augmenting Gabor-based Face Recognition with Global Soft Biometrics. In Proceedings of the 2019 7th International Symposium on Digital Forensics and Security (ISDFS), Barcelos, Portugal, 10–12 June 2019; pp. 1–5. [Google Scholar]
- Dantcheva, A.; Elia, P.; Ross, A. What else does your biometric data reveal? A survey on soft biometrics. IEEE Trans. Inf. Forensics Secur. 2015, 11, 441–467. [Google Scholar] [CrossRef]
- Niinuma, K.; Park, U.; Jain, A.K. Soft biometric traits for continuous user authentication. IEEE Trans. Inf. Forensics Secur. 2010, 5, 771–780. [Google Scholar] [CrossRef]
- Carcagnì, P.; Cazzato, D.; Del Coco, M.; Distante, C.; Leo, M. Visual interaction including biometrics information for a socially assistive robotic platform. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 391–406. [Google Scholar]
- Geng, L.; Zhang, K.; Wei, X.; Feng, X. Soft biometrics in online social networks: A case study on Twitter user gender recognition. In Proceedings of the 2017 IEEE Winter Applications of Computer Vision Workshops (WACVW), Santa Rosa, CA, USA, 24–31 March 2017; pp. 1–8. [Google Scholar]
- Leo, M.; Carcagnì, P.; Mazzeo, P.L.; Spagnolo, P.; Cazzato, D.; Distante, C. Analysis of Facial Information for Healthcare Applications: A Survey on Computer Vision-Based Approaches. Information 2020, 11, 128. [Google Scholar] [CrossRef]
- Just, M.A.; Carpenter, P.A. Eye fixations and cognitive processes. Cogn. Psychol. 1976, 8, 441–480. [Google Scholar] [CrossRef]
- Porta, M.; Barboni, A. Strengthening Security in Industrial Settings: A Study on Gaze-Based Biometrics through Free Observation of Static Images. In Proceedings of the 2019 24th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Zaragoza, Spain, 10–13 September 2019; pp. 1273–1277. [Google Scholar]
- Matthews, O.; Davies, A.; Vigo, M.; Harper, S. Unobtrusive arousal detection on the web using pupillary response. Int. J. Hum. Comput. Stud. 2020, 136, 102361. [Google Scholar] [CrossRef]
- Deravi, F.; Guness, S.P. Gaze Trajectory as a Biometric Modality. In Proceedings of the International Conference on Bio-inspired Systems and Signal Processing (BIOSIGNALS-2011), Rome, Italy, 26–29 January 2011; pp. 335–341. [Google Scholar]
- Cazzato, D.; Leo, M.; Evangelista, A.; Distante, C. Soft Biometrics by Modeling Temporal Series of Gaze Cues Extracted in the Wild. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Catania, Italy, 26–29 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 391–402. [Google Scholar]
- Cazzato, D.; Evangelista, A.; Leo, M.; Carcagnì, P.; Distante, C. A low-cost and calibration-free gaze estimator for soft biometrics: An explorative study. Pattern Recognit. Lett. 2016, 82, 196–206. [Google Scholar] [CrossRef]
- Yarbus, A.L. Eye Movements and Vision; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Zelinsky, G.J. A theory of eye movements during target acquisition. Psychol. Rev. 2008, 115, 787. [Google Scholar] [CrossRef] [PubMed]
- Tatler, B.W.; Baddeley, R.J.; Vincent, B.T. The long and the short of it: Spatial statistics at fixation vary with saccade amplitude and task. Vis. Res. 2006, 46, 1857–1862. [Google Scholar] [CrossRef]
- Itti, L.; Baldi, P.F. Bayesian surprise attracts human attention. In Advances in Neural Information Processing Systems; MIT: Cambridge, MA, USA, 2006; pp. 547–554. [Google Scholar]
- Borji, A.; Cheng, M.M.; Hou, Q.; Jiang, H.; Li, J. Salient object detection: A survey. Comput. Vis. Media 2015, 5, 117–150. [Google Scholar] [CrossRef]
- Yun, K.; Peng, Y.; Samaras, D.; Zelinsky, G.J.; Berg, T.L. Exploring the role of gaze behavior and object detection in scene understanding. Front. Psychol. 2013, 4, 917. [Google Scholar] [CrossRef] [PubMed]
- Judd, T.; Durand, F.; Torralba, A. A Benchmark of Computational Models of Saliency to Predict Human Fixations; MIT: Cambridge, MA, USA, 2012. [Google Scholar]
- Mehrani, P.; Veksler, O. Saliency Segmentation based on Learning and Graph Cut Refinement. In Proceedings of the British Machine Vision Conference, BMVC 2010, Aberystwyth, UK, 31 August–3 September 2010; pp. 1–12. [Google Scholar]
- Nelson, D. Using Gaze Detection to Change Timing and Behavior. US Patent No. 10,561,928, 18 February 2020. [Google Scholar]
- Katsini, C.; Opsis, H.; Abdrabou, Y.; Raptis, G.E.; Khamis, M.; Alt, F. The Role of Eye Gaze in Security and Privacy Applications: Survey and Future HCI Research Directions. In Proceedings of the 38th Annual ACM Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; ACM: New York, NY, USA, 2020; Volume 21. [Google Scholar]
- Cerf, M.; Harel, J.; Einhäuser, W.; Koch, C. Predicting human gaze using low-level saliency combined with face detection. In Advances in Neural Information Processing Systems; NIPS: San Diego, CA, USA, 2008; pp. 241–248. [Google Scholar]
- Maeder, A.J.; Fookes, C.B. A visual attention approach to personal identification. In Proceedings of the 8th Australian & New Zealand Intelligent Information Systems Conference; Queensland University of Technology: Brisbane, QC, Australia, 2003; pp. 55–60. [Google Scholar]
- Kasprowski, P.; Ober, J. Eye movements in biometrics. In Proceedings of the International Workshop on Biometric Authentication, Prague, Czech Republic, 15 May 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 248–258. [Google Scholar]
- Yoon, H.J.; Carmichael, T.R.; Tourassi, G. Gaze as a biometric. In Medical Imaging 2014: Image Perception, Observer Performance, and Technology Assessment; International Society for Optics and Photonics: Bellingham, DC, USA, 2014; Volume 9037, p. 903707. [Google Scholar]
- Cantoni, V.; Porta, M.; Galdi, C.; Nappi, M.; Wechsler, H. Gender and age categorization using gaze analysis. In Proceedings of the 2014 Tenth International Conference on Signal-Image Technology and Internet-Based Systems, Marrakech, Morocco, 23–27 November 2014; pp. 574–579. [Google Scholar]
- Cantoni, V.; Galdi, C.; Nappi, M.; Porta, M.; Riccio, D. GANT: Gaze analysis technique for human identification. Pattern Recognit. 2015, 48, 1027–1038. [Google Scholar] [CrossRef]
- Rigas, I.; Komogortsev, O.; Shadmehr, R. Biometric recognition via eye movements: Saccadic vigor and acceleration cues. ACM Trans. Appl. Percept. (TAP) 2016, 13, 6. [Google Scholar] [CrossRef]
- Sluganovic, I.; Roeschlin, M.; Rasmussen, K.B.; Martinovic, I. Using reflexive eye movements for fast challenge-response authentication. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; ACM: New York, NY, USA, 2016; pp. 1056–1067. [Google Scholar]
- Kasprowski, P.; Komogortsev, O.V.; Karpov, A. First eye movement verification and identification competition at BTAS 2012. In Proceedings of the 2012 IEEE fifth international conference on biometrics: Theory, applications and systems (BTAS), Arlington, VA, USA, 23–27 September 2012; pp. 195–202. [Google Scholar]
- Galdi, C.; Nappi, M.; Riccio, D.; Wechsler, H. Eye movement analysis for human authentication: A critical survey. Pattern Recognit. Lett. 2016, 84, 272–283. [Google Scholar] [CrossRef]
- Judd, T.; Ehinger, K.; Durand, F.; Torralba, A. Learning to predict where humans look. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2106–2113. [Google Scholar]
- Kasprowski, P.; Harezlak, K. Fusion of eye movement and mouse dynamics for reliable behavioral biometrics. Pattern Anal. Appl. 2018, 21, 91–103. [Google Scholar] [CrossRef]
- Cazzato, D.; Leo, M.; Carcagnì, P.; Cimarelli, C.; Voos, H. Understanding and Modelling Human Attention for Soft Biometrics Purposes. In Proceedings of the 2019 3rd International Conference on Artificial Intelligence and Virtual Reality, Singapore, 27–29 July 2019; pp. 51–55. [Google Scholar]
- Vitek, M.; Rot, P.; Štruc, V.; Peer, P. A comprehensive investigation into sclera biometrics: A novel dataset and performance study. Neural Comput. Appl. 2020, 1–15. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Baltrusaitis, T.; Robinson, P.; Morency, L.P. Constrained local neural fields for robust facial landmark detection in the wild. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 354–361. [Google Scholar]
- Belhumeur, P.N.; Jacobs, D.W.; Kriegman, D.J.; Kumar, N. Localizing parts of faces using a consensus of exemplars. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2930–2940. [Google Scholar] [CrossRef]
- Le, V.; Brandt, J.; Lin, Z.; Bourdev, L.; Huang, T.S. Interactive facial feature localization. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 679–692. [Google Scholar]
- Saragih, J.M.; Lucey, S.; Cohn, J.F. Deformable model fitting by regularized landmark mean-shift. Int. J. Comput. Vis. 2011, 91, 200–215. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Amos, B.; Ludwiczuk, B.; Satyanarayanan, M. Openface: A General-Purpose Face Recognition Library With Mobile Applications; CMU School of Computer Science: Pittsburgh, PA, USA, 2016; Volume 6. [Google Scholar]
- Wood, E.; Baltrusaitis, T.; Zhang, X.; Sugano, Y.; Robinson, P.; Bulling, A. Rendering of eyes for eye-shape registration and gaze estimation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3756–3764. [Google Scholar]
- Savitzky, A.; Golay, M.J. Smoothing and differentiation of data by simplified least squares procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Schafer, R.W. What is a Savitzky-Golay filter? [lecture notes]. IEEE Signal Process. Mag. 2011, 28, 111–117. [Google Scholar] [CrossRef]
- Hein, M.; Bühler, T. An inverse power method for nonlinear eigenproblems with applications in 1-spectral clustering and sparse PCA. In Advances in Neural Information Processing Systems; NIPS: San Diego, CA, USA, 2010; pp. 847–855. [Google Scholar]
- Takane, Y. Constrained Principal Component Analysis and Related Techniques; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Fix, E. Discriminatory Analysis: Nonparametric Discrimination, Consistency Properties; USAF School of Aviation Medicine: Dayton, OH, USA, 1951. [Google Scholar]
- Huang, Q.; Veeraraghavan, A.; Sabharwal, A. TabletGaze: Dataset and analysis for unconstrained appearance-based gaze estimation in mobile tablets. Mach. Vis. Appl. 2017, 28, 445–461. [Google Scholar] [CrossRef]
- Dorr, M.; Martinetz, T.; Gegenfurtner, K.R.; Barth, E. Variability of eye movements when viewing dynamic natural scenes. J. Vis. 2010, 10, 28. [Google Scholar] [CrossRef] [PubMed]
- Zelinsky, G. Understanding scene understanding. Front. Psychol. 2013, 4, 954. [Google Scholar] [CrossRef]
- Wolfe, J.M.; Horowitz, T.S. What attributes guide the deployment of visual attention and how do they do it? Nat. Rev. Neurosci. 2004, 5, 495–501. [Google Scholar] [CrossRef]
- Jansen, A.M.; Giebels, E.; van Rompay, T.J.; Junger, M. The influence of the presentation of camera surveillance on cheating and pro-social behavior. Front. Psychol. 2018, 9, 19–37. [Google Scholar] [CrossRef]
- Albrecht, T.L.; Ruckdeschel, J.C.; Ray, F.L.; Pethe, B.J.; Riddle, D.L.; Strohm, J.; Penner, L.A.; Coovert, M.D.; Quinn, G.; Blanchard, C.G. A portable, unobtrusive device for videorecording clinical interactions. Behav. Res. Methods 2005, 37, 165–169. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Maaten, L.v.d.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Proenca, H.; Neves, J.C.; Barra, S.; Marques, T.; Moreno, J.C. Joint head pose/soft label estimation for human recognitionin-the-wild. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2444–2456. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) | ||||
| Clip # | N. of Components | SPCA Variance | SVM Accuracy | k-NN Accuracy |
| 4 | 9 | 0.961 | 0.51 | 0.51 |
| 3 | 9 | 0.954 | 0.59 | 0.71 |
| 2 | 9 | 0.963 | 0.71 | 0.65 |
| 1 | 9 | 0.960 | 0.59 | 0.57 |
| 5 | 9 | 0.958 | 0.51 | 0.55 |
| (b) | ||||
| Clip # | N. of Components | SPCA Variance | SVM Accuracy | k-NN Accuracy |
| 4 | 50 | 1.000 | 0.16 | 0.24 |
| 3 | 50 | 1.000 | 0.16 | 0.24 |
| 2 | 50 | 1.000 | 0.14 | 0.24 |
| 1 | 50 | 1.000 | 0.16 | 0.24 |
| 5 | 50 | 1.000 | 0.14 | 0.24 |
| Work | Method | Accuracy | Dataset | Notes |
|---|---|---|---|---|
| Deravi et al. (2011) [18] | backwards Feature Selection + SVM | 0.92 | own data | initialization and calibration req. |
| Cantoni et al. (2015) [36] | features graph | 0.8179 (AUC) | GANT (16 subj.) | eye tracker req. |
| Cazzato et al. (2016) [20] | geometric model + minimax | 0.810 | own data (12 subj.) | RGBD sensor req. |
| Kasprowski et al. (2018) [42] | statistic features + SVM | 0.928 | proprietary data (24 subj.) | calibration req. |
| Cazzato et al. (2019) [43] | CNN+SVM | 0.937* | UserWGaze | a posteriori choice with rank analysis |
| Cazzato et al. (2019) [43] | CNN+SVM | 0.851* | UserWGaze | a priori 95% variance criterion |
| Proposed method | CNN+k-NN (k=1) | 0.886 | UserWGaze | a priori 95% variance criterion |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cazzato, D.; Carcagnì, P.; Cimarelli, C.; Voos, H.; Distante, C.; Leo, M. Ocular Biometrics Recognition by Analyzing Human Exploration during Video Observations. Appl. Sci. 2020, 10, 4548. https://doi.org/10.3390/app10134548
Cazzato D, Carcagnì P, Cimarelli C, Voos H, Distante C, Leo M. Ocular Biometrics Recognition by Analyzing Human Exploration during Video Observations. Applied Sciences. 2020; 10(13):4548. https://doi.org/10.3390/app10134548
Chicago/Turabian StyleCazzato, Dario, Pierluigi Carcagnì, Claudio Cimarelli, Holger Voos, Cosimo Distante, and Marco Leo. 2020. "Ocular Biometrics Recognition by Analyzing Human Exploration during Video Observations" Applied Sciences 10, no. 13: 4548. https://doi.org/10.3390/app10134548
APA StyleCazzato, D., Carcagnì, P., Cimarelli, C., Voos, H., Distante, C., & Leo, M. (2020). Ocular Biometrics Recognition by Analyzing Human Exploration during Video Observations. Applied Sciences, 10(13), 4548. https://doi.org/10.3390/app10134548